PointNet論文學習
點云
基礎知識
? 點云是指同一參考系下表達目標空間分布和目標表面特征的海量點集合,在獲取物體表面每個采樣點的空間坐標后,得到的是點的集合,這個就被我們稱為點云。
? 點云的圖像多為三維圖像,即長度、寬度和深度信息。
? 點云的測量原理主要分為兩種,一種是激光測量,一種則是攝影。激光測量得到的數據包括三維坐標和激光反射強度(強度信息與目標的表面材質、粗糙度、入射角方向及儀器發(fā)射能量等有關),攝影得到的點云數據包括三維坐標(XYZ)和顏色信息(RGB)。當然,也可以兩者進行結合,使用激光+攝影的方式,這樣得到的點云數據包括三維坐標、激光反射強度和顏色信息。
? 點云圖形的處理分為三個層次:
(1)低層次包括圖像強化,濾波,關鍵點/邊緣檢測等基本操作
(2)中層次包括連通域標記,圖像分割等操作
(3)高層次包括物體識別,場景分析等操作。工程中的任務需要用到多個層次的圖像處理手段。
《PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation》
名詞解釋
1、外在特征和內在特征
外在特征指的是觀測角度不同,可能改變的信息,比如顏色,坐標,而內在特征則不隨觀測角度改變而轉變,比如法線、曲率
2、局部特征和全局特征
局部特征主要是針對單個點及其領域的,比如法向量、局部形狀等,更加注重局部的細節(jié);全局特征關注點云整體的一些特性,例如幾何中心、形狀、大小等
公式解讀

定理1:這里的h(xi)是將輸入數據放置MLP中進行升維,以便提取更多的信息,MAX則是最大池化層,通過此函數提取特征,而后是γ,通過γ函數放入另一個MLP中,得到最終的分類結果或者分割結果,這個函數證明了PointNet的網絡結構能擬合任何連續(xù)集合函數。

定理2:
(a)這里是說,對于任意的輸入數據集S,都存在一個最小集Cs和最大集Ns,對于在Cs和Ns之間的任意集合T,其輸出都與S一致,也就是說對于存在有噪聲的數據和存在數據損壞的,都是有魯棒性的。
(b)這里的Cs是最小集,也是關鍵點數,這里是說無論點數有多少,我們至多也只需要關注k個關鍵點,意味著即使丟失Ns-k個數據也不影響結果,保證魯棒性,同時說明需要處理的關鍵參點也就k個,不會因為點數的增加而增加計算量
解決的主要問題
這篇解決了點云不規(guī)則無法直接讀取的問題,他直接讀取點云數據可以最大程度的減免精度損失,他解決的問題主要有以下幾點:
點云的無序性
因為點云是一組沒有順序的點,所以我們這里需要做到即使順序打亂,仍然不影響識別物體為同一物體,那么這里就需要我們引入一個是對稱函數的網絡,這里的PointNet采用了先個體,后整體的方式來處理點云
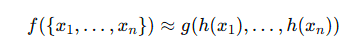
這里其實就是上面的公式解讀的一部分,h(xi)函數用于個體特征提取,通過MLP對個體進行升維,而g()函數則是使用最大池化函數來處理所有點的特征,這個函數就是一個對稱聚合的函數,無論順序如何變化,最大值始終只有一個,這樣就解決了無序的問題。
點云的相互關系
點云的這些點在一定的度量距離內,彼此之間并非孤立,因此我們需要考慮這個空間關系,而PointNet中采用的解決方案是將全局特征與局部特征進行串聯,實現聚合信息,如下圖所示:

這里的n*1088,其實就是局部特征n*64和全局特征n*1024拼接而來。
點云的旋轉不變性
變換不變性,指的是點云作為一個幾何目標,將它作為一個整體經過鋼性變換(旋轉、平移),其中的所有坐標(x,y,z)可能完全變化,但它仍然代表同一個物體,這里就需要我們去想如何實現模型能夠始終識別同一物體,PointNet采用的方式是使用T-Net網絡,它會將點云整體進行規(guī)范化,即將它調至一個規(guī)定的規(guī)范姿態(tài),變化如下
變換后的點云 = 原始點云 × 變換矩陣
[N × K] = [N × K] × [K × K]
這樣就只改變方向,而不改變大小,具體示例如下:
原始點云(側翻90度) = [[0, 10, 1], # 機頭 (x=0, y=10, z=1)
[0, 5, 3], # 機身 (x=0, y=5, z=3)
[-8, 5, 2]] # 機翼 (x=-8, y=5, z=2)
旋轉矩陣_A = [[1, 0, 0],
