
探秘Transformer系列之(12)--- 多頭自注意力
探秘Transformer系列之(12)--- 多頭自注意力
0x00 概述
MHSA(多頭自注意力) 是 Transformer 模型的核心模塊。Transformer本質上是一個通用的可微計算機,集多種優秀特性于一身。
- Transformer 類似消息傳遞的架構具有通用性(即完整性)和強大功能(即效率),能夠涵蓋許多現實世界的算法,因此Transformer具備非常強大的表現力(在前向傳播中)。
- 通過反向傳播和梯度下降,Transformer可以持續不斷的優化。
- 因為Transformer的計算圖是淺而寬的,而且自注意力機制讓我們在處理序列數據時,能夠并行計算序列中的每個元素,所以Transformer能夠更好地映射到我們的高并行計算架構(比如GPU)來進行高效計算。
- 多頭注意力機制通過并行運行多個自注意力層并綜合結果,能同時捕捉輸入序列在不同子空間的信息,增強了模型的表達能力。這種特性使得Transformer可以更好地理解數據中的復雜模式和語義信息,在自然語言處理、計算機視覺等多領域都能出色應用,泛化能力強。
多頭注意力機制就是蛋糕上的櫻桃。多頭注意力機制的巧妙之處在于,它能夠通過并行運行多個具有獨特視角的注意力頭來同時處理數據,使得模型能夠從多個角度分析輸入序列,捕捉豐富的特征和依賴關系。類似于一組專家分析復雜問題的各個方面。或者像同時有多個視角在看同一個東西,每個視角都能看到一些不同的細節。下圖形象化的解釋了多頭注意力運行機制,Query、Key和Value 被分為不同的Head,并在每個Head中獨立計算自注意力。
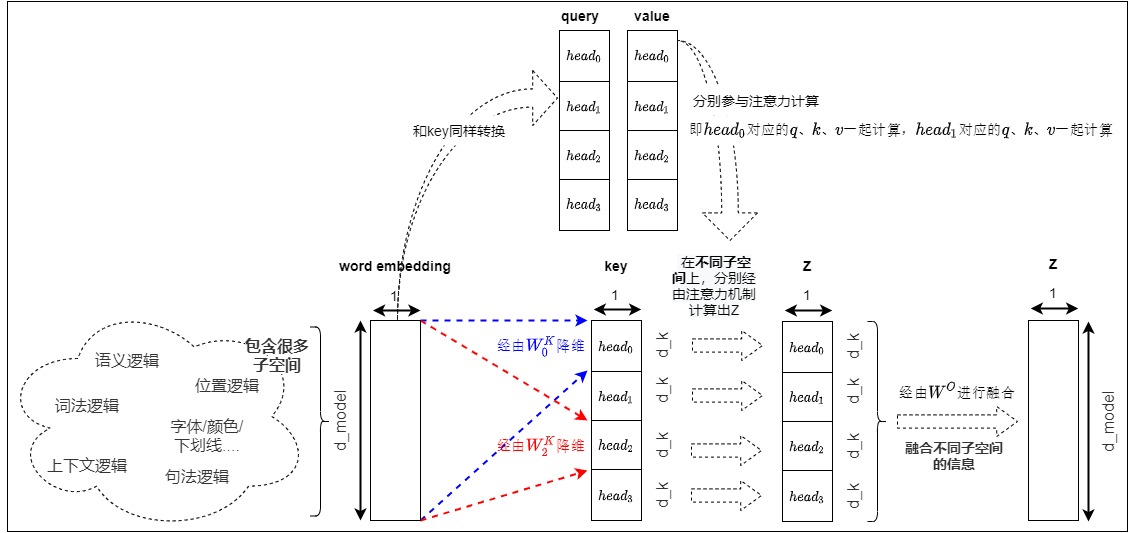
0x01 研究背景
1.1 問題
迄今為止,注意力機制看起來很美好,但是也暴露出來了一些缺陷:
比如,模型在編碼時,容易會過度的將注意力集中于當前的位置,而忽略了其它位置的信息,從而錯過某些重要的依賴關系或特征。用程序化的語言來說,因為Q、K、V都來自輸入X,在計算\(QK^T\)時,模型容易關注到自身的位置上,即\(QK^T\)對角線上的激活值會明顯比較大,這樣會削弱模型關注其它高價值位置上的能力,限制了模型的理解和表達能力。
再比如,注意力機制是使用Q去找相關的K,但是”相關“可以有不同形式和定義,比如一項事物往往有多個方面,應該綜合利用各方面的信息/特征,從多個角度進行衡量。比如下面句子中就有字體大小,背景顏色,字體顏色,加粗/下劃線/斜線這幾個不同的強調維度,需要多方考慮。

另外,人類注意力機制本身就是天然可以同時處理多個方面的信息的。設想你在一個擁擠的公交車上看書,你的大腦能自動關注到書的內容,同時也可以留意周圍的環境聲,譬如有人叫你的名字或是公交車到站播報聲。
而迄今為止,在我們的學習歷程中,當前的Transformer注意力機制只是注重事物的單獨方面,而非注意多個方面。
1.2 根源
Embedding 才是多頭注意力背后的真正內在成因。Embedding 是人類概念的映射,或者說是表達人類概念的途徑或者方法。人類的概念是一個及其復雜的系統,因為概念需要有足夠的內部復雜度才能應對外部世界的復雜度。比如對于一個詞來說,其就有語義邏輯、語法邏輯、上下文邏輯、在全句中位置邏輯、分類邏輯等多種維度。而且,詞與詞之間的關系還不僅僅限于語義上的分類所導致的定位遠近這么簡單。一個詞所代表的事物與其他詞所代表的事物之間能產生內在聯系的往往有成百上千上萬種之多。
或者說,概念是被配置為能夠跨任務工作的向量,是去除非本質信息,保留最確定性的結果。在這種基礎上,存儲在長期記憶中的單個概念向量可以通過不同的函數進行投影,以用于不同特定領域的任務。每個任務其實可以認為是一個獨立的向量空間。比如對于上面的例子,字體和顏色就是兩個不同的子空間(低維空間)。
而目前注意力只注重單獨某個向量空間,勢必導致雖然最終生成的向量可以在該空間上有效將人類概念進行映射,但是無法有效反映外部豐富的世界。因此,我們需要一種可以允許模型在不同的子空間中進行信息選擇的機制。
1.3 解決方案
多頭注意力就是研究人員給出的解決方案。多頭注意力可以理解為高維向量被拆分或者轉化為H份低維向量,并在H個低維空間里求解各自的注意力。這樣模型就可以從不同角度來分析和理解輸入信息,最終輸出包含有不同子空間中的編碼表示信息,從而增強模型的表達能力。Transformer論文中對于多注意力機制的論述如下。
Multi-head attention allows the model to jointly attend to information from different representation subspaces at different positions.
多頭注意力機制基于自注意力機制基礎上進行擴展。在傳統的自注意力機制中,你只能使用一組查詢(Q)、鍵(K)和值(V)來計算注意力權重。但是,在多頭注意力機制中,你可以使用多組不同的Q、K和V來進行計算。每個注意力頭都有自己獨立的一組Q、K和V,多組Q、K和V通過獨立的線性變換來生成。
不同的Q去查找不同方面的相關性,比如某個Q去捕捉語法依賴,另一個Q去捕捉語義依賴,這樣每個注意力頭可以關注文本中不同的方面和特征,才能不僅抓住主旨,同時也能理解各個詞匯間的關聯,進而從多角度捕捉上下文和微妙之處,并行地學習多組自注意力權重。最后,多個注意力頭的結果會被拼接在一起,并通過另一個線性變換進行整合,得到最終的輸出。多頭注意力機制具體如下圖所示。其中,D 表示 hidden size,H 表示 Head 個數,L 表示當前是在序列的第 L 個 Token。

針對上方句子的例子,我們使用多頭注意力就是同時關注字體和顏色等多方面信息,每個注意力頭關注不同的表示子空間,這樣即可以有效定位網頁中強調的內容,也可以靈活選擇文字中的各種關系和特征,從而提取更豐富的信息。模型最終的“注意力”實際上是來自不同“表示子空間”的注意力的綜合,均衡單一注意力機制可能產生的偏差。
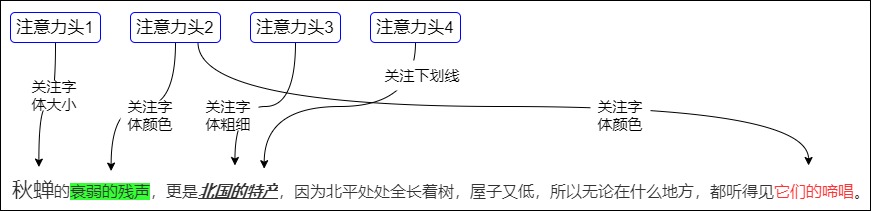
有兩個比較確切的例子,可以讓大家對多頭自注意力有直觀的感受。
-
例子1是從專家的專家角度來看。一個團隊合作完成一個軟件項目,每個團隊成員負責自己擅長的領域。產品經理負責整體項目規劃和需求分析;項目經理負責項目把控;前端開發工程師負責與用戶界面相關的工作;后端工程師負責服務器邏輯和數據庫管理;測試工程師負責項目質量保證。每個團隊成員用自己的專業能力獨立的對項目付出不同的貢獻,最終將各自的成果整合在一起,形成一個完整的軟件產品。
-
例子2更傾向于從合作的角度來看。在橄欖球領域內有一種說法,一場比賽要看四遍,第一遍從總體上粗略看,第二遍從進攻球員角度看,第三遍從防守球員角度看,第四遍則綜合之前的理解再總體看一遍。但是這樣要看四遍。不如讓幾個人一起來看一遍比賽,觀看過程中,有人負責從從進攻球員角度看,有人負責從防守球員角度看,有人負責總體把握,有人負責看重點球員,有人看教練部署,最終有人將不同的意見和見解整合起來,形成對比賽的完整理解。
0x02 原理
2.1 架構圖
多頭注意力機制是自注意力機制的變體,多頭注意力的架構及公式如下圖,h 個 Scale Dot-Product Attention(左)并行組合為 Multi-Head Attention(右)。每個Scaled Dot-Product Attention 結構對輸入上下文特征單獨做了 一次 上下文信息融合。在此基礎之上,我們把多個這樣的特征融合操作并聯起來,得到多個獨立的輸出特征張量,再把這些張量聯接(concatenate)起來。
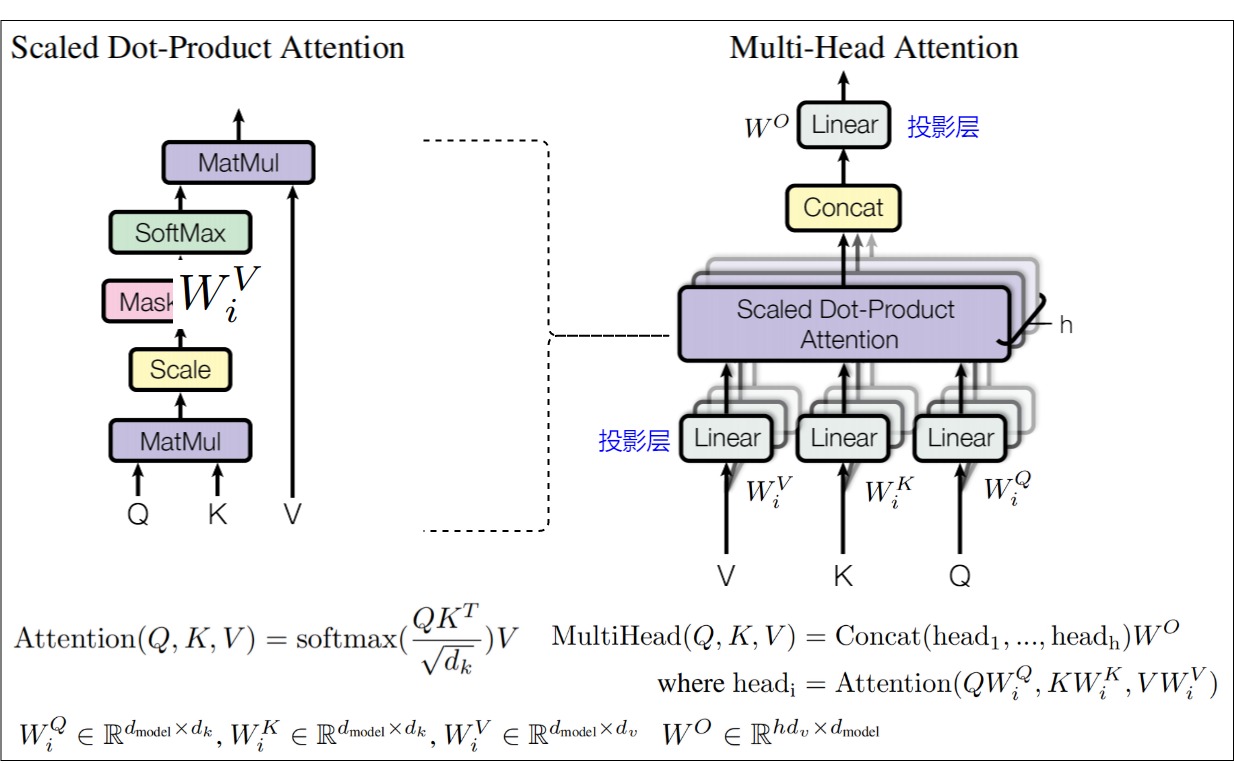
上圖中,\(W^Q\),\(W^K\),\(W^V\) 這三個矩陣列數可以不同,但是行數都是\(d_{model}\)。\(d_{model}\)為多頭注意力機制模塊輸入與輸出張量的通道維度,h為head個數。論文中h=8,因此\(d_k=d_v=d_{model}/h=64\),\(d_{model}=512\)。
偏置
\(W^Q\),\(W^K\),\(W^V\)這三個投影層以及最后的投影層\(W^O\)(Z * Output_weights)可以選擇添加或者不添加偏置。
舉例:根據LLaMA3源碼來看,其沒有加入bias。
class Attention(nn.Module):
def __init__(self, args: ModelArgs):
super().__init__()
self.n_kv_heads = args.n_heads if args.n_kv_heads is None else args.n_kv_heads
model_parallel_size = fs_init.get_model_parallel_world_size()
self.n_local_heads = args.n_heads // model_parallel_size
self.n_local_kv_heads = self.n_kv_heads // model_parallel_size
self.n_rep = self.n_local_heads // self.n_local_kv_heads
self.head_dim = args.dim // args.n_heads
self.wq = ColumnParallelLinear(
args.dim,
args.n_heads * self.head_dim,
bias=False, # 沒有偏置
gather_output=False,
init_method=lambda x: x,
)
self.wk = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False, # 沒有偏置
gather_output=False,
init_method=lambda x: x,
)
self.wv = ColumnParallelLinear(
args.dim,
self.n_kv_heads * self.head_dim,
bias=False, # 沒有偏置
gather_output=False,
init_method=lambda x: x,
)
self.wo = RowParallelLinear(
args.n_heads * self.head_dim,
args.dim,
bias=False, # 沒有偏置
input_is_parallel=True,
init_method=lambda x: x,
)
另外,PaLM: Scaling Language Modeling with Pathways 這篇論文里提到,如果對全連接層以及 layer norm 不加偏置項,可以提高訓練的穩定性。
No Biases – No biases were used in any of the dense kernels or layer norms. We found this to result in increased training stability for large models.
