
2024-12-31
? ?
?
創建時間:2024-12-31 15:47 星期二, 距離
2021-11-05? 還剩-1152? 天
Daily work-12/31
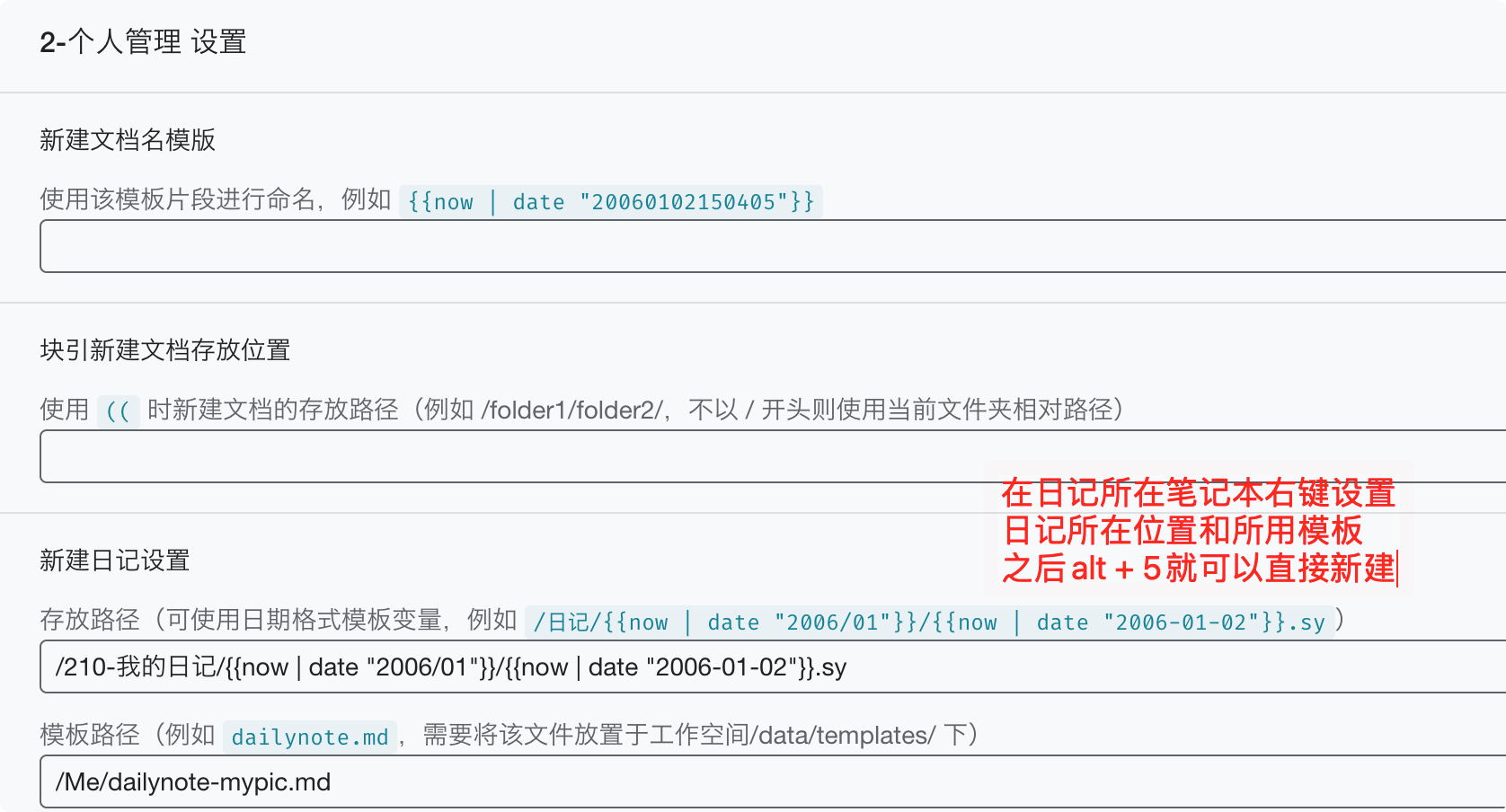
第一次日記模板設置方法:如圖
設置之后,再把模板中自己不需要的內容刪掉
? ?
