
探秘Transformer系列之(9)--- 位置編碼分類
探秘Transformer系列之(9)--- 位置編碼分類
0x00 概述
由于 Transformer 自身具有置換不變性(Permutation Invariance),無法直接捕獲每個詞在序列中的位置信息,因此使用位置編碼將序列中元素順序信息融入Transformer成為一種常見做法。根據位置編碼表示的是序列中元素的絕對位置信息還是相對位置信息,業界將位置編碼主要分為絕對位置編碼(Absolute Position Encoding,APE)和相對位置編碼(Relative Position Encoding,RPE)。絕對位置編碼的核心思想是在每個輸入序列的元素上添加一個位置向量,以表示該元素在序列中的具體位置。相對位置編碼則側重于考慮元素之間的距離信息。這里說主要是因為還有一些難以劃分的位置編碼。當然也有其它的區分方式,比如把RoPE單獨列為旋轉編碼。

0x01 區別
上一篇我們知道為了克服自注意力矩陣帶來的影響,有的研究人員提出了相對編碼。從而引出了對位置編碼的分類。我們本節從各個角度出發,來看看絕對位置編碼和相對位置編碼的區別。
1.1 從直觀角度來看
以句子“從槐樹葉底,朝東細數著一絲一絲漏下來的日光“為例,對于如何獲取序列順序?我們大體有兩個選擇方案:
- 絕對位置信息。比如:“從”是第一個token,“底”是第五個token。
- 相對位置信息。比如:“光”距離”日"差一個位置,但是距離“漏”差四個位置。
這兩個方案就分別對應了絕對位置編碼和相對位置編碼。下圖給出了從直觀角度出發來看,原始無位置編碼,絕對位置編碼和相對位置編碼的區別。
- 未引入位置編碼。在人類的語言中,單詞的位置與順序定義了語法,也影響著語義。無法捕獲的單詞順序會導致我們很難理解一句話的含義。
- 絕對位置編碼。絕對位置編碼的作用方式是告知Transformer架構每個元素在輸入序列的位置,類似于為輸入序列的每個元素打一個"位置標簽"來標明其絕對位置。
- 相對位置編碼。相對位置編碼作用于自注意力機制,告知Transformer架構兩兩元素之間的距離。
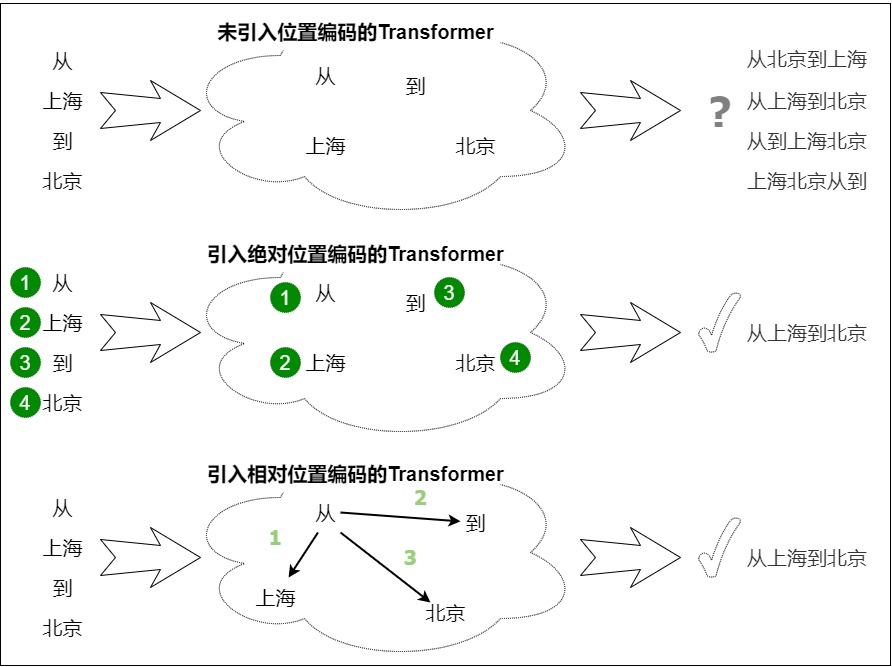
由于自然語言一般更依賴于相對位置,所以相對位置編碼通常也有著優秀的表現。
1.2 從模型處理角度來看
從模型處理角度來看,這兩種方案有如下分別:
- 絕對位置信息是在輸入層做文章,在輸入階段就將位置信息融入到token的輸入表征中,具體細節如下:
- 在Transformer中的位置。APE只在第一層之前出現。
- 建模方式。根據絕對位置k來定義位置編碼,使用公式函數或者可學習向量得到每個token的位置編碼。
- 相對距離。每個位置的位置編碼是固定的向量,且每個位置相互獨立,不考慮其與其他位置的關系,因此在和注意力機制結合時,無法計算相對距離。
- 模型輸入。對于模型來說,每個token對應的輸入是token自身編碼和其位置編碼的融合。
- 操作對象。位置編碼的操作對象是自注意力變換中的特征序列Q, K(Transformer論文是針對輸入嵌入序列 X),即將token的絕對位置信息添加到對應的\(q_t,k_s\)中。
- 相對位置信息主要是在模型網絡層做文章,通過微調注意力結構,使得模型有能力分辨不同位置的Token。
- 在Transformer中的位置。RPE通常在每一層都重復出現,而不是像APE那樣只在第一層之前出現。
- 建模方式。相對位置編碼并沒有對每個輸入的位置信息做完整建模。而是對相對位置i-j進行建模。即在計算自注意力分布時考慮兩個token間的相對位置信息,即下標之差。讓模型通過數據自己學習位置信息來分辨不同位置的Token。
- 相對距離。絕對位置編碼考慮的是各個獨立token的位置信息;相對位置編碼考慮的則是進行Attention計算時的query、key之間的相對位置信息,或者說是基于兩個token之間的相對距離來表示位置關系。
- 模型輸入。一般來說,相對位置編碼并不是將位置編碼直接加到詞嵌入上,模型的輸入依然是詞嵌入。也有的方案使用距離編碼矩陣(Distance Encoding Matrix)來計算偏移向量,然后與位置嵌入向量相加,再輸入模型。
- 操作對象。位置編碼的操作對象是自注意力變換中的自注意力矩陣 A(早期方案也有涉及特征序列 V 的操作),即將兩token的相對位置信息添加到對應的\(A_{t,s}\)上。
