
探秘Transformer系列之(23)--- 長度外推
探秘Transformer系列之(23)--- 長度外推
0x00 概述
LLM的進步正在推動更長的上下文和廣泛的文本生成,這些模型在數(shù)百萬個標(biāo)記的序列上進行訓(xùn)練。這種趨勢給系統(tǒng)內(nèi)存帶寬帶來了壓力,導(dǎo)致執(zhí)行成本增加。多輪對話場景的 LLMs 有幾個難點:1. 注意力機制的\(O(n^2)\)計算量;2. 解碼階段緩存 KV 需要耗費大量的內(nèi)存;3. 流行的 LLMs 不能拓展到訓(xùn)練長度之外。在本文,我們來討論第三點。
文本續(xù)寫和語言延展是人類語言的核心能力之一,在有限的學(xué)習(xí)資源下,人類可以通過理解它們的組成部分和結(jié)構(gòu)來理解潛在無限長度的話語。盡管Transformer在幾乎所有NLP任務(wù)中都取得了巨大成功,然而,在長度有限文本上預(yù)訓(xùn)練的語言模型卻無法像人類一樣泛化到任意長度文本,從而限制了其應(yīng)用潛力。
如何在推理階段確保模型能處理遠超預(yù)訓(xùn)練時的文本長度,已成為當(dāng)前大型模型面臨的核心問題之一,我們將此問題視為大模型的長度外推挑戰(zhàn)。因為我們總希望模型能夠處理任意長的文本,但又不可能把訓(xùn)練樣本的長度拉到任意長。
本文從位置編碼(Position Encoding, PE)的角度出發(fā)來學(xué)習(xí) Transformer 模型在長度外推方面的研究進展,研究各種旨在增強 Transformer 長度外推能力的方法,主要包括可外推的位置編碼和基于這些位置編碼的拓展方法。
注:全部文章列表在這里,后續(xù)每發(fā)一篇文章,會修改文章列表。
cnblogs 探秘Transformer系列之文章列表
0x01 背景
1.1 問題
Transformer自誕生以來就席卷了NLP領(lǐng)域。隨著LLM能力的增長,我們對它們的期望也在增長,比如希望模型可以處理更長的文本,因為理解和擴展LLM的上下文長度對于提高其在各種 NLP 應(yīng)用程序中的性能至關(guān)重要。
然而,增加LLM的上下文窗口并不是那么簡單,因為Transformer的優(yōu)勢容量是以相對于輸入序列長度的二次計算和內(nèi)存復(fù)雜度為代價的。這導(dǎo)致了Transformer 及在其基礎(chǔ)之上的 LLM 都不具備有效長度外推(Length Extrapolation)的能力。這意味著,受限于其訓(xùn)練時預(yù)設(shè)的上下文長度限制,大模型無法有效處理超過該長度限制的序列。當(dāng)輸入超過該限制時,由于模型沒有在預(yù)訓(xùn)練中見過超出上下文窗口的新的 token 位置,其性能會顯著下降。
因此,如何解決長度泛化問題成為了 LLM 的一項主要挑戰(zhàn)。
1.2 解決思路
為了實現(xiàn)更長文本的支持,當(dāng)前的解決思路主要可以分為幾個策略:
- 在預(yù)訓(xùn)練階段盡可能支持更長的文本長度。為實現(xiàn)這一階段目標(biāo),通常采用并行化方法將顯存占用分?jǐn)偟蕉鄠€ device,或者改造 attention 結(jié)構(gòu),避免顯存占用與文本長度成二次關(guān)系。
- 進行微調(diào)。比如在相對較小的窗口(例如 4K 令牌)上使用大量數(shù)據(jù)訓(xùn)練模型,然后在較大的窗口(例如 64K 令牌)上對其進行微調(diào)。
- 在推理階段盡可能外推到更大長度。為實現(xiàn)這一階段目標(biāo),通常需要在兩個方面進行考慮:對位置編碼進行外推,優(yōu)化 Attention 機制。
1.3 微調(diào)的挑戰(zhàn)
因為微調(diào)和預(yù)訓(xùn)練本質(zhì)類似,而微調(diào)難度遠遜于預(yù)訓(xùn)練,所以我們來看看微調(diào)的挑戰(zhàn)。
LLM背景下的微調(diào)代表了 NLP 領(lǐng)域的復(fù)雜演變。 這個過程涉及專門完善模型的現(xiàn)有功能,通過微調(diào),LLM可以理解而且可以準(zhǔn)確生成超出其初始訓(xùn)練數(shù)據(jù)參數(shù)的文本,在適應(yīng)新的內(nèi)容類型和結(jié)構(gòu)方面表現(xiàn)出非凡的靈活性。微調(diào)外推側(cè)重于通過額外的、有針對性的訓(xùn)練來提高模型的熟練程度。 然而,進一步擴展上下文窗口(微調(diào))則存在以下幾個主要挑戰(zhàn):
- 高微調(diào)成本:擴展預(yù)訓(xùn)練的大型語言模型(LLMs)的上下文窗口到更長的文本時,通常需要在相應(yīng)長度的文本上進行微調(diào)。但是由于attention的空間復(fù)雜度是\(O(n^2)\),這導(dǎo)致計算資源和時間上成本很高。隨著上下文窗口的繼續(xù)擴展,模型的計算量和內(nèi)存需求將顯著增加,帶來極其昂貴的微調(diào)時間成本和 GPU 資源開銷。
- 長文本稀缺:微調(diào)通常需要相應(yīng)長度的長文本,但當(dāng)前訓(xùn)練數(shù)據(jù)中長文本數(shù)量有限。在當(dāng)前的數(shù)據(jù)集中,尤其是超過1000k的長文本非常有限,這限制了通過微調(diào)來擴展上下文窗口的方法。
- 新位置引入的災(zāi)難性值:首先,未經(jīng)訓(xùn)練的新位置索引引入了許多異常值,使得微調(diào)變得困難。例如,當(dāng)從 4k tokens 擴展超過1000k時,會引入超過90%的新位置。這些位置引入了許多災(zāi)難性值,導(dǎo)致分布外問題,使得微調(diào)難以收斂。
- 注意力分散:當(dāng)擴展到超長的上下文窗口后,由于引入眾多新位置信息,大模型的注意力會分散在大量的token位置上,從而降低了大模型在原始短上下文窗口上的性能。盡管上下文長度不會影響模型權(quán)重的數(shù)量,但它確實會影響這些權(quán)重如何編碼令牌的位置信息。 即使在微調(diào)之后,這也會降低模型適應(yīng)較長上下文窗口的能力,從而導(dǎo)致性能不佳。
因此,人們普遍認為,用更長的上下文窗口對現(xiàn)有模型進行微調(diào)要么是有害的,要么是昂貴的。
1.4 長度外推的必要性
由于傳統(tǒng)的大模型的上下文窗口限制、高質(zhì)量長文本數(shù)據(jù)的稀缺、和昂貴的微調(diào)成本,通過直接在長序列上訓(xùn)練Transformer來擴展上下文窗口是不可行的。
既然微調(diào)上有眾多難度。那么我們會想到,是否可以在較短的上下文窗口上進行訓(xùn)練,在較長的上下文窗口上進行推理(train on short, test on long)?理論上是可行的,而且推理時模型的空間成本會比訓(xùn)練低很多。因此,長度外推似乎是減少訓(xùn)練開銷、同時放松Transformer上下文長度限制的最合適的方法。
0x02 長度外推
2.1 定義
外推概念的提出,最早可以追溯到ALiBi的論文中。如果模型在不經(jīng)微調(diào)的情況下,在超過訓(xùn)練長度的文本上測試,依然能較好的維持其訓(xùn)練效果,我們就稱該模型具有長度外推能力(extrapolation,也稱length extrapolation)。后來這種任務(wù)也被稱為「上下文窗口拓展」(Context Window Extension),目的依舊是用已經(jīng)訓(xùn)好的模型來生成更大的文本,只是不再強調(diào)方法是外推。
顧名思義,免訓(xùn)練長度外推,就是不需要用長序列數(shù)據(jù)進行額外的訓(xùn)練,只用短序列語料對模型進行訓(xùn)練,就可以得到一個能夠處理和預(yù)測長序列的模型,即“Train Short, Test Long(短訓(xùn)練,長推理)”。
- train short:大部分文本的長度不會特別長,特別長的輸入只是長尾情況,因此訓(xùn)練時的使用特別長的文本其實意義不大。再加上受限于訓(xùn)練成本,因此人們通常使用短序列訓(xùn)練,這樣即符合實際情況,也可以顯著降低訓(xùn)練開銷。
- test long:這里long是指推理時候的文本長度比訓(xùn)練時的最大文本長度還要長,希望不用微調(diào)就能在長文本上也有不錯的效果。
2.2 衡量
外推能力的衡量,一般是基于語言建模任務(wù),即測試序列的長度增加,對應(yīng)文本的困惑度不顯著增加、持平甚至下降。因為長文本會導(dǎo)致模型無法適應(yīng)。拿現(xiàn)在最常用的位置編碼RoPE來說,訓(xùn)練時使用短文本推理使用長文本,會使模型不認識那么長的相對距離,最終的結(jié)果可能是模型的困惑度爆表。更加符合實踐的評測則是輸入足夠長的Context,讓模型去預(yù)測答案,然后跟真實答案做對比,算BLEU、ROUGE等,LongBench就是就屬于這類榜單。
但要注意的是,長度外推應(yīng)當(dāng)不以犧牲遠程依賴為代價——否則考慮長度外推就沒有意義了,倒不如直接截斷文本——這意味著通過顯式地截斷遠程依賴的方案都需要謹(jǐn)慎選擇。如何判斷在長度外推的同時有沒有損失遠程依賴呢?比較嚴(yán)謹(jǐn)?shù)氖菧?zhǔn)備足夠長的文本,但每個模型只算每個樣本最后一段的指標(biāo)。
2.3 分析
長度外推性是一個訓(xùn)練和預(yù)測的長度不一致的問題。LLM的訓(xùn)練和推斷本質(zhì)上是不對齊的,訓(xùn)練時,解碼器總是在固定token數(shù)上進行的,例如2048個token。然而推斷時,decoder總是不定長的。這個問題體現(xiàn)有兩點:
- 預(yù)測的時候用到了沒訓(xùn)練過的位置編碼(不管絕對還是相對)。沒訓(xùn)練過的就沒法保證能處理好,無法保證很好的泛化,這是DL中很現(xiàn)實的現(xiàn)象,哪怕是Sinusoidal或RoPE這種函數(shù)式位置編碼也是如此,畢竟訓(xùn)練的時候沒有見過。
- 預(yù)測時序列更長,導(dǎo)致注意力相比訓(xùn)練時更分散。預(yù)測的時候注意力機制所處理的token數(shù)量遠超訓(xùn)練時的數(shù)量。訓(xùn)練和預(yù)測長度不一致影響什么呢?答案是熵,越多的token去平均注意力,意味著最后的分布相對來說越“均勻”(熵更大),即注意力越分散;而訓(xùn)練長度短,則意味著注意力的熵更低,注意力越集中,這也是一種訓(xùn)練和預(yù)測的差異性,也會影響效果。
2.4 方案
外推技術(shù)指的是LLM預(yù)訓(xùn)練時候的Context長度為n,在預(yù)測的時候為m(m>>n),而且可以保證模型性能。或者說,外推技術(shù)旨在將模型的理解擴展到超出其最初觀察長度的序列,采用創(chuàng)新策略來捕獲擴展范圍內(nèi)的依賴性。
總結(jié)起來外推技術(shù)包括三類:
- 基于Attention修改外推技術(shù)。因為基于 RoPE 的自注意力無法在訓(xùn)練上下文之外保持穩(wěn)定,并且表現(xiàn)出注意得分爆炸以及單調(diào)熵增加,所以這個派系注重通過調(diào)整注意力的范圍來進行外推。比如:
- 稀疏注意力:讓“聚光燈”只“照亮”那些真正重要的信息,通過限制每個 token 只關(guān)注部分上下文,降低計算復(fù)雜度。雖然Attention 雖然具備稀疏性質(zhì),但是其稀疏形狀在不同的模型甚至同一模型的不同層中都是不同的,體現(xiàn)出很強的動態(tài)性。因此,實現(xiàn)一種各種模型通用的,無需訓(xùn)練的稀疏Attention是非常困難的。
- 全局注意力:在“聚光燈”的基礎(chǔ)上,增加一個“泛光燈”,兼顧全局信息,在局部注意力的基礎(chǔ)上,增加少量全局 token,用于捕捉長距離依賴。
- 動態(tài)注意力:根據(jù)文本內(nèi)容,動態(tài)調(diào)整“聚光燈”的“亮度”和“照射范圍”,根據(jù)上下文動態(tài)調(diào)整注意力范圍,提高計算效率。
- 基于Memory機制外推技術(shù)。基于Memory機制的外推技術(shù)其實沿用的還是壓縮思想,借助外部存儲將歷史信息存儲,然后使用最近的token進行查詢,獲取一些歷史上重要的token。
- 基于位置編碼的外推技術(shù)。通過插入位置編碼(PE)來有效地擴展預(yù)訓(xùn)練 LLM 的上下文窗口。與高效 Transformer 和內(nèi)存增強等其他技術(shù)不同,基于 PE 的方法不需要改變模型的架構(gòu)或合并補充模塊。因此,基于 PE 的方法具有直接實施和快速適應(yīng)的優(yōu)勢,使其成為在涉及更大上下文窗口的任務(wù)中擴展 LLM 操作范圍的實用解決方案。
可見,長度外推性問題并不完全與設(shè)計一個良好的位置編碼等價。本篇主要來學(xué)習(xí)如何通過調(diào)整位置編碼來解決或者緩解長度外推問題。
0x03 位置編碼和長度外推
隨著文本長度的增加,位置編碼也會發(fā)生相應(yīng)的變化,因此處理好位置編碼問題是解決長文本問題的重要環(huán)節(jié)。如前所述,如何通過修改或調(diào)整位置編碼,將原本不具備外推能力的模型,經(jīng)過重訓(xùn)練或微調(diào),使之能夠很好地駕馭長文檔,就成為了當(dāng)下的一大痛點。
在 Transformer 結(jié)構(gòu)的模型中,Attention模塊的值與順序無關(guān),因此需要加入位置編碼以確定不同位置的 token。典型的位置編碼方式有兩類:
- 絕對位置編碼:即將位置信息融入到輸入中。
- 相對位置編碼:微調(diào)Attention結(jié)構(gòu),使其能夠分辨不同位置的Token。
為了解決外推問題,針對這兩種位置編碼,研究人員依據(jù)其特點進行了相應(yīng)調(diào)整和優(yōu)化。下圖給出了不同外推PE列表,該列表是根據(jù)PE是絕對的還是相對的來進行劃分。其中,Manifestation 顯示了如何引入位置信息。Learnable顯示它是否可以根據(jù)輸入進行調(diào)整。Integration 顯示了位置表示如何與token表示集成。Injection 層顯示在哪里部署位置PE。
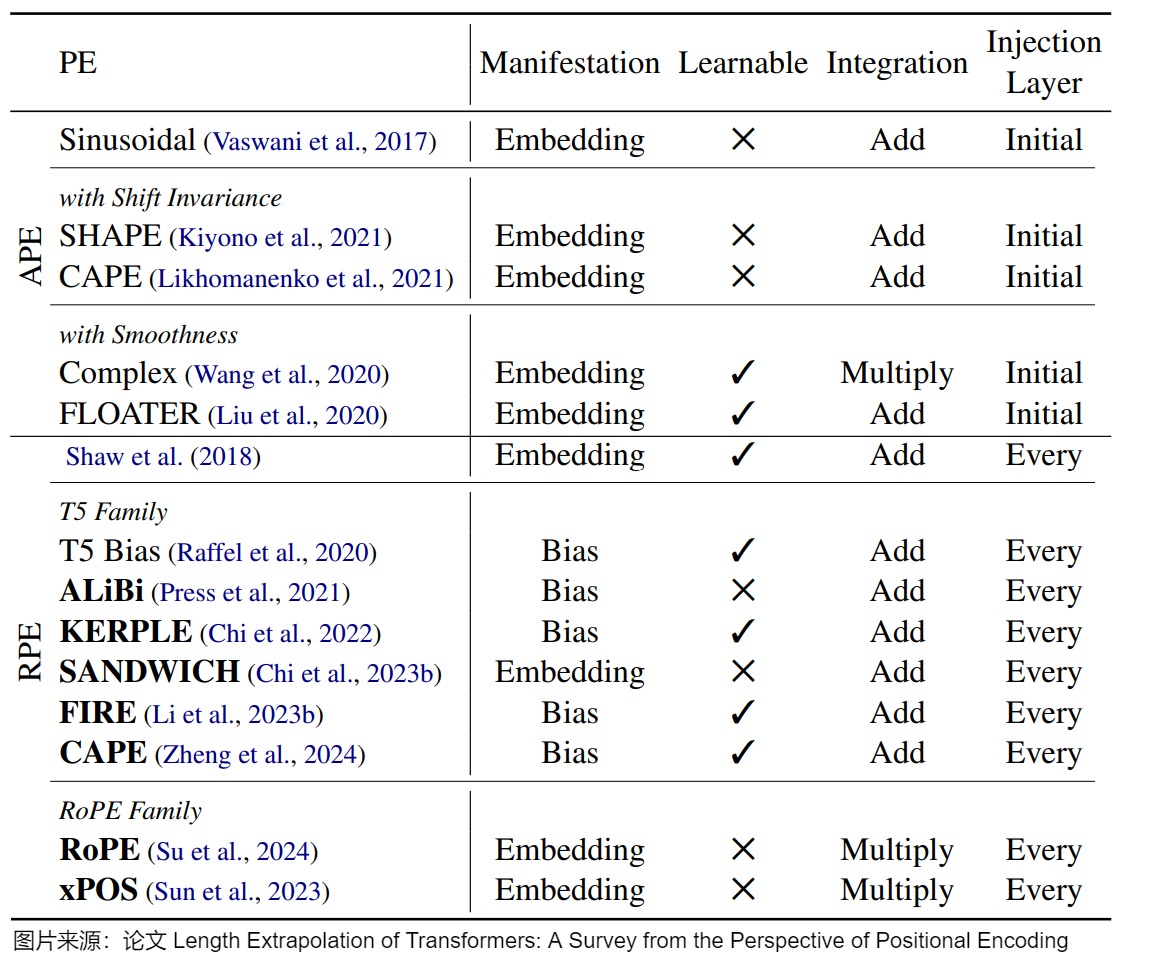
注:外推方案的分類或者闡釋各不相同,此處筆者選取一個自己認為相對容易理解的思路進行學(xué)習(xí),此思路參見下面圖。
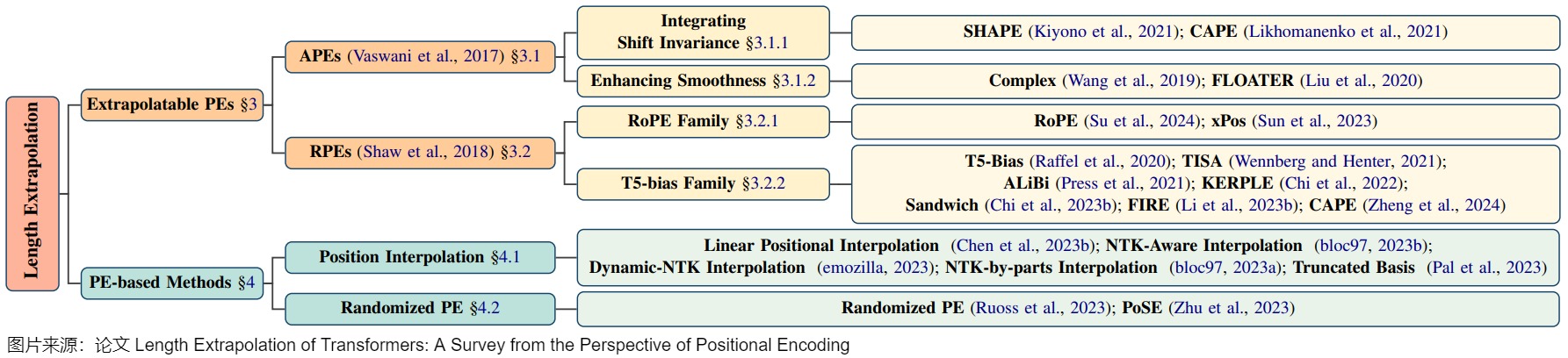
接下來我們就看看具體如何調(diào)整。
3.1 絕對位置編碼及其外推
最早的絕對位置編碼有如下兩種:可學(xué)習(xí)位置編碼和三角函數(shù)式位置編碼。可學(xué)習(xí)位置編碼不具備外推性,我們不進行討論。三角函數(shù)式位置編碼的特點是有顯式的生成規(guī)律,因此可以期望于它有一定的外推性。另外,由于三角函數(shù)有如下性質(zhì):
這說明sin-cos位置編碼具有表達相對位置的能力,即位置\(\alpha + \beta\)向量可以表達為位置\(\alpha\)向量和位置\(\beta\) 向量的組合。這提供了位置拓展的可能性。
Transformer作者聲稱正弦位置嵌入可能能夠推斷出比所看到的更長的序列。
We chose the sinusoidal version because it may allow the model to extrapolate to sequence lengths longer than the ones encountered during training.
