
大疆嵌入式筆試
2024年大疆嵌入式秋招筆試B卷
1.應用程序可直接進行系統調用,也可以使用庫函數,有的庫函數涉及系統調用,有的不涉及。這對不對?
對的。應用程序可以直接進行系統調用,也可以通過庫函數來執行任務。這里有幾點需要注意:
系統調用:應用程序通過系統調用可以直接與操作系統內核進行交互,執行諸如文件操作、內存管理等低級功能。
庫函數:許多庫函數是為了簡化系統調用的使用而設計的。這些庫函數通常在更高級的抽象層上進行調用,比如標準庫中的輸入輸出函數,它們可能會在內部使用系統調用。
有的庫函數不涉及系統調用:一些庫函數完全是在用戶空間中執行,并不需要與操作系統交互,例如一些數學計算或字符串處理函數。
因此,應用程序可以選擇直接使用系統調用或通過庫函數來間接使用系統調用,具體選擇取決于需求和設計目標。
2.使用編程語言可將系統調用封裝成庫函數,應隱藏系統調用的細節,使上層進行系統調用更加方便,這對不對?
對的。將系統調用封裝成庫函數的做法有以下幾個優點:
簡化接口:庫函數提供了更簡單、友好的接口,允許開發者更方便地進行系統調用,而無需處理底層的細節。
抽象化:封裝可以隱藏系統調用的復雜性,開發者無需了解具體的實現細節,從而提高了開發效率。
錯誤處理:庫函數可以統一處理錯誤,使上層調用者不必關注各種可能的錯誤情況,提高了代碼的健壯性。
跨平臺性:通過封裝,可以實現跨平臺的支持,使得同一套代碼能夠在不同的操作系統上運行而無需修改。
便于維護:如果需要更改底層實現,只需更新庫函數,而不必改動使用它的多個上層應用程序。
因此,將系統調用封裝成庫函數是一種良好的編程實踐。
3.系統調用和庫函數都不依賴平臺有操作性的保證接口調用的一致性
系統調用和庫函數確實在一定程度上能夠提供接口調用的一致性,但它們的依賴性和保證方式不同。
系統調用:
系統調用通常在操作系統層面實現。
不同的操作系統可能有不同的系統調用接口,這可能導致跨平臺時不一致。
盡管操作系統會努力提供兼容性,但新的版本或不同派系的系統在系統調用方面可能會有差異。
庫函數:
庫函數往往在用戶空間中實現,并依賴于特定的語言或框架。
通過標準庫(如 C 的標準庫、Python 的標準庫等),庫函數提供了一致的接口,使得開發者可以在不同平臺上調用相同的函數。
標準庫通常會處理底層的操作系統差異,從而提供統一的體驗。
綜上所述,庫函數在提供平臺無關的接口一致性方面通常更加有效,而系統調用則依賴于操作系統的兼容性。使用庫函數可以更好地確保跨平臺開發的一致性和可移植性。
4.假設ab是一個類,則執行ab x;語句時將自動調用該類的什么構造函數?
在執行 ab x; 語句時,將自動調用類 ab 的 默認構造函數。這是因為在沒有提供構造函數參數的情況下,編譯器會尋找一個無參數的構造函數來初始化對象 x。
如果類 ab 沒有定義任何構造函數,編譯器會自動生成一個默認構造函數。如果定義了其他構造函數但沒有定義默認構造函數,且類需要提供一個無參數的方式來構造對象,則會導致編譯錯誤。
5.計算機只能直接執行機器語言程序。
對的,計算機只能直接執行機器語言程序。機器語言是計算機能夠理解和執行的最低級語言,由二進制代碼組成,指令直接對應于計算機硬件的操作。其他類型的編程語言(如高級語言)需要通過編譯器或解釋器轉換成機器語言,才能被計算機執行。
這樣做的原因是:
直接控制硬件:機器語言可以直接對計算機的硬件進行控制,實現具體操作。
性能高效:機器語言指令可以被直接執行,避免了轉換過程,提升了運行效率。
硬件依賴性:不同計算機架構的機器語言格式可能不同,這使得編寫在某個體系結構上的機器語言程序不能在其他體系結構上直接執行。
因此,高級語言程序通常需要先被轉換為機器語言才能執行。
6.馮諾依曼計算機"存儲程序"工作原理的基本思想是什么?
馮諾依曼計算機的“存儲程序”工作原理的基本思想可以概括為以下幾點:
統一存儲:程序和數據都存儲在計算機的內存中,使用相同的存儲機制。這意味著計算機可以處理指令和數據的一致性,增加了靈活性。
可修改性:程序可以動態修改,這意味著計算機可以根據需要讀取、寫入和執行存儲在內存中的程序。這使得程序的自我修改成為可能。
順序執行:計算機根據存儲在內存中的機器指令的地址順序逐條執行這些指令,依據指令流控制程序的執行過程。這種順序性使得程序可以被順序、跳轉和循環控制。
控制單元:計算機的控制單元從內存中讀取指令,解析后發出控制信號,指揮算術邏輯單元(ALU)、存儲器等組件執行操作。
地址指令:指令中包含操作碼(操作類型)和地址部分(操作的數據存儲地址),使得指令能夠明確指向內存中的特定數據。
這種“存儲程序”的設計理念極大地提高了計算機的靈活性和功能性,形成了現代計算機的基礎架構。
7.下列哪個不是Linux內核里面任務調度切換的時間點?A,中斷函數處理完畢返回到用戶臺,b,系統調用處理完畢,從內核態返回到用戶態。內核主動調用schedule()函數,try_to _wake_up函數喚醒任務。
在Linux內核中,任務調度切換的時間點包括:
A,中斷函數處理完畢返回到用戶態。
B,系統調用處理完畢,從內核態返回到用戶態。
內核主動調用 schedule() 函數,這是進行任務調度的主要方式。
而 try_to_wake_up 函數 主要用于喚醒等待的任務,但它并不會直接導致任務切換,因此也不是調度切換的時間點。
因此,try_to_wake_up 函數喚醒任務 不是任務調度切換的時間點。
8.Linux系統中哪些函數調用時系統不會馬上分配物理內存?
當然可以!以下是更詳細的說明關于 Linux 系統中不會立即分配物理內存的函數和它們的工作原理:
1. malloc()
功能:在用戶空間中分配內存。
內存分配:malloc() 在調用時僅分配虛擬內存。實際的物理內存將僅在訪問分配內存時(例如寫入數據)才會被請求。
2. mmap()
功能:將文件或設備映射到進程的虛擬地址空間,允許內存映射I/O。
內存分配:mmap() 可能創建一個內存映射區域,但不分配物理內存。實際物理頁面在讀取或寫入映射區域時被分配。
3. vmalloc()
功能:在內核中分配虛擬內存,允許不連續的物理內存分配。
內存分配:vmalloc() 會為請求的虛擬地址空間分配,但背后的物理內存可能只在訪問時才被分配。
4. kmap()
功能:在內核中將物理頁映射到虛擬地址空間,用于按需訪問物理內存。
內存分配:在調用時并不直接分配物理內存,只有在實際訪問這些頁時,物理內存才會被激活。
5. get_free_page()
功能:分配一個物理頁面。
內存分配:雖然此函數分配物理頁面,但操作系統的內存管理可能會延遲一些頁面的分配直到真正需要使用它們。
6. 延遲分配的好處
性能優化:延遲分配可以減少不必要的物理內存分配,特別是在實際使用內存之前,避免了內存的浪費。
內存回收:通過推遲實際分配,操作系統可以更有效地管理內存,回收未使用或不再需要的內存。
這些機制使得 Linux 系統在內存管理上更加高效和靈活,能夠適應不同的應用需求和運行環境。
9.USB3.0接口的引腳配置是什么?
USB 3.0 接口的引腳配置如下:
USB 3.0 Type-A 接口引腳配置:
引腳 1: VBUS(電源,+5V)
引腳 2: D-(數據線,負極)
引腳 3: D+(數據線,正極)
引腳 4: GND(接地)
引腳 5: SSRX-(SuperSpeed 接收,負極)
引腳 6: SSRX+(SuperSpeed 接收,正極)
引腳 7: GND_DRAIN(接地排水)
引腳 8: SSTX-(SuperSpeed 發送,負極)
引腳 9: SSTX+(SuperSpeed 發送,正極)
USB 3.0 Type-B 接口引腳配置:
引腳 1: VBUS(電源,+5V)
引腳 2: D-(數據線,負極)
引腳 3: D+(數據線,正極)
引腳 4: GND(接地)
引腳 5: SSRX-(SuperSpeed 接收,負極)
引腳 6: SSRX+(SuperSpeed 接收,正極)
引腳 7: GND_DRAIN(接地排水)
引腳 8: SSTX-(SuperSpeed 發送,負極)
引腳 9: SSTX+(SuperSpeed 發送,正極)
總結
USB 3.0 在原有的 USB 2.0 基礎上增加了 SuperSpeed 數據線,支持更高的數據傳輸速率,達到了 5 Gbps。這個引腳配置使得 USB 3.0 向后兼容 USB 2.0,可以在相同的連接器上使用。
10.在Linux系統中,關于pagecache的工作機制和行為是什么?
在Linux系統中,pagecache 是內核用來緩存文件系統數據的一種機制,它顯著提高了文件操作的性能。以下是其工作機制和行為的主要方面:
工作機制
緩存機制:
當應用程序訪問文件時,內核會將該文件的數據載入到內存中,以減少后續訪問的延遲。
文件數據通過頁(通常為4KB或更大)進行管理,這些頁被稱為頁緩存(pagecache)。
讀取操作:
當應用程序請求文件數據時,內核首先檢查 pagecache 是否已經緩存了所需的數據頁。如果存在,直接從內存返回,避免磁盤I/O。
如果數據不在緩存中,內核會從磁盤讀取數據,并將其存儲在 pagecache 中,以備后續使用。
寫入操作:
對文件的寫操作首先會更新 pagecache 中的數據頁,而不是立即寫入磁盤。
定期或在特定條件下,內核會將緩存中的臟頁(已修改但未寫入磁盤的頁)刷新到磁盤。這一過程稱為好寫(flush)或寫回(write-back)。
行為特點
延遲寫入:
通過將寫操作推遲到適當的時候,可以減少對磁盤的頻繁訪問,提高整體性能。這種策略稱為寫回策略。
空間管理:
pagecache 占用的內存是動態分配的,內核會根據系統的可用內存情況來管理。如果系統內存緊張,內核會釋放不再使用的緩存頁,以騰出空間給其他進程。
共享性:
pagecache 允許多個進程共享同一文件的數據。當多個進程同時讀取相同的文件時,只有當數據在緩存中時,才會被有效利用。
IO調度:
Linux內核利用獨特的I/O調度算法(如CFQ、Deadline等)來優化對磁盤的請求,確保優先處理高優先級的I/O。
文件系統交互:
pagecache 與文件系統層緊密集成,任意文件操作(如讀取、寫入、刪除等)都會被影響并能利用緩存的優勢。
總結
pagecache 機制是Linux十分重要的性能優化手段,通過有效利用內存資源,降低了對磁盤的訪問頻率,提高了文件操作的速度。理解并合理配置 pagecache 可以大幅提升系統的整體性能和響應能力。
11.rtos stack中調用嵌套函數會增加棧的使用。
是的,在實時操作系統(RTOS)中,調用嵌套函數確實會增加棧的使用。以下是具體原因:
1. 棧的基本概念
棧 是用來存儲函數調用的返回地址、局部變量和參數的內存區域。每次函數調用時,都會在棧上分配一定的空間。
2. 嵌套調用的影響
當一個函數調用另一個函數時,棧中會為每個函數的局部變量和返回地址分配額外的空間。
如果存在多個嵌套函數調用,棧的深度會隨著每次調用而增加,從而消耗更多的棧空間。
3. 對系統的影響
棧溢出:如果嵌套調用層級過深、或每個函數使用的棧空間過大,可能會導致棧溢出,尤其是在資源受限的嵌入式系統中。
性能問題:過多的棧使用可能導致上下文切換變慢,因為需要更多的時間來保存和恢復堆棧狀態。
4. 優化策略
棧大小配置:在RTOS中,根據任務的需求合理配置棧大小。
避免深度嵌套:盡量減少函數的嵌套深度,或者使用非遞歸的算法。
使用靜態內存:在合適的情況下,使用靜態或全局變量來替代局部變量,減少棧的使用。
總之,管理好棧的使用對于實時操作系統的穩定性和性能非常重要。
12.rtos stack的元素是按照后進先出的順序進行操作。
是的,在實時操作系統(RTOS)中,棧(stack)的操作遵循后進先出(LIFO,Last In First Out)的原則。這意味著:
棧的操作特性
后進先出:
最后被壓入棧中的元素會最先被彈出。這種特性使得棧非常適合用于函數調用管理。
函數調用:
每次函數調用時,函數的返回地址、局部變量和參數等都會被壓入棧中。
當函數執行完畢,返回到調用它的函數時,這些數據會被從棧中彈出。
數據存取:
棧頂的元素代表當前活動的函數或任務,進一步的操作總是對棧頂的元素進行。
優勢和應用
簡化管理:后進先出機制使得函數調用和返回過程簡單高效,減少了對復雜數據結構的需求。
上下文切換:在RTOS中,任務切換時,當前任務的棧狀態會被保存,并在恢復中再次使用。
總結
后進先出的棧操作模式是RTOS運行的基礎部分,確保了函數調用和任務管理的高效性。
13.在arm架構中,關于LR寄存器的描述是什么?
在ARM架構中,LR(Link Register)寄存器的主要作用是存儲函數調用的返回地址。以下是LR寄存器的一些關鍵點:
1. 函數調用
當一個函數被調用時,程序計數器(PC)將指向調用后的位置,LR寄存器會保存這個地址,以便在函數執行完畢后能夠正確返回到調用點。
2. 返回指令
在ARM架構中,通常使用 BX LR 或者 MOV PC, LR 指令來返回到調用函數之前的地址。
3. 嵌套調用
在嵌套函數調用中,每次調用新的函數,LR寄存器的值都會被更新。為了正確返回到每個函數的調用點,通常需要將LR的值保存到棧中。
4. 異常處理
在異常或中斷發生時,LR寄存器可能記錄異常返回地址,以便在處理完異常后返回到正確的執行點。
5. 移動和特定用途
在ARM的某些模式下,例如ARM和Thumb模式,LR寄存器的存儲和使用可能有所不同。Thumb狀態下,LR的高位會被設置為1,表示返回到Thumb狀態。
總結
LR寄存器是ARM架構中重要的寄存器,用于管理函數調用和返回地址,它在程序控制流和異常處理方面發揮著關鍵作用。
14.假如你設計一個c++類,并將其析構函數標記為delete,下列哪種設計意圖是合理的?a,你希望內的對象可以在站上創建并自動銷毀。但不希望在堆上分配,b你希望類的對象只能在堆上分配,并且由外部代碼控制其生命周期。c,你希望類的對象可以被復制和移動。
在C++中,如果將類的析構函數標記為 delete,意味著該類的對象不能被銷毀。這種設計意圖通常合理的選項是:
合理的設計意圖
a,你希望類的對象可以在棧上創建并自動銷毀,但不希望在堆上分配。
解釋
選項 a:這種情況下,使用 delete 標記析構函數可以防止在堆上分配對象,這在某些情況下是合適的。例如,如果你希望類的實例只有棧上的生命周期,可以通過這種機制來阻止用戶在堆上使用 new 關鍵字。
選項 b:如果你希望對象只能在堆上分配并控制其生命周期,析構函數通常應該是公有的而不是 delete。
選項 c:如果你希望對象可以被復制和移動,構造函數和析構函數都不能被標記為 delete,因為這會阻止對象的正常管理。
因此,選項 a 是合理的設計意圖。
15.在GDB調試中,用于查看變量的值的命令是哪個
在GDB調試中,用于查看變量值的命令是 print 或 p。
16.最能確保提高頁面緩存訪問儲存的命中率的改進途徑是什么?
提高頁面緩存訪問存儲的命中率,可以通過以下途徑來實現,特別是結合LRU(最近最少使用)策略和頁面數的管理:
1. 實施LRU替換策略
LRU(最近最少使用):該策略優先保留最近使用的頁面,因而可以顯著提高頁面的命中率。LRU 會根據頁面訪問的時間軌跡來決定哪些頁面應當被替換,這樣頻繁訪問的頁面不會被移除。
2. 優化頁面數
合理配置頁面大小和數量:頁面大小的選擇直接影響到系統的頁面數。較小的頁面可能會導致內存碎片增加,但可以提高空間局部性。適當調整頁面大小,以便盡可能提高命中率。
增加頁面緩存的總數:如果可能的話,增加頁面緩存的數量,可以提高緩存的容量,進而提高命中率。
3. 監測和分析訪問模式
分析訪問模式:根據應用程序的訪問行為,調整LRU策略的實現,確保頻繁訪問的頁面始終保持在緩存中。
4. 預讀取策略
實施預讀取:借助預測算法,提前加載可能會被訪問的頁面,減少頁面缺失。
5. 減少頁面換入換出
減少頻繁的頁面置換:盡量避免頻繁的頁面換入換出,確保緩存中保持有效頁面,尤其是在訪問模式較穩定的情況下。
通過結合有效的LRU策略和優化頁面數管理,可以大幅提高頁面緩存的命中率,提升系統的整體性能
17.Linux內核調度策略有哪些?
Linux內核調度策略主要包括以下幾種:
1. 完全公平調度器 (CFS)
CFS 是 Linux 2.6.23 引入的默認調度器。它基于時間片和紅黑樹算法,旨在使所有進程公平地使用 CPU 資源。
2. 實時調度策略
SCHED_FIFO:一種實時優先級調度策略,為高優先級進程提供盡可能快速的響應,不會被其他進程搶占。
SCHED_RR:與 SCHED_FIFO 類似,但在相同優先級的進程之間輪流調度,采用時間片方式。
3. 腦死亡調度 (SCHED_DEADLINE)
用于支持基于時間的實時任務調度,允許用戶為任務定義最遲完成時間和執行周期。
4. 時間共享調度
針對交互式和非實時進程的調度,確保良好的響應速度。
5. CFS的調度類
Linux內核支持多種調度類,除了上述調度策略外,內核允許開發者實現自定義調度類以滿足特定需求。
6. 其他調度策略
SCHED_BATCH:用于長時間運行的批處理任務,優先級較低,適合對響應時間要求不高的任務。
SCHED_IDLE:最低優先級,適用于空閑時運行的任務,減少對其他任務的影響。
7. 能源感知調度
在移動和嵌入式設備中,調度策略可能會考慮節能,調整任務運行以延長電池續航。
總結
Linux內核提供多種調度策略,以支持不同類型的應用和任務,確保系統的響應性和資源的有效利用。
18.R數據通道頻率是時鐘通道頻率的幾倍?
