
Hive基礎(九):HIVE使用基礎(4) 壓縮和存儲
1 Hadoop 壓縮配置
1.1 MR 支持的壓縮編碼
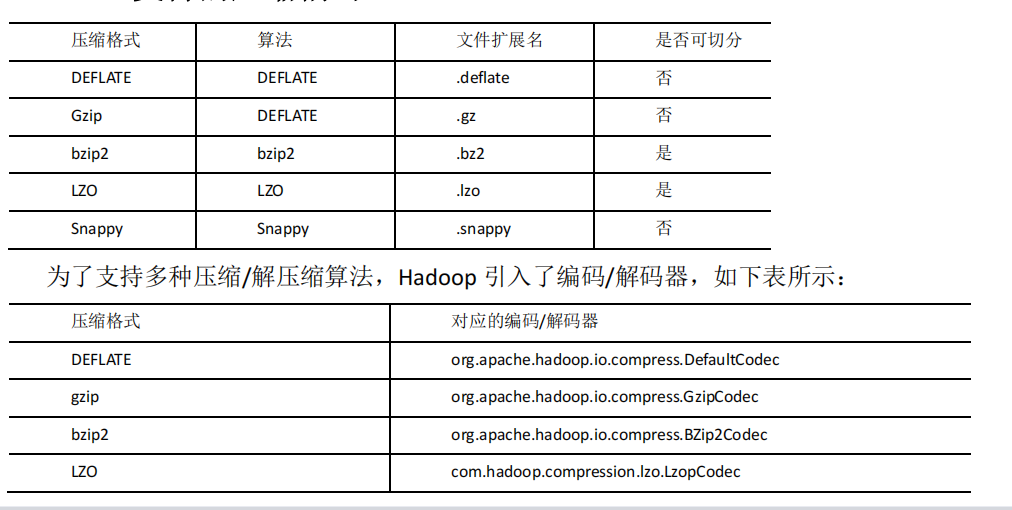
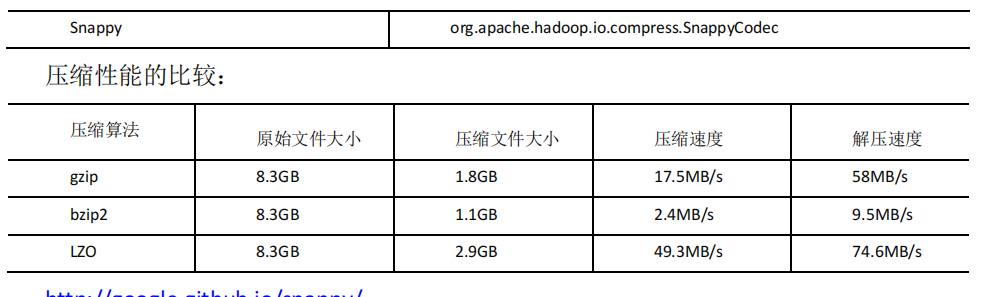
http://google.github.io/snappy/
On a single core of a Core i7 processor in 64-bit mode, Snappy compresses at about 250 MB/sec or more and decompresses at about 500 MB/sec or more.
