
MPK(Mirage Persistent Kernel)源碼筆記(4)--- 轉(zhuǎn)譯系統(tǒng)
MPK(Mirage Persistent Kernel)源碼筆記(4)--- 轉(zhuǎn)譯系統(tǒng)
0x00 概要
此處的”轉(zhuǎn)譯系統(tǒng)“包含兩部分:
- 把計(jì)算圖轉(zhuǎn)換為任務(wù)圖。
- 將 Mirage 生成的(優(yōu)化過(guò)的)計(jì)算圖轉(zhuǎn)換為高效的 CUDA 代碼
0x01 Task和Event
在 Mirage 持久化內(nèi)核(Persistent Kernel)的設(shè)計(jì)與實(shí)現(xiàn)中,需突破三個(gè)關(guān)鍵技術(shù)瓶頸:
- 如何將抽象算子轉(zhuǎn)化為可執(zhí)行任務(wù)。
- 如何處理任務(wù)間的數(shù)據(jù)依賴。
- 如何高效分配任務(wù)至 GPU 計(jì)算單元。
這三個(gè)問(wèn)題的解決,直接決定了內(nèi)核能否充分發(fā)揮 GPU 并行性能,適配復(fù)雜張量計(jì)算場(chǎng)景(如大語(yǔ)言模型推理)。Mirage 通過(guò)引入Task和Event,與三層圖一起來(lái)解決上述問(wèn)題:
- Kernel Graph 定義張量數(shù)據(jù)流
- Block Graph 定義內(nèi)存訪問(wèn)模式
- Task 執(zhí)行具體計(jì)算
- Event 管理任務(wù)依賴關(guān)系
- Thread Graph 執(zhí)行底層并行計(jì)算
1.1 可執(zhí)行任務(wù)
GPU 執(zhí)行 CUDA 或 Triton 代碼時(shí),需將算子的整體計(jì)算邏輯切分為多個(gè) “計(jì)算塊”(Block)—— 每個(gè)計(jì)算塊對(duì)應(yīng) GPU 流式多處理器(SM)可承載的基本計(jì)算單元,最終由調(diào)度系統(tǒng)分配至不同 SM 并行執(zhí)行。基于這一硬件特性,Mirage 持久化內(nèi)核將 “單個(gè)計(jì)算塊的計(jì)算” 定義為最小任務(wù)單元(Task),實(shí)現(xiàn)算子到任務(wù)的結(jié)構(gòu)化轉(zhuǎn)化。
1.1.1 任務(wù)定義
任務(wù)的由TaskDesc 來(lái)實(shí)現(xiàn)。
struct TaskDesc {
TaskDesc(TaskType t, int _variant_id)
: task_type(t), variant_id(_variant_id), num_inputs(0), num_outputs(0),
trigger_event(EVENT_INVALID_ID), dependent_event(EVENT_INVALID_ID) {}
TaskDesc() {}
TaskType task_type; // 任務(wù)類型
unsigned variant_id; // 變體ID
int num_inputs, num_outputs;
EventId trigger_event; // 觸發(fā)事件
EventId dependent_event; // 依賴事件
TensorDesc inputs[MAX_INPUTS_PER_TASK]; // 張量描述
TensorDesc outputs[MAX_OUTPUTS_PER_TASK];
};
1.1.2 任務(wù)類型
任務(wù)類型如下:
enum TaskType {
TASK_TERMINATE = 0, // 終止任務(wù)
TASK_BEGIN_TASK_GRAPH = 10, // 人物圖開(kāi)始標(biāo)記
// compute task starts from 100
TASK_EMBEDDING = 101, // 嵌入層
TASK_RMS_NORM_LINEAR = 102, // RMS歸一化和線性層組合
TASK_ATTENTION_1 = 103, // 注意力機(jī)制第一部分
TASK_ATTENTION_2 = 104, // 注意力機(jī)制第二部分
TASK_SILU_MUL_LINEAR_WITH_RESIDUAL = 105,
TASK_ALLREDUCE = 106,
TASK_REDUCE = 107,
TASK_LINEAR_WITH_RESIDUAL = 108,
TASK_ARGMAX = 109,
TASK_ARGMAX_PARTIAL = 110,
TASK_ARGMAX_REDUCE = 111,
TASK_FIND_NGRAM_PARTIAL = 112, //部分n-gram查找
TASK_FIND_NGRAM_GLOBAL = 113, // 全局n-gram查找
TASK_TARGET_VERIFY_GREEDY = 114, // 貪心目標(biāo)驗(yàn)證
TASK_SINGLE_BATCH_EXTEND_ATTENTION = 115,
TASK_NVSHMEM_COPY = 199, // 使用NVSHMEM進(jìn)行跨GPU的數(shù)據(jù)復(fù)制
TASK_SCHD_TASKS = 200, // 調(diào)度任務(wù)
TASK_SCHD_EVENTS = 201, // 調(diào)度事件
TASK_GET_EVENT = 202, // 獲取事件
TASK_GET_NEXT_TASK = 203, // 獲取任務(wù)
};
1.2 事件
傳統(tǒng)內(nèi)核設(shè)計(jì)中,數(shù)據(jù)依賴關(guān)系以算子為單位定義 —— 只有前一個(gè)算子的所有計(jì)算完全結(jié)束,后一個(gè)算子才能啟動(dòng),這種粗粒度依賴會(huì)導(dǎo)致大量計(jì)算資源閑置(例如前一算子僅剩余少量計(jì)算未完成時(shí),后一算子需持續(xù)等待)。Mirage 持久化內(nèi)核將依賴關(guān)系下沉至任務(wù)級(jí)別,實(shí)現(xiàn)更精細(xì)的并行調(diào)度。具體而言,算子級(jí)依賴會(huì)被拆解為任務(wù)間的依賴鏈,即事件。
1.2.1 事件定義
事件的由 EventDesc 來(lái)實(shí)現(xiàn)。
struct EventDesc {
EventDesc(void)
: event_type(EVENT_INVALID), num_triggers(0),
first_task_id(TASK_INVALID_ID), last_task_id(TASK_INVALID_ID) {}
EventDesc(EventType type, int nt, TaskId f, TaskId l)
: event_type(type), num_triggers(nt), first_task_id(f), last_task_id(l) {}
EventType event_type;
int num_triggers; // 觸發(fā)器數(shù)量
TaskId first_task_id, last_task_id; // 首尾任務(wù)ID范圍
};
1.2.2 事件類型
事件類型如下:
enum EventType {
EVENT_EMPTY = 900, // 空事件
EVENT_LAUNCH_TASKS = 901, // 啟動(dòng)任務(wù)
EVENT_LAUNCH_MASSIVE_TASKS = 902, // 啟動(dòng)大規(guī)模任務(wù)
EVENT_LAUNCH_DEPENDENT_TASKS = 903, // 啟動(dòng)依賴任務(wù)
EVENT_END_OF_TASK_GRAPH = 910, // 任務(wù)圖結(jié)束
EVENT_TERMINATION = 911, // 終止事件
EVENT_INVALID = 999, //無(wú)效事件
};
下圖展示了如何確定事件類型。

0x02 生成CUDA代碼
TaskDesc 結(jié)構(gòu)體本身并不直接包含可執(zhí)行代碼。它更像是一個(gè)任務(wù)的描述符或配置信息,包含了任務(wù)執(zhí)行所需的一些元數(shù)據(jù)。
2.1 生成代碼
實(shí)際的可執(zhí)行代碼是通過(guò)以下方式來(lái)生成的。
register_muggraph
- 在 runtime.cc 的 register_mugraph 函數(shù)中,會(huì)遍歷 Graph 中的 KN_CUSTOMIZED_OP 操作符。
- 對(duì)于每個(gè)操作符,它會(huì)從 task_configs(即 Graph::task_config)中查找對(duì)應(yīng)的配置(輸入數(shù)、輸出數(shù)、TaskType, variant_id)。
- 創(chuàng)建 TaskDesc 結(jié)構(gòu)體,會(huì)將獲取到的 TaskType 和 variant_id 填入 TaskDesc。
在生成計(jì)算圖時(shí)候,會(huì)調(diào)用 register_task,實(shí)際上是生成CUDA代碼,比如:
def embed_layer(
self,
input: DTensor, # [batch_size, num_spec_tokens]
weight: DTensor, # [vocab_size, hidden_size]
output: DTensor, # [batch_size, hidden_size]
grid_dim: tuple,
block_dim: tuple,
input_source: int = 0, # 0: all_tokens, 1: input_token
):
tb_graph = TBGraph(CyTBGraph(grid_dim, block_dim, 1, 64))
tb_graph.new_input(input, (-1, 1, -1), -1, True)
tb_graph.new_input(weight, (1, -1, -1), -1, True)
tb_graph.new_input(output, (1, 0, -1), -1, True)
self.kn_graph.customized([input, weight, output], tb_graph)
# 會(huì)生成CUDA代碼
self.kn_graph.register_task(tb_graph, "embedding", [input_source])
當(dāng)用戶調(diào)用 Graph::register_task 時(shí),它會(huì)獲取當(dāng)前圖中最后一個(gè)操作符(必須是 KN_CUSTOMIZED_OP),根據(jù)傳入的 task_type 字符串和參數(shù),調(diào)用 TaskRegister 對(duì)應(yīng)的 register_*_task 函數(shù)。
注冊(cè)成功后,它會(huì)將任務(wù)的輸入/輸出數(shù)量、TaskType 和 variant_id 存儲(chǔ)在 Graph 的 task_config 映射中,以 KNOperator* 為鍵。
register_task的實(shí)現(xiàn)位于graph.cc,具體代碼如下:
void Graph::register_task(char const *task_type, std::vector<int> params) {
std::string name = std::string(task_type);
KNOperator const *op = operators.back();
assert(op->op_type == type::KN_CUSTOMIZED_OP);
KNCustomizedOp const *customized = static_cast<KNCustomizedOp const *>(op);
TaskRegister *task_register = TaskRegister::get_instance();
if (name == "embedding") {
int variant_id =
task_register->register_embedding_task(customized->bgraph, params);
task_config[op] = std::make_tuple(2, 1, TASK_EMBEDDING, variant_id);
} else if (name == "rmsnorm_linear") {
int variant_id =
task_register->register_rmsnorm_linear_task(customized->bgraph, params);
task_config[op] = std::make_tuple(3, 1, TASK_RMS_NORM_LINEAR, variant_id);
} else if (name == "attention") {
int variant_id =
task_register->register_attention_task(customized->bgraph, params);
task_config[op] = std::make_tuple(7, 1, TASK_ATTENTION_1, variant_id);
} else if (name == "single_batch_extend_attention") {
int variant_id = task_register->register_single_batch_extend_attention_task(
customized->bgraph, params);
task_config[op] =
std::make_tuple(7, 1, TASK_SINGLE_BATCH_EXTEND_ATTENTION, variant_id);
} else if (name == "linear_with_residual") {
int variant_id = task_register->register_linear_with_residual_task(
customized->bgraph, params);
task_config[op] =
std::make_tuple(3, 1, TASK_LINEAR_WITH_RESIDUAL, variant_id);
} else if (name == "silu_mul_linear_with_residual") {
int variant_id = task_register->register_silu_mul_linear_with_residual_task(
customized->bgraph, params);
task_config[op] =
std::make_tuple(3, 1, TASK_SILU_MUL_LINEAR_WITH_RESIDUAL, variant_id);
} else if (name == "argmax") {
task_config[op] = std::make_tuple(1, 1, TASK_ARGMAX, 0);
} else if (name == "argmax_partial") {
int variant_id =
task_register->register_arrrgmax_partial_task(customized->bgraph, params);
task_config[op] = std::make_tuple(1, 2, TASK_ARGMAX_PARTIAL, variant_id);
} else if (name == "argmax_reduce") {
int variant_id =