在USB(通用串行總線)協議中,R數據通道頻率通常是時鐘通道頻率的兩倍。這一點在USB 2.0和更高版本的規范中都有體現。
解釋
時鐘通道:用于同步數據傳輸,提供必要的時鐘信號。
R數據通道:用于實際的數據傳輸,頻率為時鐘信號的兩倍,這樣可以在多個時鐘周期內傳輸更多數據。
這種設計使得數據傳輸更加高效,支持更高的數據帶寬。
19.UART可以實現全雙工通訊,常用波特率為9600到115200。
是的,UART(通用異步收發傳輸器)可以實現全雙工通訊。這意味著它可以同時進行發送和接收數據。常用的波特率范圍確實從 9600 bps 到 115200 bps,這使得UART在許多應用中得到了廣泛的使用。
關鍵點
全雙工通訊:UART通過獨立的發送和接收線(TX和RX)實現全雙工,允許同時發送和接收數據。
波特率:波特率是數據傳輸速率,常用值包括:
9600 bps:常用于基本串行通信。
115200 bps:適用于對速度要求較高的應用,如數據采集或高速設備。
應用場景
嵌入式系統:常用于微控制器之間的通信。
串行設備:連接傳感器、模塊或電腦等設備。
UART的全雙工特性和靈活的波特率設置,使其在串行通信中非常實用。
20.RS485總線使用差分信號進行傳輸。
是的,RS-485總線使用差分信號進行數據傳輸。這種傳輸方式具有以下優點:
關鍵特性
差分信號傳輸:
RS-485通過兩條信號線(A和B)發送相反的電壓信號。這種差分傳輸可以有效抵抗電磁干擾(EMI),提高信號的抗干擾能力。
長距離傳輸:
RS-485支持較長的傳輸距離,通常可達到1200米(約4000英尺),適合于工業環境中的遠距離通信。
多點通訊:
支持多個設備(通常達到32個)在同一總線上進行通信,非常適合應用于網絡系統。
更高的傳輸速率:
傳輸速率可以達到10 Mbps,適合高數據速率的需求。
應用場景
工業自動化:常用于控制系統和傳感器網絡。
建筑自動化:如樓宇監控和管理系統。
數據采集:適合需要遠程監測和數據收集的應用。
總之,RS-485的差分信號特性使其在多個應用中具有顯著優勢,尤其是在噪聲較多和傳輸距離較遠的環境中。
21.I2C是一種半雙工異步通訊總線。
是的,I2C(Inter-Integrated Circuit)是一種半雙工異步通信總線。
關鍵特性
半雙工通訊:
I2C通過同一條數據線(SDA)進行數據的發送和接收,但不能同時進行。數據的傳輸是雙向的,但在任意時刻只能有一個方向的數據流。
同步傳輸:
I2C使用時鐘線(SCL)進行同步,確保主從設備之間的數據傳輸的時序一致。
多主多從:
I2C支持多主機和多從機的架構,一個總線上可以連接多個設備,主機可以控制從機進行數據傳輸。
地址尋址:
每個從機有唯一的7位或10位地址,主機通過地址選擇要通信的從機。
應用場景
傳感器接口:廣泛用于連接各種傳感器和微控制器。
嵌入式系統:在各類嵌入式設備中進行短距離通信。
低速設備:適合用于需要較低速度通信的應用,通常不超過400 kbps(標準模式),有些情況下可以達到3.4 Mbps(高速模式)。
總之,I2C是一個靈活且廣泛應用的通信協議,尤其適用于多個設備之間的低速數據交換。
22. 802.11b是藍牙技術嗎?
802.11b 不是藍牙技術。它屬于無線局域網(WLAN)標準,主要用于Wi-Fi網絡。以下是兩者的主要區別:
802.11b
類別:無線局域網標準(Wi-Fi)。
頻段:工作在2.4 GHz頻段。
傳輸速率:最高可達11 Mbps。
用途:主要用于構建無線局域網,提供數據通信。
藍牙
類別:短距離無線通信技術。
頻段:也工作在2.4 GHz頻段,但與Wi-Fi及其他設備共享。
傳輸速率:通常在1 Mbps到3 Mbps之間(取決于版本)。
用途:用于短距離設備之間的無線連接,如耳機、鍵盤、手機等。
雖然兩者都在2.4 GHz頻段操作,但它們的應用、傳輸速率和通信范圍是不同的。
23.虛擬內存為進程提供了一致的地址空間,從而簡化了內存管理,對嗎?
是的,虛擬內存為進程提供了一致的地址空間,這確實簡化了內存管理。以下是相關的幾個要點:
虛擬內存的優勢
統一地址空間:
每個進程都有其獨立的虛擬地址空間,使得它們之間的地址不會沖突。每個進程視圖中的內存地址都是從0開始的。
內存隔離:
虛擬內存提供了進程之間的隔離,提高了系統的安全性和穩定性。如果一個進程崩潰,不會影響其他進程的內存。
簡化管理:
進程不需要關心物理內存的組織和管理。操作系統負責將虛擬地址映射到物理內存,簡化了編程模型。
高效利用內存:
虛擬內存允許系統以更加靈活的方式使用物理內存,通過頁面替換算法,確保活躍的頁面保留在內存中,不常用的頁面可以被換出以釋放內存。
需求分頁:
系統可以按需加載頁到內存中,優化內存使用,避免一次性加載所有進程需要的內存。
綜上所述,虛擬內存確實提高了內存管理的效率與簡潔性。
24.操作系統通過將一個虛擬內存區域與磁盤上的對象關聯起來,以初始化該虛擬內存區域的過程稱為內存分配。對嗎?
不完全正確。操作系統通過將一個虛擬內存區域與磁盤上的對象關聯起來的過程更準確地稱為內存映射(memory mapping),而不是簡單的內存分配。
主要概念
內存映射:
此過程涉及將磁盤文件或對象的內容映射到虛擬內存空間,使得程序能夠直接訪問這些數據。
內存分配:
內存分配是指操作系統為進程分配內存的過程,這包括分配虛擬內存區域,但不特指與磁盤對象的關聯。
結論
因此,雖然將虛擬內存區域與磁盤對象的關聯涉及初始化虛擬內存,但這一過程更具體地稱為內存映射,而內存分配是一個更廣泛的過程
25.MMU用來將虛擬地址轉換為物理地址。
是的,MMU(內存管理單元)用于將虛擬地址轉換為物理地址。以下是一些關鍵點:
MMU的功能
虛擬地址到物理地址的映射:
MMU負責將進程生成的虛擬地址轉換為對應的物理地址,使得程序可以使用更大的虛擬地址空間,而不必直接管理物理內存。
頁表:
MMU使用頁表來存儲虛擬地址和物理地址之間的映射關系。頁表記錄了每個虛擬頁面對應的物理頁面。
地址轉換:
當CPU發出一個虛擬地址時,MMU查找頁表以獲取相應的物理地址,并進行轉換,允許訪問真正的物理內存。
支持內存保護和隔離:
MMU確保不同進程之間的內存是隔離的,提高系統的安全性和穩定性。
總結
因此,MMU是關鍵的硬件組件,用于實現虛擬內存機制,并有效管理內存地址的轉換。
26.當處理器訪問的虛擬內存也不在物理內存中會觸發缺頁異常,對嗎?
是的,當處理器訪問的虛擬內存不在物理內存中時,會觸發缺頁異常(page fault)。
關鍵點
缺頁異常:
當進程試圖訪問一個未映射到物理內存的虛擬地址時,MMU會產生缺頁異常,通知操作系統。
處理過程:
操作系統會捕獲這個異常,檢查虛擬地址是否有效,并決定如何處理。如果該頁面在磁盤上(例如,交換區或文件存儲),操作系統會將其加載到物理內存中。
頁面調度:
操作系統可能需要選擇一個已在物理內存中的頁面進行換出,以便騰出空間來加載請求的頁面,這通常涉及頁面置換算法(如LRU、FIFO等)。
恢復執行:
一旦頁面被加載到物理內存中,處理器會重新嘗試訪問該虛擬地址,進程能夠繼續執行。
總結
因此,缺頁異常是虛擬內存管理的關鍵機制,能夠有效支持內存的動態管理和保護。
27.volatile可以修飾一個指針嗎? volatile修飾的變量可以保證多線程下的原子訪問,對嗎?volatile可以跟const一起使用嗎?
1. volatile可以修飾一個指針嗎?
是的,volatile可以修飾指針。具體來說,可以這樣使用:
volatile int* ptr;
這表示指針 ptr 所指向的整型值是 volatile 的,意味著這個值可能會在程序的其他地方被改變(例如,通過硬件或其他線程),編譯器不會進行優化。
2. volatile修飾的變量可以保證多線程下的原子訪問嗎?
不完全正確。volatile 僅表示變量的值可能被異步修改,防止編譯器對該變量進行優化。然而,它并不能保證原子性。要實現多線程的原子訪問,需要使用其他機制,如互斥鎖(mutex)或原子操作。
3. volatile可以跟const一起使用嗎?
是的,volatile可以與const一起使用,形成一個只讀的volatile變量。例如:
const volatile int value;
這表示 value 是一個 volatile 變量,且只能被讀取,不能被修改,但其值可能會被外部因素(如硬件或其他線程)改變。
總結
volatile可以修飾指針。
volatile不保證原子性。
volatile可以與const一起使用。
28.不同優先級線程競爭同一把鎖可能會導致優先級反轉。
是的,不同優先級的線程競爭同一把鎖可能會導致優先級反轉問題。
關鍵點
優先級反轉:
當一個高優先級線程需要被一個低優先級線程持有的鎖時,低優先級線程會阻塞。此時,如果有一個中等優先級的線程運行,它可能會使得低優先級線程無法運行,從而導致高優先級線程被長期阻塞。
示例:
假設有三個線程:A(高優先級)、B(中等優先級)、C(低優先級)。線程 C 持有一把鎖,線程 A 試圖獲取這把鎖,但由于 C 正在執行,A 被阻塞。如果此時線程 B 被調度并執行,那么 C 將無法執行,從而導致 A 無法繼續運行。
解決方案:
優先級繼承:低優先級線程在持有鎖時提升它的優先級至高優先級線程的優先級,直到釋放鎖。
優先級天花板:為共享資源設定一個固定的高優先級,以防止低優先級線程阻塞高優先級線程。
總結
優先級反轉是多線程編程中的一個重要問題,了解并采取適當措施來解決它是確保系統性能的關鍵。
29.在Linux系統中,兩個處于ready態的線程,高優先級的線程一定會先于低優先級的線程運行。
在Linux系統中,兩個處于ready態的線程,高優先級線程并不一定會立即先于低優先級線程運行。這是由于以下幾個原因:
關鍵因素
調度策略:
Linux使用多種調度策略,例如CFS(完全公平調度器)和實時調度策略(如 SCHED_FIFO 和 SCHED_RR)。在實時策略下,高優先級線程會優先執行,但在CFS策略下,調度并不是簡單的優先級排序。
時間片和計劃:
即使高優先級線程處于ready狀態,如果低優先級線程正在執行且其時間片尚未耗盡,它也可能繼續運行。調度器會考慮線程的時間片和其他因素。
內核負載和調度延遲:
在系統負載較高或發生上下文切換時,調度可能會受到影響,因此高優先級線程可能會延遲執行。
總結
雖然高優先級線程在ready狀態下有更高的執行優先權,但在實際運行時,由于調度策略和系統狀態的影響,它不一定總是優先運行。
30.在ARM CPU中,在同一線程中,CPU會按照c語言代碼順序執行。
在ARM CPU中,雖然C語言代碼通常按照書寫的順序執行,但實際上,CPU的執行過程可能受到多種因素的影響,導致并不總是嚴格按照代碼順序執行。這些因素包括:
關鍵因素
編譯器優化:
編譯器可能會進行優化,如重新排序代碼,以提高性能。有時這會導致指令的執行順序與源代碼不完全一致。
流水線架構:
ARM CPU通常采用流水線架構,多個指令可以在不同階段同時處理,可能會造成指令的實際執行順序與代碼順序不同。
內存訪問:
在多核或多線程環境中,內存訪問的延遲或沖突也可能影響指令的執行順序。
中斷和異常:
如果發生中斷或異常,當前線程的執行可能被暫停并轉而執行中斷處理程序,這也會影響程序的控制流。
總結
盡管在同一線程中C語言代碼通常會按照順序執行,但由于許多因素的影響,實際的執行結果可能并不總是嚴格按代碼順序。因此,特別是涉及多線程或并發編程時,需要注意這些潛在的順序問題。
31.MMU負責地址虛實轉換,同一物理地址在不同進程上的虛擬地址可能不一樣。
是的,MMU(內存管理單元)負責將虛擬地址轉換為物理地址,并且同一物理地址在不同進程中的虛擬地址確實可能不一樣。
關鍵點
虛擬地址與物理地址:
每個進程都有獨立的虛擬地址空間,MMU通過頁表將虛擬地址映射到物理地址。
地址空間隔離:
不同進程的虛擬地址空間是獨立的,意味著進程A中的虛擬地址0x1000可能對應于物理地址0xABCDEF,而進程B中的虛擬地址0x1000可以映射到不同的物理地址,這樣可以避免地址沖突。
內存保護:
這種地址映射機制不僅提供了靈活的內存管理,也增強了進程之間的隔離和保護。
總結
因此,MMU使得同一物理地址可以在不同進程中通過不同的虛擬地址進行訪問,確保了內存的有效管理與安全性。
32.DMA搬運內存過程中不會占用CPU,所以可以使用DMA優化CPU loading。
是的,DMA(直接內存訪問)在數據搬運過程中不會占用CPU,從而可以有效地優化CPU的負載。
關鍵點
DMA的工作原理:
DMA控制器可以直接在內存和外設之間傳輸數據,而無需CPU的干預。這樣,CPU可以繼續執行其他任務,提高整體系統的效率。
CPU負載優化:
通過使用DMA,CPU可以在數據傳輸過程中處理其他計算或操作,減少擁塞和提高資源的使用率。
降低延遲:
DMA可以減少數據傳輸的延遲,特別是在需要大量數據移動的場景中(如音視頻流、網卡數據包等),這對實時系統尤為重要。
中斷處理:
一旦DMA傳輸完成,DMA控制器會生成中斷通知CPU,這樣可以在完成傳輸后再進行后續處理。
總結
綜上所述,使用DMA可以顯著減輕CPU的負載,使其更加高效地執行其他任務,從而提高整個系統的性能。
33.將整型變量賦值給另一個整型變量是原子操作,可由一條匯編指令完成。
是的,將整型變量賦值給另一個整型變量通常是一個原子操作,并且可以由一條匯編指令完成。這種操作在大多數現代處理器體系結構中,例如x86或ARM,都是原子性的,意味著它不會被中斷或打斷。
關鍵點
原子性:
原子操作是不會被其他線程或處理器中斷的操作。對于整型賦值,由于它只涉及單一的數據移動,通常在硬件層面上保證了原子性。
匯編指令:
賦值操作通常可以通過簡單的匯編指令(如 MOV 指令)實現。這樣可以確保在執行賦值時,操作是不可分割的。
多線程環境:
在多線程編程中,使用原子操作可以避免競態條件。如果只涉及基本類型(如整型),賦值通常是安全的,不需要額外的鎖機制。
注意事項
盡管賦值本身是原子操作,但對整型變量的其他操作(如增加、減少)可能不是原子性的,尤其是在多處理器系統中。在這些情況下,需要使用鎖或原子操作庫提供的函數來確保整體的原子性。
總結
因此,將整型變量賦值給另一個整型變量通常是一個原子操作,并可以通過一條匯編指令完成。
34.一個多核CPU的不同核心可以同時運行不同的操作系統。
是的,一個多核CPU的不同核心可以同時運行不同的操作系統。這種架構通常被稱為異構多核系統或多虛擬化環境。
關鍵點
核心獨立性:
在多核CPU中,每個核心可以獨立地執行任務,包括不同的操作系統。如果硬件設計支持,這允許某些核心運行Linux,而其他核心可能運行Windows或其他操作系統。
虛擬化技術:
通過虛擬化技術(如KVM、VMware等),可以在同一物理CPU上創建多個虛擬機,每個虛擬機可以運行不同的操作系統。這些虛擬機可以分配到不同的CPU核心上。
應用場景:
這種能力適用于服務器環境、實驗室研究以及某些復雜的嵌入式系統,可以實現CPU資源的靈活利用和多樣化用途。
硬件支持:
需要注意,具體的支持能力取決于硬件架構和CPU設計,不是所有的多核處理器都支持這樣的特性。
總結
因此,多核CPU的不同核心確實可以同時運行不同的操作系統,這為系統設計和資源管理提供了更大的靈活性
35.SPI同步通信,I2C是異步通信。SPI涉及地址分配 I2C用于連接大量的設備,對嗎?