[0, 0, -1],
[0, 1, 0]]
對齊后的點云 = [[0, 1, -10], # 機頭:從(0,10,1)變?yōu)?0,1,-10)
[0, 3, -5], # 機身:從(0,5,3)變?yōu)?0,3,-5)
[-8, 2, -5]] # 機翼:從(-8,5,2)變?yōu)?-8,2,-5)
實際上,這個旋轉矩陣不是固定不變的,它是根據點云來逐漸學習變化的,以此實現每次變化都能將點云調整至規(guī)定的規(guī)范姿態(tài),它是如何實現的呢,接下來我們詳細跟進代碼
class STN3d(nn.Module):
def __init__(self):
super(STN3d, self).__init__()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, 9)
self.relu = nn.ReLU()
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.bn4 = nn.BatchNorm1d(512)
self.bn5 = nn.BatchNorm1d(256)
def forward(self, x):
batchsize = x.size()[0]
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = F.relu(self.bn3(self.conv3(x)))
x = torch.max(x, 2, keepdim=True)[0]
x = x.view(-1, 1024)
x = F.relu(self.bn4(self.fc1(x)))
x = F.relu(self.bn5(self.fc2(x)))
x = self.fc3(x)
iden = Variable(torch.from_numpy(np.array([1,0,0,0,1,0,0,0,1]).astype(np.float32))).view(1,9).repeat(batchsize,1)
if x.is_cuda:
iden = iden.cuda()
x = x + iden
x = x.view(-1, 3, 3)
return x
這里首先對函數進行卷積操作,從3維提升至64維,而后進行歸一化,以防出現梯度爆炸和數據差異過大等情況,再使用激活函數Relu以實現非線性變化,后續(xù)也是類似,從64->128->1024,這里不直接直接從3->1024的原因是怕調整幅度過大出現梯度爆炸,而且逐步調整的參數更多(3*1024<3*64+64*128*1024)。此時升維完成,接下來是通過torch.max(x, 2, keepdim=True)[0]進行最大池化操作,此代碼表示獲取第二個維度的最大值,這里[0]是因為它有兩個參數(值和索引),此時就獲取了每個特征通道最具代表性的響應值,接下來去除多余維度,本來是三個維度,即[batch_size,channels ,points],我們現在只需要前兩個即可,使用x = x.view(-1, 1024)自動調整,而后進行展平,再通過全連接層將參數降9個參數,再和展平后的單位矩陣進行相加,調整為3*3矩陣,就得到了空間變換矩陣。
同時這里加入了正則項約束變換矩陣接近正交:
L_reg = ||I - A @ A^T||_F^2
def feature_transform_regularizer(trans):
d = trans.size()[1]#獲取維度d
batchsize = trans.size()[0]#獲取批量大小
I = torch.eye(d)[None, :, :]#擴展一個維度,且這個新維是第一個,由[d,d]-->[1,d,d]
if trans.is_cuda:
I = I.cuda()#使用GPU
loss = torch.mean(torch.norm(torch.bmm(trans, trans.transpose(2,1)) - I, dim=(1,2)))#使用上面的公式來計算損失
return loss##loss接近0說明是正交矩陣,那么就是正確的矩陣,因為正交矩陣不影響大小只改變方向,否則則再逐步優(yōu)化
點云可能存在數據缺失
