
探秘Transformer系列之(11)--- 掩碼
探秘Transformer系列之(11)--- 掩碼
0x00 概述
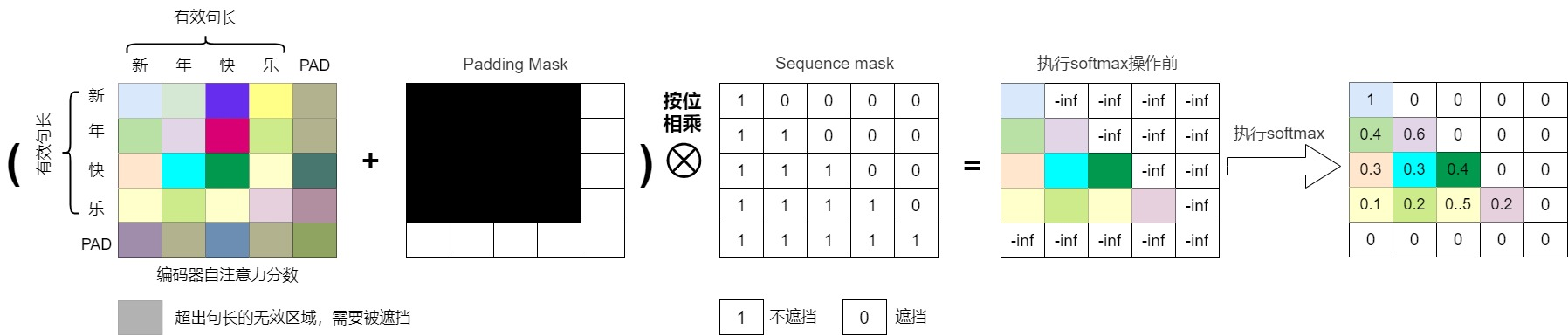
機器學習領(lǐng)域中,掩碼(Mask)本質(zhì)是一個跟需要掩蓋的目標張量大小一致的(大多數(shù)是0-1二值)張量,其思想最早起源于 word2vec 的CBOW的訓練機制:通過上下文來預測中心詞。掩碼就相當于把中心詞給遮掩住。不同的任務(wù)和應(yīng)用場景可能需要不同類型的mask操作。在自注意力模型中,常見的mask操作有兩種:Padding mask和Sequence mask。
-
Padding mask(填充掩碼):在處理變長序列時,為了保持序列的長度一致,通常會在序列的末尾添加一些特殊的填充符號(如
)。Padding mask的作用是將這些填充符號對應(yīng)位置的注意力分數(shù)設(shè)為一個很小的值(如負無窮),從而使模型在計算注意力分數(shù)時忽略這些填充符號,避免填充符號對計算產(chǎn)生干擾。 -
Sequence mask(序列掩碼):在某些任務(wù)中,為了避免模型在生成序列時看到未來的信息,需要對注意力分數(shù)進行掩碼操作。Sequence mask的作用是通過構(gòu)建下三角(或者上三角)的注意力分數(shù)矩陣,將當前位置之后位置的注意力分數(shù)設(shè)為一個很小的值,從而使模型只關(guān)注當前 token 與之前 token 的注意力關(guān)系,不理會它與后續(xù) token 的關(guān)系。這樣可以保證模型在生成序列時只依賴于已經(jīng)生成的部分,不會受到未來信息的影響,即只”看”當前及前面的 tokens。也有把Sequence mask叫做Casual Mask的。
使用掩碼的自注意力機制就叫做掩碼自注意力機制,也被稱為因果自注意力(Causal Self-Attention)。
0x01 需求
我們先來仔細分析一下為何需要掩碼。
1.1 避免偏差
實際情況
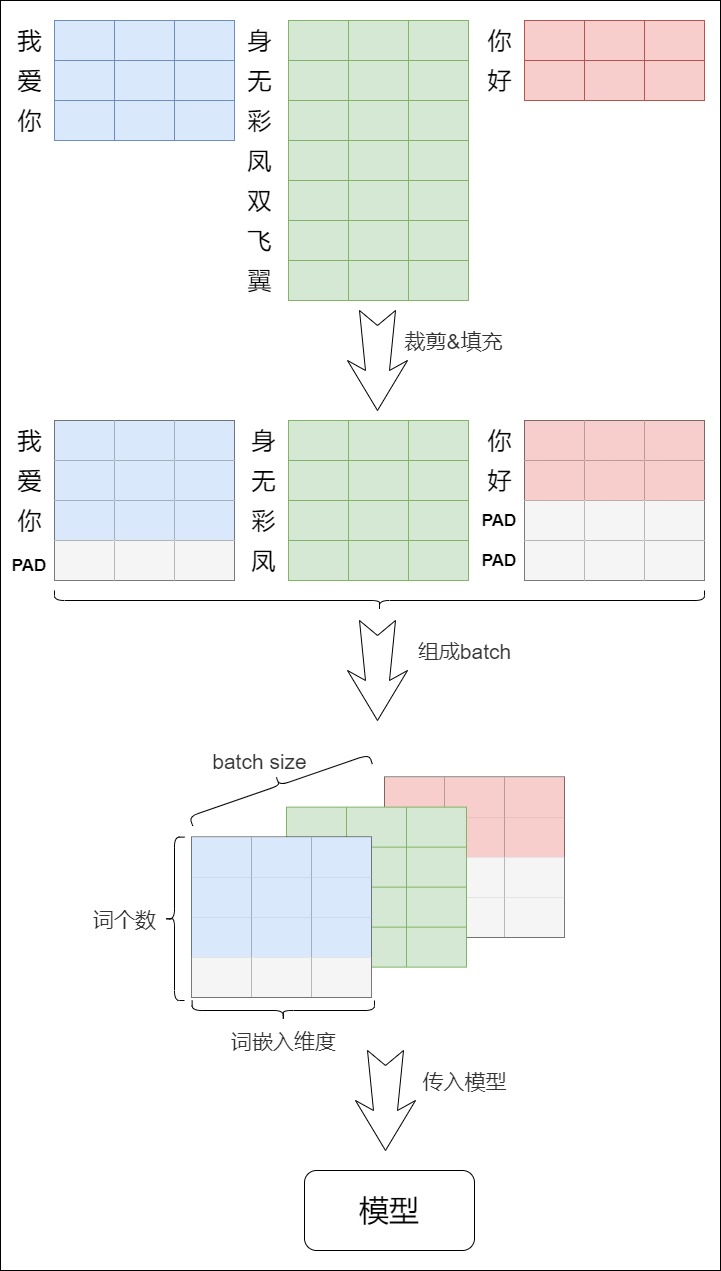
在神經(jīng)網(wǎng)絡(luò)的訓練過程中,同一個batch會包含有多個文本序列,不同的序列長度并不一定會一致。而神經(jīng)網(wǎng)絡(luò)的輸入需要一個規(guī)整的張量。為了符合模型的輸入方式,在數(shù)據(jù)集的生成過程中,我們要對輸入序列進行對齊,使同一個batch內(nèi)所有序列的長度一致。具體來說就是:
- 但是如果輸入的序列太長,我們會截取左邊的內(nèi)容,把多余的單詞直接舍棄。
- 在較短的序列后面用特殊符號來填充(比如填
)。
具體參見下圖。圖上展示了將多個句子組成一個batch時會遇到的情況:句子的長度是不同的。我們要對所有的句子按照預先設(shè)定的最長長度做填充或者裁剪,形成多個長度一樣的句子,才能組成batch(一個三維的張量),送入模型進行訓練。
問題所在
上述方案在注意力計算時會遇到問題:因為如果在注意力的計算過程中考慮到填充位置上的信息,則會給最終結(jié)果帶來誤差。我們來具體分析下。
假設(shè)某一行向量是 \([x_1, x_2, ..., x_V]\),行向量中某一個元素是\(x_i\),原生softmax的計算公式如下:
算法流程需要兩個循環(huán),首先需要迭代計算分母的和,然后再迭代計算向量中每一個值對應(yīng)的softmax值,即縮放每一個元素。因為填充詞是人為添加的,其實沒什么意義,在計算注意力分數(shù)時,我們通常不希望模型將注意力放在這些無關(guān)緊要的填充的詞上,不要浪費計算資源。我們也不希望這些位置參與后期的反向傳播過程。以此避免最后影響模型自身的效果。然而實際上,padding數(shù)值一般來說是0,\(e^0\)的數(shù)值為1,因此softmax中被padding的部分就參與了運算。這些無效部分參與運算會產(chǎn)生很大隱患,會導致注意力分數(shù)會出現(xiàn)偏差,影響全局概率值。所以我們需要進行一些處理。
解決方案
直覺的解決方案是:模型應(yīng)該把注意力聚焦在實際有意義的詞上,所以我們要找到所有非填充(nonpad)token,然后只計算這些非填充token的損失函數(shù)。當然我們也可以反向思考,用mask讓這些無效區(qū)域不參與運算。這就是padding mask。
1.2 防止偷看
實際情況
首先,我們回憶下注意力計算公式如下,我們需要針對整個輸入序列進行注意力計算。
其次,編碼器和解碼器的運行方式不同:
- Encoder因為要編碼整個句子,每個詞都需要考慮上下文的關(guān)系。所以每個詞在計算的過程中都是可以看到句子中所有詞的。
- 但是Decoder實質(zhì)上是一個單向的自注意力結(jié)構(gòu),每個詞都只能看到前面詞的狀態(tài)。原因如下:推理階段是自回歸模式,是一個詞一個詞輸入的,Decoder是不知道下文信息的。所以每次decoder只能看到之前自己生成的token和prompt,因此自然也無法計算得到當前詞和下文還沒出現(xiàn)詞的注意力。
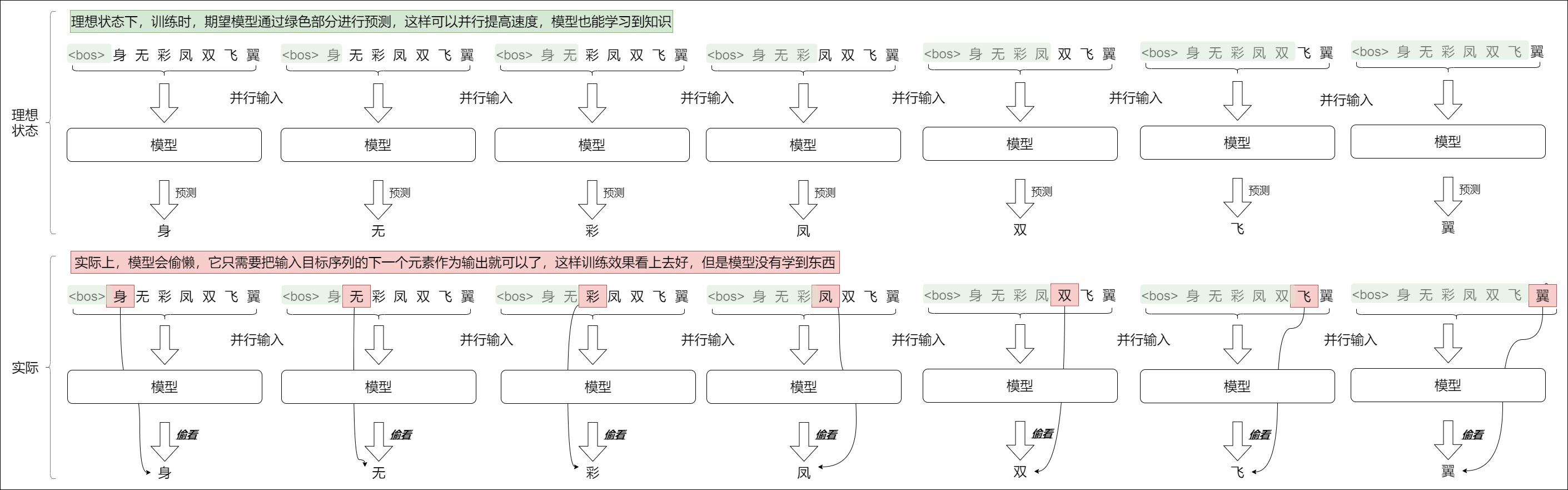
解碼器這種運行方式導致其在訓練時候需要做特殊處理。因為訓練階段采用自回歸模式,會導致訓練速度過慢。如前文所述,為了加快訓練速度,人們采用了Teacher Foring。即采用類似編碼器中的矩陣并行算法,一步就把所有目標單詞預測出來。這樣做有兩個好處,一是通過多樣本并行計算能夠加快網(wǎng)絡(luò)的訓練速度;二是在訓練過程中直接喂入解碼器正確的結(jié)果而不是上一時刻的預測值(因為訓練時上一時刻的預測值可能是錯誤的),可以讓訓練更快收斂。
我們暫時先忘記Teacher Forcing,假定我們就是要進行并行計算。最樸素的訓練方法應(yīng)該是基于一個長為 n 的預測序列來構(gòu)造 n 條樣本(每個樣本就是完整的預測序列),把這些樣本并行輸入到模型。對于第一個樣本,模型就根據(jù)

問題所在
目前每個樣本實際包括了整個句子。但是Decoder 在解碼第 t 個時刻的時候只能使用 1...t 時刻的輸入,而不能使用 t+1 時刻及其之后的輸入,即模型只應(yīng)該依據(jù)部分輸入來進行預測。把整個句子(完整的目標序列)一次性輸入給解碼器就是問題所在。因為模型已經(jīng)知道了全部句子內(nèi)容。因此,在預測某個位置的詞時,解碼器可以使用該詞之前的目標詞以及該詞之后的目標詞。這使得解碼器可以通過使用未來 "時間步 "的目標詞來 "作弊"。比如基于”我愛“來預測”我愛中國“。在輸出愛的時候,模型會用到后面“中國”的信息。
俗話說“天機不可泄露”。要是模型能未卜先知地知道自己下一步將要輸出什么,模型很容易學會偷懶,它就不用費勁計算這個輸出了,只需要把輸入目標序列的下一元素作為輸出就可以了,這樣訓練就沒有效果。另外,因為attention layer是有很多層的。在第一層,當前token \(X_{n}\)融合了下一個token \(X_{n+1}\)的信息,在下一層attention layer計算時,token \(X_{n+1}\)會看到\(X_{n}\)中包含的\(X_{n+1}\), 這樣在預測token \(X_{n+1}\)的時候,使用自己的信息預測自己,這顯然也是一種信息泄露。
所以我們在訓練的時候,解碼器不應(yīng)該提前知道下文的信息,不能計算當前詞和后面的詞的注意力,而只能計算當前詞和前面所有詞的注意力。
解決方案
為了確保模型在這一時點上不會受到未來詞匯的干擾,解碼器采用了sequence mask。 其作用就是在 time_step 為 t 的時刻,把 t 之后的信息給隱藏起來。使得 decoder 只能看到目標序列的一部分(前綴),不能看見未來的信息。即對于一個序列,我們的解碼輸出應(yīng)該只能依賴于 t 時刻之前的輸出,而不能依賴 t 之后的輸出。這就是Sequence mask。可以將這個過程想象為一個時間線:在預測一個特定的詞時,你不能“預知”它之后的詞匯,因為在實際情境中,之后的部分尚未發(fā)生。
