
探秘Transformer系列之(15)--- 采樣和輸出
探秘Transformer系列之(15)--- 采樣和輸出
0x00 概述
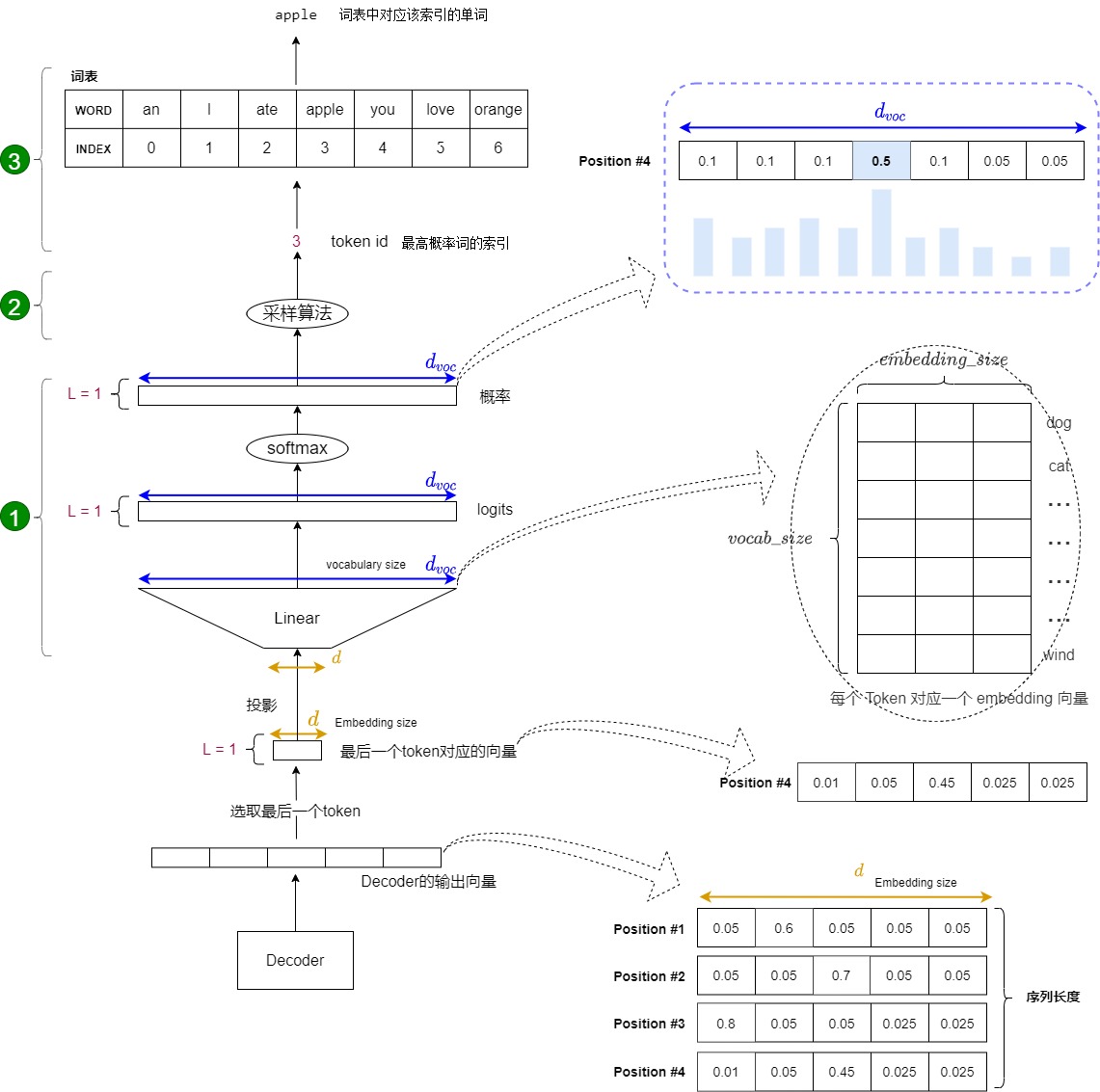
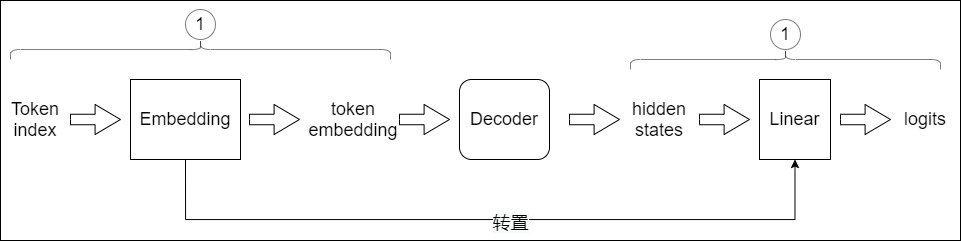
解碼器包括很多Transformer層,每一層的最后部分是"Add & Norm",其實也就是說,編碼器的最后一層的最后一個模塊是一個"Add & Norm"。該模塊的輸出是一個代表語義的浮點型向量。我們目前遇到的問題是:如何把這個浮點向量轉換成一個詞?這就是采樣和輸出部分所做的工作。簡要來說,在預測階段,采樣和輸出部分會執行下面三步:
- 計算概率。在解碼器層輸出結果后,需要經過Generator線性層進行最后的預測,Generator線性層就是個標準的分類網絡。Generator線性層會把最后一個token對應的特征向量通過一個線性層升維到詞表維度,并且把升維后的新向量通過softmax進行歸一化,最終輸出一個概率分布(每個概率對應詞匯表中的一個token)。該分布表示詞表中每個詞匹配這個特征向量的概率,或者說是表示詞表中每個 token 作為下一個 token 的概率。該部分實際是一個分類網絡。
- 采樣。根據這個概率分布來指導采樣,找出最大概率對應的詞表index。
- 生詞。依據index從詞表中選擇下一個 token 作為最終輸出。
下圖展示了上述流程:從底部以解碼器組件產生的輸出向量開始,最終轉化出一個輸出單詞。
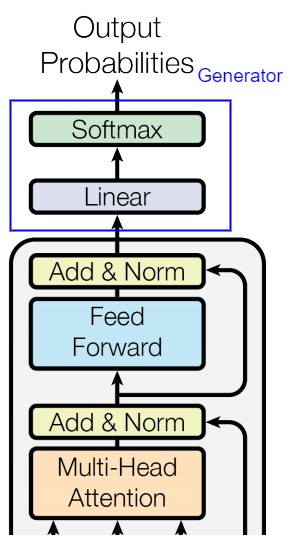
0x01 Generator
Transformer為代表的深度神經網絡是萬能函數逼近器,所做的事情是學習外部世界信息的概率分布,將其壓縮或提取,構建內部概率模型。編碼器-解碼器處理之后的輸出依然是一個實數向量,該向量是一個高維概率向量,其代表了Transformer視角下的編織起來的事物之間的各種復雜的關系。我們需要對此向量進行分類訓練,才能從復雜關系中確認下一個token。
Generator就完成了此分類功能。Generator的輸入是詞向量序列,輸出是每個位置上單詞的概率分布。其主要包括兩部分:
- Linear:將輸出擴展至Vocabulary Size,或者說把詞映射到詞典。 Linear的輸入是經過編碼器-解碼器處理后的詞向量(在推理時,Generator使用的并不是解碼器的所有輸出token,而是最后一個token),輸出是logits(對數幾率/詞表特征)。
- Softmax:Softmax將輸入的logits轉換為概率,輸出就是最后一個token對應詞表中單詞的概率分布。后續會選取概率最高的作為預測結果。
1.1 Linear
線性層主要起到轉換維度的作用,這一步的目的是將解碼器生成的向量映射到預先定義的詞典大小,從而準備進行詞預測。其相關特點如下:
- 線性層(通常被稱為 language model head 或 LM head)是一個簡單的全連接神經網絡,它可以把解碼器產生的向量投射到一個比它大得多的,被稱作logits的向量上。
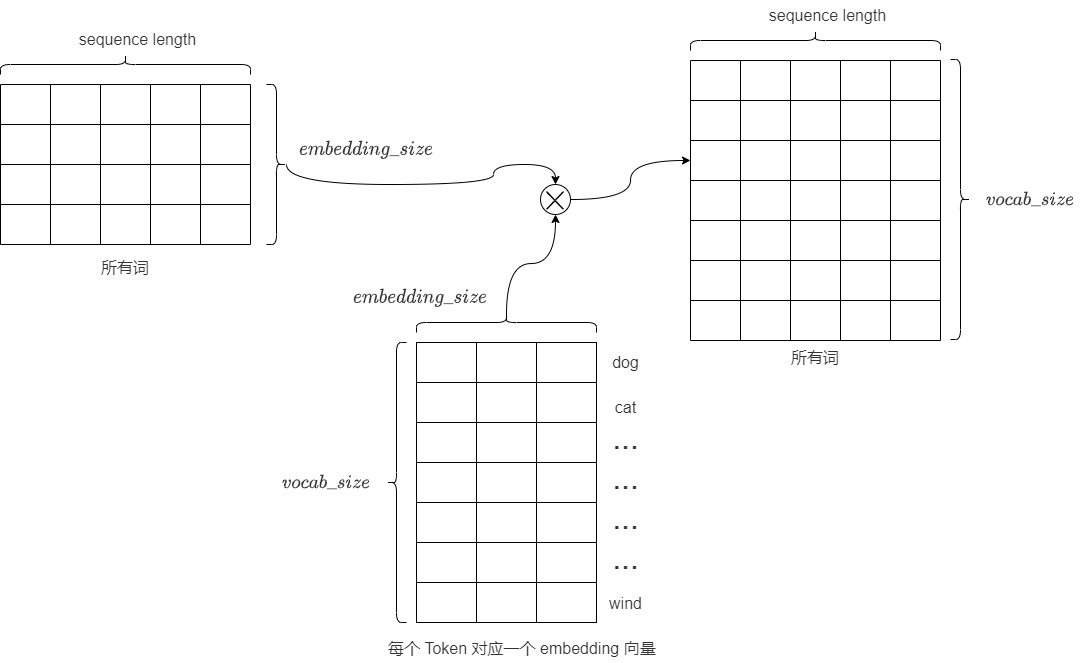
- 也可以把線性層認為是 Token Embeddings 矩陣,其行數為模型詞表中 Token 的個數,列數為 embedding 的維度,也就是每個 Token 對應一個 embedding 向量。解碼器產生的向量和Token Embeddings 矩陣相乘(也就是和每個 Token 對應的 embedding 向量做內積),得到和詞表中每個 Token 的相似性得分(logits),生成一個與模型詞匯表中每個詞作為下一詞出現的可能性相關的數值列表(即logits)。
- logits的大小是
vocab_size,對應了詞匯表的大小。假設我們的模型詞匯表是10000個詞,那logits向量維數也是10000,詞表中每個詞對應logits向量中的一個logit。如果編碼器輸出的形狀是(batch size,100,512),則把其中每個序列最后一個token取出,經過大小為[512, 10000]的線性層后,就得到形狀為(batch size, 1,10000)的logits列表。 - logits向量包含每個單詞成為序列中下一個單詞的概率,或者說是候選 Token 的得分向量。logits的每一個維度都代表目標語言單詞庫中的一個單詞,具體對應這個單詞的分數(Word Scores)或者是分數權重,表示某個特定詞元是“正確”下一個詞元的概率。logit值越高,表示相應詞元是“正確”詞元的可能性越大。具體而言,假設我們預測第i個位置的單詞,目標詞匯表中的每個單詞在第i個位置都有一個分數值,分數值表示詞匯表中的每個詞在第i個位置出現的可能性分數。向量中某維度的值越大,代表此單詞是第i個位置上單詞的概率越大。因此線性層就充當了分類頭(詞表中的每一個詞當作一個類別)的作用,只是這個分類頭的類別比較大。
- 后續要從這些單詞中找出最大概率生成的詞是哪幾個?為何要是幾個單詞?這是因為要通過類似top_k的采樣算法來調整模型的表現力,否則,你對模型說我愛你,模型回復的答案永遠是我也愛你。
比如針對上下文”I am sleepy. I start a pot of",下圖給出了預測下一個token時,詞表中每個詞的概率分布(按降序排列)。

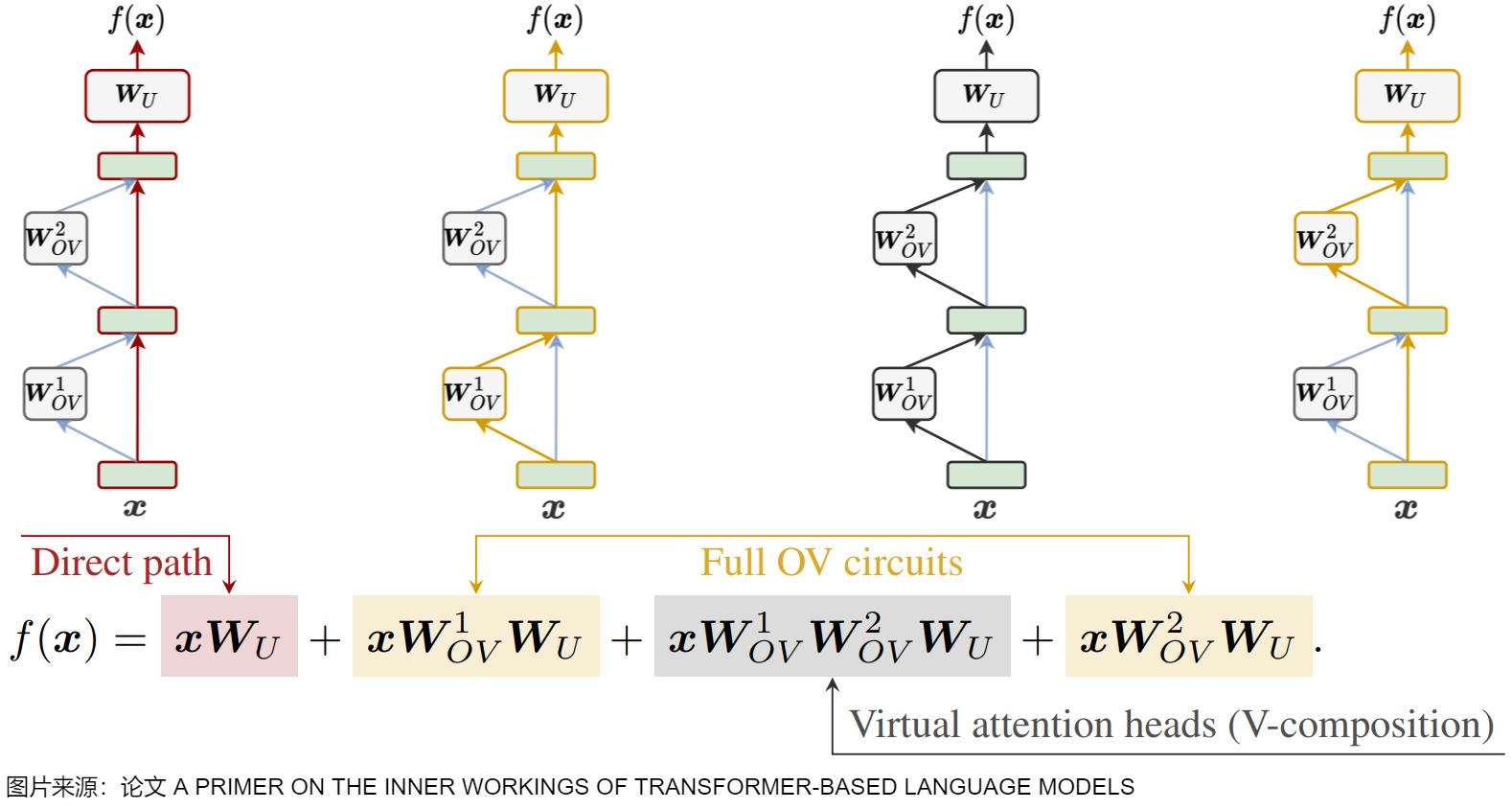
下圖給出了預測頭的數學表示,\(W_U\)就是線性層(unembedding matrix),有時還會有偏置。最后一個殘差流狀態通過該線性映射進行轉換,將表示轉換為基于logits的下一個token分布,該分布通過softmax函數轉換為概率分布。

下圖則對Transformer的前向傳播過程進行分解,圖中方程式的四項的特點如下:
- 第一項是direct path(直接路徑),該路徑把輸入embedding和 unembedding matrix 連接起來,對應圖中上方最左側的紅色路線。
- 第二項和第四項被稱為full OV circuits,該路徑流經單個OV矩陣,對應圖中上方的黃色路線。
- 第三項被稱為虛擬注意頭(virtual attention heads)。因為該部分兩個注意頭的順序讀寫,因此也被稱為V-composition(虛擬組合)。
1.2 softmax
線性層輸出的 logits難以解釋,因此我們接下來會把logits經過 softmax 轉換為概率,即把向量中最后一維的數字縮放到0-1的概率值域內,并確保這些數字的和為1。這在多分類問題中尤為重要,因為模型預測的結果可以解釋為每個類別的概率(每個位置上單詞的概率分布)。后續會按照概率分布采樣。
注意:Generator 返回的是 softmax 的 log 值。這里使用的是log_softmax而非softmax。雖然其效果應該是一樣的。但是log_softmax能夠解決溢出問題,加快運算速度,提高數據穩定性。
1.3 實現
本章第一個圖的藍圈對應下面的Generator類。Generator類包括Linear層和Softmax層。從直觀的角度看,
-
線性層的作用就是把詞映射到詞典。
-
Softmax層的作用就是選擇概率最大的詞。
Generator類的構建參數為:
- d_model:Decoder輸出的大小,即詞向量的維度。
- vocab:詞典的大小。
具體代碼如下。
# nn.functional工具包裝載了網絡層中那些只進行計算, 而沒有參數的層
import torch.nn.functional as F
# 定義一個基于 nn.Module 的生成器類,其將線性層和softmax計算層一起實現, 因為二者的共同目標是生成最后的結構,因此把此類的名字叫做Generator
class Generator(nn.Module):
"Define standard linear + softmax generation step."
