

Hive 開啟壓縮后 shuffle 階段 偶發OOM問題
一、 問題現象
查看yarn 日志確認是在 shuffle 階段 發生了異常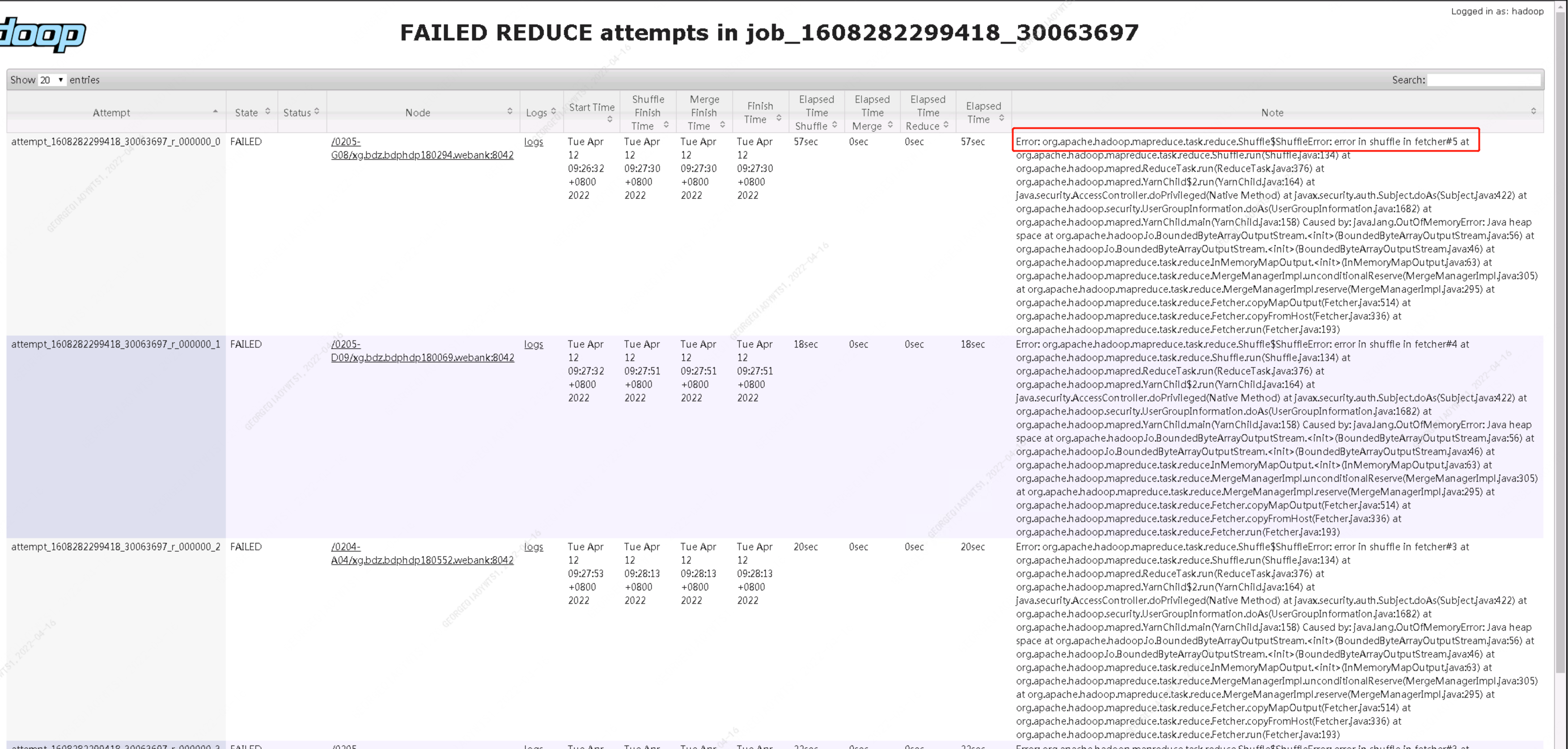
二、 初步分析
MR 流程總覽
從異常棧來看,發生了shuffle的OOM,在shuffle階段,會將map的output數據給取下來,然后根據相關參數值確認昂前shuffle可使用內存,決定是放進內存中,還是存儲到磁盤里面進行操作。