
探秘Transformer系列之(30)--- 投機(jī)解碼
探秘Transformer系列之(30)--- 投機(jī)解碼
0x00 概述
投機(jī)解碼(Speculative Decoding)也叫預(yù)測(cè)解碼/投機(jī)采樣,它會(huì)利用小模型來預(yù)測(cè)大型模型的行為,從而提升模型在解碼(decoding)階段的解碼效率問題,加速大型模型的執(zhí)行。其核心思路如下圖所示,首先以低成本的方式(以小模型為主,也有多頭,檢索,Early Exit 等方式)快速生成多個(gè)候選 Token(串行序列、樹、多頭樹等),然后通過一次并行驗(yàn)證階段快速驗(yàn)證多個(gè) Token的正確性,只要平均每個(gè) Step 驗(yàn)證的 Token 數(shù) > 1,就可以一次性生成多個(gè)token,進(jìn)而減少總的 Decoding 步數(shù),實(shí)現(xiàn)加速的目的。
下圖左側(cè)是自回歸解碼模型,右側(cè)是投機(jī)解碼機(jī)制。
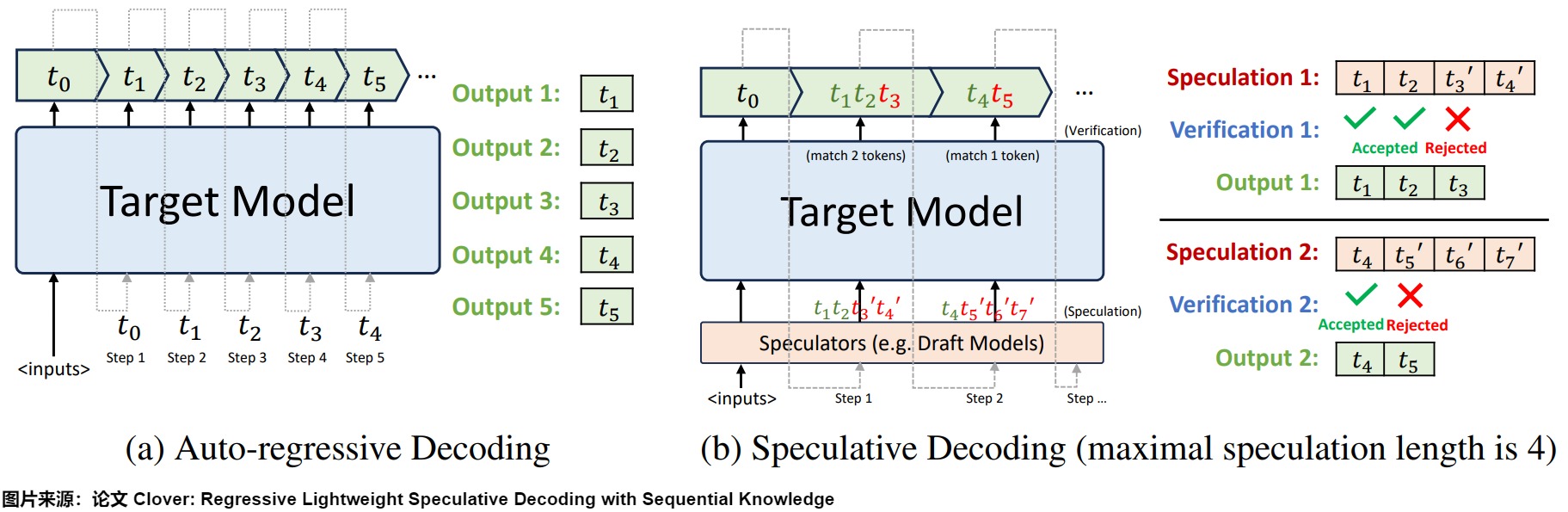
從本質(zhì)上來說,投機(jī)解碼希望在推理階段在不大幅度改變模型的情況下,通過更好利用冗余算力來并行"投機(jī)"地猜測(cè)出模型接下來要輸出的token。作為對(duì)比,也有一種方案是通過路由的方式組合多個(gè)不同規(guī)模和性能的模型。路由方式在調(diào)用之前已經(jīng)確定好需要調(diào)用哪個(gè)模型,直到調(diào)用結(jié)束。而投機(jī)解碼在一個(gè) Query 內(nèi)會(huì)反復(fù)調(diào)用大小模型。
注:
- 全部文章列表在這里,估計(jì)最終在35篇左右,后續(xù)每發(fā)一篇文章,會(huì)修改此文章列表。cnblogs 探秘Transformer系列之文章列表
- 本系列是對(duì)論文、博客和代碼的學(xué)習(xí)和解讀,借鑒了很多網(wǎng)上朋友的文章,在此表示感謝,并且會(huì)在參考中列出。因?yàn)楸鞠盗袇⒖嘉恼绿啵赡苡新┙o出處的現(xiàn)象。如果原作者或者其它朋友發(fā)現(xiàn),還請(qǐng)指出,我在參考文獻(xiàn)中進(jìn)行增補(bǔ)。
0x01 背景
1.1 問題
我們都知道,生成式 LLM 大部分是 Decoder-only 結(jié)構(gòu),其一方面模型比較大,推理時(shí)占用的存儲(chǔ)空間、所需的計(jì)算量都比較大,另一方面,大模型解碼時(shí)是一個(gè) Token 一個(gè) Token 串行生成,在 batch size 為 1 時(shí),Transformer block 中的矩陣乘都退化為矩陣乘向量操作,對(duì)于 GPU 推理來說,這是非常明顯的 IO bound,導(dǎo)致無法充分發(fā)揮 GPU 算力。
1.2 自回歸解碼
當(dāng)前的主流 LLM 基本都是 Decoder Only 的 Transformer 模型,其推理階段采用自回歸采樣,特點(diǎn)如下:
- 模型使用前綴作為輸入,將輸出結(jié)果處理+歸一化成概率分布后,采樣生成下一個(gè)token。
- 從生成第一個(gè) Token之后,開始采用自回歸方式一次生成一個(gè) Token,即當(dāng)前輪輸出token 與歷史輸入 tokens 拼接,作為下一輪的輸入 tokens,然后解碼。
- 重復(fù)執(zhí)行2。在后續(xù)執(zhí)行過程中,前后兩輪的輸入只相差一個(gè) token。
- 直到生成一個(gè)特殊的 Stop Token(或者滿足用戶的某個(gè)條件,比如超過特定長度) 才會(huì)結(jié)束。
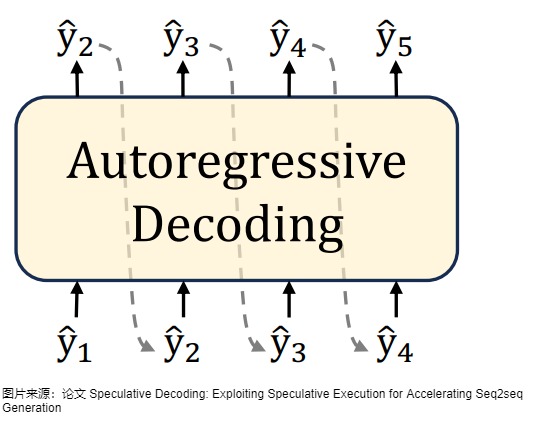
自回歸解碼對(duì)應(yīng)的算法如下圖所示。

自回歸采樣的缺點(diǎn)如下:
- 因?yàn)樵谏晌谋緯r(shí),自回歸采樣是逐個(gè) token 生成的,生成下一個(gè) token 需要依賴前面已經(jīng)生成的 token,這種串行的模式導(dǎo)致生成速度慢,效率很低。具體參見下圖。假設(shè)輸出總共有 N 個(gè) Token,則 Decoding 階段需要執(zhí)行 N-1 次 Forward,這 N-1 次 Forward 只能串行執(zhí)行。
- 在生成過程中,需要關(guān)注的 Token 越來越多(每個(gè) Token 的生成都需要和之前的 Token 進(jìn)行注意力計(jì)算),計(jì)算量也會(huì)隨之增大。
- 大型模型的推理過程往往受制于訪存速度。因?yàn)橥评硐乱粋€(gè)token的時(shí)候,需要依賴前面的結(jié)果。所以在實(shí)際使用GPU進(jìn)行計(jì)算時(shí),需要將所有模型參數(shù)以及kv-cache移至片上內(nèi)存進(jìn)行運(yùn)算,而一般來說片上內(nèi)存帶寬比計(jì)算性能要低兩個(gè)數(shù)量級(jí),這就使得大模型推理是memory-bandwidth-bound的,內(nèi)存訪問帶寬成為嚴(yán)重的瓶頸。
另外,大模型的能力遵循scaling law,也就是模型的參數(shù)越多其擁有的能力越強(qiáng),而越大的模型自然就需要越多的計(jì)算資源。scaling law告訴我們,我們沒有辦法通過直接減小模型的參數(shù)量來減小訪存的訪問量。
為了解決推理速度慢的問題,研究人員已經(jīng)進(jìn)行了許多針對(duì)推理的工程優(yōu)化,例如:
- 改進(jìn)的計(jì)算核心實(shí)現(xiàn)、多卡并行計(jì)算、批處理策略等等。其中,最樸素的做法就是增大推理時(shí)的 Batch size,比如使用 dynamic batching,將多個(gè)請(qǐng)求合并處理,將矩陣乘向量重新變?yōu)榫仃嚦瞬僮鳎?Batch size 不大的情況下,幾乎可以獲得 QPS 的線性提升。然而,這些方法并沒有從根本上解決LLM解碼過程是受制于訪存帶寬的問題。
- 對(duì)模型以及KV Cache進(jìn)行量化,使每一個(gè)token生成過程中讀取模型參數(shù)時(shí)的總比特?cái)?shù)減小,緩解io壓力。
- increasing the arithmetic intensity,即提高“浮點(diǎn)數(shù)計(jì)算量/數(shù)據(jù)傳輸量”這個(gè)比值,讓數(shù)據(jù)傳輸不要成為瓶頸。
- reducing the number of decoding steps,即縮短解碼步驟。投機(jī)解碼就屬于這個(gè)范疇。
0x02 定義 & 歷史
2.1 投機(jī)解碼
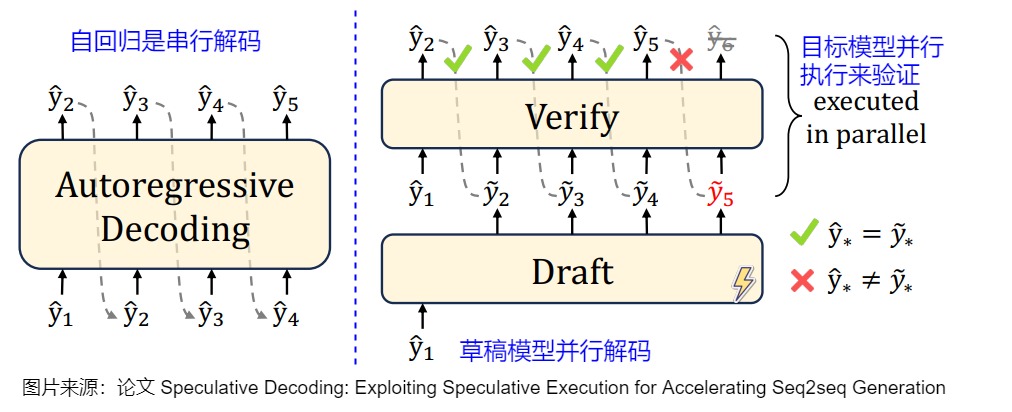
投機(jī)解碼(Speculative Decoding)允許我們將在同一個(gè)用戶請(qǐng)求內(nèi)的多個(gè) Token 一起運(yùn)算。其目的和 dynamic batching 類似,也是為了將矩陣乘向量重新變?yōu)榫仃嚦瞬僮鳎@很適合無法獲得更大 Batch size 或者只想降低端到端延時(shí)的場景。投機(jī)解碼一般使用兩個(gè)模型:Draft Model(草稿模型)快速生成多個(gè)候選結(jié)果,然后Target Model(目標(biāo)模型)并行驗(yàn)證和修改,最終得到滿意答案。具體而言:
- draft model用來猜測(cè)。draft model推理較快,承擔(dān)了串行的工作,它以自回歸的方式生成K個(gè)tokens,從而讓目標(biāo)模型能夠并行的計(jì)算。
- target model用來評(píng)估采樣結(jié)果\審核修正。target model通過并行計(jì)算多個(gè)token來從自回歸模型中采樣,用推理結(jié)果來決定是否使用draft model生成的這些tokens。
投機(jī)解碼的算法如下圖所示。

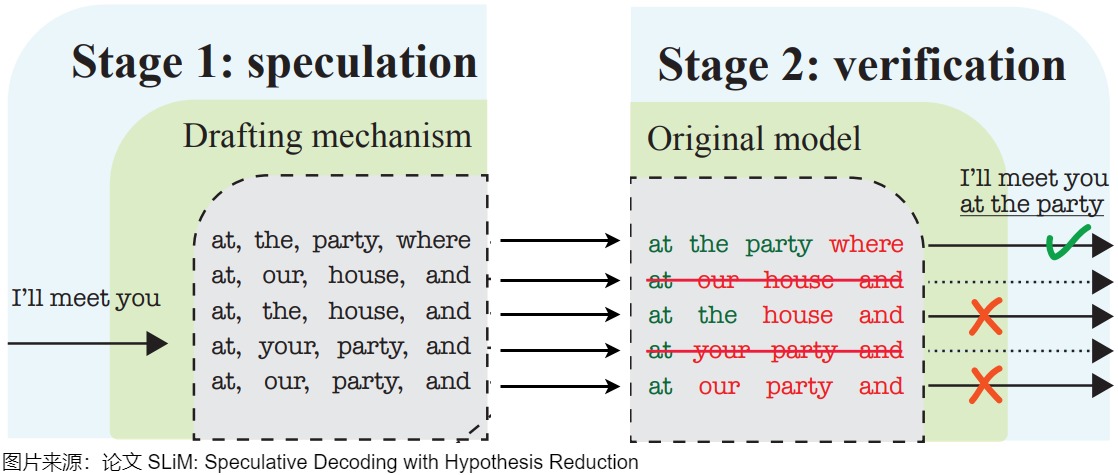
投機(jī)解碼無需對(duì)輸出進(jìn)行任何更改,就可以保證和使用原始模型的采樣分布完全相同,因此和直接用大模型解碼是等價(jià)的。下圖右側(cè),草稿模型先生成5個(gè)預(yù)測(cè)token后,將5個(gè)token一起輸入給目標(biāo)模型。以該前綴作為輸入時(shí),目標(biāo)模型會(huì)生成若干token,然后進(jìn)行驗(yàn)證。綠色表示草稿模型生成的token和目標(biāo)模型生成的token一致,預(yù)測(cè)token通過了“驗(yàn)證”——這個(gè)token本來就是LLM自己會(huì)生成的結(jié)果。紅色token是沒有通過驗(yàn)證的“推測(cè)”token。第一個(gè)沒有通過驗(yàn)證的“推測(cè)”token和其后續(xù)的“推測(cè)”token都將被丟棄。因?yàn)檫@個(gè)紅色token不是LLM自己會(huì)生成的結(jié)果,那么前綴正確性假設(shè)就被打破,這些后續(xù)token的驗(yàn)證都無法保證前綴輸入是“正確”的了。
2.2 發(fā)展歷史
下面給出了投機(jī)解碼的發(fā)展歷史。
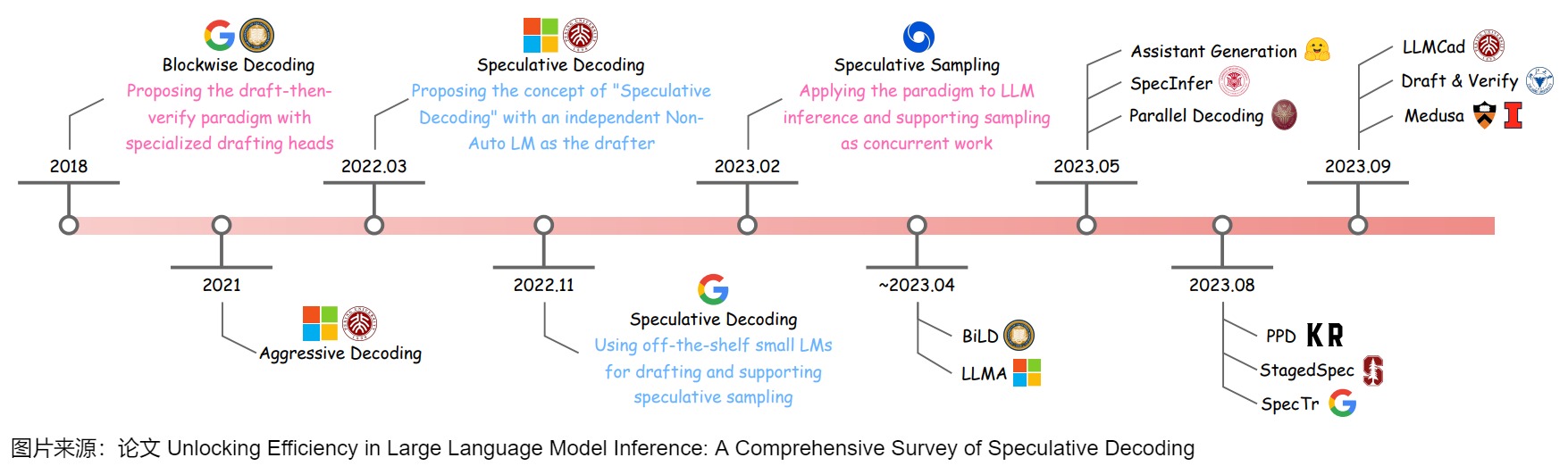
其中有兩篇文章需要特殊提一下,兩篇文章都算是投機(jī)解碼的開山之作,其中公案我們也難以說清。
Speculative Decoding
論文“Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation”是第一篇提出 Speculative Decoding 這個(gè)詞的文章,也確立了使用 draft-then-verify 這一方法加速 Auto-Regressive 生成的范式。
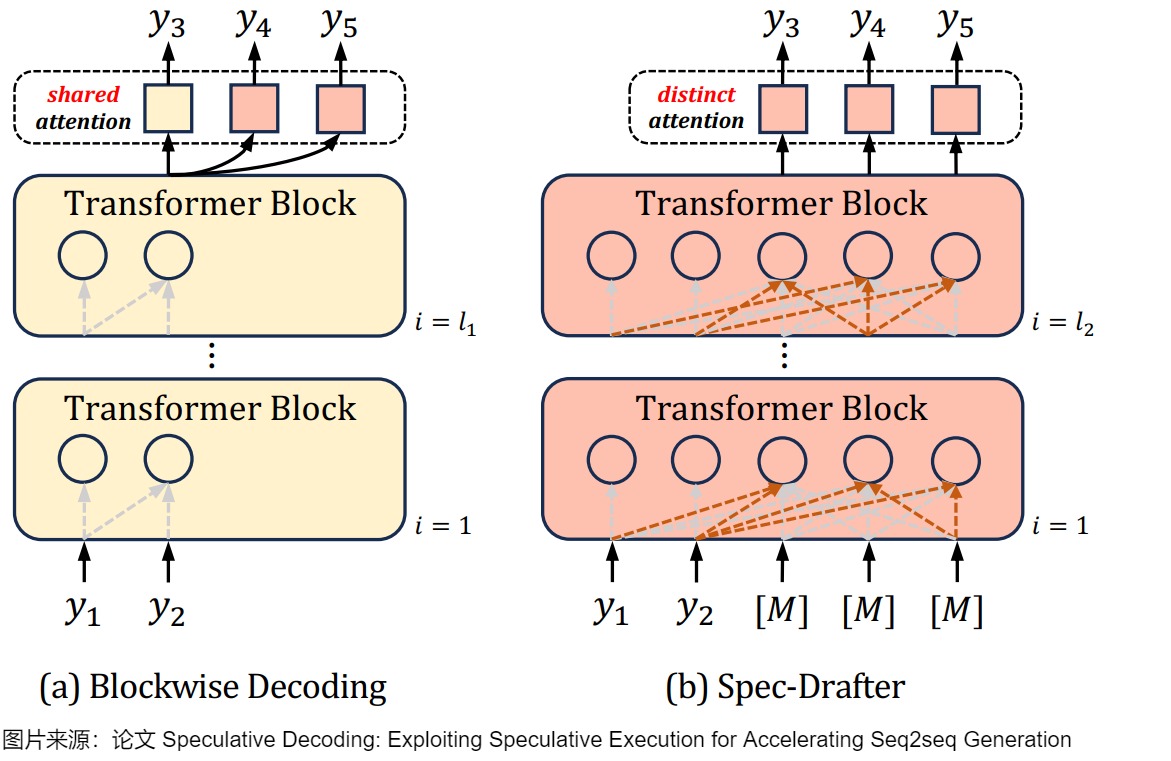
Speculative Decoding 希望解決的是現(xiàn)有的 Autoregressive 模型推理過慢的問題。下圖(a)是Blockwise Decoding,其在目標(biāo)自回歸模型上引入了k ? 1個(gè)FFN頭,這些頭使用共享注意力(shared attention)來預(yù)測(cè)下面k個(gè)tokken。(b)是Spec-Drafter模型,該模型是預(yù)測(cè)草稿token的獨(dú)立模型,它使用不同的query來預(yù)測(cè)每個(gè)草稿token。下圖上黃色部分是自回歸AR模型,紅色部分是新加入的模塊。
Speculative Sampling
論文“Fast Inference from Transformers via Speculative Decoding”最早提出了 Speculative Sampling。此文章和上一篇文章是同時(shí)期的研究,被認(rèn)為是SD的開山之作,后續(xù)許多研究都是基于此來展開。本文用 target model(目標(biāo)模型)指代待加速的大模型,用 approximation model(近似模型)指代用來幫助加速大模型的小模型。
后續(xù)我們統(tǒng)一使用speculative decoding這個(gè)術(shù)語。
接下來,我們先對(duì)本領(lǐng)域的先驅(qū)之作"Blockwise Parallel Decoding"做簡要分析,然后再結(jié)合兩篇開山之作進(jìn)行學(xué)習(xí)。
0x03 Blockwise Parallel Decoding
論文“Blockwise Parallel Decoding for Deep Autoregressive Models”提出的Blockwise Parallel Decoding是本領(lǐng)域的先行之作,或者說并行解碼的第一個(gè)工作,所以我們仔細(xì)學(xué)習(xí)下,有助于我們理解后續(xù)脈絡(luò)。Blockwise Parallel Decoding(BPD)使用多頭的方式生成候選序列(一個(gè)串行序列),然后進(jìn)行并行驗(yàn)證。
3.1 動(dòng)機(jī)
BPD旨在解決Transfomer-based Decoder串行貪心解碼的低計(jì)算效率問題:在序列生成時(shí)是串行的一個(gè)一個(gè) Token的生成,計(jì)算量和生成結(jié)果所需的時(shí)間與生成的 Token 數(shù)目成正比。
我們接下來看看BPD的出發(fā)點(diǎn)和思路。
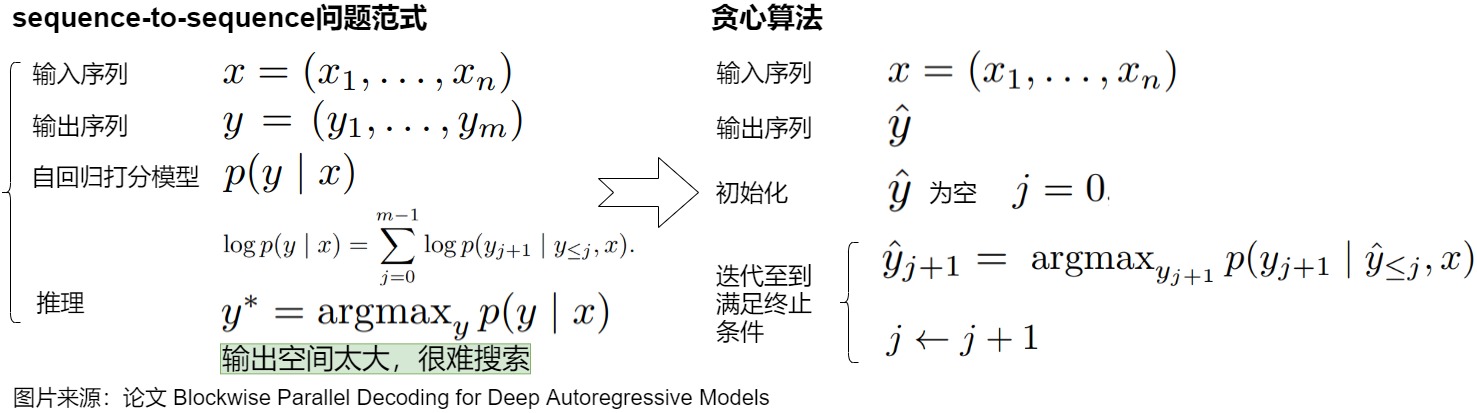
上圖是貪心解碼的展示。貪心解碼效率很高,但可能無法找到全局最優(yōu),而且存在很多問題,具體如下。
- 假設(shè)輸出序列的長度為 m,那么 Autoregressive Decoding 要執(zhí)行 m 步才能獲得最終結(jié)果,隨著模型的增大,每一步的時(shí)延也會(huì)增大,整體時(shí)延也會(huì)放大至少 m 倍。
- 因?yàn)槊看芜M(jìn)行一個(gè)token生成的計(jì)算,需要搬運(yùn)全部的模型參數(shù)和激活張量,這使解碼過程嚴(yán)重受限于內(nèi)存帶寬。
為了克服上述限制,BPD的改進(jìn)動(dòng)機(jī)如下。
- 作者期望通過 n 步就可完成整個(gè)預(yù)測(cè),其中 n 遠(yuǎn)小于 m。
- 但是如何打破串行解碼魔咒,并行產(chǎn)生后k個(gè)token?因?yàn)檎Z言模型都是預(yù)測(cè)下一個(gè)token,如果我們有k-1個(gè)輔助模型,每個(gè)模型可以根據(jù)輸入序列跳躍地預(yù)測(cè)后2到k個(gè)位置的token。那么,輔助模型和原始模型就有可能獨(dú)立運(yùn)行,從而并行生成后k個(gè)token。
3.2 思路
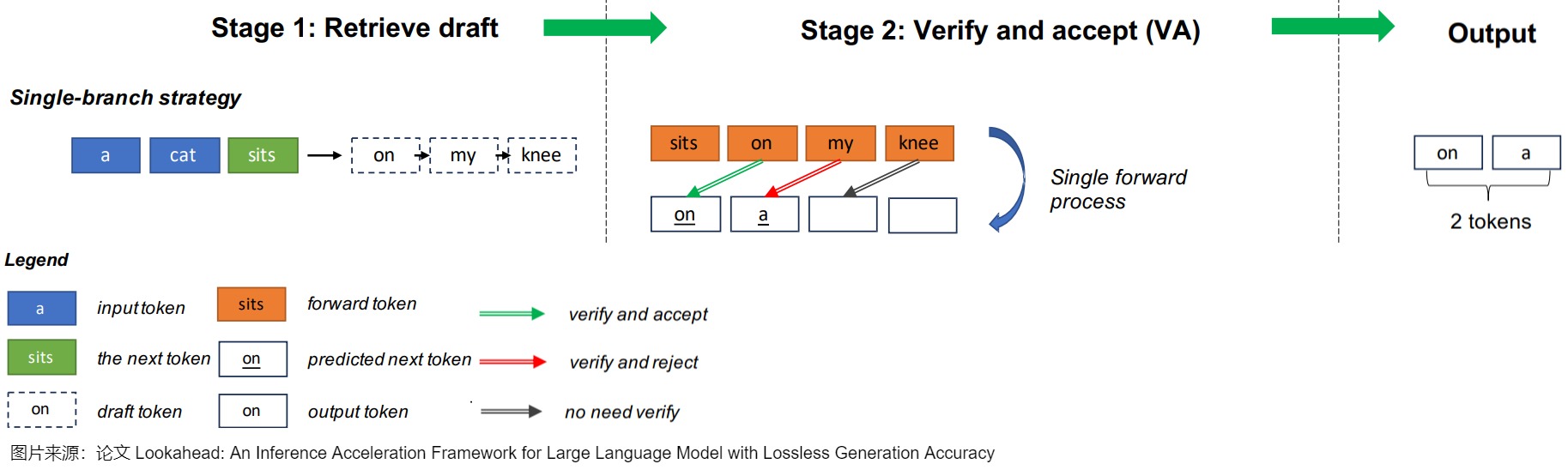
論文提出了針對(duì)深度自回歸模型的并行解碼技術(shù)——分塊并行解碼(Blockwise Parallel Decoding)方案。該方案通過訓(xùn)練輔助模型(通過在原始模型的Decoder后面增添少量參數(shù)),使得模型能夠預(yù)測(cè)未來位置的輸出(并行地預(yù)測(cè)并驗(yàn)證后k個(gè)token),然后利用這些預(yù)測(cè)結(jié)果來跳過部分貪心解碼步驟,從而加速解碼過程。具體而言,BPD提出了使用特殊drafting heads的draft-then-verify范式,其三個(gè)階段分別是Predict、Verify和Accept階段。
