
探秘Transformer系列之(20)--- KV Cache
探秘Transformer系列之(20)--- KV Cache
0x00 概述
隨著輸入給LLM的token列表增長,Transformer的自注意力階段可能成為性能瓶頸。token列表越長,意味著相乘的矩陣越大。每次矩陣乘法都由許多較小的數值運算組成,這些運算稱為浮點運算,其性能受限于GPU的每秒浮點運算能力(FLOPS)。這樣,在LLM的部署過程中,推理延遲和吞吐量問題成為了亟待解決的難題。這些問題主要源于:
- 生成推理的序列自回歸特性,需要為所有先前的標記重新計算鍵和值向量。
- 由于注意力機制與輸入序列的大小呈二次方關系增長,因此在推理過程中,注意力機制往往會產生最大的延遲開銷。
為解決推理延遲和吞吐量問題,最常用的優化技術是KV Cache。KV Cache是一種關鍵的性能優化機制。它通過緩存已計算的Key和Value矩陣,避免在自回歸生成過程中重復計算,從而顯著提升推理效率(本質就是用空間換時間)。這種機制類似于人類思維中的短期記憶系統,使模型能夠高效地利用歷史信息。通過復用 KV Cache,可以達到兩大目的:
- 提升 Prefill 效率。由于參與 Prefill 的 Tokens 數減少,所以計算量下降,Prefill 的延時也就下降,直接提升 TTFT 性能。特別適合優化多輪對話場景的性能。
- 節省顯存。KV緩存中存儲了生成推理過程中至關重要的可重用中間數據。
本篇先介紹在不使用 KV Cache 的情況下是如何一步步預測下一個 token 的,然后介紹 KV Cache。
注意:本文的分析梳理可能與實際概念產生歷史軌跡不同,這么梳理只是因為作者覺得這樣更容易解釋。
0x01 自回歸推理的問題
多輪對話是現代大型語言模型(LLM)的基本功能。在這種對話中,一個多輪對話會話由一系列連續的對話組成,記作D = [d1, d2, ... dN]。在每個對話dj中,用戶輸入一個新的問題或命令qj,然后等待LLM的響應aj。
LLM使用的是自回歸模式。自回歸模型的推理過程很有特點:推理生成 tokens 的過程是迭代式的。用前文預測下一個字/詞,并且前文中的最后一個詞經過解碼器的表征會映射為其下一個待預測詞的概率分布。具體來說是,我們給定一個輸入文本,模型會輸出一個回答(長度為N)。但實際上該過程中執行了N次推理過程。即一次推理只輸出一個token,當前輪輸出的 token 會與之前輸入 tokens 拼接在一起,并作為下一輪的輸入 tokens,這樣不斷反復直到遇到終止符或生成的 token 數目達到設置的 max_new_token 才會停止。

1.1 請求的生命周期
實際上對LLM的使用中,prompt都是較長的序列。在不考慮KV Cache的情況下,因為prompt的實際特點,導致LLM推理過程中存在著prompt phase(提示處理)和 token-generation phase(token生成)這兩個截然不同的過程。
- prompt phase:LM服務接受到用戶請求(Is tomato a fruit?),根據輸入 Tokens(Is, tomato, a, fruit, ?) 生成第一個輸出 Token(Yes)。
- token-generation phase:從生成第一個 Token(Processing) 之后開始,把 prompt 以及已生成的 tokens 組成新的模型輸入,采用自回歸方式一次生成一個 Token,直到生成一個特殊的 Stop Token(或者滿足用戶的某個條件,比如超過特定長度) 才會結束。該過程中,前后兩輪的輸入只相差一個 token,存在重復計算。
prompt phase整體算1個推理階段, token-generation phase中的每個decode各算1個推理階段,比如下圖 token-generation phase階段包括3次推理。
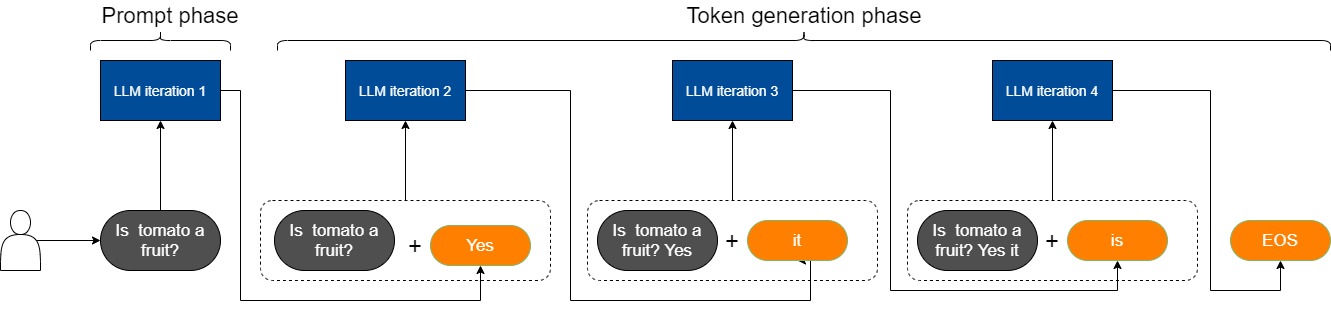
我們對兩個階段的特點進行深入分析。
prompt phase(預填充階段),也有叫啟動階段(initiation phase),其特點如下:
- 時機:發生在計算第一個輸出 token 過程中。
- 輸入:輸入一個prompt序列。
- 作用:一次性處理所有的用戶輸入。LLMs對輸入序列(即輸入提示)的上下文進行總結,并生成一個新標記作為解碼階段的初始輸入。
- 執行次數:其通過一次 Forward 就可以完成。
- 計算類型:存在大量 GEMM (GEneral Matrix-Matrix multiply) 操作,屬于 Compute-bound 類型(計算密集型)計算。
- 并行:輸入的Tokens之間以并行方式執行運算,是一種高度并行化的矩陣操作,具備比較高的執行效率。
token-generation phase的特點如下:
- 時機:在prompt階段生成第一個 Token之后,開始進入token-generation phase階段。發生在計算第二個輸出 token 至最后一個 token 過程中。
- 輸入:新生成的token會與輸入tokens 拼接在一起,作為下一次推理的輸入。
- 作用:新生成的標記被反饋回解碼階段作為輸入,從而創建了一個用于標記生成的自回歸過程。
- 執行次數:假設輸出總共有 N 個 Token,則 token-generation phase階段需要執行 N-1 次 Forward。
- 計算類型:存在大量 GEMM (GEneral Matrix-Matrix multiply) 操作,屬于 Compute-bound 類型(計算密集型)計算。
- 并行:假設輸出總共有 N 個 Token,則 Decoding 階段需要執行 N-1 次 Forward,這 N-1 次 Forward 只能串行執行,因此效率相對比較低。另外,在生成過程中,需要關注的 Token 越來越多(每個 Token 的生成都需要 Attention 之前的 Token),計算量也會適當增大。
自回歸的生成模式是兩階段的根本原因,兩階段是自回歸的生成模式的外在體現形式,KV cache是優化手段。
注:在SplitWise論文中,分別把這兩個階段稱為prompt phase 和 token-generation phase。在實踐中,“預填充(pre-fill)”和“初始化(initiation)”這兩個術語可以互換。為了更好的說明,現在我們將更傾向于使用前者。
1.2 簡化推導
我們用實例來看看LLM類模型對于給定文本的回答過程。為了更好的梳理,此處的prompt只是一個詞(與實際情況不符)。我們可以將回答過程分解為下列推理:輸入“新”,模型逐步預測出“年”,“大”,“吉”,[EOS]這幾個詞。具體推理步驟如下。
第一次推理: 輸入=[BOS]新;輸出=年
第二次推理: 輸入=[BOS]新年;輸出=大
第三次推理: 輸入=[BOS]新年大;輸出=吉
第四次推理: 輸入=[BOS]新年大吉;輸出=[EOS]
其中[BOS]和[EOS]分別是起始符號和終止符號。
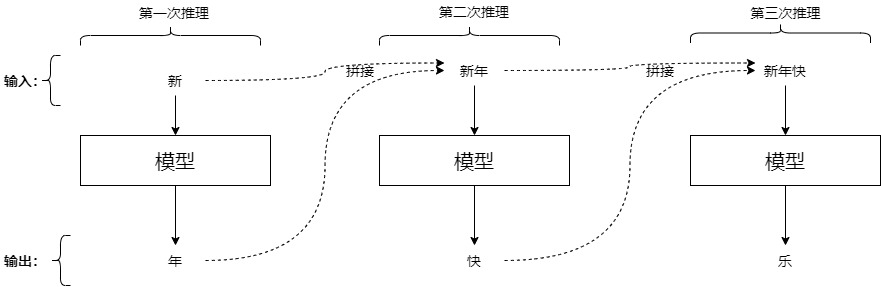
我們接下來深入到Transformer內部逐一看看上述推理流程。注意:下面的示例圖只給出了和 KV Cache 相關的細節。
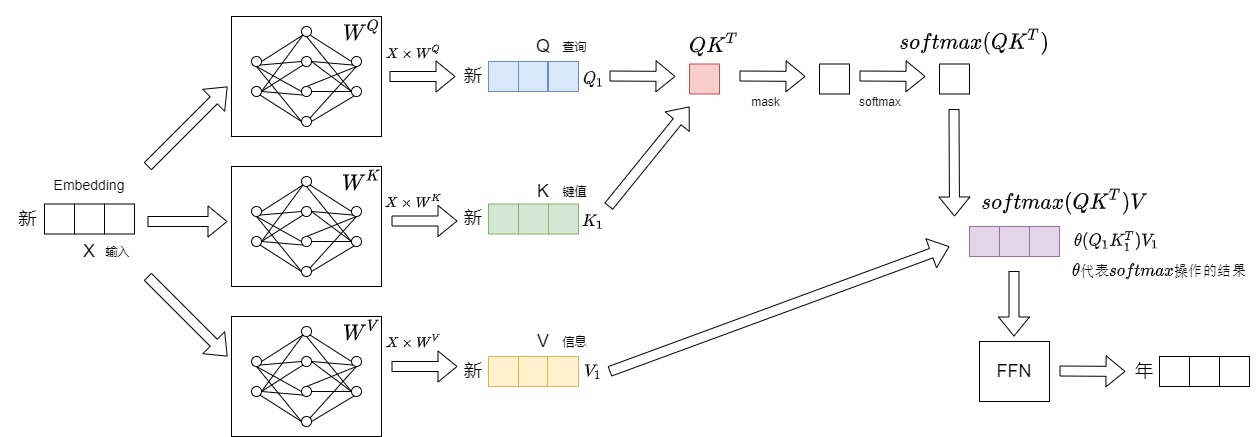
第一步輸入“新”,輸出“年"。本步驟具體數據流如下圖所示。
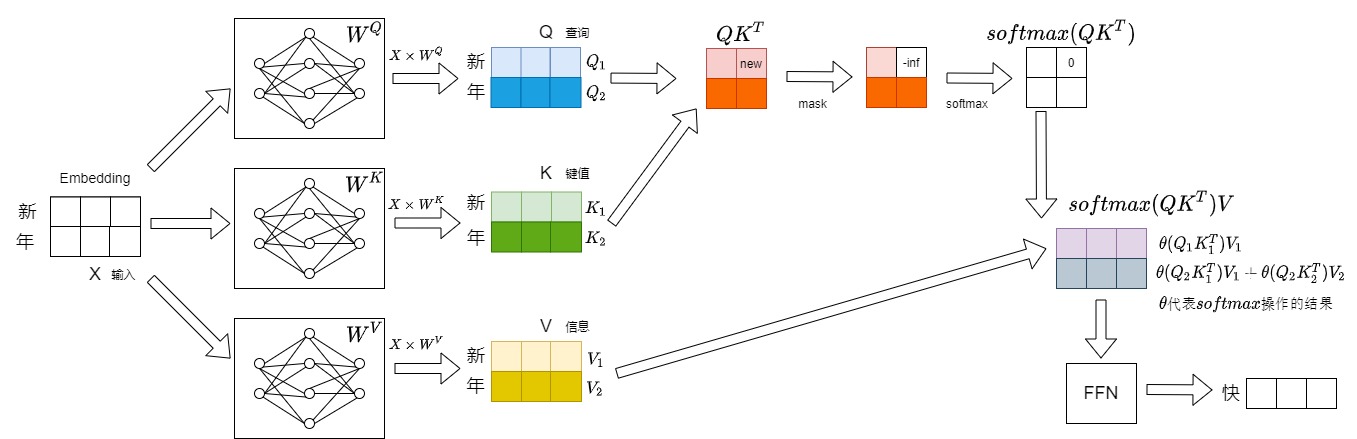
第二步會將”年“拼接到”新“的后面作為新的輸入,即本次推理的輸入為”新年“,預測得到”快“。本步驟具體數據流如下圖所示。
第三步會將”快“拼接到”新年“的后面作為新的輸入,即本次推理的輸入為”新年快“,預測得到”樂“。本步驟具體數據流如下圖所示。
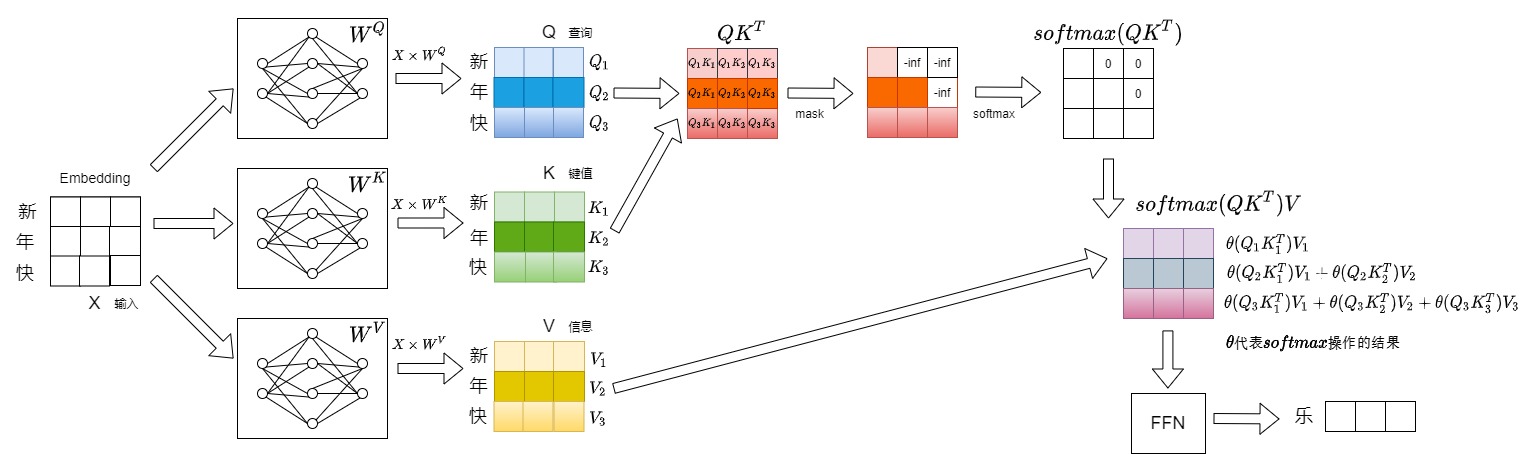
1.3 冗余分析
我們把上面三步匯總起來如下圖所示。會發現其中存在大量的冗余計算,每生成一個token需重新計算所有歷史token的Key/Value,復雜度為 \(O(n^2)\) ,顯存和計算時間隨序列長度急劇增長,比如:
- 生成embedding有冗余計算。
- KV生成有冗余計算。
- \(QK^T\)有冗余計算。
- softmax操作以及與V相乘有冗余計算。