mapreduce.reduce.shuffle.memory.limit.percent這個參數默認值是0.25,代表單個shuffle能夠消耗的內存占reduce所有內存的比例。所以解決問題的方法可以適當地將這個參數進行調小操作,那么單個shuffle能夠消耗的內存就沒辦法滿足將數據進行處理,就會使用磁盤來慢慢操作;那么應該如何配置和列參數參來避免此問題呢。
三、 深入分析
需要結合Hadoop 2.7.2的源代碼來對整個失敗過程進行簡要分析。
Fetcher線程
從異常棧可以看出,是在Fetcher.run方法執行時出現的錯誤,在Shuffle.run方法中,會啟動一定數量的Fetcher線程(數量由參數mapreduce.reduce.shuffle.parallelcopies決定,Fetcher線程用來從map端copy數據到Reducer端本地。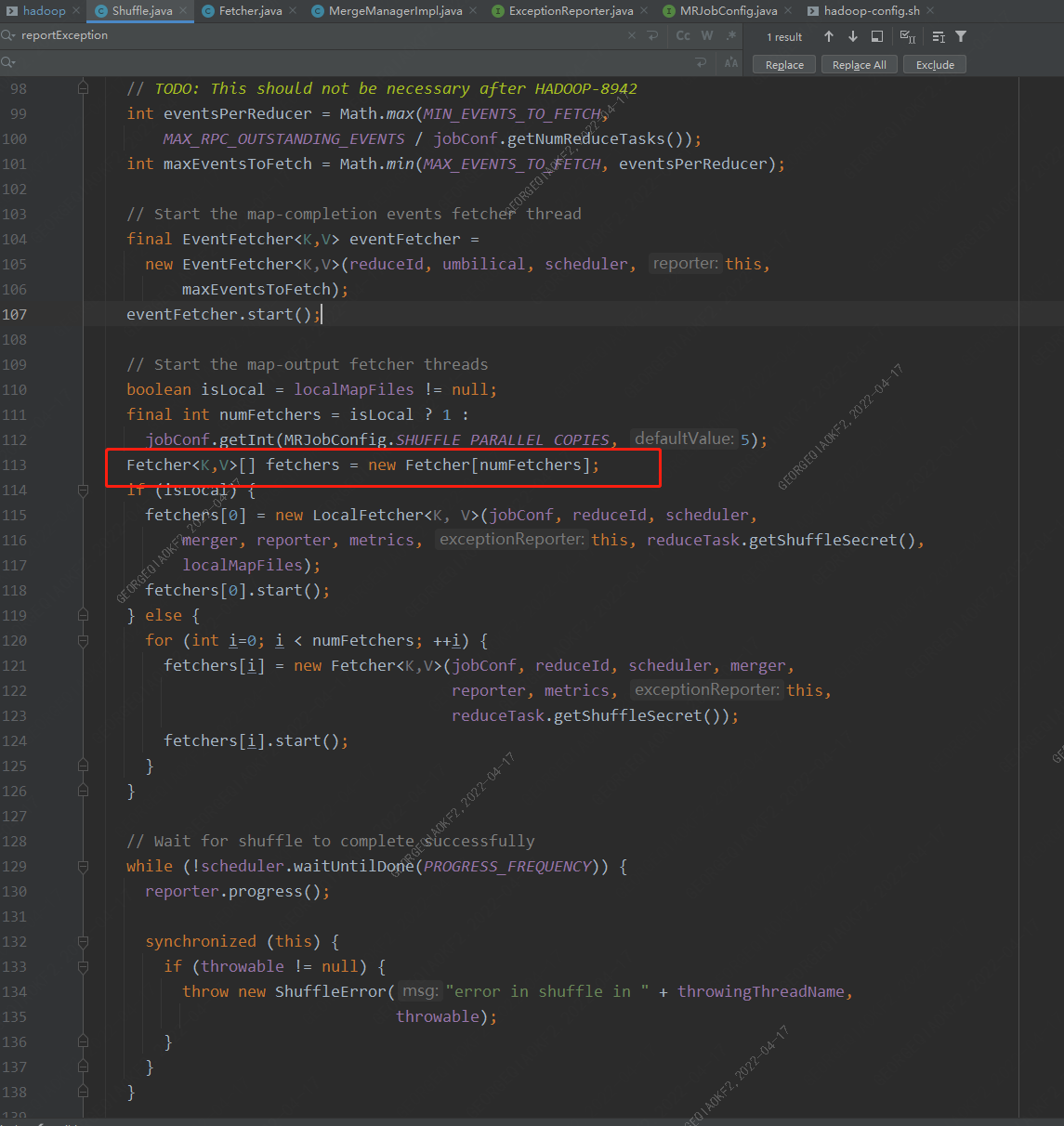
當任意一個Fetcher發生異常時,其會上報異常至主進程,停掉整個Reducer。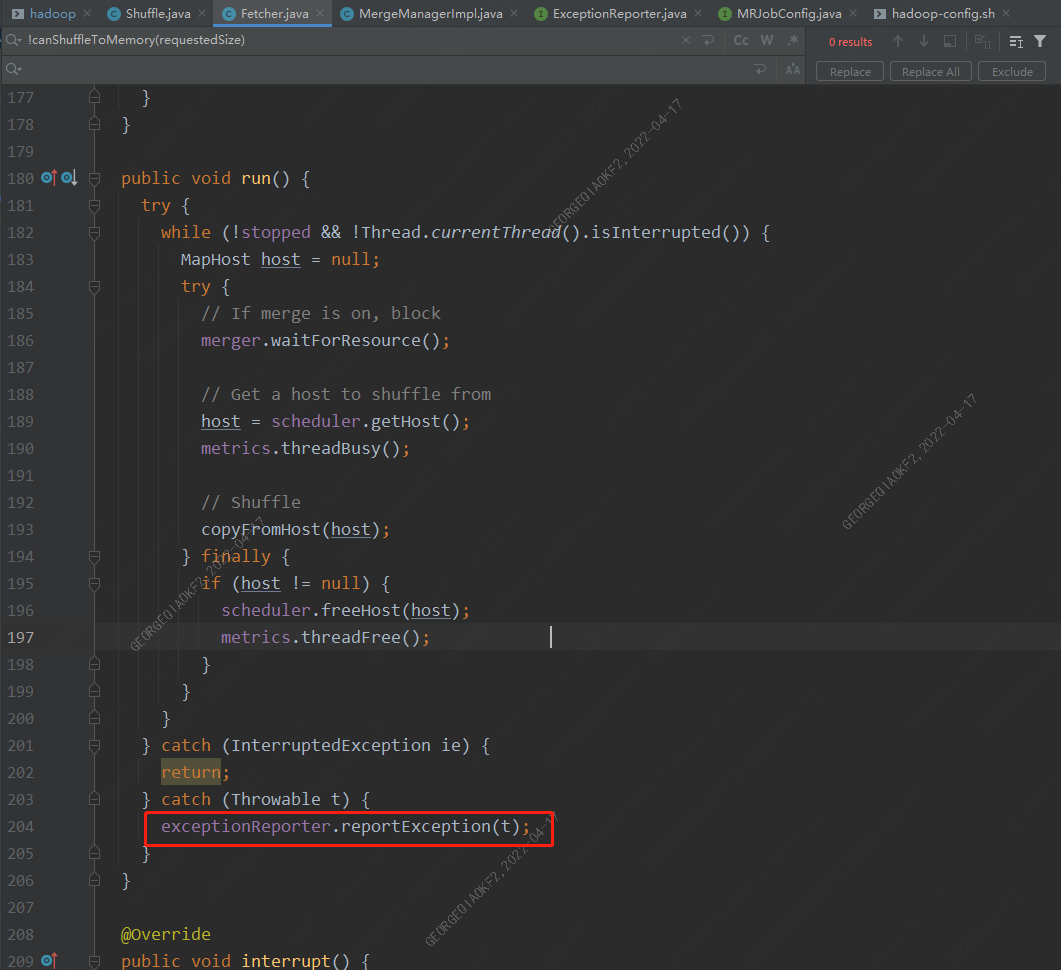

reserve的具體實現
在異常堆棧可以看出,Fetcher中調用copyFromHost方法,緊接著調用Fehcher的copyMapOutput方法,重點在這里,merger指向了MergeManagerImpl對象,調用其reserve函數,而這個函數中定義了shuffle的處理方式,是將output塞入內存(InMemoryMapOutput)還是放在磁盤上慢慢做(OnDiskMapOutput)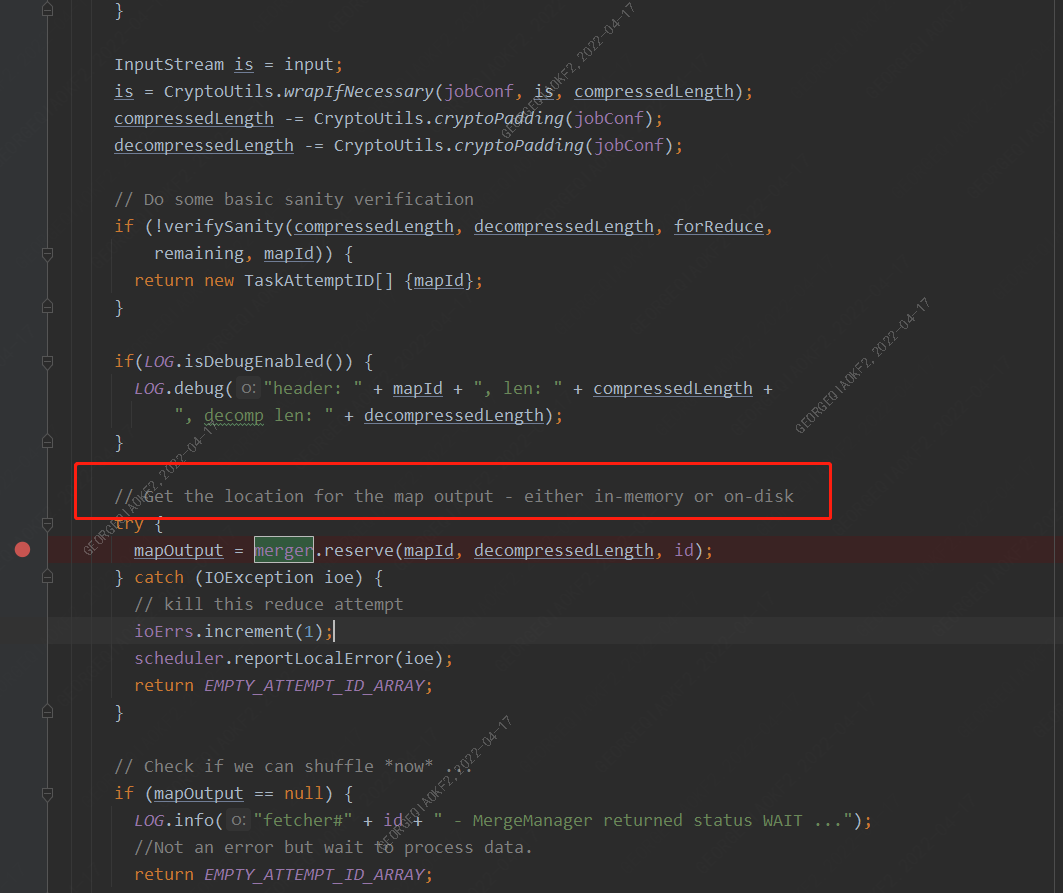
從我們這邊的出錯信息,顯然可以看到任務選擇了InMemoryMapOutput,既然認為可以在內存中進行shuffle,那么還會發生OOM 呢?
