
MySQL學(xué)習(xí)筆記
本篇摘錄自黑馬程序員的B站教學(xué)視頻,由本人學(xué)習(xí)視頻內(nèi)容后總結(jié)并提取摘要制作而成的簡要筆記。
黑馬程序員黑馬程序員 MySQL數(shù)據(jù)庫入門到精通,從mysql安裝到mysql高級、mysql優(yōu)化全囊括
本筆記只記錄到進階篇(大部分),剩下的進階篇以及運維篇由于本人職業(yè)生涯沒有用武之地,所以沒有進行學(xué)習(xí)。
在此非常感謝兩位熱愛學(xué)習(xí)的小伙伴的鼎力相助,幫助我們完成了所有的章節(jié)內(nèi)容,使得本篇超長筆記得以完結(jié)。至此,整個MySQL筆記從入門到高級的所有內(nèi)容都已編寫完畢。
特別感謝:
- wlh (wen-lh) - Gitee.com
- B站同學(xué):@守心-人
基礎(chǔ)篇
通用語法及分類
- DDL: 數(shù)據(jù)定義語言,用來定義數(shù)據(jù)庫對象(數(shù)據(jù)庫、表、字段)
- DML: 數(shù)據(jù)操作語言,用來對數(shù)據(jù)庫表中的數(shù)據(jù)進行增刪改
- DQL: 數(shù)據(jù)查詢語言,用來查詢數(shù)據(jù)庫中表的記錄
- DCL: 數(shù)據(jù)控制語言,用來創(chuàng)建數(shù)據(jù)庫用戶、控制數(shù)據(jù)庫的控制權(quán)限
DDL(數(shù)據(jù)定義語言)
數(shù)據(jù)定義語言
數(shù)據(jù)庫操作
查詢所有數(shù)據(jù)庫:SHOW DATABASES;
查詢當前數(shù)據(jù)庫:SELECT DATABASE();
創(chuàng)建數(shù)據(jù)庫:CREATE DATABASE [ IF NOT EXISTS ] 數(shù)據(jù)庫名 [ DEFAULT CHARSET 字符集] [COLLATE 排序規(guī)則 ];
刪除數(shù)據(jù)庫:DROP DATABASE [ IF EXISTS ] 數(shù)據(jù)庫名;
使用數(shù)據(jù)庫:USE 數(shù)據(jù)庫名;
注意事項
- UTF8字符集長度為3字節(jié),有些符號占4字節(jié),所以推薦用utf8mb4字符集
表操作
查詢當前數(shù)據(jù)庫所有表:SHOW TABLES;
查詢表結(jié)構(gòu):DESC 表名;
查詢指定表的建表語句:SHOW CREATE TABLE 表名;
創(chuàng)建表:
CREATE TABLE 表名(
|
最后一個字段后面沒有逗號
添加字段:ALTER TABLE 表名 ADD 字段名 類型(長度) [COMMENT 注釋] [約束];
例:ALTER TABLE emp ADD nickname varchar(20) COMMENT '昵稱';
修改數(shù)據(jù)類型:ALTER TABLE 表名 MODIFY 字段名 新數(shù)據(jù)類型(長度);
修改字段名和字段類型:ALTER TABLE 表名 CHANGE 舊字段名 新字段名 類型(長度) [COMMENT 注釋] [約束];
例:將emp表的nickname字段修改為username,類型為varchar(30)ALTER TABLE emp CHANGE nickname username varchar(30) COMMENT '昵稱';
刪除字段:ALTER TABLE 表名 DROP 字段名;
修改表名:ALTER TABLE 表名 RENAME TO 新表名
刪除表:DROP TABLE [IF EXISTS] 表名;
刪除表,并重新創(chuàng)建該表:TRUNCATE TABLE 表名;
DML(數(shù)據(jù)操作語言)
添加數(shù)據(jù)
指定字段:INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);
全部字段:INSERT INTO 表名 VALUES (值1, 值2, ...);
批量添加數(shù)據(jù):INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...);INSERT INTO 表名 VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...);
注意事項
- 字符串和日期類型數(shù)據(jù)應(yīng)該包含在引號中
- 插入的數(shù)據(jù)大小應(yīng)該在字段的規(guī)定范圍內(nèi)
更新和刪除數(shù)據(jù)
修改數(shù)據(jù):UPDATE 表名 SET 字段名1 = 值1, 字段名2 = 值2, ... [ WHERE 條件 ];
例:UPDATE emp SET name = 'Jack' WHERE id = 1;
刪除數(shù)據(jù):DELETE FROM 表名 [ WHERE 條件 ];
DQL(數(shù)據(jù)查詢語言)
語法:
SELECT
|
基礎(chǔ)查詢
查詢多個字段:SELECT 字段1, 字段2, 字段3, ... FROM 表名;SELECT * FROM 表名;
設(shè)置別名:SELECT 字段1 [ AS 別名1 ], 字段2 [ AS 別名2 ], 字段3 [ AS 別名3 ], ... FROM 表名;SELECT 字段1 [ 別名1 ], 字段2 [ 別名2 ], 字段3 [ 別名3 ], ... FROM 表名;
去除重復(fù)記錄:SELECT DISTINCT 字段列表 FROM 表名;
轉(zhuǎn)義:SELECT * FROM 表名 WHERE name LIKE '/_張三' ESCAPE '/'
/ 之后的_不作為通配符
條件查詢
語法:SELECT 字段列表 FROM 表名 WHERE 條件列表;
條件:
| 比較運算符 | 功能 |
|---|---|
| > | 大于 |
| >= | 大于等于 |
| < | 小于 |
| <= | 小于等于 |
| = | 等于 |
| <> 或 != | 不等于 |
| BETWEEN … AND … | 在某個范圍內(nèi)(含最小、最大值) |
| IN(…) | 在in之后的列表中的值,多選一 |
| LIKE 占位符 | 模糊匹配(_匹配單個字符,%匹配任意個字符) |
| IS NULL | 是NULL |
| 邏輯運算符 | 功能 |
|---|---|
| AND 或 && | 并且(多個條件同時成立) |
| OR 或 || | 或者(多個條件任意一個成立) |
| NOT 或 ! | 非,不是 |
例子:
-- 年齡等于30
|
聚合查詢(聚合函數(shù))
常見聚合函數(shù):
| 函數(shù) | 功能 |
|---|---|
| count | 統(tǒng)計數(shù)量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
語法:SELECT 聚合函數(shù)(字段列表) FROM 表名;
例:SELECT count(id) from employee where workaddress = "廣東省";
分組查詢
語法:SELECT 字段列表 FROM 表名 [ WHERE 條件 ] GROUP BY 分組字段名 [ HAVING 分組后的過濾條件 ];
where 和 having 的區(qū)別:
- 執(zhí)行時機不同:where是分組之前進行過濾,不滿足where條件不參與分組;having是分組后對結(jié)果進行過濾。
- 判斷條件不同:where不能對聚合函數(shù)進行判斷,而having可以。
例子:
-- 根據(jù)性別分組,統(tǒng)計男性和女性數(shù)量(只顯示分組數(shù)量,不顯示哪個是男哪個是女)
|
注意事項
- 執(zhí)行順序:where > 聚合函數(shù) > having
- 分組之后,查詢的字段一般為聚合函數(shù)和分組字段,查詢其他字段無任何意義
排序查詢
語法:SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1, 字段2 排序方式2;
排序方式:
- ASC: 升序(默認)
- DESC: 降序
例子:
-- 根據(jù)年齡升序排序
|
注意事項
如果是多字段排序,當?shù)谝粋€字段值相同時,才會根據(jù)第二個字段進行排序
分頁查詢
語法:SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查詢記錄數(shù);
例子:
-- 查詢第一頁數(shù)據(jù),展示10條
|
注意事項
- 起始索引從0開始,起始索引 = (查詢頁碼 - 1) * 每頁顯示記錄數(shù)
- 分頁查詢是數(shù)據(jù)庫的方言,不同數(shù)據(jù)庫有不同實現(xiàn),MySQL是LIMIT
- 如果查詢的是第一頁數(shù)據(jù),起始索引可以省略,直接簡寫 LIMIT 10
DQL執(zhí)行順序
FROM -> WHERE -> GROUP BY -> SELECT -> ORDER BY -> LIMIT
DCL
管理用戶
查詢用戶:
USE mysql;
|
創(chuàng)建用戶:CREATE USER '用戶名'@'主機名' IDENTIFIED BY '密碼';
修改用戶密碼:ALTER USER '用戶名'@'主機名' IDENTIFIED WITH mysql_native_password BY '新密碼';
刪除用戶:DROP USER '用戶名'@'主機名';
例子:
-- 創(chuàng)建用戶test,只能在當前主機localhost訪問
|
注意事項
- 主機名可以使用 % 通配
權(quán)限控制
常用權(quán)限:
| 權(quán)限 | 說明 |
|---|---|
| ALL, ALL PRIVILEGES | 所有權(quán)限 |
| SELECT | 查詢數(shù)據(jù) |
| INSERT | 插入數(shù)據(jù) |
| UPDATE | 修改數(shù)據(jù) |
| DELETE | 刪除數(shù)據(jù) |
| ALTER | 修改表 |
| DROP | 刪除數(shù)據(jù)庫/表/視圖 |
| CREATE | 創(chuàng)建數(shù)據(jù)庫/表 |
更多權(quán)限請看權(quán)限一覽表
查詢權(quán)限:SHOW GRANTS FOR '用戶名'@'主機名';
授予權(quán)限:GRANT 權(quán)限列表 ON 數(shù)據(jù)庫名.表名 TO '用戶名'@'主機名';
撤銷權(quán)限:REVOKE 權(quán)限列表 ON 數(shù)據(jù)庫名.表名 FROM '用戶名'@'主機名';
注意事項
- 多個權(quán)限用逗號分隔
- 授權(quán)時,數(shù)據(jù)庫名和表名可以用 * 進行通配,代表所有
函數(shù)
- 字符串函數(shù)
- 數(shù)值函數(shù)
- 日期函數(shù)
- 流程函數(shù)
字符串函數(shù)
常用函數(shù):
| 函數(shù) | 功能 |
|---|---|
| CONCAT(s1, s2, …, sn) | 字符串拼接,將s1, s2, …, sn拼接成一個字符串 |
| LOWER(str) | 將字符串全部轉(zhuǎn)為小寫 |
| UPPER(str) | 將字符串全部轉(zhuǎn)為大寫 |
| LPAD(str, n, pad) | 左填充,用字符串pad對str的左邊進行填充,達到n個字符串長度 |
| RPAD(str, n, pad) | 右填充,用字符串pad對str的右邊進行填充,達到n個字符串長度 |
| TRIM(str) | 去掉字符串頭部和尾部的空格 |
| SUBSTRING(str, start, len) | 返回從字符串str從start位置起的len個長度的字符串 |
| REPLACE(column, source, replace) | 替換字符串 |
使用示例:
-- 拼接
|
數(shù)值函數(shù)
常見函數(shù):
| 函數(shù) | 功能 |
|---|---|
| CEIL(x) | 向上取整 |
| FLOOR(x) | 向下取整 |
| MOD(x, y) | 返回x/y的模 |
| RAND() | 返回0~1內(nèi)的隨機數(shù) |
| ROUND(x, y) | 求參數(shù)x的四舍五入值,保留y位小數(shù) |
日期函數(shù)
常用函數(shù):
| 函數(shù) | 功能 |
|---|---|
| CURDATE() | 返回當前日期 |
| CURTIME() | 返回當前時間 |
| NOW() | 返回當前日期和時間 |
| YEAR(date) | 獲取指定date的年份 |
| MONTH(date) | 獲取指定date的月份 |
| DAY(date) | 獲取指定date的日期 |
| DATE_ADD(date, INTERVAL expr type) | 返回一個日期/時間值加上一個時間間隔expr后的時間值 |
| DATEDIFF(date1, date2) | 返回起始時間date1和結(jié)束時間date2之間的天數(shù) |
