

Hive開啟壓縮后 MapJoin 偶發OOM問題
一、 問題現象
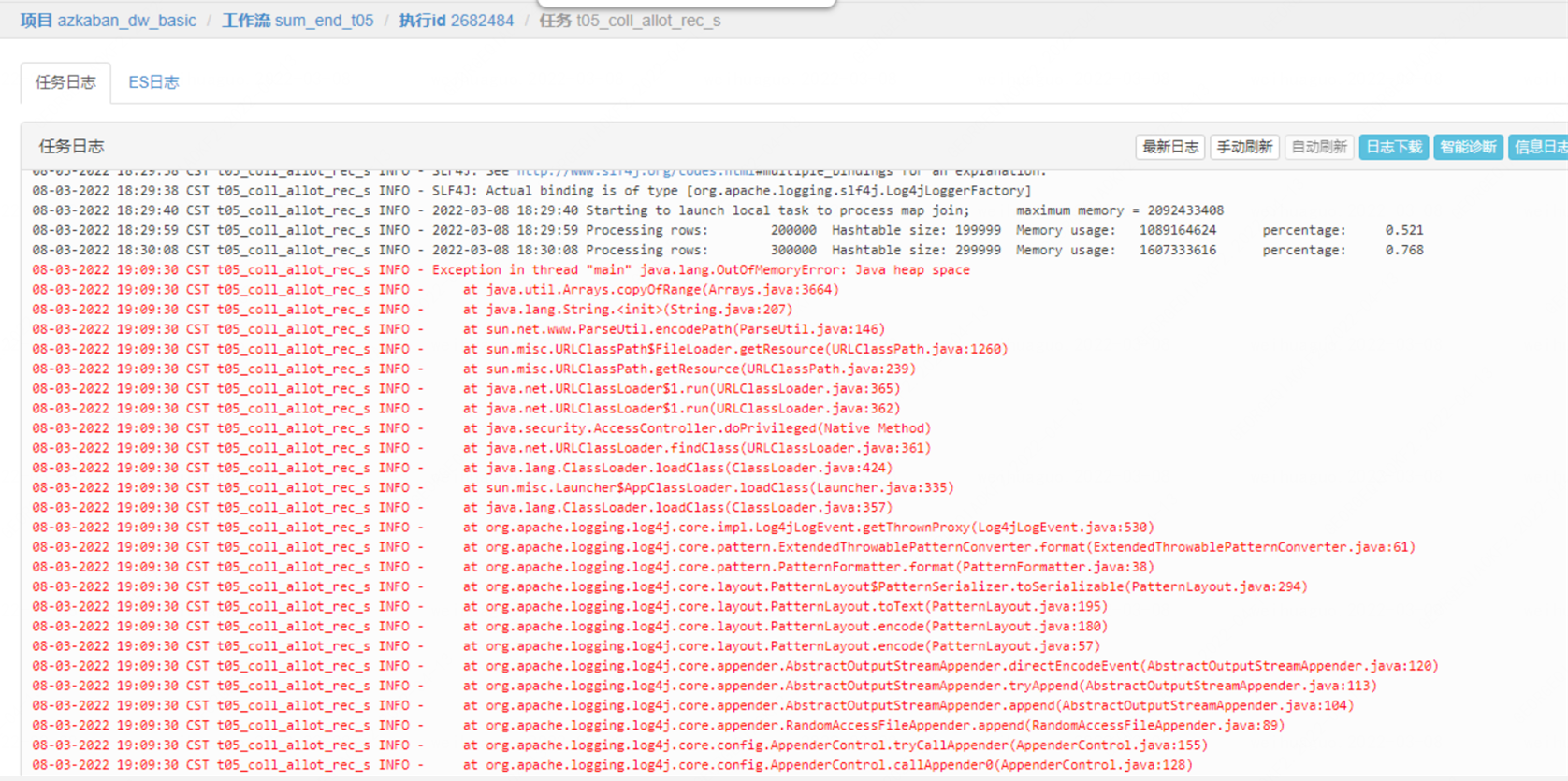
生產環境開啟默認壓縮后,Hive任務在觸發MapJoin優化時會偶發OOM,如下圖
 ??
??
