
探秘Transformer系列之(13)--- FFN
探秘Transformer系列之(13)--- FFN
0x00 概述
Transformer抽取“序列信息”并加工的方法包含兩個(gè)環(huán)節(jié):以原始Transformer結(jié)構(gòu)的編碼器為例,每一層包含multi-head self-attention block(MHSA)和一個(gè)FFN(前饋神經(jīng)網(wǎng)絡(luò)/Feed Forward Network),即在自注意力層之后,編碼器還有一個(gè)FFN。
FFN是一個(gè)包含兩個(gè)線性變換和一個(gè)激活函數(shù)的簡(jiǎn)單網(wǎng)絡(luò)(linear + relu + linear),考慮注意力機(jī)制可能對(duì)復(fù)雜過(guò)程的擬合程度不夠,Transformer作者通過(guò)增加兩層網(wǎng)絡(luò)來(lái)增強(qiáng)模型加模型的容量和非線性。

0x01 網(wǎng)絡(luò)結(jié)構(gòu)

前饋網(wǎng)絡(luò)可以分為兩種主要類型:標(biāo)準(zhǔn) FFN 和門限 FFN。
- 標(biāo)準(zhǔn) FFN:這是神經(jīng)網(wǎng)絡(luò)中常用的結(jié)構(gòu),網(wǎng)絡(luò)由兩層組成,利用一個(gè)激活函數(shù)。
- 門限 FFN(gated FFN):在標(biāo)準(zhǔn)方法之外進(jìn)一步采用了門限層,這個(gè)層增強(qiáng)了網(wǎng)絡(luò)控制和調(diào)節(jié)信息流的能力。
隨著時(shí)間的推移,人們對(duì)這些前饋神經(jīng)網(wǎng)絡(luò)類型的偏好也發(fā)生了變化。上圖的右側(cè)顯示了2022年至2024年SLM使用的前饋網(wǎng)絡(luò)類型的趨勢(shì),標(biāo)準(zhǔn)的 FFN 正在逐步被門限 FFN 所取代。本篇我們主要介紹標(biāo)準(zhǔn)FFN,就是Transformer論文的實(shí)現(xiàn)。
1.1 數(shù)學(xué)表示
FFN層是一個(gè)兩層的全連接層,第一層的激活函數(shù)為 Relu,第二層不使用激活函數(shù),在兩個(gè)線性變換之間除了 ReLu 還使用了一個(gè) Dropout。
- 第一個(gè)線性層。其輸入\(X∈R^{d_{input} \times d_{model}}\)是多頭注意力的輸出,可以看作是由每個(gè)輸入位置( \(d_{input}\) 行)的注意力結(jié)果( \(d_{model}\) 列)堆疊而成。第一個(gè)線性層通常會(huì)擴(kuò)展輸入的維度。例如,如果輸入維度是 512,輸出維度可能是 2048。這樣做是為了使模型能夠?qū)W習(xí)更復(fù)雜的函數(shù),也是為了更好的融合前面多頭注意力機(jī)制的輸出內(nèi)容。
- ReLU 激活: 這是一個(gè)非線性激活函數(shù)。此函數(shù)相對(duì)簡(jiǎn)單,如果輸入是負(fù)數(shù),則返回 0;如果輸入是正數(shù),則返回輸入本身。ReLU激活使得模型能夠?qū)W習(xí)非線性化能力,也可以理解為引入非線性對(duì)向量進(jìn)行篩選。其數(shù)學(xué)表達(dá)為\(max(0,xW_1+b_1)\)。
- 第二個(gè)線性層。這是第一個(gè)線性層的逆操作,將維度降低回原始維度。FFN最終得到的輸出矩陣維度與輸入X的維度一致。
上述結(jié)構(gòu)對(duì)輸入X的每一行進(jìn)行相同的信息變換(行與行之間無(wú)交錯(cuò),即“separately and identically”),這個(gè)線性變換在不同的位置都表現(xiàn)相同,只是在不同的層之間使用不同的參數(shù),即每行(每個(gè)token)之間共享參數(shù),但是在不同層中,學(xué)習(xí)到的參數(shù)矩陣又是不同的。我們可以將上述結(jié)構(gòu)表示如下,其中,d是embedding size(Transformer中為512),\(d_{ffn}\)是FFN的隱藏層維度(Transformer中為2048)。

最終,F(xiàn)FN的權(quán)重體現(xiàn)在這兩個(gè)線性層上。注意力機(jī)制是在同一特征空間內(nèi),對(duì)不同的實(shí)體進(jìn)行整合,強(qiáng)調(diào)了不同實(shí)體之間的重要性。而FFN完成對(duì)實(shí)體從特征空間A到特征空間B的映射。二者比較的粒度不相同。另外,從T5 開始,很多模型在FFN層都不用偏置了。
1.2 中間層比率
FFN的中間比率是指中間層維數(shù)與隱含層維數(shù)之間的比值。簡(jiǎn)單而言,它決定了中間層相對(duì)于整個(gè)網(wǎng)絡(luò)的大小。標(biāo)準(zhǔn) FFN通常設(shè)置中間比率為4。這意味著中間層通常比隱藏層小四倍。另一方面,門限 FFN 在中間比值上表現(xiàn)出更大的靈活性,比如可以是從2到8的任何范圍,依據(jù)模型特點(diǎn)進(jìn)行選擇。
如果中間比率調(diào)得過(guò)小,會(huì)導(dǎo)致模型參數(shù)變少,性能變差。如果調(diào)節(jié)過(guò)大,則會(huì)造成峰值內(nèi)存過(guò)高,因此需要綜合考慮。下面圖提供了從2022年到2024年不同前饋網(wǎng)絡(luò)中間比率的趨勢(shì)變化。

1.3 position-wise
論文中給這個(gè) FNN 取名為 Position-wise feed-forward networks。"position-wise"表示對(duì)序列中的每個(gè)元素(每個(gè)位置)分別采用相同的線性變換。作者強(qiáng)調(diào)“position-wise"是因?yàn)镕FN有如下特點(diǎn)(此處也會(huì)和注意力機(jī)制進(jìn)行一定的比對(duì)):
-
建模只考慮單獨(dú)位置。FFN層對(duì)輸入矩陣每行(每個(gè)token,即每個(gè)position)對(duì)應(yīng)的單個(gè)token的信息表征進(jìn)行獨(dú)立的非線性變換(從矩陣運(yùn)算角度可以理解為變換和平移)。因?yàn)镕FN是對(duì)序列中每個(gè)位置的token向量分別進(jìn)行相同的操作,所以每個(gè)時(shí)刻的全連接層是可以獨(dú)立并行計(jì)算的,可以提高訓(xùn)練和推理的速度。
-
不會(huì)進(jìn)行元素間的信息交換。Transformer已經(jīng)利用注意力機(jī)制來(lái)考慮單詞在不同位置的語(yǔ)義和依賴關(guān)系,在每個(gè)位置上把序列中的信息做了一次全局的匯聚。因?yàn)樾畔?dāng)?shù)竭_(dá)FFN時(shí),每個(gè)token就包括了在token層面其感興趣的信息,序列中的上下文已經(jīng)被匯聚完成,所以不需要在FFN處再進(jìn)行交互(元素間的互動(dòng)完全靠自注意力)。FFN所做的是在注意力層進(jìn)行元素間的信息交換之后,讓每個(gè)元素消化整合自己的信息,為下一層再次通過(guò)自注意力交換信息做好準(zhǔn)備。
-
計(jì)算顆粒度是 token 內(nèi)的維度。注意力機(jī)制可以捕捉序列中的上下文關(guān)系,是對(duì)不同位置的 token 混合,其計(jì)算是以token為顆粒度。而FFN在處理序列數(shù)據(jù)時(shí)只考慮單個(gè)位置的信息,是對(duì)每個(gè) token 不同維度上的特征進(jìn)行混合(各個(gè)token之間沒有進(jìn)行交互),是在token內(nèi)部完成特征映射。
-
精細(xì)再加工。MHA允許模型在不同的表示子空間中學(xué)習(xí)信息,F(xiàn)FN則允許模型利用注意力機(jī)制生成的上下文信息,并進(jìn)一步轉(zhuǎn)化這些信息,從而捕捉數(shù)據(jù)中更復(fù)雜的關(guān)系。所以,在FFN中,矩陣的每一行都是獨(dú)立運(yùn)算,把每個(gè)token的上下文信息加工成最終需要的的語(yǔ)義空間向量。

另外,也可以從卷積的角度解釋。關(guān)于矩陣 \(W_1∈R^{d_{input} \times d_{model}}\) 和\(W_2∈R^{d_{input} \times d_{model}}\) 的維度倒置,Transformer作者認(rèn)為可以將其理解為“two convolutions with kernel size 1”,即Position-wise FFN等價(jià)于kernel_size=1的卷積,這樣每個(gè)position(token)都是獨(dú)立運(yùn)算的。為何要指定kernel大小為1?因?yàn)槿绻笥?,則相鄰位置之間就具有依賴性了就不能叫做position-wise了。
綜上所述,F(xiàn)FN的本質(zhì)就是一個(gè)position-wise的"升維-過(guò)激活-降回原來(lái)維度"的MLP。
1.4 激活函數(shù)
激活函數(shù)是神經(jīng)網(wǎng)絡(luò)中的非線性函數(shù),用于在神經(jīng)元之間引入非線性關(guān)系,從而使模型能夠?qū)W習(xí)和表示復(fù)雜的數(shù)據(jù)模。如果沒有激活函數(shù),神經(jīng)網(wǎng)絡(luò)無(wú)論有多少層,都只能表示輸入和輸出之間的線性關(guān)系,這大大限制了網(wǎng)絡(luò)處理復(fù)雜問(wèn)題的能力。
常見函數(shù)
在前饋神經(jīng)網(wǎng)絡(luò)(FFN)中,有幾種常用的激活函數(shù):
- ReLU(Rectified Linear Unit):ReLU 就像一個(gè)開關(guān),打開或關(guān)閉的信息流,它應(yīng)用廣泛。
- GELU(Gaussian Error Linear Unit):GELU 是一種在平滑零值和正值之間轉(zhuǎn)換的激活函數(shù)
- SiLU(Sigmoid Linear Unit):SiLU 是一個(gè)結(jié)合了 Sigmoid 函數(shù)和線性函數(shù)特性的激活函數(shù),其實(shí)就是\(\beta\)為1時(shí)的Swish激活函數(shù)。
這些激活函數(shù)在論文“GLU Variants Improve Transformer”中有具體論述,該論文提出使用GLU的變種(將GLU中原始的Sigmoid激活函數(shù)替換為其他的激活函數(shù))來(lái)改進(jìn)Transformer的FFN層,并列舉了替換為ReLU,GELU和SwiGLU的三種變體。命名上將激活函數(shù)的縮寫加在GLU前面作為前綴。論文用這種GLU變體替換FFN中的第一層全連接和激活函數(shù),并且去除了GLU中偏置項(xiàng)bias。具體公式如下。

下圖是常見大模型的信息,從中可以看到對(duì)激活函數(shù)的使用情況。

隨著時(shí)間的推移,這些激活函數(shù)的使用發(fā)生了變化。在2022年,ReLU成為許多 FFN 的首選激活函數(shù)。然而,進(jìn)入2023年,過(guò)渡到使用 GELU 及其變體GELU Tanh。到2024年,SiLU成為激活函數(shù)的主要選擇。具體如下圖所示。

ReLU
ReLU函數(shù)是修正線性單元函數(shù),由Vinod Nair和 Geoffrey Hinton在論文"Rectified Linear Units Improve Restricted Boltzmann Machines"提出,它的公式為:
ReLU函數(shù)在輸入大于0時(shí)輸出等于輸入,否則輸出為0。ReLU函數(shù)的優(yōu)點(diǎn)是計(jì)算簡(jiǎn)單,收斂速度快。相比于Sigmoid和Tanh函數(shù),ReLU在正區(qū)間的梯度為常數(shù)1,有助于緩解梯度消失問(wèn)題,使得深層網(wǎng)絡(luò)更容易訓(xùn)練。但它也存在一個(gè)問(wèn)題,就是在輸入小于0時(shí),梯度為0,這會(huì)導(dǎo)致神經(jīng)元無(wú)法更新權(quán)重,從而出現(xiàn)“神經(jīng)元死亡”的問(wèn)題。
GLU
論文GLU Variants Improve Transformer 提出,可以利用門控線形單元 —— GLU(Gated Linear Units)對(duì)激活函數(shù)進(jìn)行改進(jìn)。GLU激活則提出于2016年發(fā)表的論文"language modeling with gated convolutional networks"中。GLU其實(shí)不算是一種激活函數(shù),而是一種神經(jīng)網(wǎng)絡(luò)層。它是一個(gè)線性變換后面接門控機(jī)制的結(jié)構(gòu)。其中門控機(jī)制是一個(gè)sigmoid函數(shù)用來(lái)控制信息能夠通過(guò)多少。其公式如下:\(GLU(x, W, V, b, c) = (xW + b) ? \sigma(xV + c)\)。其中 ? 表示逐元素乘法,\(X\) 是輸入,\(W\) 和 \(V\) 是權(quán)重矩陣,\(b\) 和 \(c\) 是偏置項(xiàng)。注,有論文對(duì)將GLU的門控放在了權(quán)重W的部分,即\(GLU(x, W, V, b, c) = \sigma(xW + b) ? (xV + c)\)。
GELU
論文“Gaussian Error Linear Units(GELUs)”提出了GELU(Gaussian Error Linear Unit,高斯誤差線性單元)函數(shù),這是ReLU的平滑版本。GELU通過(guò)高斯誤差函數(shù)(標(biāo)準(zhǔn)正態(tài)分布的累積分布函數(shù))對(duì)輸入進(jìn)行平滑處理,從而提高模型的性能。GELU函數(shù)的數(shù)學(xué)表達(dá)式為\(\text{GELU}(x) = x \cdot \Phi(x)\)$。其中:
- \(x\) 是輸入。
- \(\Phi(x)\) 是標(biāo)準(zhǔn)正態(tài)分布的累積分布函數(shù),定義為:\(\Phi(x) = \frac{1}{2} \left( 1 + \text{erf}\left( \frac{x}{\sqrt{2}} \right) \right)\) 。\(\text{erf}(x)\) 是誤差函數(shù)。
之前由于計(jì)算成本較高,因此論文提供了兩個(gè)初等函數(shù)作為近似計(jì)算,目前很多框架已經(jīng)可以精確計(jì)算。

SwiGLU
SwiGLU(Swish-Gated Linear Unit)是一種結(jié)合了Swish和GLU(Gated Linear Unit)特點(diǎn)的激活函數(shù)。SwiGLU其實(shí)就是采用Swish作為激活函數(shù),且去掉偏置的GLU變體。與ReLU相比,SwiGLU可以提升模型的性能。兩者的核心差異在于:
- ReLU 函數(shù)會(huì)將所有負(fù)數(shù)輸入直接歸零,而正數(shù)輸入則保持不變。
- SwiGLU 函數(shù)含有一個(gè)可學(xué)習(xí)的參數(shù) \(\beta\),能夠調(diào)節(jié)函數(shù)的插值程度。隨著 \(\beta\) 值的增大,SwiGLU 的行為將逐漸接近 ReLU。
Swish函數(shù)
Swish函數(shù)由Google團(tuán)隊(duì)在2017年在論文“Searching for Activation Functions”中提出,其公式和效果如下圖所示。Swish函數(shù)的曲線是平滑的,并且函數(shù)在所有點(diǎn)上都是可微的。這在模型優(yōu)化過(guò)程中很有幫助,被認(rèn)為是 Swish 優(yōu)于 ReLU 的原因之一。
Swish函數(shù)的數(shù)學(xué)表達(dá)式為:\(\text{Swish}(x) = x \cdot \sigma(\beta x)\),其中\(\sigma\)為激活函數(shù)Sigmoid,定義為 \(\sigma(x) = \frac{1}{1 + e^{-x}}\)。輸入x和\(\sigma\)相乘使得Swish類似LSTM中的門機(jī)制,因此Swish也被成為self-gated激活函數(shù),只需要一個(gè)標(biāo)量輸入即可完成門控操作。
\(\beta\) 是一個(gè)可學(xué)習(xí)的參數(shù),控制函數(shù)的形狀,通常為一個(gè)常數(shù)或者讓模型自適應(yīng)學(xué)習(xí)得到。當(dāng)\(\beta=0\) 時(shí),Swish退化為一個(gè)線性函數(shù),當(dāng)\(\beta\) 趨近于無(wú)窮大時(shí),Swish就變成了ReLU。在大多數(shù)情況下,\(\beta\) 被設(shè)置為1,從而簡(jiǎn)化為$$\text{Swish}(x) = x \cdot \sigma(x)$$,也叫SiLU( Sigmoid Gated Linear Unit)。