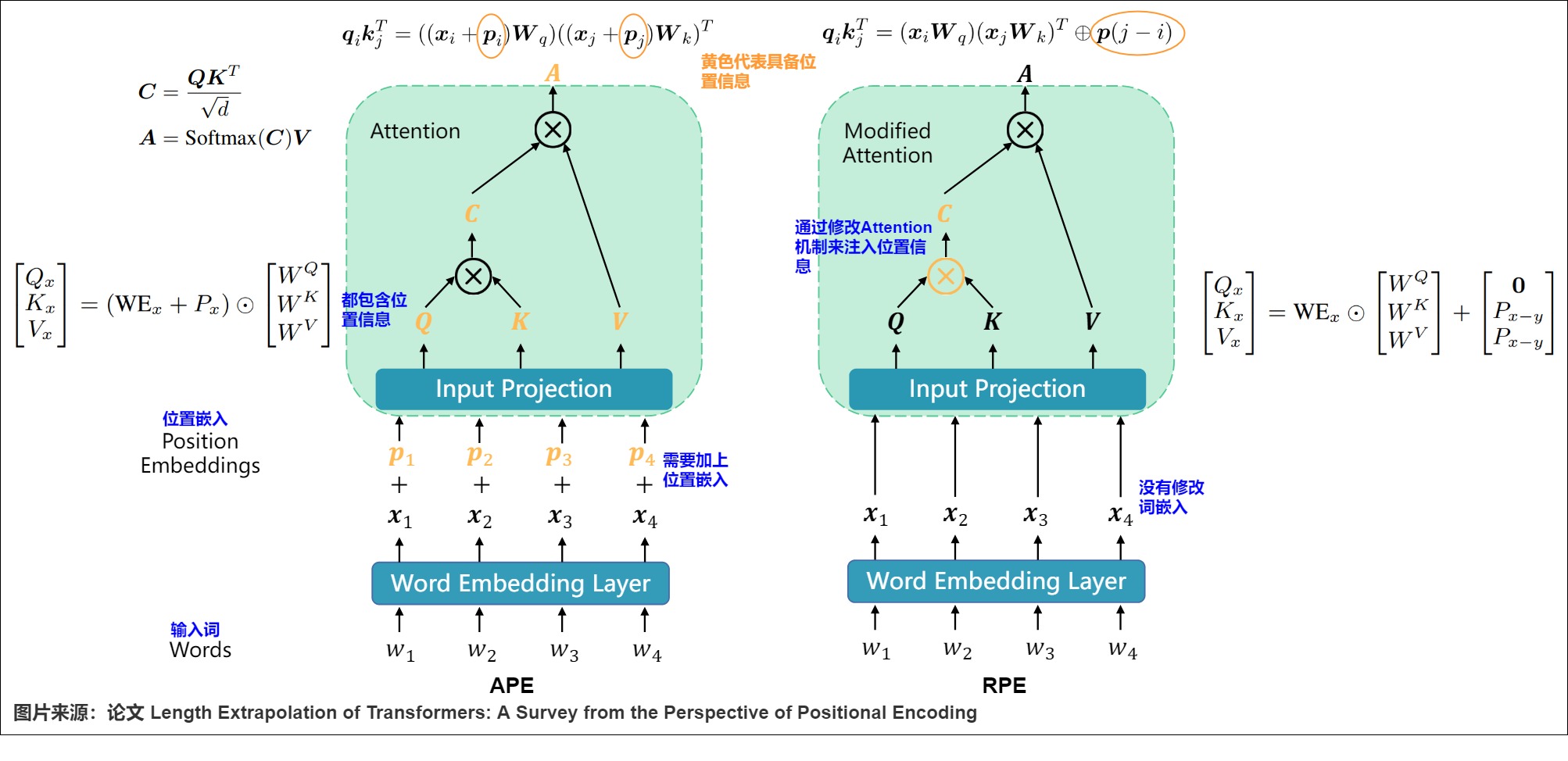
這些差異如下圖所示。其中 p(j-i) 是編碼 j - i 相對位置信息的術語。RPEs傾向于直接修改注意力機制來融合相對位置信息,這種修改獨立于值向量,使它們不與位置信息糾纏。
1.3 優劣
絕對位置編碼的優點是:實現簡單。缺點是:
- 難以泛化。
- 相對定位的缺乏可能會阻礙模型理解語言結構的細微差別的能力。
相對位置編碼的優點是:
- 可以將位置信息滲透進特征向量 $q_t $和 \(k_s\) 的每一個維度,在刻畫長距離語義關系時,不僅可以有效過濾無關信息,也為傳遞有價值的語義關聯提供了渠道。
- 能夠更好地處理序列的局部結構,因為它關注的是元素之間的相對位置。
- 建立了語義信息和位置信息之間溝通的橋梁,不再讓位置信息構成絕對的抑制。
缺點是:
- 計算效率低下。由于自注意力層中的額外計算步驟(比如獲得每個時間步的相對位置編碼,位置矩陣被添加到查詢鍵矩陣中)使得計算更復雜,可能增加訓練和推理的時間。
- KV Cache 使用的復雜性:由于每個附加token都會改變每個其他token的嵌入,這使得 Transformer 中KV Cache的有效使用變得復雜。使用 KV Cache 的一項要求是已經生成的單詞的位置編碼, 在生成新單詞時不改變(絕對位置編碼)。因此相對位置編碼不適合推理,因為每個標記的嵌入會隨著每個新時間步的變化而變化。
- 整體偏置易隨相對位置大小波動,需要更多的維度、額外的校正才能有所緩解,并且針對自身想額外抑制的語義關系,無法做到徹底的懲罰。
另外,目前這些位置編碼會讓模型過分在意局部信息,過分相信鄰近生成的內容。如何在位置編碼層面實現“三思而后行”,即讓模型在注意鄰近信息的同時,也能考慮到較遠位置的信息,從而對當前輸出進行一定的糾正,也是一個不可忽視的問題。
雖然說位置編碼主要是絕對位置編碼和相對位置編碼兩大類,但每一類其實又能衍生出各種各樣的變種,研究人員在這方面發揮了極大的聰明才智。本文就讓我們來欣賞一下研究人員為了更好地表達位置信息所構建出來的“八仙過海,各顯神通”般的編碼方案。
0x02 絕對位置編碼
形式上來看,絕對位置編碼是相對簡單的一種方案,經典的絕對位置編碼有三種:
- 可學習且無約束的。代表作是論文"Convolutional Sequence to Sequence Learning",該工作使用可訓練的嵌入形式作為位置編碼。
- 可訓練的位置編碼,代碼作是論文“BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding”。
- 三角函數位置編碼。代表作是論文"Attention Is All You Need"。文章中使用正余弦函數生成的位置編碼。
近年來,關于絕對位置編碼的工作大多數是以不同的方法生成絕對位置編碼為主,比如在三角函數編碼的基礎之上額外學習一些其他參數。
2.1 基礎方案
基礎方案是論文"Convolutional Sequence to Sequence Learning"提出來的。該方案將每個單詞的位置k映射為一個唯一的位置向量\(p_k\),然后在每個詞的嵌入\(x_k\)上加位置編碼\(p_k\)之后輸入模型。形式上如下:\(x=(x_1+p_1,...,x_k+p_k)\)。其中,x表示模型的輸入,\(x_k\)表示第k個位置的詞嵌入,\(p_k\)表示第k個位置的絕對位置編碼,且只依賴于位置編號k。
2.2 訓練式
BERT/GPT使用的是可學習的位置編碼(learned absolute positional embedding),通過在模型的嵌入層中引入可學習的參數來學習位置信息的表示。具體做法就是直接將位置編碼當作可訓練參數,初始化一個形狀為[max_length, hidden_size]的矩陣作為位置向量,讓它隨著訓練過程更新。即為每個輸入下標訓練一個嵌入向量來刻畫絕對位置特征。后續這個矩陣就像詞表一樣使用。
可學習方案的優點是可以根據任務的需要進行調整,可以更準確地區分不同位置的詞語,并捕捉到位置信息對任務的影響,進而學習到最適合特定任務的位置編碼。缺點是擴展性不強,外推性差。只能表征有限長度內的位置,無法對任意位置進行建模,不能很好地泛化到訓練時未見過的更長序列,也不具有遠程衰減性。而且由于位置信息是通過位置編碼隱式提供的,模型需要從數據中學習如何最好地利用這些信息,這可能需要更多的模型參數和訓練數據。
2.3 三角函數式