二、 初步分析
從報錯日志上面可以明顯看出,maplocaltask 總共的分配內存2092433408
處理行數:200000 哈希表大小:199999 內存使用量:1089164624 比例:0.521
處理行數:300000 哈希表大小:299999 內存使用量:1607333616 速率:0.768
在 300000 行時,哈希表的大小已經暫用了 76.8% 的堆,MapJoin 默認是每10W行數據進行一次內存檢測,那么按照這種趨勢在下一次檢測前肯定會撐爆maplocaltask的堆,導致OOM;但是比較奇怪的是,hive 在執行計劃優化的時候會檢測當前表數據的大小,只有滿足設定的堆大小才會觸發本地任務,所以說就算把數據全部方案哈希表也是完全夠用的,如果只是想避免這個問題也很簡單,通過直接設置set hive.auto.convert.join = false 關閉MapJoin,將任務放在hadoop運行;但是mapjoin作為一種hive任務的優化手段,可以大大降低任務的運行時間,如果關閉此配置,那么所有涉及mapjoin任務的運行時效都將得不到保障,所以我們只能迎難而上從根本上解決這個問題。
三、 MapJoin原理分析
1. common join的問題
首先我們來看看Hive 中的Join是如何運行,在任務啟動之初,Hive 的join可以統稱為Common Join,任務涉及 Map 階段和 Reduce 階段。Mapper 從連接表中讀取數據并將連接的 key 和連接的 value 鍵值對輸出到中間文件中。Hadoop 在所謂的 shuffle 階段對這些鍵值對進行排序和合并。Reducer 將排序結果作為輸入,并進行實Join。Shuffle 階段代價非常昂貴,因為它需要排序和合并。減少 Shuffle 和 Reduce 階段的代價可以提高任務性能。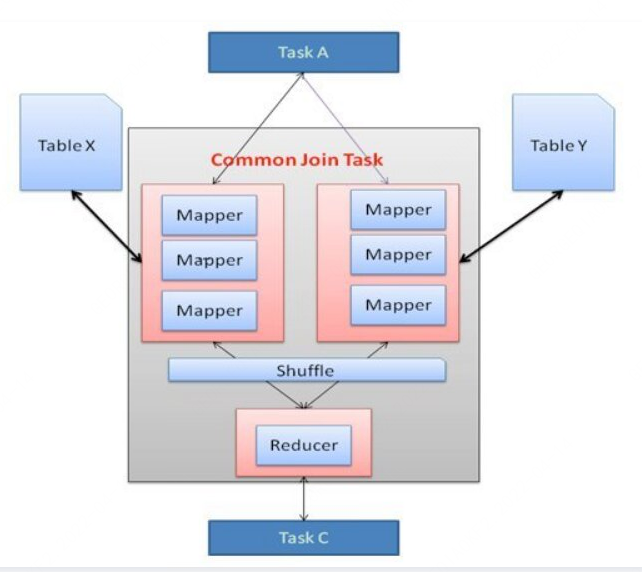
2. map join的產生
Map Join 的目的是減少 Shuffle 和 Reducer 階段的代價,并僅在 Map 階段進行 Join。通過這樣做,當其中一個連接表足夠小可以裝進內存時,所有 Mapper 都可以將數據保存在內存中并完成 Join。因此,所有 Join 操作都可以在 Mapper 階段完成。但是,這種類型的 Map Join 存在一些擴展問題。當成千上萬個 Mapper 同時從 HDFS 將小的連接表讀入內存時,連接表很容易成為性能瓶頸,導致 Mapper 在讀取操作期間超時。
3. 使用分布式緩存
Hive-1641 解決了這個擴展問題。優化的基本思想是在原始 Join 的 MapReduce 任務之前創建一個新的 MapReduce 本地任務。這個新任務是將小表數據從 HDFS 上讀取到內存中的哈希表中。讀完后,將內存中的哈希表序列化為哈希表文件。在下一階段,當 MapReduce 任務啟動時,會將這個哈希表文件上傳到 Hadoop 分布式緩存中,該緩存會將這些文件發送到每個 Mapper 的本地磁盤上。