
探秘Transformer系列之(27)--- MQA & GQA
探秘Transformer系列之(27)--- MQA & GQA
0x00 概述
在前文“優化KV Cache"中我們提到過,在”減少注意力頭的數量“這個維度上,目前主要的相關工作有 MQA和GQA。MQA 和 GQA 是在緩存多少數量KV的思路上進行優化:直覺是如果緩存的KV個數少一些,顯存就占用少一些,大模型能力的降低可以通過進一步的訓練或者增加FFN/GLU的規模來彌補。
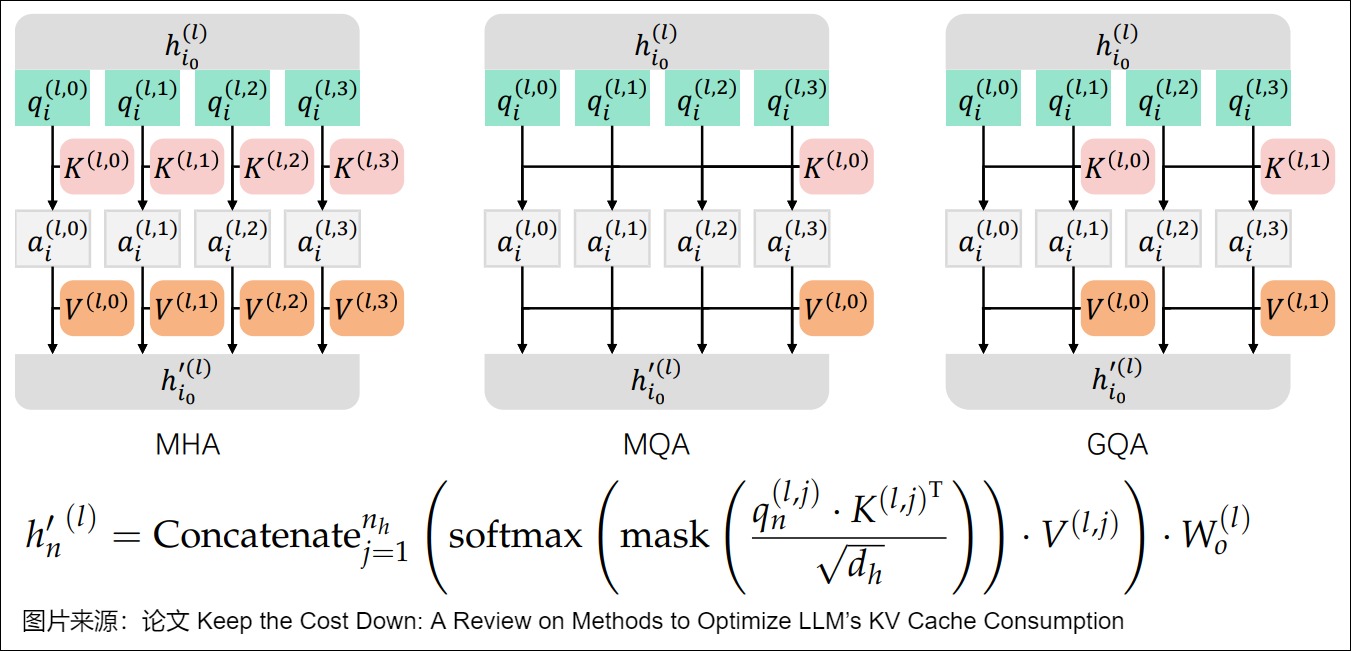
因為MQA和GQA是基于MHA進行改進,所以我們用下圖展示了三者的區別。可以看到,通過縮減注意力頭數目,MQA/GQA會降低KV Cache存儲,讓不同的注意力頭或者同一組的注意力頭共享一個K和V的集合,因為只單獨保留了一份(或者幾份)查詢參數。因此K和V的矩陣僅有一份(或者幾份),這大幅度減少了顯存占用,使其更高效。另外,傳統的基于MHA的Attention算子過于卡訪存帶寬,MQA和GQA,乃至后續的MLA都可以提計算訪存比,這樣也是對性能的極大提升。

注:
- 全部文章列表在這里,估計最終在35篇左右,后續每發一篇文章,會修改此文章列表。cnblogs 探秘Transformer系列之文章列表
- 本系列是對論文、博客和代碼的學習和解讀,借鑒了很多網上朋友的文章,在此表示感謝,并且會在參考中列出。因為本系列參考文章太多,可能有漏給出處的現象。如果原作者發現,還請指出,我在參考文獻中進行增補。
0x01 MHA
因為MQA,GQA是基于MHA進行修改,所以我們有必要先回顧下MHA。
1.1 概念
MHA(即多頭注意力機制)在2017年就隨著Transformer原始論文"Attention Is All You Need"一起提出,其主要工作是:把原來一個注意力計算拆成多個小份的注意力頭,即把Q、K、V分別拆分成多份,每個注意力頭使用獨立的Q、K、V進行計算。而多個頭可以并行計算,分別得出結果,最后再合回原來的維度。
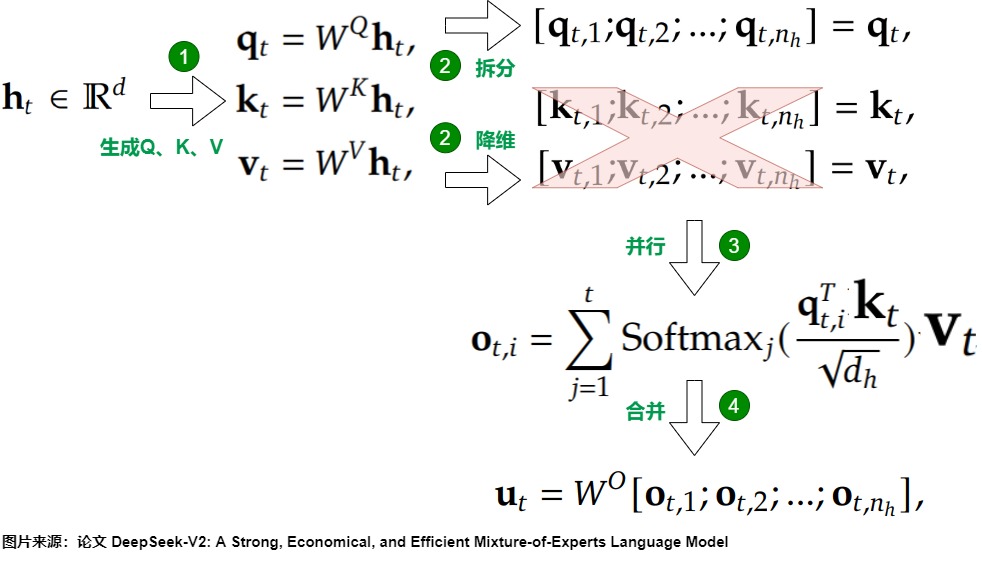
我們通過下圖來看看MHA的流程,這里設 ?? 表示詞嵌入的維度, \(??_?\) 表示注意力頭的數量, \(??_?\) 表示每一個頭的維度, \(?_??\in??^??\) 表示第 ?? 個token在一個注意力層的輸入, \(??^??∈??^{??×??_???_?}\) 表示輸出映射矩陣。則MHA可以分為以下四步:
- 通過3個參數矩陣 \(??^??,??^??,??^??∈??^{??_???_h\times d}\) 就可以得到 \(??_??,??_??,??_??∈??^{??_???_h}\) 。
- \(??_??,??_??,??_??\) 會分割成 \(??_?\) 個向量,\(??_{??,??},??_{??,??},??_{??,??}∈??^{??_?}\) 分別表示Q、K和V的第 ?? 個向量,這些拆分后的向量我們后續稱之為Q頭,K頭和V頭。
- 每個注意力頭會利用自己獲得的Q、K、V向量進行注意力計算。
- 利用\(W^O\)對多頭注意力計算結果進行合并。

1.2 實現
1.2.1 哈佛
我們回顧下“The Annotated Transformer”中MHA代碼的實現
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) \
/ math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
'''
h: head number
'''
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d
self.d = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d)
return self.linears[-1](x)
1.2.2 llm-foundry
作為對比,我們看看工業界的產品。
class MultiheadAttention(nn.Module):
"""Multi-head self attention.
Using torch or triton attention implemetation enables user to also use
additive bias.
"""
def __init__(
self,
d_model: int,
n_heads: int,
attn_impl: str = 'triton',
clip_qkv: Optional[float] = None,
qk_ln: bool = False,
softmax_scale: Optional[float] = None,
attn_pdrop: float = 0.0,
low_precision_layernorm: bool = False,
verbose: int = 0,
device: Optional[str] = None,
):
super().__init__()
self.attn_impl = attn_impl
self.clip_qkv = clip_qkv
self.qk_ln = qk_ln
self.d_model = d_model
self.n_heads = n_heads
self.softmax_scale = softmax_scale
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.d_model / self.n_heads)
self.attn_dropout_p = attn_pdrop
self.Wqkv = nn.Linear(self.d_model, 3 * self.d_model, device=device)
# for param init fn; enables shape based init of fused layers
fuse_splits = (d_model, 2 * d_model)
self.Wqkv._fused = (0, fuse_splits) # type: ignore
if self.qk_ln:
layernorm_class = LPLayerNorm if low_precision_layernorm else nn.LayerNorm
self.q_ln = layernorm_class(self.d_model, device=device)
self.k_ln = layernorm_class(self.d_model, device=device)
if self.attn_impl == 'flash':
self.attn_fn = flash_attn_fn
elif self.attn_impl == 'triton':
self.attn_fn = triton_flash_attn_fn
elif self.attn_impl == 'torch':
self.attn_fn = scaled_multihead_dot_product_attention
else:
raise ValueError(f'{attn_impl=} is an invalid setting.')