1.2 壓縮參數配置
要在 Hadoop 中啟用壓縮,可以配置如下參數(mapred-site.xml 文件中):


2 開啟 Map 輸出階段壓縮(MR 引擎)
開啟 map 輸出階段壓縮可以減少 job 中 map 和 Reduce task 間數據傳輸量。具體配置如
下:
1)案例實操:
(1)開啟 hive 中間傳輸數據壓縮功能
hive (default)>set hive.exec.compress.intermediate=true;
(2)開啟 mapreduce 中 map 輸出壓縮功能
hive (default)>set mapreduce.map.output.compress=true;
(3)設置 mapreduce 中 map 輸出數據的壓縮方式
hive (default)>set mapreduce.map.output.compress.codec=
org.apache.hadoop.io.compress.SnappyCodec;
(4)執行查詢語句
hive (default)> select count(ename) name from emp;
3 開啟 Reduce 輸出階段壓縮
當 Hive 將 輸 出 寫 入 到 表 中 時 , 輸出內容同樣可以進行壓縮。屬性
hive.exec.compress.output控制著這個功能。用戶可能需要保持默認設置文件中的默認值false,
這樣默認的輸出就是非壓縮的純文本文件了。用戶可以通過在查詢語句或執行腳本中設置這
個值為 true,來開啟輸出結果壓縮功能。
1)案例實操:
(1)開啟 hive 最終輸出數據壓縮功能
hive (default)>set hive.exec.compress.output=true;
(2)開啟 mapreduce 最終輸出數據壓縮
hive (default)>set mapreduce.output.fileoutputformat.compress=true;
(3)設置 mapreduce 最終數據輸出壓縮方式
hive (default)> set mapreduce.output.fileoutputformat.compress.codec =
org.apache.hadoop.io.compress.SnappyCodec;
(4)設置 mapreduce 最終數據輸出壓縮為塊壓縮
hive (default)> set mapreduce.output.fileoutputformat.compress.type=BLOCK;
(5)測試一下輸出結果是否是壓縮文件
hive (default)> insert overwrite local directory
'/opt/module/data/distribute-result' select * from emp distribute by
deptno sort by empno desc;
4 文件存儲格式
Hive 支持的存儲數據的格式主要有:TEXTFILE 、SEQUENCEFILE、ORC、PARQUET。
4.1 列式存儲和行式存儲
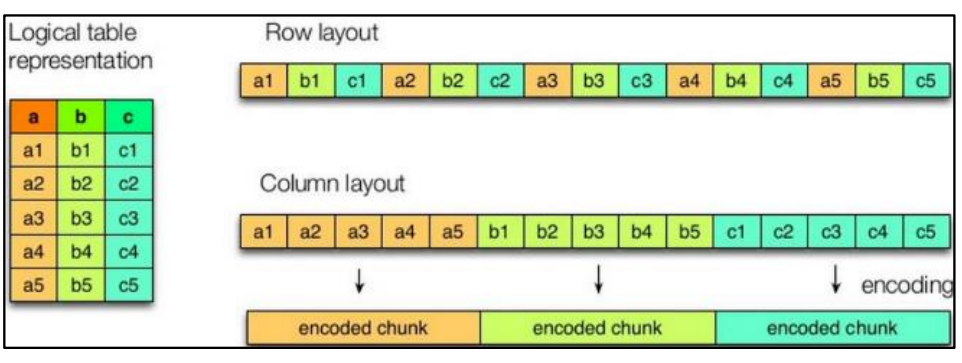
如圖所示左邊為邏輯表,右邊第一個為行式存儲,第二個為列式存儲。
1)行存儲的特點
查詢滿足條件的一整行數據的時候,列存儲則需要去每個聚集的字段找到對應的每個列
的值,行存儲只需要找到其中一個值,其余的值都在相鄰地方,所以此時行存儲查詢的速度
更快。
2)列存儲的特點
因為每個字段的數據聚集存儲,在查詢只需要少數幾個字段的時候,能大大減少讀取的
數據量;每個字段的數據類型一定是相同的,列式存儲可以針對性的設計更好的設計壓縮算
法。
TEXTFILE 和 SEQUENCEFILE 的存儲格式都是基于行存儲的;
ORC 和 PARQUET 是基于列式存儲的。
4.2 TextFile 格式
默認格式,數據不做壓縮,磁盤開銷大,數據解析開銷大。可結合 Gzip、Bzip2 使用,
但使用 Gzip 這種方式,hive 不會對數據進行切分,從而無法對數據進行并行操作。
4.3 Orc 格式
Orc (Optimized Row Columnar)是 Hive 0.11 版里引入的新的存儲格式。
如下圖所示可以看到每個 Orc 文件由 1 個或多個 stripe 組成,每個 stripe 一般為 HDFS的塊大小,每一個 stripe 包含多條記錄,這些記錄按照列進行獨立存儲,對應到 Parquet
中的 row group 的概念。每個 Stripe 里有三部分組成,分別是 Index Data,Row Data,Stripe Footer:

1)Index Data:一個輕量級的 index,默認是每隔 1W 行做一個索引。這里做的索引應該只是記錄某行的各字段在 Row Data 中的 offset。