vanilla Transformer通過固定的數學公式(使用正弦和余弦函數)來生成位置向量,從而捕捉到不同位置之間的相對關系。這里不再對細節進行贅述。因為其思路之一是希望通過絕對編碼方式來實現相對編碼,因此也有人將其歸為混合位置編碼。
2.4 其它
此外還有一些其它方法,比如:
-
Encoding Word Order in Complex Embeddings 提出一種復值詞向量函數生成絕對位置編碼,巧妙地將復值函數的振幅和相位與詞義和位置相聯系。該復值詞向量函數以位置為變量來計算每個詞在不同位置的詞向量。由于該函數對于位置變量而言是連續的,因此該方法不光建模了絕對位置,也建模了詞之間的相對位置。
-
SHAPE: Shifted Absolute Position Embedding for Transformers 提出了一種絕對位置編碼的魯棒性訓練方法。SHAPE的基本思想是在訓練過程中對絕對位置編碼隨機整體平移一段距離來實現泛化能力。
-
Rethinking Positional Encoding in Language Pretraining在注意力上添加兩個標記位置嵌入之間的點積logit。
-
也有研究人員在考慮使用xk?pk(逐位相乘)對詞嵌入和位置編碼進行融合。因為token embedding和PE相加其實是一種特征交叉,從這個角度來看的話,其實相乘也是一種特征交叉的方式。
0x03 相對位置編碼
3.1 意義
我們從幾個方面來看看相對位置的意義。
大腦中的參考系
美國國家工程院院士杰夫·霍金斯(Jeff Hawkins)在其論文和著作《千腦理論》提出來一些觀點很值得我們思考:
- 參考系與新皮質。
- 新皮質的關鍵是參考系。
- 參照系在新皮質中無處不在。
- 參考系與存儲。
- 參考系是一種信息在大腦中的存儲結構,大腦是使用參考系來管理所有知識。
- 知識存儲在與參考系相關聯的位置。我們所知的每一個事實都與參考系中的一個位置相對應。
- 參考系與建模。
- 大腦通過感官輸入與參考系中的位置聯系起來,建立世界模型。
- 參考系不僅僅為實物建模,而是為我們所知道的一切建模。除了具象的物體之外,參考系還能衍生到一些抽象的概念,例如哲學,民主都是基于新皮質中不同的參照系進行定義的。
- 參考系與思考。
- 序列識別問題。新皮質必須知道接下來的移動是什么,才能做出來對于序列的下一個輸入的預測。
- 思考是一種特殊形式的移動。假設我們所知的一切都存儲在參考系中,那么為了回憶存儲的知識,我們需要在參考系中激活適當的位置。當神經元激活一個又一個位置的時候,思考就產生了。
如上所述,參考系是人腦中的重要部分,這對于位置編碼具有極其重要的指導意義。或者更確切的說,這是相對位置編碼的重要理論支撐之一。
語義影響
在很多任務中,序列中的元素之間的相對位置關系對于理解序列的語義和結構非常重要。或者說,絕對位置編碼對句子語義的影響不大,更為重要的是相對位置編碼。比如下面句子中,相對語序比絕對語序對語義的影響更加關鍵。
- 讀書好、讀好書、好讀書。
- 四川人不怕辣、貴州人辣不怕、湖南人怕不辣。
- 有個不明生物在吃雞, 有只雞在吃不明生物。
長度外推
直觀地說,長度外推與長度和位置有很強的相關性。Transformer作者提出了正弦位置嵌入,并聲稱它可以外推到訓練之外的更長的序列。這一說法背后的想法,即只需改變位置表示方法就可以實現長度外推,已得到廣泛支持和證明。因此,開發更好的位置編碼方法已經成為增強Transformer長度外推的主要途徑。
由于 APE 在長度外推上的表現難以令人滿意,而 RPE 天然地由于其位移不變性具備更好的外推能力。并且人們普遍認為上下文中單詞的相對順序更重要。因此,近年來,RPE 已成為編碼位置信息的主要方法。
早期的 RPE 來自于對正弦位置編碼的簡單修改,并常常結合裁剪或分箱策略來避免出現分布外的位置嵌入,這些策略被認為有利于外推。此外,由于 RPE 解耦了位置和位置表示之間的一對一對應關系,因此將偏差項直接添加到注意力公式中成為將位置信息集成到 Transformer 中的一種可行甚至更好的方法。這種方法要簡單得多,并且自然地解開了值(value)向量和位置信息的糾纏。
3.2 絕對位置編碼的位置
如何在Transformer中加上相對位置信息?出發點有兩個,但是殊途同歸。
- 因為每個單詞的位置編碼是相對于其他單詞的位置差異而得到的,所以顯然就不好像APE那樣直接加到輸入上了,需要從輸入之后的模塊入手,這就是注意力模塊。