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True # type: ignore
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
query, key, value = qkv.chunk(3, dim=2)
key_padding_mask = attention_mask
if self.qk_ln:
# Applying layernorm to qk
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
context, attn_weights, past_key_value = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
)
return self.out_proj(context), attn_weights, past_key_value
scaled_multihead_dot_product_attention()代碼如下。
def scaled_multihead_dot_product_attention(
query,
key,
value,
n_heads,
past_key_value=None,
softmax_scale=None,
attn_bias=None,
key_padding_mask=None,
is_causal=False,
dropout_p=0.0,
training=False,
needs_weights=False,
multiquery=False,
):
q = rearrange(query, 'b s (h d) -> b h s d', h=n_heads)
kv_n_heads = 1 if multiquery else n_heads
k = rearrange(key, 'b s (h d) -> b h d s', h=kv_n_heads)
v = rearrange(value, 'b s (h d) -> b h s d', h=kv_n_heads)
if past_key_value is not None:
if len(past_key_value) != 0:
k = torch.cat([past_key_value[0], k], dim=3)
v = torch.cat([past_key_value[1], v], dim=2)
past_key_value = (k, v)
b, _, s_q, d = q.shape
s_k = k.size(-1)
if softmax_scale is None:
softmax_scale = 1 / math.sqrt(d)
attn_weight = q.matmul(k) * softmax_scale
if attn_bias is not None:
_s_q = max(0, attn_bias.size(2) - s_q)
_s_k = max(0, attn_bias.size(3) - s_k)
attn_bias = attn_bias[:, :, _s_q:, _s_k:]
attn_weight = attn_weight + attn_bias
min_val = torch.finfo(q.dtype).min
if key_padding_mask is not None:
attn_weight = attn_weight.masked_fill(
~key_padding_mask.view((b, 1, 1, s_k)), min_val)
if is_causal and (not q.size(2) == 1):
s = max(s_q, s_k)
causal_mask = attn_weight.new_ones(s, s, dtype=torch.float16)
causal_mask = causal_mask.tril()
causal_mask = causal_mask.to(torch.bool)
causal_mask = ~causal_mask
causal_mask = causal_mask[-s_q:, -s_k:]
attn_weight = attn_weight.masked_fill(causal_mask.view(1, 1, s_q, s_k),
min_val)
attn_weight = torch.softmax(attn_weight, dim=-1)
if dropout_p:
attn_weight = torch.nn.functional.dropout(attn_weight,
p=dropout_p,
training=training,
inplace=True)
out = attn_weight.matmul(v)
out = rearrange(out, 'b h s d -> b s (h d)')
if needs_weights:
return out, attn_weight, past_key_value
return out, None, past_key_value
1.3 資源占用
如果模型結構是MHA,在推理時,KV Cache對于每個token需要緩存的參數有 \(2??_???_???\)(?? 表示網絡層數)。當模型層數加深和頭數變多后,注意力計算所涉及的算力、IO和內存都會快速增加。但是對這些資源卻利用得不好。
就下圖而言,d 表示 hidden size,h 表示 Head 個數,l 表示當前輸入序列一共有 l 個 Token。
-
當 Batch Size 為 1 時,圖中紅色、綠色、藍色虛線圈處的乘法全部為矩陣乘向量,是明顯的 Memory Bound,算術強度不到 1。
-
當 Batch Size 大于 1 時(比如 Continuous Batching):
-
- 紅色和藍色部分:線性層計算是權重乘以激活,不同請求之間可以共享權重,因此是矩陣乘矩陣,并且 Batch Size 越大,算術強度越大,越趨近于計算密集型(FFN 層也類似)。
- 綠色部分:注意力計算是激活乘以激活。因為不同的請求之間沒有任何相關性,即使 Batching,此處也是 Batched 矩陣乘向量,并且因為序列長度可能不同,這里不同請求的矩陣乘向量是不規則的。即,這里算術強度始終不到 1,是明顯的 Memory Bound。
-
因此,綠色部分難以優化,輸入序列越長,此處的瓶頸就越大。

為了緩解這些資源占用,同時也可以更好的利用資源,相繼出現了MQA(Multi-Query Attention) 和GQA(Grouped-Query Attention )等方法,這些方法都是圍繞“如何減少資源占用且盡可能地保證效果”這個主題發展而來的產物。
0x02 MQA
目前的基本假設是,在頭維度上存在非常高的稀疏性,我們可以把頭的數量縮減到相當小的數目。在這些注意力頭中,有一些頭部專門用于檢索和長上下文相關能力,因此應該保留這些檢索頭并修剪其他頭。需要注意的是,頭部修剪通常發生在預填充之后,這意味著它們只會改善解碼、并發性和上下文切換,但并沒有改善預填充階段。
2.1 概念
MQA(Multi-Query Attention)出自論文 [2019] Fast Transformer Decoding: One Write-Head is All You Need。在MQA中,保留query的多頭性質,所有查詢頭共享相同的單一鍵和值頭,這用可以減少Key和Value矩陣的數量,從而降低計算和存儲開銷。這相當于把不同Head的注意力差異,全部都放在了Query上,需要模型僅從不同的Query Heads上就能夠關注到輸入hidden states不同方面的信息。
MQA的具體特點如下。
- Q 仍然保持原來的頭數,即線性變換之后,依然對Q進行切分(像MHA一樣),每個注意力頭單獨保留了自己的Q向量。
- K 和 V 只有一個頭,具體是在線性變換時直接把K和V的維度降到了\(d_{head}\),而不是做切分變小。
- 所有的 Q 頭共享這個K 和 V 頭,或者可以認為是 k, v矩陣參數共享。實現上,就是改一下線性變換矩陣,然后把 K、V 的處理從切分變成復制。
- 所有Q頭都使用這個相同的K頭計算它們的注意力分數,并且所有頭的輸出都使用相同的V頭計算(但注意力分數不同)。
- 最后將每個頭計算的結果拼接起來。
2.2 實現
我們還是以llm-foundry為例來進行分析。
1.2.1 精簡版
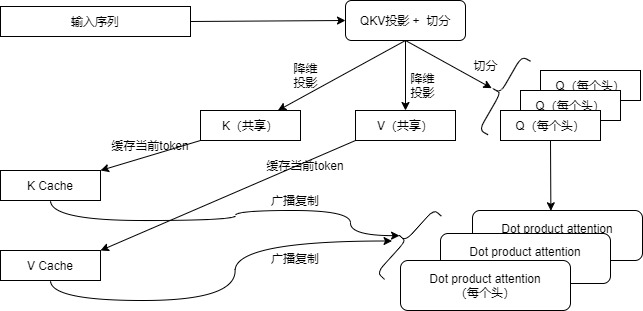
我們先給出MHA和MQA的精簡版對比。這里假設 x (tensor): (batch, hidden_state, d_model) ,比如 (1, 512, 768) 。可以看到,兩者主要不同在于:
- W矩陣的維度不同。
- QKV切分方式不同。

從代碼中可以看到,對于MQA來說,所有頭之間共享一份 key 和 value 的參數,但是如何將這 1 份參數同時讓 8 個頭都使用呢?在scaled_multihead_dot_product_attention()函數的代碼會使用矩陣乘法 matmul來廣播,使得每個頭都乘以這同一個張量,以此來實現參數共享。

MQA的總體流程可以參見下圖。
1.2.2 完整版
我們再給出完整版本代碼。
class MultiQueryAttention(nn.Module):
"""Multi-Query self attention.
Using torch or triton attention implemetation enables user to also use
additive bias.
"""
def __init__(
self,
d_model: int,
n_heads: int,
attn_impl: str = 'triton',
clip_qkv: Optional[float] = None,
qk_ln: bool = False,
softmax_scale: Optional[float] = None,
attn_pdrop: float = 0.0,
low_precision_layernorm: bool = False,
verbose: int = 0,
device: Optional[str] = None,
):
super().__init__()
self.attn_impl = attn_impl
self.clip_qkv = clip_qkv
self.qk_ln = qk_ln
self.d_model = d_model
self.n_heads = n_heads
self.head_dim = d_model // n_heads
self.softmax_scale = softmax_scale
if self.softmax_scale is None:
self.softmax_scale = 1 / math.sqrt(self.head_dim)
self.attn_dropout_p = attn_pdrop
# NOTE: if we ever want to make attn TensorParallel, I'm pretty sure we'll
# want to split Wqkv into Wq and Wkv where Wq can be TensorParallel but
# Wkv shouldn't be TensorParallel
# - vchiley
self.Wqkv = nn.Linear(
d_model,
d_model + 2 * self.head_dim,
device=device,
)
# for param init fn; enables shape based init of fused layers
fuse_splits = (d_model, d_model + self.head_dim)
self.Wqkv._fused = (0, fuse_splits) # type: ignore
if self.qk_ln:
layernorm_class = LPLayerNorm if low_precision_layernorm else nn.LayerNorm
self.q_ln = layernorm_class(d_model, device=device)
self.k_ln = layernorm_class(self.head_dim, device=device)
if self.attn_impl == 'flash':
self.attn_fn = flash_attn_fn
elif self.attn_impl == 'triton':
self.attn_fn = triton_flash_attn_fn
elif self.attn_impl == 'torch':
self.attn_fn = scaled_multihead_dot_product_attention
else:
raise ValueError(f'{attn_impl=} is an invalid setting.')