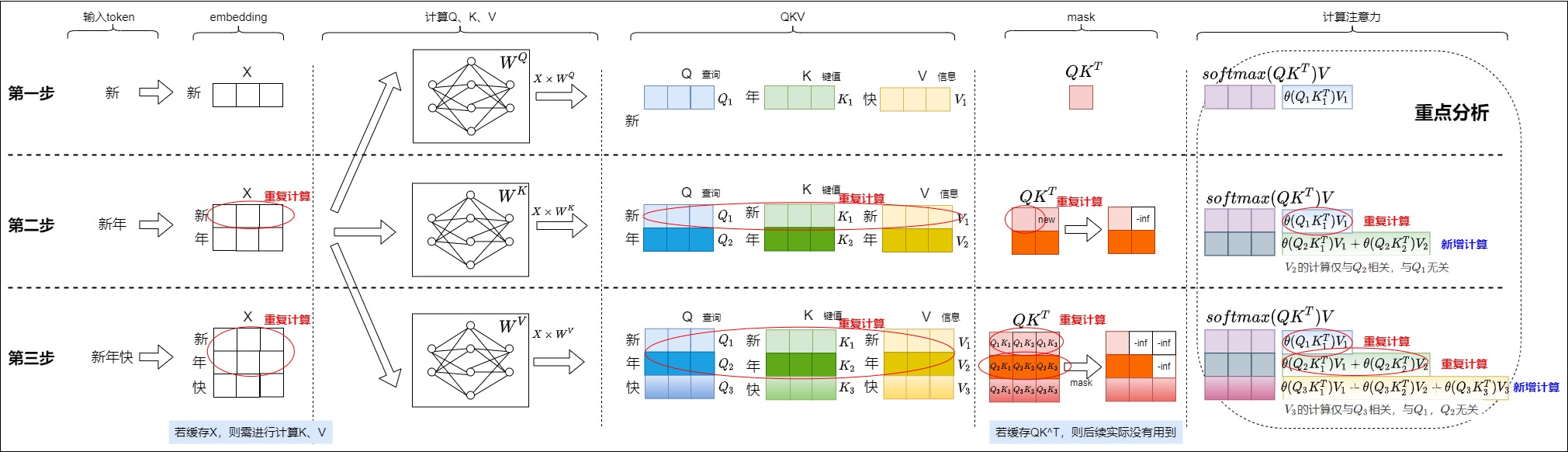
因為每一步中前面的操作都是為計算注意力做準備,因此我們針對注意力部分進行重點分析。每一步中涉及注意力的計算如下(下面的\(\theta\)指代softmax操作后的結果,比如第二步中,\(\theta(Q_2K_1^T)\)可能是0.4,\(\theta(Q_2K_2^T)\)可能是0.6)。
- 第一步涉及的計算為:\(\theta(Q_1K_1^T)V_1\)。
- 第二步涉及的計算為:\(\theta(Q_1K_1^T)V_1\),\(\theta(Q_2K_1^T)V_1 + \theta(Q_2K_2^T)V_2\)。
- 有一步重復計算\(\theta(Q_1K_1^T)V_1\),這步重復計算僅僅依賴于\(Q_1K_1V_1\),和\(Q_2K_2V_2\)沒有關系。
- \(V_2\)的計算是新增計算,從\(\theta(Q_2K_1^T)V_1 + \theta(Q_2K_2^T)V_2\)中可以看到,\(V_2\)的計算僅與\(Q_2\)相關,與\(Q_1\)無關。
- 第三步涉及的計算為:\(\theta(Q_1K_1^T)V_1\),\(\theta(Q_2K_1^T)V_1 + \theta(Q_2K_2^T)V_2\),\(\theta(Q_3K_1^T)V_1 + \theta(Q_3K_2^T)V_2 + \theta(Q_3K_3^T)V_3\)。
- 有兩步重復計算,具體道理和第二步類似。
- \(V_3\)的計算是新增計算,其僅與\(Q_3\)相關,與\(Q_1\),\(Q_2\)無關。
看起來,在預測第i個字時,只有最后一步引入了新的計算,而第1個到第i-1步的計算和前面是完全重復的。
1.4 冗余根源
現在我們探尋冗余計算的原因,即為什么之前的詞不需要重復計算。
1.4.1 看處理邏輯
為了生成與上下文緊密相關的新標記,LLMs需要在注意力層中計算最后一個token與所有之前token(包括輸入序列中的token)之間的關系。一種簡單的方法是在每個迭代中重新計算所有之前標記的鍵和值。因此每一步中,當前輪輸出token與輸入tokens拼接作為下一輪的輸入tokens。第i+1輪輸入數據只比第i輪輸入數據新增了一個token,其他全部相同。然而,這樣第i+1輪推理時必然包含了第 i輪的部分計算,再對前面的單詞做計算就是冗余。而且計算開銷隨著之前標記數量的增加而線性增長,即對于更長的序列,開銷會更大。
對于每次token生成,其查詢是從當前token計算出來的,而鍵和值是從所有token派生出來的,并且對于后續token不會更改。vanilla Transformer的實現會在生成每個新token時重新計算鍵和值們,從而不必要地增加了 GPU 每個注意力塊所需的計算量。
1.4.2 看處理過程
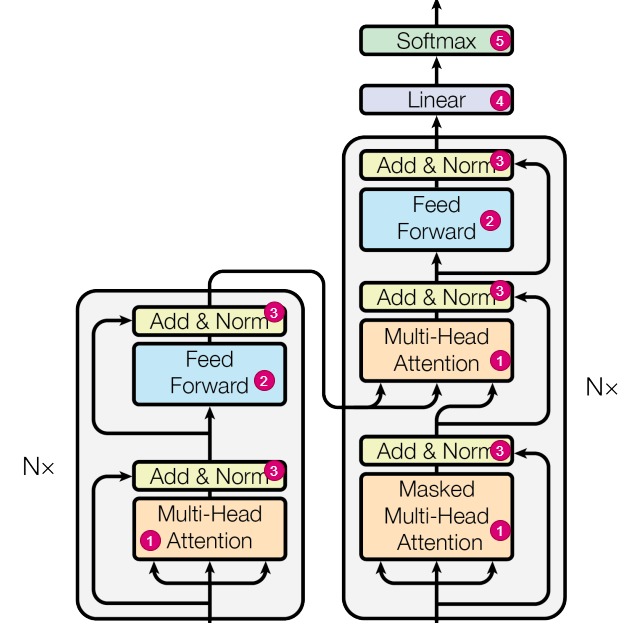
從網絡結構來看,Transformer的主要模塊決定了不需要重復計算:
-
注意力模塊(對應下圖中標號1)。
-
推理時,前面生成的token看不到后續生成的token,所以前面已經生成的 token不需要與后面的 token進行注意力計算。在“單向 attention”的影響下,序列預測過程的第 i 個時間步的 query 向量 \(q_i\) 不會影響前序所有時間步的 \([k_1, k_2,..., k_{i-1}]\) 和\([v_1, v_2,..., v_{i-1}]\) 。比如, i=3 時的 \(k_2\) 和 i=4 時的\(k_2\) 完全相同。在 Transformer 的每一層,Key 和 Value 都不會被重復計算。
-
訓練時,由于掩碼技術的使用,在生成當前 tokens 的輸出表征時,僅使用之前已生成 tokens 的信息,而不使用之后生成的 tokens 的信息。即\(Q_i\)與\(K_{i+j}\),\(V_{i+j}\)的計算會被mask掉,不需要計算。掩碼的主要優點是將(自)注意力機制的FLOPs需求從與總序列長度呈二次方擴展變為線性擴展。在每個生成步驟中,我們實際上可以避免重新計算過去token的鍵和值,而只需計算最后生成的token。每次計算新的鍵和值時,我們的確可以將它們緩存到GPU內存中以供未來重復使用,因此節省了重新計算它們時所需的浮點運算次數。
-
-
FFN(對應下圖中標號2)。在FFN計算中,序列中各個詞對應的特征不會交互信息,不會互相影響,并且最終只取最后一個位置的輸出特征作為下一個token的概率分布。因此,經過FNN層后,第 i 個輸出的新增計算只和第 i 個輸入有關,和其他輸入無關,比如下面\(Y_1\)的計算只和\(X_1\)相關。
\[\begin{bmatrix} X_0 \\ X_1 \\ X_2 \\ X_3 \\ \end{bmatrix}W^T = \begin{bmatrix} X_0 W^T\\ X_1 W^T\\ X_2 W^T\\ X_3 W^T\\\end{bmatrix} = \begin{bmatrix} Y_0 \\ Y_1 \\ Y_2 \\ Y_3 \\ \end{bmatrix}\]- Add & Norm(對應下圖中標號3)。對于LayerNorm,它是在
d_model方向上計算均值和方差,然后進行歸一化,因此它的輸出也只與輸入hidden_state的最后一行相關。 - Linear(對應下圖中標號4)。這是一個將
hidden_state的維度從d_model變換到vocab_size的線性映射,根據矩陣乘法的性質,可以知道logits的最后一行只與hidden_state的最后一行相關。 - Softmax(對應下圖中標號5)。softmax只要把之前的計算結果存儲起來,就可以結合新計算的結果來進行計算。
- Add & Norm(對應下圖中標號3)。對于LayerNorm,它是在
1.5 如何改進
雖然我們推導出來有冗余計算,但是vanilla Transformer在推理的時候可不管這些,無論你是不是只要最后一個字的輸出,它都把所有輸入計算一遍,導致輸出結果中間有很多我們用不到的計算,這樣就造成了浪費。這就是問題所在。因此我們要看看如何改進。因為涉及到對某些和前文相關的中間變量進行緩存或者丟棄,我們需要仔細斟酌究竟緩存哪些、丟棄哪些。
1.5.1 從網絡角度看
我們從模型架構來看看幾種選擇方式。
| 選擇 | 結論 | 原因 |
|---|---|---|
| 丟棄前面的X(輸入的token) | 不行 | 下面詳細解釋 |
| 緩存X | 可以,但不是最優選擇 | 因為即便緩存了X,還需要計算K和V |
| 緩存\(QK^T\) | 不行 | 實際計算下一個token時候并沒有使用到之前的\(QK^T\) |
| 丟棄之前的query | 可以 | 模型的第i個輸出只和query'的第 i 個token有關,和其他query無關,新增計算只和當前\(Q_i\)關聯,但是和之前的\(Q_{0,i-1}\)沒有關聯,所以完全沒有必要緩存之前的query。 |
| 丟棄之前的KV | 不行 | 下面詳細解釋 |
| 緩存之前的KV | 可以 | 下面詳細解釋 |
為何不能丟棄前面的輸入token
我們知道,推理最終只會選取最后一個位置的輸出特征作為下一個token的概率分布,即下一個token是由當前最后一個token的網絡輸出所決定的。但這不代表可以僅輸入最后一個token來進行推理。因為雖然在結果層僅由最后一個token來決定,但是中間的注意力過程依賴于前文所提供的Key、Value向量來攜帶前文信息,因此也不能拋棄前文不管。
或者說,由X生成Q、K、V三個分支,因為前面的K和V不能丟棄。所以不能單純丟棄前面的X。但是由于Q在自回歸Transformer模型中的使用特性和計算過程中的不對稱性,緩存Q不會帶來推理效率的提升,因此LLM推理過程中通常不緩存Q。
當然,因為X派生了K和V,如果緩存K和V,就可以丟棄輸入X。
為何不能丟棄之前的KV
前面提到了KV不可或缺。我們接下來再深入分析。
在注意力機制中,第 i 個輸出 $O_i \((可以拓展到每個transformer block的輸出)和完整的K、V以及當前時刻的\)Q_i\(都有關。我們以第二步計算為例:紅圈表示\)O_0\(計算所涉及的元素,藍圈表示\)O_1$計算所涉及的元素。可以看到藍圈涉及到所有K和V。