- 前文分析過,原始transformer中的相對位置表達能力是在計算注意力階段被破壞的。因此,研究人員自然想到,用過在注意力計算時候再把相對位置信息加上。
因此,研究人員通過修改自注意力計算的過程,把相對位置信息植入到Transformer架構的每一層的注意力機制中。相對位置編碼會根據矩陣元素的下標,直接考慮每個元素對應的兩個token間的相對位置關系。比如在計算自注意力矩陣時,無論是在query和key的dot product,以及最終注意力權重和value矩陣乘時,都會分別額外添加一個表示位置m和位置n相對位置信息的僅依賴于m-n的bias。這樣通過將每個元素的位置嵌入向量與其他位置的偏移向量進行組合,來編碼元素之間的相對距離。每個元素的位置嵌入向量會隨著其與其他元素的位置關系而變化,從而更好地捕捉序列中的局部結構信息,從而提高序列建模的性能。
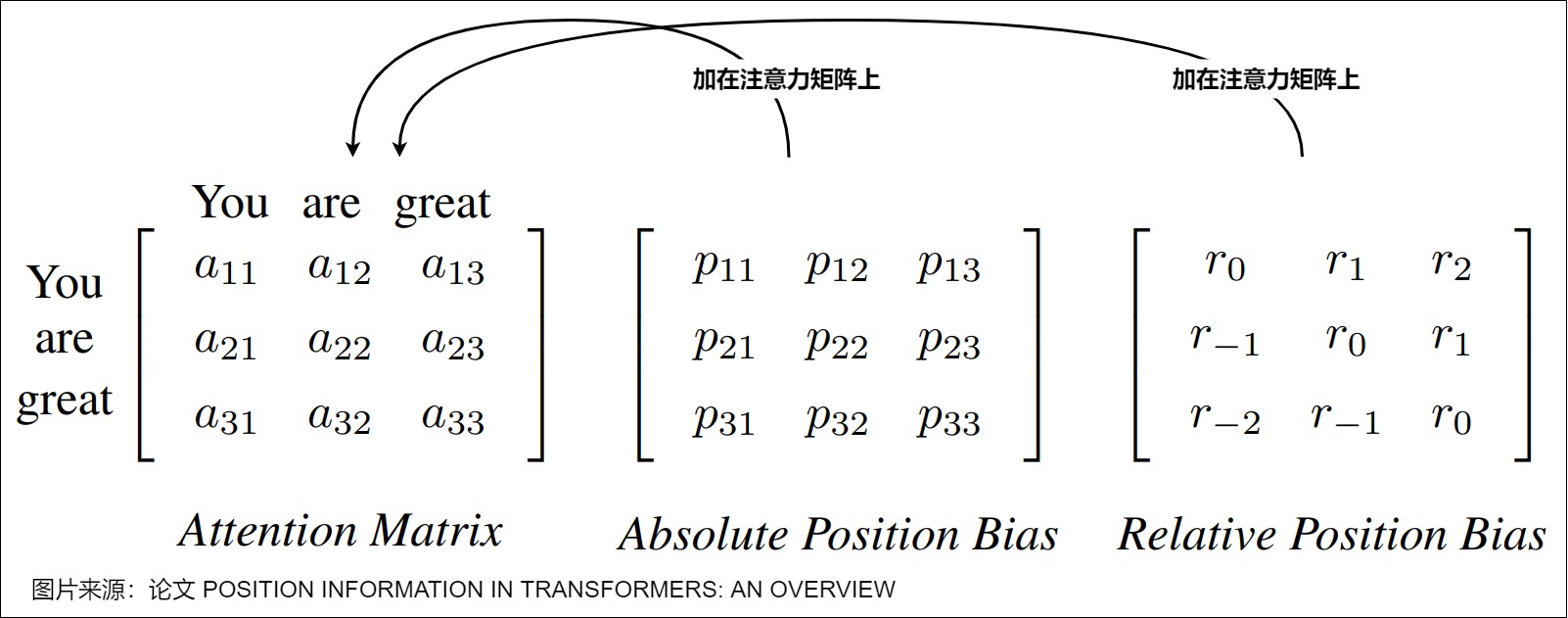
以“You are great“這句子為例,如何獲取序列順序?我們大體有兩個選擇方案。
- 絕對位置信息。比如:“You”是第一個token,“are”是二個token。
- 相對位置信息。比如:“great”距離”are"差一個位置,但是距離“great”差兩個位置。
而下圖展示了可以添加到注意力矩陣中的絕對和相對位置偏差的示例。左:例句中的注意力矩陣。中間:可學習的絕對位置偏置(bias)。右:相對參考位置的位置偏置。它們表現出直觀的權重分配模式,這是絕對位置編碼所不具備的。
3.3 絕對位置編碼的公式
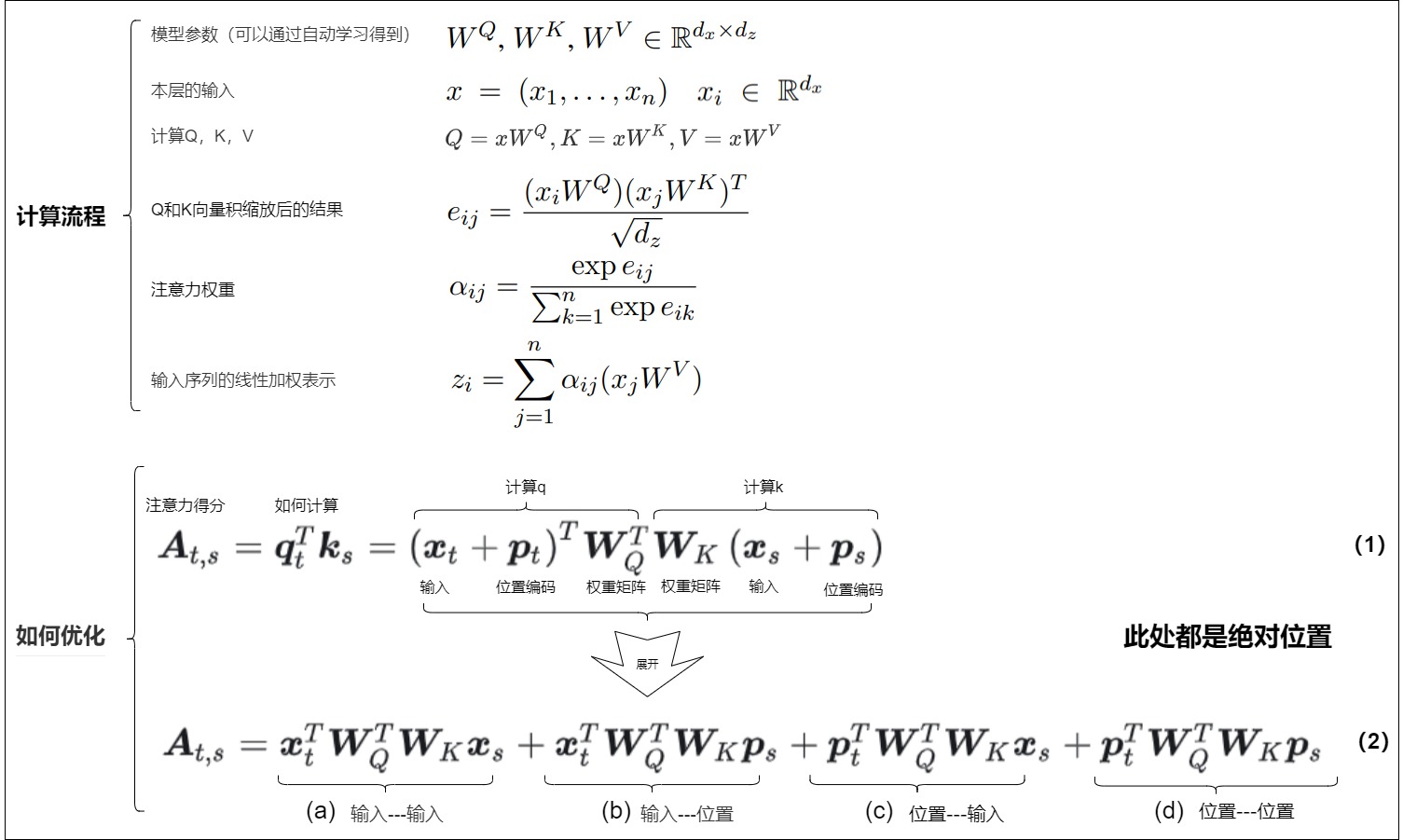
因為相對位置編碼大多是在正弦位置編碼的基礎上修改得到,因此我們先考慮一般的帶絕對位置編碼的注意力機制。下圖上方出了Transformer模型的某一層中自注意力機制的計算流程。最終輸出的點乘結果\(z_i\)是當前位置i和和序列中所有位置間的關系,是輸入序列的線性加權表示結果。
下圖下方的公式 (2) 是query、key之間的向量內積展開式,一共是四項注意力的組合,其中每一項的分別為
- “輸入-輸入”。 沒有考慮位置編碼的原始分數,只是基于內容的尋址(content-based addressing)。
- “輸入-位置”。相對于當前內容的位置偏差(content-dependent positional bias)。
- “位置-輸入”。從內容層面衡量key的重要性,表示全局的內容偏差(global content bias)。
- “位置-位置”。從相對位置層面衡量key的重要性,表示全局的位置偏差(global positional bias)。
相對位置編碼的引入,一般就會從這里出發。有的方案將其中某些項變成可訓練的參數,有的甚至把中間兩項都去掉了。總之,如何刻畫序列不同位置間的相對距離、如何通過相對距離控制自注意力矩陣不同位置的偏置大小,一直是位置編碼設計的重中之重。而不同位置編碼方案添加偏置的方式則各不相同。
接下來,筆者將帶領讀者分析一些較為經典的相對位置編碼工作。
3.4 經典式
相對位置編碼起源于論文《Self-Attention with Relative Position Representations》,作者是Transformer的原班人馬,他們應該早就知道三角函數編碼的問題。
下圖給出了三角函數編碼的改造過程,主要思路是以當前位置\(q_t\)為錨點,在計算注意力分數\(e_{ij}\)和加權求和\(z_i\)時各引入一個可訓練的相對位置向量\(a_{ij}^V\)和\(a_{ij}^K\),具體技術細節如下:
- 形式上與正弦位置編碼有聯系。
- 把相對位置信息i-j加在K和V上面,并且在多頭之間共享,其中i-j是有約束條件的。
- 相對位置編碼的目標是序列元素的邊或者距離。所謂相對位置,是將本來依賴于二元坐標(i,j)的向量,改為只依賴于相對距離i?j的向量\(R^K_{i,j},R^V_{i,j}\),并且通常來說會進行截斷,以適應不同任意的距離,避免分布外位置。 這樣只需要有限個位置編碼,就可以表達出任意長度的相對位置(因為進行了截斷)。或者說,通過在確定的范圍內裁剪相對位置,減少了要學習的位置嵌入數量,增強了長度外推。
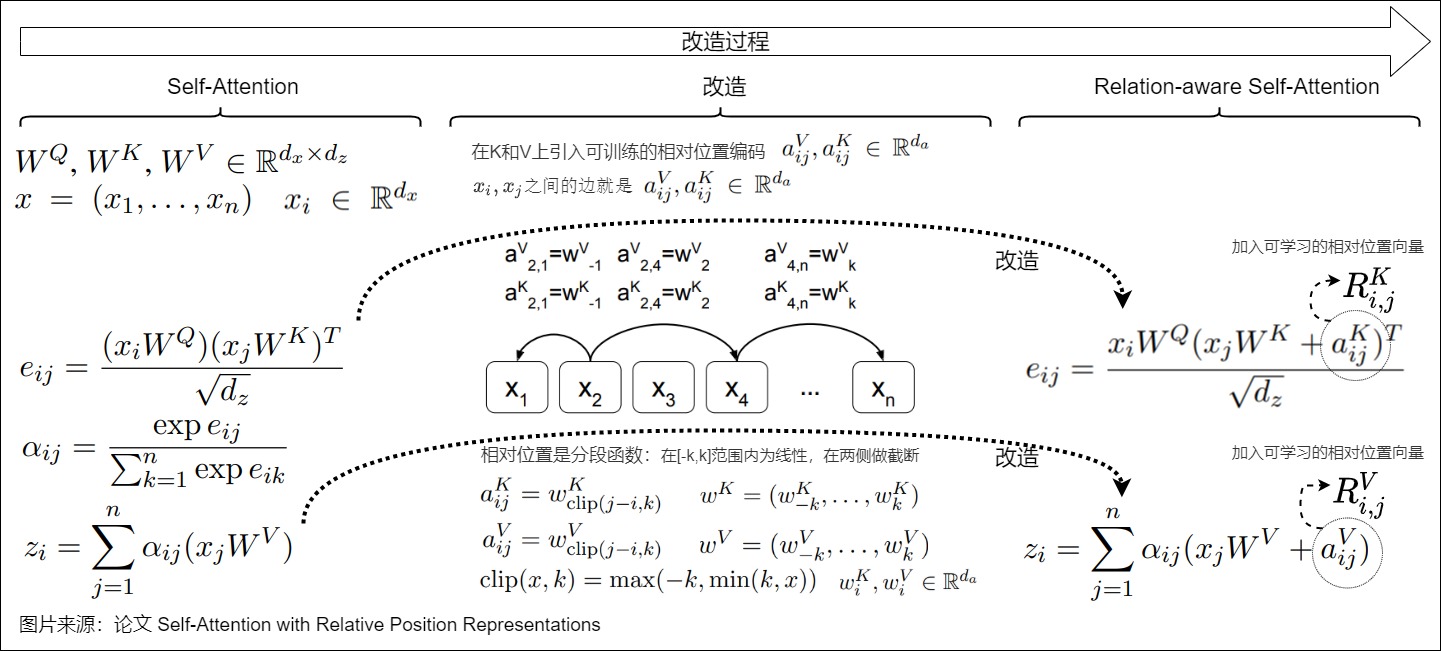
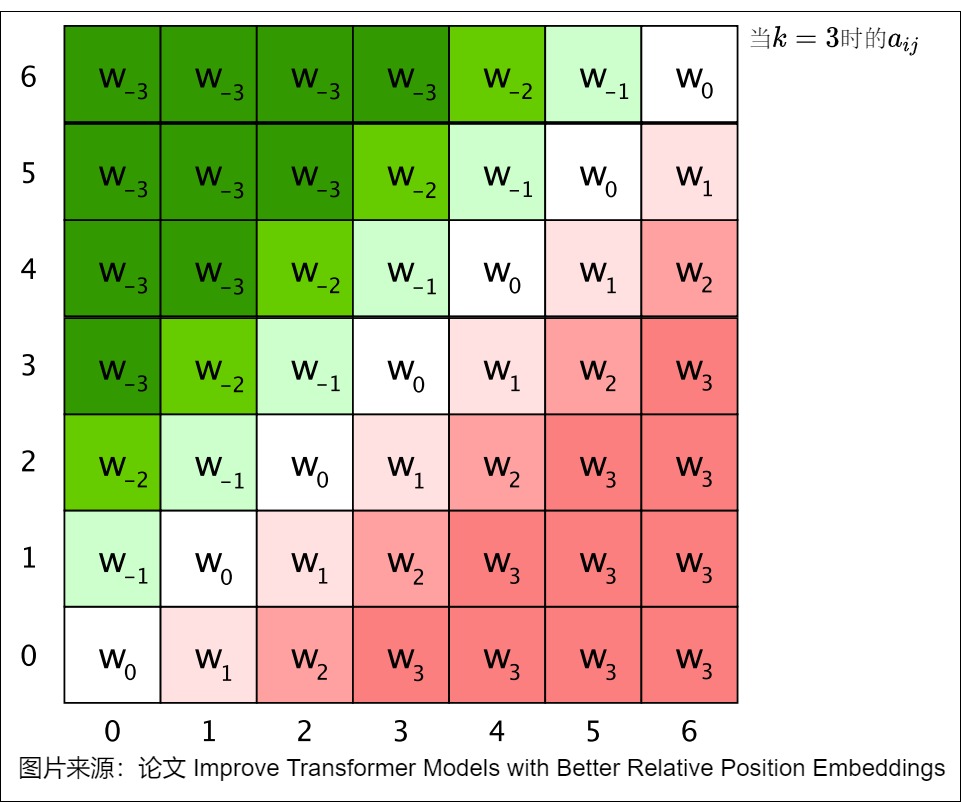