# 初始化方法,接收模型維度(d_model)和詞匯表大小(vocab)作為參數
def __init__(self, d_model, vocab):
"""初始化函數的輸入參數有兩個, d_model代表詞嵌入維度, vocab_size代表詞表大小."""
super(Generator, self).__init__() # 調用 nn.Module 的初始化方法
# 這個線性層的參數有兩個, 就是初始化函數傳進來的兩個參數: d_model, vocab_size
self.proj = nn.Linear(d_model, vocab) # 定義一個線性層,將向量從模型的輸出維度映射到詞匯表大小
# 前向傳播方法,輸入x是Decoder的輸出,x的形狀是[1, d_model],因為x是序列中最后一個token對應的向量
def forward(self, x):
# 將輸入 x 傳入線性層,然后對輸出應用 log-softmax 激活函數(在最后一個維度上)
# 在函數中, 首先使用self.proj對x在最后一個維度上進行線性變化,
# 然后使用F中已經實現的log_softmax進行的softmax處理.
# log_softmax就是對softmax的結果又取了對數, 因為對數函數是單調遞增函數, 因此對最終我們取最大的概率值沒有影響. 最后返回結果即可
return log_softmax(self.proj(x), dim=-1)
1.4 使用
如何使用Generator類?以及如何使用生成的概率?
推理
在推理時,只需要拿Decoder輸出的最后一個token對應的張量送給Generator,得到一個詞的概率分布。以下是推理代碼。
def inference_test():
test_model = make_model(11, 11, 2)
test_model.eval()
src = torch.LongTensor([[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]])
src_mask = torch.ones(1, 1, 10)
memory = test_model.encode(src, src_mask)
ys = torch.zeros(1, 1).type_as(src)
for i in range(9):
out = test_model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
prob = test_model.generator(out[:, -1])
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0]
ys = torch.cat(
[ys, torch.empty(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
print("Example Untrained Model Prediction:", ys)
torch.max(prob, dim=1)實際上就是下面要學習的貪心解碼。next_token = vocabulary[np.argmax(probs)] 便可以獲取詞表中的token。
訓練
在訓練時,需要將Decoder的所有輸出送給Generator,然后對于輸出的每個詞,都會得到一個詞的概率分布。在每個位置,我們先找到概率最高的單詞索引(貪婪搜索),然后將該索引映射到詞匯表中的相應單詞。這些詞就構成了 Transformer 的輸出序列。
具體示例代碼如下。
def example_simple_model():
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
)
batch_size = 80
for epoch in range(20):
model.train()
run_epoch(
data_gen(V, batch_size, 20),
model,
SimpleLossCompute(model.generator, criterion), # 調用Generator類的實例
optimizer,
lr_scheduler,
mode="train",
)
model.eval()
run_epoch(
data_gen(V, batch_size, 5),
model,
SimpleLossCompute(model.generator, criterion), # 調用Generator類的實例
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)[0]
model.eval()
src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len)
print(greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0))
# execute_example(example_simple_model)
具體是在計算損失里面調用了model.generator進行預測。假設batch size是2,序列長度是100,代碼中會對最后一個維度進行softmax操作,得到bx100個單詞的概率分布,在訓練過程中bx100個單詞是知道真值的,故可以直接采用損失函數進行訓練。
class SimpleLossCompute:
"A simple loss compute and train function."
def __init__(self, generator, criterion):
self.generator = generator
self.criterion = criterion
def __call__(self, x, y, norm):
x = self.generator(x)
sloss = (
self.criterion(
x.contiguous().view(-1, x.size(-1)), y.contiguous().view(-1)
)
/ norm
)
return sloss.data * norm, sloss
0x02 采樣
拿到logits后,下一步是根據它來選擇下一個詞元。這個過程稱為采樣。通過 logits 生成的概率來提取 tokens 的過程是通過一種被稱為采樣方法、搜索策略(search strategy)、生成策略(generation strategy)或解碼策略(decoding strategy)的啟發式方法來完成的。由于語言的順序結構,token不僅要在上下文中合適,而且要自然地流動以創建連貫的句子和段落。采樣方法有助于選擇遵循語言模式和結構的token。此外,采樣方法有助于在確定性輸出和創造性、多樣化響應之間取得平衡。
所有采樣方法的基本原理是設定一個概率閾值 \(??^{(??)}∈[0,1]\)。概率大于該閾值的token將形成采樣的核心集(nucleus),其累積概率確定了nucleus的質量,具體參見下圖。
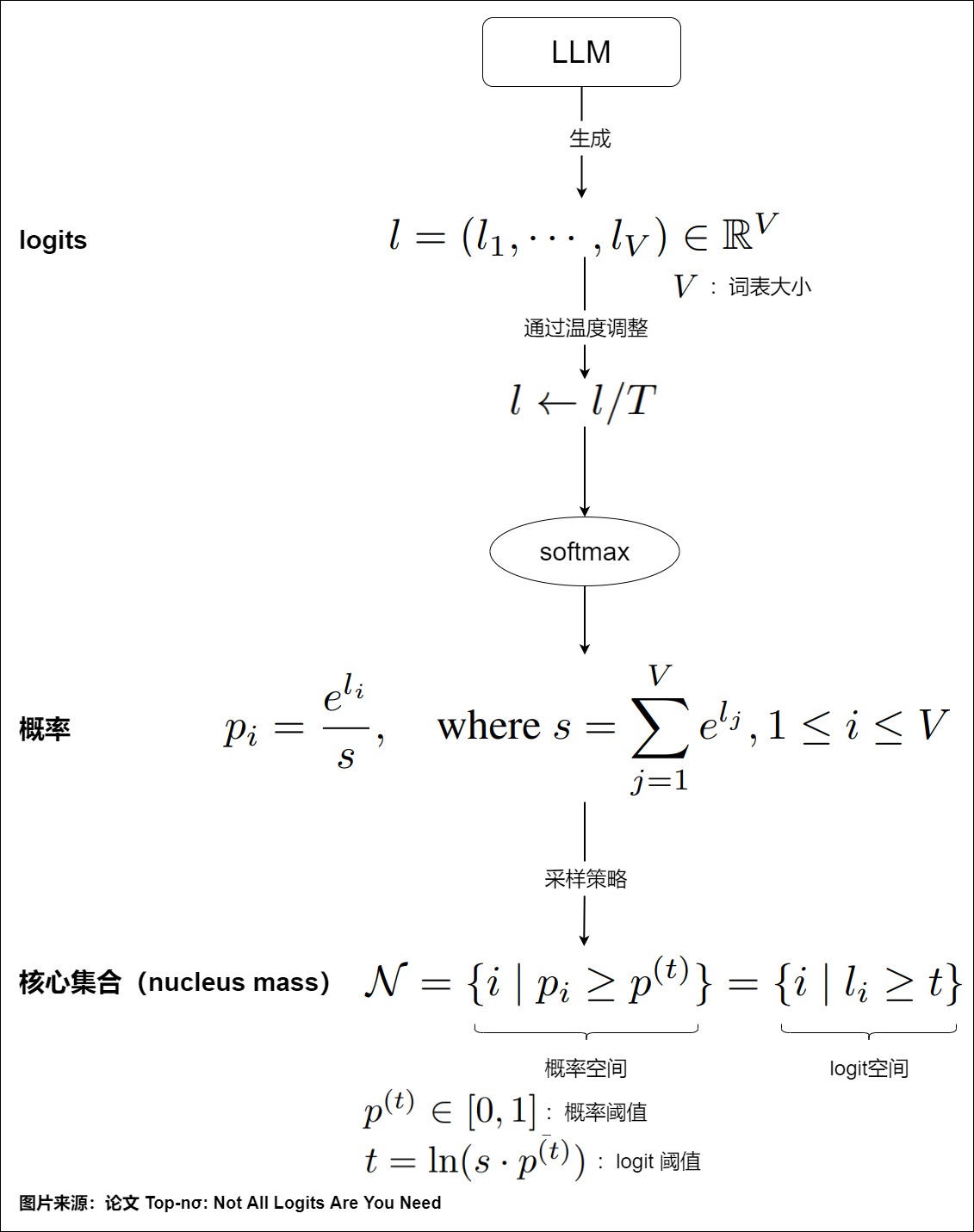
針對不同的使用場景,有多種采樣方法可用。不論那種策略,最終解碼的結果應該滿足在給定輸入文本的條件下,輸出的文本在所有候選文本中得分最高,表現為輸出文本每個位置上的單詞的聯合概率最大。上面推理示例中的torch.max(prob, dim=1)實際上就是貪心解碼。每次都選擇最可能的 token 稱為貪婪解碼。這并不總是最好的方法,因為它可能導致次優結果。我們接下來深入學習解碼策略。
2.1 采樣方法
LLM模型的輸出是在詞表上的概率分布,采樣方法直接決定了我們會得到怎么樣的輸出效果。有時候我們希望得到完全確定的結果,有時候希望得到更加豐富有趣的結果。下面我們介紹兩大類采樣方法:確定性采樣和概率性采樣。
確定性采樣
確定性采樣顧名思義就是輸出結果是確定性的,本質上是搜索過程。常見的如Greedy Search(貪心搜索)和Beam Search(集束搜索)。
- 貪心解碼是一種高效獲取預測序列的近似方法。它每次選擇概率最大(與logit值最相似的)的下一個token,并且丟棄其他詞,直到滿足終止條件。
- beam-search是在當前步驟根據歷史記錄選擇最好的幾個(這個數字也被稱為beam-width)作為候選,每次都根據歷史信息選擇最好的。Beam Search集束搜索是Greedy Search的改進版,它拓展了Greedy Search在每一步的搜索空間,每一步保留當前最優的K個候選,在一定程度上緩解了Greedy Search的問題。K就是Beam Size,代表了束寬。Beam Size是一個超參數,它決定搜索空間的大小,越大搜索結果越接近最優,但是搜索的復雜度也越高,當Beam Size等于1的時候,Beam Search退化為Greedy Search。
概率性采樣
概率性采樣會基于概率分布做采樣,以條件概率隨機挑選下一個詞,因此有機會生成小概率的token。在這種采樣中,模型的 logits 被看作是一個多項分布,然后基于該分布進行抽樣。換句話說,概率性采樣就是通過抽樣從詞匯表(vocabulary)中選擇一個token,而我們可以先通過一些簡單操作(如temperature scaling、top-k和top-p)來對這種抽樣分布進行調整。
常見的概率性采樣有以下3種:Multinomial采樣(直接基于概率分布做純隨機采樣,容易采到極低概率的詞),Top-k采樣和Top-p采樣。top_p 和 top_k 都可以用于增加模型生成結果的多樣性。top-p和top-K采樣可以結合使用,在開放式語言生成上產生比Greedy Search和Beam Search更為流暢的文本。
2.2 貪心解碼
貪心搜索是最簡單的解碼方法。它從詞匯表 V 中選擇具有最高條件概率的token。在每一步中,它選擇概率最高的token并將其添加到序列中。它繼續進行,直到遇到一個結束token或達到最大序列長度。
我們從數學角度來解釋一下貪心解碼。在sequence-to-sequence問題中,給定一個輸入序列\(x = (x_1, . . . , x_n)\),我們希望預測相應的輸出序列\(y = (y_1, . . . , y_m)\)。解決這個問題的一種常見方法是學習一個自回歸評分模型(auto-regressive scoring model)\(p(y|x)\)。該模型從左到右逐個生成答案中的一部分(比如一個 Token)。
假設詞表空間為 K(也就是所有可能的輸出),那么每次預測都會有 K 種可能,整個答案將要有 \(K^m\) 種可能,這個計算代價太高。為了降低計算量,可以每次都只選擇得分最高的輸出 \(y_j\)作為當前步驟的生成結果,然后重復上述過程,直到獲得最終的結果。這種方式就稱為貪心解碼,具體如下圖所示。

貪心解碼的好處是實現簡單,可作為解碼的快速實現。而且非常適合模型效果嚴格對齊的場合,即適合需要確定性輸出的場景。因為在推理階段,模型的權重是確定的,并且也不會有 dropout 等其他隨機性(忽略不可抗的硬件計算誤差,比如并行規約求和的累積誤差等),因此對于同一個輸入,在多次運行貪心解碼后,模型的輸出結果應該完全一致。
貪心解碼的問題如下:
- 模型效果可能不是最優的。因為貪心解碼只能保證每一步的局部最優(只管當前步驟的信息),不會關心輸出序列的聯合概率是否達到最大值(沒有綜合歷史信息),這樣達不到全局最優,忽視了潛在的長期利益。另外,如果在時刻 t 模型的最優輸出并不是正確的結果,從 t+1 開始的每個時刻,模型都會受到這樣一個錯誤輸出的影響,具有錯誤的累加效果。最后導致模型“越走越偏”。
- 貪心搜索也會缺乏一定的多樣性。貪心搜索總是選擇最可能的詞,傾向于偏愛經常使用的短語,導致可預測的結果和單調的輸出。
- 需要m步來產生長度為m的輸出,隨著模型的增大,每一步的時延也會增大,整體時延也會放大至少 m 倍。
- 每次進行一個token生成的計算需要搬運全部的模型參數和激活張量,這使解碼過程嚴重受限于內存帶寬。
- 貪心搜索不能糾正其錯誤。一旦它做出了不理想的選擇,每個隨后的決策都會受到影響。
貪心解碼的代碼如下。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
"""
進行模型推理,推理出所有預測結果。
:param model: Transformer模型,即EncoderDecoder類對象