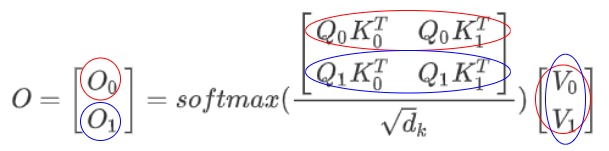
我們再用高階向量來細化到具體運算,從下圖可以看到,\(O_3\)的計算涉及所有的QKV。
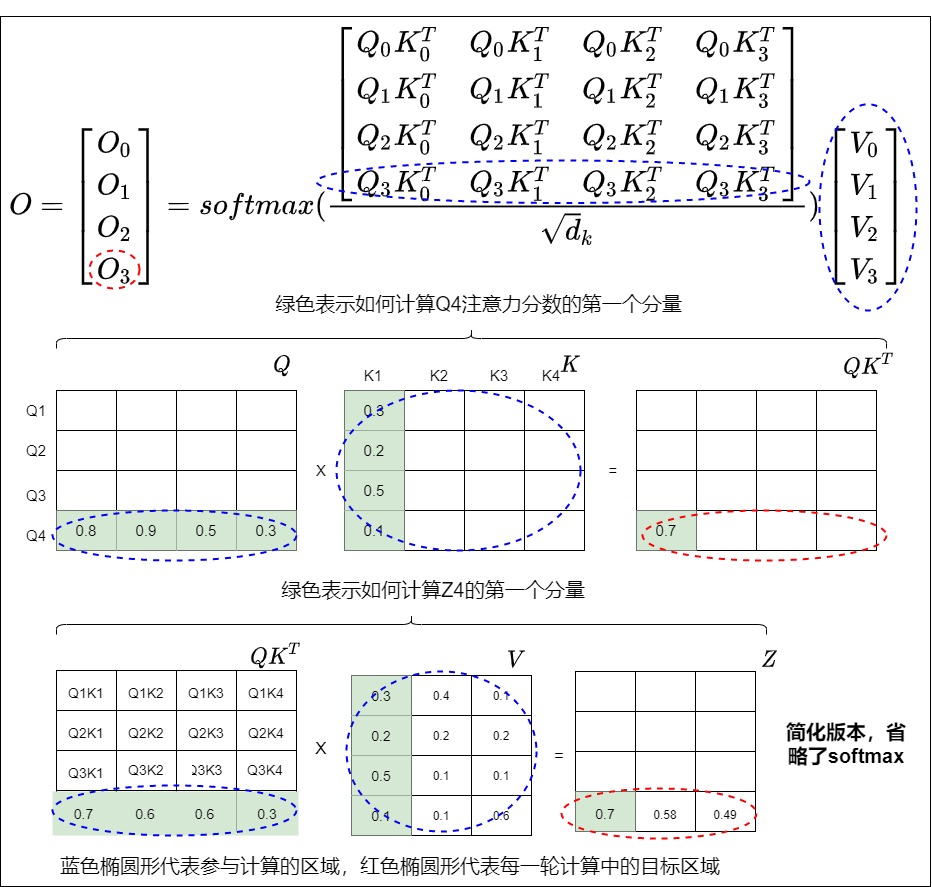
緩存之前KV的可行性
既然之前的KV是必需的,我們接下來就看看緩存的可行性。
- 首先,K、V的歷史值只和歷史的O有關,和當前的O無關,從這個角度看可以緩存K和V。
- 其次,先前的token在后續迭代過程中保持不變,因此對于該特定token的輸出表征對于所有后續迭代也將是相同的。在推理時,模型的權重已經固定(\(W^Q\),\(W_K\),\(W^V\)的權重固定),對于同一個詞,如果它的Token Embedding和位置編碼都是固定的,則從\(W^Q\),\(W_K\),\(W^V\)計算得到的Q,K,V是固定的。因此計算一次即可。
因此,我們可以通過緩存歷史的K、V來避免重復計算歷史K、V。
1.5.2 從數學角度看
假設矩陣A和矩陣B相乘,我們將矩陣A拆分為[:s], [s]兩部分,分別和矩陣B相乘,那么最終結果可以直接拼接,該結果與不分拆結果一致。注意力和FFN都是矩陣乘法操作,因此將[:s]部分緩存,來避免[:]整體輸入導致的重復計算。
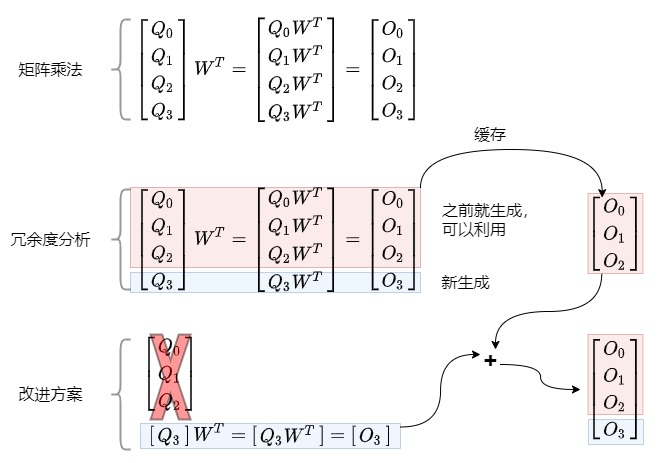
1.5.3 結論
以上的分析證明了緩存KV再拼接計算的結果和正常的輸入全序列計算是等價的,但是計算量大大減少了,這就是KV Cache。
0x02 用KV Cache來優化
KV Cache 的想法很直觀:用空間換時間,緩存上一輪的 K, V,從而避免每次生成token時重新計算key、value向量,利用預先計算好的key值和value值就可以生成新token,這樣可達到減少計算,提速的效果。KV Cache的大體作用如下。
- KV Cache充當自回歸生成模型的內存庫,來存儲所有之前標記的鍵(K)和值(V),以便將來重復使用,保證KV是全的。
- 每次迭代計算新的鍵向量和值向量時,KV緩存都會更新生成的標記的鍵和值。
- 模型的第一次輸入是完整的prompt,后續輸入只有上一次推理生成的 token,而不是整個 prompt 序列。
- 當計算第
K+1個token的注意力分數時,模型不需要重新計算所有先前K個token的鍵和值,而僅需從緩存中檢索先前K個token的鍵和值并串接至當前向量。
2.1 術語
我們首先看看KV-cache的結構和術語。LLM由多個transformer塊層組成,每個層都維護其自己的鍵和值的緩存。在本文中,我們將所有transformer塊的緩存統稱為KV-cache,同時使用術語K-cache或V-cache分別表示鍵和值。在深度學習框架中,每個層的K-cache(或V-cache)通常表示為形狀為[??, ??, ??, ??]的4D張量,其中 B 表示批量大小,L 表示請求的最大可能上下文長度。我們將在連續存儲的K和V上計算注意力分數的內核實現稱為vanilla內核。下圖是KV Cache的數學表達。

2.2 流程
我們接下來看看加入KV Cache之后的自回歸流程。以下圖為例,我們輸入的prompt為"新年快“,期望輸出“樂”。此時會把“新年快”這三個詞的KV計算出來,存儲在KV Cache中。
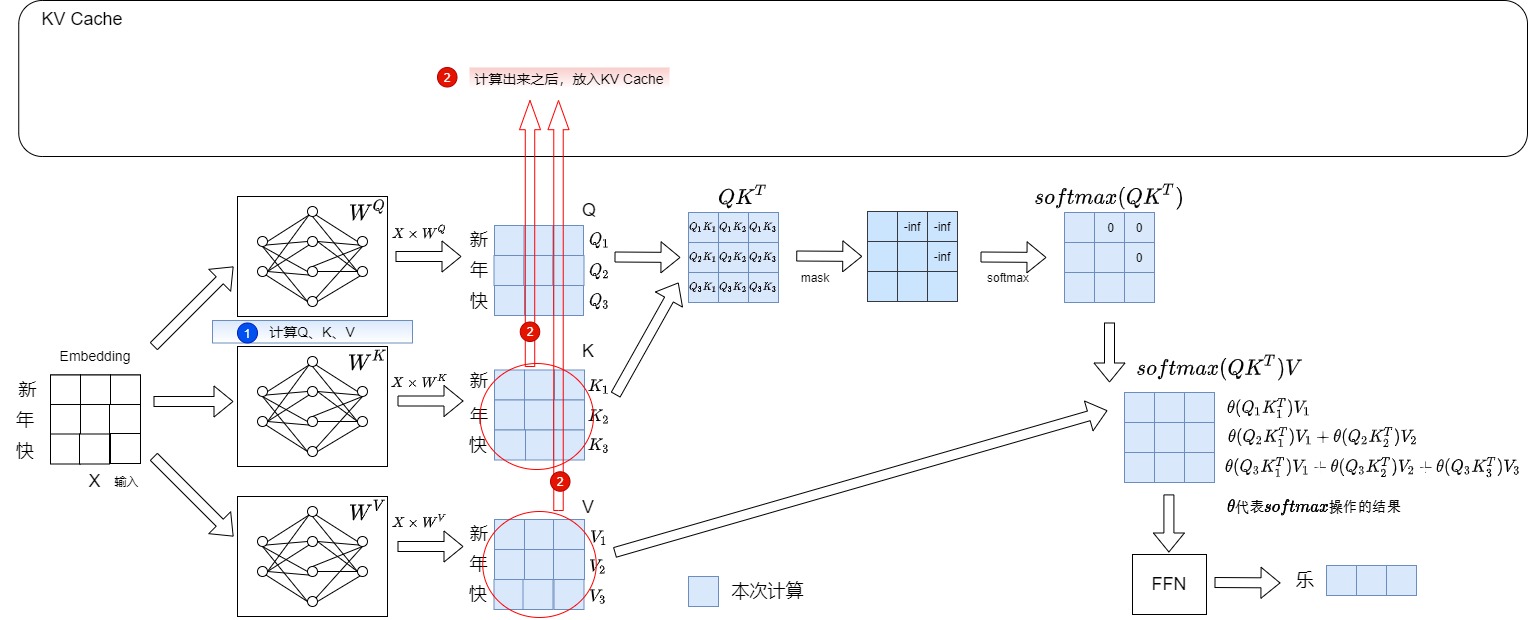
然后輸入“樂”,希望輸出“萬”。具體操作如下:
- 計算“樂”對應的Q,K,V值。對應下圖的標號1。
- 從KV Cache中提取“新年快”這三個token對應的的K和V。拼接歷史K、V的值,得到完整的K、V,即Key-Value Cache 機制將前序所有時間步的 Key 和 Value 緩存起來。對應下圖的標號2。
- 把”樂“對應的K和V存儲到KV Cache中。對應下圖的標號3。
- 計算注意力,對應下圖的標號4。此時注意力機制的輸入變為最后生成的token\(q_i\)(而不是整個序列)和KV緩存與最后token(\(k_i\),\(v_i\))的拼接。:
此時\(q_i\)、\(k_i\)和\(v_i\)對應“樂”,\(k_1, k_2, ..., k_{i-1}\)和\(v_1, v_2, ..., v_{i-1}\)對應“新年快”。
- 得到新的輸出“萬”對應的logits,對應下圖的標號5。
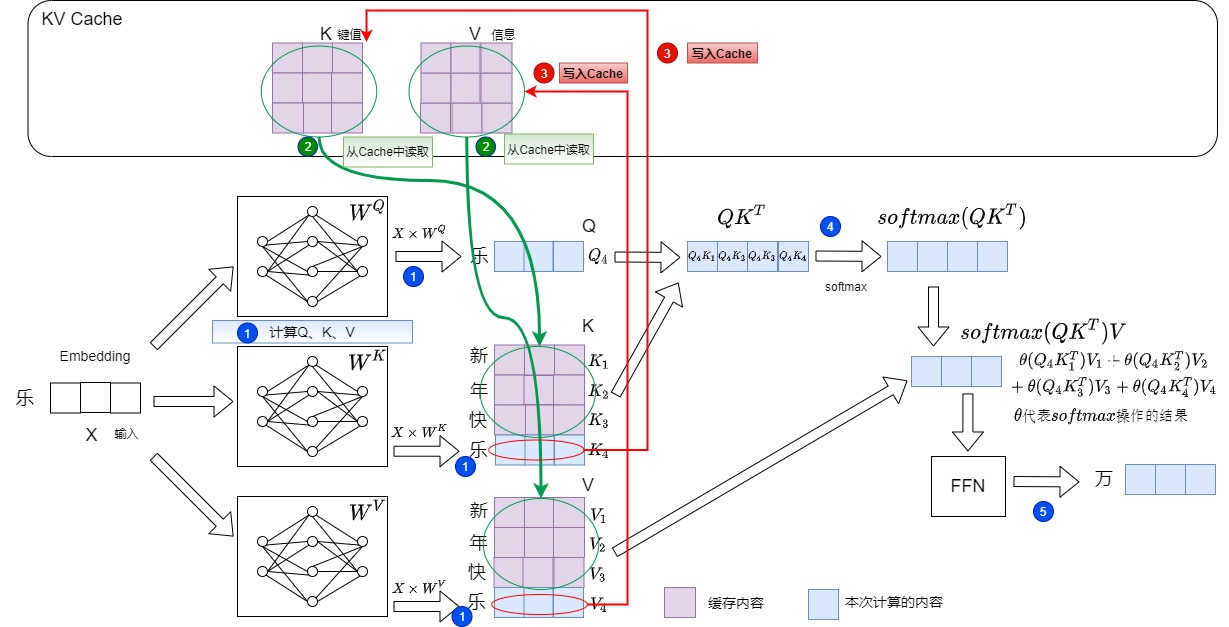
后續步驟是:
- 輸入新token“萬”,僅計算其Key/Value,與緩存的4個Key/Value(”新年快樂“)合并,生成“事”。
- 輸入新token“事”,僅計算其Key/Value,與緩存的5個Key/Value(”新年快樂萬“)合并,生成“如”。
- 輸入新token“如”,僅計算其Key/Value,與緩存的6個Key/Value(”新年快樂萬事“)合并,生成“意”。
2.3 重新定義階段
在KV Cache 的引入之后,我們把之前講的推理過程兩個階段重新定義,并且依據特點來重新命名。即prompt階段被命名為prefill階段(生成第1個Token),token generation階段被命名為decoding階段(生成其余Token)。進而影響到后續的其他優化方法。將推理分為Prefill和Decode2個流程,是考慮到生成第1個Token和其余Token時計算模式的差異較大,分開實現有利于針對性的優化。
2.3.1 定義
注:此處僅僅給出與之前定義有差別的部分。
Prefill(預填充階段),也有叫啟動階段(initiation phase),其特點如下:
- 作用:邏輯作用依然如前文所述(對輸入序列進行總結,并生成一個新標記作為解碼階段的初始輸入),但是此時也會將1個請求的Prompt一次性轉換為KV Cache(為每個Transformer層都執行此操作),因此通常被稱為預填充階段。
- 緩存使用:實際上不會受到 KV 緩存策略的影響,因為先前沒有步驟被執行。
Decoding階段(解碼階段)的特點如下:
- 輸入:我們不再使用整個序列作為輸入。而是每次輸入一個token,輸出一個token。
- 計算類型:計算類型發生變化,現在類似于矩陣-向量操作,即GEMM 變為 GEMV (GEneral Matrix-Vector multiply) 操作。因為FLOPs 降低,所以此階段對算力的要求并沒有那么大。雖然相比prompt階段,GPU的計算能力沒有得到充分利用,但本身已經是一種計算優化,把矩陣Q退化為當前時間步向量q,把兩個矩陣間的QK運算退化為向量和矩陣之間的qK計算。由于需要將權重和KV緩存值從內存系統傳輸到計算單元,這一階段受到內存帶寬的限制,屬于Memory-bound 類型計算(內存密集型)。這種內存瓶頸問題在長上下文和廣泛文本生成的應用中尤為明顯。
- 緩存使用:這時 KV Cache 已存有歷史鍵值結果,因此每輪推理只需讀取 Cache,然后結合輸入token的KV一起計算出下一個token,同時將當前輪計算出的新的 Key、Value 追加寫入至 Cache。
- 速度:推理速度比之前不使用KV Cache的token generation phase要快,因為省略很多冗余計算。
對應的圖也更新如下。
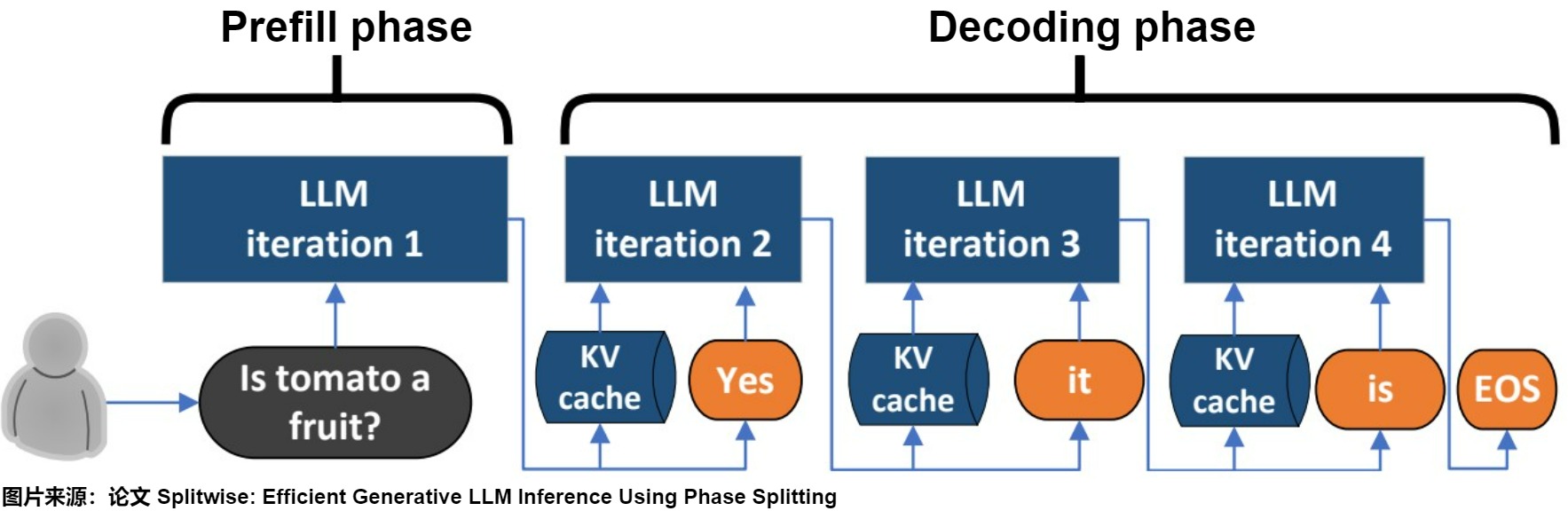
下圖則結合模型結構來闡釋這兩個階段如何使用KV Cache。
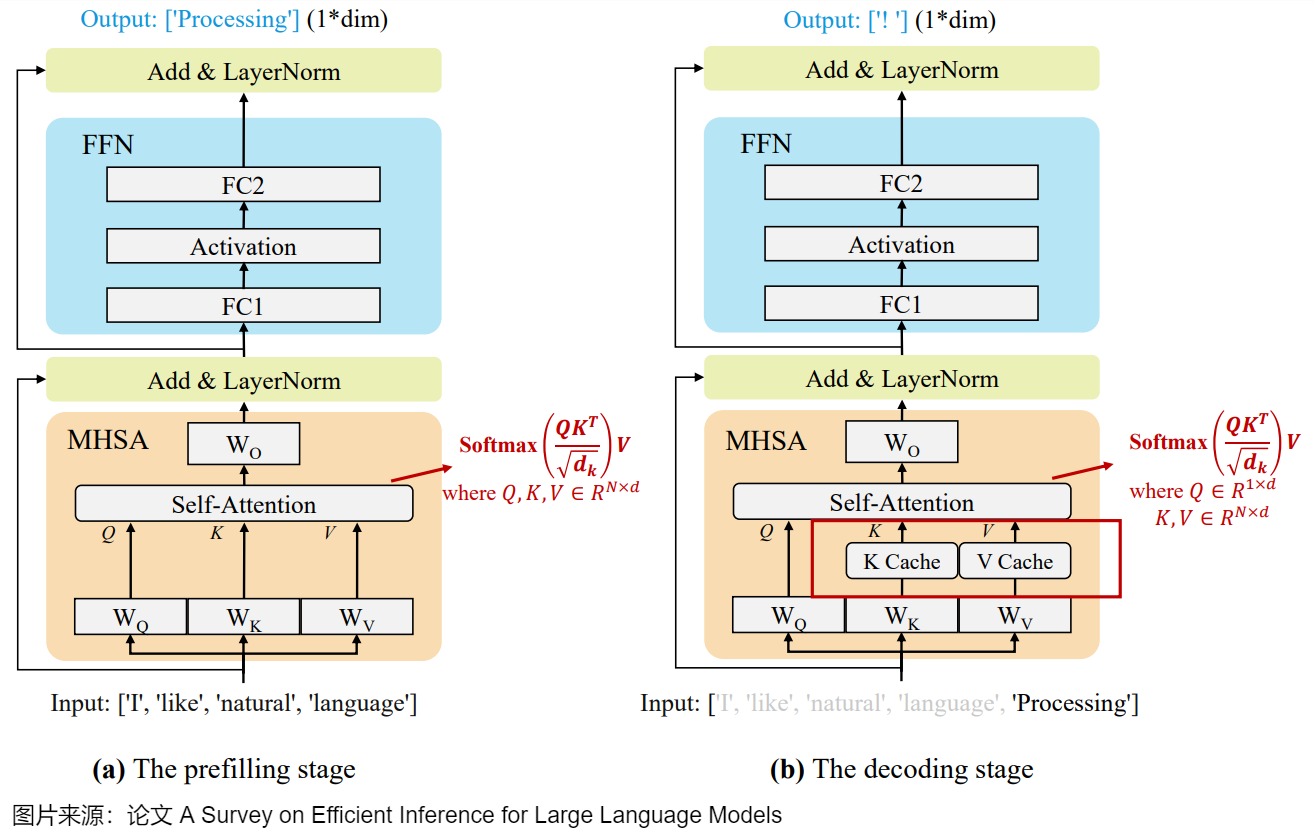
- prefill 是將1個請求的Prompt一次性轉換為KV Cache,并生成第1個Token的過程。僅對最后一個Logit進行解碼得到第1個生成的Token;中間過程計算得到的K、V將被保留在顯存中。
- decode 是后續新生成token的階段,此時會利用prefill的cache以及階段本身產生的cache進行結算,中間過程計算得到的K、V追加到KV Cache中。
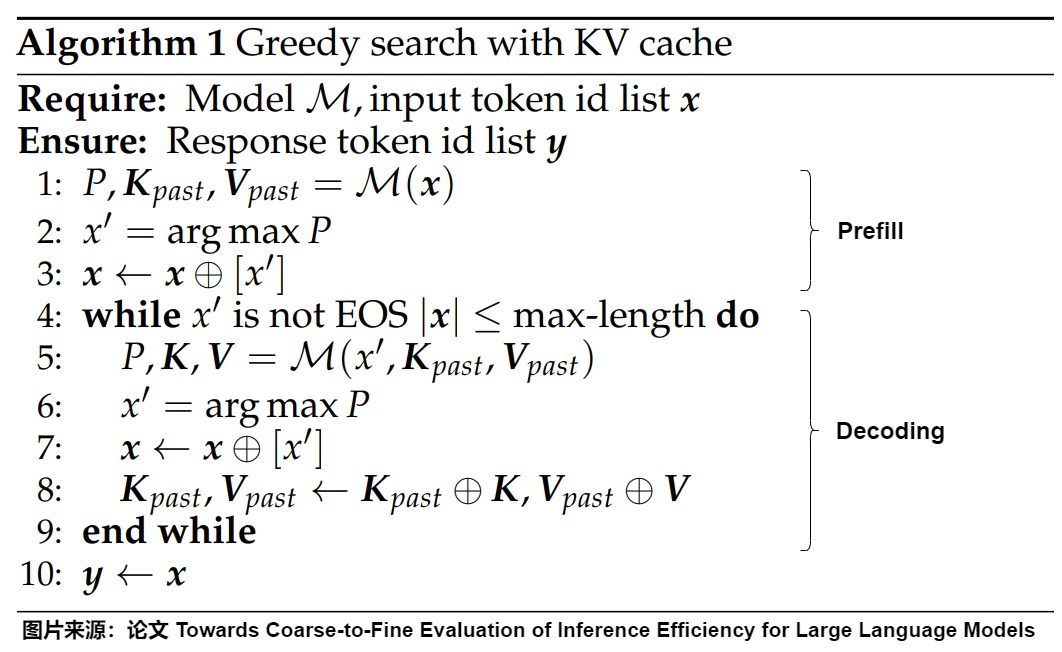
下圖給出了具體算法。
2.3.2 分析
研究人員對prefill和decode兩個階段也做了深入的分析,了解這些特性有助于我們更好的做針對性優化,我們接著來看一下。
- 不同的推理服務可能具有截然不同的提示(prompt)和解碼(decode)分布。