因此,所有 Mapper 都可以將此持久化的哈希表文件加載回內存,并像之前一樣進行 Join。優化的 Map Join 的執行流程如下圖所示。優化后,小表只需要讀取一次。此外,如果多個 Mapper 在同一臺機器上運行,則分布式緩存只需將哈希表文件的一個副本發送到這臺機器上。
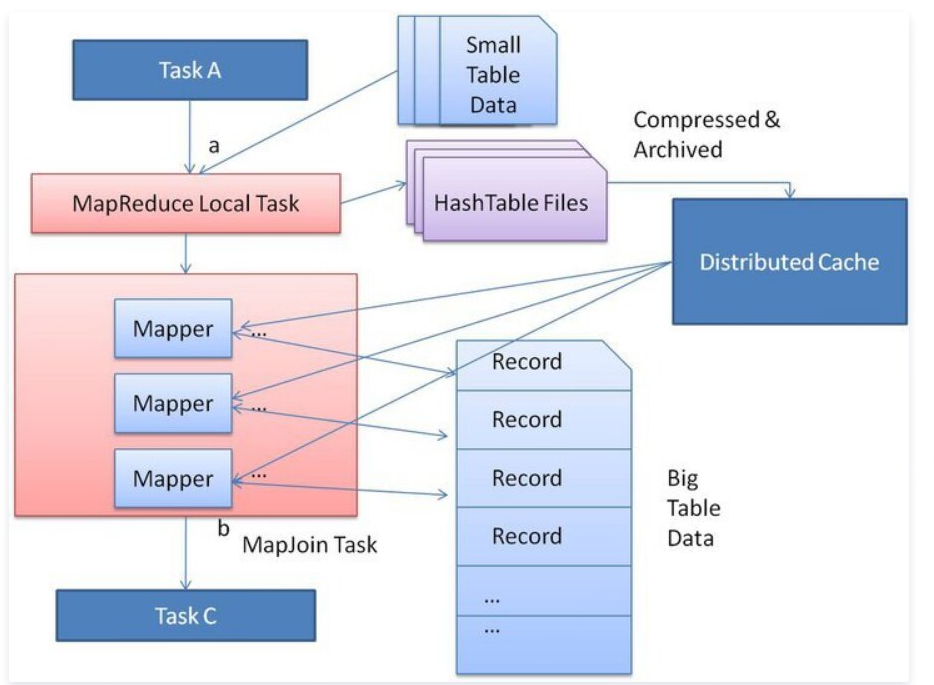
對于 Map Join,查詢處理器應該知道哪個輸入表是大表。其他輸入表在執行階段被識別為小表,并將這些表保存在內存中。然而,查詢處理器在編譯時不知道輸入文件大小,因為一些表可能是從子查詢生成的中間表。因此查詢處理器只能在執行期間計算出輸入文件的大小。
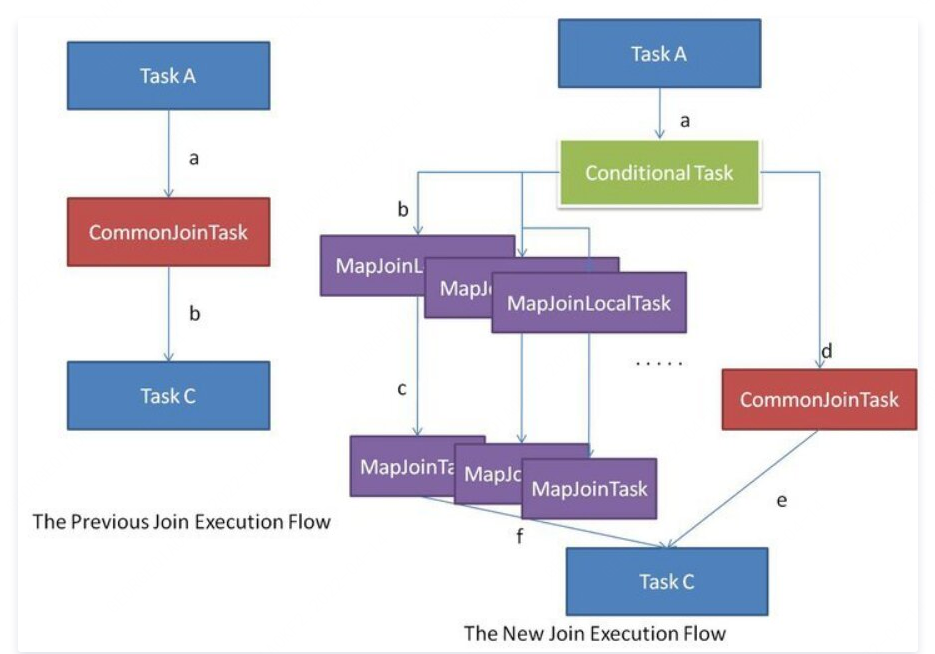
如上圖所示,左側流程顯示了先前的 Common Join 執行流程,這非常簡單。另一方面,右側流程是新的 Common Join 執行流程。在編譯期間,查詢處理器生成一個包含任務列表的 Conditional Task。在執行期間運行其中一個任務。首先,應將原始的 Common Join 任務放入任務列表中。然后,查詢處理器通過假設每個輸入表可能是大表來生成一系列的 Map Join 任務。