權重矩陣
如果是Scaled Dot-Product Attention,即單頭注意力機制,其要學的參數其實就是三個矩陣 \(W^Q,W^K,W^V\),這個參數量往往不多,且容易是稀疏矩陣。當語義逐漸復雜后,容易因為參數量達到容量上限而造成模型性能不足。
多頭就意味著需要把詞嵌入分成若干的塊,即每個字都轉換為若干512/H維度的信息。然后我們將這些塊分配到不同的頭上,每個頭將獨立地進行注意力計算。對于每個頭得到的Q、K和V,我們都需要分別進行線性變換。計算 Q、K 和 V 的過程還是一樣,不過現在執行變換的權重矩陣從一組\((W^Q, W^K, W^V)\)變成了多組:\((W_0^Q, W_0^K, W_0^V)\),\((W_1^Q, W_1^K, W_1^V)\),....\((W_h^Q, W_h^K, W_h^V)\)。通過這些權重矩陣的轉換,我們就可以讓多組關注不同的上下文的 Q、K 和 V。
多頭注意力機制通過更多的權重矩陣來增加了模型的容量,使得模型能夠學習到更復雜的表示。在多頭注意力中,每個注意力頭只關注輸入序列中的一個獨立子空間,不同頭(角度)有不同的關注點,綜合多個頭可以讓模型就能夠更全面地理解輸入數據。或者這么理解:不同的注意力頭可以學習到序列中不同位置之間的不同依賴關系,組合多頭注意力可以捕捉多種依賴關系,提供更豐富、更強大的表示。從而使得多頭的Q、K、V權重可以在參數量相同的情況提升模型的表達能力。
這些自注意力“頭”的關注點并非預設,而是從隨機開始,通過處理大量數據并自我學習,自然而然地識別出各種語言特征。它們學習到的一些特征我們能夠理解,有些則更加難以捉摸。
\(W^O\)矩陣
上面的操作相當于把一個進程拆分成8個獨立的子進程進行操作,每個進程處理原始Embedding的1/n。最終每個進程得到的向量長度是原來embedding長度的1/n。怎樣把不同注意力頭的輸出合起來呢?系統會在d這個維度,通過 Concat 方式把8個子進程的結果串聯起來,直接拼接成一個長向量。此時 Concat 后的矩陣實際上并不是有機地融合 8 個“小Embedding”,而只是簡單地做了矩陣的前后鏈接 Concat。這就帶來了幾個問題:
-
多個頭直接拼接的操作, 相當于默認了每個頭或者說每個子空間的重要性是一樣的, 在每個子空間里面學習到的相似性的重要度是一樣的,即這些頭的權重是一樣的。然而,各個頭的權重事實上肯定不同,如何有機融合?或者說,如何調整不同頭之間的權重比例?
-
自注意力機制模塊會接到全連接網絡,FFN需要的輸入是一個矩陣而不是多個矩陣。而且因為有殘差連接的存在,多頭注意力機制的輸入和輸出的維度應該是一樣的。
綜上,我們需要一個壓縮、轉換和融合的手段,把 8 個小的語義邏輯子空間有機地整合成一個總體的 Embedding,而且需要把多頭注意力的輸出恢復為原 Embedding 的維度大小,即512維的向量長度。但是有機融合是個復雜的情況,只憑借人力難以做好。因此研發人員提出來把融合直接做成可學習、可訓練的。即設定一個可學習參數,如果它覺得某個頭重要, 那干脆讓那個頭對應的可學習參數大些,輸出的矩陣大些,這就類似于增加了對應頭的權重。
最終就得到是\(W^O\)方案。利用\(W^O\) 對多頭的輸出進行壓縮和融合來提升特征表征和泛化能力。\(W^{O}\)類似 \(W^{Q}\),\(W^{K}\),$W^{V} \(,也是在模型訓練階段一同訓練出來的權重矩陣(右上角 O 意為輸出 Output 的意思)。\)W^O$操作前后,維度沒有變化。即最終輸出的結果和輸入的詞嵌入形狀一樣。
2.2 設計思路
我們來反推或者猜測一下Transformer作者的設計思路大致為:以分治+融合的模式對數據進行加工。分治是對數據進行有差別的對待,而融合是做數據融合。
子空間&分治
Embedding
前面提到,Embedding 才是多頭背后的真正內在成因。那么讓我們再看看這個 Embedding 中的語義邏輯子空間。我們假設有8個注意力頭,每個注意頭都有自己的可學習權重矩陣\(W_i^Q\), \(W_i^K\)和\(W_i^V\)。$W^{Q} \(,\)W{K}$,$W$ 均是 Transformer 大模型在訓練階段時,通過海量的對照語料訓練集訓練出來的,他們是專門用來拆解每個 token 在 Embedding 空間中的邏輯細分子空間用的。
通過這些權重矩陣可以把原始高維向量分解成 8 個細分的 Embedding 向量,每個向量對應到一個細分語義邏輯子空間(語義邏輯、語法邏輯、上下文邏輯、分類邏輯等)。實際上便是把 Attention 機制分割在 Embedding 中的不同細分邏輯子空間中來運作了。每個注意力頭互相獨立的關注到不同的子空間上下文,同時考慮諸多問題,從而獲得更豐富的特征信息。
特征提取
Transformer的多頭注意力應該也借鑒了CNN中同一卷積層內使用多個卷積核的思想。CNN中使用了不同的卷積核來關注圖像中的不同特征,學習不同的信息。然后CNN中逐通道卷積最后沿著通道求和做特征融合。
Transformer的角色定位是特征抽取器或者萬能函數逼近器。我們期望捕捉更多的模式,從而利于下游多樣的任務微調時,一旦這類模式有用,就可以激活出來讓下游任務可以學習到。所以Transformer使用多頭對一個向量切分不同的維度來捕捉不同的模式,讓模型可能從多種維度去理解輸入句子的含義。單個概念向量可以通過不同的函數進行投影,以用于不同特定領域的任務。然后也會接著一個特征融合過程。映射到不同子空間其實就是在模仿卷積神經網絡以支持多通道模式的輸出。
ensemble&融合
上面重點說的是將輸入切分,然后提取不同子空間的信息。接下來我們從另一個方面來解釋,多頭的核心思想就是ensemble。
大量學術論文證明,很難只依靠單個頭就可以同時捕捉到語法/句法/詞法信息,因此需要多頭。但是多頭中每個頭的功能不同,有的頭可能識別不到啥信息,有的頭可能主要識別位置信息,有的頭可能主要識別語法信息,有的頭主要識別詞法信息。multi-head的作用就是為了保證這些pattern都能夠被抽取出來。
我們可以把MHA的多個attention計算視為多個獨立的小模型,每個head就像是一個弱分類器,最終整體的concat計算相當于把來自多個小模型的結果進行了融合,從而讓最后得到的embedding關注多方面信息。而且,單頭容易只關注自身的注意力權重,多頭(需要讓其有一定的頭的基數)無疑是通過多次投票降低這種概率,這樣效果比較好也是比較符合直覺的。做個比喻來說,這就好像是八個有不同閱讀習慣的翻譯家一同翻譯同一個句子,他們每個人可能翻譯時閱讀順序和關注點都有所不同,綜合他們八個人的意見,最終得出來的翻譯結果可能會更加準確。
