
爬蟲-Day1
爬蟲相關介紹
爬蟲的本質就是模擬客戶端請求來獲取服務端數據
若無法爬取到想要的數據,因為爬蟲模擬的力度不夠
-
通用爬蟲:將一個頁面中所有的數據都爬取到
-
聚焦爬蟲:建立于通用爬蟲之上,針對指定數據爬取(如:圖片,標題等)
-
增量式爬蟲:監控網站更新情況,爬取最新的數據
案例應用
需用到requests 模塊可通過 :
pip install requests進行下載
東方財富首頁數據爬取
-
通過數據包分析可很輕松的找到的大多數數據存在的數據包,其余的請求可發現都是請求的圖片或其他格式

-
分析此數據包的請求信息,數據包為網站的默認根路徑,請求方式為GET (也就是說我們只需要構建一個GET 請求包訪問根路徑即可)
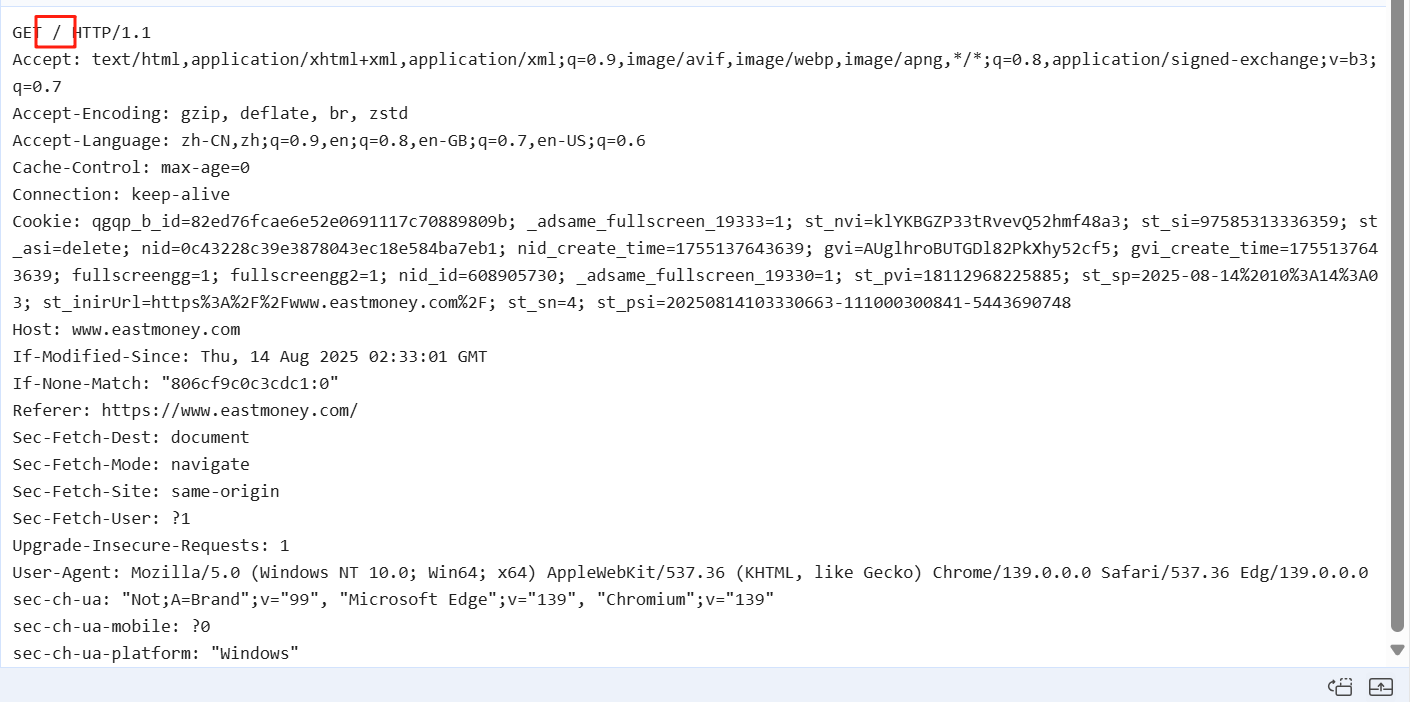
-
使用requests 模塊進行get 方式請求發送
import requests #1.指定服務器url url = "https://www.eastmoney.com/" #2.發送請求:根據指定url發送get 請求,得到響應對象 response = requests.get(url) # 3. 查看響應狀態碼 print(response.status_code) # 得到響應狀態碼 200 # 設置獲取響應數據的編碼格式 response.encoding='utf-8' #4.獲取字符串形式的響應數據 data=response.text #5.持久化存儲,響應數據存儲于caifu.html with open ('caifu.html','w',encoding='utf-8') as f: f.write(data) -
獲取到此響應包數據(這里由于響應包為html 格式所以存儲同樣為html)
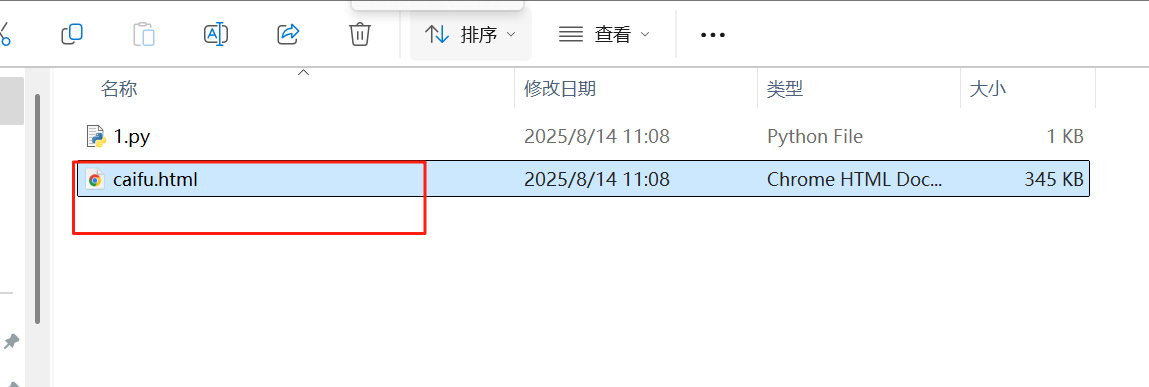
爬取51游戲中任何游戲對應的搜索結果頁面數據
-
首頁存在游戲搜索功能,進行搜索的話會新發起新請求
-
可采用開發者工具進行分析,若對于HTTP 協議較熟悉的話,可直接分析確認為GET 請求,參數為"傳奇"