SPI(串行外設接口)
同步通信:
SPI是一種同步通信協議,采用時鐘信號來協調數據傳輸。
地址分配:
SPI通常不需要地址分配。每個外設通常通過片選信號(CS)進行選擇,允許在同一總線上連接多個設備。
優勢:
SPI提供高速數據傳輸,適合需要快速通信的應用。
I2C(互連集成電路)
異步通信:
I2C是一種同步通信協議,也采用時鐘信號來協調數據傳輸,因此它不是異步協議。
地址分配:
I2C支持地址分配,每個設備都有唯一的地址,便于在同一總線上連接多個設備。
用于連接多個設備:
I2C特別適合連接大量設備,最多可以連接127個設備。
總結
SPI是同步通信協議,使用片選信號控制設備,不進行地址分配。
I2C是同步通信協議,支持地址分配,適合連接多個設備。
36.TCP的擁塞控制通過調整發射窗口來控制發射速率。第二,用手控制是為了避免網絡擁塞,防止傳輸性能下降。第三,TCP的擁塞控制可以僅依賴于接收方的反饋。第四,用設窗口的大小是動態調整的。第五,用色控制的唯一目的是限制接收方的數據處理速度。
TCP擁塞控制
通過調整窗口控制發射速率:
正確。TCP的擁塞控制確實通過調整擁塞窗口(cwnd)來控制發送速率,從而避免網絡擁塞。
避免網絡擁塞:
正確。TCP擁塞控制的主要目標是避免網絡擁塞,防止數據傳輸性能下降。
接收方的反饋:
不完全正確。TCP的擁塞控制不僅依賴于接收方的反饋,還依賴于網絡的反饋信息(如數據包丟失情況)。接收方的窗口大小主要用于流量控制,而非擁塞控制。
窗口大小動態調整:
正確。擁塞窗口的大小是動態調整的,TCP會根據網絡狀況(如延遲、丟包)來調整窗口大小。
限制接收方的數據處理速度:
不完全正確。TCP的流量控制(通過接收方的窗口大小)主要目的是避免接收方處理不及,而擁塞控制則是根據網絡的實際情況調整發送速率,是兩個不同的功能。
總結
TCP擁塞控制通過調整窗口大小來控制發送速率,以避免網絡擁塞。
它并不僅僅依賴接收方的反饋,而是同時考慮網絡狀態。
流量控制和擁塞控制是TCP中的兩個不同機制。
37. Gcc -S可以將c代碼編譯成匯編代碼。
是的,gcc -S 命令可以將C代碼編譯成匯編代碼。具體來說,這個命令的作用是將源代碼中的C語言編譯成對應的匯編語言文件,而不會生成目標文件或可執行文件。
gcc -S source_file.c
輸出文件:
執行完該命令后,會生成一個 .s 后綴的匯編語言文件,文件名通常與源文件相同。例如,source_file.c 會生成 source_file.s。
用途:
該命令對于學習和分析生成的匯編代碼很有用,特別是在進行性能優化或理解編譯過程時。
總結
因此,gcc -S 確實可以將C代碼編譯成匯編代碼,用于進一步的分析或處理
38. If #defined symbol可用來判斷symbol是否被定義。
是的,#defined 符號在C和C++中用于判斷某個宏是否已被定義。這種用法通常與條件編譯指令一起使用。
#ifdef SYMBOL
// 如果 SYMBOL 被定義,執行這段代碼
#endif
#define MY_MACRO
#ifdef MY_MACRO
// 這個塊會被編譯
printf("MY_MACRO is defined.\n");
#else
// 這個塊不會被編譯
printf("MY_MACRO is not defined.\n");
#endif
39.Include <filename.h>會直接到庫函數所在的目錄去查找頭文件。
是的,#include <filename.h> 語句用于引用標準庫或外部庫的頭文件,其查找機制如下:
查找過程
尖括號語法:
使用尖括號(< >)時,編譯器會在系統的標準庫路徑中查找指定的頭文件。通常這些路徑包括編譯器安裝時的標準目錄。
查找順序:
首先,編譯器會查找預定義的標準目錄,例如 /usr/include 或其他編譯器特定的目錄。
如果在這些目錄中未找到該文件,則會產生編譯錯誤。
與雙引號的區別
使用雙引號(#include "filename.h")時,編譯器會首先在當前源文件所在目錄查找頭文件,如果找不到,才會去標準目錄查找。
總結
因此,#include <filename.h> 確實會直接到庫函數所在的標準目錄查找頭文件,而不在源文件目錄中查找。
40.Typedef有類型檢查嗎?
typedef 本身并不提供類型檢查,它只是一種為已有類型創建別名的機制。在編譯器的視角下,typedef 后的別名與原始類型是完全相同的。
關鍵點
類型別名:
使用 typedef 創建的別名只是在代碼中為某個類型提供了一個新的名字,不會影響類型系統。
沒有額外的類型檢查:
編譯器在處理 typedef 時不會進行額外的類型檢查,任何與原類型相同的操作都適用。
實用性:
盡管沒有類型檢查,typedef 可以提高代碼的可讀性和可維護性,尤其是對于復雜類型(如結構體、指針等)。
typedef unsigned long ulong;
ulong a = 5; // 這實際上是 unsigned long a = 5;
在這種情況下,ulong 與 unsigned long 是等價的,編譯器不會針對 ulong 進行額外的類型檢查。
總結
因此,typedef 不提供類型檢查,其主要功能是創建類型的別名。
41.在Linux內核驅動開發中,哪些函數不能在中斷上下文中調用?wait_event(),spinlock(),mutex_lock()函數呢?
在Linux內核驅動開發中,還有許多其他函數和操作不適合在中斷上下文中調用。以下是一些常見的例子:
不能在中斷上下文中調用的函數
睡眠操作:
wait_event_interruptible() 或 wait_event():這些函數導致進程進入睡眠狀態。
msleep() 和類似的函數:導致調用線程睡眠,無法在中斷上下文中使用。
大多數 I/O 操作:
如 copy_from_user() 和 copy_to_user():這些函數中涉及進程上下文的操作。
動態內存分配:
kmalloc():雖然可以在某些中斷上下文中使用,但應盡量避免,因為它可能導致休眠。
信號發送:
kill_fasync() 等會導致進程調度的函數。
調度函數:
schedule(), schedule_timeout() 等,這些會將執行權轉給其他任務。
其他注意事項
打印函數:
printk() 是可以在中斷上下文中調用,但輸出會被限制,且可能影響性能。
復雜操作:
避免調用復雜的函數鏈,因為它們可能依賴于可能會導致睡眠的其他函數。
總結
在設計中斷處理程序時,應該僅限于簡單且快速的操作,避免睡眠和復雜的內存操作。確保使用合適的同步機制,如自旋鎖等,來避免在中斷上下文中引入阻塞。這樣可以保證系統的穩定性和性能。
在Linux內核驅動開發中,有些函數和操作不適合在中斷上下文中調用。以下是對于你提到的函數的分析:
1. wait_event()
不能在中斷上下文中調用:這個函數會導致進程睡眠,而在中斷上下文中,不能進行睡眠操作。中斷上下文非常短暫,不允許進行阻塞。
2. spin_lock()
可以在中斷上下文中調用:spin_lock() 可以在中斷上下文中使用,它是自旋鎖,適合在這種上下文中,因為它不會導致進程睡眠。但需要注意,使用自旋鎖時要小心死鎖和性能問題。
3. mutex_lock()
不能在中斷上下文中調用:mutex_lock() 是一個可能導致進程睡眠的操作,因此無法在中斷上下文中使用。使用互斥鎖時要確保在進程上下文中。
總結
wait_event() 和 mutex_lock() 不能在中斷上下文中調用。
spin_lock() 可以在中斷上下文中使用,但需謹慎對待。
42.用戶進程通常情況只能訪問用戶空間的虛擬地址,不能訪問內核空間虛擬地址。Cortex m3體系結構中,系統復位后所有代碼都是由用戶在psp。Git commit命令用于將暫存區的內容添加到本地倉庫中。自選鎖在等待獲取鎖的過程中會讓出CPU資源。MMU可以支持虛擬內存的概念,允許虛擬內存的大小超過實際的RAM容量。
1. 用戶進程訪問內核空間
正確:用戶進程通常只能訪問用戶空間的虛擬地址,無法直接訪問內核空間的虛擬地址。這種保護機制通過硬件和操作系統共同實現,以防止用戶進程干擾和破壞內核的操作。
2. Cortex-M3體系結構
部分正確:在Cortex-M3體系結構中,系統復位后所有代碼確實從用戶模式(PSP,Process Stack Pointer)開始執行。然而,Cortex-M3不具有高級的虛擬內存管理(MMU),而是使用簡單的內存保護機制,所有代碼最初都在用戶模式下執行。
3. Git commit命令
正確:git commit 命令用于將暫存區(staging area)中的更改提交到本地倉庫中。它會創建一個新的提交,記錄當前項目的狀態。
4. 自選鎖
不完全正確:自選鎖(例如自旋鎖)在等待獲取鎖的過程中不會讓出CPU資源。自旋鎖會持續忙等待,直到它被獲取。相比之下,互斥鎖(mutex)在等待時可能會讓出CPU控制權,允許其他線程運行。
5. MMU與虛擬內存
正確:內存管理單元(MMU)確實支持虛擬內存的概念,允許程序使用的虛擬內存空間超出物理RAM容量。通過頁面置換等技術,系統能有效管理內存
43.匯編語言程序不一定包括.data和.bss段,但必須包括.text段。
匯編語言程序的段
.text段:
必須包括**.text段**,因為這是存放程序代碼的地方。執行代碼必須在這個段中定義。
.data段:
可選的**.data段**用于存放已初始化的全局和靜態變量。雖然常用,但并不是所有匯編程序都需要包含它。
.bss段:
可選的**.bss段**用于存放未初始化的全局和靜態變量。類似于.data段,并不是每個程序都必須使用這個段。
總結
因此,匯編語言程序必須包含**.text段**,而**.data和.bss**段是可選的。這種結構允許開發者根據具體需求靈活地組織代碼與數據。
44.在c++中,操作符new的功能和calloc函數的功能完全一樣。
在C++中,new 操作符和 C 語言中的 calloc 函數的功能并不完全相同。以下是它們之間的主要區別:
1. 基本功能
new:
分配內存并調用構造函數。如果分配失敗,會拋出 std::bad_alloc 異常(可以使用 new(nothrow) 來返回 nullptr)。
calloc:
分配一塊內存并初始化為零。如果分配失敗,返回 NULL。
2. 內存初始化
new:
僅在分配基礎類型時不初始化。例如,new int 不會初始化,但 new int() 會初始化為零。
calloc:
默認將分配的內存初始化為零。
3. 使用方式
new:
用于對象和基本數據類型。語法示例:
int* p = new int; // 不初始化
int* q = new int(); // 初始化為零
MyClass* obj = new MyClass(); // 調用構造函數
calloc:
主要用于 C 語言中進行低級內存管理。語法示例:
int* arr = (int*)calloc(10, sizeof(int)); // 初始化為零
4. 釋放內存
new:
應用 delete 來釋放內存,并調用析構函數:
delete p;
delete[] arr; // 對于數組
calloc:
應用 free 來釋放內存:
free(arr);
總結
雖然 new 和 calloc 都用于動態內存分配,但它們有不同的功能、初始化行為和釋放方式,因此不能說它們的功能完全一樣。
45.在Linux內核中為一個數據結構分配空間調用kmalloc函數。
是的,在Linux內核中,為數據結構分配空間通常會使用 kmalloc 函數。這是一個用于動態分配內存的內核函數。
使用 kmalloc 的主要特點
分配內存:
kmalloc 用于在內核空間中分配指定大小的內存塊。函數原型如下
void *kmalloc(size_t size, gfp_t flags);
參數:
size: 要分配的字節數。
flags: 分配的標志,控制內存分配的行為,例如可以使用 GFP_KERNEL(在進程上下文中允許睡眠)或 GFP_ATOMIC(在中斷上下文中不允許睡眠)。
返回值:
返回指向分配內存的指針。如果分配失敗,返回 NULL。
內存釋放:
使用 kfree 函數釋放分配的內存:
kfree(ptr);
示例代碼
#include <linux/slab.h>
struct my_struct {
int data;
// 其他成員
};
void my_function(void) {
struct my_struct *obj;
// 分配內存
obj = kmalloc(sizeof(struct my_struct), GFP_KERNEL);
if (!obj) {
// 處理分配失敗
}
// 使用 obj...
// 釋放內存
kfree(obj);
}
總結
在Linux內核開發中,kmalloc 是用于動態分配內存的標準方法,適用于內核中的數據結構管理。
46.SPI無起始位和停止位數據可以持續傳輸,不會中斷。
是的,SPI(串行外設接口)是一種全雙工通信協議,具有以下特點:
SPI 特點
無起始位和停止位:
SPI 數據傳輸不使用起始位和停止位。數據流是連續的,發送和接收可以在同一時刻進行。
持續傳輸:
一旦建立起通信,數據可以持續傳輸,直到滿足特定條件(如發送特定字節或手動結束傳輸)。
全雙工通信:
SPI 支持全雙工傳輸,因此數據可以同時從主設備和從設備傳輸,增加了傳輸效率。
時鐘信號:
SPI 使用時鐘信號來同步數據的發送和接收,通常由主設備提供。
應用場景
這種持續、無起始位和停止位的傳輸方式使得 SPI 特別適合高速度和實時數據傳輸應用,如傳感器數據讀取和顯示控制等。
總結
因此,您的描述是正確的,SPI 支持連續的數據傳輸而不會中斷,提供了一種高效的通信方式。
47.在Linux系統中對IO端口的訪問和IO空間的訪問方式是一樣的。
在Linux系統中,對I/O端口的訪問和I/O空間的訪問是有區別的。
I/O端口訪問
I/O端口(Port I/O):
使用特定指令(如 inb、outb)直接訪問I/O設備的端口。
這種方式一般是在 x86 架構上使用,通過特定的CPU指令進行數據傳輸。
通常在驅動程序中使用 #include <linux/io.h>。
I/O內存映射訪問
內存映射I/O(Memory Mapped I/O):
將I/O設備的寄存器映射到內存地址空間,從而使用普通的內存訪問指令(如 read 和 write)進行訪問。
使用 ioremap() 函數將設備寄存器映射到內核虛擬地址范圍。
訪問方式類似于訪問內存,能夠利用緩存和更靈活的尋址。
總結
盡管在功能上都能訪問I/O設備,但訪問方式和實現機制截然不同。I/O端口使用特定指令,而I/O內存映射則利用內存訪問指令。根據硬件架構和設備驅動的設計,驅動開發者會選擇適合的方式進行I/O訪問。
48.leetcode23合并k個升序鏈表
#include <stdio.h>
#include <stdlib.h>
struct ListNode {
int val;
struct ListNode *next;
};
// 最小堆節點結構
struct MinHeapNode {
struct ListNode *node;
};
// 最小堆結構
struct MinHeap {
struct MinHeapNode *array;
int size;
};
// 創建一個新的鏈表節點
struct ListNode* createNode(int val) {
struct ListNode *newNode = (struct ListNode*)malloc(sizeof(struct ListNode));
newNode->val = val;
newNode->next = NULL;
return newNode;
}
// 創建最小堆
struct MinHeap* createMinHeap(int capacity) {
struct MinHeap *minHeap = (struct MinHeap*)malloc(sizeof(struct MinHeap));
minHeap->array = (struct MinHeapNode*)malloc(capacity * sizeof(struct MinHeapNode));
minHeap->size = 0;
return minHeap;
}
// 交換兩個最小堆節點
void swap(struct MinHeapNode *a, struct MinHeapNode *b) {
struct MinHeapNode temp = *a;
*a = *b;
*b = temp;
}
// 維護最小堆性質
void minHeapify(struct MinHeap *minHeap, int idx) {
int smallest = idx;
int left = 2 * idx + 1;
int right = 2 * idx + 2;
if (left < minHeap->size && minHeap->array[left].node->val < minHeap->array[smallest].node->val)
smallest = left;
if (right < minHeap->size && minHeap->array[right].node->val < minHeap->array[smallest].node->val)
smallest = right;
if (smallest != idx) {
swap(&minHeap->array[smallest], &minHeap->array[idx]);
minHeapify(minHeap, smallest);
}
}
// 插入節點到最小堆
void insertMinHeap(struct MinHeap *minHeap, struct ListNode *node) {
minHeap->size++;
int i = minHeap->size - 1;
minHeap->array[i].node = node;
while (i && minHeap->array[i].node->val < minHeap->array[(i - 1) / 2].node->val) {
swap(&minHeap->array[i], &minHeap->array[(i - 1) / 2]);
i = (i - 1) / 2;
}
}
// 移除最小堆的最小節點
struct ListNode* removeMin(struct MinHeap *minHeap) {
if (minHeap->size == 0)
return NULL;
struct ListNode *root = minHeap->array[0].node;
minHeap->array[0] = minHeap->array[minHeap->size - 1];
minHeap->size--;
minHeapify(minHeap, 0);
return root;
}
// 合并 K 個升序鏈表
struct ListNode* mergeKLists(struct ListNode **lists, int listsSize) {
struct MinHeap *minHeap = createMinHeap(listsSize);
// 將每個鏈表的頭節點加入最小堆
for (int i = 0; i < listsSize; i++) {
if (lists[i]) {
insertMinHeap(minHeap, lists[i]);
}
}
struct ListNode dummy;
struct ListNode *tail = &dummy;
dummy.next = NULL;
// 合并鏈表
while (minHeap->size > 0) {
struct ListNode *minNode = removeMin(minHeap);
tail->next = minNode;
tail = tail->next;
if (minNode->next) {
insertMinHeap(minHeap, minNode->next);
}
}
free(minHeap->array);
free(minHeap);
return dummy.next; // 返回合并后的鏈表頭
}
// 示例代碼用法
void printList(struct ListNode *head) {
while (head) {
printf("%d -> ", head->val);
head = head->next;
}
printf("NULL\n");
}
int main() {
// 示例鏈表
struct ListNode *l1 = createNode(1);
l1->next = createNode(4);
l1->next->next = createNode(5);
struct ListNode *l2 = createNode(1);
l2->next = createNode(3);
l2->next->next = createNode(4);
struct ListNode *l3 = createNode(2);
l3->next = createNode(6);
struct ListNode *lists[] = {l1, l2, l3};
struct ListNode *mergedList = mergeKLists(lists, 3);
printList(mergedList);
return 0;
}
2020年大疆秋招嵌入式筆試題A卷(部分)
一、單選題
1、3個進程,需要的資源數依次為4,5,6,為了防止死鎖,所需的最少資源數為(B)
A、12 B、13 C、14 D、15
解析:最差情況各進程占用3,4,5,再有一個資源時候,其中一個進程完成釋放資源,所以3+4+5+1=13
2、Thumb指令集支持16位、32位。
3、類似宏定義計算問題(64位系統,char **a[5][6],sizeof(a))
define PRODUCT (x) (x*x)
int main()
{
int a,b=3;
a=PRODUCT(b+2);
}
解答
b+2b+2=3+23+2=11
參見博客:https://blog.csdn.net/qingzhuyuxian/article/details/81459346
4、嵌入式系統的特點:
專用型
隱蔽型
資源受限
高可靠性
軟件固化
實時性
5、mov尋址方式
6、MMU的特點
大疆筆試題目解析
大疆公司每年秋招是分批考試,考試時間自選,分為AB卷,本文分享是B卷。
選考時間:2020.08.16,19:00-20:30(A卷為2020.08.10)
題型:單選(2' * 10)、多選(3' * 5)、填空(4' * 4)、簡答(6' * 3)、編程( * 2 = 31')
B卷主要考察C語言,還考察一些Liunx和ARM知識點
一、單選
1、
const char 和 const char 定義變量的區別
2、關于cache錯誤的是?