self.out_proj = nn.Linear(self.d_model, self.d_model, device=device)
self.out_proj._is_residual = True # type: ignore
def forward(
self,
x,
past_key_value=None,
attn_bias=None,
attention_mask=None,
is_causal=True,
needs_weights=False,
):
qkv = self.Wqkv(x)
if self.clip_qkv:
qkv.clamp_(min=-self.clip_qkv, max=self.clip_qkv)
query, key, value = qkv.split(
[self.d_model, self.head_dim, self.head_dim], dim=2)
key_padding_mask = attention_mask
if self.qk_ln:
# Applying layernorm to qk
dtype = query.dtype
query = self.q_ln(query).to(dtype)
key = self.k_ln(key).to(dtype)
context, attn_weights, past_key_value = self.attn_fn(
query,
key,
value,
self.n_heads,
past_key_value=past_key_value,
softmax_scale=self.softmax_scale,
attn_bias=attn_bias,
key_padding_mask=key_padding_mask,
is_causal=is_causal,
dropout_p=self.attn_dropout_p,
training=self.training,
needs_weights=needs_weights,
multiquery=True,
)
return self.out_proj(context), attn_weights, past_key_value
2.3 效果
2.3.1 內存
MQA需要緩存的 K、V 值從所有頭變成一個頭,因此直接將KV Cache減少到了原來的1/?。MHA的單個Token需要保存的KV數( \(2??????_?\) ),而MQA減少到了( 2×?? )個,即每一層共享使用一個 ?? 向量和一個 ?? 向量。
2.3.2 速度
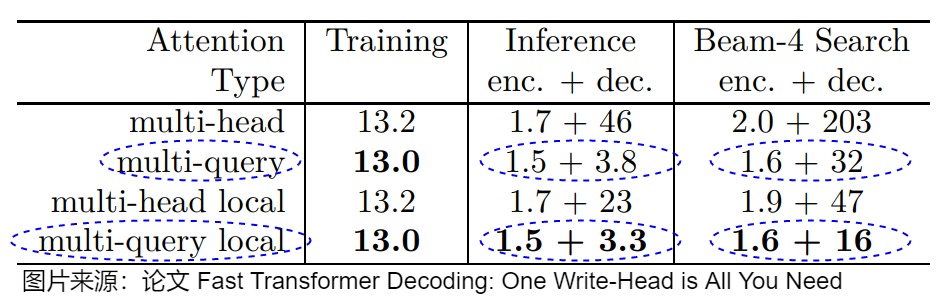
論文作者做了一系列測試,具體參見上表(數值是平均生成每個token所需要的毫秒數)。需要注意的幾個點是:
- 訓練速度幾乎沒有變化。
- 推理時間和Beam search時間都顯著縮短。
- 推理速度中,encoder的推理速度基本不變,decoder的推理快了很多。
雖然MQA只有一組KV頭,但實際上MQA是讀取這組KV頭之后,復制給所有Q頭使用,因此按照道理來說,MQA只能降低顯存的使用,運算量并沒有減少,為啥速度能提高這么多?其實主要收益是因為降低了KV Cache而帶來計算量的減少,具體如下:
- KV-Cache空間占用降低。因為頭數量的減少,所以需要存儲在GPU內存中的張量也減少了(假設之前要存儲32個頭的KV Cache,目前只需要存儲1個頭的KV Cache)。節省的空間可以用來增加批次大小,提升吞吐,從而提高效率(雖然單條請求的總時延會增加,但服務的總吞吐量是明顯增加)。
- 降低內存讀取模型權重的時間開銷。因為頭數量的減少,所以減少了從顯存中讀取的數據量,減少了計算單元的等待時間,從內存密集型趨近于計算密集型。另外,同一個 Request 中的不同 Head 可以共享,這就提升了 Q、K 和 V 的 Attention 計算的算術強度。
2.3.3 表征能力
因為目前只有一個共享的KV頭,所以原先多QKV頭帶來的注意力差異都需要僅僅依靠多個Q頭完成,這樣限制了模型的表征能力,因此MQA雖然能好地支持推理加速,但是在效果上比MHA略差。為了彌補共享KV帶來的參數量減少,人們往往會相應地增大FFN/GLU的規模,以此來維持模型總參數量的不變,進而彌補一部分效果損失。
另外需要注意的是,由于MQA和GQA改變了注意力機制的結構,因此模型通常需要從訓練開始就支持 MQA或者GQA 。如果模型已經訓練好了,將KV Cache強行換成這兩個方法,效果會很差,因此需要需要借助微調來彌補。有研究表明需要約 5% 的原始訓練數據量就可以達到不錯的效果。
2.3.3 通信
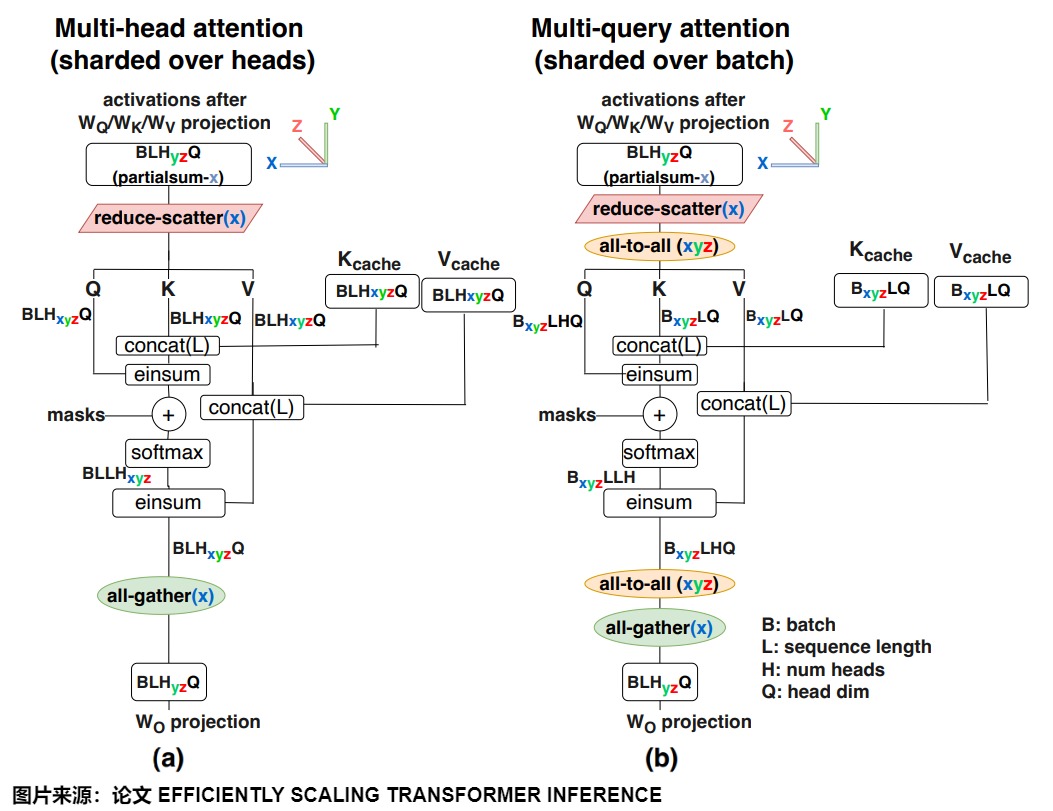
在多卡并行情況下,MQA減少了訪存,但是增加了并行通信開銷。因為K和V張量在所有頭部之間共享,每個GPU上都需要有自己的備份。與下圖(a)中MHA并行策略相比,MQA需要使用all-to-all對進行輸入輸出激活張量resharding,從而產生額外的通信成本。具體如下圖(b)所示。另外,因為每個卡上都有備份,這可能會導致MQA的內存成本節省將會喪失。
0x03 GQA
對于更大的模型而言,徹底剝離所有頭過于激進。例如,相比從32減少到1,將頭數從64減少到1在模型的表征能力上是一個更大的削減。而且根據GQA論文的實驗說,MQA雖然”drastically“提升了decoder中的推理性能,但這樣做會帶來生成質量的顯著下降以及導致訓練不穩定。所以為了在犧牲更小性能前提下加速,GQA應運而生。
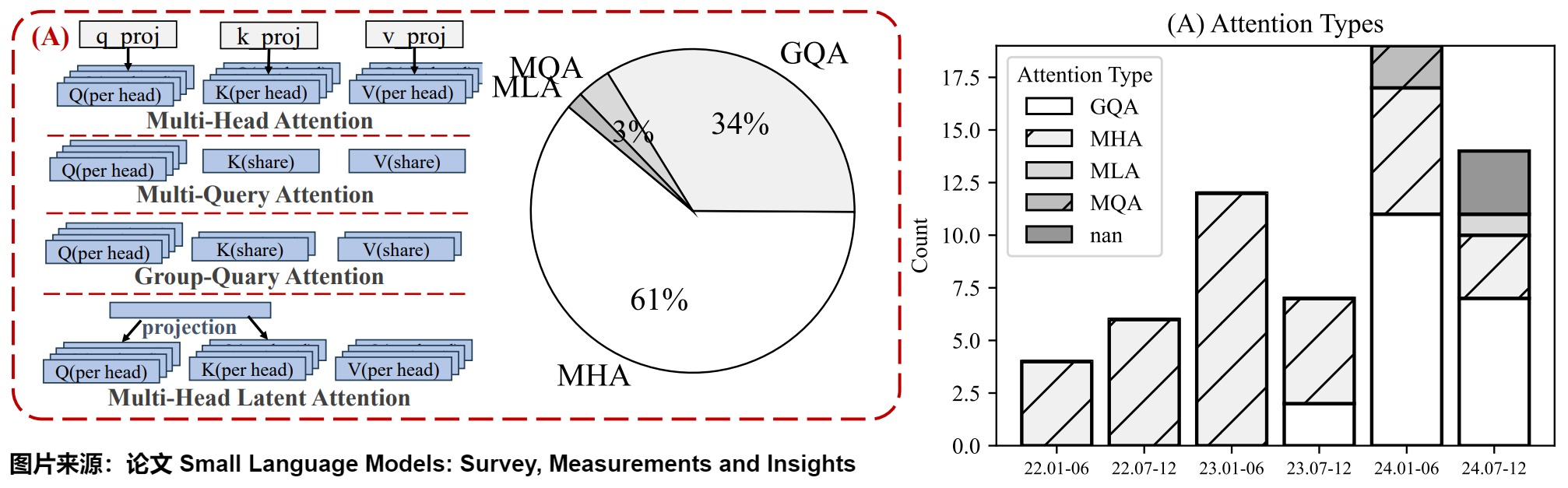
上圖顯示了從2022年到2024年期間自注意力機制的演變趨勢。可以看出,MHA 正在逐步淘汰,并被 GQA 所取代。
3.1 概念
GQA(Grouped Query Attention/分組查詢注意力機制)由論文“GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints”提出,它通過分組查詢的方式來提高信息處理的效率和效果。GQA的核心改進點在于:讓 多個 Query 共享少量的 Key 和 Value,減少計算開銷,并通過 分組機制(Grouping Mechanism) 進行更高效的計算。