總結(jié)一下,Padding Mask的作用是避免填充符號帶來的偏差。Sequence mask的作用是屏蔽未來信息,防止偷看,保證每個位置只能看到前面的tokens。
0x02 Padding Mask
我們接下來看看Padding Mask如何實現(xiàn)。
2.1 邏輯
核心邏輯就是讓填充詞在經(jīng)過softmax操作不應(yīng)該有對應(yīng)的輸出。
掩碼矩陣
研究人員找到的一個方法就是在訓練時使用掩碼矩陣。對于已經(jīng)padding到同一長度的一個batch中的句子,在應(yīng)用softmax函數(shù)之前,使用掩碼矩陣把將補全的位置給掩蓋掉。掩碼矩陣有不同實現(xiàn)方式:
- 矩陣每個值都是一個 Boolean,值為 false 的地方就是我們要進行處理的地方。
- 在掩碼矩陣中,填充詞的對應(yīng)位置放置一個非常大的負數(shù)(如-1e9),否則放置0。
在經(jīng)過掩碼矩陣處理之后,這些被掩蓋位置在經(jīng)過softmax激活函數(shù)后,得到的注意力分數(shù)(Attention Score)會歸零或者接近于0,這樣對應(yīng)位置的token表征就不參與上文提到的按照權(quán)重加和的過程,即沒有注意力分配到這個上面,不再影響全局概率的預測。
計算注意力步驟
加入mask之后的注意力計算的具體步驟如下:
-
創(chuàng)建一個掩碼矩陣。如果輸入序列中的某個位置是填充詞,則在掩碼矩陣的對應(yīng)位置放置一個非常大的負數(shù)(如-1e9),否則放置0。
-
將掩碼矩陣加到注意力分數(shù)上。因為掩碼矩陣中填充詞的位置是非常大的負數(shù),加上它們之后,這些位置的注意力分數(shù)也會變成非常大的負數(shù)。
-
應(yīng)用softmax函數(shù)。在加了掩碼的注意力分數(shù)上應(yīng)用softmax函數(shù)。由于填充詞位置的分數(shù)是非常大的負數(shù),經(jīng)過softmax函數(shù)后,這些位置的權(quán)重將接近于0,而其他位置的權(quán)重將保持不變(因為softmax是一個歸一化函數(shù))。
-
計算加權(quán)和。使用softmax的輸出作為權(quán)重,計算值(Value)的加權(quán)和。
下圖中,上方是編碼器輸入對應(yīng)的掩碼操作,下方是解碼器輸入對應(yīng)的掩碼操作。

2.2 實現(xiàn)
我們來分析哈佛代碼,為了更好的說明,我們把padding的代碼一起加入進來。
設(shè)置填充符號
我們以目標句子為例,在數(shù)據(jù)加載時,collate_batch()函數(shù)會為目標句子加入掩碼。
def collate_batch(
batch, # 句子對的列表
max_padding=128, # 句子最大長度
pad_id=2,
):
# 省略其它代碼
processed_tgt = torch.cat( # 獲取目標句子
[
bs_id,
torch.tensor(
tgt_vocab(tgt_pipeline(_tgt)),
dtype=torch.int64,
device=device,
),
eos_id,
],
0,
)
"""
調(diào)用torch.pad()函數(shù)對processed_src進行處理,如果processed_src的長度小于max_padding,則使用pad_id進行填充,如果大于max_padding,則截斷。
然后把處理后的processed_tgt加入到tgt_list。
"""
tgt_list = []
tgt_list.append(
pad(
processed_tgt,
(0, max_padding - len(processed_tgt)),
value=pad_id,
)
)
# 省略其它代碼
建立mask
此處把Batch類中關(guān)于mask的部分拿出來再進行分析。生成src_mask的語句比較簡單,只有self.src_mask = (src != pad).unsqueeze(-2) 這一行代碼,其主要起到兩個作用:
- 把src中非pad的部分置為True,pad部分置為False。假設(shè)某個句子內(nèi)容是[0, 3, 1, 2, 2],則其對應(yīng)的掩碼是[True, True, True, False, False]。“
”、“ ”和“ ”算作句子成分,因此不做掩碼處理。 - 使用unsqueeze()函數(shù)增加一維度,因為后續(xù)src_mask要和注意力分數(shù)進行掩碼計算,而注意力分數(shù)是三個維度,所以這里要保持一致。最終src_mask返回的是一個布爾矩陣,其形狀是[批量大小,1,句子最長長度]。其中第i行第j列表示的是query的第i個詞對key的第j個詞的注意力是否無意義。若無意義則為True,有意義的為False(即被padding的位置是True)。后續(xù)在處理mask時,為False的位置是需要被mask掉的,True的位置是不需要動的。處理之后,占位符就無法吸收到query的注意力。
class Batch:
def __init__(self, src, tgt=None, pad=2): # 2 = <blank>
self.src = src # 源語言句子列表,形狀是[batch_size,Length]
# 創(chuàng)建源語言的掩碼,這樣可以忽略填充部分,unsqueeze()的作用是增加一維度,因為后續(xù)要和注意力分數(shù)進行掩碼計算,而注意力分數(shù)是三個維度,所以這里要保持一致。
# (src != pad)返回一個等大的布爾張量,src元素等于pad的位置為False,否則為True
# unsqueeze(1)作用是增加了一個維度,變成pad_attn_mask: [batch_size,1,seq_len]
# 最終得到返回一個[batch_size, 1, seq_len]大小的布爾張量,F(xiàn)alse是需要mask掉的位置
self.src_mask = (src != pad).unsqueeze(-2)
實施mask
具體應(yīng)用掩碼矩陣的代碼位于 attention()函數(shù)中。注意,此時是把padding mask和sequence mask都在一起應(yīng)用。
def attention(query, key, value, mask=None, dropout=None):
"Compute 'Scaled Dot Product Attention'"
# 先計算注意力分數(shù)
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
# 在query和key的轉(zhuǎn)置相乘得出(len_q,len_k)這個注意力分數(shù)矩陣以后,使用mask來掩蓋相乘結(jié)果矩陣,此處把創(chuàng)建掩碼矩陣和應(yīng)用掩碼矩陣合二為一
if mask is not None:
# 如果發(fā)現(xiàn)mask是0,就用-1e9來替換它
scores = scores.masked_fill(mask == 0, -1e9)
# 然后才開始實施softmax操作
p_attn = scores.softmax(dim=-1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
0x03 Sequence mask
3.1 邏輯