task_register->register_argmax_reduce_task(customized->bgraph, params);
task_config[op] = std::make_tuple(2, 1, TASK_ARGMAX_REDUCE, variant_id);
} else if (name == "allreduce") {
task_config[op] = std::make_tuple(2, 1, TASK_ALLREDUCE, 0);
} else if (name == "find_ngram_partial") {
int variant_id = task_register->register_find_ngram_partial_task(
customized->bgraph, params);
task_config[op] =
std::make_tuple(1, 1, TASK_FIND_NGRAM_PARTIAL, variant_id);
} else if (name == "find_ngram_global") {
int variant_id = task_register->register_find_ngram_global_task(
customized->bgraph, params);
task_config[op] = std::make_tuple(2, 1, TASK_FIND_NGRAM_GLOBAL, variant_id);
} else if (name == "target_verify_greedy") {
int variant_id = task_register->register_target_verify_greedy_task(
customized->bgraph, params);
task_config[op] =
std::make_tuple(2, 1, TASK_TARGET_VERIFY_GREEDY, variant_id);
}
}
以register_embedding_task為例,其代碼如下:
int TaskRegister::register_embedding_task(threadblock::Graph const &bgraph,
std::vector<int> const ¶ms) {
assert(params.size() == 1);
// params[0]: input source (0: tokens, 1: input_token)
int batch_size = 0, output_size = 0, output_stride = 0;
std::vector<tb::TBInputOp *> input_ops;
std::vector<tb::TBInputOp *> output_ops;
int num_inputs = 2;
int num_outputs = 1;
assert(bgraph.operators.size() == (size_t)num_inputs + num_outputs);
for (auto const &op : bgraph.operators) {
assert(op->op_type == mirage::type::TB_INPUT_OP);
if (input_ops.size() < (size_t)num_inputs) {
input_ops.push_back(static_cast<tb::TBInputOp *>(op));
} else {
output_ops.push_back(static_cast<tb::TBInputOp *>(op));
}
}
assert(output_ops[0]->output_tensors[0].num_dims == 2);
batch_size = output_ops[0]->output_tensors[0].dim[0];
output_size = output_ops[0]->output_tensors[0].dim[1];
kn::KNInputOp *kn_input_op =
static_cast<kn::KNInputOp *>(output_ops[0]->dtensor.owner_op);
output_stride = static_cast<int>(kn_input_op->input_strides[0]);
mirage::transpiler::CodeKeeper code;
code.inc_indent();
code.e("kernel::embedding_kernel<bfloat16, $, $, $>(",
batch_size,
output_size,
output_stride);
if (params[0] == 0) {
code.e(" runtime_config.tokens + runtime_config.step[0], ");
} else if (params[0] == 1) {
code.e(" task_desc.inputs[0].base_ptr,");
}
code.e(" task_desc.inputs[1].base_ptr,");
code.e(" task_desc.outputs[0].base_ptr);");
return register_task_variant(TASK_EMBEDDING, code.to_string());
}
最終算子embedding_kernel定義如下:
namespace kernel {
template <typename T, int BATCH_SIZE, int CHUNK_SIZE, int OUTPUT_DIM_SIZE>
__device__ __forceinline__ void
embedding_kernel(void const *__restrict__ input_ptr,
void const *__restrict__ embedding_ptr,
void *__restrict__ output_ptr) {
int64_t const *__restrict__ input_ids =
static_cast<int64_t const *>(input_ptr);
T const *__restrict__ embedding = static_cast<T const *>(embedding_ptr);
T *__restrict__ output = static_cast<T *>(output_ptr);
#pragma unroll
for (int batch_idx = 0; batch_idx < BATCH_SIZE; batch_idx++) {
int64_t wordIdx = input_ids[batch_idx];
if (wordIdx >= 0) {
#pragma unroll
for (int i = threadIdx.x; i < CHUNK_SIZE; i += NUM_THREADS) {
output[batch_idx * OUTPUT_DIM_SIZE + i] =
embedding[wordIdx * OUTPUT_DIM_SIZE + i];
}
} else {
// TODO: This might not be necessary
for (int i = threadIdx.x; i < CHUNK_SIZE;
i += NUM_THREADS) { // writing 0 to output
output[batch_idx * OUTPUT_DIM_SIZE + i] = T(0.0f);
}
}
}
}
} // namespace kernel
2.2 注冊(cè)代碼
上述代碼TaskRegister::register_embedding_task 調(diào)用了 register_task_variant 函數(shù)來(lái)對(duì)all_task_variants 進(jìn)行設(shè)置。TaskRegister:register_*_task 函數(shù)(如 register_embedding_task, register_custom_task 等)會(huì)根據(jù) TaskBlock::Graph 和參數(shù)生成特定的 CUDA 調(diào)用代碼字符串,并將其注冊(cè)到 all_task_variants 中,返回該變體在向量中的索引(即 variant_id)。
TaskRegister 單例:
mirage::runtime::TaskRegister 是一個(gè)單例類,負(fù)責(zé)管理和注冊(cè)所有可能的任務(wù)變體代碼。它內(nèi)部維護(hù)一個(gè)映射:std::map<runtime::TaskType, std::vector<std::string> all_task_variants>。
all_task_variants 的作用是:存儲(chǔ)和管理不同類型任務(wù)的代碼變體。
- 鍵是任務(wù)類型(TaskType),task_type 指定了任務(wù)的大類(例如 TASK_EMBEDDING, TASK_ATTENTION_1, TASK_LINEAR_WITH_RESIDUAL 等)。
- 值是該類型任務(wù)的代表變體列表。
- all_task_variants為每種任務(wù)類型維護(hù)一個(gè)代碼變體集合。在register_task_variant中,會(huì)檢查是否存在相同的代碼變體,避免重復(fù)存儲(chǔ)。這樣可以允許同一種任務(wù)類型有不同的實(shí)現(xiàn)方式。variant_id 指定了同一任務(wù)類型下的具體變體(因?yàn)橥贿壿嬋蝿?wù)可能有多種不同的實(shí)現(xiàn)或參數(shù)配置)。
即,all_task_variants這個(gè)映射將每個(gè) TaskType 關(guān)聯(lián)到一個(gè)字符串向量,向量中的每個(gè)字符串代表該任務(wù)類型的一個(gè)具體實(shí)現(xiàn)代碼(通常是以字符串形式生成的 CUDA kernel 調(diào)用代碼)。
register_task_variant函數(shù)
register_task_variant函數(shù)代碼如下:
int TaskRegister::register_task_variant(runtime::TaskType type,
std::string const &code) {
std::vector<std::string> &variants = all_task_variants[type];
for (size_t i = 0; i < variants.size(); i++) {
if (variants[i] == code) {
return (int)(i);
}
}
// Add a new variant
variants.push_back(code);
return (int)(variants.size() - 1);
}
2.3 獲取代碼
回憶下,在生成任務(wù)圖時(shí),會(huì)做如下操作。
- 在 runtime.cc 的 register_mugraph 函數(shù)中,會(huì)遍歷 Graph 中的 KN_CUSTOMIZED_OP 操作符。
- 對(duì)于每個(gè)操作符,它會(huì)從 task_configs(即 Graph::task_config)中查找對(duì)應(yīng)的配置(輸入數(shù)、輸出數(shù)、TaskType, variant_id)。
- 創(chuàng)建 TaskDesc 結(jié)構(gòu)體,會(huì)將獲取到的 TaskType 和 variant_id 填入 TaskDesc。
運(yùn)行時(shí)獲取代碼的過(guò)程如下:
- 當(dāng)持久化內(nèi)核(persistent kernel)運(yùn)行時(shí),執(zhí)行到某個(gè) TaskDesc,它會(huì)根據(jù)其 task_type 和 variant_id進(jìn)行操作。
- task_type 指定了任務(wù)的大類(例如 TASK_EMBEDDING, TASK_ATTENTION_1, TASK_LINEAR_WITH_RESIDUAL 等)。
- variant_id 指定了同一任務(wù)類型下的具體變體(因?yàn)橥贿壿嬋蝿?wù)可能有多種不同的實(shí)現(xiàn)或參數(shù)配置)。
- 在 TaskRegister::all_task_variants 中找到對(duì)應(yīng)的任務(wù)類型向量。
- 使用 variant_id 作為索引,從該向量中取出預(yù)先生成好的 CUDA kernel 調(diào)用代碼字符串。
- 這個(gè)字符串通常會(huì)被編譯成實(shí)際的 kernel 函數(shù)(可能通過(guò) JIT 編譯或預(yù)先編譯的庫(kù)),然后通過(guò) CUDA API(如 cudaLaunchKernel 或類似的封裝)來(lái)執(zhí)行。
0x03 生成任務(wù)圖
3.1 入口
persistent_kernel.py 的 compile 函數(shù)會(huì)調(diào)用kn_graph.generate_task_graph來(lái)生成任務(wù)圖,即從計(jì)算圖生成cu文件。
def compile(
self,
**kwargs,
):
output_dir = kwargs.get("output_dir", None)
MIRAGE_ROOT, INCLUDE_PATH, DEPS_PATH = get_key_paths()
tempdir_obj = tempfile.TemporaryDirectory()
tempdir = tempdir_obj.name
results = self.kn_graph.generate_task_graph(num_gpus=self.world_size, my_gpu_id=self.mpi_rank)
generate_task_graph的代碼如下:
def generate_task_graph(self, num_gpus: int, my_gpu_id: int):
return self.cygraph.generate_task_graph(num_gpus, my_gpu_id)
3.2 runtime.cc主體
generate_task_graph 調(diào)用register_mugraph來(lái)進(jìn)行轉(zhuǎn)換(建立event和task),調(diào)用print_task_graph把代碼轉(zhuǎn)換出來(lái)。
TaskGraphResult Graph::generate_task_graph(int _num_gpus, int _my_gpu_id) {
std::vector<TaskDesc> all_tasks;
std::vector<EventDesc> all_events;
std::vector<TaskId> first_tasks;
int num_gpus, my_gpu_id;
std::map<kernel::KNOperator *, std::map<dim3, TaskId, Dim3Comparator>>
all_task_maps;
num_gpus = _num_gpus;
my_gpu_id = _my_gpu_id;
// add the termination event to the event lists
EventDesc e(EVENT_TERMINATION, 1, 0, 0);
all_events.push_back(e);
TaskDesc t(TASK_TERMINATE, 0 /*variant_id*/);