SwiGLU激活函數(shù)
SwiGLU的數(shù)學(xué)表達(dá)式為$ f(X) = (X ? W + b) ? Swish(X ? V + c) \(,\)\otimes$ 表示逐元素乘法(Hadamard乘積)。此公式也可以轉(zhuǎn)換為:$$\text{SwiGLU}(a, b) = \text{Swish}(a) \otimes \sigma(b)$$,其中,\(a\) 和 \(b\) 是輸入張量。\(\sigma(x) = \frac{1}{1 + e^{-x}}\) 是Sigmoid激活函數(shù)。\(\text{Swish}(x) = x \cdot \sigma(x)\) 是Swish激活函數(shù)。
SwiGLU本質(zhì)上是對(duì)Transformer的FFN前饋傳播層的第一層全連接和ReLU進(jìn)行替換。在原生的FFN中采用兩層全連接,第一層升維,第二層降維回歸到輸入維度,兩層之間使用ReLE激活函數(shù)。SwiGLU也是全連接配合激活函數(shù)的形式,不同的是SwiGLU采用兩個(gè)權(quán)重矩陣和輸入分別變換,再配合Swish激活函數(shù)做哈達(dá)馬積的操作,因?yàn)镕FN本身還有第二層全連接,所以帶有SwiGLU激活函數(shù)的FFN模塊一共有三個(gè)權(quán)重矩陣,其中W1,V為SwiGLU模塊的兩個(gè)權(quán)重矩陣,W2為原始FFN的第二層全連接權(quán)重矩陣,Swish為激活函數(shù)。

由于SwiGLU的原因,F(xiàn)FN從2個(gè)權(quán)重矩陣變成3個(gè)權(quán)重矩陣,為了使得模型的參數(shù)量大體保持不變,研究人員通常會(huì)對(duì)隱藏層的大小做一個(gè)縮放,比如把中間層維度縮減為原來(lái)的2/3,每個(gè)矩陣的形狀應(yīng)該是 (?,8?/3)。進(jìn)一步為了使得中間層是256的整數(shù)倍,也會(huì)做取模再還原的操作。
實(shí)現(xiàn)
我們使用LlamaMLP的代碼來(lái)看看。在LLaMA中采用常數(shù)\(\beta\) =1,此時(shí)Swish簡(jiǎn)化為$$\text{Swish}(x) = x \cdot \sigma(x)$$,SwiGLU就是使用了nn.SiLU。
class LlamaMLP(nn.Module):
def __init__(self, config):
super().__init__()
self.config = config
self.hidden_size = config.hidden_size
self.intermediate_size = config.intermediate_size
self.gate_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.up_proj = nn.Linear(self.hidden_size, self.intermediate_size, bias=config.mlp_bias)
self.down_proj = nn.Linear(self.intermediate_size, self.hidden_size, bias=config.mlp_bias)
self.act_fn = ACT2FN[config.hidden_act]
def forward(self, x):
down_proj = self.down_proj(self.act_fn(self.gate_proj(x)) * self.up_proj(x))
return down_proj
從ACT2CLS可以看出來(lái),使用了nn.SiLU。
ACT2CLS = {
"gelu": GELUActivation,
"gelu_10": (ClippedGELUActivation, {"min": -10, "max": 10}),
"gelu_fast": FastGELUActivation,
"gelu_new": NewGELUActivation,
"gelu_python": (GELUActivation, {"use_gelu_python": True}),
"gelu_pytorch_tanh": PytorchGELUTanh,
"gelu_accurate": AccurateGELUActivation,
"laplace": LaplaceActivation,
"leaky_relu": nn.LeakyReLU,
"linear": LinearActivation,
"mish": MishActivation,
"quick_gelu": QuickGELUActivation,
"relu": nn.ReLU,
"relu2": ReLUSquaredActivation,
"relu6": nn.ReLU6,
"sigmoid": nn.Sigmoid,
"silu": nn.SiLU,
"swish": nn.SiLU,
"tanh": nn.Tanh,
}
ACT2FN = ClassInstantier(ACT2CLS)
dReLU
研究人員一直沒有停止優(yōu)化的腳步,比如,因?yàn)榧せ钕∈栊钥梢栽诓挥绊懶阅艿那闆r下顯著加速大型語(yǔ)言模型的推理過(guò)程,所以論文 Turbo Sparse: Achieving LLM SOTA Performance with Minimal Activated Parameters 提出了一種新的dReLU函數(shù),該函數(shù)旨在提高LLM激活稀疏性(實(shí)現(xiàn)了接近90%的稀疏性)。dReLU公式和效果如下。

0x02 實(shí)現(xiàn)
2.1 哈佛代碼
兩個(gè)線性層的特點(diǎn)如下,其中B為batch_size,L是seq長(zhǎng)度,D是特征維度。
| 名稱 | 算子類型 | 輸入形狀 | 權(quán)重形狀 | 輸出形狀 | 其他說(shuō)明 |
|---|---|---|---|---|---|
| FFN expansion | dense | (B, L, D) | (D, 4D) | (B, L, 4D) | 維度擴(kuò)增到4D |
| FFN contraction | dense | (B, L, 4D) | (4D, D) | (B, L, D) | 維度縮減回D |
代碼實(shí)現(xiàn)非常簡(jiǎn)單:
# 定義一個(gè)繼承自nn.Module,名為PositionwiseFeedForward的類來(lái)實(shí)現(xiàn)前饋全連接層
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
"""
d_model:線性層的輸入維度也是第二個(gè)線性層的輸出維度
d_ff:隱層的神經(jīng)元數(shù)量。是第二個(gè)線性層的輸入維度和第一個(gè)線性層的輸出維度
dropout:置0比率
"""
super(PositionwiseFeedForward, self).__init__()
# 使用nn.Linear實(shí)例化了兩個(gè)線性層對(duì)象,self.w1和self.w2
self.w_1 = nn.Linear(d_model, d_ff) # 第一個(gè)全連接層,輸入維度為d_model,輸出維度為d_ff
self.w_2 = nn.Linear(d_ff, d_model) # 第二個(gè)全連接層,輸入維度為d_ff,輸出維度為d_model
self.dropout = nn.Dropout(dropout) # 定義一個(gè)dropout層,dropout概率為傳入的dropout參數(shù)
# 前向傳播方法
def forward(self, x):
"""輸入?yún)?shù)為x,代表來(lái)自上一層的輸出"""
"""
操作如下:
1. 經(jīng)過(guò)第一個(gè)線性層
2. 使用Funtional中relu函數(shù)進(jìn)行激活,公式中的max(0, xW+b)其實(shí)就是ReLU的公式
3. 使用dropout進(jìn)行隨機(jī)置0
4. 通過(guò)第二個(gè)線性層w2,返回最終結(jié)果
"""
return self.w_2(self.dropout(self.w_1(x).relu()))
2.2 llama3
llama3的實(shí)現(xiàn)如下,其使用ColumnParallelLinear和RowParallelLinear這樣分布式線性層。從llama的源碼中可以看到,其有三個(gè)w參數(shù)需要訓(xùn)練。
class FeedForward(nn.Module):
def __init__(
self,
dim: int,
hidden_dim: int,
multiple_of: int,
ffn_dim_multiplier: Optional[float],
):
super().__init__()
hidden_dim = int(2 * hidden_dim / 3)
# custom dim factor multiplier
if ffn_dim_multiplier is not None:
hidden_dim = int(ffn_dim_multiplier * hidden_dim)
hidden_dim = multiple_of * ((hidden_dim + multiple_of - 1) // multiple_of)
self.w1 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
self.w2 = RowParallelLinear(
hidden_dim, dim, bias=False, input_is_parallel=True, init_method=lambda x: x
)
self.w3 = ColumnParallelLinear(
dim, hidden_dim, bias=False, gather_output=False, init_method=lambda x: x
)
def forward(self, x):
return self.w2(F.silu(self.w1(x)) * self.w3(x))
0x03 FFN的作用
論文"Attention is Not All You Need: Pure Attention Loses Rank Doubly Exponentially with Depth"中發(fā)現(xiàn),如果不加殘差和FFN,堆疊再多層自注意力,整個(gè)模型的秩也會(huì)很快坍縮,也即所有表征趨于一個(gè)向量,模型都會(huì)變得不可用。因此,Attention, FFN, ResNet 可以被認(rèn)為是 Transformers 架構(gòu)的三駕馬車,各司其職、缺一不可。了解了FFN的重要性,我們?cè)賮?lái)看FFN的幾個(gè)作用:
- 提取更多語(yǔ)義信息。
- 增加表達(dá)能力。
- 存儲(chǔ)知識(shí)。
我們接下來(lái)一一進(jìn)行分析。
3.1 提取更多語(yǔ)義信息
我們?cè)賮?lái)看看一個(gè)問(wèn)題,為什么FFN要先升維后降維?具體分析如下:
LLM在自己構(gòu)造的高維語(yǔ)言空間中,通過(guò)預(yù)訓(xùn)練,記錄了人類海量的語(yǔ)言實(shí)例,從中提取了無(wú)數(shù)的結(jié)構(gòu)與關(guān)聯(lián)信息。我們可以把這個(gè)高維的語(yǔ)言空間,加上訓(xùn)練提取的結(jié)構(gòu)與關(guān)聯(lián)信息,理解為L(zhǎng)LM的腦。而FFN就是提取信息的關(guān)鍵模塊。FFN在把輸入的詞向量映射到輸出的詞向量的過(guò)程中,將多頭注意力學(xué)到的東西進(jìn)行一波混合操作,以提取更豐富的語(yǔ)意信息,混合操作具體分為兩步:
- 升維。其主要作用是擬合一個(gè)更高維的映射空間,從而提升模型的表達(dá)能力和擬合精度。
- 第一個(gè)線性層及激活函數(shù)組合,可以看作是在學(xué)習(xí)一組基函數(shù),每個(gè)神經(jīng)元可以視作一個(gè)簡(jiǎn)單的分類器,用以近似輸入數(shù)據(jù)的高維映射。升維操作有效擴(kuò)展了網(wǎng)絡(luò)的自由度,使得模型能夠?qū)W習(xí)更多的特征表示,從而提升模型的擬合能力。從一維卷積的角度看,升維可以提取更多的特征,以哈佛代碼為例,就是使用了2048個(gè)[1, 512]的卷積核來(lái)提取特征。
- 升維把輸入的詞向量映射到一個(gè)更大維度的特征空間。FFN并非簡(jiǎn)單的直接在輸入維度這個(gè)嵌入空間上進(jìn)行建模,而是通過(guò)一系列線性變換來(lái)擬合一個(gè)高維的映射空間。若僅使用線性基,理論上我們只需使用等同于輸入維度的基數(shù)量。然而,所有可能的平滑映射組成的空間是無(wú)限維的,因而需要通過(guò)升維來(lái)完整表示這一空間。
- 降維。其主要作用是還原維度,限制計(jì)算復(fù)雜度。
- 降維可以將維度還原,讓下一層能夠繼續(xù)計(jì)算,從而保證encoder layer和decoder layer能夠堆疊。
- 降維可以濃縮特征,防止過(guò)擬合。盡管升維帶來(lái)更多的特征表示,但隱藏維度(或鍵值對(duì)數(shù)量)并非越大越好。過(guò)多的隱藏維度可能導(dǎo)致信息瓶頸和過(guò)擬合,甚至使模型難以有效傳遞信息。
- 降維可以限制計(jì)算復(fù)雜度。盡管升維有助于捕捉更多的信息,但理論上需要無(wú)限多的自由度來(lái)表達(dá)完整的光滑映射。然而,實(shí)踐中我們不可能擁有無(wú)限的計(jì)算資源,因此必須通過(guò)降維來(lái)控制網(wǎng)絡(luò)的規(guī)模和計(jì)算復(fù)雜度。降維操作通過(guò)將高維表示映射回較低維空間,有效地控制了模型的復(fù)雜度。
3.2 增加表達(dá)能力
Transformer架構(gòu)中的非線性特征對(duì)Transformer模型的能力有重大影響。增強(qiáng)非線性可以有效地緩解特征坍塌的問(wèn)題,并提高Transformer模型的表達(dá)能力。
注意力機(jī)制本質(zhì)上是對(duì)Value的線性變換。雖然變換的權(quán)重是通過(guò)非線性的softmax計(jì)算得到,但是對(duì)于 value 來(lái)說(shuō),并沒有任何的非線性變換。每一次 Attention 的計(jì)算相當(dāng)于是對(duì) value 代表的向量進(jìn)行了加權(quán)平均,即使堆疊多個(gè) Self Attention,依然只是對(duì) value 向量的加權(quán)平均而已,無(wú)法處理一些非線性的特征。因此,無(wú)論堆疊多少層,都是最開始輸入 x 的一個(gè)線性變換,其整體運(yùn)算仍然是線性的,和單層變化沒有本質(zhì)區(qū)別,則其假設(shè)空間受限,無(wú)法充分利用多層表示的優(yōu)勢(shì)。
FFN中的激活函數(shù)是一個(gè)主要的能提供非線性變換的單元。通過(guò)它可以增加特征學(xué)習(xí)能力。非線性激活函數(shù)的引入打破了線性模型的限制,使得模型可以對(duì)數(shù)據(jù)進(jìn)行更復(fù)雜的變換。降維操作將升維后的結(jié)果映射回原始維度,從而將這些非線性特征組合到最終的輸出中。這種操作增強(qiáng)了模型的表達(dá)能力,使其能夠表示更加復(fù)雜的函數(shù)關(guān)系。這就是 FFN 必須要存在的原因,或者說(shuō) FFN 提供了最簡(jiǎn)單的非線性變換。
3.3 存儲(chǔ)知識(shí)
大型語(yǔ)言模型的強(qiáng)大能力離不開其對(duì)知識(shí)的記憶:比如模型想要回答“中國(guó)的首都是哪座城市?”,就必須在某種意義上記住“中國(guó)的首都是北京”。Transformer并沒有外接顯式的數(shù)據(jù)庫(kù),記憶只能隱式地表達(dá)在參數(shù)當(dāng)中。而記憶可以通過(guò)兩個(gè)基本能力實(shí)現(xiàn)普遍計(jì)算:遞歸狀態(tài)維護(hù)和可靠的歷史訪問(wèn)。
真正學(xué)到的知識(shí)或者信息大多都存儲(chǔ)在 FFN 中。從某個(gè)角度來(lái)看,F(xiàn)FN可以類比為一種鍵值對(duì)存儲(chǔ)結(jié)構(gòu)。第一個(gè)線性層生成“鍵”,即為每個(gè)token計(jì)算一組召回權(quán)重。第二個(gè)線性層則計(jì)算“值”,并與召回權(quán)重進(jìn)行加權(quán)求和。這種方式類似于通過(guò)大規(guī)模的記憶存儲(chǔ)(升維)來(lái)提升網(wǎng)絡(luò)的長(zhǎng)期記憶能力。
但是,F(xiàn)FN這種存儲(chǔ)是分布式的,或者說(shuō)是多義的,即面對(duì)看似不相關(guān)的輸入,神經(jīng)元都會(huì)做出反應(yīng)。特征與輸出結(jié)果有因果關(guān)系,但特征與神經(jīng)元并不對(duì)應(yīng)。關(guān)于多義性的成因,有一種理論稱為疊加假說(shuō)(superposition):神經(jīng)網(wǎng)絡(luò)通過(guò)存儲(chǔ)多個(gè)特征的線性組合的方式來(lái)表示比其神經(jīng)元更多的獨(dú)立的特征。如果我們將每個(gè)特征視為一個(gè)神經(jīng)元對(duì)應(yīng)的向量,那么這些特征組成了激活空間上的一組過(guò)完備基。對(duì)模型性能有幫助的特征,如果其在訓(xùn)練數(shù)據(jù)中的頻率是稀疏的,那么在神經(jīng)網(wǎng)絡(luò)訓(xùn)練過(guò)程中會(huì)自然出現(xiàn)疊加現(xiàn)象。與壓縮感知一樣,給定任意的激活空間中的向量,稀疏性允許模型消除疊加現(xiàn)象帶來(lái)的歧義。另外,根據(jù)交叉熵?fù)p失訓(xùn)練的模型通常更傾向于用多義表示更多特征,而不是單義表示較少的 "真實(shí)特征",即使在稀疏性約束使得疊加不可能的情況下也是如此。
既然FFN是存儲(chǔ)知識(shí)的模塊,那就意味著其難以壓縮和加速,因?yàn)椋喝绻鸉FN變小,則意味著模型容量變小,從而導(dǎo)致模型性能變差。而且FFN中間的激活難以看出低秩,沒法加速。
3.4 增加參數(shù)量
大模型的涌現(xiàn)現(xiàn)象是一個(gè)復(fù)雜且引人入勝的話題。其產(chǎn)生原因主要與參數(shù)量有關(guān)。當(dāng)大模型的訓(xùn)練參數(shù)達(dá)到一定規(guī)模時(shí),模型內(nèi)部各組件之間的相互作用開始顯現(xiàn)。這種相互作用隨著參數(shù)數(shù)量的增加而逐漸增強(qiáng),最終可能導(dǎo)致模型整體性能的顯著提升,即涌現(xiàn)現(xiàn)象。因此,參數(shù)量對(duì)于大模型至關(guān)重要。語(yǔ)言模型中的參數(shù)數(shù)量決定了語(yǔ)言模型在訓(xùn)練期間學(xué)習(xí)和存儲(chǔ)信息的能力。更多的參數(shù)通常允許模型覆蓋更多知識(shí)維度,捕獲更復(fù)雜的模式和細(xì)微差別,從而提高語(yǔ)言任務(wù)的性能。
使用FNN替代RNN有個(gè)好處就是可以避免參數(shù)稀疏化,我們都知道CNN和RNN都是具備參數(shù)共享功能的,這種參數(shù)共享在處理簡(jiǎn)單任務(wù)的時(shí)候,可能具備一定的好處,但是在處理復(fù)雜任務(wù)的時(shí)候,參數(shù)的共享可能不會(huì)帶來(lái)優(yōu)勢(shì),反而是稠密連接的FNN有更大的優(yōu)勢(shì),稠密連接意味著參數(shù)量的增加,而參數(shù)量的增加,至少可以讓模型可承載的信息量變大。
不考慮詞嵌入層,一個(gè)transformer架構(gòu)的模型里,F(xiàn)FN 和 Attention 參數(shù)占據(jù)了模型參數(shù)的絕大部分,基本上超過(guò)了 90%。其中 FFN 和 Attention 參數(shù)量比例接近 2:1。或者可以說(shuō),前饋層占了模型大約三分之二的參數(shù)量。我們可以使用PyTorch快速獲得答案。
import torch.nn as nn
def count_parameters(model):
return sum(p.numel() for p in model.parameters() if p.requires_grad)
d_model = 512
n_heads = 8
multi_head_attention = nn.MultiheadAttention(embed_dim=d_model, num_heads=n_heads)
print(count_parameters(multi_head_attention)) # 1050624
print(4 * (d_model * d_model + d_model)) # 1050624
3.5 小結(jié)
最后,我們總結(jié)一下在Transformer模型中,為何要區(qū)分MHA和MLP?其原因就是這兩個(gè)核心組件各有分工又彼此配合。Transformer用embedding解決無(wú)法定義的概念,用MHA+FFN來(lái)解決不能用已有運(yùn)算符來(lái)表達(dá)的計(jì)算和變化。
- MHA考慮單詞在不同位置的語(yǔ)義和依賴關(guān)系,并使用這些信息來(lái)捕捉句子的內(nèi)部結(jié)構(gòu)和表示,MHA是Transformer中最靚的仔。
- FFN 允許模型利用注意力機(jī)制生成的上下文信息,并進(jìn)一步整合和轉(zhuǎn)化這些信息,從而捕捉數(shù)據(jù)中更復(fù)雜的關(guān)系,為學(xué)習(xí)過(guò)程提供了深度和復(fù)雜性。同時(shí)FFN也提供了存儲(chǔ)知識(shí)的場(chǎng)所。FFN是Transformer模型中的無(wú)名英雄。
這兩者共同工作以提高模型的性能。
0x04 知識(shí)利用
既然提到了FFN是用來(lái)存儲(chǔ)知識(shí)的,我們就來(lái)做進(jìn)一步的分析。
知識(shí)被定義為對(duì)事實(shí)、概念等的認(rèn)知和理解。掌握知識(shí)一直是人工智能系統(tǒng)發(fā)展的核心追求。在人工智能快速發(fā)展的今天,LLM展現(xiàn)出了令人驚嘆的能力,經(jīng)常被視為支撐知識(shí)導(dǎo)向任務(wù)的虛擬知識(shí)庫(kù),或者說(shuō),Transformer 的出色表現(xiàn)一定程度上要?dú)w功于其海量參數(shù)中存儲(chǔ)的豐富信息,包括但不限于語(yǔ)言學(xué)知識(shí)、常識(shí)、算術(shù)知識(shí)以及世界知識(shí)等。然而,在這些表面性能的背后,LLM學(xué)習(xí)、存儲(chǔ)、利用知識(shí)以及知識(shí)的動(dòng)態(tài)演化規(guī)律依然是未解之謎。比如,針對(duì)“劉翔出生在哪個(gè)城市?”之類的問(wèn)題,我們無(wú)法判斷模型是真正理解它所處理的概念,并且基于內(nèi)部知識(shí)和邏輯推理得到的答案,還是單純因?yàn)樵搯?wèn)題在訓(xùn)練集中出現(xiàn)過(guò)而依據(jù)表層的統(tǒng)計(jì)模式匹配之后輸出答案。因此,我們需要探尋語(yǔ)言模型中概念形成、對(duì)齊及其認(rèn)知機(jī)制的內(nèi)在規(guī)律,需要探尋 LLMs 存儲(chǔ)和管理事實(shí)知識(shí)的機(jī)制。
另外,盡管 LLMs 具有巨大的潛力,但直接將它們視作新一代知識(shí)庫(kù)仍然存在某些局限,通常表現(xiàn)為實(shí)際應(yīng)用中輸出不準(zhǔn)確或者錯(cuò)誤的結(jié)果。而一個(gè)理想的知識(shí)庫(kù),不僅能夠存儲(chǔ)大量信息,還允許對(duì)其中的信息進(jìn)行高效且有針對(duì)性的更新,以糾正這些錯(cuò)誤并提高準(zhǔn)確性。為了彌補(bǔ)這一差距,針對(duì) LLMs 的知識(shí)編輯領(lǐng)域應(yīng)運(yùn)而生。這種方法旨在在保持模型處理通用輸入的總體性能的同時(shí),高效地改進(jìn) LLM 在特定領(lǐng)域的表現(xiàn)。
我們接下來(lái)從幾個(gè)角度來(lái)學(xué)習(xí)下模型如何在 Transformer 的復(fù)雜架構(gòu)中有效地檢索、處理和運(yùn)用已學(xué)習(xí)的信息,即如何更好的利用知識(shí),具體包括。
- 記憶,指模型如何存儲(chǔ)知識(shí)。
- 定位,指模型如何回憶基本知識(shí)。
- 修改,指模型如何修改存儲(chǔ)的某個(gè)知識(shí)。
4.1 提取步驟
我們首先看看知識(shí)提取的步驟,不同論文提出了不同思路和方案。
論文"Dissecting Recall of Factual Associations in Auto-Regressive Language Models"通過(guò)對(duì)信息流的分析,揭示了一個(gè)屬性提取的內(nèi)部機(jī)制。我們用實(shí)例進(jìn)行說(shuō)明,假設(shè)輸入的prompt是"Beat music is owned by",LLM返回的正確答案應(yīng)該是”apple"。和很多方案一樣,此論文也把知識(shí)抽象成如下三元組 (??, ??, ??),s代表頭部實(shí)體(主語(yǔ)??),尾部實(shí)體(對(duì)象,??),以及它們之間的關(guān)系r。我們首先確定關(guān)鍵點(diǎn):關(guān)系和實(shí)體。這個(gè)例子里,“Beat music”是個(gè)實(shí)體,“is owned by ”是關(guān)系,“Apple”是這個(gè)實(shí)體對(duì)應(yīng)的某個(gè)屬性。然后,通過(guò)分析這些點(diǎn)的信息,可以確定屬性提取的三步如下:
- 融入信息。經(jīng)過(guò)早期的多層MLP處理之后,最后一個(gè)主語(yǔ)位置的表示(Music)會(huì)融入很多與主語(yǔ)相關(guān)的屬性,比如融入Beats的信息。
- 傳播關(guān)系。模型的最初幾層會(huì)把所查詢的關(guān)系 r 的信息傳播到整個(gè)輸入的最后一個(gè) token 位置(by)上。
- 屬性提取。最后一個(gè)位置(by)已經(jīng)集成了單詞“own”的信息,此時(shí)通過(guò)注意力機(jī)制(使用關(guān)系r)把“beats music”對(duì)應(yīng)的屬性“apple”提取出來(lái)。