- Predict 階段使用“原模型+k-1個(gè)輔助模型”進(jìn)行k個(gè)位置token的預(yù)測(cè)。論文將模型原來的單 head(最后用于預(yù)測(cè) Token 分布的 MLP)轉(zhuǎn)換為多個(gè) head,第一個(gè) head 為保留原始模型的 head,用于預(yù)測(cè)下一個(gè) Token,后面新增的 head 分別預(yù)測(cè)下下一個(gè) Token,下下下一個(gè) Token,相當(dāng)于一次預(yù)測(cè)多個(gè) Token。
- Verify(驗(yàn)證)階段使用原模型并行地驗(yàn)證這k個(gè)位置上候選詞所形成的幾種可能。因?yàn)橐呀?jīng)生成了多個(gè)token,因此在下一次推理的時(shí)候,即可使用原模型并行地驗(yàn)證這些 Token 序列(由于模型計(jì)算本身是 IO bound,并行驗(yàn)證增加的計(jì)算幾乎不會(huì)增加推理的時(shí)延)。Verify 過程會(huì)將這些token組成batch,實(shí)現(xiàn)合適的attention mask,一次性獲得這個(gè)k個(gè)位置的詞表概率。因?yàn)榈谝粋€(gè) head 就是原始模型的 head,所以結(jié)果肯定是對(duì)的,這樣就可以保證每個(gè) decoding step 實(shí)際生成的 Token 數(shù)是 >= 1 的,以此達(dá)到降低解碼次數(shù)的目的。另外,在驗(yàn)證同時(shí)也可順帶生成新的需要預(yù)測(cè)的 Token。
- Accept階段會(huì)接受驗(yàn)證過的最長前綴,附加到原始序列上。此階段會(huì)貪心地選擇概率最大的token,如果驗(yàn)證結(jié)果的token和Predict階段預(yù)測(cè)的token相同則保留。如果不同,則后面的token預(yù)測(cè)都錯(cuò)誤。
需要說明的是,這篇論文的工作只支持貪婪解碼(Greedy Decoding),不適合其他的解碼算法(而Speculative Sampling可以適配Beam Search),在不犧牲效果的情況下,有效 Token 數(shù)可能并不多。而且模型還需要使用訓(xùn)練數(shù)據(jù)進(jìn)行微調(diào)。因此,Blockwise Parallel Decoding=multi-draft model +top-1 sampling+ parallel verification。受此啟發(fā),后續(xù)提出的Speculative Sampling方法也使用小模型并行預(yù)測(cè),大模型驗(yàn)證的方式解決相同的問題。
3.3 架構(gòu)
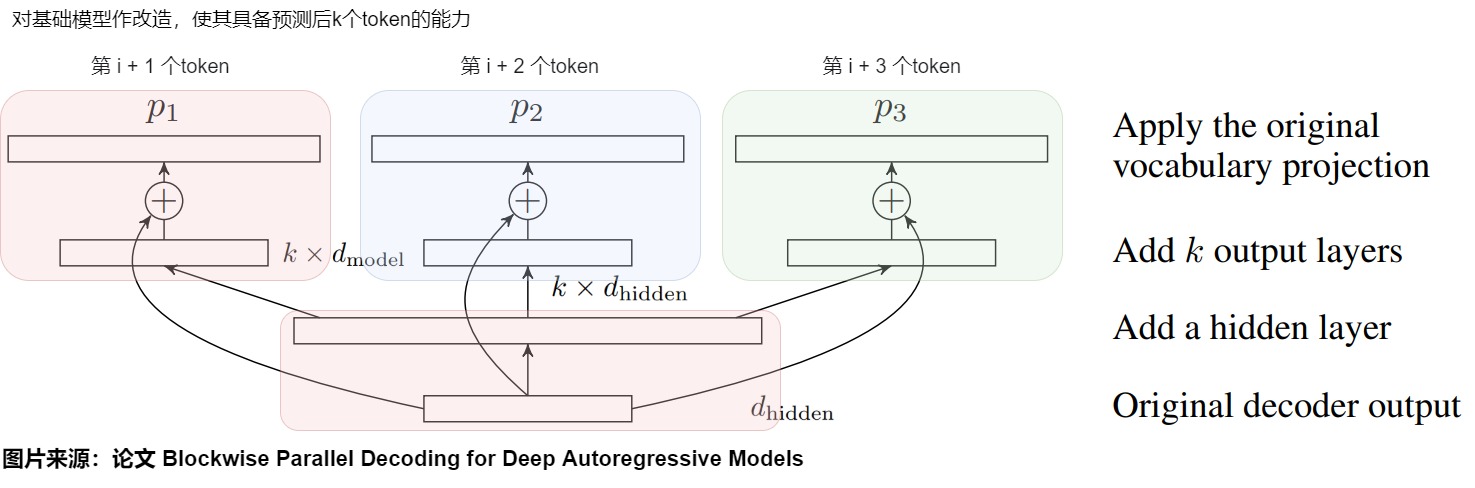
BPD提出了多頭并行解碼機(jī)制。除了原始模型 p 外,在 Predict 階段還有幾個(gè)輔助模型 p2,...,pk 。用這些模型來輔助預(yù)測(cè)。但是我們會(huì)面臨一個(gè)問題:如果這些輔助模型采用和原始模型 p 同樣的結(jié)構(gòu)并單獨(dú)訓(xùn)練,那么在 Predict 階段的計(jì)算量就是生成一個(gè) Token 的 K 倍。即使忽略 Verify 階段,理想情況下整個(gè)訓(xùn)練任務(wù)的計(jì)算量也沒有降低。而且這K個(gè)模型對(duì)于內(nèi)存的占用將是非常驚人的。因此,論文并沒有真的構(gòu)造出k-1個(gè)輔助模型,即p2,...,pk 并非是獨(dú)立的原始模型的副本。論文是對(duì)原始模型略作改造,讓這些輔助模型與原始模型 p1 共享 backbone,然后增加一個(gè)隱藏層,針對(duì)每個(gè)模型 p1,...,pk 都有獨(dú)立的輸出層。這樣就就可以讓新模型具備預(yù)測(cè)后k個(gè)token的能力,能保證 Predict 段實(shí)際的計(jì)算量與之前單個(gè) Token 預(yù)測(cè)的計(jì)算量基本相當(dāng)。
具體模型架構(gòu)如下圖所示,在原始模型之上一共增加了三層(從下至上):
- 在原始模型的最后一個(gè) Transformer Decoder 層之后先加上一個(gè)隱層,它的輸入是(batch_size, sequence_length, d_model),輸出是(batch_size, sequence_length, k* d_model)。
- 在隱層之后會(huì)額外加上幾個(gè) head,分別為 p2,...,pk。Transformer Decoder 層輸出的 logit 會(huì)先傳給隱層進(jìn)行投影,投影后的輸出會(huì)分別傳給這幾個(gè)頭。這些頭的計(jì)算結(jié)果會(huì)分別再與原始模型的logit做殘差連接。每個(gè)頭負(fù)責(zé)預(yù)估一個(gè)token,這k個(gè)頭的輸出就是k個(gè)不同位置token的logits。頭1 負(fù)責(zé)預(yù)估 next token, 頭2 負(fù)責(zé)預(yù)估 next next token, 以此類推。
- 最后再將結(jié)果送入到詞表投影層(包括一個(gè)線性變換和一個(gè)Softmax),預(yù)估每個(gè)詞的概率分布,最終通過某種采樣方法生成token。這個(gè)詞表投影層是在多Head之間共享的。
主干網(wǎng)絡(luò) + 頭1(下圖紅色)是原模型或者說基礎(chǔ)模型,也就是預(yù)訓(xùn)練的模型。其他Head是論文說的輔助網(wǎng)絡(luò)(auxiliary model)(藍(lán)色和綠色分別是兩個(gè)輔助網(wǎng)絡(luò))。既然可以根據(jù)輸入序列預(yù)測(cè)下一個(gè) Token,那么也就可以根據(jù)同樣的序列預(yù)測(cè)下下一個(gè),下下下一個(gè) Token,只是準(zhǔn)確率可能會(huì)低一些而已,這樣就可以在 Decoding step 的同時(shí)額外生成一個(gè)候選序列,讓基礎(chǔ)模型在下次 Decoding step 來驗(yàn)證即可。
3.4 訓(xùn)練
改造后的模型還需要使用訓(xùn)練數(shù)據(jù)進(jìn)行訓(xùn)練。由于訓(xùn)練時(shí)的內(nèi)存限制,論文無法使用對(duì)應(yīng)于k個(gè)project layer輸出的k個(gè)交叉熵?fù)p失的平均值作為loss。而是為每個(gè)minibatch隨機(jī)均勻選擇其中的一個(gè)layer輸出作為loss。
訓(xùn)練FFN的參數(shù)可以使用如下幾種方式:
- Frozen Parameters:將原始模型參數(shù)凍結(jié),只更新那些新加入的FFN層參數(shù)。這樣預(yù)測(cè)下一個(gè)token肯定是準(zhǔn)確的,但可能影響輔助模型預(yù)測(cè)的準(zhǔn)確性。
- Finetuning:以原始參數(shù)為初始化值對(duì)全部參數(shù)進(jìn)行微調(diào),這可能會(huì)提高模型的內(nèi)部一致性,但在最終性能上可能會(huì)有所損失。
- Distillation:蒸餾很適合并行解碼,因?yàn)閠eacher和student都有相同的結(jié)構(gòu)。蒸餾數(shù)據(jù)是原始模型用相同的超參數(shù)但不同的隨機(jī)種子進(jìn)行beam search產(chǎn)生的。
3.5 步驟
下圖展示了blockwise decoding的三個(gè)階段,分別是Predict、Verify和Accept階段。
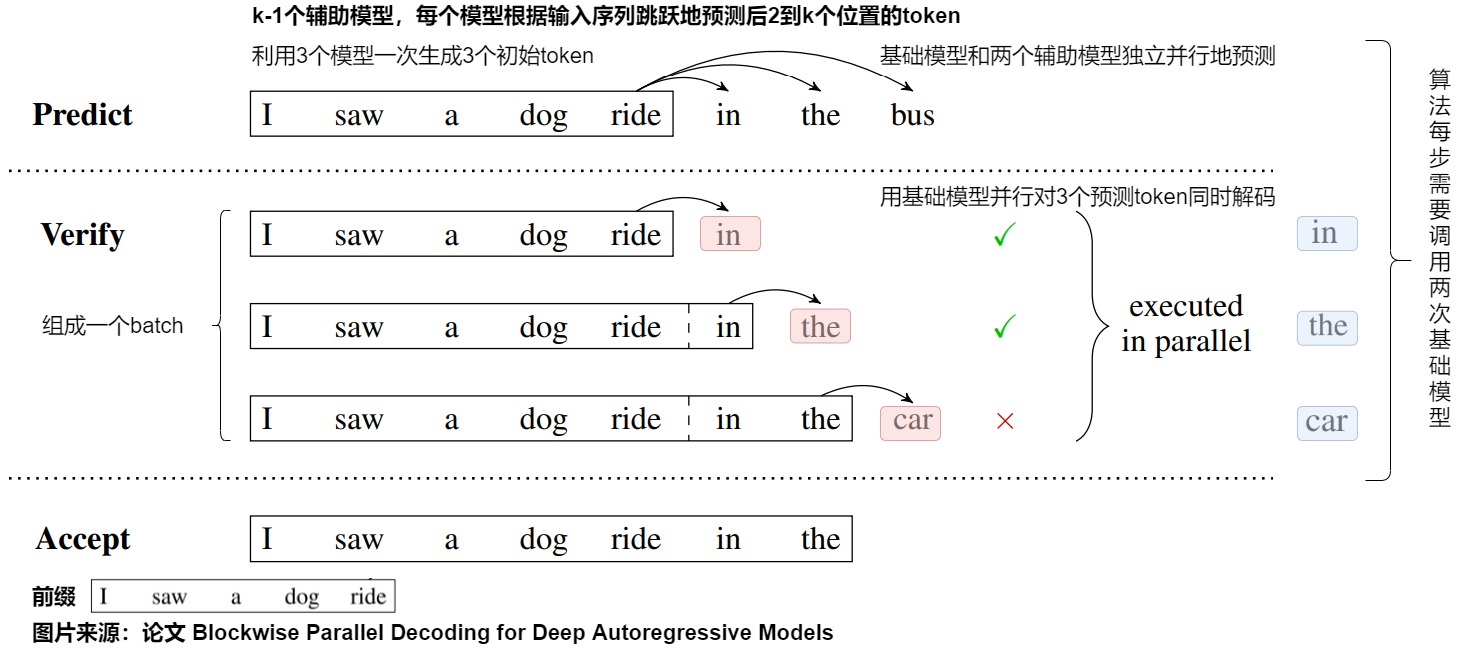
我們基于上圖進(jìn)行詳細(xì)解讀,假設(shè)要生成的序列長度為?? ,并行Head數(shù)為k。
在Predict階段中。
- 預(yù)測(cè)即使用原模型+k-1個(gè)輔助模型進(jìn)行k個(gè)位置token的預(yù)測(cè)。原模型 p1 和輔助模型 p2,...,pk 都是相互獨(dú)立的,可以并行的執(zhí)行,因此生成這個(gè)k個(gè)單詞的時(shí)間和生成一個(gè)單詞時(shí)間基本一致,所以可降低整體生成的步數(shù),也就幫助降低整體時(shí)延。
- 針對(duì)上圖,則是原模型和兩個(gè)輔助模型獨(dú)立并行地預(yù)測(cè)出后三個(gè)token,即“in”、“the”和“bus”。
Verify階段中,我們需要在上一步中生成的 K 個(gè)單詞里選擇符合要求的最長前綴。
- 將原始的序列和生成的 ?? 個(gè)token拼接成
????????<????????????????_??????????,??????????>,這 ?? 個(gè)????????<????????????????_??????????,??????????>將組成一個(gè)Batch(也會(huì)加上對(duì)應(yīng)的掩碼),一次性發(fā)給頭1并行地驗(yàn)證這k個(gè)位置(看看頭1生成的token是否跟 ?????????? 一致)。 - 針對(duì)上圖,則是對(duì)上一步生成的三個(gè)token進(jìn)行打分。具體而言,我們把生成的’in the bus’和前綴拼接后送入原始模型進(jìn)行一次前向推理運(yùn)算,上圖Verify階段中的黑框里是 ????????????????_?????????? ,藍(lán)色的是要驗(yàn)證的 ?????????? ,箭頭指向的紅色是預(yù)測(cè)結(jié)果。這樣只進(jìn)行一次前向推理運(yùn)算,就可以獲得后三個(gè)輸出位置詞表的概率分布。
- batch的第一個(gè)輸入是“I saw a dong ride",輸出是”in“。
- batch的第二個(gè)輸入是“I saw a dong ride in",輸出是”the“。
- batch的第三個(gè)輸入是“I saw a dong ride in the",輸出是”car“。
在Accept階段中會(huì)選擇 ????????1 預(yù)估結(jié)果與 ?????????? 一致的最長的 ?? 個(gè)token,作為可接受的結(jié)果。
- 我們可以貪心地選擇概率最大的token作為驗(yàn)證結(jié)果。從左到右看,如果驗(yàn)證結(jié)果的token和Predict階段預(yù)測(cè)的token相同,則保留這個(gè)token。如果不同,則該token和其之后的token預(yù)測(cè)都錯(cuò)誤。
- 因?yàn)橹唤邮艿谝粋€(gè)不一致的單詞之前的單詞,并且驗(yàn)證時(shí)候使用的就是原始模型 p1 ,這也就保證了最終結(jié)果是與原始序列預(yù)測(cè)的結(jié)果是完全一致的。
- 針對(duì)上圖,因?yàn)椤癱ar“和”bus“不一致,所以只保留”in“和”the“。
假設(shè)要生成的序列長度為?? ,并行Head數(shù)為??。自回歸生成方法中,總共需要 m 步執(zhí)行。BDP中,對(duì)每 ?? 個(gè)token執(zhí)行一次上述三階段過程,predict階段執(zhí)行1步產(chǎn)出多個(gè)Head的輸出, verify階段并行執(zhí)行1步,accept階段不耗時(shí)。因此在理想情況下(每次生成的 K 個(gè) Token 都能接受),總的解碼次數(shù)從 m 降低到 2m/K。這其中由于 Predict 階段 p1 和 Verify 階段都使用的原始模型,所以只使用兩次原模型。
3.6 優(yōu)化
由于存在 Predict 和 Verify 兩個(gè)階段,因此即使理想情況下整體的解碼次數(shù)也是 2m/K,而不是最理想的 m/K。事實(shí)上,由于 Predict 階段的模型有共同的 backbone,并且 Verify 階段使用的模型也是原始模型 p1,因此就可以利用第 n 步的 Verify 結(jié)果來直接生成第 n+1 步的 Predict 結(jié)果。于是作者們進(jìn)一步優(yōu)化這個(gè)算法,在原始模型驗(yàn)證時(shí)同時(shí)預(yù)測(cè)后k個(gè)token。這樣Predict和Verify階段可以合并,驗(yàn)證同時(shí)也獲得了后k個(gè)token的候選。
優(yōu)化之后,模型第一次推理只執(zhí)行predict階段( 1 步),調(diào)用一次原始模型。然后進(jìn)入verify和predict重疊的階段,每次處理序列往前走 ?? 長度,直到生成終止token(共m/k步,調(diào)用m/k次原始模型)。即,除了第一次迭代,每次迭代只需調(diào)用一次模型forward,而不是兩次,從而將解碼所需的模型調(diào)用次數(shù)減半。進(jìn)一步將模型調(diào)用次數(shù)從2m/k減少到m/k + 1。
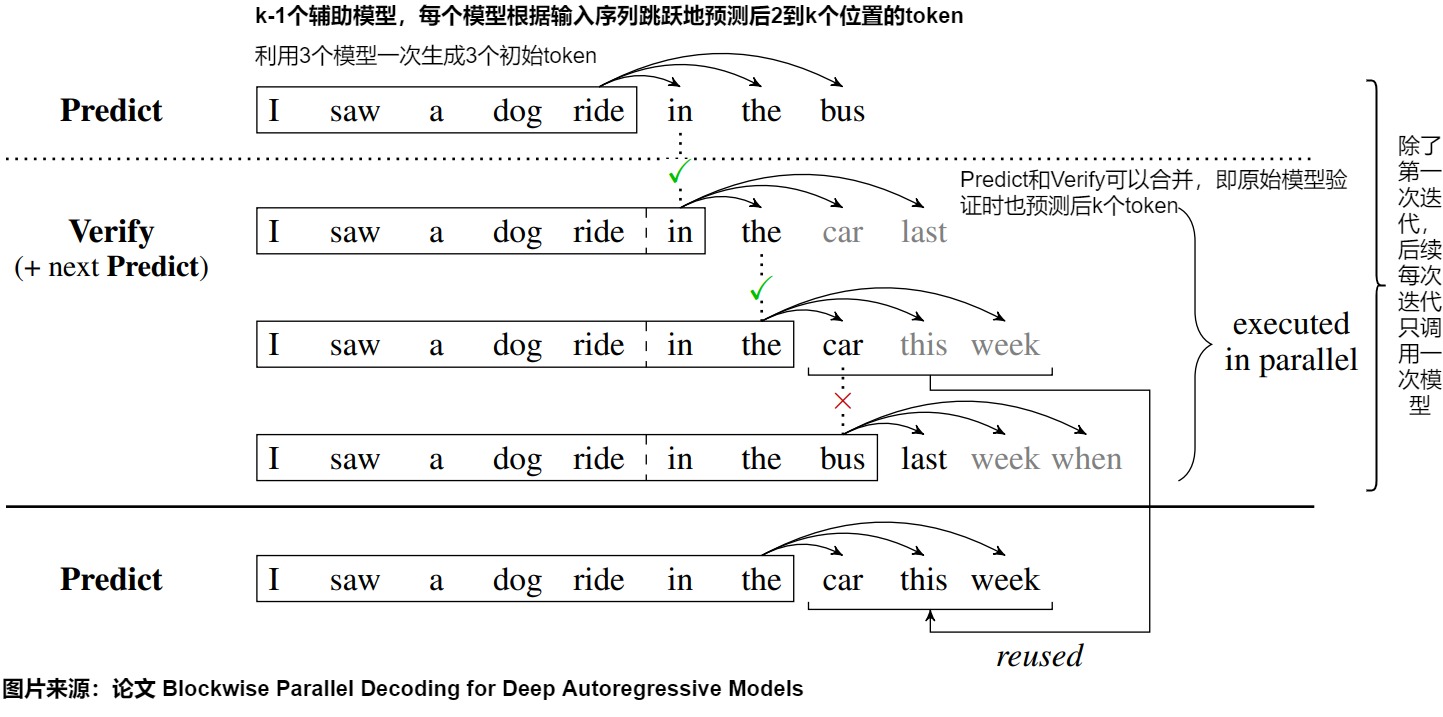
如上圖所示,還是以之前的例子為例:
-
Predict 階段,輸入單詞 I saw a dog ride in the,進(jìn)行一次原模型推理,生成了新單詞 in,the,bus。
-
Verify 階段:
- 第一組:輸入 I saw a dog ride,待驗(yàn)證單詞為 in,實(shí)際預(yù)測(cè)得到 in,the,car,last,第一個(gè)單詞的 Top1 為 in,結(jié)果相同,接受 in 這個(gè)單詞
- 第二組:輸入 I saw a dog ride in,待驗(yàn)證單詞為 the,實(shí)際預(yù)測(cè)得到 the,car,this,week,第一個(gè)單詞的 Top1 為 the,結(jié)果相同,接受 the 這個(gè)單詞
- 第三組:輸入 I saw a dog ride in the,待驗(yàn)證單詞為 car,實(shí)際預(yù)測(cè)得到 bus,last,week,when,第一個(gè)單詞的 Top1 為 bus,結(jié)果不相同,不接受 car 這個(gè)單詞。
-
Accept 階段。因?yàn)榈谌M的 bus 和 car 不相同,所以不接受第三組的結(jié)果,接受第二組的結(jié)果。因此可以把 car,this,week 作為新的 Predict 結(jié)果,繼續(xù)進(jìn)行 Verify。
3.7 收益
我們接下來看看收益。
這種方案之所以可以加速解碼,在于Verify階段可以用基礎(chǔ)模型 p1 并行對(duì)k個(gè)預(yù)測(cè)token進(jìn)行同時(shí)解碼。因?yàn)槊總€(gè)迭代Predict階段產(chǎn)生k個(gè)token可以看成一個(gè)block,故這種方法被稱為blockwise parallel decoding。這種方法推理時(shí)得到的結(jié)果和自回歸方式解碼的結(jié)果一樣,因此沒有任何生成效果的精度損失。