all_tasks.push_back(t);
register_mugraph(*this,
num_gpus,
my_gpu_id,
all_tasks,
all_events,
first_tasks,
all_task_maps,
task_config);
assert(sanity_check(*this, all_tasks, all_events, first_tasks));
return print_task_graph(*this,
num_gpus,
my_gpu_id,
all_tasks,
all_events,
first_tasks,
all_task_maps,
task_config,
io_config,
true /*use_json_format*/);
}
這些代碼都位于runtime.cc。
3.2.1 runtime.cc的功能
runtime.cc本質(zhì)是轉(zhuǎn)譯器,將高級(jí)內(nèi)核圖轉(zhuǎn)換為可以在持久化內(nèi)核運(yùn)行時(shí)系統(tǒng)中執(zhí)行的低級(jí)任務(wù)圖表示。
runtime.cc和persistent_kernel.py共同構(gòu)成了Mirage系統(tǒng)中持久化內(nèi)核執(zhí)行系統(tǒng)的核心部分。
- runtime.cc:C++實(shí)現(xiàn),負(fù)責(zé)底層的任務(wù)圖生成、事件管理和代碼生成。
- persistent_kernel.py:Python實(shí)現(xiàn),提供高層接口和抽象,用于定義和配置持久化內(nèi)核的數(shù)據(jù)流關(guān)系。
persistent_kernel.py中定義的內(nèi)核配置和圖結(jié)構(gòu)會(huì)被傳遞給runtime.cc,runtime.cc會(huì)使用這些信息生成實(shí)際的CUDA代碼和任務(wù)圖。兩者的協(xié)同工作流程如下:
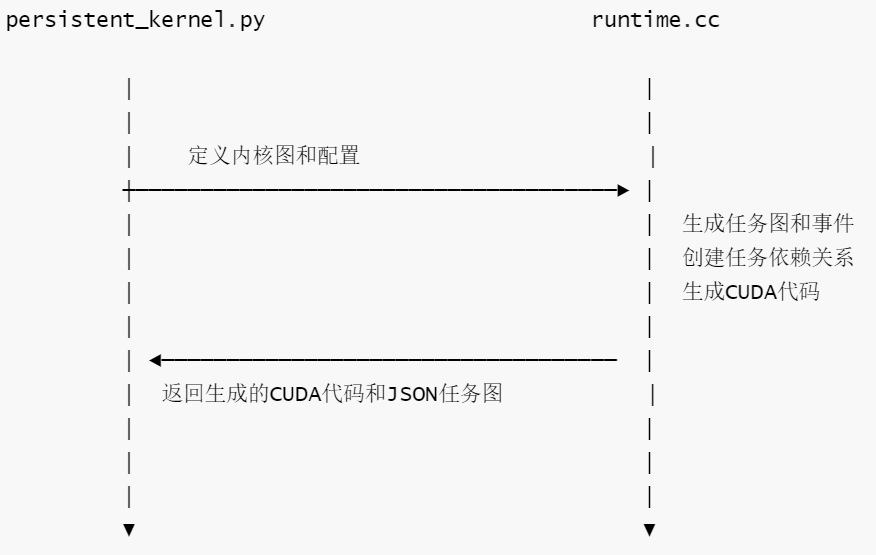
具體交互點(diǎn)如下:
- 任務(wù)配置傳遞。
- persistent_kernel.py的配置通過(guò)task_config傳遞給runtime.cc
- runtime.cc的register_mugraph函數(shù)使用這些配置來(lái)創(chuàng)建任務(wù)
- I/O配置傳遞
- persistent_kernel.py定義的I/O配置通過(guò)io_config傳遞給runtime.cc
- runtime.cc的print_task_graph函數(shù)使用這些配置來(lái)生成正確的內(nèi)存分配代碼。
- 代碼生成
- runtime.cc的print_task_graph函數(shù)生成實(shí)際的CUDA代碼,生成的代碼例如
_init_persistent_kernel和_execute_task函數(shù),這些生成的函數(shù)會(huì)被persistent_kernel.py使用,來(lái)執(zhí)行實(shí)際的內(nèi)核
- runtime.cc的print_task_graph函數(shù)生成實(shí)際的CUDA代碼,生成的代碼例如
- 事件和任務(wù)管理
- runtime.cc負(fù)責(zé)創(chuàng)建和管理事件及任務(wù)之間的依賴關(guān)系,這些事件(如EVENT_LAUNCH_TASKS)在兩個(gè)文件中都 被使用。
3.2.2 runtime.cc總體流程
runtime.cc總體流程如下:
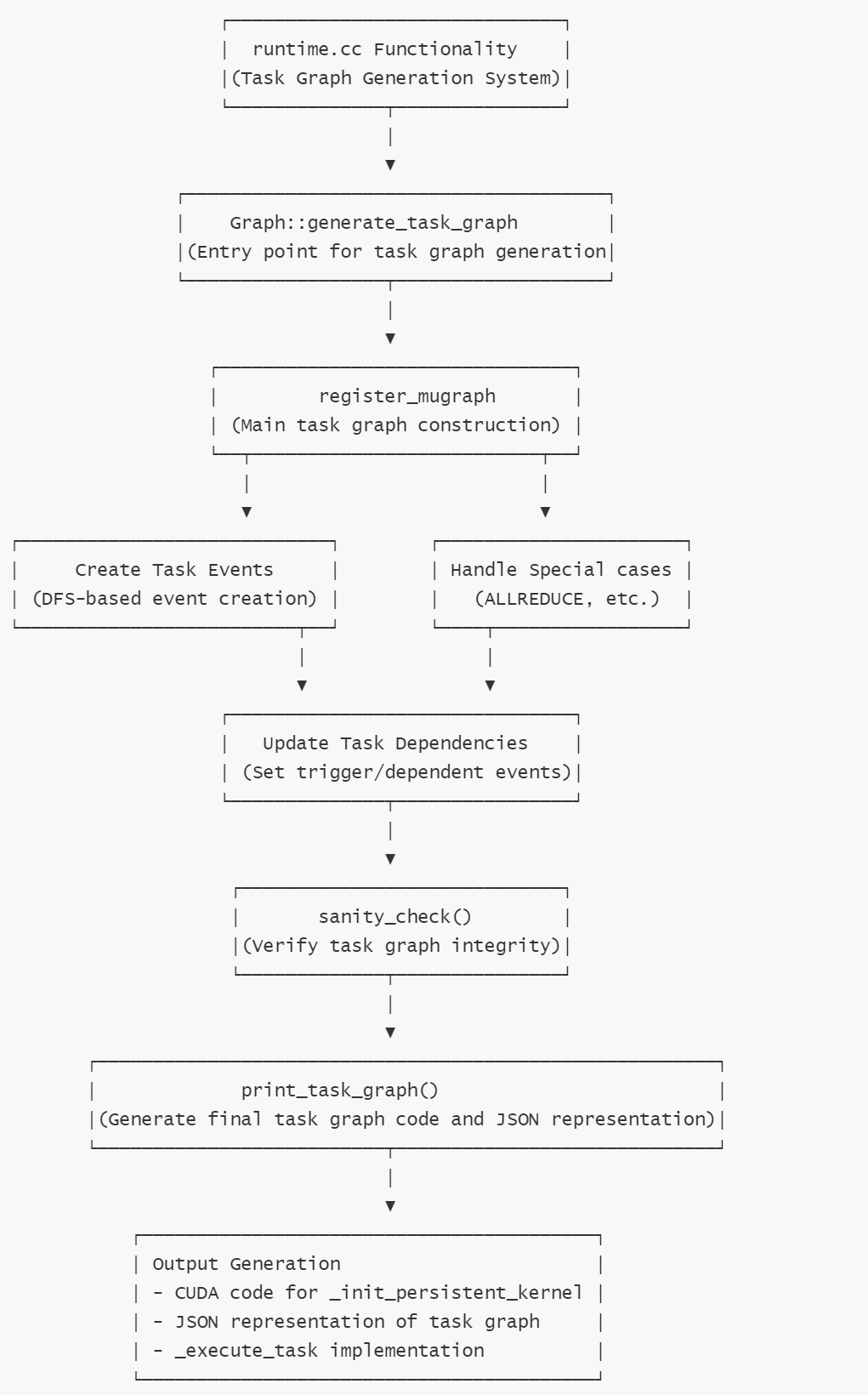
3.2.3 runtime.cc的具體函數(shù)
具體函數(shù)如下:
- generate_task_graph:主入口點(diǎn),協(xié)調(diào)整個(gè)任務(wù)圖的生成過(guò)程。
- register_mugraph:核心函數(shù),負(fù)責(zé):
1 將內(nèi)核圖轉(zhuǎn)換為任務(wù)和事件,即TaskDesc和EventDesc序列
2 處理特殊操作如ALLREDUCE。
3 使用事件設(shè)置任務(wù)間的正確依賴關(guān)系。
4 根據(jù)任務(wù)數(shù)量確定適當(dāng)?shù)氖录愋汀?br> 5 建立操作符到任務(wù)ID的映射關(guān)系 - dfs_create_events_add_tasks :遞歸函數(shù),負(fù)責(zé):
1 使用深度優(yōu)先搜索方法創(chuàng)建事件和任務(wù)。
2 處理多維任務(wù)分區(qū)。
3 在生成者和消費(fèi)者任務(wù)之間分配正確的依賴關(guān)系。 - sanity_check():驗(yàn)證函數(shù),負(fù)責(zé):
1 確保所有任務(wù)都能被執(zhí)行。
2 驗(yàn)證所有事件都能被觸發(fā)。 - print_task_graph:輸出生成函數(shù),負(fù)責(zé):
1 創(chuàng)建用于初始化持久化內(nèi)核的CUDA代碼
2 生成任務(wù)圖的JSON表示
3 生成執(zhí)行任務(wù)的設(shè)備函數(shù)
3.3 建立依賴關(guān)系
register_mugraph函數(shù)完成了從內(nèi)核圖(由KNOperator組成)到可執(zhí)行的任務(wù)圖的關(guān)鍵轉(zhuǎn)換過(guò)程:
- 圖結(jié)構(gòu)轉(zhuǎn)換:將 KNOperator 圖轉(zhuǎn)換為 TaskDesc 和 EventDesc 序列
- 依賴關(guān)系建立:通過(guò)事件機(jī)制建立任務(wù)間的依賴關(guān)系
- 分布式支持:特殊處理 ALLREDUCE 等分布式操作
- 任務(wù)映射:建立操作符到任務(wù)ID的映射關(guān)系
- 資源配置:為運(yùn)行時(shí)執(zhí)行準(zhǔn)備必要的任務(wù)和事件描述
register_mugraph函數(shù)是連接計(jì)算圖定義和實(shí)際 GPU 執(zhí)行的重要橋梁。
3.3.1 流程
具體流程如下:
- 初始化任務(wù)圖結(jié)構(gòu)
- 添加開(kāi)始任務(wù)和事件來(lái)啟動(dòng)依賴任務(wù)。
- 遍歷圖中所有操作符。
- 特殊處理ALLREDUCE操作等分布式操作。
- 創(chuàng)建NVSHMEM復(fù)制任務(wù)用于跨GPU數(shù)據(jù)傳輸
- 創(chuàng)建REDUCE任務(wù)用于規(guī)約操作。
- 為每個(gè)操作創(chuàng)建任務(wù)描述
- 創(chuàng)建操作間依賴事件。
- 特殊處理ALLREDUCE操作等分布式操作。
- 更新觸發(fā)事件。
其中, num_shared_tensors 變量的作用時(shí)統(tǒng)計(jì)當(dāng)前操作符與前一個(gè)操作符之間共享的張量數(shù)量。當(dāng)找到共享變量時(shí),會(huì)記錄下相關(guān)的映射信息,這些信息會(huì)在后續(xù)創(chuàng)建事件和任務(wù)時(shí)會(huì)使用。

3.3.2 結(jié)果
register_mugraph生成的主要結(jié)果為:
- 任務(wù)描述列表all_tasks:
- 包含所有需要執(zhí)行的任務(wù)描述(TaskDesc)
- 每個(gè)任務(wù)包含任務(wù)類型、變體ID、輸入輸出張量等描述信息。
- 任務(wù)按照?qǐng)?zhí)行順序排列。
- 事件描述列表all_events:
- 包含所有事件的描述(EventDesc)。
- 每個(gè)事件描述包含事件類型、觸發(fā)任務(wù)數(shù)量、任務(wù)ID范圍等。
- 控制任務(wù)間的依賴關(guān)系和執(zhí)行順序。
- 首任務(wù)列表 first_tasks
- 包含任務(wù)圖中第一批可以執(zhí)行的任務(wù)ID
- 任務(wù)映射表 all_tasks_maps
- 映射每個(gè)操作符到其對(duì)應(yīng)的任務(wù)ID映射表
- 用于定位特定操作符生成的任務(wù)。
后續(xù)print_task_graph會(huì)利用這些生成結(jié)果。
3.3.3 代碼
register_mugraph具體代碼如下:
void register_mugraph( // 接受一個(gè)kernel圖,GPU數(shù)量,當(dāng)前GPU ID,以及任務(wù)和事件相關(guān)容器
mirage::kernel::Graph const &graph,
int num_gpus,
int my_gpu_id,
std::vector<TaskDesc> &all_tasks,
std::vector<EventDesc> &all_events,
std::vector<TaskId> &first_tasks,
std::map<kernel::KNOperator *, std::map<dim3, TaskId, Dim3Comparator>>
&all_task_maps,
std::unordered_map<kn::KNOperator const *,
std::tuple<int, int, TaskType, int>> const
&task_configs) {
// push a begin-graph task and a event to launch dependent asks
// 添加一個(gè)開(kāi)始任務(wù)圖的事件和任務(wù),即初始化任務(wù)圖結(jié)構(gòu)
{
EventDesc e(EVENT_LAUNCH_DEPENDENT_TASKS, 1, 0, 0);
TaskDesc t(TASK_BEGIN_TASK_GRAPH, 0 /*variant_id*/);
// 設(shè)置任務(wù)觸發(fā)事件ID
t.trigger_event = get_event_id(my_gpu_id, all_events.size(), false);
all_tasks.push_back(t);
all_events.push_back(e);
}
// 保存前一個(gè)操作的輸出操作符和映射關(guān)系
std::vector<tb::TBInputOp *> pre_output_ops;
kn::KNCustomizedOp const *pre_op = nullptr;
std::map<dim3, TaskId, Dim3Comparator> pre_task_map;
// 遍歷圖中所有的操作符
for (auto const &op : graph.operators) {
// 跳過(guò)輸入操作符
if (op->op_type == type::KNOperatorType::KN_INPUT_OP) {
continue;
}
// 獲取當(dāng)前操作的任務(wù)配置
std::tuple<int, int, TaskType, int> task_config =
task_configs.find(op)->second;
// 獲取當(dāng)前操作的任務(wù)映射
std::map<dim3, TaskId, Dim3Comparator> cur_task_map;
assert(op->op_type == type::KNOperatorType::KN_CUSTOMIZED_OP);
// Customized op
// 將操作轉(zhuǎn)換為自定義操作類型
kn::KNCustomizedOp const *cur_op =
dynamic_cast<kn::KNCustomizedOp const *>(op);
// 獲取線程塊圖
tb::Graph const &bgraph = cur_op->bgraph;
dim3 bid;
// 存儲(chǔ)任務(wù)描述的向量
std::vector<TaskDesc> tasks;
// 存儲(chǔ)輸入輸出操作符
std::vector<tb::TBInputOp *> input_ops;
std::vector<tb::TBInputOp *> output_ops;
// 從配置中獲取輸入輸出數(shù)量和任務(wù)類型
int num_inputs = std::get<0>(task_config);
int num_outputs = std::get<1>(task_config);
TaskType task_type = std::get<2>(task_config);
int variant_id = std::get<3>(task_config);
// 確保操作符數(shù)量為輸出輸出之和
assert(bgraph.operators.size() == (size_t)num_inputs + num_outputs);
// 分離輸入輸出操作符
for (auto const &op : bgraph.operators) {
assert(op->op_type == mirage::type::TB_INPUT_OP);
if (input_ops.size() < (size_t)num_inputs) {
input_ops.push_back(static_cast<tb::TBInputOp *>(op));
} else {
output_ops.push_back(static_cast<tb::TBInputOp *>(op));
}
}
// Specical handling for ALLREDUCE
if (task_type == TASK_ALLREDUCE) {
// Shouldn't have AllReduce when num_gpus == 1
assert(num_gpus > 1); // 需要多個(gè)GPU
assert(input_ops.size() == 2); // 確保輸入輸出數(shù)量正確
assert(output_ops.size() == 1);
// To simplify the implementation, asserting that
// produce/consumer must have the same partition
int num_shared_tensors = 0;
int3 input_map, output_map;
// 查找共享張量并獲取映射關(guān)系
for (auto const &input : input_ops) {
for (auto const &output : pre_output_ops) {
if (input->dtensor.guid == output->dtensor.guid) {
input_map = input->input_map;
output_map = output->input_map;
num_shared_tensors++;
}
}
}
assert(num_shared_tensors == 1); // 確保有一個(gè)共享張量
assert(input_map == output_map); // 確保映射關(guān)系相同且網(wǎng)格維度一致
assert(bgraph.grid_dim == pre_op->bgraph.grid_dim);
dim3 bid;
// 存儲(chǔ)ALLGather前任務(wù)映射
std::map<dim3, std::map<int, TaskId>, Dim3Comparator> ag_pre_task_map;
// 遍歷所有線程塊維度
for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) {
