
探秘Transformer系列之(35)--- 大模型量化基礎(chǔ)
探秘Transformer系列之(35)--- 大模型量化基礎(chǔ)
0x00 概述
將現(xiàn)有的量化技術(shù)直接應(yīng)用于大模型存在困難,會出現(xiàn)較大量化誤差和精度下降。這主要是因為大模型的特點是規(guī)模和復(fù)雜性。與較小的模型相比,大模型的權(quán)重和激活通常表現(xiàn)出更多的outlier(離群值),并且具有更寬的分布范圍。LLM.int()的作者就發(fā)現(xiàn):
-
與較小的模型不同,LLM 表現(xiàn)出獨特的權(quán)重和激活分布,其特點是存在大量的outlier。因為outlier 的存在,如果我們使用 INT8 量化,大多正常數(shù)值將被清零。
-
Emergent Features的phase shift出現(xiàn)在模型參數(shù)量達到6.7B時,這說明參數(shù)量在6.7B之前和在6.7B之后的模型表現(xiàn)非常不一樣。
這些異常值對量化過程有顯著影響,因為它們會增加量化步長,同時降低中間值的精度。因此,將參數(shù)量在6.7B之下的transformer模型上適用的方法泛化到參數(shù)量在6.7B以上的模型時要十分謹慎。比如,針對小型模型的最好的量化裁剪(clipping)方法對于LLM來說并不是開箱即用的。 這需要我們開發(fā)量身定制的量化技術(shù),以便在不影響模型性能或效率的情況下處理這些獨特的特征。
0x01 outlier
在模型內(nèi)部,數(shù)據(jù)通常以多維張量(可以理解為多維數(shù)組)表示。對于注意力機制,這些張量包含批次大小、序列長度、注意力頭數(shù)量和頭部維度等維度。而大規(guī)模值是指在LLM的注意力頭部維度中,某些元素的數(shù)值明顯高于該頭部其他維度平均值的情況(通常為5倍以上)。
1.1 定義
LLM.int8()作者給出了outlier的如下定義:
對于一個有 l 層的transformer,隱狀態(tài)(hidden state)為\(X_l ∈ R^{s×?},l=0…L\),其中s是sequence維度,?是feature維度。我們定義一個feature \(h_i\)為隱狀態(tài)\(X_{l_i}\)里面一個特定的維度。我們在所有層里面跟蹤每個維度\(h_i\),0≤i≤?, 如果某個維度滿足以下條件,我們稱之為一個outlier:
- 至少有一個值的絕對值(magnitude)大于等于6;
- 滿足條件1的\(h_i\)在transformer的至少25%的層里出現(xiàn);
- 滿足條件1的\(h_i\)至少在6%的sequence dimension的隱狀態(tài)中出現(xiàn)。

上面是一個outlier示例(一共有4個黃色的outliear feature),橫軸是hidden_dim維度,縱軸是sequence維度。上圖中seq_len = 3,所以一個outlier feature是一個3×1的向量。
1.2 特點
研究人員發(fā)現(xiàn),量化前權(quán)重和激活值分布的平坦度 (flatness) 是影響 LLM 量化誤差的關(guān)鍵因素。直觀來看,分布越平坦,離群值就越少,量化時的精度也就越高。激活和權(quán)重分布越不均勻時候,量化誤差越大。
下圖展示了激活和權(quán)重上異常值的特點。紅色為激活,綠色為異常值。

激活
對于激活來說,其異常值特點如下:
- 在訓(xùn)練開始后,殘差激活值迅速從高斯分布轉(zhuǎn)變?yōu)檫壿嫹植迹↙ogistic Distribution),并且出現(xiàn)較大的outlier。
- 當(dāng)模型參數(shù)超過某個閾值之后,異常點比例突然增大。
- 激活的每個channel在不同token分布相似,比如在某個token權(quán)重數(shù)值量級很大的channel,在其它token上數(shù)值量級也很大。
權(quán)重
對于權(quán)重來說,其異常值特點如下:
- 權(quán)重分布相當(dāng)均勻,平坦,易于量化。用 INT8 甚至 INT4 量化 LLM 的權(quán)重不會降低精度。
- FFN部分權(quán)重從隨機初始化的高斯分布,開始時較為穩(wěn)定;在訓(xùn)練一定階段后開始劇烈變化;隨后整體分布再次穩(wěn)定下來。權(quán)重整體保留了高斯分布,但是存在一些不是非常大的outlier。
- LLM的離群值很少,集中于確定的幾列,這幾列可能存儲了一些上下文無關(guān)的信息。
- 另外,在具有門控線性單元(GLU)的模型中,激活和權(quán)重大多是對稱分布的,使得使用對稱量化成為最佳選擇。
梯度
梯度分布的變化趨勢與權(quán)重類似,訓(xùn)練過程也未出現(xiàn)較大的outlier,說明梯度本身也具備較好的穩(wěn)定性,存在低精度計算和存儲的可能性。
1.3 出現(xiàn)過程
LLM.int8()作者Tim Dettmers在其博客 LLM.int8() and Emergent Features 中提到了Emergent Features這個概念。Emergent Features就是Emergent outlier features。
The other pitch talks about emergent outliers in transformers and how they radically change what transformers learn and how they function.
This blog post is a more speculative version of the paper that teases out the super curious details about the fascinating properties surrounding the emergent outlier features I found.
“Emergent”描述的是這些離群值逐漸增長,并在經(jīng)歷phase shift(指離群值會突然迅速增長的現(xiàn)象)之后,對模型性能產(chǎn)生嚴重影響的現(xiàn)象。此處的增長是指:離群值的數(shù)值變大,數(shù)量變多,受該離群值影響的token數(shù)和模型層數(shù)變多。
LLM.int8()論文中的實驗發(fā)現(xiàn),在我們把transformers規(guī)模擴大到6B的時候,異常值首次在25%的transformer層出現(xiàn),然后逐漸向其它層擴散。當(dāng)模型達到6.7B的時候,所有的transformer層都會受到異常值的影響,受到影響的sequence維度也從35%擴大到75%。它們的分布在所有的transformer層中集中在6個feature維度。下圖展示了 Transformer 中,受到異常值特征影響的層的百分比和序列維度的百分比,這些數(shù)值和模型大小存在相關(guān)性。

論文作者在博客中也介紹了Emergent Features隨著模型參數(shù)量的增加而增長的過程。
- 即使在參數(shù)量為125M的比較小的Transformer模型中,Emergent Features也是存在的。但此時Emergent Features只存在注意力投影層(attention projection, query/key/value/output)的輸出中。
- 當(dāng)Transformer模型的參數(shù)量提高到350M至1.3億,Emergent Features開始出現(xiàn)在注意力和FFN的輸出中,并且出現(xiàn)在同一個維度上,但在不同的mini-batch或者不同層中出現(xiàn)的位置是不一樣的。原博客認為這種一致性在一定程度上代表了模型各個層的協(xié)作。同時,Emergent Features分布開始呈現(xiàn)一些規(guī)律。
- 當(dāng)模型的參數(shù)量達到2.7B至6B時,在60%的層中,Emergent Features出現(xiàn)在同樣的維度上。
- Transformer 所有層上的大幅異常值特征突然出現(xiàn)在 6B 和 6.7B 參數(shù)之間,即出現(xiàn)了phase shift。原博客還描述了在這種情況下,模型內(nèi)出現(xiàn)的一些變化:
- 受到異常值影響的層的數(shù)量百分比從 65% 增加到 100%,受到異常值影響的 token 的數(shù)量百分比從 35% 增加到 75%。同時,量化開始失敗。量化方法從 6.7B 開始失敗的核心原因可能是:量化分布的范圍太大,導(dǎo)致大多數(shù)量化 bins 為空,小的量化值被量化為零,基本上消除了有效信息。
- 注意力層變得非常稀疏;FFN層變得更密集;Transformer變得更穩(wěn)定。如果將離群值從模型中分離出來,剩下的部分可以用8-bit甚至更低的精度進行運算。
1.4 分布規(guī)律
新出現(xiàn)的離群特征(Emergent Features)的分布是有規(guī)律的。LLM.int8()作者在博客總結(jié)了原論文中報告的關(guān)于Emergent Features的幾個現(xiàn)象:
- Emergent Features在大型模型中是系統(tǒng)性的:要么出現(xiàn)在大多數(shù)層中,要么不出現(xiàn)。但是,在小型模型中是概率性出現(xiàn)的:只是有時出現(xiàn)在某些層中。
- Emergent Features容易出現(xiàn)的潛在位置包括:注意力投影層(attention projection, query/key/value/output)、FFN的第一層。
- 激活中的異常值集中在一小部分通道中。通常,這些離群特征只分布在 Transformer 層的少數(shù)幾個維度。比如對于一個參數(shù)量為6.7億的transformer模型來說,如果輸入句子序列長度是2048,每個序列在整個模型中找到大約 150k 個異常值特征,但它們僅集中在 6 個不同的特征維度中。
- 這些激活上的離群點會出現(xiàn)在幾乎所有的 token 上,但是局限于隱層維度上的固定的 channel 中;給定一個 token,不同 channels 間的方差會很大,但是對于不同的 token,相同 channel 內(nèi)的方差很小。考慮到激活中的這些離群點通常是其他激活值的 100 倍,這使得激活量化變得困難。
- Emergent Features是隨著ppl指數(shù)增長的,與模型大小無關(guān)。
如下圖所示,大量異常值特征的出現(xiàn)呈現(xiàn)一種平滑的趨勢,而且基本體現(xiàn)為隨著困惑度變化的指數(shù)函數(shù)。這表明異常值的出現(xiàn)并不是突然的。并且通過研究較小模型中的指數(shù)趨勢,論文作者能夠在相移(相位移動,Phase shift,它指的是一個波形在時間上發(fā)生的移位現(xiàn)象)發(fā)生之前就檢測到異常值特征的出現(xiàn)。這也表明,異常值的出現(xiàn)不僅與模型大小有關(guān),還涉及困惑度,也與所使用的訓(xùn)練數(shù)據(jù)量和數(shù)據(jù)質(zhì)量等多個附加因素有關(guān)。論文作者推測模型大小只是離散特征出現(xiàn)所需的眾多協(xié)變量中的一個重要協(xié)變量。

另外,這些大規(guī)模值還有個奇特現(xiàn)象:它們在不同的注意力頭部中呈現(xiàn)出驚人的一致性,集中分布在相似的位置索引上。這打破了我們的傳統(tǒng)理解——各注意力頭部應(yīng)該獨立運作,處理不同類型的信息。想象一下,如果10個人思考同一個問題,正常情況下他們會關(guān)注不同的角度,但現(xiàn)在研究發(fā)現(xiàn),他們都不約而同地關(guān)注了相同的幾個點,這非常反直覺。你可能注意到,這些值的分布并非隨機,而是遵循某種結(jié)構(gòu)化模式,這暗示著它們在模型的信息處理中扮演著特定且關(guān)鍵的角色。
1.5 出現(xiàn)原因
關(guān)于outlier出現(xiàn)的原因,人們也做了研究,提出了很多觀點。總結(jié)大致如下:softmax 和 RoPE 是產(chǎn)生異常值的起點,當(dāng)token在Transformer架構(gòu)中流動時,F(xiàn)FN、Norm等模塊會對異常值做進一步放大,我們接下來就逐一分析。
1.5.1 softmax
有一種觀點認為,outlier和softmax的機制有關(guān)系。在 LLM 上下文中,outlier產(chǎn)生的原因是,因為某個注意力頭不想關(guān)注某些有實際語義的token,所以就把更多的關(guān)注放在非語義 token(逗號等)上。如何才能把更多的關(guān)注放在非語義token上呢?這就是通過進行大量加權(quán)來產(chǎn)生outlier。我們使用論文“Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing”和“StableMask: Refining Causal Masking in Decoder-only Transformer”來進行學(xué)習(xí)。
LLM模型
論文“Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing”研究結(jié)果如下:
-
超過97%的離群值都是分割符token,如[SEP],逗號","和句號"."等。
![]()
-
注意力頭部將幾乎所有的概率分配給[SEP]token和其他信息量較小的token,如點/逗號(下圖(a)中左側(cè)),而這些token對應(yīng)的value很小(下圖(a)中間)。這導(dǎo)致兩者之間的乘積很小(下圖(a)中右側(cè))。
-
在其他情況下(圖b和c),我們觀察到,很大一部分注意力概率仍然分配給了分隔符token。然而,通過在其他token上分配一些概率,這會引起hidden representation的(軟)選擇性更新。