2)Row Data:存的是具體的數據,先取部分行,然后對這些行按列進行存儲。對每個列進行了編碼,分成多個 Stream 來存儲。
3)Stripe Footer:存的是各個 Stream 的類型,長度等信息。
每個文件有一個 File Footer,這里面存的是每個 Stripe 的行數,每個 Column 的數據類型信息等;每個文件的尾部是一個 PostScript,這里面記錄了整個文件的壓縮類型以及
FileFooter 的長度信息等。在讀取文件時,會 seek 到文件尾部讀 PostScript,從里面解析到File Footer 長度,再讀 FileFooter,從里面解析到各個 Stripe 信息,再讀各個 Stripe,即從后
往前讀。
4.4 Parquet 格式
Parquet 文件是以二進制方式存儲的,所以是不可以直接讀取的,文件中包括該文件的數據和元數據,因此 Parquet 格式文件是自解析的。
(1)行組(Row Group):每一個行組包含一定的行數,在一個 HDFS 文件中至少存儲一個行組,類似于 orc 的 stripe 的概念。
(2)列塊(Column Chunk):在一個行組中每一列保存在一個列塊中,行組中的所有列連
續的存儲在這個行組文件中。一個列塊中的值都是相同類型的,不同的列塊可能使用不同的
算法進行壓縮。
(3)頁(Page):每一個列塊劃分為多個頁,一個頁是最小的編碼的單位,在同一個列塊
的不同頁可能使用不同的編碼方式。
通常情況下,在存儲 Parquet 數據的時候會按照 Block 大小設置行組的大小,由于一般
情況下每一個 Mapper 任務處理數據的最小單位是一個 Block,這樣可以把每一個行組由一
個 Mapper 任務處理,增大任務執行并行度。Parquet 文件的格式。

上圖展示了一個 Parquet 文件的內容,一個文件中可以存儲多個行組,文件的首位都是該文件的 Magic Code,用于校驗它是否是一個 Parquet 文件,Footer length 記錄了文件元數
據的大小,通過該值和文件長度可以計算出元數據的偏移量,文件的元數據中包括每一個行組的元數據信息和該文件存儲數據的 Schema 信息。除了文件中每一個行組的元數據,每一頁的開始都會存儲該頁的元數據,在 Parquet 中,有三種類型的頁:數據頁、字典頁和索引頁。數據頁用于存儲當前行組中該列的值,字典頁存儲該列值的編碼字典,每一個列塊中最多包含一個字典頁,索引頁用來存儲當前行組下該列的索引,目前 Parquet 中還不支持索引頁。
4.5 主流文件存儲格式對比實驗
從存儲文件的壓縮比和查詢速度兩個角度對比。
存儲文件的壓縮比測試:
1)測試數據
2)TextFile
(1)創建表,存儲數據格式為 TEXTFILE
create table log_text ( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as textfile;
(2)向表中加載數據
hive (default)> load data local inpath '/opt/module/hive/datas/log.data'
into table log_text ;
(3)查看表中數據大小
hive (default)> dfs -du -h /user/hive/warehouse/log_text;
18.13 M /user/hive/warehouse/log_text/log.data
3)ORC
(1)創建表,存儲數據格式為 ORC
create table log_orc( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as orc tblproperties("orc.compress"="NONE"); -- 設置 orc 存儲不使用壓縮
(2)向表中加載數據
hive (default)> insert into table log_orc select * from log_text;
(3)查看表中數據大小
hive (default)> dfs -du -h /user/hive/warehouse/log_orc/ ;
7.7 M /user/hive/warehouse/log_orc/000000_0
4)Parquet
(1)創建表,存儲數據格式為 parquet
create table log_parquet( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as parquet;
(2)向表中加載數據
hive (default)> insert into table log_parquet select * from log_text;
(3)查看表中數據大小
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet/;