GQA是MHA和MQA 之間的泛化,或者說是介于MHA和MQA之間的折中方案。MHA 有 H 個 query、key 和 value 頭。MQA 在所有 query 頭中共享單個 key 和 value 頭。而GQA不再讓所有查詢頭共享相同的唯一KV頭,而是將所有的Q頭分成g組,同一組的Q頭共享一個K頭(Key Head)和一個V頭(Value Head)。
下圖中4個Q頭(Query Heads)被分成2組,每個組包含2個Q頭,每組又對應一個K頭,一個V頭。圖上標號1為一組,標號2為另外一組。
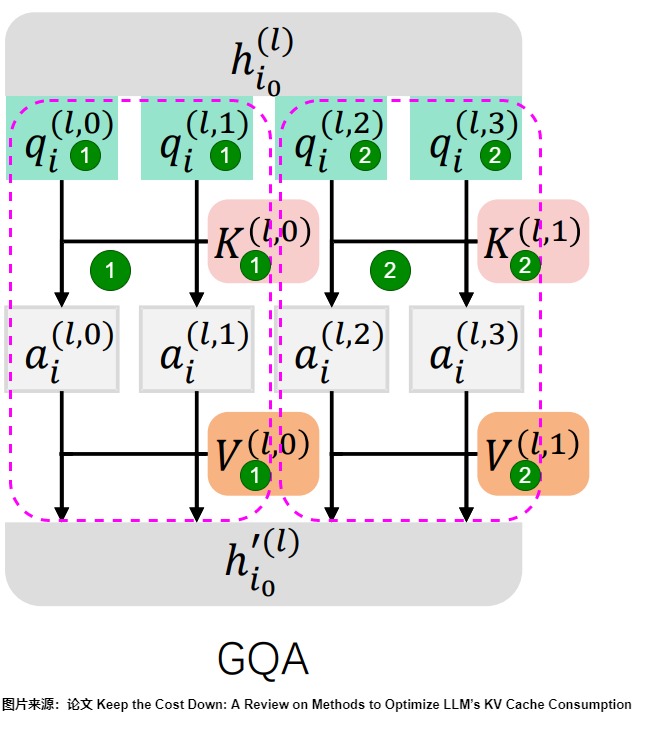
下圖是GQA的公式和流程。

蘇神則指出,GQA其實是一個\(x_i\)的低秩投影。

3.2 架構比對
GQA巧妙地結合了MHA和MQA的元素,創造了一種更有效的注意力機制。GQA是在MHA和MQA之間進行插值,將KV頭的數量從\(n\_heads\)減少到\(1<g<n\_heads\),而不是將頭數從\(n\_heads\)減少到1個KV頭。這個新參數g可以這么表達:
引入這個參數g之后,GQA就構成了一個統一視角。在這個視角下,MHA和MQA都是GQA的特殊情況(分別對應于g=1和 g=\(n\_heads\))。
- g = 1:相當于MQA,即在所有 N 個頭中使用共享的鍵和值投影。
- g = 注意力頭數:相當于MHA。
GQA能更順暢地在模型準確性/KV緩存大小(與時延和吞吐量有關),和MHA以及MQA這兩個極端用例間進行權衡。或者說,GQA每個組內是一個小型的MQA,而組間是傳統的MHA。
大型模型的MHA會將單個鍵和值頭復制到模型分區的數量,MQA代表了內存帶寬和容量的更大幅度的削減,而GQA 使我們能夠隨著模型大小的增加保持帶寬和容量的相同比例下降,可以為較大的模型提供特別好的權衡。GQA 消除了這種分片帶來的浪費。因此,我們預計 GQA 將為較大的模型提供特別好的權衡。
下圖則給出了三者架構上的區別。
3.3 實現
在目前大部分主流訓推框架或算法,都已經支持MQA/GQA,比如FlashAttention中,也支持MQA和GQA。對于MQA和GQA的情形,FlashAttention采用Indexing的方式,而不是直接復制多份KV Head的內容到顯存然后再進行計算。Indexing,即通過傳入KV/KV Head索引到Kernel中,然后計算內存地址,直接從內存中讀取KV。

順帶一提,GQA 不應用于編碼器自注意力層,編碼器表示是并行計算的,因此內存帶寬通常不是主要瓶頸。
我們使用llama3的代碼來進行分析。首先給出利于學習的精簡版,然后給出完整版。
3.3.1 精簡版
為了更好的分析,我們給出精簡版代碼如下。
本來 MHA 中 Query, Key, Value 的矩陣的大小為 (batch_size, n_head, seq_length, hidden_size)。而 GQA 中 Query 的大小保持不變,Key, Value 的矩陣的大小變為 (batch_size, n_head / group_size, seq_length, hidden_size)。即,在GQA中,key和value都要比query小group倍。為了在后續做矩陣乘法,一般有兩種做法:
-
利于廣播機制把QKV的形狀進行調整,即Query : (batch_size, n_head / group_size, group_size, seq_length, hidden_size),Key : (batch_size, n_head / group_size, 1, seq_length, hidden_size),Value : (batch_size, n_head / group_size, 1, seq_length, hidden_size)。但是這樣需要做廣播和最終合并的處理,要對 MHA 的代碼進行多處修改。
-
把GQA拓展到MHA再進行計算,即先把
key和value的head利用expand擴展張量到和query相同的維度,然后進行計算。
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads # 設定組數目
self.head_dim = args.dim // args.n_heads
# 用self.n_kv_heads * self.head_dim初始化,當n_kv_heads小于n_heads時,參數量變少
self.wq = ColumnParallelLinear(args.dim, args.n_heads * self.head_dim,)
self.wk = ColumnParallelLinear(args.dim, self.n_kv_heads * self.head_dim,)
self.wv = ColumnParallelLinear(args.dim, self.n_kv_heads * self.head_dim,)
self.wo = RowParallelLinear(args.n_heads * self.head_dim, args.dim,)
self.cache_k = torch.zeros((args.max_batch_size, args.max_seq_len,
self.n_local_kv_heads, self.head_dim,)).cuda()
self.cache_v = torch.zeros((args.max_batch_size, args.max_seq_len,
self.n_local_kv_heads, self.head_dim,)).cuda()
def forward(self, x: torch.Tensor, start_pos: int, freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
'''
self.n_rep = q_heads // kv_heads
query頭數大于KV的頭數,一對KV對應多個query,需要把每個KV復制n_rep份,這樣第2個維度就和q一樣了
即,num_key_value_heads就是q_heads // kv_heads
repeat_kv方法將hidden states從(batch, num_key_value_heads, seqlen, head_dim) 變成 (batch, num_attention_heads, seqlen, head_dim),相當于是復制了self.num_key_value_groups份
'''