上圖其實就展示了Attention的“不注意/不更新”機制,具體解釋如下:
- 序列中存在一些不相關(guān)的token,如初始token或標(biāo)點符號等非功能性單詞,這些token更常被其他token觀察到,我們可以稱之為非語義 token。
- 注意力機制通常需要很少的重要token,其他token可能只是干擾。注意力機制應(yīng)該只更新這些重要token的權(quán)重參數(shù)。對于這種干擾token,理想狀態(tài)是把它們的注意力得分歸零。畢竟不是所有token都需要學(xué)的,即不是所有token參與權(quán)重參數(shù)的更新。
- 在某些情況下,模型可能會發(fā)現(xiàn)“沒什么token值得注意的”,這時它選擇將不成比例的注意力(disproportional attention)放到非語義 token上,盡量不給其它token分配注意力概率,這種非語義 token會輸出較小的value。這樣才不會誤更新那些有意義的token,起到“不注意/不更新”的作用。作者把這種機制稱為attention的“no-op” 現(xiàn)象。
論文“Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing”作者對“no-op” 現(xiàn)象給出了幾點假設(shè)和推理,我們結(jié)合論文“StableMask: Refining Causal Masking in Decoder-only Transformer”的思路一并分析:
-
為了讓注意力模塊在殘差上不更新一個token的表示,一些注意力頭希望將它們大部分的注意力概率分配給一些固定且常見的具有低信息量(例如,分隔符token或背景塊)的token,這些token在學(xué)習(xí)之后可以產(chǎn)生小的value。
-
從softmax函數(shù)的定義中可以很容易地看出,這將使得softmax的輸入具有相對較大的動態(tài)范圍。實際上,在softmax恰好為零的極限情況下,此動態(tài)范圍將無限大。
![]()
-
由于層歸一化(Layer Normalization)會歸一化離群值,前一層FFN輸出的大小必須非常高,這樣才可以在LayerNorm之后,仍然產(chǎn)生足夠大的動態(tài)范圍。注意,這也適用于在自注意力或線性變換之前應(yīng)用LayerNorm的Transformer模型。
-
在原始的softmax函數(shù)中,所有的輸入都會被映射到0到1之間,并且所有的輸出值之和為1,因此需要在所有可見token上不可避免地分配注意力。在這種情況下,softmax函數(shù)所施加的要求阻止了模型有效地將無關(guān)token的注意力得分歸零。這意味著即使某些輸入值非常小,它們在softmax函數(shù)處理后也會有一個非零的輸出值。由于softmax永遠不會輸出精確的零,它總是會反向傳播梯度信號以產(chǎn)生更大的離群值。因此,網(wǎng)絡(luò)訓(xùn)練的時間越長,異常值的幅度就越大。
-
在Decoder Only模型中,序列最前面的token更容易成為離群值。這可能因為在序列逐漸被mask的過程中,序列最前面的token所占注意力較高,因為剛開始輸入時還沒有幾個token,做softmax后由于分母的項少所以更容易分得更多注意力。而隨著token數(shù)量的增加,更多的token參與了softmax操作,甚至為每個token分配非常小的概率也會導(dǎo)致顯著的累積概率。因此,sink token不能像在序列開始時那樣獲得那么多的關(guān)注值。而且,因為初始token對幾乎所有后續(xù)的token都是可見的,因此最初的token更容易被訓(xùn)練成為注意力匯集點,吸引一些不必要的注意力。
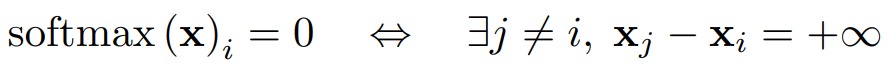
下圖是BERT中注意力層的示意圖,該圖展示了前一層中的異常值如何影響下一層中注意力機制的行為。隱激活張量用x表示。生成幅度最大異常值的FFN的輸出以紅色來突出顯示。

VIT模型
論文“Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing”通過分析ViT模型的特征圖,發(fā)現(xiàn)其也是有離群值的。ViT中的離群值主要出現(xiàn)在圖片背景上,背景token也都是沒什么信息的。下圖給出了在ImageNet驗證集中的隨機圖像上展示的ViT異常值分析摘要。(a) 輸入圖像。(b) 第11層輸出中的異常值。(c)在注意力頭#1、層#12的每個補丁上花費的累積注意力權(quán)重(按行求和的注意力概率矩陣)。(d) 相應(yīng)的注意力概率矩陣。(e) 異常值和非異常值補丁(patches)的平均值大小。

論文“Vision Transformers Need Registers”的觀點如下:
- 和Quantizable Transformer一樣,作者觀察幾種視覺Transformer模型發(fā)現(xiàn):其特征圖中有許多離群值特征,離群值特征就是L2范數(shù)很大的特征,并且更多地出現(xiàn)在更深的層、較大型模型的長時間訓(xùn)練中。
- 通過測量離群特征和相鄰的四個token特征的余弦相似度,作者發(fā)現(xiàn)這些特征之間是高度相似的,進而暗示著離群特征的信息是高度冗余的。
- 作者推測離群特征包含更少的位置信息與像素信息。
- 作者又設(shè)計了一個實驗,拿單個的離群特征和正常特征去預(yù)測其token所屬圖片的類別,結(jié)果是離群token分類的準(zhǔn)確率更高,從而說明了離群token可能包含更多的全局信息。
- 作者的猜測和之前的研究差不多:充分訓(xùn)練的大模型在訓(xùn)練的時候會識別一些冗余的token,用這些token來處理、存儲、檢索一些全局信息。作者假定這種行為模式本身并不壞,但是對于模型的輸出如果包含這種 tokens 就不太可取。事實上,這種異常的 tokens 會引導(dǎo)模型丟棄局部的信息,導(dǎo)致密集預(yù)測任務(wù)性能的降低。
1.5.2 RoPE
論文"Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding"作者認為,RoPE 是驅(qū)動 QK 表征中結(jié)構(gòu)化“離群值”出現(xiàn)的根本原因。
現(xiàn)象
論文發(fā)現(xiàn)的現(xiàn)象如下:
- 在使用RoPE的模型中(如Llama、Gemma、Qwen等),注意力機制的查詢(Q)和鍵(K)組件中存在顯著的大規(guī)模值(massive values),這些值集中分布在特定區(qū)域,而在值(V)組件中卻不存在此類現(xiàn)象。
- 而未使用 RoPE的模型(如GPT-2、OPT等)中并未觀察到上述特性。
- 那些特意保留這些極端數(shù)值的量化技術(shù)(例如 AWQ 和 SmoothQuant)能夠維持模型的原有性能;反之,若采用未能保留這些數(shù)值的方法(例如 GPTQ),模型的上下文推理能力將遭受重創(chuàng)。
- 在涵蓋自回歸 LLM(大語言模型)及多模態(tài)模型等多種 Transformer 架構(gòu)中,作者均一致地觀察到了這種“巨大值”集中的現(xiàn)象。
- 大規(guī)模值從第一層就開始出現(xiàn),且在應(yīng)用RoPE前后保持相對一致的模式。這表明大規(guī)模值的形成是模型訓(xùn)練過程中逐步形成的結(jié)果,而非簡單由RoPE添加導(dǎo)致。
分析
論文作者認為,RoPE 機制通過將嵌入維度劃分為成對并應(yīng)用不同頻率的旋轉(zhuǎn)操作,使得低頻區(qū)域編碼了豐富的語義內(nèi)容而非位置信息,從而促成了大規(guī)模值的集中分布。這種模式在未采用 RoPE 的 LLMs(大語言模型)中則不會存在。
1.5.3 FFN
下面文字摘錄自 從Training Dynamics到Outlier——LLM模型訓(xùn)練過程中的數(shù)值特性分析。
矩陣乘法的動態(tài)性分析
給定矩陣乘法 \(C = A \times B \in \mathbb{R}^{m×n}\),可將其元素分解為:
進一步有:
其中 \(\theta_{ij}\) 為兩個向量的夾角,若兩者均值為零,則 \(\cos{\theta_{ij}}\) 與兩向量線性相關(guān)性 \(\rho\) 相等。根據(jù)上述分析,可以將矩陣乘法分解成兩部分:
其中 \(a_i\) 表示的是每個token的能量, \(b_j\) 表示權(quán)重矩陣對每個特征通道的固有縮放。兩者張成的能量矩陣 \(\mathbf{E}\) 表示了輸入到矩陣乘法環(huán)節(jié)的總能量分布,而相關(guān)性矩陣 \(\mathbf{R}\) 則表示了能量傳輸效率與信息選擇。通常來說,能量矩陣 \(\mathbf{E}\) 具有較高的動態(tài)范圍,而相關(guān)性矩陣 \(\mathbf{R}\) 需要較高的計算精度。
FFN主要計算
FFN的主要計算如下:
其中三次線性變換 \(W_1\) 被稱為gate projection, \(W_2\) 被稱為up projection,而 \(W_3\) 被稱為down projection。這三次projection的能量矩陣與相關(guān)性矩陣之間的特性如下:
- 權(quán)重矩陣分布基本服從正態(tài)分布且較為穩(wěn)定,而激活輸入則經(jīng)常出現(xiàn)顯著的異常值(outlier);
- 相關(guān)性矩陣與能量矩陣之間沒有相關(guān)性;
- 能量矩陣 \(\mathbf{E}\)與輸出激活值之間相關(guān)性較弱,對異常值的產(chǎn)生影響有限;
- 相關(guān)性矩陣\(\mathbf{R}\)與輸出激活值呈明顯的線性相關(guān)關(guān)系,是產(chǎn)生大幅異常值的主導(dǎo)因素;
我們再來對SwiGLU的異常值產(chǎn)生過程進行數(shù)學(xué)機理分析:SwiGLU可看作一個門控選擇放大單元,其計算可以分解為:
這使得門控向量成為特征選擇器,僅允許正相關(guān)特征通過。門控放大單元的機制也導(dǎo)致了以下作用:
- 異常值協(xié)同放大作用,當(dāng)門控單元處于線性區(qū),即\(W_{\text{gate}}x > 0\)時,\(\text{Swish}(z) \approx z\),此時門控輸出對up projection進行線性放大。當(dāng)門控值與up projection都比較大時,up projection與gate projection中的outlier“撞”到了一起,相乘之后輸出了非常大的數(shù)值,致使down projection輸入激活值分布通常呈現(xiàn)高度尖銳特性。
- 零值聚集效應(yīng),當(dāng)門控單元處于飽和區(qū), 當(dāng) \(W_{\text{gate}}x < 0\) 時, \(\text{Swish}(z) \rightarrow 0\),導(dǎo)致大量激活值被拉到零附近,進而導(dǎo)致了down projection的輸入的動態(tài)范圍被壓縮。至此,down projection即包含了遠遠偏離零的outlier,又包含了非常靠近零的小值,最后導(dǎo)致該input對低精度訓(xùn)練來講非常難以處理。
1.5.4 LayerNorm
LayerNorm結(jié)構(gòu)中的尺度參數(shù)γ作為一個放大器,也會放大輸出中的離群值。
下圖給出了BERT-ST-2上LayerNorm的異常值表示,可以看出,維度308處具有更尖銳的值,而且,乘數(shù)γ和輸出\(\widetilde X\)在相同的嵌入維度上包含異常值。如果刪除γ,則可以發(fā)現(xiàn)\(X'\)的分布就更加平緩。

1.5.5 RMSNorm
RMSNorm層是當(dāng)前主流大模型所使用的歸一化層,相較傳統(tǒng)的LayerNorm減少了對均值的計算,進而是的歸一化層的計算更加高效。RMSNorm定義如下:
在大模型中,RMSNorm先對每個token的表達進行歸一化,再對每個channel進行縮放。我們可以直觀的看到歸一化與縮放兩個階段對數(shù)值范圍的影響。歸一化能夠較好的抑制outlier,而縮放過程會放大某些重要的channel,但也會導(dǎo)致部分數(shù)值變得很大,反而加劇了outlier的情況。總的來說,RMSNorm主要作用是對outlier進行動態(tài)范圍的壓縮,這種壓縮作用大多數(shù)情況能成功,但部分layer只能提供很少的壓縮比。在這種情況下,就會對離群值
1.6 作用
1.6.1 負面作用
異常值(離群值)會給量化帶來什么影響?根據(jù) Llm.int8() 和 Smoothquant 中的發(fā)現(xiàn),LLM中,權(quán)重和激活都存在顯著的異常值 。 這些異常值對量化過程有顯著影響,因為它們會增加量化步長,同時降低中間值的精度。保留這些稀疏離群值也會導(dǎo)致速度大幅下降(例如1.5%的離群值導(dǎo)致SpQR的速度下降超過30%)。
假設(shè)有一個向量A=[-0.10, -0.23, 0.08, -0.38, -0.28, -0.29, -2.11, 0.34, -0.53, -67.0]。我們可以看到異常值是有害的:
- 如果我們在保留emergent feature -67.0的情況下對該向量做量化和反量化,處理后的結(jié)果是:[ -0.00, -0.00, 0.00, -0.53, -0.53, -0.53, -2.11, 0.53, -0.53, -67.00],大部分信息在處理后都丟失了。
- 如果我們?nèi)サ鬳mergent feature -67.0對向量A做量化和反量化,處理后的結(jié)果是:[-0.10, -0.23, 0.08, -0.38, -0.28, -0.28, -2.11, 0.33, -0.53]。出現(xiàn)的誤差只有其中一個數(shù)值-0.29變成了-0.28。
我們再用數(shù)學(xué)公式來推導(dǎo)下。