:param src: Encoder的輸入inputs,Shape為(batch_size, 詞數) ,例如:[[1, 2, 3, 4, 5, 6, 7, 8, 0, 0]]代表一個句子,該句子有10個詞
:param src_mask: src的掩碼,掩蓋住非句子成分。
:param max_len: 一個句子的最大長度。
:param start_symbol: '<bos>' 對應的index,在本例中始終為0
:return: 預測結果,例如[[1, 2, 3, 4, 5, 6, 7, 8]]
"""
memory = model.encode(src, src_mask) # 將src送入Transformer的Encoder,輸出memory
ys = torch.zeros(1, 1).fill_(start_symbol).type_as(src.data) # 初始化ys為[[0]],用于保存預測結果,其中0表示'<bos>'
# 循環調用decoder,一個個的進行預測。例如:假設我們要將“I love you”翻譯成“我愛你”,則第一次的`ys`為(<bos>),然后輸出為“I”。第二次`ys`為(<bos>, I) ,輸出為"love",依次類推,直到decoder輸出“<eos>”或達到句子最大長度。
for i in range(max_len - 1):
# 將encoder的輸出memory和之前Decoder的所有輸出作為參數,讓Decoder來預測下一個token
out = model.decode(
memory, src_mask, ys, subsequent_mask(ys.size(1)).type_as(src.data)
)
# 將Decoder的輸出送給generator進行預測。這里只取最后一個詞的輸出進行預測。
# 因為傳的tgt的詞數是變化的,第一次是(<bos>),第二次是(<bos>, I)
# 所以out的維度也是變化的,變化的就是(batch_size, 詞數,詞向量)中詞數這個維度
prob = model.generator(out[:, -1]) # 只取出最后一個向量來預測,即 從 seq_len 維度選擇最后一個詞
# 取出數值最大的那個,它的index在詞典中對應的詞就是預測結果
_, next_word = torch.max(prob, dim=1)
next_word = next_word.data[0] # 取出預測結果
# ys就是Decoder之前的所有輸出
ys = torch.cat( # 將這一次的預測結果和之前的拼到一塊,作為之后Decoder的輸入
[ys, torch.zeros(1, 1).type_as(src.data).fill_(next_word)], dim=1
)
return ys # 返回最終的預測結果
"""out torch.Size([1, 2, 512]) (batch_size, seq_len, dimension)
out[:, -1] torch.Size([1, 512])
prob torch.Size([1, 11]) (1, vocab_size)
"""
2.3 Beam(束搜索)
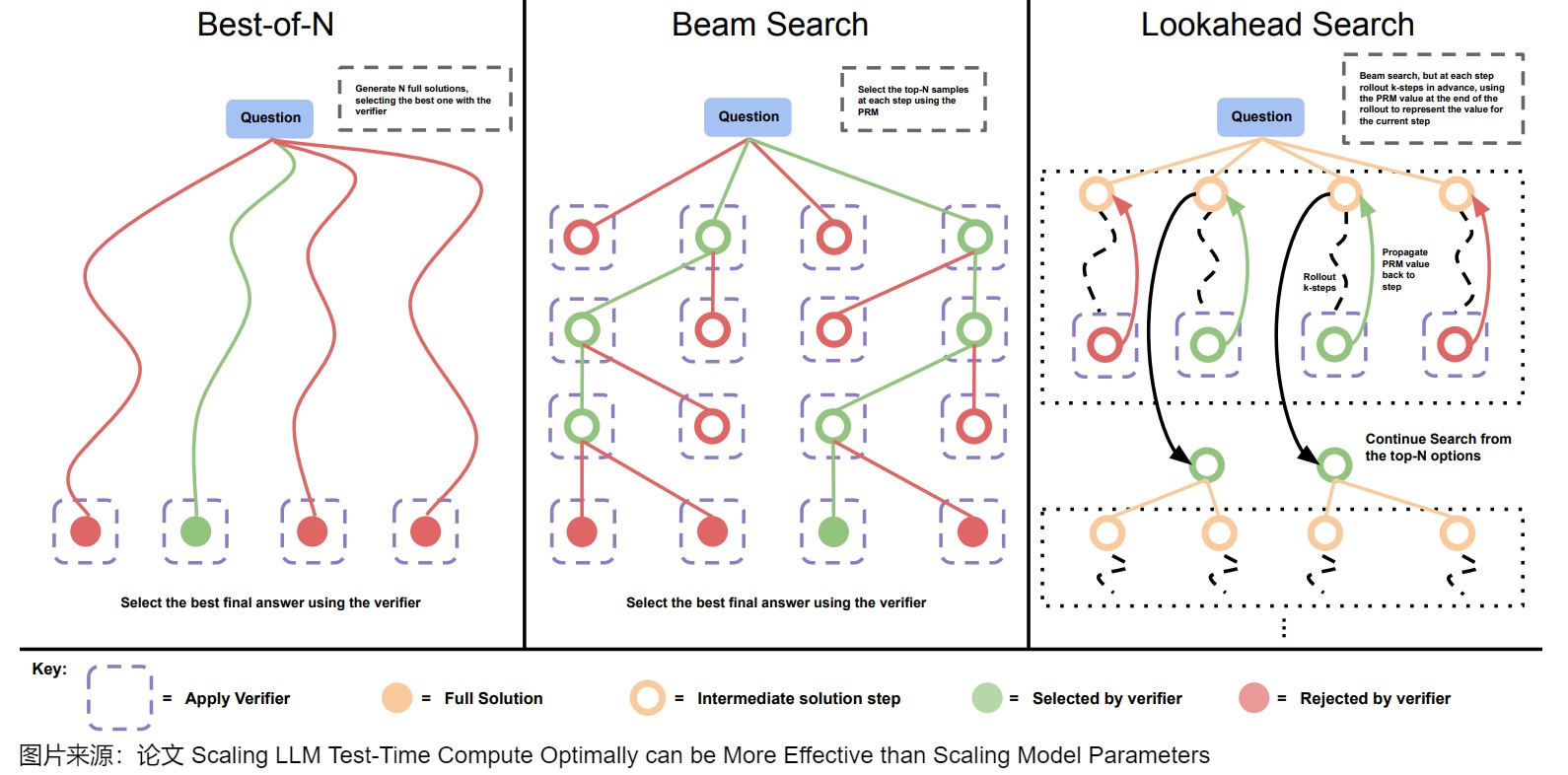
在LLM(大型語言模型)任務如機器翻譯中,用戶通常期望得到最合適的前??個翻譯結果。Beam Search就可以完成這個效果。Beam Search的核心思想是:雖然每一步貪心可能并不是最優解,但是接下來生成的若干個 tokens 連乘起來的概率最大。下圖給出了Beam搜索和其它方案的比較。
問題
Beam Search是要解決在實際預測環節如何構造一個理想輸出的問題。從概率的視角來看,全局最優輸出序列就是指在整個詞空間中,使得輸出序列聯合概率取得最大的詞匯的組合。我們先來分析兩種極端的著眼方式:
- “放眼全局”的窮舉搜索(exhaustive search)。窮舉搜索是遍歷詞序列的所有可能組成并在其中挑選概率最大者,因此可以得到全局最優輸出。窮舉搜索看的是聯合分布表示的全局最優,可謂“不計一城一地之得失”。
- “只看眼前”的貪心搜索。貪心搜索在進行第 t 步預測時,以 t?1 步得到具有最大概率的預測詞匯作為輸入。
這兩種方法都有嚴重的問題,窮舉搜索計算量太大,無法實際使用,而貪心搜索“目光短淺”,容易產生誤差的累積。既然兩個極端方法都有問題,那么只能采取一些折中手段,集束搜索(beam search)就是其中的典型算法。
思路
Beam Search 是 Greedy Search 的改進版本,其不再是每次都取得分最大的 Token,而是始終保留 beam_size 個得分最大的序列。在第t 步的詞預測中,beam search既不像窮舉搜索那樣用到全部詞的組合,也不像貪心搜索那樣只用到前面最大的那個預測詞匯,而是用到上一步概率值排在前 k 個的詞預測作為當前步驟的輸入,這里的參數 k 被稱為beam width(集束寬度)或者beam size,該參數決定每一步保留的最頂尖的候選序列數量。beam search就是在一個窗口長度的 scope 下使用貪心算法,優化的是每個分支從0到時間步t的log probability。vanilla Transformer使用的就是beam search,在Transformer中,對集束寬度的設置為4。
其實beam search和人類解決問題的思考方式類似。因為自然語言中充斥著模糊性,我們在時刻t無法得知足夠的信息來做出選擇。所以在日常交流的過程中我們的大腦就不做出選擇,先保留時刻t的語言模糊性,等到積累了足夠的上下文信息后,我們再返回來t時刻進行決擇(進行去模糊化操作)。
與 greedy search 類似,雖然 beam search 保留了多個序列,但最終輸出時還是返回的得分最大的序列,因此對于同一個輸入,使用 beam search,多次運行模型最終的輸出依然是固定不變的。

在Beam search中,解碼器在 t 時刻因為對解碼結果的不同解讀產生不同的時間線分叉。在每個分叉中,我們使用不同的詞向量作為 t+1 時刻的解碼器輸入。 然后我們可以將解碼器繼續“分叉”,在不同的假設上繼續推理并在未來回溯至該時刻進行選擇。當解碼器所有的分支都結束輸出以后,我們可以對每一個分支輸出的序列進行評估并在其中選擇最優的序列。
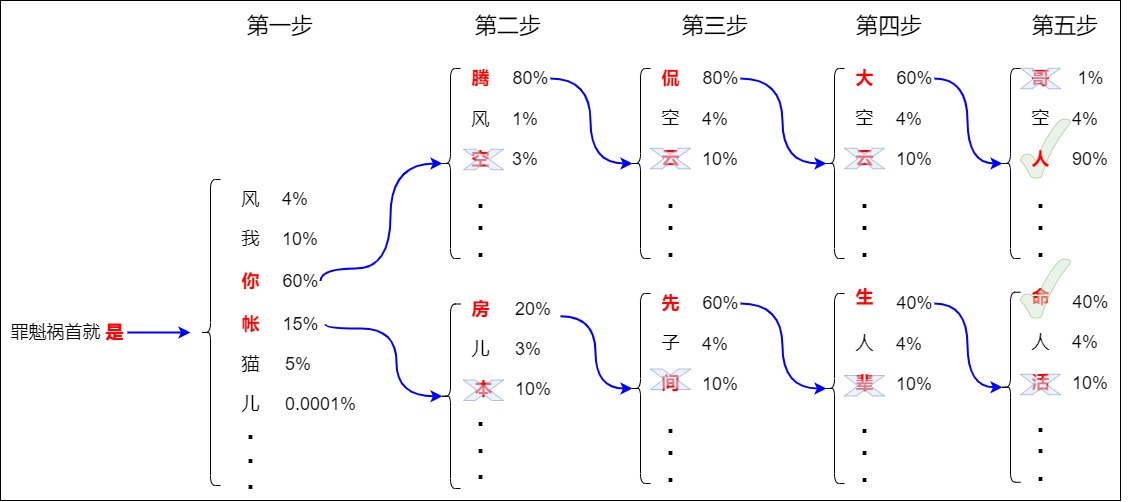
如下圖所示,假設 beam_size 為 2,也就是始終保留兩個得分最大的序列。在解碼過程中,Beam search會在1 個時間步保留2個最高概率的輸出詞,然后先根據第一個詞計算第2個位置的詞的概率分布,再取出第2個位置上2個概率最高的詞。對于第3個位置和第4個位置,我們也重復這個過程,但是后續步驟中,計算的是歷史預測序列和下一個候選詞的聯合概率。比如第二步計算的是”你騰“,”你空“,”你風“,”賬房“,”帳兒“,”賬本“等的聯合概率。以此類推,該步驟一直持續到解碼到end或者超過最大解碼步長為止,最終會形成2條完整候選序列,取其中的聯合概率得分最大值即可得到最佳解碼序列。另外,第一個 token 是從 V 中選擇 k 個概率最大的 token ,剩下的都是從 kV 個候選 token 選擇 k 個概率最大的。
最終得到4個序列。從以上 4 個序列中選出概率最高的 2 個保留,由于此時得分最高的 “罪魁禍首就是你騰侃大人” 因為已經生成終止符 Token “EOS”,不會有其他得分更高的序列,所以可以在此終止。
效率
由于 beam search 會同時保留多個序列,因此就更容易得到得分更高的序列,并且 beam_size 越大,獲得更高得分的概率越高。
相較于窮舉搜索和貪心搜索,Beam Search在計算量和準確性方面進行了平衡,通過限制每一步保留的候選數量來降低完全遍歷樣本空間的計算復雜度。特別地,當 k=|V| 時,集束搜索就變成了窮舉搜索,其中 |V| 為詞典大小,而當 k=1 時,集束搜索就退化為貪心搜索。從數據結構角度看,窮舉搜索是 |V| 叉樹結構,貪心搜索是鏈表,而集束搜索是 k 叉樹結構。令解碼步長為T,詞表長度為N,束寬為K,則Beam Search的時間復雜度是O(K * N * T),因為在每一個步長T下都需要運算K次推理全部詞表長度N,且對N進行排序。
因為每個 step 都需要進行 beam_size 次前向計算,beam search的計算量會比貪心搜索擴大 beam_size 倍。另一方面,LLM 推理中一般都會使用 Key、Value cache,這也就會進一步增大 Key、Value cache 的內存占用,同時增加了 Key、Value cache 管理的復雜度。另外,Beam Search也不能保證找到最可能的序列,特別是如果束寬度‘k’與詞匯表的大小相比太小。這也就是在 LLM 推理中為什么比較少使用 beam search。
雜項
我們接下來針對Beam Search做進一步討論。
懲罰
解碼的目標是獲得聯合概率P最大的單詞序列。該公式是一個概率累乘,數值是一個負數,序列越長聯合概率越小,該數值就越接近0,因此為了方便計算避免出錯,在具體操作中,會采用log將概率的累乘改為負數的累加。但是又有一個新問題:在采用對數似然作為得分函數時,Beam Search 通常會傾向于更短的序列。這是因為對數似然是負數,隨著解碼文本長度的增加,序列的得分也在不斷變得越來越負,因此算法會給短文本結果更高的得分,導致一個更合理的翻譯結果因為文本較長被一個不合理的短文本結果淘汰。
Beam Search可以采用基于文本長度的懲罰項來解決這個問題,目的是使得長文本的得分不要那么得負。比如可以使用基于“n-gram 懲罰”的技術。這種技術確保任何給定的 n-gram 只出現一次:一個 n-gram 序列會被生成放入序列中,如果該 n-gram 已經在序列中存在,則其概率被設置為零。
論文“Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation”提出把對數似然、length normalization(對長度進行歸一化) 和 coverage penalty 結合在一起構建新的得分函數來解決這一問題,具體如下面的公式所示,其中 lp 是 length normalization,cp 是 coverage penalty。coverage penalty 主要用于使用 Attention 的場合,通過 coverage penalty 可以讓 Decoder 均勻地關注于輸入序列 x 的每一個 token,防止一些 token 獲得過多的 Attention。
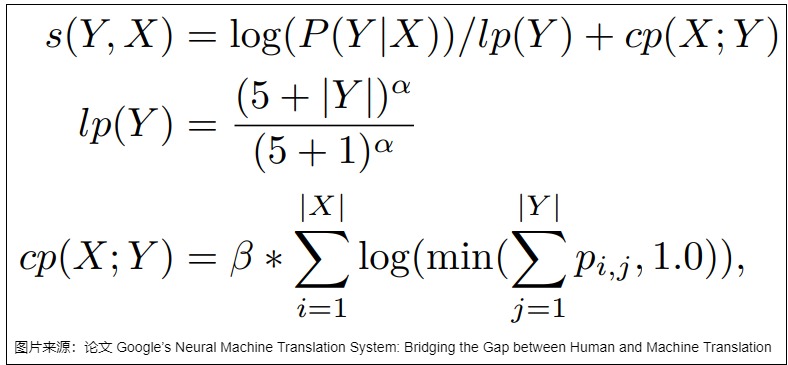
停止
Beam Search單條候選序列停止條件細分有兩種情況,分別是
- 候選序列解碼到
停止。具體而言是對于單條翻譯文本的單個候選序列解碼到 停止,此時若其他候選序列還沒有解碼到 ,則不影響其他候選序列繼續尋找。 - 早停,候選序列得分已經低于已解碼完的當前最優序列。由于解碼長度越大,序列得分越小,如果都等到所有候選都解碼到
,則最終的解碼結果集合會很大。既然很多得分很小的結果是沒有必要的,應該有這么一種情況當解碼到某個單詞的時候,已經可以斷定不需要再繼續以此為基礎繼續搜索了。Beam Search引入早停機制來實現這個效果。早停的機制是比較當前得分和已經全部解碼完的序列的得分,如果當前得分遠遠小于最優路徑得分,則執行早停,通過給最大得分乘以α倍來控制這個遠遠小于的程度。
至此討論的都是某條候選序列停止條件,什么時候整個待翻譯文本結束搜索呢?答案是當前一個步下可用的候選為0的時候,該樣本的Beam Search結束。如果是一個批次下好多文本輸入給Transformer,則所有樣本并行構造自身的候選,待所有樣本的都已經沒有可用的候選時候,整個批次文本的Beam Search解碼停止。
優化
針對Beam Search有很多優化方案,這里給出一個方案讓大家學習下。論文"Best-First Beam Search"作者給出了一種通用的 Beam Search 偽代碼,偽代碼包括 4 種可替換的關鍵成分。傳統的 Beam Search、Best-First Beam Search 和 A* Beam Search 都可以通過修改偽代碼的可替換成分得到。

另外,在自回歸模型的推理過程中,使用波束搜索時,TopK 操作通常跟隨在 Softmax 之后,而 TopK 不需要計算所有 \(y_i\) 值。這使得性能可以獲得更大的提升。