對于裁剪我們做下說明:這里的相對位置其實就是一個分段函數,在[-k,k]范圍內為線性,在兩側做了截斷。通過預先設定的最大相對位置k來強化模型對以當前詞為中心的左右各k個詞的注意力計算。因此,最終的窗口大小為2k+1。對于邊緣位置窗口超出2k的單詞,則采用了裁剪的機制,即只對有效的臨近詞進行建模。相對位置權重矩陣\(a_{ij}\)如下圖所示。
結合絕對位置編碼的公式,本方案的具體推導過程如下:

3.5 XLNET
XLNET式位置編碼源自Transformer-XL的論文Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context。
Transformer-XL 對絕對位置編碼公式做了改動:保留了正余弦頻率的取值以及位置信息與語義信息的交互,增加了兩個全局可學習的變量u、v,Key的變換矩陣也區分為基于內容的和基于相對位置的兩個W。具體細節如下。
- 把絕對位置編碼替換為相對位置編碼。
- 以\(q_t\)為錨點,將所有的\(p_s\)改為\(r_{t-s}\),表示對key而言由絕對位置編碼換成相對于\(q_t\)的相對位置編碼。相對位置信息 \(r_{t-s}\) (content-dependent positional bias)是依照Transformer中的通過正余弦頻率方式來獲取的,該項不需要學習,因此本身也沒有被截斷。從XLNet論文公式角度看,此處是把絕對位置編碼 \(U_j\)換成了相對位置編碼\(R_{i-j}\)。
- 在key上引入相對位置信息,key的變換矩陣\(W_K\)被拆分為基于內容的和基于相對位置的兩個W,也就是說輸入序列和位置編碼不再共享權值。從XLNet論文公式角度看,兩個W對應\(W_{k,E}\)和\(W_{k,R}\)。
- 調整絕對位置編碼公式的第二項。通過矩陣 \(W_R\) 刻畫相對距離與上下文語義之間的關系。
- 調整絕對位置編碼公式的第三項和第四項。
- 在第三項和第四項中引入引入了兩個新的可學習的參數 \(u∈R^d\) 和 \(v∈R^d\) 來替換Transformer中的query向量。這是因為無論query位置如何,其對不同詞的注意偏差都保持一致。因為我們已經把相對位置編碼融入了key端,那么query端就不再需要位置編碼了。
- 如果從XLNet論文公式角度看是替換掉 \(U_i^TW_q^T\)。
結合絕對位置編碼的公式,本方案的具體推導過程如下:

應該是從這個工作開始,后續的RPE都只加到K上去,而不加到V上了。
3.6 TENER
從位置編碼的角度,TENER作者發現了傳統三角式位置編碼在實踐中不具備單調性,在理論上也缺少前后token間相對方向的感知。因此,TENER作者提出了將相對方向和相對距離都納入到位置編碼當中。TENER的位置編碼和Transformer-XL的位置編碼類似,形式上,只是去掉了相對位置信息 \(r_{t,s}\) 的變換矩陣。此外,TENER還發現,去除自注意力變換中的校正系數 \(\sqrt d\) ,可以提升其在NER任務上的效果。
結合絕對位置編碼的公式,本方案的具體推導過程如下:
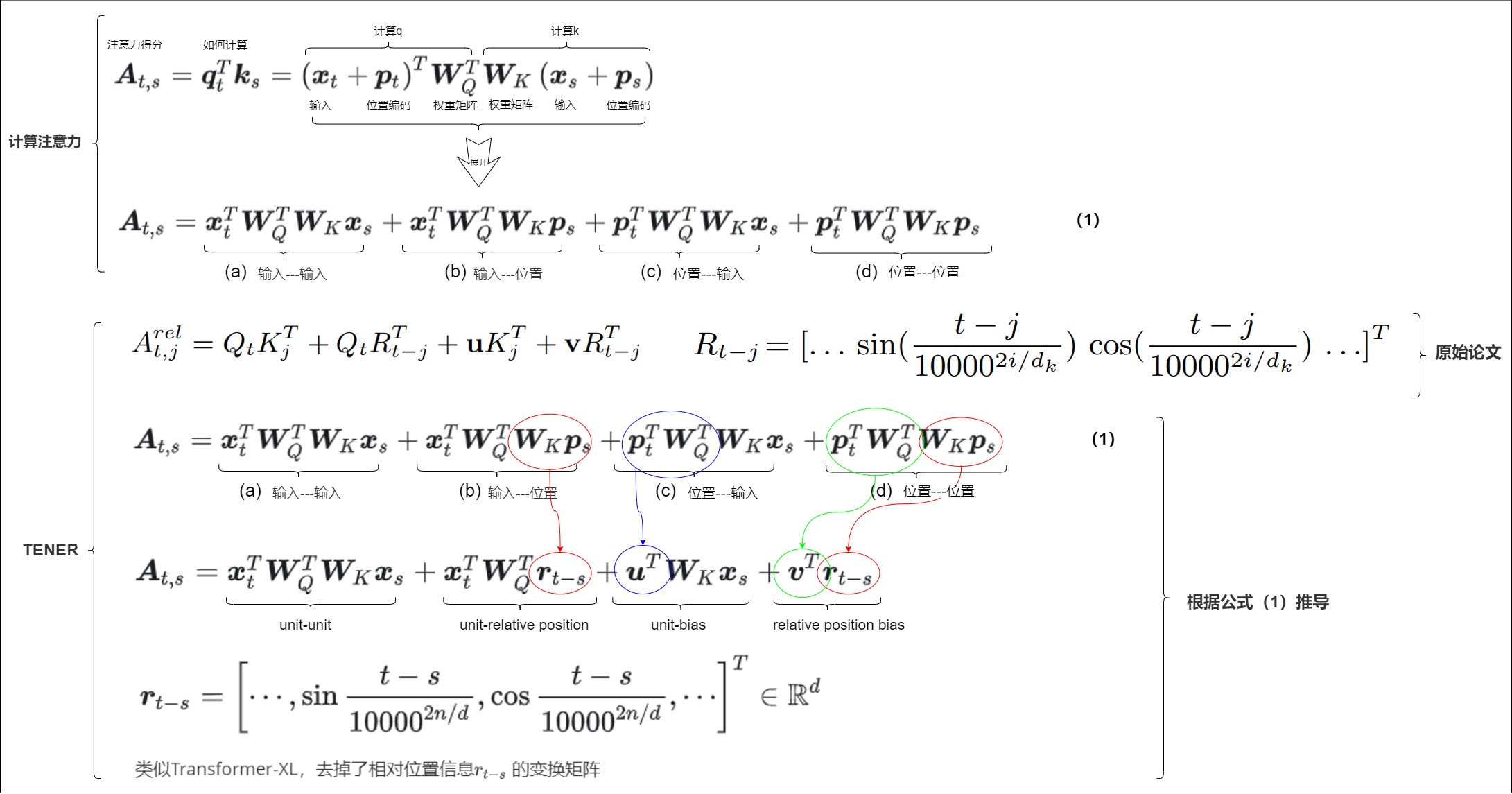
TENER其實揭示了目前位置編碼的一些弊病,即:已有的位置編碼主要刻畫兩個token之間的相對距離,缺少對于token間相對方向的刻畫,如何實現一個可拆分可解釋的方向感知位置編碼,是一個很大的挑戰。
3.7 T5
同樣基于注意力分數計算的分解,T5采用了一種簡單的相對位置編碼方案,將相對位置直接映射成可學習的標量。從絕對編碼公式角度看,T5去除了位置信息和語義信息的交互,直接刻畫相對位置信息,使用偏差(浮點數)來表示每個可能的位置偏移。例如,偏差 B1 表示任意兩個相距一個位置的標記之間的相對距離,無論它們在句子中的絕對位置如何。 這保證了偏置隨著相對位置的單調性。
簡要的說,T5直接將絕對位置公式的后三項換成一個可學習的bias,或者說,它是在(概率未歸一化的)Attention矩陣的基礎上加一個可訓練的偏置項。具體如下:
- 刪除(b),(c)項。因為T5作者認為輸入信息與位置信息應該是獨立(解耦)的,它們就不應該有過多的交互。
- 簡化(d)項為\(b_{ij}\)。第4項相對位置信息實際上只是一個只依賴于(i,j)的標量,可以將直接映射成可學習的標量,作為參數訓練出來。該相對位置偏差矩陣被添加到自注意力層中的查詢矩陣和關鍵矩陣的乘積中。這確保了相同相對距離的標記始終由相同的偏差表示,無論它們在序列中的位置如何。
