
P1315 [NOIP 2011 提高組] 觀光公交
個人認為是個好題。另外,推薦一下這篇題解,看著這篇題解學明白的。
首先,我們要求的是最小的 \(\sum\limits_{i=1}^{m}{arr_{to_i}}-tim_{i}\),其中 \(arr_i\) 表示大巴到達景點 \(i\) 的時間,\(to_i\) 表示游客 \(i\) 的目的地,\(tim_i\) 表示游客 \(i\) 的出發時間。
既然 \(tim_i\) 是固定的,所以我們要想辦法讓 \(\sum\limits_{i=1}^{m}{arr_{to_i}}\) 盡可能小。
如果不考慮乘客和加速器的話,就讓公交正常開,那么這會是時間關于景點的函數圖像:
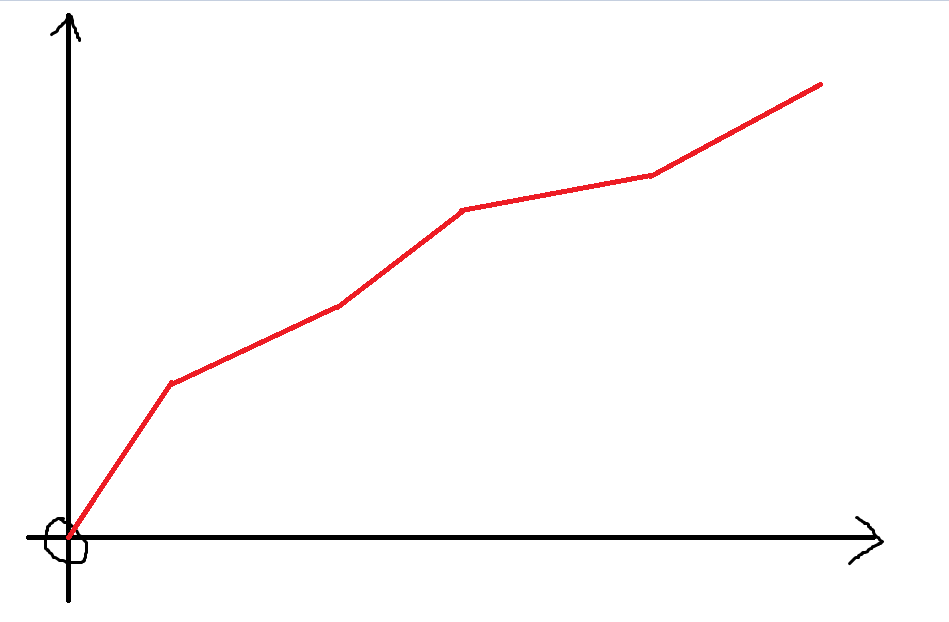
如果加上乘客的影響的話,那么到了部分景點后車還要等乘客,圖像會有部分的抬升,并形成多個斷點:
(如果一個景點 \(i\) 被稱作斷點,那么 \(arr_i \le lst_i\),其中 \(lst_i\) 表示最晚到達該出發點的游客是幾點到的)
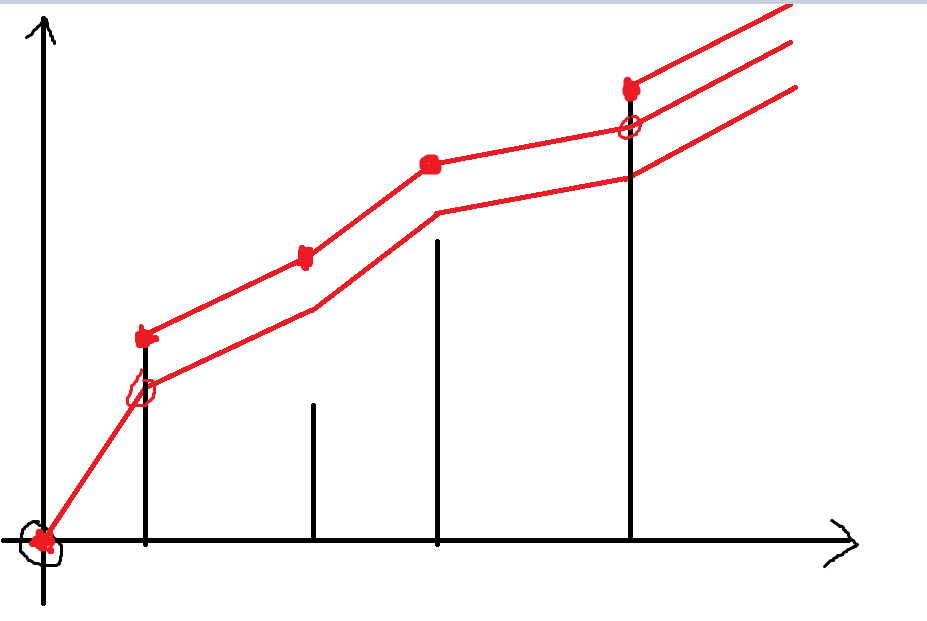