shuffle中可用內存的設置
shuffle在初始化MergeManager的時候設置了reduce總共可以使用的內存,MRJobConfig.REDUCE_MEMORY_TOTAL_BYTES(mapreduce.reduce.memory.totalbytes)這個參數我們并沒有設置,因此使用的Runtime.getRuntime.maxMemory()*maxInMemCopyUse
MRJobConfig.SHUFFLE_INPUT_BUFFER_PERCENT(mapreduce.reduce.shuffle.input.buffer.percent) 參數使用的是0.70,也就是最大內存的70%用于做Shuffle/Merge,比如當前環境Reducer端內存設置成4G,那么就會有2.8G內存。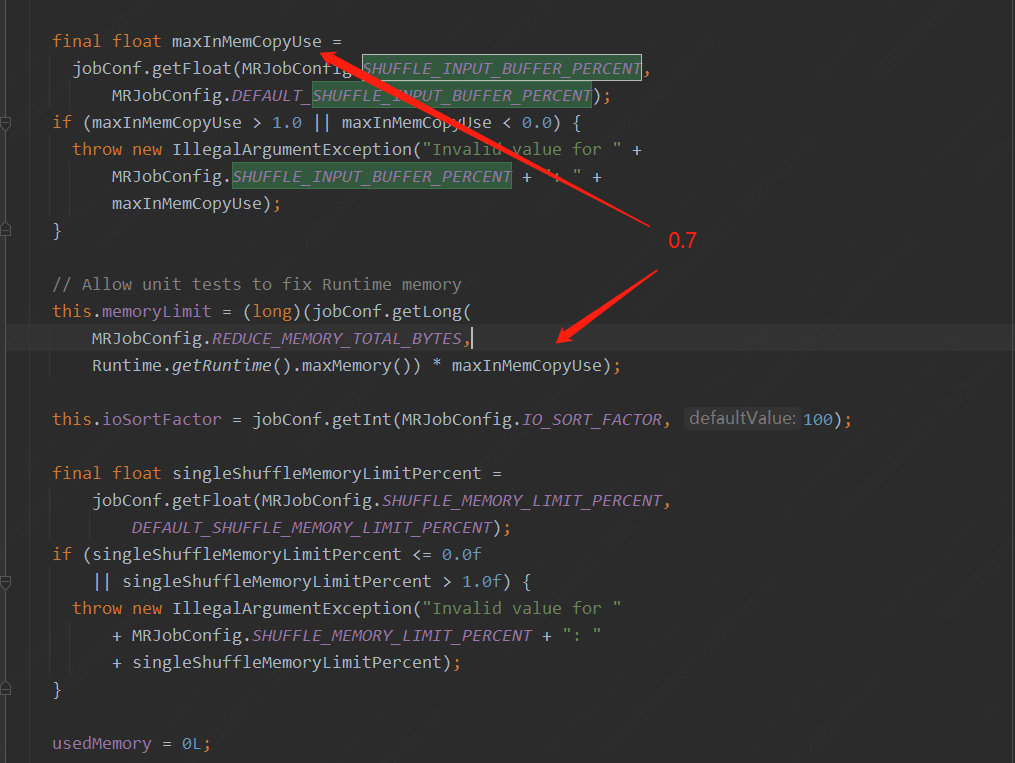
而單個shuffle 的最大內存使用量還需要,在乘以一個系數 mapreduce.reduce.shuffle.memory.limit.percent (默認0.25),那么也就是700M
獲取 MapOutput
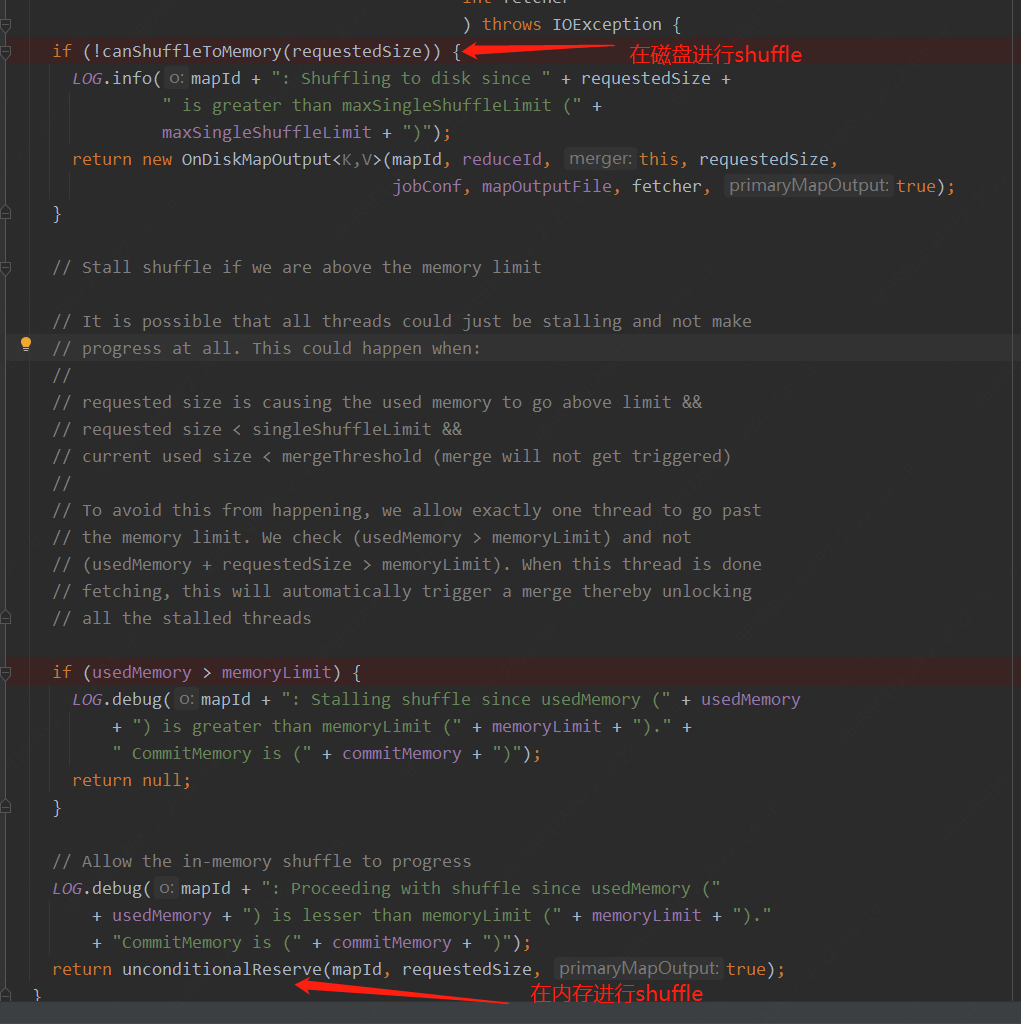