Sequence mask的核心邏輯是:解碼的時候掩蓋掉當前時刻之后的信息。因此我們需要想一個辦法,把 t 之后的信息給隱藏起來。Sequence mask操作只針對自回歸模型的訓練過程和推理時的 prefill 階段,推理時的 decode 階段無需應(yīng)用 mask 操作。但是因為方便實現(xiàn),代碼依然使用同一套。
掩碼矩陣
我們需要產(chǎn)生一個Mask 矩陣,在計算注意力的時候,加入這個掩碼(mask)。通過設(shè)計合適的mask,就可以實現(xiàn)在輸出每一個元素的時候,切斷它從未來獲得信息的通路(把對應(yīng)的注意力強制置零),這樣就可以屏蔽或限制模型在計算注意力分數(shù)時對某些位置的關(guān)注。這個mask矩陣的特點如下:
- 該矩陣的形狀跟注意力分布矩陣一樣,尺寸為 [seq_len, seq_len]。
- 從矩陣內(nèi)容上來看,這是一個下三角矩陣。內(nèi)容依據(jù)實際情況而定,如果是布爾矩陣,可以上三角的值全為 0,下三角的值全為1,對角線也是 1。如果是浮點矩陣,可以把上三角的值賦值為負無窮。這樣可以單獨調(diào)節(jié)每一個源元素與每一個目標元素之間的注意力強度。
- 在進行softmax計算之前,把這個矩陣作用在每一個序列上。即在 \(QK^T\) 點積上施加掩碼,被屏蔽的元素被設(shè)置為負無窮大(表示它們是“無限不相似”的,即互不相關(guān))。就是讓query(t)和未來時刻的key的內(nèi)積值為負無窮大(-inf)。
- 在作Softmax操作時,模型會把這些負無窮大值所對應(yīng)的權(quán)重變成零。后續(xù)再乘V的時候,當前的位置就無法看到后面的詞信息了。所以計算t時刻概率時只用到了t-1以前時刻的key-value對的信息。
通過這個操作,我們就可以一次性計算整個Decoder輸出序列的損失,而不用逐個Token計算,這個過程就是我們之前提到的Teacher Forcing。
Mask 矩陣示例如下,這是個10維度的下三角矩陣。當解碼第一個字的時候,第一個字只能與第一個字計算相關(guān)性,當解出第二個字的時候,只能計算出第二個字與第一個字和第二個字的相關(guān)性。
[[1, 0, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 0, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 0, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 0, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 0, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 0, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 0, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 0, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 0],
[1, 1, 1, 1, 1, 1, 1, 1, 1, 1]]
具體公式如下。
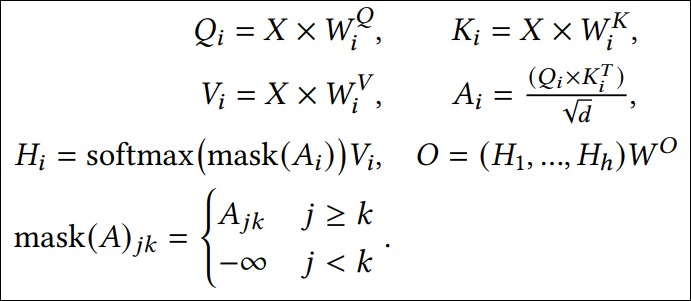
掩碼自注意力
我們接下來再看看Masked Self-Attention。在解碼Decoder Block中,輸入序列首先遇到的是Masked Self-Attention(所謂Masked,即遮蔽的意思)。Masked Self-Attention的Q,K,V均來自同一個部分,滿足max_len_q = max_len_k_v = max_len。masked multi-head self-attention與上面描述的multi-head Attention計算過程的不同之處在于score矩陣送入到softmax計算weight矩陣先進行一步mask操作。即句子中的每個詞,都只能對包括自己在內(nèi)的前面所有詞進行Attention,這實質(zhì)是單向Transformer。也向我們展示了Masked Self-Attention的設(shè)計動機:防止模型看到未來時刻的輸入,也保證了訓練時和預測時解碼器運行的情況是一樣的。
我們用第一個解碼器層來解釋其操作序列如下。
-
經(jīng)過Input embedding和位置編碼之后,得到詞嵌入\(\mathbf{X}\)。
-
\(\mathbf{X}\)分別乘以三個權(quán)重矩陣,\(\mathbf{W^q}\),\(\mathbf{W^k}\),\(\mathbf{W^v}\),經(jīng)過三次線性變化,得到\(\mathbf{Q}\),\(\mathbf{K}\),\(\mathbf{V}\)矩陣。
-
\(\mathbf{Q}\)矩陣乘以\(\mathbf{K}\)矩陣的轉(zhuǎn)置矩陣,得到\(\mathbf{QK^T}\),即注意力分數(shù)分布。
-
\(\mathbf{QK^T}\)乘以一個Mask矩陣,按位相乘,得到遮蔽的注意力分數(shù)分布(\(Masked \ \mathbf{QK^T}\)),保存此次解碼應(yīng)該看到的,隱藏看不到或者不應(yīng)該看到的。即保持score矩陣的下三角部分不變,將上三角部分全部mask掉,置為負無窮。這樣處理后,score矩陣的第i行,即q對應(yīng)的第i個時間步,只保留了q與前i個時間步的k的關(guān)系得分,后面的部分都被mask掉了。
-
\(Masked \ \mathbf{QK^T}\)經(jīng)過softmax操作,得到\(\mathbf{A} = \text{softmax}(\mathbf{Q}\mathbf{K}^\top / \sqrt{d_k})\)。顯然被mask掉(置為-inf)的部分經(jīng)過softmax處理都變成了0(無限接近0),即weight矩陣的第i行中,前i個權(quán)重之和為1,后面的權(quán)重都為0。
-
\(\mathbf{A}\)乘以\(\mathbf{V}\)矩陣,最終得到\(\mathbf{Z}\)矩陣。將mask后的weight與V矩陣相乘。前面的討論已經(jīng)知道,\(\mathbf{Z}\)矩陣的第i行,是V中的所有行基于weight矩陣第i行中的各個權(quán)重進行加權(quán)平均的結(jié)果,然而經(jīng)過mask處理,weight矩陣的第i行中只剩下了前i個權(quán)重值,也就是說,context矩陣的第i行實際上是由V的前i行加權(quán)平均的結(jié)果。
\[\mathbf{Z_i} = \sum_{j=1}^{max\_len} weight(i,j) \cdot v(j) = \sum_{j=1}^i weight(i,j) \cdot v(j) \]此外,Y中每句話的第一個單詞是開始符號的編碼,所以Y中實際信息的時間步向前錯了一位,因此,在masked multi-head self-attention結(jié)構(gòu)中,計算第i個時間步的context信息時實際上只是使用前i-1個時間步的信息。
-
以上說的是單一注意力頭得到的矩陣\(\mathbf{Z_i}\),如果是多頭注意力,則把多個\(\mathbf{Z_i}\)拼接之后,經(jīng)過線性變換,得到最終的\(\mathbf{Z}\)矩陣。
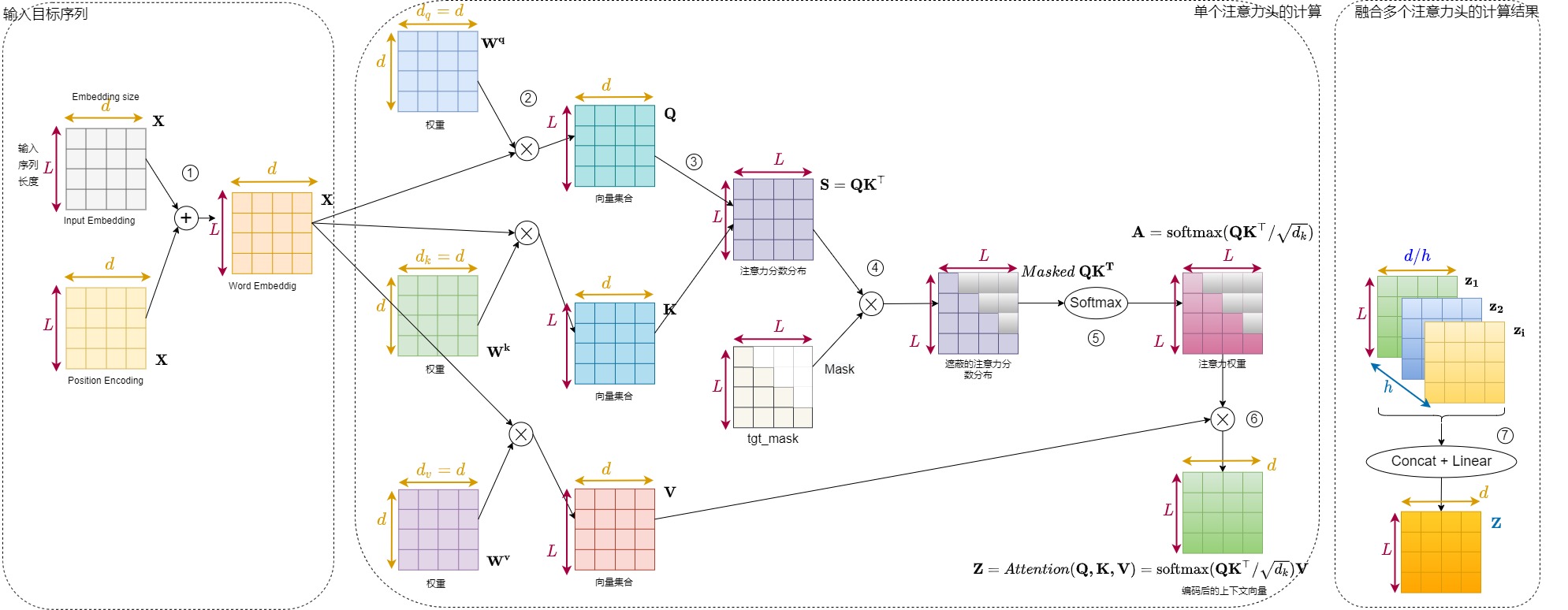
交叉注意力
現(xiàn)在思考一個問題:masked attention后面的cross-attention需要也加一個attention mask嗎?答案是不需要。