緩解稀疏
通過觀察大量樣本的attention矩陣我們發現,其實幾乎每一個token在全句中的注意力都是稀疏的,即每個token只關注非常有限個其他token,其余注意力基本可以看成是0(softmax無法嚴格為0)。
稀疏就意味著我們用較小的矩陣就可以來合較大的稀疏矩陣,其效果差不多,但是計算量卻小很多。因此就不如把Q、K和V切分成多個小段,計算多次注意力矩陣,再再以某種方式整合,這樣一來計算量其實跟直接 算單個注意力差不多,但這樣模型融合的效果應該至少不差于單個注意力,甚至可能更好,因此有了多頭注意力。
2.3 計算
計算流程
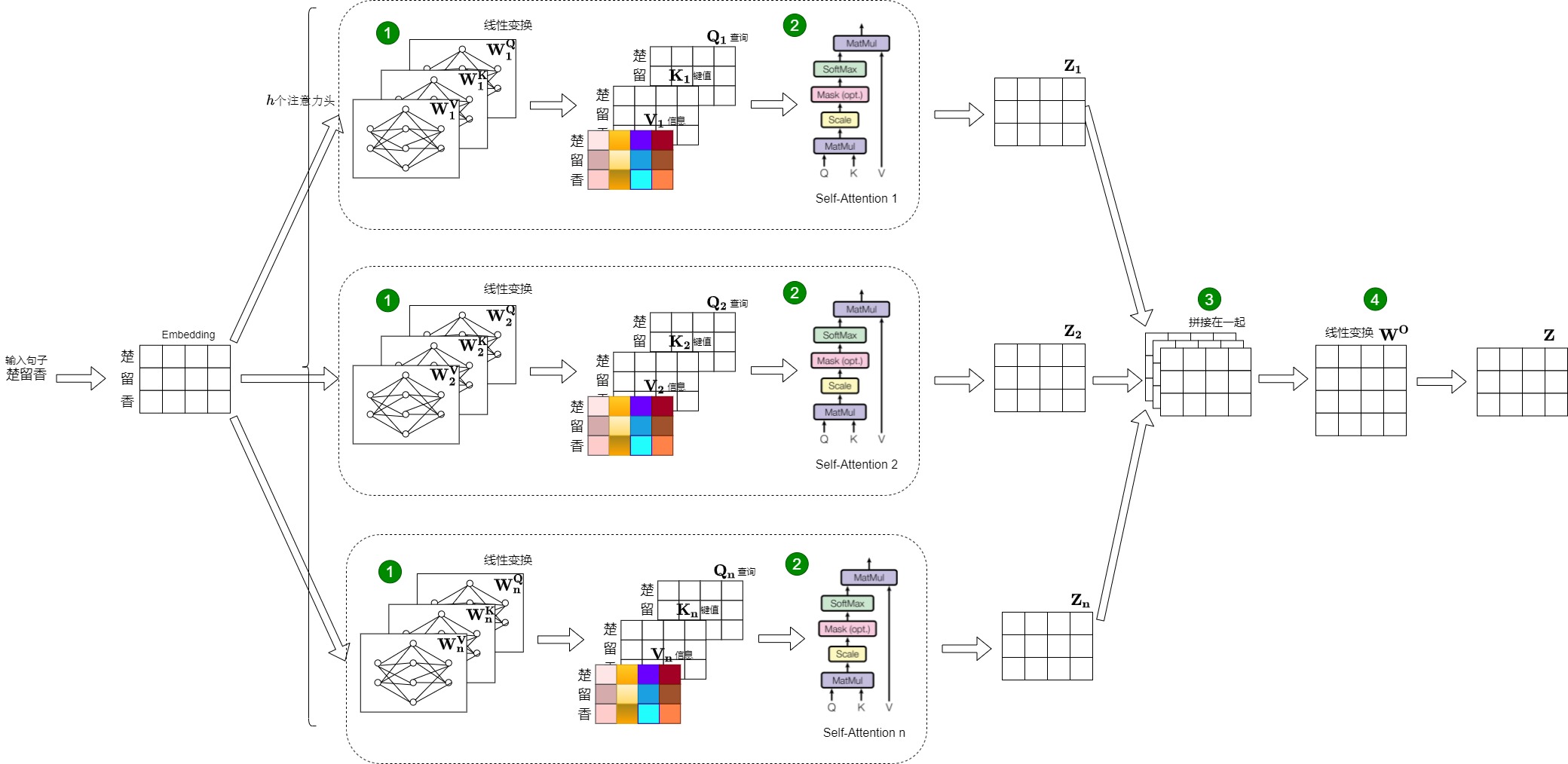
多頭注意力的計算流程就是把高維向量切分為若干份低維向量,在若干低維空間內分別求解各自的Scaled Dot-Product Attention(點積自注意力)。總體流程分為:切分,計算,拼接,融合四部分,這里涉及很多步驟和矩陣運算,我們用一張大圖把整個過程表示出來。
- 輸入依然是原始的Q,K 和 V。
- 切分。每個注意頭都有自己的可學習權重矩陣\(W_i^Q\), \(W_i^K\)和\(W_i^V\)。輸入的Q、K和V經過這些權重矩陣進行多個線性變換后得到 N 組Query,Key 和 Value。這些組Q、K和V可以理解為把輸入的高維向量線性投影到比較低的維度上。每個新形成的Q在本質上都要求不同類型的相關信息,從而允許注意力模型在上下文向量計算中引入更多信息。此處對于下圖的標號1。
- 計算。每個頭都使用 Self-Attention 計算得到 N 個向量。每個頭可以專注學習輸入的不同部分,從而使模型能夠關注更多的信息。此處對于下圖的標號2。
- 拼接。我們的目標是創建一個單一的上下文向量作為注意力模型的輸出。因此,由單個注意頭產生的上下文向量被拼接為一個向量。此處對于下圖標號3。
- 融合。使用權重矩陣\(W^O\)以確保生成的上下文向量恢復為原 Embedding 的維度大小。這即是降維操作,也是融合操作。此處對于下圖的標號4。
計算強度
我們以下圖為基礎來思考計算強度,D 表示 hidden size,H 表示 Head 個數,L 表示當前是在序列的第 L 個 Token。
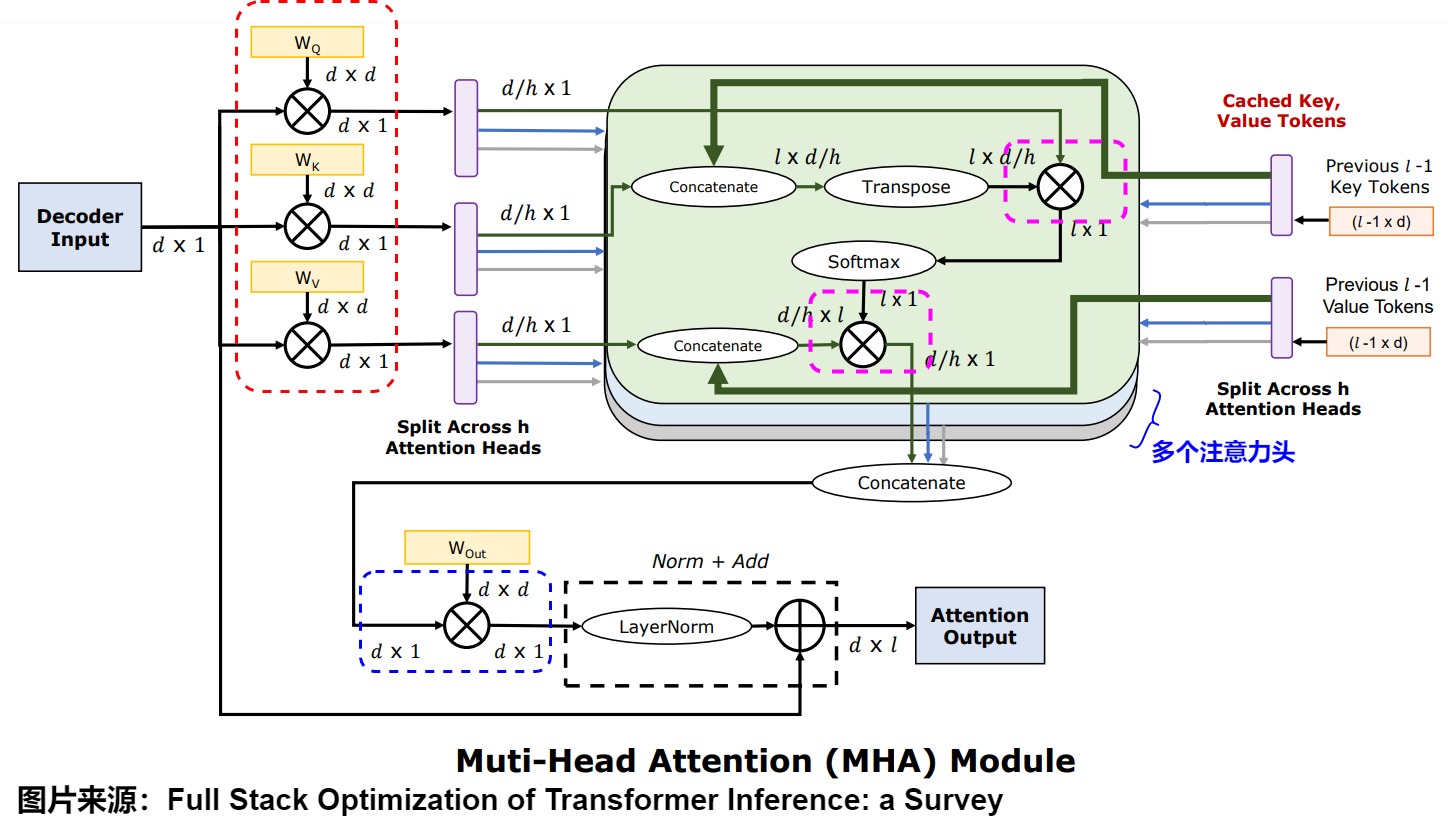
- 當 Batch Size 為 1 時,圖中紅色、紫色、藍色虛線框處的矩陣乘法全部為矩陣乘向量,是 Memory Bound(內存受限操作),算術強度不到 1。
- 當 Batch Size 大于 1 時(比如 Continuous Batching):
- 紅色和藍色虛線框部分:因為是權重乘以激活,所以不同的請求之間可以共享 Weight。這里變成矩陣乘矩陣,并且 Batch Size 越大,算術強度越大,也就越趨近于 Compute Bound(FFN 層也類似)。
- 紫色虛線框部分:這里 Q、K 和 V 的 Attention 計算,是激活乘以激活,所以不同的請求之間沒有任何相關性。即使 Batching,這里也是 Batched 矩陣乘向量,并且因為序列長度可能不同,這里不同請求的矩陣乘向量是不規則的。也就是說,這里算術強度始終不到 1,是明顯的 Memory Bound。
從上可以看出,通過 Continuous Batching 可以很好的將 Memory Bound 問題轉變為 Compute Bound,但 Q、K 和 V 的 Attention 計算的算術強度卻始終小于 1。Sequence Length 越長,這里的計算量就越不可忽略,因為其屬于系統的短板處。
2.4 效果
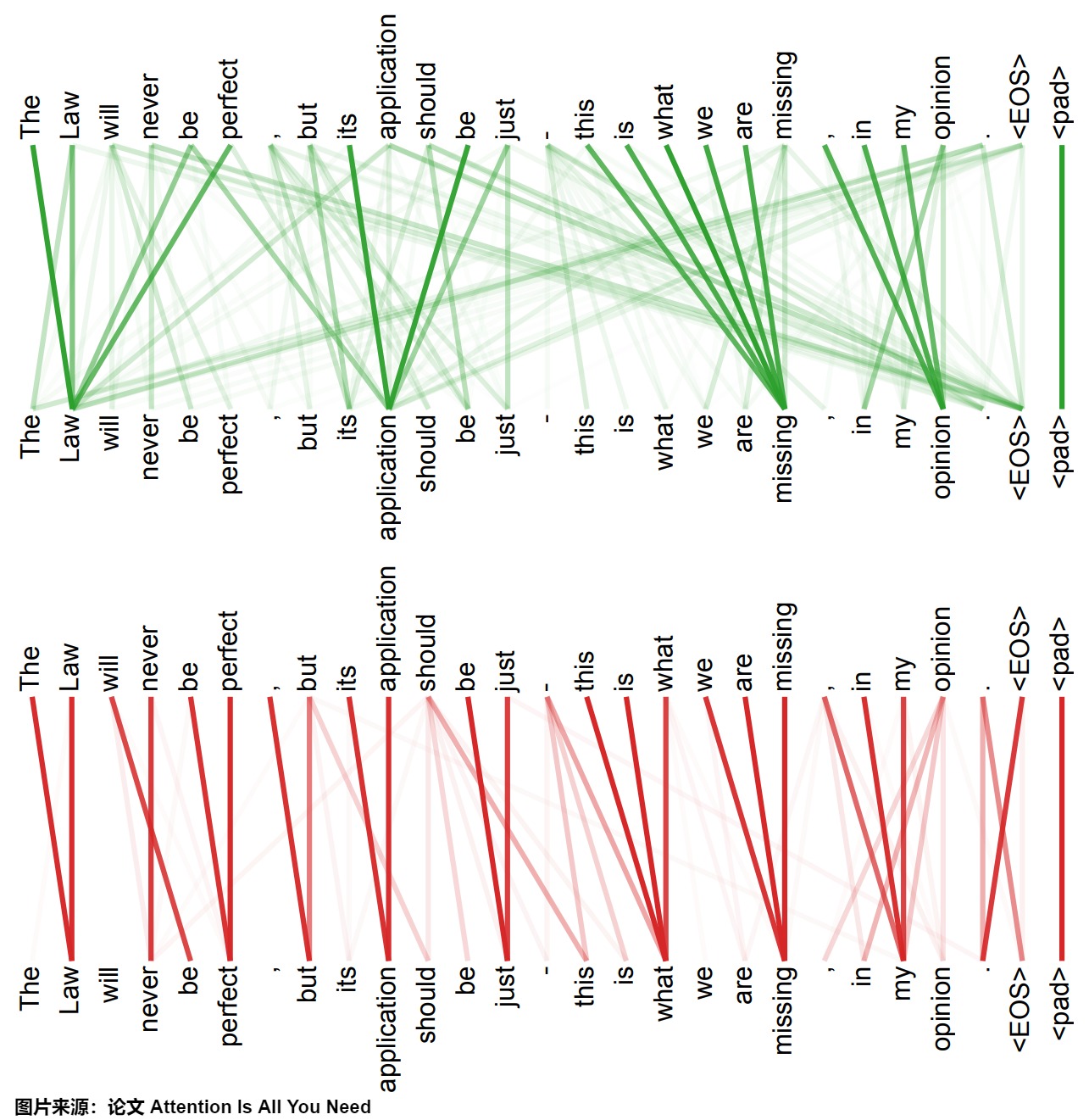
Transformer論文末尾給出了多頭注意力機制中兩個頭的attention可視化結果,如下所示。圖中,線條越粗表示attention的權重越大,可以看出,兩個頭關注的地方不一樣,綠色圖說明該頭更關注全局信息,紅色圖說明該頭更關注局部信息。
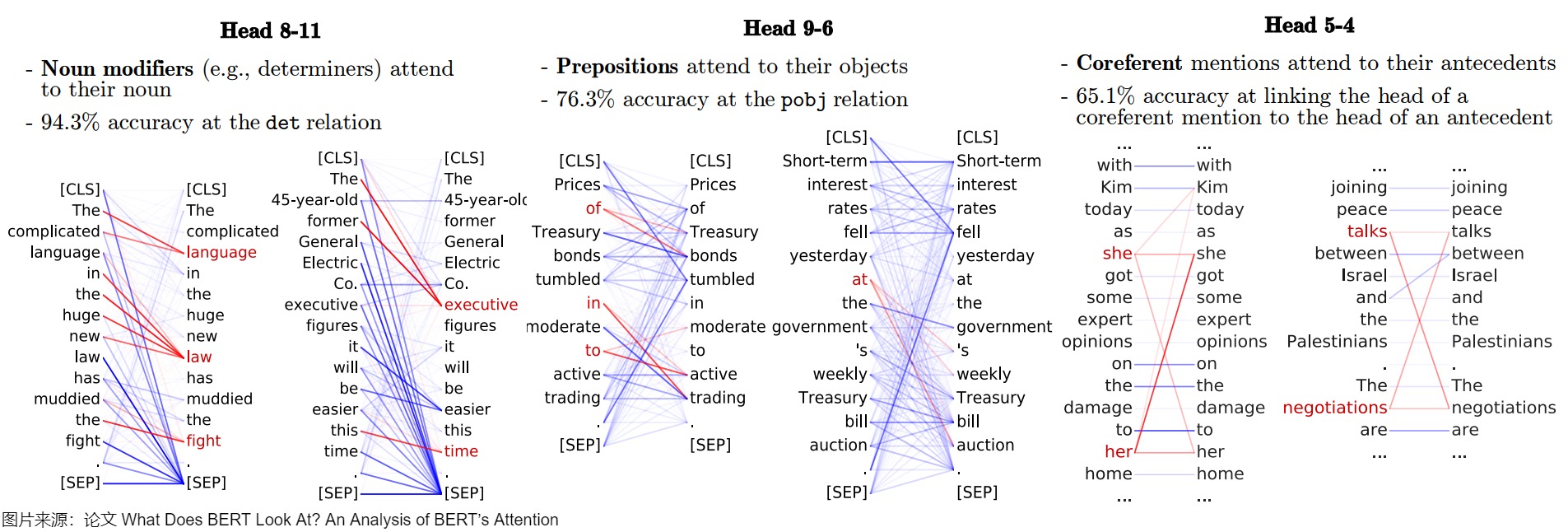
論文“What Does BERT Look At? An Analysis of BERT’s Attention”也給出了不同注意力頭的示例。線條的粗細表示注意力權重的強度(一些注意力權重太低,以至于看不見)。
2.5 融合方式
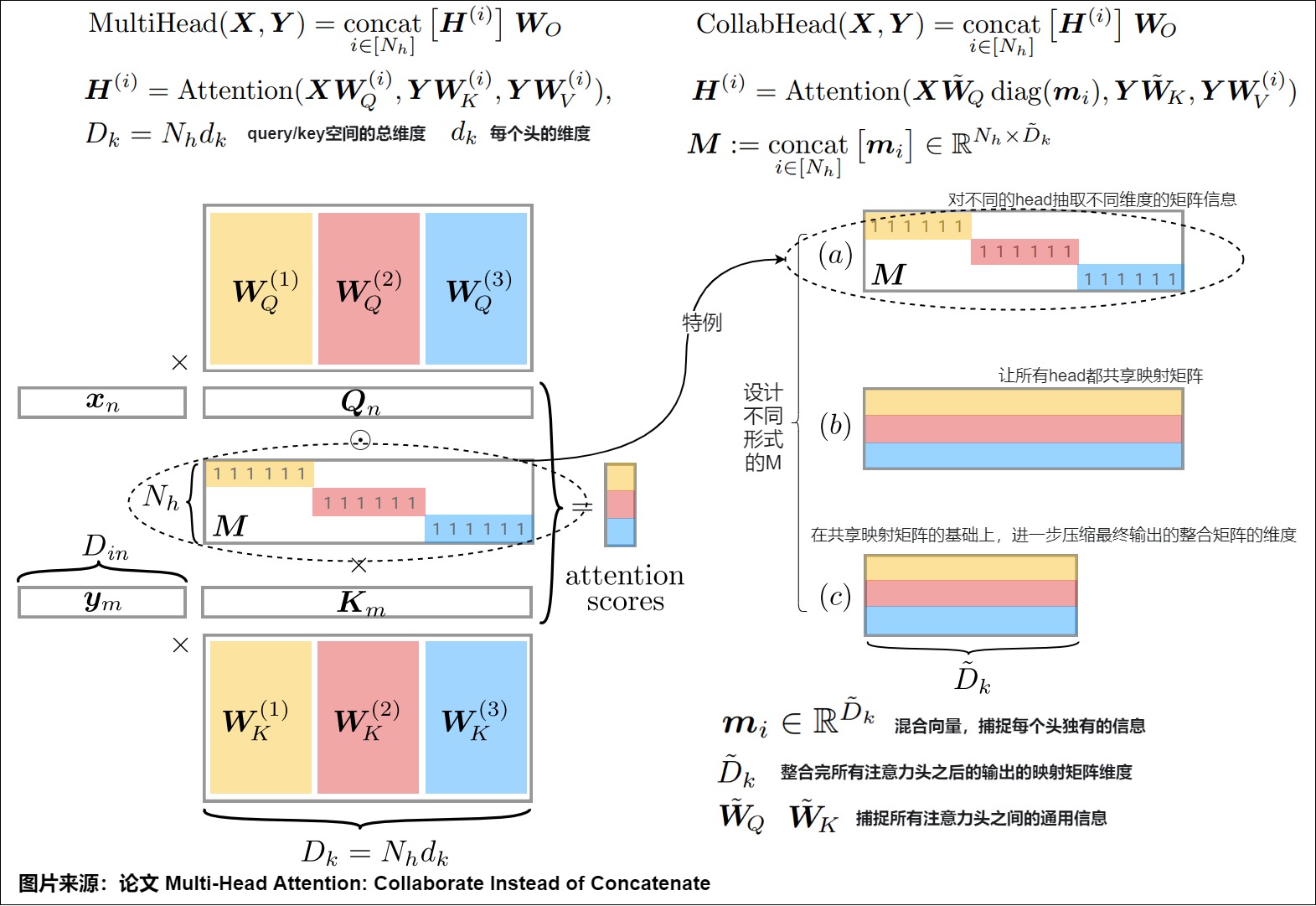
vanilla Transformer中,對于不同的注意力采取的整合方式是直接拼接。論文"Multi-Head Attention: Collaborate Instead of Concatenate“提出了其它整合方式。該論文發現所有注意力頭之間捕捉的信息肯定是存在冗余的,頭與頭之間存在較多的通用信息。拼接后的 \(??_????_??^??\) 只需要大概1/3的維度就足夠捕捉絕大部分的信息了。因此論文作者設計了一個混合向量來提取注意力頭之間的通用信息。這個向量可以通過跟模型一起學習得到,然后應用到原始的多頭注意力計算中。這種方案可以讓注意力頭的表示方式更加靈活,注意力頭的維度可以根據實際情況進行改變。也讓參數計算更加高效。
下圖左面是vanilla Transformer的原始拼接方式,右面是該論文提出的方案CollabHead。
- (a)是vanilla Transformer的原始拼接方式(相當于對不同的head抽取不同維度的矩陣信息),也是CollabHead方式的一種特例。\(m_i\)是一個由1和0兩種元素組成的向量,其中1的元素位置為其對應注意力頭的映射矩陣在拼接后的整體矩陣中的位置。這使得模型在整合注意力頭的時候,讓每個注意力頭之間都互相獨立。
- (b)是讓所有head都共享映射矩陣。
- (c)在共享映射矩陣的基礎上,進一步壓縮最終輸出的整合矩陣的維度,達到壓縮維度的效果。
2.6 分析
研究人員對多頭注意力做了深入的分析(比如論文"What Does BERT Look At? An Analysis of BERT’s Attention"),其中一些洞察和觀點如下:
頭數目
- 頭數越少,注意力會更傾向于關注token自己本身或者其他的比較單一的模式,比如都關注CLS。
- 已有論文證明頭數目不是越多越好(頭的數量增多會導致各個子空間變小,這樣子空間能表達的內容就減少了,而當有足夠多的頭,已經能夠關注位置信息,語法信息,關注罕見詞的能力了,再多一些頭,可能是增進也可能是噪聲)。頭太多太少都會變差,具體多少要視模型規模,任務而定。目前可以看到的趨勢是,模型越大(也就是hidden size越大),頭數越多,就越能帶來平均效果上的收益。