Blockwise Decoding的速度取決于執(zhí)行模型forward的次數(shù)。在訪存受限的情況下,對(duì)”I saw a dog ride”進(jìn)行forward運(yùn)算的時(shí)間和對(duì)“I saw a dog ride in the car”進(jìn)行forward運(yùn)算的時(shí)間近似相同,因?yàn)樗鼈兌夹枰L問模型參數(shù)和KV Cache,多出幾個(gè)tokens帶來的激活訪存開銷顯得微不足道。
0x04 原理
看完了BPD這個(gè)基礎(chǔ)之作,我們?cè)賮砜纯赐稒C(jī)解碼。
4.1 動(dòng)機(jī)
投機(jī)解碼的動(dòng)機(jī)來自幾點(diǎn)觀察和一個(gè)借鑒。
4.1.1 觀察
我們首先看看幾點(diǎn)關(guān)鍵觀察結(jié)果:
- 困難任務(wù)包含容易子任務(wù)。在困難的語言建模任務(wù)中,通常包含了一些相對(duì)容易的子任務(wù),比如,預(yù)測(cè)有些token時(shí),softmax輸出的概率分布會(huì)集中在某些token上,這說明模型有較大的置信度確定下一個(gè)輸出的token。這意味著不是所有的解碼步驟都同樣困難,如果我們用小模型去回答這些簡單的問題,在遇到難題的情況下再調(diào)用大模型,就可以提高整體的生成效率。即,大多數(shù)容易生成的tokens其實(shí)用更少參數(shù)的模型也可以生成。
- 內(nèi)存帶寬和通信是大模型推理的瓶頸。對(duì)于 LLM 推理來說,通常瓶頸不是數(shù)學(xué)計(jì)算,而是內(nèi)存帶寬及通信量、通訊速度。LLM每個(gè)解碼步所用的推理時(shí)間大部分并不是用于模型的前向計(jì)算,而是消耗在了將LLM巨量的參數(shù)從GPU顯存(High-Bandwidth Memory,HBM)遷移到高速緩存(cache)上(以進(jìn)行運(yùn)算操作)。這意味著在某些情況下,適當(dāng)增加計(jì)算量并不會(huì)影響推理速度,可以用于提高并發(fā)性。
- 大模型在做推理任務(wù)(decoding階段)時(shí),往往batch size為1,一次只能生成一個(gè)token,無法并行計(jì)算,導(dǎo)致大量算力冗余。事實(shí)上,在數(shù)量增加有限的情況下,輸入多個(gè)tokens和輸入一個(gè)token單輪的計(jì)算時(shí)延基本一致。如果我們能讓大模型一次處理一批tokens,就能利用上算力,讓大模型達(dá)到計(jì)算和訪存平衡。
4.1.2 借鑒
"Speculative execution"(猜測(cè)性執(zhí)行)是一種在處理器(CPU)中常見的優(yōu)化技術(shù)。
它的基本思想是在不確定某個(gè)任務(wù)是否真正需要執(zhí)行時(shí),提前執(zhí)行該任務(wù),然后再來驗(yàn)證被執(zhí)行任務(wù)是否真的被需要,這樣做的好處可以增加并發(fā)性和性能,一個(gè)典型的例子是分支預(yù)測(cè)(branch prediction)。在處理器中,"speculative execution"通常用于處理分支(branch)指令。當(dāng)處理器遇到一個(gè)分支指令時(shí),它不知道分支條件的具體結(jié)果,因此會(huì)選擇一條路徑來執(zhí)行。如果分支條件最終符合預(yù)期,那么一切正常,程序?qū)⒗^續(xù)執(zhí)行。但如果條件不符合,處理器會(huì)回滾到分支前的狀態(tài),丟棄之前的操作,然后選擇正確的路徑進(jìn)行執(zhí)行。
4.2 思路
上文提到,投機(jī)解碼最早在兩篇論文中被提出。基于上述的觀察結(jié)果和Speculative execution的機(jī)制,在解碼自回歸模型方面,兩篇論文的作者將"speculative execution"這一優(yōu)化技術(shù)進(jìn)行了推廣,將其應(yīng)用于自回歸模型的解碼過程中。
投機(jī)解碼使用兩個(gè)模型:一個(gè)是原始target model(目標(biāo)模型),另一個(gè)是比原始模型小得多的draft model(近似模型/草稿模型)。draft model和target mode聯(lián)合推理,draft模型生成γ個(gè)token,而target模型則去驗(yàn)證γ個(gè)token是否為最后需要的token。就是使用一個(gè)小模型來生成多個(gè)草稿token,然后使用大模型對(duì)這多個(gè)草稿token做并行驗(yàn)證、糾正和優(yōu)化。這樣就可以在接近大參數(shù)模型的生成一個(gè)token的時(shí)間里面生成多個(gè)tokens。我們來做具體分析。
- "投機(jī)解碼"指的是用小模型的輸出去投機(jī)。
- 先用更高效的近似小模型預(yù)測(cè)后續(xù)的若干個(gè)tokens(一些可能的推理結(jié)果,這些結(jié)果被稱為"speculative prefixes"),這充分利用了小模型decoding速度快的優(yōu)點(diǎn)。
- 解碼過程中,某些token的解碼相對(duì)容易,某些token的解碼則很困難。因此,簡單的token生成可以交給小型模型處理,這些小模型應(yīng)該也可以獲取正確的預(yù)測(cè)結(jié)果。而困難的token則交給大型模型處理。如果當(dāng)前的問題比較簡單,則小模型有更大的可能猜對(duì)多個(gè)token。
- 論文里的并行就是指大模型一次計(jì)算多個(gè)token,節(jié)省下來傳輸損耗。即用大模型并行驗(yàn)證這一些token是否符合大模型的輸出,其思路如下。
- 在一次前向傳播中,同時(shí)驗(yàn)證多個(gè) draft token。在第一個(gè) draft token 與原始模型輸出不相符的位置截?cái)啵G棄在此之后的所有 draft token。這就是"Speculative execution"中的丟棄。
- 利用prefill階段比decoding階段計(jì)算效率高的特點(diǎn)。大模型可以一次prefill輸入幾個(gè)小模型decode步結(jié)果來仲裁、提高推理速度。用大模型的prefill模式代替decode模式可以節(jié)約大模型的訪存,以及充分利用tensor core來加速矩陣乘法。這不是一個(gè)純算法或者純硬件系統(tǒng)角度考慮問題的加速方案,而是一個(gè)同時(shí)從考慮算法以及硬件系統(tǒng)的解決方案。
- 然后,利用一種新穎的采樣方法(speculative sampling)來最大化這些推測(cè)性任務(wù)被接受的概率。"speculative decoding"這種驗(yàn)證和重采樣過程在理論上是等價(jià)于直接從目標(biāo) LLM 采樣,因此,可以保證最終生成的文本分布與目標(biāo) LLM 一致。
總結(jié)下,"speculative decoding"可以通過充分利用模型之間的復(fù)雜度差異,以及采用并行計(jì)算的方法,使得從大型自回歸模型中進(jìn)行推理變得更快速和高效。同時(shí)保持了與目標(biāo)模型相同的輸出分布(在實(shí)現(xiàn)對(duì)target LLM推理加速的同時(shí),不損失LLM的解碼質(zhì)量),而無需更改模型架構(gòu)、訓(xùn)練過程或輸出。下圖給出了執(zhí)行流程。
4.3 對(duì)比
投機(jī)執(zhí)行和投機(jī)解碼對(duì)比如下。
| 類別 | 投機(jī)執(zhí)行 | 投機(jī)解碼 |
|---|---|---|
| 提前執(zhí)行 | 遇到一個(gè)分支指令時(shí),CPU不知道分支條件的具體結(jié)果,因此會(huì)選擇一條路徑來執(zhí)行 | draft model串行推理,生成草稿token。相當(dāng)于用draft model做逐個(gè)token的decoding |
| 驗(yàn)證 | 驗(yàn)證執(zhí)行結(jié)果 | target model針對(duì)draft model的串行產(chǎn)生結(jié)果并行推理,做驗(yàn)證和優(yōu)化。相當(dāng)于用大模型一次prefill輸入小模型的幾個(gè)decode步結(jié)果來仲裁 |
| 驗(yàn)證成功 | 如果分支條件最終符合預(yù)期,那么一切正常,程序?qū)⒗^續(xù)執(zhí)行 | 接受小模型產(chǎn)生的token |
| 驗(yàn)證失敗 | 如果條件不符合,處理器會(huì)回滾到分支前的狀態(tài),丟棄之前的操作 | 在第一個(gè) draft token 與target model輸出不相符的位置截?cái)啵G棄在此之后的所有 draft token |
| 失敗后修復(fù) | 選擇正確的路徑進(jìn)行執(zhí)行 | 調(diào)整概率分布 |
投機(jī)解碼和之前方法對(duì)比如下。
| 類別 | 之前方案 | 投機(jī)解碼 |
|---|---|---|
| 是否改變模型架構(gòu) | 許多先前的方法需要修改模型的結(jié)構(gòu),以使推理過程更高效 | 不需要 |
| 是否改變訓(xùn)練程序 | 一些方法可能需要修改訓(xùn)練過程,以便模型在推理階段能夠更有效地運(yùn)行 | 不需要修改訓(xùn)練過程,可在現(xiàn)有模型上直接應(yīng)用 |
| 是否重新訓(xùn)練 | 先前的方法可能需要對(duì)模型進(jìn)行重新訓(xùn)練,以適應(yīng)新的架構(gòu)或訓(xùn)練程序 | 不需要 |
| 是否改變輸出分布 | 先前的方法在加速推理過程時(shí)可能會(huì)導(dǎo)致模型的輸出分布發(fā)生變化 | 通過"speculative sampling"方法,保證了從模型中生成的結(jié)果具有與原始模型相同的分布 |
另外,塊并行解碼(blockwise parallel decodin)和推測(cè)解碼之間的主要區(qū)別在于它們的模型使用。投機(jī)解碼需要額外的小模型來自回歸地生成speculative tokens。這些小型模型受到約束,比目標(biāo)模型更有效,因此加速可以覆蓋它們的成本。
總的來說,作者提出的方法在加速推理過程時(shí)避免了許多先前方法所涉及的模型結(jié)構(gòu)和訓(xùn)練方面的變化,同時(shí)保持了相同的輸出特性。
4.4 分類&設(shè)計(jì)
投機(jī)解碼實(shí)現(xiàn)加速的關(guān)鍵主要在于如下兩點(diǎn):
- “推測(cè)”的高效性和準(zhǔn)確性:如何又快又準(zhǔn)地“推測(cè)”LLM未來多個(gè)解碼步的生成結(jié)果。
- “驗(yàn)證“策略的選擇:如何在確保質(zhì)量的同時(shí),讓盡可能多的“推測(cè)”token通過驗(yàn)證,提高解碼并行性。
因此,研究人員通常基于這兩點(diǎn)來對(duì)投機(jī)解碼的實(shí)現(xiàn)和研究進(jìn)行分類。當(dāng)然,其分類方式也會(huì)略有差別。下圖是論文“Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding”給出的投機(jī)解碼技術(shù)的一個(gè)正式分類,包括:
- draft model的策略。具體涵蓋如何設(shè)計(jì)模型,運(yùn)行終止條件,如何管理多個(gè)模型(如果有)。“推測(cè)”階段的設(shè)計(jì)聚焦在“推測(cè)精度(accuracy)”和“推測(cè)耗時(shí)(latency)“的權(quán)衡上。一般來說,用以推測(cè)的模型越大,推測(cè)精度越高(即通過驗(yàn)證的token越多),但是推測(cè)階段的耗時(shí)越大。如何在這兩者之間達(dá)到權(quán)衡,使得推測(cè)解碼總的加速比較高,是推測(cè)階段主要關(guān)注的問題。
- 驗(yàn)證策略。此類別涉及到驗(yàn)證方案和驗(yàn)收標(biāo)準(zhǔn)的設(shè)計(jì)。驗(yàn)證模型通常是目標(biāo)模型,其首要目的是保證解碼結(jié)果的質(zhì)量。接受標(biāo)準(zhǔn)旨在判斷草稿token是否應(yīng)(部分)接受,即接受的token長度是否小于k。在每個(gè)解碼步驟中,驗(yàn)證模型會(huì)并行驗(yàn)證草稿token,以確保輸出與目標(biāo)LLM對(duì)齊。此過程還決定了每一步接受的token數(shù)量,這是影響加速的一個(gè)重要因素。采樣方法具體來說也分為無損采樣和有損采樣。(a)無損采樣主要是說對(duì)于原始LLM來說仍然采用原先的采樣方法比如貪婪采樣或者溫度采樣等等,然后對(duì)應(yīng)地檢查draft中是否有符合要求的token。這種方法核心就是drafting對(duì)于原始LLM來說完全透明,不會(huì)損失模型性能。(b)有損采樣主要是說通過校驗(yàn)階段對(duì)draft質(zhì)量的評(píng)估,然后根據(jù)一些先驗(yàn)的閾值來篩選一些高質(zhì)量的draft接受,這種方法的核心就是為了提高draft的接受率,在可接受的一些質(zhì)量損失情況下獲得更高的加速。常見驗(yàn)證標(biāo)準(zhǔn)包括Greedy Decoding,Speculative Sampling,Token Tree Verification等。因?yàn)椋⒉皇撬懈怕首畲蟮膖oken都是最合適的解碼結(jié)果,所以也有一些工作提出可以適當(dāng)?shù)胤潘伞膀?yàn)證”要求,使得更多高質(zhì)量的“推測(cè)”token被接受,進(jìn)一步提升加速比。
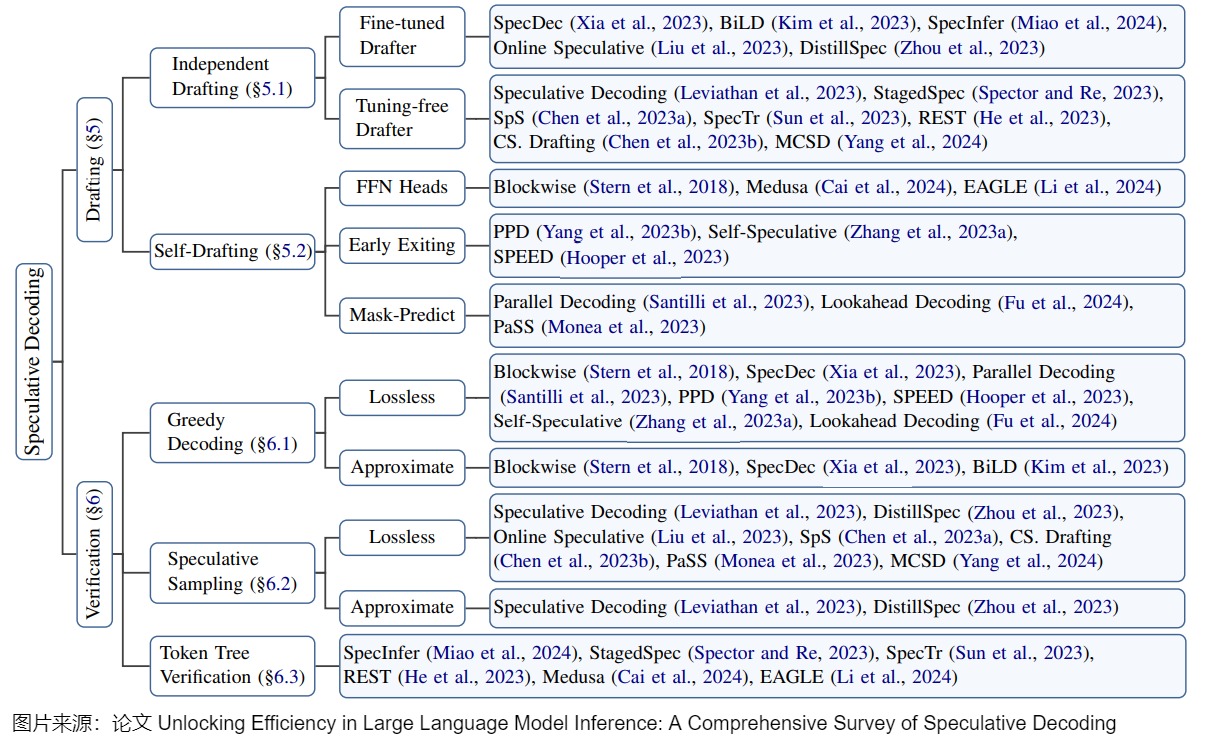
下圖則是該論文中對(duì)分類內(nèi)容的進(jìn)一步細(xì)化。draft model的策略對(duì)應(yīng)下圖標(biāo)號(hào)1。驗(yàn)證策略對(duì)應(yīng)下圖標(biāo)號(hào)2。具體的投機(jī)解碼方法則對(duì)應(yīng)下圖標(biāo)號(hào)3。
4.4.1 推測(cè)階段的策略
推測(cè)階段的策略主要有如下幾個(gè)部分。
產(chǎn)生草稿
在某種程度上,草稿模型本身通常是一個(gè)因果語言模型,可以生成推測(cè)性的標(biāo)記。草稿模型可以是目標(biāo)模型之外的一個(gè)額外的小模型,如 speculative decoding 中生成候選token,也可以是連接到目標(biāo)模型的幾個(gè)輕量級(jí)預(yù)測(cè)頭,如blockwise parallel decoding中預(yù)測(cè)即將到來的token。最近的進(jìn)展表明,草稿模型也可以是從大型語料庫中檢索標(biāo)記的檢索者(retriever),以完成前面的上下文。