例子:
-- DATE_ADD
|
流程函數(shù)
常用函數(shù):
| 函數(shù) | 功能 |
|---|---|
| IF(value, t, f) | 如果value為true,則返回t,否則返回f |
| IFNULL(value1, value2) | 如果value1不為空,返回value1,否則返回value2 |
| CASE WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果val1為true,返回res1,… 否則返回default默認值 |
| CASE [ expr ] WHEN [ val1 ] THEN [ res1 ] … ELSE [ default ] END | 如果expr的值等于val1,返回res1,… 否則返回default默認值 |
例子:
select
|
約束
分類:
| 約束 | 描述 | 關(guān)鍵字 |
|---|---|---|
| 非空約束 | 限制該字段的數(shù)據(jù)不能為null | NOT NULL |
| 唯一約束 | 保證該字段的所有數(shù)據(jù)都是唯一、不重復(fù)的 | UNIQUE |
| 主鍵約束 | 主鍵是一行數(shù)據(jù)的唯一標識,要求非空且唯一 | PRIMARY KEY |
| 默認約束 | 保存數(shù)據(jù)時,如果未指定該字段的值,則采用默認值 | DEFAULT |
| 檢查約束(8.0.1版本后) | 保證字段值滿足某一個條件 | CHECK |
| 外鍵約束 | 用來讓兩張圖的數(shù)據(jù)之間建立連接,保證數(shù)據(jù)的一致性和完整性 | FOREIGN KEY |
約束是作用于表中字段上的,可以再創(chuàng)建表/修改表的時候添加約束。
常用約束
| 約束條件 | 關(guān)鍵字 |
|---|---|
| 主鍵 | PRIMARY KEY |
| 自動增長 | AUTO_INCREMENT |
| 不為空 | NOT NULL |
| 唯一 | UNIQUE |
| 邏輯條件 | CHECK |
| 默認值 | DEFAULT |
例子:
create table user(
|
外鍵約束
添加外鍵:
CREATE TABLE 表名(
|
刪除外鍵:ALTER TABLE 表名 DROP FOREIGN KEY 外鍵名;
刪除/更新行為
| 行為 | 說明 |
|---|---|
| NO ACTION | 當在父表中刪除/更新對應(yīng)記錄時,首先檢查該記錄是否有對應(yīng)外鍵,如果有則不允許刪除/更新(與RESTRICT一致) |
| RESTRICT | 當在父表中刪除/更新對應(yīng)記錄時,首先檢查該記錄是否有對應(yīng)外鍵,如果有則不允許刪除/更新(與NO ACTION一致) |
| CASCADE | 當在父表中刪除/更新對應(yīng)記錄時,首先檢查該記錄是否有對應(yīng)外鍵,如果有則也刪除/更新外鍵在子表中的記錄 |
| SET NULL | 當在父表中刪除/更新對應(yīng)記錄時,首先檢查該記錄是否有對應(yīng)外鍵,如果有則設(shè)置子表中該外鍵值為null(要求該外鍵允許為null) |
| SET DEFAULT | 父表有變更時,子表將外鍵設(shè)為一個默認值(Innodb不支持) |
更改刪除/更新行為:ALTER TABLE 表名 ADD CONSTRAINT 外鍵名稱 FOREIGN KEY (外鍵字段) REFERENCES 主表名(主表字段名) ON UPDATE 行為 ON DELETE 行為;
多表查詢
多表關(guān)系
- 一對多(多對一)
- 多對多
- 一對一
一對多
案例:部門與員工
關(guān)系:一個部門對應(yīng)多個員工,一個員工對應(yīng)一個部門
實現(xiàn):在多的一方建立外鍵,指向一的一方的主鍵
多對多
案例:學(xué)生與課程
關(guān)系:一個學(xué)生可以選多門課程,一門課程也可以供多個學(xué)生選修
實現(xiàn):建立第三張中間表,中間表至少包含兩個外鍵,分別關(guān)聯(lián)兩方主鍵
一對一
案例:用戶與用戶詳情
關(guān)系:一對一關(guān)系,多用于單表拆分,將一張表的基礎(chǔ)字段放在一張表中,其他詳情字段放在另一張表中,以提升操作效率
實現(xiàn):在任意一方加入外鍵,關(guān)聯(lián)另外一方的主鍵,并且設(shè)置外鍵為唯一的(UNIQUE)
查詢
合并查詢(笛卡爾積,會展示所有組合結(jié)果):select * from employee, dept;
笛卡爾積:兩個集合A集合和B集合的所有組合情況(在多表查詢時,需要消除無效的笛卡爾積)
消除無效笛卡爾積:select * from employee, dept where employee.dept = dept.id;
內(nèi)連接查詢
內(nèi)連接查詢的是兩張表交集的部分
隱式內(nèi)連接:SELECT 字段列表 FROM 表1, 表2 WHERE 條件 ...;
顯式內(nèi)連接:SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 連接條件 ...;
顯式性能比隱式高
例子:
-- 查詢員工姓名,及關(guān)聯(lián)的部門的名稱
|
外連接查詢
左外連接:
查詢左表所有數(shù)據(jù),以及兩張表交集部分數(shù)據(jù)SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 條件 ...;
相當于查詢表1的所有數(shù)據(jù),包含表1和表2交集部分數(shù)據(jù)
右外連接:
查詢右表所有數(shù)據(jù),以及兩張表交集部分數(shù)據(jù)SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 條件 ...;
例子:
-- 左
|
左連接可以查詢到?jīng)]有dept的employee,右連接可以查詢到?jīng)]有employee的dept
自連接查詢
當前表與自身的連接查詢,自連接必須使用表別名
語法:SELECT 字段列表 FROM 表A 別名A JOIN 表A 別名B ON 條件 ...;
自連接查詢,可以是內(nèi)連接查詢,也可以是外連接查詢
例子:
-- 查詢員工及其所屬領(lǐng)導(dǎo)的名字
|
聯(lián)合查詢 union, union all
把多次查詢的結(jié)果合并,形成一個新的查詢集
語法:
SELECT 字段列表 FROM 表A ...