學習模式
- 對于大部分query,每個頭都學習了某種固定的模式。
- 每個頭確實學到東西有所不同,但大部分頭之間的差異沒有我們想的那么大(比如一個學句法,一個學詞義這樣明顯的區分)。
- 少部分頭可以比較好地捕捉到各種文本信息,而不會過分關注自身位置,一定程度緩解了上文提到的計算 \(QK^T\)之后對角線元素過大的問題。
下圖給出了注意力頭展示情況,有的注意力頭關注所有的詞(broadly),有的注意力頭關注下一個token,有的注意力頭關注SEP符號,有的注意力頭關注標點符號。線條的粗細表示注意力權重的強度(一些注意力權重太低,以至于看不見)。

頭與層級的關系
- 越靠近底層的注意力,其pattern種類越豐富,關注到的點越多。
- 模式隨著層數的增加而慢慢固定。頭之間的差距(或者說方差)隨著所在層數變大而減少,即越來越包含更多的位置信息。
- 越到頂層的注意力,大部分注意力頭的pattern趨同。
- 最后留下來的極少不相同的注意力頭就是這個模型表達語義信息的注意力頭。這也可以說明,為什么需要多層的Transformer堆疊,因為有些信息可能在某一層之中無法捕捉到,需要在其它層捕捉。
論文"What Does BERT Look At? An Analysis of BERT’s Attention"還分析了BERT對詞語之間依存關系的識別效果。依存關系是詞語和詞語之間的依賴關系,比如“謂語”是一個句子的中心,其他成分與動詞或直接或間接的產生關系。通過對詞語之間依存關系的分析,論文作者發現BERT無法對所有的依存關系有比較好的處理,但是特定的層會對特定的依存關系識別的比較好。

論文”Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned“對多個Head進行了分析,發現多個Head的作用有大多數是冗余的,很多可以被砍掉。文中通過在多個數據集上跑實驗,發現大部分Head可以分為以下幾種:
- Positional Head:主要關注鄰居的位置頭。這個Head計算的權值通常指向臨近的詞,規則是這個Head在90%的情況下都會把最大的權值分配給左邊或者右邊的一個詞。
- Syntactic Head:指向具有特定語法關系的token的句法頭。這個Head計算的權值通常會將詞語之間的關系聯系起來,比如名詞和動詞的指向關系。
- Rare Head:指向句子中生僻詞的頭。這個Head通常會把大的權值分配給稀有詞。
證明其頭部分類重要性的最好方法是修剪其他類別。以下是他們的修剪策略示例,該策略基于普通transformer的 48 個頭(8 個頭乘以 6 個塊)的頭進行分類。
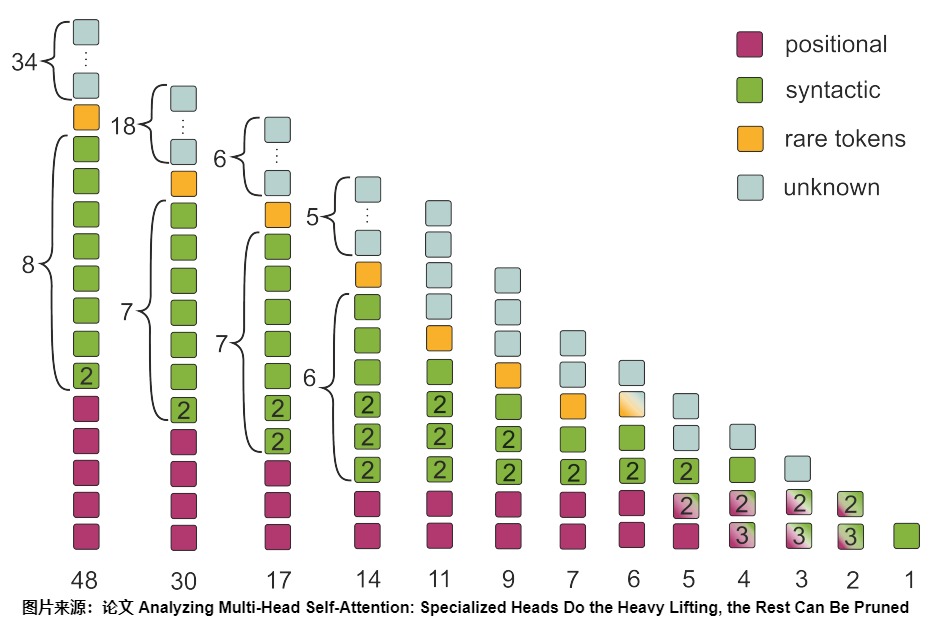
上圖展示了修剪后保留編碼器頭的功能。每列代表不同修剪量。可以發現,通過保留被歸類為主要類別的注意力頭,他們設法保留了 48個頭中的 17 個。請注意,這大約相當于編碼器總頭數的 2/3。每列下面數字代表剩余多少頭。
該論文還分析了如何去精簡Heads,優化的方法如下(給各個Head加個權值,相當于門控):

2.7 優點
多頭注意力的優點如下:
- 豐富上下文理解增加模型的表達能力和學習能力,讓模型可以捕捉到更加豐富的特征和信息。
- 提高計算效率:由于每個頭工作在較低維度的空間中,注意力計算的復雜度降低,從而提高了計算效率。注意力計算的復雜度與維度的平方成正比,所以降維可以顯著減少計算量。
- 并行化能力:多頭注意力機制允許模型在不同的表示子空間上并行地學習,這提高了訓練和推理的效率。
- 更好的泛化能力:由于多頭注意力機制能夠從多個角度分析輸入數據,模型的泛化能力得到提升。同時,也使得模型對輸入中的噪聲和變化更加魯棒。即使某些頭被噪聲或者不相關的信息干擾,其他頭仍然可以提供有用的信息。
- 提高模型容量:即使每個頭工作在較低維度的子空間中,組合多個頭的結果可以捕捉到不同子空間中的信息,從而增加模型的容量。
0x03 實現

3.1 定義
多頭注意力由類MultiHeadedAttention來實現,其中關鍵參數及變量如下。
- d_model是模型的維度,也就是單頭注意力下,query,key,value和詞嵌入的向量維度。我們假設是512。
- h是注意力頭數,假設為8。
- d_k是單個頭的注意力維度,大小是d_model / h,所以512/8=64。
另外,注釋中:
- seq_len是句子長度,也就是token個數(可以認為是句子中最大包含多少單詞),我們假設是10個單詞。shape指的是張量形狀。
- batch_size是batch size。
MultiHeadedAttention的初始化代碼如下。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
# 因為后續要給每個頭分配等量的詞特征,把詞嵌入拆分成h組Q/K/V,所以要確保d_model可以被h整除,保證 d_k = d_v = d_model/h
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h # 單個頭的注意力維度
self.h = h # 注意力頭數量
# 定義W^Q, W^K, W^V和W^O矩陣,即四個線性層,每個線性層都具有d_model的輸入維度和d_model的輸出維度,前三個線性層分別用于對Q向量、K向量、V向量進行線性變換,第四個用來融合多頭結果
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None # 初始化注意力權重
self.dropout = nn.Dropout(p=dropout) # 進行dropout操作時置0比率,默認是0.1
3.2 運算邏輯
結合哈佛代碼中的具體函數從整體上把多頭注意力的計算過程(這里從第一個編碼層來演示,所以涵蓋了詞嵌入)梳理如下圖所示。
注:
- 為方便理解,下圖去掉 batch_size 維度,聚焦于剩下的維度。
- 圖上限定為2個頭。注意:代碼之中沒有切分線性層權重\(W^Q,W^K,W^V\)的部分,而是合用,因此圖上省略。
- 實際上代碼實現的時候可以忽略concat,最樸素的實現都是在通道維度reshape成多頭,然后過兩個矩陣乘就可以了。
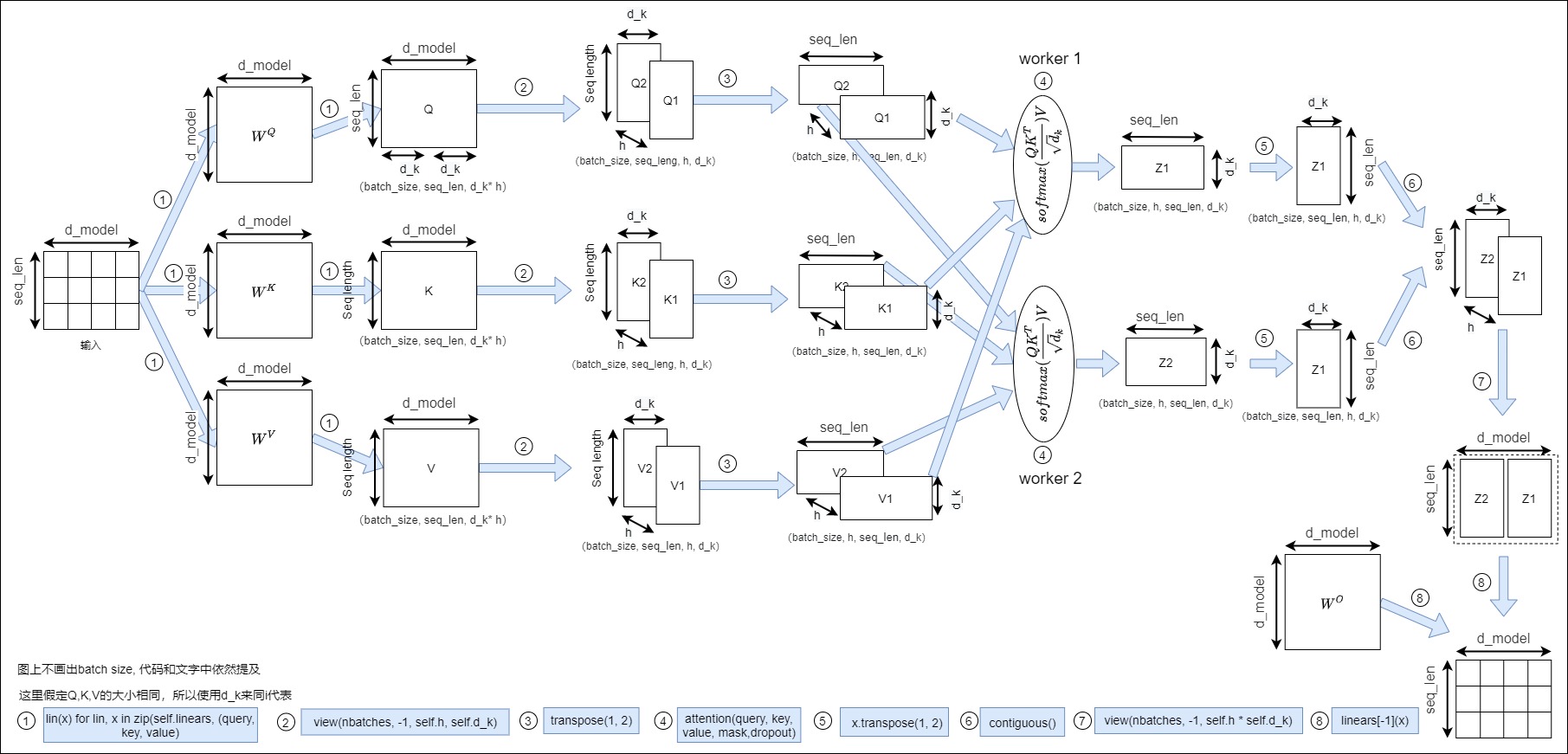
輸入
編碼器的輸入是詞嵌入,其數據維度為(batch_size, seq_len, d_model)。需要注意的是,論文的架構圖中,投影和切分通過\(3 \times h\)個小權重矩陣來完成。
投影
此處對應圖上的序號1。