TopK 至少需要讀取輸入向量的每個元素一次。如果分別運行safe Softmax 和 TopK,則每個輸入元素需要進行 5 次內存訪問,如果使用online Softmax 而非safe Softmax(但仍然分別依次運行),則需要 4 次內存訪問。我們可以通過 Softmax + TopK 融合運行,實現每個輸入向量元素只進行一次內存訪問。
即在softmax算法中,不僅在遍歷輸入向量時保持最大值 ?? 和歸一化項 ?? 的運行,還保存 TopK 輸入值 ?? 和它們的索引 ?? 的向量。

2.4 top-k
從上面的介紹可以看出,不管是 greedy search,還是 beam search,對于固定輸入,模型的輸出是固定不變的,這就顯得比較單調,為了增加模型輸出的多樣性,人們提出了 top-k 采樣策略。
top-k不像 greedy search 那樣每次取分數最高的,而是選取概率前 TopK 的樣本作為候選項,也就是每一步都保留有 K 個候選項,token從這個受限的池中選擇,這樣能在一定程度上保證全局最優。因為Top-K 采樣用top-k個樣本的分數作為權重進行隨機采樣來得到下一個 Token。這也就引入了隨機性,允許概率較高但非最高的 token 也有機會被選擇,所以也可解決模型生成多樣性的問題,并且K越大多樣性越豐富。
top-k的特點如下:
- 根據下一個token的輸出概率分布,從大到小排序選出前k個。為了避免采樣出過低概率token,采樣候選數k始終保持不變。
- 將這k個token重新做概率歸一化,按新的分布采樣輸出token。
- 如果 top_k = 1,則top k算法退化為貪心解碼。
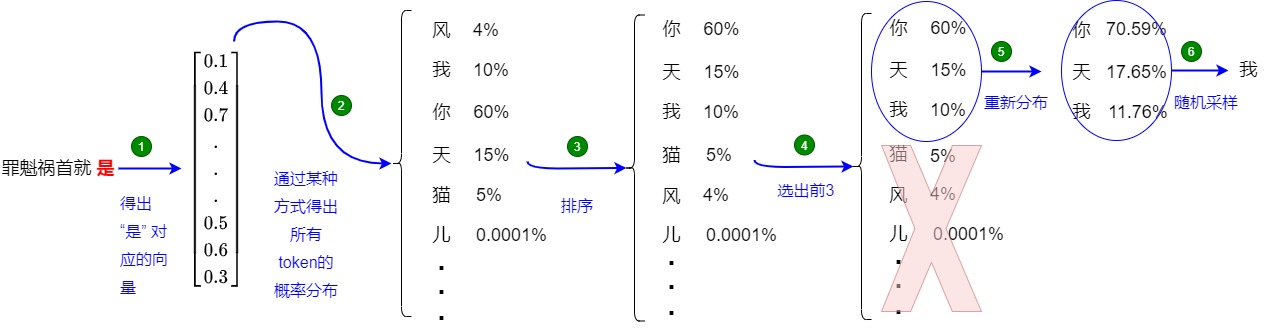
還是以上面的例子來介紹,如上圖所示(假設 k = 3),top-k的每一步又可以分為兩個步驟:
- 確定候選集:
- 使用最后一個 Token “是” 對應的新生成的 embedding 來計算相似性得分(logits)。
- 使用softmax對logits進行處理,得到概率,每個單詞(或 token)都有一個概率。
- 選出概率最高的 3 個 Token:[“你”、“天”、“我”],對應的權重為:[0.6, 0.15, 0.1]。
- 從候選集中采樣:使用該權重進行隨機采樣,獲得新 Token “天”。
top-k 里面有一個比較難的問題就是如何選擇K才能保證全局最優。對于概率分布比較均勻的分布來說(對于下一個詞,有很多同樣好的選項),比如每個數的概率都是1/n,這時候top-k 里面K應該選擇比較大的數,因為這時候從準確度來說,每一個都是一樣的,應該選擇比較大的K來增加diversity。反之,如果概率分布極其不均勻,比如最大的概率是0.95,那這時候如果就需要選擇比較小的K,因為除了概率最大的數能夠保證準確度之外其它的都不行。而在其它上下文中,一些token主導了概率分布。一個小 k 可能會導致通用文本,一個大 k 可能包括不合適的詞候選。
2.5 top-p
top-p 采樣(也稱為核采樣,Nucleus Sampling),與 top-k 采樣類似,但在候選 token 集的選擇方式上有所不同。top-k采用的是選擇概率最高的k個詞匯,而top-p 采樣不是限制為固定數量的 token(K),而是動態選擇概率累積值超過預設閾值 P(例如 0.9)的 token 集。
論文”The Curious Case of Neural Text Generation“提出了 top-p 采樣。在 top-k 中,每次都是從 k 個 Token 中采樣,但是難免會出現一些特殊的 case,比如某一個 Token 的分數非常高,其他分數都很低,此時仍舊會有一定的概率采樣到那些分數非常低的 Token,導致生成輸出質量變差。此時,如果 k 是可變的,那么就可以過濾掉分數很低的 Token。為了平衡生成文本的多樣性和質量,在top-p中,在每一步生成 next_token 時,都從累積概率超過閾值 p 的tokens 集合中進行隨機采樣,即算法不是選擇最可能的 K 個詞,而是選擇組合概率超過閾值 p的最小詞集。
top-p的特點如下:
- 對模型在當前時間步生成的所有詞匯的概率進行降序排序。
- 在排序后的詞匯中,以從概率最大的到概率最小的順序進行選擇(同時將概率從大到小累加),直到選擇的數對應的概率和大于等于p就停止。然后選擇這個最小token集合,記為 V_p。例如,若 p=0.9,則選擇前幾個詞,使其概率之和至少為 0.9。
- 只從累積概率超過某個閾值p的token集合中進行隨機采樣,不考慮其它低概率的token。這樣,每次候選的 Token 個數都會因為 Token 分數的分布不同而不一樣。因為采樣候選數動態變化,這樣可以避免采樣出過低概率token。
- 將這些token重新做概率歸一化,按新的分布隨機采樣輸出token。
- top-p 采樣方法可以動態調整候選詞的數量,避免了固定數量候選詞可能帶來的問題。
- top-p 越小,則過濾掉的小概率 token 越多,采樣時的可選項目就越少,生成結果的多樣性也就越小。
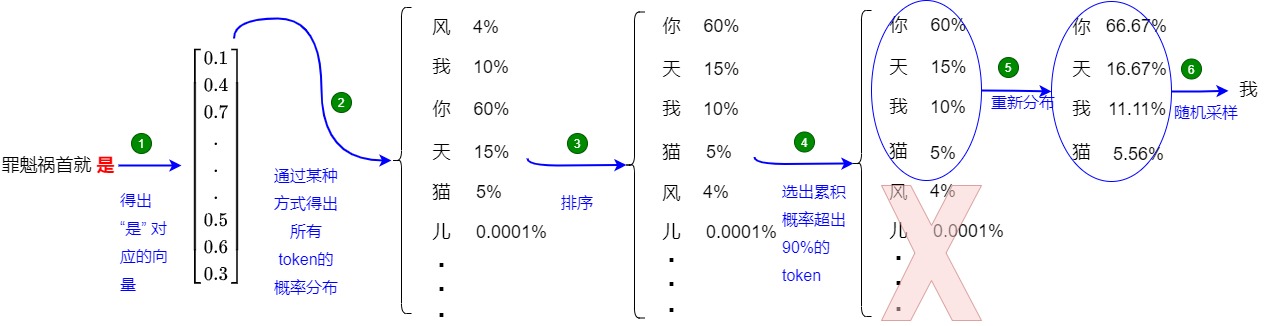
還是以上面的例子來介紹,如上圖所示(假設 p = 0.85),top-p可以分為兩個步驟:
- 確定候選集:
- 使用最后一個 Token “是” 對應的新生成的 embedding 來計算相似性得分(logits)。
- 使用softmax對logits進行處理,得到概率,每個單詞(或 token)都有一個概率。
- 對概率降序排列,逐步累加概率,直到累積概率達到某個閾值,比如0.85。
- 選出累積得分超過 0.85 的 Token:[“我”、“你”、“天”],對應的概率為:[0.1, 0.6, 0.15]。
- 從候選集中采樣:把候選集中的概率重新歸一化,根據歸一化后的概率進行隨機采樣,獲得新 Token “天”。
我們選取Llama3的代碼來學習。
top_p算法
def sample_top_p(probs, p):
"""
對概率分布進行 top-p (nucleus) 采樣
Args:
probs (torch.Tensor): 概率分布張量,形狀是(batch_size, vocab_size).
p (float): 用于 top-p 采樣的概率閾值
Returns:
torch.Tensor: 采樣后的 token 索引,形狀是 (batch_size, 1)
Note:
Top-p 采樣首先獲取累積概率超過閾值p的最小 token 集合。然后據選定的 token 重新規范化概率分布.
該方法之所以可以控制生成的隨機性, 是因為通過設置閾值p就可以控制采樣得到的 token 集合中小權重 token 的數量.
- 當 p 趨近 1 時, 采樣的集合中會有更多小權重的 token, 生成的文本更加隨機.
- 當 p 趨近 0 時, 僅有權重較大的 token 被采樣, 生成的文本更加確定.
"""
# 對概率進行降序排序. 降序是因為要按概率從大到小選擇 token 集合.
# 假如probs是torch.tensor([0.1,0.2,0.3,0.25,0.15])
# probs_sort里面是排序后的概率,形狀和probs相同:[0.3000, 0.2500, 0.2000, 0.1500, 0.1000]
# probs_idx是排序后的索引,用于映射回原始詞匯表
probs_sort, probs_idx = torch.sort(probs, dim=-1, descending=True)
# 計算累積概率. 這是為了后續快速做差分然后判斷 token 是否在 top-p 集合中.
# probs_sum里面是累積到當前的概率和[0.3000, 0.5500, 0.7500, 0.9000, 1.0000]
probs_sum = torch.cumsum(probs_sort, dim=-1)
# 創建一個掩碼, 排除累積概率超過閾值 p 的部分, 所以需要減去當前概率判斷是否已經超過閾值.
# 假如p是0.8,mask是[False, False, False, False, True]
mask = probs_sum - probs_sort > p
# 使用掩碼將超過閾值的 tokens 概率設置為 0.
# probs_sorts是[0.3000, 0.2500, 0.2000, 0.1500, 0.0000]
probs_sort[mask] = 0.0
# 對篩選后的概率重新做歸一化,確保總和為1。div_方法將規范化后的概率分布保存在 probs_sort 中.
# probs_sort是[0.3333, 0.2778, 0.2222, 0.1667, 0.0000]
probs_sort.div_(probs_sort.sum(dim=-1, keepdim=True))
# 從規范化的后的概率分布中采樣一個 token.
# 用多項式采樣,得到排序后的索引。probs_sort中概率大的元素被采樣的幾率就大
# torch.multinomial基于輸入的概率權重進行采樣
next_token = torch.multinomial(probs_sort, num_samples=1)
# 根據采樣的索引probs_idx映射回原始詞匯表索引
# torch.gather函數按照給定的索引張量index,從輸入張量中收集 (獲取) 數據,并返回一個與索引張量形狀一致的張量
next_token = torch.gather(probs_idx, -1, next_token)
# 返回采樣得到的 token 索引.
return next_token
如何調用
torch.inference_mode()
ef generate(
self,
prompt_tokens: List[List[int]],
max_gen_len: int,
temperature: float = 0.6,
top_p: float = 0.9,
logprobs: bool = False,
echo: bool = False,
-> Tuple[List[List[int]], Optional[List[List[float]]]]:
"""
Generate text sequences based on provided prompts using the language generation model.
Args:
prompt_tokens (List[List[int]]): List of tokenized prompts, where each prompt is represented as a list of integers.
max_gen_len (int): Maximum length of the generated text sequence.
temperature (float, optional): Temperature value for controlling randomness in sampling. Defaults to 0.6.
top_p (float, optional): Top-p probability threshold for nucleus sampling. Defaults to 0.9.
logprobs (bool, optional): Flag indicating whether to compute token log probabilities. Defaults to False.
echo (bool, optional): Flag indicating whether to include prompt tokens in the generated output. Defaults to False.
Returns:
Tuple[List[List[int]], Optional[List[List[float]]]]: A tuple containing generated token sequences and, if logprobs is True, corresponding token log probabilities.
Note:
This method uses the provided prompts as a basis for generating text. It employs nucleus sampling to produce text with controlled randomness.
If logprobs is True, token log probabilities are computed for each generated token.