例如,select * from src1 x join src2 y on x.key=y.key因為表 src2 和 src1 都可以是大表,所以處理器生成兩個 Map Join 任務,其中一個假設 src1 是大表,另一個假設 src2 是大表。
在執行階段,Conditional Task 知道每個輸入表的確切文件大小,即使該表是中間表。如果所有表都太大而無法轉換為 Map Join,那么只能像以前一樣運行 Common Join 任務。如果其中一個表很大而其他表足夠小可以運行 Map Join,則將 Conditional Task 選擇相應 Map Join 本地任務來運行。通過這種機制,可以自動和動態地將 Common Join 轉換為 Map Join。
至此通過原理,對于開始提到的MapJoin中存在的OOM問題,我們可以大概猜測,系統是將某一張表識別為小表而觸發了mapjoin后,在本地任務中將小表放入哈希表的過程中撐爆了內存,如果小表的總大小大于25MB,Conditional Task 會選擇原始 Common Join 來運行,(可使用 set hive.smalltable.filesize 來修改),那么為什么大于25M的表hive也觸發了mapjoin呢,從日志是看不出什么了,下面我們來從源碼層面來分析。
四、 定位真相
我們以如下三張表的join為例來跟蹤源碼,分別為一張orc的小表和兩張txt類型的大表