請注意,計算 \(\Delta\) 時使用的是最大值,因此 X 中的超離群值會大大增加步長。導(dǎo)致離群值平均會被舍入到更遠的值,從而增加量化誤差。隨著超離群值的增加,離群值被舍入到更少的離散值中,更多的量化 bin 未被使用。這樣,超離群值就會導(dǎo)致量化保真度降低。
1.6.2 正面作用
保持性能
LLM.int8()作者發(fā)現(xiàn),異常值特征強烈影響 Attention 和 Transformer 的整體性能。事實證明,在量化過程中裁剪這些異常值不利于 LLM 的性能。保留異常值對于大語言模型的性能至關(guān)重要。 比如:
- 在訓(xùn)練的初始階段,任何基于裁剪的方法都會導(dǎo)致異常高的困惑度(perplexity)分數(shù)(即> 10000),從而導(dǎo)致大量信息丟失,很難通過微調(diào)來恢復(fù)。而且,對于越大的模型,離群值對于模型性能的影響越大,模型對outlier的依賴更強。
- 保留稀疏離群值可以提高準(zhǔn)確率。如果去除異常值,即使最多有 7 個異常值特征維度,top-1 softmax 概率就會從約 40% 降低到約 20%,驗證集困惑度增加了 600-1000%。當(dāng)改為刪除 7 個隨機特征維度時,top-1 概率僅下降 0.02-0.3%,困惑度增加 0.1%。這些結(jié)果突出了異常值特征的關(guān)鍵性質(zhì)。這些異常值特征的量化精度至關(guān)重要,因為即使是微小的誤差也會極大地影響模型性能。
上下文理解
在理解大規(guī)模值的作用前,我們需要區(qū)分兩種知識類型。"參數(shù)知識"是指模型在訓(xùn)練過程中學(xué)到并存儲在其參數(shù)中的知識,例如"巴黎是法國首都";而"上下文知識"是指模型從當(dāng)前輸入上下文中獲取的信息,例如理解一篇文章后回答其中提到的細節(jié)。
論文"Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding"作者認為,大規(guī)模值在處理上下文知識(contextual knowledge)方面扮演至關(guān)重要的角色,而對參數(shù)知識(parametric knowledge)的影響相對較小。
- 此類極端數(shù)值對模型的上下文理解能力至關(guān)重要,相較之下,其對于參數(shù)化知識的倚重程度則較低。實驗顯示,若此類數(shù)值受到干擾,模型仍能回憶既有事實(例如,回答“中國首都是哪里?”),但在需要依賴上下文的任務(wù)中(如 GSM8K 數(shù)學(xué)推理測試),其表現(xiàn)則會顯著下滑。
- 當(dāng)作者刻意讓上下文信息與模型的內(nèi)在知識產(chǎn)生沖突時(例如"地理知識已改變,紐約現(xiàn)已成為英國的一個城市"),發(fā)現(xiàn) LLMs(大語言模型)的表現(xiàn)與隨機猜測無異。然而,當(dāng)大規(guī)模值被破壞后,模型的準(zhǔn)確率反而顯著高于隨機水平。這暗示 LLMs(大語言模型)在默認情況下更傾向于依賴其內(nèi)部知識,而這些“巨大值”則在引導(dǎo)模型理解上下文方面扮演著關(guān)鍵角色。當(dāng)大規(guī)模值被破壞后,模型失去了處理誤導(dǎo)性上下文信息的能力,轉(zhuǎn)而默認使用其參數(shù)知識,有效地忽略了矛盾的上下文。
- 這些“巨大值”對于需要依賴上下文的任務(wù)——例如密鑰信息檢索、文本情感分析以及邏輯推理——具有不可或缺的作用,而對于參數(shù)化知識的直接調(diào)取,其影響則相對有限。
因此,人們往往選擇保留這些異常值。 樸素且高效的量化方法(W8A8、ZeroQuant等)會導(dǎo)致量化誤差增大,精度下降。而GPTQ不特別保護大規(guī)模值,在上下文知識理解任務(wù)上表現(xiàn)顯著下降(準(zhǔn)確率降至約75%,歸一化后),但在參數(shù)知識檢索任務(wù)上依然表現(xiàn)不錯。為了更有效地處理異常值,LLM.int8()提出了混合精度分解,以確保激活中的一些異常值的準(zhǔn)確性。SmoothQuant通過平滑激活中的異常值來降低量化的難度。SpQR識別敏感權(quán)重以確保其精度,同時將其他權(quán)重量化到較低的比特寬度。AWQ通過在量化過程中選擇性地保護"重要"權(quán)重來維持大規(guī)模值,在所有任務(wù)上保持較強的性能表現(xiàn)。
1.7 難點
我們總結(jié)大模型量化困難的原因為如下幾點:
-
激活比權(quán)重更難量化。權(quán)重分布較均勻,易于量化。有研究表明 LLMs 的權(quán)重量化到 INT8 甚至 INT4 并不會影響精度。
-
激活難以量化的原因是因為異常值。在 per-tensor 量化的情況下,大的異常值主導(dǎo)了最大幅度,異常值規(guī)模比大多數(shù)激活值大約 100 倍。這壓縮了非異常通道的有效量化位數(shù),導(dǎo)致非離群點 channel 的有效量化 bits/levels 較低:假設(shè) channel ?? 的最大幅值為 \(??_??\) ,整個矩陣的最大值為 ?? ,channel ?? 的有效量化級別為 \(2^8·??_??/??\) 。對于非離群點 channel,有效的量化級別將非常小 (2-3),導(dǎo)致量化誤差較大。
-
可以認為異常值對應(yīng)了涌現(xiàn)特征。這些異常值代表了模型進行預(yù)測所依賴的重要特征,在模型的決策過程中起著至關(guān)重要的作用,可以有效地充當(dāng)模型已學(xué)會識別的特征的指示符,有助于網(wǎng)絡(luò)處理和解釋輸入數(shù)據(jù)。因此,應(yīng)該以原始精度保留這些異常值,這樣才能讓網(wǎng)絡(luò)保留其所學(xué)知識,保持模型的性能和準(zhǔn)確性。
-
異常值持續(xù)存在于一小部分特定的通道(channel)中(固定通道存在異常值,并且異常值通道值較大)。如果一個 channel 有一個異常值,它持續(xù)出現(xiàn)在所有 token 中。對于特定 token,不同通道的激活值差異很大(少部分通道激活值很大,大部分通道較小),但同一通道內(nèi)不同 tokens 的激活值幅度差異小(異常值通道幅度持續(xù)較大)。
由于異常值的持久性和每個 channel 內(nèi)部的小方差,如果可以做 activation 的 per-channel 量化 (對每個 channel 使用不同的量化 step),與 per-tensor 量化相比,量化誤差會小得多,而 per-token 量化幫助不大。
上述現(xiàn)象總結(jié)起來就是,離群值跟通道相關(guān),跟 token 無關(guān)。因此應(yīng)該對激活采用逐通道量化 (即每個通道使用不同的量化系數(shù)),這可以大幅降低量化誤差。逐 token 量化則幫助不大。但是,逐通道激活量化并不適合硬件加速的 GEMM 內(nèi)核(線性層計算),因為這些內(nèi)核依賴于高吞吐量的連續(xù)操作(如 Tensor Core MMAs),無法容忍低吞吐量指令(如轉(zhuǎn)換或 CUDA Core FMAs)的插入,而量化公式中無論是量化系數(shù)還是浮點數(shù)到定點數(shù)的轉(zhuǎn)換都是用 CUDA Core 計算單元。
0x02 超異常值
在實際工作中,研究人員發(fā)現(xiàn)在異常值中有些另類個體,其特點是:1. 數(shù)值非常大,通常比其他的異常值大很多 。 2. 它們的數(shù)量非常少。有研究者將這些有問題的,數(shù)量很少,但是絕對值又特別大的異常值稱為超異常值,這里包括(包括超級權(quán)重和超級激活值)。
2.1 超級權(quán)重
我們接下來看看超級權(quán)重。有研究人員發(fā)現(xiàn),在大模型中,有一小部分特別重要的特征(稱之為「超權(quán)重」),它們雖然數(shù)量不多,但對模型的表現(xiàn)非常重要。如果去掉其他一些不那么重要的特征,模型的表現(xiàn)只會受到一點點影響。如果去掉這些「超權(quán)重」,模型就開始胡言亂語,可能都不會生成文本。
2.2.1 作用
為了量化「超權(quán)重」對模型的影響有多大,研究團隊修剪了所有的離群值權(quán)重,結(jié)果發(fā)現(xiàn),去掉一個「超權(quán)重」的影響,比去掉其他 7000 個離群值權(quán)重加起來還要嚴重。研究團隊發(fā)現(xiàn)超級權(quán)重有兩種主要影響:
- 引發(fā)「超激活」。超權(quán)重會放大輸入 token 激活的離群值,這種現(xiàn)象研究者們稱之為「超激活」(super activation)。論文發(fā)現(xiàn),在降維投影之前,門控和上投影的 Hadamard 乘積產(chǎn)生了一個相對較大的激活,而「超權(quán)重」進一步放大了這個激活并創(chuàng)造了「超激活」。無論輸入什么提示詞,「超激活」在整個模型中都以完全相同的幅度和位置持續(xù)存在。而這源于神經(jīng)網(wǎng)絡(luò)中的「跨層連接」。
- 抑制了停用詞(stopword)的生成概率。含有「超權(quán)重」的原始模型能夠以 81.4% 的高概率正確預(yù)測。然而,移除「超權(quán)重」后,模型預(yù)測的最多的詞變成了停用詞「the」,并且「the」的概率僅為 9.0%,大多數(shù)情況是在胡言亂語。這表明,「超權(quán)重」對于模型正確且有信心地預(yù)測具有語義的詞匯至關(guān)重要。
研究團隊還分析了超級權(quán)重幅值變化對模型質(zhì)量的影響,通過將超級權(quán)重按 0.0 到 3.0 的縮放因子放大。結(jié)果表明,適度放大幅值可以提升模型準(zhǔn)確率。

2.2.2 識別
不同的大模型的「超權(quán)重」的分布卻出奇地相似,比如:它們總是出現(xiàn)在mlp.down_proj。
但是如何識別具體的「超權(quán)重」?論文提出了一種高效的方法:通過激活的峰值可以進一步定位「超權(quán)重」。具體而言,我們可以通過檢測層間降維投影輸入和輸出分布中的峰值來定位「超權(quán)重」。這種方法只需要輸入一個提示詞,非常簡單方便,不再需要一組驗證數(shù)據(jù)或具體示例了。
假設(shè)存在降維投影(down proj)權(quán)重矩陣\(W \in R^{D \times H}\),其中 D 表示激活特征的維度,H 是中間隱藏層的維度。設(shè)\(X \in R^{L \times H}\)為輸入矩陣,其中 L 表示序列長度。定義輸出矩陣為\(Y=XW^T\),「超激活」為\(Y_{ij}\),\(Y_{ij} = \sum_{k=1}^d x_{ik}W_{jk}\)。如果 \(X_{ik}\) 和 \(W_{jk}\)都是遠大于其他值的異常值,那么 \(Y_{ij}\) 的值將主要由這兩個異常值的乘積決定。在這種情況下,j 和 k 是由 \(X_{ik}\) 和 \(Y_{ij}\) 的值決定的。因此,可以首先繪制出 mlp.down proj 層的輸入和輸出激活中的極端異常值。接著確定超權(quán)重所在的層和坐標(biāo)。一旦檢測到一個超權(quán)重,將其從模型中移除并重復(fù)上述過程,直到抑制住較大的最大激活值。
下圖給出了超級權(quán)重的行為。
- I:超級權(quán)重通常出現(xiàn)在模型早期層的向下投影中,用藍紫色框表示。超級權(quán)重會立即產(chǎn)生令人難以置信的超大激活值。
- II: 超級激活通過skip connection 進行傳播,用藍紫色線表示。
- III: 這有一個凈效應(yīng)(net effect),即抑移除超權(quán)重會導(dǎo)致生成停用詞的可能性飆升,用藍紫色堆疊條表示。