論文"A mechanism for solving relational tasks in transformer language models" 則將語(yǔ)言模型完成事實(shí)回憶任務(wù)的過(guò)程分為兩個(gè)階段:
- 形成參數(shù):當(dāng)我們問(wèn)模型“法國(guó)的首都是”,在殘差流中解碼出來(lái)的答案會(huì)首先形成被查詢的國(guó)家,即“法國(guó)”。可以將這個(gè)過(guò)程比作模型形成了類似于“get_capital(x)”的隱式函數(shù),將殘差流逐漸形成“法國(guó)”信息的過(guò)程比喻成模型正在形成隱式函數(shù)的參數(shù)。
- 應(yīng)用函數(shù):隨著層數(shù)繼續(xù)加深,殘差流中解碼出的高概率token會(huì)由國(guó)家過(guò)渡到首都名字,即“巴黎”。可以將這個(gè)變化比喻成模型應(yīng)用了“get_capital(x)”隱式函數(shù)。
這些觀察提供了很有價(jià)值的研究基礎(chǔ),但是仍有很多問(wèn)題沒有被回答,這些問(wèn)題對(duì)于進(jìn)一步理解語(yǔ)言模型中的事實(shí)回憶機(jī)制至關(guān)重要:
- 模型如何完成“傳參”?
- 隱式函數(shù)到底是怎么被應(yīng)用的?MLP在這個(gè)過(guò)程中是怎么工作的?
- 論文主要關(guān)注了one-shot設(shè)定,zero-shot或者few-shot情況下模型的工作機(jī)制如何?
論文”Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models"做了進(jìn)一步研究,其將語(yǔ)言模型在zero-shot場(chǎng)景下完成事實(shí)回憶任務(wù)的過(guò)程總結(jié)為以下幾步:
- 注意力頭對(duì)“隱式函數(shù)”傳參。首先,在淺層形成的任務(wù)語(yǔ)義會(huì)激活一些中至深層的特定任務(wù)的注意力頭。 這些注意力頭具有對(duì)與特定主語(yǔ)(例如國(guó)家名稱)相關(guān)的token敏感的QK矩陣。 它們關(guān)注這些主語(yǔ)token并將它們移動(dòng)到殘差流的末尾位置。 這種機(jī)制使得模型能夠從上下文中提取“參數(shù)”并將其傳遞給“隱式函數(shù)”。 此外,一些注意力頭的OV矩陣可以直接將“參數(shù)”映射到所需的輸出,而無(wú)需通過(guò)后續(xù)的MLP進(jìn)一步處理。 這種映射可以看作是完成了部分“函數(shù)應(yīng)用”。
- MLP是注意力頭輸出的“激活函數(shù)”。注意力頭之后的MLP充當(dāng)了每個(gè)頭輸出的“激活函數(shù)”,使得特定任務(wù)頭傳遞的“參數(shù)”會(huì)在殘差流中脫穎而出。鑒于所有注意力頭的輸出在添加到殘差流之前被等權(quán)地相加在一起, 該MLP可以通過(guò)使用生成與頭輸出方向相一致或相反的向量來(lái)擦除或放大各個(gè)頭的輸出。
- 參數(shù)應(yīng)用即“ \(b+r_{mid}\) ”。MLP的輸出中,一個(gè)“任務(wù)相關(guān)”的分量,即這里的截距項(xiàng),在與殘差流相加的時(shí)候,完成了“函數(shù)應(yīng)用”,將殘差流引導(dǎo)向MLP認(rèn)為正確的輸出的方向。我們可以從MLP的輸出中分解出一個(gè)任務(wù)感知的分量,這個(gè)分量在與殘差流相加的時(shí)候會(huì)完成對(duì)殘差流方向的操控,MLP可以通過(guò)這個(gè)分量將殘差流引導(dǎo)向目標(biāo)答案的unembedding vector的方向。這個(gè)分量與殘差流相加的操作可以被認(rèn)為是“函數(shù)應(yīng)用”的基本實(shí)現(xiàn)。
- 另外,模型最后一層普遍存在Anti-overconfidence機(jī)制。無(wú)論是模型最后一層的注意力頭,還是MLP,都是在將模型的輸出向“高頻”或者換句話說(shuō)“安全”的方向引導(dǎo),這樣即使模型預(yù)測(cè)錯(cuò)了,從整個(gè)訓(xùn)練集來(lái)看,獲得的loss的期望還是比較小的。
下圖給出了基于Transformer的語(yǔ)言模型所采用的事實(shí)回憶的關(guān)鍵機(jī)制。
- 圖上(1)展示,特定任務(wù)相關(guān)的注意力頭\(??^{??,1}\)將主語(yǔ)實(shí)體(即“法國(guó)”)移動(dòng)到殘差流的最終位置。
- 圖上(2)展示,MLP將“France”作為隱式函數(shù)“get_capital(X)”的參數(shù)。其輸出將殘差流重定向到其預(yù)期答案的方向,即本例中的“Paris”。
- 圖上(3)展示,MLP的輸出會(huì)擦除或放大殘留流中單個(gè)磁頭的輸出。在這種情況下,\(??^{??,1}\)的“法國(guó)”輸出被放大,而其他磁頭的輸出被擦除。

4.2 知識(shí)記憶
知識(shí)記憶的目的是記憶和回憶知識(shí),例如具體術(shù)語(yǔ)、語(yǔ)法和概念等,王堅(jiān)院士稱:“記憶就是重塑神經(jīng)元之間的連接,記憶的偏好,就是神經(jīng)元之間相互鏈接的關(guān)系改變了。而對(duì)于今天的大語(yǔ)言模型來(lái)講,就是權(quán)重發(fā)生了變化“。現(xiàn)有大量研究工作致力于揭示 LLMs 的行為機(jī)制,特別是 LLMs 中的知識(shí)存儲(chǔ)模式,下圖是一個(gè)簡(jiǎn)要的匯總。