3366670 2022-04-12 20:51 viewfs://bdphdp10/user/hive/warehouse/hadoop/mapjoin_join/data.txt5748 2022-04-12 20:52 viewfs://bdphdp10/user/hive/warehouse/hadoop/mapjoin_orc/000000_03366670 2022-04-12 20:51 viewfs://bdphdp10/user/hive/warehouse/hadoop/mapjoin_txt/data.txtset hive.auto.convert.join = true;set hive.auto.convert.join.noconditionaltask=true;set hive.mapjoin.smalltable.filesize = 2000000;set hive.auto.convert.join.noconditionaltask.size=2000000;select count(tmp1.cate)from mapjoin_orc tmp1inner join mapjoin_join tmp2 on tmp1.cate=tmp2.cateinner join mapjoin_15_txt tmp3 on tmp3.cate=tmp2.categroup by tmp1.cate,tmp2.cate,tmp3.cate;
我們知道MapJoin的優化是發生在將邏輯執行計劃轉換為物理執行計劃后,對于物理執行計劃的優化階段發生的,如下圖:
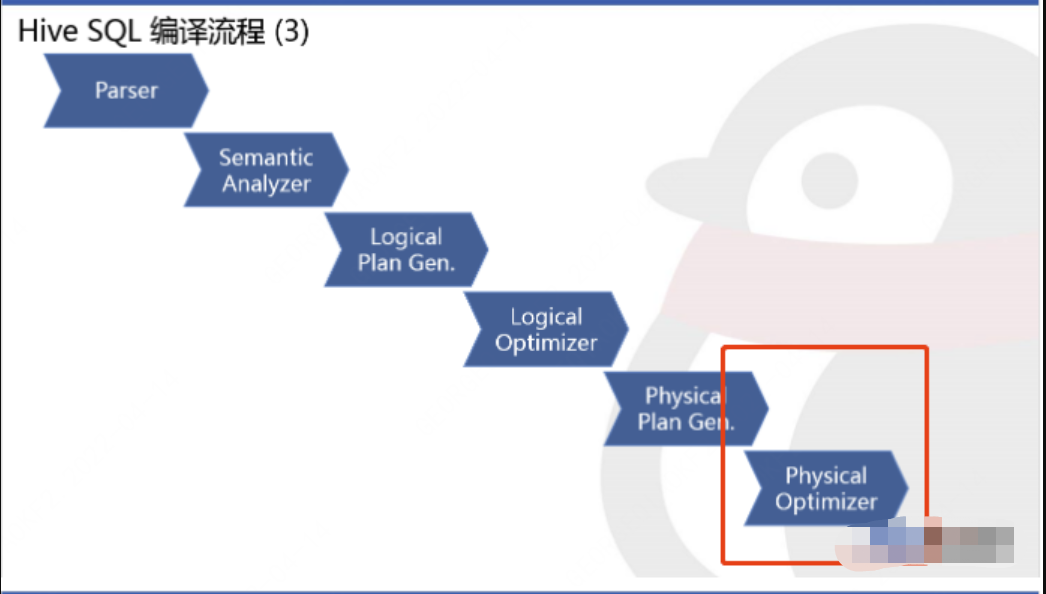
所以我們直接從物理執行計劃優化切入,其中關鍵點在于兩個邏輯:
1. 針對兩個表的join,對于小表大小邏輯判斷如下代碼:
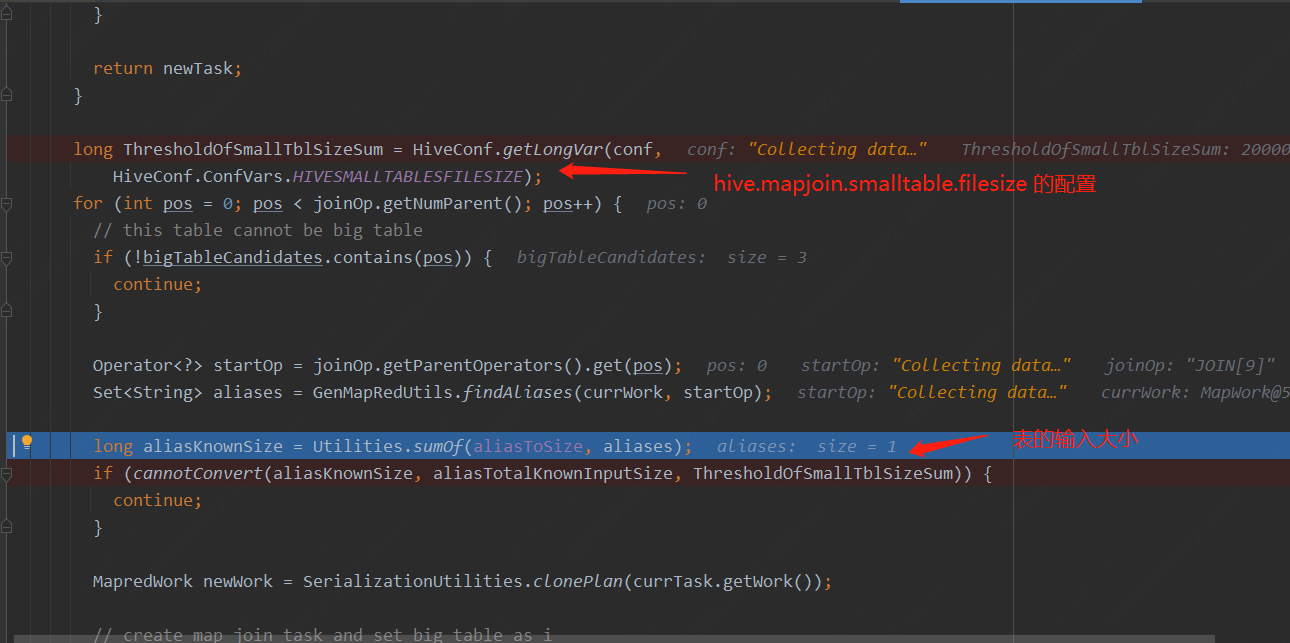
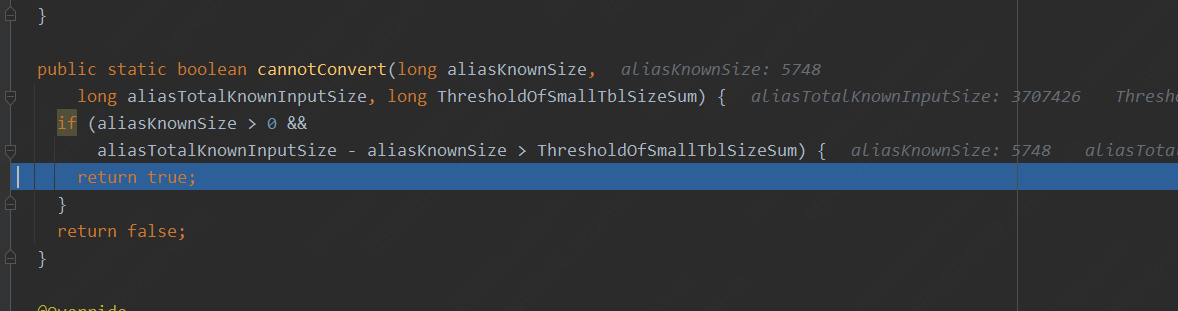
2. 針對多表的join,通常會對于小表大小邏輯判斷如下代碼:
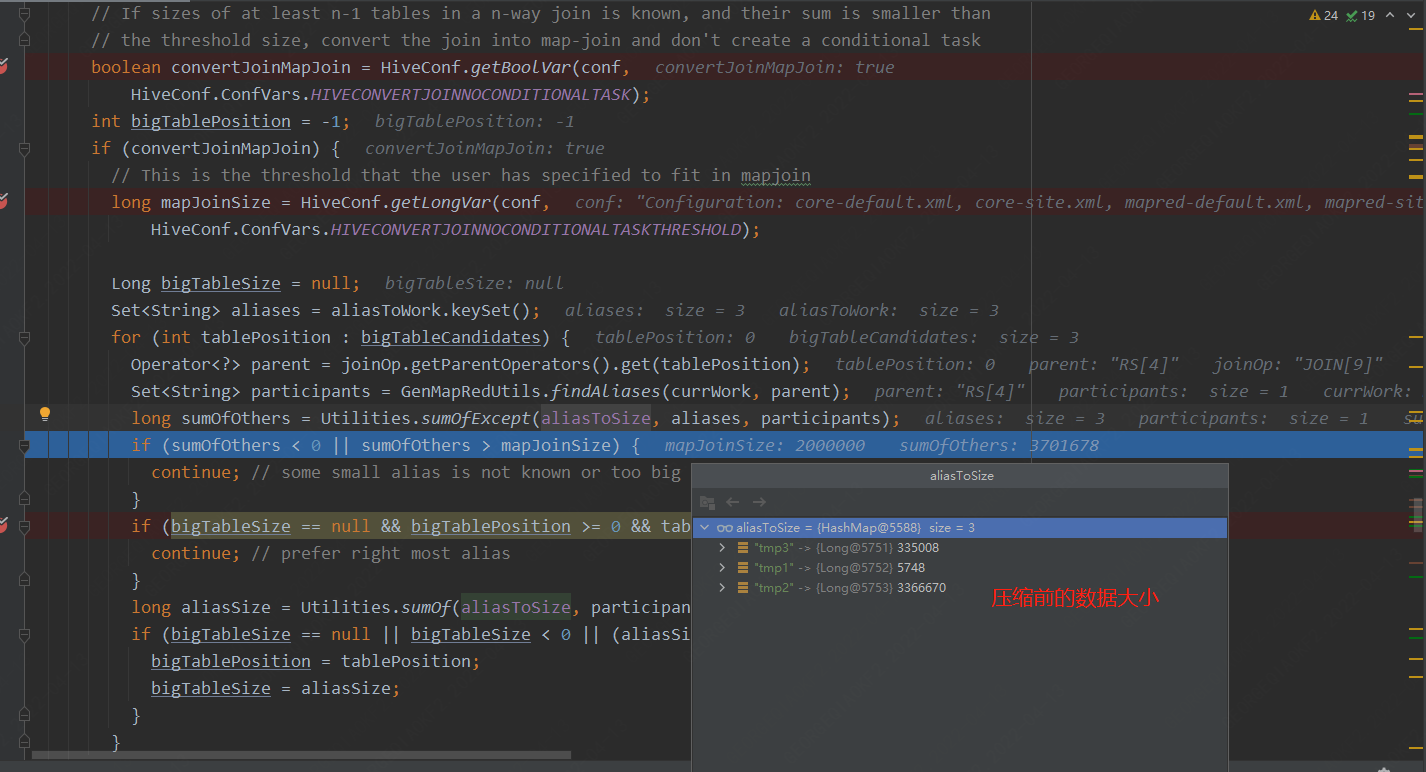
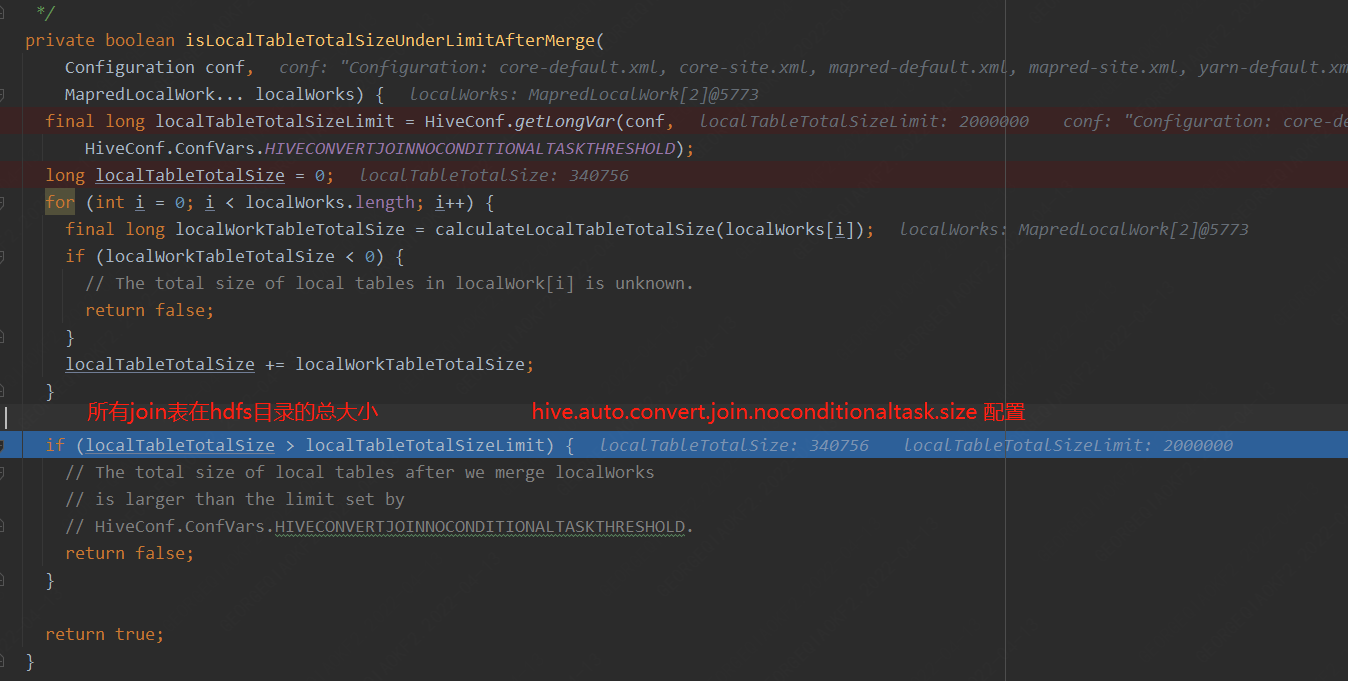
loacltask任務
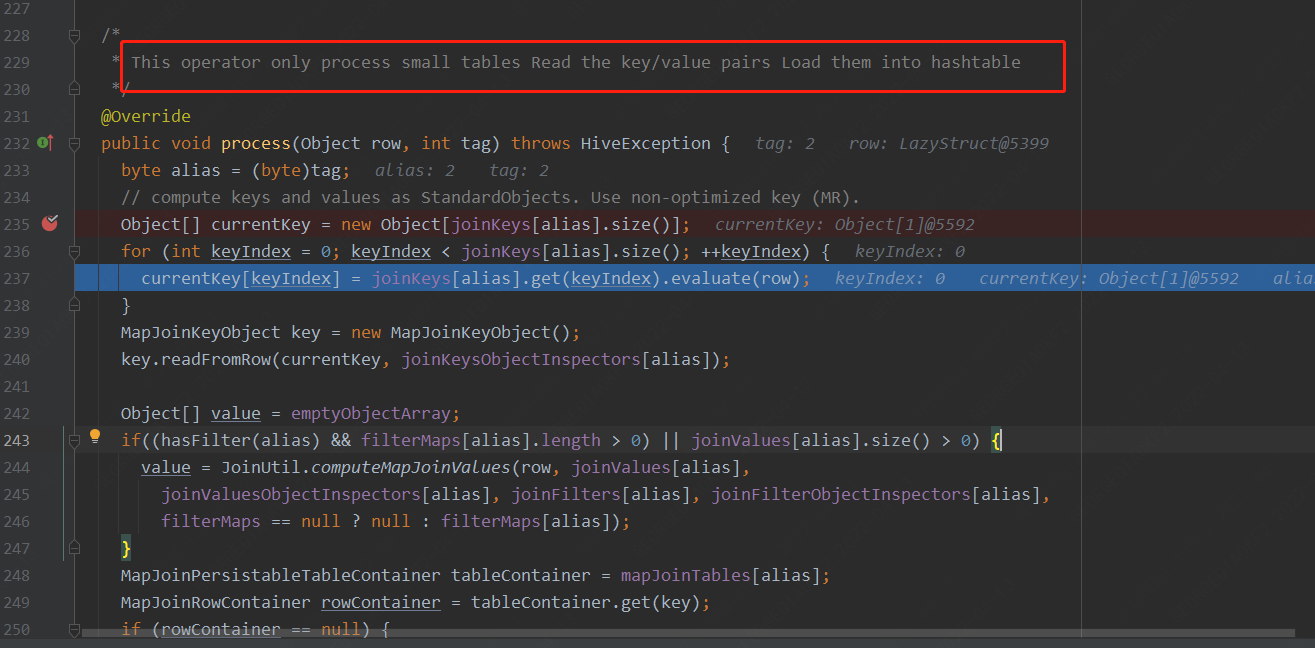
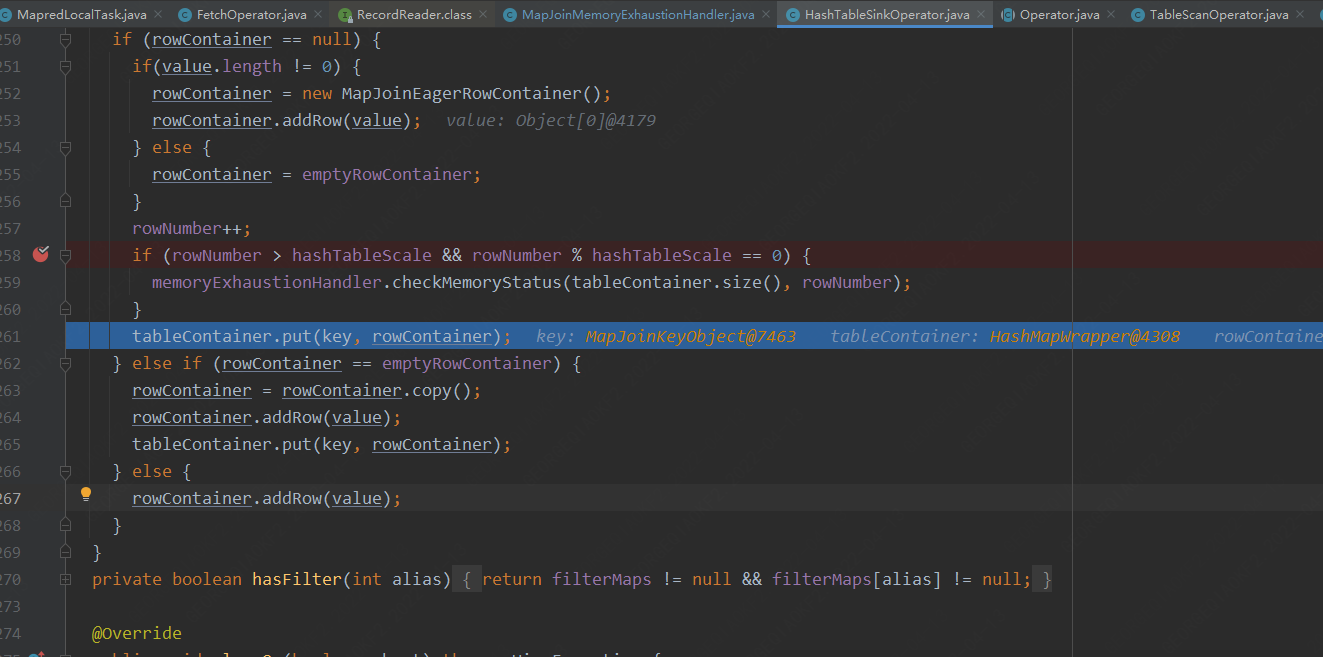
此處為讀取每行數據,將數據放入哈希表的邏輯
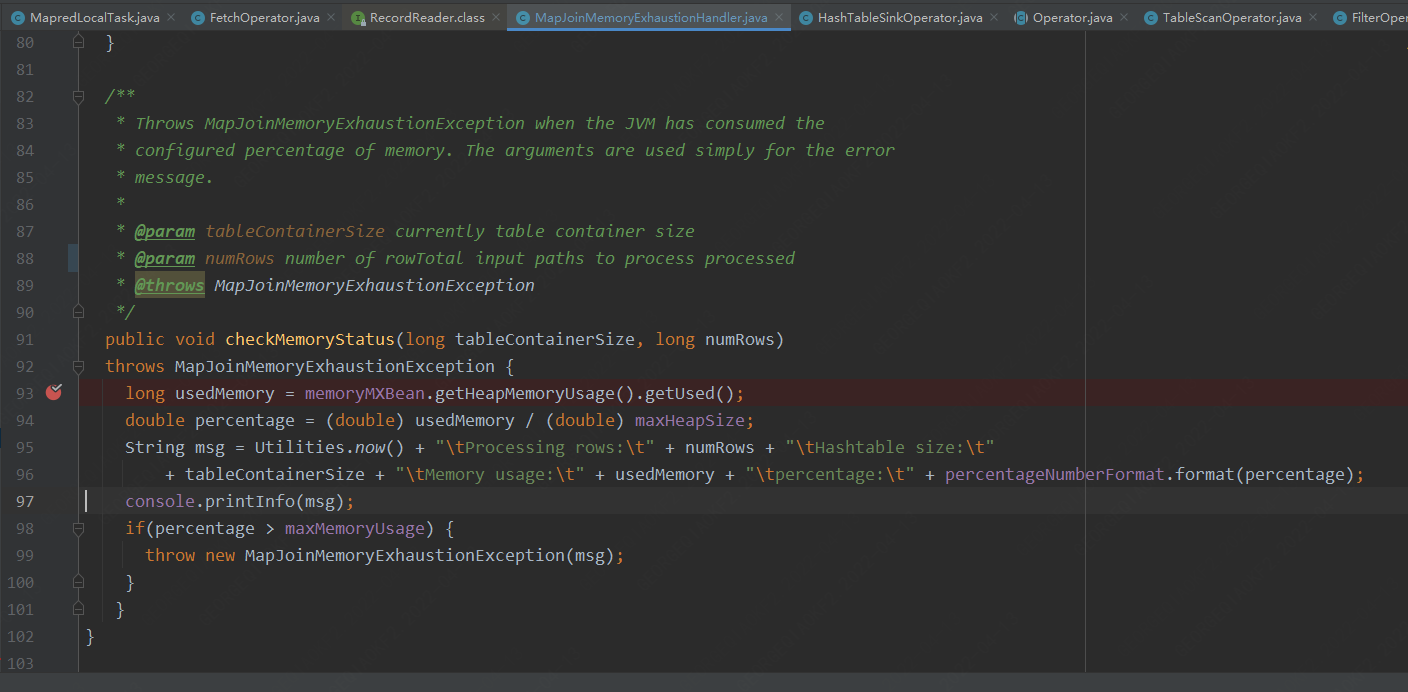
此處為每處理10W行數據,檢測一下當前堆的使用情況。
可以看出,不管是兩表join ,還是多表join,對于表大小邏輯的檢測都是直接讀取hdfs上存儲的數據的大小,當表被壓縮存儲時,表大小可能不會太大,但是當它被解壓縮時,它可以增長 10 倍或更多,在此之上表示哈希表中的數據會占用更多空間. 