這些超離群值對模型質(zhì)量非常重要,因此在量化過程中保留它們至關(guān)重要。
2.2 massive outlier
事實上,人們更多的將超級激活叫做massive activation,或者massive outlie(大規(guī)模異常值)。
人們常說的LLM的Outliers更多是指激活值的Outliers,因為權(quán)重的整體變化幅度還是比較小的。早期對Outliers是不做區(qū)分的,人們認為的Outliers一般指Normal Outliers,其更多地出現(xiàn)在Channel維度,這也是之前的通道級量化方法想解決的。最近的工作如Massive Activations in Large Language Models等將在token維度出現(xiàn)的值特別大,但又非常少的Outliers視為Massive outlier,這是之前通道級量化方法解決不了的,但是可以通過旋轉(zhuǎn)矩陣或者CushionCache(Prompt)吸收的方式來解決。

2.2.1 定義
為了定量的分析,研究人員提供了一個寬松但廣泛的定義: 如果激活的幅值超過100,并且至少或大約是其隱藏狀態(tài)的中值幅度的1000倍,則認為該激活是 massive activations。
Massive Outliers特點是它們的值非常高,在token子集中的出現(xiàn)有限。下圖分別給出了不同模型中 Massive Outliers 的現(xiàn)象。
- 上方是 LLaMA2-7B中的激活幅度(Magnitudes )(z軸)。x和y軸是序列和特征維度。對于這個特定的模型,我們觀察到具有巨大幅度的激活出現(xiàn)在兩個固定的特征維度(1415和2533)和兩種類型的token中——起始token和第一個句點(.)或換行符(\n)。
- 中間是LLaMA2-13B中的massive activation。在這個模型中,它們出現(xiàn)在兩個固定的特征維度(2100和4743)中,并且僅限于起始token。
- 下方是Mixtral-8x7B中的massive activation。在這個模型中,它們位于兩個特征維度(2070和3398)中,并且位于起始token、分隔符token和某些單詞token(“and”和“of”)中。

2.2.2 作用
論文“Massive Activations in Large Language Models” 認為,massive activations 起到了類似 bias 的作用。

特點
針對bias,massive activations 展示出的具體特點如下:
- massive activations主要出現(xiàn)在:
- 起始token。這可以歸因為,因為起始token是序列所有token都會使用的,所以適合將更多的 bias信息放在這里。
- delimiter token(標(biāo)點符號)和弱語義token。這些 token 的語義值相對較低,因此可以作為存儲bias的低成本選項。
- 大部分的massive activations從前幾層后開始出現(xiàn)并幾乎保持常數(shù)不變,最后在最后幾層開始消散。ViT 中的 massive activation 比 LLM要少,但是仍然存在。massive activations 僅僅出現(xiàn)在幾個初始層之后,是因為LLM將需要一些初始層來處理與大規(guī)模激活相關(guān)聯(lián)的token的含義。在這些層處,token的語義可以經(jīng)由自注意機制被轉(zhuǎn)移到其他token上,并且前向傳播中被保留。
- massive activations 非常重要,大多數(shù) token 會把注意力放在 這些 massive Activations上。僅僅將 四個 massive activations 設(shè)置為零,就會導(dǎo)致模型性能的災(zāi)難性崩潰,當(dāng)然將它們們設(shè)置為平均值并不會損害模型,這表明massive activation非常重要,但并不是具體精確值重要,而是作為一個偏置項bias對整體計算非常重要。
論文作者認為,massive activations實際上很像ViT中的Register Token,作者指出它們同樣擁有超大激活值。為了說明它們的實質(zhì)作用,他們對所有的Register Token拉平均以破壞其含有的信息,但是性能卻沒有變化。
論證
論文作者跟蹤了這些token的embeds在attention層的表現(xiàn)。發(fā)現(xiàn)超大激活值經(jīng)過LayerNorm的Scale之后消失。此外,這些token提供的信息“看起來很類似”,比較穩(wěn)定。
下圖展示了從輸入隱藏狀態(tài)到查詢、鍵和值狀態(tài)的激活軌跡。
圖a展示了在LLM中,在每一層,輸入特征都經(jīng)過層歸一化處理3,然后通過線性投影轉(zhuǎn)換為查詢、鍵和值狀態(tài)。
圖b顯示了此示意圖中計算的所有隱藏狀態(tài)(LLaMA2-7b,第3層)。我們發(fā)現(xiàn),在所有階段,與大規(guī)模激活相關(guān)的兩個token的特征與其他token截然不同。具體來說,在第一個“歸一化”步驟之后,這兩個token的嵌入表現(xiàn)為具有兩個不同非零元素的稀疏向量。值得注意的是,后續(xù)的QKV狀態(tài)在每個嵌入中表現(xiàn)出相當(dāng)小的變化。
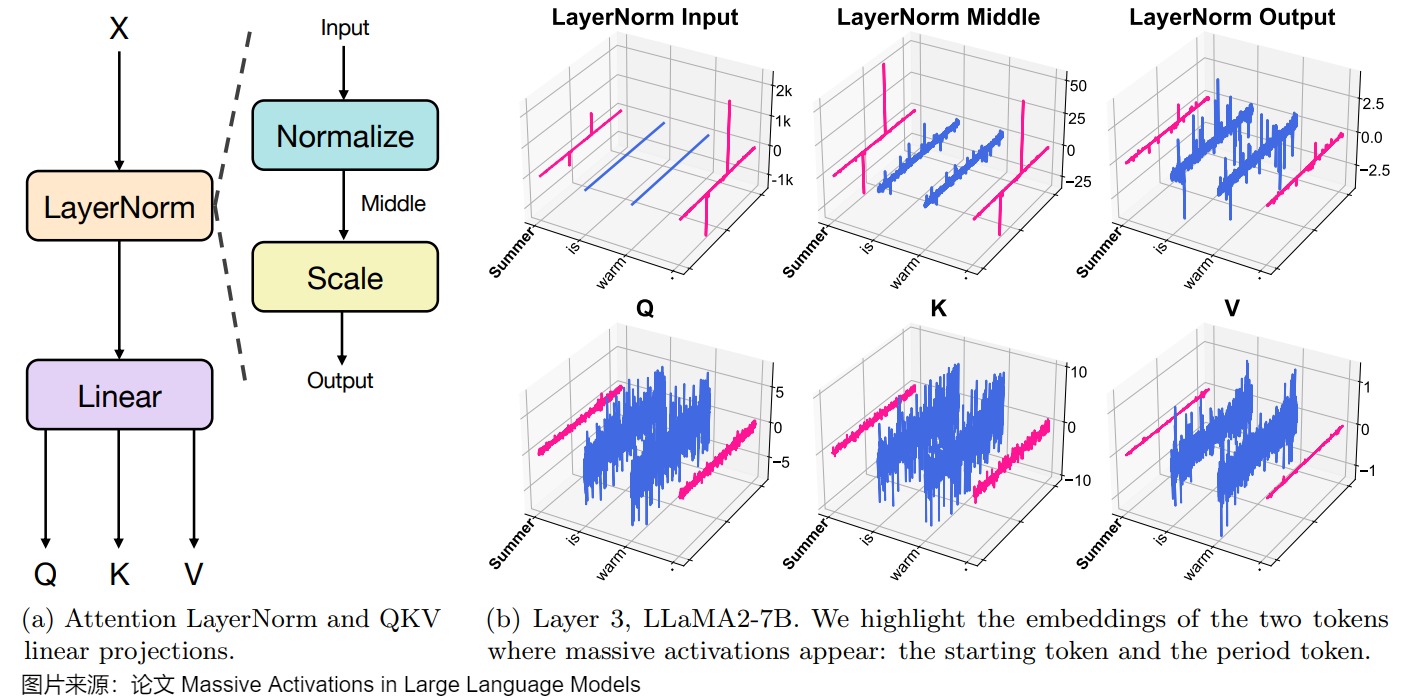
作者猜測這些token目標(biāo)是在attention中提供一個固定的偏置。鑒于注意力也集中在與大規(guī)模激活相關(guān)的token上,作者因此分離出這些token,并研究它們對注意力輸出的影響(注意力矩陣層乘以值向量)。
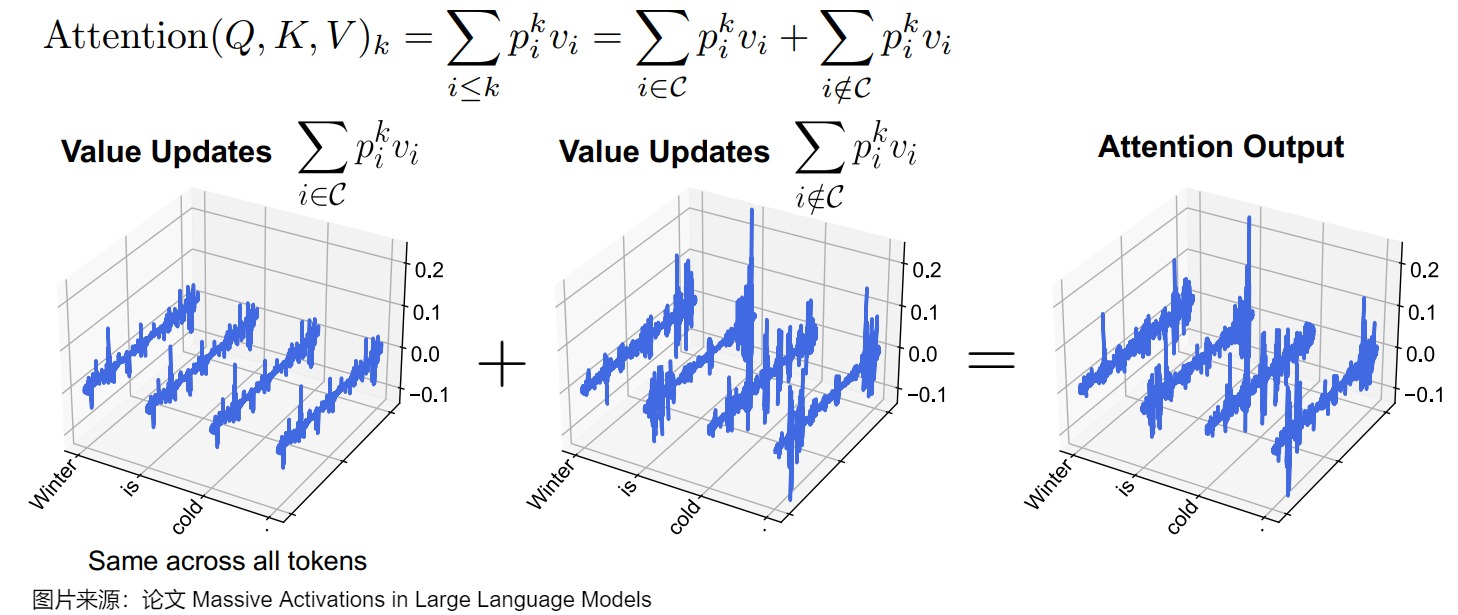
下圖顯示了LLaMA2-7B中的分解值更新和注意力輸出。在下圖的等式中,作者將每個 token k 處的注意力輸出分解為兩部分:來自token集C的值更新(value updates),這些注意力被集中化;以及從其他token聚集而來的值更新。下圖的輸入提示為“Summer is warm. Winter is cold.”。在這種情況下,集合C由tokenSummer和第一個周期token組成。我們可以看到,C的值更新在token之間幾乎是相同的,也就是說,它們充當(dāng)了加性偏差項,盡管沒有明確施加。此外,我們注意到,這種值更新模式在各種輸入中非常相似。總體而言,論文的結(jié)果表明,LLM使用大量激活來在某些代幣上分配大量注意力。然后,在計算注意力輸出時,這些token被用來形成一個恒定的偏差項。
2.2.3 難點
在LLM量化方法中,一個主要問題是存在激活異常值,這會擴大量化步長,從而導(dǎo)致顯著的精度損失。為了緩解這個問題,目前的研究已經(jīng)開發(fā)了各種方法來解決激活中的正常異常值。不幸的是,現(xiàn)有的LLM量化方法很難有效地解決Massive Outliers。通道級量化方法大多在通道維度對權(quán)重和激活值做等價變換,從而降低通道上Outlier的幅度,使得量化更容易進行。但是并沒有考慮到Outlier并不只在通道維度上,這么做還可能引入新的Outlier。
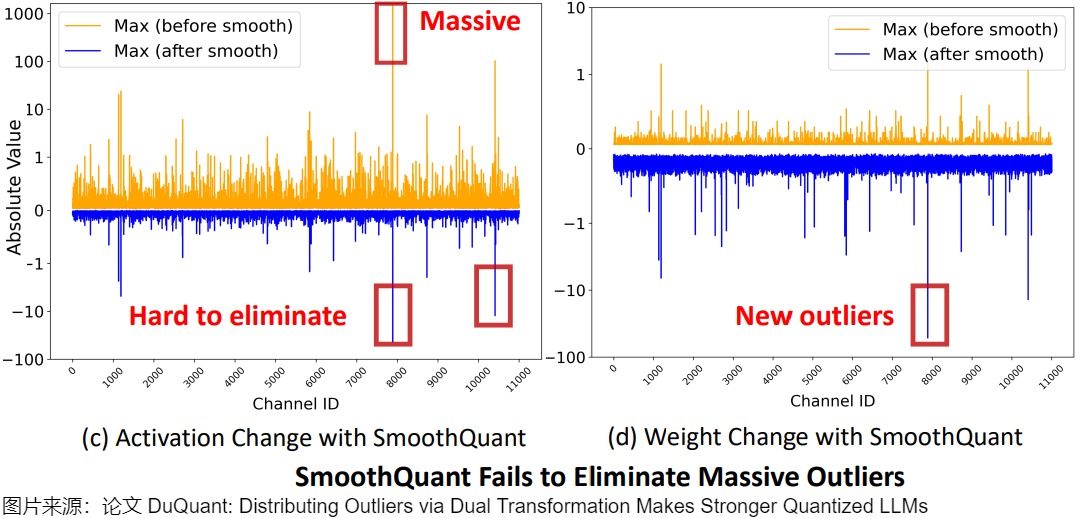
例如,SmoothQuant 盡管使用平滑因子將一些激活異常值轉(zhuǎn)移到權(quán)重部分,但仍然無法有效處理具有極大值的Massive Outliers。具體如下圖所示,SmoothQuantit的相應(yīng)權(quán)重變化導(dǎo)致了新異常值的出現(xiàn)。
因此,迫切需要一種LLM量化方法,有效地解決正態(tài)和大規(guī)模異常值問題。這就是旋轉(zhuǎn)矩陣或者CushionCache(Prompt)吸收的方式,我們會在后續(xù)專門論述。
0x03 Transformer量化
3.1 原理分析
我們首先從效率分析開始,說明量化技術(shù)如何減少大模型的端到端推理延遲。
3.1.1 推理特點
LLMs模型的推理可以大致分為兩個stage: prefill和decoding. 兩個stage有其各自的鮮明的特點,
- prefill階段的行為可以類比訓(xùn)練的前向過程。在多數(shù)情況下, prefill階段是compute bound。
- decoding階段的sequence length恒等于1,是IO bound。很多情況下, decoding較prefill在應(yīng)用中出現(xiàn)頻率更高, 推理的自回歸階段實際上是受內(nèi)存帶寬限制的,所以能夠更快地計算并沒有太多價值。由于推理受內(nèi)存帶寬限制,我們實際上只對減少內(nèi)存占用感興趣,因為這意味著數(shù)據(jù)傳輸更少。
3.1.2 對框架的要求
上述特點要求推理框架需要支持兩套計算邏輯以適配其不同的特點.
- 權(quán)重激活量化。在prefilling階段,大模型通常處理長token序列,主要操作是通用矩陣乘法(GEMM)。Prefilling階段的延遲主要受到高精度CUDA內(nèi)核執(zhí)行的計算操作的限制。為了解決這個問題,現(xiàn)有的研究方法對權(quán)重和激活都進行量化,以使用低精度Tensor核來加速計算。在每次GEMM操作之前會在線執(zhí)行激活量化,從而允許使用低精度Tensor核(例如INT8)進行計算。這種量化方法被稱為權(quán)重激活量化。
- 僅權(quán)重量化。在解碼階段,大模型在每個生成步中只處理一個token,其使用通用矩陣向量乘法(GEMV)作為核心操作。解碼階段的延遲主要受到加載大權(quán)重張量的影響。為了解決這個問題,現(xiàn)有的方法主要關(guān)注使用量化權(quán)重來加速內(nèi)存訪問。首先對權(quán)重進行離線量化,然后將低精度權(quán)重去量化為FP16格式進行計算。而量化模型由于其低位寬的權(quán)重表征, 可以大大緩解IO bound現(xiàn)象。
下圖中,(a)是僅權(quán)重量化推理流程。(b)是權(quán)重激活量化推理流程。