那么reserve方法是如何決定是啟動OnDiskMapOutput還是InMemoryMapOutput類,其中有一個canShuffleToMemory方法,確認請求內存數量是否小于單個shuffle設置的內存限制。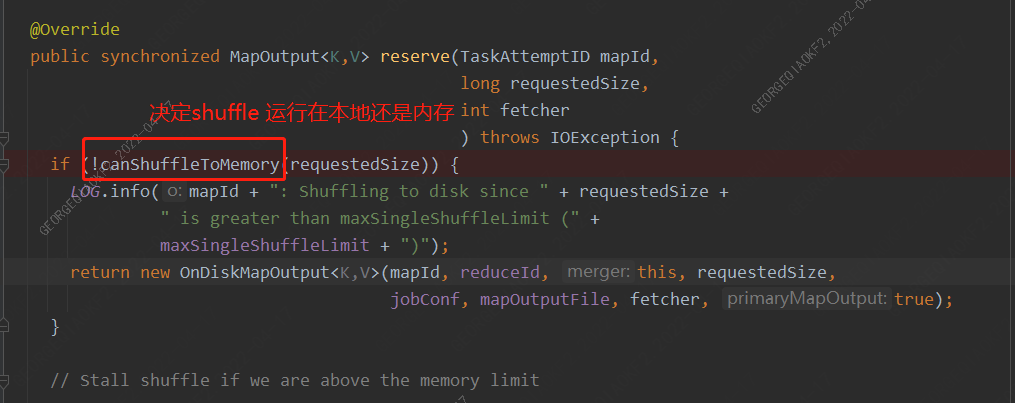
InMemory會在初始化時接收一個size參數,用于初始化其BoundedByteArrayOutputStream,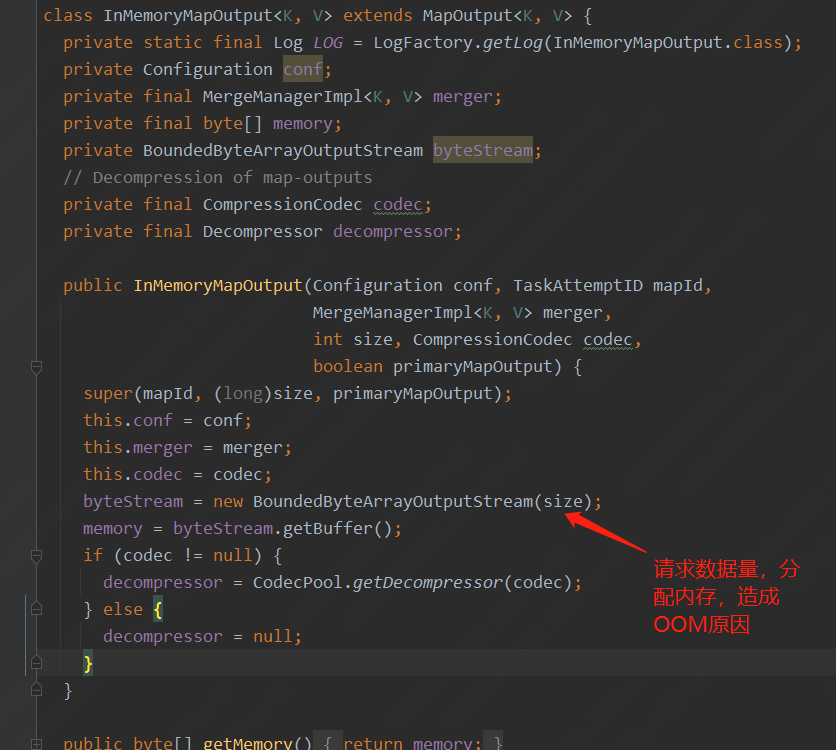
Fetcher線程取到數據后,進行mapOutput的commit操作,說明信息讀取結束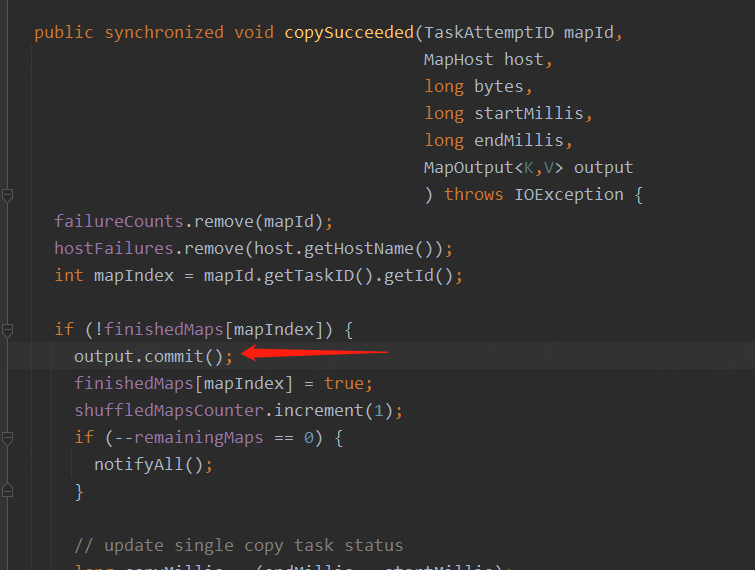
commit后這個mapOutput可以和其他的mapOutput進行合并。這里需要注意的是內存空間分給mapoutput后并不能啟動merge操作,只有當commit完成后才可以進行Mapouput的合并并釋放內存。
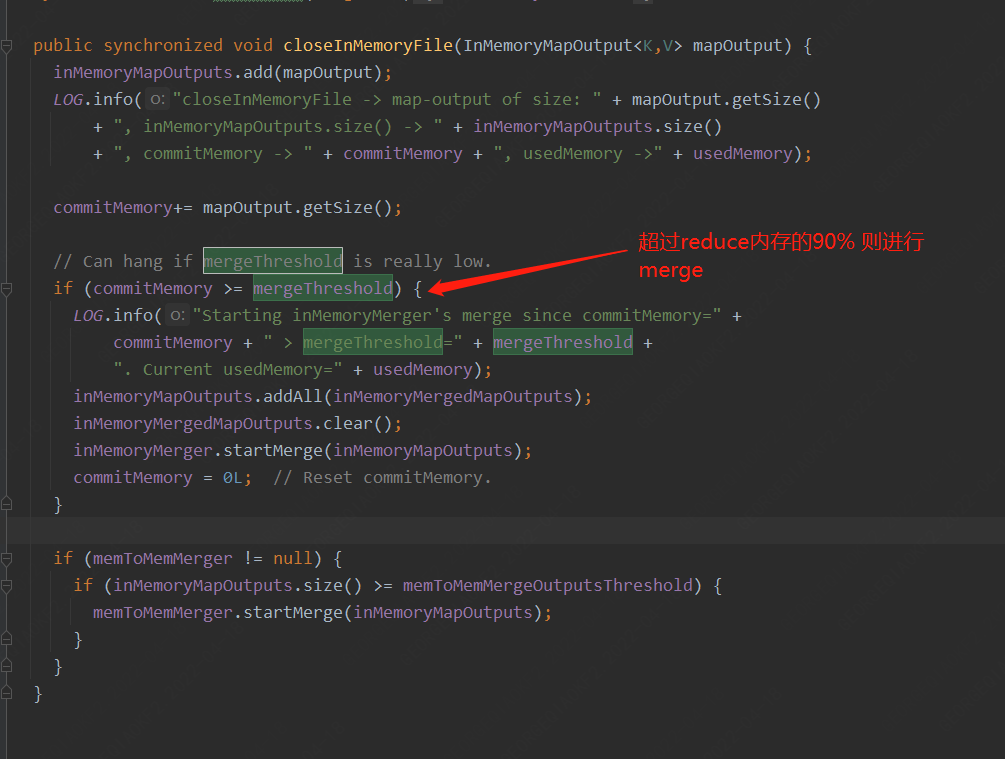
usedMemory: 已經分配的內存總量。
commitMemory: 已經提交的內存總量。
有關的幾個重要參數事先說明:mapreduce.reduce.shuffle.input.buffer.percent默認0.7 (2.8 G) shuffile在reduce內存中的數據最多使用內存量為:0.7 × maxHeap of reduce task,緩存的數據量超過了這個值,便開始將緩存數據寫入磁盤。