我們首先看看一些典型的思考和研究。目前的工作中,有兩個(gè)方向的嘗試比較重要:
- 鍵值對(duì)。該方向認(rèn)為事實(shí)以鍵值對(duì)的形式存儲(chǔ)在mlp中,在這個(gè)基礎(chǔ)上人們使用知識(shí)編輯(knowledge editing),遺忘學(xué)習(xí)(machine unlearning),祛毒(detoxification)等方法對(duì)模型的mlp層修改,以緩解修復(fù)模型的缺陷。
- 知識(shí)回路。該方向認(rèn)為知識(shí)不是單獨(dú)的存儲(chǔ)在某一區(qū)域的,而是由不同的組件共同構(gòu)成的。
鍵值對(duì)形式
下圖展示了鍵值對(duì)的概念,我們接下來(lái)看看這個(gè)領(lǐng)域內(nèi)的幾篇重要論文。

記憶網(wǎng)絡(luò)
2015年,論文“End-To-End Memory Networks”提出了記憶網(wǎng)絡(luò)的概念,這是一種 Key-Value Memory 的結(jié)構(gòu),借此可以在神經(jīng)網(wǎng)絡(luò)中添加記憶模塊。該論文將需要存儲(chǔ)的信息分別映射為key向量與value向量,然后以向量?jī)?nèi)積的指數(shù)形式建模鍵(key)對(duì)于輸入(x)的條件概率,進(jìn)而得到記憶網(wǎng)絡(luò)的整體是對(duì)每個(gè)鍵值對(duì)的加權(quán)求和。模型的架構(gòu)如下圖所示。每個(gè)文本都會(huì)分別映射成向量\(c_i\)和\(m_i\),query也被編碼成一個(gè)內(nèi)部狀態(tài)u。在嵌入的空間中,模型通過(guò)計(jì)算u和\(m_i\)的內(nèi)積以及一個(gè)softmax 來(lái)得到計(jì)算u和mi之間的交互關(guān)系\(p_i\)。最終輸出向量O是用\(c_i\)和\(p_i\) 計(jì)算得到。

我們對(duì)模型結(jié)構(gòu)做進(jìn)一步抽象,給定輸入x和鍵k,我們有 \(x,k_i ∈R^d\),則記憶網(wǎng)絡(luò)的結(jié)構(gòu)為\(MemoryNet(x)=softmax(x?K^?)?V\),具體細(xì)節(jié)如下圖所示。

我們已經(jīng)知道FFN 的公式為\(FFN(H)=f(H?W_1)W_2\),這里 \(f\) 是 ReLU 激活函數(shù)。因此可以發(fā)現(xiàn),記憶網(wǎng)絡(luò)和注意力機(jī)制很類似,而FFN幾乎與記憶網(wǎng)絡(luò)的key-value memory相同。唯一的區(qū)別在于:記憶網(wǎng)絡(luò)使用 softmax 進(jìn)行歸一化,F(xiàn)FN的采用 ReLU 進(jìn)行篩選,并不要求歸一化。假設(shè)FFN層是一個(gè)key-value memory,每一個(gè)key向量 \(??_??\) 可以捕獲輸入序列的模式,\(??_??\)對(duì)應(yīng)的value向量 \(v_??\) 可以表示遵循該模式的token分布。
Key-Value
基于上述信息,"Transformer Feed-Forward Layers Are Key-Value Memories"和“Knowledge Neurons in Pretrained Transformers”這兩篇論文也做了深入研究,發(fā)現(xiàn)FFN 確實(shí)將一些 pattern 或者知識(shí)記憶和存儲(chǔ)起來(lái)了,其中一些相關(guān)論點(diǎn)如下:
- Transformer 架構(gòu)下的FFN在形式上高度類似于記憶神經(jīng)網(wǎng)絡(luò),都是一個(gè)雙層 Key-Value 記憶網(wǎng)絡(luò)。并且FFN第一層前饋網(wǎng)絡(luò)權(quán)重 \(??_{????}^{(??)}\)對(duì)應(yīng)記憶網(wǎng)絡(luò)里鍵值對(duì)(KEY-VALUE)的KEY,而第二層前饋網(wǎng)絡(luò)權(quán)重 \(??_{????????}^{(??)}\) 對(duì)應(yīng)著VALUE。中間層維度對(duì)應(yīng)memory token數(shù)量(或許是中間層維度需要較大的一種解釋)。
- FFN 學(xué)到的記憶有一定的可解釋性。前饋網(wǎng)絡(luò)的KEY捕捉了輸入的某種模式,或者說(shuō),每個(gè)KEY至少與一個(gè)人類可理解的輸入模式高度相關(guān)。儲(chǔ)存的模式來(lái)源于訓(xùn)練數(shù)據(jù)。
- 每個(gè)KEY神經(jīng)元都會(huì)觸發(fā)人類可理解的淺輸入模式,相應(yīng)的VALUE 神經(jīng)元存儲(chǔ)下一個(gè)詞的輸出概率。
- VALUE 可以基于KEY捕獲的模式,預(yù)測(cè)下一個(gè)輸出詞的分布。或者說(shuō),VALUE對(duì)應(yīng)的KEY所關(guān)聯(lián)的模式句子的下一個(gè)詞會(huì)以高概率值出現(xiàn)在該分布中。
- 每層的輸出相當(dāng)于合并了數(shù)以千百計(jì)的激活記憶分布,最后形成全新的分布。該分布的預(yù)測(cè)會(huì)隨著每層里的殘差鏈接被不斷校正、細(xì)化,直到最后一層。最終產(chǎn)生模型的預(yù)測(cè)結(jié)果。FFN 的最終輸出可以理解為激活值的加權(quán)和。
- 淺層傾向于檢測(cè)出淺層模式,高層傾向于檢測(cè)語(yǔ)義模式。
下面是論文中推導(dǎo)出的FFN的KV詳細(xì)結(jié)構(gòu),F(xiàn)FN的第一層可以認(rèn)為是KEY,第二層可以認(rèn)為是VALUE。

在下圖上可以看到由模式到VALUE的流程。

我們接下來(lái)詳細(xì)分析下這些論點(diǎn)。
Key模式
關(guān)于key的模式,"Transformer Feed-Forward Layers Are Key-Value Memories"也做了研究。論文作者標(biāo)注了一批鍵值對(duì)應(yīng)的句子,要求模式必須滿足:重復(fù)三次以上,可描述,并且包含淺表模式(重復(fù)詞句n-gram)或者語(yǔ)義模式(多次重復(fù)的主語(yǔ))。通過(guò)實(shí)驗(yàn),作者發(fā)現(xiàn)每個(gè)鍵向量至少對(duì)應(yīng)一種人類可解讀的模式。低層鍵向量趨向于捕捉淺顯的模式,比如一些通用 pattern(比如以某某結(jié)尾),而高層的 Key 趨向于捕捉抽象的語(yǔ)義模式(比如句子的分類)。這個(gè)發(fā)現(xiàn)類似于CNN里,底層趨向于捕捉顯示的圖像特征,而高層趨向于捕捉抽象的特征。也類似于ELMO等論文在NLP學(xué)界的發(fā)現(xiàn)。
另外,論文作者針對(duì)移去尾部詞和移去頭部詞的效果做了實(shí)驗(yàn),相較于高層鍵值來(lái)說(shuō),底層的淺表模式的記憶系數(shù)對(duì)"移去尾部詞"的影響更敏感。這佐證了高層和底層關(guān)注的模式抽象層次不同的結(jié)論。

值向量表示的是分布
記憶網(wǎng)絡(luò)的值向量表示的是輸出詞匯的分布,其傾向于補(bǔ)全對(duì)應(yīng)key的prefix的下一個(gè)詞,具體特點(diǎn)如下:
- 每一個(gè)key \(k_i^l\)對(duì)應(yīng)的value \(v_i^l\),即FF層第二個(gè)參數(shù)矩陣的第 ?? 行,可以視為輸出詞表的一個(gè)分布,同時(shí)可以作為 \(k_i^l\)所捕獲的模式的一種補(bǔ)充。
- 直接將 \(v_i^l\) 和輸出詞表的embedding矩陣E(假設(shè)模型每一層都使用的是同一個(gè)詞表矩陣)進(jìn)行相乘,然后進(jìn)行softmax,即 \(p_i^l=??????????????(v_i^l???)\) ,就可以將values轉(zhuǎn)換為輸出詞表的分布。這個(gè) \(p_i^l\) 沒有被校準(zhǔn),不是一個(gè)真正的詞表分布。因?yàn)镕F包含了兩個(gè)參數(shù)矩陣,第一個(gè)參數(shù)矩陣會(huì)得到記憶系數(shù) \(??_??^??=??(?????_??)\) ,該系數(shù)會(huì)與第二個(gè)參數(shù)矩陣相乘,得到 \(m_i^l \cdot v_i^l\) ,而這里直接使用 \(v_i^l\) 得到詞表分布。
- 對(duì)于每一層,根據(jù) \(????????????(??_??^??)\) 得到 top-ranked 的token,然后該token和 \(w_i^l\)進(jìn)行比較。 \(w_i^l\)是分?jǐn)?shù)最高的\(m_i^l\)所觸發(fā)前綴序列的下一個(gè)token,即通過(guò)value得到的詞表分布遵循了key捕獲的模式。
分布式存儲(chǔ)和記憶聚合
截至目前,我們討論的依然是某個(gè)特定的鍵值對(duì)。但我們知道一個(gè)記憶網(wǎng)絡(luò)是所有值向量的加權(quán)(記憶系數(shù))求和(并加上偏置項(xiàng))。如果值向量表示的是在詞空間的分布,那么這些信息是如何聚合到一個(gè)最終分布的呢?
有研究表明,大腦中所有只是不會(huì)只存儲(chǔ)在一個(gè)地方,也不是像全息圖一樣在任何地方存儲(chǔ)所有東西。關(guān)于一個(gè)物體的知識(shí)會(huì)分布在成千上萬(wàn)根皮質(zhì)柱中。比如,卡爾·拉什利(Karl Lashley)在20世紀(jì)早期就給出了一個(gè)非定位結(jié)論:大腦中沒有專門的記憶器官,信息根本不是存儲(chǔ)在特定的文件柜中,而是分布在神經(jīng)元中。這一結(jié)論被后來(lái)改進(jìn)的實(shí)驗(yàn)方案證明是基本正確的。
和人腦類似,F(xiàn)FN中對(duì)于某個(gè)知識(shí)也是分布存儲(chǔ)的,用以存儲(chǔ)一個(gè)特定模式的權(quán)重會(huì)分布的存于不同層。FFN不單是激活一個(gè)key及其value,而是多個(gè)value的加權(quán)和。每一層的輸出又進(jìn)一步是FFN的輸出與殘差的組合。
知識(shí)回路
論文"Knowledge Circuits in Pretrained Transformers"發(fā)現(xiàn)了Transformer架構(gòu)中的知識(shí)回路(Knowledge Circuits)。知識(shí)回路將語(yǔ)言模型看作一個(gè)由組件(input,output,attention_head,mlp)為節(jié)點(diǎn),連接組件的邊(殘差流),共同組成的一個(gè)計(jì)算圖,信息在這些組件中流動(dòng)。相對(duì)于知識(shí)編輯關(guān)注知識(shí)的存儲(chǔ)區(qū)域,知識(shí)回路更關(guān)注信息的流動(dòng)。
下圖為模型回答“The official language of France is ”這個(gè)問(wèn)題時(shí),所經(jīng)過(guò)回路。對(duì)于下圖的回路來(lái)說(shuō),基于一個(gè)事實(shí)三元組“(Franch, official language, French)” ,讓模型補(bǔ)全”The official language of France is “這句話,從而預(yù)測(cè)出客體是French。在回路中,MLP14類似的點(diǎn)代表著第14層的MLP層;L18H14代表著第18層的第14個(gè)注意力頭,點(diǎn)之間的褐色連線代表這他們之間的信息流動(dòng)。通過(guò)消融節(jié)點(diǎn)(即參數(shù)置為0)之間的邊就可以判斷出某個(gè)邊對(duì)于知識(shí)是否為關(guān)鍵邊,通過(guò)保留重要的邊就可以構(gòu)造出關(guān)于這個(gè)事實(shí)的回路。

論文做了一些實(shí)驗(yàn),把每一層的中間輸出解碼,然后觀察其預(yù)測(cè)結(jié)果。針對(duì)“The official language of France is French”這一事實(shí),下圖給出了在最后一個(gè)主語(yǔ)(subject )token位置和最后一個(gè)token位置上,目標(biāo)實(shí)體的排名和概率。圖上幾個(gè)標(biāo)志的說(shuō)明如下:
- Target Entity at Last Position表示”French“這個(gè)詞在”is“位置時(shí)輸出logits的預(yù)測(cè)排名。數(shù)值越低,排名越高。
- Target Entity at Subject Position表示“French”這個(gè)詞在“France”位置時(shí)輸出logits的預(yù)測(cè)排名。數(shù)值越低,排名越高。
- Prob. of Entity表示實(shí)體的可能性,數(shù)值越高,實(shí)體的可能性越大。

從上圖可以看出,在MLP17層以后,目標(biāo)實(shí)體的可能性開始漸漸上升。從再上面的的網(wǎng)絡(luò)圖可以看到,連接MLP17的邊是(L14H13 → MLP17), (L14H7 → MLP17)和(L15H0 → MLP17) ,因此,該論文判斷,不同的注意力頭起不同的作用。
- 注意力頭L14H13是一個(gè)關(guān)系頭(relation head),它更關(guān)注上下文中的關(guān)系(relation)token。這個(gè)頭部的輸出是與關(guān)系相關(guān)的token,如“l(fā)anguage”和“Language”。
- 注意力頭L14H7是一個(gè)移動(dòng)(mover )頭,它將信息從主語(yǔ)位置“France”移動(dòng)到最后一個(gè)token。
- MLP17層則是結(jié)合之前組件提供的信息,提升目標(biāo)token的最高rank。
注意力模塊
另外,注意力模塊在存儲(chǔ)關(guān)系知識(shí)方面也發(fā)揮了重要作用。這表明在分析和修改LLMs中的知識(shí)時(shí),不能僅僅關(guān)注MLP層,還需要考慮注意力機(jī)制的作用。比如,論文"EXBERT: A Visual Analysis Tool to Explore Learned Representations in Transformer Models"解釋了每個(gè)注意頭所學(xué)習(xí)到的知識(shí)。具體來(lái)說(shuō),注意頭會(huì)存儲(chǔ)明顯的語(yǔ)言特征、位置信息等。此外,事實(shí)信息和偏見也會(huì)通過(guò)注意力頭傳遞。

