
Flink實戰(102):配置(一)管理配置
來源:http://www.54tianzhisheng.cn/2019/03/28/flink-additional-data/
前言
如果你了解 Apache Flink 的話,那么你應該熟悉該如何向 Flink 發送數據或者如何從 Flink 獲取數據。但是在某些情況下,我們需要將配置數據發送到 Flink 集群并從中接收一些額外的數據。
在本文的第一部分中,我將描述如何將配置數據發送到 Flink 集群。我們需要配置很多東西:方法參數、配置文件、機器學習模型。Flink 提供了幾種不同的方法,我們將介紹如何使用它們以及何時使用它們。在本文的第二部分中,我將描述如何從 Flink 集群中獲取數據。
一 如何發送數據給 TaskManager?
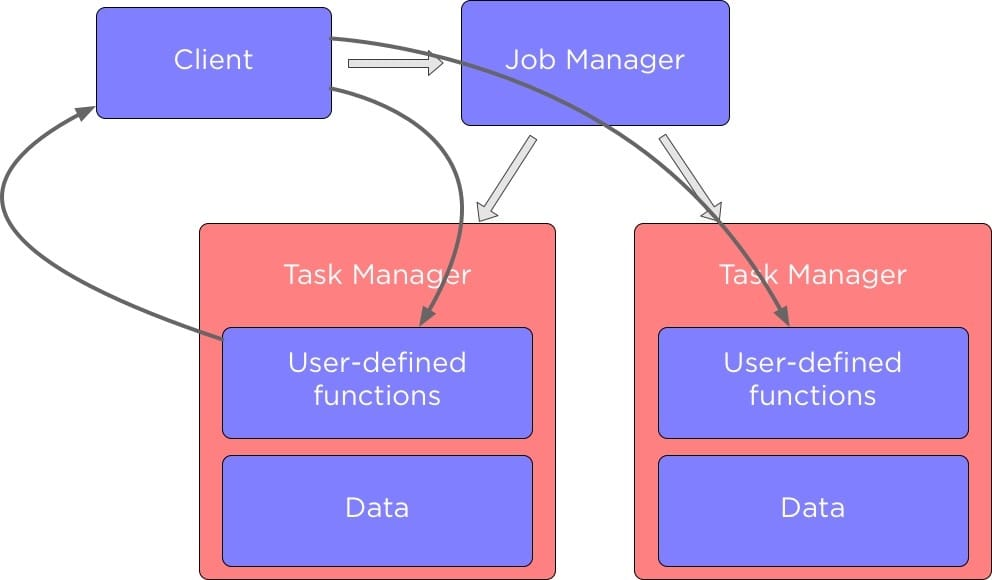
在我們深入研究如何在 Apache Flink 中的不同組件之間發送數據之前,讓我們先談談 Flink 集群中的組件,下圖展示了 Flink 中的主要組件以及它們是如何相互作用的:

當我們運行 Flink 應用程序時,它會與 Flink JobManager 進行交互,這個 Flink JobManager 存儲了那些正在運行的 Job 的詳細信息,例如執行圖。
JobManager 它控制著 TaskManager,每個 TaskManager 中包含了一部分數據來執行我們定義的數據處理方法。
在許多的情況下,我們希望能夠去配置 Flink Job 中某些運行的函數參數。根據用例,我們可能需要設置單個變量或者提交具有靜態配置的文件,我們下面將討論在 Flink 中該如何實現?
除了向 TaskManager 發送配置數據外,有時我們可能還希望從 Flink Job 的函數方法中返回數據。
如何配置用戶自定義函數?