但是后來的研究成果否定了這一猜想。然而,研究人員隨后發(fā)現(xiàn),正弦APE很難外推。即,正弦APE有一定的外推性,但是缺少相對位置關(guān)系,效果較差。這是因為正弦編碼將絕對位置信息融入輸入\(x\)中:在輸入的第i個輸入向量\(x_i\) 中加入位置向量\(p_i\) 得到 \(x_i+p_i\) ,其中 \(p_i\) 僅依賴于位置 i 。因此查詢 \(q_i\) 與鍵 \(k_j\) 之間的兼容性得分形式化為:
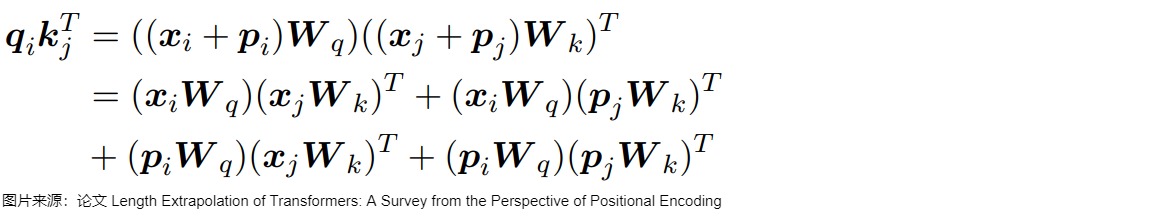
由于絕對位置編碼最終是由兩部分組成,且兩部分相互獨立,因此無法計算相對距離。
正弦位置編碼是許多不同PE的基礎(chǔ)和重點。因此,人們提出了各種APEs和RPEs,以增強正弦位置編碼,從而增強Transformer的外推。后續(xù)的絕對位置編碼主要從兩個方向試圖改善外推性:
- 生成隨位置平滑變化的位置嵌入并期望模型能夠?qū)W會推斷這一變化函數(shù)。
- 通過隨機位移(random shift)將位移不變性(shift invariance)融入正弦 APE 中。
3.1.1 增加平滑
這種方案試圖直接捕捉位置表示之間的依賴關(guān)系或動態(tài)關(guān)系,比如引入一個動態(tài)系統(tǒng)來對單詞的全局絕對位置及其順序關(guān)系進行建模。這樣可以使位置編碼隨位置索引平滑變化,并期望模型在訓(xùn)練過程中學(xué)會這一變化規(guī)律并推斷出從未見過的位置編碼。論文”Encoding word order in complex embeddings“就提出將每個單詞嵌入擴展為一個獨立變量(即位置)上的連續(xù)詞函數(shù)(而不是用一個詞向量和位置編碼的加和來表示一個詞),以便單詞表示隨著位置的增加而平滑變化。連續(xù)函數(shù)相對于可變位置的好處是,單詞表示隨著位置的增加而平滑地移動。因此,不同位置的單詞表示可以在連續(xù)函數(shù)中相互關(guān)聯(lián)。

3.1.2 隨機偏移
有些研究人員推測優(yōu)異的外推性能來自PE的平移不變性:即使輸入發(fā)生移動,函數(shù)也不會改變其輸出。因此,他們在位置索引中引入隨機偏移來解決外推性。此方案在三角函數(shù)編碼公式中,將每個位置索引移位一個隨機偏移,這阻止了模型使用絕對位置,而是鼓勵使用相對位置。論文”CAPE: encoding relative positions with continuous augmented positional embeddings“除了用相同的隨機偏移量移動APE的每個位置索引(全局偏移)外,還引入了局部偏移和全局縮放。這三種增廣方法的形式如下。
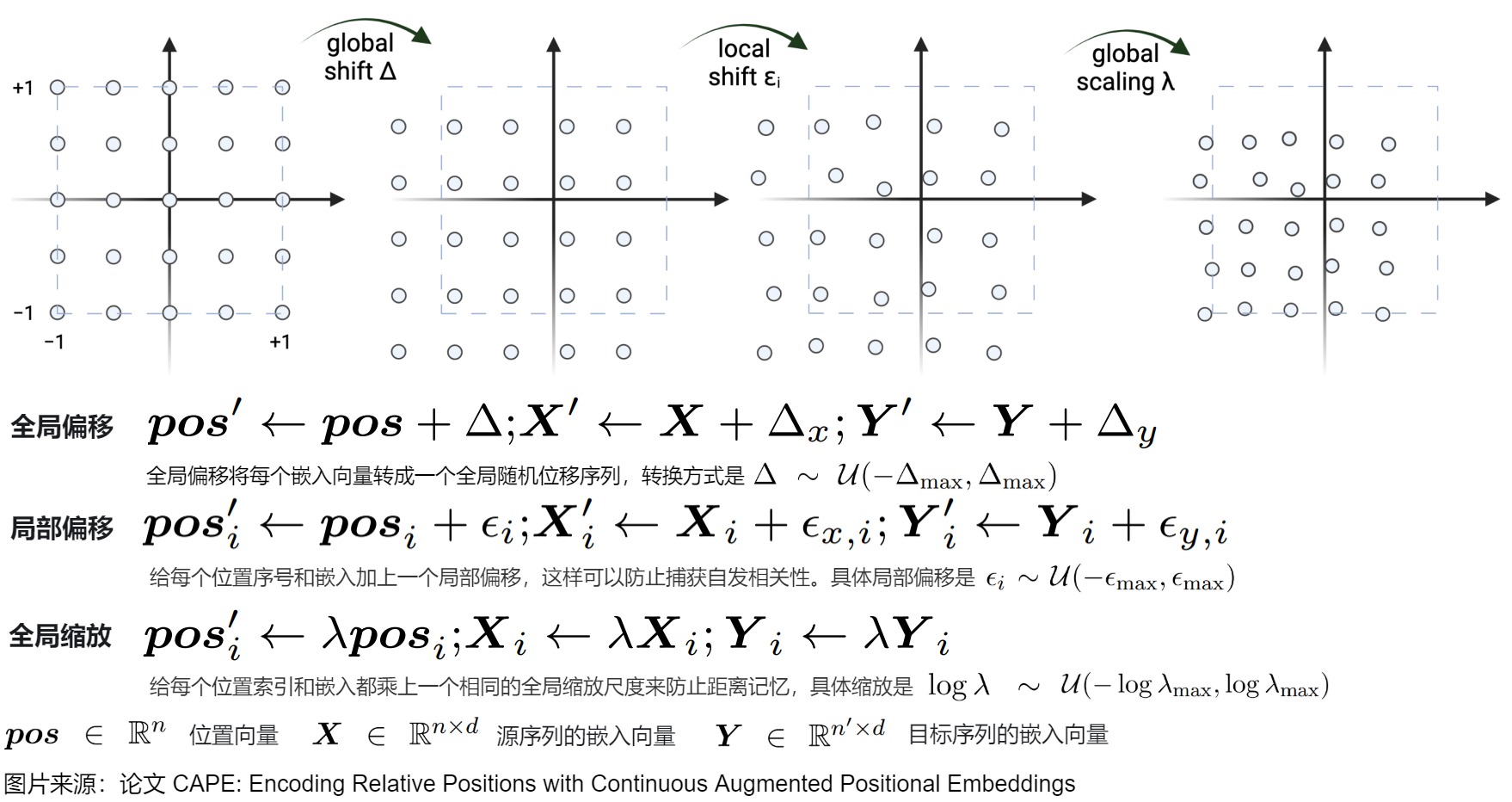
3.1.3 小結(jié)
正弦APE作為Transformer的第一個PE,對以后的PE有重要影響。然而,它的外推性很差。為了增強Transformer的外推性,研究人員要么利用隨機移位將移位不變性納入正弦APE中,要么生成隨位置平滑變化的位置嵌入。基于這些思想的方法展現(xiàn)出比正弦 APE 更強的外推能力,但仍無法達到 RPE 的水平。原因之一是,APE 將不同的位置映射到不同的位置嵌入,外推意味著模型必須推斷出不曾見過的位置嵌入。然而,這對于模型來說是一項艱巨的任務(wù)。因為在廣泛的預(yù)訓(xùn)練過程中重復(fù)出現(xiàn)的位置嵌入數(shù)量有限,特別是在 LLM 的情況下,模型極易對這些位置編碼過擬合。
3.2 相對位置編碼及其外推
相對位置編碼天然有平移不變性,更易外推。目前已經(jīng)提出了許多新的RPE,這些RPE可以通過刻畫序列不同位置間的相對距離來增強外推。因為在前文中已經(jīng)介紹過這些RPE。這里不再贅述。
3.3 LLM時代的長度外推
LLM徹底改變了NLP領(lǐng)域,并對長度外推提出了很高的要求,以更好地適應(yīng)各種業(yè)務(wù),也導(dǎo)致了許多新的PE的出現(xiàn)。其實前文介紹的很多RPE就是這種產(chǎn)物。基于這些PE,已經(jīng)提出了許多方法來進一步增強LLM的長度外推。在LLM時代主要有以下兩種優(yōu)化思路:
-
提出新型可泛化的位置編碼,比如 Alibi,XPOS。
-
以內(nèi)插、外推等方式修改已有位置編碼(以 RoPE 為主),比如PI、YaRN、隨機PE。
我們先介紹隨機PE,在后續(xù)會詳解位置插值。
3.4 隨機化位置編碼
本質(zhì)上,隨機PE是通過在訓(xùn)練過程中引入隨機位置,將預(yù)訓(xùn)練的上下文窗口與較長的推理長度解耦,從而提高了較長的上下文窗口中所有位置的暴露。
對于沒有clipping(窗口截斷)機制的APE和RPE,長度外推意味著位置表示超出了訓(xùn)練期間觀察到的位置表示,導(dǎo)致分布外位置表示,從而性能下降。限制模型的長文本能力的關(guān)鍵在于訓(xùn)練長度與測試長度的鴻溝,即”預(yù)測的時候用到了沒訓(xùn)練過的位置編碼”。為了解決這個問題,最直觀的方法之一是使模型在訓(xùn)練期間觀察所有可能的位置表示,即“訓(xùn)練階段把預(yù)測所用的位置編碼也訓(xùn)練一下”。這正是隨機PEs背后的核心思想。
作為這一想法的具體化,研究人員提出模擬更長的序列的位置,并隨機選擇一個隨機(或有序)子集來適應(yīng)訓(xùn)練上下文窗口,這個子集可以覆蓋每個訓(xùn)練樣本測試期間可能位置的整個范圍。具體來說, 設(shè)N為訓(xùn)練長度(論文N=40),M為預(yù)測長度(論文M=500),M 的長度遠大于訓(xùn)練和評估過程中的最大長度。選定一個較大L>M(這是一個超參,論文L=2048),訓(xùn)練階段原本長度為N的序列對應(yīng)的位置序列是[0,1,?,N?2,N?1],現(xiàn)在改為從{0,1,?,L?2,L?1}中隨機不重復(fù)地選N個并從小到大排列,作為當(dāng)前序列的位置序列。 對于每個訓(xùn)練步驟,長度為 N 的序列的隨機位置是較大范圍位置的升序子樣本,且不包含重復(fù)。
但是這有一個問題:訓(xùn)練階段和預(yù)測階段的相鄰位置差不一樣,這也可以說是某種不一致性,但它表現(xiàn)依然良好,這是為什么呢?我們可以從“序”的角度去理解它。由于訓(xùn)練階段的位置id是隨機采樣的,那么相鄰位置差也是隨機的,所以不管是相對位置還是絕對位置,模型不大可能通過精確的位置id來獲取位置信息,取而代之是一個模糊的位置信號,更準(zhǔn)確地說,是通過位置序列的“序”來編碼位置而不是通過位置id本身來編碼位置。比如,位置序列[1,3,5]跟[2,4,8]是等價的,因為它們都是從小到大排列的一個序列,隨機位置訓(xùn)練“迫使”模型學(xué)會了一個等價類,即所有從小到大排列的位置序列都是等價的,都可以相互替換,這是位置魯棒性的真正含義。
因此,通過充分的訓(xùn)練,可以確保模型遇到足夠的唯一位置,并且在推理之前已經(jīng)充分訓(xùn)練了從1到 M 的所有位置,從而在推理中的任何序列上實現(xiàn)與訓(xùn)練一致的性能。
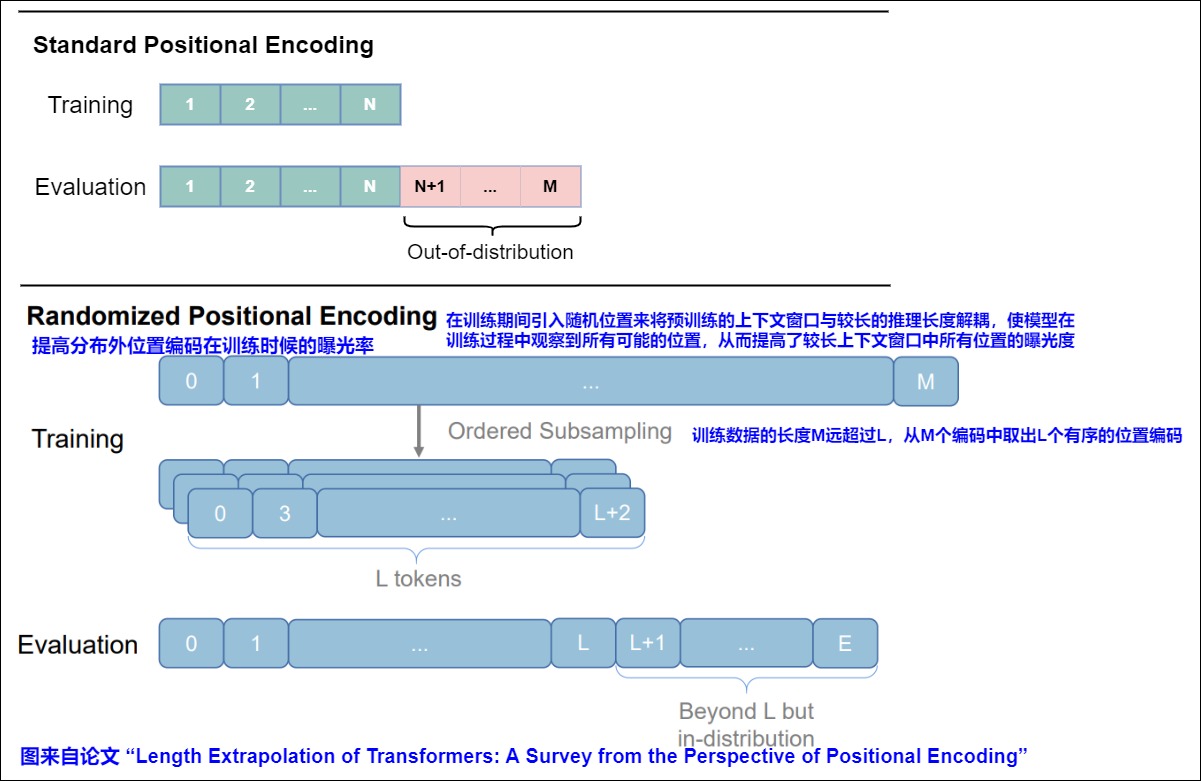
簡單來說,隨機化 PE 只是通過在訓(xùn)練期間引入隨機位置來將預(yù)訓(xùn)練的上下文窗口與較長的推理長度解耦,從而提高了較長上下文窗口中所有位置的曝光度。隨機化 PE 的思想與位置插值方法有很大不同,前者旨在使模型在訓(xùn)練過程中觀察到所有可能的位置,而后者試圖在推理過程中對位置進行插值,使它們落入既定的位置范圍內(nèi)。出于同樣的原因,位置插值方法大多是即插即用的,而隨機化 PE 通常需要進一步微調(diào),這使得位置插值更具吸引力。然而,這兩類方法并不互斥,因此可以結(jié)合它們來進一步增強模型的外推能力。
0x04 RoPE外推
RoPE(Rotary Position Embedding/旋轉(zhuǎn)位置編碼)被廣泛應(yīng)用于目前的大模型中,包括但不限于Llama、Baichuan、ChatGLM、Qwen等。盡管RoPE可以理論上可以編碼任意長度的絕對位置信息,并且通過三角計算將任意長度的相對位置信息呈現(xiàn)出來,RoPE仍然存在外推問題(length extrapolation problem),即對于基于RoPE的大語言模型,在推理時,當(dāng)模型的輸入長度超出訓(xùn)練長度,模型的效果會有顯著的崩壞,具體表現(xiàn)為困惑度的急劇上升。因此,人們提出了許多方法來增強現(xiàn)有的用RoPE進行預(yù)訓(xùn)練的LLM的外推,其中最流行的是位置插值方法。
4.1 原因
當(dāng)推理長度超出RoPE的訓(xùn)練長度 L 時,為什么模型的性能會下降?這主要原因是RoPE的頻率不變性和頻率分布的剛性(所有維度的頻率分布固定,不支持動態(tài)調(diào)整)。
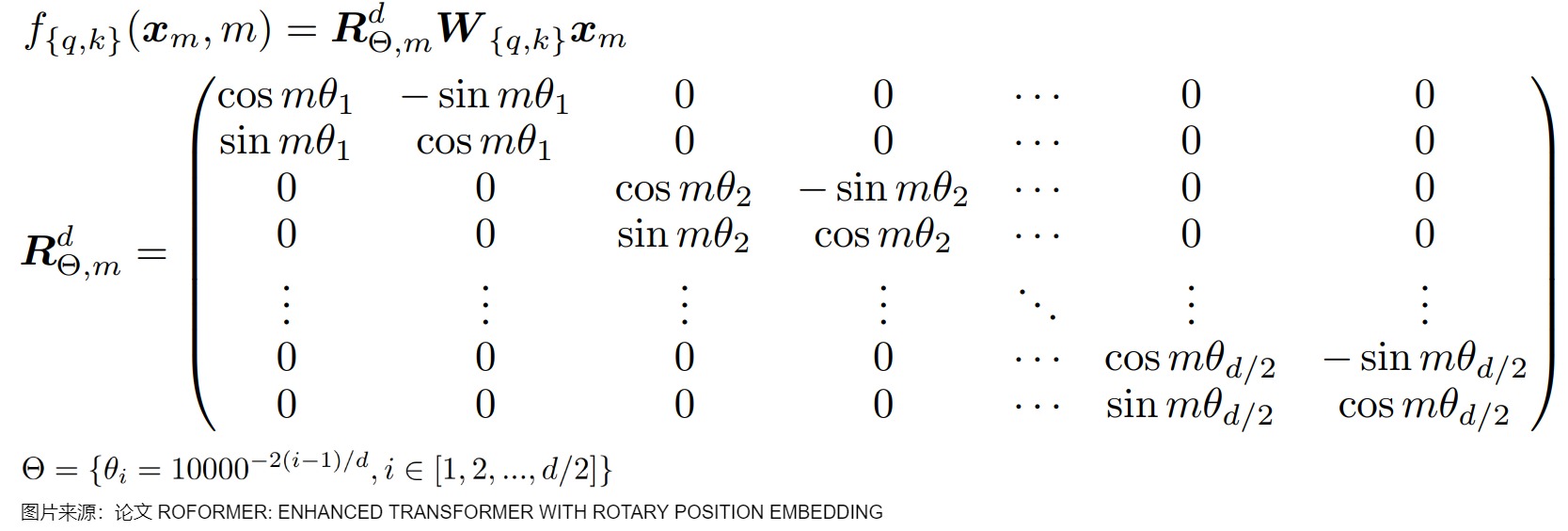
從直觀角度來看。位置編碼外推問題是在于訓(xùn)練過程中的過擬合問題。\(\theta_d\)在預(yù)訓(xùn)練時被固定,位置編碼誘導(dǎo)模型錯誤地理解短序列上的特征,從而使得模型學(xué)習(xí)到的規(guī)律無法拓寬至長序列上,無法適應(yīng)更長的上下文長度。在RoPE中,每個位置 i 都對應(yīng)一個旋轉(zhuǎn)弧度\(\theta\) ,任意向量q位于位置m時,它的第 i 組分量的旋轉(zhuǎn)弧度為\(m\theta_i = m \times base ^{-2i/d}\),其中d表示向量q的維度。具體參見下圖。當(dāng)模型的訓(xùn)練長度為L 時,位置0到位置 L?1 對應(yīng)的旋轉(zhuǎn)弧度范圍為$ [0,(L?1)\theta] $。我們可以合理地猜想:模型在訓(xùn)練時,只見過 $ [0,(L?1)\theta] $ 范圍內(nèi)的旋轉(zhuǎn)弧度,未見過大于 $ (L?1)\theta $的旋轉(zhuǎn)弧度,所以當(dāng)推理長度大于 $ (L?1)\theta $ 時,模型難以理解新的旋轉(zhuǎn)弧度,無法正確注入位置信息,導(dǎo)致模型性能下降。
對于模型的性能下降或者說外推能力不足,也有其它的論點,我們摘錄如下:
- RoPE的偏置曲線本身就是不具有單調(diào)性的。在這種情況下,模型很難無法理解位置信息的特征與規(guī)律。xPos通過加入指數(shù)校正,讓較遠位置的RoPE偏置強行收斂于0,有效地改善了外推性能。
- 旋轉(zhuǎn)角取值不當(dāng)會導(dǎo)致RoPE的偏置曲線在其鄰近位置就有所波動;在這種情況下,語言模型的每次預(yù)測都會造成一定的損失,隨長度的增加而單調(diào)增加。這些波動都會影響到梯度回傳過程,從而讓模型將預(yù)測損失錯誤地歸因到無關(guān)位置,最終掌握了一個扭曲的錯誤的位置分布規(guī)律;正是由于這種“被扭曲的意識”,使得模型在預(yù)測長序列時出現(xiàn)崩潰一般的效果。
- RoPE有限的維度會導(dǎo)致擬合精度不夠,相對距離越大,擬合誤差越大。
- 訓(xùn)練過程中的過擬合問題也是一個原因,即位置編碼誘導(dǎo)模型錯誤地理解短序列上的特征,從而使得模型學(xué)習(xí)的規(guī)律無法拓寬至長序列上。
- RoPE相對偏置的長尾問題也可能是影響其外推能力的一個原因。
我們接下來看看RoPE的一些關(guān)于外推的性質(zhì)。
4.2 性質(zhì)
論文"Scaling Laws of RoPE-based Extrapolation"對RoPE進行了詳細的分析。接下來以該論文為主,結(jié)合其它論文進行解讀。
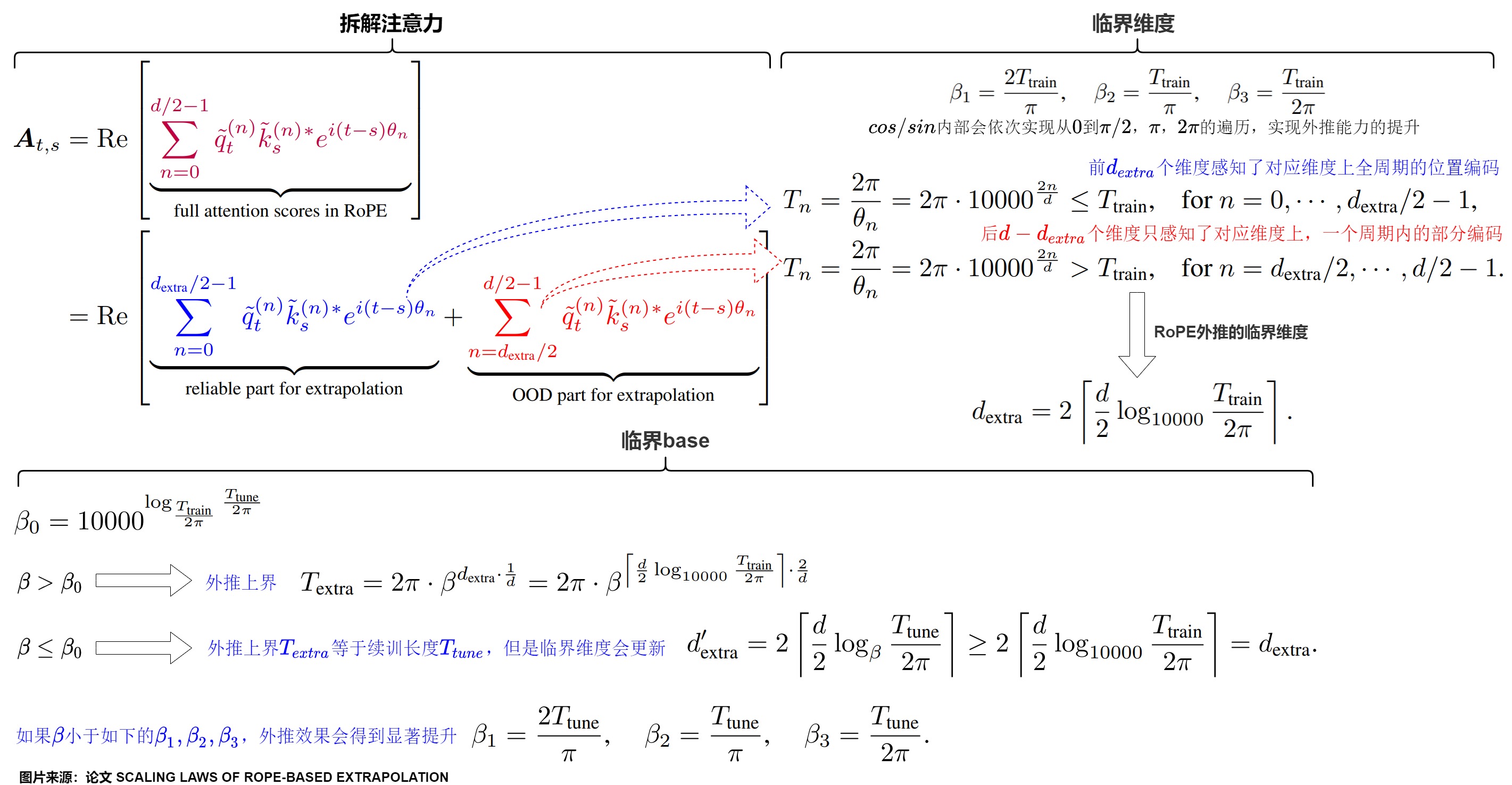
4.2.1 性質(zhì)1 臨界維度
在原始RoPE中,維度和訓(xùn)練有一定的相關(guān)性。每個維度對應(yīng)的旋轉(zhuǎn)角是否在訓(xùn)練階段就已經(jīng)完成一個周期的旋轉(zhuǎn)是一個非常關(guān)鍵的問題。
-
維度越靠前,其對應(yīng)的\(\theta\)取值越大,周期越短,這樣該維度在訓(xùn)練階段就可以見過全周期的信息。
-
相反,最靠后的一些維度并不會在訓(xùn)練時見過本維度完整的cos/sin值域。