3、sizeof 結構體(含位域的)
unit16_t
unit32_t
unit8_t
4、FIQ中斷向量入口地址?(考察ARM知識點)
回答:FIQ的中斷向量地址在0x0000001C,而IRQ的在0x00000018。
5、R15除了本身的功能還可以作為程序計數器?
回答:寄存器R13在ARM指令中常用作堆棧指針SP,寄存器R14稱為子程序鏈接寄存器LR(Link Register),寄存器R15用作程序計數器(PC)。
ARM微處理器共有37個32位寄存器,其中31個為通用寄存器,6個位狀態寄存器。通用寄存器R0~R14、程序計數器PC(即R15)是需要熟悉其功能的。
6、如何判斷機器大小端?

聯合體方法判斷方法:利用union結構體的從低地址開始存,且同一時間內只有一個成員占有內存的特性。大端儲存符合閱讀習慣。聯合體占用內存是最大的那個,和結構體不一樣。
a和c公用同一片內存區域,所以更改c,必然會影響a的數據
include<stdio.h>
int main(){
union w
{
int a;
char b;
}c;
c.a = 1;
if(c.b == 1)
printf("小端存儲\n");
else
printf("大端存儲\n");
return 0;
}
指針方法
通過將int強制類型轉換成char單字節,p指向a的起始字節(低字節)
include <stdio.h>
int main ()
{
int a = 1;
char *p = (char )&a;
if(p == 1)
{
printf("小端存儲\n");
}
else
{
printf("大端存儲\n");
}
return 0;
}
二、多選
1、哪些類型可以自加:i++
2、全雙工總線類型有哪幾個?
3、線程間同步方式?
進程間通訊:
(1)有名管道/無名管道(2)信號(3)共享內存(4)消息隊列(5)信號量(6)socket
線程通訊:
(1)信號量(2)讀寫鎖(3)條件變量(4)互斥鎖(5)自旋鎖
三、填空
1、填一種編譯優化選項:-o
2、在有數據cache情況下,DMA數據鏈路為:外設-DMA-DDR-cache-CPU,CPU需要對cache做什么操作,才可以得到數據?
3、面向對象編程三大特點?
回答:封裝、繼承和多態
四、簡答
1、SPI四種模式,簡述其中一種模式,畫出時序圖?
回答:請參考CSDN博客。
2、判斷大小端的三種方式?
3、為什么TCP是穩定傳輸?
回答:可以從TCP和UDP的區別出發去回答。
五、編程
1、求最大的和:
取兩個不重復的字串,求他們的最大的和
輸入
10
1 -1 2 2 3 -3 4 -4 5 -5
取 2、2、3、-3、4、5,最大輸出13
輸入
5
-5 9 -5 11 20
取9、11、20,加起來40
輸入
10
-1 -1 -1 -1 -1 -1 -1 -1 -1 -1
答案是-2
2、停車,求收費最多(數據太多,可能有誤,自己可以想思路)
用戶編號 1 2 3 4
開始時間 1 2 3 7
結束時間 4 4 12 9
同一時間只能服務一個用戶
1<=t<6 10元一小時
6<=t<10 5元一小時
10<=t 2元一小時
嵌入式基本知識
1、簡述處理器中斷處理的過程(中斷向量、中斷保護現場、中斷嵌套、中斷返回等)。(總分10分)
解答:將中斷處理過程之前,首先先看一下什么是中斷:
所謂中斷,就是指CPU在正常執行程序的時候,由于內部/外部事件的觸發、或由程序預先設定,而引起CPU暫時中止當前正在執行的程序,保存被執行程序相關信息到棧中,轉而去執行為內部/外部事件、或由程序預先設定的事件的中斷服務子程序,待執行完中斷服務子程序后,CPU再獲取被保存在棧中被中斷的程序的信息,繼續執行被中斷的程序,這一過程叫做中斷。
了解了中斷的定義,再來看一下中斷的幾個概念:
中斷向量:中斷服務程序的入口地址;
中斷向量表:把系統中所有的中斷類型碼及其對應的中斷向量按一定的規律存放在一個區域內,這個存儲區域就叫做中斷向量表;
中斷源:軟中斷/內中斷、外中斷/硬件中斷、異常等。
處理器在中斷處理的過程中,一般分為以下幾個步驟:
請求中斷→中斷響應→保護現場→中斷服務→恢復現場→中斷返回。
詳細地講解:
請求中斷:當某一中斷源需要CPU為其進行中斷服務時,就輸出中斷請求信號,使中斷控制系統的中斷請求觸發器置位,向CPU請求中斷。系統要求中斷請求信號一直保持到CPU對其進行中斷響應為止;
中斷響應:CPU對系統內部中斷源提出的中斷請求必須響應,而且自動取得中斷服務子程序的入口地址,執行中斷服務子程序。對于外部中斷,CPU在執行當前指令的最后一個時鐘周期去查詢INTR引腳,若查詢到中斷請求信號有效,同時在系統開中斷(即IF=1)的情況下,CPU向發出中斷請求的外設回送一個低電平有效的中斷應答信號,作為對中斷請求INTR的應答,系統自動進入中斷響應周期;
保護現場:主程序和中斷服務子程序都要使用CPU內部寄存器等資源,為使中斷處理程序不破壞主程序中寄存器的內容,應先將斷點處各寄存器的內容(主要是當前IP(將要執行的下一條地址)和CS值(代碼段地址))壓入堆棧保護起來,再進入的中斷處理。現場保護是由用戶使用PUSH指令來實現的;
中斷服務:中斷服務是執行中斷的主體部分,不同的中斷請求,有各自不同的中斷服務內容,需要根據中斷源所要完成的功能,事先編寫相應的中斷服務子程序存入內存,等待中斷請求響應后調用執行;
恢復現場:當中斷處理完畢后,用戶通過POP指令將保存在堆棧中的各個寄存器的內容彈出,即恢復主程序斷點處寄存器的原值。
中斷返回:在中斷服務子程序的最后要安排一條中斷返回指令IRET(interrupt return),執行該指令,系統自動將堆棧內保存的 IP(將要執行的下一條地址)和CS值(代碼段地址)彈出,從而恢復主程序斷點處的地址值,同時還自動恢復標志寄存器FR或EFR的內容,使CPU轉到被中斷的程序中繼續執行。
而中斷嵌套是指中斷系統正在執行一個中斷服務時,有另一個優先級更高的中斷提出中斷請求,這時會暫時終止當前正在執行的級別較低的中斷源的服務程序,去處理級別更高的中斷源,待處理完畢,再返回到被中斷了的中斷服務程序繼續執行,這個過程就是中斷嵌套。
最后,補充幾個知識點:
CS:IP兩個寄存器:指示了 CPU 當前將要讀取的指令的地址,其中CS為代碼段寄存器,而IP為指令指針寄存器 。可以簡單地認為,CS段地址,IP是偏移地址。
RET:也可以叫做近返回,即段內返回。處理器從堆棧中彈出IP或者EIP,然后根據當前的CS:IP跳轉到新的執行地址。如果之前壓棧的還有其余的參數,則這些參數也會被彈出;
RETF:也叫遠返回,從一個段返回到另一個段。先彈出堆棧中的IP/EIP,然后彈出CS,有之前壓棧的參數也會彈出。(近跳轉與遠跳轉的區別就在于CS是否壓棧);
IRET:用于從中斷返回,會彈出IP/EIP,然后CS,以及一些標志。然后從CS:IP執行。
參考文章:牛客網試題。
2、簡述處理器在讀內存的過程中,CPU核、cache、MMU如何協同工作?畫出CPU核、cache、MMU、內存之間的關系示意圖加以說明(可以以你熟悉的處理器為例)。(總分10分)
解答:現代操作系統普遍采用虛擬內存管理(Virtual Memory Management) 機制,這需要MMU( Memory Management Unit,內存管理單元) 的支持。有些嵌入式處理器沒有MMU,則不能運行依賴于虛擬內存管理的操作系統。
也就是說:操作系統可以分成兩類,用MMU的、不用MMU的。用MMU的是:Windows、MacOS、Linux、Android;不用MMU的是:FreeRTOS、VxWorks、UCOS……與此相對應的:CPU也可以分成兩類,帶MMU的、不帶MMU的。帶MMU的是:Cortex-A系列、ARM9、ARM11系列;不帶MMU的是:Cortex-M系列……(STM32是M系列,沒有MMU,不能運行Linux,只能運行一些UCOS、FreeRTOS等等)。
首先我來說一下MMU的作用,MMU就是負責虛擬地址(virtual address)轉化成物理地址(physical address)。
下面我來說一下ARM CPU上的地址轉換過程涉及三個概念:虛擬地址(VA)(CPU內核對外發出VA),變換后的虛擬地址(MVA)(VA被轉換為MVA供cache和MMU使用,在此將MVA轉換為PA),物理地址(PA)(最后使用PA讀寫實際設備)。
CPU看到的用到的只是VA,CPU不管VA最終是怎樣到PA的;
而cache、MMU也是看不到VA的,它們使用的是MVA(VA到MVA的轉換是由硬件自動完成的);
實際設備看不到VA、MVA,讀寫設備使用的是PA物理地址。
CPU通過地址來訪問內存中的單元,如果CPU沒有MMU,或者有MMU但沒有啟動,那么CPU內核在取指令或者訪問內存時發出的地址(此時必須是物理地址,假如是虛擬地址,那么當前的動作無效)將直接傳到CPU芯片的外部地址引腳上,直接被內存芯片(物理內存)接收,這時候的地址就是物理地址;
如果CPU啟用了MMU(一般是在bootloader中的eboot階段的進入main()函數的時候啟用),CPU內核發出的地址將被MMU截獲,這時候從CPU到MMU的地址稱為虛擬地址,而MMU將這個VA翻譯成為PA發到CPU芯片的外部地址引腳上,也就是將VA映射到PA中。
MMU將VA映射到PA是以頁(page)為單位的,對于32位的CPU,通常一頁為4k,物理內存中的一個物理頁面稱頁為一個頁框(page frame)。虛擬地址空間劃分成稱為頁(page)的單位,而相應的物理地址空間也被進行劃分,單位是頁框(frame)。頁和頁框的大小必須相同。

CPU訪問內存時的硬件操作順序,各步驟在圖中有對應的標號:
CPU內核(圖1中的ARM)發出VA請求讀數據,TLB(translation lookaside buffer)接收到該地址,那為什么是TLB先接收到該地址呢?因為TLB是MMU中的一塊高速緩存(也是一種cache,是CPU內核和物理內存之間的cache),它緩存最近查找過的VA對應的頁表項,如果TLB里緩存了當前VA的頁表項就不必做translation table walk了,否則就去物理內存中讀出頁表項保存在TLB中,TLB緩存可以減少訪問物理內存的次數;
頁表項中不僅保存著物理頁面的基地址,還保存著權限和是否允許cache的標志。MMU首先檢查權限位,如果沒有訪問權限,就引發一個異常給CPU內核。然后檢查是否允許cache,如果允許cache就啟動cache和CPU內核互操作;
如果不允許cache,那直接發出PA從物理內存中讀取數據到CPU內核;
如果允許cache,則以VA為索引到cache中查找是否緩存了要讀取的數據,如果cache中已經緩存了該數據(稱為cache hit)則直接返回給CPU內核,如果cache中沒有緩存該數據(稱為cache miss),則發出PA從物理內存中讀取數據并緩存到cache中,同時返回給CPU內核。但是cache并不是只去CPU內核所需要的數據,而是把相鄰的數據都取上來緩存,這稱為一個cache line。ARM920T的cache line是32個字節,例如CPU內核要讀取地址0x300001340x3000137的4個字節數據,cache會把地址0x300001200x3000137(對齊到32字節地址邊界)的32字節都取上來緩存。
關于translation table walk的具體步驟,可以參考文章:MMU和cache詳解(TLB機制)、硬件篇之MMU。
基本通信知識
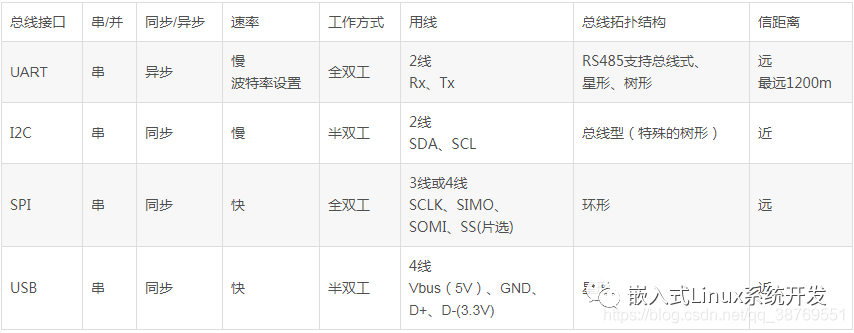
1、請說明總線接口USRT、I2C、USB的異同點(串/并、速度、全/半雙工、總線拓撲等)。(總分5分)
解答:UART、I2C、SPI、USB的異同點:
UART:通用異步串行口,速率不快,可全雙工,結構上一般由波特率產生器、UART發送器、UART接收器組成,硬件上兩線,一收一發;
I2C:雙向、兩線、串行、多主控接口標準。速率不快,半雙工,同步接口,具有總線仲裁機制,非常適合器件間近距離經常性數據通信,可實現設備組網;
SPI:高速同步串行口,高速,可全雙工,收發獨立,同步接口,可實現多個SPI設備互聯,硬件3~4線;
USB 通用串行總線,高速,半雙工,由主機、hub、設備組成。設備可以與下級hub相連構成星型結構。

2、列舉你所知道的linux內核態和用戶態之間的通信方式并給出你認為效率最高的方式,說明理由。(總分5分)
解答:首先對內核態和用戶態的概念有所了解:
內核態(Kernel Mode):在內核態,代碼擁有完全的,不受任何限制的訪問底層硬件的能力。可以執行任意的CPU指令,訪問任意的內存地址。內核態通常情況下,都是為那些最底層的,由操作系統提供的,可信可靠的代碼來運行的。內核態的代碼崩潰將是災難性的,它會影響到整個系統。
用戶態(User Mode):在用戶態,代碼不具備直接訪問硬件或者訪問內存的能力,而必須借助操作系統提供的可靠的,底層的APIs來訪問硬件或者內存。由于這種隔離帶來的保護作用,用戶態的代碼崩潰(Crash),系統是可以恢復的。我們大多數的代碼都是運行在用戶態的。
Linux下內核空間與用戶空間進行通信的方式主要有syscall(system call)、procfs和netlink等。
syscall:一般情況下,用戶進程是不能訪問內核的。它既不能訪問內核所在的內存空間,也不能調用內核中的函數。Linux內核中設置了一組用于實現各種系統功能的子程序,用戶可以通過調用他們訪問linux內核的數據和函數,這些系統調用接口(SCI)稱為系統調用;
procfs:是一種特殊的偽文件系統 ,是Linux內核信息的抽象文件接口,大量內核中的信息以及可調參數都被作為常規文件映射到一個目錄樹中,這樣我們就可以簡單直接的通過echo或cat這樣的文件操作命令對系統信息進行查取。
在這幾個通信方式中,選擇netlink,原因如下:
全雙工:procfs是基于文件系統,用于內核向用戶發送消息;syscall是用戶訪問內核。它們都是單工通信方式。netlink是一種特殊的通信方式,用于在內核空間和用戶空間傳遞消息,是一種雙工通信方式。使用地址協議簇AF_NETLINK,使用頭文件include/linux/netlink.h;
易于添加:為新特性添加system call、或者procfs是一件復雜的工作,它們會污染kernel(內核),破壞系統的穩定性,這是非常危險的。Netlink的添加,對內核的影響僅在于向netlink.h中添加一個固定的協議類型,然后內核模塊和應用層的通信使用一套標準的API。
這里再多介紹一個,用戶態和內核態的轉換方式:
系統調用:這是用戶進程主動要求切換到內核態的一種方式,用戶進程通過系統調用申請操作系統提供的服務程序完成工作。而系統調用的機制其核心還是使用了操作系統為用戶特別開放的一個中斷來實現,例如Linux的ine 80h中斷;
異常:當CPU在執行運行在用戶態的程序時,發現了某些事件不可知的異常,這是會觸發由當前運行進程切換到處理此異常的內核相關程序中,也就到了內核態,比如缺頁異常;
外圍設備的中斷:當外圍設備完成用戶請求的操作之后,會向CPU發出相應的中斷信號,這時CPU會暫停執行下一條將要執行的指令轉而去執行中斷信號的處理程序,如果先執行的指令是用戶態下的程序,那么這個轉換的過程自然也就發生了有用戶態到內核態的切換。比如硬盤讀寫操作完成,系統會切換到硬盤讀寫的中斷處理程序中執行后續操作等。
從出發方式看,可以在認為存在前述3種不同的類型,但是從最終實際完成由用戶態到內核態的切換操作上來說,涉及的關鍵步驟是完全一樣的,沒有任何區別,都相當于執行了一個中斷響應的過程,因為系統調用實際上最終是中斷機制實現的,而異常和中斷處理機制基本上是一樣的,用戶態切換到內核態的步驟主要包括:
從當前進程的描述符中提取其內核棧的ss0及esp0信息;
使用ss0和esp0指向的內核棧將當前進程的cs,eip,eflags,ss,esp信息保存起來,這個過程也完成了由用戶棧找到內核棧的切換過程,同時保存了被暫停執行的程序的下一條指令;
將先前由中斷向量檢索得到的中斷處理程序的cs,eip信息裝入相應的寄存器,開始執行中斷處理程序,這時就轉到了內核態的程序執行了。
系統設計
有一個使用UART進行通信的子系統X,其中UART0進行數據包接收和回復,UART1進行數據包轉發。子系統X的通信模塊職責是從UART0接收數據包,如果為本地數據包(receiver 為子系統X),則解析數據包中的命令碼(2字節)和數據域(0~128字節),根據命令碼調用內部的處理程序,并將處理結果通過UART0回復給發送端,如果非本地數據包,則通過UART1轉發。如果由你來設計子系統X的通信模塊:
1)請設計通信數據包格式,并說明各字段的定義;(總分5分)
2)在一個實時操作系統中,你會如何部署模塊中的任務和緩存數據,畫出任務間的數據流視圖加以說明;(總分5分)
3)你會如何設置任務的優先級,說說優缺點;(總分5分)
4)如果將命令碼對應的處理優先級分為高、低兩個等級,你又會如何設計;(總分5分)
解答:1)采用幀頭+檢驗位+數據+幀尾的形式,并且數據由數據頭、數據內容和數據尾確定。
比如:TB/校驗位OR/命令碼/ORME/數據域/ME/TE。
其中:“TB/”為幀頭,校驗位用于判斷是否為本地數據包,“OR/”和“/OR”之間的為命令碼,“ME/”和“/ME”之間的為數據域,“/TE”為幀尾。
2014大疆嵌入式筆試題試題
編程基礎
1、有如下CAT_s結構體定義,回答:
1)在一臺64位的機器上,使用32位編譯,Garfield變量占用多少內存空間?64位編譯又是如何?(總分5分)
2)使用32位編譯情況下,給出一種判斷所使用機器大小端的方法。(總分5分)
struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char Name;
void(Jump)(void);
}Garfield;
2、描述下面XXX這個宏的作用。(總分10分)
define offsetof(TYPE,MEMBER) ((size_t)&((TYPE*)0)->MEMBER)
define XXX(ptr,type,member)({\
const typeof(((type*)0)->member) *__mptr=(ptr);\
(type*)((char*)__mptr – offsetof(type,member));})
3、簡述C函數:
1)參數如何傳遞(__cdecl調用方式);
2)返回值如何傳遞;
3)調用后如何返回到調用前的下一條指令執行。(總分10分)
4、在一個多任務嵌入式系統中,有一個CPU可直接尋址的32位寄存器REGn,地址為0x1F000010,編寫一個安全的函數,將寄存器REGn的指定位反轉(要求保持其他bit的值不變)。(總分10分)
5、有10000個正整數,每個數的取值范圍均在1到1000之間,編程找出從小到大排在第3400(從0開始算起)的那個數,將此數的值返回,要求不使用排序實現。(總分10分)
嵌入式基本知識