在單頭注意力機制中,輸入會與 \(W^Q,W^K,W^V\) 矩陣相乘。\(W^Q,W^K,W^V\) 是三個獨立的線性層。每個線性層都有自己獨立的權重。輸入數據與三個線性層分別相乘,產生 Q、K、V。而哈佛代碼中此處依然是用三個大的權重矩陣\(W^Q,W^K,W^V\) ,并非論文所列出的\(3 \times h\)個小權重矩陣,然而,隨著訓練的進行,物理上的三個大的權重矩陣會自然而然的變成邏輯上的\(3 \times h\)個小權重矩陣。
切分數據
此處對應圖上的序號2。切分并非是直接在物理層面上簡單的把詞嵌入切分成h份,而是要進行降維變化,即通過權重矩陣將它們從原始維度映射到較低的維度,得到 h 個具有獨立語義邏輯的在不同子空間上小“Embedding”。
邏輯角度
經由線性層輸出的 Q、K 和 V 矩陣將被分割到多個注意頭中,以便每個注意頭能夠獨立地處理它,此處會改變 Q、K 和 V 矩陣形狀。從邏輯上來說是做如下操作。
從向量角度而言,分割操作將張量中每一行 d_model (原始詞嵌入)都拆成了h個 d_k長度的行向量(帶有子語義邏輯的“小Embedding”)。即:(batch_size, seq_len, d_model) -> (batch_size, seq_len, nums_heads, d_k)。雖然從 Embedding 向量的角度看是從 d_model維降到了每一個頭的 d_k 維,每個頭注意力對應的維度減少了,但實際上每一個頭 head 同樣可以在某個子空間中表達某些細分的語義邏輯。
從神經網絡角度而言:由于對于單層全連接網絡,輸入層與隱層節點的任何一個子集結合,都是一個完整的單隱層全連接網絡。也就是說,這種拆分完全可以看做將前一步input_depth 個節點到 d_model 個節點的全連接網絡,拆分成了h個小的 input_depth 個節點到d_k個節點的全連接網絡。
物理角度
實際上在代碼中會采用大矩陣的方式來進行。具體會通過view(nbatches, -1, self.h, self.d_k)操作把投影輸出 Query, Key, Value拆分成多頭,即增加一個維度,將最后一個維度變成d_k。或者說,把最后一個維度分拆為 (h, d_k)。現在每個 "切片"對應于每個頭的一個矩陣。
如前所述,投影是邏輯投影,那么切分也只是邏輯上的切分。對于參數矩陣 Query, Key, Value 而言,并沒有物理切分成對應于每個注意力頭的獨立矩陣,僅邏輯上每個注意力頭對應于 Query, Key, Value 的獨立一部分。同樣,各注意力頭沒有單獨的線性層,而是所有的注意力頭共用線性層,只是不同的注意力頭在獨屬于其的邏輯部分上進行操作。這種邏輯分割,是通過將輸入數據以及線性層權重,均勻劃分到各注意頭中來完成的。
基于此,所有 Heads 的計算可通過對一個的矩陣操作來實現,而不需要h個單獨操作。這使得計算更加有效,同時保持模型的簡單:所需線性層更少,同時獲得了多頭注意力的效果。
其實,也可采用小矩陣的方式進行計算,即把做 Query, Key, Value做物理切分,然后利于for循環一個一個計算頭,再將結果列表進行concat,這樣代碼上更清晰一點,但是性能不如大矩陣的方案。
小結
輸入的維度是:batch_size, seq_len, d_model)。\(W^Q,W^K,W^V\) 線性層的維度是(d_model, d_model),實際上線性層并沒有針對多頭做切分。實際上多頭的 \(W^Q,W^K,W^V\) 矩陣仍然是三個單一矩陣,但可以把它們看作是每個注意力頭的邏輯上獨立的\(W^Q,W^K,W^V\) 矩陣。這樣得到的單頭對應的 Q、K 和 V 邏輯矩陣形狀是(batch_size, seq_len, h, d_k)。
調整維度
此處對應圖上的序號3。
為了更好的并行,接下來會通過交換 h和 seq_len 這兩個維度改變 Q、K 和 V 矩陣的形狀。圖示中未表達出 batch 維度,實際上每一個注意力頭的 'Q' 的維度是(batch_size, h, seq_len, d_k)。
為每個頭計算注意力
如前所述,有兩種方式來計算每個頭的注意力。
- 大矩陣方式,該種方式將8個注意頭全部平鋪在三維輸入矩陣的第0維batch_size上,一起進行點乘操作,點乘結果再通過reshape和轉置整理為8個頭在第2維上的拼接,這種方式計算快。
- for循環一個一個計算頭,再將結果列表進行concat,代碼上更清晰一點。
vanilla Transformer使用大矩陣方式。此處對應圖上的序號4。
單獨分組
目前在邏輯上已經把每個query,key,value按照各自的維度分割為若干段,形成若干獨立的query,key,value分組,每個分組對應一個注意力頭。接下來每個分組內進行點積運算和加權平均,比如query的第一段只和key的第一段進行點積,其結果也只是value第一段的權重,以此類推。這是獨立的分組,在每個組內進行注意力操作,不會跨組操作。從原理層面上看,這是把 Attention 機制分割在 Embedding 中的不同細分邏輯子空間中(語義邏輯、語法邏輯、上下文邏輯、分類邏輯等)來運作了,即把原來在一個高維空間里衡量一個文本的任意兩個字之間的相關度,變成了在8維空間里去分別衡量任意兩個字的相關度的變化。
并行
每個頭的注意力計算其實和單頭注意力沒啥區別,但是有一個點可以留意下,即單頭計算是使用最后兩個維度(seq_len, d_k),跳過前兩個維度(batch_size, h)。而每個注意力頭的輸出形狀為:(batch_size,h,seq_len,d_k)。之所以要這么處理,完全是因為計算的需要。因為Q、K和V的前兩個維度(多頭與 batch)是等價的,本質上都是并行計算。所以計算時也可以把它們放在同一個維度上:batch_size * num_heads。也正是因為計算的需要,注意力權重 ( QK^T ) 的形狀有時是三維張量 (batch_size*num_heads, tgt_seq_len, src_seq_len),有時是四維張量 (batch_size, num_heads, tgt_seq_len, src_seq_len) ,會根據需要在二者間切換。
通常,獨立計算具有非常簡單的并行化過程。盡管這取決于 GPU 線程中的底層低級實現。理想情況下,我們會為每個batch 和每個頭部分配一個 GPU 線程。例如,如果我們有 batch=2 和 heads=3,我們可以在 6 個不同的線程中運行計算。即使尺寸是d_k=d_model/heads。由于每個頭的計算是并行進行的(不同的頭拿到相同的輸入,進行相同的計算),模型可以高效地處理大規模輸入。相比于順序處理的 RNN,注意力機制本身支持并行,而多頭機制進一步增強了這一點。