|
注意事項
- UNION ALL 會有重復(fù)結(jié)果,UNION 不會
- 聯(lián)合查詢比使用or效率高,不會使索引失效
子查詢
SQL語句中嵌套SELECT語句,稱謂嵌套查詢,又稱子查詢。SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2);
子查詢外部的語句可以是 INSERT / UPDATE / DELETE / SELECT 的任何一個
根據(jù)子查詢結(jié)果可以分為:
- 標量子查詢(子查詢結(jié)果為單個值)
- 列子查詢(子查詢結(jié)果為一列)
- 行子查詢(子查詢結(jié)果為一行)
- 表子查詢(子查詢結(jié)果為多行多列)
根據(jù)子查詢位置可分為:
- WHERE 之后
- FROM 之后
- SELECT 之后
標量子查詢
子查詢返回的結(jié)果是單個值(數(shù)字、字符串、日期等)。
常用操作符:- < > > >= < <=
例子:
-- 查詢銷售部所有員工
|
列子查詢
返回的結(jié)果是一列(可以是多行)。
常用操作符:
| 操作符 | 描述 |
|---|---|
| IN | 在指定的集合范圍內(nèi),多選一 |
| NOT IN | 不在指定的集合范圍內(nèi) |
| ANY | 子查詢返回列表中,有任意一個滿足即可 |
| SOME | 與ANY等同,使用SOME的地方都可以使用ANY |
| ALL | 子查詢返回列表的所有值都必須滿足 |
例子:
-- 查詢銷售部和市場部的所有員工信息
|
行子查詢
返回的結(jié)果是一行(可以是多列)。
常用操作符:=, <, >, IN, NOT IN
例子:
-- 查詢與xxx的薪資及直屬領(lǐng)導(dǎo)相同的員工信息
|
表子查詢
返回的結(jié)果是多行多列
常用操作符:IN
例子:
-- 查詢與xxx1,xxx2的職位和薪資相同的員工
|
事務(wù)
事務(wù)是一組操作的集合,事務(wù)會把所有操作作為一個整體一起向系統(tǒng)提交或撤銷操作請求,即這些操作要么同時成功,要么同時失敗。
基本操作:
-- 1. 查詢張三賬戶余額
|
操作方式二:
開啟事務(wù):START TRANSACTION 或 BEGIN TRANSACTION;
提交事務(wù):COMMIT;
回滾事務(wù):ROLLBACK;
操作實例:
start transaction;
|
四大特性ACID
- 原子性(Atomicity):事務(wù)是不可分割的最小操作單元,要么全部成功,要么全部失敗
- 一致性(Consistency):事務(wù)完成時,必須使所有數(shù)據(jù)都保持一致狀態(tài)
- 隔離性(Isolation):數(shù)據(jù)庫系統(tǒng)提供的隔離機制,保證事務(wù)在不受外部并發(fā)操作影響的獨立環(huán)境下運行
- 持久性(Durability):事務(wù)一旦提交或回滾,它對數(shù)據(jù)庫中的數(shù)據(jù)的改變就是永久的
并發(fā)事務(wù)
| 問題 | 描述 |
|---|---|
| 臟讀 | 一個事務(wù)讀到另一個事務(wù)還沒提交的數(shù)據(jù) |
| 不可重復(fù)讀 | 一個事務(wù)先后讀取同一條記錄,但兩次讀取的數(shù)據(jù)不同 |
| 幻讀 | 一個事務(wù)按照條件查詢數(shù)據(jù)時,沒有對應(yīng)的數(shù)據(jù)行,但是再插入數(shù)據(jù)時,又發(fā)現(xiàn)這行數(shù)據(jù)已經(jīng)存在 |
這三個問題的詳細演示:https://www.bilibili.com/video/BV1Kr4y1i7ru?p=55cd
并發(fā)事務(wù)隔離級別:
| 隔離級別 | 臟讀 | 不可重復(fù)讀 | 幻讀 |
|---|---|---|---|
| Read uncommitted | √ | √ | √ |
| Read committed | × | √ | √ |
| Repeatable Read(默認) | × | × | √ |
| Serializable | × | × | × |
- √表示在當前隔離級別下該問題會出現(xiàn)
- Serializable 性能最低;Read uncommitted 性能最高,數(shù)據(jù)安全性最差
查看事務(wù)隔離級別:SELECT @@TRANSACTION_ISOLATION;
設(shè)置事務(wù)隔離級別:SET [ SESSION | GLOBAL ] TRANSACTION ISOLATION LEVEL {READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE };
SESSION 是會話級別,表示只針對當前會話有效,GLOBAL 表示對所有會話有效
進階篇
存儲引擎
MySQL體系結(jié)構(gòu):
構(gòu)圖")

存儲引擎就是存儲數(shù)據(jù)、建立索引、更新/查詢數(shù)據(jù)等技術(shù)的實現(xiàn)方式。存儲引擎是基于表而不是基于庫的,所以存儲引擎也可以被稱為表引擎。
默認存儲引擎是InnoDB。
相關(guān)操作:
-- 查詢建表語句
|
InnoDB
InnoDB 是一種兼顧高可靠性和高性能的通用存儲引擎,在 MySQL 5.5 之后,InnoDB 是默認的 MySQL 引擎