3.2 量化模塊
基于上述信息,研究人員對Transformer進行了量化改造。因為對于大語言模型而言,其性能瓶頸在于矩陣乘法算子(占系統(tǒng)運行時間的80%以上),以及Self Attention(占系統(tǒng)顯存開銷的50%以上) ,所以,目前大多LLMs模型的量化算法可以理解為僅關(guān)心Linear算子的量化,對于其他部件(norm, embedding, softmax, add...)都沒有進行研究。
下圖是LLM的量化推理過程。紫色矩形框是量化的模塊。量化主要針對具有權(quán)重的線性層,即自注意力模塊中的Q、K、V和O層以及FFN模塊中的Up、Gate和Down層。圖的右側(cè)顯示了3種量化類型,包括weight-activation量化、weight-only量化和KV-cache量化。其中,X、 K和V以per-token的方式量化。W的范圍在部署前進行了靜態(tài)校準(zhǔn)。對于僅權(quán)重(weight-only)設(shè)置,W采用per-group量化,對于權(quán)重激活量化,W采用per-channel量化。
假設(shè)輸入為[batchsize, seq_len, dim],將batchsize乘以seq_len進行合并,我們可以得到[num_tokens, dim],進行per token量化的話就是按行量化,即每一個token都有一個對應(yīng)的scale。對于一個權(quán)重[input_dim, output_dim],執(zhí)行per channel量化就是對output_dim進行按列量化,權(quán)重的每一列都對應(yīng)一個scale。

下圖則給出了量化的推理數(shù)據(jù)流(data-flow)。

下圖給出了INT量化的范式。
- FP32作為基準(zhǔn),提供了最大的數(shù)值范圍和零精度損失,但存儲開銷最大。
- 如果用戶不太關(guān)心效率,那么INT16格式是最佳選擇。INT16格式是最精確的,如果是轉(zhuǎn)換FP32,INT16甚至比FP16更精確。
- 對于對實時性要求高的服務(wù),建議采用INT8量化方案,可以在保持較高精度的同時獲得顯著的性能提升。如果你的網(wǎng)絡(luò)中某些層需要更高的精度,可以使用W8A16來解決這個問題。
- 在資源受限但對精度要求相對較低的場景,則可以采用INT4方案以獲得最大的資源效益。

3.3 分類
下面分類來自三個不同的論文,我們可以比對進行學(xué)習(xí)。可以看到,這些分類基本都是從量化進程進行區(qū)分,基本都是從QAT(Quantization-Aware Training)和PTQ(Post-Training Quantization)兩個分類往下展開。
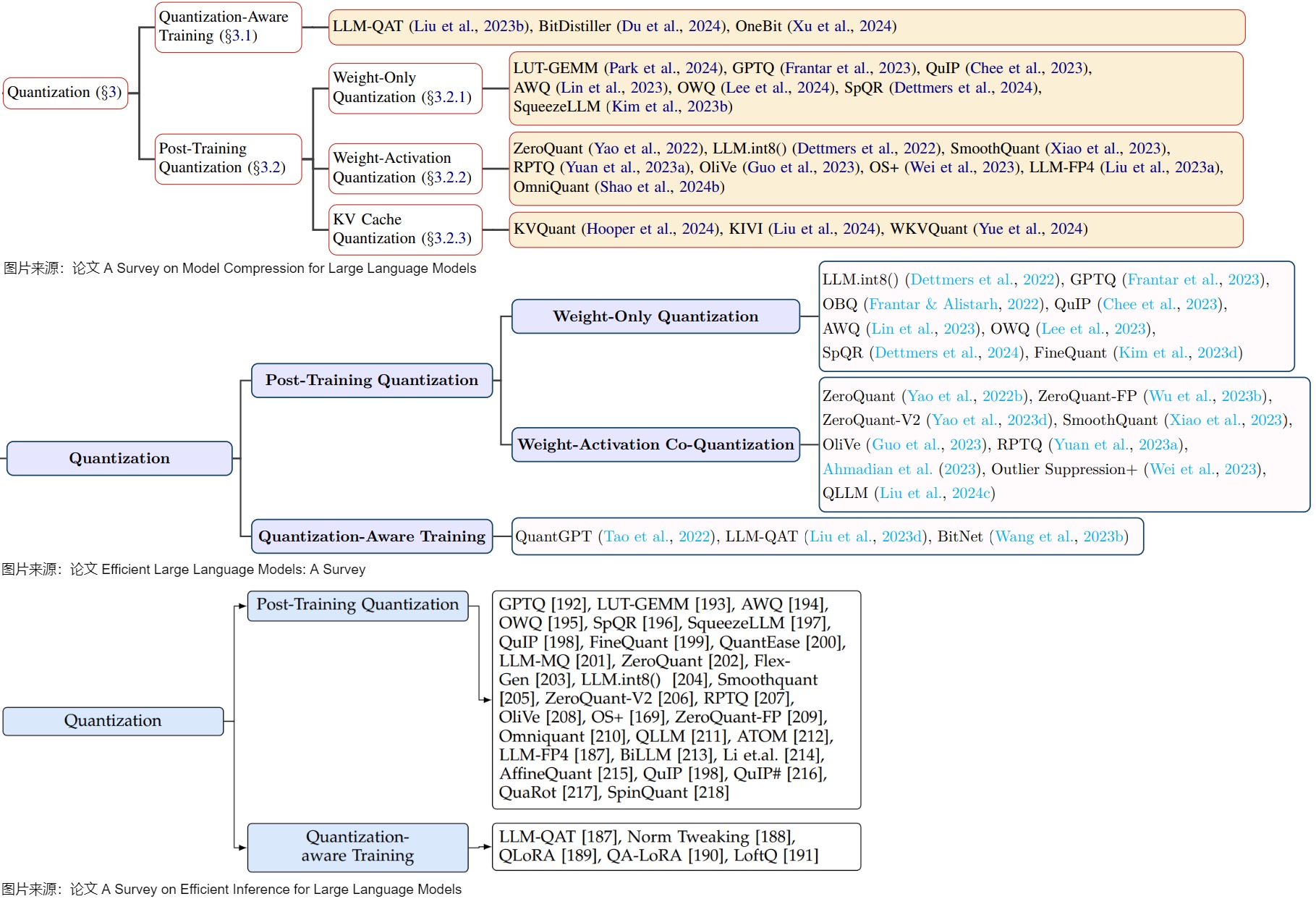
而再往下就是對PTQ進行細分,比如可以分為:僅量化權(quán)重;權(quán)重與激活同時量化;KV Cache量化三種。具體可以參見下圖。