融合每個頭的Z
我們現在對每個頭都有單獨的Z,而編碼器的下一層希望得到是一個矩陣,而不是h個矩陣,因此前面怎么拆分,現在還需要拼回去。將多頭輸出的多個Z通過全連接合并為一個輸出Z。這個合并操作本質上是與分割操作相反,通過重塑結果矩陣以消除 d_k 維度來完成的。其步驟如下:
-
為了能夠方便地將多頭結果拼合起來,首先我們將h轉置到倒數第二個維度,即交換頭部和序列維度來重塑注意力分數矩陣。換句話說,矩陣的形狀從(batch_size,h,seq_len,d_k)變成(batch_size,seq_len,h,d_k)。此處對應圖上的序號5。
-
將意力分數矩陣放到一塊連續的物理內存中,是深拷貝,不改變原數據。此處對應圖上的序號6。
-
通過重塑 (batch_size,seq_len,d_model)來折疊頭部維度。這就有效地將每個頭的注意得分向量連接成一個合并的注意得分。此處對應圖上的序號7。
-
通過全連接層的線性變換把拼合好的輸出進行有機融合,經過全連接層融合后的最后一維仍然是
d_model。此處對應圖上序號8。
可以看到 Multi-Head Attention 輸出的矩陣Z與其輸入的矩陣X的維度是一樣的。
forward()函數
上面運算邏輯對應的是MultiHeadedAttention的forward()函數,具體如下。
def forward(self, query, key, value, mask=None):
"""
本函數是論文中圖2(多頭注意力的架構圖)的實現。
- query, key, value:并非論文公式中經過W^Q, W^K, W^V計算后的Q, K, V,而是原始輸入X。query, key, value的維度是(batch_size, seq_len, d_model)
- mask:注意力機制中可能需要的mask掩碼張量,默認是None
"""
if mask is not None:
# 對所有h個頭應用同樣的mask
# 單頭注意力下,mask和X的維度都是3,即(batch_size, seq_len, d_model),但是多頭注意力機制下,會在第二個維度插入head數量,因此X的維度變成(batch_size, h,seq_len,d_model/h),所以mask也要相應的把自己拓展成4維,這樣才能和后續的注意力分數進行處理
mask = mask.unsqueeze(1) # mask增加一個維度
nbatches = query.size(0) # 獲取batch_size
# 1) Do all the linear projections in batch from d_model => h x d_k
"""
1). 批量執行從 d_model 到 h x d_k 的線性投影,即計算多頭注意力的Q,K,V,所以query、value和key的shape從(batch_size,seq_len,d_model)變化為(batch_size,h,seq_len,d_model/h)。
zip(self.linears, (query, key, value)) 是把(self.linears[0],self.linears[1],self.linears[2])這三個線性層和(query, key, value)放到一起
然后利用for循環將(query, key, value)分別傳到線性層中進行遍歷,每次循環操作如下:
1.1 通過W^Q,W^K,W^V(self.linears的前三項)求出自注意力的Q,K,V,此時Q,K,V的shape為(batch_size,seq_len,d_model), 對應代碼為linear(x)。
以self.linears[0](query)為例,self.linears[0] 是一個 (512, 512) 的矩陣,query是(batch_size,seq_len,d_model),相乘之后得到的新query還是512(d_model)維的向量。
key和value 的運算完全相同。
1.2 把投影輸出拆分成多頭,即增加一個維度,將最后一個維度變成(h,d_model/h),投影輸出的shape由(batch_size,seq_len,d_model)變為(batch_size,seq_len,h,d_model/h)。對應代碼為`view(nbatches, -1, self.h, self.d_k)`,其中的-1代表自適應維度,計算機會根據這種變換自動計算這里的值。
因此我們分別得到8個頭的64維的key和64維的value。這樣就意味著每個頭可以獲得一部分詞特征組成的句子。
1.3 交換“seq_len”和“head數”這兩個維度,將head數放在前面,最終shape變為(batch_size,h,seq_len,d_model/h)。對應代碼為`transpose(1, 2)`。交換的目的是方便后續矩陣乘法和不同頭部的注意力計算。也是為了讓代表句子長度維度和詞向量維度能夠相鄰,這樣注意力機制才能找到詞義與句子位置的關系,從attention函數中可以看到,利用的是原始輸入的倒數第一和第二維.這樣我們就得到了每個頭的輸入。
多頭與batch本質上都是并行計算。所以計算時把它們放在同一個維度上,在用GPU計算時,大多依據batch_size * head數來并行劃分。就是多個樣本并行計算,具體到某一個token上,可以理解為n個head一起并行計算。
"""
query, key, value = [
lin(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2) # 對應圖上的序號2,3
for lin, x in zip(self.linears, (query, key, value)) # 對應圖上的序號1
]
# 2) Apply attention on all the projected vectors in batch.
"""
2) 在投影的向量上批量應用注意力機制,具體就是求出Q,K,V后,通過attention函數計算出Attention結果。因為head數量已經放到了第二維度,所以就是Q、K、V的每個頭進行一一對應的點積。則:
x的shape為(batch_size,h,seq_len,d_model/h)。
self.attn的shape為(batch_size,h,seq_len,seq_len)
"""
x, self.attn = attention( # 對應圖上的序號4
query, key, value, mask=mask, dropout=self.dropout
)