解碼器內(nèi)部的帶有mask的MultiHeadAttention的qkv向量輸入來自目標單詞嵌入或者前一個解碼器輸出,三者是相同的,但是后面的MultiHeadAttention的qkv向量中的kv來自最后一層編碼器的輸入,而q來自帶有mask的MultiHeadAttention模塊的輸出。因為encoder可以看到整條輸入序列,已經(jīng)獲得了全量信息,所以decoder這一條Q可以看到context vector全部的K和V。換句話說,在訓練和預測的時候,我們是允許decoder看到目標序列輸入的全部信息的,這些信息不需要 mask。但是在實際操作時還是需要加一個src_mask,就是源語言的padding mask。
總結(jié)下,對于解碼器,實際操作會將兩種掩碼合并,每個位置取最小值,相當于兩個掩碼只要有任意一種情況需要被遮蔽,則就應(yīng)該被遮蔽。具體可以參見下圖。
3.2 實現(xiàn)
生成掩碼
此處把Batch類中關(guān)于mask的部分拿出來再進行分析。
生成src_mask的語句比較簡單,只有self.src_mask = (src != pad).unsqueeze(-2) 這一行代碼。 具體如上面Padding mask實現(xiàn)中解析,這里不再贅述。
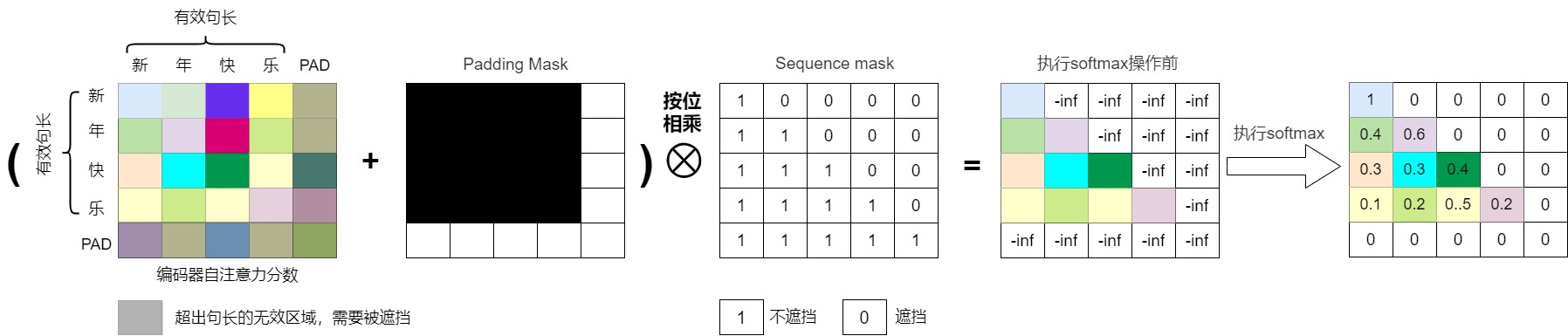
生成tgt_mask則比較復雜,具體邏輯在make_std_mask()函數(shù)中。tgt_mask與src_mask略有不同,除了需要蓋住pad部分,還需要將對角線右上的也都蓋住。就是要結(jié)合填充詞對應(yīng)的掩碼和未來詞匯相關(guān)的掩碼。make_std_mask()函數(shù)的邏輯如下:
-
首先生成填充詞對應(yīng)的掩碼。假設(shè)某個句子內(nèi)容是[0, 3, 1, 2, 2],則其對應(yīng)的掩碼是[True, True, True, False, False]。
-
然后調(diào)用subsequent_mask()函數(shù)來生成未來詞匯相關(guān)的掩碼,這是一個對角線以及之下都是True的矩陣,具體掩碼如下。
[[ [ True, False, False, False, False ], [ True, True, False, False, False ], [ True, True, True, False, False ], [ True, True, True, True, False ], [ True, True, True, True, True ], ]] -
最后填充詞對應(yīng)的掩碼和未來詞匯相關(guān)的掩碼會做與操作,得到最終掩碼如下
[[ [ True, False, False, False, False ], [ True, True, False, False, False ], [ True, True, True, False, False ], [ True, True, True, False, False ], [ True, True, True, False, False ], ]]
make_std_mask()函數(shù)的源碼如下。
@staticmethod
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
# 生成填充詞對應(yīng)的掩碼,用于忽略填充部分
tgt_mask = (tgt != pad).unsqueeze(-2) # 創(chuàng)建目標語言的掩碼,用于忽略填充部分
"""
subsequent_mask()函數(shù)會生成未來詞匯相關(guān)的掩碼。然后再和tgt_mask進行與操作,得到最終掩碼
tgt.size(-1) 表示的是序列的長度
"""
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
)
return tgt_mask
subsequent_mask()函數(shù)的源碼如下。
def subsequent_mask(size):
"""
Mask out subsequent positions.
該方法在會在構(gòu)建tgt的mask時使用。
"""
# 首先需要定義掩碼張量的形狀,具體會生成一個Shape為(1, size, size)的矩陣
# 前面加個1是為了和tgt的維度保持一致,因為tgt的第一維是batch_size
attn_shape = (1, size, size)
# 首先使用torch.triu()函數(shù)產(chǎn)生一個上三角陣,幾個注意點是:
# 1. diagonal=1意為不包含主對角線(從主對角線向上偏移1開始)
# 2. 使用np.ones方法向矩陣中添加1元素,形成上三角陣(左上角全為1)
# 3. 為了節(jié)約空間, 使上三角陣的數(shù)據(jù)類型變?yōu)閡nit8
subsequent_mask = torch.triu(torch.ones(attn_shape), diagonal=1).type(
torch.uint8
)
# subsequent_mask == 0其實是做了一個三角陣的反轉(zhuǎn), subsequent_mask中的每個元素都會被1減,這樣將 0全部變?yōu)門rue, 1變?yōu)镕alse
return subsequent_mask == 0
我們打印輸出看看。print(subsequent_mask(5))的結(jié)果如下。
tensor([[[ True, False, False, False, False],
[ True, True, False, False, False],
[ True, True, True, False, False],
[ True, True, True, True, False],
[ True, True, True, True, True]]])
它輸出的是一個方陣,該方陣對角線與左下全為True,右上全為False。第一行只有第一列是 True,它的意思是時刻 1 只能 attend to 輸入 1,第三行說明時刻 3 可以 attend to 1,2,3 而不能attend to 4,5 的輸入,因為對于 Decoder 來說,這是屬于未來的信息。
施加掩碼
和前面padding mask是合并在一起施加的,此處不再贅述。
3.3 Transformer
我們再來看看Transformer的代碼,基本和哈佛思路一致,只是加上了kv cache。
# Copied from transformers.models.bart.modeling_bart._make_causal_mask
def _make_causal_mask(
input_ids_shape: torch.Size,
dtype: torch.dtype,
device: torch.device,
past_key_values_length: int = 0,
):
"""
Create a causal mask for bi-directional self-attention.
Args:
input_ids_shape (torch.Size): The shape of input_ids tensor, typically (batch_size, tgt_len).
dtype (torch.dtype): The data type of the mask.
device (torch.device): The device on which the mask will be placed.
past_key_values_length (int, optional): The length of past key values. Default is 0.
Returns:
torch.Tensor: The causal mask tensor.