3.3.1 PTQ
PTQ 的主要優(yōu)勢在于其簡單和高效,無需對 LLM 架構(gòu)進行修改或重新訓(xùn)練,僅使用有限的校準(zhǔn)數(shù)據(jù)進行校準(zhǔn)即可。然而,值得注意的是,PTQ可能會在量化過程中引入一定程度的精度損失。PTQ特別適合需要大幅度壓縮模型的場景。對于通常包含數(shù)十億參數(shù)的 LLMs 來說,量化感知訓(xùn)練(QAT)的訓(xùn)練成本過高,PTQ 因此成為一種更實際的替代方案。盡管PTQ方法已經(jīng)在較小的模型中得到了很好的探索,但是,大模型以其規(guī)模和復(fù)雜性為特征,需要用專門的方法來有效地處理量化過程。
我們可以將LLM的PTQ分為三組:僅權(quán)重量化、權(quán)重激活量化和KV緩存量化,這些組之間的差異在于它們的量化目標(biāo)。
- 僅權(quán)重量化僅關(guān)注量化權(quán)重。先前的工作發(fā)現(xiàn),激活量化通常更容易受到權(quán)重量化的影響,因此我們可以僅靠權(quán)重量化就可以實現(xiàn)較低的位寬。然而,由于量化權(quán)重在與激活相乘之前需要反量化,因此僅權(quán)重量化在推理過程中不可避免地會引入額外的計算開銷,并且無法享受特定硬件支持的加速低位操作。
- 權(quán)重激活量化將其目標(biāo)擴展到權(quán)重和激活。
- kv緩存量化針對的kv緩存。KV緩存通常會消耗大量內(nèi)存,成為內(nèi)存瓶頸。實現(xiàn)kv緩存量化可以提高吞吐量,并更有效地容納具有更長token的輸入。
下圖給出了代表性算法,具體從四個維度進行了分類。
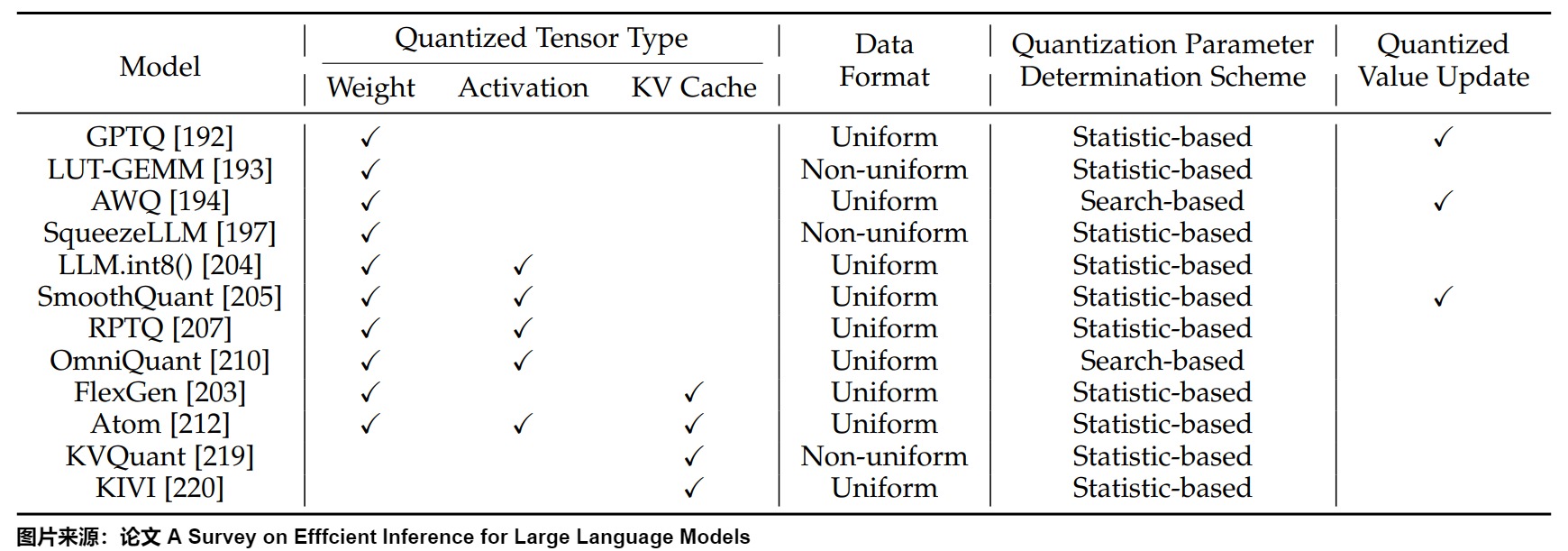
我們接下來介紹僅權(quán)重量化和權(quán)重激活量化的一些典型方案,會在后續(xù)專門開篇來介紹KV緩存量化。
weight-only quantization
在PTQ中,某些方法專注于僅對LLM的權(quán)重進行量化,以提高效率并減少計算需求。
-
GPTQ:GPTQ是一種訓(xùn)練后權(quán)重量化方法,使用基于二階信息的逐層量化,成功將每個權(quán)重量化至 3-4 位,幾乎沒有精度損失。GPTQ 對某個 block 內(nèi)的所有參數(shù)逐個量化,每個參數(shù)量化后,需要適當(dāng)調(diào)整這個 block 內(nèi)其他未量化的參數(shù),以彌補量化造成的精度損失。 GPTQ 量化需要準(zhǔn)備校準(zhǔn)數(shù)據(jù)集。
-
QuantEase的工作建立在GPTQ之上。QuantEase在對每一層進行量化時,會用一種基于坐標(biāo)下降的方法來更精確地補償未量化的權(quán)重。此外,QuantEase可以利用來自GPTQ的量化權(quán)重作為初始化,并進一步完善補償過程。
-
LUT- GEMM:LUT- GEMM是一種利用查找表(Look-Up Table, LUT)的去量化方法,它采用了一種稱為二進制編碼量化(BCQ)的非均勻量化方法,該方法包含了可學(xué)習(xí)的量化區(qū)間。
-
AWQ :AWQ觀察到權(quán)重通道對性能的重要性各不相同,通過保留1%的顯著權(quán)重可以大大減少量化誤差。基于此觀察,AWQ采用了激活感知權(quán)重量化來量化LLM,具體會專注于激活值較大的權(quán)重通道,并通過每通道縮放實現(xiàn)最佳量化效果。
-
OWQ:OWQ作者觀察到,激活異常值會放大權(quán)重量化損失。他們提出了異常值感知權(quán)重量化(OWQ)來識別那些具有激活異常值的脆弱權(quán)重,并為它們分配更高的精度,同時以較低的精度級別量化其余權(quán)重。
-
SpQR:SpQR在量化過程中識別并分離容易產(chǎn)生較大量化誤差的離群值權(quán)重,把這些離群值權(quán)重以更高的精度來存儲,而其余權(quán)重被壓縮到3-4位。此外,他們引入了一種專為SpQR格式量身定制的解碼方案,提高了逐個token的推理效率。
-
SqueezeLLM提出將離群值存儲在全精度稀疏矩陣中,并對剩余權(quán)重應(yīng)用非均勻量化。根據(jù)量化靈敏度確定非均勻量化的值,能夠提高量化模型的性能。
-
FineQuant采用了一種基于經(jīng)驗的啟發(fā)式方法,將不同級別的粒度分配給不同的權(quán)重矩陣。
-
LLM-MQ采用FP16格式來保存權(quán)重異常值,并將其存儲在壓縮稀疏行(CSR)格式中,以提高計算效率。此外,LLM-MQ將每個層的位寬分配,建模為整數(shù)規(guī)劃問題,并采用高效的求解器在幾秒內(nèi)求解。
weight-activation quantization
許多PTQ中的工作嘗試對LLM的權(quán)重和激活同時進行量化。
- ZeroQuant采用細粒度量化權(quán)重和激活(對權(quán)重做group-wise,對激活值做token-wise),并利用核融合來最小化量化過程中的內(nèi)存訪問成本,并逐層進行知識蒸餾以恢復(fù)性能。
- LLM.int8() 發(fā)現(xiàn)激活中的異常值集中在一小部分通道中。基于這一點,LLM.int8() 根據(jù)輸入通道內(nèi)的離群值分布將激活和權(quán)重分成兩個不同的部分。包含激活值和權(quán)重的異常數(shù)據(jù)的通道以FP16格式存儲,其他通道則以INT8格式存儲。
- SmoothQuant觀察到不同的token在它們的通道上展示出類似的變化,因此SmoothQuant引入了逐通道縮放變換,有效地平滑了幅度,使得模型更易于量化。
- FlexGen將權(quán)重和KV緩存直接量化到INT4中,以減少大批量推理期間的內(nèi)存占用。
- OliVe觀察到離群值附近的普通值不那么關(guān)鍵。因此,它將每個離群值與一個普通值配對,用犧牲普通值來獲得更大的離群值表示范圍。
- OS+觀察到異常值的分布不對稱的,并且集中在特定通道中,這對大模型的量化提出了挑戰(zhàn)。為了解決這個問題,OS+引入了一種通道級別的移動和縮放技術(shù)。在搜索過程去確定移動和縮放參數(shù),能有效地處理集中和不對稱的離群值分布。
- LLM-FP4努力將整個模型量化為FP4格式,并引入了預(yù)移位指數(shù)偏置技術(shù)。該方法將激活值的比例因子與權(quán)重相結(jié)合,以解決異常值帶來的量化問題。
- Omniquant與先前依賴量化參數(shù)的經(jīng)驗設(shè)計的方法不同。相反,它優(yōu)化了權(quán)值裁剪的邊界和等效變換的縮放因子,以最小化量化誤差。
- QLLM通過實現(xiàn)通道重組來解決異常值對量化的影響。此外,QLLM還設(shè)計了可學(xué)習(xí)的低秩參數(shù),來減小post-quantized模型的量化誤差。
- RPTQ發(fā)現(xiàn)不同激活通道的分布,實質(zhì)上是變化的,這給量化帶來了挑戰(zhàn)。為了緩解這個問題,RPTQ將具有相似激活分布的通道進行聚類分組,并在每個組內(nèi)獨立地應(yīng)用量化,有效地減輕了通道范圍的差異。
- Outlier Suppression+ 通過確認激活中的有害異常呈現(xiàn)出不對稱分布,主要集中在特定通道中。因此,Outlier 引入了一種新的涉及通道級的平移和縮放操作的策略,以糾正異常的不對稱呈現(xiàn)。
3.3.2 QAT
在量化感知訓(xùn)練(QAT)中,量化過程被無縫地集成到大型語言模型(LLMs)的訓(xùn)練中,使這些模型能夠適應(yīng)低精度表示,從而減輕了精度損失。因為通常涉及整個模型的重新訓(xùn)練,通常需要大量的訓(xùn)練數(shù)據(jù)和計算資源,這對QAT的實施構(gòu)成了潛在的瓶頸。不幸的是,當(dāng)前最好的低于8比特的PTQ方法也會導(dǎo)致模型質(zhì)量急劇下降。因此,對于更高的量化水平,人們發(fā)現(xiàn)有必要使用量化感知訓(xùn)練(QAT)。
當(dāng)前針對LLM的QAT方法分為兩類:全參數(shù)重新訓(xùn)練和參數(shù)-高效再訓(xùn)練。
- 全參數(shù)重新訓(xùn)練是一種在量化LLM時對LLM進行完整的參數(shù)重新訓(xùn)練的方法,通過使用數(shù)據(jù)生成方法以及QAT和蒸餾技術(shù),這樣可以保留原始模型的涌現(xiàn)能力,同時減少內(nèi)存使用和計算量。
- 參數(shù)-高效再訓(xùn)練是指采用參數(shù)高效的方法重新訓(xùn)練LLM。其中,QLoRA和QA-LoRA提出了將組量化集成到QLoRA中,緩解量化與低秩適應(yīng)之間的不平衡問題。此外,還有如凍結(jié)量化指數(shù)并僅微調(diào)量化參數(shù)、使用二進制量化等。這些方法在具有相對可接受的計算預(yù)算下,采用低秩適應(yīng)來重新訓(xùn)練量化LLM。
使用QAT量化LLM在幾個主要方面面臨挑戰(zhàn):
- 對數(shù)據(jù)要求高。如果訓(xùn)練數(shù)據(jù)域太窄或者與原始預(yù)訓(xùn)練數(shù)據(jù)分布存在顯著不同,則可能會損害模型的性能。
- 對算力要求高。大模型的訓(xùn)練對于算力資源要求比較集中,通常需要大量的訓(xùn)練數(shù)據(jù)和計算資源。
- 由于LLM訓(xùn)練及其復(fù)雜,因此,很難準(zhǔn)確地復(fù)現(xiàn)原始的訓(xùn)練設(shè)置。
我們用優(yōu)化點來進行分類。
減少數(shù)據(jù)需求
為了減少數(shù)據(jù)需求,LLM-QAT引入了一種無數(shù)據(jù)的方法,利用原始FP16的大模型生成訓(xùn)練數(shù)據(jù),然后利用預(yù)訓(xùn)練模型生成的結(jié)果來實現(xiàn)無數(shù)據(jù)蒸餾。具體來說,LLM-QAT使用詞表中的每個token作為生成句子的起始token。基于生成的訓(xùn)練數(shù)據(jù),LLM-QAT應(yīng)用了基于蒸餾的工作流來訓(xùn)練量化的LLM,以匹配原始FP16大模型的輸出分布。
減少計算量
為了減少計算量,許多方法采用高效參數(shù)微調(diào)(parameter-efficient tuning,PEFT)策略來加速Q(mào)AT。
- QLoRA將大模型的權(quán)重量化為4位,隨后在BF16中對每個4位權(quán)重矩陣使用LoRA來對量化模型進行微調(diào)。
- LoftQ指出,在QLoRA中用零初始化LoRA矩陣對于下游任務(wù)是低效的。作為一種替代方案,LoftQ建議使用原始FP16權(quán)重與量化權(quán)重之間差距的奇異值分解(Singular Value Decomposition,SVD)來初始化LoRA矩陣。LoftQ迭代地應(yīng)用量化和奇異值分解來獲得更精確的原始權(quán)重近似值。
- PEQA是一種新的量化感知 PEFT 技術(shù),可以促進模型壓縮并加速推理。它采用了雙階段過程運行。在第一階段,每個全連接層的參數(shù)矩陣被量化為低比特整數(shù)矩陣和標(biāo)量向量。在第二階段,對每個特定下游任務(wù)的標(biāo)量向量進行微調(diào)。這種策略大大壓縮了模型的大小,從而降低了部署時的推理延遲并減少了所需的總體內(nèi)存。 同時,快速的微調(diào)和高效的任務(wù)切換成為可能。
3.3.3 常見方案
總體來說,對于權(quán)重量化,可以通過區(qū)分不同的敏感度來進行差異性量化。對于敏感度的度量,可以分為用激活值來進行度量,用Hessian矩陣度量,用近似的Fisher information度量。在處理方式上,有平滑的方式,有混合精度稠密稀疏分解的表示方式,或者圍繞混合精度設(shè)計不同的硬件友好的方式。對于激活值量化,則需要對離群值做特殊處理,處理的方式有平滑的方式、內(nèi)存重排的方式、混合精度的處理方式(離群值高精度+普通值低精度)和裁剪的方式,
我們接下來從量化的技術(shù)方案角度來看看一些常見方法,此處和上面的PTQ/QAT分類不是正交的。
優(yōu)化
GPTQ 的核心思想是通過最小化量化引入的輸出誤差,實現(xiàn)高精度低比特量化。GPTQ使用優(yōu)化的方法,在量化前面的元素的時候,解析地更新后面的元素,使得量化的優(yōu)化目標(biāo)公式最小化。
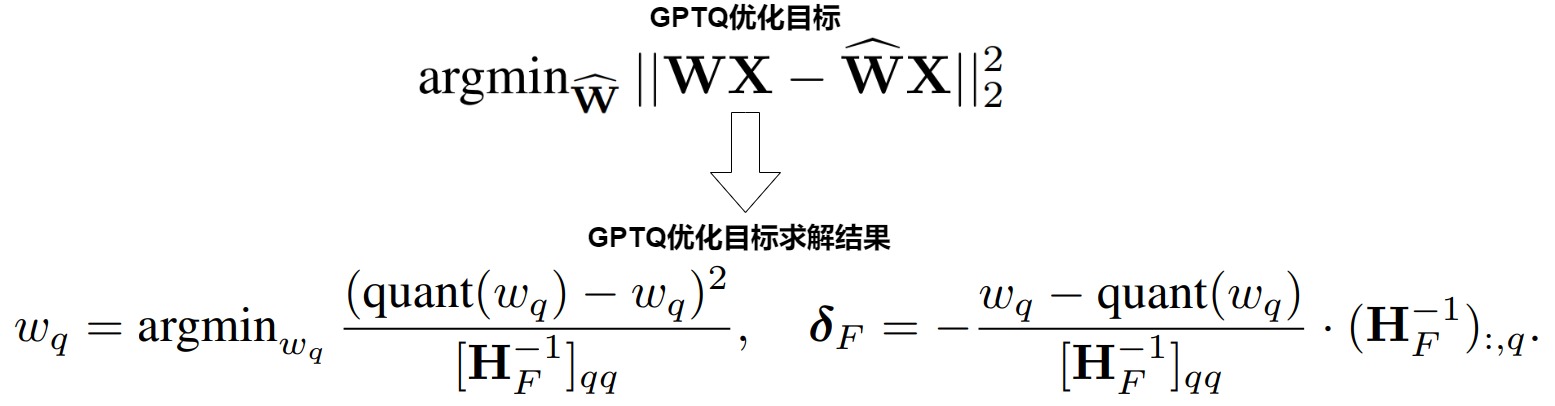
轉(zhuǎn)移
大模型量化的難點在于outlier的存在,AWQ和Smooth Quant使用一個平滑系數(shù),將activation的outlier轉(zhuǎn)移到weight上,一方面可以提升顯著channel上的weight量化范圍,另一方面可以減緩activation量化誤差。
旋轉(zhuǎn)
但是,這種轉(zhuǎn)移outlier并不能消滅outlier;于是研究人員想出了旋轉(zhuǎn)方案。這類方法一般利用單位隨機矩陣和權(quán)重變換之后再量化,使得變換后的權(quán)重更容易量化。Spinquant使用旋轉(zhuǎn)矩陣(Hadamard矩陣或者其他可學(xué)習(xí)的正交矩陣)來分別左乘和右乘weight和activation矩陣,由于旋轉(zhuǎn)矩陣的正交性,該變換是等價變換。DuQuant通過學(xué)習(xí)旋轉(zhuǎn)變換和通道置換變換,在激活矩陣內(nèi)部將 outliers 轉(zhuǎn)移到其他通道,最終得到平滑的激活矩陣,從而大幅度降低了量化難度。
可學(xué)習(xí)
很多方法都是手動設(shè)計或者網(wǎng)格搜索搜出來的縮放參數(shù),有研究人員認為這是次優(yōu)的。解決方式應(yīng)該是在量化過程中學(xué)習(xí)轉(zhuǎn)換參數(shù)和裁剪參數(shù)。
OmniQuant將平滑因子和量化截斷閾值都設(shè)置為可學(xué)習(xí)的,在block范圍內(nèi)對其進行訓(xùn)練,能取得不錯的效果。
查表和VQ
LUT(Look Up Table)方法和前面方法的最大區(qū)別是映射關(guān)系的轉(zhuǎn)變。因為現(xiàn)實模型的權(quán)重矩陣不可能是均勻分布的。有相當(dāng)大的一部分權(quán)重是“聚集”在一起的,故考慮將這些權(quán)重聚類,用一個聚類中心來映射這些權(quán)重,保存聚類中心(FP16)和聚類索引(INT)即可。當(dāng)我們需要推理時,可以使用索引Table或者說Vector里的FP16的值進行運算。這是一種理論上更優(yōu)的壓縮方式。
在LLM的極低比特(2-3bit)量化方向上,常規(guī)的標(biāo)量量化方法由于數(shù)值表達范圍的限制,通常很難達到一個可以接受的精度。近年來有不少研究者開始采用VQ(Vector Quantization)的方法來進行LLM的weight-only 量化。Vector Quantization,屬于一種數(shù)據(jù)壓縮技術(shù),具體而言,這是一種把高維向量映射至一組預(yù)先設(shè)定好的低維向量之上,并且低維向量事先被存儲于碼本(codebook)當(dāng)中的技術(shù)。獲取codebook是一個涉及數(shù)據(jù)驅(qū)動的學(xué)習(xí)過程,目的是找到一組最優(yōu)的碼詞,以便高效地表示和壓縮數(shù)據(jù)向量。編碼時每個數(shù)據(jù)點都由碼本中相應(yīng)向量的索引表示;解碼時使用這些索引對原始數(shù)據(jù)進行近似。這種方法大大降低了數(shù)據(jù)的存儲要求,同時允許通過簡單的索引引用來快速重建原始向量。
從理論上來講,VQ就是在數(shù)據(jù)中尋找共性以及去除數(shù)據(jù)中的冗余,因此,它可以實現(xiàn)比標(biāo)量量化更高的數(shù)據(jù)壓縮效率,這也就是把VQ用于LLM權(quán)重壓縮的理論基礎(chǔ)。雖然VQ可以突破標(biāo)量量化的瓶頸,但是將VQ方法應(yīng)用于LLM權(quán)重壓縮還面臨著以下挑戰(zhàn):
-
在極低比特壓縮率的情況下保證壓縮的精度;
-
由于LLM參數(shù)龐大,在LLM上如何高效的應(yīng)用壓縮量化算法;
-
從量化壓縮的權(quán)重之中還原原有的模型權(quán)重帶來的計算開銷;
我們使用VPTQ為例來進行學(xué)習(xí)。VPTQ主要是面向極低bit(eg. 2bit)的場景,是向量量化(Vector Quantization)和GPTQ的結(jié)合體,可以簡單理解為將GPTQ的逐列scale量化替換為vq量化。向量量化核心想法就是將數(shù)據(jù)按照向量 (vector) 組織聚類,并將聚類結(jié)果保存為查找表(codebook),而原始數(shù)據(jù)就可以用 Index 表示。 壓縮后的模型權(quán)重可以壓縮成 index + codebook。在 LLM 推理的時候只需要在當(dāng)前算子執(zhí)行之前,用 index和codebook 解壓就可以得到想要的原始權(quán)重。
VPTQ將量化問題視為優(yōu)化問題,通過二階優(yōu)化方法指導(dǎo)量化算法的設(shè)計。該方法的創(chuàng)新點主要體現(xiàn)在以下幾個方面:
- 通道獨立的二階優(yōu)化:VPTQ對每一列的權(quán)重矩陣進行獨立量化,使用二階優(yōu)化來指導(dǎo)量化算法設(shè)計。
- 初始代碼本的優(yōu)化:采用加權(quán)Kmeans聚類方法初始化codebook,確保量化過程中的錯誤最小化。
- 低解量化開銷:VPTQ在推理過程中只需讀取codebook中的中心點來進行解量化,顯著提高了推理吞吐量。