mapreduce.reduce.shuffle.memory.limit.percent默認0.25 (700M) 每個fetch取到的輸出的大小能夠占的內存比的大小,低于此值可以輸出到內存,否則輸出到磁盤。默認是0.25。mapreduce.reduce.shuffle.merge.percent默認0.66 merge的百分比,shuffle的數據量到達shuffle總內存的多少百分比后開始做merge操作。mapreduce.reduce.shuffle.parallelcopies默認 5 Fetcher 數量
基于以上邏輯在如下兩種情況可能出現OOM(以下說明都是按照hadoop的默認配置下):
-
如果前4個Fetcher已經使用了全部的shuffle可分配內存的99%(4G 0.7 0.25 = 700M ,700 * 4 ≈ 2.8G),并且還未commit(copysuccess 之后才能 commit ),第5個Fetcher取的數據為699M,因為小于700M,這時會為第5個fetcher分配25%的內存。總內存使用量達到124%,超出shuffle限制。
-
如果前4個fetcher已經使用shuffle內存的65%,并已經commit,由于未達到設定值,這時merge不會啟動(commitmemory > 0.66 才會進行merge),第5個Fetcher取的數據為699M,因為小于700M,這時會為第5個fetcher分配25%的內存。總內存使用量達到90%,超出shuffle限制,此時如果reduce在做消耗內存的操作,那么會發生OOM。
四、解決方案
將shuffle內存比例調整為0.6,單個shuffle最大比例調整為0.18,merge比例保持不變 0.66
調整后參數如下:mapreduce.reduce.shuffle.parallelcopies=5mapreduce.reduce.shuffle.input.buffer.percent=0.6(2.4G)mapreduce.reduce.shuffle.memory.limit.percent=0.18(0.432G)mapreduce.reduce.shuffle.merge.percent=0.66
這樣在shuffle內存分配到接近100%時,最多可以分配15%的shuffle內存,總Shuffle內存不超過0.6 + 0.6 * 0.18 = 0.7,雖然超過了我們的60%,但是對整個reduce JVM而言,70%不會OOM,而超過0.66后會進行merge釋放內存。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號