"""
params = self.model.params
bsz = len(prompt_tokens)
min_prompt_len = min(len(t) for t in prompt_tokens)
max_prompt_len = max(len(t) for t in prompt_tokens)
total_len = min(params.max_seq_len, max_gen_len + max_prompt_len)
pad_id = self.tokenizer.pad_id
tokens = torch.full((bsz, total_len), pad_id, dtype=torch.long, device="cuda")
for k, t in enumerate(prompt_tokens):
tokens[k, : len(t)] = torch.tensor(t, dtype=torch.long, device="cuda")
if logprobs:
token_logprobs = torch.zeros_like(tokens, dtype=torch.float)
prev_pos = 0
eos_reached = torch.tensor([False] * bsz, device="cuda")
input_text_mask = tokens != pad_id
if min_prompt_len == total_len:
logits = self.model.forward(tokens, prev_pos)
token_logprobs = -F.cross_entropy(
input=logits.transpose(1, 2),
target=tokens,
reduction="none",
ignore_index=pad_id,
)
stop_tokens = torch.tensor(list(self.tokenizer.stop_tokens))
for cur_pos in range(min_prompt_len, total_len):
logits = self.model.forward(tokens[:, prev_pos:cur_pos], prev_pos)
if temperature > 0:
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
next_token = sample_top_p(probs, top_p)
else:
next_token = torch.argmax(logits[:, -1], dim=-1)
next_token = next_token.reshape(-1)
# only replace token if prompt has already been generated
next_token = torch.where(
input_text_mask[:, cur_pos], tokens[:, cur_pos], next_token
)
tokens[:, cur_pos] = next_token
if logprobs:
token_logprobs[:, prev_pos + 1 : cur_pos + 1] = -F.cross_entropy(
input=logits.transpose(1, 2),
target=tokens[:, prev_pos + 1 : cur_pos + 1],
reduction="none",
ignore_index=pad_id,
)
eos_reached |= (~input_text_mask[:, cur_pos]) & (
torch.isin(next_token, stop_tokens)
)
prev_pos = cur_pos
if all(eos_reached):
break
if logprobs:
token_logprobs = token_logprobs.tolist()
out_tokens, out_logprobs = [], []
for i, toks in enumerate(tokens.tolist()):
# cut to max gen len
start = 0 if echo else len(prompt_tokens[i])
toks = toks[start : len(prompt_tokens[i]) + max_gen_len]
probs = None
if logprobs:
probs = token_logprobs[i][start : len(prompt_tokens[i]) + max_gen_len]
# cut to after eos tok if any
for stop_token in self.tokenizer.stop_tokens:
try:
eos_idx = toks.index(stop_token)
toks = toks[:eos_idx]
probs = probs[:eos_idx] if logprobs else None
except ValueError:
pass
out_tokens.append(toks)
out_logprobs.append(probs)
return (out_tokens, out_logprobs if logprobs else None)
top-p解決了top-p面臨的難題。這種動態方法提供了更大的靈活性,因為候選 token 的數量可以根據生成的上下文而變化。通過調整閾值 P,模型可以控制每一步中被考慮的 token 數量,從而在生成輸出的多樣性和連貫性之間取得平衡。對于固定的p,在最極端的均勻分布的時候,可以取到更多的點;對于分布極其不均勻的時候,top-p只會取到概率最大的一個或者幾個值,避免了錯誤的引入。當然,top-p里面的p如何選擇,依然是一個需要考慮的事情。p值減小容易減小diversity,p值增大容易引入更多的小概率token,無論p怎么選,也都有可能把概率值很少的概率取到候選集合。為了解決這個問題,人們引入了temperature調節的機制。
另外,雖然從理論上講,top_p 似乎比 top_k 更優雅,但這兩種方法在實踐中都很好用。top_p 也可以與 top_k 結合使用(當結合使用時,token 集首先被限制為 K 個候選,然后進一步縮小到滿足概率累積閾值 P 的 token),這可以避免分數非常低的 Token,同時提供一些動態選擇的空間。
2.6 性能
有研究人員對比單獨應用每種采樣方法的結果,結果發現 Top-K 的開銷最大,其次是 Top-P,而重復懲罰的開銷最小。值得注意的是,與 Top-K 和 Top-P 采樣相比,重復懲罰的開銷較低,因為前兩者需要排序算法。
另外,在計算受限的情況下,采樣技術的額外計算開銷更加顯著。例如高請求速率、解碼任務較重的數據集或較大的批量大小。在此類情況下,需謹慎考慮采樣開銷。
當請求速率較低時,采樣幾乎沒有導致性能下降。這是因為請求速率增加時,工作負載變得更偏向計算受限。較高的請求速率導致更大的運行批量大小(running batch size),以及更高的操作密度。
0x03 采樣參數
常見的采樣參數如下所示,不同模型可能有不同的參數和閾值。
| 參數 | 默認值 | 含義 |
|---|---|---|
| top_p | 0.95 | top-p概率閾值。如果top_p小于1,則從高到低累加直到top_p,取這前N個詞作為候選 |
| top_k | 50 | 保留前K個結果詞作為候選 |
| repetition_penalty | 1.0 | 重復處罰的參數。1.0意味著沒有懲罰。 |
| temperature | 1.0 | 用于控制生成語言模型中生成文本的隨機性和創造性的溫度值,越小意味著選擇最有可能的詞的概率更高。相同的輸入更可能出現相同的輸出。而值越大,則出現其他結果的可能性越高。 |
3.1 temperature
概念
雖然 Softmax 可以得到一個分布,但同時也有其缺點:容易擴大/縮小內部元素的差異(退化成 max / mean)。即,對于一些數值上相近的向量數值,概率卻相差很大。例如對”The boy _ to the market.“進行預測,可能的答案為有 [goes,go,went,comes],假設分類器的輸出數值為 [38,20,40,39],則通過上述公式求得其 Softmax 結果為:[0.09, 0.00, 0.6, 0.24]。如果依據該分布采樣,60% 的可能為 went,但填空的答案根據上下文也可能是 goes 和 comes。分類器的 words 的初始值是比較接近的,但 Softmax值卻會將差距拉得很開。
參數Temperature便是用來解決這個問題,其用于調節 Softmax,讓其分布進一步符合我們的預期,進而控制LLM的生成結果的可信度、隨機性、創造性和多樣性。為什么叫 temperature 呢?我們知道:溫度越高,布朗運動越劇烈;同理,temperature 越高,采樣得到的結果越隨機,生成的內容多樣性就會越大。
從數學上來說,設置溫度是一個非常簡單的操作,temperature就是對每個詞的概率分布進行softmax處理時候的溫度系數。模型輸出 logits 只需除以 temperature即可。具體公式如下圖所示。\(z_i\) 是第i個logit。
T會放大logits之間的差異。T設置得越高,生成的結果越隨機,輸出分布就越平滑。T越小,隨機性越弱,輸出分布越陡峭。
- T < 1:較低的溫度通過銳化概率分布使模型更加自信和確定性,從而產生更可預測的輸出。當T→0的時候,極致放大貧富差距,讓最大值的元素概率趨向1,其他變成0,此時信息熵為0,softmax的效果和argmax差不多。
- 當 T=1 時,將 logits 除以 1 對 softmax 輸出沒有影響,輸出分布將與標準 softmax 輸出相同。
- T > 1:較高的溫度會使概率分布更平滑,模型更有可能選擇概率較低的 token。這可以生成更具創意和多樣化的文本,但也增加了生成不連貫結果的風險。當T→∞的時候會極致縮小貧富差距,讓把所有輸出概率都趨于一樣的值,分布變成均勻分布,就是完全隨機,此時信息熵是最大的。有些人稱“較高的溫度”為模型的“創造力”。
應用代碼如下所示:
# logits 是LLM的推理輸出, 形狀為 [batch_size, seq_len, vocab_size]
# logits[:, -1]表示選擇的是最后一個token(seq_len 維度的最后一項)對應的logits,形狀為[batch_size, vocab_size]
probs = torch.softmax(logits[:, -1] / temperature, dim=-1)
我們還需要對當溫度=0時的行為做一些特殊分析。
當溫度=0時,模型執行貪婪解碼(greedy decoding):它在每一步總是選擇概率最高的下一個標記,本質上是預測概率分布中的argmax選擇。理論上,貪婪解碼應該消除生成過程中的隨機性。如果模型和輸入固定,每次生成的標記序列應該是相同的。然而,將溫度設置為零并不能在實踐中保證100%的確定性。比如,如果兩個或多個下一個標記選項具有(幾乎)相同的最高概率,模型或解碼庫可能會以任意方式打破平局。這種情況很少見,但可能發生。在這種情況下,即使溫度=0,標記之間的選擇也可能是非確定性的。另外,現代LLM架構和硬件行為也會引入一定的變異性。比如,專家混合模型架構的復雜性(容量限制和批處理競爭都會造成輸出不一致)、并行硬件上浮點運算的微妙之處以及其他實現細節意味著,即使沒有任何“隨機性”參數,對同一模型的相同提示的兩次調用偶爾也會產生分歧。
動態溫度系數
vanilla Transformer的溫度參數是靜態的,我們接下來看看在LLM解碼過程中動態調整溫度的思路。
KL-Divergence Guided Temperature Sampling
論文"KL-Divergence Guided Temperature Sampling作者提出了一種基于KL散度的方法調整溫度的思路。KL散度用于衡量兩個分布的統計距離。論文的出發點是根據當前token和prompt的關聯性來調整這次解碼的T。具體來說,作者又額外引入一個LLM參與解碼,它的輸入不包括prompt,也含有\(x_{<t}\)(已經解碼出來的response前綴)。
兩個模型同時運行,然后計算原LLM logit和引入LLM logit的KL散度,再依據KL散度來計算temperature。兩個分布越相似,那么值越接近0,反之就會越接近0。物理含義是:對prompt來說,下一個token解碼是否重要。
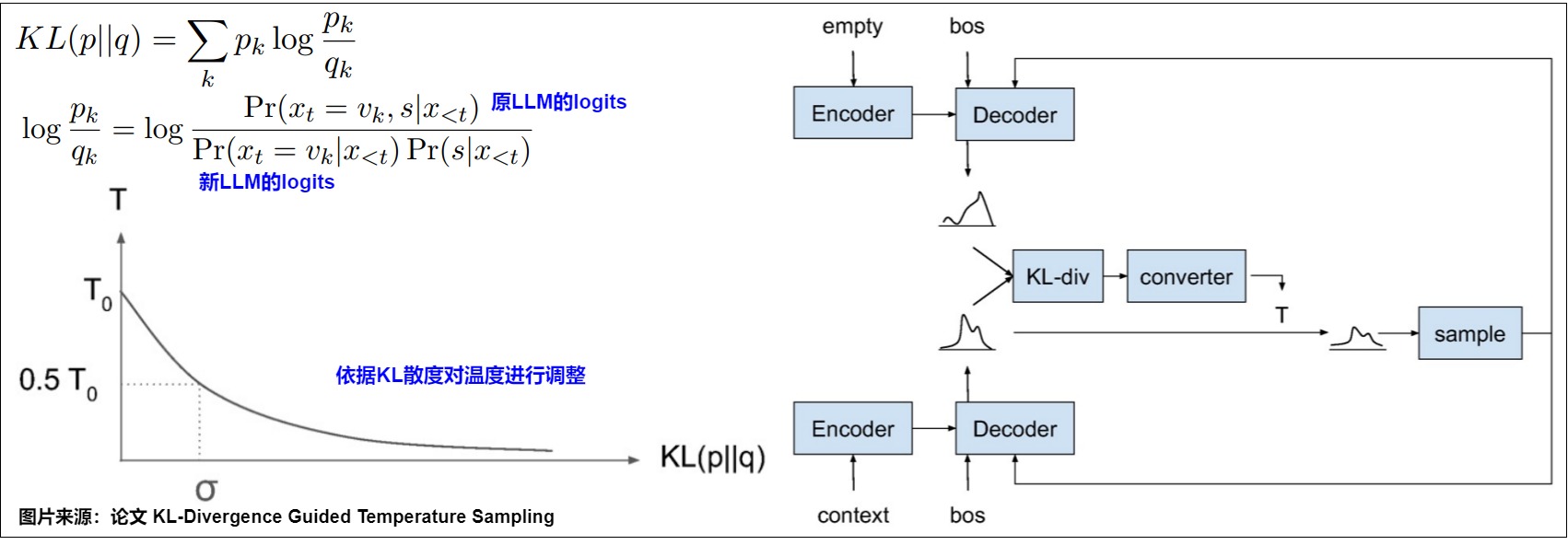
但是這種方法的缺點很明顯,需要額外一個LLM,會使用兩倍的顯存和計算量,對于大模型來說,這是一個非常大的開銷。從效率來看基本不可接受。
Hot or Cold
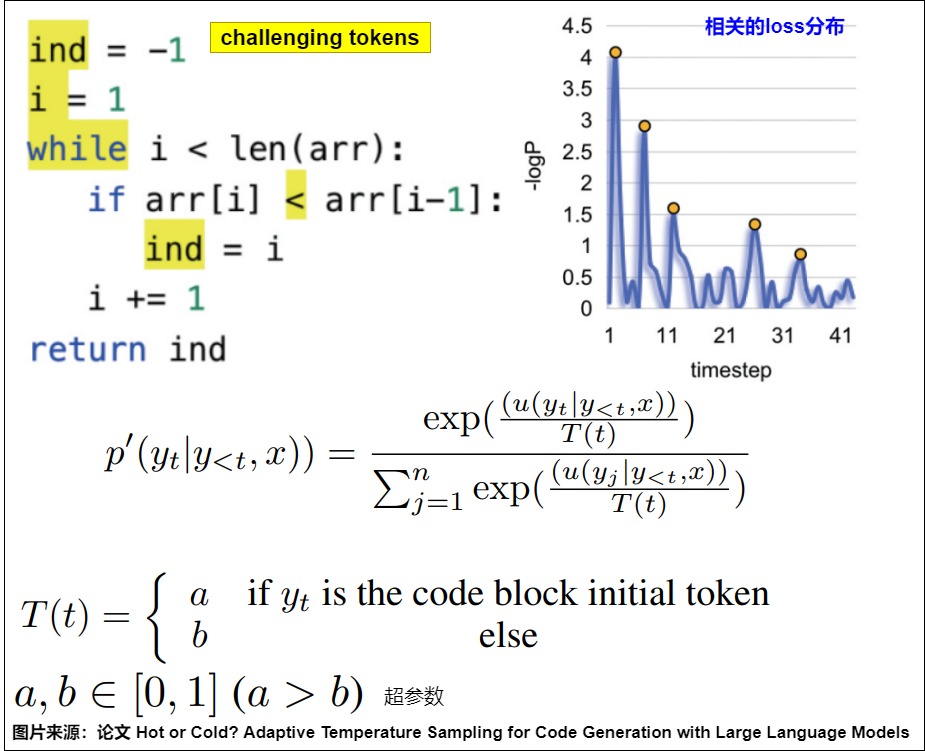
論文"Hot or Cold? Adaptive Temperature Sampling for Code Generation with Large Language Models"提出了一種相當簡單的方法,論文在代碼生成任務中,把token分為challenging(損失高)和confident兩類,前者對于LLM來說難以預測,所以需要更大的讓LLM做更多的探索,下圖就是判斷token是否challenging以及調整T的規則。此方案相對簡單,因為是完全基于規則來調節。
EDT
論文”EDT(Entropy-based Dynamic Temperature“通過使用熵來動態計算temperature。一個”n個狀態(n-state)“系統的熵定義如下,其中\(p_i\)是第i個事件發生的概率。
論文用logit的熵衡量LLM對下一個token的confident。
- 熵越大代表大模型對于本輪生成的token越不置信,極端情況是每個token的logit值相同。在大模型本身對于生成哪個token都沒有把握的時候,我們應該讓系統增加多樣性,也就是應該使用一個大的temperature去做探索;
- 熵越小代表大模型對于本輪應該生成的token越肯定。大模型對于本輪應該生成哪個token非常置信的時候,我們應該使用一個小的temperature讓系統更加肯定它的選擇,同時這么做也可以解決掉一些小概率值被錯誤選中的問題。
下圖是EDT解碼過程的示意圖。在每個解碼步驟中,系統首先獲得logits(?)并生成下一個令牌的概率分布(?)。然后根據初始概率分布計算所有token的熵(?)。接下來模型依據熵來選擇溫度(?),再依據溫度獲得新的分布(?),并對下一個令牌進行采樣(?)。
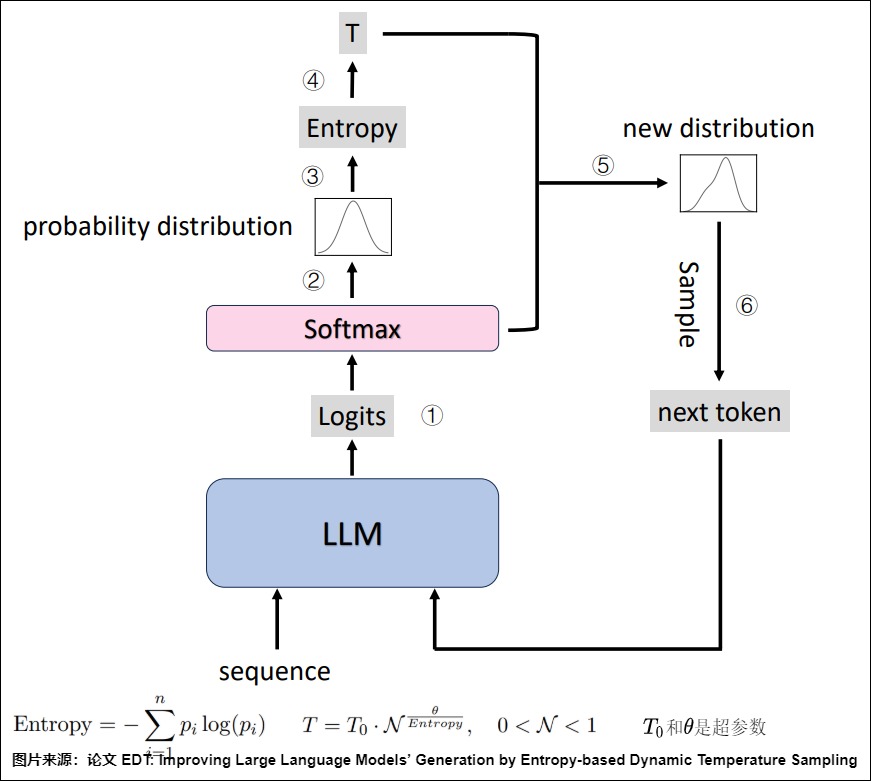
3.2 repetition_penalty
repetition_penalty(重復懲罰)參數用于避免模型一直輸出重復的結果,repetition_penalty 越大,出現重復性可能越小,repetition_penalty 越小,出現重復性可能越大。
問題原因
論文"Learning to Break the Loop: Analyzing and Mitigating Repetitions for Neural Text Generation"系統性地研究了LLM為什么會在貪心解碼時傾向生成重復句子的問題,并通過定量研究回答了以下提問:
- 為什么會發生句子級的重復?