- 對于大多數請求來說,端到端(E2E,用戶請求總時間)的大部分時間都花在 decode 階段。
- Prefill階段是compute-bound,可以充分使用算力,因此算力是瓶頸。Decode階段是memory-bound,內存是瓶頸,無法充分使用算力。
- Prefill可以有效利用GPU,適合選用高算力 GPU;Decode階段可以使用算力不是特別強而訪存帶寬比較大的 GPU。
- Prefill優化方向是算子合并、簡化等,降低模型計算量。Decoding的優化主要為kv cache的訪問優化,比如tile計算和cache量化等。
- Prefill階段的計算時間通常隨著輸入長度的增加而超線性增加,Prefill階段應該限制Batch size從而避免影響性能,相反,Decode階段應該增大Batch size來獲得更高的計算強度和吞吐。

可以看到這兩個階段的特征完全不同,即便使用很好的batching技術,也無法解決兩個如此明顯不同階段所帶來的問題,比如:由于硬件資源利用不足,使得為用戶提供服務將產生更高的花費。
2.4 思考
我們接下來看看和KV Cache 相關的一些特性。
2.4.1 歷史上下文
讓我們把視野拓展到序列生成問題。對于序列模型,一個簡單且無狀態的推斷過程會在每次迭代中重新計算整個序列中的所有鍵和值,包括客戶提供的輸入標記和迄今生成的輸出標記。為了避免這種重新計算,人們一般會緩存歷史上下文,記錄需要在多個迭代中保持的內部狀態,該內部狀態會在后續迭代中重復使用。下圖給出了序列模型的建模方式,也給出了三種模型作為案例。其中TTT是把上下文壓縮到模型的權重中,這種「隱藏狀態模型」既能在時間上保持固定大小,又能大大增強表達能力。因為不是本文重點,我們略過。

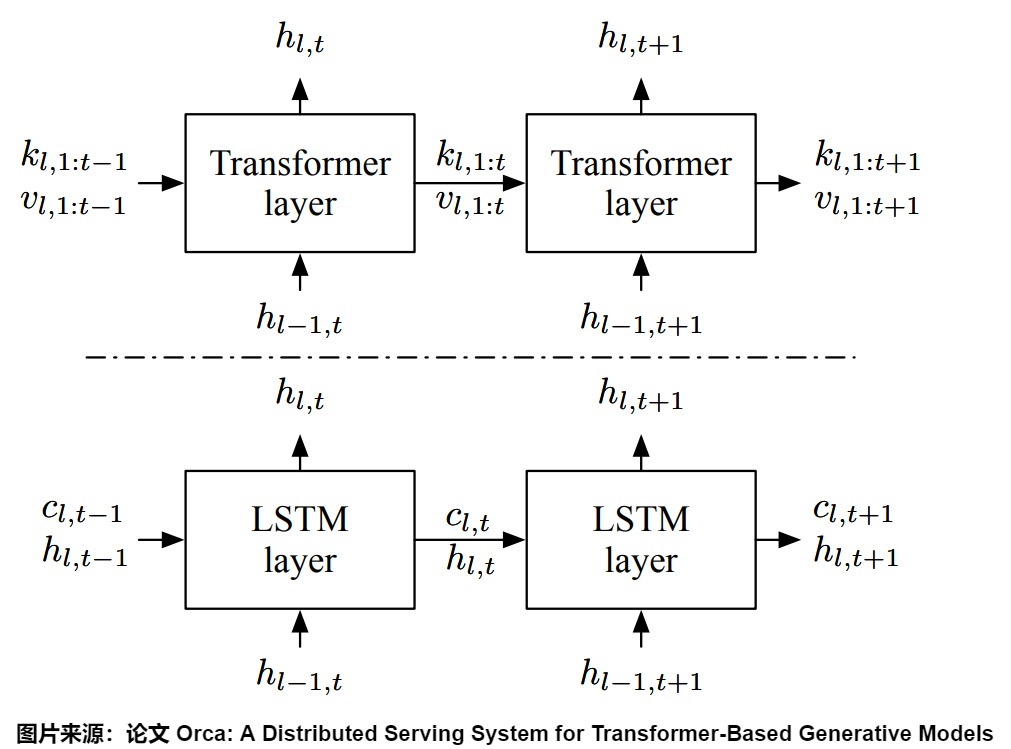
下圖展示了Transformer與LSTM的狀態使用模式。LSTM會把歷史上下文(比如包含過去所有的token等信息)壓縮到一個低維向量hidden state(隱藏狀態)中。在LSTM中,內部存儲器(c)和層的輸入/輸出(h)的大小保持不變。
而在Transformer中,由于Attention操作需要所有前面標記的鍵(keys)和值(values),所以將這些K和V都保存起來。Transformer并沒有壓縮狀態,而是使用緩存。每個被處理過的token都有一個自己的hidden vector,所有被處理過的hidden vector共同構成了hidde state。新的token和過去的hidden state可以交互。這就是KV cache。KV cache會隨著時間的推移不斷增長。這個狀態不會壓縮任何歷史上下文,但隨著上下文長度的增加,成本也會越來越高。
我們具體看看Attention鍵(k)和值(v)的大小如何隨著迭代增加。當處理索引為t的標記時,Attention操作需要使用所有先前的Attention鍵\(k_{l,1:t?1}\)和值\(v_{l,1:t?1}\),以及當前的鍵\(k_{l,t}\)和值\(v_{l,t}\)。因此,Attention操作根據已處理標記的數量,在不同形狀的張量上進行計算。
2.4.2 Q其實也被緩存了
我們雖然緩存了K和V,但實際上,之前的Q其實在一定程度上也被緩存了。
首先,對于自注意力,Q、K和V都是由X派生,本身就彼此有聯系。其次,因為Transformer是多層結構,在單層中,Q的信息會和K,V進行交互,Q的信息其實也在一定程度上也被蘊含K、V中了。多層計算時,某些Q的信息也會被傳到下一層的KV Cache中。意味在多層Attention計算中, 除了當前token的Q 值, 也會有過去Tokens的一定程度的Q值信息參與。
2.4.3 每層都有獨立的KV Cache
KV Cache 在Transformer的所有層中都存在,而不僅僅是在第一層。這是因為:
- 每層的KV Cache不同。
- 在所有層中,每個token的鍵和值向量僅依賴于先前的token。當在后續迭代中添加新token時,現有token的鍵和值向量保持不變。
每層的KV Cache不同
每一層 decode layer 都需要單獨緩存 K 和 V,因為每層的 attention 運算是獨立的,即第 L 層的 \(K_L\) 和 \(V_L\) 是獨立的、與其他層不同的。如果不緩存每一層的 K 和 V,在生成下一個 token 時,模型就需要重新計算之前所有 token 的 K 和 V,這將導致大量冗余計算,通過緩存,避免了重復計算 K 和 V,從而加速了生成過程。
每層都僅依賴先前的token
對于第一層,token的鍵向量是通過將token的固定嵌入向量與固定的wk參數矩陣相乘確定的。因此,無論引入了多少新token,在后續迭代中,它都保持不變。同樣的道理也適用于值向量。對于第二層及后續層,為了理解其原因,我們可以考慮第一層自注意力階段的KQV矩陣的輸出。KQV矩陣中的每一行是一個加權和,取決于:
- 前面token的值向量。
- 由前面token的鍵向量計算的得分。
因此,KQV矩陣中的每一行僅依賴于之前的token。經過一些基于行的操作后,這個矩陣作為第二層的輸入。這意味著,除了新增的行外,第二層的輸入在未來的迭代中將保持不變。通過歸納法,這一邏輯可以延伸到剩余的各層。
2.4.4 計算機架構
我們從計算架構角度來看。\(W^K\)和\(W^V\)可以理解為存儲指令的內存。注意力機制相當于控制器,Token序列相當于寄存器,KV Cache就相當于指令緩存。
2.4.5 適用前提
KVCache是一種用更大的顯存空間換取更快的推理速度的手段。那么,它是否能夠無條件適用于所有的LLM呢?其實并不是的。
- 首先,只有滿足“因果性”的LLM才有適用KV Cache的可能。即每一個token的輸出只依賴于它自己以及之前的輸入,與之后的輸入無關。在transformer類模型中,BERT類encoder模型不滿足這一性質,而GPT類decoder模型因為使用了causal mask,所以滿足這一性質。
- 另外,KV Cache對位置編碼也有一定的要求,需要位置編碼也滿足因果性,即加入更多的token時,對之前原有token不會產生影響。像一些ReRope之類的技術,在增加新的token時會把整個序列的positional embedding進行調整,同一個token,上一次的token embedding和這一次的token embedding不相同,則KVCache的條件不再成立。而一旦輸入預處理層不滿足KVCache的條件,后續transformer層的輸入(即預處理層的輸出)就發生了改變,也將不再適用于KVCache。
另一個重要的事情是,由于模型的位置編碼,token的 KV 緩存是位置相關的。這意味著在文本中重復出現的token不能共享相同的 KV 緩存。
0x03 實現
從 GPT2 、 Baichuan2 和 LLaMA 的源碼中可以看到 KV Cache 核心代碼的實現就幾行,并不復雜。
3.1 總體思路
KV Cache的基本思路如下:
KV-Cache會在模型連續推理的過程中持續調用和更新past_key_values。當模型首次推理時,past_key_values為空,需要對past_key_values進行初始化,首次推理需將全部文本一齊輸入,將中間過程的所有Key,Value添加到past_key_values中。
從第二次推理開始,僅需要輸入當前最后一個token,單獨對該token做Q,K,V映射,將past_key_values中前文所有的K,V和該token的K,V進行拼接得到完成的Key、Value向量,最終和該token的Query計算注意力,拼接后的Key、Value也同步更新到past_key_values。
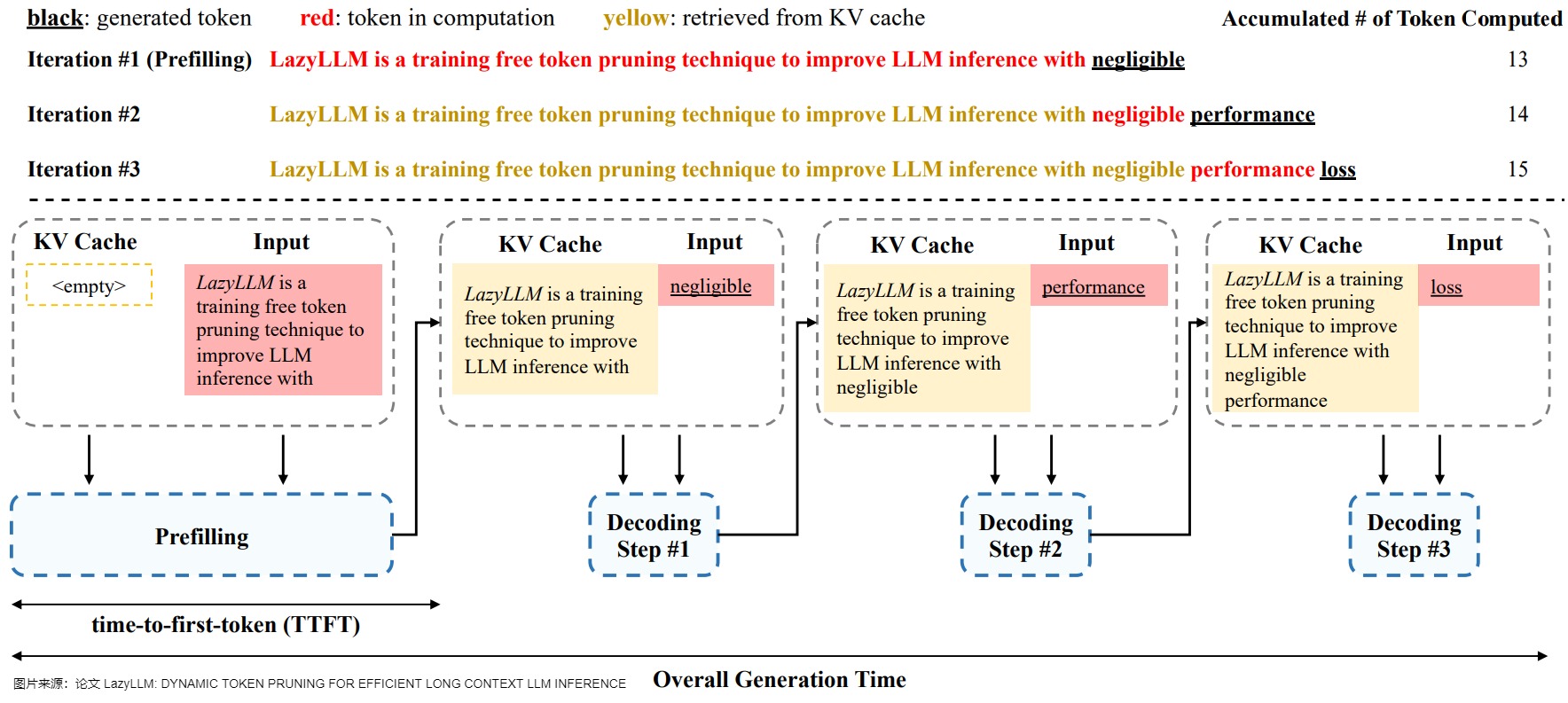
KV-Cache的代碼實現流程圖如下,可以看到,KV Cache的內容來源于兩個方面:
- 輸入prompt;
- 生成的token。
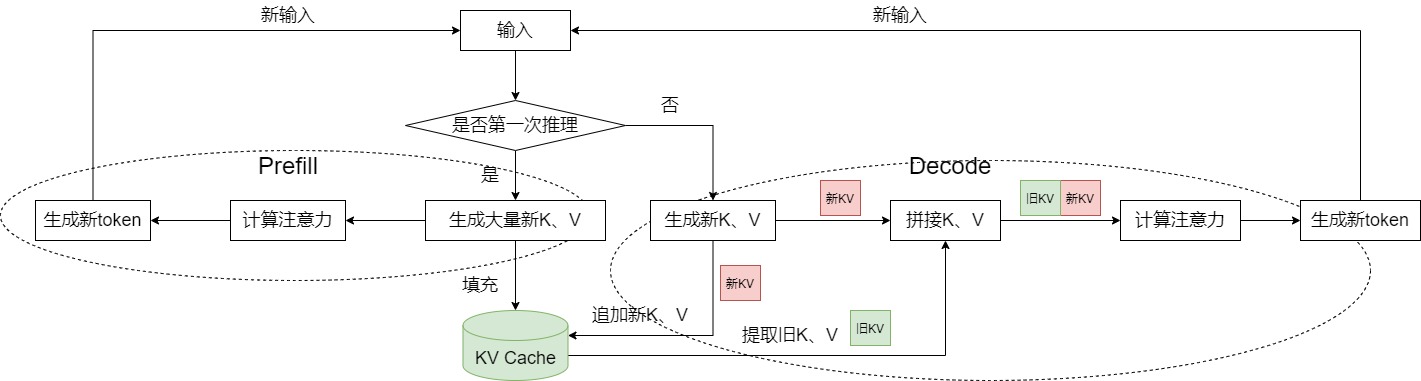
另外,因為KV Cache是高頻讀寫,數量級非常大,需要高效管理,比如使用多級內存池。而且,kv cache的實際業務有多種,MHA、GQA、MLA、DoubleSparse等,需要做好業務的隔離。比如一級內存池記錄high level信息,跟具體業務隔離,跟蹤每個請求使用的token位置。具體的kv cache(MHA,MLA,DoubleSparse)在二級內存池。