特點:
- DML 操作遵循 ACID 模型,支持事務(wù)
- 行級鎖,提高并發(fā)訪問性能
- 支持外鍵約束,保證數(shù)據(jù)的完整性和正確性
文件:
- xxx.ibd: xxx代表表名,InnoDB 引擎的每張表都會對應(yīng)這樣一個表空間文件,存儲該表的表結(jié)構(gòu)(frm、sdi)、數(shù)據(jù)和索引。
參數(shù):innodb_file_per_table,決定多張表共享一個表空間還是每張表對應(yīng)一個表空間
知識點:
查看 Mysql 變量:show variables like 'innodb_file_per_table';
從idb文件提取表結(jié)構(gòu)數(shù)據(jù):
(在cmd運行)ibd2sdi xxx.ibd
InnoDB 邏輯存儲結(jié)構(gòu):構(gòu)")
MyISAM
MyISAM 是 MySQL 早期的默認存儲引擎。
特點:
- 不支持事務(wù),不支持外鍵
- 支持表鎖,不支持行鎖
- 訪問速度快
文件:
- xxx.sdi: 存儲表結(jié)構(gòu)信息
- xxx.MYD: 存儲數(shù)據(jù)
- xxx.MYI: 存儲索引
Memory
Memory 引擎的表數(shù)據(jù)是存儲在內(nèi)存中的,受硬件問題、斷電問題的影響,只能將這些表作為臨時表或緩存使用。
特點:
- 存放在內(nèi)存中,速度快
- hash索引(默認)
文件:
- xxx.sdi: 存儲表結(jié)構(gòu)信息
存儲引擎特點
| 特點 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| 存儲限制 | 64TB | 有 | 有 |
| 事務(wù)安全 | 支持 | - | - |
| 鎖機制 | 行鎖 | 表鎖 | 表鎖 |
| B+tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | - | - | 支持 |
| 全文索引 | 支持(5.6版本之后) | 支持 | - |
| 空間使用 | 高 | 低 | N/A |
| 內(nèi)存使用 | 高 | 低 | 中等 |
| 批量插入速度 | 低 | 高 | 高 |
| 支持外鍵 | 支持 | - | - |
存儲引擎的選擇
在選擇存儲引擎時,應(yīng)該根據(jù)應(yīng)用系統(tǒng)的特點選擇合適的存儲引擎。對于復(fù)雜的應(yīng)用系統(tǒng),還可以根據(jù)實際情況選擇多種存儲引擎進行組合。
- InnoDB: 如果應(yīng)用對事物的完整性有比較高的要求,在并發(fā)條件下要求數(shù)據(jù)的一致性,數(shù)據(jù)操作除了插入和查詢之外,還包含很多的更新、刪除操作,則 InnoDB 是比較合適的選擇
- MyISAM: 如果應(yīng)用是以讀操作和插入操作為主,只有很少的更新和刪除操作,并且對事務(wù)的完整性、并發(fā)性要求不高,那這個存儲引擎是非常合適的。
- Memory: 將所有數(shù)據(jù)保存在內(nèi)存中,訪問速度快,通常用于臨時表及緩存。Memory 的缺陷是對表的大小有限制,太大的表無法緩存在內(nèi)存中,而且無法保障數(shù)據(jù)的安全性
電商中的足跡和評論適合使用 MyISAM 引擎,緩存適合使用 Memory 引擎。
性能分析
查看執(zhí)行頻次
查看當前數(shù)據(jù)庫的 INSERT, UPDATE, DELETE, SELECT 訪問頻次:SHOW GLOBAL STATUS LIKE 'Com_______'; 或者 SHOW SESSION STATUS LIKE 'Com_______';
例:show global status like 'Com_______'
profile
show profile 能在做SQL優(yōu)化時幫我們了解時間都耗費在哪里。通過 have_profiling 參數(shù),能看到當前 MySQL 是否支持 profile 操作:SELECT @@have_profiling;
profiling 默認關(guān)閉,可以通過set語句在session/global級別開啟 profiling:SET profiling = 1;
查看所有語句的耗時:show profiles;
查看指定query_id的SQL語句各個階段的耗時:show profile for query query_id;
查看指定query_id的SQL語句CPU的使用情況show profile cpu for query query_id;
explain
EXPLAIN 或者 DESC 命令獲取 MySQL 如何執(zhí)行 SELECT 語句的信息,包括在 SELECT 語句執(zhí)行過程中表如何連接和連接的順序。
語法:
# 直接在select語句之前加上關(guān)鍵字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 HWERE 條件;
EXPLAIN 各字段含義:
- id:select 查詢的序列號,表示查詢中執(zhí)行 select 子句或者操作表的順序(id相同,執(zhí)行順序從上到下;id不同,值越大越先執(zhí)行)