假設(shè)模型的預(yù)訓(xùn)練文本長度為\(T_{train}\),自注意力頭維度數(shù)量為d,對于RoPE-based LLMs,存在這樣一個特征維度\(d_{extra} = 2\lceil \fracw0obha2h00{2} log_{10000} \frac{T_{train}}{2\pi} \rceil\),該維度的前后維度在行為上存在很大差異。
-
前\(d_{extra}\)個維度被稱為"pre-critical dimensions"(前關(guān)鍵維度),即在模型的預(yù)訓(xùn)練階段已經(jīng)覆蓋了所有可能的旋轉(zhuǎn)角度的特征維度。其特點如下:
- 這些維度的波長(wavelength)較短,其\(\theta_n\)對應(yīng)的三角函數(shù)周期\(T_n\)能夠被涵蓋在訓(xùn)練長度\(T_{train}\)范圍內(nèi)。
- 預(yù)訓(xùn)練期間,在這些維度上,每個位置的標(biāo)記都能夠經(jīng)歷一次或多次完整的旋轉(zhuǎn)周期。在預(yù)訓(xùn)練階段都能看到全部的位置信息并得到充分的訓(xùn)練。
- 因為訓(xùn)練充分,所以在這些維度上可以進行外推。
-
后\(d - d_{extra}\)個維度被稱為"post-critical dimensions"(后關(guān)鍵維度)。即指的是那些在模型的預(yù)訓(xùn)練階段未被完全覆蓋的RoPE特征維度。其特點如下:
- 這些維度的波長(wavelength)較長,其\(\theta_n\)對應(yīng)的三角函數(shù)周期\(T_n\)長于訓(xùn)練長度\(T_{train}\)。
- 在預(yù)訓(xùn)練期間,在這些維度上,模型沒有機會看到所有可能的旋轉(zhuǎn)角度。只感知了對應(yīng)維度上一個周期內(nèi)的部分編碼。
- 因為缺乏足夠的訓(xùn)練,沒有感知到完整的位置信息,所以沒有感知完整的位置信息是外推問題的根源。對于\(d_{extra}\)之后的維度,當(dāng)基于 RoPE LLM 在 \(T_{train}\)之外進行外推時,新加入token的絕對位置信息是訓(xùn)練中沒有見過的,將變成分布外 (OOD),這些新token相對于先前 token 的相對位置信息也會是分布外。這種錯位意味著與這些維相關(guān)的注意得分偏離其預(yù)期分布,導(dǎo)致整體注意得分明顯表現(xiàn)分布外,從而導(dǎo)致外推問題。使得整個模型的attention score在超出訓(xùn)練長度之后產(chǎn)生顯著崩壞。
- 當(dāng)模型在測試階段遇到超出預(yù)訓(xùn)練序列長度的序列時,這些維度的特征會遭遇到在訓(xùn)練期間未見過的旋轉(zhuǎn)角度,導(dǎo)致模型難以泛化到這些新的位置。
-
\(d_{extra}\)就是RoPE外推的臨界維度(Critical Dimension),即????,????中感知了全周期位置編碼的維度的數(shù)量。本質(zhì)上,\(d_{extra}\)是 \(cos (t ? s)θ_n\) 和 \(sin (t ? s)θ_n\) 在預(yù)訓(xùn)練或微調(diào)期間可以在一個周期內(nèi)循環(huán)其值的維數(shù),在增強外推方面起著關(guān)鍵作用。
臨界維度和外推效果之間存在因果性。臨界維度的存在,導(dǎo)致推理長度超過訓(xùn)練長度時的超出臨界維度部分的attention score波動,限制了模型的外推上限,也證明了,從周期角度解釋并改進基于RoPE的大語言模型外推表現(xiàn)是合理、正確、有效的。一旦上下文長度超過臨界維度規(guī)定的外推上限,新的維度就會面對未曾見過的位置信息,對應(yīng)到attention score上就是產(chǎn)生OOD的數(shù)值,同時困惑度開始急速攀升,模型外推失效。
4.2.2 性質(zhì)2 臨界base
在RoPE中,base(基數(shù))是一個關(guān)鍵的超參數(shù),對于外推性能同樣起到了關(guān)鍵作用。
- base變小,意味著\(??_??\)變大,對應(yīng)的三角函數(shù)周期變短,\(\theta_n\)對應(yīng)的周期更可能會被限制在訓(xùn)練長度以內(nèi)。q和k的不同維度在訓(xùn)練或者續(xù)訓(xùn)的時候都會見識到更完整周期的cos/sin值域,都會得到更充分的學(xué)習(xí),因此有更多的維度感知到位置信息。
- base變大,意味著\(??_??\)越小,對應(yīng)的三角函數(shù)周期變長,則可以表示更長的位置信息,有利于模型捕捉上下文對應(yīng)的低頻特征。但是會存在\(??_??\)對應(yīng)的周期超出訓(xùn)練長度的情況,有的維度可能出現(xiàn)在測試時沒有見到的超出訓(xùn)練范圍的位置編碼。雖然訓(xùn)練時不能見過完整的 cos/sin 值域,但是外推時仍處于單調(diào)區(qū)間。
因此,對于RoPE-based LLMs,存在一個臨界base \(\beta_0\),臨界base是外推的最差基,也是迫使 RoPE 根據(jù)關(guān)鍵維內(nèi)的特征維進行外推的最小基。該base由 “續(xù)訓(xùn)文本長度 \(??_{tune}\) ”和 “預(yù)訓(xùn)練文本長度 \(??_{train}\)”共同決定:
-
如果 \(??>??_0\),外推上界根據(jù) base取值 \(\beta\) 和 臨界維度 \(d_{extra}\) 決定,\(T_{extra} = 2\pi \cdot \beta ^{d_{extra}\cdot \frac{1}w0obha2h00} = 2\pi \cdot \beta^{\lceil \fracw0obha2h00{2} log_{10000} \frac{T_{train}}{2\pi} \rceil\cdot \frac{2}w0obha2h00}\)
因為base大于等于臨界base,那么微調(diào)階段能遍歷周期的維度在訓(xùn)練階段就已經(jīng)可以遍歷了一整個周期,因此模型外推的臨界維度不變。
-
如果 \(??≤??_0\),外推上界就是續(xù)訓(xùn)長度 \(??_{tune}\),但是 臨界維度會更新為\(d'_{extra} = 2\lceil \fracw0obha2h00{2} log_\beta \frac{T_{tune}}{2\pi} \rceil \geq 2\lceil \fracw0obha2h00{2} log_\beta \frac{T_{train}}{2\pi} \rceil = d_{extra}.\)
因為base小于臨界base,那么微調(diào)階段遍歷周期的維度超過原始臨界維度,臨界維度更新,但是由于該維度取決于續(xù)訓(xùn)長度,因此模型的外推上限仍然受續(xù)訓(xùn)長度限制。雖然如此,如果base足夠小,使得模型的每個維度在續(xù)訓(xùn)長度內(nèi)遍歷0到??/2或??或2??的取值,那么模型的外推效果又會進一步提升。模型還是可以外推超過\(??_{tune}\);特別地,如果 ?? 小于如下的$ ??_1,??_2,??_3$,外推效果會得到顯著提升。
我們來總結(jié)下:base更小,可以讓更多的維度感知到位置信息;base更大,可以表示更長的位置信息。當(dāng)我們把 ?? 的基數(shù)設(shè)得很大時,每個圓盤的轉(zhuǎn)速都很慢,這樣就可以保證不管有多少個token,它們的絕對位置編碼都不會重復(fù)。
論文“Fortify the Shortest Stave in Attention: Enhancing Context Awareness of Large Language Models for Effective Tool Use”則發(fā)現(xiàn)同一個模型改不同的base然后將輸出取平均,能增強模型的整體性能,這表明不同大小的base各有所長,不能單純?yōu)榱送馔贫フ{(diào)小它。
4.3 法則
4.3.1 縮小base時的縮放法則
縮放法則如下: 對于基于RoPE的大語言模型(RoPE-based LLMs),假設(shè)其預(yù)訓(xùn)練文本長度為\(??_{train}\),如果在微調(diào)階段將base調(diào)整為??<10000,并且使用預(yù)訓(xùn)練文本長度\(??_{train}\)續(xù)訓(xùn),那么模型的外推能力將會提升。
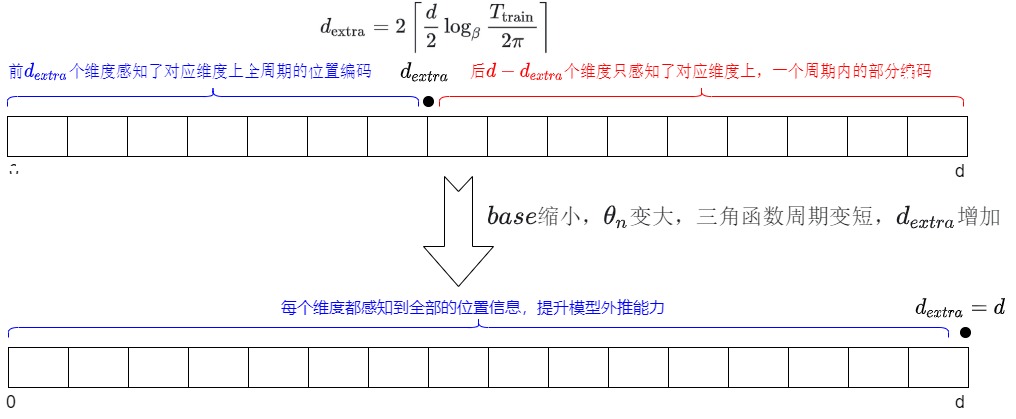
當(dāng)base縮小時,縮小base的attention score在訓(xùn)練長度范圍內(nèi)就學(xué)習(xí)到了來自cos/sin的波動,也正是由于這些波動在訓(xùn)練長度中就已經(jīng)感知過了,相較于原始的base設(shè)為較大的情形,每個維度不會出現(xiàn)在測試時沒有見到的超出訓(xùn)練范圍的位置編碼,由此就實現(xiàn)了外推能力的提升。并且base越小感知越充分,對應(yīng)外推曲線越平坦。特別地,如果 ?? 小于如下的$ ??_1,??_2,??_3$,那么每個維度位置編碼中,cos/sin內(nèi)部會依次實現(xiàn)從0到??/2,??,2??的遍歷,由此實現(xiàn)外推能力進一步的提升。
base縮小改進RoPE外推的過程是臨界維度更新一個的過程。每縮小一段base(RoPE兩維度一組,一次更新兩個維度)就會讓兩個維度感知到完整的位置信息;最終,base縮小到??3,\(d_{extra}=d\),就可以讓每個維度都感知到全部的位置信息,模型外推能力就可以取得飛躍式提升。
4.3.2 base放大時RoPE外推的縮放法則
縮放法則如下:對于基于RoPE的大語言模型(RoPE-based LLMs),假設(shè)其預(yù)訓(xùn)練文本長度為\(??_{train}\),如果在微調(diào)階段將base調(diào)整為??>10000,并且使用預(yù)訓(xùn)練文本長度\(??_{train}\)續(xù)訓(xùn),那么模型的外推能力將會提升。
外推上限和base之間的數(shù)學(xué)關(guān)系如下:根據(jù)臨界維度對應(yīng)????在更新base后的周期\(??_??\),就可以求出模型外推的上限。
相反,如果為了讓模型支持\(??_{extra}\)的上下文長度,那么存在一個最小的base \(\beta_0\),如下公式所示。
base、維度和周期的關(guān)系如下:
- 針對周期都被涵蓋在訓(xùn)練長度\(??_{train}\)以內(nèi)的維度,其能夠適應(yīng)每個對應(yīng)維度位置編碼的周期變化,因此在更長的周期上微調(diào)的時候,雖然這些維度沒有見過完整的周期,但是他仍然可以表征這個周期內(nèi)的位置信息,可以適應(yīng)擴展上下文中位置嵌入的新周期性變化。或者說,放大base雖然放大了周期,但所得到的\(\theta_n(t?s)\)仍然在原先預(yù)訓(xùn)練所見過的范圍內(nèi)。
- 對于周期超過訓(xùn)練長度\(??_{train}\)的維度,因為本身在訓(xùn)練過程中就沒有見過全部的周期,缺乏對周期性的充分理解會存在參數(shù)學(xué)習(xí)過擬合的問題,而且在放大base之后,更加無法感受到一個完整周期內(nèi)的位置信息。因此,只有當(dāng)先前觀察到 \(\theta_n(t?s)\) 的值時,這些維才是可靠的。可以將關(guān)鍵維的更新周期作為基于 RoPE LLM 外推的上限。

0x05 RoPE外推基本方案
在RoPE中,位置信息是通過位置索引和旋轉(zhuǎn)角度的乘積的三角函數(shù)來表示的。為了保持索引增加時該乘積在預(yù)訓(xùn)練范圍內(nèi),研究人員提出了一些方案,比如限制索引增長或減少旋轉(zhuǎn)角度。
5.1 直接外推
這里的外推指對編碼不做更多的改變,即可拓展長度。其實就是不做操作。下圖就是保持相鄰點的間隔為1不變,將取值范圍從[1,10]直接將取值范圍擴展至[1,17]。
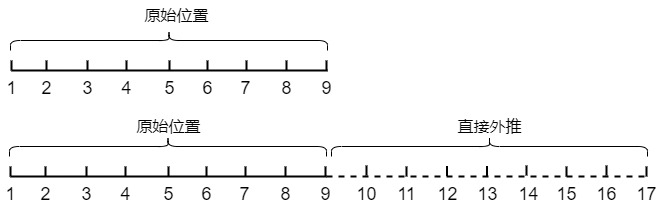