3.2 存儲結構
3.2.1 llama3
我們以llama3為例,來看看KV Cache的存儲結構。
下面是Attention類的成員變量。因為每個TransformerBlock都有Attention,所以這就是單層的成員變量。
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
.cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
.cuda()
3.2.2 Transformer庫
我們接下來用Transformer庫來進行比對學習。
在每層中,每個頭的Key向量和Value向量存儲在內存中。在HuggingFace的代碼實現中,使用past_key_values變量進行存儲,past_key_values是一個矩陣,其維度為[n, 2, b, h, s, d],類似一個六維的矩陣,每個維度的含義如下:
- 第一維 num_layers:以每一個堆疊的Block為單位,例如堆疊12層,則一共有12組Key、Value信息。
- 第二維 2:代表Key和Value這兩個信息對象,索引0是Key向量,索引1是Value向量。
- 第三維 batch_size:代表batch_size,和輸入需要推理的文本條數相等,如果輸入是一條文本,則b=1。
- 第四維 num_heads:代表注意力頭的數量,例如每層有12個頭,則h=12。
- 第五維 seq_len:代表截止到當前token為止的文本長度,在每一個歷史token位置上該token在每一層每個頭下的Key,Value信息。
- 第六維 d:代表Key、Value向量的映射維度,若token總的映射維度為768,注意力頭數為12,則d=768/12=64。

past_key_values的結構如上圖所示,隨著模型推理步長的增長,past_key_values在每一步也同步更新,上一個past_key_values和下一個past_key_values的差異僅僅產生在seq_len這個維度上。具體的,seq_len維度大小會加1,它是由新推理的那一個token所對應的Key,Value拼接到上一個past_key_values的seq_len維度中所導致的,如果除開這個加1的因素,上一個past_key_values和下一個past_key_values在seq_len這個維度上的向量完全相同。
Huggingface Transformer 庫中對Cache進行了抽象,里面實現了各種Cache。其中主要的Cache舉例如下:
-
DynamicCache:隨著生成更多 Token 而動態增長的Cache。它將鍵和值狀態存儲為張量列表,每層一個張量。每個張量的期望形狀是[batch_size, num_heads, seq_len, head_dim]。
-
StaticCache:與 torch.compile(model) 一起使用的靜態 Cache 類。
-
SinkCache:實現了Attention Sinks 論文中所描述的緩存。它允許模型生成超出其上下文窗口的長度,而不會失去會話的流暢性。因為它拋棄了過去tokens,模型將失去生成依賴于被丟棄的上下文的tokens的能力。它將鍵和值狀態存儲為張量列表,每層一個張量。每個張量的期望形狀是[batch_size, num_heads, seq_len, head_dim]。
我們以StaticCache為例,看看具體的數據結構。
past_key_values = StaticCache(
model.config,
batch_size=batch_size,
device=device,
dtype=torch.float16,
max_cache_len=seq_length + num_tokens_to_generate,
)
可以看到每個KV Cache的形狀是cache_shape = (self.batch_size, self.num_key_value_heads, self.max_cache_len, self.head_dim)。KV Cache的外面套了new_layer_key_cache,即一共有num_hidden_layers層cache_shape 。每層有兩個KV Cache。
class StaticCache(Cache):
"""
Static Cache class to be used with `torch.compile(model)` and `torch.export()`.
Parameters:
config (`PretrainedConfig`):
The configuration file defining the shape-related attributes required to initialize the static cache.
batch_size (`int`):
The batch size with which the model will be used. Note that a new instance must be instantiated if a
smaller batch size is used. If you are manually setting the batch size, make sure to take into account the number of beams if you are running beam search
max_cache_len (`int`):
The maximum sequence length with which the model will be used.
device (`torch.device` or `str`):
The device on which the cache should be initialized. Should be the same as the layer.
dtype (`torch.dtype`, *optional*, defaults to `torch.float32`):
The default `dtype` to use when initializing the layer.
layer_device_map(`Dict[int, Union[str, torch.device, int]]]`, `optional`):
Mapping between the layers and its device. This is required when you are manually initializing the cache and the model is splitted between differents gpus.
You can know which layers mapped to which device by checking the associated device_map: `model.hf_device_map`.
Example:
```python
>>> from transformers import AutoTokenizer, AutoModelForCausalLM, StaticCache
>>> model = AutoModelForCausalLM.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
>>> tokenizer = AutoTokenizer.from_pretrained("meta-llama/Llama-2-7b-chat-hf")
>>> inputs = tokenizer(text="My name is Llama", return_tensors="pt")
>>> # Prepare a cache class and pass it to model's forward
>>> # Leave empty space for 10 new tokens, which can be used when calling forward iteratively 10 times to generate