"""
bsz, tgt_len = input_ids_shape
mask = torch.full((tgt_len, tgt_len), torch.finfo(dtype).min, device=device)
mask_cond = torch.arange(mask.size(-1), device=device)
mask.masked_fill_(mask_cond < (mask_cond + 1).view(mask.size(-1), 1), 0)
mask = mask.to(dtype)
if past_key_values_length > 0:
mask = torch.cat(
[
torch.zeros(
tgt_len, past_key_values_length, dtype=dtype, device=device
),
mask,
],
dim=-1,
)
return mask[None, None, :, :].expand(
bsz, 1, tgt_len, tgt_len + past_key_values_length
)
0x04 數(shù)據(jù)流
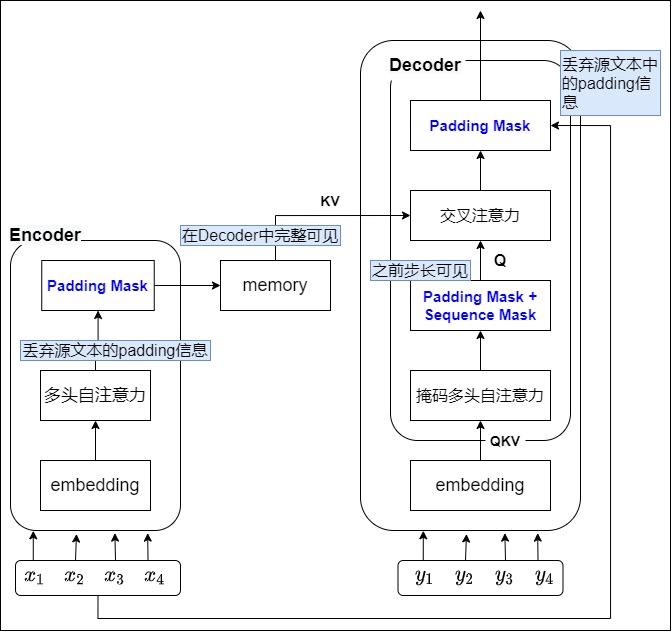
哈佛代碼中通過兩個變量把兩種掩碼做了糅合,又加上編碼器和解碼器兩個模塊的排列組合,讓人難以理解。我們再仔細梳理下數(shù)據(jù)流程。總的來說,對于兩種掩碼,其在編碼器和解碼器兩個模塊中的需求如下:
- 對于Encoder來說,不應(yīng)該注意
的部分,因為這不屬于句子成分。但是不需要防止“窺視未來信息”。 - 對于Decoder來說,前面的詞不應(yīng)該注意后面的詞,同時,也不能注意
的部分。padding mask 和sequence mask是可以同時存在的。
我們再給出一個表格,大家可以看到在代碼中兩個變量的特性。
| 變量名稱 | mask類型 | 編碼器Self-attention | 解碼器masked self-attention | 解碼器Cross-attention |
|---|---|---|---|---|
| src_mask | Padding Mask | 使用 | 不使用(padding的功能在tgt_mask中完成) | 使用 |
| tgt_mask | Padding Mask + Sequence Mask | 不使用 | 使用 | 不使用 |
4.1 如何應(yīng)用于注意力
我們首先看看兩種掩碼在邏輯上應(yīng)該用于哪個模塊的哪種注意力。
Padding Mask。只要有padding的地方,都會用到padding mask,所以Encoder和Decoder都有padding mask。
- 因為編碼時不需要對當前時刻之后的信息進行掩蓋,任何位置的信息都可以被任何位置的單詞獲取。所以編碼器的掩碼就只是padding mask。在自注意力中會用到。
- 對于解碼器來說:
- 在交叉注意力中會用到padding mask。
- 在自注意力中會用到padding mask。
Sequence Mask(Attention Mask)
-
解碼器 的 cross-attention不需要Sequence Mask。因為編碼器的輸出作為K和V,已經(jīng)知道了序列的所有信息。
-
在解碼器的Self-Attention里面會用到Sequence Mask。在 Decoder 中的 Self-attention 中:掩蔽的作用是,防止解碼器在當前時間步預測時 ,"偷看 "目標句余下幾個時間步的部分。所以對于 decoder 的 self-attention里面使用到的 scaled dot-product attention,同時需要padding mask 和 sequence mask 作為 attn_mask,具體實現(xiàn)就是兩個mask相加作為attn_mask。
實際上在交叉自注意力中,如果我們想限制 Decoder 只能獲取某一部分的 Encoder 信息,即 memory bandwidth,也可以使用mask。PyTorch里面就有memory mask,但一般場景下,我們允許 Decoder 獲取全部的 Encoder 信息,所以 memory mask 不常用到。
4.2 變量說明
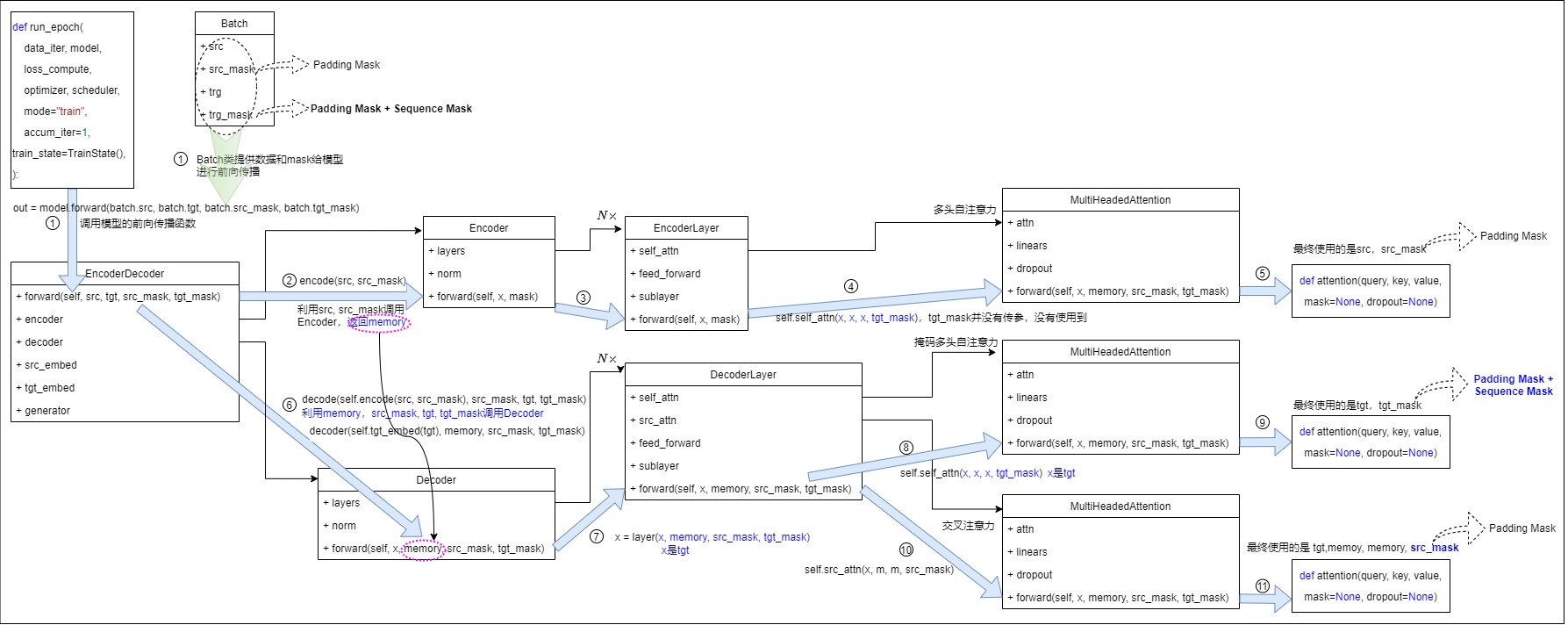
在代碼中,有兩個關(guān)于掩碼的變量:src_mask和tgt_mask。Encoder只會看src_mask。Decoder會看src_mask和tgt_task。src_mask就是Padding Mask,而tgt_mask是包含了padding mask和sequence mask的融合mask。
Batch類的代碼中設(shè)定掩碼有兩步,在這兩步設(shè)定之后tgt_mask就是融合掩碼。這兩步分別是:
- 第一步:設(shè)定padding mask;
- 第二步,設(shè)定padding mask限定之下的sequence mask;
具體代碼是:
def make_std_mask(tgt, pad):
"Create a mask to hide padding and future words."