ROPE位置編碼具有遠程衰減性,理論上是可以支持無限長度。如果在擴展長度較小,這種方法對性能的影響并不大。但是如果擴展長度較大,這種直接外推通常會嚴(yán)重地影響性能。因為模型對沒被訓(xùn)練過的情況不一定具有適應(yīng)能力。假定L是當(dāng)前樣本長度。當(dāng)L明顯超出了訓(xùn)練長度時,多出來的位置由于沒有被訓(xùn)練過,或者說由于某些維度的訓(xùn)練數(shù)據(jù)不充分,所以直接進行外推通常會導(dǎo)致模型的性能嚴(yán)重下降。為了減少長度外推對性能的影響,需要讓模型在更長的上下文上做少量步驟的微調(diào)。
5.2 線性內(nèi)插
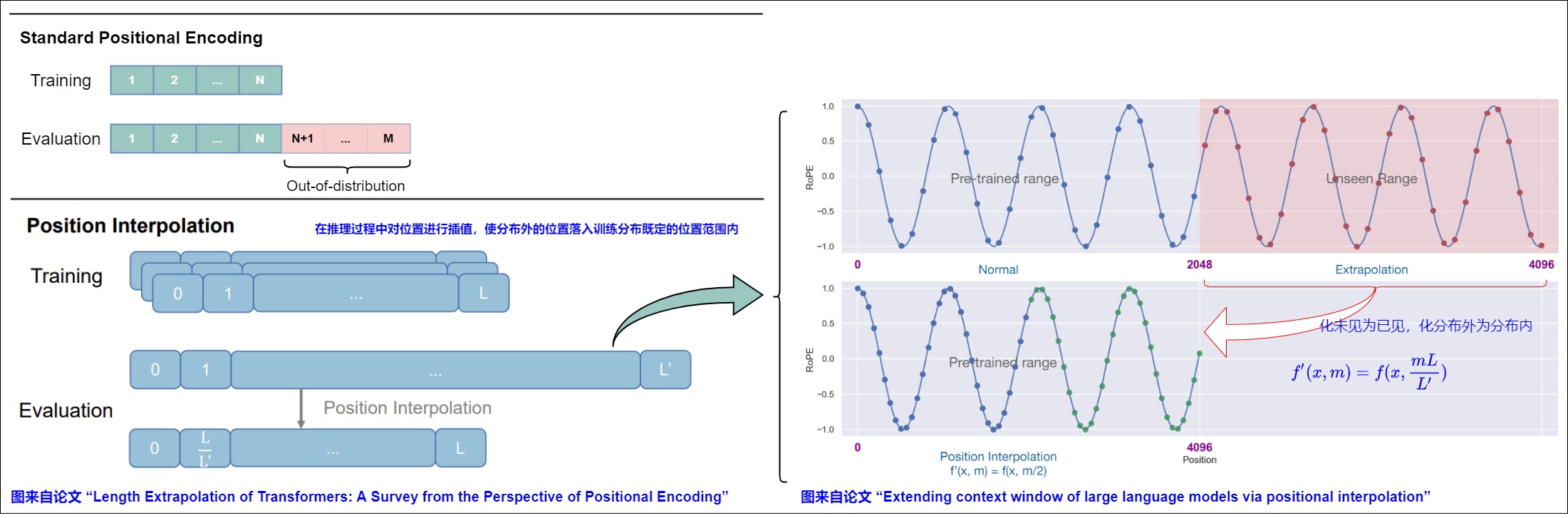
論文“EXTENDING CONTEXT WINDOW OF LARGE LANGUAGE MODELS VIA POSITION INTERPOLATION”提出了一種名為“位置插值”(Position Interpolation, PI)的索引調(diào)整方案,首次引入了通過縮放因子對位置索引進行線性縮放,以擴展上下文長度。具體而言,PI通過在推理時對把目標(biāo)位置等比例放縮到模型支持的位置處。能夠?qū)⒒赗oPE的預(yù)訓(xùn)練LLM(例如LLaMA模型)的上下文窗口大小擴展到32768,并且僅需少量的微調(diào)(在1000步中)。然而,這種方法仍然受到訓(xùn)練長度的限制,并且忽略了RoPE查詢和鍵向量維度之間的特征差異。
5.2.1 思路
既然超出 L 的位置沒有被訓(xùn)練過,那么在 L 之內(nèi)多選一些位置為分?jǐn)?shù)的點不就行了?這樣我們就能在已經(jīng)學(xué)好的編號范圍內(nèi)多選一些位置,實現(xiàn)長度外推。這就是位置插值。相比于直接微調(diào)和長度外推,位置插值的關(guān)鍵思想是:在超過訓(xùn)練所用的上下文長度外并不進行外推,而是線性的向下縮放了位置索引,來和預(yù)訓(xùn)練階段的原始上下文窗口大小相匹配。即把更大的上下文長度壓縮回預(yù)訓(xùn)練時的上下文長度。
位置插值是化未見為已見,化分布外為分布內(nèi)。這種方法實現(xiàn)很簡單。形式上,這個方法將RoPE f 替換為 f′ ,其定義如下面公式所示。通過讓RoPE的位置下標(biāo)去除以一個系數(shù),把位置編碼的取值約束到訓(xùn)練長度范圍以內(nèi);其中 L 是預(yù)訓(xùn)練期間的長度限制(原先上下文窗口最大值),L′ 是推理時較長的上下文窗口(擴展后的上下文窗口最大值)。PI 就是把長度為0 ~ L ' 的位置線性壓縮到0 ~ L 內(nèi)。由于位置編號會被送進正弦函數(shù)里,所以編號哪怕是分?jǐn)?shù)也沒關(guān)系。
比如希望將預(yù)訓(xùn)練階段的位置向量范圍[0,2048] 外推到[0,4096],只需要將對應(yīng)位置縮放到原先支持的區(qū)間([0,2048])內(nèi),L為原先支持的長度(如2048),L′為需要擴展的長度(如4096):
對于我們想要實現(xiàn)的任何上下文長度 L‘ > L,我們可以定義比例因子s = L/ L’ < 1。
位置插值將絕對位置索引從 [0,L′) 減少到 [0,L) 以匹配原始范圍,這也減少了從 L′ 到 L 的最大相對距離。因此,位置插值通過對齊位置索引的范圍和擴展前后的相對距離,使得原本超出模型訓(xùn)練長度的位置編碼在插值后落入已訓(xùn)練位置區(qū)間,減輕了由于上下文窗口擴展對注意力分?jǐn)?shù)計算的影響,這可以讓模型更容易適應(yīng)。
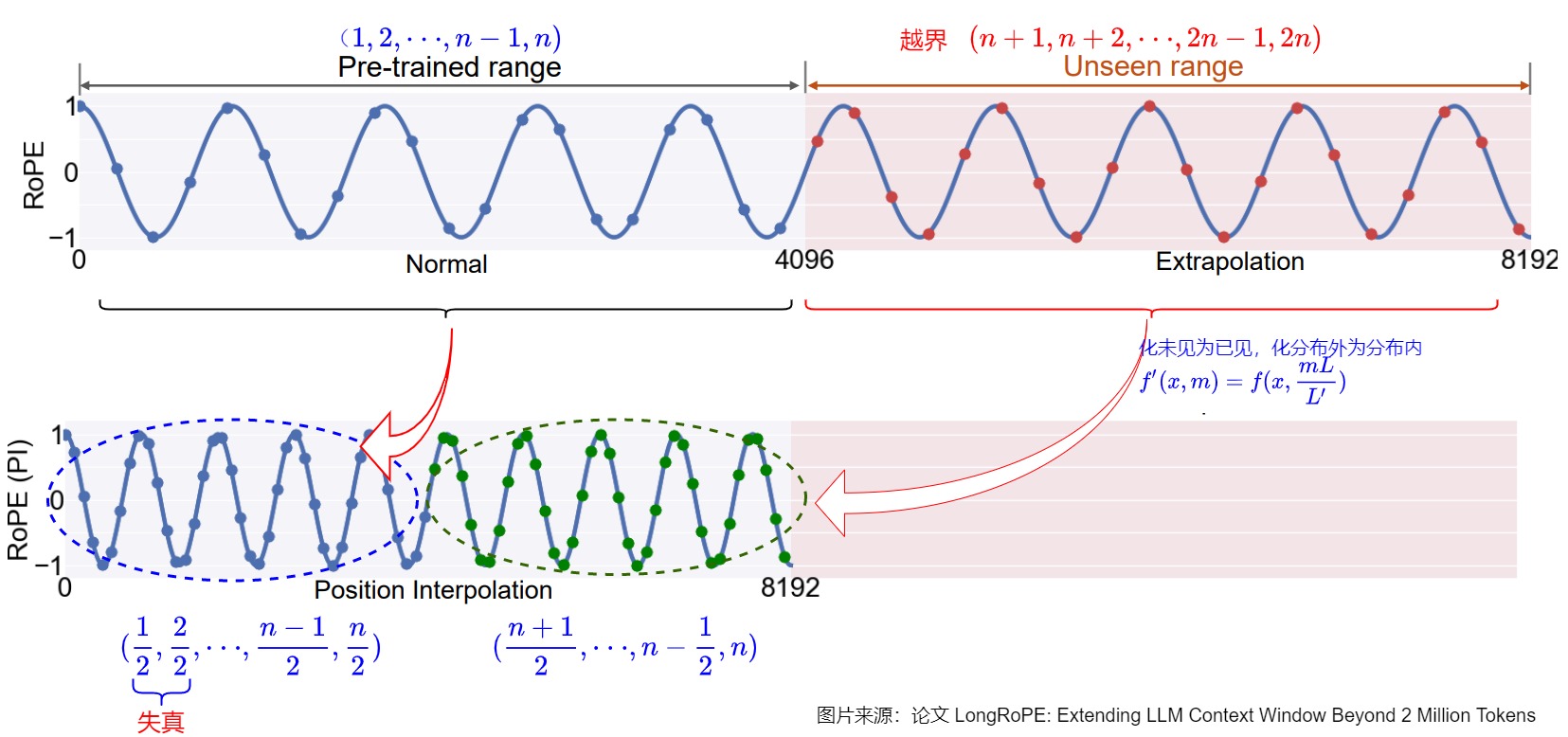
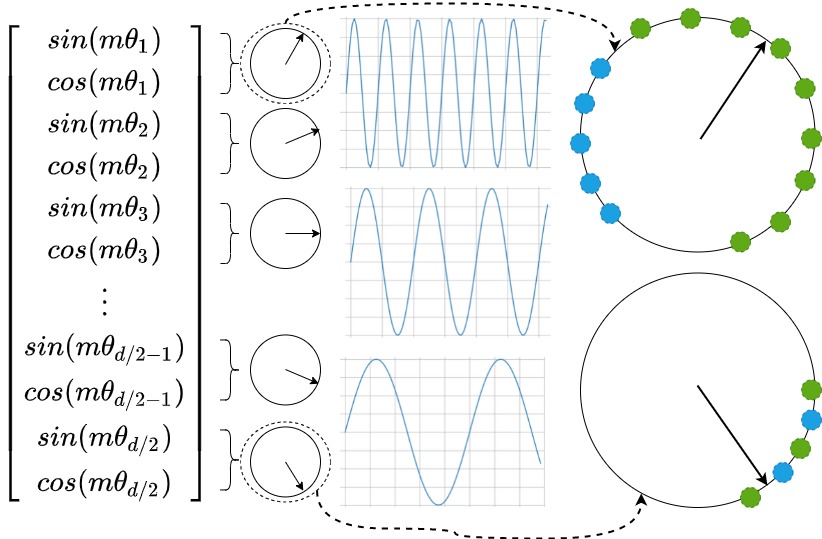
我們再繼續(xù)細化。如果我們想將位置編碼可以應(yīng)用的位置加倍,我們設(shè) L=4096,L'=8192,也就是將模型的長度從4096擴展至8192,Position Interpolation將每個位置的旋轉(zhuǎn)弧度均變?yōu)樵瓉淼囊话搿O聢D直觀地展示了第0組分量的旋轉(zhuǎn)弧度的變化情況,原來 [0,2047] 的旋轉(zhuǎn)弧度范圍就可以用來表示4096的長度范圍。這相當(dāng)于在原來的弧度范圍內(nèi),插入更多的位置,由于旋轉(zhuǎn)弧度是線性變化的,所以也稱為線性位置插值。從下圖可以看到:
- 左上為預(yù)訓(xùn)練階段的位置向量范圍[0,4096],對應(yīng)LLM模型的正常使用。輸入位置索引(藍點)在預(yù)先訓(xùn)練的范圍內(nèi)。
- 右上角為長度外推的部分(4096,8192],其中模型需要操作最多 4096 個看不見的位置(紅點)。
- 左下角為位置插值法,我們將位置索引(藍色和綠點)本身從 [0, 4096] 降采樣縮小到 [0, 2048]這個預(yù)訓(xùn)練階段支持的范圍,將位置索引(紅點)本身從 [4096,8192] 降采樣縮小到 [2048,4096]這個預(yù)訓(xùn)練階段支持的范圍。
換句話說,為了容納更多的輸入token,作者利用位置編碼可以應(yīng)用于非整數(shù)位置的事實,在相鄰整數(shù)位置處插入位置編碼,而不是在訓(xùn)練位置之外進行推斷。這相當(dāng)于在原來的弧度范圍內(nèi),插入更多的位置,由于旋轉(zhuǎn)弧度是線性變化的,所以也稱為線性位置插值。
5.2.2 原理
我們接下來分析為何PI會起作用。
從視野的角度來看。假設(shè)推理長度為訓(xùn)練長度的a倍,簡單對位置縮減a倍,實現(xiàn)位置內(nèi)插值。等價于將偏置系數(shù)縮小a倍,即將注意力視野擴大了a倍。
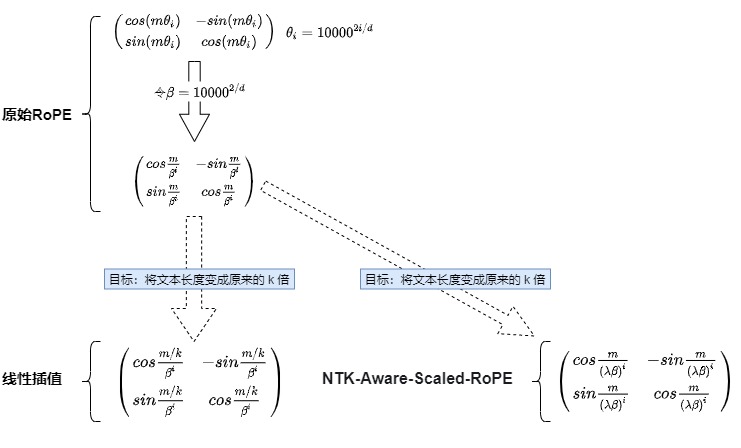
RoPE通過將位置信息編碼為復(fù)數(shù)向量來工作,其中每個維度的嵌入可以看作是一個旋轉(zhuǎn),其頻率由基底b決定。任意向量q位于位置m時,它的第 i 組分量的旋轉(zhuǎn)弧度為\(m\theta_i = m \times base ^{-2i/d}\),其中d表示向量的維度。
從旋轉(zhuǎn)角度的視角來看。縮放系數(shù)既可以理解為除在下標(biāo)上,也可以理解為除在旋轉(zhuǎn)角\(\theta_i\)上,通過一個常數(shù)讓\(\theta_i\)縮小。
其中s為內(nèi)插的scale,即L‘/L。經(jīng)過這種放縮操作后,位置為 m 的 維度為 i 的旋轉(zhuǎn)角變?yōu)?\(\frac{mL}{L'} * base^{?2i/d}\) 。第 i 組向量相鄰位置之間旋轉(zhuǎn)角度的差值由\(\theta_i\)減小成了\(\frac{L}{L'}\theta_i\)。線性插值通過縮小每個位置的旋轉(zhuǎn)弧度,讓向量旋轉(zhuǎn)得慢一些,周期變大,頻率降低,每個位置的旋轉(zhuǎn)弧度變?yōu)樵瓉淼?L/L',長度擴大幾倍,則旋轉(zhuǎn)弧度縮小幾倍。
下面將給出論文的上界推導(dǎo)過程:

5.2.3 微調(diào)
內(nèi)插之后,映射方式不一致;從相對數(shù)值來看會導(dǎo)致維度更加“擁擠”。所以,做了內(nèi)插修改后,通常都需要微調(diào)訓(xùn)練。在對指定長度范圍內(nèi)的序列(插值)進行初步訓(xùn)練后,模型會經(jīng)歷微調(diào)過程以提高其在較長序列上的性能。 這種適應(yīng)提高了模型泛化到擴展上下文的能力,確保無縫處理最初觀察的和推斷的輸入長度。或者說,微調(diào)讓模型重新適應(yīng)擁擠的映射關(guān)系。與外推方案相比,內(nèi)插方案微調(diào)所需要的步數(shù)要少得多,因為很多場景(比如位置編碼)下,相對大小(或許說序信息)更加重要,換句話說模型只需要知道874.5比874大就行了,不需要知道它實際代表什么多大的數(shù)字。而原本模型已經(jīng)學(xué)會了875比874大,加之模型本身有一定的泛化能力,所以再多學(xué)一個874.5比874大不會太難。
5.2.4 對比
下圖是外推法與內(nèi)插法的比較。
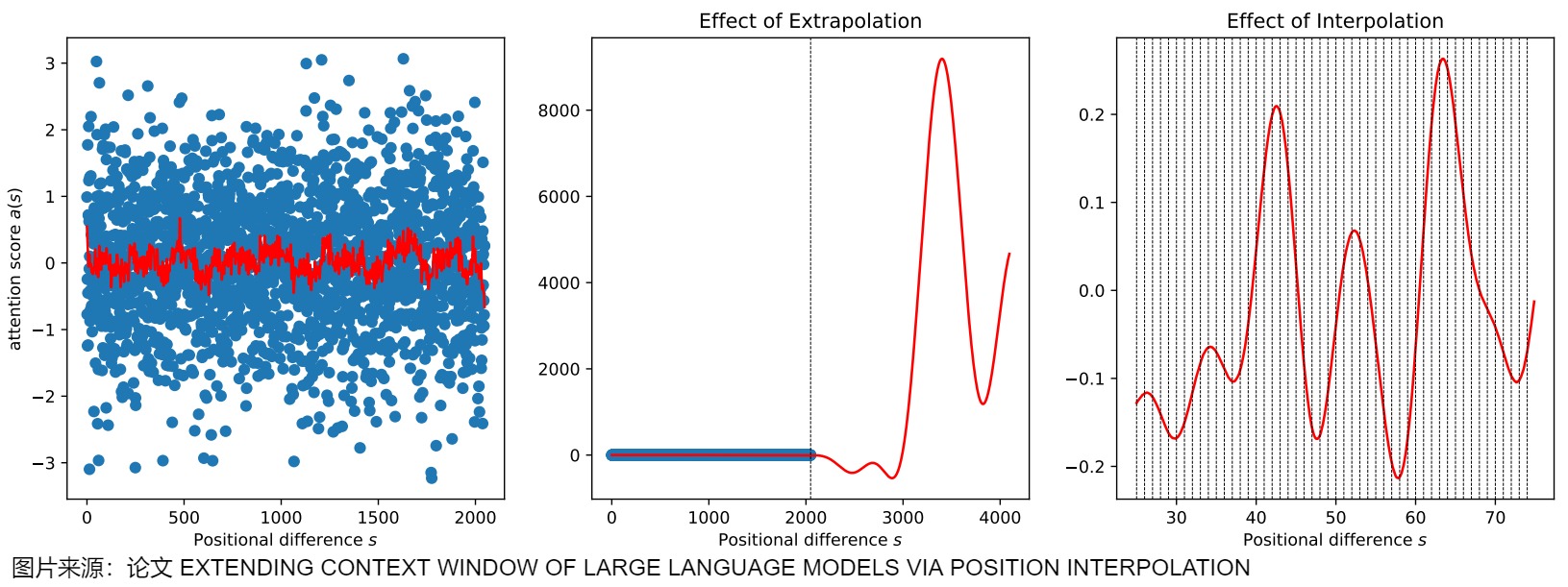
- 左圖中紅色曲線為擬合的注意力得分曲線,可見基本范圍在區(qū)間[-1,1]內(nèi)。
- 中間圖說明在[0,2048]內(nèi),擬合曲線表現(xiàn)很好,但是當(dāng)直接擴展到訓(xùn)練中未見的較大上下文窗口時,與未經(jīng)訓(xùn)練的模型相比,困惑度可能會飆升至非常高的數(shù)字。比如超過2048后注意力得分出現(xiàn)災(zāi)難性的高,甚至超過8000。這樣就完全破壞了注意力機制。
- 右圖說明內(nèi)插法要更穩(wěn)定,整數(shù)位置差(i.e., integer positional difference)下的表現(xiàn)更平滑、更好。
與直接外推相比,位置插值優(yōu)勢在于:
- 位置插值可以輕松啟用非常長的上下文窗口(如 32768)。位置插值的上界小于外推的上界,避免出現(xiàn)災(zāi)難性高的注意力分?jǐn)?shù),證明位置插值具有更高的穩(wěn)定性。
- 位置插值生成強大的模型,這些模型可以有效地利用擴展的上下文窗口。通過位置插值擴展的模型保留了其原始網(wǎng)絡(luò)結(jié)構(gòu),并可以重復(fù)使用大多數(shù)預(yù)先存在的優(yōu)化和基礎(chǔ)架構(gòu)。
- 通過位置插值擴展的模型在其原始上下文窗口內(nèi)的任務(wù)上也相對較好地保留了質(zhì)量。
5.2.5 缺點
RoPE的特點或者優(yōu)勢是:低維度具有更快的旋轉(zhuǎn)(對應(yīng)局部細節(jié)捕捉),高維度具有更慢的旋轉(zhuǎn)(對應(yīng)長距離依賴)。這種設(shè)計巧妙地結(jié)合了長距離和短距離的信息編碼能力。
直接外推的問題是遠處越界。直接外推保持了局域性(0附近位置編碼不變),效果差是因為引入了超出訓(xùn)練長度的位置編碼。因此直接外推在長距離情況下的使用容易出問題,在短距離情況下使用不受影響。
位置內(nèi)插的問題是局部失真、高頻信息的損失和動態(tài)縮放的缺乏。
位置插值方法是線性的,這樣會平等對待地所有維度,將向量的所有分組不加區(qū)分地同等減少倍數(shù)、縮小旋轉(zhuǎn)弧度,降低旋轉(zhuǎn)速度(進一步體現(xiàn)為對其正弦函數(shù)進行拉伸)。即高頻旋轉(zhuǎn)角度縮小的倍數(shù)和低頻旋轉(zhuǎn)角度縮小的倍數(shù)是一樣的,沒有考慮針對不同維度作出不同的縮放。這可能會造成以下問題:在處理相近的token時可能無法準(zhǔn)確區(qū)分它們的順序和位置,嚴(yán)重擾亂了模型的局部分辨率。這樣會導(dǎo)致模型丟失原先高頻分量中的細節(jié)信息,使得模型難以區(qū)分相對位置接近而本身語義又相似的token。
換句話說,內(nèi)插方法使得不同維度的分布情況不一樣,每個維度變得不對等起來,對于高頻的低維度,插值后變得異常擁擠。導(dǎo)致模型的高頻信息缺失,該模型不太能夠識別小旋轉(zhuǎn),無法計算出附近標(biāo)記的位置順序,模型進一步學(xué)習(xí)難度也更大。盡管位置內(nèi)插避免了遠處的位置越界問題,但是線性插值但擾亂了局域性(0附近位置編碼被壓縮為1/k),損失了視野分辨率,在短距離情況下的使用容易出現(xiàn)問題,所以不微調(diào)效果也不好。
另外,PI方法在擴展上下文窗口時采用靜態(tài)的插值策略,不考慮輸入序列的實際長度。這可能導(dǎo)致在處理長度變化的序列時性能下降。
因此,實現(xiàn)免訓(xùn)練長度外推的要領(lǐng)是“保近壓遠”,即“保證局部不失真”和“壓縮遠處不越界”,
5.2.6 實現(xiàn)
Transformer庫主要改動點如下:
- 新增scaling_factor參數(shù),控制插值比例。
- 索引除以插值比例。
具體代碼如下。
class OpenLlamaLinearScalingRotaryEmbedding(OpenLlamaRotaryEmbedding):
"""OpenLlamaRotaryEmbedding extended with linear scaling. """