上圖展示了在預(yù)訓(xùn)練模型BERTbase和不同語(yǔ)料庫(kù)下,不同注意力頭的效果。
- (a)顯示,注意力頭5-3通過(guò)助動(dòng)詞(AUX)“to“來(lái)預(yù)測(cè)掩碼的單詞應(yīng)該是一個(gè)動(dòng)詞。
- (b顯示,注意力頭7-5找到了輸入句子中介詞(PREP)與其賓語(yǔ)(POBJ)之間的關(guān)系。
- (c)顯示,注意力頭5-5學(xué)習(xí)到了關(guān)于實(shí)體關(guān)系的的共同參考(co-reference),因?yàn)橐驗(yàn)椤皊he”和“her”都明確指向“Kim”。
4.3 知識(shí)的定位
除了知識(shí)存儲(chǔ)之外,其實(shí)已經(jīng)開始有一些研究從網(wǎng)絡(luò)架構(gòu)或者注意力機(jī)制的角度探究知識(shí)的檢索以及利用的問(wèn)題。
事實(shí)的定位
事實(shí)知識(shí)的定位可以分為兩步:知識(shí)歸因 (Knowledge Attribution)、精煉神經(jīng)元 (Knowledge Neuron Refining)。
知識(shí)歸因 (Knowledge Attribution)
論文"Axiomatic Attribution for Deep Networks" 提出可以使用積分梯度法(Integrated Gradients)來(lái)計(jì)算每一個(gè)特征對(duì)輸出的歸因,以此來(lái)解釋模型預(yù)測(cè)和輸入特征之間的關(guān)系。
積分梯度法有個(gè)重要的性質(zhì),那就是所有的歸因加起來(lái)就是f(x)和f(x')的差值。公式如下,其中函數(shù)F表示神經(jīng)網(wǎng)絡(luò)。如果F(x')=0, F(x)=1,那么每個(gè)特征的歸因可以認(rèn)為是對(duì)該樣本屬于label=1的貢獻(xiàn)。

深度網(wǎng)絡(luò)歸因定義如下圖所示:假設(shè)函數(shù)F表示一個(gè)深度網(wǎng)絡(luò),該網(wǎng)絡(luò)輸入為x,另有一個(gè)基線輸入x'。 則x相較x'的歸因是一個(gè)向量\(A_F(x,x')\),其中\(a_i\)就是輸入\(x_i\)對(duì)于預(yù)測(cè)結(jié)果F(x)的貢獻(xiàn)。

精煉神經(jīng)元 (Knowledge Neuron Refining)
我們可以通過(guò)一種精煉策略去更準(zhǔn)確地定位事實(shí)知識(shí)。雖然在經(jīng)過(guò)初篩的神經(jīng)元集合中,很多“true-positive”知識(shí)神經(jīng)元會(huì)對(duì)最后的輸出做主要貢獻(xiàn),但是集合中還有很多“false-positive”知識(shí)神經(jīng)元,它們表示其他知識(shí)(比如句法信息和詞法信息,即它們代表的是附屬信息或者上下文信息)。所以,我們需要過(guò)濾掉這些“false-positive”知識(shí)神經(jīng)元來(lái)提升定位效果。

如何過(guò)濾?我們先看看“false-positive”神經(jīng)元的特點(diǎn)。比如由若干描述李世民的prompts,因?yàn)樗鼈冎g有著各種各樣的句法,詞匯信息,所以它們的“false-positive”知識(shí)神經(jīng)元會(huì)不同。但是它們都有相同的事實(shí)信息:李世民。所以,我們能通過(guò)提煉出不同 prompts 之間共享的神經(jīng)元,從而定位出那些普遍的事實(shí)信息。具體來(lái)說(shuō),給定一個(gè)關(guān)系事實(shí),識(shí)別其知識(shí)神經(jīng)元的完整過(guò)程描述如下:
- 構(gòu)建 n 個(gè)不同的 prompts 去表達(dá)這個(gè)事實(shí)。
- 對(duì)于每個(gè)提示,計(jì)算神經(jīng)元的知識(shí)歸因得分。
- 對(duì)于每個(gè)提示,保留歸因得分大于歸因閾值 t 的神經(jīng)元,獲得粗略的知識(shí)神經(jīng)元集。
- 設(shè)置一個(gè)共享閾值 p%(是否被多個(gè) prompt 共享)。
- 將所有的粗略的知識(shí)神經(jīng)元集聚合在一起,只保留達(dá)到這個(gè)閾值的神經(jīng)元。
以下圖為例,對(duì)于一個(gè)關(guān)系和它的激活神經(jīng)元,我們輸入 10 個(gè) prompts(包含 head 和 tail 實(shí)體)來(lái)獲取知識(shí)神經(jīng)元的平均激活。然后,我們對(duì)這些 prompts 進(jìn)行排序,保留 top-2(activation 最高的),bottom-2(activation 最低的)。我們發(fā)現(xiàn),top-2 總是表示相應(yīng)的關(guān)系事實(shí),而 bottom-2 盡管包含相同的 head 和 tail 實(shí)體,但沒有表示相應(yīng)的關(guān)系。這個(gè)發(fā)現(xiàn)表明,知識(shí)神經(jīng)元可以捕獲關(guān)系事實(shí)的語(yǔ)義模式,并且再一次驗(yàn)證了知識(shí)神經(jīng)元是由知識(shí)探測(cè) prompt 激活的。

關(guān)系的定位
前面主要從實(shí)體的角度調(diào)查 LLMs 中的知識(shí)。如果我們從關(guān)系的角度來(lái)處理相同的知識(shí),可能會(huì)得到完全不同的觀察結(jié)果。理論上,一條知識(shí)包括實(shí)體和它們之間的關(guān)系,缺少任何一個(gè),知識(shí)就是不完整的。因此,在這種情況下,實(shí)體和關(guān)系應(yīng)該是等價(jià)的,這也是當(dāng)前許多模型編輯工作的前提,因?yàn)樾枰谀P蛥?shù)中修改知識(shí)。
論文"Does Knowledge Localization Hold True? Surprising Differences Between Entity and Relation Perspectives in Language Models" 研究了實(shí)體和關(guān)系之間的差異,具體是通過(guò)修改實(shí)體或關(guān)系知識(shí)來(lái)確定這些變化是否會(huì)產(chǎn)生一致的結(jié)果,并從兩個(gè)角度觀察效果。理想情況下,這些效果應(yīng)該是相同的,因?yàn)榫庉嫷闹R(shí)涉及同一條信息。

研究者提出了以下研究問(wèn)題:
- 關(guān)系知識(shí)存儲(chǔ)在哪里?它是否像實(shí)體知識(shí)一樣存儲(chǔ)在 MLPs 中?
- 無(wú)論存儲(chǔ)位置如何,關(guān)系和實(shí)體知識(shí)在知識(shí)三元組中是否同等重要?
論文針對(duì)兩個(gè)問(wèn)題的回答如下:
-
實(shí)體和關(guān)系知識(shí)可能以不同的方式存儲(chǔ)和表示。
- 實(shí)體和關(guān)系知識(shí)并不簡(jiǎn)單地存儲(chǔ)在相同的位置或以相同的方式表示,而應(yīng)該是分開存儲(chǔ)的。
- 注意力模塊在存儲(chǔ)關(guān)系知識(shí)方面也發(fā)揮了重要作用。關(guān)系知識(shí)與較高的 MLP 層和中上層注意力層密切相關(guān)。
-
實(shí)體知識(shí)和關(guān)系知識(shí)是可互換的。基于這一假設(shè),研究者認(rèn)為通過(guò)改變關(guān)系知識(shí)來(lái)修改實(shí)體知識(shí)在理論上是可能的。但是編輯實(shí)體知識(shí)和關(guān)系知識(shí)并不完全等價(jià)。
字典學(xué)習(xí)和稀疏自編碼器
我們首先看看幾個(gè)概念。
-
線性表示假設(shè)(linear representation hypothesis):這個(gè)假設(shè)認(rèn)為神經(jīng)網(wǎng)絡(luò)將有意義的概念(稱為特征)表示為其激活空間中的方向。簡(jiǎn)單來(lái)說(shuō),就是模型對(duì)于某個(gè)概念的理解和表示,可以被看作是在一個(gè)多維空間中的一種方向。更改這個(gè)方向,即改變特征的值,就可以改變模型對(duì)于這個(gè)概念的理解和處理。
-
疊加假設(shè)(superposition hypothesis):從上面假設(shè)進(jìn)一步拓展,神經(jīng)網(wǎng)絡(luò)利用高維空間中幾乎正交方向的存在,來(lái)表示比維數(shù)更多的特征。這意味著,即使我們的模型只有有限的維度,但是通過(guò)在不同的方向上疊加和組合這些維度,我們可以表示和理解更多的特征和概念。
-
字典學(xué)習(xí):字典學(xué)習(xí)是一種常用的特征提取方法,通過(guò)學(xué)習(xí)一個(gè)字典,可以把高維數(shù)據(jù)表示為字典中元素的線性組合。該技術(shù)借鑒了經(jīng)典機(jī)器學(xué)習(xí),分離了在許多不同背景下反復(fù)出現(xiàn)的神經(jīng)元激活模式,將神經(jīng)元激活模式(稱為特征)與人類可解釋的概念進(jìn)行匹配。對(duì)于上下文,字典學(xué)習(xí)的目標(biāo)是將 LLM 神經(jīng)元內(nèi)部的激活解開為一小組可解釋的特征。然后,我們可以查看這些特征來(lái)檢查模型在處理給定上下文時(shí)內(nèi)部發(fā)生的情況。
-
稀疏自編碼器是一種特殊的字典學(xué)習(xí)方法,它通過(guò)限制字典元素的數(shù)量和它們的線性組合的稀疏性,可以有效地提取出數(shù)據(jù)的關(guān)鍵特征。
基于這些概念,論文"Towards Monosemanticity: Decomposing Language Models With Dictionary Learning"從另一個(gè)角度為我們拓展了LLM中知識(shí)的可解釋性。其核心是:使用稀疏自編碼器能從單層transformer模型中提取大量可解釋的特征。
從某種意義上說(shuō),下圖是最簡(jiǎn)單的人無(wú)法理解的語(yǔ)言模型。論文的目標(biāo)是將它的 MLP 激活向量并分解到各個(gè)特征。這是通過(guò)在MLP的activation后接上一個(gè)過(guò)完備的autoencoder來(lái)完成的,即autoencoder是用來(lái)解釋模型內(nèi)在激活(MLP層后的激活)的。autoencoder分解后的特征數(shù)量多于神經(jīng)元數(shù)量,隱狀態(tài)的每一個(gè)維度都可以作為一個(gè)抽象出的特征,并且具有很強(qiáng)的可解釋性。這是因?yàn)槲覀冋J(rèn)為 MLP 層很可能使用疊加來(lái)表示比它的神經(jīng)元更多的特征(當(dāng)然,不只是發(fā)生了疊加,還對(duì)特征進(jìn)行了非線性的映射)。

這樣就可以通過(guò)在多維空間中找到表示不同概念的"方向",并通過(guò)在這些方向上進(jìn)行疊加和組合,來(lái)理解和處理復(fù)雜的數(shù)據(jù)和概念。通過(guò)字典學(xué)習(xí)和稀疏自編碼器,我們可以有效地提取出這些方向,從而更好地理解和控制模型的行為。
下圖給出了Transformer和稀疏自編碼器的對(duì)比。


論文中的一些有趣的結(jié)論如下。
- 稀疏自編碼器能提取相對(duì)單一的語(yǔ)義特征。
- 稀疏自編碼器能產(chǎn)生可解釋的特征,而這些特征在神經(jīng)元中實(shí)際上是不可見的。
- 稀疏自編碼器特征可用于干預(yù)和引導(dǎo)transformer的內(nèi)容生成。
- 稀疏自編碼器能產(chǎn)生相對(duì)通用的特征。
- 增加自編碼器的大小時(shí),特征會(huì) "分裂"。
- 僅 512 個(gè)神經(jīng)元就能表示數(shù)以萬(wàn)計(jì)的特征。盡管 MLP 層非常小,但隨著稀疏自編碼器的規(guī)模擴(kuò)大,我們?nèi)阅懿粩喟l(fā)現(xiàn)新的特征。
- 這些功能在類似于 "有限狀態(tài)自動(dòng)機(jī) "的系統(tǒng)中相互連接,從而實(shí)現(xiàn)復(fù)雜的行為。例如,我們可以找到共同生成有效 HTML 的特征。
4.3 修改知識(shí)
LLM在理解和生成自然語(yǔ)言方面表現(xiàn)出了非凡的能力。然而,由于巨量參數(shù)的存在,其訓(xùn)練過(guò)程中需要大量算力。現(xiàn)實(shí)世界在不斷發(fā)展變化,因此需要頻繁地更新 LLM 以移除過(guò)時(shí)信息或者整合新的知識(shí)。這使得對(duì)于算力的挑戰(zhàn)變得愈發(fā)嚴(yán)峻。除了為了保證 LLM 能夠進(jìn)行持續(xù)學(xué)習(xí)而需要對(duì)其頻繁更新參數(shù)外,許多應(yīng)用也需要在訓(xùn)練后不斷調(diào)整模型,以解決預(yù)訓(xùn)練模型存在的不足或不良行為。
因此,越來(lái)越多的工作嘗試提出能夠?qū)崟r(shí)修改模型的高效、輕量級(jí)方法。近年來(lái),作為這類方法的代表性技術(shù)路線---知識(shí)編輯技術(shù),在LLM 領(lǐng)域取得了突破性進(jìn)展。該技術(shù)通過(guò)對(duì) LLMs 快速準(zhǔn)確的修改,使它們生成更準(zhǔn)確、更相關(guān)的輸出結(jié)果。這樣一來(lái),就有望彌補(bǔ)當(dāng)前 LLMs 存在的不足,從而充分發(fā)揮它們作為動(dòng)態(tài)、準(zhǔn)確的知識(shí)庫(kù)在各種下游應(yīng)用中的潛力。
相關(guān)路線
下圖展示了一些與知識(shí)編輯相關(guān)的幾條技術(shù)路線,包括參數(shù)高效的微調(diào)(parameter-efficient fine-tuning)、知識(shí)增強(qiáng)(knowledge augmentation)、持續(xù)學(xué)習(xí)(continue learning)以及機(jī)器遺忘)(machine unlearning)。

符號(hào)? 表示技術(shù)中存在特定特征,而?表示不存在,+表示LLM能力的增強(qiáng),-表示模型中某些能力的減少或刪除。
如上圖所示,知識(shí)編輯與其它技術(shù)相互交叉、博采眾家之長(zhǎng)。知識(shí)編輯技術(shù)針對(duì)性地定位 LLMs 內(nèi)嵌的知識(shí),并利用這些模型中固有的知識(shí)機(jī)制。這不僅僅是將已知技術(shù)應(yīng)用到新模型中,而是更關(guān)乎理解和操縱 LLMs 微妙的知識(shí)存儲(chǔ)和處理能力。此外,知識(shí)編輯代表了一種更精確、更細(xì)粒度的模型操縱形式,因?yàn)樗婕暗竭x擇性地改變或增強(qiáng)模型知識(shí)庫(kù)的特定方面,而不是重新訓(xùn)練或微調(diào)整個(gè)模型。因此,與簡(jiǎn)單地對(duì)現(xiàn)有方法進(jìn)行修改不同,知識(shí)編輯需要更深入地理解 LLMs 的功能。這些特點(diǎn)使得知識(shí)編輯可能成為更新和優(yōu)化 LLMs 以適應(yīng)特定任務(wù)或應(yīng)用的更有效且高效的技術(shù)路線。
功能
作為一個(gè)理想的知識(shí)庫(kù),針對(duì) LLMs 的知識(shí)編輯必須能實(shí)現(xiàn)以下三個(gè)基本功能:知識(shí)插入、知識(shí)修改和知識(shí)擦除。
-
知識(shí)插入。隨著各個(gè)新興領(lǐng)域和實(shí)體的涌現(xiàn)與發(fā)展,賦予 LLMs 吸收新知識(shí)的能力至關(guān)重要。知識(shí)插入通過(guò)賦予 LLMs 現(xiàn)有范圍之外的新知識(shí)來(lái)實(shí)現(xiàn)這一點(diǎn):即 ??′=??(??,{?}→{??}) 。
-
知識(shí)修改。知識(shí)修改則是指改變 LLMs 中已存儲(chǔ)的知識(shí):??′=??(??,{??}→{??′}) ,具體可分為兩類:
- 知識(shí)修正 - 旨在糾正 LLMs 中的不準(zhǔn)確信息,以確保其能夠傳遞準(zhǔn)確的信息。作為龐大的知識(shí)庫(kù),LLMs 中容易存在過(guò)時(shí)或錯(cuò)誤的信息。知識(shí)修正旨在糾正這些謬誤,確保模型始終產(chǎn)生準(zhǔn)確的、與時(shí)俱進(jìn)的信息。
- 知識(shí)干擾 - 修改 LLMs 以回答反事實(shí)或存在排印錯(cuò)誤(非故意造成的謬誤)的問(wèn)題輸入。這是一件更難的事情。現(xiàn)有工作表明,與事實(shí)性知識(shí)相比,反事實(shí)觀念在 LLMs 中得分很低,導(dǎo)致被生成的概率遠(yuǎn)低于事實(shí)性知識(shí),因此需要進(jìn)行更有針對(duì)的修改。
-
知識(shí)擦除。知識(shí)擦除是在模型中移除已有的知識(shí),主要是為了重置事實(shí)、關(guān)系或?qū)傩裕??′=??(??,{??}→{?}) 。實(shí)施知識(shí)擦除對(duì)于消除有偏見的以及有害的知識(shí)至關(guān)重要,且有助于限制對(duì)機(jī)密或私人數(shù)據(jù)的回放,從而形成負(fù)責(zé)任的、值得信賴的人工智能應(yīng)用。
總而言之,知識(shí)插入、修改和擦除之間的相互作用構(gòu)成了針對(duì) LLMs 的知識(shí)編輯技術(shù)的基本框架。當(dāng)這些技術(shù)結(jié)合在一起時(shí),它們能夠賦予 LLMs 在必要時(shí)進(jìn)行自我轉(zhuǎn)換、自我糾正和道德適應(yīng)的能力。