?
?
Notes-12/31
?
隨機復習
距離
2022-01-01? 還剩-1095? 天,加油!
- https://zhuanlan.zhihu.com/p/138668785 - 知乎專欄
- (一) CPU的浮點計算性能公式 我們常用雙精度浮點運算能力衡量一個處理器的科學計算的能力,就是處理64bit小數點浮動數據的能力 intel的最新cpu支持高級矢量指令集AVX2、AVX512, 其中AVX2的處理器的單指令的長度…
- 2023-05-31 10:58:07
(一) CPU的浮點計算性能公式
我們常用雙精度浮點運算能力衡量一個處理器的科學計算的能力,就是處理64bit小數點浮動數據的能力?
?
intel的最新cpu支持高級矢量指令集AVX2、AVX512, 其中AVX2的處理器的單指令的長度是256bit,每顆intelCPU包含2個FMA,一個FMA一個時鐘周期可以進行2次乘或者加的運算,那么這個處理器在1個核心1個時鐘周期可以執行256bit * *2FMA ** 2M/A/64=16次浮點運算,也稱為16FLOPs,就是Floating Point Operations Per Second;
?
?
支持AVX512的處理器的單指令的長度是512Bit,每個intel核心假設包含2個FMA,一個FMA一個時鐘周期可以進行2次乘或者加的運算,那么這個處理器在1個核心1個時鐘周期可以執行512bit2FMA 2MA / 64=32次浮點運算,也稱為32FLOPs,
?
?
就是說理論上后者的運算能力其實是前者的一倍,但是實際中不可能達到,因為進行更長的指令運算,流水線之間更加密集,但核心頻率會降低;導致整個處理器的能力降低;
一個處理器的計算能力和核心的個數,核心的頻率,核心單時鐘周期的能力三個因素有關系
例如:現在intel purley platform的旗艦skylake 8180是28Core@2.5GHZ,支持AVX512,其理論雙精度浮點性能是:**28Core2.5GHZ32FLOPs/Cycle=2240GFLPs=2.24TFLOPs**
例如:現在intel purley platform的旗艦cascade lake Xeon Platinum 8280是28核@2.7GHZ,支持AVX512,其理論雙精度浮點性能是:**28Core*2.7GHZ*32FLOPs/Cycle=2419.2GFLPs=2.4192TFLOPs**
但是還是要注意并不是所有的處理器都有支持AVX512的指令集,也并不是每個支持處理器都有2個FMA的運算單元。(二) GPU的浮點性能計算公式
?
?
GPU能做的CPU都能做,CPU能做的GPU卻不一定能夠做到,GPU一般一個時鐘周期可以操作64bit的數據,1個核心實現1個FMA。
這個GPU的計算能力的單元是:64bit1FMA2M/A/64bit=2FLOPs/Cycle
GPU的計算能力也是一樣和核心個數,核心頻率,核心單時鐘周期能力三個因素有關。
但是架不住GPU的核心的數量多呀?
?
例如:對現在nvidia 的pascal架構超算卡--- Tesla P100,是1792核@1.328GHz,其理論的雙精度浮點性能是:**1792Core1.328GHZ2FLOPs/Cycle=4759.552GFLOPs=4.7TFLOPs**
例如:對現在nvidia 的Volta架構的超算卡---Tesla V100,是2560核@1.245GHz,其理論的雙精度浮點性能是:2560Core*1.245GHZ*2FLOPs/Cycle=6374.4GFLOPs=6.3TFLOPs現在ML繁榮的時代,對64bit長度的浮點運算需求不是那么的大,反而是32bit或者16bit、8bit INT、4bit INT的運算需求比較大。
因此nvidia 最新的tesla一直在強調單精度甚至半精度,turing就是這樣的。
intel為了加速這些計算,也在其處理器中實現了一些加速低精度運算的指令。
 ?
? ?
? ?
? ?
? ?
?
 浙公網安備 33010602011771號
浙公網安備 33010602011771號