-
邏輯分析完成,進行爬蟲代碼塊編寫
import requests # 用于動態請求參數的指定 game_name = input("請輸入游戲關鍵字") url = 'https://game.51.com/search/action/game/' # 構建字典,用于指定發送參數, p = { 'q':game_name } # 發起get 請求,指定發送參數為q字典中的參數 response = requests.get(url,parmes=p) page_html = response.text with open(f"{game_name}.html",'w',encoding='utf-8') as f: f.wirte(page_html) -
成功獲取到相應的html 頁面

中國人事考試網爬取[UA偽裝]
-
UA(User-Agent) 頭 :HTTP 協議請求頭的一個頭部字段,其作用是告知服務器當前瀏覽器、系統等信息,服務器可針對UA提供服務
反爬機制:采用各種手段,用來檢測爬蟲程序,并拒絕為其提供服務,其中就存在典型的UA 頭檢測(requests庫默認會使用自己的UA)
反反爬機制:繞過服務器檢測的各種手段,進行數據爬出
-
爬取方式與第一個案例方法一致,這里就不過多贅述了,這里只做差異的演示 ,這里采用無任何反反爬機制的爬取
import requests url = " http://www.cpta.com.cn" response = requests.get(url) data = response.text with open('人事考試.html','w',encoding='utf-8') as f: f.write(data) -
最終爬取下來的頁面內容為,進行分析,推測后端服務器的WAF 規則庫存在UA 頭的檢測
- WAF (應用防火墻): 一種惡意請求的檢測手段