1、簡述處理器中斷處理的過程(中斷向量、中斷保護現場、中斷嵌套、中斷返回等)。(總分10分)
2、簡述處理器在讀內存的過程中,CPU核、cache、MMU如何協同工作?畫出CPU核、cache、MMU、內存之間的關系示意圖加以說明(可以以你熟悉的處理器為例)。(總分10分)
基本通信知識
1、請說明總線接口USRT、I2C、USB的異同點(串/并、速度、全/半雙工、總線拓撲等)。(總分5分)
2、列舉你所知道的linux內核態和用戶態之間的通信方式并給出你認為效率最高的方式,說明理由。(總分5分)
系統設計
有一個使用UART進行通信的子系統X,其中UART0進行數據包接收和回復,UART1進行數據包轉發。子系統X的通信模塊職責是從UART0接收數據包,如果為本地數據包(receiver 為子系統X),則解析數據包中的命令碼(2字節)和數據域(0~128字節),根據命令碼調用內部的處理程序,并將處理結果通過UART0回復給發送端,如果非本地數據包,則通過UART1轉發。如果由你來設計子系統X的通信模塊:
1)請設計通信數據包格式,并說明各字段的定義;(總分5分)
2)在一個實時操作系統中,你會如何部署模塊中的任務和緩存數據,畫出任務間的數據流視圖加以說明;(總分5分)
3)你會如何設置任務的優先級,說說優缺點;(總分5分)
4)如果將命令碼對應的處理優先級分為高、低兩個等級,你又會如何設計;(總分5分)
試題解答
編程基礎
1、有如下CAT_s結構體定義,回答:
1)在一臺64位的機器上,使用32位編譯,Garfield變量占用多少內存空間?64位編譯又是如何?(總分5分)
2)使用32位編譯情況下,給出一種判斷所使用機器大小端的方法。(總分5分)
struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char Name;
void(Jump)(void);
}Garfield;
解答:1)這是一條很經典的判斷結構體大小的題目,經典到只要面試C語言或者C++的工作,無論是嵌入式還是互聯網公司,絕大多數情況下都會問到的一種題型。
這題主要考的就是:內存對齊。
對于大多數的程序員來說,內存對齊基本上是透明的,這是編譯器該干的活,編譯器為程序中的每個數據單元安排在合適的位置上,從而導致了相同的變量,不同聲明順序的結構體大小的不同。
那么編譯器為什么要進行內存對齊呢?主要是為了性能和平臺移植等因素,編譯器對數據結構進行了內存對齊。
為了分析造成這種現象的原因,我們不得不提及內存對齊的3大規則:
對于結構體的各個成員,第一個成員的偏移量是0,排列在后面的成員其當前偏移量必須是當前成員類型的整數倍;
結構體內所有數據成員各自內存對齊后,結構體本身還要進行一次內存對齊,保證整個結構體占用內存大小是結構體內最大數據成員的最小整數倍;
如程序中有#pragma pack(n)預編譯指令,則所有成員對齊以n字節為準(即偏移量是n的整數倍),不再考慮當前類型以及最大結構體內類型。
按照上面的3大規則直接來進行分析:
使用32位編譯,int占4, char 占1, unsigned short int占2,char占4,函數指針占4個,由于是32位編譯是4字節對齊,所以該結構體占16個字節。(說明:按幾字節對齊,是根據結構體的最長類型決定的,這里是int是最長的字節,所以按4字節對齊);
使用64位編譯 ,int占4, char 占1, unsigned short int占2,char占8,函數指針占8個,由于是64位編譯是8字節對齊,(說明:按幾字節對齊,是根據結構體的最長類型決定的,這里是函數指針是最長的字節,所以按8字節對齊)所以該結構體占24個字節。
2)大端小端問題:
所謂的大端模式(BE big-endian),是指數據的低位保存在內存的高地址中,而數據的高位,保存在內存的低地址中(低對高,高對高);
所謂的小端模式(LE little-endian),是指數據的低位保存在內存的低地址中,而數據的高位保存在內存的高地址中(低對低,高對高)。
為什么要有大小端區分呢?
這是因為在計算機系統中,我們是以字節為單位的,每個地址單元都對應著一個字節,一個字節為 8bit。但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具體的編譯器),另外,對于位數大于8位的處理器,例如16位或者32位的處理器,由于寄存器寬度大于一個字節,那么必然存在著一個如果將多個字節安排的問題。因此就導致了大端存儲模式和小端存儲模式。例如一個16bit的short型x,在內存中的地址為0x0010,x的值為0x1122,那么0x11為高字節,0x22為低字節。對于大端模式,就將0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011中。小端模式,剛好相反。我們常用的X86結構是小端模式,而KEIL C51則為大端模式。很多的ARM,DSP都為小端模式。有些ARM處理器還可以由硬件來選擇是大端模式還是小端模式。
首先給出一個方法(Linux操作系統的源碼中的判斷):
static union {
char c[4];
unsigned long mylong;
} endian_test = {{ 'l', '?', '?', 'b' } };
define ENDIANNESS ((char)endian_test.mylong)
這是利用:聯合體union的存放順序是所有成員都從低地址開始存放的特性。由于聯合體的各個成員共用內存,并應該同時只能有一個成員得到這塊內存的使用權(即對內存的讀寫)。如果是“l”(小端)、“b”(大端)。
除了這種方法之外,也可以利用數據類型轉換的截斷特性:
void Judge_duan()
{
int a = 1; //定義為1是為了方便 如果你喜歡你可以隨意,
//只要你能搞清楚 例如:0x11223344;
char *p = (char *)&a;//在這里將整形a的地址轉化為char*;
//方便后面取一個字節內容
if(*p == 1)//在這里解引用了p的一個字節的內容與1進行比較;
printf("小端\n");
else
printf("大端\n");
}
順便提一下,大小端之間的轉化,以小端轉化為大端為例:
int endian_convert(int t)
{
int result=0;
int i;
for (i = 0; i < sizeof(t); i++) {
result <<= 8;
result |= (t & 0xFF);
t >>= 8;
}
return result;
}
2、描述下面XXX這個宏的作用。(總分10分)
define offsetof(TYPE,MEMBER)((size_t)&((TYPE*)0)->MEMBER)
define XXX(ptr,type,member)({\
const typeof(((type*)0)->member)*__mptr=(ptr);\
(type*)((char*)__mptr – offsetof(type,member));})
解答:其實這個宏定義是Linux內核結構體container_of的宏定義,幾乎沒修改過(該宏定義在kernel.h中)。當然,我們先認為這是一個陌生的宏定義來進行分析它的作用。
首先你得能看出來這是兩個宏定義……,第二個宏定義是換行的宏定義方式,以“\”結尾。
先來看第一個宏定義:
define offsetof(TYPE,MEMBER) ((size_t)&((TYPE*)0)->MEMBER)
(TYPE)0:將0強轉為TYPE類型的指針,且指向了0地址空間;
(TYPE)0->MEMEBER:指向結構體中的成員;
&((TYPE*)0->MEMBER):獲取成員在結構體的位置,因為起始為0,所以獲取的地址即為實際的偏移地址。
分析:(TYPE *)0,將 0 強制轉換為 TYPE 型指針,記 p = (TYPE *)0,p是指向TYPE的指針,它的值是0。那么 p->MEMBER 就是 MEMBER 這個元素了,而&(p->MEMBER)就是MENBER的地址,而基地址為0,這樣就巧妙的轉化為了TYPE中的偏移量。再把結果強制轉換為size_t型的就OK了,size_t其實也就是unsigned int。
再來看需要我們描述功能的宏定義XXX:
define XXX(ptr,type,member)({\
const typeof(((type*)0)->member) *__mptr=(ptr);\
(type*)((char*)__mptr – offsetof(type,member));})
typeof構造的主要應用是用在宏定義中。可以使用typeof關鍵字來引用宏參數的類型。也就是說,typeof(((type*)0)->member)是引用與type結構體的member成員的數據類型;
獲得了數據類型之后,定義一個與type結構體的member成員相同的類型的指針變量__mptr,且將ptr值賦給它;
用宏offsetof(type,member),獲取member成員在type結構中的偏移量;
最后將__mptr值減去這個偏移量,就得到這個結構變量的地址了(亦指針)。
XXX宏的實現思路:計算type結構體成員member在結構體中的偏移量,然后ptr的地址減去這個偏移量,就得出type結構變量的首地址。
具體的功能就是:ptr是指向正被使用的某類型變量指針;type是包含ptr指向的變量類型的結構類型;member是type結構體中的成員,類型與ptr指向的變量類型一樣。功能是計算返回包含ptr指向的變量所在的type類型結構變量的指針。
參考文章:老生常談的Linux內核中常用的兩個宏定義。
3、簡述C函數:
1)參數如何傳遞(__cdecl調用方式);
2)返回值如何傳遞;
3)調用后如何返回到調用前的下一條指令執行。(總分10分)
解答:1)參數如何傳遞 (__cdecl調用方式) :
__cdecl是C Declaration的縮寫(declaration,聲明),是C語言中函數調用約定中的一種(默認)。
什么是函數調用約定?
當一個函數被調用時,函數的參數會被傳遞給被調用的函數,同時函數的返回值會被返回給調用函數。函數的調用約定就是用來描述參數(返回值)是怎么傳遞并且由誰來平衡堆棧的。也就是說:函數調用約定不僅決定了發生函數調用時函數參數的入棧順序,還決定了是由調用者函數還是被調用函數負責清除棧中的參數,還原堆棧。
常見的函數調用約定有:__stdcall,__cdecl(默認),__fastcall,__thiscall,__pascal等等。
它們按參數的傳遞順序對這些約定可劃分為:
從右到左依次入棧:__stdcall,__cdecl,__thiscall;
從左到右依次入棧:__pascal,__fastcall。
下面比較一下最為常見的兩種:
__cdecl:是C Declaration的縮寫(declaration,聲明),表示C語言默認的函數調用方法:所有參數從右到左依次入棧,由調用者負責把參數壓入棧,最后也是由調用者負責清除棧的內容 ;
__stdcall:是StandardCall的縮寫,是C++的標準調用方式:所有參數從右到左依次入棧,由調用者負責把參數壓入棧,最后由被調用者負責清除棧的內容。
另外,還要注意的是,如printf此類支持可變參數的函數,由于不知道調用者會傳遞多少個參數,也不知道會壓多少個參數入棧,因此函數本身內部不可能清理堆棧,只能由調用者清理了。
也就是說:支持可變參數的函數調用約定:__cdecl,帶有可變參數的函數必須是cdecl調用約定,由函數的調用者來清除棧,參數入棧的順序是從右到左。由于每次函數調用都要由編譯器產生清除(還原)堆棧的代碼,所以使用__cdecl方式編譯的程序比使用__stdcall方式編譯的程序要大很多。
2)C語言返回值如何傳遞:
一般情況下,函數返回值是通過eax進行傳遞的,但是eax只能存儲4個字節的信息,對于那些返回值大于4個字節的函數,返回值是如何傳遞的呢?
假設返回值大小為M字節:
M <= 4字節,將返回值存儲在eax返回;
4 < M <=8,把eax,edx聯合起來。其中,edx存儲高位,eax存儲低位;
M > 8,如何傳遞呢?用一下代碼測試:
typedef struct big_thing
{
char buf[128];
}big_thing;
big_thing return_test()
{
big_thing b;
b.buf[] = 0;
return b;
}
int main()
{
big_thing n = return_test();
}
首先main函數在棧額外開辟了一片空間,并將這塊空間的一部分作為傳遞返回值的臨時對象,這里稱為temp;
將temp對象的地址作為隱藏參數傳遞個return_test函數;
return_test 函數將數據拷貝給temp對象,并將temp對象的地址用eax傳出;
return_test返回以后,mian函數將eax指向的temp對象的內容拷貝給n。
也就是說,如果返回值的類型的尺寸太大,c語言在函數的返回時會使用一個臨時的棧上內存作為中轉,結果返回值對象會被拷貝兩次。整個過程使用的是指向返回值的指針來進行拷貝的,而指針本身是通過eax返回的。因而不到萬不得已,不要輕易返回大尺寸對象。
那么上面的eax、edx是什么呢?
eax是"累加器"(accumulator), 它是很多加法乘法指令的缺省寄存器;
ebx 是"基地址"(base)寄存器, 在內存尋址時存放基地址;
ecx是計數器(counter), 是重復(REP)前綴指令和LOOP指令的內定計數器;
edx則總是被用來放整數除法產生的余數。
函數返回值為什么一般放在寄存器中?
這主要是為了支持中斷;如果放在堆棧中有可能因為中斷而被覆蓋。
參考文章: C函數參數傳遞與返回值傳遞。
3)C語言調用后如何返回到調用前的下一條指令執行:
這就涉及到函數的堆棧幀這個概念。
棧在程序運行中具有舉足輕重的地位。最重要的,棧保存了一個函數調用所需要的維護信息,被稱為堆棧幀(Stack Frame),一個函數(被調函數)的堆棧幀一般包括下面幾個方面的內容:
函數的參數;函數的局部變量;寄存器的值(用以恢復寄存器);函數的返回地址以及用于結構化異常處理的數據(當函數中有try…catch語句時才有)等等。
由于在函數的堆棧幀中存放了函數的返回地址,即調用方調用此函數的下一條指令的地址。故而,在函數調用后,由函數調用方執行,直接返回調用前的下一條指令。
參考文章:淺談C/C++堆棧指引——C/C++堆棧很強大(絕美)。
4、在一個多任務嵌入式系統中,有一個CPU可直接尋址的32位寄存器REGn,地址為0x1F000010,編寫一個安全的函數,將寄存器REGn的指定位反轉(要求保持其他bit的值不變)。(總分10分)
解答:指定為反轉用異或,多任務嵌入式系統保證安全性!
void bit_reverse(uint32_t nbit)
{
*((volatile unsigned int *)0x1F000010) ^= (0x01 << nbit);
}
對于位運算的一些小總結:特定位清零用&;特定位置1用|;所有位取反用~;特定位取反用^。
參考文章:2.2.位與位或位異或在操作寄存器時的特殊作用。
5、有10000個正整數,每個數的取值范圍均在1到1000之間,編程找出從小到大排在第3400(從0開始算起)的那個數,將此數的值返回,要求不使用排序實現。(總分10分)
解答:10000個正整數找出從小到大的第3400個(從0開始算起),第一個想到的就是排序(冒泡排序、插入排序、選擇排序……),或者使用桶排序。但這些顯然都不滿足這個題目的要求。
關鍵的點是:正整數,每個數的取值均在1-1000之間,這是本題一個特殊性。
本題思路:維護一個數組count[1000],分別存儲1-1000每個數字的出現次數。
include
using namespace std;
define TOTAL 10000
define RANGE 1000
define REQUIRED 3400
int main()
{
int number[TOTAL] = { 0 };
int count[RANGE] = { 0 };
int i, sum = 0;
for (i = 0; i < 10000; i++) {
number[i] = (rand() % 1000) + 1; /*產生10000個1-1000之間的隨機數*/
}
for (i = 0; i < 10000; i++) {
count[number[i] - 1]++; /*計算10000個整數出現次數*/
}
for (i = 0; i < 1000; i++) {
sum += count[i];
if (sum >= REQUIRED + 1) {
cout << i + 1 << endl;
break;
}
}
return 0;
}
2020大疆校招嵌入式B卷編程題
題考的比較基礎,同時也很注重細節,最坑的是不能用本地編譯器編譯測試,在線的也不能,只能手寫
1、寫宏定義
(1)x對a向下取整數倍的宏定義ALIGN_DOWN(x, a) 例子(65,3)->63
(2)x對a向上取整數倍的宏定義ALIGN_UP(x, a) 例子(65,3)->66
其實這個就是個取余的問題,向下就是減掉余數,向上加上a-余數,注意宏定義細節,括號都加上加好,防止出現輸入64+1或者其他的情況,造成計算錯誤
define ALIGN_DOWN(x, a) ((x) - (x) % (a))
define ALIGN_UP(x, a) ((x) + a - (x) % (a))
(3)x對a向下取整數倍的宏定義ALIGN_2N_DOWN(x, a) ,a是2的n次冪例子(65,4)->64
(4)x對a向上取整數倍的宏定義ALIGN_2N_UP(x, a) 例子,a是2的n次冪例子(65,4)->68
注意要用2的n次冪這個特性進行加速
筆者做的時候知道這個是利用位運算,然而在筆試時緊張第二個寫錯了,現在想想真的二啊我。。。。
首先2的n次冪有個特性,減一之后低于n的位全部變為1,舉例4d,0100b,減一變為0011,取反1100,利用這個特性便可以做出第三四來(好氣啊,筆試緊張,向上的我寫錯了!!!)
define ALIGN_2N_DOWN(x, a) ((x)&~(a - 1))
define ALIGN_2N_UP(x, a) ((x + a - 1)&~(a - 1))
其實最后一個向上2n次冪向上取整是在linux內核中定義的,哎多看源碼,多積累把~~~
linux原始定義如下,和我們寫的一樣,注意(),我上面沒有寫。
define ALIGN(x,a) (((x)+(a)-1)&~(a-1))
2、第二考察特別細節,
硬件數據寄存器地址0x8000_0000
狀態寄存器0x8000_0004
狀態寄存器31位為1時數據有效讀出來,并清除,有效返0,無效返回負數
注意volatile、const、assert、等等吧
具體見下面代碼,筆試時重定位寫錯了,哎,注意細節!!!!