這里使用理論分析來保證模型魯棒性,先解釋下什么是魯棒性,魯棒性是指系統在面對不確定性、干擾、異常情況或輸入變化時,仍能保持穩(wěn)定性能和正常工作的能力。比如模型對輸入數據噪聲不敏感,數據缺失抵抗力強以及參數擾動及計算誤差都有很好的穩(wěn)定性,就可以說明其魯棒性強。具體理論證明見上面公式解讀(2)部分。
流程
主代碼如下所示:(分析見注釋)
class PointNetfeat(nn.Module):
def __init__(self, global_feat = True, feature_transform = False):
super(PointNetfeat, self).__init__()
self.stn = STN3d()
self.conv1 = torch.nn.Conv1d(3, 64, 1)
self.conv2 = torch.nn.Conv1d(64, 128, 1)
self.conv3 = torch.nn.Conv1d(128, 1024, 1)
self.bn1 = nn.BatchNorm1d(64)
self.bn2 = nn.BatchNorm1d(128)
self.bn3 = nn.BatchNorm1d(1024)
self.global_feat = global_feat
self.feature_transform = feature_transform
if self.feature_transform:
self.fstn = STNkd(k=64)
def forward(self, x):
n_pts = x.size()[2]#x=[批量大小,維度,點數]獲取點數N
trans = self.stn(x)#獲取空間變換矩陣,結構3*3
x = x.transpose(2, 1)#轉換張量格式,由[B,3,N]-->[B,N,3],以便和空間變換矩陣做乘法
x = torch.bmm(x, trans)#進行矩陣相乘以轉換為標準姿態(tài)
x = x.transpose(2, 1)#從[B,N,3]-->[B,3,N]
x = F.relu(self.bn1(self.conv1(x)))#先做卷積操作,嵌套標準化,再使用激活函數進行操作
if self.feature_transform:#是否使用特征空間變換
trans_feat = self.fstn(x)#同之前一樣,變換維度乘上空間變換矩陣,不過這里是64*64的維度
x = x.transpose(2,1)
x = torch.bmm(x, trans_feat)
x = x.transpose(2,1)
else:
trans_feat = None
pointfeat = x #保留[批量大小,維度,點數]局部特征,用于后續(xù)分割任務
x = F.relu(self.bn2(self.conv2(x)))#64->128
x = self.bn3(self.conv3(x))#128->1024
x = torch.max(x, 2, keepdim=True)[0]#最大池化提取特征,[B,1024,N]-->[B,1024,1]
x = x.view(-1, 1024)#三維變二維,取消多余維度
if self.global_feat:#如果是分類任務,應用全局特征
return x, trans, trans_feat
else:#分割任務,局部+全局特征
x = x.view(-1, 1024, 1).repeat(1, 1, n_pts)#[B,1024]-->[B,1024,N],將全局特征復制到每個點
return torch.cat([x, pointfeat], 1), trans, trans_feat#拼接,[B,1024,N]-->[B,1088,N]
以上主要是獲取特征的代碼,Pointnet主要有兩個任務,分類和分割任務,首先看分類任務
class PointNetCls(nn.Module):#分類任務
def __init__(self, k=2, feature_transform=False):
super(PointNetCls, self).__init__()
self.feature_transform = feature_transform