# 一定要注意,這里有兩步
tgt_mask = (tgt != pad).unsqueeze(-2) # 第一步,設(shè)定padding mask
tgt_mask = tgt_mask & subsequent_mask(tgt.size(-1)).type_as(
tgt_mask.data
) # 第二步,設(shè)定padding mask限定之下的sequence mask
return tgt_mask
src_mask的形狀是(batch size, 1, 1, seq_length),這是因為:
- src要對句子中的填充詞做mask,所以只需要在最后一維做掩碼就行了。即其實用一個向量就夠了。
- 因為所有head的mask都一樣,所以第二維是1,masked_fill 時使用 broadcasting 就可以了。
- 這里是 self-attention 的mask,所以每個時刻都可以 attend 到所有其它時刻,所以第三維也是 1,也使用broadcasting。
tgt_mask形狀是(batch size, 1, seq_length, seq_length)。tgt需要斜著進行mask,所以需要一個方陣來進行,這個矩陣代表若干個時刻。
Encoder數(shù)據(jù)流
我們可以舉一個例子,為了簡單,我們假設(shè) batch=2,head=2,最大允許的序列長度為5, 第一個序列長度為 3,第二個為 5。分別如下:
[<bos>, 你,<eos>,<pad>, <pad>]。[<bos>, 你,好,嗎,<eos>]。
編碼器中的掩碼只是padding mask。因為padding位置的信息不需要帶有權(quán)重去干擾有實詞位置的embedding表征。掩碼形狀 為 (2, 1, 1, 5),我們可以用兩個向量表示:
- 第一個向量是$ \begin{Bmatrix} 1 & 1 & 1 &0 & 0 \end{Bmatrix} $。其含義是:第一個句子前3個是單詞,后面2個是填充。而mask就是要對后面2個進行mask。因此本序列的任一時刻可以同前 3 個時刻交互來計算注意力。
- 第二個向量是$ \begin{Bmatrix} 1 & 1 & 1 & 1 & 1 \end{Bmatrix} $。其含義是:本序列的任意單詞可以同所有時刻的輸入進行交互。
在實際運算中,因為是多頭,所以對于第一個序列,首先會對兩個頭進行broadcast,得到如下。
然后會施加掩碼,得到
對于第二個序列,也是兩個頭進行廣播,在掩碼前后序列的內(nèi)容都是
Decoder數(shù)據(jù)流
解碼器的掩碼自注意力中同時需要padding mask 和 sequence mask 的組合來作為 attn_mask。這是因為在解碼器模塊不僅要考慮padding導致的mask,還要考慮后詞偷看問題。:
-
答案是一起輸入的,而實際的部署場景是步進預測的,理論上當前步長是看不到當前步長之后的詞的信息的。
-
答案本身會進行該批次下的統(tǒng)一padding,因此還需要再疊加padding的mask掩碼,杜絕padding單詞對實詞的表征影響。
注意:上述信息僅僅對于訓練有效,然而為了保持代碼復用,所以推理時候也使用同樣的代碼。
具體實現(xiàn)就是將兩個掩碼合并,每個位置取最小值,相當于兩個掩碼只要有任意一種情況需要被遮蔽則就應(yīng)該被遮蔽。而 Decoder 的 src-attention 的 mask 形狀為 (2, 1, 5, 5)。
第一個序列的mask矩陣是兩個mask做與操作,其結(jié)果作為attn_mask。第一個是padding mask,第二個是sequence mask。即:
和
相與,得到
第二個序列的mask矩陣兩個mask相加作為attn_mask。因為是5個單詞,所以padding mask是全1。全1矩陣再與三角矩陣做與操作,得到如下。
實際運算中,對于第一個序列
掩碼之后得到
對于第二個序列
掩碼之后得到
4.3 使用
從掩碼角度出發(fā),訓練和推理的最大不同之處在于每個時間步的輸入?yún)^(qū)別。訓練過程中每個時間步的輸入是全部目標序列。推理過程中每個時間步的輸入,是直到當前時間步所產(chǎn)生的整個輸出序列。
為了在訓練時候模擬實際推理的效果,需要借助掩碼把后面單詞的信息隱藏掉,以是確保解碼器只能關(guān)注到它之前已經(jīng)生成的詞,而不能看到未來的詞。此邏輯是為了訓練特殊打造,因為訓練使用Teacher Forcing模式,需要讓前面的token不能觀察到后面token的信息。雖然推理時候所有輸入都是已知輸入,可以互相看到,不需要掩碼,但是為了保持一致,也保留了此處代碼和模型結(jié)構(gòu)。
訓練
接下來我們來追溯一下訓練時候的 mask 是怎么來的。我們最終構(gòu)建的模塊是 EncoderDecoder 類的實例,編碼器的參數(shù)是src_mask,解碼器的參數(shù)是src_mask和tgt_mask。
class EncoderDecoder(nn.Module):
def forward(self, src, tgt, src_mask, tgt_mask):
"Take in and process masked src and target sequences."
return self.decode(self.encode(src, src_mask), src_mask, tgt, tgt_mask)
def encode(self, src, src_mask):
return self.encoder(self.src_embed(src), src_mask)
def decode(self, memory, src_mask, tgt, tgt_mask):
return self.decoder(self.tgt_embed(tgt), memory, src_mask, tgt_mask)
我們接著深入到解碼器中看看其參數(shù)。在DecoderLayer類的forward()函數(shù)可以看到:
- 自注意力機制使用的是tgt_mask,作用是對目標語言做 padding mask。
- 交叉注意力機制使用src_mask,作用是對目標語言做sequence mask。
在多層 Transformer 的解碼過程中,每個 Decoder 在交叉注意力中所使用的 Memory 都是同一個。
class DecoderLayer(nn.Module):
"Decoder is made of self-attn, src-attn, and feed forward (defined below)"
def forward(self, x, memory, src_mask, tgt_mask):
"Follow Figure 1 (right) for connections."
m = memory
# 目標語言的自注意力, 這里 mask的作用就是用到上面所說的 softmax 之前的部分
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, tgt_mask))
# m 是encoder的輸出,x是decoder第一部分的輸出,因為上面一部分的輸出中, 未被預測單詞的 query 其實是 0(padding), 在這里可以直接使用 src_mask
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, src_mask))
# 最后是兩個線形層,
return self.sublayer[2](x, self.feed_forward)
最終進入注意力函數(shù)attention()中,這里不再贅述。
推理
對于推理,只有 prefill 階段需要 mask,用了 kv cache 優(yōu)化的 decode 階段不需要 mask 操作。在prefill時, 只有源語言輸入的 Batch,因此在 class Batch 中, trg 為 None。從下面代碼可以看出來,預測過程的 Attention Mask 設(shè)置了padding mask。
def example_simple_model():
V = 11
criterion = LabelSmoothing(size=V, padding_idx=0, smoothing=0.0)
model = make_model(V, V, N=2)
optimizer = torch.optim.Adam(
model.parameters(), lr=0.5, betas=(0.9, 0.98), eps=1e-9
)
lr_scheduler = LambdaLR(
optimizer=optimizer,
lr_lambda=lambda step: rate(
step, model_size=model.src_embed[0].d_model, factor=1.0, warmup=400
),
)
batch_size = 80
for epoch in range(20):
model.train()
run_epoch(
data_gen(V, batch_size, 20),
model,
SimpleLossCompute(model.generator, criterion),
optimizer,
lr_scheduler,
mode="train",
)
model.eval()
run_epoch(
data_gen(V, batch_size, 5),
model,
SimpleLossCompute(model.generator, criterion),
DummyOptimizer(),
DummyScheduler(),
mode="eval",
)[0]
# 在這里進行配置
model.eval()
src = torch.LongTensor([[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]])
max_len = src.shape[1]
src_mask = torch.ones(1, 1, max_len) # padding mask
# 這里調(diào)用到
print(greedy_decode(model, src, src_mask, max_len=max_len, start_symbol=0))
我們直接來看預測過程中的 decoder 的實現(xiàn)。
def greedy_decode(model, src, src_mask, max_len, start_symbol):
memory = model.encode(src, src_mask)
# memory 是 encoder 的中間結(jié)果
batch_size = src.shape[0]
ys = torch.ones(batch_size, 1).fill_(start_symbol).type_as(src)
# 預測句子的初始化
for i in range(max_len-1):
out = model.decode(memory, src_mask, ys, transformer.subsequent_mask(ys.size(1)).type_as(src))
# ys 的維度是 batch_size * times, 所以target_mask 矩陣必須是 times * times
# 根據(jù) decoder 的訓練步驟, 這里的 out 輸出就應(yīng)該是 batch_size * (times+1) 的矩陣
prob = model.generator(out[:, -1])
# out[:, -1] 這里是最新的一個單詞的 embedding 向量
# generator 就是產(chǎn)生最后的 vocabulary 的概率, 是一個全連接層
_, next_word = torch.max(prob, dim = 1)
# 返回每一行的最大值, 并且會返回索引
next_word = next_word.unsqueeze(1)
ys = torch.cat([ys, next_word.type_as(src)], dim=1)
# 將句子拼接起來
return ys
上面代碼的 transformer.subsequent_mask(ys.size(1)).type_as(src) 這一部分就很好的解釋了 target_mask 矩陣的構(gòu)造方法。
我們再看看Decoder的forward函數(shù),發(fā)現(xiàn)還是進入到了attention()。但這次輸入的x是tgt。
class Decoder(nn.Module):
"Generic N layer decoder with masking."