- 為什么模型會陷入重復循環?
- 什么樣的句子更容易被重復?
論文通過分析指出,自我強化效應(Self-Reinforcement Effect)是導致重復的核心問題。模型傾向于生成重復結果的原因可能是:基于最大化的解碼算法生成前一句的概率相對較高,且模型傾向于進一步增大該句重復的概率。具體而言,一旦模型生成一個重復句子,則該句之后出現的概率將進一步增加,因為有更多重復共享相同句子級的上下文來支持這個復制的操作。其結果就是,由于自我強化效應,模型陷入了這種句子級重復。我們用輸入“I love orange. I love"作為輸入來預測下一個token為例。
-
為什么會發生句子級的重復? 由于模型在之前的上下文中已經看到了“I love orange”的模式,因此模型為Pθ('oranges'|'I love oranges . I love')分配的概率高于Pθ('oranges'|'I love')。所以模型可能對之前的上下文重復過于自信,并學習了一種“廉價”的快捷方式,直接復制下一個token “orange”。
-
為什么模型會陷入重復循環? 這個可以從注意力角度來理解。第一次重復的時候,某個token在注意力中的權重為w,這個token在句子中不同位置的表示是相似的。隨著前面多次重復出現這個token,那么這個token會在attention weight中多次出現w的權重,相當于增加了這個token的權重。那就更容易重復這個token。
-
什么樣的句子更容易被重復?具有高初始句概率\(TP_0\)(average token probability)的句子,具有更強的自我強化效應,而且基于最大化的解碼算法生成的句子重復的可能性越大(生成的句子具有更高的初始似然性)。
另外還有一個問題:為什么模型越大,重復卻越少?LLM是預測下一個token,而下一個token可以分成幾種來討論:
- true tokens,正確的tokens。
- context tokens,前面出現的tokens。
- random tokens/other,其他tokens。
理想情況下,模型對這三種token的預測概率的大小關系應該是:P(true tokens) > P(context tokens) > P(random tokens)。模型將prefix映射到一個表示空間,對這個表示空間解碼來預測下一個token。這個表示空間應該能區分不同語義、解碼到對應的正確token;然而存在一種較差的情況:表示空間對不同語義的區分度不夠,容易解碼到錯誤的token上。模型能力差、容量小,能表示的空間小,就難以將prefix映射到更好的表示空間并解碼到正確的token。也就容易出現P(true tokens) < P(context tokens) ,于是模型開始重復。
參數原理
repetition_penalty參數最早在論文"CTRL: A Conditional Transformer Language Model for Controllable Generation"中被提出,目的是解決語言模型中重復生成的問題。其思路是:記錄之前已經生成過的 Token,當預測下一個 Token 時,人為降低已經生成過的 Token 的分數,使其再次被采樣到的概率降低(即對在之前步驟中已經被選擇的 token 進行懲罰),這樣可以平衡文本的連貫性、增加生成的多樣性。
如下圖所示,直接基于上述帶溫度系數 T 的 softmax 進行實現,其中的 g 表示已經生成過的 Token 列表,如果某個 Token 已經在生成過的 Token 列表 g 中,則對其對應的溫度系數 T 乘上一個系數 θ,θ 為大于 0 的任意值。
- θ=1,表示不進行任何懲罰。
- θ>1,相當于盡量避免重復。用戶可以減少退化現象,同時保持句子的連貫性。然而,較高的懲罰可能導致輸出的連貫性下降,因為它可能過度懲罰那些對句子結構至關重要的 token。
- θ<1,相當于希望出現重復。
或者說,temperature是對所有token都除以T。repetition_penalty是對已生成的token才除以\(\theta\)。

我們從mnn的代碼中來學習下。
int Llm::sample(VARP logits, const std::vector<int>& pre_ids, int offset, int size) {
std::unordered_set<int> ids_set(pre_ids.begin(), pre_ids.end());
auto scores = (float*)(logits->readMap<float>()) + offset;
if (0 == size) {
size = logits->getInfo()->size;
}
// repetition penalty
const float repetition_penalty = 1.1;
for (auto id : ids_set) {
float score = scores[id];
# 小于0的數會乘以repetition_penalty, 否則是除以repetition_penalty
scores[id] = score < 0 ? score * repetition_penalty : score / repetition_penalty;
}
// argmax
float max_score = scores[0];
int token_id = 0;
for (int i = 1; i < size; i++) {
float score = scores[i];
if (score > max_score) {
max_score = score;
token_id = i;
}
}
return token_id;
}
此外,還有其他方法可以控制重復性輸出:頻率懲罰(Frequency Penalty)和 存在性懲罰(Presence Penalty)。兩者通過從 logits 中減去一定數值來施加懲罰。此外,頻率懲罰根據重復次數施加懲罰,而其他方法僅基于 token 是否存在進行懲罰。
0x04 logits分析
Transformer中的token其實是向量在不同維度和不同語義空間的表示,而思考的過程,就是從一個語義空間向另一個語義空間運動的過程。Transformer的最終隱層logits就是最終思考的結果。我們接下來在對logits的性質進行深入分析,也會看看一些基于logits的方案。
4.1 壓縮信息
我們先看看為何推理時候只使用最后一個token對應的embedding就可以進行預測下一個token。
示例
我們把《大唐狄公案之四漆屏》的前面部分文字輸入到模型:
牟平縣縣令滕侃直立在書齋的門后呆呆地發愣。只覺頭暈目眩,神魂顛倒,眼前飛星亂閃,什么都看不清楚了。他閉上了眼睛,慢慢抬起雙手壓一任太陽穴,劇烈的頭痛漸漸緩解,耳朵也不嗡嗡作響了。時已入夏,縣衙里午休后的衙役們又開始忙碌起來。他聽到后院傳來了熟悉的聲音,心想。該是管家來給他送茶了。
.....
在老管家引狄公進了滕侃的書齋。滕侃已換上了公余穿的青衿舊袍,頭上一頂軟翅紗巾。他見狄公進房,趕忙稽首讓座,老管家送上茶盤便唯唯退出。這個場面使狄公回想起他們第一次在這兒見面時的情景。
滕侃給狄公倒茶,狄公忽然發現那四扇漆屏不見了。滕侃苦笑一聲,說道:“我不想再看見它了。狄年兄,我已把漆屏搬到樓上鎖起來了。你知道,它會引起我許多痛苦的回憶。”
狄公突然把茶杯放下,語氣嚴厲地說:“滕相公,請你不要再跟我重復這套漆屏的謊話了!一次已經夠了!”
滕侃吃了一驚,呆呆地看著狄公毫無表情的臉,問道:“狄年兄這話是什么意思?”
我們加入一個新句子:
狄公冷冷地對滕侃說:“罪魁禍首就是”
把上述所有文字輸入模型進行預測,則模型大概率會輸出:“你”。
分析
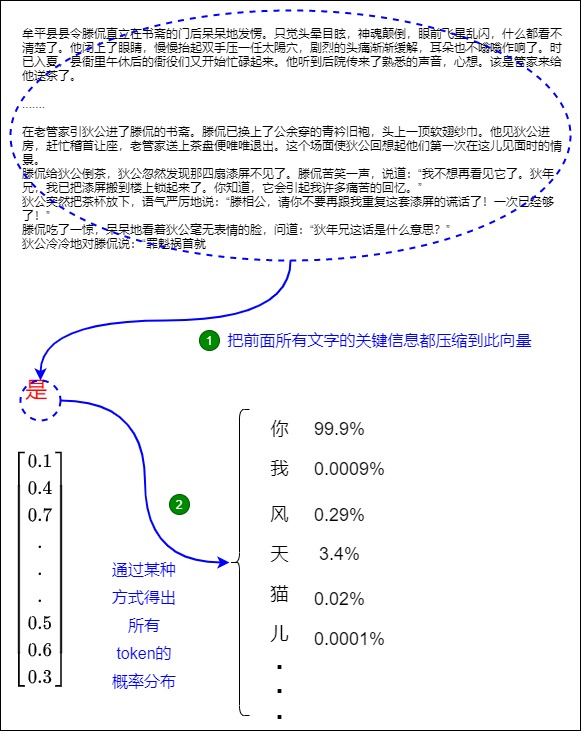
處理過程如下。
首先,模型前面對《大唐狄公案之四漆屏》的前面所有文字的處理,得到了一個處理結果。該處理結果被匯聚到”是“這個向量中。”是“這個向量,在訓練最初只是從查找表中得到的一個向量,經過訓練之后,Transformer把全部文字的所有關鍵語義都融合到序列的最后一個向量,即“是”。
其次,模型對“是“向量進行操作,得出所有token的概率分布,就是接下來詞表中各個token出現的概率。在本例中,我們選擇概率最高的單詞「你」作為下一個單詞。
4.2 變化
論文”How Alignment and Jailbreak Work:Explain LLM Safety through Intermediate Hidden States“指出,語言模型的中間隱藏狀態的變化實際上是一個逐層分配特征的過程。即,模型判斷輸入是否屬于“可回答”范疇是在早期的layer中完成的(模型在早期的幾個layer之后就為hidden states分配了足以被一個超平面分開的特征),并在中期layer中關聯情緒類的淺層猜測,最后細化成對應格式的輸出。越獄就是干擾了早期的激活,使得中期的‘猜測關聯’發生了變化,并最后導致模型響應有害問題。
4.3 預處理logits
背景和動機
傳統的采樣策略在推理任務中面臨諸多挑戰。尤其是,盡管采樣方法能夠提供多樣化的輸出,但其在需要精確推理的任務中卻經常表現不佳。例如,基于概率的采樣方法(如溫度縮放、nucleus sampling、top k 采樣以及min p 采樣等)往往更注重輸出的多樣性和減少重復,而非推理的準確性。這些技術往往難以有效過濾掉無關的token,從而導致在多樣性與推理精度之間產生了一種看似不可避免的權衡。
為了挑戰這一傳統觀念,論文“Top-nσ: Not All Logits Are You Need"提出了top-nσ方法,這是一種全新的采樣策略,旨在將統計閾值直接作用于pre-softmax(前softmax)logits。該方法認為,logits自然分布為包含高斯噪聲的區域和一個明顯的信息區域,這種特點可以在不進行復雜概率運算的情況下也能夠高效地過濾出token。與現有方法相比,top-nσ方法即便在高溫度下也能保持穩定的采樣空間,這一特性使其在推理任務中具有顯著優勢。
論文主要探尋了三個關鍵問題:
- 如何從logit空間解釋基于概率的采樣方法。
- 大語言模型中logit分布的基本特征。
- 如何利用這些分布有效地區分噪聲區域和信息區域。
洞察
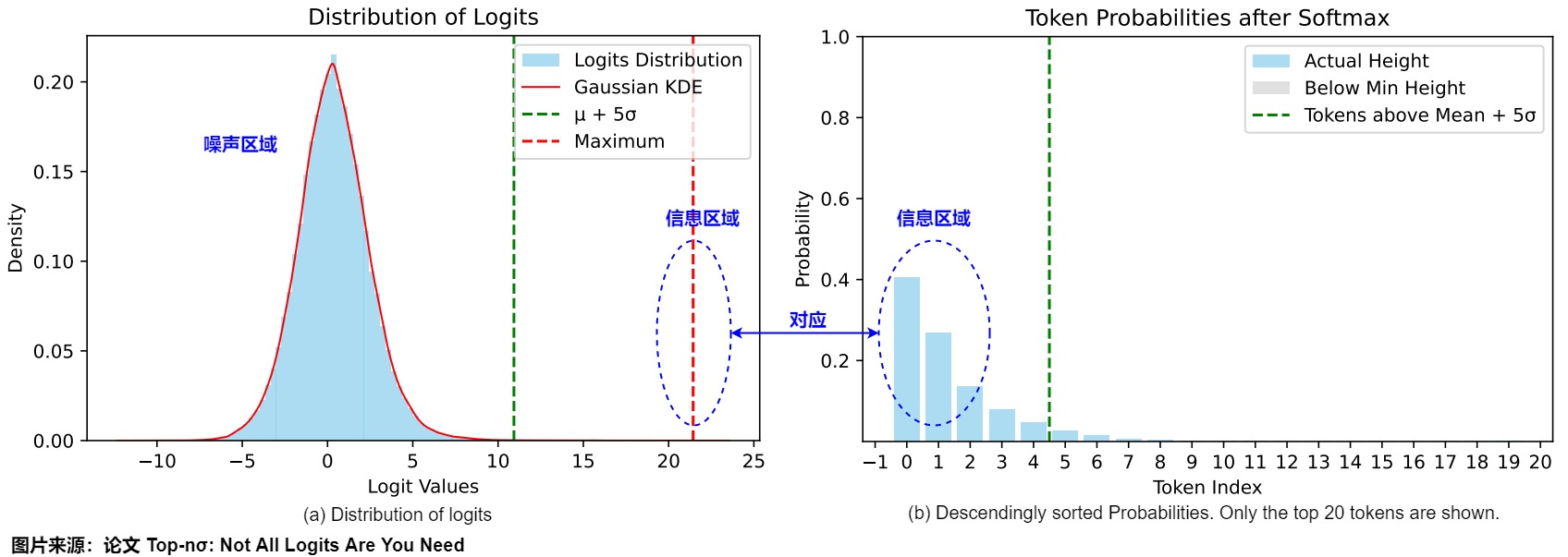
雖然現有的方法主要側重于處理概率分布,但該論文認為,檢查pre-softmaxl ogits可以揭示對模型生成過程的更深入見解。下圖給出了AQuA樣本上LLaMA3-8B-Instruct的logits分布和按照降序排序的概率。下圖a中的前方(leading)token(概率較高)對應于logits分布的右側區域。最大logit大約比分布的平均值高10σ。一個有趣的觀察結果是,pre-softmax logit分布呈現出高度規則的模式,通常由兩個不同的部分組成:背景標記的類高斯分布和一組突出的異常值。盡管大多數標記遵循高斯分布,但異常值尾部(outlier tail )在概率集(mass)中占主導地位(如下圖b所示)。我們分別將這些分量稱為噪聲區域和信息區域。值得注意的是,最大logit與平均值的偏差超過5σ(標準偏差),大大超過了異常值識別的典型統計標準。
噪聲區域
盡管logits確實顯示出噪聲分布的特征,但大多數token的logits通常表現出高斯分布。當這些logits對應于的概率通常被認為是可以忽略的(negligible),它們被歸類為噪聲區域。此噪聲區域的特征符合統計直覺:高斯分布通常指示系統中的隨機噪聲存在。
正如上圖所示,當噪聲區域與信息區域之間的邊界越來越窄時,由噪聲帶來的概率干擾會影響模型生成的質量,尤其在高溫采樣情境下尤為明顯。過高的溫度導致當前非確定性采樣算法的表現下降,主要原因在于噪聲分布主導了概率空間。
信息區域
相反,只有少量token占據了大多數概率集的區域被稱為信息區域。正如上圖所示,盡管該區域中的token數量有限,但其承載非常多的信息。