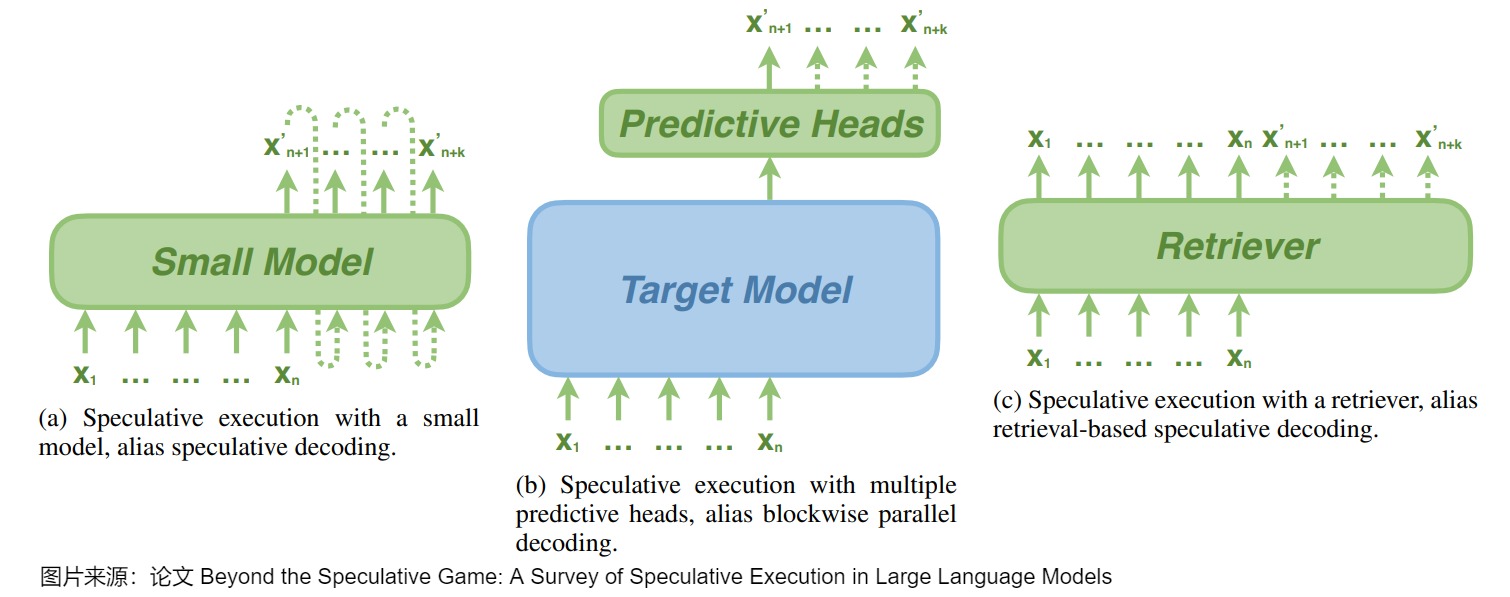
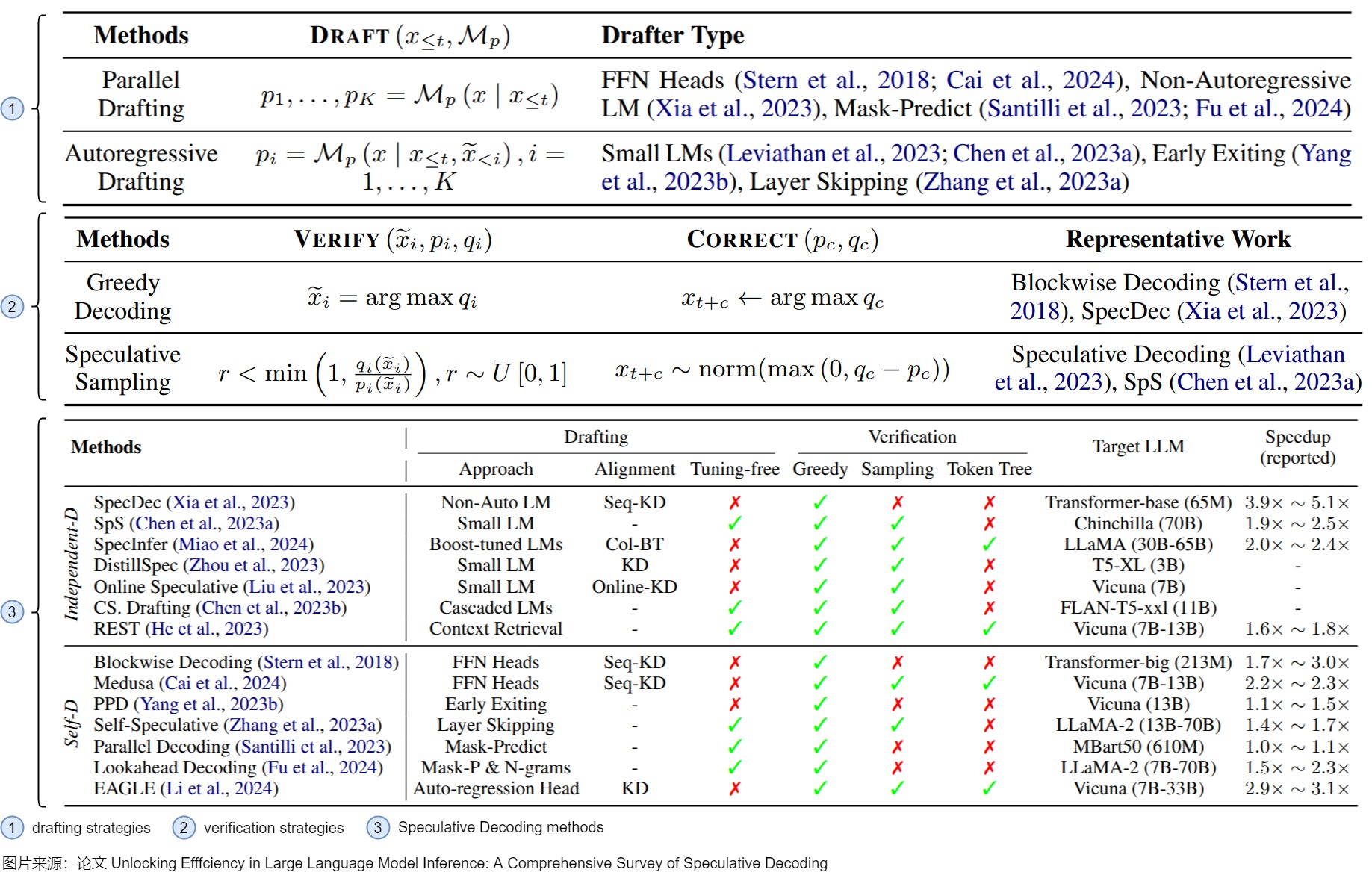
這些草稿模型具體特點(diǎn)如下。
- Independent Drafting。主要思路是:拿一個(gè)跟target LLM同系列的smaller LM進(jìn)行“推測(cè)”。因?yàn)槭峭盗械哪P停栽撔∧P捅旧砭痛嬖谝欢ǖ暮蛅arget LLM之間的“行為相似性“(behavior alignment),適合用來作為高效的“推測(cè)“模型。需要強(qiáng)調(diào)的是,小模型必須與目標(biāo)模型具有完全相同的詞表。目前對(duì)于該思路的優(yōu)化主要集中在增強(qiáng)小模型和大模型之間的“行為相似性”(behavior alignment),讓小模型模仿得“更像”一些。比如知識(shí)蒸餾。這種方案的優(yōu)點(diǎn)是易于實(shí)踐和部署。缺點(diǎn)是:并不是所有的LLM都能找到現(xiàn)成的小模型;在單個(gè)系統(tǒng)中集成兩個(gè)不同的模型會(huì)引入額外的計(jì)算復(fù)雜性,尤其不利于分布式部署場景;而且往往需要從頭開始訓(xùn)練一個(gè)草稿模型,此預(yù)訓(xùn)練過程需要大量額外的計(jì)算資源。此外,單獨(dú)的預(yù)訓(xùn)練可能會(huì)在草稿模型和原始模型之間產(chǎn)生分布變化,從而導(dǎo)致原始模型可能不喜歡的序列結(jié)果。
- Self-Drafting。因?yàn)樯鲜隽觿?shì),相關(guān)研究工作提出利target LLM自己進(jìn)行“高效推測(cè)”,即使用驗(yàn)證模型本身的作為drafting model,比如,重用在原始LLM中的一些中間結(jié)果或者參數(shù),用隱藏層狀態(tài)來更好地預(yù)測(cè)未來序列。這種方式天然就沒有模型表現(xiàn)一致方面的問題,減少了額外的計(jì)算開銷,對(duì)分布式推理也很友好。在時(shí)延方面,Self-Drafting使用一些策略來使得驗(yàn)證模型平均參數(shù)量減少,以此來達(dá)到高效的目的。比如Blockwise Decoding和Medusa在target LLM最后一層decoder layer之上引入了多個(gè)額外的FFN Heads,使得模型可以在每個(gè)解碼步并行生成多個(gè)token,作為“推測(cè)”結(jié)果。然而,這些FFN Heads依然需要進(jìn)行額外的訓(xùn)練。除了這兩個(gè)工作,還有一些研究提出利用Early-Existing或者Layer-Skipping來進(jìn)行“高效推測(cè)“,甚至僅僅是在模型輸入的最后插入多個(gè)[PAD] token,從而實(shí)現(xiàn)并行的“推測(cè)”。Early-Existing則是基于saturation的觀察:在生成某個(gè)token時(shí),如果在經(jīng)過第
i層的前后輸出token完全一致,我們就認(rèn)為已經(jīng)達(dá)到飽和點(diǎn),后續(xù)層不需要再繼續(xù)處理,直接返回第 i 層生成的 token即可。因?yàn)槌チ说趇層后面的層,所以模型參數(shù)量會(huì)減少。Layer-Skipping是判別哪些token如果被跳過,但是對(duì)大多數(shù)token生成影響不大,就在生成token時(shí)跳過這些層,以此減少drafting model的參數(shù)量。 - 基于檢索的方法。其思想是大部分常見的句子里面的單詞組是可以統(tǒng)計(jì)出來的,因此在生成某個(gè)token之后,可以通過這個(gè)token去檢索統(tǒng)計(jì)的數(shù)據(jù)庫得到這個(gè)token之后大概率是哪些tokens,然后把這些tokens取出來去做驗(yàn)證。
此外,草稿模型不僅限于一個(gè)小模型。有人認(rèn)為,在集成學(xué)習(xí)的推動(dòng)下,不同尺度的分階段或級(jí)聯(lián)小模型可以進(jìn)一步提高性能。比如論文“Cascade Speculative Drafting for Even Faster LLM Inference”提出了Vertical Cascade 和 Horizontal Cascade。Vertical Cascade 用 Speculative Decoding 來加速 Speculative Decoding。Horizontal Cascade 指的是在接受率較高的前幾個(gè) token 用較大的 Draft Model,在接受率較小的靠后的 token 用較小的模型來“糊弄”。
終止條件
speculative tokens的序列太短或太長都是次優(yōu)的,但是也難以找到非常合適的判別標(biāo)準(zhǔn)。因此,研究人員也對(duì)終止條件進(jìn)行了深入研究,具體大致分為幾種。
- Static Setting:最簡單的解決方案是將長度k設(shè)置為一個(gè)靜態(tài)值,該值可以迭代和手動(dòng)重新設(shè)置。
- Adaptive Thresholding:雖然靜態(tài)設(shè)置可以滿足大多數(shù)用例,但需要不停的手動(dòng)調(diào)節(jié)也可能很麻煩。為了解決這個(gè)問題,已經(jīng)提出了自適應(yīng)閾值方法,旨在盡早停止基于每個(gè)token一致性(per-token conffdence)的草稿生成動(dòng)作。如果一致性低于閾值,草稿模型的生成動(dòng)作將停止。閾值可以根據(jù)某些優(yōu)化目標(biāo)(例如,草稿token的質(zhì)量)進(jìn)行自適應(yīng)調(diào)整。
- Heuristic Rules:一些啟發(fā)式規(guī)則也可以用于終止條件的判斷。比如,如果驗(yàn)證中完全接受之前的猜測(cè),則推測(cè)token的長度將增加,否則將減少。另一種方法可能是從系統(tǒng)服務(wù)的角度根據(jù)批量大小來改變長度。
盡管已經(jīng)開發(fā)了各種方法來自動(dòng)檢測(cè)終止條件的理想值,但仍然很難判斷它們是否足夠好。在這種需求下,我們應(yīng)該建立更穩(wěn)健的方法來搜索和設(shè)置這些參數(shù),從而獲得更穩(wěn)定、更吸引人的性能。
4.4.2 驗(yàn)證階段的策略
在verification階段,也就是使用大模型校驗(yàn)階段中,分為驗(yàn)證方案(如何組織多個(gè)序列的輸入,比如token樹驗(yàn)證(token tree verification))和驗(yàn)收標(biāo)準(zhǔn)的設(shè)計(jì)(采樣方法,比如貪婪采樣,nucleus 采樣,typical 采樣)。
驗(yàn)證方案
組織多個(gè)序列的輸入最簡單的方法就是直接將所有可能輸入形成多個(gè)batch。
如果只需要驗(yàn)證一個(gè)token,那么基于鏈的驗(yàn)證器(將token作為序列或鏈接收的通用驗(yàn)證器)應(yīng)該就足夠了。但是,如果使用多個(gè)token,逐一連續(xù)驗(yàn)證這些token會(huì)有冗余計(jì)算的問題,將過于耗時(shí)。比如有兩個(gè)序列”maching learning is a“和”machine learning is the“,其實(shí)區(qū)別只在于最后一個(gè)token 是”a“還是”the“,前綴相同。
因此,有研究人員提出了一種基于樹的驗(yàn)證方法,該策略使目標(biāo)LLM能夠并行驗(yàn)證多個(gè)草稿序列。該方法首先通過共享前綴從多個(gè)候選token序列建立一個(gè)trie,并從trie樹中修剪不太頻繁的節(jié)點(diǎn)。然后,它在一次運(yùn)行中用樹注意力對(duì)其進(jìn)行并行驗(yàn)證(即,子token只能通過注意力掩碼看到其父token),這促進(jìn)了對(duì)潛在多token的并行驗(yàn)證。作為對(duì)比,如果是單個(gè)token,只需要一個(gè)注意力鏈。而基于樹的驗(yàn)證方法所依賴的是因果關(guān)系和下三角關(guān)系(causal and lower-triangular)掩碼,如下圖所示。
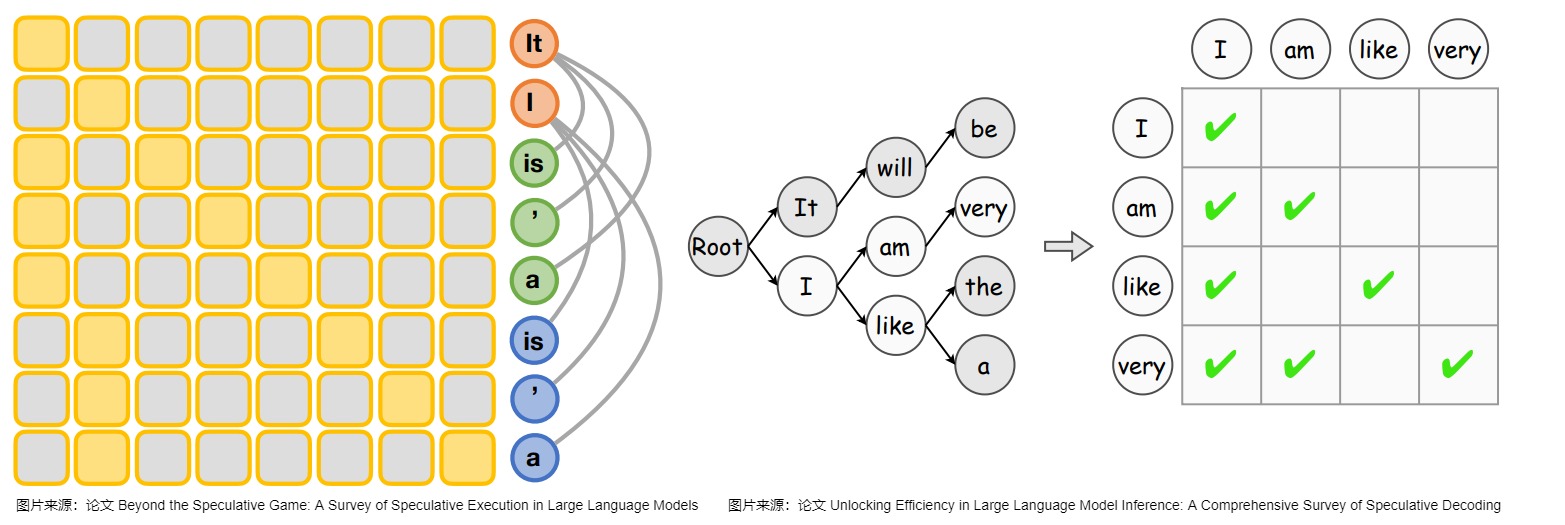
驗(yàn)收標(biāo)準(zhǔn)
一旦草稿token被輸入目標(biāo)模型,我們就可以獲得相應(yīng)的輸出概率。通過對(duì)齊推測(cè)token和概率,我們可以推斷每個(gè)token在草稿中是否有效。
精確匹配
最簡單的接受標(biāo)準(zhǔn)是精確匹配,它檢查speculative token是否相應(yīng)地具有最大概率。該策略是基于貪心算法的。貪心采樣的驗(yàn)證主要是保證Drafting model和Verification model都使用貪心策略的時(shí)候結(jié)果一致。也就是說,需要驗(yàn)證驗(yàn)證模型的每一個(gè)生成是否和drafting model的生成完全一樣。
注意:兩篇開山之作的\(M_p\),\(M_q\)是相反的,請(qǐng)大家在閱讀時(shí)候務(wù)必注意。

雖然精確匹配簡單清晰直接,可以用較小的成本來保證經(jīng)過驗(yàn)證的輸出與目標(biāo)模型本身的輸出一致,但是存在一些問題:
- 雖然精確匹配可以用較小的成本來保證經(jīng)過驗(yàn)證的輸出與目標(biāo)模型本身的輸出一致,但只有在使用貪婪解碼時(shí),這種等式才成立。
- 對(duì)于目標(biāo)模型使用采樣解碼(sampling decoding)的情況,精確匹配很難從草稿模型中接受token,這可能會(huì)導(dǎo)致解碼速度減慢而不是加快。
- 過于嚴(yán)格的匹配要求通常會(huì)導(dǎo)致拒絕高質(zhì)量的token,僅僅是因?yàn)樗鼈兣c目標(biāo)LLM的前1個(gè)預(yù)測(cè)不同,從而限制了范式的加速。
拒絕采樣(Rejection Sampling)
基于上述問題,多項(xiàng)研究提出了各種近似驗(yàn)證標(biāo)準(zhǔn)。與無損標(biāo)準(zhǔn)相比,這些方法略微放寬了匹配要求,以更加信任草稿,從而提高了草稿token的接受度。比如,研究人員提出了一種從拒絕采樣(Rejection Sampling)中修改的驗(yàn)收標(biāo)準(zhǔn)來緩解這一問題(就是那兩篇開山之作)。理論上,這種接受標(biāo)準(zhǔn)可以應(yīng)用于貪婪解碼和采樣解碼。

Typical Acceptance
上述兩個(gè)驗(yàn)收標(biāo)準(zhǔn)為質(zhì)量提供了嚴(yán)格的保證。然而,過于嚴(yán)格的驗(yàn)收標(biāo)準(zhǔn)可能會(huì)抵消并行驗(yàn)證的努力,并降低推測(cè)執(zhí)行的負(fù)擔(dān),尤其是在施加溫度參數(shù)的情況下。因此,在某些情況下,需要適度放寬接受標(biāo)準(zhǔn),以實(shí)現(xiàn)更明顯的加速。Typical Acceptance就可以做到這一點(diǎn):如果token的投機(jī)概率超過硬閾值,則接受草稿中的token。另外,閾值也是可以通過top-k約束動(dòng)態(tài)調(diào)整的。對(duì)于提供多個(gè)token的情況,Typical Acceptance將考慮形成最長序列的token,并放棄其他token。
0x05 算法
5.1 總體流程
下圖給出了投機(jī)解碼的算法總體流程。該算法通過首先使用更高效的近似模型 \(M_q\) 生成多個(gè)猜測(cè)token,然后使用目標(biāo)模型 \(M_p\)并行評(píng)估這些猜測(cè)token的概率,并根據(jù)評(píng)估結(jié)果來決定哪些猜測(cè)token可以被接受(并行地接受那些能夠?qū)е孪嗤植嫉牟聹y(cè)token)。如果需要,算法還會(huì)調(diào)整目標(biāo)模型的分布以保持一致性。最終,算法會(huì)返回從 \(M_p\)和 \(M_q\)中得到的生成結(jié)果。這個(gè)過程有效地利用了兩個(gè)模型的優(yōu)勢(shì),加速了生成過程。
這里假設(shè)\(p_i(x)\),\(q_i(x)\)分別是target,draft模型的分布。

我們用一個(gè)例子展示隨機(jī)采樣的工作方式。下圖中,每一行代表一次迭代。綠色的token是由近似模型提出、且目標(biāo)模型接受的建議。紅色token:近似模型提出但目標(biāo)模型拒絕的建議;藍(lán)色token:目標(biāo)模型對(duì)于紅色token的訂正,即拒絕紅色的token并重新采樣得到藍(lán)色的token。
在第一行中,近似模型生成了5個(gè)token,目標(biāo)模型使用這5個(gè)token和前綴拼接后的句子”[START] japan’s bechmark bond”作為輸入,通過一次推理執(zhí)行來驗(yàn)證小模型的生成效果。因?yàn)樽詈笠粋€(gè)token ”bond“被目標(biāo)模型拒絕,重新采樣生成”n“。這樣中間的四個(gè)tokens,”japan” “’s” “benchmark”都是小模型生成的。以此類推,由于用大模型對(duì)輸入序列并行地執(zhí)行,大模型只forward了9次,就生成了37個(gè)tokens。盡管大模型的總計(jì)算量不變,但是大模型推理一個(gè)token的延遲和小模型生成5個(gè)token延遲類似(并行總是比一個(gè)一個(gè)生成要快),從而顯著提高了生成速度。

5.2 關(guān)鍵步驟
我們接下來分析SpeculativeDecodingStep算法的關(guān)鍵步驟和操作。
5.2.1 前置條件
算法的輸入有三個(gè)參數(shù):目標(biāo)模型(target model)\(M_p\),草稿模型(draft model)\(M_q\)和已知前綴prefix。
target model
- 目標(biāo)模型是指原始的大型自回歸模型,例如大型的Transformer模型。它是進(jìn)行推理的主要模型,負(fù)責(zé)生成精確的輸出。目標(biāo)模型通常擁有更多的參數(shù)和計(jì)算資源,但也因此導(dǎo)致單步推理速度較慢。
- 假設(shè) \(M_p\) 為目標(biāo)模型,模型推理就是給定前綴輸入 x<t,從模型獲得對(duì)應(yīng)的分布 p(xt|x<t)。投機(jī)解碼要做的就是加速這個(gè)推理過程。
draft model