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, src_mask, tgt_mask):
for layer in self.layers:
x = layer(x, memory, src_mask, tgt_mask)
return self.norm(x)
4.4 PyTorch
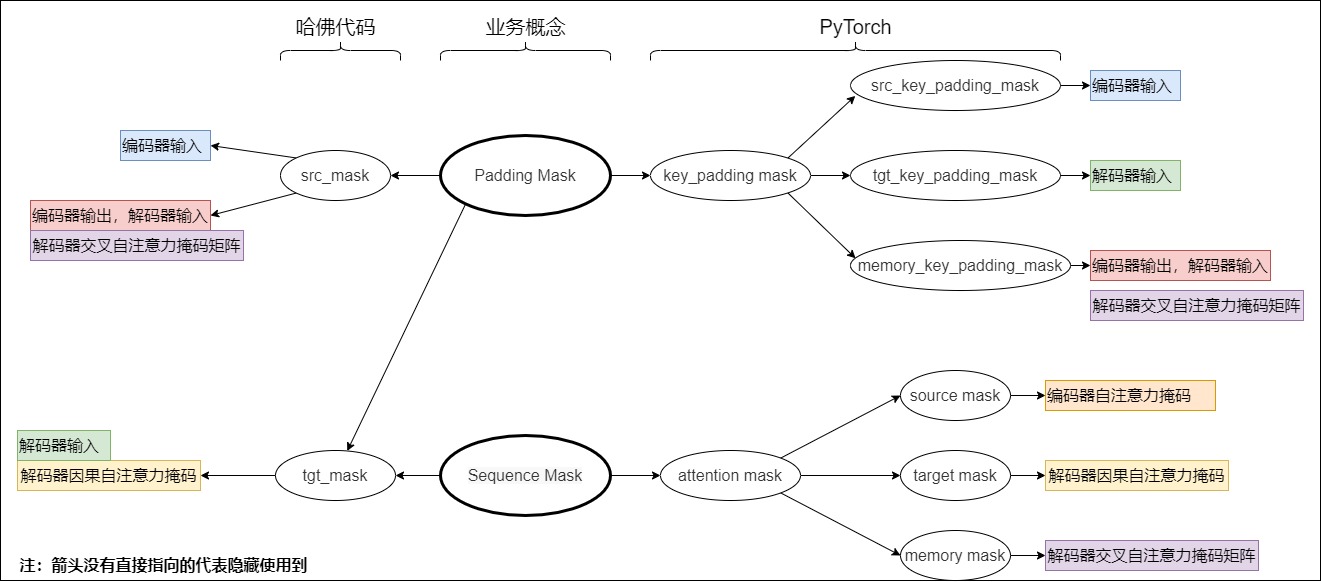
如果我們?nèi)タ?Pytorch Transformer 的文檔,會發(fā)現(xiàn)有六種掩碼矩陣。我們可以把六種掩碼矩陣分成兩類。
第一類叫做 attention mask,用來定義輸入序列的哪些部分被允許關(guān)注。對應(yīng)了哈佛代碼中的sequence mask。
- source mask:Encoder 中的自注意力掩碼,形狀為 (source_len, source_len)
- target mask:Decoder 中因果自注意力掩碼,形狀為 (target_len, target_len)
- memory mask:交叉自注意力中用到的掩碼矩陣,形狀為 (target_len, source_len)。此掩碼用于解碼器中的交叉注意力,主要是為了綜合編碼器和解碼器中的padding。交叉注意力中的Q來自解碼器,需要和編碼器中的key-value sets求相關(guān)性矩陣,這里就不涉及窺探未來信息的問題了,只需要考慮padding。
第二類叫做 key_padding mask,分別在 source seq,target seq,memory seq(即 Encoder 的輸出序列) 中標注 token 的位置,從而讓這些不被關(guān)注。對應(yīng)了哈佛代碼中的padding mask。
- src_key_padding_mask: 形狀為 (batch_size, source_len)
- tgt_key_padding_mask: 形狀為 (batch_size, target_len)
- memory_key_padding_mask: 形狀為 (batch_size, source_len)
從下面這個例子中可以看到,attention mask和key_padding mask是“各司其職”的。
# 生成一個下三角矩陣,即為 target mask
def generate_square_subsequent_mask(sz):
mask = (torch.triu(torch.ones((sz, sz), device=DEVICE)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
# 或者等價地:
def generate_square_subsequent_mask(sz):
mask = torch.triu(torch.full((sz, sz), float('-inf'), , device=DEVICE)), diagonal=1)
def create_mask(src, tgt):
src_seq_len = src.shape[0]
tgt_seq_len = tgt.shape[0]
# attention mask 部分
tgt_mask = generate_square_subsequent_mask(tgt_seq_len)
src_mask = torch.zeros((src_seq_len, src_seq_len),device=DEVICE).type(torch.bool)
# key_padding mask 部分
src_padding_mask = (src == PAD_IDX).transpose(0, 1)
tgt_padding_mask = (tgt == PAD_IDX).transpose(0, 1)
return src_mask, tgt_mask, src_padding_mask, tgt_padding_mask
其實,就是把哈佛代碼中的掩碼給細化了。我們總結(jié)其聯(lián)系如下。
4.5 小結(jié)
下面流程圖梳理了代碼邏輯,可以看到,Encoder只會看src_mask,Decoder則會看src_mask和tgt_task。
我們再從模型架構(gòu)角度給出交互數(shù)據(jù)流圖,具體如下。
0x05 進階
5.1 Sample Packing和mask
當上下文長度增加時,batch對齊問題就會浮出水面。長文本訓練在批大小大于一的情況下可能會因為 Pad tokens 浪費非常多的空間,這是因為長文本往往在長度分布上可以跨越多個數(shù)量級。下面的圖是一個例子。
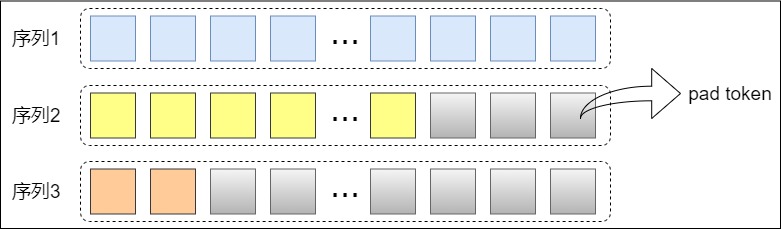
比如一個 4K 的樣本和一個 64K 的樣本可能會出現(xiàn)在同一個 batch 中。這種情況下 4K 的樣本后面會被使用 pad token 補全到 batch 中最長的樣本的長度。這意味著可能一個 4K 的樣本被填充了 60K 的長度。造成了很大的浪費。
定義
所幸現(xiàn)在的精調(diào)框架大多能夠通過 Sample Packing 技術(shù)解決這個問題。Sample Packing 實際上去除了batch size的概念。一個包含 3 樣本的 batch 現(xiàn)在被拼接成一個更長的單個序列。三個樣本頭尾相接成一個序列,同時attention mask也會對應(yīng)得發(fā)生改變,來防止同一個序列中的不同樣本相互影響。這樣的好處就是再也沒有 pad token:一個輸入可能包含 2 個長的樣本,也可能包含 100 個短樣本。
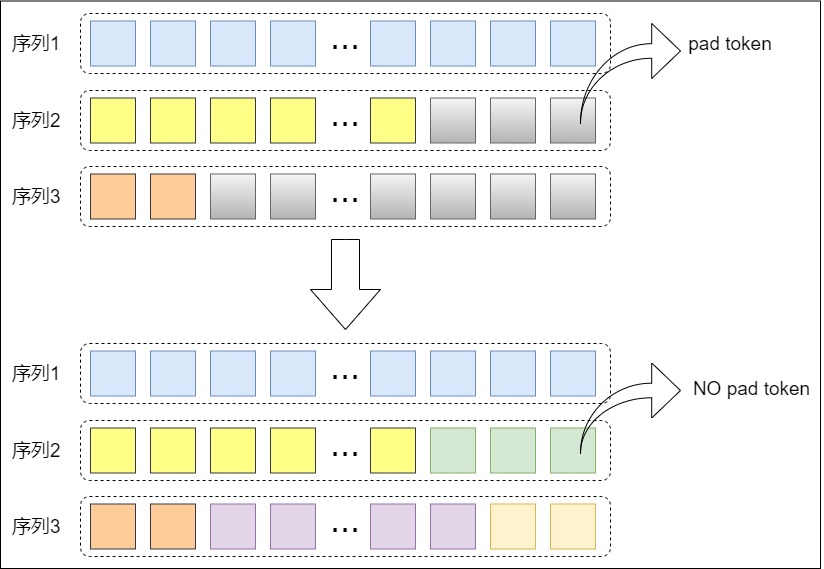
不過實踐中,LongAlign 論文提到,長的樣本和極短的樣本出現(xiàn)在同一個 batch 中可能會影響模型收斂,為了解決這個問題,一般會在訓練時讓長度相近的樣本出現(xiàn)在同一個batch中。
Attention mask
以Megatron-LM(DeepSpeed-Megatron)為例,預訓練通常包含很多不同的數(shù)據(jù)集,每個數(shù)據(jù)集又包含許多 Document。為了提升訓練效率,在實際訓練的時候一個 Sample(Sequence)里面可能會包含多個不同的 Document(Sample Packing)。比如 8K 的預訓練 Sequence Length,則一個 Sample 可以包含 8 個 1K 的 Document。
對于單個 Document 而言,Decoder Only 的 GPT 模型具有 Causal 特性,也就是每個 Token 不能看到之后的 Token,因此在實際訓練中需要添加 Attention Mask。這種情況下 Attention Mask 是一個標準的下三角矩陣(Causal Mask)。也就是綠色部分為 1,其他部分為 0:
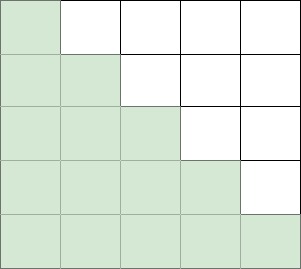
如果一個 Sample 里包含多個樣本,則 Attention Mask 矩陣需要變成如下圖所示的塊對角矩陣形式(Block Diagonal Mask)。比如 Sequence Length 為 16,4 個 Document 的長度分別為 3,4,5,4,則對應(yīng) Attention Mask 矩陣如下圖所示,對角線上的 4 個矩陣(紅框)都是標準的下三角矩陣。按照這種方式可以保證和 4 個 Document 單獨作為 Sample 訓練是等價的:
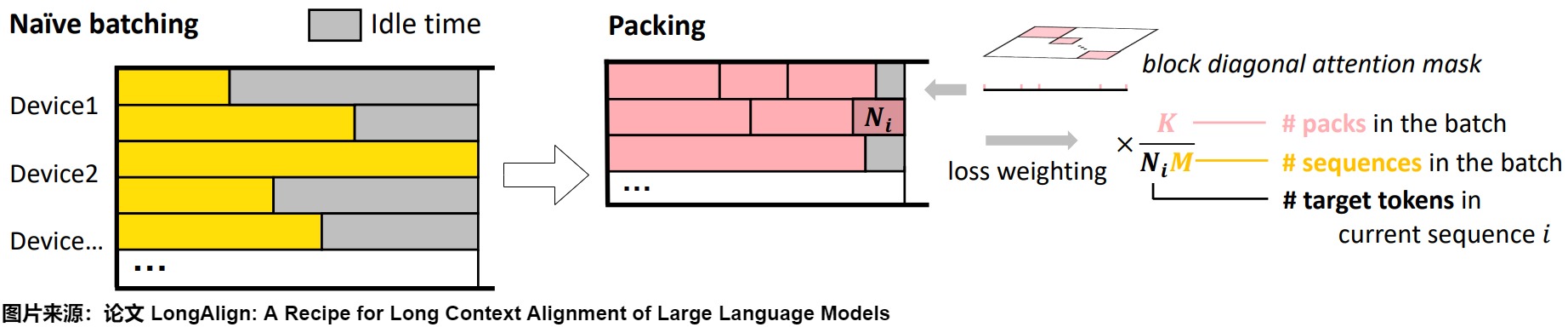
論文“LongAlign: A Recipe for Long Context Alignment of Large Language Models”中討論了部分 Sample Packing 相關(guān)問題。如下圖左所示,Sequence 的長度各不相同,從 0 - 60K,如果采用 Naive Batching 方式,會導致明顯的 Bubble 問題。為了解決效率和效果問題,作者提出了 3 種解決方案:Packing、Loss Weighting 和 Sorted Batching。
下圖右側(cè)就是我們之前介紹的 Sample Packing:將不同的 Sample 拼接在一個 Sequence 里,并且保證盡可能接近 Max Sequence Length,末尾的部分 Token 進行 Padding。然后通過 Block Diagonal Attention Mask 來區(qū)別不同的 Sample,以避免 Sample 之間的交叉污染,也就是 Document Level Attention。
策略
在論文“Enhancing Training Efficiency Using Packing with Flash Attention”中,作者總結(jié)了不同 Packing 策略、Mask 方式及與 FlashAttention 結(jié)合的優(yōu)勢。