以下稱兩個斷點中間的區域為一個區間。
加上加速器的情況有點復雜。如果在某個位置使用了加速器的話,那么從它開始,到它所在區間的末尾,所有的點的到達時間都會-1。而后面的區間,由于制約因素是最晚的游客的到達時間,所以并不對它們起作用。

然后我們就會發現,在一個區間里,如果我們決定對它使用一個加速器,那么越早使用的話,受益的游客越多。所以對于一個區間,我們盡可能會往前選擇使用加速器的邊:

當然,也有一種可能,使用完加速器后出現了新的斷點:

我們使用一個加速器的時候,當然是希望它造福盡可能多的游客,也就是希望 \(\sum\limits_{i=1}^{m}{arr_{to_i}}\) 減小的最多。所以我們使用一個加速器的時候,挨個考慮每個區間,取那個最合適的地方用掉就好。
但是我們如何考慮“造福多少游客”呢?我們記 \(des_i\) 表示以 \(i\) 為目的地的游客有多少。顯然,如果在 \(pos\) 向 \(pos+1\) 的邊使用加速器,并且當前區間靠右的斷點是 \(r\),它就能使答案減 \(\sum\limits_{i=pos+1}^{r-1}{des_i}\)。
于是,我們重復這個過程 \(k\) 次,用掉 \(k\) 個加速器后統計答案即可。時間復雜度 \(O(kn)\)。
代碼:
P1315
#include<bits/stdc++.h>
#define int long long
using namespace std;
inline int read(){
int x=0,f=1;char c=getchar();
while(c<48){
if(c=='-') f=-1;
c=getchar();
}
while(c>47) x=(x<<1)+(x<<3)+(c^48),c=getchar();
return x*f;
}
const int N=1e3+3;
const int M=1e4+4;
const int K=1e5+5;
int n,m,k,d[N],lst[N],des[N],to[M],tim[M],arr[N],cut[N],cnt;
//cut[i]:第i個發現的斷點是幾號
//cnt:cut數組的指針
//其余變量名同題解
signed main(){
n=read(),m=read(),k=read();
for(int i=1;i<n;i++){
d[i]=read();
}
//輸入&預處理tim,lst
for(int i=1;i<=m;i++){
tim[i]=read();int l=read();to[i]=read();
lst[l]=max(lst[l],tim[i]);
des[to[i]]++;
}
int TIM=0;
//模擬法處理arr,cut
for(int i=1;i<=n;i++){
arr[i]=TIM;
TIM=max(TIM,lst[i]);
if(arr[i]<=lst[i]){
cut[++cnt]=i;
}
TIM+=d[i];
}
while(k--){
int mx=-1,gai=0;
for(int i=1;i<=cnt;i++){
int pos=cut[i];
while(!d[pos]){
//注意有些路段是不可以使用加速器的,要接著往后跳
pos++;
if(arr[pos]<=lst[pos]||pos>=n){
//如果跳到斷點還是找不到合適的邊時,那該區間就用不了加速器了
pos=-20100325;//這串數字懂得都懂
break;
}
}
if(pos==-20100325){
continue;
}
//這里是在模擬 如果當前這個地方用加速器,能使答案減多少
int loc=pos+1,res=0;
while(1){
res+=des[loc];
if(arr[loc]<=lst[loc]||loc>=n){
break;
}
//警示后人:要判斷當前點是否進了下一個邊界,越過了就必須跳出,否則可以接著往下找。
//例如樣例里, 不判的話loc=2直接跳3,進入下一個區間了,不合規的
loc++;
}
if(res>mx){
mx=res,gai=pos;
}
}
d[gai]--;//就決定減這里了
//這里是在進行一個減的過程
while(++gai){
arr[gai]--;
if(arr[gai]==lst[gai]){
//出現了新的斷點
cut[++cnt]=gai;
}
if(arr[gai]<lst[gai]||gai>=n){
//否則跳到了原有斷點上
break;
}
}
}
//統計答案
int ans=0;
for(int i=1;i<=m;i++){
ans+=arr[to[i]]-tim[i];
}
printf("%lld",ans);
return 0;
}
還有一些實現細節值得注意(或者說,我當時閱讀題解的一些問題):
(以下僅為個人理解)
1.為什么斷點的判定可以取等?個人認為取等的話出現新斷點時,方便判斷是舊斷點還是新斷點,并且如果它的 \(arr\) 減了 1 的話,它的制約因素是 \(lst\),還是無法造福它。
2.為什么我們找使用加速器的點時從斷點右側的邊開始試,而不是斷點左側的那條邊?因為你找那條邊沒啥用,就算用了加速器,制約因素是游客到達時間,不會造福后面的點。但是斷點右側的邊可以造福后面的點。
3.有關代碼里的警示后人:這個純屬我當時寫的時候腦抽,我應該先判斷當前這個點是不是斷點再往后跳,否則如果先往后跳再判斷點的話,有可能直接越過一個斷點統計答案去了。
4.如果我們決定讓 \(d_{pos}--\),那么造福的是 \(pos+1\) 之后的該區間的點。
如果你覺得這篇題解講的還不錯的話,不妨點點贊呀 qwq

 浙公網安備 33010602011771號
浙公網安備 33010602011771號