for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) {
for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) {
// event_desc_0 is the trigger_event of previous_task
// event_desc_1 is the trigger_event of allgather
// 創(chuàng)建事件描述,用于觸發(fā)前一個(gè)任務(wù)
EventDesc event_desc_0;
event_desc_0.event_type = EVENT_LAUNCH_TASKS;
event_desc_0.num_triggers = 1;
event_desc_0.first_task_id = all_tasks.size();
event_desc_0.last_task_id = all_tasks.size() + num_gpus - 1;
// 確保前一個(gè)任務(wù)映射中存在當(dāng)前塊
assert(pre_task_map.find(bid) != pre_task_map.end());
int task_id = pre_task_map.find(bid)->second;
// 設(shè)置前一個(gè)任務(wù)的觸發(fā)事件
all_tasks[task_id].trigger_event =
get_event_id(my_gpu_id, all_events.size(), false);
all_events.push_back(event_desc_0);
// Step 1: create (num_gpus - 1) tasks for allgather
std::map<int, TaskId> pre_tasks;
for (int tgt_gpu_id = 0; tgt_gpu_id < num_gpus; tgt_gpu_id++) {
if (tgt_gpu_id == my_gpu_id) {
continue; // 跳過(guò)當(dāng)前GPU
}
// 創(chuàng)建 TASK_NVSHMEM_COPY 復(fù)制任務(wù)
TaskDesc task(TASK_NVSHMEM_COPY, 0 /*variant_id*/);
// task.trigger_event = get_event_id(
// tgt_gpu_id, all_events.size(), true /*nvshmem_event*/);
// Initialize input tensors to the task
{
TensorDesc desc;
assert(input_ops[0]->output_tensors.size() == 1);
tb::STensor stensor = input_ops[0]->output_tensors[0];
desc.num_dims = stensor.num_dims;
desc.data_type = stensor.data_type;
for (int d = stensor.num_dims - 1; d >= 0; d--) {
desc.dim[d] = stensor.dim[d];
desc.stride[d] = (d == stensor.num_dims - 1)
? 1
: desc.stride[d + 1] *
input_ops[0]->dtensor.dim[d + 1];
}
task.inputs[task.num_inputs++] = desc;
}
// Initialize output tensors to the task
{
TensorDesc desc;
assert(input_ops[1]->output_tensors.size() == 1);
tb::STensor stensor = input_ops[1]->output_tensors[0];
desc.num_dims = stensor.num_dims;
desc.data_type = stensor.data_type;
for (int d = stensor.num_dims - 1; d >= 0; d--) {
desc.dim[d] = stensor.dim[d];
desc.stride[d] = (d == stensor.num_dims - 1)
? 1
: desc.stride[d + 1] *
input_ops[1]->dtensor.dim[d + 1];
}
task.outputs[task.num_outputs++] = desc;
}
all_tasks.push_back(task);
pre_tasks[tgt_gpu_id] = all_tasks.size() - 1;
} // for tgt_gpu_id
ag_pre_task_map[bid] = pre_tasks;
} // for bid.z
} // for bid.y
} // for bid.x
// 遍歷所有線程塊維度,處理reduce 任務(wù)
for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) {
for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) {
for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) {
// event_desc_1 is the trigger_event of allgather
// 創(chuàng)建allgather 的觸發(fā)事件
EventDesc event_desc_1;
event_desc_1.event_type = EVENT_LAUNCH_TASKS;
event_desc_1.first_task_id = all_tasks.size();
event_desc_1.last_task_id = all_tasks.size() + 1;
event_desc_1.num_triggers = num_gpus - 1;
// 確保存在當(dāng)前任務(wù)映射
assert(ag_pre_task_map.find(bid) != ag_pre_task_map.end());
std::map<int, TaskId> pre_tasks = ag_pre_task_map.find(bid)->second;
// 設(shè)置所有前任務(wù)的觸發(fā)事件
for (auto const &t : pre_tasks) {
all_tasks[t.second].trigger_event =
get_event_id(t.first, all_events.size(), true);
}
all_events.push_back(event_desc_1);
// Step 2: create a task for reduce
TaskDesc task(TASK_REDUCE, 0 /*variant_id*/);
// 初始化輸入張量
for (int i = 0; i < 2; i++) {
TensorDesc desc;
tb::STensor stensor = input_ops[i]->output_tensors[0];
desc.num_dims = stensor.num_dims;
desc.data_type = stensor.data_type;
for (int d = stensor.num_dims - 1; d >= 0; d--) {
desc.dim[d] = stensor.dim[d];
desc.stride[d] =
(d == stensor.num_dims - 1)
? 1
: desc.stride[d + 1] * input_ops[1]->dtensor.dim[d + 1];
}
task.inputs[task.num_inputs++] = desc;
}
// Create output tensor
{
TensorDesc desc;
tb::STensor stensor = output_ops[0]->output_tensors[0];
desc.num_dims = stensor.num_dims;
desc.data_type = stensor.data_type;
for (int d = stensor.num_dims - 1; d >= 0; d--) {
desc.dim[d] = stensor.dim[d];
desc.stride[d] = (d == stensor.num_dims - 1)
? 1
: desc.stride[d + 1] *
output_ops[0]->dtensor.dim[d + 1];
}
task.inputs[task.num_outputs++] = desc;
all_tasks.push_back(task);
// Update current task map
// 當(dāng)前任務(wù)映射
cur_task_map[bid] = all_tasks.size() - 1;
}
}
}
}
// 更新前操作相關(guān)變量
pre_output_ops = output_ops;
pre_op = cur_op;
pre_task_map = cur_task_map;
all_task_maps.emplace(op, cur_task_map);
continue;
}
// Step 1: add all tasks based on their blockIdx
// (bid.x, bid.y, bid.z) ordering
// 根據(jù) blockIdx 添加所有任務(wù) (bid.x, bid.y, bid.z)的順序
for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) {
for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) {
for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) {
TaskDesc task(task_type, variant_id); // 創(chuàng)建任務(wù)描述
// Initialize input tensors to the task
for (auto const &input : input_ops) { // 初始化任務(wù)的輸入張量
TensorDesc desc;
assert(input->output_tensors.size() == 1);
tb::STensor stensor = input->output_tensors[0];
desc.num_dims = stensor.num_dims;
desc.data_type = stensor.data_type;
for (int d = stensor.num_dims - 1; d >= 0; d--) {
desc.dim[d] = stensor.dim[d];
desc.stride[d] =
(d == stensor.num_dims - 1)
? 1
: desc.stride[d + 1] * input->dtensor.dim[d + 1];
}
task.inputs[task.num_inputs++] = desc;
}
// Initialize output tensors to the task
for (auto const &output : output_ops) { // 初始化任務(wù)的輸出張量
TensorDesc desc;
assert(output->output_tensors.size() == 1);
tb::STensor stensor = output->output_tensors[0];
desc.num_dims = stensor.num_dims;
desc.data_type = stensor.data_type;
for (int d = stensor.num_dims - 1; d >= 0; d--) {
desc.dim[d] = stensor.dim[d];
desc.stride[d] =
(d == stensor.num_dims - 1)
? 1
: desc.stride[d + 1] * output->dtensor.dim[d + 1];
}
task.outputs[task.num_outputs++] = desc;
}
tasks.push_back(task);
}
}
}
// Step 2: create events between operators
// 在操作符之間創(chuàng)建事件
if (pre_op == nullptr) {
// 如果是第一個(gè)操作符,添加到first_tasks
dim3 bid;
for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) {
for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) {
for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) {
cur_task_map[bid] = all_tasks.size();
int offset = bid.x * bgraph.grid_dim.y * bgraph.grid_dim.z +
bid.y * bgraph.grid_dim.z + bid.z;
first_tasks.push_back(all_tasks.size());
all_tasks.push_back(tasks[offset]);
}
}
}
} else {
// Step 2.1: analyze dependencies between thread blocks of the two ops
// 分析兩個(gè)操作之間線程塊的依賴關(guān)系
std::vector<int> producer_partition(mirage::config::MAX_TENSOR_DIMS, 1);
std::vector<int> consumer_partition(mirage::config::MAX_TENSOR_DIMS, 1);
int num_shared_tensors = 0;
int3 input_map, output_map;
// 查找共享張量并獲取映射關(guān)系
for (auto const &input : input_ops) {
for (auto const &output : pre_output_ops) {
if (input->dtensor.guid == output->dtensor.guid) {
input_map = input->input_map;
output_map = output->input_map;
num_shared_tensors++;
}
}
}
// assert that their is at least a single tensor shared between ops
assert(num_shared_tensors >= 1); // 確保至少有一個(gè)共享張量
// 設(shè)置生產(chǎn)者和消費(fèi)者的分區(qū)
for (int d = 0; d < mirage::config::MAX_TENSOR_DIMS; d++) {
if (d == input_map.x) {
consumer_partition[d] = bgraph.grid_dim.x;
}