-
進行UA 頭偽造,反反爬對方的爬蟲檢測
import requests url = " http://www.cpta.com.cn" # 指定請求頭字段中的UA h={ "user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0" } # 指定get請求,且指定請求頭為h 字典中字段,發送請求 response = requests.get(url,headers=h) data = response.text with open('人事考試.html','w',encoding='utf-8') as f: f.write(data) -
反反爬繞過成功,成功爬取下首頁數據(但目前該網站似乎進行了規則庫的更新,僅僅UA 頭偽造無法繞過)
中國人事考試網(站內搜索post + 請求參數)
-
進行數據包的分析,分析為POST 請求,請求體參數為 keywords + 固定搜索參數
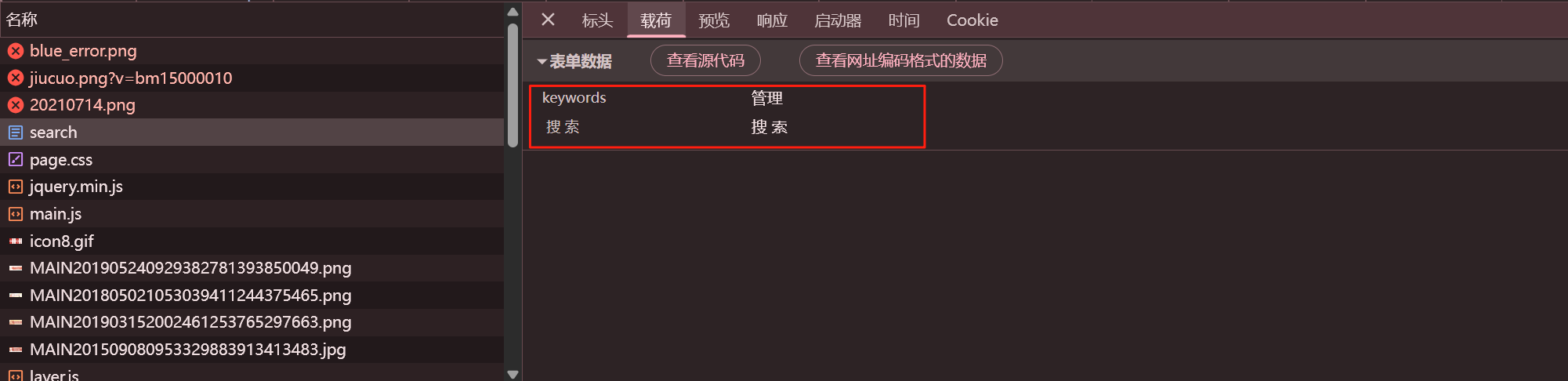
-
進行數據包構造,keywords 可為變量,爬取指定內容
keyword={ keywords:變量 "搜 索":"搜 索" } -
構思完成,進行爬蟲代碼編寫
import requests url = 'http://www.cpta.com.cn/category/search' keyword = input('請輸入:') # 構建指定UA 頭,繞過反爬 h={ "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36" } # 構建請求體 d={ "keywords":keyword, "搜 索":"搜 索" } # 以post 請求發送參數和指定請求頭 response = request.post(url,header=h,data=p) # 持久化存儲 with open(f'{keyword}.html','w',encoding='utf-8') as f: f.write(response.text) -
爬取成功

智慧職教(動態加載數據爬取)(重點)
-
https://www.icve.com.cn/search
動態加載數據:不是通過單一數據包進行頁面渲染,也就無法進行一個數據包爬完數據了
需求分析:獲取到教師姓名、來源學校、課程熱度、
-
數據包獲取,無法快速定位爬取的數據包? 可用到開發者工具搜索關鍵字找到需求數據包

-
數據包分析:GET方式請求,通過pagenum 參數判斷返回頁,響應包為序列化后的JSON 數據(后端應該是以先加載框架,后加載數據的方式將兩者分離了出來)