- select_type:表示 SELECT 的類型,常見取值有 SIMPLE(簡單表,即不適用表連接或者子查詢)、PRIMARY(主查詢,即外層的查詢)、UNION(UNION中的第二個或者后面的查詢語句)、SUBQUERY(SELECT/WHERE之后包含了子查詢)等
- type:表示連接類型,性能由好到差的連接類型為 NULL、system、const、eq_ref、ref、range、index、all
- possible_key:可能應(yīng)用在這張表上的索引,一個或多個
- Key:實際使用的索引,如果為 NULL,則沒有使用索引
- Key_len:表示索引中使用的字節(jié)數(shù),該值為索引字段最大可能長度,并非實際使用長度,在不損失精確性的前提下,長度越短越好
- rows:MySQL認為必須要執(zhí)行的行數(shù),在InnoDB引擎的表中,是一個估計值,可能并不總是準確的
- filtered:表示返回結(jié)果的行數(shù)占需讀取行數(shù)的百分比,filtered的值越大越好
索引
索引是幫助 MySQL 高效獲取數(shù)據(jù)的數(shù)據(jù)結(jié)構(gòu)(有序)。在數(shù)據(jù)之外,數(shù)據(jù)庫系統(tǒng)還維護著滿足特定查找算法的數(shù)據(jù)結(jié)構(gòu),這些數(shù)據(jù)結(jié)構(gòu)以某種方式引用(指向)數(shù)據(jù),這樣就可以在這些數(shù)據(jù)結(jié)構(gòu)上實現(xiàn)高級查詢算法,這種數(shù)據(jù)結(jié)構(gòu)就是索引。
優(yōu)缺點:
優(yōu)點:
- 提高數(shù)據(jù)檢索效率,降低數(shù)據(jù)庫的IO成本
- 通過索引列對數(shù)據(jù)進行排序,降低數(shù)據(jù)排序的成本,降低CPU的消耗
缺點:
- 索引列也是要占用空間的
- 索引大大提高了查詢效率,但降低了更新的速度,比如 INSERT、UPDATE、DELETE
索引結(jié)構(gòu)
| 索引結(jié)構(gòu) | 描述 |
|---|---|
| B+Tree | 最常見的索引類型,大部分引擎都支持B+樹索引 |
| Hash | 底層數(shù)據(jù)結(jié)構(gòu)是用哈希表實現(xiàn),只有精確匹配索引列的查詢才有效,不支持范圍查詢 |
| R-Tree(空間索引) | 空間索引是 MyISAM 引擎的一個特殊索引類型,主要用于地理空間數(shù)據(jù)類型,通常使用較少 |
| Full-Text(全文索引) | 是一種通過建立倒排索引,快速匹配文檔的方式,類似于 Lucene, Solr, ES |
| 索引 | InnoDB | MyISAM | Memory |
|---|---|---|---|
| B+Tree索引 | 支持 | 支持 | 支持 |
| Hash索引 | 不支持 | 不支持 | 支持 |
| R-Tree索引 | 不支持 | 支持 | 不支持 |
| Full-text | 5.6版本后支持 | 支持 | 不支持 |
B-Tree

二叉樹的缺點可以用紅黑樹來解決:
紅黑樹也存在大數(shù)據(jù)量情況下,層級較深,檢索速度慢的問題。
為了解決上述問題,可以使用 B-Tree 結(jié)構(gòu)。
B-Tree (多路平衡查找樹) 以一棵最大度數(shù)(max-degree,指一個節(jié)點的子節(jié)點個數(shù))為5(5階)的 b-tree 為例(每個節(jié)點最多存儲4個key,5個指針)
構(gòu)")
B-Tree 的數(shù)據(jù)插入過程動畫參照:https://www.bilibili.com/video/BV1Kr4y1i7ru?p=68
演示地址:https://www.cs.usfca.edu/~galles/visualization/BTree.html
B+Tree
結(jié)構(gòu)圖:
構(gòu)圖")
演示地址:https://www.cs.usfca.edu/~galles/visualization/BPlusTree.html
與 B-Tree 的區(qū)別:
- 所有的數(shù)據(jù)都會出現(xiàn)在葉子節(jié)點
- 葉子節(jié)點形成一個單向鏈表
MySQL 索引數(shù)據(jù)結(jié)構(gòu)對經(jīng)典的 B+Tree 進行了優(yōu)化。在原 B+Tree 的基礎(chǔ)上,增加一個指向相鄰葉子節(jié)點的鏈表指針,就形成了帶有順序指針的 B+Tree,提高區(qū)間訪問的性能。
構(gòu)圖")
Hash
哈希索引就是采用一定的hash算法,將鍵值換算成新的hash值,映射到對應(yīng)的槽位上,然后存儲在hash表中。
如果兩個(或多個)鍵值,映射到一個相同的槽位上,他們就產(chǎn)生了hash沖突(也稱為hash碰撞),可以通過鏈表來解決。
特點:
- Hash索引只能用于對等比較(=、in),不支持范圍查詢(betwwn、>、<、…)
- 無法利用索引完成排序操作
- 查詢效率高,通常只需要一次檢索就可以了,效率通常要高于 B+Tree 索引
存儲引擎支持:
- Memory
- InnoDB: 具有自適應(yīng)hash功能,hash索引是存儲引擎根據(jù) B+Tree 索引在指定條件下自動構(gòu)建的
面試題
- 為什么 InnoDB 存儲引擎選擇使用 B+Tree 索引結(jié)構(gòu)?