- 去除\(v_j = (x_j + p_j)W_V\)中的位置編碼。
結合絕對位置編碼的公式,本方案的具體推導過程如下:

該方法的一個顯著優點是其可擴展性。它可以擴展到任意長的序列,這比絕對位置嵌入有明顯的優勢。
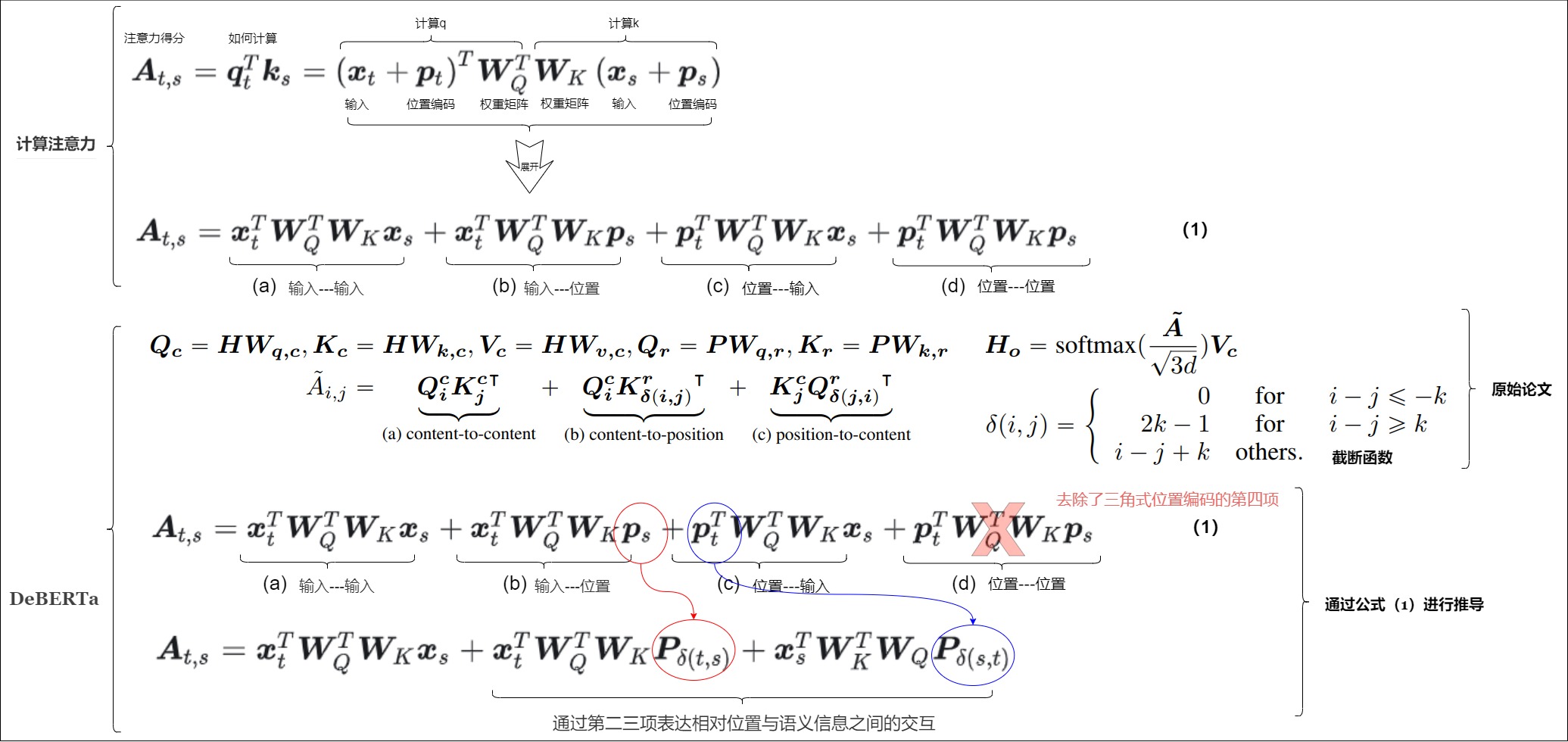
3.8 DeBERTa式
DeBERTa出自《DeBERTa: Decoding-enhanced BERT with Disentangled Attention》。和T5恰恰相反,DeBERTa去掉了分解后的第四項,在第二、三項中將絕對位置編碼改為相對位置編碼。其思路如下:
- 將二三項中的位置編碼換成相對位置編碼。首先通過 \(\delta(t,s)\) 將 t?s 直接截斷在區間 (?k,k] 內,接著通過參數矩陣 \(P∈R^{2k×d}\) 刻畫將相對位置映射為特征向量;即采用相對位置編碼,并解耦了內容和位置的注意力。
- 將第4項扔掉。因為已經使用了相對位置編碼,position2position不會帶來額外的信息。
另外,DeBERTa提供了使用相對位置和絕對位置編碼的一個新視角,它指出NLP的大多數任務可能都只需要相對位置信息,但確實有些場景下絕對位置信息更有幫助,于是它將整個模型分為兩部分來理解。它一共有13層,前11層只是用相對位置編碼,這部分稱為Encoder,后面2層加入絕對位置信息,這部分它稱之為Decoder。
結合絕對位置編碼的公式,本方案的具體推導過程如下:
3.9 TUPE
TUPE出自論文"RETHINKING POSITIONAL ENCODING IN LANGUAGE PRE-TRAINING"。
注:TUPE有APE和RPE兩個版本,本文歸類時是按照其出發點來歸為APE。
TUPE其實可以看作是T5和DeBERTa的位置編碼的結合。TUPE位置編碼去掉絕對位置編碼的公式的第二三項,保留第四項。相較于T5壓縮后學習一個標量刻畫相對位置,TUPE將語義信息和位置信息同等看待、分開刻畫:以 \(W_Q\), \(W_K\) 刻畫語義關系,并以 \(U_Q\),$U_K $來刻畫位置關系(directly model the relationships between a pair of words or positions by using different projection matrices)
針對絕對位置編碼的公式的四項,論文認為存在兩個問題:
- 位置嵌入和詞嵌入不應該耦合。
- 在絕對位置編碼中,應用于位置嵌入和詞嵌入的加法運算帶來了兩種異構信息資源之間的混合相關性。 它可能會在注意力中帶來不必要的隨機性,并進一步限制模型的表達能力。
- 論文作者對這四項做了可視化,發現中間兩項看起來很均勻,說明position和token之間沒有太大的關聯。因此,TUPE移除了二三項,即移除了單詞-位置、位置-單詞的對應關系。
- token和position之間用了相同的矩陣做QKV變化,但是position和token之間所包含的信息不同,所以共享矩陣不合理。因此,TUPE解耦了token和position的投影矩陣,通過不同的參數化分別計算詞的上下文相關性和位置相關性,然后將它們相加。
- 引用T5模型中的偏置項。
- 其次,考慮到符號 [CLS] 在下游任務中的特殊作用(整個句子的表示),論文質疑將符號 [CLS] 的位置與其他單詞一樣對待是否是一個合理的設計。 因此,TUPE 將 [CLS] 符號與其他位置分開(untie),從而使其更容易從所有位置捕獲信息。
TUPE架構如下圖所示。
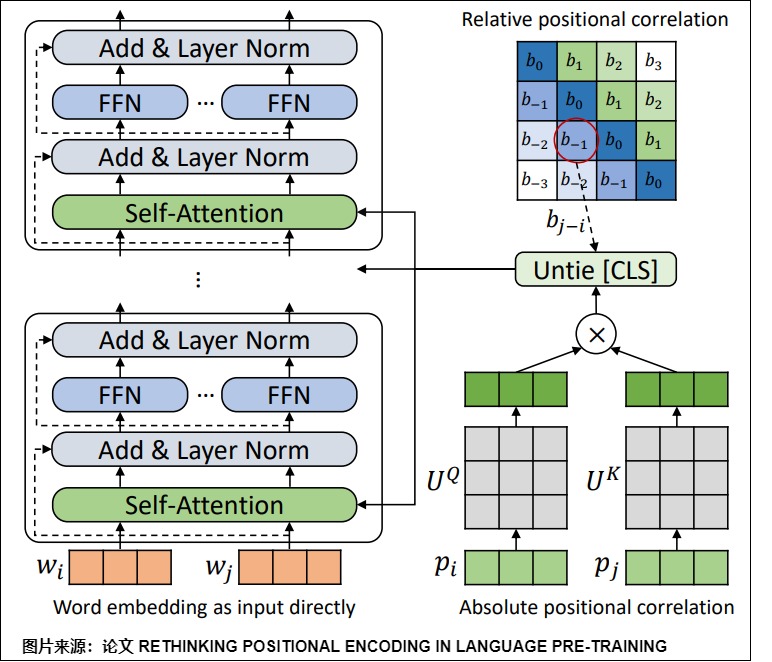
解耦的邏輯如下圖所示。

結合絕對位置編碼的公式,本方案的具體推導過程如下:
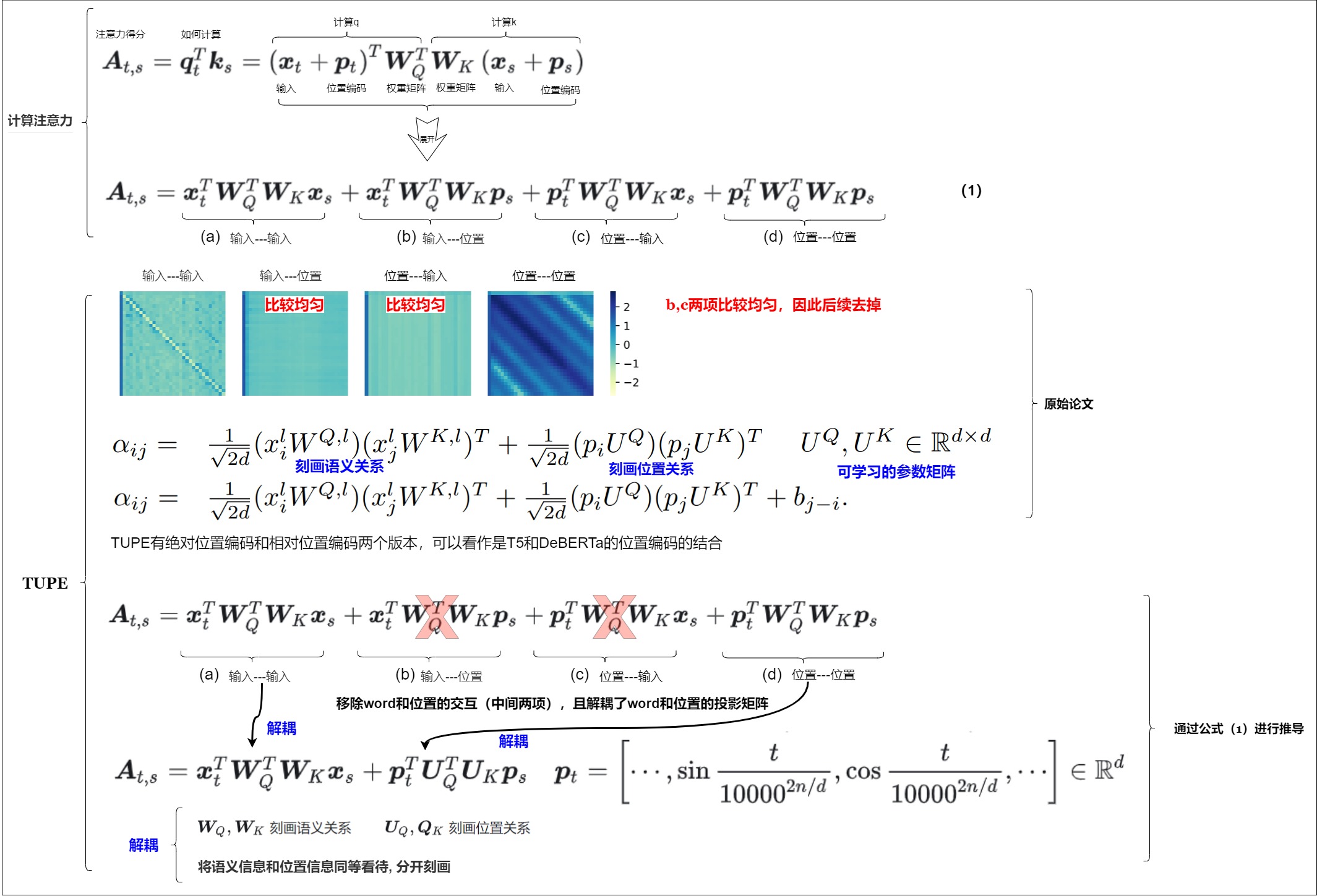
3.10 ALiBi
ALiBi編碼出自論文“rain Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation”。ALiBi (Attention with Linear Biases) 其實和T5類似,直接給(未概率歸一化的)注意力分數加上了一個線性的bias,通過線性偏置項,讓自注意力分布更加關注相對距離較小,即鄰近位置的語義信息。區別在于:T5 的偏置是可訓練參數,而 ALiBi 的偏置是預設好、不可訓練的。