- 草稿模型是一個(gè)更為高效的近似模型,其設(shè)計(jì)旨在在給定前綴的情況下,能夠更快地生成下一個(gè)token。相對(duì)于目標(biāo)模型,它可能具有較少的參數(shù)和更高的計(jì)算效率,以便提高整體推理速度。草稿模型可以采用與原始模型相同的結(jié)構(gòu),但參數(shù)更少,或者干脆使用n-gram模型。
- 假設(shè) \(M_q\) 為針對(duì)相同任務(wù)的更高效的近似模型,給定前綴輸入 x<t,從模型可以獲得對(duì)應(yīng)的分布 q(xt|x<t)。
論文“Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation”確立了 草稿模型的兩個(gè)原則:Capability Principle(盡可能準(zhǔn))和 Latency Principle(盡可能快)。另外需要注意的是,小模型的參數(shù)量要遠(yuǎn)小于原模型參數(shù)量一個(gè)級(jí)別才效果明顯;草稿模型和原模型需要使用同樣的tokenizer,不然會(huì)增加額外的解碼、編碼時(shí)間。
5.2.2 第一步 - 采樣
對(duì)于輸入prefix,在用LLM(目標(biāo)模型)做推理的同時(shí),并行地讓草稿模型基于輸入prefix以自回歸的方式串行運(yùn)行 \(\gamma\) 次,生成得到 \(\gamma\) 個(gè)token(稱作guesses或draft tokens)。即,對(duì)于每個(gè) \(i \in \gamma\),計(jì)算 \(q_i(x)\),其中 \(q_i\) 是 \(M_q\) 在 \(prefix+[x_1, ..., x_{i-1}]\) 上的分布,然后從這個(gè)分布\(q_i\)中采樣一個(gè)token \(x_i\)。
5.2.3 第二步 - 并行運(yùn)行目標(biāo)模型
把生成的 \(\gamma\) 個(gè)tokens和前綴拼接一起送進(jìn)目標(biāo)模型\(M_p\)執(zhí)行一次前向傳播(驗(yàn)證模型把候選tokens輸入采樣以prefill的方式并行計(jì)算)。即,對(duì)于每個(gè)猜測(cè)的token \(x_i\),將它附加到前綴 \(prefix+[x_1, ..., x_{i-1}]\) 上,然后并行運(yùn)行目標(biāo)模型\(M_p\),分別得到了\(M_p\)的輸出 \(p_1(x), ..., p_{γ+1}(x)\)。和自回歸相比,盡管計(jì)算量一樣,但是 \(\gamma\) 個(gè)tokens可以同時(shí)參與計(jì)算,計(jì)算訪存比顯著提升。
5.2.4 第三步 - 計(jì)算接受的猜測(cè)token數(shù)量
既然得到了目標(biāo)模型和草稿模型的輸出,我們就可以計(jì)算接受的猜測(cè)token數(shù)量。但是,如何評(píng)價(jià)一個(gè)token生成的好壞與否?這是通過比較 \(M_q\) 生成的猜測(cè)和 \(M_p\) 對(duì)這些猜測(cè)的評(píng)估概率(p,q表示在大小模型采樣概率,也就是logits歸一化后的概率分布)來決定的。即,依次使用每個(gè) Token 對(duì)應(yīng)的分布進(jìn)行對(duì)比,找到滿足要求的 Token 個(gè)數(shù) n,或者說,根據(jù)p/q針對(duì)每個(gè)token進(jìn)行拒絕采樣,以此來確定接受的token數(shù)。
-
如果\(q(x) \leqslant p(x)\), 說明大模型在小模型采樣出的這個(gè)token x上置信度更高,不需要再消減在這個(gè)token上的概率分布,就接受這個(gè)結(jié)果。
-
反之,如果q(x) > p(x),說明大模型在token x上的置信度低于小模型,那么需要把大模型在這個(gè)token上的一些采樣概率分給其它大模型上信心更高的token,則以\(\frac{p(x)}{q(x)}\)的概率接受當(dāng)前token,以\(1-\frac{p(x)}{q(x)}\)的概率丟棄x。
5.2.5 第四步 - 調(diào)整概率分布
這一步會(huì)依據(jù)需要來調(diào)整\(M_p\) 的分布。
- 如果接受的猜測(cè)token數(shù)量n小于γ,那么可能需要對(duì) Mp 生成的分布進(jìn)行調(diào)整,以確保接受的猜測(cè)與目標(biāo)模型的輸出分布保持一致。
- 具體是通過創(chuàng)建一個(gè)新的分布 \(p\prime (x) = norm(max(0,p_{n+1}(x) ? q_{n+1}(x)))\)來調(diào)整。
需要注意的是,如果一個(gè)樣本被拒絕,這意味著我們需要重新進(jìn)行計(jì)算,這會(huì)導(dǎo)致一些計(jì)算資源的浪費(fèi)。因此,在算法運(yùn)行過程中,我們希望盡可能地接受 Mq 生成的樣本,以減少計(jì)算成本。
我們后續(xù)會(huì)詳細(xì)闡釋調(diào)整概率分布的意義。
5.2.6 第五步 - 返回生成的結(jié)果
調(diào)整概率分布之后,會(huì)返回生成的結(jié)果。
-
如果小模型生成結(jié)果都滿意,則用大模型采樣下一個(gè)token。即,用 \(M_p\) 采樣下一個(gè)token,加上 \(M_q\) 生成的 n 個(gè) tokens,一并返回。
-
如果某一個(gè)token x 不滿意,x 被拒絕,則從token x 之后的tokens都被丟棄。因?yàn)榈谒牟揭呀?jīng)調(diào)整了Mp的分布,會(huì)從這個(gè)新的概率分布\(p’(x) = norm(max(0, p(x) ? q(x)))\)中重新采樣一個(gè)token作為糾正。
因?yàn)榧由狭撕竺孢@個(gè)大模型拒絕采樣,并補(bǔ)充大模型概率分布差采樣的過程,所以上面這個(gè)采樣過程和直接從p(x) 采樣是等價(jià)的。
一共最多可以生成多少個(gè)token?如果把驗(yàn)證過程看成接受概率為\(\alpha\)的連續(xù)γ次判定過程,從上述算法流程知道輸出token的長度范圍是[1,γ+1],有以下3種情況
- 情況1:當(dāng)?shù)?個(gè)token就被大模型拒絕了,那么就直接用大模型的采樣輸出,生成長度為γ=1
- 情況2:當(dāng)?shù)趖個(gè)token被大模型接受,但是第t+1個(gè)token被大模型拒絕的時(shí)候,生成長度為L=t+1。注意此時(shí)t≤γ?1
- 情況3:當(dāng)所有k個(gè)token都被大模型接受,此時(shí)理應(yīng)達(dá)到最大生成長度L=γ。但如果draft生成的γ個(gè)token都通過驗(yàn)證,那還可以從已經(jīng)計(jì)算的第γ+1個(gè)token的logits中額外采樣出一個(gè),而且這個(gè)token是target模型生成的,也就不需要驗(yàn)證了。因此最終生成長度L=γ+1
5.3 重點(diǎn)分析
我們接下來看看投機(jī)解碼中的一些重點(diǎn)。
5.3.1 并行驗(yàn)證
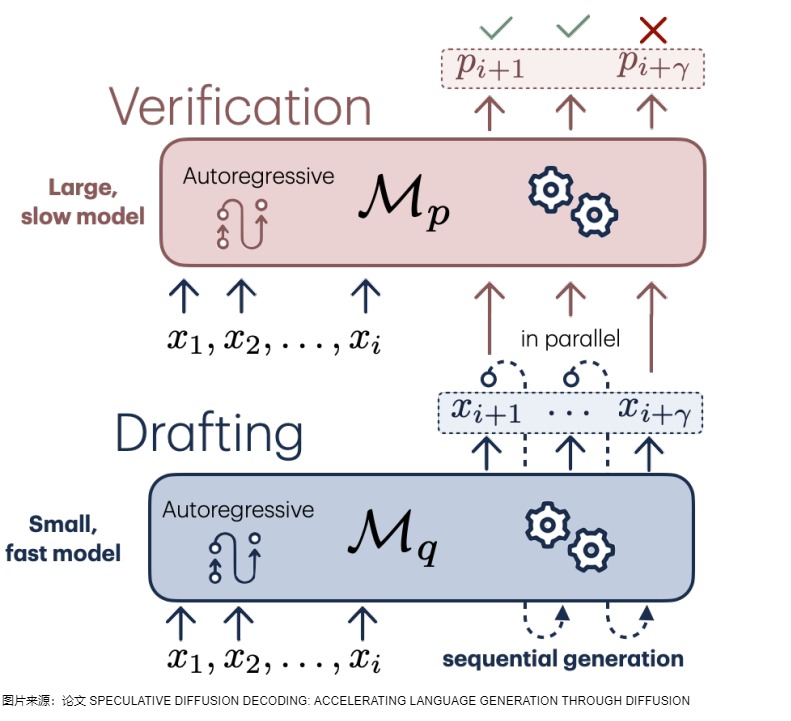
我們用示例來看看如何進(jìn)行并行驗(yàn)證。
下圖中,輸入為:Our technique illustrated in the case of 。小模型串行生成三個(gè)token,小模型每次都是接受(1, vocal_size)的輸入。具體參見下圖標(biāo)號(hào)1。
- 第1次推理,小模型生成 unconditional。
- 第2次推理,小模型生成 language。
- 第3次推理,小模型生成 modeling。
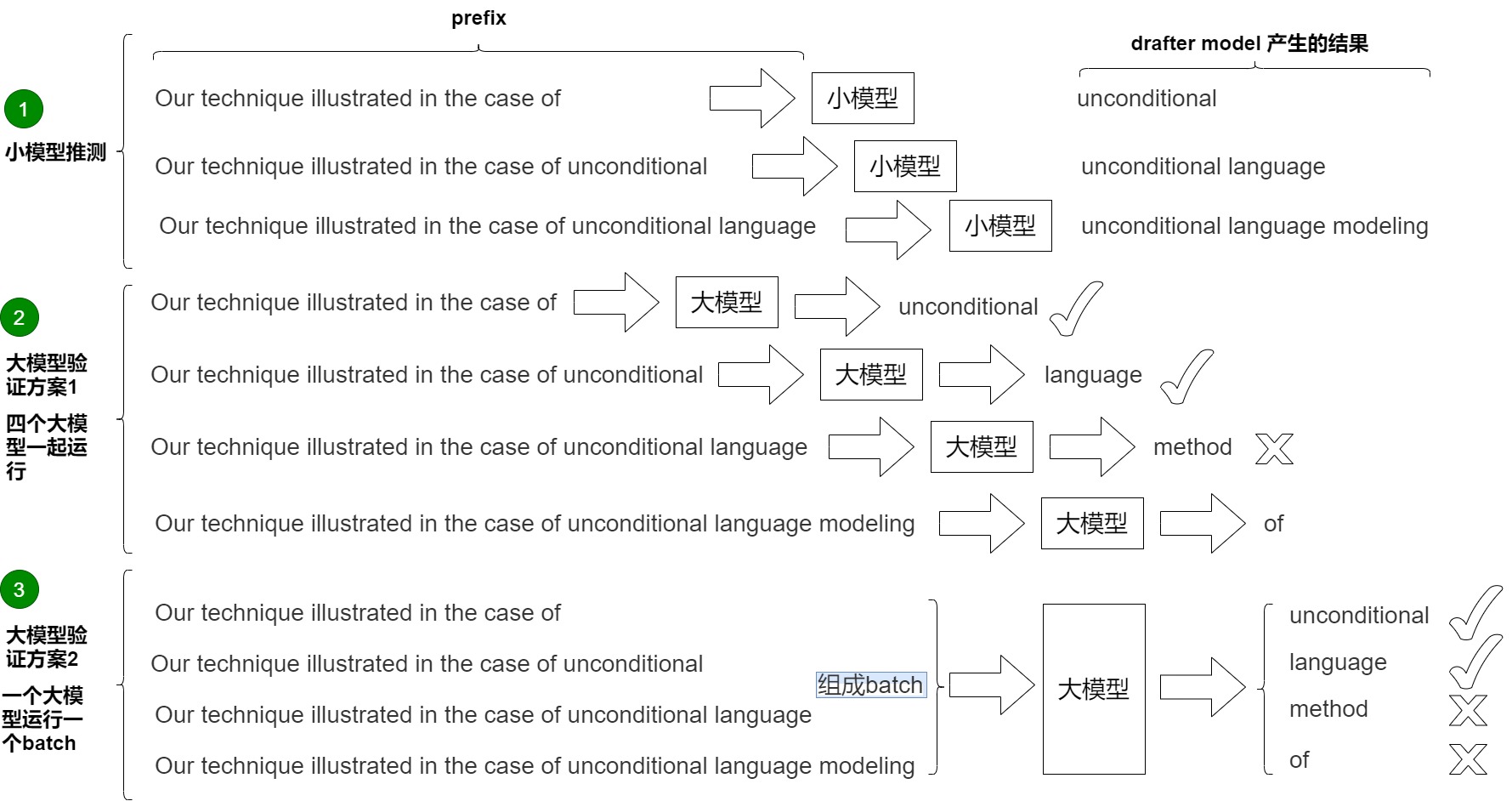
有兩種方案來驗(yàn)證這些token。
方案1是論文中提出的方案,具體參見上圖標(biāo)號(hào)2。論文里的并行就是指一次計(jì)算多個(gè)token,節(jié)省傳輸損耗。然而,論文里對(duì)\(M_p\)進(jìn)行并行計(jì)算,是一種不顧及計(jì)算資源的加速。它在每一步都嘗試并行計(jì)算大模型的觀點(diǎn),從而達(dá)到速度上的最優(yōu)化,但同時(shí)對(duì)并行計(jì)算能力要求極高。比如r為3時(shí),就需要4個(gè)大模型同時(shí)計(jì)算。在極致并行的情況下,速度可以達(dá)到理論最優(yōu),但代價(jià)是算力的浪費(fèi),這在工程上是不可接受的。
方案2是實(shí)際工作中的方案,利用prefill階段(并行處理多個(gè)token)比decoding階段(串行生成多個(gè)token)計(jì)算效率高的特點(diǎn)來完成加速。target模型的任務(wù)不是生成,而是驗(yàn)證。由于現(xiàn)代計(jì)算機(jī)的并行能力,我們可以近似的認(rèn)為大模型處理一個(gè)token和并行處理多個(gè)token的用時(shí)是幾乎一樣的。這就保證額驗(yàn)證這一過程可以并行實(shí)現(xiàn),即調(diào)用一次target模型執(zhí)行prefill操作,就可以完成對(duì)多個(gè)草稿模型(多個(gè)decoding步驟)的一次性驗(yàn)證,從而減少了推理步驟。同時(shí),根據(jù) Mq 對(duì) Mp 的逼近程度,還可能生成多個(gè)新token,最多可以生成 γ + 1 個(gè)。上圖標(biāo)號(hào)3展示了這個(gè)過程。大模型一次性接受的是(3, vocal_size)的輸入,即,直接檢查unconditional ”、“l(fā)anguage ”、“modeling” 這3個(gè)新token,所以叫并行。其思路和 LLM 訓(xùn)練階段的交叉熵驗(yàn)證一樣,通過錯(cuò)位方和矩陣計(jì)算的并行性,一步計(jì)算就可以驗(yàn)證小模型生成的3個(gè)結(jié)果對(duì)不對(duì),即可完成驗(yàn)證。需要并行執(zhí)行四次驗(yàn)證(以 argmax 為例):
- Prefix “Our technique illustrated in the case of”,生成 “unconditional ”,與近似模型生成的第一個(gè) Token “unconditional ” 相同,接受。
- Prefix “Our technique illustrated in the case of unconditional”,生成 “l(fā)anguage”,與近似模型生成的第二個(gè) Token “l(fā)anguage” 相同,接受。
- Prefix “Our technique illustrated in the case of unconditional language”,生成 “method”,與近似模型生成的第三個(gè) Token “modeling” 不相同,不接受。
- Prefix “Our technique illustrated in the case of unconditional language modeling”,生成 “of”,作為候選,如果前面都接受,則接受該 Token。
5.3.2 加速效果
實(shí)現(xiàn)加速的原理是什么?簡而言之,投機(jī)解碼相比自回歸采樣之所以有加速效果,是因?yàn)樗鼫p少了對(duì)原始模型串行調(diào)用的次數(shù)。因此,投機(jī)解碼需要將以下兩個(gè)步驟結(jié)合在一起,才能實(shí)現(xiàn)推理的加速。
- 草稿生成。Mq 生成 γ 個(gè)補(bǔ)全。因?yàn)閐raft模型參數(shù)量少,相比于target模型生成token更快,是更高效的模型 ,所以減少了生成補(bǔ)全的時(shí)間。
- 草稿校驗(yàn)。使用目標(biāo)模型 Mp 并行評(píng)估來自 Mq 的所有猜測(cè)及其相應(yīng)的概率,接受那些可以導(dǎo)致相同分布的猜測(cè),并從調(diào)整后的分布中抽取額外的一個(gè)token,以修復(fù)第一個(gè)被拒絕的token,或者如果所有token都被接受,則添加一個(gè)額外的token。即,通過錯(cuò)位和矩陣計(jì)算的并行性,一步計(jì)算就可以驗(yàn)證小模型生成的 γ 個(gè)結(jié)果對(duì)不對(duì)。
下圖示例中包含不同的 ??(驗(yàn)證的 Token 數(shù)目),其中紫色為執(zhí)行目標(biāo)模型 Mp 的 decoder,藍(lán)色為執(zhí)行近似模型 Mq 的 decoder,黃色和橙色為調(diào)用 encoder。這里規(guī)定一次迭代可以接收小模型的tokens數(shù)為generated tokens。加速效果和 γ ,p,q都相關(guān)。直覺上講,γ 越大,p、q分布越接近,則 generated tokens越大。
用通俗的話來解釋。
- 最下方是大模型直接預(yù)測(cè)新的token,耗費(fèi)時(shí)間太長。
- 中間和上方是先使用小模型預(yù)測(cè) ?? 個(gè) token,然后大模型借助矩陣計(jì)算的并行特性,一次性就可以驗(yàn)證這 ?? 個(gè)中,前面哪幾個(gè)是對(duì)的。如果有對(duì)的,那就節(jié)約很多時(shí)間(因?yàn)樾∧P瓦h(yuǎn)小于大模型,所以小模型消耗的時(shí)間基本可以忽略不記)。
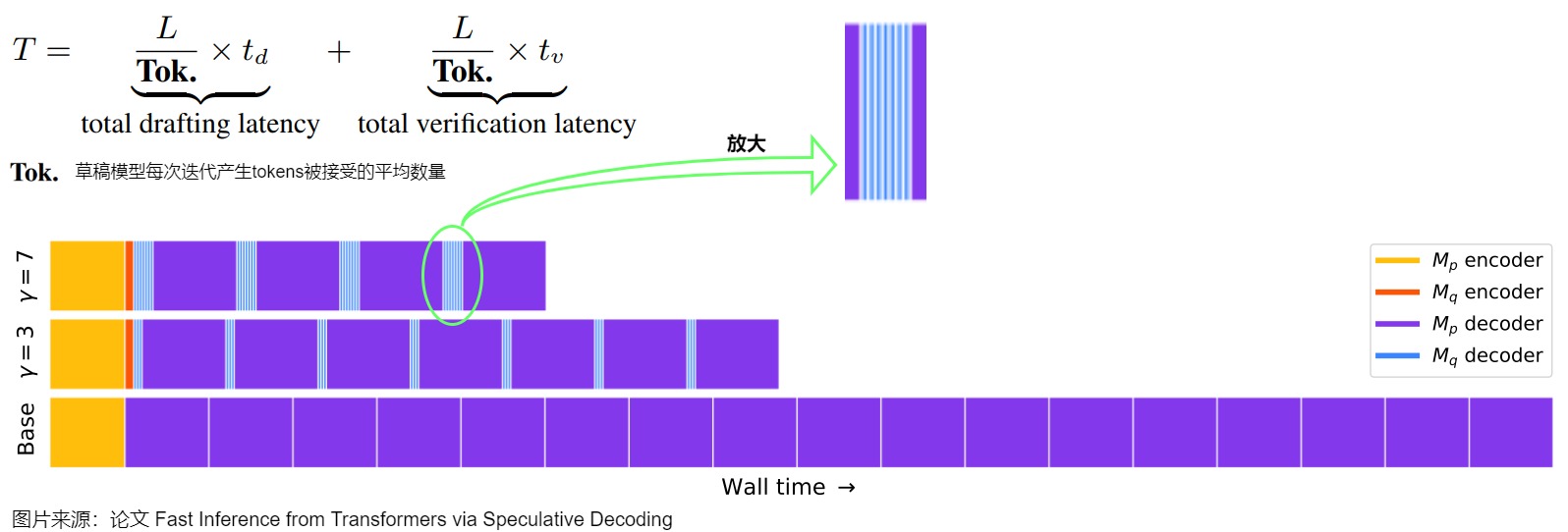
影響加速比的因素是:
- 小模型的尺寸及一次推理的token數(shù)目。
- 小模型生成候選tokens的時(shí)延。
- 大模型對(duì)小模型推理token的接受率,或者說小模型和大模型的Align程度。
因此,如果小模型的輸出草稿接受率足夠高,且生成候選tokens的時(shí)延不長,那么投機(jī)解碼就能夠獲得更高的加速比。假設(shè)我們一次猜n個(gè)tokens,平均有m個(gè)token會(huì)被最終接收,那么在這個(gè)過程中:我們調(diào)用了n次小模型D,1次大模型T,生成了m個(gè)token。只要nD顯著地小于(m-1)T,就能實(shí)現(xiàn)很好的加速效果。
理解了原理,我們就可以知道這個(gè)方法加速的限制:小模型生成的分布是否與大模型一致。驗(yàn)證的接受率會(huì)很大程度上影響最終的加速比,接受率越高,減少的 Decoding Step 數(shù)量就越多,因未接收而浪費(fèi)的計(jì)算就越少。
5.3.3 調(diào)整分布
我們提出一個(gè)問題:在算法的第四步,當(dāng) n < γ 時(shí),為什么需要調(diào)整從目標(biāo)模型(Mp)得到的分布?這個(gè)調(diào)整的目的是什么?