【機試題】2019.8.6大疆嵌入式筆試題B卷筆試題目總結
關鍵字volatile
表示一個變量也許會被后臺程序改變,關鍵字 volatile 是與 const 絕對對立的。它指示一個變量也許會被某種方式修改,這種方式按照正常程序流程分析是無法預知的(例如,一個變量也許會被一個中斷服務程序所修改)。這個關鍵字使用下列語法定義:volatile data-definition。
變量如果加了 volatile 修飾,則會從內存重新裝載內容,而不是直接從寄存器拷貝內容。 volatile 的作用是作為指令關鍵字,確保本條指令不會因編譯器的優化而省略,且要求每次直接讀值。
volatile應用比較多的場合,在中斷服務程序和cpu相關寄存器的定義。
//示例一
include <stdio.h>
int main (void)
{
int i = 10;
int a = i; //優化
int b = i;
printf ("i = %d\n", b);
return 0;
}
//示例二
include <stdio.h>
int main (void)
{
volatile int i = 10;
int a = i; //未優化
int b = i;
printf ("i = %d\n", b);
return 0;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
使用 volatile 的代碼編譯未優化。volatile 指出 i 是隨時可能發生變化的,每次使用它的時候必須從 i的地址中讀取,因而編譯器生成的匯編代碼會重新從i的地址讀取數據放在 b 中。而優化做法是,由于編譯器發現兩次從 i讀數據的代碼之間的代碼沒有對 i 進行過操作,它會自動把上次讀的數據放在 b 中。而不是重新從 i 里面讀。這樣以來,如果 i是一個寄存器變量或者表示一個端口數據就容易出錯,所以說 volatile 可以保證對特殊地址的穩定訪問。
volatile 使用:1.并行設備的硬件寄存器(如:狀態寄存器);2.一個中斷服務子程序中會訪問到的非自動變量(Non-automatic variables);3.多線程應用中被幾個任務共享的變量。
關鍵字volatile參考鏈接
關鍵字volatile參考鏈接
關鍵字 inline
大多數的機器上,調用函數都要做很多工作:調用前要先保存寄存器,并在返回時恢復,復制實參,程序還必須轉向一個新位置執行C++中支持內聯函數,其目的是為了提高函數的執行效率,用關鍵字 inline 放在函數定義(注意是定義而非聲明,下文繼續講到)的前面即可將函數指定為內聯函數,內聯函數通常就是將它在程序中的每個調用點上“內聯地”展開。
關鍵字 inline參考鏈接
關鍵字 inline參考鏈接
C語言編譯過程中,volatile關鍵字和extern關鍵字分別在哪個階段起作用
volatile應該是在編譯階段,extern在鏈接階段。
volatile關鍵字的作用是防止變量被編譯器優化,而優化是處于編譯階段,所以volatile關鍵字是在編譯階段起作用。
請你說一下源碼到可執行文件的過程
對于C++源文件,從文本到可執行文件一般需要四個過程:
預處理階段:對源代碼文件中文件包含關系(頭文件)、預編譯語句(宏定義)進行分析和替換,生成預編譯文件。
編譯階段:將經過預處理后的預編譯文件轉換成特定匯編代碼,生成匯編文件
匯編階段:將編譯階段生成的匯編文件轉化成機器碼,生成可重定位目標文件
鏈接階段:將多個目標文件及所需要的庫連接成最終的可執行目標文件

1)預編譯
主要處理源代碼文件中的以“#”開頭的預編譯指令。處理規則見下
1、刪除所有的#define,展開所有的宏定義。
2、處理所有的條件預編譯指令,如“#if”、“#endif”、“#ifdef”、“#elif”和“#else”。
3、處理“#include”預編譯指令,將文件內容替換到它的位置,這個過程是遞歸進行的,文件中包含其他文件。
4、刪除所有的注釋,“//”和“/**/”。
5、保留所有的#pragma 編譯器指令,編譯器需要用到他們,如:#pragma once 是為了防止有文件被重復引用。
6、添加行號和文件標識,便于編譯時編譯器產生調試用的行號信息,和編譯時產生編譯錯誤或警告是能夠顯示行號。
2)編譯
把預編譯之后生成的xxx.i或xxx.ii文件,進行一系列詞法分析、語法分析、語義分析及優化后,生成相應的匯編代碼文件。
1、詞法分析:利用類似于“有限狀態機”的算法,將源代碼程序輸入到掃描機中,將其中的字符序列分割成一系列的記號。
2、語法分析:語法分析器對由掃描器產生的記號,進行語法分析,產生語法樹。由語法分析器輸出的語法樹是一種以表達式為節點的樹。
3、語義分析:語法分析器只是完成了對表達式語法層面的分析,語義分析器則對表達式是否有意義進行判斷,其分析的語義是靜態語義——在編譯期能分期的語義,相對應的動態語義是在運行期才能確定的語義。
4、優化:源代碼級別的一個優化過程。
5、目標代碼生成:由代碼生成器將中間代碼轉換成目標機器代碼,生成一系列的代碼序列——匯編語言表示。
6、目標代碼優化:目標代碼優化器對上述的目標機器代碼進行優化:尋找合適的尋址方式、使用位移來替代乘法運算、刪除多余的指令等。
3)匯編
將匯編代碼轉變成機器可以執行的指令(機器碼文件)。 匯編器的匯編過程相對于編譯器來說更簡單,沒有復雜的語法,也沒有語義,更不需要做指令優化,只是根據匯編指令和機器指令的對照表一一翻譯過來,匯編過程有匯編器as完成。經匯編之后,產生目標文件(與可執行文件格式幾乎一樣)xxx.o(Windows下)、xxx.obj(Linux下)。
4)鏈接
將不同的源文件產生的目標文件進行鏈接,從而形成一個可以執行的程序。鏈接分為靜態鏈接和動態鏈接:
1、靜態鏈接:
函數和數據被編譯進一個二進制文件。在使用靜態庫的情況下,在編譯鏈接可執行文件時,鏈接器從庫中復制這些函數和數據并把它們和應用程序的其它模塊組合起來創建最終的可執行文件。
空間浪費:因為每個可執行程序中對所有需要的目標文件都要有一份副本,所以如果多個程序對同一個目標文件都有依賴,會出現同一個目標文件都在內存存在多個副本;
更新困難:每當庫函數的代碼修改了,這個時候就需要重新進行編譯鏈接形成可執行程序。
運行速度快:但是靜態鏈接的優點就是,在可執行程序中已經具備了所有執行程序所需要的任何東西,在執行的時候運行速度快。
2、動態鏈接:
動態鏈接的基本思想是把程序按照模塊拆分成各個相對獨立部分,在程序運行時才將它們鏈接在一起形成一個完整的程序,而不是像靜態鏈接一樣把所有程序模塊都鏈接成一個單獨的可執行文件。
共享庫:就是即使需要每個程序都依賴同一個庫,但是該庫不會像靜態鏈接那樣在內存中存在多分,副本,而是這多個程序在執行時共享同一份副本;
更新方便:更新時只需要替換原來的目標文件,而無需將所有的程序再重新鏈接一遍。當程序下一次運行時,新版本的目標文件會被自動加載到內存并且鏈接起來,程序就完成了升級的目標。
性能損耗:因為把鏈接推遲到了程序運行時,所以每次執行程序都需要進行鏈接,所以性能會有一定損失。
sizeof
1.如果是數組
include<stdio.h>
int main()
{
int a[5]={1,2,3,4,5};
printf(“sizeof數組名=%d\n”,sizeof(a));
printf(“sizeof 數組名=%d\n”,sizeof(a));
}
運行結果
sizeof數組名=20
sizeof 數組名=4
2.如果是指針,sizeof只會檢測到是指針的類型,指針都是占用4個字節的空間(32位機)。
char p = “sadasdasd”;
sizeof( p):4
sizeof(p):1//指向一個char類型的
sizeof(數組名)與sizeof(數組名)參考鏈接
sizeof(指針)與sizeof(*指針)參考鏈接
結構體struct內存對齊的3大規則:
1.對于結構體的各個成員,第一個成員的偏移量是0,排列在后面的成員其當前偏移量必須是當前成員類型的整數倍;
2.結構體內所有數據成員各自內存對齊后,結構體本身還要進行一次內存對齊,保證整個結構體占用內存大小是結構體內最大數據成員的最小整數倍;
3.如程序中有#pragma pack(n)預編譯指令,則所有成員對齊以n字節為準(即偏移量是n的整數倍),不再考慮當前類型以及最大結構體內類型。
pragma pack(1)
struct fun{
int i;
double d;
char c;
};
sizeof(fun) = 13
struct CAT_s
{
int ld;
char Color;
unsigned short Age;
char Name;
void(Jump)(void);
}Garfield;
按照上面的3大規則直接來進行分析:
1.使用32位編譯,int占4, char 占1, unsigned short 占2,char* 占4,函數指針占4個,由于是32位編譯是4字節對齊,所以該結構體占16個字節。(說明:按幾字節對齊,是根據結構體的最長類型決定的,這里是int是最長的字節,所以按4字節對齊);
2.使用64位編譯 ,int占4, char 占1, unsigned short 占2,char* 占8,函數指針占8個,由于是64位編譯是8字節對齊,(說明:按幾字節對齊,是根據結構體的最長類型決定的,這里是函數指針是最長的字節,所以按8字節對齊)所以該結構體占24個字節。
//64位
struct C
{
double t; //8 1111 1111
char b; //1 1
int a; //4 0001111
short c; //2 11000000
};
sizeof(C) = 24; //注意:1 4 2 不能拼在一起
聯合體union內存對齊的2大規則:
1.找到占用字節最多的成員;
2.union的字節數必須是占用字節最多的成員的字節的倍數,而且需要能夠容納其他的成員.
//x64
typedef union {
long i;
int k[5];
char c;
}D
要計算union的大小,首先要找到占用字節最多的成員,本例中是long,占用8個字節,int k[5]中都是int類型,仍然是占用4個字節的,然后union的字節數必須是占用字節最多的成員的字節的倍數,而且需要能夠容納其他的成員,為了要容納k(20個字節),就必須要保證是8的倍數的同時還要大于20個字節,所以是24個字節。
內存對齊作用:
1.平臺原因(移植原因):不是所有的硬件平臺都能訪問任意地址上的任意數據的;某些硬件平臺只能在某些地址處取某些特定類型的數據,否則拋出硬件異常。
2.性能原因:數據結構(尤其是棧)應該盡可能地在自然邊界上對齊。原因在于,為了訪問未對齊的內存,處理器需要作兩次內存訪問;而對齊的內存訪問僅需要一次訪問。
結構體占用內存
在32位系統中有如下定義,則sizeof(data_t)的值是()
A.15 B.19 C.11 D.8
typedef struct_data{
char m:3;
char n:5;
short s;
union{
int a;
char b;
};
int h;
}attribute((packed)) data_t;
片上系統中,常用來在片內做數據傳輸的總線是
A. UART B .I2C C.AXI D SPI
AXI總線參考鏈接
ARM指令和Thumb指令
ARM指令和Thumb指令參考鏈接
請簡述linux或RTOS中,棧空間最大使用率和棧溢出檢測方法。
方法一:在任務切換時檢測任務指針是否過界了,如果過界了,在任務切換的時候會觸發棧溢出的鉤子函數。
方法二:任務創建的時候將任務棧所有的數據初始化為0xa5,任務切換時進行任務棧檢測的時候會檢測末尾的16個字節是否都是0xa5,通過這種方式來檢測任務棧是否溢出了。
搶占式內核中,任務調度實際有哪些
Linux內核
搶占式內核參考鏈接
一個程序中含有以下代碼塊,請說明其中各個變量的生命周期,作用域和存儲位置(提示:存儲位置可以選澤 ‘text’ ‘data’ ‘bss’ ‘heap’ ‘stack’)
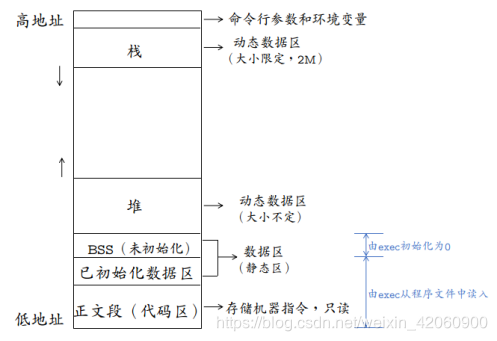
一個程序本質上都是由BSS段、data段、text段(代碼區)三個組成的。可以看到一個可執行程序在存儲(沒有調入內存)時分為代碼段、數據區和未初始化數據區三部分。
BSS段(未初始化數據區):通常用來存放程序中未初始化的全局變量和靜態變量的一塊內存區域。BSS段屬于靜態分配,程序結束后靜態變量資源由系統自動釋放。
數據段:數據段也屬于靜態內存分配。該區包含了在程序中明確被初始化的全局變量、已經初始化的靜態變量(包括全局靜態變量和局部靜態變量)和常量數據(如字符串常量)。
代碼段:存放程序執行代碼的一塊內存區域。這部分區域的大小在程序運行前就已經確定,并且內存區域屬于只讀。在代碼段中,也有可能包含一些只讀的常數變量
text段和data段在編譯時已經分配了空間,而BSS段并不占用可執行文件的大小,它是由鏈接器來獲取內存的。
bss段(未進行初始化的數據)的內容并不存放在磁盤上的程序文件中。其原因是內核在程序開始運行前將它們設置為0。需要存放在程序文件中的只有正文段和初始化數據段。
data段(已經初始化的數據)則為數據分配空間,數據保存到目標文件中。
數據段包含經過初始化的全局變量以及它們的值。BSS段的大小從可執行文件中得到,然后鏈接器得到這個大小的內存塊,緊跟在數據段的后面。當這個內存進入程序的地址空間后全部清零。包含數據段和BSS段的整個區段此時通常稱為數據區。
可執行程序在運行時又多出兩個區域:棧區和堆區。
棧區:由編譯器自動釋放,存放函數的參數值、局部變量等。每當一個函數被調用時,該函數的返回類型和一些調用的信息被存放到棧中。然后這個被調用的函數再為他的自動變量和臨時變量在棧上分配空間。每調用一個函數一個新的棧就會被使用。棧區是從高地址位向低地址位增長的,是一塊連續的內存區域,最大容量是由系統預先定義好的,申請的棧空間超過這個界限時會提示溢出,用戶能從棧中獲取的空間較小。
堆區:用于動態分配內存,位于BSS和棧中間的地址區域。由程序員申請分配和釋放。堆是從低地址位向高地址位增長,采用鏈式存儲結構。頻繁的malloc/free造成內存空間的不連續,產生碎片。當申請堆空間時庫函數是按照一定的算法搜索可用的足夠大的空間。因此堆的效率比棧要低的多。

int a0=1;
static int a1;
const static a2=0;
extern int a3;
void fun(void)
{
int a4;
volatile int a5;
return;
}
a0 :全局初始化變量;生命周期為整個程序運行期間;作用域為所有文件;存儲位置為data段。
a1 :全局靜態未初始化變量;生命周期為整個程序運行期間;作用域為當前文件;儲存位置為BSS段。
a2 :全局靜態變量
a3 :全局初始化變量;其他同a0。
a4 :局部變量;生命周期為fun函數運行期間;作用域為fun函數內部;儲存位置為棧。
a5 :局部易變變量;生命周期為
內存管理參考鏈接
變量的類型、作用域、存儲空間、生命周期參考鏈接
static extern 局部變量 全局變量 生命周期 作用域
變量類型參考鏈接
請用c語言直接編寫以下四個宏
1、ALGN_DOWN(x,a)將數值x按照a的整數倍向下取整,例如ALGN_DOWN(65,3)—>63
2、ALGN_UP(x,a) 將數值x按照a的整數倍向上取整,例如ALGN_UP(65,3)—>66
3、ALGN_2N_DOWN(x,a) 將數值x按照a的整數倍向下取整,a是2的n次冪,例如ALGN_2N_DOWN(65,4)—>64.
4、ALGN_2N__UP(x,a) 將數值x按照a的整數倍向上取整,a是2的n次冪,例如ALGN_2N_UP(65,4)—>68.
備注:數值位unsigned int;對2的n次冪的情況只要利用這個特性用更高效的方法實現。
問題3.4執行運算符右移操作,右移就是原數除2
C語言編程
已知某外設有兩個32—bit的寄存器
數據寄存器,內存映射地址為0x80000000
狀態寄存器,內存映射地址0x80000004
狀態寄存器的bit31為A功能的標志位
請補充完成以下結構體描述兩個寄存器,
Typedef struct{
………
}A_regs_t;
請用c語言實現如下函數;
/*
*read A data if A status is 1,and then clear the A status bit.