動機
ALiBi的動機是:靠近的詞比遠離的詞更重要。
實施
ALiBi編碼不是給詞向量加入位置嵌入向量,而是用一個和query, key之間的距離成比例的一個“懲罰項”來偏置query-key的注意力得分。這個偏置根據 query 和 key 的相對距離來懲罰 attention score,相對距離越大,懲罰項越大。相當于兩個 token 的距離越遠,相互貢獻就越小。比如,針對原始attention層中第i個Token的Query向量和第j個Token的Key向量進行相乘操作,ALiBi通過加入位置i、j的絕對值差將位置i和位置j的相對位置信息嵌入到attention計算過程中。該絕對值差是常量,可以事先計算出來,并且每個頭(head)的值都有所不同。
具體公式是\(q_ik_j^T \rightarrow q_ik_j^T - \lambda|i-j|\),其中 \(\lambda\) 是超參數,對于每一個head采用不同數值設置,論文經過實驗發現對超參數 \(\lambda\) 以 \(\frac{1}{2^1},\frac{1}{2^2},\frac{1}{2^3},...,\frac{1}{2^8},\)區間進行設置效果最佳,即如果有 n 個head,則區間 \(\lambda\) 起始從$ 2^{?8/n}$ 開始到終點 \(2^{?8}\)。
實施過程如下圖所示。

特色
ALIBI是一個很樸素(當然也很有效)的光滑局部注意力技巧,但如果將它理解為“位置編碼”,又并非十分妥當。
ALIBI通過線性偏置項,讓自注意力分布更加關注相對距離較小,即鄰近位置的語義信息,相當于增強局域性的作用。雖然其是線性偏置項,但是經過softmax變化之后,真正乘以自注意力分布上的卻是指數的衰減。其次,線性的偏置意味著當相對距離很大時,偏置項趨近于負無窮。因此,ALiBi的偏置項更像是在計算注意力分數時通過一個帶坡度的滑動窗口或者掩碼來直接實現注意力計算過程中的遠程衰減,即只能獲取到訓練長度內的信息。而只要相對距離足夠大,ALiBi都會對其給予嚴格的懲罰。隨著序列長度的增加,ALiBi 往往從全局注意力過渡到幾乎局部的注意力,這就是為什么 ALiBi 在訓練長度內的表現比大多數基線差,但在超出訓練長度后表現更好的原因。
與此同時,還要注意的是,以ALiBi為代表的絕對偏置編碼,無法將對 \(A_{t,s}\) 的操作拆分至 \(q_t\),\(k_s\) ;而從參數角度,由于偏置 b(t-s) 是直接加在 \(q_t\),\(k_s\) 內積上的,因此對于參數矩陣 \(W_q\), \(W_k\) ,每個特征維度間缺少區分性,相比其他兩種偏置形式更難優化。
結合絕對位置編碼的公式,本方案的具體推導過程如下:

3.11 偏置編碼&上下文模式
分析完上述相對位置編碼之后,我們看看一種分類方式。無論是絕對位置編碼,還是相對位置編碼,如何刻畫序列不同位置間的相對距離、如何通過相對距離控制自注意力矩陣不同位置的偏置大小,一直是位置編碼設計的重中之重。而不同位置編碼方案添加偏置的方式則各不相同。但是基本上都可以整理成如下形式。
其中,\(b_{ij}\)被稱為位置偏置,依據其不同形式,可以把相對位置編碼分為以下兩種流派。
- bias方案。以T5、TUPE、ALiBi為代表的位置編碼,其\(b_{ij}\)是一個與\(q_j\),\(k_j\)無關的標量。直接把偏置加\(q_j\),\(k_j\)的內積上,直接對自注意力矩陣操作。這種方式直接將偏置加在自注意力矩陣 \(A_{t,s}\) 上,計算簡單理解容易,但懲罰過于絕對。
- 上下文方案。包括比如Transfomrer-XL,DeBERTa,其中\(b_{ij}=f(x_i,x_j,r_{ij})\)。這種方案將偏置滲透進特征向量 \(q_t\),\(k_s\) 的每個維度上,能很好區分特征維度,并以過濾取代懲罰,具有更強表達能力。但其其整體偏置易隨相對位置大小波動,需要更多的維度、額外的校正才能有所緩解。

3.12 小結
一般來說,絕對位置編碼具有實現簡單、計算速度快等優點,而相對位置編碼則直接地體現了相對位置信號,更符合直覺也更符合文本的特性,實際效果往往也更好。如何做到集二者之所長呢?很自然的想法是,通過絕對位置編碼來實現相對位置編碼!也就是混合位置編碼。因此,APE和RPE兩者最終統一于旋轉位置編碼(Rotary Position Embedding,RoPE),以絕對位置編碼的形式,實現了相對位置編碼的效果。