def __init__(self, dim, max_position_embeddings=2048, base=10000, device=None, scaling_factor=1.0):
self.scaling_factor = scaling_factor
super().__init__(dim, max_position_embeddings, base, device)
def _set_cos_sin_cache(self, seq_len, device, dtype):
# 線性插值比較簡單,就是直接將原來的各整數(shù)之間插上帶小數(shù)點的值,經(jīng)過少量數(shù)據(jù)微調(diào)后,可以較好的擴展到較長的文本上
self.max_seq_len_cached = seq_len
t = torch.arange(self.max_seq_len_cached, device=device, dtype=torch.int64).type_as(self.inv_freq)
# 線性插值方法的關(guān)鍵,通過下面的操作,將所有的頻率都降低了
t = t / self.scaling_factor
# 計算[seq_len, dim//2]矩陣,得到絕對位置編碼矩陣的核心要素, dim默認是偶數(shù)
freqs = torch.outer(t, self.inv_freq)
# Different from paper, but it uses a different permutation in order to obtain the same calculation
# 在最后一個維度復(fù)制一份,符合前面的矩陣計算公式
emb = torch.cat((freqs, freqs), dim=-1)
# 分別得到cos和sin分量,并設(shè)置為模型的常量
self.register_buffer("cos_cached", emb.cos().to(dtype), persistent=False)
self.register_buffer("sin_cached", emb.sin().to(dtype), persistent=False)
0x06 RoPE外推進階方案
對于修改位置編碼的外推方案,主要是有兩種:
- 事前修改,如ALIBI、KERPLE、XPOS以及HWFA等,它們可以不加改動地實現(xiàn)一定的長度外推,但相應(yīng)的改動需要在訓(xùn)練之前就引入,因此無法不微調(diào)地用于現(xiàn)成模型。
- 事后修改,比如NTK-RoPE、ReRoPE等,這類方法的特點是直接修改推理模型,無需微調(diào)就能達到一定的長度外推效果,但缺點是它們都無法保持模型在訓(xùn)練長度內(nèi)的恒等性。
本節(jié)介紹的大模型長度擴展方法,都是事后修改。
除了Giraffe,這些方案本質(zhì)上都是通過改變base來影響每個位置對應(yīng)的旋轉(zhuǎn)角度,進而影響模型的位置編碼信息,最終達到長度外推的目的。具體而言,是通過縮小RoPE的旋轉(zhuǎn)弧度,降低旋轉(zhuǎn)速度,有利于捕捉長上下文對應(yīng)的低頻特征,從而達到擴展長度的目的。調(diào)整旋轉(zhuǎn)弧度后,將對模型的注意力分布產(chǎn)生影響,如要達到更優(yōu)的效果,一般還需要使用少量長文本進行微調(diào),讓模型適應(yīng)調(diào)整后的位置信息。一句話總結(jié)各種方法的特點:
- Position Interpolation:通過擴展比例來對RoPE的旋轉(zhuǎn)角度進行線性插值。目標(biāo)長度是原來的n倍,則旋轉(zhuǎn)弧度減小至原來的1/n。
- NTK-Aware Interpolation:非線性插值方法,通過對RoPE不同維度頻率進行不同程度的縮放(減少高頻和增加低頻)來將插值密度分散到多個維度,從而解決RoPE插值過程中可能丟失的高頻信息問題。具體而言,NTK-Aware Interpolation直接對RoPE的基數(shù)進行縮放,使得高頻分量旋轉(zhuǎn)速度降幅低,低頻分量旋轉(zhuǎn)速度降幅高,這樣可以在高頻部分進行外推,低頻部分進行內(nèi)插。在短距離情況下具有外推特性,在長距離情況下具有內(nèi)插特性。
- NTK-by-parts Interpolation:進一步細化了插值策略:不改變高頻部分,僅縮小低頻部分的旋轉(zhuǎn)弧度。而且強加兩個閾值來限制縮放比例高于和低于某些維度。
- Dynamic NTK Interpolation:在模型的不同推理步驟中動態(tài)調(diào)整插值策略。推理長度小于等于訓(xùn)練長度時,不進行插值;推理長度大于訓(xùn)練長度時,每一步都通過NTK-Aware插值動態(tài)放大base。在推理過程中動態(tài)調(diào)整s。
- YaRN:NTK-by-parts Interpolation與注意力分布修正策略的結(jié)合,通過溫度系數(shù)修正注意力分布。YaRN將RoPE維度分為三組,并根據(jù)頻率對每組應(yīng)用不同的插值策略,即:直接外推,NTK-aware 插值和線性插值。可以認為YaRN方法 = NTK-aware + NTK-by-parts + Dynamic NTK。
此外,Meta在其論文“Effective Long-Context Scaling of Foundation Models”中,將NTK-RoPE改稱為RoPE-ABF(Adjusted Base Frequency),相比神秘的NTK,ABF的名稱能更直觀體現(xiàn)出它的含義。
6.1 位置編碼的通用公式
下面參考 從ROPE到Y(jié)arn, 一條通用公式速通長文本大模型中的位置編碼 和 論文“YaRN: Efffcient Context Window Extension of Large Language Models”的思路。
Yarn的作者認為編碼函數(shù)是一個關(guān)于輸入向量x、位置m 和\(\theta\) 的函數(shù),無論是ROPE還是它的所有變種,本質(zhì)上都可以被以下公式所統(tǒng)一。
其中:
- f′ 是調(diào)整后的查詢(query)和鍵(key)向量。
- f 是原始的查詢和鍵向量計算函數(shù)。
- \(x_m\) 是輸入序列中位置m的嵌入向量。
- m 是序列中的位置索引。
- \(θ_d\) 是RoPE中的旋轉(zhuǎn)角度參數(shù),即頻率參數(shù)。
- g(m) 是一個可調(diào)函數(shù),用于根據(jù)比例因子s調(diào)整位置索引m,描述位置的變換邏輯。
- $?(θ_d) $是一個可調(diào)函數(shù),用于根據(jù)比例因子s調(diào)整RoPE的旋轉(zhuǎn)角度參數(shù) \(θ_d\) ,描述頻率的變換邏輯。$?(θ_d) \(的調(diào)整策略會很復(fù)雜,因為它需要考慮到不同維度的波長和上下文長度的關(guān)系。在YaRN中,\) ?(θ_d)$ 的設(shè)計旨在保持高頻信息的同時避免對低頻信息的過度插值。
這條公式背后隱藏的邏輯是:如何通過適配 g(m) 和 \(h(\theta_d)\)來在固定上下文長度的限制下延展語言模型的能力。
6.1.1 三角函數(shù)編碼
三角函數(shù)編碼可以用通用公式拓展為:
其中:
- W是線性投影矩陣,用于變換向量。
- \(PE_m\)是位置編碼。\(PE_m[2d] = sin(m \cdot h(\theta_d)), PE_m[2d+1] = cos(m \cdot h(\theta_d))\) 。
6.1.2 RoPE
Yarn論文中給出了RoPE的推導(dǎo)。

然后,論文給出了RoPE在通用公式中的表示,把RoPE直接映射為:g(m)=m,\(h(\theta_d) = \theta_d\),保持頻率參數(shù)不變。
旋轉(zhuǎn)角度 \(m\cdot \theta_d\)決定了頻率,即每個維度的旋轉(zhuǎn)速度。
- 當(dāng) \(\theta_d\) 接近 1(d值較小的低維度),\(m\cdot \theta_d\)的變化較大,旋轉(zhuǎn)更快。
- 當(dāng) \(\theta_d\) 接近 0(d值較大的高維度),\(m\cdot \theta_d\)的變化較小,旋轉(zhuǎn)更慢。

6.1.3 PI
PI嘗試通過重新定義 g(m) 將位置索引均勻拉伸到預(yù)訓(xùn)練窗口內(nèi)。
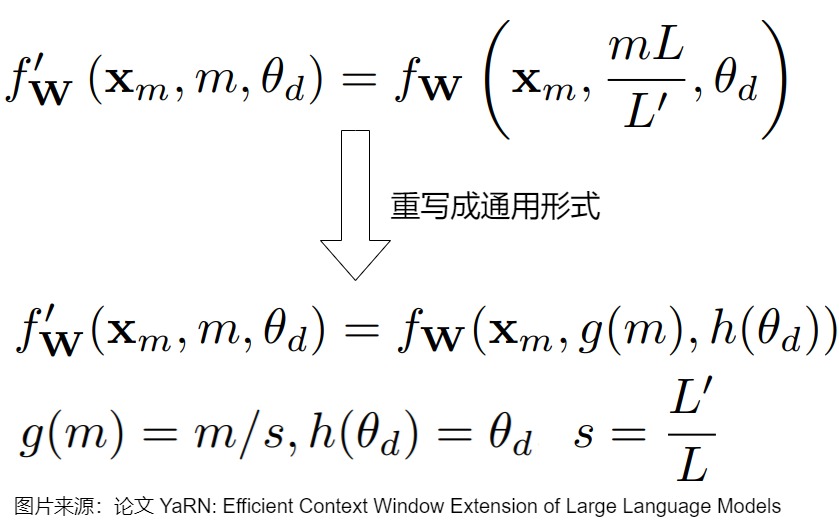
接下來,我們看看RoPE的幾個變種,這些方法主要是通過調(diào)整RoPE的旋轉(zhuǎn)基,實現(xiàn)了即插即用的長度外推。
6.2 NTK-Aware Interpolation
RoPE中,位置越靠前的向量分組,旋轉(zhuǎn)速度越快,頻率越高。而線性插值對位置編碼的所有維度只進行簡單的內(nèi)插(除一個常數(shù)),這導(dǎo)致高頻信息丟失,妨礙模型區(qū)分附近的位置。這是因為對于\(f′(x,m)=f(x, \frac{mL}{L′})\)來說,\(\frac{L}{L'}\)是一個小于1的數(shù)字,所以,加上線性內(nèi)插后,所有項的頻率都變小了。自然,公式能表達的最大頻率也變小了,擬合高頻信息的能力下降了。
就在位置內(nèi)插提出不久,研究者Bowen Peng在社區(qū) (https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_scaled_rope_allows_llama_models_to_have/) 提出了一種效果更好,完全不需要微調(diào)的長度外推技術(shù):NTK-aware Scaled RoPE (也簡稱為"NTK-aware RoPE")。Bowen Peng后續(xù)將此方法進一步整理優(yōu)化,發(fā)表了論文YaRN: Efficient Context Window Extension of Large Language Models。
論文“Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains ”的NTK(Neural Tangent Kernel)理論指出,深度神經(jīng)網(wǎng)絡(luò)在學(xué)習(xí)高頻信息時可能會遇到困難,特別是當(dāng)輸入維度較低時。解決辦法是要將深度神經(jīng)網(wǎng)轉(zhuǎn)化為Fourier特征。從神經(jīng)切線核(Neural Tangent Kernel, NTK)理論的角度來看,簡單進行RoPE線性插值會造成高頻信息的丟失,而網(wǎng)絡(luò)需要這些細節(jié)來解析非常相似且非常接近的標(biāo)記。

因此,Bowen Peng根據(jù)NTK理論:提出對三角函數(shù)的相位進行非線性內(nèi)插。具體而言,Bowen Peng的方案是在擴展上下文長度時,對不同頻率的維度進行不同程度的縮放,讓高頻分量旋轉(zhuǎn)速度降幅低(保留高頻信息),低頻分量旋轉(zhuǎn)速度降幅高。即進行“短距離高頻外推(對高頻變動小,讓其保持原本不變)、長距離低頻內(nèi)插(對低頻變動大,讓其內(nèi)插)”。這樣可以保持模型對高頻信息的敏感性。這里的外推指對編碼不做更多的改變,即可拓展長度。
為什么NTK-Aware Interpolation能夠奏效?或者說,為何要在高頻部分進行外推,低頻部分進行內(nèi)插?我們可以將NTK-Aware Interpolation奏效的原因按照如下方式進行解釋:位置越靠后的分組的旋轉(zhuǎn)速度越慢,頻率越低,周期越長。
- 靠前的維度分組,在訓(xùn)練中見過非常多完整的旋轉(zhuǎn)周期,位置信息得到了充分的訓(xùn)練,所以具有較強的外推能力。
- 靠后的維度分組,在訓(xùn)練中無法見到完整的旋轉(zhuǎn)周期,或者見到的旋轉(zhuǎn)周期非常少,訓(xùn)練不夠充分,外推性能弱,需要進行位置插值。
另外,Bowen Peng基于自己對NTK(Neural Tangent Kernel)的相關(guān)經(jīng)驗,判斷高頻(i→0)是學(xué)習(xí)相對距離的,所以不用改變,低頻(i→d/2?1)是學(xué)習(xí)絕對距離的,因此要進行內(nèi)插。
6.2.1 方案
在Yarn論文中,給出了從PI開始的具體推導(dǎo)參見下圖。當(dāng)d=0,\(h(\theta_d)=1\),s不會造成影響,變成了直接外推。當(dāng)\(d=|D|/2\)時,\(h(\theta_d)=1\),變成了線性內(nèi)插。
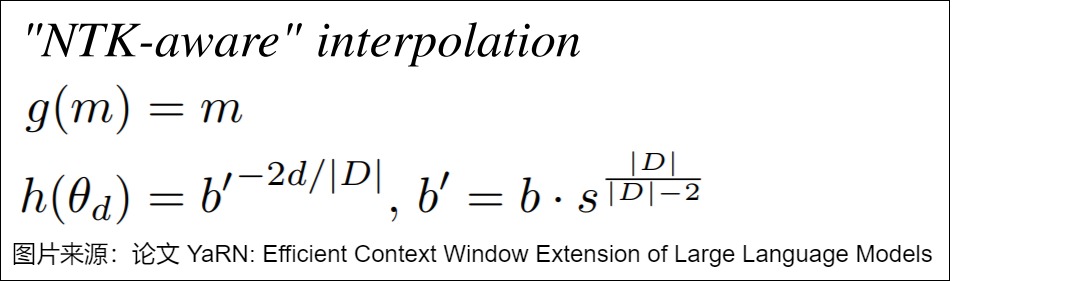
Yarn也將 \(\lambda_d\) 定義為第 ?? 個隱藏維度上RoPE嵌入的波長,波長描述了嵌入在該維度上完成一次完整旋轉(zhuǎn)(2π)所需的token數(shù)量。波長與RoPE嵌入的頻率有關(guān),且在不同維度上可能有所不同。我們可以計算出RoPE每個維度對應(yīng)的波長是\(2????^{\frac{2d}{|D|}}\)。當(dāng)給定一個長度L,有的維度會出現(xiàn)周期比L更長,當(dāng)出現(xiàn)這個情況的時候,所有的位置都能獲得一個唯一的編碼,也就是絕對位置都保留了下來。反之,周期比較短的維度只能保留相對位置信息。
以下是NTK-aware Interpolation方法的具體步驟:
- 確定新的基底b':為了在擴展上下文窗口時保持高頻信息,需要找到一個新基底b' ,使得在新的上下文長度L' 下,最低頻率的波長與線性位置縮放的波長相匹配。新基底b' 可以通過以下公式計算: ??′=????? 其中b是原RoPE中的基底,s是上下文長度擴展的比例因子。 \(b′^{\frac{|D|?2}{|D|}}=s·b^{\frac{|D|?2}{|D|}}\) 。 \(b′=b·s^{\frac{|D|}{|D|-2}}\)。
- 調(diào)整RoPE嵌入:使用新基底b' 對每個維度的旋轉(zhuǎn)角度參數(shù) \(θ_i\) 進行調(diào)整。\(h(\theta_i) = b'^{\frac{-2d}{|D|}}\),其中|D|是維度的綜述,i 是特定維度的索引。
- 把旋轉(zhuǎn)角修改為\(m\theta_i=m*(base*\alpha)^{-2i/d}=m*(10000*\alpha)^{-2i/d}\),其中 \(\alpha\) 表示 base 的縮放因子。
- 在不同維度上修改的程度不同。這種方式保留了高頻信息,即高頻分量旋轉(zhuǎn)速度降幅低,低頻分量旋轉(zhuǎn)速度降幅高。越靠后的分組,旋轉(zhuǎn)弧度縮小的倍數(shù)越大。
- 以Code LlaMA為例,其\(\alpha=100\),也就是將原始模型的 base 放大100倍。調(diào)整后的旋轉(zhuǎn)弧度與原始旋轉(zhuǎn)弧度的倍數(shù)關(guān)系如下:\(\frac{m*(1000000)^{-2i/d}}{m*(10000*\alpha)^{-2i/d}}=100^{-2i/d}\)。其中第0分組的旋轉(zhuǎn)弧度保持不變,和原始的RoPE等價,可以理解為這個維度直接進行的外推;最后一個分組的旋轉(zhuǎn)弧度變?yōu)樵瓉淼?/100,等價于線性內(nèi)插。中間維度其實代表了介于外推和內(nèi)插之間,所以NTK-aware Interpolation方案其實簡單巧妙地將外推和內(nèi)插結(jié)合了起來。
- 計算新的查詢和鍵向量:根據(jù)調(diào)整后的 θ′ ,計算新的查詢$ q’_m$ 和鍵 \(k′_m\)向量。
6.2.2 分析
我們分別從幾個角度來對NTK-Aware進行分析。
進制
因為接下來我們要用進制分析來進行學(xué)習(xí),所以我們先看看蘇神在Transformer升級之路:10、RoPE是一種β進制編碼中對進制和位置編碼的觀點,解讀如下。
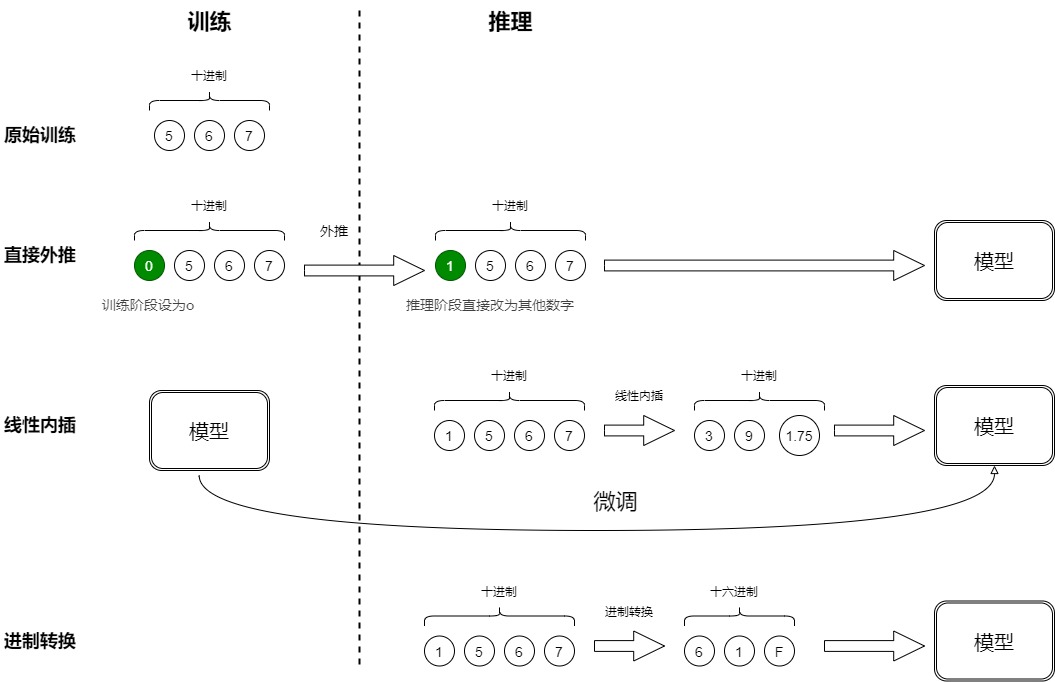
567是一個十進制三位數(shù),每位數(shù)字是0~9。用三維向量[a,b,c]來表示這個數(shù)字,a,b,c分別是"567"的百位、十位、個位。我們使用三維10進制對模型進行訓(xùn)練。假如現(xiàn)在要輸入一個4位數(shù)的數(shù)字“1567”,而原本的模型是針對三維向量設(shè)計和訓(xùn)練的,新增一個維度后,模型就無法處理了。那么我們應(yīng)該如何應(yīng)對?下面是幾種外推的思路:
- 直接外推:提前預(yù)留多幾維,訓(xùn)練階段設(shè)為0,推理階段直接改為其他數(shù)字。比如原來訓(xùn)練時就是"0567",推理時候改變?yōu)椤?567”。因為訓(xùn)練階段預(yù)留的最高位一直是0,所以這些維度會訓(xùn)練不充分,直接外推效果理想。
- 線性內(nèi)插:將“1567”壓縮到1000以內(nèi),比如除以4得到“391.75”,3個位數(shù)字分別為:[3,9,1.75]。這樣也需要微調(diào)來使得模型重新適應(yīng)擁擠的映射關(guān)系。但是這樣會使得不同維度的分布情況和相鄰差異不同。比如目前,百位、十位,還是保留了相鄰差異為1。個位數(shù)變成了小數(shù)。這樣使得每個維度變得不對等起來,模型進一步學(xué)習(xí)難度也更大。
- 進制轉(zhuǎn)換:目前有三維向量[a,b,c],如果用10進制編碼,表示范圍是0~999。如果變成16進制,最大可以表示為\(16^3?1=4095>1999\)。可以涵蓋1567。代價是每個維度的數(shù)字從0~9變?yōu)?~15。我們關(guān)心的場景主要利用序信息,原來訓(xùn)練好的模型已經(jīng)學(xué)會了875>874,而在16進制下同樣有875>874,比較規(guī)則是一模一樣的(模型根本不知道你輸入的是多少進制)。唯一擔(dān)心的是每個維度超過9之后(10~15)模型還能不能正常比較,但事實上一般模型也有一定的泛化能力,所以每個維度稍微往外推一些是沒問題的。所以,這個轉(zhuǎn)換進制的思路,甚至可能不微調(diào)原來模型也有效!另外,為了進一步縮窄外推范圍,我們還可以換用更小的\(\sqrt[3]{2000}=13\)進制而不是16進制。
修改base
其實,進制轉(zhuǎn)換就是修改base。
Bowen Peng認為,直接對RoPE做線性內(nèi)插是次優(yōu)的,因為它會阻止模型去區(qū)分兩個位置非常靠近的Token的位置信息;但是如果直接采用非線性的內(nèi)插,它改變的不是 RoPE 的“scale”而是RoPE的“base”,它影響的實際上是被作用向量每個維度的“旋轉(zhuǎn)”速度,即越后面的維度,旋轉(zhuǎn)速度越快。 因此,NTK-aware Interpolation的非線性插值方案改變RoPE的base而不是比例,從而改變每個RoPE維度向量與下一個向量的“旋轉(zhuǎn)”速度。由于它不直接縮放傅里葉特征,因此即使在極端情況下,所有位置都可以完美區(qū)分。
為了解開這個謎底,我們需要理解RoPE的構(gòu)造可以視為一種 \(\beta\) 進制編碼,位置n的旋轉(zhuǎn)位置編碼(RoPE),本質(zhì)上就是數(shù)字n的β進制編碼。在這個視角之下,NTK-aware Scaled RoPE可以理解為對進制編碼的不同擴增方式。
直接外推會將外推壓力集中在“高位”上,位置內(nèi)插則會將“低位”的表示變得更加稠密,不利于區(qū)分相對距離。而NTK-aware Scaled RoPE其實就是進制轉(zhuǎn)換,它將外推壓力平攤到每一位上,并且保持相鄰間隔不變,這些特性對明顯更傾向于依賴相對位置的LLM來說是非常友好和關(guān)鍵的,所以它可以不微調(diào)也能實現(xiàn)一定的效果。

對比
事實上,在原始RoPE中,隨著 i 的增大, \(\theta_i\) 從1開始逐漸變小,極限是 1/base ;換句話說,較小的 i 對應(yīng)著高頻部分,較大的 i 對應(yīng)著低頻部分。PI方法則會丟棄掉高頻部分,假設(shè)在2倍長度的上下文中應(yīng)用PI, 所有 \(\theta_i\) 都等價變成原來的一半,旋轉(zhuǎn)編碼的最高頻率會直接減半。
NTK-aware RoPE 還是沿用位置線性內(nèi)插的思路,但是它對 RoPE 的影響更加平滑:對于位置編碼高頻項,公式幾乎不變;對于最低頻項,公式完全等于線性內(nèi)插時的公式。
利用時鐘做比喻,Bowen Peng 解釋了不應(yīng)該像線性內(nèi)插一樣修改最高頻率的原因:就像我們用秒針來區(qū)分最精確的時間一樣,神經(jīng)網(wǎng)絡(luò)用最高頻的正弦編碼區(qū)分相對位置關(guān)系,且只能看清 1 秒以上的偏差。使用線性內(nèi)插后,最小的時間偏差是 0.5 秒,神經(jīng)網(wǎng)絡(luò)就不能很好地處理最高頻的那塊信息了。而 NTK-aware RoPE 不會修改一秒的定義,只會在分鐘、小時等更低頻的分量上多插值一點,神經(jīng)網(wǎng)絡(luò)依然能區(qū)分最精細的時間。
NTK-aware Interpolation這種修改底數(shù)的方式,在 i 較小時, \(\theta_i\) 變小的程度也會很小,只有在 i 較大時, \(\theta_i\) 會變小很多(具體程度由 \(\alpha\) 決定),不會直接丟棄掉高頻部分。當(dāng)處理超出預(yù)訓(xùn)練上下文長度的文本時,高頻部分仍然以進行外推為主,而低頻部分就會類似于PI方法在進行內(nèi)插。
我們再從時鐘角度來看。RoPE 的行為就像一個時鐘,每一個 ?? 值就控制著一塊圓盤的轉(zhuǎn)動速度,一共有d/2個圓盤。
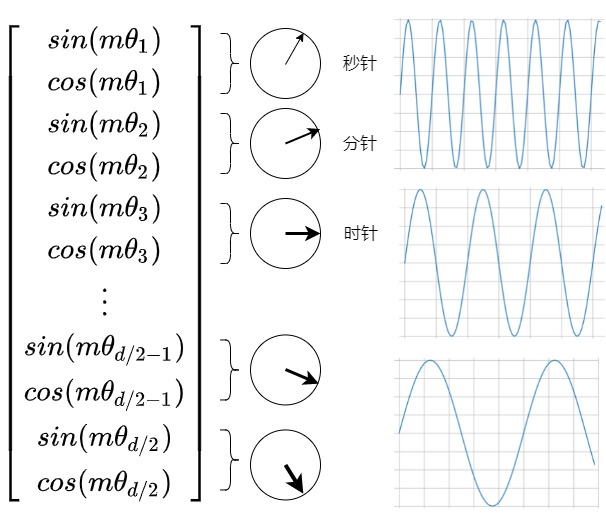
我們假設(shè)前三個轉(zhuǎn)盤是秒針,分針和時針。12小時時鐘基本上是一個維度為 3、底數(shù)為 60 的 RoPE。秒針,分針和時針是不同的頻率在旋轉(zhuǎn)。(頻率從高到低)每秒鐘,分針轉(zhuǎn)動 1/60 分鐘,每分鐘,時針轉(zhuǎn)動 1/60。現(xiàn)在RoPE時鐘一天最大能表達:60 * 60 * 12=43200s。如果希望時鐘表達的時間變長,假如想表達4天,則需要將時鐘減慢4倍,那么有如下兩種方法:
- PI:將每秒,分鐘,時鐘的頻率平等的縮小4倍(周期變長),可以實現(xiàn)這個目標(biāo)。不幸的是,現(xiàn)在很難區(qū)分每一秒,因為現(xiàn)在秒針幾乎每秒都不會移動。因此,如果有人給你兩個不同的時間,僅相差一秒,你將無法從遠處區(qū)分它們。
- NTK-Aware RoPE:我們應(yīng)該對頻率高的秒鐘,不做縮放,而會將分鐘減慢 1.5 倍,將小時減慢 2 倍,即可以在一小時內(nèi)容納 90 分鐘,在半天內(nèi)容納 24 小時。現(xiàn)在時鐘可以表達:60 * (60 * 1.5)*(2 * 12)=129600.0。我們只關(guān)注整體的時間:那么不需要精確測量時針,所以與秒相比,將小時縮放得更多是至關(guān)重要的。我們不想失去秒針的精度,但我們可以承受分針甚至?xí)r針的精度損失。
擬合曲線
NTK-aware Interpolation方法其實是將外推的程度定義成一個與組別 d 有關(guān)的函數(shù)\(\gamma(d)\)。
- d = 0 為最高頻分量,我們希望完全外推,此時\(\gamma(d)\)= 1.0。
- d = D/2 -1 為最低頻分量,我們希望完全內(nèi)插,此時\(\gamma(d)\) = L/L'。
這個函數(shù)可以用一條以分組d為變量的經(jīng)過點(0,1)與點(??/2?1,L/L′)的單調(diào)遞減的曲線。具體曲線形式有多種,Bowen Pen使用指數(shù)函數(shù)來擬合這條曲線,得到\(\gamma(d) = s^{\frac{-2d}{D-2}}\),s = L'/L。
6.3 NTK-by-parts Interpolation
實際上,在RoPE的訓(xùn)練過程中存在一些足夠低頻的分量,這些低頻分量對應(yīng)的波長\(\lambda_d\)長到即使是訓(xùn)練過程中最長的序列,也沒有辦法讓這些分量經(jīng)過一個完整周期。對于這些分量,我們顯然不應(yīng)該對他們進行任何的外推。否則可能會引入一些從未見過的旋轉(zhuǎn)角度,這些旋轉(zhuǎn)角度對應(yīng)的正余弦值在訓(xùn)練過程中模型也從未見過,會導(dǎo)致模型的效果下降。另外,無論是縮放位置索引還是修改base,所有token都變得彼此更接近,這將損害LLM區(qū)分相近token的位置順序的能力。