假設我們有一個從 CSV 文件中讀取電影列表的應用程序(它要過濾特定類型的所有電影):
//讀取電影列表數據集合 DataSet<Tuple3<Long, String, String>> lines = env.readCsvFile("movies.csv") .ignoreFirstLine() .parseQuotedStrings('"') .ignoreInvalidLines() .types(Long.class, String.class, String.class); lines.filter((FilterFunction<Tuple3<Long, String, String>>) movie -> { // 以“|”符號分隔電影類型 String[] genres = movie.f2.split("\\|"); // 查找所有 “動作” 類型的電影 return Stream.of(genres).anyMatch(g -> g.equals("Action")); }).print();
我們很可能想要提取不同類型的電影,為此我們需要能夠配置我們的過濾功能。 當你要實現這樣的函數時,最直接的配置方法是實現構造函數:
// 傳遞類型名稱 lines.filter(new FilterGenre("Action")) .print(); ... class FilterGenre implements FilterFunction<Tuple3<Long, String, String>> { //類型 String genre; //初始化構造方法 public FilterGenre(String genre) { this.genre = genre; } @Override public boolean filter(Tuple3<Long, String, String> movie) throws Exception { String[] genres = movie.f2.split("\\|"); return Stream.of(genres).anyMatch(g -> g.equals(genre)); } }
或者,如果你使用 lambda 函數,你可以簡單地使用它的閉包中的一個變量:
final String genre = "Action"; lines.filter((FilterFunction<Tuple3<Long, String, String>>) movie -> { String[] genres = movie.f2.split("\\|"); //使用變量 return Stream.of(genres).anyMatch(g -> g.equals(genre)); }).print();
Flink 將序列化此變量并將其與函數一起發送到集群。
如果你需要將大量變量傳遞給函數,那么這些方法就會變得非常煩人了。 為了解決這個問題,Flink 提供了 withParameters 方法。 要使用它,你需要實現那些 Rich 函數,比如你不必實現 MapFunction 接口,而是實現 RichMapFunction。
Rich 函數允許你使用 withParameters 方法傳遞許多參數:
// Configuration 類來存儲參數 Configuration configuration = new Configuration(); configuration.setString("genre", "Action"); lines.filter(new FilterGenreWithParameters()) // 將參數傳遞給函數 .withParameters(configuration) .print();
要讀取這些參數,我們需要實現 “open” 方法并讀取其中的參數:
class FilterGenreWithParameters extends RichFilterFunction<Tuple3<Long, String, String>> { String genre; @Override public void open(Configuration parameters) throws Exception { //讀取配置 genre = parameters.getString("genre", ""); } @Override public boolean filter(Tuple3<Long, String, String> movie) throws Exception { String[] genres = movie.f2.split("\\|"); return Stream.of(genres).anyMatch(g -> g.equals(genre)); } }
所有這些選項都可以使用,但如果需要為多個函數設置相同的參數,則可能會很繁瑣。在 Flink 中要處理此種情況, 你可以設置所有 TaskManager 都可以訪問的全局環境變量。
為此,首先需要使用 ParameterTool.fromArgs 從命令行讀取參數:
public static void main(String... args) { //讀取命令行參數 ParameterTool parameterTool = ParameterTool.fromArgs(args); ... }
然后使用 setGlobalJobParameters 設置全局作業參數:
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); env.getConfig().setGlobalJobParameters(parameterTool); ... //該函數將能夠讀取這些全局參數 lines.filter(new FilterGenreWithGlobalEnv()) //這個函數是自己定義的 .print();
現在我們來看看這個讀取這些參數的函數,和上面說的一樣,它是一個 Rich 函數:
class FilterGenreWithGlobalEnv extends RichFilterFunction<Tuple3<Long, String, String>> { @Override public boolean filter(Tuple3<Long, String, String> movie) throws Exception { String[] genres = movie.f2.split("\\|"); //獲取全局的配置 ParameterTool parameterTool = (ParameterTool) getRuntimeContext().getExecutionConfig().getGlobalJobParameters(); //讀取配置 String genre = parameterTool.get("genre"); return Stream.of(genres).anyMatch(g -> g.equals(genre)); } }
要讀取配置,我們需要調用 getGlobalJobParameter 來獲取所有全局參數,然后使用 get 方法獲取我們要的參數。
廣播變量
如果你想將數據從客戶端發送到 TaskManager,上面文章中討論的方法都適合你,但如果數據以數據集的形式存在于 TaskManager 中,該怎么辦? 在這種情況下,最好使用 Flink 中的另一個功能 —— 廣播變量。 它只允許將數據集發送給那些執行你 Job 里面函數的任務管理器。
假設我們有一個數據集,其中包含我們在進行文本處理時應忽略的單詞,并且我們希望將其設置為我們的函數。 要為單個函數設置廣播變量,我們需要使用 withBroadcastSet 方法和數據集。