基于Attention Sink的量化方法
massive outlier 的特點是,其在所在的 token 中,自己都是比較大的數(shù)值,這樣就沒辦法做 per-tensor量化,所以 PrefixQuant的目標(biāo)就是徹底去除這些massive outlier。
考慮到異常值標(biāo)記的數(shù)量是有限的,并且它們通常出現(xiàn)在輸入序列的開頭。PrefixQuant 在識別到 Massive Token之后,離線地將它們放在了KVCache的前綴中,防止在推理過程中產(chǎn)生Massive Outlier。
該方法主要源于如下現(xiàn)象:在Transformer模型的輸入前加入可學(xué)習(xí)的"prefix token"或者叫"register token",這些token就能吸收多余的注意力,也就是說量化激活值或者KV-Cache的時候把這些token去掉,剩下的值就更容易量化了。
PrefixQuant不學(xué)習(xí)這個"prefix token",而是將大于設(shè)定閾值的outlier token直接存儲到KV-Cache前,從而實現(xiàn)更高效的計算。具體來說,給定一個LLM模型,PrefixQuant首先計算N個異常token數(shù),然后在KVCache中選擇Top-N個高頻離群token作為前綴。這樣再結(jié)合smooth、rotate、reorder等經(jīng)典等效操作后,剩下的outlier就可以忽略不計了,這樣針對activation就可以用per-tensor量化來替換per-token量化,從而在保證推理精度的前提下提升了推理速度。

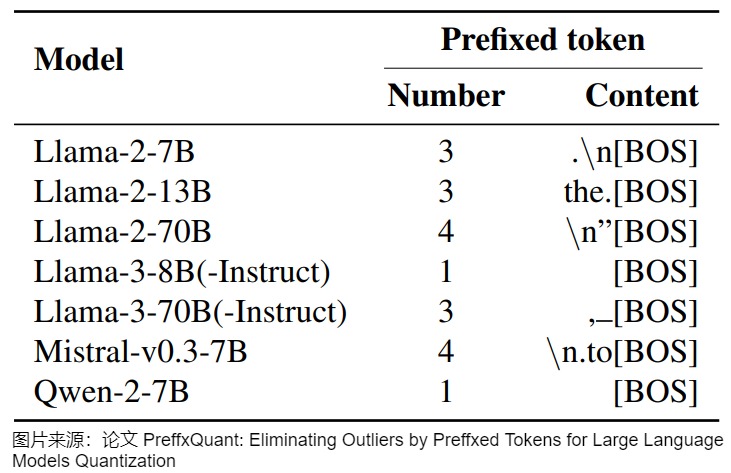
這個方法的問題在于添加了可學(xué)習(xí)的"prefix token"或者叫"register token"后,如果不在下游數(shù)據(jù)集上微調(diào)的話,這些token可能會對性能起副作用,所以找個好的前綴是比較重要的。這些token一般是". \n [BOS]"等特殊符號。下圖展示了KV緩存中不同模型的前綴令牌。[BOS]表示序列開始的特殊標(biāo)記(例如Llama-2的<s>和Llama-3的|begin of text|)。請注意,以下'‘’表示空格。
3.4 效果
我們接下來通過幾篇論文來看看量化的效果。
3.4.1 對比實驗與分析
論文“A Survey on Efffcient Inference for Large Language Models”對不同場景下的weight-only quantization技術(shù)所產(chǎn)生的加速效果進行了分析。模型使用了LLaMA-2-7B和LLaMA-2-13B,并使用AWQ將它們的權(quán)重量化至4-bit;GPU卡是NVIDIA A100;部署框架是TensorRT-LLM和LMDeploy。
論文評估了這些推理框架在不同的輸入序列上實現(xiàn)的加速,這些序列是批大小和上下文長度不同的。實驗結(jié)果表明:
- Weight-only quantization可以在decoding階段加速,進而實現(xiàn)端到端的加速。這種提升主要源于從高帶寬內(nèi)存(High Bandwidth Memory,HBM)可以更快地加載具有低精度權(quán)重張量的量化模型,量化顯著減少了內(nèi)存訪問開銷。
- 對于prefilling階段,weight-only quantization可能會增加延遲。這是因為prefilling階段的瓶頸是計算成本,而不是內(nèi)存訪問開銷。因此,只量化沒有激活的權(quán)重對延遲的影響最小。此外,weight-only quantization需要將低精度權(quán)重去量化到FP16,這會導(dǎo)致額外的計算開銷,從而減慢prefilling。
- 隨著批量大小和輸入長度的增加,weight-only quantization的加速程度逐漸減小。這主要是因為,對于更大的批處理大小和輸入長度,計算成本構(gòu)成了更大比例的延遲。雖然weight-only quantization主要降低了內(nèi)存訪問成本,但隨著批量大小和輸入長度增大,計算需求變得更加突出,它對延遲的影響變得不那么顯著。
- 由于內(nèi)存訪問開銷與模型的參數(shù)量規(guī)模相關(guān),weight-only quantization為參數(shù)規(guī)模較大的模型提供了更大的好處。因為隨著模型的復(fù)雜度與尺寸的增長,存儲和訪問權(quán)重所需的內(nèi)存量也會成比例地增加。通過量化模型權(quán)重,weight-only quantization可以有效地減少內(nèi)存占用和內(nèi)存訪問開銷。