# 3) "Concat" using a view and apply a final linear.
"""
3) 把多個頭的輸出拼接起來,變成和輸入形狀相同。
通過多頭注意力計算后,我們就得到了每個頭計算結果組成的4維張量,我們需要將其轉換為輸入的形狀以方便后續的計算,即將多個頭再合并起來,進行第一步處理環節的逆操作,先對第二和第三維進行轉置,將x的shape由(batch_size,h,seq_len,d_model/h)轉換為 (batch_size,seq_len,d_model)。
3.1 交換“head數”和“seq_len”這兩個維度,結果為(batch_size,seq_len,h,d_model/h),對應代碼為:`x.transpose(1, 2).contiguous()`。`contiguous()`方法將變量放到一塊連續的物理內存中,是深拷貝,不改變原數據,這樣能夠讓轉置后的張量應用view方法,否則將無法直接使用。
3.2 然后將“head數”和“d_model/head數”這兩個維度合并,結果為(batch_size,seq_len,d_model),代碼是view(nbatches, -1, self.h * self.d_k)。
比如,把8個head的64維向量拼接成一個512的向量。然后再使用一個線性變換(512,512),shape不變。因為有殘差連接的存在使得輸入和輸出的維度至少是一樣的。
即(5, 8, 10, 64) ==> (5, 10, 512)
"""
x = (
x.transpose(1, 2) # 對應圖上的序號5
.contiguous() # 對應圖上的序號6
.view(nbatches, -1, self.h * self.d_k) # 對應圖上的序號7
)
del query
del key
del value
# 當多頭注意力機制計算完成后,將會得到一個形狀為[src_len,d_model]的矩陣,也就是多個z_i水平堆疊后的結果。因此會初始化一個線性層(W^O矩陣)來對這一結果進行一個線性變換得到最終結果,并且作為多頭注意力的輸出來返回。
# self.linears[-1]形狀是(512, 512),因此最終輸出還是(batch_size, seq_len, d_model)。
return self.linears[-1](x) # 對應圖上的序號8
3.3 調用
我們接下來看看如何調用。在 Transformer 里,有 3 個地方用到了 MultiHeadedAttention,Encoder層用到一處,Decoder層用到兩處。
編碼器
Encoder使用自注意力的目的是:找到自身的關系,因此對于其內部的多頭自注意力(Multi-Head Attentyion)機制來說,調用MultiHeadedAttention.forward(query, key, value, mask)時候,query,key 和 value 都是相同的輸入值X或者下層(對應Transformer架構圖)的輸出。在代碼之中,對應如下:
class EncoderLayer(nn.Module):
"Encoder is made up of self-attn and feed forward (defined below)"
def forward(self, x, mask):
# 這里調用MultiHeadedAttention.forward(query, key, value, mask)
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
解碼器
Decoder的目的是:
- 使用自注意力找到輸出序列自身內部的語義關系。讓目標序列之中,每個token都搜集到本字和目標序列之中其他哪幾個字比較相關。
- 使用交叉注意力讓源序列與目標序列對齊。
因此,
- 對于Decoder最前面的掩碼多頭注意力機制(Masked Multi-Head Attentyion)來說,調用MultiHeadedAttention.forward(query, key, value, mask)時候,query,key 和 value 都是相同的值X(Decoder的輸入)。但是 Mask 使得它不能訪問未來的輸入,即為了并行一次喂入所有解碼部分的輸入,所以要用mask來進行掩蓋當前時刻之后的位置信息。
- 對于Decoder中間的多頭注意力機制(Multi-Head Attentyion)來說,會將Encoder的輸出memory
作為key和value,將下層的輸出作為本層的query。
代碼如下:
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def forward(self, x, memory, src_mask, tgt_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
return self.sublayer[2](x, self.feed_forward)
0x04 改進
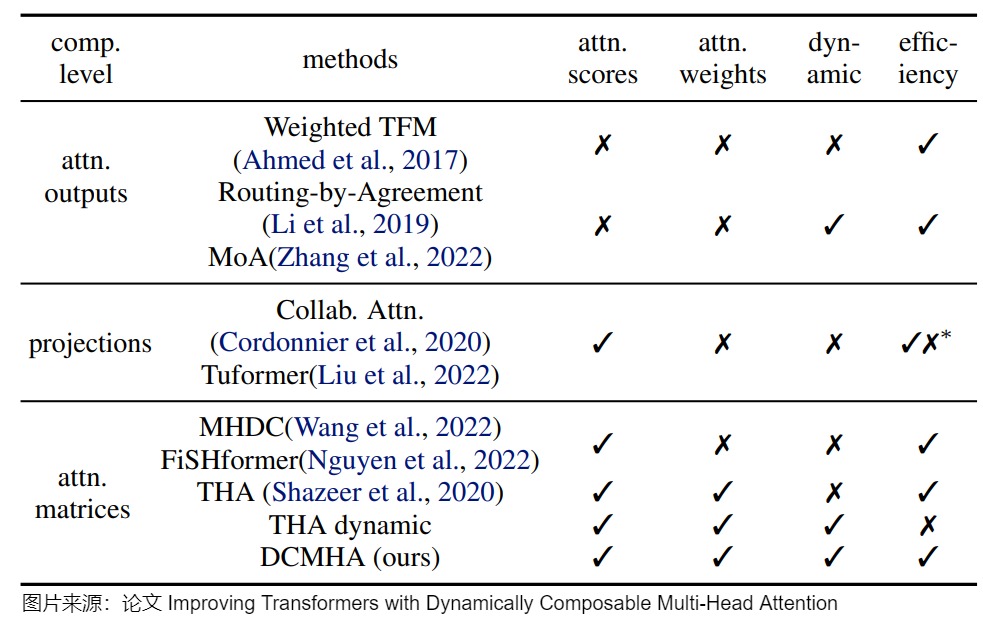
人們也對多頭注意力進行了一些改進。下圖給出了注意力頭合并方式的一些方案(head composition approaches)的比較。
4.1 MOHSA
Transformer模型成功的主要原因是不同 Token 之間的有效信息交換,從而使每個 Token 都能獲得上下文的全局視圖。然而,每個Head中的 Query 、 Key和Value 是分開的,沒有重疊,當在各個Head中計算注意力時也沒有信息交換。換句話說,在計算當前Head的注意力時,它沒有其他Head中的信息。盡管 Token 在注意力之后會通過線性投影進行處理,但那時的信息交換僅限于每個 Token。
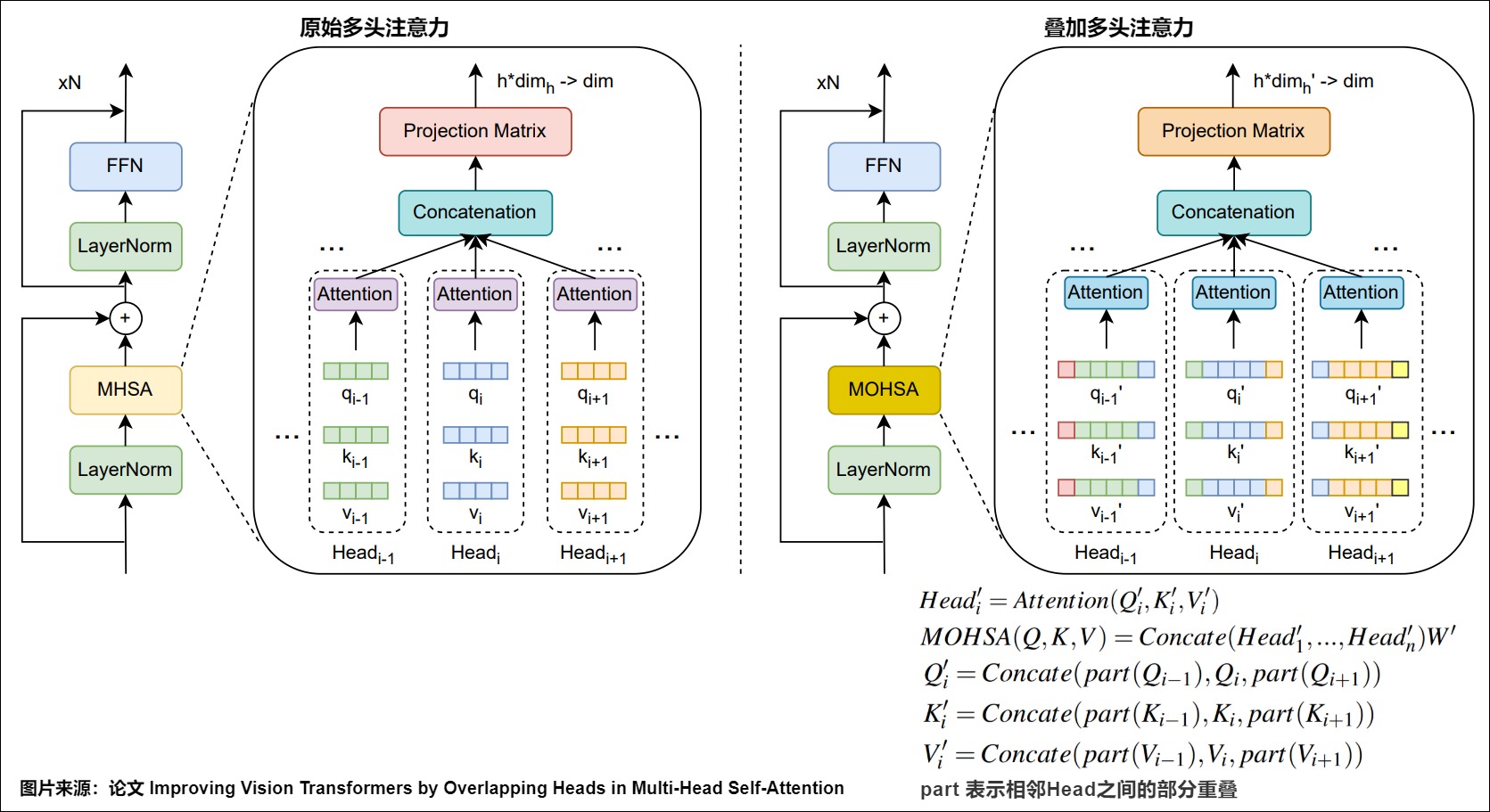
論文“Improving Vision Transformers by Overlapping Heads in Multi-Head Self-Attention”就對此進行了研究。作者提出信息交換在視覺 Transformer (Vision Transformers)的注意力計算過程中可以提高性能。這可以通過將每個Head的 queries、keys和values與相鄰Head的 queries、keys和values重疊來實現。為此,作者提出了一種名為MOHSA(Multi-Overlapped-Head Self-Attention/多重疊頭自注意力)的方法,通過重疊Head來改進多Head自注意力(Multi-Head Self-Attention)機制,使得在計算注意力時,每個Head中的 Q、 K和 V也可以被其相鄰Head的 Q、 K和 V所影響,Head間信息交流可以為視覺 Transformer 帶來更好的性能。如圖所示。
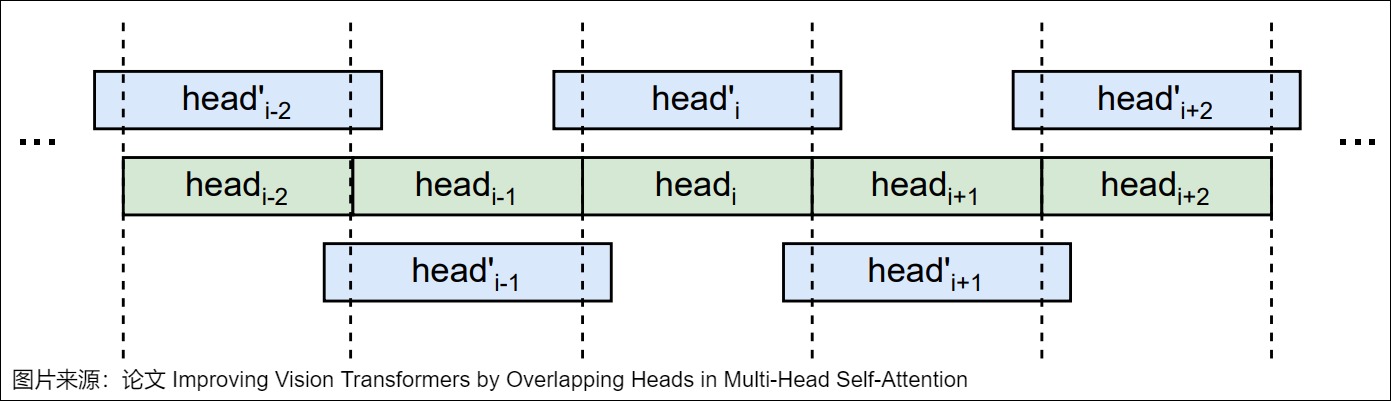