這種現象可以被min ??采樣方法所利用,帶來生成質量方面的改善,這種方法設定了基線概率閾值??,并消除了所有低于\(??_{??????}???\)的概率值。通過理論推導,我們發現min ??采樣本質上是logit空間中的一種靜態截斷,這進一步指出信息區域近似遵循均勻分布。
核心思路
確定邊界
為了有效地區分信息和噪聲區域,論文提出可以將信息區域視為噪聲分布的異常值。然而,基于實證觀察,傳統的基于??+3??規則的方法并不適合此任務。因此論文提出了??-distance的概念,它定義為最大概率和分布均值之間的標準差間隔,如下所示:
通過分析,論文作者發現最大概率與均值之間的距離始終大于10??,而且生成過程中表現出顯著波動。這一發現表明,信息token并不應被視為噪聲token的異常值。相反,更高的??-distance表明模型對生成結果的強置信度。
總結下,我們應該消除噪聲區域中的token,保留明顯(distinct)信息區域中的token。為此,論文文提出的top-????算法從最大概率開始向下擴展,并使用標準差動態調整邊界,以有效區分信息token和噪聲token。
算法
top-nσ算法的核心思想是從logits的最大值開始,結合標準差來確定分界線,從而有效地區分信號tokens和噪聲tokens。具體步驟如下:
-
生成logits:給定輸入序列,模型首先生成logit向量 \(( l = (l_1, l_2, \ldots, l_V) \in \mathbb{R}^V )\),其中 ( V ) 為詞匯表大小。
-
計算最大值和標準差。
-
確定篩選閾值:算法從最大值往下進行擴展\(n\sigma\),參數n通常取1.0。因此閾值為:$ [ M - n\sigma ]$。
-
過濾候選tokens:選擇所有滿足以下條件的tokens: $[ l'_i \geq M - n\sigma ] $。該條件確保根據logits的統計特性來僅選擇具有較高信息量的tokens。
-
進行采樣:從篩選出的tokens中隨機選擇,進行文本生成。

4.2 隱式思維鏈
我們接下來看看讓大模型在隱空間中思考的思路。
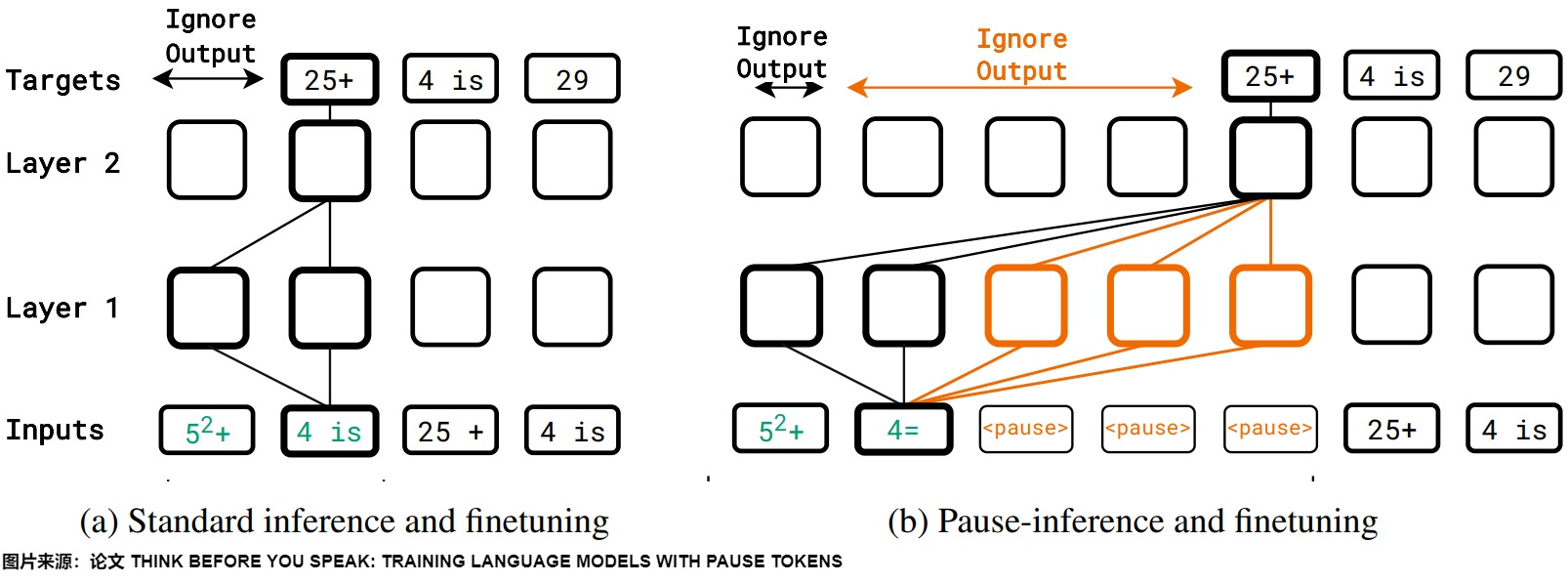
pause tokens/Filler Token
論文"Think before you speak: Training language models with pause tokens "提出了一種獨特的方法,通過引入Pause Token來訓練語言模型。其核心思想在于模擬人類在思考過程中的停頓,讓模型在生成回答之前有一個 “思考” 的間隙,從而提升回答的質量和邏輯性。這種Pause Token還有個好處:在推理的時候不需要再花費時間去生成CoT了,只需要先輸入問題,然后拼接上一串Pause Token,就可以改善答案的準確性了。
下圖展示了這個思路,在Pretraining/SFT階段插入Pause Token,在推理的時候也加入。
而論文"Let's think dot by dot: Hidden computation in transformer language models"發現了一個很有趣的現象: 一些無意義的填充Token(Filler Token)可以明顯改善LLM的性能。和Pause Token很像。然而,要讓模型學會使用Filler Token,需要特定的,密集的監督訓練,在普通CoT上訓練的模型沒辦法去利用Filler Token。
CoT
論文"Chain-of-Thought Reasoning without Prompting"發現,LLM 無需任何提示,只需通過簡單地改變解碼過程,便可展示推理能力。
下圖展示了這種現象:給定一個推理問題,LLM通過標準的貪婪解碼路徑生成了錯誤答案,而CoT解碼通過明確鼓勵在首次解碼步驟中的多樣性來運作,從而取得更好的效果。
LLM確實在僅依賴貪婪解碼路徑時面臨推理困難。采樣效果不佳的原因在于,模型在解碼過程中有強烈的傾向直接給出答案,因此第一個詞元的多樣性較低。而CoT 解碼模型使用不同的工作流程,它不是直接選擇最佳答案(沒有采用貪婪解碼),而是從最佳答案列表中進行選擇。具體而言,CoT解碼是在第一步中,通過使用前k個token(top-??)來進行解碼,在后續步驟中依然使用貪婪解碼。使用這種方法時,模型對最終答案的信心更高。當考慮前k個詞元中的替代路徑時,CoT推理模式自然地在LLM的解碼軌跡中顯現。下圖中的解碼路徑2和4就是更準確的答案。該解碼修改跳過了提示過程,完全在無監督的情況下實現,無需進行模型微調。
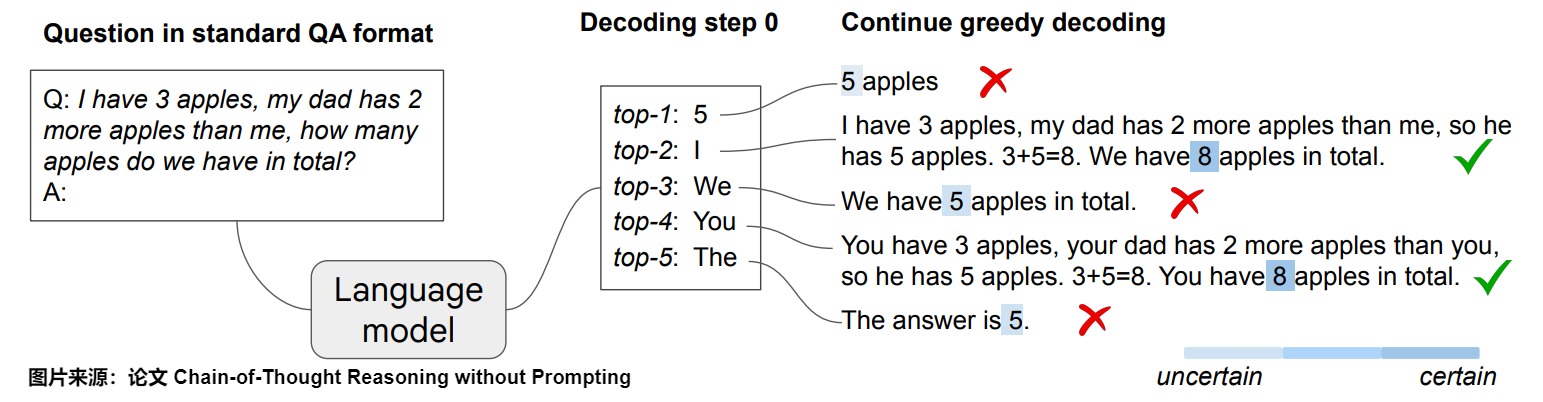
工作流程
讓我們看看CoT解碼是如何工作的:
- 輸入格式:首先,我們需要使用標準的問答(QA)格式進行輸入:“Q:[問題] \nA:”,其中[問題]是實際問題。
- 解碼過程:我們不再只使用貪婪解碼,而是需要探索第一個解碼位置上的前 k 個備選標記。默認情況下,本文使用 k=10。
- 路徑探索:在考慮了第一個位置的前 k 個標記后,我們可以繼續對序列的其余部分進行貪婪解碼。這會創建多個潛在的響應路徑。
- 路徑選擇:基于這種置信度模式,我們可以開發一種方法來篩選前 k 條路徑并選擇最可靠的輸出。我們提出了一種加權聚合方法,即選擇使 \(\tilde Δ_??=∑_??Δ_{??,??}\) 最大的答案,其中 \(Δ_{??,??}\) 是第 ?? 條解碼路徑中答案為 ?? 的路徑。我們發現,采用這種方法可以增強結果的穩定性。
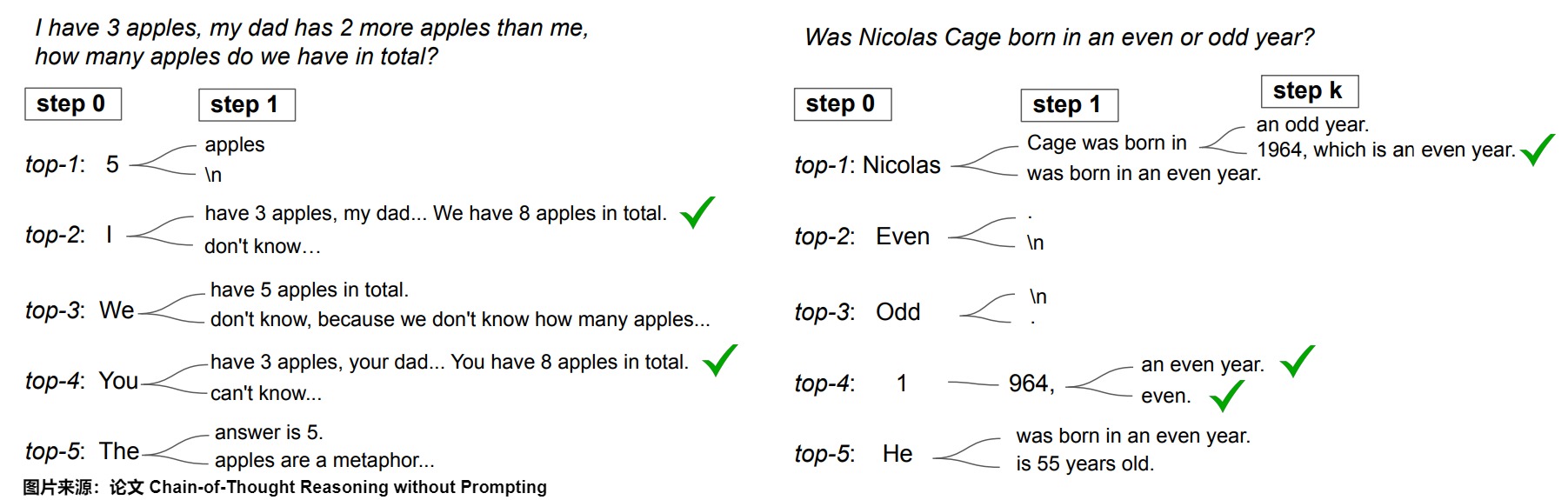
在其他解碼步驟進行分支。
另一個自然的問題是,相比僅在首次解碼步驟進行分支,是否可以在后續解碼階段進行分支。在下圖中,論文突出了在隨后的解碼步驟中考慮替代詞元的影響。很明顯,早期分支(例如在首次解碼步驟)顯著增強了潛在路徑的多樣性。相反,后期分支則受到先前生成詞元的顯著影響。例如,如果解碼從詞元“5”開始,則糾正錯誤路徑的可能性大大降低。然而,最佳的分支點可能因任務而異;在年份奇偶性任務中,中途分支可以有效地生成正確的CoT路徑。
coconut
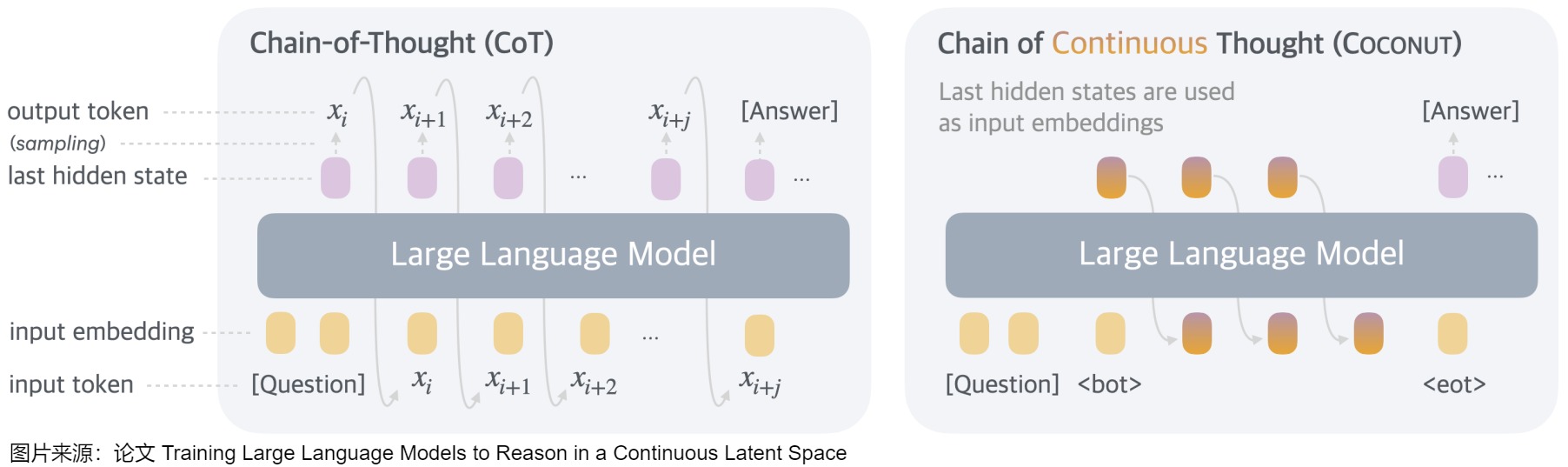
論文"Training Large Language Models to Reason in a Continuous Latent Space"提出來了Coconut。Coconut 涉及對傳統 CoT(Chain of Thought)過程的簡單修改:Coconut 不再通過語言模型頭(language model head)和嵌入層將隱藏狀態與語言 token 進行映射,而是直接將最后的隱藏狀態(hidden states,即連續思維)作為下一個 token 的輸入嵌入(如下圖所示)送入到LLM。從而解決了使用Pause Token/Filler Token不好泛化的問題。
下圖是連續思維鏈(Coconut )與思維鏈(CoT)的比較。
- 在CoT中,該模型作為標準語言模型運行,自回歸生成下一個 token。模型將推理過程生成為單詞記號序列。即 CoT 會把中間推理步驟用自然語言明文輸出。
- 在Coconut中,模型將最后一個隱藏狀態作為當前推理狀態的表示(稱為“連續思維”),并作為下一個輸入嵌入。即,CoconUT方法允許模型在"隱藏層"或"潛在向量"里進行中間推理步驟,不必轉換成可見的語言符號。這種做法擺脫了語言生成的束縛,讓模型可以更加靈活、高效地思考。
這種范式帶來了高效的推理模式,具體如下。
- 將推理從語言空間中解放出來,并且由于連續思維是完全可微的,因此可以通過梯度下降對系統進行端到端優化。
- 支持并行探索(類似寬度優先搜索)的潛在能力。在隱空間的推理與基于語言的推理不同,Coconut 中的連續思維可以同時編碼多個潛在下一步,從而實現類似于 BFS(breadth-first search)的推理過程。作者強調,模型不一定在第一步就做出"硬性決策",而是能同時在隱藏層里保留多條可能的推理路徑。隨著推理過程的展開,它會"淘汰"一些看起來不合理的候選路徑,保留更加可行的分支。這種方式與普通的自回歸生成不同,后者通常一步一步做出"不可撤銷"的決策。
- 與輸入token相比,輸入hidden states也不會被argmax操作所帶來的信息損耗/誤差累積所影響。
具體訓練把CoT里的Discrete Tokens逐漸替換成Continuous Tokens。這是一種多階段的訓練過程(受"漸進式"或者"分段式"思想啟發)。這個過程從顯式的語言推理開始,一點點引導模型將推理步驟"內化"到連續向量空間中。并且訓練過程中會把Continuous Tokens上的Next-Token-Prediction Loss給Mask掉,確保讓Continuous Tokens不只是原始CoT的壓縮。為了增強潛在推理的訓練,論文采用了多階段訓練策略,該策略有效地利用語言推理鏈來指導訓練過程。
4.3 基于熵的采樣
當想減少模型的幻覺時,工程師可能會將模型的采樣超參數如temperature設為 0。但是這樣做并不一定能提高模型不產生幻覺輸出的概率,而只是迫使它對相對于其他單詞而言的一個單詞賦予更高的概率。我們接下來看看基于熵的一些采樣思路或者解碼思路。
SED
在生成token的過程中的一種極端情況是:所有的token的概率都很小,top-k的概率相差無幾。EDT認為這種情況下,選擇哪一個都是對的,進而增大temperature來增加LLM的多樣性。與此相反,論文"SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation"認為這種情況下,稍不注意就會生成錯誤的答案。這種錯誤通過beam-search等方法無法解決,并且PPL指標也很小。要解決這種問題,就需要新的方法來對這種情況進行判別然后修正。
論文把token概率差不多的情況稱為chaotic point,下圖展示了兩種判斷方法。

識別到當前step是chaotic point之后,我們就必須采取修正措施了,具體流程如下圖。

二者聯合起來,就得到了完整的處理算法:

entropix
是否有必要每個token都生成CoT,很顯然沒必要。比如當前的token是"蘋",下一個token根本不需要什么思考,是"果"的概率非常大。有沒有什么簡單方法就能決定在哪些token后面插入CoT呢?entropix就給出了自己的思路。
相關信息
- 熵 : 在信息理論中,熵量化了概率分布的不確定性和隨機性。對于語言模型,熵衡量了預測下一個詞的概率分布的不確定性。我們來看看關于熵給模型帶來的啟示。
- 熵低表示模型對下一個詞的預測非常確定。
- 熵尖峰現象。當模型面對多個等概率的下一詞選項時,會形成熵尖峰。這些尖峰表明了高不確定性情況下的挑戰。
- 中等熵水平下的穩定行為。當熵值在1到2.5這個中等范圍內時,模型的行為更加穩定和可預測。這種穩定狀態有助于模型生成既有創意又連貫的輸出。
- 熵崩潰現象。當模型的不確定性大大降低時,模型的輸出變得高度確定。雖然這可以帶來自信且正確的預測,但也可能導致模型產生過度自信但不正確的回應。
- 方差熵 : 方差熵是熵的方差,衡量模型的不確定性在不同詞或不同模型層上的變化情況。varentropy衡量的是不同可能的下一詞信息內容的方差。不同于熵衡量的是平均不確定性,varentropy捕捉的是這種不確定性的變化,有助于模型在復雜情況下的適應性。當熵和varentropy都高時,模型可以識別出復雜情況并調整其采樣策略,生成更深層次的推理步驟。
核心思路
Entropix的核心思想是量化模型的不確定性,通過熵和方差熵來指導解碼過程中的采樣策略。當模型自信時(低熵和低方差熵)繼續正常采樣;當模型不確定時(高熵和/或高方差熵)就探索不同的詞或推理路徑。
這種自適應方法是通過調整采樣策略來模擬思維鏈過程,允許模型在更復雜的場景中動態調整,讓模型來做出更多的“思考”,提升其決策能力,從而可能產生更準確連貫的輸出。