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(keys, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(values, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
repeat_kv()函數代碼如下。為什么要用expand之后再reshape而不能直接用tensor自帶的repeat?因為使用expand()函數可以在運算的時候節省很多顯存。
expand方法用于對張量進行擴展,但不實際分配新的內存。它返回的張量與原始張量共享相同的數據repeat方法通過實際復制數據來擴展張量。它返回的新張量不與原始張量共享數據,擴展后的張量占用了更多的內存。
# 定義輸入x, n_rep是需要重復的次數,在這里一般是組數
def repeat_kv(x: torch.Tensor, n_rep: int) -> torch.Tensor:
"""torch.repeat_interleave(x, dim=2, repeats=n_rep)"""
bs, slen, n_kv_heads, head_dim = x.shape
if n_rep == 1:
return x
return (
# 第4維進行擴維,擴展成5維
x[:, :, :, None, :]
# first we expand x to (bs, seq_len, head, group, head_dim),即第4維從1擴展為n_rep
.expand(bs, slen, n_kv_heads, n_rep, head_dim) # 進行廣播,k,v向量共享
# reshape make head -> head * group,縮成4維,即把第3維從n_kv_heads擴展n_rep份
# 這樣第3個維度就和q一樣了
.reshape(bs, slen, n_kv_heads * n_rep, head_dim)
)
3.3.2 完整版
完整版代碼如下。
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(
keys, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(
values, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(
1, 2
) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
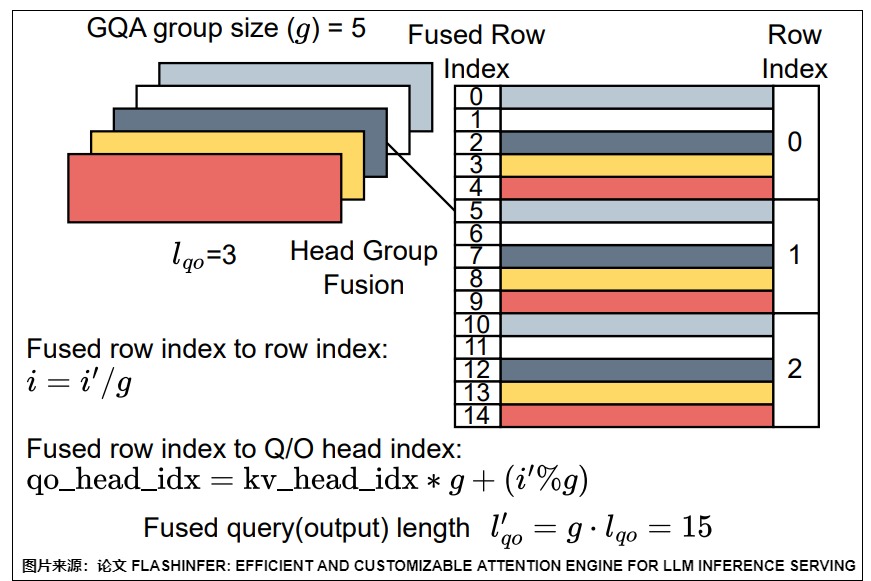
另外,對于MQA和GQA的解碼階段,一種常用的優化技巧是把共用一個KV頭的所有QO頭,與query的行數融合(因為他們需要跟相同的KV-Cache做Attention計算)。這樣的效果是增加了有效的行數,增加了算子密度,自回歸解碼階段雖然說查詢的長度是1,但是經過Head Group融合之后,有效行數增大到 \(H_{QO}/H_{KV}\)。
3.4 效果
3.4.1 內存
GQA在推理階段可以顯著降低 KV Cache 的大小,為更大的 Batch Size 提供了空間,可以進一步提升吞吐。
在MHA下,對于所有輸入批次和序列中的每個token,KV緩存的總大小可以用以下公式表示:
- B代表batch size,
- L代表總序列長度,sequence length(輸入序列+輸出序列,或者說是提示 + 完成部分),
- H代表number of head,
- D代表size of head,每個head的維度。
- N代表層數
在MQA下,每個token的對應為:
在GQA下,每個token的對應為:
具體比對也可以參考下圖,其中 g 是KV頭的組數(\(??_?/??\)個Head 共享一個KV),h 是查詢的頭數 ,\(d_k\)是頭維度,l 是層數,s 是序列長度,b 是batch size。
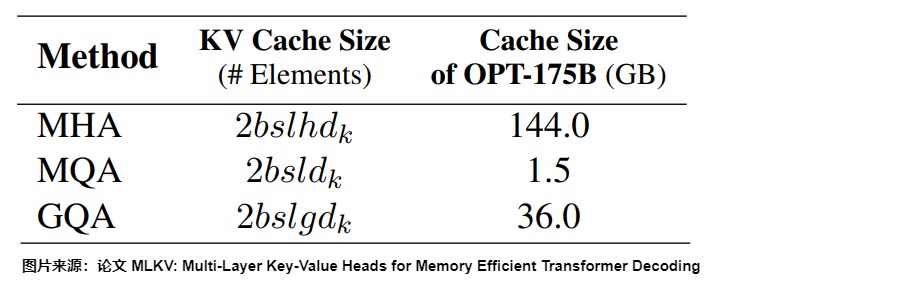
GQA和MQA在GPU 上的實現帶來的收益來主要自于KV cache 的減少,從而能放下更多的token。但是,GQA和MQA的性能容易受到并行策略的影響。如果GQA kernel在Q head維度做并行(一個Q head是一個block),則會導致共享一個KV head 的block 被調度在不同的SM上,每個SM 都會對同一份KV head 做重復加載。則內存減少的收益會大大降低。另外,加載 KV 是MHA 和 GQA 的瓶頸。因此需要減少Q head的并行度。
3.4.2 速度
GQA并沒有降低Attention的計算量(FLOPs),因為Key、Value映射矩陣會以廣播變量的形式拓展到和MHA和一樣,因此計算量不變,只是Key、Value參數共享。但是,因為GQA 將查詢矩陣 Q 分成多個組,每個組分別計算注意力分數和加權求和。這樣一來,每個注意力頭只需要計算一部分查詢的注意力分數,從而降低了計算復雜度,特別是在處理長序列時。所以,雖然GQA 的 QKV 計算量沒有減少,但是速度得到了很大提高,速度提高的原因和MQA相同。
3.4.3 表征能力
GQA既保留了多頭注意力的一定表達能力,又通過減少內存訪問壓力來加速推理速度。
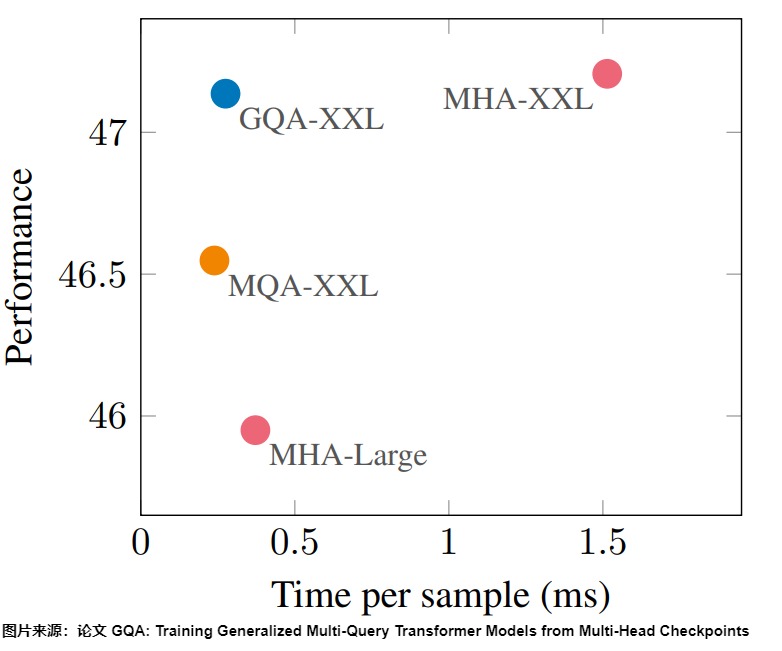
論文”GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints“研究了模型的精度和推理效率。論文作者采用T5模型作為研究對象,模型版本采用T5-Large和T5-XXL。下圖中,橫軸代表平均每條樣本的推理耗時,越大代表延遲越大,縱軸代表在眾多數據集上的評價得分,越大代表得分越高。
下圖表明,MQA略微損失了模型精度,但是確實能夠大幅降低推理開銷,而如果選擇了合適的分組數,GQA能夠兩者皆得。GQA的表征能力顯著高于MQA,幾乎跟MHA一致(GQA還是有可能導致精度的損失),而且推理速度上GQA跟MQA的區別不大,比起MHA依舊有顯著提升。其中,GQA的分組數是一個超參數,組數越大越接近MHA,推理延遲越大,同時模型精度也越高。另外,也可以增加模型深度來緩解模型效果的下降。
3.5 轉換
雖然最新的模型基本都在預訓練階段默認采用 GQA,我們也可以思考下,如何將已經訓練好的MHA結構的模型轉換成MQA或者GQA?