>>> max_generated_length = inputs.input_ids.shape[1] + 10
>>> past_key_values = StaticCache(config=model.config, batch_size=1, max_cache_len=max_generated_length, device=model.device, dtype=model.dtype)
>>> outputs = model(**inputs, past_key_values=past_key_values, use_cache=True)
>>> outputs.past_key_values # access cache filled with key/values from generation
StaticCache()
```
"""
def __init__(
self,
config: PretrainedConfig,
batch_size: int = None,
max_cache_len: int = None,
device: torch.device = None,
dtype: torch.dtype = torch.float32,
max_batch_size: Optional[int] = None,
layer_device_map: Optional[Dict[int, Union[str, torch.device, int]]] = None,
) -> None:
super().__init__()
self.batch_size = batch_size or max_batch_size
self.max_cache_len = config.max_position_embeddings if max_cache_len is None else max_cache_len
self.head_dim = (
config.head_dim if hasattr(config, "head_dim") else config.hidden_size // config.num_attention_heads
)
self.dtype = dtype
self.num_key_value_heads = (
config.num_attention_heads
if getattr(config, "num_key_value_heads", None) is None
else config.num_key_value_heads
)
self.key_cache: List[torch.Tensor] = []
self.value_cache: List[torch.Tensor] = []
cache_shape = (self.batch_size, self.num_key_value_heads, self.max_cache_len, self.head_dim)
for idx in range(config.num_hidden_layers):
if layer_device_map is not None:
layer_device = layer_device_map[idx]
else:
layer_device = device
new_layer_key_cache = torch.zeros(cache_shape, dtype=self.dtype, device=layer_device)
new_layer_value_cache = torch.zeros(cache_shape, dtype=self.dtype, device=layer_device)
if not is_torchdynamo_compiling():
self.register_buffer(f"key_cache_{idx}", torch.zeros(cache_shape, dtype=dtype, device=layer_device))
self.register_buffer(f"value_cache_{idx}", torch.zeros(cache_shape, dtype=dtype, device=layer_device))
new_layer_key_cache = getattr(self, f"key_cache_{idx}")
new_layer_value_cache = getattr(self, f"value_cache_{idx}")
torch._dynamo.mark_static_address(new_layer_key_cache)
torch._dynamo.mark_static_address(new_layer_value_cache)
self.key_cache.append(new_layer_key_cache)
self.value_cache.append(new_layer_value_cache)
def update(
self,
key_states: torch.Tensor,
value_states: torch.Tensor,
layer_idx: int,
cache_kwargs: Optional[Dict[str, Any]] = None,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Updates the cache with the new `key_states` and `value_states` for the layer `layer_idx`.
It is VERY important to index using a tensor, otherwise you introduce a copy to the device.
Parameters:
key_states (`torch.Tensor`):
The new key states to cache.
value_states (`torch.Tensor`):
The new value states to cache.
layer_idx (`int`):
The index of the layer to cache the states for.
cache_kwargs (`Dict[str, Any]`, `optional`):
Additional arguments for the cache subclass. The `StaticCache` needs the `cache_position` input
to know how where to write in the cache.
Return:
A tuple containing the updated key and value states.
"""
cache_position = cache_kwargs.get("cache_position")
k_out = self.key_cache[layer_idx]
v_out = self.value_cache[layer_idx]
if cache_position is None:
k_out.copy_(key_states)
v_out.copy_(value_states)
else:
# Note: here we use `tensor.index_copy_(dim, index, tensor)` that is equivalent to
# `tensor[:, :, index] = tensor`, but the first one is compile-friendly and it does explicitly an in-place
# operation, that avoids copies and uses less memory.
try:
k_out.index_copy_(2, cache_position, key_states)
v_out.index_copy_(2, cache_position, value_states)
except NotImplementedError:
# The operator 'aten::index_copy.out' is not currently implemented for the MPS device.
k_out[:, :, cache_position] = key_states
v_out[:, :, cache_position] = value_states
return k_out, v_out
3.3 如何使用
我們以LLaMA3為例來進行說明KV Cache如何使用。啟用KV緩存后,forward方法返回一個張量對的列表(一個鍵張量對,一個值張量對)。這些張量對的數量與模型中的解碼器塊數量相同(通常稱為解碼器層,記為n_layers)。對于批處理中每個序列的每個token,每個注意力頭都有一個維度為d_head的鍵/值向量,因此每個鍵/值張量的形狀為(batch_size, seq_length, n_heads, d_head)。
緩存的工作方式如下:
- 在初始迭代期間,所有token的鍵和值向量都會進行計算,并保存到KV緩存中。
- 在后續迭代中,僅需要計算最新token的鍵和值向量。緩存的鍵值向量與新token的鍵值向量一起被拼接,形成K和V矩陣。這避免了重新計算所有先前token的鍵值向量,從而大大提高了效率。
- 在后續迭代中,只計算最新token的鍵向量,其他的從緩存中提取,并與新計算的鍵向量一起組成K矩陣。新計算的鍵向量也會被保存到緩存中。對于值向量,同樣的過程也適用。
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False,
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False,
input_is_parallel=True,
init_method=lambda x: x,
)
# 初始化KV Cache
self.cache_k = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
self.cache_v = torch.zeros(
(
args.max_batch_size,
args.max_seq_len,
self.n_local_kv_heads,
self.head_dim,
)
).cuda()
def forward(
self,
x: torch.Tensor,
start_pos: int,
freqs_cis: torch.Tensor,
mask: Optional[torch.Tensor],
):
bsz, seqlen, _ = x.shape
xq, xk, xv = self.wq(x), self.wk(x), self.wv(x)
xq = xq.view(bsz, seqlen, self.n_local_heads, self.head_dim)
xk = xk.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xv = xv.view(bsz, seqlen, self.n_local_kv_heads, self.head_dim)
xq, xk = apply_rotary_emb(xq, xk, freqs_cis=freqs_cis)
# 將當前 Token 的 kv 值更新到 KV Cache,并返回新的 KV
self.cache_k = self.cache_k.to(xq)
self.cache_v = self.cache_v.to(xq)
self.cache_k[:bsz, start_pos : start_pos + seqlen] = xk
self.cache_v[:bsz, start_pos : start_pos + seqlen] = xv
keys = self.cache_k[:bsz, : start_pos + seqlen]
values = self.cache_v[:bsz, : start_pos + seqlen]
# repeat k/v heads if n_kv_heads < n_heads
keys = repeat_kv(
keys, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
values = repeat_kv(
values, self.n_rep
) # (bs, cache_len + seqlen, n_local_heads, head_dim)
xq = xq.transpose(1, 2) # (bs, n_local_heads, seqlen, head_dim)
keys = keys.transpose(1, 2) # (bs, n_local_heads, cache_len + seqlen, head_dim)
values = values.transpose(
1, 2
) # (bs, n_local_heads, cache_len + seqlen, head_dim)
scores = torch.matmul(xq, keys.transpose(2, 3)) / math.sqrt(self.head_dim)
if mask is not None:
scores = scores + mask # (bs, n_local_heads, seqlen, cache_len + seqlen)
scores = F.softmax(scores.float(), dim=-1).type_as(xq)
output = torch.matmul(scores, values) # (bs, n_local_heads, seqlen, head_dim)
output = output.transpose(1, 2).contiguous().view(bsz, seqlen, -1)
return self.wo(output)
0x04 資源占用
4.1 維度變化
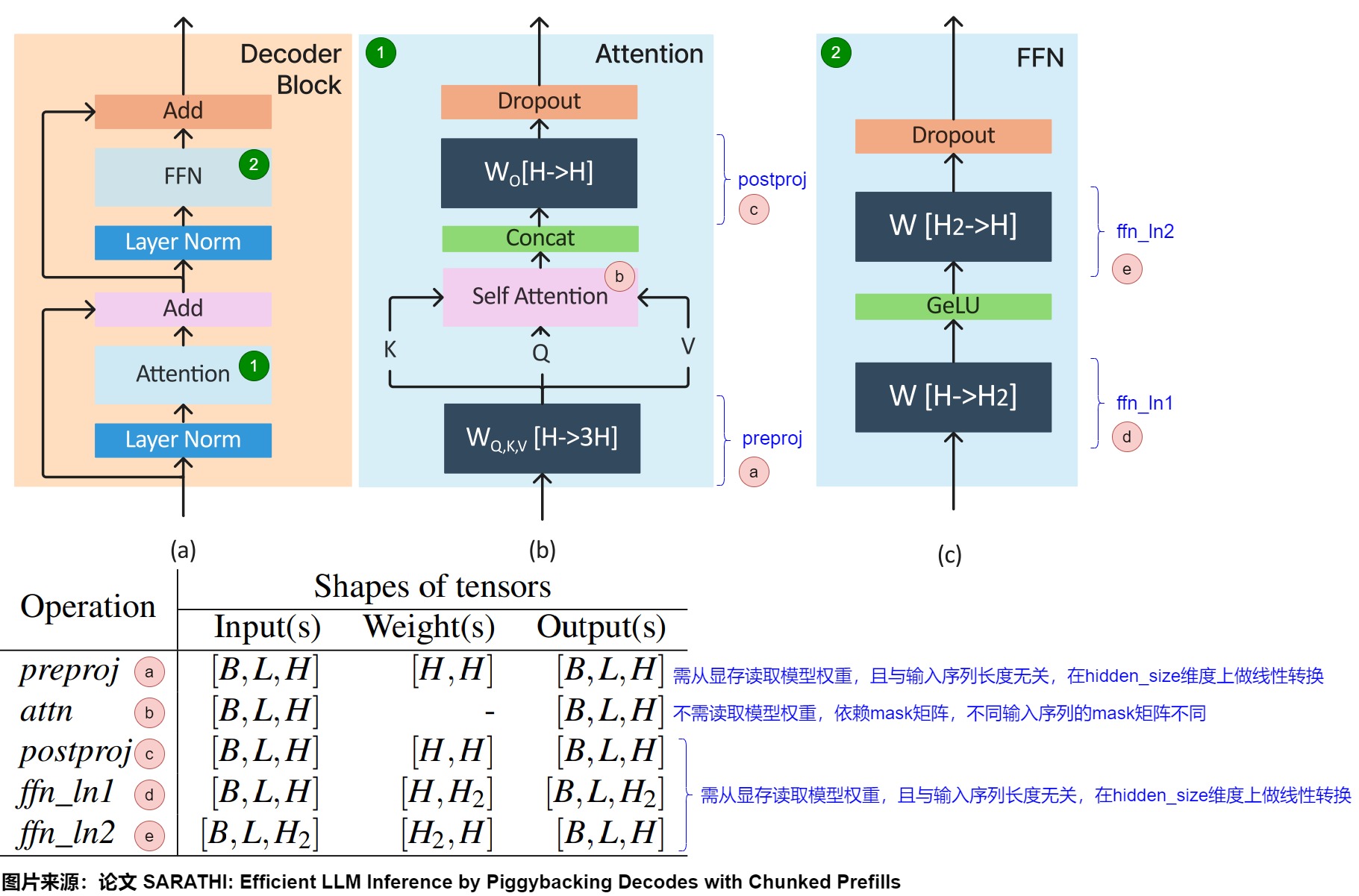
下圖給出了Transformer架構、各種操作的輸入、輸出和權重張量的形狀。假定輸入是為形狀為[B,L,H]的張量X,其中B表示batch size,L表示每個請求的序列長度(即給定查詢中的輸入token數量),H是模型的嵌入大小。
在只考慮一個頭情況下,Transformer的prefill階段的維度變化如下:
- 預處理階段:主要是preproj模塊。X經由形狀分別為[H,H]的權重矩陣\(W^Q\)、\(W^K\)和\(W^V\)轉換之后,會生成Q、K和V,每個輸出張量形狀是[B、L、H]。該階段的特點是:preproj計算時需要從顯存讀取模型權重,且計算和輸入序列長度無關(只是在hidden_size維度上做線性轉換)。
- 計算注意力階段:該階段主要由self attention模塊和postproj模塊構成。
- self attention:使用Q、K和V計算注意力分數的過程。該階段的輸出是形狀為[B,L,H]的張量Y。該階段的特點是:分數計算時不需要從顯存讀取模型權重,你只需要利用算好的QKV即可;計算時依賴mask矩陣,而不同序列的mask矩陣是不同的。
- postproj:使用 \(W^O\) 權重矩陣,對經過注意力計算后的序列Y做映射,返回形狀為[B,L,H].的張量Z。其特性和preproj一致。
- FFN階段。FFN模塊執行兩次批量矩陣乘法。在ffn_ln1中,Z與形狀為[H,H2]的權重張量相乘,產生形狀為[B,L,H2],然后將其與ffn_ln2中形狀為[H2,H]的權重張量相乘,輸出形狀為/B,L,H]。這里,H2是指模型的第二個隱藏維度。ffn_ln1的特性和preproj一致。
解碼階段執行與prefll相同的操作,但僅針對上次自回歸迭代中生成的單個token。因此,解碼階段的輸入張量的形狀為[B,1,H](與prefill的[B,L,H]相反)。
- 預處理階段:得到的Q、K、V都是[B, 1, H]。每個token的K和V張量的形狀為[1,H]。
- 注意力計算階段:從KV Cache中得出來的K、V張量形狀是[B, prev_kv_seq_len, H]。與當前K、V拼接之后,張量形狀是[B, prev_kv_seq_len + 1, H]。\(QK^T\)結果的形狀是[B, 1, H] x [B, , H, prev_kv_seq_len + 1] -> [B, 1, prev_kv_seq_len + 1]; \((Q^TK)V\) 形狀是 [B, 1, prev_kv_seq_len + 1] x [B, prev_kv_seq_len + 1, H]-> [B, 1, H]。
- FFN階段。輸出為[B, 1, H]。
從以上的分析中,我們不難發現,attention算子中的訪存開銷主要取決于KV的序列長度,而計算開銷主要取決于Q的序列長度,在prefill階段,Q序列一般較長,attention算子是計算密集;而在decode階段,Q序列長度為1,attention算子是訪存密集。
4.2 存儲量
4.2.1 單層
所有輸入批次序列中的每個token 的大小與模型配置相關,并且是固定的。基于此,KV緩存的總大小可以用以下公式表示:
其中:
- 2代表代表 Key/Value 兩個向量,每層都需存儲這兩個向量。
- B代表batch size。
- L代表總序列長度,sequence length(輸入序列+輸出序列,或者說是提示 + 完成部分)。
- H代表number of head。
- D代表size of head,每個head的維度。
- P代表kv的數據格式需要多少比特才能存儲,即為每存放一個 KV Cache 數據所需的字節數。比如fp16就需要2 byte。
4.2.2 多層
如果N代表Block數量,即模型深度,那么一個模型總共需要的KV Cache的存儲空間為
4.2.3 實際樣例
假定100K上下文,60層,8的頭,128的嵌入維度,使用bf16存儲,則KV Cache大小為:
或者以LLaMa-7B為例,模型加載占用顯存14GB,向量維度4096,堆疊32層,最大推理步長4096,若推理一個batch為2,長度為4096的句子,KV-Cache占用的存儲空間為2×2×32×4096×2×4096=21474836480字節,約等于4GB,隨著推理的batch增大,推理長度變長,KV-Cache占用的存儲空間可能超過模型本身。例如,如果 batch size = 4,在 LLaMA 2 70B 中,假設輸入和輸出的 token 數量達到了模型的極限 4096,80 層的 KV Cache 一共需要 2 (K, V) * 80 * 8192 * 4096 * 8 * 2B = 80 GB。如果 batch size 更大,那么 KV Cache 占據的空間將超過參數本身占的 140 GB。
4.2.4 存儲實現
KVCache正比于當前token數量、向量維度、層數。這里面,最令人頭疼的是當前token數量,它是在推理過程中不斷變大的一個量。變長數據的存儲總是很煩人的,具體解決起來無外乎三種方法:
- 分配一個最大容量的緩沖區,要求提前預知最大的token數量。但是,按照最大容量來分配是非常浪費的。
- 動態分配緩沖區大小,類似經典的vector append的處理方式,超過容量了就擴增一倍。這也是一種可行的解決方案,但是(在GPU設備上)頻繁申請、釋放內存的開銷很大,效率不高。
- 把數據拆散,按最小單元存儲,用一份元數據記錄每一塊數據的位置。