3.4.2 量化準(zhǔn)確度
盡管 LLM 量化在推理加速方面非常流行,但各種量化格式的準(zhǔn)確性-性能之間的權(quán)衡仍然存在很大的不確定性。論文"Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization"對量化準(zhǔn)確度進行了全面的研究,評估了整個 LLaMA-3.1 系列模型在學(xué)術(shù)基準(zhǔn)和現(xiàn)實任務(wù)中的常見量化格式(FP8、INT8、INT4)。此外,作者還研究考察了量化模型與未量化模型生成的文本之間的差異。作者的實驗涵蓋了 500,000 多次單獨評估,主要評估了 3 種量化類型:
-
W8A8-FP:所有線性層的權(quán)重和激活都是 FP8 格式。
-
W8A8-INT8:Transformer Block 中所有線性層的權(quán)重和激活都使用 INT8 格式。
- 對于權(quán)重:采用對稱式 Per Channel 的 GPTQ 量化方法。
- 對于激活:采用 Per Token 的動態(tài)量化技術(shù)。
-
W4A16-INT4:Transformer Block 中所有線性層權(quán)重被量化為 INT4,而激活值則保持在16 位精度。權(quán)重通過 GPTQ 量化進行壓縮,應(yīng)用于每組 128 個連續(xù)元素,并采用均方誤差(MSE)最優(yōu)的裁剪因子。
并得出了幾個關(guān)鍵發(fā)現(xiàn):
-
FP8 權(quán)重和激活量化(W8A8-FP)在所有模型上基本都是無損的。
-
INT8 權(quán)重和激活量化(W8A8-INT)在適當(dāng)調(diào)整后,準(zhǔn)確度下降幅度很低,僅為 1%-3%。
-
INT4 權(quán)重量化(W4A16-INT4)與 W8A8-INT 不相上下。
為了解決在給定環(huán)境的“最佳”格式問題,作者使用流行的開源 vLLM 框架在各種 GPU 上進行推理分析,發(fā)現(xiàn) W4A16 適合 Latency 敏感場景(Synchronous Inference)以及中端 GPU 上的 Throughout 敏感場景(Asynchronous Inference)。同時,W8A8 很適合高端 GPU 上的 Throughout 敏感場景。
3.4.3 QAT和PTQ
論文 A Comprehensive Evaluation of Quantized Instruction-Tuned Large Language Models: An Experimental Analysis up to 405B 對量化技術(shù)在指令調(diào)優(yōu)大語言模型(LLMs)中的表現(xiàn)進行了全面評估。這篇文章回應(yīng)了一個關(guān)鍵問題:在資源受限的環(huán)境中,如何通過量化技術(shù)有效部署超大規(guī)模LLM。
論文分析了兩大主流量化方法——量化感知訓(xùn)練(QAT)和訓(xùn)練后量化(PTQ)。雖然PTQ能夠顯著減少內(nèi)存和計算需求,但可能會犧牲模型的精度。為此,研究者使用13個不同的基準(zhǔn)數(shù)據(jù)集,對量化后的模型在各類復(fù)雜任務(wù)上的表現(xiàn)進行了測試,特別關(guān)注模型的推理、數(shù)學(xué)和知識能力。 通過實驗,論文發(fā)現(xiàn)了幾個關(guān)鍵結(jié)論:
- 量化后的模型通常表現(xiàn)優(yōu)于更小的模型,尤其是在非真值檢測和指令跟隨任務(wù)上。例如,4-bit量化后的Llama-2-13B在多數(shù)任務(wù)上超過了原始的Llama-2-7B。
- 不同量化方法和模型規(guī)模對性能有不同的影響。權(quán)重量化方法通常保持更高的精度,其中AWQ比GPTQ表現(xiàn)更佳。
- 量化不會顯著影響任務(wù)難度與準(zhǔn)確性之間的關(guān)系,無論任務(wù)是簡單還是復(fù)雜,量化后的模型基本能夠保持與全精度模型相似的性能。
- 量化方法在不同模型上的表現(xiàn)差異明顯,例如,AWQ在大多數(shù)測試中都優(yōu)于GPTQ。
這些結(jié)果對未來LLM的壓縮與優(yōu)化具有重要意義。論文指出,雖然量化能有效壓縮模型并提升性能,但并不是所有任務(wù)都能從中受益。在特定任務(wù)上,比如指令跟隨和復(fù)雜推理,部分高精度模型仍然有優(yōu)勢。這篇論文為未來的量化研究提供了強大的實驗基礎(chǔ),也為大模型的實際部署提出了重要參考。
0xFF 參考
[EMNLP2023] [W8A8] Outlier Suppression+: Accurate quantization of large language models by equivalent and effective shifting and scaling
NeurIPS 2024 Oral:用 DuQuant 實現(xiàn) SOTA 4bit 量化 青稞
壓縮神經(jīng)網(wǎng)絡(luò)的藝術(shù): MIT 韓松教授的兩篇經(jīng)典論文解析 Yixin
從Training Dynamics到Outlier——LLM模型訓(xùn)練過程中的數(shù)值特性分析 Reiase
【讀點論文】A Survey of Quantization Methods for Efficient Neural Network Inference 羞兒
A Survey of Quantization Methods for Efficient Neural Network Inference
https://www.armcvai.cn/2023-03-05/model-quantization.html
模型量化技術(shù)綜述:揭示大型語言模型壓縮的前沿技術(shù) [DeepHub IMBA](javascript:void(0)??
大模型性能優(yōu)化(一):量化從半精度開始講,弄懂fp32、fp16、bf16
便捷的post training quantization方案: GPTQ
【AI不惑境】模型量化技術(shù)原理及其發(fā)展現(xiàn)狀和展望 龍鵬-筆名言有三
AWQ, Activation-aware Weight Quantization
大模型量化感知訓(xùn)練開山之作:LLM-QAT 吃果凍不吐果凍皮
LLM-QAT: Data-Free Quantization Aware Training for Large Language Models
https://link.zhihu.com/?target=https%3A//github.com/facebookresearch/LLM-QAT)
、王文廣萬字長文揭秘大模型量化的GPTQ方法:從OBS經(jīng)OBQ到GPTQ,海森矩陣的魔力
王文廣萬字長文揭秘大模型量化技術(shù):探究原理,理解大模型高效推理最重要的技術(shù)
akaihaoshuai:從0開始實現(xiàn)LLM:6、模型量化理論+代碼實戰(zhàn)(LLM-QAT/GPTQ/BitNet 1.58Bits/OneBit)
akaihaoshuai:從0開始實現(xiàn)LLM:6.1、模型量化(AWQ/SqueezeLLM/Marlin)
https://zhuanlan.zhihu.com/p/703513611
AI大模型高效推理的技術(shù)綜述! 花哥 [AI大模型前沿](javascript:void(0)??
Zirui Liu, Jiayi Yuan, Hongye Jin, Shaochen Zhong, Zhaozhuo Xu, Braverman, V., Beidi Chen, & Hu, X. (2023). KIVI : Plug-and-play 2bit KV Cache Quantization with Streaming Asymmetric Quantization.
Databricks 博文: LLM Inference Performance Engineering: Best Practices
Coleman Hooper, Sehoon Kim, Hiva Mohammadzadeh, Michael W. Mahoney, Yakun Sophia Shao, Kurt Keutzer, & Amir Gholami. (2024). KVQuant: Towards 10 Million Context Length LLM Inference with KV Cache Quantization.
T. Dettmers, M. Lewis, Y. Belkada, and L. Zettlemoyer, (2022). LLM.int8(): 8-bit Matrix Multiplication for Transformers at Scale.
A. Gholami, S. Kim, Z. Dong, Z. Yao, M. W. Mahoney, and K. Keutzer, (2021). A Survey of Quantization Methods for Efficient Neural Network Inference.
KIVI: A Tuning-Free Asymmetric 2bit Quantization for kv Cache :https://arxiv.org/abs/2402.02750
Xiao, Guangxuan, et al. “Smoothquant: Accurate and efficient post-training quantization for large language models.” International Conference on Machine Learning. PMLR, 2023.
[2] Ashkboos, Saleh, et al. "Quarot: Outlier-free 4-bit inference in rotated llms." arXiv preprint arXiv:2404.00456 (2024).
Sun, Mingjie, et al. "Massive Activations in Large Language Models." arXiv preprint arXiv:2402.17762 (2024).
Liu, Ruikang, et al. "IntactKV: Improving Large Language Model Quantization by Keeping Pivot Tokens Intact."arXiv preprint arXiv:2403.01241(2024).
[5] Liu, Zechun, et al. "SpinQuant--LLM quantization with learned rotations."arXiv preprint arXiv:2405.16406(2024).
[2411.02355] "Give Me BF16 or Give Me Death"? Accuracy-Performance Trade-Offs in LLM Quantization [1]
Integer Quantization for Deep Learning Inference Principles and Empirical Evaluation
深度學(xué)習(xí)Int8的部署推理原理和經(jīng)驗驗證
Quantization and training of neural networks for effificient integer-arithmetic-only inference
Quantizing deep convolutional networks for effificient inference: A whitepaper
Discovering low-precision networks close to full-precision networks for effificient embedded inference
Pact: Parameterized clipping activation for quantized neural networks
干貨:深度學(xué)習(xí)模型量化(低精度推理)大總結(jié)
The Super Weight in Large Language Models
2w字解析量化技術(shù),全網(wǎng)最全的大模型量化技術(shù)解析 柏企閱文
白話版Scaling Laws for Precision 解讀 賈斯丁不姓丁
Efficient Deep Learning-學(xué)習(xí)筆記-4-Model Quantization 回溯的貓
LLMs量化系列|LLMs Quantization Need What ? 回溯的貓
LLMs量化系列|MiLo:如何利用LoRA補償MoE模型的量化損失 回溯的貓
[LLM量化系列] VQ之路:從AQLM、GPTVQ到VPTQ 進擊的Killua
[LLM量化系列] PTQ量化經(jīng)典研究解析 進擊的Killua
decoupleQ 2bit 量化技術(shù)介紹 行云流水
最新發(fā)現(xiàn):大規(guī)模值,注意力機制的關(guān)鍵密碼。ICML2025 AI修貓Prompt
Massive Values in Self-Attention Modules are the Key to Contextual Knowledge Understanding
ICML25研究發(fā)現(xiàn):RoPE又立大功了! 一只小茄墩
[ICML2024] StableMask: Refining Causal Masking in Decoder-only Transformer
Massive Activation in LLM 菜鳥脫貧戶
Transformers need glasses! Information over-squashing in language tasks
讀論文【大語言模型量化】Outlier Suppression: Pushing the Limit of Low-bit Transformer Language Models Mr.Liu
Quantizable Transformers: Removing Outliers by Helping Attention Heads Do Nothing
Massive Activations in Large Language Models
A Survey on Model Compression for Large Language Models
[ICLR2024] [W4A4] OmniQuant: Omnidirectionally Calibrated Quantization for Large Language Models
[進擊的Killua:LLM量化系列] VQ之路:從AQLM、GPTVQ到VPTQ41 贊同 · 2 評論文章
[MLSys2024] QMoE: Practical Sub-1-Bit Compression of Trillion-Parameter Models.
VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models
狂降90%!參數(shù)壓縮還能這樣玩?VQ量化三大奇招,模型瘦身新思路 深藍學(xué)院
VPTQ: Extreme Low-bit Vector Post-Training Quantization for Large Language Models
PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs
PrefixQuant: Static Quantization Beats Dynamic through Prefixed Outliers in LLMs 錘煉小助手

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號