3.5.1 平均池化
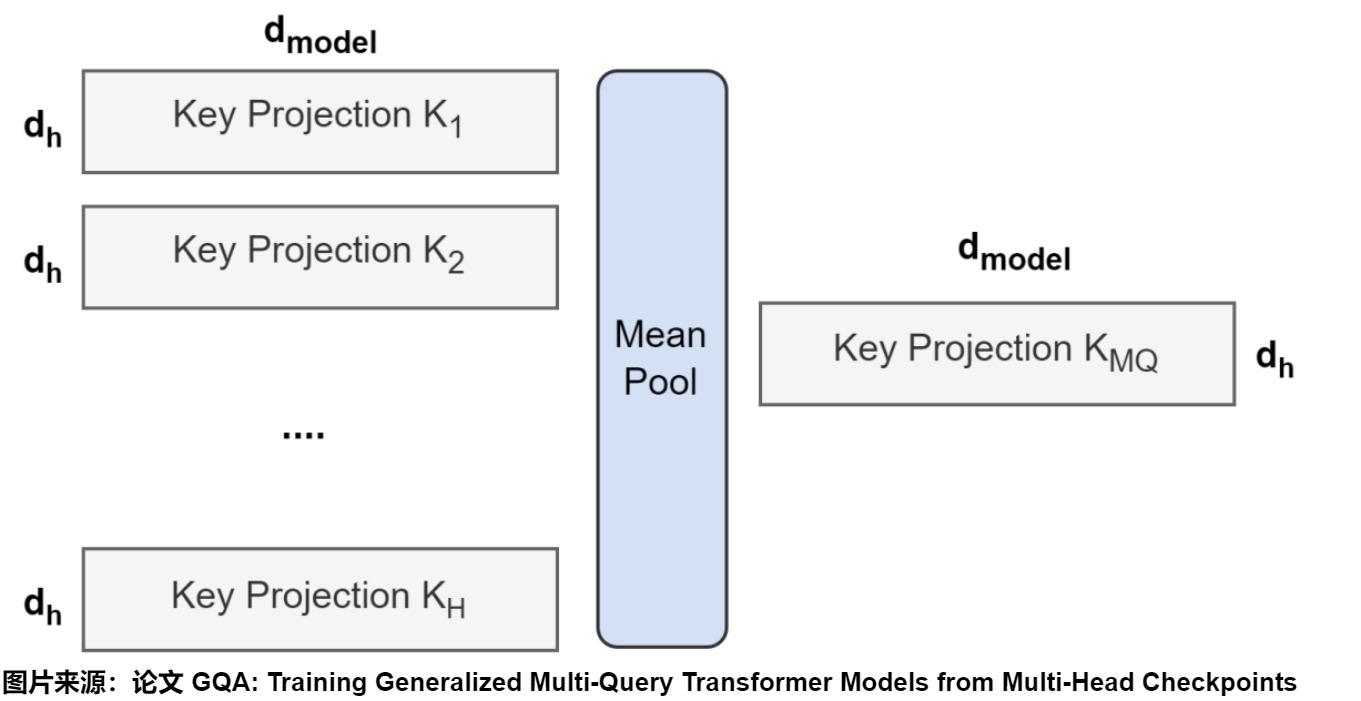
如果是從已有的 multi-head model 開始繼續訓練 multi-query model (Uptraining),我們可以對MHA的頭進行分組,通過對該組中所有原始頭進行平均池化(mean pool)來構建每個組的鍵和值頭,然后繼續進行預訓練即可。實驗證明mean pool的映射效果好于選則第一個head或者任意初始化。人們把這個訓練過程叫做uptraining。
具體參考代碼如下。
import torch.nn as nn
n_heads=4
n_kv_heads=2
hidden_size=3
group = n_heads // n_kv_heads
k_proj = nn.Linear(hidden_size, n_heads)
# mean pool操作
k_proj_4d = k_proj.weight.data.unsqueeze(dim=0).unsqueeze(dim=0)
pool=nn.AvgPool2d(kernel_size=(group,1))
pool_out = pool(k_proj_4d).squeeze(dim=0).squeeze(dim=0)
k_proj_gaq = nn.Linear(hidden_size, n_kv_heads)
k_proj_gaq.weight.data = pool_out
3.5.2 基于掩碼
論文”Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA“提出了一種低成本方法,可將 MHA 模型按任意 KV Head 壓縮比修剪為 GQA 模型。該方法基于 \(L_0\) 掩碼逐步剔除冗余參數。此外,在不改變模型的前提下,對注意力頭施加正交變換,以在修剪訓練前提升 Attention Head 間的相似度,從而進一步優化模型性能。
具體方案分為如下幾步:網絡轉換;進行分組;剪枝訓練。
網絡轉換
這一步是在剪枝訓練之前,對模型進行轉換。具體的過程大概為:
- 使用部分 C4 的訓練集來收集相應的 KV Cache,這樣才能對KV Cache進行更有效的分析。
- 基于余弦相似性或者歐氏距離,計算最優的正交矩陣。

- 將計算得到的正交矩陣融合到對應的 Q、K、V 投影矩陣中,保證計算不變性。因為RoPE的原因,所以對于 Q 和 K 的投影矩陣,分別在子空間應用正交變換。
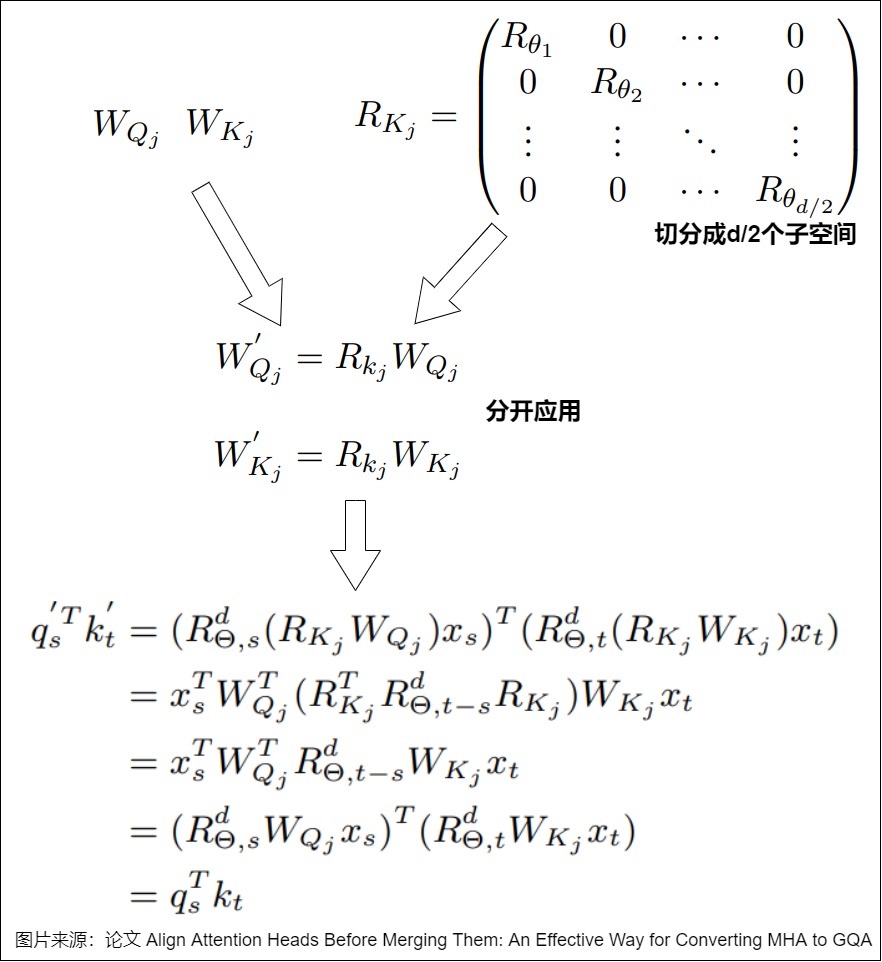
通過正交變換,可以使得同一組內不同 Attention Head 在特征空間中更加接近,從而在后續的剪枝訓練過程中更容易找到合適的參數共享方式,提高模型的壓縮效果和性能。
找到更好的分組方法
在獲取了每對 Attention Head 之間的相似度評分后,可依據這些評分對 Attention Head 進行重新分組。單個組的相似度評分是該組內每對 Attention Head 之間相似度評分的總和,而每種分組結果的總相似度評分則是所有組相似度評分的累加。算法的目標是找到得分最高的分組方法。
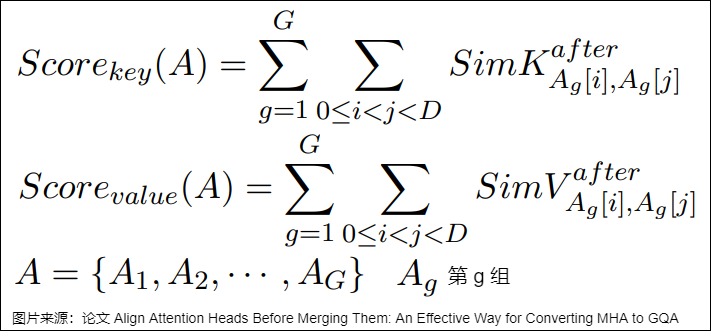
合理的分組方式可以使得同一組內的 Attention Head 在特征空間中更加相似,從而在剪枝時更容易找到合適的參數共享方式,提高模型的壓縮效果和性能。
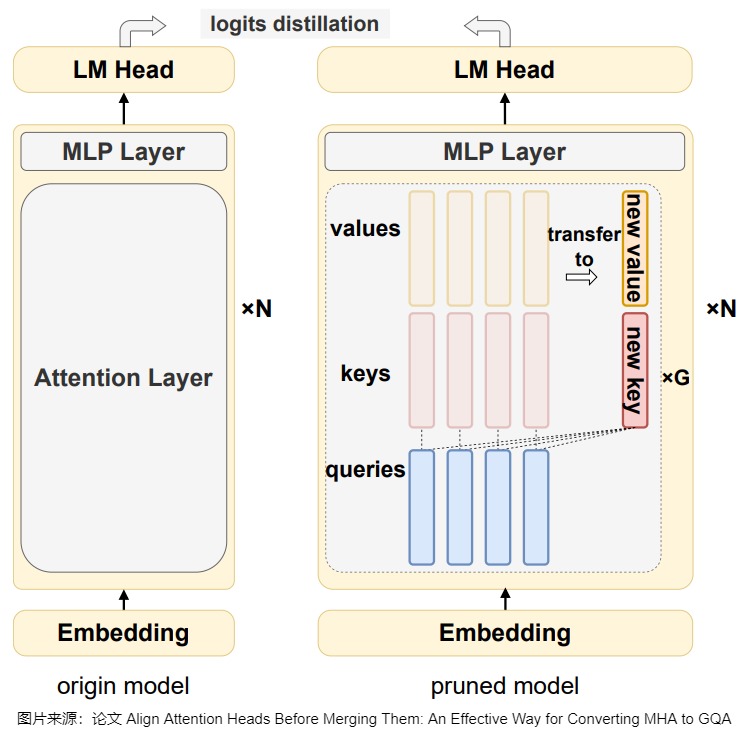
剪枝訓練
此步驟會通過剪枝訓練,逐步將原始的 KV Head 轉移到新的 KV Head 上,同時保持模型性能。如下圖 所示,具體過程包括:
- 添加新的投影矩陣:在每組內使用 Mean Pooling 初始化新的投影矩陣。
- 應用 \(L_0\) 掩碼:引入 \(L_0\) 掩碼來控制原始 KV Head 和新 KV Head 之間的轉換。初始時,掩碼值為 1,表示使用原始 KV Head;在剪枝過程中,逐步將掩碼值約束為 0(表示使用新的 KV Head)。
- 知識蒸餾:使用 KL 損失和 BiLD 損失,鼓勵學生模型與教師模型的輸出對齊,從而保持模型性能。
3.6 優化
論文“A Survey on Large Language Model Acceleration based on KV Cache Management”給出了MQA、GQA以及其改進方案的總結,具體參見下圖。
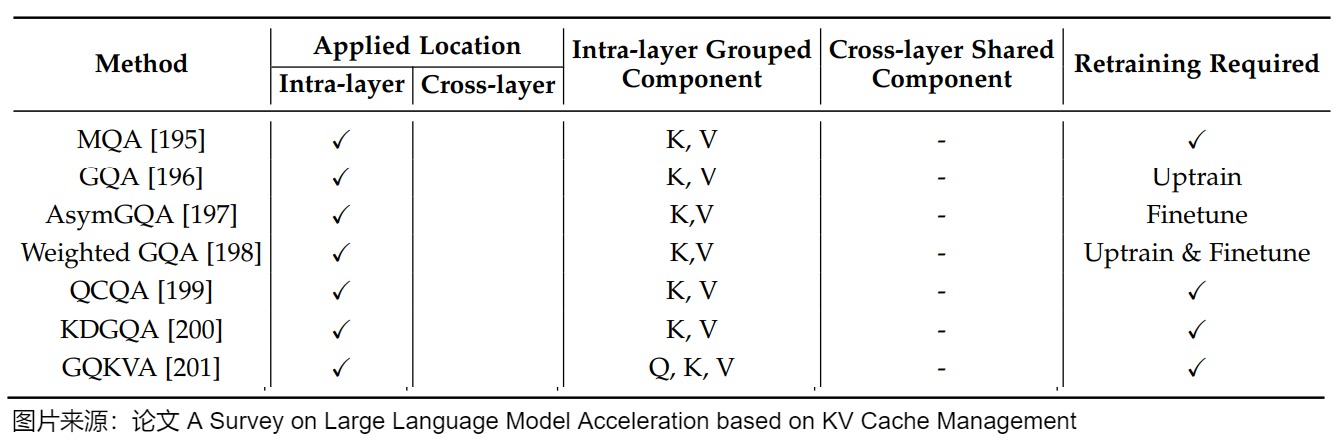
幾種改進方案具體如下。
- 加權GQA(Weighted GQA)為每個鍵和值頭引入了額外的可訓練權重,這些權重可以無縫集成到現有的GQA模型中。通過在訓練過程中調整權重,它可以在不增加額外推理開銷的情況下提高模型的性能。

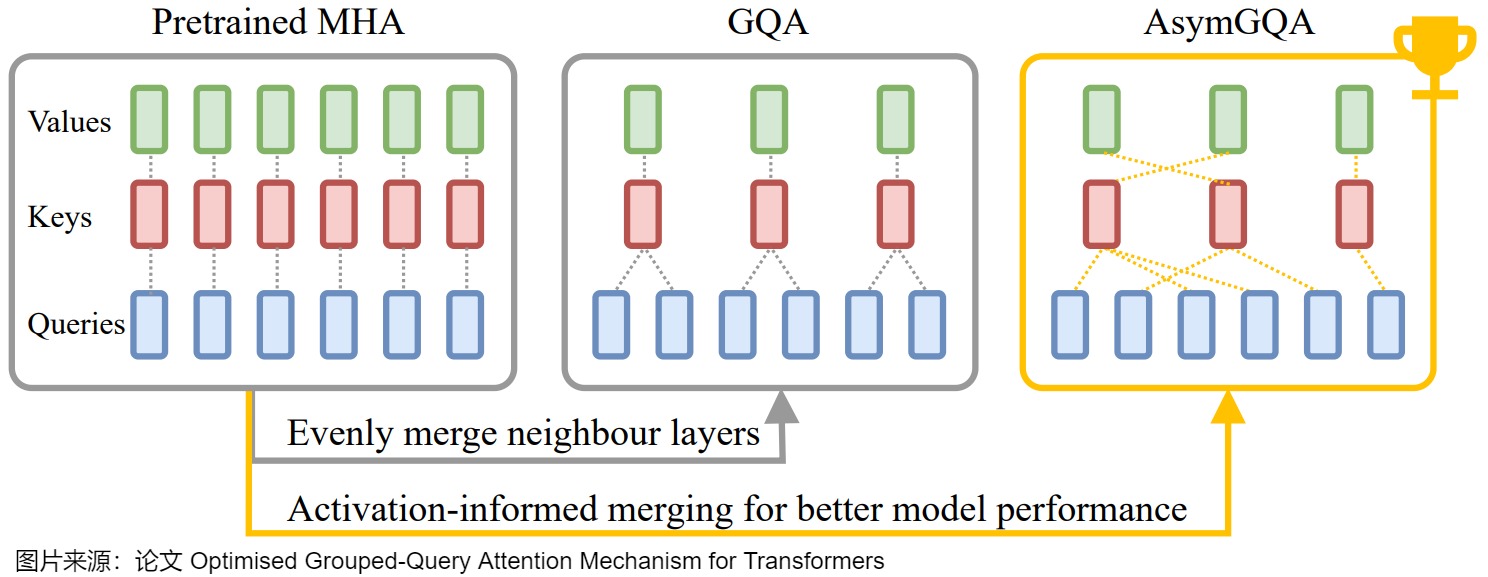
- AsymGQA通過提出激活通知合并策略(activationinformed merging strategy)來擴展GQA。AsymGQA不是通過統一聚類(uniform clustering)對頭進行分組,而是根據訓練過程中的激活相似性來動態確定如何分組,并構建不對稱的組,從而實現更好的優化和泛化。
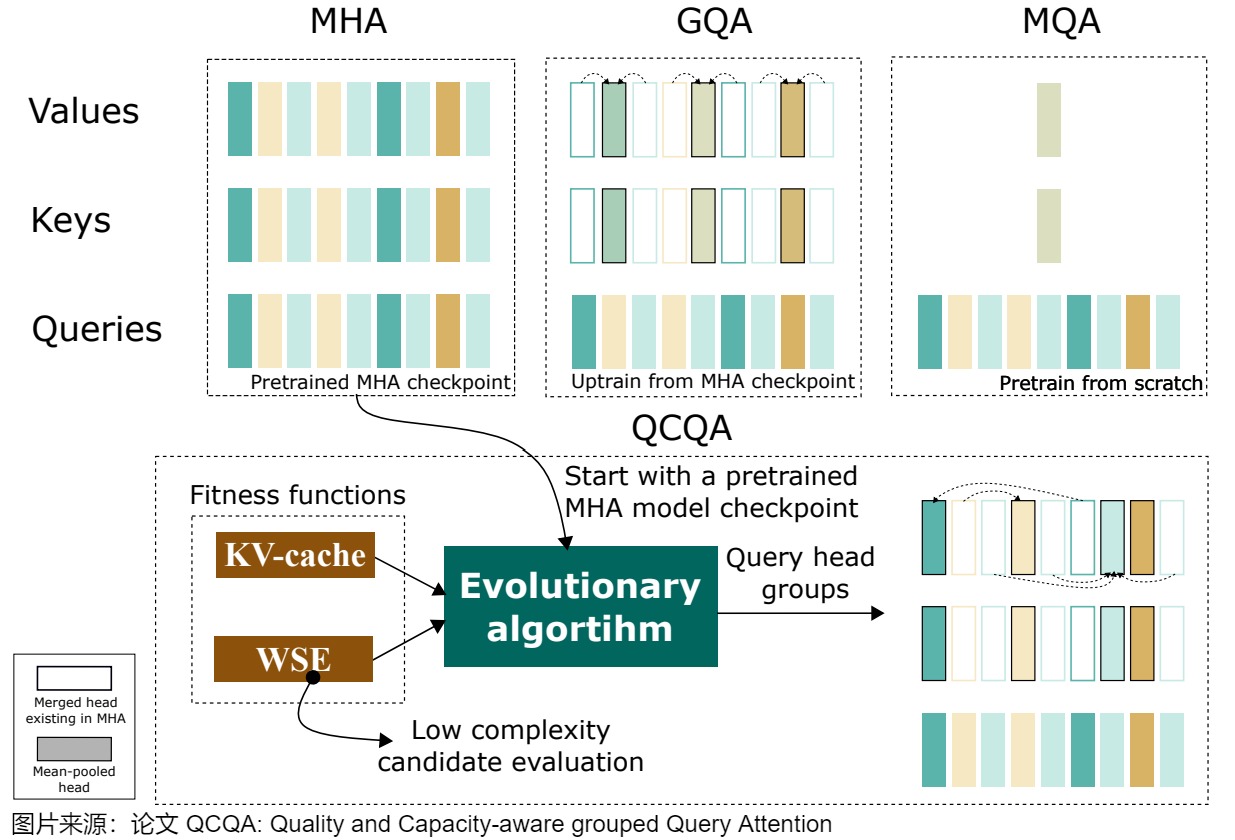
- QCQA利用進化(evolutionary)算法來識別GQA的最佳查詢頭分組,該算法由一個計算高效的適應度(computationally efficient fitness)函數指導,該函數利用權重共享(weight-sharing)誤差和KV緩存來評估文本生成質量和內存容量。
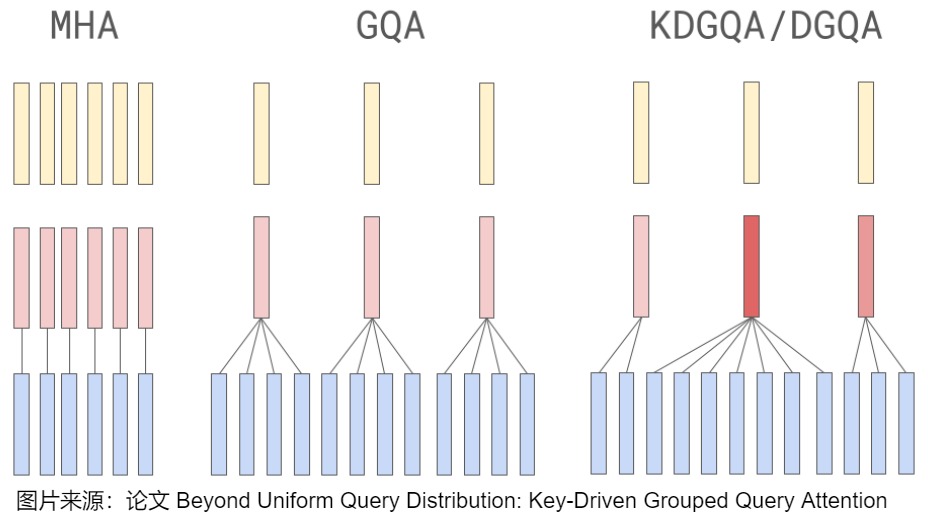
- KDGQA認為,GQA的許多變體采用固定的分組策略,因此缺乏對訓練過程中鍵值交互演變的動態適應性。他們的Dynamic Key-Driven GQA通過在訓練過程中使用key head norms自適應地分組來解決這些問題,從而產生了一種靈活的策略來將查詢頭分組并提高性能。
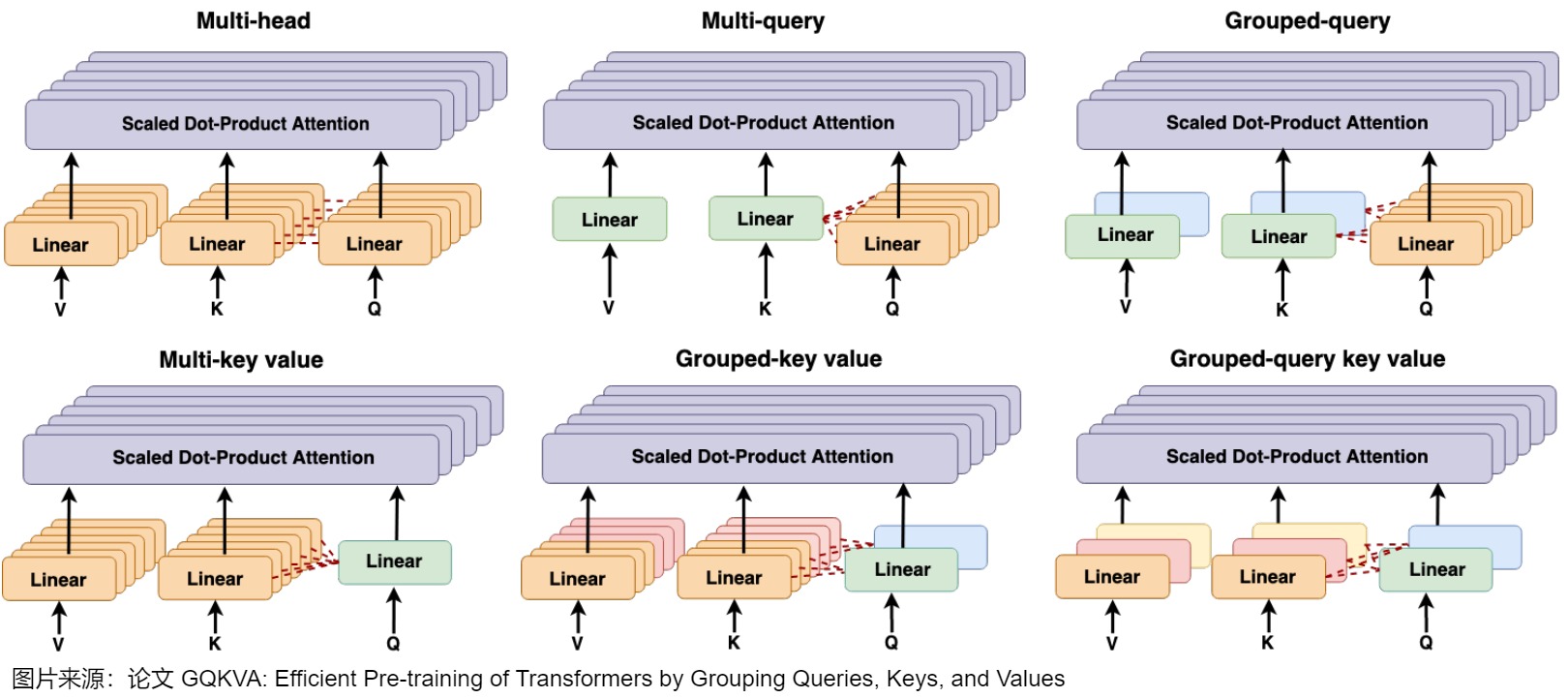
- GQKVA提出了分組策略,并提出了一種通用的查詢、鍵和值分組機制。它首先介紹了MKVA和GKVA,其中鍵和值被分組以共享同一個查詢。在此基礎上,該論文提出使用GQKVA將查詢和鍵值對分開分組。通常,查詢被劃分為\(g_q\)組,鍵值被劃分為\(g_{kv}\)組,查詢和鍵值對的每個組合都會使用點積注意力進行交互。這導致\(g_q×g_{kv}\)產生不同的輸出。GQKVA在查詢、鍵和值上推廣了不同的組策略,并保持了良好的計算效率和與MHA相當的性能。下圖展示了在注意力機制中對查詢、鍵和值進行分組的各種策略,包括Vanilla MHA、MQA、GQA、MKVA、GKVA和GQKVA。
0xFF 參考
【LLM 加速技巧】Muti Query Attention 和 Attention with Linear Bias(附源碼) 何枝
https://github.com/meta-llama/llama3
2萬字長文!一文了解Attention,從MHA到DeepSeek MLA,大量圖解,非常詳細! ShuYini [AINLPer](javascript:void(0)??