這就涉及到投機(jī)解碼的另外一個(gè)核心:如何確保通過投機(jī)解碼得到的token的概率和從大模型直接采樣相同。事實(shí)上,投機(jī)解碼和投機(jī)解碼兩篇論文都給出了證明:這種驗(yàn)證和重采樣過程在理論等價(jià)于直接從目標(biāo) LLM 采樣,因此,可以保證最終生成的文本分布與目標(biāo) LLM 一致。即,對(duì)于任意分布p(x)和q(x),通過從p(x)和q(x)進(jìn)行投機(jī)解碼所得到的token的分布與僅從p(x)進(jìn)行采樣所得到的token的分布是相同的。
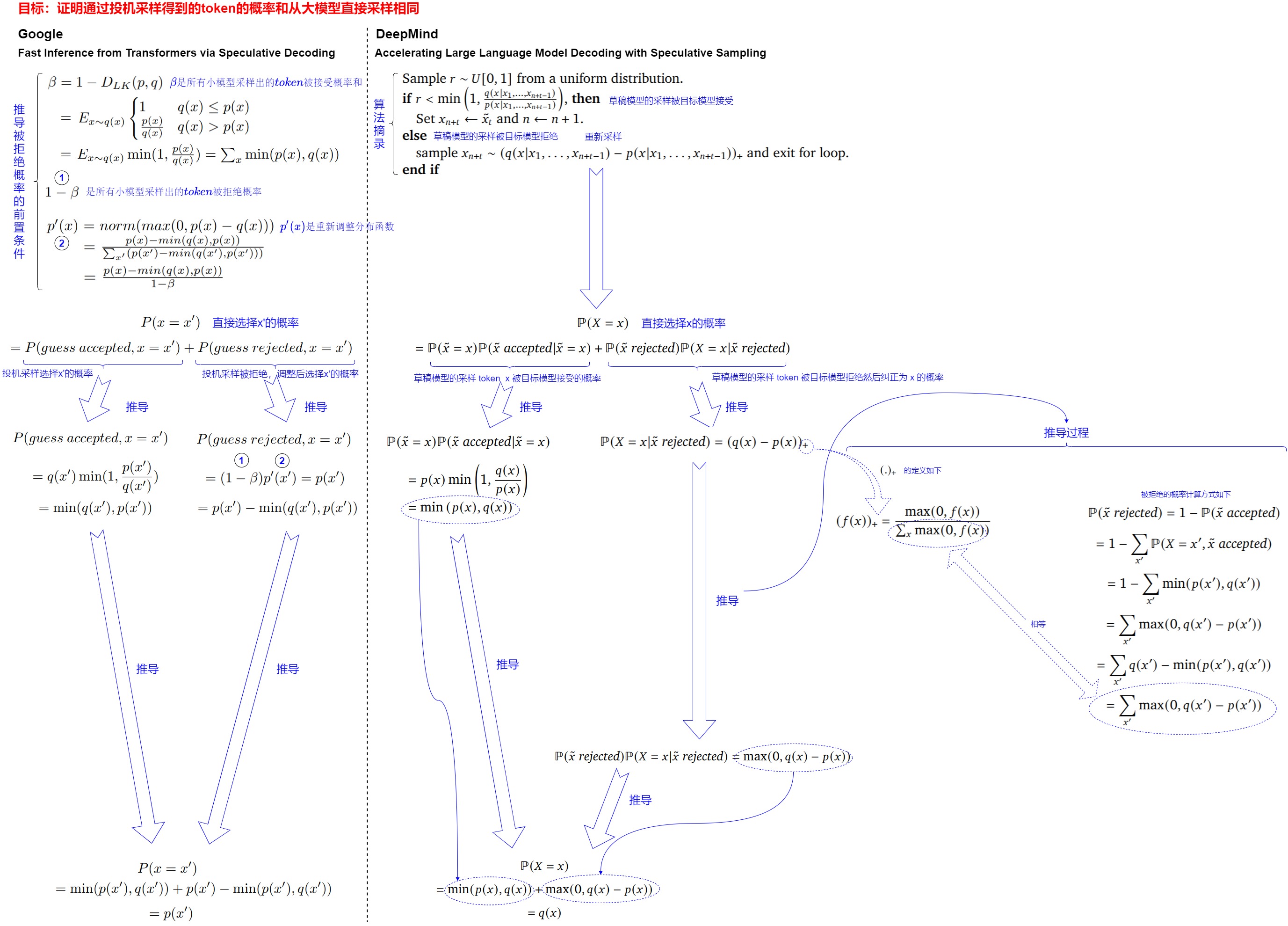
我們首先概述下如何證明。本質(zhì)上我們想考察的是\(p(x=\tilde x)\)的概率,在使用了投機(jī)解碼策略之后,是否還依然等于我們的原始概率\(q(x=\tilde x)\),即\(q(\tilde x)\)。概率拆解思路為:有兩種可能采樣出\(\tilde x\),可以證明通過重采樣之后,總體概率和原始概率一致。
- 路徑1:小模型p(?|?)采樣出了\(\tilde x\),并且成功的接受了。注意,如果此時(shí)對(duì)\(\tilde x\)發(fā)生了拒絕,是不可能通過重采樣得到\(\tilde x\)。原因是,發(fā)生拒絕就說明\(q(\tilde x)\)小于\(p(\tilde x)\),因此在重采樣中\(max(q(\tilde x)?p(\tilde x),0)\)為0,不可能重采樣出\(\tilde x\)。
- 路徑2:小模型p(?|?)采樣得到了其他值\(x≠\tilde x\),并且發(fā)生了拒絕,此時(shí)重采樣得到\(\tilde x\)。
其次,詳細(xì)推導(dǎo)流程參見下圖,我們基于論文 "Accelerating Large Language Model Decoding with Speculative Sampling" 的公式進(jìn)行整理和注釋。
產(chǎn)生偏差
當(dāng) n < γ 時(shí),意味著從更高效的近似模型 Mq 中采樣的token數(shù)量少于 γ,也就是說,其中一些猜測(cè)被目標(biāo)模型 Mp 拒絕了。這可能是因?yàn)?\(M_q\) 生成的猜測(cè)與目標(biāo)模型 \(M_p\) 的真實(shí)分布存在一定的偏差。
當(dāng)使用這個(gè)近似模型 \(M_q\) 生成的token的概率小于或等于目標(biāo)模型 \(M_p\) 生成這個(gè) token 的概率時(shí),我們會(huì)保留這個(gè)token。當(dāng)近似模型 \(M_q\) 生成的token的概率大于目標(biāo)模型 \(M_p\) 生成這個(gè) token 的概率時(shí),我們不能簡單地接受這個(gè)token,因?yàn)檫@可能會(huì)導(dǎo)致生成的結(jié)果與目標(biāo)模型的分布不一致。因此,在這種情況下,我們會(huì)以一定的概率拒絕這個(gè)token,并重新從調(diào)整后的概率分布中重新采樣。
注:快速理解,如果 \(M_p\) 生成某個(gè)token的概率是0.5,\(M_q\) 生成該token的概率是0.6,說明 \(M_q\)已經(jīng)比大模型還飄,不可信了。
彌補(bǔ)偏差
調(diào)整目標(biāo)模型 \(M_p\) 分布的目的是為了彌補(bǔ)從近似模型 \(M_q\) 中得到的猜測(cè)與目標(biāo)模型 \(M_p\) 分布之間的差異,以保證最終生成的結(jié)果符合目標(biāo)模型的真實(shí)分布。這樣可以確保在猜測(cè)性解碼過程中得到的結(jié)果保持了一定的準(zhǔn)確性和一致性。
調(diào)整分布操作彌補(bǔ)了小模型 \(M_q\) 和大模型 \(M_p\) 之間的概率分布的gap。思路是:對(duì)于小模型 \(M_q\) 的每一次猜測(cè),根據(jù)大模型 \(M_p\) 和小模型 \(M_q\) 的概率分布去判斷這一次猜測(cè)有多大概率是正確的。相當(dāng)于是從小模型 \(M_q\) 的采樣到大模型 \(M_p\) 的采樣之間做了一個(gè)映射。可以把小模型 \(M_q\) 和大模型 \(M_p\) 的概率分別看成若干個(gè)隨機(jī)事件,然后將小模型 \(M_q\) 的隨機(jī)事件和大模型 \(M_p\) 的隨機(jī)事件做映射,如果兩邊的隨機(jī)事件的結(jié)果一致,我們就認(rèn)為這個(gè)猜測(cè)是正確的。特別地,如果兩個(gè)概率分布一樣,則猜測(cè)正確的概率為1。如果在某一步中,我們認(rèn)為小模型 \(M_q\) 的猜測(cè)是錯(cuò)誤的,那么后面的結(jié)果都是無效的。此時(shí)用大模型 \(M_p\) 最后一步得到的概率分布做一個(gè)采樣后退出。這一步既是保證輸出是同分布的,又可以保證每次至少輸出一個(gè)token。
具體來說,作者需要定義一個(gè)新的分布 \(p'(x)\),它是根據(jù)目標(biāo)模型 \(M_p\) 的原始輸出分布 \(p_{n+1}(x)\) 調(diào)整而來的。如果 n < γ(即目標(biāo)模型拒絕了一些猜測(cè)),作者使用了一個(gè)調(diào)整函數(shù)來修改 \(p_{n+1}(x)\)。這個(gè)調(diào)整函數(shù)是 \(max(0, p_{n+1}(x) - q_{n+1}(x))\),它的作用是確保 \(p_{n+1}(x)\) 不小于 \(q_{n+1}(x)\)。這樣做的目的是為了盡量保持目標(biāo)模型生成的分布與近似模型的分布一致。
這里給一個(gè)直觀的解釋。這個(gè)調(diào)整后的概率分布\(p'(x)\)是通過將目標(biāo)模型的概率分布(p(x))與來自近似模型的概率分布(q(x))進(jìn)行相減,并取結(jié)果的最大值,然后將其歸一化得到的。這個(gè)調(diào)整后的分布確保了我們從目標(biāo)模型中采樣的結(jié)果具有相同的分布特性,同時(shí)也能夠處理那些被拒絕的token,保證最終的生成結(jié)果保持一致性。
p(x’) > q(x’)說明大模型在token x’上概率大于小模型,則大模型對(duì)生成token x’更有把握,說明小模型生成的問題不大,可以保留x’。如果p(x’) ≤ q(x’)則小模型更有把握,大模型就以1-p(x)/q(x)為概率概率拒絕,并重新采樣。因?yàn)榻邮盏母怕矢騫(x)大的位置,重新采樣的概率應(yīng)該更偏向p(x)大的位置,所以是norm(max(0, p(x)-q(x))。
彌補(bǔ)結(jié)果
從調(diào)整后的分布中生成一個(gè)額外的 Token(根據(jù)第一個(gè)出錯(cuò) Token 之前的 Token 生成),來修復(fù)第一個(gè)出錯(cuò)的 Token,如果所有 Token 都被接受,則額外新增一個(gè)新生成的 Token(這個(gè)token是target模型生成的,也就不需要驗(yàn)證了),以此來保證每次至少生成一個(gè)新的 Token。這樣,即使在最壞情況下,目標(biāo)模型相當(dāng)于完全串行運(yùn)行,運(yùn)行次數(shù)也不會(huì)超過常規(guī)模式直接串行運(yùn)行目標(biāo)模型的次數(shù)(每個(gè)目標(biāo)模型的并行運(yùn)行至少會(huì)生成一個(gè)新的標(biāo)記);當(dāng)然,也很可能能夠生成更多的 Token,最多可以達(dá)到 ??+1,這取決于近似模型 Mq 對(duì)目標(biāo)模型 Mp 的逼近程度。
5.3.4 優(yōu)化
在推測(cè)解碼方法中,草稿token的接受率受到草稿模型的輸出分布與原始大模型的輸出分布的一致程度的顯著影響。因此,大量的研究工作都是在改進(jìn)草稿模型。
DistillSpec直接從目標(biāo)大模型中提取較小的草稿模型。SSD包括從目標(biāo)大模型中自動(dòng)識(shí)別子模型(模型層的子集)作為草稿模型,從而消除了對(duì)草稿模型進(jìn)行單獨(dú)訓(xùn)練的需要。OSD動(dòng)態(tài)調(diào)整草稿模型的輸出分布,以匹配在線大模型服務(wù)中的用戶查詢分布。它通過監(jiān)視來自大模型的被拒絕的草稿token,并使用該數(shù)據(jù)通過蒸餾來改進(jìn)草稿模型來實(shí)現(xiàn)這一點(diǎn)。PaSS提出利用目標(biāo)大模型本身作為草稿模型,將可訓(xùn)練的token(lookahead token)作為輸入序列,以同時(shí)生成后續(xù)token。REST引入了一種基于檢索的推測(cè)解碼方法,采用非參數(shù)檢索數(shù)據(jù)存儲(chǔ)作為草稿模型。SpecInfer引入了一種集體提升調(diào)優(yōu)技術(shù)來對(duì)齊一組草稿模型的輸出分布通過目標(biāo)大模型。Lookahead decoding 包含大模型并行生成n-grams來生成草稿token。Medusa對(duì)大模型的幾個(gè)頭進(jìn)行微調(diào),專門用于生成后續(xù)的草稿token。Eagle采用一種稱為自回歸頭的輕量級(jí)Transformer層,以自回歸的方式生成草稿token,將目標(biāo)大模型的豐富上下文特征集成到草稿模型的輸入中。
另一項(xiàng)研究側(cè)重于設(shè)計(jì)更有效的草稿構(gòu)建策略。傳統(tǒng)的方法通常產(chǎn)生單一的草稿token序列,這對(duì)通過驗(yàn)證提出了挑戰(zhàn)。對(duì)此,Spectr主張生成多個(gè)草稿token序列,并采用k-sequential草稿選擇技術(shù)并發(fā)驗(yàn)證k個(gè)序列。該方法利用推測(cè)抽樣,確保輸出分布的一致性。類似地,SpecInfer采用了類似的方法。然而,與Spectr不同的是,SpecInfer將草稿token序列合并到一個(gè)“token tree”中,并引入了一個(gè)用于驗(yàn)證的樹形注意力機(jī)制。這種策略被稱為“token tree verifier”。由于其有效性,token tree verifier在眾多推測(cè)解碼算法中被廣泛采用。除了這些努力之外,Stage Speculative Decoding和Cascade Speculative Drafting(CS Drafting)建議通過將投機(jī)解碼直接集成到token生成過程中來加速草稿構(gòu)建。
0x06 實(shí)現(xiàn)
我們使用 https://github.com/huggingface/transformers/src/transformers/generation/utils.py來進(jìn)行學(xué)習(xí)。
6.1 全局循環(huán)
在_assisted_decoding()函數(shù)中的while循環(huán)里面進(jìn)行投機(jī)解碼。
def _assisted_decoding(
self,
input_ids: torch.LongTensor,
candidate_generator: CandidateGenerator,
logits_processor: LogitsProcessorList,
stopping_criteria: StoppingCriteriaList,
generation_config: GenerationConfig,
synced_gpus: bool,
streamer: Optional["BaseStreamer"],
**model_kwargs,
) -> Union[GenerateNonBeamOutput, torch.LongTensor]:
# init values
do_sample = generation_config.do_sample
output_attentions = generation_config.output_attentions
output_hidden_states = generation_config.output_hidden_states
output_scores = generation_config.output_scores
output_logits = generation_config.output_logits
return_dict_in_generate = generation_config.return_dict_in_generate
# init attention / hidden states / scores tuples
scores = () if (return_dict_in_generate and output_scores) else None
raw_logits = () if (return_dict_in_generate and output_logits) else None
decoder_attentions = () if (return_dict_in_generate and output_attentions) else None
cross_attentions = () if (return_dict_in_generate and output_attentions) else None
decoder_hidden_states = () if (return_dict_in_generate and output_hidden_states) else None
# if model is an encoder-decoder, retrieve encoder attention weights and hidden states
if return_dict_in_generate and self.config.is_encoder_decoder:
encoder_attentions = model_kwargs["encoder_outputs"].get("attentions") if output_attentions else None
encoder_hidden_states = (
model_kwargs["encoder_outputs"].get("hidden_states") if output_hidden_states else None
)
# keep track of which sequences are already finished
batch_size = input_ids.shape[0]
unfinished_sequences = torch.ones(batch_size, dtype=torch.long, device=input_ids.device)
model_kwargs = self._get_initial_cache_position(input_ids, model_kwargs)
this_peer_finished = False
is_first_iteration = True # to preserve the same API in the output as other generation methods
# while循環(huán)里面進(jìn)行投機(jī)解碼
while self._has_unfinished_sequences(this_peer_finished, synced_gpus, device=input_ids.device):
6.2 外層邏輯
此處包括獲取草稿模型的輸出,調(diào)用論文的算法,依據(jù)算法結(jié)果對(duì)token進(jìn)行調(diào)整。
while self._has_unfinished_sequences(this_peer_finished, synced_gpus, device=input_ids.device):
cur_len = input_ids.shape[-1]
# 1. Fetch candidate sequences from a `CandidateGenerator` and move to the correct device
candidate_input_ids, candidate_logits = candidate_generator.get_candidates(input_ids)
candidate_input_ids = candidate_input_ids.to(self.device)
if candidate_logits is not None:
candidate_logits = candidate_logits.to(self.device)
candidate_length = candidate_input_ids.shape[1] - input_ids.shape[1]
is_done_candidate = stopping_criteria(candidate_input_ids, None)