分類
面向 LLMs 的知識(shí)編輯主要分為以下幾類,其對(duì)應(yīng)了人類知識(shí)獲取的三個(gè)不同階段:識(shí)別、關(guān)聯(lián)和掌握。
- 外部知識(shí)依賴。代表方案是提示工程和知識(shí)檢索,具體發(fā)生在知識(shí)識(shí)別階段。這種方法類似于人類認(rèn)知過(guò)程中的識(shí)別階段,需要在相關(guān)背景下接觸新知識(shí),就像人們第一次接觸新信息一樣。例如,可以給大模型提供具有事實(shí)更新的示范語(yǔ)句,從而實(shí)現(xiàn)大模型對(duì)待編輯知識(shí)的初步識(shí)別。或者通過(guò)檢索來(lái)校驗(yàn)LLM的回答,一旦檢索的事實(shí)與 LLM 的輸出沖突,則更新 LLM 的回答;反之則沿用 LLM 的輸出作為最終答案。
- 外部知識(shí)注入。代表方案是增加參數(shù)、替換輸出,具體發(fā)生在知識(shí)關(guān)聯(lián)階段。這種方法與人類認(rèn)知過(guò)程中的關(guān)聯(lián)階段非常相似,讓新知識(shí)和模型中現(xiàn)有知識(shí)之間形成聯(lián)系。此類方法一般會(huì)使用一套習(xí)得的知識(shí)表示來(lái)對(duì)大模型的輸出或中間結(jié)果進(jìn)行增強(qiáng)或替換。總體而言,我們可以統(tǒng)一表示這些方法為:\(?_{final} =?+?_{know}\) 。然而,這些方法將新知識(shí)與原始模型相結(jié)合,使得不同來(lái)源的知識(shí)的加權(quán)成為一個(gè)需要考慮的關(guān)鍵參數(shù)。其實(shí),外部知識(shí)依賴和外部知識(shí)注入都算是保留權(quán)重方法。即通過(guò)引入外部模型、利用上下文學(xué)習(xí)或改變LLM的表示空間來(lái)實(shí)現(xiàn)這種保留。也可以叫做基于記憶的方法。
- 內(nèi)在知識(shí)編輯。這種方法類似于人類認(rèn)知過(guò)程中的掌握階段,通過(guò)修改大模型權(quán)重并利用這些權(quán)重來(lái)讓大模型完全整合知識(shí)。
下表匯總了 LLMs 知識(shí)編輯領(lǐng)域的代表性方法。No Training 表示不需要額外訓(xùn)練的方法;Batch Edit 意味著這些方法是否能在支持一次同時(shí)編輯多個(gè)案例。Edit Area 是指使用模型組件的位置;Editor #Params 表示編輯時(shí)需要更新的參數(shù)數(shù)目。?? 表示需要更新的層數(shù)。$??_? \(表示 Transformers 中隱藏層的維數(shù)。\)??_??$ 是指在上投影和下投影之間的中間維數(shù)。?? 表示在每個(gè)單獨(dú)層中進(jìn)行更新的神經(jīng)元總數(shù)。表中方法對(duì)應(yīng)的具體論文請(qǐng)參考論文“A Comprehensive Study of Knowledge Editing for Large Language Models”。

內(nèi)在知識(shí)編輯
盡管外部知識(shí)依賴和外部知識(shí)注入這兩類方法在不同任務(wù)上表現(xiàn)良好,但我們?nèi)匀幻媾R著模型如何存儲(chǔ)知識(shí)以及如何利用和表達(dá)知識(shí)的問(wèn)題。因此,我們來(lái)到了發(fā)生在掌握階段的內(nèi)在知識(shí)編輯(更新參數(shù))。在掌握階段,模型需要學(xué)習(xí)關(guān)于它自身參數(shù)的知識(shí),并自主掌握這些知識(shí)。
微調(diào)模型是編輯內(nèi)在知識(shí)最直接的方式。然而,前面我們也提到,訓(xùn)練整個(gè)模型需要大量的計(jì)算資源,而且耗時(shí)較長(zhǎng)。同時(shí),微調(diào)技術(shù)通常容易出現(xiàn)災(zāi)難性遺忘和過(guò)擬合現(xiàn)象。目前,屬于掌握階段的研究大多在使用專門針對(duì)特定知識(shí)的方法來(lái)對(duì)模型參數(shù)進(jìn)行更新。這些方法可以分為兩類:元學(xué)習(xí)(meta-learning)和定位-編輯。
元學(xué)習(xí)并非直接更新模型權(quán)重,而是訓(xùn)練一個(gè)超網(wǎng)絡(luò)來(lái)學(xué)習(xí)模型權(quán)重的變化 Δ??,比如可以直接使用新知識(shí)的表示來(lái)訓(xùn)練超網(wǎng)絡(luò)。或者引入一個(gè)新的訓(xùn)練目標(biāo),考慮順序、局部和泛化模型更新,用以保證在使用超網(wǎng)絡(luò)更新內(nèi)在相關(guān)知識(shí)的同時(shí),保持其他知識(shí)不變。
定位-編輯則是首先定位到知識(shí)存儲(chǔ)在大模型中的位置,然后通過(guò)修改這些特定區(qū)域來(lái)進(jìn)行知識(shí)編輯。
FFN
論文“Knowledge Neurons in Pretrained Transformers.”提出了一種通過(guò)計(jì)算梯度變化敏感性的知識(shí)歸因方法用以定位知識(shí)存儲(chǔ)的位置。既然可以定位到對(duì)某些事實(shí)或者知識(shí)影響較大的神經(jīng)元,于是論文作者直接使用目標(biāo)知識(shí)的嵌入來(lái)修改相應(yīng)的值槽,具體包括以下:
- 對(duì)這些神經(jīng)元內(nèi)的數(shù)值進(jìn)行增強(qiáng)或者抑制,從而讓Transformers 對(duì)這些事實(shí)或者知識(shí)的回答效果也會(huì)變好或者變差。
- 將這些神經(jīng)元?jiǎng)h掉,從而讓 Transformers 完全忘記了這些知識(shí)。比如當(dāng)識(shí)別到和這個(gè)知識(shí)有關(guān)的所有知識(shí)神經(jīng)元之后。設(shè)置一個(gè)閾值 m=5,然后通過(guò)將這m個(gè)神經(jīng)元設(shè)置為 [UNK]來(lái)刪除這些神經(jīng)元。
下圖上方給出了把第二列修改為第三列,所需要修改的神經(jīng)元數(shù)目。下方說(shuō)明通過(guò)修改與知識(shí)神經(jīng)元對(duì)應(yīng)的幾個(gè)值槽,可以擦除部分知識(shí)。也給出了知識(shí)擦除前后四種關(guān)系的缺失實(shí)體預(yù)測(cè)準(zhǔn)確性。

這種對(duì)模型中的FFN層的值矩陣進(jìn)行編輯的方案可能會(huì)引起遺忘和其他的副作用。因此,論文"WISE: Rethinking the Knowledge Memory for Lifelong Model Editing of Large Language Models"參考人類學(xué)習(xí)的方式—即人類不斷的漸進(jìn)的獲取新的知識(shí),然后遺忘舊的知識(shí)—設(shè)計(jì)了一種終身學(xué)習(xí)的模型編輯方法,既可以實(shí)現(xiàn)模型高效的更新,又能避免災(zāi)難性遺忘等知識(shí)變價(jià)的副作用。終生學(xué)習(xí)編輯的目的是確保大模型經(jīng)歷數(shù)百上千次編輯之后,能夠?qū)R人類的期望并且維持以前的知識(shí)和能力。為了達(dá)到這個(gè)目的,該論文引入了兩個(gè)組件輔助記憶模塊和知識(shí)分片和合并機(jī)制。
- 輔助記憶設(shè)計(jì)。該組件將模型中的值矩陣復(fù)制一份作為輔助記憶,進(jìn)而在輔助記憶上進(jìn)行編輯,從而繞過(guò)了這些缺陷。而在推理過(guò)程中,通過(guò)一個(gè)路由機(jī)制來(lái)判斷是否使用輔助記憶。如果給定查詢?cè)谥暗木庉嫹秶鷥?nèi),輔助記憶會(huì)被使用;否則,使用主要記憶。
- 知識(shí)分片與合并。為了實(shí)現(xiàn)終生學(xué)習(xí)編輯,需要在參數(shù)空間進(jìn)行數(shù)百甚至上千次編輯,最終一定會(huì)引起編輯知識(shí)沖突,最終造成災(zāi)難性遺忘。為了避免在一個(gè)參數(shù)空間中進(jìn)行多次編輯,該論文提出將將輔助記憶復(fù)制k次,然后將n次編輯應(yīng)用到k個(gè)分片中,從而實(shí)現(xiàn)持續(xù)的編輯。對(duì)于多個(gè)輔助記憶分片,存在著重疊的元素和不相交的元素。該論文采用Ties-Merge的合并方法,把重疊的部分當(dāng)作錨點(diǎn),最終將多個(gè)記憶分片合并為一個(gè)記憶。

注意力頭
上述將的是對(duì)FFN進(jìn)行知識(shí)編輯。除了在 FFN 區(qū)域進(jìn)行知識(shí)編輯外,論文”PMET: Precise Model Editing in a Transformer”還對(duì)注意力頭進(jìn)行了編輯,如下圖所示:

這篇文章分別對(duì) MHSA 的輸出與 FFN 的輸出進(jìn)行處理,更新的時(shí)候還是只處理 FFN 對(duì)應(yīng)的輸出。
研究者們觀察到MHSA部分包含的知識(shí)比FFN部分有更多的變化和動(dòng)態(tài)性。這種觀察可能意味著MHSA在捕捉和編碼輸入數(shù)據(jù)中的某些模式或關(guān)系時(shí),其內(nèi)部表示和權(quán)重需要更頻繁的調(diào)整。基于這種觀察以及對(duì)現(xiàn)有研究的回顧,研究者們進(jìn)一步提出了一個(gè)新的假設(shè),即MHSA可以視為一個(gè)“知識(shí)提取器”。它不僅能夠識(shí)別輸入數(shù)據(jù)中的模式和關(guān)系,而且還能夠存儲(chǔ)一些通用的知識(shí)提取模式,這些模式可以幫助模型更好地從數(shù)據(jù)中提取和理解有價(jià)值的信息或知識(shí)。
基于這種新的理解和假設(shè),研究者們提出了一種新的優(yōu)化策略。他們認(rèn)為,可以通過(guò)對(duì)MHSA的隱藏狀態(tài)(或稱為Transformer組件的隱藏狀態(tài))進(jìn)行優(yōu)化來(lái)擴(kuò)展其功能空間,從而使其能夠更好地提取和存儲(chǔ)知識(shí)。而且,這種優(yōu)化可以在不更新MHSA權(quán)重的情況下實(shí)現(xiàn)。
ROME
最后,我們看看論文”Locating and Editing Factual Associations in GPT“。該論文主要提出了一種LLM的編輯方法,作者通過(guò)知識(shí)三元組(s,r,o)來(lái)完成模型編輯。首先,作者通過(guò)實(shí)驗(yàn)發(fā)現(xiàn)在subject的最后一個(gè)token中,MLP發(fā)揮了主要的中介作用,因此,作者假設(shè)這個(gè)位置的中間層MLP存儲(chǔ)了事實(shí)之間的關(guān)聯(lián)信息。即 \(w_{fc}\)存儲(chǔ)subject信息,\(w_{proj}\)存儲(chǔ)事實(shí)之間的關(guān)聯(lián)信息。作者將 \(w_{fc}\)看作key,\(w_{proj}\)看作value,通過(guò)編輯鍵值對(duì)來(lái)修改LLM中的事實(shí)信息,從而達(dá)到模型編輯,提高模型泛化能力和可移植性的目的。

論文將每個(gè)事實(shí)表示為一個(gè)知識(shí)三元組 ??=(s,r,??) ,其中包含主語(yǔ) s、客體 o 以及連接兩者的關(guān)系 r。然后,提供了描述 (s,r) 的自然語(yǔ)言提示 ?? 并檢查模型對(duì) ?? 的預(yù)測(cè)。論文將$ ??_{??r????}^{(??)}$ 視為線性聯(lián)想記憶(linear associative memory)。從這個(gè)角度來(lái)看,通過(guò)求解 WK≈V,任何線性運(yùn)算 ?? 都可以作為一組向量鍵 K=[k1|k2|...] 和相應(yīng)的向量值 ??=[v1|v2|...] 的鍵值存儲(chǔ)。通過(guò)求解約束最小二乘問(wèn)題,論文在全連接層中得出一個(gè)封閉形式的解,如上圖標(biāo)號(hào)1。一旦計(jì)算出 (k?,v?) ,我們就可以直接插入任何事實(shí)。于是我們來(lái)看看如何找合適的 k? 和 v? 。具體步驟如下:
-
步驟1:選擇 k? 來(lái)選擇主語(yǔ)。基于 MLP 輸入在最終主語(yǔ)token中的決定性作用,我們將選擇代表主語(yǔ)的最后一個(gè)token的輸入作為查找鍵 k? 。具體來(lái)說(shuō),我們通過(guò)收集激活來(lái)計(jì)算 k? :將包含主語(yǔ) s 的文本 ?? 傳遞給語(yǔ)言模型 ?? ;然后在 ??? 層中最后一個(gè)主語(yǔ)token索引 ?? 處,我們讀取 MLP 內(nèi)部非線性層之后的數(shù)值。因?yàn)闋顟B(tài)會(huì)根據(jù)文本中 s 之前的token而變化,所以我們將 k? 設(shè)置為以主語(yǔ) s 結(jié)尾的一小組文本的平均值。見上圖標(biāo)號(hào)2。
-
步驟 2:選擇 v? 來(lái)回憶事實(shí)。接下來(lái),我們希望選擇一些向量值 v? ,將新關(guān)系 (r,???) 編碼為 s 的屬性。我們的具體處理如下,如上圖標(biāo)號(hào)3。
第一項(xiàng)(方程 a)尋找一個(gè)向量 z,當(dāng)用 z 替換掉主語(yǔ)末尾token i 的 MLP 輸出時(shí),模型對(duì)于提示 p 將會(huì)預(yù)測(cè)出目標(biāo)對(duì)象 o * 。
第二項(xiàng)(方程 b)的作用是,對(duì)于未更改模型和提示 p'(形式為“{subject} is a”),此項(xiàng)會(huì)最小化 KL 散度(該優(yōu)化不會(huì)直接改變模型權(quán)重),這有助于保持模型對(duì)主語(yǔ)本質(zhì)的理解。方程 b 會(huì)識(shí)別出 v? 的向量表示,如果目標(biāo) MLP 模塊輸出 v?,就說(shuō)明 v? 是主語(yǔ) s 的新屬性 (r, o*)。
-
步驟 3:插入事實(shí)。一旦我們計(jì)算出代表完整事實(shí) (s,r,???) 的對(duì) (k?,v?) ,我們就應(yīng)用上圖標(biāo)號(hào)1的方程,通過(guò)直接插入新的鍵值關(guān)聯(lián)的rank one更新來(lái)更新 MLP 權(quán)重 $ ??_{??r????}^{(??)}$。
下圖給出了完整流程。