if (d == input_map.y) {
consumer_partition[d] = bgraph.grid_dim.y;
}
if (d == input_map.z) {
consumer_partition[d] = bgraph.grid_dim.z;
}
if (d == output_map.x) {
producer_partition[d] = pre_op->bgraph.grid_dim.x;
}
if (d == output_map.y) {
producer_partition[d] = pre_op->bgraph.grid_dim.y;
}
if (d == output_map.z) {
producer_partition[d] = pre_op->bgraph.grid_dim.z;
}
}
// Step 2.2: create events and add tasks 創(chuàng)建事件并添加任務(wù)
// number of events is the product of gcd of producer/consumer
std::vector<int> event_dims(mirage::config::MAX_TENSOR_DIMS, 1);
for (int d = 0; d < mirage::config::MAX_TENSOR_DIMS; d++) {
event_dims[d] = std::gcd(producer_partition[d], consumer_partition[d]);
}
// 利用深度優(yōu)先搜索創(chuàng)建事件和添加任務(wù)
dfs_create_events_add_tasks(0, /*depth*/
my_gpu_id, /*my_gpu_id*/
event_dims, /*event_dims*/
input_map, /*input_map*/
output_map, /*output_map*/
bgraph.grid_dim, /*consumer_grid_dim*/
pre_op->bgraph.grid_dim, /*producer_grid_dim*/
dim3(0, 0, 0), /*consumer_lo_bid*/
bgraph.grid_dim, /*consumer_hi_bid*/
dim3(0, 0, 0), /*producer_lo_bid*/
pre_op->bgraph.grid_dim, /*producer_hi_bid*/
all_events,
all_tasks,
tasks, /*cur_op_tasks*/
pre_task_map, /*pre_task_map*/
cur_task_map /*cur_task_map)*/);
}
pre_output_ops = output_ops;
pre_op = cur_op;
pre_task_map = cur_task_map;
all_task_maps.emplace(op, cur_task_map);
}
// Update the trigger event for all tasks in pre_task_map
for (auto const &it : pre_task_map) {
all_tasks[it.second].trigger_event =
get_event_id(my_gpu_id, all_events.size(), false /*nvshmem_event*/);
}
// 添加任務(wù)圖結(jié)束事件
all_events.push_back(
EventDesc(EVENT_END_OF_TASK_GRAPH, pre_task_map.size(), 0, 0));
// Prelaunch all tasks at the begining of an iteration
// 迭代開(kāi)始時(shí),預(yù)啟動(dòng)所有任務(wù)
all_events[1].first_task_id = 2;
all_events[1].last_task_id = all_tasks.size();
for (size_t e = 2; e < all_events.size(); e++) {
// 對(duì)于任務(wù)啟動(dòng)事件,將其轉(zhuǎn)換為空事件
if (all_events[e].event_type == EVENT_LAUNCH_TASKS ||
all_events[e].event_type == EVENT_LAUNCH_MASSIVE_TASKS) {
all_events[e].event_type = EVENT_EMPTY;
// 為相關(guān)任務(wù)設(shè)置依賴事件
for (size_t t = all_events[e].first_task_id;
t < all_events[e].last_task_id;
t++) {
all_tasks[t].dependent_event =
get_event_id(my_gpu_id, e, false /*nvshmem_event*/);
}
}
}
}
3.4 輸出代碼
print_task_graph包括兩部分。
- 代碼生成:在print_task_graph中生成完整的CUDA源文件。
- 文件輸出:將生成的CUDA代碼寫入.cu文件供后續(xù)編譯使用。
上述方式允許系統(tǒng)根據(jù)計(jì)算圖結(jié)構(gòu)動(dòng)態(tài)生成優(yōu)化的CUDA kernel代碼。

3.4.1 邏輯
print_task_graph接受register_mugraph生成的所有關(guān)鍵數(shù)據(jù)結(jié)構(gòu):
- all_tasks:包含所有任務(wù)描述的向量。
- all_events:包含所有事件描述的向量。
- first_tasks:包含第一批任務(wù)ID的向量。
- all_task_maps:操作符到任務(wù)的映射表。
print_task_graph生成的CUDA代碼包括:
- 任務(wù)圖構(gòu)造函數(shù) construct_task_graph
- 任務(wù)和事件的初始化代碼 _init_persistent_kernel。
- 內(nèi)存分配代碼(CUDA,NVSHMEM張量)
- _execute_task
print_task_graph生成的JSON包括
- 從task_graph.json文件讀取任務(wù)信息
- 解析任務(wù)輸入輸出張量描述
- 重建完整的任務(wù)結(jié)構(gòu)。
print_task_graph 利用如下信息生成任務(wù)依賴關(guān)系。
- all_tasks中的trigger_event和dependent_event字段
- all_events中的事件觸發(fā)關(guān)系
- first_tasks確定任務(wù)圖的入口點(diǎn)。
3.4.2 代碼
print_task_graph具體代碼如下:
TaskGraphResult print_task_graph(
// 函數(shù)參數(shù):內(nèi)核圖、GPU數(shù)量、當(dāng)前GPU ID、所有任務(wù)描述、所有事件描述、首任務(wù)列表
mirage::kernel::Graph const &graph,
int num_gpus,
int my_gpu_id,
std::vector<TaskDesc> const &all_tasks,
std::vector<EventDesc> const &all_events,
std::vector<TaskId> const &first_tasks,
// 所有操作符到任務(wù)映射的映射
std::map<kernel::KNOperator *, std::map<dim3, TaskId, Dim3Comparator>> const
&all_task_maps,
// 操作符到任務(wù)設(shè)置的映射
std::unordered_map<kn::KNOperator const *,
std::tuple<int, int, TaskType, int>> const &task_configs,
// 輸入輸出配置映射
std::map<mirage::type::GuidType, IODesc> const &io_configs,
bool use_json_format) {
using mirage::runtime::IODesc;
// 創(chuàng)建代碼生成器實(shí)例
mirage::transpiler::CodeKeeper code;
mirage::transpiler::CodeKeeper tgbody;
tgbody.inc_indent();
// 添加必要的頭文件包含
code.e("#include \"persistent_kernel.cuh\"");
if (use_json_format) {
code.e("#include <nlohmann/json.hpp>");
code.e("#include <fstream>");
code.e("#include <filesystem>");
code.e("using json = nlohmann::json;");
}
// 添加運(yùn)行時(shí)命名空間聲明
code.e("using namespace mirage::runtime;");
// 生成獲取事件ID的函數(shù)
code.e("size_t get_event_id(int my_gpu_id, size_t event_pos, bool "
"nvshmem_event) {");
code.e("size_t event_id = ((static_cast<size_t>(my_gpu_id) << 32) | "
"event_pos);");
code.e("if (nvshmem_event) {");
code.e("event_id = event_id | EVENT_NVSHMEM_TAG;");
code.e("}");
code.e("return event_id;");
code.e("}");
code.e("");
// function that loads json file and generates task graph
// 如果使用JSON格式,生成從JSON文件構(gòu)造人物圖的函數(shù)
if (use_json_format) {
code.e("void construct_task_graph(int num_gpus,");
code.e(" int my_gpu_id,");
code.e(" std::vector<TaskDesc> &all_tasks,");
code.e(" std::vector<EventDesc> &all_events,");
code.e(" std::vector<TaskId> &first_tasks,");
code.e(" std::map<std::string, void*> const "
"&all_tensors) {");
code.e("std::filesystem::path file_path(__FILE__);");
code.e("std::ifstream "
"json_file(file_path.parent_path().string()+\"/task_graph.json\");");
code.e("nlohmann::json json_task_graph;");
code.e("json_file >> json_task_graph;");
// load tasks
// 加載任務(wù)
code.e("for (json const &task : json_task_graph[\"all_tasks\"]) {");
code.e("TaskDesc task_desc(static_cast<TaskType>(task.at(\"task_type\")),");
code.e(" task.at(\"variant_id\"));");
code.e("if (task.at(\"trigger_event\").is_number_integer()) {");
code.e("task_desc.trigger_event = task.at(\"trigger_event\").get<unsigned "
"long long int>();");
code.e("}");
code.e("else {");
code.e("assert(false);");
code.e("}");
code.e("if (task.at(\"dependent_event\").is_number_integer()) {");
code.e("task_desc.dependent_event = "
"task.at(\"dependent_event\").get<unsigned long long int>();");
code.e("}");
code.e("else {");
code.e("assert(false);");
code.e("}");
// load inputs 加載輸入張量
code.e("task_desc.num_inputs = 0;");
code.e("for (json const &tensor : task[\"inputs\"]) {");
code.e("TensorDesc input;");
code.e("std::string name = tensor.at(\"base_ptr\").get<std::string>();");
code.e("assert(all_tensors.find(name) != all_tensors.end());");
code.e("off_t offset = tensor.at(\"offset\").get<off_t>();");
code.e("input.base_ptr = static_cast<char*>(all_tensors.at(name))+offset;");
code.e(
"assert(tensor.at(\"dims\").size() == tensor.at(\"strides\").size());");
code.e("input.num_dims = tensor.at(\"dims\").size();");
code.e("input.data_type = tensor.at(\"data_type\").get<int>();");
code.e("for (int i = 0; i < input.num_dims; i++) {");
code.e("input.dim[i] = tensor[\"dims\"][i].get<int>();");
code.e("input.stride[i] = tensor[\"strides\"][i].get<int>();");
code.e("}");
code.e("task_desc.inputs[task_desc.num_inputs++] = input;");
code.e("}");
// load outputs 加載輸出張量
code.e("task_desc.num_outputs = 0;");
code.e("for (json const &tensor : task[\"outputs\"]) {");
code.e("TensorDesc output;");
code.e("std::string name = tensor.at(\"base_ptr\").get<std::string>();");
code.e("assert(all_tensors.find(name) != all_tensors.end());");