13.1 M /user/hive/warehouse/log_parquet/000000_0
存儲文件的對比總結:
ORC > Parquet > textFile
存儲文件的查詢速度測試:
(1)TextFile
hive (default)> insert overwrite local directory '/opt/module/data/log_text' select substring(url,1,4) from log_text;
(2)ORC
hive (default)> insert overwrite local directory '/opt/module/data/log_orc' select substring(url,1,4) from log_orc;
(3)Parquet
hive (default)> insert overwrite local directory '/opt/module/data/log_parquet' select substring(url,1,4) from log_parquet;
存儲文件的查詢速度總結:查詢速度相近。
5 存儲和壓縮結合
5.1 測試存儲和壓縮
官網:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+ORC
ORC 存儲方式的壓縮:
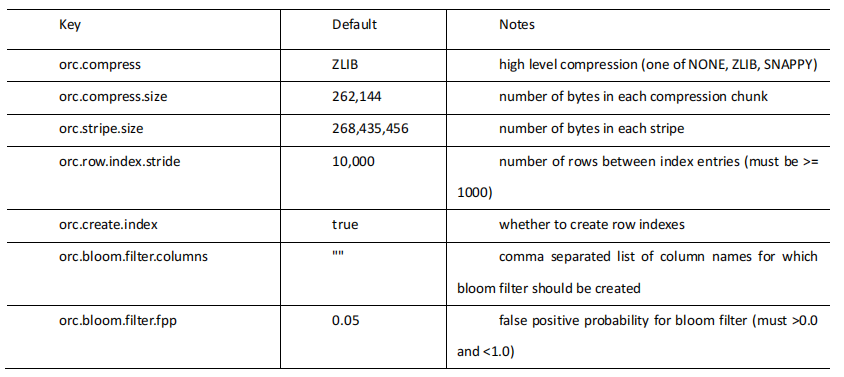
注意:所有關于 ORCFile 的參數都是在 HQL 語句的 TBLPROPERTIES 字段里面出現
1)創建一個 ZLIB 壓縮的 ORC 存儲方式
(1)建表語句
create table log_orc_zlib( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as orc tblproperties("orc.compress"="ZLIB");
(2)插入數據
insert into log_orc_zlib select * from log_text;
(3)查看插入后數據
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_zlib/ ;
2.78 M /user/hive/warehouse/log_orc_none/000000_0
2)創建一個 SNAPPY 壓縮的 ORC 存儲方式
(1)建表語句
create table log_orc_snappy( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as orc tblproperties("orc.compress"="SNAPPY");
(2)插入數據
insert into log_orc_snappy select * from log_text;
(3)查看插入后數據
hive (default)> dfs -du -h /user/hive/warehouse/log_orc_snappy/;
3.75 M /user/hive/warehouse/log_orc_snappy/000000_0
ZLIB 比 Snappy 壓縮的還小。原因是 ZLIB 采用的是 deflate 壓縮算法。比 snappy 壓縮的壓縮率高。
3)創建一個 SNAPPY 壓縮的 parquet 存儲方式
(1)建表語句
create table log_parquet_snappy( track_time string, url string, session_id string, referer string, ip string, end_user_id string, city_id string ) row format delimited fields terminated by '\t' stored as parquet tblproperties("parquet.compression"="SNAPPY");
(2)插入數據
insert into log_parquet_snappy select * from log_text;
(3)查看插入后數據
hive (default)> dfs -du -h /user/hive/warehouse/log_parquet_snappy/;
6.39 MB /user/hive/warehouse/ log_parquet_snappy /000000_0
4)存儲方式和壓縮總結
在實際的項目開發當中,hive 表的數據存儲格式一般選擇:orc 或 parquet。壓縮方式一般選擇 snappy,lzo。
本文來自博客園,作者:秋華,轉載請注明原文鏈接:http://www.rzrgm.cn/qiu-hua/p/13358340.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號