self.feat = PointNetfeat(global_feat=True, feature_transform=feature_transform)
self.fc1 = nn.Linear(1024, 512)
self.fc2 = nn.Linear(512, 256)
self.fc3 = nn.Linear(256, k)
self.dropout = nn.Dropout(p=0.3)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.relu = nn.ReLU()
def forward(self, x):
x, trans, trans_feat = self.feat(x)#特征提取,其中x=[B,1024],trans=[B,3,3],trans_feat=[B,64,64](如果存在)
x = F.relu(self.bn1(self.fc1(x)))#經過全連接層,從1024->512
x = F.relu(self.bn2(self.dropout(self.fc2(x))))#第二個全連接層,512->256,帶有dropout,以防過擬合情況出現
x = self.fc3(x)#第三個全連接層,256->k
return F.log_softmax(x, dim=1), trans, trans_feat#返回類別概率
分割任務如下
class PointNetDenseCls(nn.Module):#分割任務
def __init__(self, k = 2, feature_transform=False):
super(PointNetDenseCls, self).__init__()
self.k = k #分割類別數
self.feature_transform=feature_transform
self.feat = PointNetfeat(global_feat=False, feature_transform=feature_transform)
self.conv1 = torch.nn.Conv1d(1088, 512, 1)
self.conv2 = torch.nn.Conv1d(512, 256, 1)
self.conv3 = torch.nn.Conv1d(256, 128, 1)
self.conv4 = torch.nn.Conv1d(128, self.k, 1)
self.bn1 = nn.BatchNorm1d(512)
self.bn2 = nn.BatchNorm1d(256)
self.bn3 = nn.BatchNorm1d(128)
def forward(self, x):
batchsize = x.size()[0]#獲取批量大小B
n_pts = x.size()[2]#獲取點數N
x, trans, trans_feat = self.feat(x)#獲取特征和空間變換矩陣
x = F.relu(self.bn1(self.conv1(x)))#[B,1088,N]-->[B,512,N]
x = F.relu(self.bn2(self.conv2(x)))#[B,512,N]-->[B,256,N]
x = F.relu(self.bn3(self.conv3(x)))#[B,256,N]-->[B,128,N]
x = self.conv4(x)#[B,128,N]-->[B,k,N]
x = x.transpose(2,1).contiguous()## [B, k, N] --> [B, N, k]
x = F.log_softmax(x.view(-1,self.k), dim=-1)#計算類別概率
x = x.view(batchsize, n_pts, self.k)#重塑維度為[B,N,K]
return x, trans, trans_feat
這里解釋一下可能存在疑問的地方:為什么64維是局部特征,而1024是全局特征?
局部特征的特點是MLP對每個點單獨處理,每個點只知道自己的坐標而不知道其他的信息,反觀全局特征,他的特點是基于整個點云的所有點,包含了所有點的統計信息。在具體看這里,64維時是MLP對每個點單獨進行升維,而1024維則是進行了最大池化操作,它匯聚了所有點的最大值,包含了整個點云的信息,所以它是全局特征。