為了實現Head之間的信息交換,作者在Q、K和V被劃分為不同Head時,使用重疊(Soft)除而不是直接除。通過重疊相鄰Head,其他Head中的信息也可以參與當前Head的注意力計算。由于將不同Head的 Token 連接后,重疊會使 Token 維度增加,因此線性投影會將其減小回原始大小。
4.2 MoH
論文“MoH: Multi-Head Attention as Mixture-of-Head Attention”借鑒并非所有注意力頭都具有同等重要性的觀點,提出了混合頭注意力(Mixture-of-Head,MoH)的新架構,將注意力頭視為混合專家機制(Mixture-of-Experts,MoE)中的專家,這樣就升級了Transformer模型的核心——多頭注意力機制。MoH具有兩個顯著優點:
- 使每個詞元能夠選擇合適的注意力頭,從而提高推理效率而不犧牲準確率或增加參數數量;
- 用加權求和取代了多頭注意力的標準求和,為注意力機制引入了靈活性,無需增加參數數量,并釋放了額外的性能潛力。
MoH總體架構如下圖右側所示,包括多個注意力頭和一個路由器(激活Top-K個頭)。MoH的輸出是K個選定頭的輸出的加權和。

MoH主要改進如下圖所示。
- 共享頭:指定一部分頭為始終保持激活的共享頭,在共享頭中鞏固共同知識,減少其他動態路由頭之間的冗余。
- 兩階段路由:路由分數由每個單獨頭的分數和與頭類型相關的分數共同決定。相關路由分數公式如下圖標號1。
- 負載平衡損失:為避免不平衡負載,應用了負載平衡損失。公式如下圖標號2。
- 總訓練目標:總訓練損失是任務特定損失和負載平衡損失的加權和,公式如下圖標號3。其中β是權衡超參數,默認設置為0.01。

4.3 DCMHA
論文“Improving Transformers with Dynamically Composable Multi-Head Attention”提出用可動態組合的多頭注意力(DCMHA,Dynamically Composable Multi-Head Attention)來替換Transformer核心組件多頭注意力模塊(MHA),從而解除了MHA注意力頭的查找選擇回路和變換回路的固定綁定,讓它們可以根據輸入動態組合,從根本上提升了模型的表達能力。
可以把DCMHA近似理解為,原來每層有固定的H個注意力頭,現在用幾乎同樣的參數量和算力,可按需動態組合出多至HxH個注意力頭。這樣即插即用,可在任何Transformer架構中替換MHA,得到通用、高效和可擴展的新架構DCFormer。
研究背景
在Transformer的多頭注意力模塊(MHA)中,各個注意力頭彼此完全獨立的工作。這個設計因其簡單易實現的優點已在實踐中大獲成功,但同時也帶來注意力分數矩陣的低秩化削弱了表達能力、注意力頭功能的重復冗余浪費了參數和計算資源等一些弊端。基于此,近年來有一些研究工作試圖引入某種形式的注意力頭間的交互。
動機
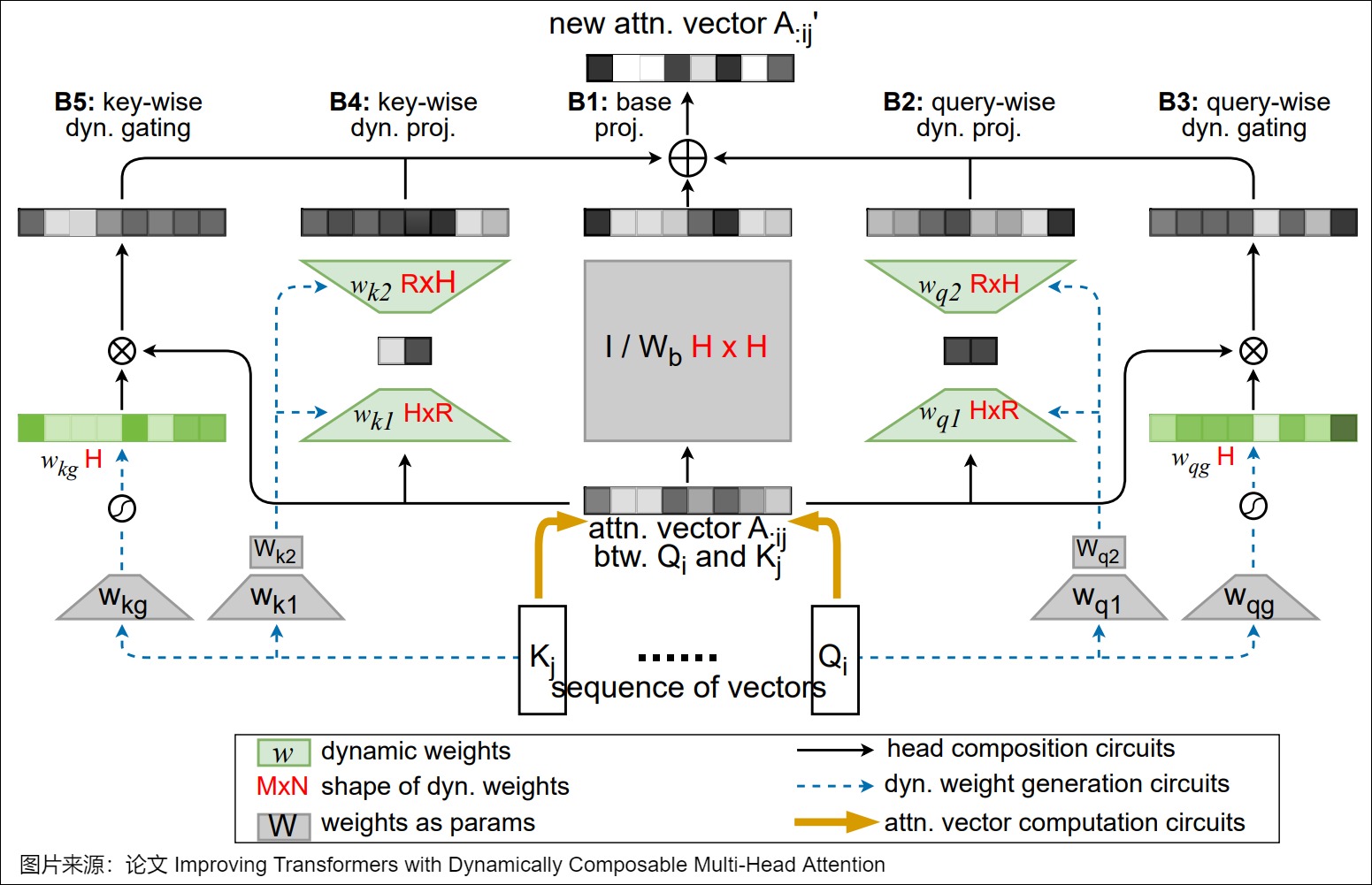
根據Transformer回路理論,在MHA中 ,每個注意力頭的行為由\(W^Q\)、\(W^K\)、\(W^V\)、\(W^O\)四個權重矩陣刻畫(其中\(W^O\)由MHA的輸出投影矩陣切分得到),其中:
- \(W^QW^K\)叫做QK回路(或叫查找選擇回路),決定從當前token關注上下文中的哪個(些)token
- \(W^OW^V\)叫做OV回路(或叫投影變換回路),決定從關注到的token取回什么信息(或投影什么屬性)寫入當前位置的殘差流,進而預測下一個token。
研究人員注意到,查找(從哪拿)和變換(拿什么)本來是獨立的兩件事,理應可以分別指定并按需自由組合,MHA硬把它們放到一個注意力頭的QKOV里“捆綁銷售”,限制了靈活性和表達能力。
思路
以此為出發點,本文研究團隊在MHA中引入compose操作,從而得到DCMHA如下圖所示。

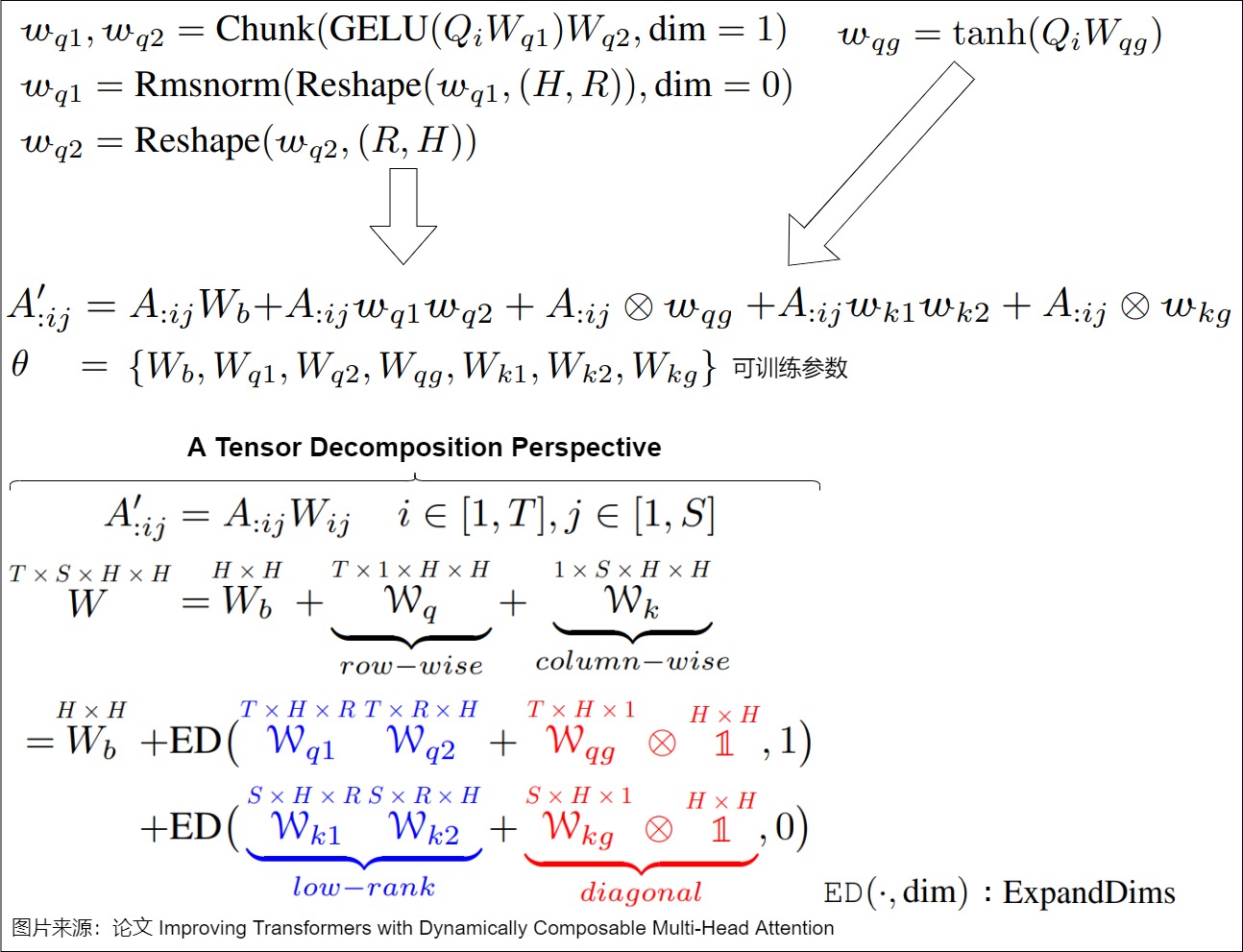
為了最大限度的增強表達能力,研究人員提出了動態決定注意力頭怎樣組合,即映射矩陣由輸入動態生成。為了降低計算開銷和顯存占用,他們進一步將映射矩陣分解為一個輸入無關的靜態矩陣\(W_b\)、兩個低秩矩陣\(w_1,w_2\)和一個對角矩陣\(Diag(w_g)\)之和,分別負責基礎組合、注意力頭間的有限方式(即秩R<=2)的動態組合和頭自身的動態門控。其中后兩個矩陣由Q矩陣和K矩陣動態生成。具體公式如下圖:
下圖給出了compose的計算方式。
0xFF 參考
On the Role of Attention Masks and LayerNorm in Transformers
MOH: MULTI-HEAD ATTENTION AS MIXTURE-OFHEAD ATTENTION
Improving Transformers with Dynamically Composable Multi-Head Attention
PaLM: Scaling Language Modeling with Pathways
Multi-Head-Attention的作用到底是什么 MECH
[硬核]徹底搞懂多頭注意力:全面解讀Andrej Karpathy MHA代碼 取個好名字真難
Transformer自下而上理解(5) 從Attention層到Transformer網絡
Multiscale Visualization of Attention in the Transformer Model
What Does BERT Look At? An Analysis of BERT’s Attention
Improving Deep Transformer with Depth-Scaled Initialization and Merged Attention
Adaptively Sparse Transformers
Analyzing Multi-Head Self-Attention: Specialized Heads Do the Heavy Lifting, the Rest Can Be Pruned
《Are Sixteen Heads Really Better than One?》
Transformer多頭自注意力機制的本質洞察 作者:Nikolas Adaloglou 編譯:王慶法
Transformer系列:Multi-Head Attention網絡結構和代碼解析 xiaogp
Transformer系列:殘差連接原理詳細解析和代碼論證 xiaogp
PaLM: Scaling Language Modeling with Pathways
MHA -> GQA:提升 LLM 推理效率 AI閑談 [AI閑談](javascript:void(0)??
Align Attention Heads Before Merging Them: An Effective Way for Converting MHA to GQA

 浙公網安備 33010602011771號
浙公網安備 33010602011771號