
HADOOP MAPREDUCE(4):MapReduce工作流程
1.流程示意圖,如圖4-6,4-7所示
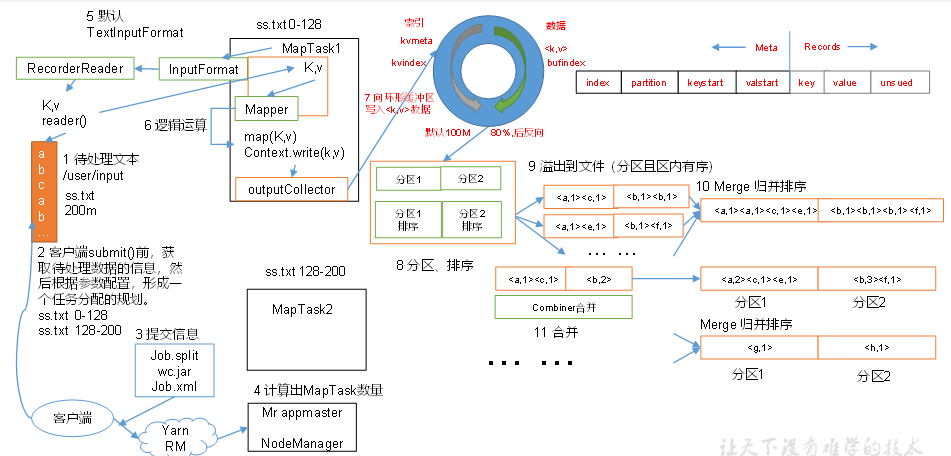
圖4-6 MapReduce詳細工作流程(一)
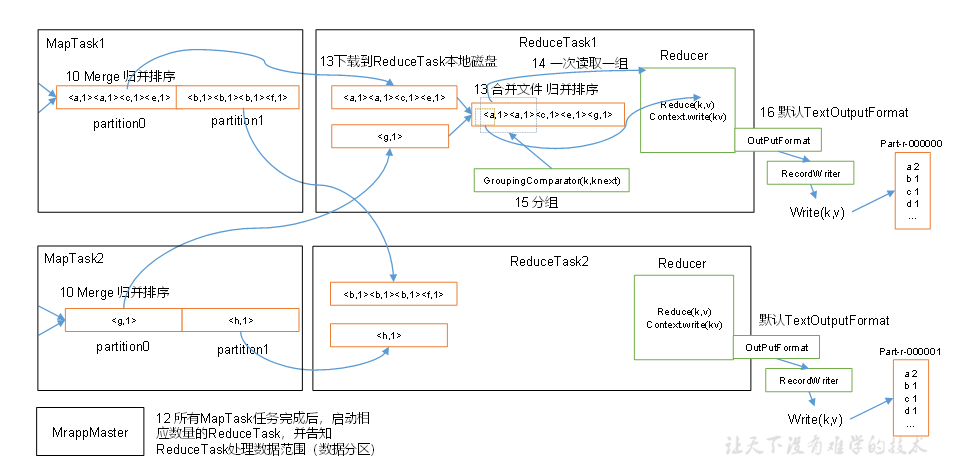
圖4-7 MapReduce詳細工作流程(二)
2.流程詳解
上面的流程是整個MapReduce最全工作流程,但是Shuffle過程只是從第7步開始到第16步結束,具體Shuffle過程詳解,如下:
1)MapTask收集我們的map()方法輸出的kv對,放到內存緩沖區中
2)從內存緩沖區不斷溢出本地磁盤文件,可能會溢出多個文件
3)多個溢出文件會被合并成大的溢出文件
4)在溢出過程及合并的過程中,都要調用Partitioner進行分區和針對key進行排序
5)ReduceTask根據自己的分區號,去各個MapTask機器上取相應的結果分區數據
6)ReduceTask會取到同一個分區的來自不同MapTask的結果文件,ReduceTask會將這些文件再進行合并(歸并排序)
7)合并成大文件后,Shuffle的過程也就結束了,后面進入ReduceTask的邏輯運算過程(從文件中取出一個一個的鍵值對Group,調用用戶自定義的reduce()方法)
3.注意
(1)Shuffle中的緩沖區大小會影響到MapReduce程序的執行效率,原則上說,緩沖區越大,磁盤io的次數越少,執行速度就越快。
(2)緩沖區的大小可以通過參數調整,參數:io.sort.mb默認100M。
(3)源碼解析流程

本文來自博客園,作者:秋華,轉載請注明原文鏈接:http://www.rzrgm.cn/qiu-hua/p/13337843.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號