code.e("off_t offset = tensor.at(\"offset\").get<off_t>();");
code.e(
"output.base_ptr = static_cast<char*>(all_tensors.at(name))+offset;");
code.e(
"assert(tensor.at(\"dims\").size() == tensor.at(\"strides\").size());");
code.e("output.num_dims = tensor.at(\"dims\").size();");
code.e("output.data_type = tensor.at(\"data_type\").get<int>();");
code.e("for (int i = 0; i < output.num_dims; i++) {");
code.e("output.dim[i] = tensor[\"dims\"][i];");
code.e("output.stride[i] = tensor[\"strides\"][i];");
code.e("}");
code.e("task_desc.outputs[task_desc.num_outputs++] = output;");
code.e("}");
code.e("all_tasks.push_back(task_desc);");
code.e("}");
// load events 加載事件
code.e("for (json const &e : json_task_graph[\"all_events\"]) {");
code.e("EventType event_type = "
"static_cast<EventType>(e.at(\"event_type\").get<int>());");
code.e("int num_triggers = e.at(\"num_triggers\").get<int>();");
code.e("int first_task_id = e.at(\"first_task_id\").get<int>();");
code.e("int last_task_id = e.at(\"last_task_id\").get<int>();");
code.e("all_events.push_back(EventDesc(event_type, num_triggers, "
"first_task_id, last_task_id));");
code.e("}");
// load first tasks 加載首任務(wù)
code.e("for (json const &t : json_task_graph[\"first_tasks\"]) {");
code.e("first_tasks.push_back(t.get<int>());");
code.e("}");
code.e("}");
code.e("");
}
// 生成初始化持久內(nèi)核的函數(shù)
code.e(
"static void _init_persistent_kernel(std::vector<TaskDesc> &all_tasks,");
code.e(" std::vector<EventDesc> "
"&all_events,");
code.e(" std::vector<TaskId> &first_tasks,");
code.e(" int num_gpus,");
code.e(" int my_gpu_id) {");
code.e("assert(num_gpus = $);", num_gpus);
if (use_json_format) {
// 創(chuàng)建張量映射
code.e("std::map<std::string, void*> all_tensors;");
}
for (auto const &iter : io_configs) { // 輸出輸入輸出配置
IODesc desc = iter.second;
switch (desc.type) {
case IODesc::TorchTensor: { // 處理Torch張量
code.e("char *$ = (char*)($);", desc.name, desc.torch_data_ptr);
if (use_json_format) {
code.e("all_tensors[\"$\"] = $;", desc.name, desc.name);
}
break;
}
case IODesc::FusedTorchTensor: { // 處理融合張量
for (auto const &sdesc : desc.sub_descs) {
code.e("char *$ = (char*)($);", sdesc.name, sdesc.torch_data_ptr);
if (use_json_format) {
code.e("all_tensors[\"$\"] = $;", sdesc.name, sdesc.name);
}
}
break;
}
case IODesc::CUDAMallocTensor: { // 處理CUDA分配張量
code.e("void *$;", desc.name);
size_t size = mirage::type::get_datatype_size(
static_cast<type::DataType>(desc.tensor.data_type));
for (int i = 0; i < desc.tensor.num_dims; i++) {
size *= desc.tensor.dim[i];
}
code.e("cudaMalloc(&$, $);", desc.name, size);
if (use_json_format) {
code.e("all_tensors[\"$\"] = $;", desc.name, desc.name);
}
break;
}
case IODesc::NVSHMEMMallocTensor: { // 處理NVSHMEM分配張量
size_t size = mirage::type::get_datatype_size(
static_cast<type::DataType>(desc.tensor.data_type));
for (int i = 0; i < desc.tensor.num_dims; i++) {
size *= desc.tensor.dim[i];
}
code.e("void *$ = nvshmem_malloc($);", desc.name, size);
if (use_json_format) {
code.e("all_tensors[\"$\"] = $;", desc.name, desc.name);
}
break;
}
default:
assert(false);
}
}
json json_task_graph = { // 創(chuàng)建jSON任務(wù)圖對(duì)象
{"all_tasks", {}}, {"all_events", {}}, {"first_tasks", {}}};
// generate task[0] 終止任務(wù)
{
tgbody.e("all_tasks.push_back(TaskDesc(TASK_TERMINATE));");
json_task_graph["all_tasks"].push_back(
json{{"task_type", TASK_TERMINATE},
{"variant_id", 0},
{"inputs", {}},
{"outputs", {}},
{"trigger_event", EVENT_INVALID_ID},
{"dependent_event", EVENT_INVALID_ID}});
}
// generate task[1] 任務(wù)圖任務(wù),
{
tgbody.e("all_tasks.push_back(TaskDesc(TASK_BEGIN_TASK_GRAPH));");
json_task_graph["all_tasks"].push_back(
json{{"task_type", TASK_BEGIN_TASK_GRAPH},
{"variant_id", 0},
{"inputs", {}},
{"outputs", {}},
{"trigger_event",
get_event_id(my_gpu_id, 1 /*event_pos*/, false /*is_nvshmem*/)},
{"dependent_event", EVENT_INVALID_ID}});
}
// generate all other tasks 生成所有其它任務(wù)
size_t task_pos = 2;
for (auto const &op : graph.operators) {
if (op->op_type == type::KNOperatorType::KN_INPUT_OP) {
continue;
}
assert(op->op_type == type::KNOperatorType::KN_CUSTOMIZED_OP);
std::tuple<int, int, TaskType, int> task_config =
task_configs.find(op)->second;
assert(all_task_maps.find(op) != all_task_maps.end());
std::map<dim3, TaskId, Dim3Comparator> const &task_map =
all_task_maps.find(op)->second;
// Customized op
kn::KNCustomizedOp const *cur_op =
dynamic_cast<kn::KNCustomizedOp const *>(op);
tb::Graph const &bgraph = cur_op->bgraph;
dim3 bid;
std::vector<tb::TBInputOp *> input_ops;
std::vector<tb::TBInputOp *> output_ops;
int num_inputs = std::get<0>(task_config);
// int num_outputs = std::get<1>(task_config);
TaskType task_type = std::get<2>(task_config);
// 收集輸入和輸出操作
for (auto const &op : bgraph.operators) {
assert(op->op_type == mirage::type::TB_INPUT_OP);
if (input_ops.size() < (size_t)num_inputs) {
input_ops.push_back(static_cast<tb::TBInputOp *>(op));
} else {
output_ops.push_back(static_cast<tb::TBInputOp *>(op));
}
}
if (task_type == TASK_ALLREDUCE) { // 處理特殊任務(wù)
for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) {
for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) {
for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) {
// To perform allreduce, we first launch (num_gpus-1) tasks for
// allgather
for (int tgt_gpu_id = 0; tgt_gpu_id < num_gpus; tgt_gpu_id++) {
if (tgt_gpu_id == my_gpu_id) {
continue;
}
TaskDesc task_desc = all_tasks[task_pos];
assert(task_desc.task_type == TASK_NVSHMEM_COPY);
tgbody.e("http:// task[$]", task_pos);
tgbody.e("{");
tgbody.e("TaskDesc task_desc(static_cast<TaskType>($));",
task_desc.task_type);
bool is_nvshmem_event =
((task_desc.trigger_event & EVENT_NVSHMEM_TAG) > 0);
assert(is_nvshmem_event);
assert(task_desc.dependent_event != EVENT_INVALID_ID);
assert(task_desc.num_inputs == 1);
assert(task_desc.num_outputs == 1);
json json_task = {{"task_type", task_desc.task_type},
{"variant_id", task_desc.variant_id},
{"inputs", {}},
{"outputs", {}},
{"trigger_event", task_desc.trigger_event},
{"dependent_event", task_desc.dependent_event}};
off_t offset = 0;
// Add input
int3 input_map = input_ops[0]->input_map;
IODesc io_desc =
io_configs.find(input_ops[0]->dtensor.guid)->second;
if (input_map.x >= 0) {
size_t block_size =
io_desc.tensor.dim[input_map.x] / bgraph.grid_dim.x;
offset +=
block_size * bid.x * io_desc.tensor.stride[input_map.x];
}
if (input_map.y >= 0) {
size_t block_size =
io_desc.tensor.dim[input_map.y] / bgraph.grid_dim.y;
offset +=
block_size * bid.y * io_desc.tensor.stride[input_map.y];
}
if (input_map.z >= 0) {
size_t block_size =
io_desc.tensor.dim[input_map.z] / bgraph.grid_dim.z;
offset +=
block_size * bid.z * io_desc.tensor.stride[input_map.z];
}
tgbody.e("TensorDesc input$;", 0);
tgbody.e("input$.base_ptr = static_cast<char*>($) + $;",
0,
io_desc.name,
offset *
type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type)));
tgbody.e("input$.num_dims = $;", 0, task_desc.inputs[0].num_dims);
tgbody.e(
"input$.data_type = $;", 0, task_desc.inputs[0].data_type);
json json_dims = json::array(), json_strides = json::array();