entropix作者在每一個token解碼前,計算logit的entropy(熵)和varentropy(熵的方差),這提供了一個關于跨不同token不確定性的度量。低varentropy意味著模型的不確定性在token間是恒定的,高則意味著token間不確定性很大。然后模型根據entropy決定是否插入CoT以及調整溫度系數。具體規則舉例如下:
- logit的熵和熵方差都小,LLM很有信心,按照常規方法直接greedy decoding。
- logit的熵大,熵方差都小,LLM沒啥信心,插入CoT并且用attention的熵調整得到更大的T,會探索替代標記或推理路徑。
0x05 權重共享
在大模型中,參數共享技術允許在網絡的不同部分重復使用相同的權重集。這不僅有助于減少參數數量,還能在保持性能的同時提高模型的效率。一種常見的方法是embedding-lm的head共享,即單詞嵌入層與最終語言模型的head層共享相同的權重。另一個例子是分層注意力/FFN共享,其在模型的多個層中使用相同的權重(Cross-layer parameter sharing)。這種共享技術可以在Gemma和Qwen等模型中看到,層之間的參數共享機制能夠有效的防止參數量隨著網絡深度的加深而增加,顯著提升了模型的訓練和推理效率。
5.1 vanilla Transformer
vanilla Transformer在兩個地方進行了權重共享:
-
Encoder和Decoder間的Embedding層權重共享;
-
Decoder中Embedding層和FC層權重共享。
Transformer原始論文說
In our model, we share the same weight matrix between the two embedding layers and the pre-softmax linear transformation, similar to (cite). In the embedding layers, we multiply those weights by \(\sqrt{d_{\text{model}}}\).
哈佛作者則寫到
- Shared Embeddings: When using BPE with shared vocabulary we can share the same weight vectors between the source / target / generator. See the (cite) for details. To add this to the model simply do this:
具體代碼舉例如下,其中weight就是形狀為[vocab, d_model]的詞嵌入矩陣。
if False:
# Encoder和Decoder間的Embedding層權重共享
model.src_embed[0].lut.weight = model.tgt_embeddings[0].lut.weight
# Decoder中Embedding層和FC層權重共享
model.generator.lut.weight = model.tgt_embed[0].lut.weight
5.2 共享詞表權重
原理
之所以可以共享詞表權重,是因為在機器翻譯任務中,如果源語言和目標語言很接近(比如英語和德語同屬日耳曼語族,有很多相同的詞根或者子詞),因此源語言和目標語言可以共享一個詞嵌入矩陣。而且對于Encoder和Decoder,嵌入時都只有對應語言的embedding會被激活,因此是可以共用一張詞表做權重共享的,甚至可以實現編碼器的輸入embedding、解碼器的輸入embedding和解碼器的輸出embedding 三者共享。這樣對于兩種語言中共同出現的詞(比如:數字,標點等等)可以得到更好的表示。而像中英這樣相差較大的語系,則完全沒有共享詞嵌入矩陣的必要。
但是,共用詞表會使得詞表數量增大,增加softmax的計算時間,因此實際使用中是否共享可能要根據情況權衡。
歷史基礎
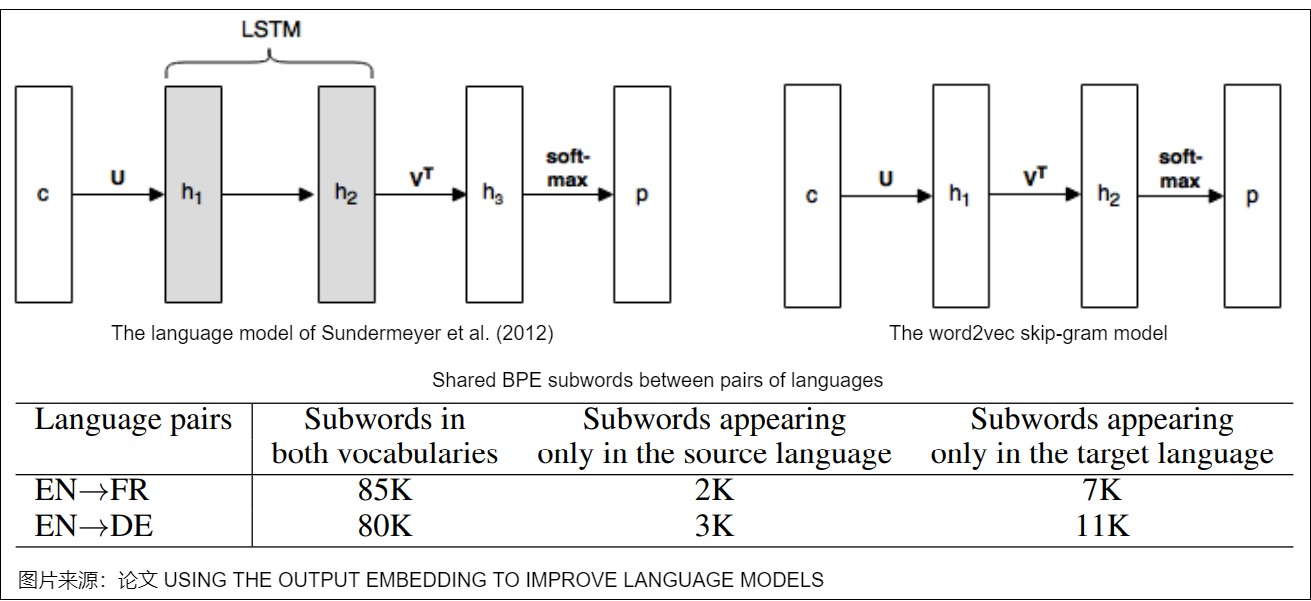
我們再來看看vanilla Transformer可以共享權重的參考。論文"Using the Output Embedding to Improve Language Model"是共享詞表早期的工作。該論文將模型的輸入詞向量和輸出詞向量綁定在一起,即共享一個詞向量空間,同一個詞在輸入詞向量時和輸出詞向量時會組合成一個詞向量。在一個常見的神經網絡語言模型中,向量的流轉歷程如下:
- 當前輸入詞首先會被表示為向量 \(c\in R^C\)。
- 使用word embedding矩陣 U 將c 投影為稠密的表示。
- 對詞向量 \(U^Tc\) 執行一些計算,從而得到激活向量 \(h_2\)。
- 使用第二個矩陣 V 把 \(h_2\) 投影到向量 \(h_3\),即\(h_3=Vh_2\)。向量 \(h_3\)包含很多分數值,詞表中每個單詞都對應其中一個分數。
- 使用softmax函數將分數向量轉換為概率值向量 p,其表示模型對下一個單詞的預測。
基于上述歷程,論文進行了推導。論文稱 U 為輸入embedding, V 為輸出embedding。模型訓練完成后,通常只是用U作為預訓練詞向量給其他上游模型使用,而忽略V。論文也比較了輸入詞向量和輸出詞向量的質量,其主要結果如下:
- 在Word2Vec Skipgram模型中,輸出詞向量與輸入詞向量相比,效果較差。
- 在基于RNN的語言模型中,輸出詞向量的效果要優于輸入詞向量。
- 通過將兩個詞向量結合在一起,即強制 U = V,則組合后的詞向量更類似于未綁定(untied)模型中的輸出詞向量的方式發展,而非未綁定模型的輸入詞向量。
- 將輸入和輸出詞向量結合之后可以改進善各種語言模型的困惑度。無論是否使用dropout。
- 當不使用dropout時,建議在 V 之前添加一個額外的投影 P,并對 P應用正則化。
- 神經翻譯模型中的權重綁定(weight tying)可以在不影響性能的前提下,將模型大小(參數數量)減少到其原始大小的一半以下。
相關信息如下圖所示。圖上方是"Using the Output Embedding to Improve Language Model"中的示例圖,下方是英語和法語,英語和德語之間子詞的比較情況。
5.2 FC和embedding共享
在語言模型的輸出端重用Embedding權重的做法,英文稱之為“Tied Embeddings”或者“Coupled Embeddings”。其思想主要是Embedding矩陣跟輸出端轉換到logits的投影矩陣大小是相同的(只差個轉置),并且由于這個參數矩陣比較大,所以為了避免不必要的浪費,干脆共用同一個權重。在某種意義上,我們可以把解碼中的Embedding層和線性層看作是逆過程。
- 解碼開始前,模型會利用獨熱編碼從Embedding層中獲取獨熱編碼對應的embedding向量。
- 解碼器生成隱向量之后,FC層(輸出端轉換到logits的投影矩陣)中和隱向量最接近的那一行對應的詞,會獲得更大的預測概率。
因為Embedding矩陣跟FC矩陣大小是相同的(只差個轉置),并且由于這個參數矩陣比較大,所以為了避免不必要的浪費,就讓FC和embedding層共用同一個權重。這樣可以減少參數的數量,加快收斂。
如果語言模型較小時,因為當模型主干部分不大且詞表很大時,Embedding層的參數量很可觀,所以可以考慮在輸出端重用Embedding權重是很常見的操作。如果Embedding層在模型參數的占比較小,則需要考慮是否有必要共享權重。
另外,共享Embedding可能會有些負面影響,比如它會導致預訓練的初始損失非常大。這是因為我們通常會使用類似DeepNorm的技術來降低訓練難度,它們都是將模型的殘差分支初始化得接近于零。換言之,模型在初始階段近似于一個恒等函數,這使得初始模型相當于共享Embedding的2-gram模型。
0xFF 參考
CTRL: A Conditional Transformer Language Model for Controllable Generation
字節大模型一面:“Beam Search 最壞時間復雜度是多少?” 看圖學
Beam search搜索算法、相關概念與C++代碼 iyayaai
Chain-of-Thought Reasoning without Prompting
Dola: decoding by contrasting layers improves factuality in large language models
EDT: Improving Large Language Models’ Generation by Entropy-based Dynamic Temperature Samplinghttps://arxiv.org/abs/2403.14541v1)
EDT: 動態調整LLM里面的temperature 杜凌霄 [探知軒]
entropix,終于找到了真正解決幻覺的方法了 Python編程杰哥
Google’s Neural Machine Translation System: Bridging the Gap between Human and Machine Translation
Hot or Cold? Adaptive Temperature Sampling for Code Generation with Large Language Models
How Alignment and Jailbreak Work:Explain LLM Safety through Intermediate Hidden States
Kl-divergence guided temperature sampling. arXiv preprint arXiv:2306.01286
KL-Divergence Guided Temperature Sampling
[learning to break the loop: analyzing and mitigating repetitions](https://arxiv.org/pdf/2206.02369.pdf)
LLM 推理常見參數解析 AI閑談
LLM的解碼策略和代碼實現 Alex [算法狗]
penalty decoding: well suppress the self-reinforcement effect in open-ended
SED: Self-Evaluation Decoding Enhances Large Language Models for Better Generation
SED:增強LLM Decoding階段的正確性 杜凌霄 [探知軒]
Top-nσ: Not All Logits Are You Need Chenxia Tang, Jianchun Liu, Hongli Xu, Liusheng Huang
Training Large Language Models to Reason in a Continuous Latent Space
《Rethinking embedding coupling in pre-trained language models》
不需要Prompt也能激發大模型思維鏈能力?谷歌DeepMind新作提出CoT新范式 青云遮夜雨
動態溫度系數T和最近比較火的entropix 機器愛學習 [一萬篇論文筆記]
如何生成文本:通過 Transformers 用不同的解碼方法生成文本
溫度系數與 top-p 采樣策略詳解 Zhang
生成重復:Learning to Break the Loop 流逝
語言模型輸出端共享Embedding的重新探索 - 知乎 (zhihu.com)
大語言模型中的“溫度”參數到底是什么?如何正確設置? 智能體AI
大模型溫度設為0,LLM輸出就能完全確定?真相來了! Alex [算法狗](javascript:void(0)??
隱空間推理的起源 |Meta的COCONUT是什么? Tensorlong 看天下

 浙公網安備 33010602011771號
浙公網安備 33010602011771號