NTK-by-parts Interpolation 建議完全不插值較高的頻率維度,而總是插值較低的頻率維度。其核心思想是:不改變高頻部分,僅縮小低頻部分的旋轉(zhuǎn)弧度。即不改變靠前分組(小維度)的旋轉(zhuǎn)弧度,僅減小靠后分組(大維度)的旋轉(zhuǎn)弧度,這就是by-patrs的含義。這樣可以在擴展上下文長度時,保持模型對局部位置關(guān)系的敏感性,同時避免對高頻信息的過度插值。
- 如果波長??遠小于上下文大小 ?? ,我們不進行插值;
- 如果波長??等于或大于上下文大小 ?? ,我們只進行插值并避免任何推斷(與“NTK-aware”方法不同);
- 中間的尺寸可以同時具有兩者,類似于“NTK-aware”插值。
那么,怎么確定哪些分量是足夠高頻的,哪些分量是足夠低頻的呢?可以通過序列長度與波長的比值$ r_i=\frac{L}{\lambda_i}\(來判斷。第 i 個維度的旋轉(zhuǎn)周期為:\) \lambda_i=\frac{2 \pi}{\theta_i}=2 \pi * {ba s e} ^{2 i / d}\(,其在訓(xùn)練長度內(nèi)旋轉(zhuǎn)的周期個數(shù)如下:\) r_i=\frac{L}{\lambda_i}$。接下來我們定義用來調(diào)整波長的斜坡函數(shù),其中超參數(shù) \(\alpha,\beta\) 表示旋轉(zhuǎn)周期個數(shù)的約束條件。
$\gamma(r_i)= \begin{cases}0, & \text { if } r_i<\alpha \ 1, & \text { if } r_i>\beta \ \frac{r_i-\alpha}{\beta-\alpha}, & \text { otherwise }\end{cases} $
- 當(dāng)$ r_i > \beta$ ,說明周期遠小于長度L,不進行插值。即旋轉(zhuǎn)周期數(shù)量足夠多,則認為該分組為高頻部分,無需改變。
- 當(dāng) \(r_i < \alpha\) ,說明周期大于或等于長度L,即旋轉(zhuǎn)周期數(shù)量少,則為低頻分組,只進行插值,不進行外推。對于波長大于或等于原始上下文長度L的維度,模型在預(yù)訓(xùn)練期間已經(jīng)學(xué)習(xí)到了所有可能的相對位置關(guān)系。因此,這些維度的嵌入在擴展上下文時不需要插值。對于波長小于L的維度,模型需要插值來適應(yīng)新的上下文長度L' 。
- 當(dāng) \(\alpha \leq r_i \leq \beta\) ,說明周期介于兩者之間,可以使用ntk aware插值。
綜合以上條件,對于需要插值的維度,使用坡度函數(shù) \(γ_d\) 來調(diào)整波長 \(??_??\) ,以得到新的波長 $??_??′=(1?γ_??)??λ_??+γ_??λ_?? $,其中s是上下文長度擴展的比例因子。然后使用新的波長 \(??_??′\) ,調(diào)整RoPE嵌入的旋轉(zhuǎn)角度參數(shù) ,以便在新的上下文長度L' 下保持局部相對距離信息。調(diào)整后的RoPE嵌入可以通過以下公式計算:
調(diào)整后的旋轉(zhuǎn)角可以表示為 \(h\left(\theta_i\right)=(1-\gamma(r_i)) \frac{\theta_i}{s}+\gamma(r_i) \theta_i\)。這里 \(?(θ_i)\) 是調(diào)整后的旋轉(zhuǎn)角度參數(shù)。位置函數(shù)不做變更。其中 \(s=\frac{L'}{L}\) , 超參數(shù)的經(jīng)驗取值為$ \alpha=1,\beta=32$。
如果針對上面描述的通用公式,則NTK-by-parts Interpolation可以表示為如下。

6.4 Dynamic NTK Interpolation
Dynamic-NTK Interpolation 是一種動態(tài)插值的方法,其在預(yù)訓(xùn)練的上下文窗口中為token使用精確的位置值,以防止性能下降。并隨著推理上下文的增長,可以通過動態(tài)放大base,讓RoPE不斷適應(yīng)新的上下文長度。
Dynamic NTK Interpolation 的思路很簡單:推理長度小于等于訓(xùn)練長度時,不進行插值;只有當(dāng)推理長度大于訓(xùn)練長度時,此方法才會在每一步都通過NTK-Aware Interpolation動態(tài)更新base。即,base會隨著推理上下文的增長而增長。序列長度剛剛超出預(yù)訓(xùn)練上下文長度時,ROPE底數(shù)基本不變,即使設(shè)置了很大的scale factor;只有當(dāng)序列長度顯著超出預(yù)訓(xùn)練上下文長度時,scale factor才會起作用,而且序列越長,base被放大的倍數(shù)越高。
以下是Dynamic NTK方法的具體步驟:
-
動態(tài)調(diào)整比例因子:Dynamic NTK方法引入了一個動態(tài)的比例因子
s,它根據(jù)當(dāng)前處理的序列長度動態(tài)調(diào)整。比例因子s的計算方式如下,其中 L 表示模型訓(xùn)練長度,L′ 是當(dāng)前序列的長度。\[??=\begin{cases}\frac{??′}{??} \ if\ ??′>?? \\1 \ \ otherwise \end{cases} \]- 當(dāng) L' ≤?? 時,不改變模型原始的旋轉(zhuǎn)弧度,不進行插值;
- 當(dāng) L' >?? 時,使用NTK-Aware Interpolation調(diào)整旋轉(zhuǎn)弧度。旋轉(zhuǎn)角調(diào)整為 \(m* (base*\alpha)^{-2 \mathrm{i} / \mathrmw0obha2h00}\) ,其中$ \alpha = (\frac{l}{L})^{d/(d-2)}$。
每生成一個token后,L′ 都會加1,當(dāng) L′ >?? 時,每一次生成都會根據(jù) L′ 重新調(diào)整旋轉(zhuǎn)弧度,然后再進行下一次生成。
-
調(diào)整RoPE嵌入:使用動態(tài)比例因子s來調(diào)整RoPE嵌入的旋轉(zhuǎn)角度參數(shù) $θ_?? \(。這是通過應(yīng)用一個新的基底b' 來實現(xiàn)的,該基底與比例因子s相關(guān)聯(lián):\) ??′=?????$ 其中b是原始RoPE方法中的基底。
-
計算新的查詢和鍵向量:根據(jù)調(diào)整后的 $θ_??′ $,計算新的查詢 \(??_??′\)和鍵 $??_??′ $向量。這些向量將用于模型的自注意力機制,以處理擴展后的上下文長度。
-
推理時的動態(tài)擴展:在推理時,模型會根據(jù)輸入序列的實際長度動態(tài)調(diào)整RoPE嵌入。這意味著模型可以在處理短序列時保持原始性能,在處理長序列時擴展其上下文窗口。
以下是transformer庫的實現(xiàn):
class LlamaDynamicNTKScalingRotaryEmbedding(LlamaRotaryEmbedding):
"""LlamaRotaryEmbedding extended with Dynamic NTK scaling. Credits to the Reddit users /u/bloc97 and /u/emozilla"""
def forward(self, x, position_ids):
# difference to the original RoPE: inv_freq is recomputed when the sequence length > original length
seq_len = torch.max(position_ids) + 1
if seq_len > self.max_position_embeddings:
# 當(dāng)模型拓展長度后,才進行NTK-ROPE
# Dynamic NTK方法的關(guān)鍵計算公式,通過修改base值來改變每個位置的頻率
base = self.base * (
(self.scaling_factor * seq_len / self.max_position_embeddings) - (self.scaling_factor - 1)
) ** (self.dim / (self.dim - 2))
inv_freq = 1.0 / (
base ** (torch.arange(0, self.dim, 2, dtype=torch.int64).float().to(x.device) / self.dim)
)
self.register_buffer("inv_freq", inv_freq, persistent=False) # TODO joao: this may break with compilation
cos, sin = super().forward(x, position_ids)
return cos, sin
6.5 YaRN
YaRN是一種高效擴展使用旋轉(zhuǎn)位置嵌入(RoPE)的大型語言模型上下文窗口的方法,在中間維度實現(xiàn)了動態(tài)縮放,同時在低維度保持無插值,在高維度實現(xiàn)完全插值。
無論是Position Interpolation還是NTK類方法,本質(zhì)都是通過減小旋轉(zhuǎn)弧度,降低旋轉(zhuǎn)速度,來達到長度擴展的目的。向量的內(nèi)積公式如下。
向量旋轉(zhuǎn)不改變模長,當(dāng) q 和 k 的旋轉(zhuǎn)弧度變小,這將導(dǎo)致位置之間的旋轉(zhuǎn)弧度差距變小(它們之間的夾角 \(\gamma\)變小),詞向量之間的距離變得比原來更近,所以兩者的內(nèi)積會變大,最終會改變模型的注意力分布。這實際上弱化了RoPE注意力分?jǐn)?shù)的遠程衰減。從注意力分?jǐn)?shù)的分布角度出發(fā),這會低估實際的注意力分?jǐn)?shù)的分布差異(弱化注意力分?jǐn)?shù)的遠程衰減,注意力分?jǐn)?shù)的diff也相應(yīng)被弱化),破壞模型原始的注意力分布。所以經(jīng)過插值之后,模型在原來的訓(xùn)練長度內(nèi)的困惑度均有所提升,性能受損。并且可以發(fā)現(xiàn),RoPE的注意力遠程衰減的性質(zhì)變?nèi)酰@也將導(dǎo)致整個序列的注意力分布變得更加平滑。
YaRN本質(zhì)上是NTK-by-parts Interpolation與注意力分布修正策略的結(jié)合,僅縮小低頻部分的旋轉(zhuǎn)弧度,且通過溫度系數(shù)修正注意力分布,將上述這種under-estimation通過softmax的溫度系數(shù)補償回來,即將原來的注意力分?jǐn)?shù)除以溫度 t。
因為長度的外推,平均最小距離隨著token數(shù)量的增加而變得更近,使注意力 softmax 分布的峰度值變得比較高(即減少了注意力 softmax 的平均熵),換句話說,長距離的衰減會因為插值而減弱,網(wǎng)絡(luò)會關(guān)注更多的token。所以為了去扭轉(zhuǎn)這種熵的減少,可以在attention計算的softmax之前乘以一個溫度 t, 并且t > 1來實現(xiàn),但是因為ROPE是是一個旋轉(zhuǎn)矩陣,可以對ROPE的長度進行縮放。以LLaMA為例,針對最小化LLaMA的困惑度,t和s之間大概遵循經(jīng)驗公式 $\sqrt t ≈0.1?ln?(??)+1 $。當(dāng)長度從2048擴展至16384時,長度擴展為原來的8倍,代入公式,計算得到 ??=0.6853 。回顧溫度系數(shù)對注意力分布的影響,當(dāng) ?? 變大,注意力分布更加平滑,方差更小;當(dāng) ?? 變小,注意力分布更加尖銳,區(qū)分度變大,方差變大。 ??=0.6853 意味著緩解注意力分布過于平滑的問題,讓注意力分布方差更大些。
以下是YaRN方法的具體步驟:
- 引入NTK-aware Interpolation:為了解決在擴展上下文窗口時可能出現(xiàn)的高頻信息丟失問題,YaRN采用了NTK-aware Interpolation技術(shù),通過對不同頻率的維度進行不同程度的縮放來保持高頻信息。
- 應(yīng)用NTK-by-parts Interpolation:YaRN方法根據(jù)維度的波長(wavelength)來決定是否對RoPE嵌入進行插值。對于波長大于或等于原始上下文長度的維度,不進行插值;對于波長小于原始上下文長度的維度,進行線性插值。
- 應(yīng)用Dynamic NTK動態(tài)調(diào)整上下文長度:YaRN使用動態(tài)上下文長度調(diào)整,這意味著在推理時,模型可以根據(jù)輸入序列的實際長度動態(tài)調(diào)整其上下文窗口。
- 溫度縮放:為了解決在擴展上下文窗口時可能出現(xiàn)的注意力分布變化問題,YaRN引入了溫度縮放機制。通過調(diào)整注意力得分的溫度參數(shù),可以增加注意力分布的熵,從而保持模型的注意力集中在相關(guān)的標(biāo)記上。 $\sqrt t ≈0.1?ln?(??)+1 $。
6.6 Giraffe
Giraffe通過保留高頻旋轉(zhuǎn)并抑制低頻旋轉(zhuǎn)來實現(xiàn)外推。
\(??_??\)從小到大對應(yīng)低頻至高頻的不同特征。而在訓(xùn)練過程中,模型已經(jīng)看到了全范圍的高頻分量,卻沒有看到全部的低頻分量。這種不平衡使得模型對低頻進行外推是一項特別困難的任務(wù)。因此,除以一個常數(shù)顯然過于簡單。Giraffe讓每個維度乘上一個隨維度自適應(yīng)變化的系數(shù)。系數(shù)和維度之間滿足冪函數(shù)的關(guān)系,因此該操作被稱為冪校正(Power Scaling),此外Giraffe還把校正后較小的\(??_??\)直接設(shè)為0。

其中 k 是要設(shè)置的參數(shù),ρ是一個相對較小的固定值, a 和 b 是選定的截斷值。模型將通過選擇適當(dāng)?shù)慕財嘀担谖⒄{(diào)期間使用的上下文長度中體驗所有基值,這樣可以在推理過程中進行更好的推斷。通過應(yīng)用這種變換,基礎(chǔ)的高頻(短距離)元素比低頻(長距離)元素受到的影響更小。
6.7 訓(xùn)練
蘇神有一個利于圓盤來講解編碼訓(xùn)練的精彩示例Transformer升級之路:16、“復(fù)盤”長度外推技術(shù),而且猛猿的大作避開復(fù)數(shù)推導(dǎo),我們還可以怎么理解RoPE? 也有精彩分析。我們來學(xué)習(xí)解讀下。
\(??^{(?????)????}\) 實際就是單位圓上的點,這個點逆時針旋轉(zhuǎn) (?????)???? 度,當(dāng)m?n逐漸變大時,這個點就在單位圓上轉(zhuǎn)圈,θi越大則轉(zhuǎn)得越快,反之越慢。在訓(xùn)練位置編碼的過程中,我們可以看成是在訓(xùn)練d/2個轉(zhuǎn)速不一的單位圓。(如果圓上的點都被訓(xùn)練過了,就認為訓(xùn)練充分了)。如果測試的時候遇到更大的文本,那么就超出了訓(xùn)練過的弧范圍,從而有無法預(yù)估的表現(xiàn)。這個時候就要想辦法將它壓縮到已經(jīng)被充分訓(xùn)練過的那段弧上(位置內(nèi)插)。
讓我們來延續(xù)圓盤訓(xùn)練的視角,來可視化理解一下NTK-RoPE的設(shè)計原理和運作流程。
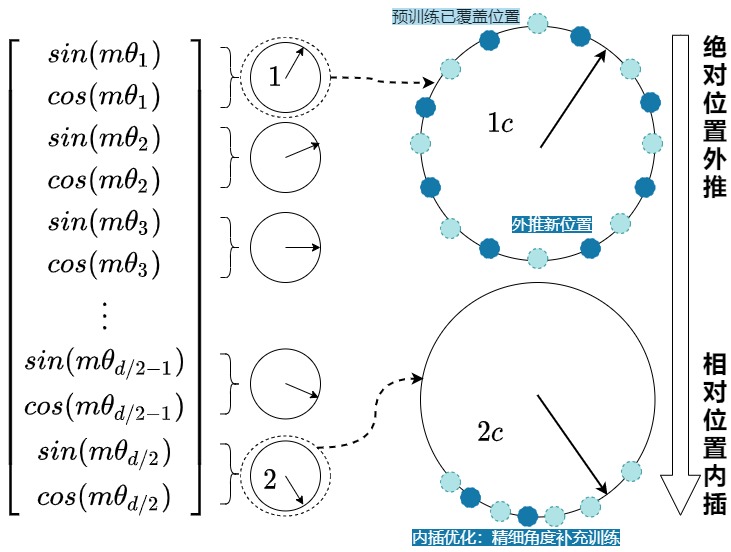
假設(shè)現(xiàn)在我們已經(jīng)過一次預(yù)訓(xùn)練,那么對于不同轉(zhuǎn)速的圓盤,其被訓(xùn)練過的圓周長度也是不一樣的,對于高頻(i更靠近0)的圓盤來說,它被訓(xùn)練過的圓周長度越長。而對于低頻(i更靠近d/2-1)的圓盤來說,它被訓(xùn)練過的圓周長度越短,如下圖所示:

在這個基礎(chǔ)上,現(xiàn)在我們想使用更長的文本做continue-pretrain或者推理,這個時候,從直覺上來說,我們肯定希望圓盤能實現(xiàn)下面的要求:
- (1) 盡量不要偏移已經(jīng)訓(xùn)練過的圓周范圍。例如,對于圖中第一個圓盤,我們就在pretrain走過的綠點的圓周范圍內(nèi),做細節(jié)填充(藍色點),這個操作也就等于盡可能利用已經(jīng)訓(xùn)練好的位置相關(guān)信息。即,對于靠前的圓盤,我們盡量讓它學(xué)習(xí)到【絕對位置】信息,嘗試突破pretrain看過的圓周部分(外推)。
- (2) 盡量學(xué)到比pretrain更多的位置信息。雖然我們希望盡可能實現(xiàn)(1),但同時圓盤上那些沒訓(xùn)練過的圓周位置,我們就不管了嗎?如果我們引入了更長的文本,我們當(dāng)然希望在保守訓(xùn)練的同時,能學(xué)到一些新知識。所以希望對于下圖最后一個圓盤,我們希望引入新的藍色點。即,靠后的圓盤,我們盡量讓它學(xué)習(xí)到【相對位置】信息,保持在pretrain看過的圓周部分,只做精細角度的訓(xùn)練(內(nèi)插)。
我們可以將NTK-Aware Interpolation奏效的原因按照如下方式進行解釋:
- 靠前的分組,在訓(xùn)練中見過非常多完整的旋轉(zhuǎn)周期,位置信息得到了充分的訓(xùn)練,所以具有較強的外推能力。
- 靠后的分組,在訓(xùn)練中無法見到完整的旋轉(zhuǎn)周期,或者見到的旋轉(zhuǎn)周期非常少,訓(xùn)練不夠充分,外推性能弱,需要進行位置插值。
也可以得到目前訓(xùn)練長文本的一個常用方法:
- 先用“小基數(shù) + 短數(shù)據(jù)”做訓(xùn)練(讓每個圓盤都盡量轉(zhuǎn)滿一圈)。
- 再用“大基數(shù) + 長文本”做微調(diào)(彌補圓盤上的空隙),之前已經(jīng)學(xué)過的點就是先驗知識,讓我們微調(diào)效果更好。
另外,這種訓(xùn)練方法也和Kimi 提出的"long2short"方法暗合。"long2short"方法是將長上下文模型中習(xí)得的推理能力遷移至更高效的短上下文模型。這有效解決了實際應(yīng)用痛點 —— 長上下文模型運行成本高昂,將其知識蒸餾至更輕量、更快速的模型具有重要商業(yè)價值。這也正是 R1 模型成功實現(xiàn) Qwen 與 Llama 系列模型蒸餾(長思維鏈到短思維鏈的知識蒸餾)的技術(shù)基礎(chǔ)。
0xFF 參考
Fourier Features Let Networks Learn High Frequency Functions in Low Dimensional Domains
Scaling Laws of RoPE-based Extrapolation
Randomized Positional Encodings Boost Length Generalization of Transformers
ENCODING WORD ORDER IN COMPLEX EMBEDDINGS
Encoding Word Order in Complex Embeddings Jsgfery
LongRoPE: Extending LLM context window beyond 2 million tokens
RoPE外推的縮放法則 —— 嘗試外推RoPE至1M上下文 河畔草lxr
Scaling Laws of RoPE-based Extrapolation
Transformer升級之路:7、長度外推性與局部注意力 蘇劍林
Transformer升級之路:16、“復(fù)盤”長度外推技術(shù)
Transformer升級之路:10、RoPE是一種β進制編碼
Transformer升級之路:12、無限外推的ReRoPE?
Bias項的神奇作用:RoPE + Bias = 更好的長度外推性
Transformer升級之路:9、一種全局長度外推的新思路
Transformer升級之路:15、Key歸一化助力長度外推
[通俗易讀]無痛理解旋轉(zhuǎn)位置編碼RoPE(數(shù)學(xué)基礎(chǔ),理論(復(fù)數(shù)的指數(shù)表達,矩陣,幾何意義),代碼,分析) 車中草同學(xué)
避開復(fù)數(shù)推導(dǎo),我們還可以怎么理解RoPE? 猛猿
大模型結(jié)構(gòu)基礎(chǔ)(二):Positional Encodings 的升級 張峻旗
【手撕LLM-NTK RoPE】長文本“高頻外推、低頻內(nèi)插“從衰減性視角理解 小冬瓜AIGC
EXTENDING CONTEXT WINDOW OF LARGE LANGUAGE MODELS VIA POSITION INTERPOLATION
LLM中Long Context技術(shù)解析 Jarlene
ALiBi位置編碼深度解析:代碼實現(xiàn)、長度外推 JMXGODLZ
上下文擴展探索:FOT與MT的外部存儲策略 JMXGODLZ
Transformer升級之路:15、Key歸一化助力長度外推 蘇劍林
akaihaoshuai:從0開始實現(xiàn)LLM:4、長上下文優(yōu)化(理論篇)
[ICLR 2024]大模型的連續(xù)長度外推--將LLMs高效擴展到100K以上 Orthogonality
Transformer升級之路:16、“復(fù)盤”長度外推技術(shù) - 科學(xué)空間|Scientific Spaces
讓預(yù)訓(xùn)練 Transformer 生成更長的文本/圖像:位置編碼長度外推技術(shù) [天才程序員周弈帆](javascript:void(0)??
Transformer位置編碼(基礎(chǔ)) 河畔草lxr
RoPE外推的縮放法則 —— 嘗試外推RoPE至1M上下文 河畔草lxr
Transformer升級之路:10、RoPE是一種β進制編碼
Giraffe: Adventures in Expanding Context Lengths in LLMs
Yutao Sun, Li Dong, Barun Patra, Shuming Ma, Shaohan Huang, Alon Benhaim, Vishrav Chaudhary, Xia Song, and Furu Wei. 2023. A Length-Extrapolatable Transformer. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), pages 14590–14604, Toronto, Canada. Association for Computational Linguistics.
深度長文|大模型“長考”失利:NoLiMa 揭示“長度”焦慮下的能力真相 chouti
NoLiMa: Long-Context Evaluation Beyond Literal Matching: https://arxiv.org/abs/2502.05167
上下文長度擴展:從RoPE到Y(jié)ARN barely
bloc97. NTK-Aware Scaled RoPE allows LLaMA models to have extended (8k+) context size without any fine-tuning and minimal perplexity degradation., 2023. URL https://www.reddit.com/r/LocalLLaMA/comments/14lz7j5/ntkaware_ scaled_rope_allows_llama_models_to_have/
bloc97. Add NTK-Aware interpolation "by parts" correction, 2023. URL https://github.com/jquesnelle/scaled-rope/pull/1.
從ROPE到Y(jié)arn, 一條通用公式速通長文本大模型中的位置編碼 Whisper
Thus Spake Long-Context Large Language Model
長上下文大語言模型如是說(上篇) Meet DSA

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號