for (int d = 0; d < task_desc.inputs[0].num_dims; d++) {
tgbody.e(
"input$.dim[$] = $;", 0, d, task_desc.inputs[0].dim[d]);
tgbody.e("input$.stride[$] = $;",
0,
d,
task_desc.inputs[0].stride[d]);
json_dims.push_back(task_desc.inputs[0].dim[d]);
json_strides.push_back(task_desc.inputs[0].stride[d]);
}
tgbody.e("task_desc.inputs[$] = input$;", 0, 0);
json_task["inputs"].push_back(json{
{"base_ptr", io_desc.name},
{"offset",
offset * type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type))},
{"data_type", task_desc.inputs[0].data_type},
{"dims", json_dims},
{"strides", json_strides}});
// Add nvshmem_copy output
// Note that nvshmem_copy's output is stored in input_ops[1]
offset = my_gpu_id * input_ops[0]->dtensor.num_elements();
int3 output_map = input_ops[1]->input_map;
io_desc = io_configs.find(input_ops[1]->dtensor.guid)->second;
if (output_map.x >= 0) {
size_t block_size =
io_desc.tensor.dim[output_map.x] / bgraph.grid_dim.x;
offset +=
block_size * bid.x * io_desc.tensor.stride[output_map.x];
}
if (output_map.y >= 0) {
size_t block_size =
io_desc.tensor.dim[output_map.y] / bgraph.grid_dim.y;
offset +=
block_size * bid.y * io_desc.tensor.stride[output_map.y];
}
if (output_map.z >= 0) {
size_t block_size =
io_desc.tensor.dim[output_map.z] / bgraph.grid_dim.z;
offset +=
block_size * bid.z * io_desc.tensor.stride[output_map.z];
}
tgbody.e("TensorDesc output$;", 0);
tgbody.e("output$.base_ptr = static_cast<char*>($) + $;",
0,
io_desc.name,
offset *
type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type)));
tgbody.e(
"output$.num_dims = $;", 0, task_desc.outputs[0].num_dims);
tgbody.e(
"output$.data_type = $;", 0, task_desc.outputs[0].data_type);
json_dims = json::array();
json_strides = json::array();
for (int d = 0; d < task_desc.outputs[0].num_dims; d++) {
tgbody.e(
"output$.dim[$] = $;", 0, d, task_desc.outputs[0].dim[d]);
tgbody.e("output$.stride[$] = $;",
0,
d,
task_desc.outputs[0].stride[d]);
json_dims.push_back(task_desc.outputs[0].dim[d]);
json_strides.push_back(task_desc.outputs[0].stride[d]);
}
tgbody.e("task_desc.outputs[$] = output$;", 0, 0);
json_task["outputs"].push_back(json{
{"base_ptr", io_desc.name},
{"offset",
offset * type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type))},
{"data_type", task_desc.outputs[0].data_type},
{"dims", json_dims},
{"strides", json_strides}});
tgbody.e("all_tasks.push_back(task_desc);");
json_task_graph["all_tasks"].push_back(json_task);
tgbody.e("}");
task_pos++;
} // for tgt_gpu_id
} // for bid.z
} // for bid.y
} // for bid.x
} // if task_type == TASK_ALLREDUCE
// 為每個(gè)線程塊生成任務(wù)
for (bid.x = 0; bid.x < bgraph.grid_dim.x; bid.x++) {
for (bid.y = 0; bid.y < bgraph.grid_dim.y; bid.y++) {
for (bid.z = 0; bid.z < bgraph.grid_dim.z; bid.z++) {
TaskId task_id = task_map.at(bid);
TaskDesc task_desc = all_tasks[task_pos];
assert(task_desc.task_type == task_type ||
task_type == TASK_ALLREDUCE);
assert(task_pos == (task_id & 0xffffffff));
tgbody.e("http:// task[$]", task_pos);
tgbody.e("{");
tgbody.e("TaskDesc task_desc(static_cast<TaskType>($));",
task_desc.task_type);
size_t gpu_id = ((task_desc.trigger_event >> 32) & 0xffff);
size_t event_pos = (task_desc.trigger_event & 0xffffffff);
bool is_nvshmem_event =
((task_desc.trigger_event & EVENT_NVSHMEM_TAG) > 0);
assert(gpu_id == my_gpu_id);
assert(!is_nvshmem_event);
json json_task; // 創(chuàng)建任務(wù)描述
json_task = {{"task_type", task_desc.task_type},
{"variant_id", task_desc.variant_id},
{"inputs", {}},
{"outputs", {}},
{"trigger_event", task_desc.trigger_event},
{"dependent_event", task_desc.dependent_event}};
for (int i = 0; i < task_desc.num_inputs; i++) { // 處理輸入張量
if (input_ops[i]->dtensor == kernel::DTensor::EMPTY_TENSOR) {
json json_dims = json::array();
json json_strides = json::array();
json_task["inputs"].push_back(
json{{"base_ptr", "nullptr"},
{"offset", 0},
{"data_type", type::DT_UNKNOWN},
{"dims", json_dims},
{"strides", json_strides}});
continue;
}
off_t offset = 0;
int num_dims = input_ops[i]->dtensor.num_dims;
int3 input_map = input_ops[i]->input_map;
IODesc io_desc =
io_configs.find(input_ops[i]->dtensor.guid)->second;
assert(input_ops[i]->dtensor.owner_op->op_type ==
type::KN_INPUT_OP);
if (io_desc.type == IODesc::FusedTorchTensor) { // 處理融合張量
// Currently assert that we fuse the 0-th dim (i.e., 0)
int fused_group_size = 0;
std::vector<int> group_sizes;
for (auto const &sub_desc : io_desc.sub_descs) {
assert(sub_desc.tensor.num_dims == num_dims);
assert(sub_desc.tensor.dim[0] % io_desc.num_groups == 0);
int my_group_size = sub_desc.tensor.dim[0] / io_desc.num_groups;
fused_group_size += my_group_size;
group_sizes.push_back(my_group_size);
}
assert(io_desc.tensor.dim[0] ==
fused_group_size * io_desc.num_groups);
assert(io_desc.tensor.num_dims == num_dims);
int fused_dim_off = 0;
if (input_map.x == 0) {
fused_dim_off =
io_desc.tensor.dim[0] / bgraph.grid_dim.x * bid.x;
}
if (input_map.y == 0) {
fused_dim_off =
io_desc.tensor.dim[0] / bgraph.grid_dim.y * bid.y;
}
if (input_map.z == 0) {
fused_dim_off =
io_desc.tensor.dim[0] / bgraph.grid_dim.z * bid.z;
}
int fused_dim_off_in_group = fused_dim_off % fused_group_size;
size_t index = 0;
while (index < group_sizes.size()) {
if (fused_dim_off_in_group >= group_sizes[index]) {
fused_dim_off_in_group -= group_sizes[index];
index++;
} else {
break;
}
}
IODesc sub_desc = io_desc.sub_descs[index];
int fused_dim_off_subtensor =
fused_dim_off / fused_group_size * group_sizes[index] +
fused_dim_off_in_group;
// Assert that it is within range
assert(fused_dim_off_subtensor < sub_desc.tensor.dim[0]);
if (input_map.x > 0) {
size_t block_size =
sub_desc.tensor.dim[input_map.x] / bgraph.grid_dim.x;
offset +=
block_size * bid.x * sub_desc.tensor.stride[input_map.x];
} else if (input_map.x == 0) {
offset += fused_dim_off_subtensor *
sub_desc.tensor.stride[input_map.x];
}
if (input_map.y > 0) {
size_t block_size =
sub_desc.tensor.dim[input_map.y] / bgraph.grid_dim.y;
offset +=
block_size * bid.y * sub_desc.tensor.stride[input_map.y];
} else if (input_map.y == 0) {
offset += fused_dim_off_subtensor *
sub_desc.tensor.stride[input_map.y];
}
if (input_map.z > 0) {
size_t block_size =
sub_desc.tensor.dim[input_map.z] / bgraph.grid_dim.z;
offset +=
block_size * bid.z * sub_desc.tensor.stride[input_map.z];
} else if (input_map.z == 0) {
offset += fused_dim_off_subtensor *
sub_desc.tensor.stride[input_map.z];
}
tgbody.e("TensorDesc input$;", i);
tgbody.e("input$.base_ptr = static_cast<char*>($) + $;",
i,
sub_desc.name,
offset *
type::get_datatype_size(static_cast<type::DataType>(
sub_desc.tensor.data_type)));
tgbody.e("input$.num_dims = $;", i, task_desc.inputs[i].num_dims);
tgbody.e(
"input$.data_type = $;", i, task_desc.inputs[i].data_type);
json json_dims = json::array();
json json_strides = json::array();
for (int d = 0; d < task_desc.inputs[i].num_dims; d++) {
tgbody.e(
"input$.dim[$] = $;", i, d, task_desc.inputs[i].dim[d]);
tgbody.e(
"input$.stride[$] = $;", i, d, sub_desc.tensor.stride[d]);
json_dims.push_back(task_desc.inputs[i].dim[d]);