# 2. Use the original model to obtain the next token logits given the candidate sequence. We obtain
# `candidate_length + 1` relevant logits from this process: in the event that all candidates are correct,
# we use this forward pass to also pick the subsequent logits in the original model.
# 2.1. Prepare the model inputs
candidate_kwargs = copy.copy(model_kwargs)
candidate_kwargs = _prepare_attention_mask(
candidate_kwargs, candidate_input_ids.shape[1], self.config.is_encoder_decoder
)
candidate_kwargs = _prepare_token_type_ids(candidate_kwargs, candidate_input_ids.shape[1])
if "cache_position" in candidate_kwargs:
candidate_kwargs["cache_position"] = torch.cat(
(
candidate_kwargs["cache_position"],
torch.arange(cur_len, cur_len + candidate_length, device=input_ids.device, dtype=torch.long),
),
dim=0,
)
model_inputs = self.prepare_inputs_for_generation(candidate_input_ids, **candidate_kwargs)
if "logits_to_keep" in model_inputs:
model_inputs["logits_to_keep"] = candidate_length + 1
# 2.2. Run a forward pass on the candidate sequence
# prepare variable output controls (note: some models won't accept all output controls)
model_inputs.update({"output_attentions": output_attentions} if output_attentions else {})
model_inputs.update({"output_hidden_states": output_hidden_states} if output_hidden_states else {})
outputs = self(**model_inputs)
# 2.3. Process the new logits
# .float() is needed to retain precision for later logits manipulations
new_logits = outputs.logits[:, -candidate_length - 1 :].float() # excludes the input prompt if present
new_logits = new_logits.to(input_ids.device)
next_token_logits = new_logits.clone()
if len(logits_processor) > 0:
for i in range(candidate_length + 1):
new_logits[:, i, :] = logits_processor(candidate_input_ids[:, : cur_len + i], new_logits[:, i, :])
# 3. Select the accepted tokens. There are two possible cases:
# Case 1: `do_sample=True` and we have logits for the candidates (originally from speculative decoding)
# ?? Apply algorithm 1 from the speculative decoding paper (https://arxiv.org/pdf/2211.17192.pdf).
if do_sample and candidate_logits is not None:
valid_tokens, n_matches = _speculative_sampling(
candidate_input_ids,
candidate_logits,
candidate_length,
new_logits,
is_done_candidate,
)
# Case 2: all other cases (originally from assisted generation) ?? Compare the tokens selected from the
# original model logits with the candidate tokens. We can keep the candidate tokens until the first
# mismatch, or until the max length is reached.
else:
if do_sample:
probs = new_logits.softmax(dim=-1)
selected_tokens = torch.multinomial(probs[0, :, :], num_samples=1).squeeze(1)[None, :]
else:
selected_tokens = new_logits.argmax(dim=-1)
candidate_new_tokens = candidate_input_ids[:, cur_len:]
n_matches = ((~(candidate_new_tokens == selected_tokens[:, :-1])).cumsum(dim=-1) < 1).sum()
# Ensure we don't generate beyond max_len or an EOS token
if is_done_candidate and n_matches == candidate_length:
n_matches -= 1
valid_tokens = selected_tokens[:, : n_matches + 1]
# 4. Update variables according to the number of matching assistant tokens. Remember: the token generated
# by the model after the last candidate match is also valid, as it is generated from a correct sequence.
# Because of this last token, assisted generation search reduces to a normal greedy search/sample if there
# is no match.
# 4.1. Get the valid continuation, after the matching tokens
input_ids = torch.cat((input_ids, valid_tokens), dim=-1)
if streamer is not None:
streamer.put(valid_tokens.cpu())
new_cur_len = input_ids.shape[-1]
# 4.2. Discard past key values relative to unused assistant tokens
new_cache_size = new_cur_len - 1
outputs.past_key_values = _crop_past_key_values(self, outputs.past_key_values, new_cache_size)
# 5. Update the candidate generation strategy if needed
candidate_generator.update_candidate_strategy(input_ids, new_logits, n_matches)
6.3 實(shí)施算法
注釋中寫到,實(shí)現(xiàn)了論文“Fast Inference from Transformers via Speculative Decoding”的算法1,即如下算法。

代碼如下。
def _speculative_sampling(
candidate_input_ids,
candidate_logits,
candidate_length,
new_logits,
is_done_candidate,
):
"""
Applies sampling as in the speculative decoding paper (https://arxiv.org/pdf/2211.17192.pdf, algorithm 1). Returns
the selected tokens, as well as the number of candidate matches.
NOTE: Unless otherwise stated, the variable names match those in the paper.
"""
new_candidate_input_ids = candidate_input_ids[:, -candidate_length:]
# Gets the probabilities from the logits. q_i and p_i denote the assistant and model probabilities of the tokens
# selected by the assistant, respectively.
q = candidate_logits.softmax(dim=-1)
q_i = q[:, torch.arange(candidate_length), new_candidate_input_ids].squeeze(0, 1)
p = new_logits.softmax(dim=-1)
p_i = p[:, torch.arange(candidate_length), new_candidate_input_ids].squeeze(0, 1)
probability_ratio = p_i / q_i
# When probability_ratio > 1 (i.e. q_i(x) < p_i(x), or "assistant probability of the candidate token is smaller
# than the model probability for the same token"), keep the token. Otherwise reject with p = 1 - probability_ratio
# (= keep with p = probability_ratio). Keep all the tokens until the first rejection
r_i = torch.rand_like(probability_ratio)
is_accepted = r_i <= probability_ratio
n_matches = ((~is_accepted).cumsum(dim=-1) < 1).sum() # this is `n` in algorithm 1
# Ensure we don't generate beyond max_len or an EOS token (not in algorithm 1, but needed for correct behavior)
if is_done_candidate and n_matches == candidate_length:
# Output length is assumed to be `n_matches + 1`. Since we won't generate another token with the target model
# due to acceptance on EOS we fix `n_matches`
n_matches -= 1
valid_tokens = new_candidate_input_ids[:, : n_matches + 1]
else:
# Next token selection: if there is a rejection, adjust the distribution from the main model before sampling.
gamma = candidate_logits.shape[1]
p_n_plus_1 = p[:, n_matches, :]
if n_matches < gamma:
q_n_plus_1 = q[:, n_matches, :]
p_prime = torch.clamp((p_n_plus_1 - q_n_plus_1), min=0)
p_prime.div_(p_prime.sum())
else:
p_prime = p_n_plus_1
t = torch.multinomial(p_prime, num_samples=1).squeeze(1)[None, :]
# The selected tokens include the matches (if any) plus the next sampled tokens
if n_matches > 0:
valid_tokens = torch.cat((new_candidate_input_ids[:, :n_matches], t), dim=-1)
else:
valid_tokens = t
return valid_tokens, n_matches
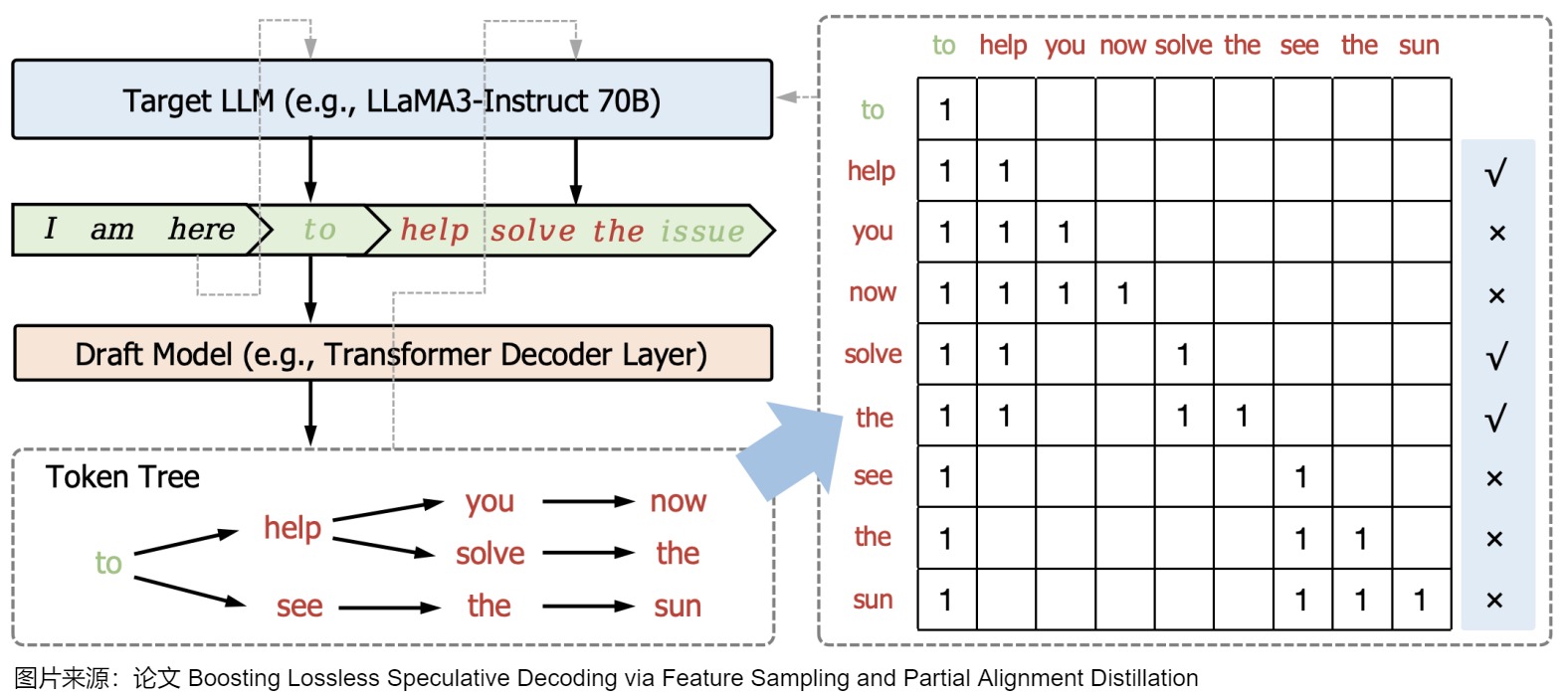
0x07 Token Tree Verification
因?yàn)門oken Tree Verification的重要性,我們單獨(dú)用一節(jié)來進(jìn)行闡釋。
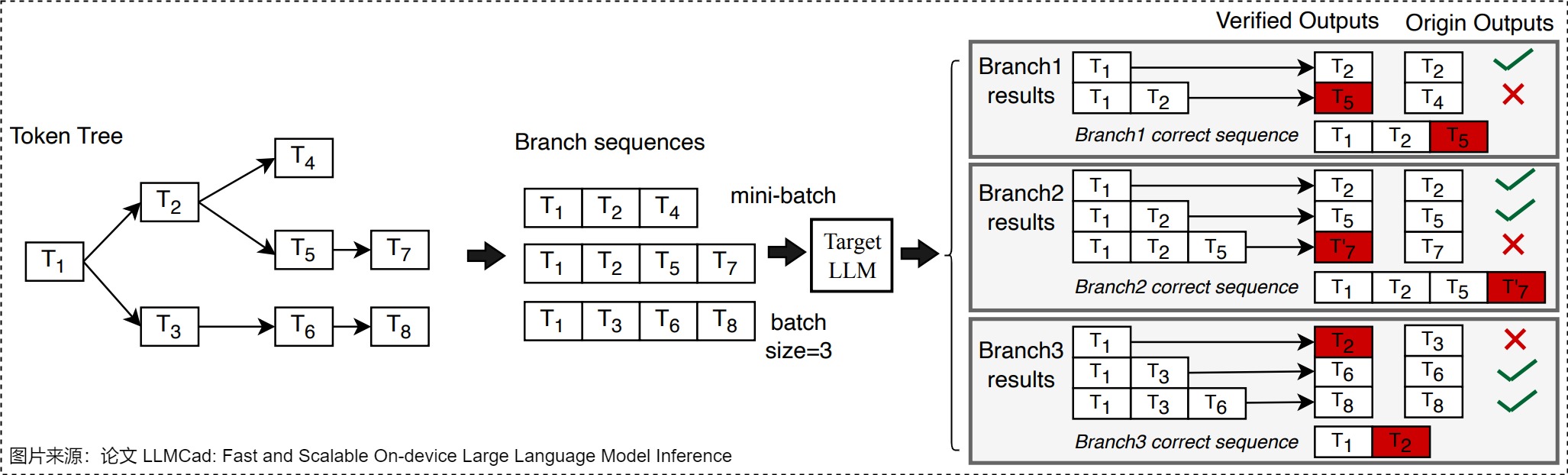
前文提到過,Token Tree Verification使目標(biāo)LLM能夠并行驗(yàn)證多個(gè)草稿序列。其思路就是:讓草稿模型在每個(gè)時(shí)間步都輸出k個(gè)候選token,然后通過共享前綴從多個(gè)候選token序列建立一個(gè)trie,并從trie樹中修剪不太頻繁的節(jié)點(diǎn)。最后在一次運(yùn)行中用樹注意力對(duì)其進(jìn)行并行驗(yàn)證(子token被注意力掩蔽,只能看到其父token)。
7.1 問題
7.1.1 采樣多個(gè)序列
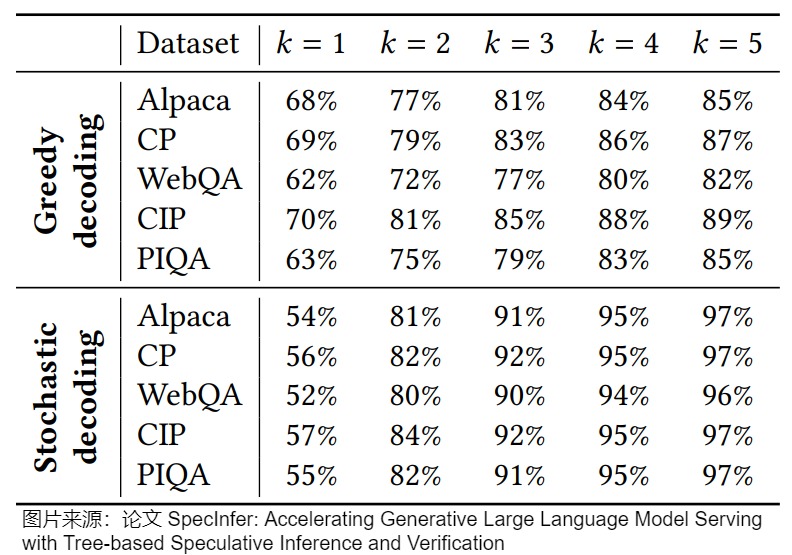
論文“SpecInfer: Accelerating Generative Large Language Model Serving with Tree-based Speculative Inference and Verification”發(fā)現(xiàn),大模型驗(yàn)證失敗的時(shí)候,真實(shí)生成的token大多數(shù)時(shí)候其實(shí)也是小參數(shù)模型的top-k的tokens。下圖展示了使用greedy和stochastic decoding兩種方法topK里面k從1到5在各個(gè)數(shù)據(jù)集上的驗(yàn)證成功率。可以看出,盡管預(yù)測(cè)next next token的top-1準(zhǔn)確率徘徊在60%左右,但是在小參數(shù)模型每一個(gè)step都保留top-5的時(shí)候,最后的驗(yàn)證成功率都大大提高。如果使用necleus sampling,top-3的成功率就已經(jīng)超過了90%。
基于此,我們不應(yīng)該采樣一個(gè)單獨(dú)的序列型的的tokens,而是采樣一個(gè)樹狀的token樹。不止在第一步猜k個(gè)token,我們可以在每一步都猜多個(gè)tokens,這樣每一步的幾率都會(huì)變大。只要由此帶來的額外的計(jì)算開銷小于更高的帶來的加速,那么猜更多的token就是可以接受的。