4.4 學(xué)習(xí)知識(shí)
我們接下來(lái)回頭看看學(xué)習(xí)知識(shí)的過(guò)程中,Transformer內(nèi)部是如何調(diào)整或者修改的。
前向傳播
現(xiàn)有的方法主要集中在研究前向傳播的隱狀態(tài)和權(quán)重的映射上。例如,Logit Lens 是一種用于分析和解釋大型語(yǔ)言模型內(nèi)部機(jī)制的方法,其通過(guò)將 LM 的隱狀態(tài)轉(zhuǎn)換為詞匯概率來(lái)展示了模型在生成過(guò)程中的表現(xiàn)。這種投影有助于理解 LM 在生成過(guò)程中逐漸構(gòu)建輸出的模式。
Logit Lens的原理非常簡(jiǎn)單。解碼新token的過(guò)程是先把隱向量用線性層變換,然后經(jīng)過(guò)softmax轉(zhuǎn)換為詞典的概率分布。那么對(duì)中間每一層的這個(gè)流程進(jìn)行破解,就能獲取中間層的token了。具體到某一層,Logit Lens通過(guò)直接將特定神經(jīng)元或?qū)拥妮敵雠cunembedding矩陣相乘,然后通過(guò)觀察得到的top tokens來(lái)定位模型中存儲(chǔ)的信息,排在前面的tokens說(shuō)明這個(gè)neuron/layer output存儲(chǔ)了這些tokens的信息。
下圖是一個(gè)實(shí)例。

另外,論文”Physics of Language Models“指出,LLM對(duì)知識(shí)的存儲(chǔ)能力符合 2 bit / param 的線性scaling law,前提是該知識(shí)在預(yù)訓(xùn)練階段被充分訓(xùn)練,充分訓(xùn)練的標(biāo)準(zhǔn)大致是一個(gè)知識(shí)要在訓(xùn)練語(yǔ)料中出現(xiàn)1000次以上(相同語(yǔ)義的不同表達(dá)都可以算作是多次出現(xiàn))。該能力只與模型參數(shù)量有關(guān),而與模型結(jié)構(gòu)、深度、訓(xùn)練超參數(shù)等都無(wú)關(guān),甚至即使去掉MLP層也是如此。
但如果知識(shí)的訓(xùn)練不夠充分(例如出現(xiàn)次數(shù)降低到100次),其存儲(chǔ)能力大概會(huì)降低到 1 bit / param。在這種情況下,不同模型架構(gòu)的差異開始顯現(xiàn):Llama和Mistral的架構(gòu)表現(xiàn)要比GPT-2差大約1.3倍。
- 將GPT-2的MLP層縮減到1/4,其存儲(chǔ)能力沒有太明顯的損失,但如果完全移除MLP層,則會(huì)有顯著的損失。
- 如果把Llama的結(jié)構(gòu)中GatedMLP換成標(biāo)準(zhǔn)的MLP,其存儲(chǔ)能力將恢復(fù)到與GPT-2一致。
這里的bit是語(yǔ)義意義上的,即數(shù)據(jù)集中的語(yǔ)義相同但措辭可能不同的數(shù)據(jù)條目的模板都算做相同的信息,指對(duì)其中填入的不同數(shù)值/內(nèi)容進(jìn)行信息計(jì)量,即只考慮語(yǔ)義上不同的信息。該實(shí)驗(yàn)是在針對(duì)單問(wèn)題數(shù)據(jù)集上訓(xùn)練和測(cè)試的。
反向傳播
論文"Backward Lens: Projecting Language Model Gradients into the Vocabulary Space"擴(kuò)展了現(xiàn)有的可解釋性方法,尤其是將其應(yīng)用于 LM 的反向傳播過(guò)程。通過(guò)分析反向傳播中的梯度矩陣,我們能夠更全面地理解信息在模型中的流動(dòng)。此外,論文還提出了一種新的思路,通過(guò)將梯度矩陣映射到詞匯空間來(lái)揭示 LM 在學(xué)習(xí)新知識(shí)時(shí)的內(nèi)在機(jī)制。通過(guò)這一方法,研究者希望能夠明確地理解模型如何在多層次上進(jìn)行信息存儲(chǔ)和記憶。
反向傳播算法通過(guò)計(jì)算每一層的梯度,更新模型中的權(quán)重。這一機(jī)制不僅使模型能夠?qū)W習(xí)新的信息,也為研究人員提供了解釋模型行為的機(jī)會(huì)。近期的可解釋性研究已提出了多種方法,試圖通過(guò)可視化權(quán)重和隱藏狀態(tài)來(lái)解讀語(yǔ)言模型的內(nèi)部運(yùn)作,尤其是在前向傳播階段。然而,關(guān)于反向傳遞的梯度如何影響模型學(xué)習(xí)和知識(shí)存儲(chǔ)的探討仍然較為稀缺。
下圖展示了梯度在 MLP 層前向與反向過(guò)程中對(duì)模型更新的影響,具體表現(xiàn)為梯度(以綠色表示)和權(quán)重(以藍(lán)色表示)之間的相互作用。論文主要關(guān)注如何將這些梯度信息有效地應(yīng)用于模型的知識(shí)更新與編輯中。

論文作者通過(guò)將Logit Lens應(yīng)用于梯度矩陣,提出了一種稱為“印記與偏移”(imprint and shift)的方法,該方法可以揭示信息儲(chǔ)在MLP中的機(jī)制。
每個(gè) MLP 層的梯度可以表示為正向傳遞的輸入向量和反向傳遞的 VJP(向量雅可比乘積)的組合。具體而言,梯度在更新過(guò)程中的表現(xiàn)可以表示為:
在這個(gè)表達(dá)式中, \(x_i\)是前向傳播的輸入,\(\delta_i\)而 是相應(yīng)的 VJP。當(dāng)使用反向傳播更新 LM 的 MLP 層時(shí),會(huì)發(fā)生以下兩個(gè)主要階段的變化:
- 印記(imprint)階段:在這一階段,輸入 \(x_i\)被加入或減去到 \(FF_1\) 的神經(jīng)元中,從而調(diào)整每個(gè)對(duì)應(yīng)的 \(FF_2\)神經(jīng)元的激活程度。這個(gè)過(guò)程賦予了 MLP 層對(duì)于給定輸入的“印記”。這相當(dāng)于對(duì)最有可能的詞匯進(jìn)行強(qiáng)化。
- 偏移(shift)階段:此階段涉及調(diào)整或者改變 \(FF_2\)的輸出,因此叫做偏移。具體表現(xiàn)為從 \(FF_2\)的神經(jīng)元中減去 VJP \(\delta_i\),以放大在啟用 VJP 值后輸出的影響。這相當(dāng)于將之前概率較低的詞匯提升為可能性更高的目標(biāo)。
此“印記與偏移”機(jī)制可以用在知識(shí)更新過(guò)程中:給定層的原始輸入和新目標(biāo),該過(guò)程通過(guò)更新\(FF_1\)來(lái)強(qiáng)化類似的輸入,隨后將\(FF_2\)的輸出移向新目標(biāo)。這種方法的優(yōu)勢(shì)是:只依靠單次的前向傳播就能在 MLP 層中有效地存儲(chǔ)和調(diào)整信息。

0x05 優(yōu)化與演進(jìn)
我們接下來(lái)看看對(duì)FFN的優(yōu)化與演進(jìn)方案。
5.1 MoE
在這個(gè)領(lǐng)域,許多研究都集中在將混合專家(MoE)技術(shù)集成到LLM中,以提高其性能,同時(shí)保持計(jì)算成本。MoE的核心思想是動(dòng)態(tài)地將不同的計(jì)算預(yù)算分配給不同的輸入令牌。在基于MoE的Transformers中,多個(gè)FFN(即專家)與可訓(xùn)練的路由模塊一起使用。在推理過(guò)程中,該模型有選擇地為路由模塊控制的每個(gè)令牌激活特定的專家。
下圖為論文“A Survey on Efficient Inference for Large”給出了FFN高效設(shè)計(jì)的方法,可以看到,大多數(shù)方案是與MoE相關(guān)的。

我們會(huì)在后續(xù)文章中對(duì)MoE進(jìn)行學(xué)習(xí)。
5.2 MemoryFormer
大型語(yǔ)言模型具有卓越的語(yǔ)境理解和融合新信息能力。然而,由于有效上下文長(zhǎng)度的限制,這種方法的潛力常常受到約束。解決這個(gè)問(wèn)題的一個(gè)方法是通過(guò)讓注意力層訪問(wèn)外部存儲(chǔ)器,包含有 (key, value) 對(duì)。
論文"MemoryFormer: Minimize Transformer Computation by Removing Fully-Connected Layers"提出了一種名為 MemoryFormer 的新型 Transformer 架構(gòu)。該架構(gòu)用創(chuàng)新的 Memory Layer 設(shè)計(jì)來(lái)替代了傳統(tǒng) Transformer 中計(jì)算成本高昂的全連接層,顯著降低了計(jì)算復(fù)雜度和資源需求,同時(shí)保持了模型的性能和靈活性。
動(dòng)機(jī)與挑戰(zhàn)
雖然多頭注意力機(jī)制在捕捉序列數(shù)據(jù)的內(nèi)在關(guān)系方面表現(xiàn)出色,但全連接層在計(jì)算負(fù)載中占據(jù)主導(dǎo)地位。隨著模型規(guī)模的擴(kuò)大,全連接層的計(jì)算復(fù)雜度和內(nèi)存需求呈指數(shù)級(jí)增長(zhǎng),這使得模型的訓(xùn)練和推理成本急劇上升。盡管已有方法嘗試優(yōu)化 Transformer 的計(jì)算效率,例如模型剪枝、權(quán)重量化以及重新設(shè)計(jì)注意力機(jī)制(如線性注意力和閃光注意力),但這些方法大多忽視了全連接層的計(jì)算瓶頸,導(dǎo)致整體優(yōu)化效果有限。為應(yīng)對(duì)上述挑戰(zhàn),MemoryFormer 提出了全新的解決方案,通過(guò)引入內(nèi)存層替代全連接層,從根本上減少計(jì)算復(fù)雜度和資源消耗。
原理與創(chuàng)新
下圖左側(cè)給出了 Memory Layer 的示意圖,右側(cè)給出了MemoryFormer的一個(gè)組成部分。

MemoryFormer 的核心在于其 Memory Layer 設(shè)計(jì),該層通過(guò)內(nèi)存查找表和局部敏感哈希(LSH)算法取代傳統(tǒng)的全連接層。以下是其關(guān)鍵技術(shù)細(xì)節(jié):
內(nèi)存層的設(shè)計(jì)與工作原理
Memory Layer 的主要功能是通過(guò)內(nèi)存檢索預(yù)計(jì)算的向量表示來(lái)替代傳統(tǒng)的矩陣乘法。具體而言,輸入嵌入首先通過(guò)局部敏感哈希算法進(jìn)行哈希處理,將相似的嵌入映射到相同的內(nèi)存位置。然后,模型從內(nèi)存中檢索預(yù)存儲(chǔ)的向量,這些向量能夠近似矩陣乘法的結(jié)果。
這種設(shè)計(jì)的優(yōu)勢(shì)在于:
- 降低計(jì)算復(fù)雜度:通過(guò)預(yù)計(jì)算和內(nèi)存查找,避免了傳統(tǒng)全連接層中高昂的矩陣運(yùn)算。
- 減少內(nèi)存需求:輸入嵌入被劃分為更小的塊并獨(dú)立處理,從而顯著降低了內(nèi)存占用。
- 支持端到端訓(xùn)練:內(nèi)存層中的哈希表整合了可學(xué)習(xí)向量,允許模型通過(guò)反向傳播進(jìn)行優(yōu)化。
局部敏感哈希(LSH)算法的應(yīng)用
局部敏感哈希是一種高效的近似最近鄰搜索算法,其核心思想是通過(guò)哈希函數(shù)將高維數(shù)據(jù)投影到低維空間,從而快速定位相似數(shù)據(jù)。在 MemoryFormer 中,LSH 算法用于將輸入嵌入映射到內(nèi)存中的特定位置。這種映射方式確保了哈希表中存儲(chǔ)的特征能夠不斷適應(yīng)輸入數(shù)據(jù),并在推理階段根據(jù)輸入特征的相似性高效檢索出近似的輸出結(jié)果,實(shí)現(xiàn)全連接層所需的特征變換功能。
可擴(kuò)展的內(nèi)存查找表
MemoryFormer 的內(nèi)存查找表設(shè)計(jì)支持動(dòng)態(tài)擴(kuò)展,能夠根據(jù)任務(wù)需求靈活調(diào)整存儲(chǔ)容量和檢索精度。此外,通過(guò)引入可學(xué)習(xí)的向量,查找表可以在訓(xùn)練過(guò)程中不斷優(yōu)化,從而提高模型的整體性能。此外,MemoryFormer通過(guò)多表分塊和向量分段的方式來(lái)控制哈希表的存儲(chǔ)規(guī)模,使得內(nèi)存需求不會(huì)因哈希表的引入而暴增。其推導(dǎo)過(guò)程如下。

5.3 Memory Layers at Scale
預(yù)訓(xùn)練語(yǔ)言模型通常在其參數(shù)中編碼大量信息,并且隨著規(guī)模的增加,它們可以更準(zhǔn)確地回憶和使用這些信息。對(duì)于主要將信息編碼為線性矩陣變換權(quán)重的密集深度神經(jīng)網(wǎng)絡(luò)來(lái)說(shuō),參數(shù)大小的擴(kuò)展直接與計(jì)算和能量需求的增加相關(guān)。語(yǔ)言模型需要學(xué)習(xí)的一個(gè)重要信息子集是簡(jiǎn)單關(guān)聯(lián)。雖然前饋網(wǎng)絡(luò)原則上(給定足夠的規(guī)模)可以學(xué)習(xí)任何函數(shù),但使用聯(lián)想記憶(associative memory)會(huì)更高效。
記憶層(memory layers)使用可訓(xùn)練的鍵值查找機(jī)制向模型添加額外的參數(shù),而不會(huì)增加 FLOP。從概念上講,稀疏激活的記憶層補(bǔ)充了計(jì)算量大的密集前饋層,提供了廉價(jià)地存儲(chǔ)和檢索信息的專用容量。
論文“Memory Layers at Scale”使記憶層超越了概念驗(yàn)證階段,通過(guò)用記憶層替換一個(gè)或多個(gè) transformer 層的前饋網(wǎng)絡(luò)(FFN)來(lái)實(shí)現(xiàn)這一點(diǎn)(保持其他層不變)。這證明了記憶層在大型語(yǔ)言模型(LLM)擴(kuò)展中的實(shí)用性。該研究將鍵-值對(duì)的數(shù)量擴(kuò)展到數(shù)百萬(wàn)。
可訓(xùn)練的記憶層類似于注意力機(jī)制。給定一個(gè)查詢,一組鍵,以及值。可訓(xùn)練的記憶層會(huì)輸出值的軟組合,該組合是根據(jù) q 和相應(yīng)鍵之間的相似性進(jìn)行加權(quán)的。在使用時(shí),記憶層與注意力層之間存在兩個(gè)區(qū)別。
- 首先,記憶層中的鍵和值是可訓(xùn)練參數(shù),而不是激活參數(shù);
- 其次,記憶層在鍵和值的數(shù)量方面通常具有更大的規(guī)模,因此稀疏查詢和更新是必需的。
一個(gè)簡(jiǎn)單的記憶層可以用下面的等式來(lái)描述:

擴(kuò)展記憶層
擴(kuò)展記憶層時(shí)面臨的一個(gè)瓶頸是「查詢 - 鍵」檢索機(jī)制。簡(jiǎn)單的最近鄰搜索需要比較每一對(duì)查詢 - 鍵,這對(duì)于大型記憶來(lái)說(shuō)很快就變得不可行。雖然可以使用近似向量相似性技術(shù),但當(dāng)鍵正在不斷訓(xùn)練并需要重新索引時(shí),將它們整合起來(lái)是一個(gè)挑戰(zhàn)。相反,本文采用了可訓(xùn)練的「product-quantized」鍵。
并行記憶
記憶層是記憶密集型的,主要是由于可訓(xùn)練參數(shù)和相關(guān)優(yōu)化器狀態(tài)的數(shù)量龐大導(dǎo)致的。該研究在多個(gè) GPU 上并行化嵌入查找和聚合,記憶值在嵌入維度上進(jìn)行分片。在每個(gè)步驟中,索引都從進(jìn)程組中收集,每個(gè) worker 進(jìn)行查找,然后將嵌入的部分聚合到分片中。此后,每個(gè) worker 收集與其自身索引部分相對(duì)應(yīng)的部分嵌入。該過(guò)程如圖 所示。

共享記憶
深度網(wǎng)絡(luò)在不同層上以不同的抽象級(jí)別對(duì)信息進(jìn)行編碼。向多個(gè)層添加記憶可能有助于模型以更通用的方式使用其記憶。與以前的工作相比,該研究在所有記憶層中使用共享記憶參數(shù)池,從而保持參數(shù)數(shù)量相同并最大化參數(shù)共享。

該研究通過(guò)引入具有 silu 非線性的輸入相關(guān)門控來(lái)提高記憶層的訓(xùn)練性能。
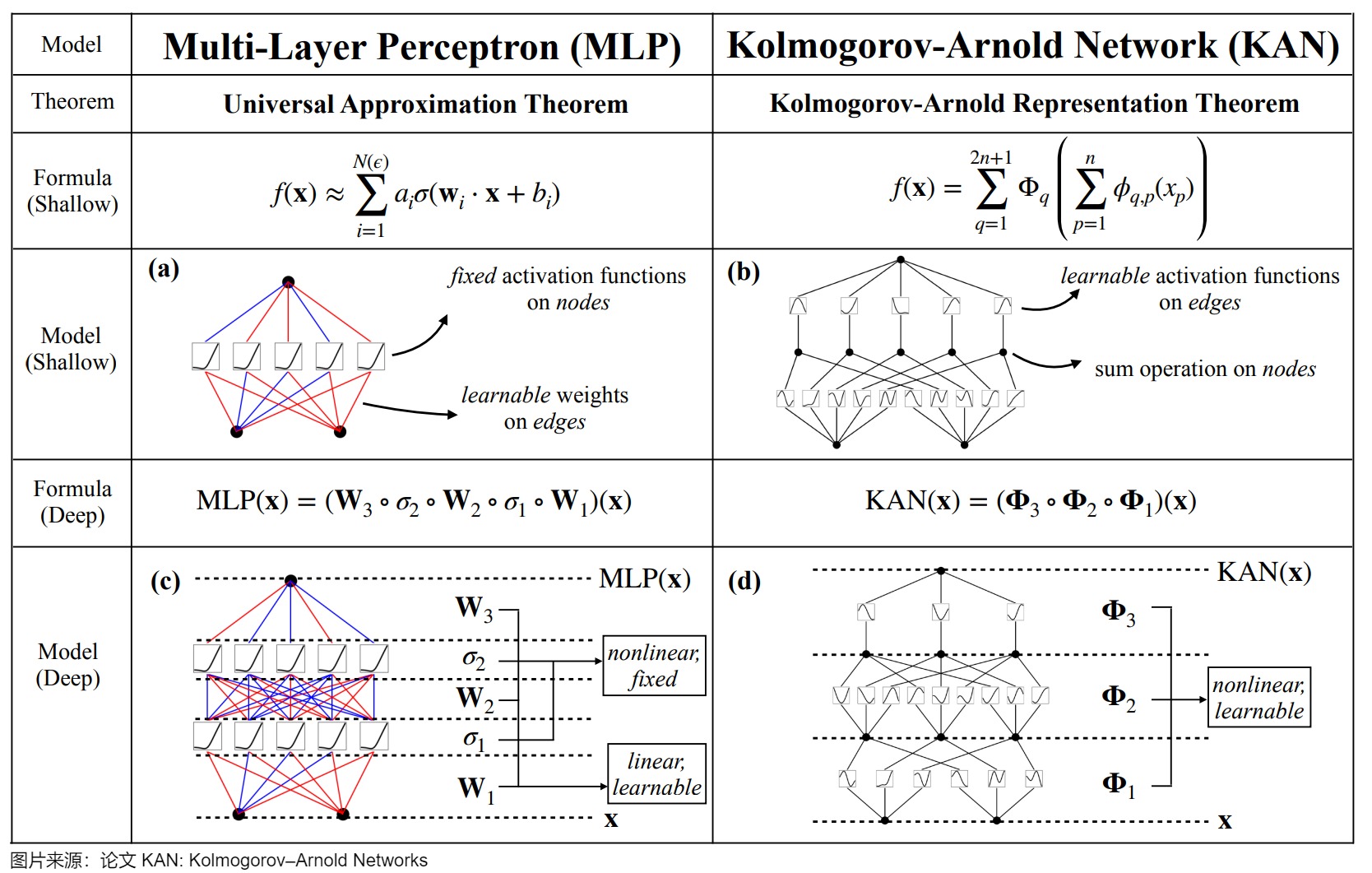
5.4 KAN
論文"KAN: Kolmogorov–Arnold Networks"的作者認(rèn)為MLPs是當(dāng)今神經(jīng)網(wǎng)絡(luò)的基礎(chǔ)構(gòu)建模塊,但并非最優(yōu)解,存在一些缺點(diǎn),因此提出了一種新的神經(jīng)網(wǎng)絡(luò)架構(gòu)KAN(Kolmogorov–Arnold Networks)。作者選擇用參數(shù)樣條函數(shù)替代參數(shù)+激活函數(shù)的組合,并宣稱KAN是MLPs的有力替代者,其在準(zhǔn)確性和可解釋性方面超越了傳統(tǒng)的多層感知器(MLPs),為進(jìn)一步改進(jìn)當(dāng)前嚴(yán)重依賴MLPs的深度學(xué)習(xí)模型提供了新的可能性(更快的神經(jīng)縮放規(guī)律)。
論文主要觀點(diǎn)如下:
- KANs的設(shè)計(jì)靈感來(lái)源于Kolmogorov-Arnold表示定理,而不是MLPs所依據(jù)的通用逼近定理,通過(guò)其獨(dú)特的結(jié)構(gòu)設(shè)計(jì)和權(quán)重表示方式(可學(xué)習(xí)的激活函數(shù),表示為樣條曲線),能夠在保持高效計(jì)算的同時(shí),實(shí)現(xiàn)比傳統(tǒng)MLPs更高的模型性能,展示了KANs在資源受限環(huán)境中作為高效非線性逼近器的潛力。
- KANs的主要特點(diǎn)是去掉了線性權(quán)重和固定的激活函數(shù),將權(quán)重替換為可學(xué)習(xí)的激活函數(shù),這些激活函數(shù)是用單變量樣條函數(shù)來(lái)表示的(單變量輸入,多參數(shù),可以控制該函數(shù)在不同區(qū)間形狀不同,用于生成一條平滑曲線)。
- 作者認(rèn)為KANs是樣條(splines)和多層感知機(jī)(MLPs)的組合,它們各自發(fā)揮優(yōu)勢(shì)并避免各自的弱點(diǎn)(樣條函數(shù)在低維函數(shù)上非常準(zhǔn)確,存在嚴(yán)重的維數(shù)災(zāi)難問(wèn)題;LPs由于其特征學(xué)習(xí)能力而較少受到維數(shù)災(zāi)難的影響,但在低維情況下,它們不如樣條準(zhǔn)確)。在外層有MLPs來(lái)學(xué)習(xí)特征,在內(nèi)層有樣條來(lái)優(yōu)化這些學(xué)習(xí)的特征以達(dá)到高準(zhǔn)確性,這使得KANs在處理高維函數(shù)時(shí)既能學(xué)習(xí)組合結(jié)構(gòu),又能很好地逼近單變量函數(shù)。
- 作者強(qiáng)調(diào)了使用Kolmogorov-Arnold表示定理來(lái)構(gòu)建神經(jīng)網(wǎng)絡(luò)(即KANs)的潛力,之前已經(jīng)有使用Kolmogorov-Arnold表示定理來(lái)構(gòu)建神經(jīng)網(wǎng)絡(luò)的研究,但大多數(shù)工作都局限于原始的深度為2、寬度為(2n + 1)的表示形式,這些研究并沒有充分利用現(xiàn)代技術(shù)(如反向傳播)來(lái)訓(xùn)練網(wǎng)絡(luò)。作者將原始的Kolmogorov-Arnold表示定理推廣到了任意寬度和深度,使其更加適應(yīng)于當(dāng)今深度學(xué)習(xí)的環(huán)境。
0xFF 參考
Axiomatic Attribution for Deep Networks
[NeurIPS 2024] MemoryFormer:華為提出存儲(chǔ)代替計(jì)算的Transformer新架構(gòu),推理計(jì)算量減小10倍 王云鶴
[語(yǔ)言模型的物理學(xué) 3.1:知識(shí)存儲(chǔ)和提取](http://www.banxian-w.com/article/2023/12/14/2667.html) Digital Garden | 王半仙
ACL 2020 | 最佳主題論文獎(jiǎng)“ 邁向NLU:關(guān)于數(shù)據(jù)時(shí)代的意義、形式和理解” 學(xué)術(shù)頭條
Analyzing Memorization in Large Language Models through the Lens of Model Attribution
Climbing towards NLU: On Meaning, Form, and Understanding in the Age of Data
Efficient softmax approximation for GPUs
EMNLP 2024 | 大語(yǔ)言模型的知識(shí)機(jī)理:綜述和觀點(diǎn) [ZJUKG]
EMNLP 2024最佳論文:從反向傳播矩陣來(lái)理解Transformer的運(yùn)作機(jī)制 [PaperWeekly]
Focused Transformer: Contrastive Training for Context Scaling
In-The-Wild可解釋性:GPT-2 Small 中的間接目標(biāo)識(shí)別電路 Hao Bai
Interpreting Key Mechanisms of Factual Recall in Transformer-Based Language Models
KAN: Kolmogorov–Arnold Networks
Knowledge Circuits in Pretrained Transformers
Knowledge Neurons in Pretrained Transformer
Memory-Based Model Editing at Scale Fred
MemoryFormer:一種新穎的高效且可擴(kuò)展的大型語(yǔ)言模型架構(gòu) 袁焱 [頓數(shù)AI]
Meta探索大模型記憶層,擴(kuò)展至1280億個(gè)參數(shù),優(yōu)于MoE 機(jī)器之心
PMET: Precise Model Editing in a Transformer
ROME: Locating and Editing Factual Associations in GPT Hao Bai
Transformer Circuits的數(shù)學(xué)框架 Hao Bai
Transformer Feed-Forward Layers Are Key-Value Memories
Transformer Feed-Forward Layers Are Key-Value Memories pureDemon
Transformer是否真正理解了自然語(yǔ)言的語(yǔ)義信息,還是單純的模式識(shí)別 中森
【模型編輯技術(shù)】論文閱讀筆記(一)PMET: Precise Model Editing in a Transformer [
從數(shù)學(xué)到神經(jīng)網(wǎng)絡(luò)(二)計(jì)算篇:從計(jì)算到構(gòu)建 大象Alpha
從認(rèn)知和邏輯思維的角度談?wù)勛匀徽Z(yǔ)言理解 [
北京大學(xué) & 微軟:預(yù)訓(xùn)練模型(Transformer)中的知識(shí)神經(jīng)元 機(jī)器學(xué)習(xí)社區(qū)
可解釋性之積分梯度算法(Integrated Gradients) Shepherd
大型語(yǔ)言模型系列解讀(二):Transformer中FFN的記憶功能 丁稼宇
大型語(yǔ)言模型記憶機(jī)制分析與干預(yù)研究綜述 可可 [頓數(shù)AI]
大模型中的知識(shí)存儲(chǔ),到底是怎么回事 芝士AI吃魚
大模型也有側(cè)腦?揭秘WISE如何帶來(lái)終生學(xué)習(xí)新突破 bhn
大模型承重墻,去掉了就開始擺爛!蘋果給出了「超級(jí)權(quán)重」 [機(jī)器之心]
打開AI黑箱的新視角,LMs概念對(duì)齊:揭示LLM的認(rèn)知機(jī)制 | 普林斯頓大學(xué) AI修貓Prompt
機(jī)器閱讀理解之推理網(wǎng)絡(luò)(一)End-To-End Memory Networks全文翻譯 低級(jí)煉丹師
模型可解釋性:Axiomatic Attribution for Deep Networks knight
模型解釋新方向!浙大揭秘LLM隱層之間的知識(shí)流動(dòng)! bhn [深度學(xué)習(xí)自然語(yǔ)言處理]
看圖學(xué)大模型:Transformers 的前生今世(中) 看圖學(xué)
算法冷知識(shí)第1期-大模型的FFN有什么變化? Sam多吃青菜
聊一聊Transformer中的FFN 潘梓正 [青稞AI]
論文筆記:Dissecting Recall of Factual Associations in Auto-Regressive Language Models Vicle
論文解讀:Physics of Language Models(面向應(yīng)用層讀者)【2024.7】 原創(chuàng) 孔某人 [孔某人的低維認(rèn)知]
語(yǔ)言模型完成事實(shí)回憶任務(wù)使用到的若干重要機(jī)制 GSAI-ALOHA
讀論文 LINEARITY OF RELATION DECODING IN TRANSFORMER LANGUAGE MODELS Fred
讀論文《Locating and Editing Factual Associations in GPT》 Fred
邁向單義性:通過(guò)字典學(xué)習(xí)分解語(yǔ)言模型 Hao Bai
面向大語(yǔ)言模型的知識(shí)編輯:(一) 前言與背景知識(shí) 長(zhǎng)頸鹿騎著鯊魚
面向大語(yǔ)言模型的知識(shí)編輯:(三) 知識(shí)編輯任務(wù)定義及方法分類 長(zhǎng)頸鹿騎著鯊魚
https://arxiv.org/abs/2411.12992
https://zhuanlan.zhihu.com/p/409287967
https://zhuanlan.zhihu.com/p/432553711
https://zhuanlan.zhihu.com/p/558937247
https://zhuanlan.zhihu.com/p/604739354
Rectified Linear Units Improve Restricted Boltzmann Machines
Rectifier Nonlinearities Improve Neural Network Acoustic Models
Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification
Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs)
Language Modeling with Gated Convolutional Networks
Searching for Activation Functions
Self-Normalizing Neural Networks
Gaussian Error Linear Units (GELUs)
Mish: A Self Regularized Non-Monotonic Neural Activation Function

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)