- 相對于二叉樹,層級更少,搜索效率高
- 對于 B-Tree,無論是葉子節(jié)點還是非葉子節(jié)點,都會保存數(shù)據(jù),這樣導(dǎo)致一頁中存儲的鍵值減少,指針也跟著減少,要同樣保存大量數(shù)據(jù),只能增加樹的高度,導(dǎo)致性能降低
- 相對于 Hash 索引,B+Tree 支持范圍匹配及排序操作
索引分類
| 分類 | 含義 | 特點 | 關(guān)鍵字 |
|---|---|---|---|
| 主鍵索引 | 針對于表中主鍵創(chuàng)建的索引 | 默認自動創(chuàng)建,只能有一個 | PRIMARY |
| 唯一索引 | 避免同一個表中某數(shù)據(jù)列中的值重復(fù) | 可以有多個 | UNIQUE |
| 常規(guī)索引 | 快速定位特定數(shù)據(jù) | 可以有多個 | |
| 全文索引 | 全文索引查找的是文本中的關(guān)鍵詞,而不是比較索引中的值 | 可以有多個 | FULLTEXT |
在 InnoDB 存儲引擎中,根據(jù)索引的存儲形式,又可以分為以下兩種:
| 分類 | 含義 | 特點 |
|---|---|---|
| 聚集索引(Clustered Index) | 將數(shù)據(jù)存儲與索引放一塊,索引結(jié)構(gòu)的葉子節(jié)點保存了行數(shù)據(jù) | 必須有,而且只有一個 |
| 二級索引(Secondary Index) | 將數(shù)據(jù)與索引分開存儲,索引結(jié)構(gòu)的葉子節(jié)點關(guān)聯(lián)的是對應(yīng)的主鍵 | 可以存在多個 |
演示圖:


聚集索引選取規(guī)則:
- 如果存在主鍵,主鍵索引就是聚集索引
- 如果不存在主鍵,將使用第一個唯一(UNIQUE)索引作為聚集索引
- 如果表沒有主鍵或沒有合適的唯一索引,則 InnoDB 會自動生成一個 rowid 作為隱藏的聚集索引
思考題
1. 以下 SQL 語句,哪個執(zhí)行效率高?為什么?
select * from user where id = 10;
|
答:第一條語句,因為第二條需要回表查詢,相當于兩個步驟。
2. InnoDB 主鍵索引的 B+Tree 高度為多少?
答:假設(shè)一行數(shù)據(jù)大小為1k,一頁中可以存儲16行這樣的數(shù)據(jù)。InnoDB 的指針占用6個字節(jié)的空間,主鍵假設(shè)為bigint,占用字節(jié)數(shù)為8.
可得公式:n * 8 + (n + 1) * 6 = 16 * 1024,其中 8 表示 bigint 占用的字節(jié)數(shù),n 表示當前節(jié)點存儲的key的數(shù)量,(n + 1) 表示指針數(shù)量(比key多一個)。算出n約為1170。
如果樹的高度為2,那么他能存儲的數(shù)據(jù)量大概為:1171 * 16 = 18736;
如果樹的高度為3,那么他能存儲的數(shù)據(jù)量大概為:1171 * 1171 * 16 = 21939856。
另外,如果有成千上萬的數(shù)據(jù),那么就要考慮分表,涉及運維篇知識。
語法
創(chuàng)建索引:CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name, ...);
如果不加 CREATE 后面不加索引類型參數(shù),則創(chuàng)建的是常規(guī)索引
查看索引:SHOW INDEX FROM table_name;
刪除索引:DROP INDEX index_name ON table_name;
案例:
-- name字段為姓名字段,該字段的值可能會重復(fù),為該字段創(chuàng)建索引
|
使用規(guī)則
最左前綴法則
如果索引關(guān)聯(lián)了多列(聯(lián)合索引),要遵守最左前綴法則,最左前綴法則指的是查詢從索引的最左列開始,并且不跳過索引中的列。
如果跳躍某一列,索引將部分失效(后面的字段索引失效)。
聯(lián)合索引中,出現(xiàn)范圍查詢(<, >),范圍查詢右側(cè)的列索引失效。可以用>=或者<=來規(guī)避索引失效問題。
索引失效情況
- 在索引列上進行運算操作,索引將失效。如:
explain select * from tb_user where substring(phone, 10, 2) = '15'; - 字符串類型字段使用時,不加引號,索引將失效。如:
explain select * from tb_user where phone = 17799990015;,此處phone的值沒有加引號 - 模糊查詢中,如果僅僅是尾部模糊匹配,索引不會是失效;如果是頭部模糊匹配,索引失效。如:
explain select * from tb_user where profession like '%工程';,前后都有 % 也會失效。 - 用 or 分割開的條件,如果 or 其中一個條件的列沒有索引,那么涉及的索引都不會被用到。
- 如果 MySQL 評估使用索引比全表更慢,則不使用索引。
SQL 提示
是優(yōu)化數(shù)據(jù)庫的一個重要手段,簡單來說,就是在SQL語句中加入一些人為的提示來達到優(yōu)化操作的目的。
例如,使用索引:explain select * from tb_user use index(idx_user_pro) where profession="軟件工程";