如下圖所示,作者分析了不同的 Packing 方案以及它們的影響,具體包含如下幾種方式:
- RandomSampling + Padding:最傳統(tǒng)的隨機采樣,然后 Padding 的方式。存在冗余計算,并且占比很高。
- GroupByLength+Padding:先排序,然后盡量保證每個 Batch 中的序列長度接近。可以減少 Padding 的占比。
- RandomSampling + PosID:隨機采樣,但是不 Padding,而是通過 PosID 支持變長序列。幾乎沒有冗余計算,但可能存在明顯的負載不均衡(計算量)。
- FixedLengthPacking:隨機采樣,隨機 Packing,并且最后一個 Sample 可能截斷,保證填滿 Max Sequence Length。沒有區(qū)分不同 Sample,也就是 Causal Mask,沒有冗余計算,并且負載很均衡。
- FixedLengthPacking + PosID:相比 FixedLengthPacking 多了 PosID,也就是可以區(qū)分不同 Sample,對應(yīng) Block Diagonal Mask。但依然會存在末尾截斷,并且可能負載不均衡。
- MultiPack + PosID:使 Sequence 中的數(shù)據(jù)盡量接近 Batch 的 Max Sequence Length,降低 Sequence 中的長度不均衡,可以參考 GitHub - imoneoi/multipack_sampler: Multipack distributed sampler for fast padding-free training of LLMs。需要對數(shù)據(jù)進行排序。
- SortedPacking + PosID:通過排序,使同一個 Batch 中的計算復雜度盡量接近。可以盡可能降低計算負載不均衡問題。
- RandomPacking + PosID:與 FixedLengthPacking + PosID 相比主要的區(qū)別就是最后一個 Sample 不截斷,可能存在部分 Bubble。

5.2 功用
有研究表明,純自注意力機制在深度增加時會經(jīng)歷秩崩潰,限制了模型的表達能力和進一步利用模型深度的能力。然而,現(xiàn)有的關(guān)于秩崩潰的文獻大多忽略了Transformer中的其他關(guān)鍵組件,這些組件可能緩解秩崩潰問題。論文“On the Role of Attention Masks and LayerNorm in Transformers”對自注意力機制下的秩崩潰進行了綜合分析,考慮了注意力掩碼和層歸一化(LayerNorm)的影響。具體來說,作者發(fā)現(xiàn)盡管純掩碼注意力仍然會指數(shù)級地崩潰到一個秩為1的子空間,但稀疏或局部掩碼注意力可以證明減緩崩潰速率。在LayerNorm的情況下,作者首先展示了對于某些類別的值矩陣,秩為1的子空間崩潰仍然會指數(shù)級發(fā)生。然而,通過構(gòu)建非平凡的反例,作者證明了在適當選擇值矩陣的情況下,一類通用的序列可能不會收斂到秩為1的子空間,并且?guī)в蠰ayerNorm的自注意力動態(tài)可以同時擁有從1到滿秩的任意秩的平衡點。作者的結(jié)果反駁了之前關(guān)于LayerNorm在自注意力秩崩潰中不起作用的假設(shè),并表明帶有LayerNorm的自注意力構(gòu)成了一個比最初認為的更具表達力和多功能的非線性動力系統(tǒng)。
創(chuàng)新點
注意力掩碼對秩崩潰的影響分析:論文首次系統(tǒng)性地分析了注意力掩碼對Transformer中秩崩潰現(xiàn)象的影響。通過引入圖論方法,論文證明了在準強連通圖的情況下,即使使用稀疏或局部注意力掩碼,令牌的秩崩潰仍然會發(fā)生,但速率會減緩。這一發(fā)現(xiàn)為設(shè)計更高效的注意力機制提供了理論基礎(chǔ)。
LayerNorm對秩崩潰的緩解作用:作者通過構(gòu)建非平凡的反例,證明了LayerNorm在某些情況下可以有效緩解令牌的秩崩潰問題。在適當選擇值矩陣的情況下,帶有LayerNorm的自注意力動態(tài)可以同時擁有從1到滿秩的任意秩的平衡點。
掩碼注意力
作者首先分析不帶LayerNorm的情況,并關(guān)注注意力掩碼的影響。

上述結(jié)果表明,在純自注意力下,只要序列中存在一個令牌,所有其他令牌都可以在固定層數(shù)內(nèi)直接或間接參與,那么令牌的秩崩潰就會指數(shù)級發(fā)生。特別是,這個結(jié)論可以推廣到更一般的注意力模式類別:注意力模式只需要是準強連通的,這意味著對于實踐中使用的各種注意力掩碼,包括GPT系列中使用的因果掩碼,或許多高效Transformer模型中部署的稀疏注意力模式,都會存在秩崩潰現(xiàn)象。
作者討論了以下幾個有趣的含義。
- 局部 vs. 全局注意力 指數(shù)速率\((1-\epsilon^r)^{1/r}\)在圖半徑r上是單調(diào)的。這意味著對于半徑較大的圖,秩崩潰應(yīng)該較慢。這說明使用局部注意力模式不僅使注意力計算更高效,而且隱式地緩解了秩崩潰問題。
- 聚焦 vs. 均勻注意力 此外,指數(shù)速率在\(\epsilon\)上單調(diào)遞減,這意味著\(\epsilon\)越小,秩崩潰越慢。可以將\(\epsilon\)解釋為注意力在可達token之間的“聚焦”程度,因為\(\epsilon\)在注意力均勻分布在可達token時達到最大值。除了應(yīng)用注意力掩碼和限制可達令牌的數(shù)量外,控制注意力聚焦程度的另一種方法是通過溫度項\(d_{QK}\)。較大的\(d_{QK}\)值會使可達令牌之間的注意力分配更加均勻,從而使秩崩潰在各層之間更快發(fā)生。
- 秩崩潰與通用逼近能力的權(quán)衡 最后,對于強連通圖,上述結(jié)果還揭示了通用函數(shù)逼近能力與秩崩潰速率之間的權(quán)衡。有研究表明,帶有強連通圖掩碼的Transformer是sequence-to-sequence函數(shù)通用逼近器,然而,對于掩碼\(g\),它們需要至少\(g\)的直徑那么多的層數(shù)才能實現(xiàn)完整的sequence-to-sequence的函數(shù)逼近屬性。這意味著直徑較小的掩碼在函數(shù)逼近能力方面更高效,但它們更容易發(fā)生秩崩潰。
帶LayerNorm的掩碼注意力
我們接下來看看帶LayerNorm的掩碼注意力會有什么性質(zhì)。
論文作者首先展示一個負面結(jié)果,表明對于某些類別的值矩陣,如果初始時所有token對的余弦相似度都是非負的,那么只要\(g\)是準強連通的,仍然會發(fā)生token以指數(shù)級的速度崩潰到一個共同向量,即秩崩潰。但如果\(g\)是因果圖(causal graph),掩碼將只有一個中心節(jié)點,上界會更寬松,這表明因果掩碼在緩解秩崩潰速率方面相對于全掩碼具有優(yōu)勢。
然后,作者展示了反例,對于一類通用的輸入序列,當僅使用LayerNorm時,token會收斂到一個均衡狀態(tài),在該狀態(tài)下不會發(fā)生秩崩潰。然后,作者展示了一個普適性的結(jié)果,表明在LayerNorm和適當選擇值矩陣的情況下,自注意力動態(tài)可以擁有從1到滿秩的任意秩的平衡點。
0xFF 參考
LLM 預訓練語料、預處理和數(shù)據(jù)集索引、加載總結(jié) AI閑談
FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention by Team PyTorch: Horace He, Driss Guessous, Yanbo Liang, Joy Dong
Sample Packing:長序列 LLM 訓練的 Attention 問題及優(yōu)化
https://blog.csdn.net/zhaohongfei_358/article/details/125858248
Transformer系列:圖文詳解Decoder解碼器原理 xiaogp
LongAlign: A Recipe for Long Context Alignment of Large Language Models
NIPS 2024 | 注意力掩碼和LayerNorm在Transformer中的作用 [CV技術(shù)指南]
On the Role of Attention Masks and LayerNorm in Transformers
【深度學習】Transformer中的mask機制超詳細講解 Articoder
Transformer Encoder/Decoder結(jié)構(gòu)中的掩碼Mask介紹? [AIGC小白入門記]

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號