*@param[in] a_regs;pointer to registers of A function
*@param[out] result;data read from register
@retval 0:successs;<0:error code
*/
Int32_t_get_A_result(A_regs_t a_regs,uint32 _tresult);
并寫出調用這個函數的代碼。
談一談大疆的嵌入式筆試題
這次總的來說筆試題并不難,可能頭一次參加正規的筆試,稍微有點緊張導致很多簡單的題漏掉了一些轉換,比如bit和Byte等等。
題型:
一、選擇 10道 2*10
以Linux和C為主,還有操作系統,內存帶寬等等,題目不是很難,但是一定一定要沉下心來做,爭取做一個對一個。
二 多選 3道 4*3
涉及類型跟選擇差不多。
三 填空 忘了,3道應該 4*3
循環,內存填充,進程通信方式
四 簡答 3道 6*3
1.實時操作系統優缺點。
2.給個程序問里面的四個函數分別調用了多少次,
- mmap比fread讀的快的原因。
五 編程 2道 31
兩道考的全是鏈表,這里要多說幾句,之前有的人考的是環形隊列和有序數組的組合,相對而言,這次的B卷題目有點難,考鏈表,加上緊張,可能有的指針的指針的指針就給搞迷糊了,編程就在文本編輯框里寫,說是能用本地IDE,但是系統還是會記錄你跳出的次數,這是我們也是很糾結,干脆直接純手撕代碼了,程序八九不離十跑不起來肯定。
刪除雙向鏈表倒數第N個節點后的所有節點。
反轉鏈表。
通過這次筆試,最重要的還是歷練一下筆試的心態問題,再就是知識點涉及范圍很廣,重在平時的積累。
【機試題】2019大疆嵌入式筆試題A卷(附超詳細解答)
填空選擇題
1、ARM指令和Thumb指令。(選擇題)
解答:在ARM的體系結構中,可以工作在三種不同的狀態,一是ARM狀態,二是Thumb狀態及Thumb-2狀態,三是調試狀態。而ARM狀態和Thumb狀態可以直接通過某些指令直接切換,都是在運行程序,只不過指令長度不一樣而已。
ARM狀態:arm處理器工作于32位指令的狀態,所有指令均為32位;
Thumb狀態:arm執行16位指令的狀態,即16位狀態;
thumb-2狀態:這個狀態是ARM7版本的ARM處理器所具有的新的狀態,新的thumb-2內核技術兼有16位及32位指令,實現了更高的性能,更有效的功耗及更少地占用內存。總的來說,感覺這個狀態除了兼有arm和thumb的優點外,還在這兩種狀態上有所提升,優化;
調試狀態:處理器停機時進入調試狀態。
也就是說:ARM狀態,此時處理器執行32位的字對齊的ARM指令;Thumb狀態,此時處理器執行16位的,半字對齊的THUMB指令。
ARM狀態和Thumb狀態切換程序:
從ARM到Thumb: LDR R0,=lable+1 BX R0(狀態將寄存器的最低位設置為1,BX指令、R0指令將進入thumb狀態);
從ARM到Thumb: LDR R0,=lable BX R0(寄存器最低位設置為0,BX指令、R0指令將進入arm狀態)。
當處理器進行異常處理時,則從異常向量地址開始執行,將自動進入ARM狀態。
關于這個知識點還有幾個注意點:
ARM處理器復位后開始執行代碼時總是只處于ARM狀態;
Cortex-M3只有Thumb-2狀態和調試狀態;
由于Thumb-2具有16位/32位指令功能,因此有了thumb-2就無需Thumb了。
另外,具有Thumb-2技術的ARM處理器也無需再ARM狀態和Thumb-2狀態間進行切換了,因為thumb-2具有32位指令功能。
2、哪種總線方式是全雙工類型、哪種總線方式傳輸的距離最短?(選擇題)
解答:幾種總線接口的通信方式的總結如下圖所示:
3、TCP與UDP的區別。(選擇題)
解答:TCP和UDP的區別總結如下圖所示:

4、Linux的用戶態與內核態的轉換方法。(選擇題)
解答:Linux下內核空間與用戶空間進行通信的方式主要有syscall(system call)、procfs、ioctl和netlink等。
syscall:一般情況下,用戶進程是不能訪問內核的。它既不能訪問內核所在的內存空間,也不能調用內核中的函數。Linux內核中設置了一組用于實現各種系統功能的子程序,用戶可以通過調用他們訪問linux內核的數據和函數,這些系統調用接口(SCI)稱為系統調用;
procfs:是一種特殊的偽文件系統 ,是Linux內核信息的抽象文件接口,大量內核中的信息以及可調參數都被作為常規文件映射到一個目錄樹中,這樣我們就可以簡單直接的通過echo或cat這樣的文件操作命令對系統信息進行查取;
netlink:用戶態應用使用標準的 socket API 就可以使用 netlink 提供的強大功能;
ioctl:函數是文件結構中的一個屬性分量,就是說如果你的驅動程序提供了對ioctl的支持,用戶就可以在用戶程序中使用ioctl函數控制設備的I/O通道。
5、linux目錄結構,選項是/usr、/tmp、/etc目錄的作用。(選擇題)
解答:linux目錄圖:
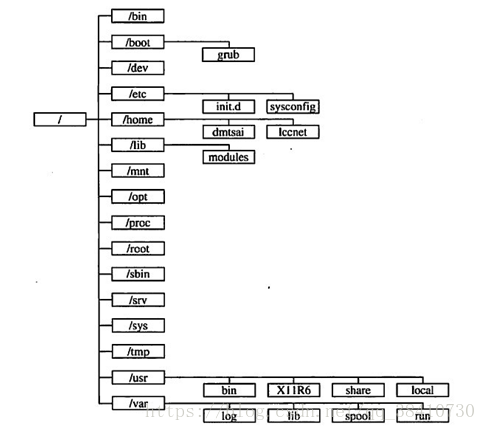
/usr:不是user的縮寫,其實usr是Unix Software Resource的縮寫, 也就是Unix操作系統軟件資源所放置的目錄,而不是用戶的數據啦。這點要注意。 FHS建議所有軟件開發者,應該將他們的數據合理的分別放置到這個目錄下的次目錄,而不要自行建立該軟件自己獨立的目錄;
/tmp:這是讓一般使用者或者是正在執行的程序暫時放置檔案的地方。這個目錄是任何人都能夠存取的,所以你需要定期的清理一下。當然,重要資料不可放置在此目錄啊。 因為FHS甚至建議在開機時,應該要將/tmp下的資料都刪除;
/etc:系統主要的設定檔幾乎都放置在這個目錄內,例如人員的帳號密碼檔、各種服務的啟始檔等等。 一般來說,這個目錄下的各檔案屬性是可以讓一般使用者查閱的,但是只有root有權力修改。 FHS建議不要放置可執行檔(binary)在這個目錄中。 比較重要的檔案有:/etc/inittab, /etc/init.d/, /etc/modprobe.conf, /etc/X11/, /etc/fstab, /etc/sysconfig/等等。
6、下面這段程序的運行結果?(選擇題)
int main(){
const int x=5;
const int *ptr;
ptr=&x;
*ptr=10;
printf("%d\n",x);
return 0;
}
解答:編譯出錯。
這道題主要是講解const與指針的問題:
const int a;
int const a;
const int a;
int * const a;
const int * const a;
int const * const a;
前兩個的作用是一樣,a是一個常整型數;
第三個意味著a是一個指向常整型數的指針(也就是,整型數是不可修改的,但指針可以);
第四個意思a是一個指向整型 數的常指針(也就是說,指針指向的整型數是可以修改的,但指針是不可修改的);
最后兩個意味著a是一個指向常整型數的常指針(也就是說,指針指向的整型數 是不可修改的,同時指針也是不可修改的)。
也就是說:本題x是一個常量,不能改變;ptr是一個指向常整型數的指針。而當ptr=10;的時候,直接違反了這一點。同時要記得一點,const是通過編譯器在編譯的時候執行檢查來確保實現的。
7、在32位系統中,有如下結構體,那么sizeof(fun)的數值是()
pragma pack(1)
struct fun{
int i;
double d;
char c;
};
解答:13。
可能是一般的內存對齊做習慣了,如果本題采用內存對齊的話,結果就是24(int 4 double char 7)。但是#pragma pack(1)讓編譯器將結構體數據強制按1來對齊。
每個特定平臺上的編譯器都有自己的默認“對齊系數”(32位機一般為4,64位機一般為8)。我們可以通過預編譯命令#pragma pack(k),k=1,2,4,8,16來改變這個系數,其中k就是需要指定的“對齊系數”。
只需牢記:
第一個數據成員放在offset為0的地方,對齊按照對齊系數和自身占用字節數中,二者比較小的那個進行對齊;
在數據成員完成各自對齊以后,struct或者union本身也要進行對齊,對齊將按照對齊系數和struct或者union中最大數據成員長度中比較小的那個進行;
參考文章:#pragma pack()的解讀。
8、Linux中的文件/目錄權限設置命令是什么?(選擇題)
解答:chmod

10、C語言的各種變量的存取區域,給你一段小程序,讓你分析各個變量的存儲區域(填空題)
解答:具體的題目內容忘了,但是大體上給出各個變量可能的存儲區域:
堆:堆允許程序在運行時動態地申請某個大小的內存。一般由程序員分配釋放;
棧:由編譯器自動分配釋放,存放函數的參數值,局部變量等值;
靜態存儲區:一定會存在且不會消失,這樣的數據包括常量、常變量(const 變量)、靜態變量、全局變量等;
常量存儲區:常量占用內存,只讀狀態,決不可修改,常量字符串就是放在這里的。
11、下面這段程序的運行結果?(填空題)
int main() {
int a[10] = { 0,1,2,3,4,5,6,7,8,9 };
memcpy(a + 3, a, 5);
for (int i = 0; i<10; i++){
printf("%d ", a[i]);
}
return 0;
}
解答:0 1 2 0 1 5 6 7 8 9
首先看一下內存復制函數memcpy()函數的定義:
void * memcpy ( void * destination, const void * source, size_t num );
將source指向的地址處的 num 個字節 拷貝到 destination 指向的地址處。注意,是字節。
因為memcpy的最后一個參數是需要拷貝的字節的數目!一個int類型占據4個字節!這樣的話,本題5字節,實際上只能移動2個數字(往大的去)。如果要想達到將a地址開始的5個元素拷貝到a+3地址處,需要這么寫:
memcpy(a + 3, a, 5*sizeof(int));
參考文章:memcpy使用時需要注意的地方。
12、C語言編譯過程中,volatile關鍵字和extern關鍵字分別在哪個階段起作用?(填空題)
解答:volatile應該是在編譯階段,extern在鏈接階段。
volatile關鍵字的作用是防止變量被編譯器優化,而優化是處于編譯階段,所以volatile關鍵字是在編譯階段起作用。
參考文章:C語言文件的編譯與執行的四個階段并分別描述和volatile為什么要修飾中斷里的變量。
13、linux系統打開設備文件,進程可能處于三種基本狀態,如果多次打開設備文件,驅動程序應該實現什么?(填空題)
不太清楚……
簡答題
1、簡述實時操作系統和非實時操作系統特點和區別。
解答:實時操作系統是保證在一定時間限制內完成特定功能的操作系統。實時操作系統有硬實時和軟實時之分,硬實時要求在規定的時間內必須完成操作,這是在操作系統設計時保證的;軟實時則只要按照任務的優先級,盡可能快地完成操作即可。
實時性最主要的含義是:任務的最遲完成時間是可確認預知的。

2、簡述static關鍵字對于工程模塊化的作用。
解答:在C語言中,static有下3個作用:
函數體內的static變量的作用范圍為該函數體,不同于auto變量,該變量的內存只被分配一次,以為其值在下次調用時仍維持上次的值(該變量存放在靜態變量區);
在模塊內static全局變量可以被模塊內所有函數訪問,但不能被模塊外其他函數訪問。(注意,只有在定義了變量后才能使用。如果變量定義在使用之后,要用extern 聲明。所以,一般全部變量都會在文件的最開始處定義。);
在模塊內的static函數只可被這一模塊內的其他函數調用,這個函數的使用范圍被限制在聲明它的模塊內。
在嵌入式系統中,要時刻懂得移植的重要性,程序可能是很多程序員共同協作同時完成,在定義變量及函數的過程,可能會重名,這給系統的集成帶來麻煩,因此保證不沖突的辦法是顯示的表示此變量或者函數是本地的,static即可。在Linux的模塊編程中,這一條很明顯,所有的函數和全局變量都要用static關鍵字聲明,將其作用域限制在本模塊內部,與其他模塊共享的函數或者變量要EXPORT到內核中。
3、無鎖可以提高整個程序的性能,但是CPU需要對此提供支持,請以x86/ARM為例簡述。
解答:無鎖編程具體使用和考慮到的技術方法包括:原子操作(atomic operations), 內存柵欄(memory barriers), 內存順序沖突(memory order), 指令序列一致性(sequential consistency)和順ABA現象等等。
在這其中最基礎最重要的是操作的原子性或說原子操作。原子操作可以理解為在執行完畢之前不會被任何其它任務或事件中斷的一系列操作。原子操作是非阻塞編程最核心基本的部分,沒有原子操作的話,操作會因為中斷異常等各種原因引起數據狀態的不一致從而影響到程序的正確。
對于原子操作的實現機制,在硬件層面上CPU處理器會默認保證基本的內存操作的原子性,CPU保證從系統內存當中讀取或者寫入一個字節的行為肯定是原子的,當一個處理器讀取一個字節時,其他CPU處理器不能訪問這個字節的內存地址。但是對于復雜的內存操作CPU處理器不能自動保證其原子性,比如跨總線寬度或者跨多個緩存行(Cache Line),跨頁表的訪問等。這個時候就需要用到CPU指令集中設計的原子操作指令,現在大部分CPU指令集都會支持一系列的原子操作。
而在無鎖編程中經常用到的原子操作是Read-Modify-Write (RMW)這種類型的,這其中最常用的原子操作又是 COMPARE AND SWAP(CAS),幾乎所有的CPU指令集都支持CAS的原子操作,比如X86平臺下中的是 CMPXCHG(Compare Are Exchange)。
繼續說一下CAS,CAS操作行為是比較某個內存地址處的內容是否和期望值一致,如果一致則將該地址處的數值替換為一個新值。CAS操作具體的實現原理主要是兩種方式:總線鎖定和緩存鎖定。所謂總線鎖定,就是CPU執行某條指令的時候先鎖住數據總線的, 使用同一條數據總線的CPU就無法訪問內存了,在指令執行完成后再釋放鎖住的數據總線。鎖住數據總線的方式系統開銷很大,限制了訪問內存的效率,所以又有了基于CPU緩存一致性來保持操作原子性作的方法作為補充,簡單來說就是用CPU的緩存一致性的機制來防止內存區域的數據被兩個以上的處理器修改。
最后這里隨便說一下CAS操作的ABA的問題,所謂的ABA的問題簡要的說就是,線程a先讀取了要對比的值v后,被線程b搶占了,線程b對v進行了修改后又改會v原來的值,線程1繼續運行執行CAS操作的時候,無法判斷出v的值被改過又改回來。
解決ABA的問題的一種方法是,一次用CAS檢查雙倍長度的值,前半部是指針,后半部分是一個計數器;或者對CAS的數值加上版本號。
參考文章:無鎖編程技術及實現。
編程題
1、已知循環緩沖區是一個可以無限循環讀寫的緩沖區,當緩沖區滿了還繼續寫的話就會覆蓋我們還沒讀取到的數據。下面定義了一個循環緩沖區并初始化,請編寫它的Write函數:
typedef struct RingBuf {
char *Buf;
unsigned int Size;
unsigned int RdId;
unsigned int WrId;
}RingBuf;
void Init(RingBuf *ringBuf, char *buf, unsigned int size) {
memset(ringBuf, 0, sizeof(RingBuf));
ringBuf->Buf = buf;
ringBuf->Size = size;
ringBuf->RdId = 0;
ringBuf->WrId = 0;
}
解答:實際上我覺得提供的初始化代碼部分,對WrId的初始化有點問題,Write()函數的完整代碼如下:
typedef struct RingBuf {
char *Buf;
unsigned int Size;
unsigned int RdId;
unsigned int WrId;
}RingBuf;
void Init(RingBuf *ringBuf, char *buf, unsigned int size) {
memset(ringBuf, 0, sizeof(RingBuf));
ringBuf->Buf = buf;
ringBuf->Size = size;
ringBuf->RdId = 0;
ringBuf->WrId = strlen(buf);
}
void Write(RingBuf *ringBuf, char *buf, unsigned int len) {
unsigned int pos = ringBuf->WrId;
while (pos + len > ringBuf->Size) {
memcpy(ringBuf->Buf + pos, buf, ringBuf->Size - pos);
buf += ringBuf->Size - pos;
len -= ringBuf->Size - pos;
pos = 0;
}
memcpy(ringBuf->Buf + pos, buf, len);
ringBuf->WrId = pos + len;
}
void Print(RingBuf *ringBuf) {
for (int i = 0; i < ringBuf->Size; i++) {
cout << ringBuf->Buf[i];
}
cout << endl;
}
int main()
{
RingBuf *rb = (RingBuf *)malloc(sizeof(RingBuf));
char init_str[] = "ABC";
int size = 6;
Init(rb, init_str, size);
char p[] = "1234567";
Write(rb, p, 7);
Print(rb);
return 0;
}
2、已知兩個已經按從小到大排列的數組,將它們中的所有數字組合成一個新的數組,要求新數組也是按照從小到大的順序。請按照上述描述完成函數:
int merge(int *array1, int len1, int *array2, int len2, int *array3);
解答:這道題本質上就是一道合并排序,網上一大堆的程序案例,就不多介紹了。下面這段程序是我自己寫的,并不是從網上貼的,如果有一些BUG,還請指出。
int merge(int *array1, int len1, int *array2, int len2, int array3) {
int retn = len1 + len2;
if ((array1 < *array2 || len2 == 0) && len1 > 0) {
*array3 = array1;
merge(++array1, --len1, array2, len2, ++array3);
}
if ((array1 >= *array2 || len1 == 0) && len2 > 0) {
*array3 = *array2;
merge(array1, len1, ++array2, --len2, ++array3);