復現
需要注意的點是官網的數據集已不可訪問,下載時需要找到非normal版本的,否則與此代碼是不適配的,同時此代碼原來是在linux系統下跑的,所以中間有用到so文件,具體是render_balls_so.so這個文件,show_seg.py用到了show3d_balls.py里面的showpoints函數,show3d_balls.py用到了一個它,需要我們使用Visual Studio來轉換為dll文件
分類任務
分類任務訓練,在參數里給定具體的值,然后直接運行文件即可
parser.add_argument('--dataset', type=str, default="../dataset/shapenetcore_partanno_segmentation_benchmark_v0", help="dataset path")
parser.add_argument('--dataset_type', type=str, default='shapenet', help="dataset type shapenet|modelnet40")
parser.add_argument(
'--nepoch', type=int, default=5, help='number of epochs to train for')
訓練結果如下圖

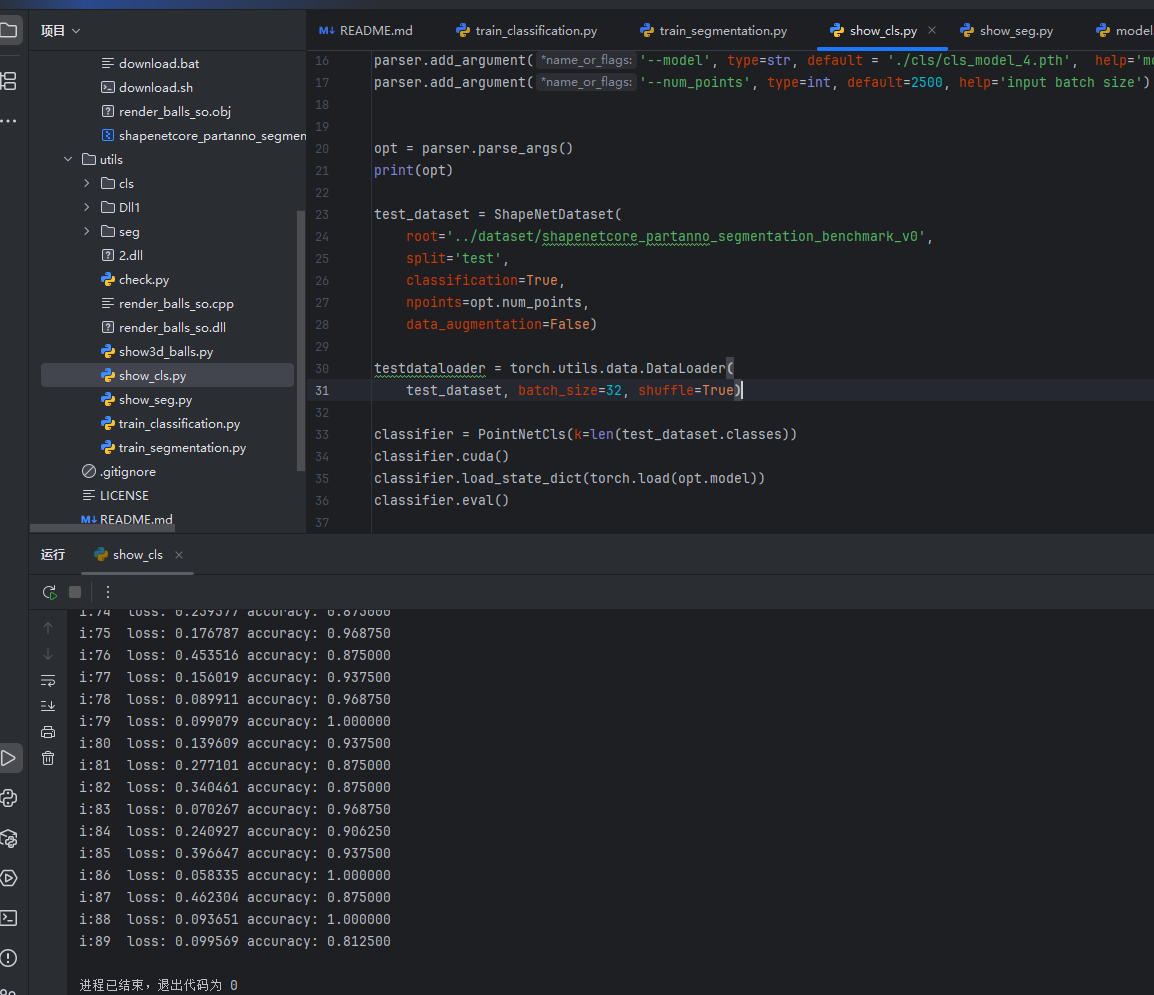
接下來就可以進行測試了,再運行show_cls文件即可查看結果
分割任務
這里需要指定一下分割的物體,在參數里設定即可,這里以飛機為例
parser = argparse.ArgumentParser()
parser.add_argument(
'--batchSize', type=int, default=16, help='input batch size')
parser.add_argument(
'--workers', type=int, help='number of data loading workers', default=0)
parser.add_argument(
'--nepoch', type=int, default=25, help='number of epochs to train for')
parser.add_argument('--outf', type=str, default='seg', help='output folder')
parser.add_argument('--model', type=str, default='', help='model path')
parser.add_argument('--dataset', type=str, default="../dataset/shapenetcore_partanno_segmentation_benchmark_v0", help="dataset path")
parser.add_argument('--class_choice', type=str, default='Chair', help="class_choice")
parser.add_argument('--feature_transform', action='store_true', help="use feature transform")

運行完后可以發(fā)現損失和精確度如圖,最后在show_seg即可查看分割結果

Reference
https://binaryoracle.github.io/3DVL/簡析PointNet.html
https://cloud.tencent.com/developer/article/1418693
https://blog.csdn.net/qq_46450354/article/details/126490251
https://liao-ziqiang.github.io/fyaxm-blog/pointnet/pointnet-Interpretion.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號