-
編寫爬蟲代碼,需接受格式為JSON 數據,這里已經成功獲取到值,接下來進行篩選和持久化存儲即可
import requests # 可定義爬出頁面 url = "https://www.icve.com.cn/prod-api/homePage/zykCourseList?pageSize=16&pageNum=1" # 定義UA頭和Referer headers={ "User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/139.0.0.0 Safari/537.36 Edg/139.0.0.0", "Referer":"https://www.icve.com.cn/search" } # 發送請求包并以json 形式接受響應包 response=requests.get(url,headers=headers) json_data=response.json() print(json_data)
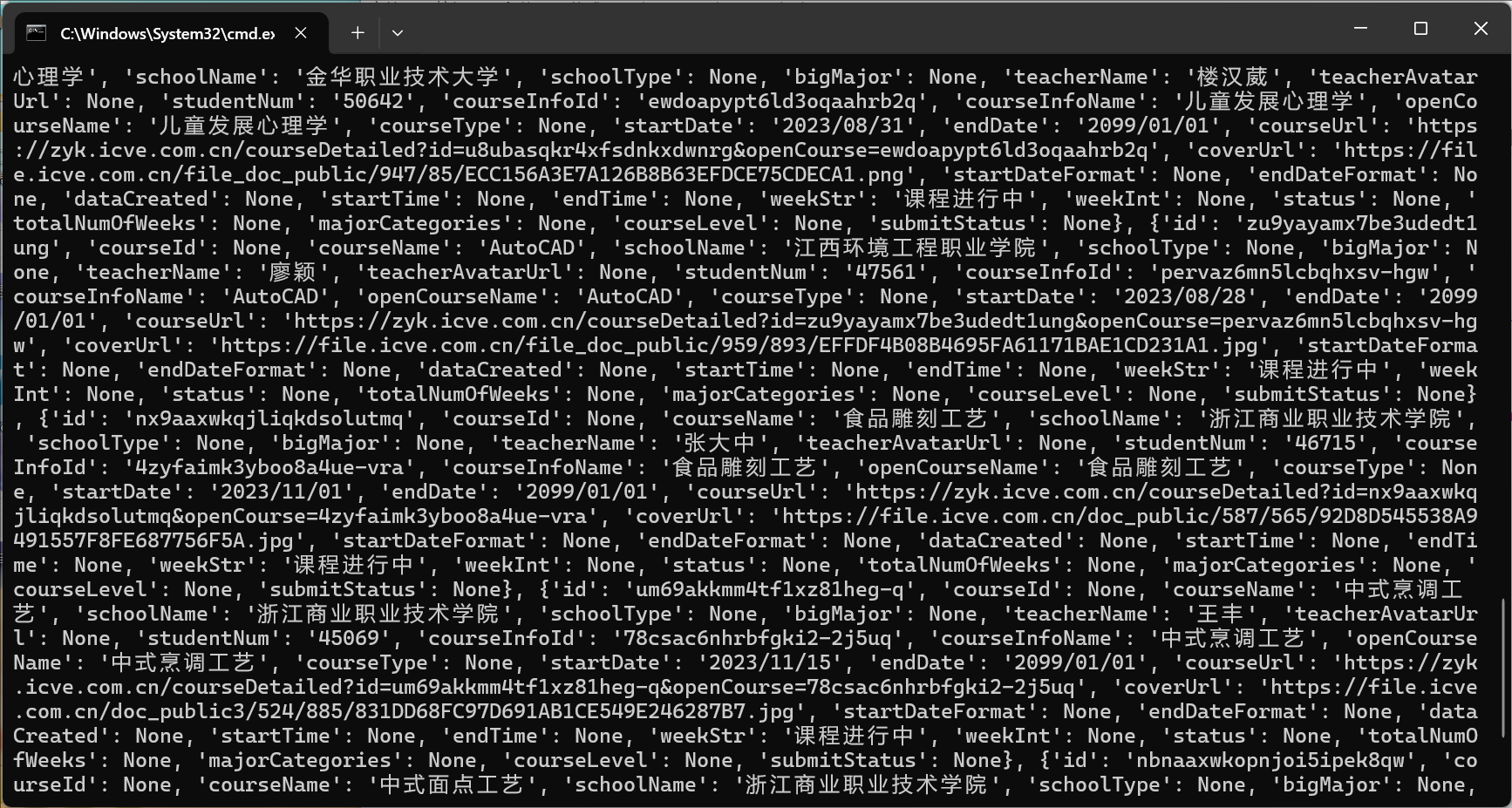
- 這里分析,響應包為嵌套于rows 列表中的每個字典

-
編寫篩選代碼
# 進行數據篩選 for i in json_data["rows"]: data=f"教師姓名:{i["teacherName"]},學校:{i["schoolName"]},熱度:{i["studentNum"]}" # 進行數據持久存儲 with open('智慧.cvs','a+',encoding='utf-8') as f: f.write(f"{data}\n") f.close print("爬取完畢")

- 這里還可以再根據GET 請求中**pageNum **或 pageSize 參數進行多頁爬取,步驟于之前實例的步驟一致修改,指定parmes 即可,這里不做演示了
圖片數據爬取
-
response.text 接受數據為字符串形式
-
response.json() 接受數據為 json 格式*數據
-
response.content 接受數據為二進制形式,如視頻、音頻、壓縮包等
圖片爬取僅需注意接受數據時為content ,接受二進制即可
import requests
url = 'https://ts1.tc.mm.bing.net/th/id/R-C.a22ba862dc4024396921dee05c16b698?rik=j6jky8wC6ZrBUQ&riu=http%3a%2f%2fpic.baike.soso.com%2fp%2f20100127%2fbki-20100127214000-1068687119.jpg&ehk=8f8CTwGTqQyZY0AuFfHuo41VxikBPGpKPafik0dKVfA%3d&risl=&pid=ImgRaw&r=0'
respons = requests.get(url)
# 二進制形式接受圖片
img = respons.content
# 二進制形式寫入jpeg 圖片中
with open("pikachu.jpeg",'wb') as f:
f.write(img)


 浙公網安備 33010602011771號
浙公網安備 33010602011771號