因此,表在hdfs上壓縮后的存儲空間可能小于25MB( hive.mapjoin.smalltable.filesize 設置的值),但它的解壓縮后,數據可能遠遠超過25嗎,這就是 hive 嘗試將表加載到內存中的原因,最終導致OutOfMemoryError 異常. 這是MapJoin在設計時候考慮不周到的地方(對于壓縮表沒有檢查表是否是壓縮表以及表的潛在大小可以是多少)。
五、 解決方案
明白了問題根源,那么解決問題的核心主要是圍繞表大小檢測,在針對壓縮表的情況下如何檢測到表的真正大小。
比較可惜的是目前Hadoop壓縮庫snappy并沒有提供在未解壓的情況下針對固定表或者目錄計算解壓后大小的API,但是snappy的JAVA-API庫(xerial)進行身份信息解碼提供了一個uncompressedLength的方法,用于在解壓的時候提前分配內存空間,這樣針對壓縮表大小預估的代碼可以這樣改
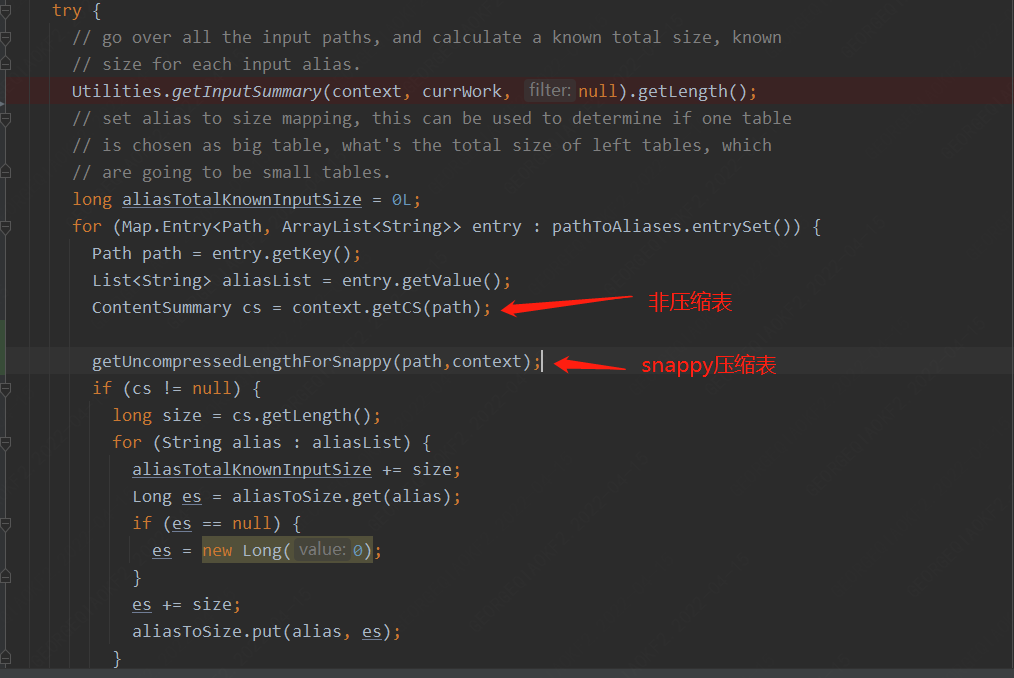
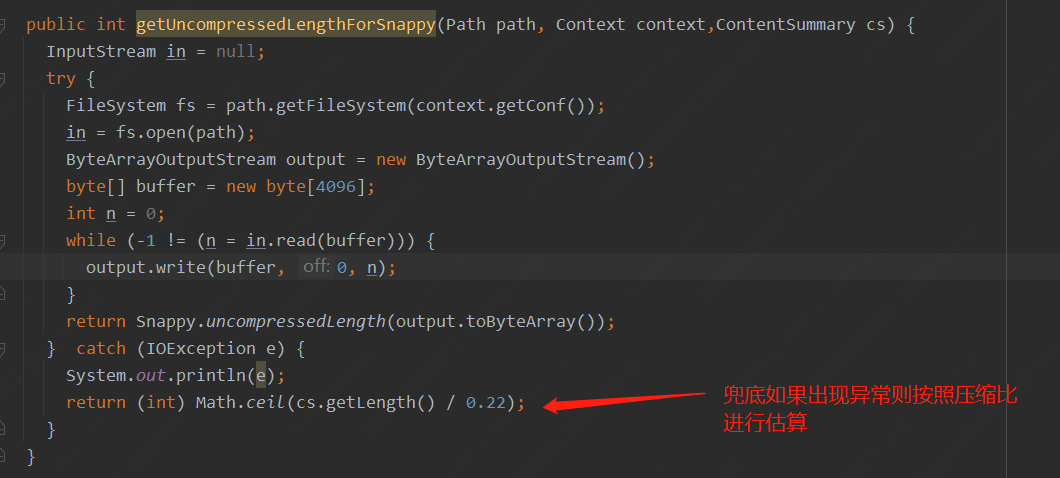
六、 總結雖然對于此類問題我們可以通過調整參數,例如增大mapjoin內存,調整內存占用比,甚至關閉mapjoin來解決此問題,但是治標不治本,單個任務調整對用戶來說增加了開發成本,整體集群調整甚至可能對集群性能造成影響,我們需要從原理出發,從根本上解決此問題。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號