json_strides.push_back(sub_desc.tensor.stride[d]);
}
tgbody.e("task_desc.inputs[$] = input$;", i, i);
json_task["inputs"].push_back(json{
{"base_ptr", sub_desc.name},
{"offset",
offset * type::get_datatype_size(static_cast<type::DataType>(
sub_desc.tensor.data_type))},
{"data_type", task_desc.inputs[i].data_type},
{"dims", json_dims},
{"strides", json_strides}});
} else {
// Non-fused case, use io_desc
if (input_map.x >= 0) {
size_t block_size =
io_desc.tensor.dim[input_map.x] / bgraph.grid_dim.x;
offset +=
block_size * bid.x * io_desc.tensor.stride[input_map.x];
}
if (input_map.y >= 0) {
size_t block_size =
io_desc.tensor.dim[input_map.y] / bgraph.grid_dim.y;
offset +=
block_size * bid.y * io_desc.tensor.stride[input_map.y];
}
if (input_map.z >= 0) {
size_t block_size =
io_desc.tensor.dim[input_map.z] / bgraph.grid_dim.z;
offset +=
block_size * bid.z * io_desc.tensor.stride[input_map.z];
}
tgbody.e("TensorDesc input$;", i);
tgbody.e("input$.base_ptr = static_cast<char*>($) + $;",
i,
io_desc.name,
offset *
type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type)));
tgbody.e("input$.num_dims = $;", i, task_desc.inputs[i].num_dims);
tgbody.e(
"input$.data_type = $;", i, task_desc.inputs[i].data_type);
json json_dims = json::array();
json json_strides = json::array();
for (int d = 0; d < task_desc.inputs[i].num_dims; d++) {
tgbody.e(
"input$.dim[$] = $;", i, d, task_desc.inputs[i].dim[d]);
tgbody.e("input$.stride[$] = $;",
i,
d,
task_desc.inputs[i].stride[d]);
json_dims.push_back(task_desc.inputs[i].dim[d]);
json_strides.push_back(task_desc.inputs[i].stride[d]);
}
tgbody.e("task_desc.inputs[$] = input$;", i, i);
json_task["inputs"].push_back(json{
{"base_ptr", io_desc.name},
{"offset",
offset * type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type))},
{"data_type", task_desc.inputs[i].data_type},
{"dims", json_dims},
{"strides", json_strides}});
}
}
for (int i = 0; i < task_desc.num_outputs; i++) {
off_t offset = 0;
int3 output_map = output_ops[i]->input_map;
IODesc io_desc =
io_configs.find(output_ops[i]->dtensor.guid)->second;
assert(io_desc.type != IODesc::FusedTorchTensor);
if (output_map.x >= 0) {
size_t block_size =
io_desc.tensor.dim[output_map.x] / bgraph.grid_dim.x;
offset +=
block_size * bid.x * io_desc.tensor.stride[output_map.x];
}
if (output_map.y >= 0) {
size_t block_size =
io_desc.tensor.dim[output_map.y] / bgraph.grid_dim.y;
offset +=
block_size * bid.y * io_desc.tensor.stride[output_map.y];
}
if (output_map.z >= 0) {
size_t block_size =
io_desc.tensor.dim[output_map.z] / bgraph.grid_dim.z;
offset +=
block_size * bid.z * io_desc.tensor.stride[output_map.z];
}
tgbody.e("TensorDesc output$;", i);
tgbody.e("output$.base_ptr = static_cast<char*>($) + $;",
i,
io_desc.name,
offset *
type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type)));
tgbody.e("output$.num_dims = $;", i, task_desc.outputs[i].num_dims);
tgbody.e(
"output$.data_type = $;", i, task_desc.outputs[i].data_type);
json json_dims = json::array();
json json_strides = json::array();
for (int d = 0; d < task_desc.outputs[i].num_dims; d++) {
tgbody.e(
"output$.dim[$] = $;", i, d, task_desc.outputs[i].dim[d]);
tgbody.e("output$.stride[$] = $;",
i,
d,
task_desc.outputs[i].stride[d]);
json_dims.push_back(task_desc.outputs[i].dim[d]);
json_strides.push_back(task_desc.outputs[i].stride[d]);
}
tgbody.e("task_desc.outputs[$] = output$;", i, i);
json_task["outputs"].push_back(json{
{"base_ptr", io_desc.name},
{"offset",
offset * type::get_datatype_size(static_cast<type::DataType>(
io_desc.tensor.data_type))},
{"data_type", task_desc.outputs[i].data_type},
{"dims", json_dims},
{"strides", json_strides}});
}
tgbody.e("all_tasks.push_back(task_desc);");
tgbody.e("}");
json_task_graph["all_tasks"].push_back(json_task);
task_pos++;
}
}
}
}
assert(task_pos == all_tasks.size()); // 驗(yàn)證任務(wù)位置
// Add all events
for (auto const &event : all_events) { // 添加所有事件
tgbody.e(
"all_events.push_back(EventDesc(static_cast<EventType>($), $, $, $));",
event.event_type,
event.num_triggers,
event.first_task_id,
event.last_task_id);
json_task_graph["all_events"].push_back(
json{{"event_type", event.event_type},
{"num_triggers", event.num_triggers},
{"first_task_id", event.first_task_id},
{"last_task_id", event.last_task_id}});
}
// Add first task 添加首任務(wù)
for (auto const &task : first_tasks) {
tgbody.e("first_tasks.push_back($);", task);
json_task_graph["first_tasks"].push_back(task);
}
if (use_json_format) {
// Add nullptr for tensors set as None
code.e("all_tensors[\"nullptr\"] = nullptr;");
code.e("construct_task_graph(num_gpus, my_gpu_id, all_tasks, all_events, "
"first_tasks, all_tensors);");
} else {
code.e(tgbody.to_string());
}
code.e("}");
code.e("");
// Generate task implementation 生成任務(wù)實(shí)現(xiàn)
std::map<TaskType, std::string> task_type_to_name;
task_type_to_name[TASK_EMBEDDING] = "TASK_EMBEDDING";
task_type_to_name[TASK_RMS_NORM_LINEAR] = "TASK_RMS_NORM_LINEAR";
task_type_to_name[TASK_ATTENTION_1] = "TASK_ATTENTION_1";
task_type_to_name[TASK_SILU_MUL_LINEAR_WITH_RESIDUAL] =
"TASK_SILU_MUL_LINEAR_WITH_RESIDUAL";
task_type_to_name[TASK_LINEAR_WITH_RESIDUAL] = "TASK_LINEAR_WITH_RESIDUAL";
task_type_to_name[TASK_ARGMAX_PARTIAL] = "TASK_ARGMAX_PARTIAL";
task_type_to_name[TASK_ARGMAX_REDUCE] = "TASK_ARGMAX_REDUCE";
task_type_to_name[TASK_FIND_NGRAM_PARTIAL] = "TASK_FIND_NGRAM_PARTIAL";
task_type_to_name[TASK_FIND_NGRAM_GLOBAL] = "TASK_FIND_NGRAM_GLOBAL";
task_type_to_name[TASK_TARGET_VERIFY_GREEDY] = "TASK_TARGET_VERIFY_GREEDY";
task_type_to_name[TASK_SINGLE_BATCH_EXTEND_ATTENTION] =
"TASK_SINGLE_BATCH_EXTEND_ATTENTION";
code.e("__device__ __forceinline__");
code.e("void _execute_task(TaskDesc const& task_desc,");
code.e(" RuntimeConfig const &runtime_config) {");
TaskRegister *task_register = TaskRegister::get_instance();
bool first_task = true;
for (auto const &task : task_register->all_task_variants) { // 為每個(gè)任務(wù)變體生成執(zhí)行代碼
for (size_t variant_id = 0; variant_id < task.second.size(); variant_id++) {
std::string cond = first_task ? "if" : "else if";
assert(task_type_to_name.find(task.first) != task_type_to_name.end());
code.e("$ (task_desc.task_type == $ && task_desc.variant_id == $) {",
cond,
task_type_to_name[task.first],
variant_id);
code.e("$", task.second[variant_id]);
code.e("}");
first_task = false;
}
}
code.e("}");
// Write json to output file
// std::ofstream out("task_graph.json");
// out << json_task_graph.dump(2);
// out.close();
TaskGraphResult result; // 創(chuàng)建結(jié)果對(duì)象并返回
result.cuda_code = code.to_string();
result.json_file = json_task_graph.dump(2);
return result;
}
0xFF 參考
如何評(píng)價(jià)CMU將LLM轉(zhuǎn)化為巨型內(nèi)核的Mirage Persistent Kernel(MPK)工作?
Mirage: A Multi-Level Superoptimizer for Tensor Programs 簡(jiǎn)記 塵伊光
OSDI2025論文筆記:Mirage: A Multi-Level Superoptimizer for Tensor Programs 畫餅充饑
Mirage: A Compiler for High-Performance Tensor Programs on GPUs
https://mirage-project.readthedocs.io/en/latest/mugraph.html
https://mirage-project.readthedocs.io/en/latest/transpiler.html

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)