}
return retn;
【機試題】2019.8.4大疆嵌入式筆試題A卷
1、求a的值
經過表達式a = 5 ? 0 : 1的運算,變量a的最終值是 0
1
boolean虛擬機取值時候是掩碼去掉前七位之后取末尾判斷,0是false,1是true,而5對應的是00001001,所以這塊表示的是1,也就是true,所以對應的是三目運算里面的結果是 0。
2、數組int a[3][4]中的a[2][1]用其他形式表示:
((a+2)+1)
1
*(a[2] + 1)
1
int *p = &a[0][0] ;//p[9], 表示 a[2][1];
1
3、在soc中常常用做對外設寄存器配置總線的是:i2c,spi
4、哈佛結構和馮諾依曼結構的區別:
要理解哈弗結構和馮諾依曼結構的區別,首先要知道我們在編寫程序的時候其實可以對程序的代碼劃分為兩個部分,一部分是程序編寫完成后就不再需要對其進行修改了的(也就是邏輯代碼部分)另一部分就是在程序編寫完畢后其內容會隨著程序的運行而不斷變化的部分(也就是定義變量)。而哈佛結構和馮諾依曼結構就是對于這個兩部分代碼的存儲方式的區別。
哈佛結構(Harvard architecture)是一種將程序指令儲存和數據儲存分開的存儲器結構。
中央處理器首先到程序指令儲存器中讀取程序指令內容,解碼后得到數據地址,再到相應的數據儲存器中讀取數據,并進行下一步的操作(通常是執行)。程序指令儲存和數據儲存分開,數據和指令的儲存可以同時進行,可以使指令和數據有不同的數據寬度。
哈佛結構的微處理器通常具有較高的執行效率。其程序指令和數據指令分開組織和儲存的,執行時可以預先讀取下一條指令。
大多數ARM、DSP是哈佛結構。

馮.諾伊曼結構(von Neumann architecture)是一種將程序指令存儲器和數據存儲器合并在一起的存儲器結構。
大多數CPU和GPU是馮諾依曼結構的。

馮諾依曼結構則是將邏輯代碼段和變量統一都存儲在內存當中,他們之間一般是按照代碼的執行順序依次存儲。這樣就會導致一個問題,如果當程序出現BUG的時候,由于程序沒有對邏輯代碼段的讀寫限定,因此,他將擁有和普通變量一樣的讀寫操作權限。于是就會很容易的死機,一旦他的邏輯執行出現一點該變就會出現非常嚴重的錯誤。但是,馮諾依曼結構的好處是可以充分利用有限的內存空間,并且會使CPU對程序的執行十分的方便,不用來回跑。
5、聯合體和結構體
結構體(struct)各成員各自擁有自己的內存,各自使用互不干涉,同時存在的,遵循內存對齊原則。一個struct變量的總長度等于所有成員的長度之和。
而聯合體(union)各成員共用一塊內存空間,并且同時只有一個成員可以得到這塊內存的使用權(對該內存的讀寫),各變量共用一個內存首地址。因而,聯合體比結構體更節約內存。一個union變量的總長度至少能容納最大的成員變量,而且要滿足是所有成員變量類型大小的整數倍。
include<stdio.h>
//結構體
struct u //u表示結構體類型名
{
char a; //a表示結構體成員名
int b;
short c;
}U1;
//U1表示結構體變量名
//訪問該結構體內部成員時可以采用U1.a=1;其中"點"表示結構體成員運算符
//聯合體
union u1 //u1表示聯合體類型名
{
char a; //a表示聯合體成員名
int b;
short c;
}U2;
//U2表示聯合體變量名
//訪問該聯合體內部成員時可以采用U2.a=1;其中"點"表示聯合體成員運算符
//主函數
int main(){
printf("%d\n",sizeof(U1));
printf("%d\n",sizeof(U2));
return 0;
}
/程序運行結果是:
12
4/
填空題4道
1、大小端問題
A=0x12345678存入地址1000H~10003H中,
小端模式:1000H=78 1001H=56 1002H=34 1003H=12
大端模式:1000H=12 1001H=34 1002H=56 1003H=78
2、宏定義計算問題
define PRODUCT (x) (x*x)
int main()
{
int a,b=3;
a=PRODUCT(b+2);
}
1
2
3
4
5
6
7
求a值:
b+2b+2=3+23+2=11
1
3、有符號和無符號混合三目運算問題
void foo(void)
{
unsigned int a = 6;
int b = -20;
int c;
(a+b > 6) ? (c=1) : (c=0);
}
1
2
3
4
5
6
7
這個問題測試C語言中的整數自動轉換原則,這無符號整型問題的答案是c=1。原因是當表達式中存在有符號類型和無符號類型時所有的操作數都自動轉換為無符號類型。因此-20變成了一個非常大的正整數,所以該表達式計算出的結果c=1。
簡答題3道
1、簡述任務/線程之間的同步方式
互斥鎖:鎖機制是同一時刻只允許一個線程執行一個關鍵部分的代碼。
條件變量:條件變量是利用線程間共享全局變量進行同步的一種機制。條件變量上的基本操作有:觸發條件(當條件變為 true 時),等待條件,掛起線程直到其他線程觸發條件。
信號量:為控制一個具有有限數量用戶資源而設計。
事 件:用來通知線程有一些事件已發生,從而啟動后繼任務的開始。
Linux中四種進程或線程同步互斥控制方法
2、簡述可執行程序的內存布局


3、設計機制保證鎖可以按照先到先得的方式被任務獲取,并且占用內存空間最小(題目沒有說全,記不清,考察操作系統和隊列的應用)
編程題2道
1、比較輸入字符串s1和s2前n個字符,忽略大小寫,如果字符串s1和s2相同則返回0,不同則返回第一個不同字符的差值。
tolower是一種函數,功能是把字母字符轉換成小寫,非字母字符不做出處理。
include <stdio.h>
include <string.h>
include <ctype.h>
int strcmpx(const char s1, const char s2, unsigned int n)
{
int c1, c2;
do {
c1 = tolower(s1++);
c2 = tolower(s2++);
} while((--n > 0) && c1 == c2 && c1 != 0);
return c1 - c2;
}
int main(void)
{
int n = 4;
char str3[] = "ABCf";
char str4[] = "abcd";
printf("strcmpx(str3, str4, n) = %d", strcmpx(str3, str4, n));
return 0;
}
2、N X N數組,輸出行中最小,列中最大的數的位置,比如:
1 2 3
4 5 6
7 8 9
輸出:row=2,col=0
分析:
在矩陣中,一個數在所在行中是最大值,在所在列中是最小值,則被稱為鞍點。
鞍點C++實現
//C語言輸出矩陣馬鞍點
include<stdio.h>
void Input_Matrix(int m,int n,int a[100][100]) //輸入矩陣元素
{
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
scanf("%d", &a[i][j]);
}
}
}
void Output_Matrix(int m, int n, int a[100][100]) //輸出矩陣元素
{
for (int i = 0; i < m; i++)
{
for (int j = 0; j < n; j++)
{
printf("%-5d", a[i][j]);
}
printf("\n");
}
}
void Matrix_Mn(int m, int n, int a[100][100]) //輸出矩陣馬鞍點
{
int flag = 0;
int min, max, k, l;
for (int i = 0; i < n; i++)
{
for (int j = 0; j < m; j++)
{
min = a[i][j];
for (k = 0; k < m; k++)
{
if (min < a[i][k])
break;
}
if (k == m)
{
max = a[i][j];
for (l = 0; l < n; l++)
{
if (max > a[l][j])
break;
}
if (l == n)
{
printf("%-5d%-5d\n", i, j);
printf("矩陣元素為:a[%d][%d]=%d\n",i,j, a[i][j]);
flag = 1;
}
}
}
}
if (flag == 0)
{
printf("該矩陣沒有馬鞍點!\n");
}
}
int main(void)
{
int m, n;
int a[100][100];
for (;;)
{
printf("請輸入矩陣的行數和列數:\n");
scanf("%d %d", &n, &m);
printf("請輸入矩陣中的元素:\n");
Input_Matrix(m, n, a);
printf("矩陣輸出為:\n");
Output_Matrix(m, n, a);
printf("馬鞍點輸出(該點所在的行數和列數):\n");
Matrix_Mn(m, n, a);
}
return 0;
}
題目要求是一個數在所在行中是最小值,在所在列中是最大值,不確定還能不能稱為鞍點,但是算法思路相似的。
思路:
先找第i行上最小的元素t,以及所在列minj
判斷t是否為第minj列的最大值,如果不是則在minj列中繼續尋找最大值并輸出,如果是則輸出
include <stdio.h>
define N 3
int a[N][N]={1,2,3,4,5,6,7,8,9};
int main()
{
int i,j,t,minj;
for(i=0;i<N;i++)
{
t=a[i][0];
minj=0;
for(j=1;j<N;j++)//行上最小
{
if(a[i][j]<t)
{
t=a[i][j];
minj=j;//找到了行上最小的數所在的列
}
}
int k;
for(k=0;k<N;k++)
if(a[k][minj]>t)//判斷是否列上最大
break;
if(k<N) continue;//接著查找下一行
printf("所求點是:a[%d][%d]:%d\n",i,minj,t);
}
return 0;
}
相關基礎知識:
break:
(1).結束當前整個循環,執行當前循環下邊的語句。忽略循環體中任何其它語句和循環條件測試。
(2).只能跳出一層循環,如果你的循環是嵌套循環,那么你需要按照你嵌套的層次,逐步使用break來跳出。
continue:
(1).終止本次循環的執行,即跳過當前這次循環中continue語句后尚未執行的語句,接著進行下一次循環條件的判斷。
(2).結束當前循環,進行下一次的循環判斷。
(3).終止當前的循環過程,但他并不跳出循環,而是繼續往下判斷循環條件執行語句.他只能結束循環中的一次過程,但不能終止循環繼續進行。
2020屆校招大疆嵌入式部分筆試題
在32位系統中有如下定義,則sizeof(data_t)的值是()
typedef struct data{
char m:3;
char n:5;
short s;
union{
int a;
char b;
};
int h;
}__attribute__((packed)) data_t;
sizeof(data_t) = 11;
attribute((packed))的作用就是告訴編譯器取消結構在編譯過程中的優化對齊,按照實際占用字節數對齊,union聯合體里面的變量是共享一個地址空間的,以及結構體的位段操作知識點。
參考博客:
attribute((packed))詳解
結構體、位段與聯合體
程序按64位編譯,運行下列程序代碼,打印輸出結果是多少
define CALC(x,y) (x*y)
int main(void) {
int i=3;
int calc;
char **a[5][6];
calc = CALC(i++, sizeof(a)+5);
printf("i=%d, calc=%d\n", i, calc);
return 0;
}
輸出結果為:i=4, calc=725
注意在宏定義中帶參數時括號的用法,在本題中#define CALC(x, y) (xy)的結果是725,但是如果這樣寫:#define CALC(x,y) (x)(y) 的結果就是735
一般32位機器就是564 = 120,64位則是568=240 ,char *a是字符型指針,char **a是指針的指針,在64位和32位中指針的大小是不一樣的
參考博客:
帶參數的宏定義
Linux系統中內核線程和普通線程的區別
普通線程和內核線程
內核線程和用戶線程
大疆嵌入式筆試總結
單選,多選和填空
(1)緩存和寄存器哪個比較快
CPU <— > 寄存器<— > 緩存<— >內存
(2)波特率是以什么為單位,比特率又是以為什么為單位
1波特即指每秒傳輸1個碼元符號(通過不同的調制方式,可以在一個碼元符號上負載多個bit位信息),1比特每秒是指每秒傳輸1比特(bit)。
用實際使用中,最常用的串口通訊協議舉例,注意前置條件為:1 個起始位,8 個數據位,0 個校驗位,1 個停止位,也就是我們常說的:8,N,1;8 個數據位,一個停止位,無校驗位。
這個條件分析一下就是,如果我要傳輸一個字節(8 位)的數據,則我應該在總線上產生 10 個電平變換,也就是串行總線上,需要 10 位,才能發送 1 個字節數據。
1 秒可以發送 9600 位,那么用 9600/10 ,就是1秒可以發送 960 個字節數據,則每發送一個字節需要的時間就是:1/960 ~= 0.00104166…s ~= 1.0416667 ms。
此時就可以得出一個結論,在 9600 波特率下,大概 1ms 發送 1 個字節的數據。
(3)對ARM處理器異常的理解
外部中斷,內部異常,系統調用都屬于
(4)Cotex_M基礎知識的掌握
(5)LDR R0,=0x12345678是直接將值賦給R0嗎
就是把0x12345678這個地址中的值存放到r0中。
(6)IO密集型類知識
(7)支持優先級繼承調度器會動態改變任務優先級?
(8)git命令相關知識
(9)哪些不是實時操作系統
需要注意的是帶有RT的基本上都是實時性操作系統
WIN,Linux都是分時操作系統
(10)ARM_V8支持64位?
大致來說,ARMv8架構跟AMD和Intel的做法一樣,采取64位兼容32位的方式。應用程序可以以32位模式執行,也可以以64位模式執行。
(11)NEON,PMIPB等操作
(12)SPI有幾種工作模式
SPI總線有四種工作方式(SP0, SP1, SP2, SP3),其中使用的最為廣泛的是SPI0和SPI3方式。
(13)棧空間大小會不會影響編譯出來的bin固件大小
這個。。暫時還沒聽說過
(14)00編譯優化是不是默認不優化
(15)inline內聯基礎知識及其作用
在 c/c++ 中,為了解決一些頻繁調用的小函數大量消耗棧空間(棧內存)的問題,特別的引入了 inline 修飾符,表示為內聯函數。棧空間就是指放置程序的局部數據(也就是函數內數據)的內存空間。
(16)給圖片大小和碼率還是啥,求帶寬多少Gbps
(17)VTOR作用,普通中斷是不是只把R0-R3數據壓棧,PRIMASK作用
VTOR中斷向量表偏移寄存器
cortex-M3 中斷調用過程
入棧
中斷發生后,中斷服務函數運行前,會先把xPSR, PC, LR, R12以及R3‐R0總共8個寄存器由硬件自動壓入適當的堆棧中(中斷前使用的MSP就壓入MSP,中斷前使用的是PSP就壓入PSP
(18)內聯函數的作用
避免函數調用的開銷
(19)ARM Cotex -M 都是哈佛體系?-A馮諾依曼體系?
有一些ARM(Cortex-M系列)是哈佛結構,而另一些ARM(Cortex-A)是馮諾依曼結構(或者更準確說是混合結構)。
(20)I2S總線相關知識
I2S特點
①支持全雙工和半雙工通信。(單工數據傳輸只支持數據在一個方向上傳輸;半雙工數據傳輸允許數據在兩個方向上傳輸,但是在某一時刻,只允許數據在一個方向上傳輸,它實際上是一種切換方向的單工通信;全雙工數據通信允許數據同時在兩個方向上傳輸,因此,全雙工通信是兩個單工通信方式的結合,它要求發送設備和接收設備都有獨立的接收和發送能力。
②支持主/從模式。(主模式:就是主CPU作為主機,向從機(掛載器件)發送接收數據。從模式:就是主CPU作為從機,接收和發送主機(掛載器件)數據。而主從機的分別其實是一個觸發的作用,主機主動觸發,從機只能被動響應觸發。)
I2S總線擁有三條數據信號線:
1、SCK: (continuous serial clock) 串行時鐘
對應數字音頻的每一位數據,SCK都有1個脈沖。SCK的頻率=2×采樣頻率×采樣位數。
2、WS: (word select) 字段(聲道)選擇
用于切換左右聲道的數據。WS的頻率=采樣頻率。
命令選擇線表明了正在被傳輸的聲道。
WS為“1”表示正在傳輸的是左聲道的數據。
WS為“0”表示正在傳輸的是右聲道的數據。
WS可以在串行時鐘的上升沿或者下降沿發生改變,并且WS信號不需要一定是對稱的。在從屬裝置端,WS在時鐘信號的上升沿發生改變。WS總是在最高位傳輸前的一個時鐘周期發生改變,這樣可以使從屬裝置得到與被傳輸的串行數據同步的時間,并且使接收端存儲當前的命令以及為下次的命令清除空間。
3、SD: (serial data) 串行數據
用二進制補碼表示的音頻數據。 I2S格式的信號無論有多少位有效數據,數據的最高位總是被最先傳輸(在WS變化(也就是一幀開始)后的第2個SCK脈沖處),因此最高位擁有固定的位置,而最低位的位置則是依賴于數據的有效位數。也就使得接收端與發送端的有效位數可以不同。如果接收端能處理的有效位數少于發送端,可以放棄數據幀中多余的低位數據;如果接收端能處理的有效位數多于發送端,可以自行補足剩余的位(常補足為零)。這種同步機制使得數字音頻設備的互連更加方便,而且不會造成數據錯位。為了保證數字音頻信號的正確傳輸,發送端和接收端應該采用相同的數據格式和長度。當然,對I2S格式來說數據長度可以不同。
(21)I2C主機發送__作為初始信號
起始信號:SCL為高電平期間,SDA線由高電平向低電平的變化
問答:
(1)棧空間大小多大,往一個數組寫4K btye數據棧會不會溢出?如果會還有哪些情況會溢
出?如果不會溢出會發生什么問題?
自行測試linux的棧的默認空間在7~8Mbyte之間接近8M,通過ulimit -s可以知道理論值是8M
但是棧的空間是不固定的,我們可以用ulimit -s 10240 更改其棧空間,單位KByte
當然不同系統的默認棧值可能不一樣,比如win系統的棧不到1M
對于堆內存來說,可以申請的內存非常大,幾乎可以申請超萬個G我也不知道為什么。
當一個進程退出后,不管是正常退出或者是異常退出,操作系統都會釋放這個進程的資源。包括這個進程分配的內存。
(2)寫一個宏定義,給一個結構體成員地址,返回結構體的首地址
編程題:
(1)給一個正整數n,求從1-n這些數字總共出現’1’的次數
(2)求圓周率的N位精度,這個N可能非常非常大

 浙公網安備 33010602011771號
浙公網安備 33010602011771號