7.1.2 驗(yàn)證多個(gè)序列
但是,如何對(duì)這個(gè)token樹進(jìn)行驗(yàn)證?即,如何組織多個(gè)序列的輸入?組織多個(gè)序列的輸入最簡單的方法就是直接把每一個(gè)葉子節(jié)點(diǎn)到根節(jié)點(diǎn)的所有token組成一個(gè)序列,然后進(jìn)行驗(yàn)證,這種方案存在幾個(gè)問題:
- 逐一連續(xù)驗(yàn)證這些token會(huì)有冗余計(jì)算的問題,將過于耗時(shí)。
- 一些工作發(fā)現(xiàn),一次預(yù)測(cè)一條鏈的話,概率衰減的非常快,所以不能預(yù)測(cè)很長的鏈,導(dǎo)致不能充分利用上大模型驗(yàn)證的并行度。
另一個(gè)方法是把每一個(gè)葉子節(jié)點(diǎn)到根節(jié)點(diǎn)的所有token組成一個(gè)序列,n多個(gè)葉子節(jié)點(diǎn)就會(huì)組成n個(gè)序列,然后把這n個(gè)序列當(dāng)成batch size=n的輸入進(jìn)行prefill。然而這種方式的問題是根節(jié)點(diǎn)的計(jì)算不能被復(fù)用。
我么接下來看看研究人員是如何解決上述問題。
7.2 思路
7.2.1 開山之作SpecInfer
為了解決上述問題,SpecInfer設(shè)計(jì)了 Tree Based Parallel Decoding 機(jī)制。其核心思路為:通過一系列小模型 SSM(Small Speculative Model)聯(lián)合預(yù)測(cè) LLM 輸出,并將這些小模型的預(yù)測(cè)輸出組織為 Token 樹,樹中每個(gè)分支表示一個(gè)唯一的候選 Token 序列。最后,LLM 使用基于樹的并行解碼(Tree-Based Parallel Decoding)機(jī)制來并行的驗(yàn)證 Token 樹中所有 Token 的正確性,這里樹的解碼算法還可以重用這些序列之間共享的中間結(jié)果。SpecInfer 使用 LLM 作為 Token 樹驗(yàn)證器而非增量解碼器,這顯著降低了生成式 LLM 的端到端延遲,同時(shí)可以保持模型的質(zhì)量。
SpecInfer的具體流程如下。
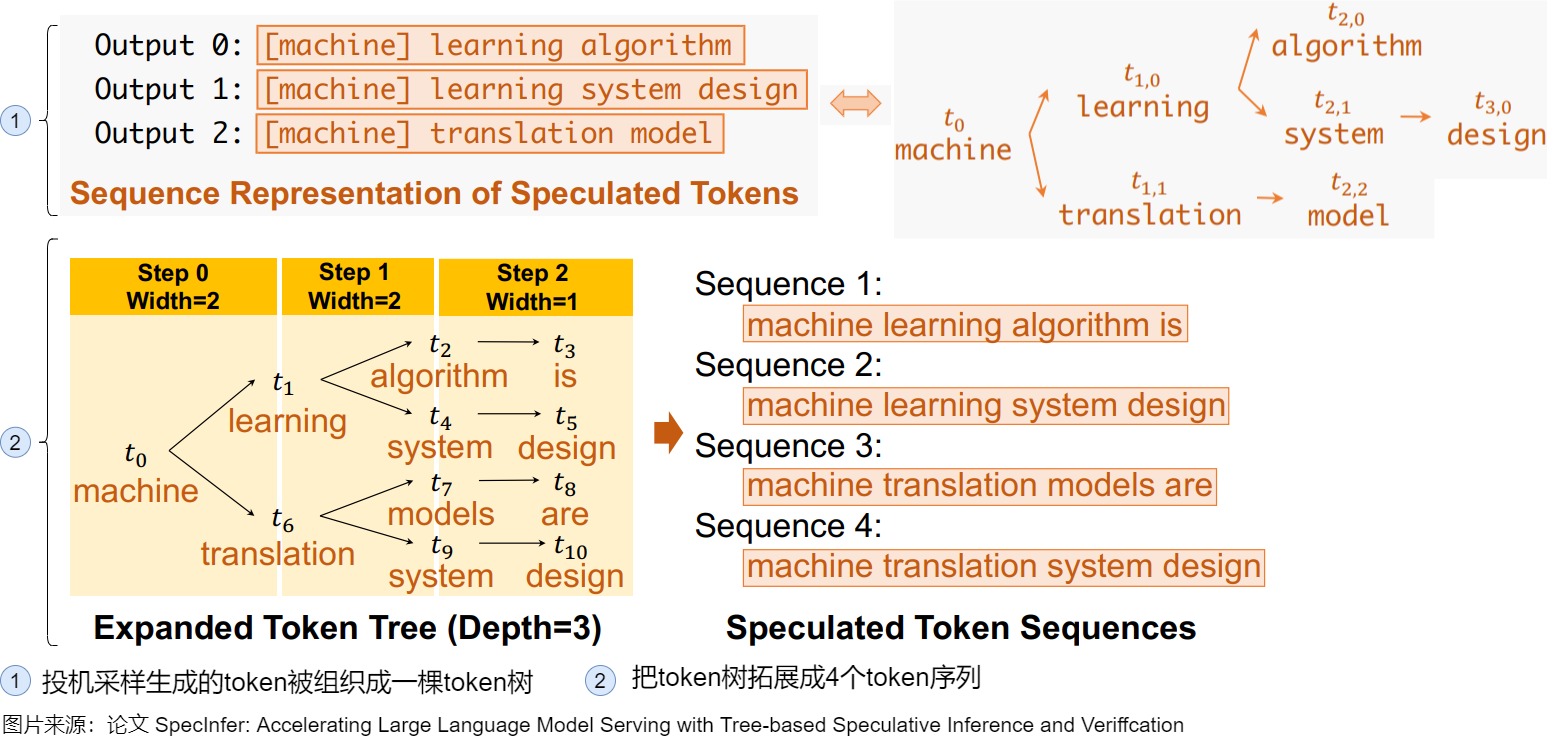
-
先為每個(gè) SSM 生成了一棵輸出樹,即在每個(gè) token 取若干種可能性構(gòu)成一棵樹,之后將這些樹合并成一棵更大的樹。當(dāng)生成更大的樹之后,把該樹拓展成若干個(gè)token序列。
![]()
-
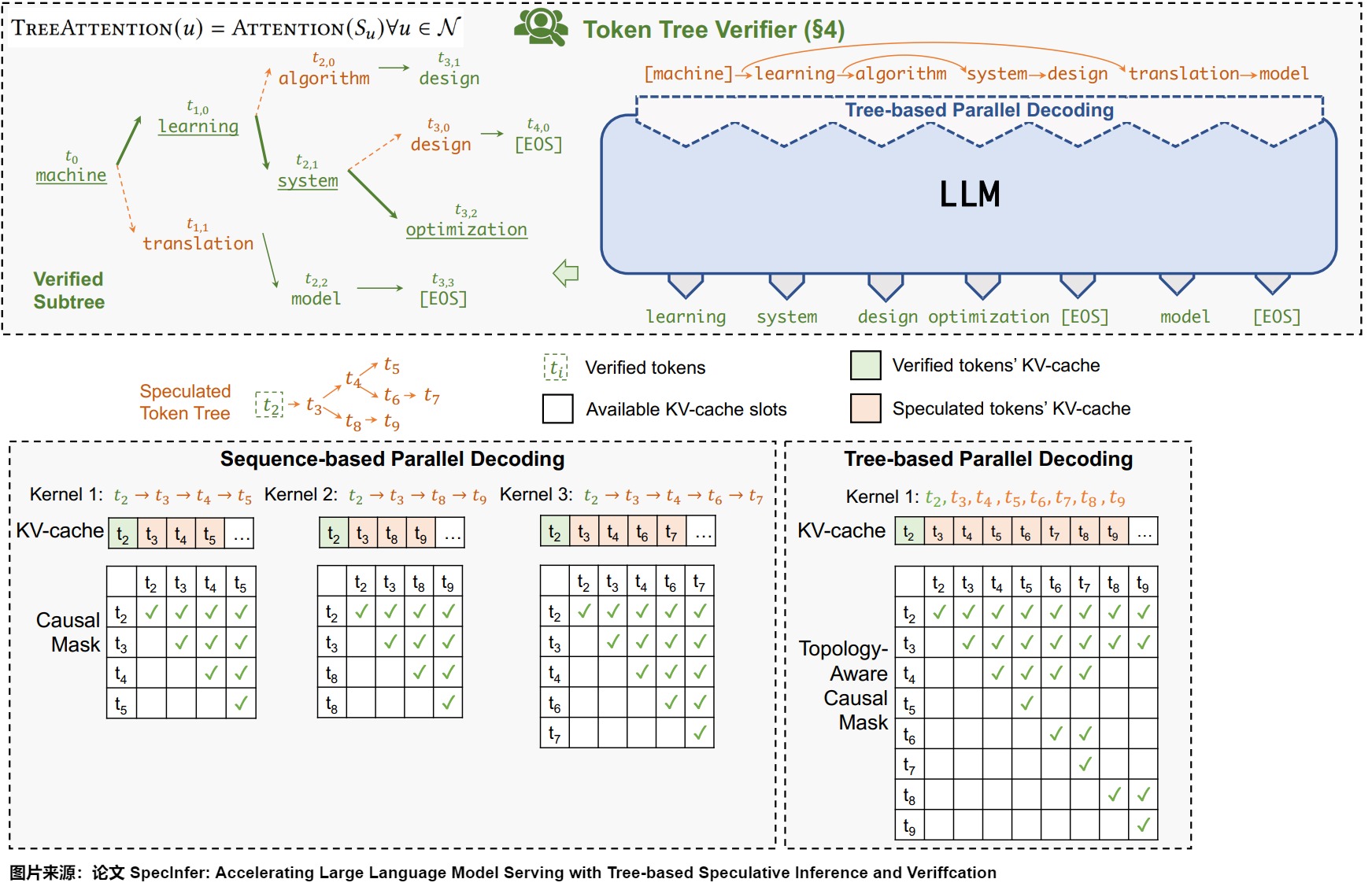
將生成的樹進(jìn)行驗(yàn)證。樹結(jié)構(gòu)會(huì)帶來token之間復(fù)雜的依賴關(guān)系,如果對(duì)樹上的每一個(gè)從root到leaf的路徑都用大模型做一次驗(yàn)證,大量的葉子節(jié)點(diǎn)也會(huì)導(dǎo)致算法退化到最原始的一次預(yù)測(cè)一個(gè)token的場景。針對(duì)這個(gè)情況,SpecInfer提出了tree attention來加速decoding的速度。方法是將樹上的祖先關(guān)系變成attention-mask的可見關(guān)系,使得模型可以一次驗(yàn)證多個(gè) sequence。如下圖所示,對(duì)于這樣一棵樹,如果采用常規(guī)的 mask 方式,t6 是可以看到 t5 的,但在圖上的 mask 矩陣下,每個(gè) token 只可以看到自己的 prefix,從而使得 LLM 可以一次完成對(duì)于多個(gè) sequence 的不互相干擾的驗(yàn)證。
![]()
7.2.2 如何組織樹
有多種組織樹的方法,具體參見下圖。
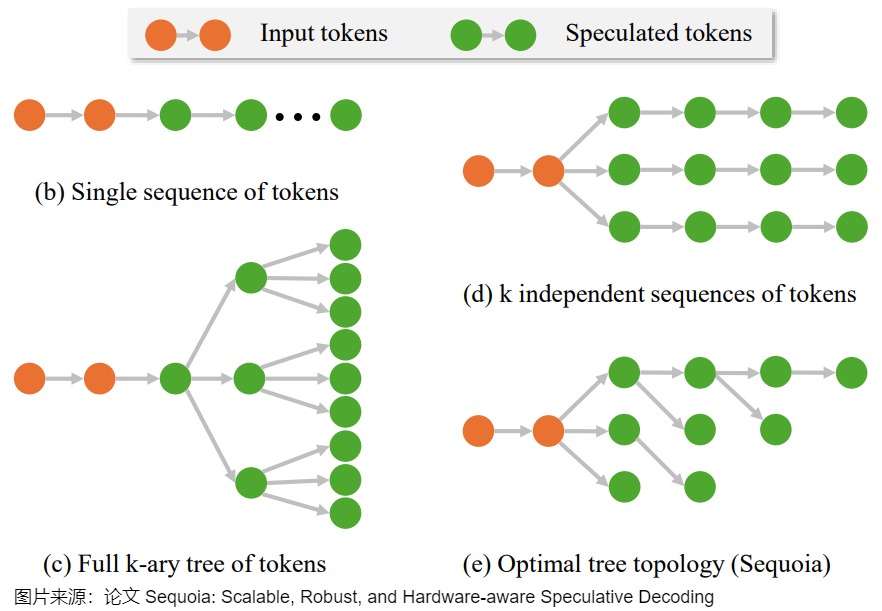
以下圖右下角的Sequoia為例,接受向量是p=(p1,p2,…,pk,…),其中驗(yàn)證算法在子位置k接受token的概率為pk。樹的具體構(gòu)建方法基于 positional acceptance assumption:假設(shè)token t 是已接受token的第k個(gè)子token,則驗(yàn)證算法接受token t 的概率僅取決于 k 的值 。每個(gè)子節(jié)點(diǎn)的得分為從根節(jié)點(diǎn)到此節(jié)點(diǎn)的所有 \(p_k\) (驗(yàn)證算法在子位置 k 接受token的概率)相乘。最后的目標(biāo)是,在給定節(jié)點(diǎn)數(shù)量的情況下使整棵樹所有節(jié)點(diǎn)得分相加最大。這個(gè)問題的解可以用更小的子問題的解來表示,因此可以通過動(dòng)態(tài)規(guī)劃求解。求得的樹結(jié)構(gòu)滿足預(yù)測(cè)概率較大的子節(jié)點(diǎn)會(huì)有更多的子孫。
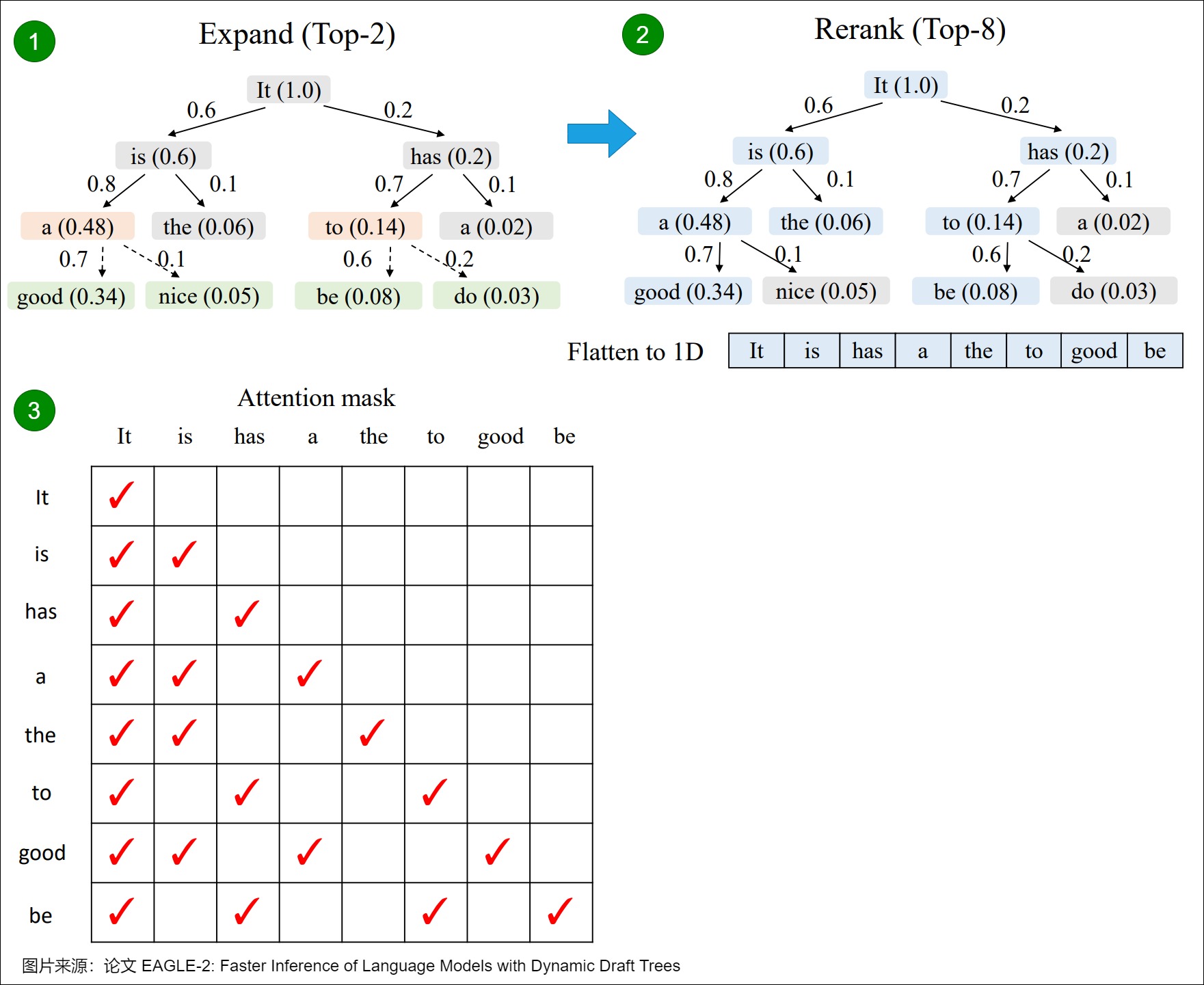
再比如,下圖給出了EAGLE-2的Token Tree Verification。樹的邊上的數(shù)字表示草稿模型的置信度得分,塊內(nèi)括號(hào)中的數(shù)字表示節(jié)點(diǎn)的值。在擴(kuò)展階段,我們從當(dāng)前層(橙色塊)中選擇值最高的前2個(gè)節(jié)點(diǎn)作為草稿模型的輸入,并將生成的token(綠色塊)連接到草稿樹。在重新排序階段,我們從所有節(jié)點(diǎn)(藍(lán)色塊)中選擇值最高的前8個(gè)節(jié)點(diǎn),將其展平為一維序列以形成最終草稿。然后,我們根據(jù)樹結(jié)構(gòu)來構(gòu)建注意力掩碼,確保每個(gè)token只能看到其祖先節(jié)點(diǎn)。
7.3 Attention Mask
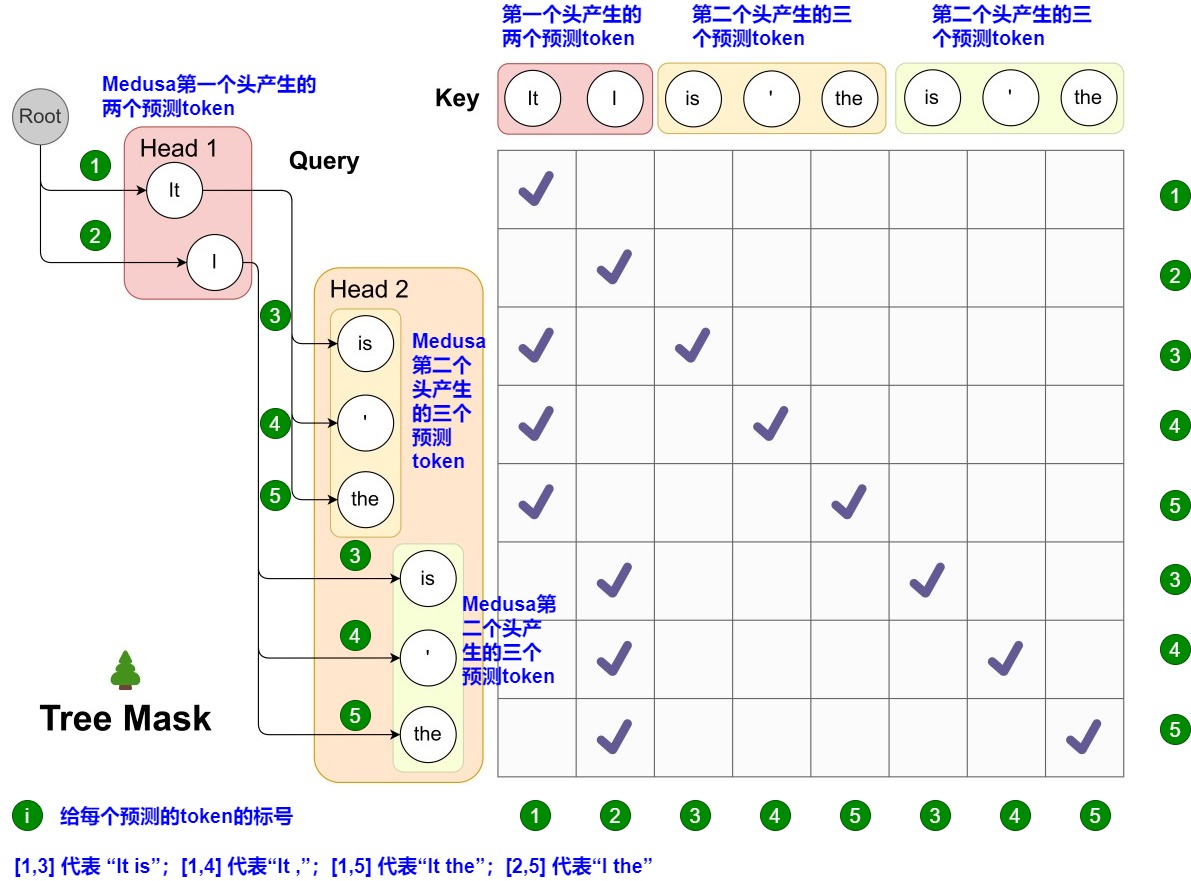
Medusa 中的 Attention Mask 矩陣如下圖所示。左側(cè)給出了候選序列。而其對(duì)應(yīng)的 Attention Mask 矩陣如右側(cè)所示。在圖上,Head 1 在下一個(gè)位置生成 2 個(gè)可能的 Token(It 和 I),Head 2 在下下一個(gè)位置生成 3 個(gè)可能的 Token(is,’ 和 the)。因?yàn)榈谝粋€(gè)頭部的任何預(yù)測(cè)都可以與第二個(gè)頭部的任何預(yù)測(cè)配對(duì),這樣下一個(gè)位置和下下一個(gè)位置就有了 2 x 3 = 6 種可能的候選序列,最終形成一個(gè)多層樹結(jié)構(gòu)。這棵樹的每一層都對(duì)應(yīng)于一個(gè)Medusa Head的預(yù)測(cè)。在這棵樹內(nèi),Attention Mask只限制一個(gè)token對(duì)其前面token的注意力。
0xFF 參考
加速大模型之投機(jī)采樣(Speculative Decoding) 杜凌霄
Speculative Decoding: Exploiting Speculative Execution for Accelerating Seq2seq Generation]
LLM推理加速新范式!推測(cè)解碼(Speculative Decoding)最新綜述 hemingkx
有沒有speculative decoding的綜述? 木葉
LLM(18):LLM 的推理優(yōu)化技術(shù)縱覽 紫氣東來
3萬字詳細(xì)解析清華大學(xué)最新綜述工作:大模型高效推理綜述 zenRRan
LLM推理加速: Speculative Decoding 概述 zssloth
加速大模型之投機(jī)采樣(Speculative Decoding) 杜凌霄
deepseek技術(shù)解讀(2)-MTP(Multi-Token Prediction)的前世今生 姜富春
[讀書筆記]Multi-token prediction 多詞預(yù)測(cè) 迷途小書僮
Deepseek-v3技術(shù)報(bào)告-圖的逐步解析-3-不容易看懂的MTP-公式有拼寫錯(cuò)誤 迷途小書僮
萬字綜述 10+ 種 LLM 投機(jī)采樣推理加速方案 AI閑談
https://github.com/hemingkx/SpeculativeDecodingPapers
【手撕LLM-Speculative Decoding】大模型邁向"并行"解碼時(shí)代 小冬瓜AIGC
【手撕LLM-Medusa】并行解碼范式: 美杜莎駕到, 通通閃開!! 小冬瓜AIGC
https://zhuanlan.zhihu.com/p/684217993
https://mp.weixin.qq.com/s/PyAKiFzbQNq6w7HmaTnSEw
https://zhuanlan.zhihu.com/p/690504053
https://zhuanlan.zhihu.com/p/699166575
https://zhuanlan.zhihu.com/p/658298728
LLM推理加速之Medusa:Blockwise Parallel Decoding的繼承與發(fā)展 方佳瑞
方佳瑞:LLM推理加速的文藝復(fù)興:Noam Shazeer和Blockwise Parallel Decoding 方佳瑞
Accelerating Large Language Model Decoding with Speculative Sampling Charlie Chen, Sebastian Borgeaud, Geoffrey Irving, Jean-Baptiste Lespiau, Laurent Sifre and John Jumper All authors from DeepMind
Speculative Decoding 論文閱讀合訂本 灰瞳六分儀
【自然語言處理】【大模型】投機(jī)采樣加速LLM解碼 白強(qiáng)偉
推測(cè)解碼算法(Speculative Decoding)快速理解與代碼實(shí)現(xiàn) iyayaai
想了解投機(jī)采樣?一起來看看這篇論文吧! 時(shí)空貓的問答盒
猜測(cè)解碼(speculative decoding)的等效性證明 paperplanet
大模型推理妙招—投機(jī)采樣(Speculative Decoding) 方佳瑞
LLM投機(jī)采樣(Speculative Sampling)為何能加速模型推理 Venda
萬字綜述 10+ 種 LLM 投機(jī)采樣推理加速方案 AI閑談
3萬字詳細(xì)解析清華大學(xué)最新綜述工作:大模型高效推理綜述 zenRRan
[2401.07851] Unlocking Efficiency in Large Language Model Inference: A Comprehensive Survey of Speculative Decoding
Stern, Mitchell, Noam Shazeer, and Jakob Uszkoreit. "Blockwise parallel decoding for deep autoregressive models."Advances in Neural Information Processing Systems31 (2018)
Xia, Heming, et al. "Unlocking efficiency in large language model inference: A comprehensive survey of speculative decoding."arXiv preprint arXiv:2401.07851(2024).
Agrawal, Amey, et al. "Sarathi: Efficient llm inference by piggybacking decodes with chunked prefills."arXiv preprint arXiv:2308.16369(2023).
Cai, Tianle, et al. "Medusa: Simple llm inference acceleration framework with multiple decoding heads."arXiv preprint arXiv:2401.10774(2024).
Li, Yuhui, et al. "Eagle: Speculative sampling requires rethinking feature uncertainty."arXiv preprint arXiv:2401.15077(2024).
Chen, Charlie, et al. "Accelerating large language model decoding with speculative sampling." arXiv preprint arXiv:2302.01318 (2023).
Leviathan, Yaniv, Matan Kalman, and Yossi Matias. "Fast inference from transformers via speculative decoding." International Conference on Machine Learning. PMLR, 2023.
Sun, Ziteng, et al. "Spectr: Fast speculative decoding via optimal transport." Advances in Neural Information Processing Systems 36 (2024).
Miao, Xupeng, et al. "Specinfer: Accelerating generative llm serving with speculative inference and token tree verification." arXiv preprint arXiv:2305.09781 (2023).
Chen, Zhuoming, et al. "Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding." arXiv preprint arXiv:2402.12374 (2024).
https://arxiv.org/abs/2401.07851
https://arxiv.org/abs/2308.16369
https://github.com/openppl-public
https://arxiv.org/abs/1811.03115
https://arxiv.org/abs/2211.17192
https://huggingface.co/blog/assisted-generation
https://arxiv.org/abs/2305.09781
https://arxiv.org/abs/2401.10774
https://arxiv.org/abs/2311.08252
https://lmsys.org/blog/2023-11-21-lookahead-decoding/
https://arxiv.org/abs/2401.15077
https://arxiv.org/abs/2312.12728
https://github.com/microsoft/unilm
https://arxiv.org/abs/2308.04623
https://arxiv.org/abs/2310.08461
TriForce:KV Cache 稀疏化+投機(jī)采樣,2.3x LLM 無損加速 AI閑談
https://arxiv.org/abs/1811.03115
https://arxiv.org/abs/2404.19737
https://mp.weixin.qq.com/s/PyAKiFzbQNq6w7HmaTnSEw
Blockwise Parallel Decoding for Deep Autoregressive Models
投機(jī)解碼——What makes for efficient speculative decoding? 密排六方橘子
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding
Sequoia: Scalable, Robust, and Hardware-aware Speculative Decoding

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)