阿里一面代碼題:"實現一下 GQA" 看圖學 [看圖學](javascript:void(0)??
MHA -> GQA:提升 LLM 推理效率 AI閑談 [AI閑談](javascript:void(0)??
Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA
FLASHINFER: EFFICIENT AND CUSTOMIZABLE ATTENTION ENGINE FOR LLM INFERENCE SERVING
FlashInfer中DeepSeek MLA的內核設計 yzh119
大模型并行推理的太祖長拳:解讀Jeff Dean署名MLSys 23杰出論文 方佳瑞
由GQA性能數據異常引發的對MHA,GQA,MQA 在GPU上的感性分析 代碼搬運工
MHA->MQA->GQA->MLA的演進之路 假如給我一只AI
Y. Chen, C. Zhang, X. Gao, R. D. Mullins, G. A. Constantinides, and Y. Zhao, “Optimised Grouped-Query Attention Mechanism for Transformers,” in Workshop on Efficient Systems for Foundation Models II @ ICML2024, Jul. 2024. [Online]. Available: https://openreview.net/forum?id=13MMghY6Kh
S. S. Chinnakonduru and A. Mohapatra, “Weighted Grouped Query Attention in Transformers,” Jul. 2024. [Online]. Available: http://arxiv.org/abs/2407.10855
V. Joshi, P. Laddha, S. Sinha, O. J. Omer, and S. Subramoney, “QCQA: Quality and Capacity-aware grouped Query Attention,” Jun. 2024. [Online]. Available: http://arxiv.org/abs/2406.10247
Z. Khan, M. Khaquan, O. Tafveez, B. Samiwala, and A. A. Raza, “Beyond Uniform Query Distribution: Key-Driven Grouped Query Attention,” Aug. 2024. [Online]. Available: http://arxiv.org/abs/2408.08454
F. Javadi, W. Ahmed, H. Hajimolahoseini, F. Ataiefard, M. Hassanpour, S. Asani, A. Wen, O. M. Awad, K. Liu, and Y. Liu, “GQKVA: Efficient Pre-training of Transformers by Grouping Queries, Keys, and Values,” Dec. 2023. [Online]. Available: http://arxiv.org/abs/2311.03426

 浙公網安備 33010602011771號
浙公網安備 33010602011771號