DataSet<Integer> toBroadcast = env.fromElements(1, 2, 3); // 獲取要忽略的單詞集合 DataSet<String> wordsToIgnore = ... data.map(new RichFlatMapFunction<String, String>() { // 存儲要忽略的單詞集合. 這將存儲在 TaskManager 的內存中 Collection<String> wordsToIgnore; @Override public void open(Configuration parameters) throws Exception { //讀取要忽略的單詞的集合 wordsToIgnore = getRuntimeContext().getBroadcastVariable("wordsToIgnore"); } @Override public String map(String line, Collector<String> out) throws Exception { String[] words = line.split("\\W+"); for (String word : words) //使用要忽略的單詞集合 if (wordsToIgnore.contains(word)) out.collect(new Tuple2<>(word, 1)); } //通過廣播變量傳遞數據集 }).withBroadcastSet(wordsToIgnore, "wordsToIgnore");
你應該記住,如果要使用廣播變量,那么數據集將會存儲在 TaskManager 的內存中,如果數據集和越大,那么占用的內存就會越大,因此使用廣播變量適用于較小的數據集。
如果要向每個 TaskManager 發送更多數據并且不希望將這些數據存儲在內存中,可以使用 Flink 的分布式緩存向 TaskManager 發送靜態文件。 要使用 Flink 的分布式緩存,你首先需要將文件存儲在一個分布式文件系統(如 HDFS)中,然后在緩存中注冊該文件:
ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment(); //從 HDFS 注冊文件 env.registerCachedFile("hdfs:///path/to/file", "machineLearningModel") ... env.execute()
為了訪問分布式緩存,我們需要實現一個 Rich 函數:
class MyClassifier extends RichMapFunction<String, Integer> { @Override public void open(Configuration config) { File machineLearningModel = getRuntimeContext().getDistributedCache().getFile("machineLearningModel"); ... } @Override public Integer map(String value) throws Exception { ... } }
請注意,要訪問分布式緩存中的文件,我們需要使用我們用于注冊文件的 key,比如上面代碼中的 machineLearningModel。
二、如何從 TaskManager 中返回數據
Accumulator(累加器)
我們前面已經介紹了如何將數據發送給 TaskManager,但現在我們將討論如何從 TaskManager 中返回數據。 你可能想知道為什么我們需要做這種事情。 畢竟,Apache Flink 就是建立數據處理流水線,讀取輸入數據,處理數據并返回結果。
為了表達清楚,讓我們來看一個例子。假設我們需要計算每個單詞在文本中出現的次數,同時我們要計算文本中有多少行:
//要處理的數據集合 DataSet<String> lines = ... // Word count 算法 lines.flatMap(new FlatMapFunction<String, Tuple2<String, Integer>>() { @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split("\\W+"); for (String word : words) { out.collect(new Tuple2<>(word, 1)); } } }) .groupBy(0) .sum(1) .print(); // 計算要處理的文本中的行數 int linesCount = lines.count() System.out.println(linesCount);
問題是如果我們運行這個應用程序,它將運行兩個 Flink 作業!首先得到單詞統計數,然后計算行數。
這絕對是低效的,但我們怎樣才能避免這種情況呢?一種方法是使用累加器。它們允許你從 TaskManager 發送數據,并使用預定義的功能聚合此數據。 Flink 有以下內置累加器:
-
IntCounter,LongCounter,DoubleCounter:允許將 TaskManager 發送的 int,long,double 值匯總在一起
-
AverageAccumulator:計算雙精度值的平均值
-
LongMaximum,LongMinimum,IntMaximum,IntMinimum,DoubleMaximum,DoubleMinimum:累加器,用于確定不同類型的最大值和最小值
-
直方圖 - 用于計算 TaskManager 的值分布
要使用累加器,我們需要創建并注冊一個用戶定義的函數,然后在客戶端上讀取結果。下面我們來看看該如何使用呢:
lines.flatMap(new RichFlatMapFunction<String, Tuple2<String, Integer>>() { //創建一個累加器 private IntCounter linesNum = new IntCounter(); @Override public void open(Configuration parameters) throws Exception { //注冊一個累加器 getRuntimeContext().addAccumulator("linesNum", linesNum); } @Override public void flatMap(String line, Collector<Tuple2<String, Integer>> out) throws Exception { String[] words = line.split("\\W+"); for (String word : words) { out.collect(new Tuple2<>(word, 1)); } // 處理每一行數據后 linesNum 遞增 linesNum.add(1); } }) .groupBy(0) .sum(1) .print(); //獲取累加器結果 int linesNum = env.getLastJobExecutionResult().getAccumulatorResult("linesNum"); System.out.println(linesNum);
這樣計算就可以統計輸入文本中每個單詞出現的次數以及它有多少行。
如果需要自定義累加器,還可以使用 Accumulator 或 SimpleAccumulator 接口實現自己的累加器。
本文來自博客園,作者:秋華,轉載請注明原文鏈接:http://www.rzrgm.cn/qiu-hua/p/14087528.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號