注:此處分類模糊,有人把RoPE看作是混合位置編碼,也有人把其歸結為相對位置編碼,也有人把其單獨列為旋轉位置編碼。
0xFF 參考
Length Extrapolation of Transformers: A Survey from the Perspective of Position Encoding
LLaMA長度外推高性價比trick:線性插值法及相關改進源碼閱讀及相關記錄
Train Short, Test Long: Attention with Linear Biases Enables Input Length Extrapolation
Bias項的神奇作用:RoPE + Bias = 更好的長度外推性
DeBERTa: Decoding-enhanced BERT with Disentangled Attention\
Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
EXTENDING CONTEXT WINDOW OF LARGE LANGUAGE MODELS VIA POSITION INTERPOLATION
GitHub - dvlab-research/LongLoRA: Code and documents of LongLoRA and LongAlpaca
https://blog.csdn.net/weixin_44826203/article/details/129255185
https://medium.com/@ddxzzx/why-and-how-to-achieve-longer-context-windows-for-llms-5f76f8656ea9
https://twitter.com/GregKamradt/status/1727018183608193393
Kimi Chat 公布“大海撈針”長文本壓測結果,也搞清楚了這項測試的精髓 (qq.com)
RETHINKING POSITIONAL ENCODING IN LANGUAGE PRE-TRAINING
RoPE外推的縮放法則 —— 嘗試外推RoPE至1M上下文 河畔草lxr
TENER: Adapting Transformer Encoder for Named Entity Recognition
Transformer-XL: Attentive Language Models Beyond a Fixed-Length Context
Transformer升級之路:15、Key歸一化助力長度外推 蘇劍林
Transformer升級之路:1、Sinusoidal位置編碼追根溯源 - 科學空間|Scientific Spaces
Transformer升級之路:2、博采眾長的旋轉式位置編碼
Transformer升級之路:6、旋轉位置編碼的完備性分析
RoFormer: Enhanced Transformer with Rotary Position Embedding
Self-Attention with Relative Position Representations
分析transformer模型的參數量、計算量、中間激活、KV cache - 知乎 (zhihu.com)
干貨!On Position Embeddings AI TIME
理解Transformer的位置編碼51CTO博客transformer的位置編碼
羊駝再度進化,“長頸鹿版”LongLLaMA 來啦,上下文長度沖向 100K ,性能不減
讓研究人員絞盡腦汁的Transformer位置編碼 - 科學空間|Scientific Spaces
詳解基于調整RoPE旋轉角度的大模型長度外推方法 (qq.com)
https://blog.csdn.net/qq_27590277/article/details/106264402
Ke G, He D, Liu T Y. Rethinking positional encoding in language pre-training[J]. arXiv preprint arXiv:2006.15595, 2020.

 浙公網安備 33010602011771號
浙公網安備 33010602011771號