最后一種方案,就是目前采用最多的方案,也叫PageAttention。程序在初始化時申請一整塊顯存(例如4GB),按照KVCache的大小劃分成一個一個的小塊,并記錄每個token在推理時要用到第幾個小塊。小塊顯存的申請、釋放、管理,類似操作系統對物理內存的虛擬化過程,這就是大名鼎鼎的vLLM的思路(具體參見論文Efficient Memory Management for Large Language Model Serving with PagedAttention)。
4.3 計算量
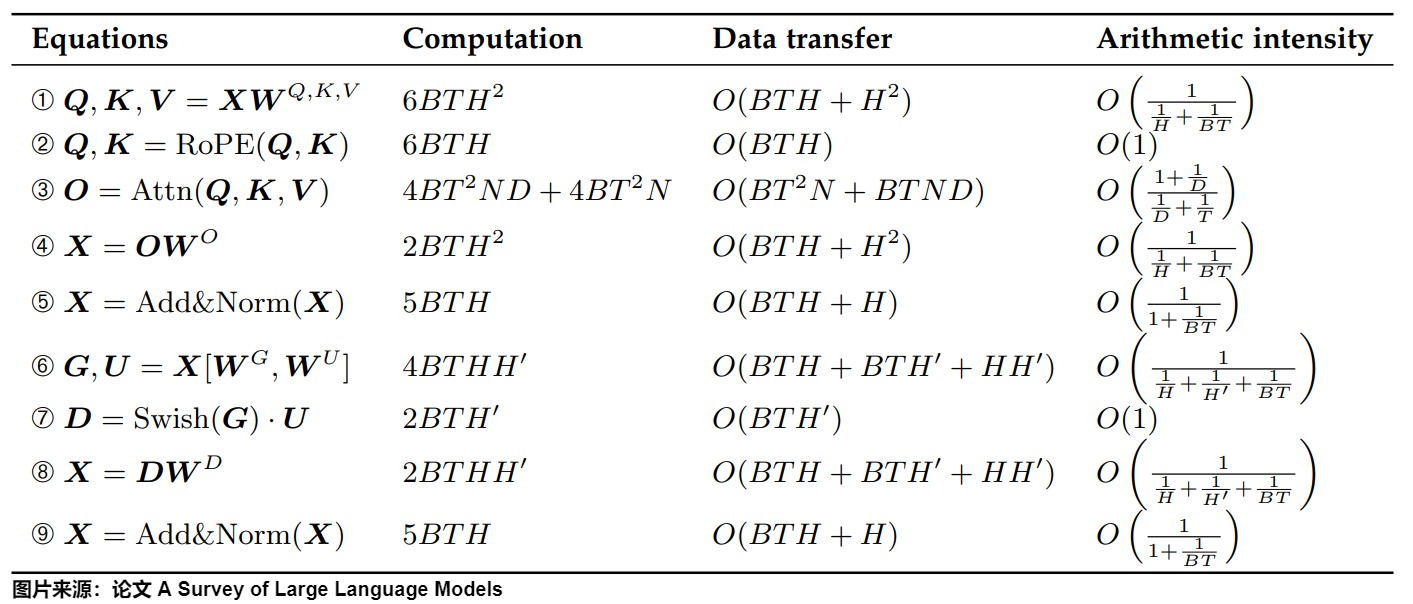
下圖給出額預填充階段的計算、數據傳輸和算術強度。我們使用漸近符號O來表示數據傳輸量的復雜性,其中復雜性的常數因子與具體的實現方法有關。
下圖給出了解碼階段的計算、數據傳輸和算術強度。
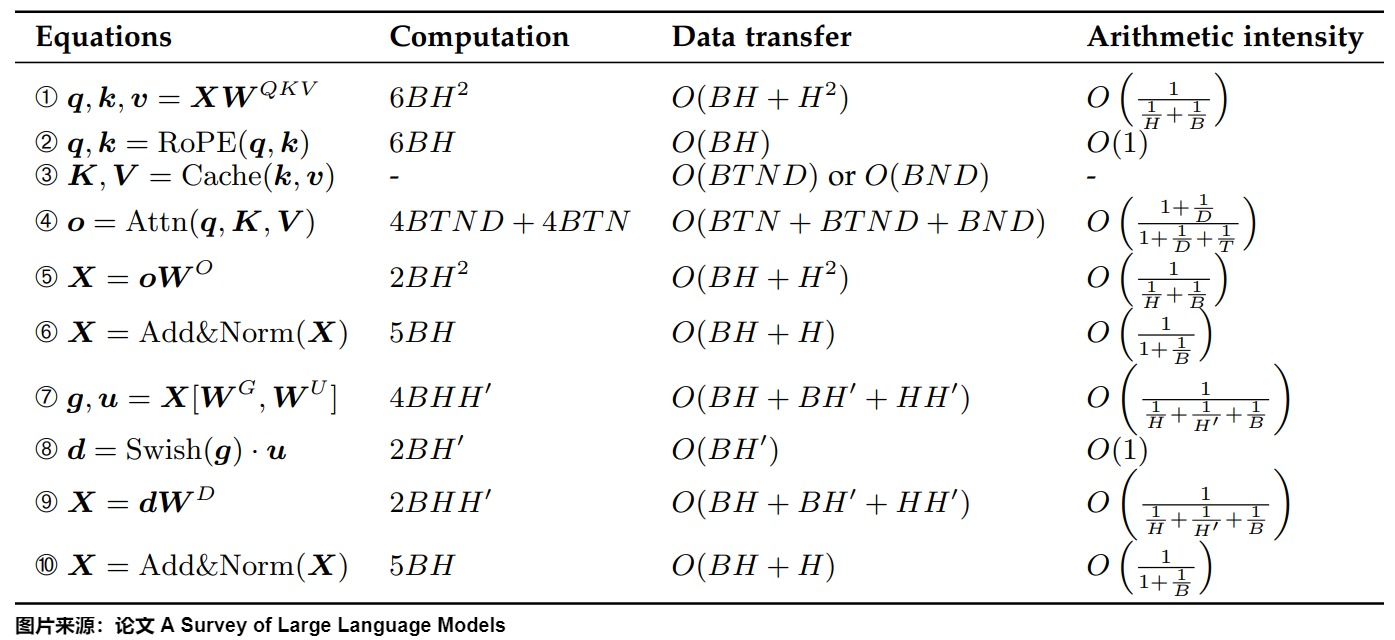
在prefill中,我們需要計算Attn(Q, K, V),還需要填充KV Cache,計算量沒有減少。因此我們要看Decoding階段的計算量。KV Cache主要節省如下兩部分。
- 前面 n-1 次的 K 和 V 的計算,這部分是被緩存過不需要再重新計算的部分。
- FFN:因為只輸出一個token的logits,所以這部分運算量也減少。
我們具體按照執行流程來看看。
4.3.1 查表
雖然查表階段不占據太多計算,但是使用 KV 緩存可以省略為前 t+N-1 個 tokens 查詢所需要的計算。
4.3.2 \(W^Q, W^K, W^V\)計算
為特定的 tokens 計算鍵或值向量就是簡單地將其 size 為 d_model 的嵌入向量與 shape 為(d_model,d_head)的權重矩陣相乘即可。
單次推理
- 標準模式下,這部分的計算量為\(6 bsh^2\)。
- kv cache模式下,query修改為單token,此時所需的計算量\(6 bh^2\)。
4.3.3 Attention
在decode階段,我們要在原來的序列上增加一個輸出(token),由于之前kv的結果可以重用,我們只需要計算Decode: Attn(q, K, V)。其中,q的長度為1,而K=[k_cache, k]和V=[v_cache, v]的序列長度大于1。即,使用 KV Cache 之后,Multi-Head Attention 里的矩陣乘矩陣操作全部降級為矩陣乘向量。
單次推理
- 標準模式下,注意力計算量為\(6bs^2h\)。
- kv cache模式下,query修改為單token,注意力計算量是\(4bsh + 2bsh^2\)。
4.3.4 MLP
FFN 中 Token 之間不會交叉融合,也就是任何一個 Token 都可以獨立計算,因此在 Decoding 階段不用 Cache 之前的結果,但同樣會出現矩陣乘矩陣操作降級為矩陣乘向量。則單次推理如下:
- 標準模式下計算量為\(8 bs?^2\)。
- kv cache模式下,query修改為單token,計算量是\(8bh^2\)。
4.3.5 對比
沒有KV cache時
每個transformer層的計算量大約為 $24bs?2+4bs2? $。具體如下。
| 模塊 | 操作 | 輸出 | 輸出形狀 | 計算量 |
|---|---|---|---|---|
| Embedding | 查表 | X | [b, s, h] | - |
| Attention | 計算Q、K、V | Q、K、V | [b, s, h] | \(6 bsh^2\) |
| Attention | QK^T | 注意力分數 | [b, head_num, s, s] | \(2 bs^2h\) |
| Attention | 乘以V | 注意力權重 | [b, head_num, s, head_dim] | \(2 bs^2h\) |
| Attention | post-attention linear projection | 注意力權重 | [b,s,?] | \(2 bs?^2\) |
| FFN | 第一個線性層 | 中間狀態 | [b,s,4?] | \(8 bs?^2\) |
| FFN | 第二個線性層 | Z | [b,s,?] | \(8 bs?^2\) |
KV Cache
當存在KV Cache時,每個transformer層的計算量大約為$24b?^2+4bs? $,具體如下。
| 模塊 | 操作 | 輸出 | 輸出形狀 | 計算量 |
|---|---|---|---|---|
| Embedding | 查表 | X | [b, 1, h] | - |
| Attention | 計算Q、K、V | Q、K、V | [b, 1, h] | \(6 bh^2\) |
| Attention | QK^T | 注意力分數 | [b, head_num, 1, prev_kv_seq_len + 1],約等于[b, head_num, 1, s] | \(2 bsh\) |
| Attention | 乘以V | 注意力權重 | [b, head_num, 1, head_dim] | \(2 bsh\) |
| Attention | post-attention linear projection | 注意力權重 | [b,1,?] | \(2 b?^2\) |
| FFN | 第一個線性層 | 中間狀態 | [b,1,4?] | \(8 b?^2\) |
| FFN | 第二個線性層 | Z | [b,1,?] | \(8 b?^2\) |
可見,對于單次運算,計算量減少了s倍。如果結合序列長度,則就是平方級別。
小結
假設有一批輸入序列(input sequences),數量為 b 個。每個序列由 N 個生成的 tokens 和 t 個輸入的 tokens (總長度為N+t)組成。
選擇 KV 緩存將在前 N 個生成步驟中節省大約如下數量的FLOP:
其實,可以把token數目去掉,就看單個token省了多少計算量。
即通過 KV 緩存節省的運算數量與 tokens 數量成正比。文本長度越長,減少的計算量越明顯。
還是以LLaMa-7B為例,推理一個batch為2,長度為4096的句子,光計算KV一共節省了2×2×32×4096×4096×4096×2=17592186044416 FLOPs的計算量。而且,KV Cache不僅省去了前文所有token的Key、Value的映射,由此導致后續這些token的注意力權重計算,注意力的MLP層,FFN前饋傳播層也都不需要再計算了,相當于推理階段的計算復雜度永遠等于只對一個token進行完整的forward推理,因此計算量大幅降低。
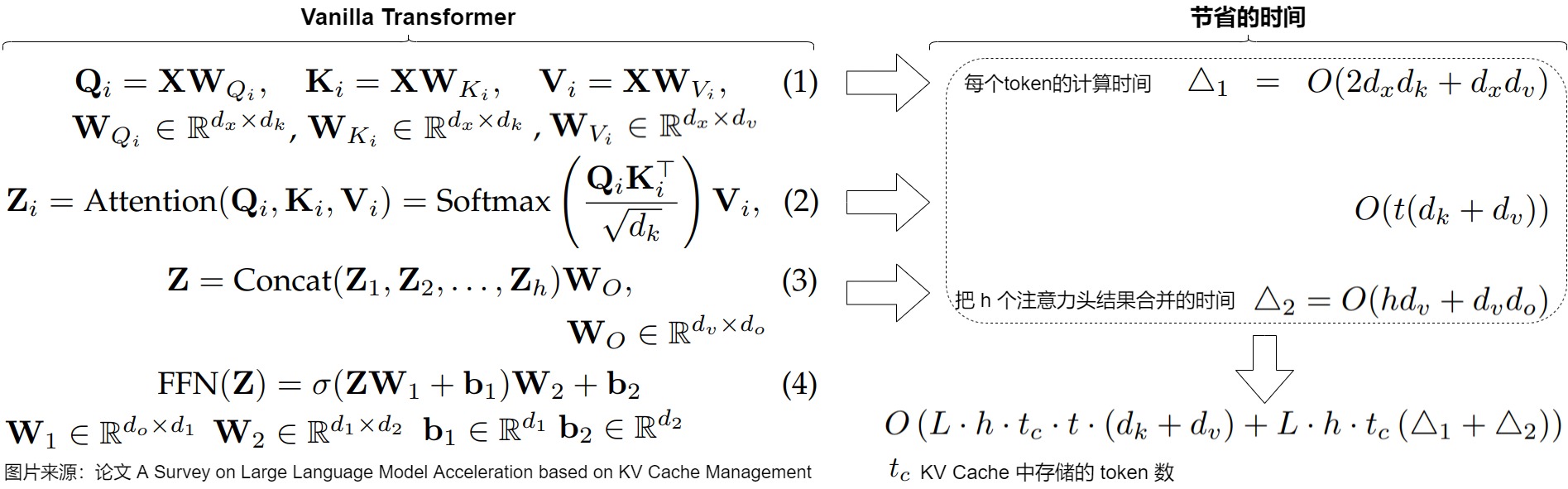
下圖來自論文“A Survey on Large Language Model Acceleration based on KV Cache Management”,圖中給出了KV Cache所節約的計算量。對于每個token,節省的計算時間來自避免重復計算方程(1)中的鍵和值、方程(2)中的自注意力計算結果和方程(3)中的線性變換。論文省略了對Transformer中不影響對KV緩存加速理解的操作時間,如layer norm和位置編碼。
4.4 總結
我們首先進行核心對比。
| 維度 | 無KV Cache | 有KV Cache |
|---|---|---|
| 計算復雜度 | \(O(n^2)\) 隨序列長度平方增長 | \(O(n)\) 僅需計算新token |
| 顯存占用 | 存儲完整序列中間結果,顯存需求高 | 緩存Key/Value,顯存需求可控 |
| 生成速度 | 慢(重復計算歷史token) | 快(僅計算新token,復用緩存) |
| 適用場景 | 短序列生成(<100 tokens) | 長序列生成(如API輸入、視頻生成) |
具體而言,KV Cache的優勢主要體現在以下維度:
- 減少重復計算。在自注意力機制中,如果沒有KV Cache,每次生成新token時,模型需要重新計算整個歷史序列的Key和Value向量,并參與注意力計算,這導致了大量的重復計算。KV Cache通過緩存已處理token的Key和Value表示,有效消除了重復計算的開銷,顯著降低推理的計算復雜度。
- 提升推理速度。KV Cache通過緩存Key和Value向量,使得模型在生成新token時只需計算當前token的Query向量,并與緩存的Key和Value進行注意力計算。比起全量計算 \(QK^T\),退化為 \(qK^T\) 后大幅削減了FLOPs,顯著提升推理速度;
- 降低計算復雜度。自注意力機制的計算復雜度為O(n^2?d),其中n是序列長度,d是向量維度。使用KV Cache后,計算復雜度可以降低到O(n?d)。比起全量計算 \(QK^T\),退化為 \(qK^T\) 后大幅削減了FLOPs,這樣可以大幅削減了FLOPs,顯著減少了計算量。
- 最大內存消耗隨序列變長的增長曲線,從二次方變為線性,得到有效控制;
- 在上下文處理能力上,KV Cache通過維持完整的長序列表示,確保了模型對上下文的準確理解。這種機制增強了注意力機制的效果,使模型能夠精確檢索歷史信息,從而保證了長文本生成時的語義連貫性和質量穩定性。
- 在動態特性方面,KV Cache展現出優秀的自適應能力。系統能夠根據輸入序列的長度動態調整緩存大小,靈活應對不同場景的需求,尤其適合實時交互式對話等動態應用場景。
- 跨請求復用。在某些場景下,多次請求的Prompt可能會共享同一個前綴(Prefix),這些情況下,很多請求的前綴的KV Cache計算結果是相同的,可以被緩存起來,給下一個請求復用。
綜上所述,KV Cache在LLM推理中通過緩存Key和Value向量,有效減少了重復計算,降低了計算復雜度,提升了推理速度,并且優化了顯存資源的使用,從而提高了模型的推理效率和吞吐量。
0xFF 參考
Notion – The all-in-one workspace for your notes, tasks, wikis, and databases.
ZHANG Mingxing:Mooncake (1): 在月之暗面做月餅,Kimi 以 KVCache 為中心的分離式推理架構
大模型并行推理的太祖長拳:解讀Jeff Dean署名MLSys 23杰出論文 方佳瑞
圖解Mixtral 8 * 7b推理優化原理與源碼實現 猛猿
圖解大模型計算加速系列:分離式推理架構2,模糊分離與合并邊界的chunked-prefills 猛猿
Llama.cpp 代碼淺析(一):并行機制與KVCache 。
DeepSeek開源FlashMLA之際從原理到代碼詳解MLA 杜凌霄 [探知軒]
談談大模型架構的演進之路, The Art of memory 渣B [zartbot]
圖解KV Cache:解鎖LLM推理效率的關鍵 致Great [ChallengeHub]
https://github.com/zhaochenyang20/Awesome-ML-SYS-Tutorial/tree/main/sglang/kvcache-code-walk-through
A Survey on Large Language Model Acceleration based on KV Cache Management
《基于KV Cache管理的LLM加速研究綜述》精煉版 常華Andy

 浙公網安備 33010602011771號
浙公網安備 33010602011771號