不使用哪個索引:explain select * from tb_user ignore index(idx_user_pro) where profession="軟件工程";
必須使用哪個索引:explain select * from tb_user force index(idx_user_pro) where profession="軟件工程";
use 是建議,實際使用哪個索引 MySQL 還會自己權(quán)衡運行速度去更改,force就是無論如何都強制使用該索引。
覆蓋索引&回表查詢
盡量使用覆蓋索引(查詢使用了索引,并且需要返回的列,在該索引中已經(jīng)全部能找到),減少 select *。
explain 中 extra 字段含義:using index condition:查找使用了索引,但是需要回表查詢數(shù)據(jù)using where; using index;:查找使用了索引,但是需要的數(shù)據(jù)都在索引列中能找到,所以不需要回表查詢
如果在聚集索引中直接能找到對應(yīng)的行,則直接返回行數(shù)據(jù),只需要一次查詢,哪怕是select *;如果在輔助索引中找聚集索引,如select id, name from xxx where name='xxx';,也只需要通過輔助索引(name)查找到對應(yīng)的id,返回name和name索引對應(yīng)的id即可,只需要一次查詢;如果是通過輔助索引查找其他字段,則需要回表查詢,如select id, name, gender from xxx where name='xxx';
所以盡量不要用select *,容易出現(xiàn)回表查詢,降低效率,除非有聯(lián)合索引包含了所有字段
面試題:一張表,有四個字段(id, username, password, status),由于數(shù)據(jù)量大,需要對以下SQL語句進行優(yōu)化,該如何進行才是最優(yōu)方案:select id, username, password from tb_user where username='itcast';
解:給username和password字段建立聯(lián)合索引,則不需要回表查詢,直接覆蓋索引
前綴索引
當字段類型為字符串(varchar, text等)時,有時候需要索引很長的字符串,這會讓索引變得很大,查詢時,浪費大量的磁盤IO,影響查詢效率,此時可以只降字符串的一部分前綴,建立索引,這樣可以大大節(jié)約索引空間,從而提高索引效率。
語法:create index idx_xxxx on table_name(columnn(n));
前綴長度:可以根據(jù)索引的選擇性來決定,而選擇性是指不重復(fù)的索引值(基數(shù))和數(shù)據(jù)表的記錄總數(shù)的比值,索引選擇性越高則查詢效率越高,唯一索引的選擇性是1,這是最好的索引選擇性,性能也是最好的。
求選擇性公式:
select count(distinct email) / count(*) from tb_user;
|
show index 里面的sub_part可以看到接取的長度
單列索引&聯(lián)合索引
單列索引:即一個索引只包含單個列
聯(lián)合索引:即一個索引包含了多個列
在業(yè)務(wù)場景中,如果存在多個查詢條件,考慮針對于查詢字段建立索引時,建議建立聯(lián)合索引,而非單列索引。
單列索引情況:explain select id, phone, name from tb_user where phone = '17799990010' and name = '韓信';
這句只會用到phone索引字段
注意事項
- 多條件聯(lián)合查詢時,MySQL優(yōu)化器會評估哪個字段的索引效率更高,會選擇該索引完成本次查詢
設(shè)計原則
- 針對于數(shù)據(jù)量較大,且查詢比較頻繁的表建立索引
- 針對于常作為查詢條件(where)、排序(order by)、分組(group by)操作的字段建立索引
- 盡量選擇區(qū)分度高的列作為索引,盡量建立唯一索引,區(qū)分度越高,使用索引的效率越高
- 如果是字符串類型的字段,字段長度較長,可以針對于字段的特點,建立前綴索引
- 盡量使用聯(lián)合索引,減少單列索引,查詢時,聯(lián)合索引很多時候可以覆蓋索引,節(jié)省存儲空間,避免回表,提高查詢效率
- 要控制索引的數(shù)量,索引并不是多多益善,索引越多,維護索引結(jié)構(gòu)的代價就越大,會影響增刪改的效率
- 如果索引列不能存儲NULL值,請在創(chuàng)建表時使用NOT NULL約束它。當優(yōu)化器知道每列是否包含NULL值時,它可以更好地確定哪個索引最有效地用于查詢
SQL 優(yōu)化
插入數(shù)據(jù)
普通插入:
- 采用批量插入(一次插入的數(shù)據(jù)不建議超過1000條)
- 手動提交事務(wù)
- 主鍵順序插入
大批量插入:
如果一次性需要插入大批量數(shù)據(jù),使用insert語句插入性能較低,此時可以使用MySQL數(shù)據(jù)庫提供的load指令插入。
# 客戶端連接服務(wù)端時,加上參數(shù) --local-infile(這一行在bash/cmd界面輸入)
|
主鍵優(yōu)化
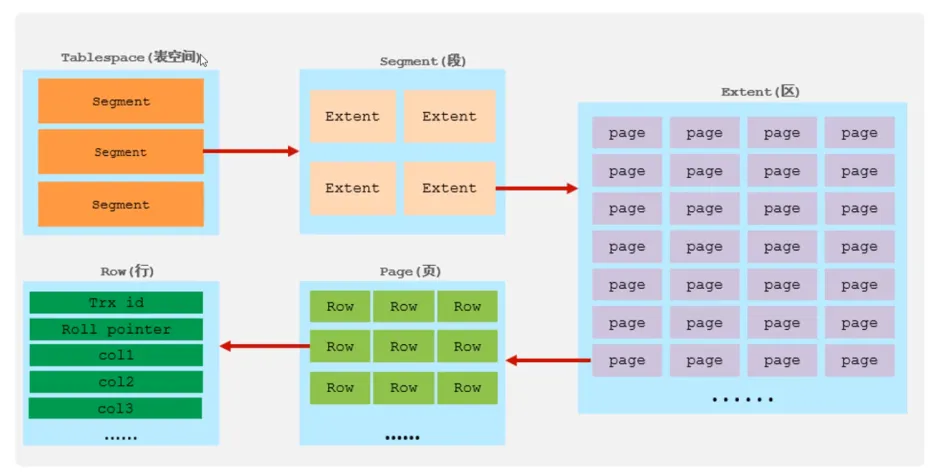
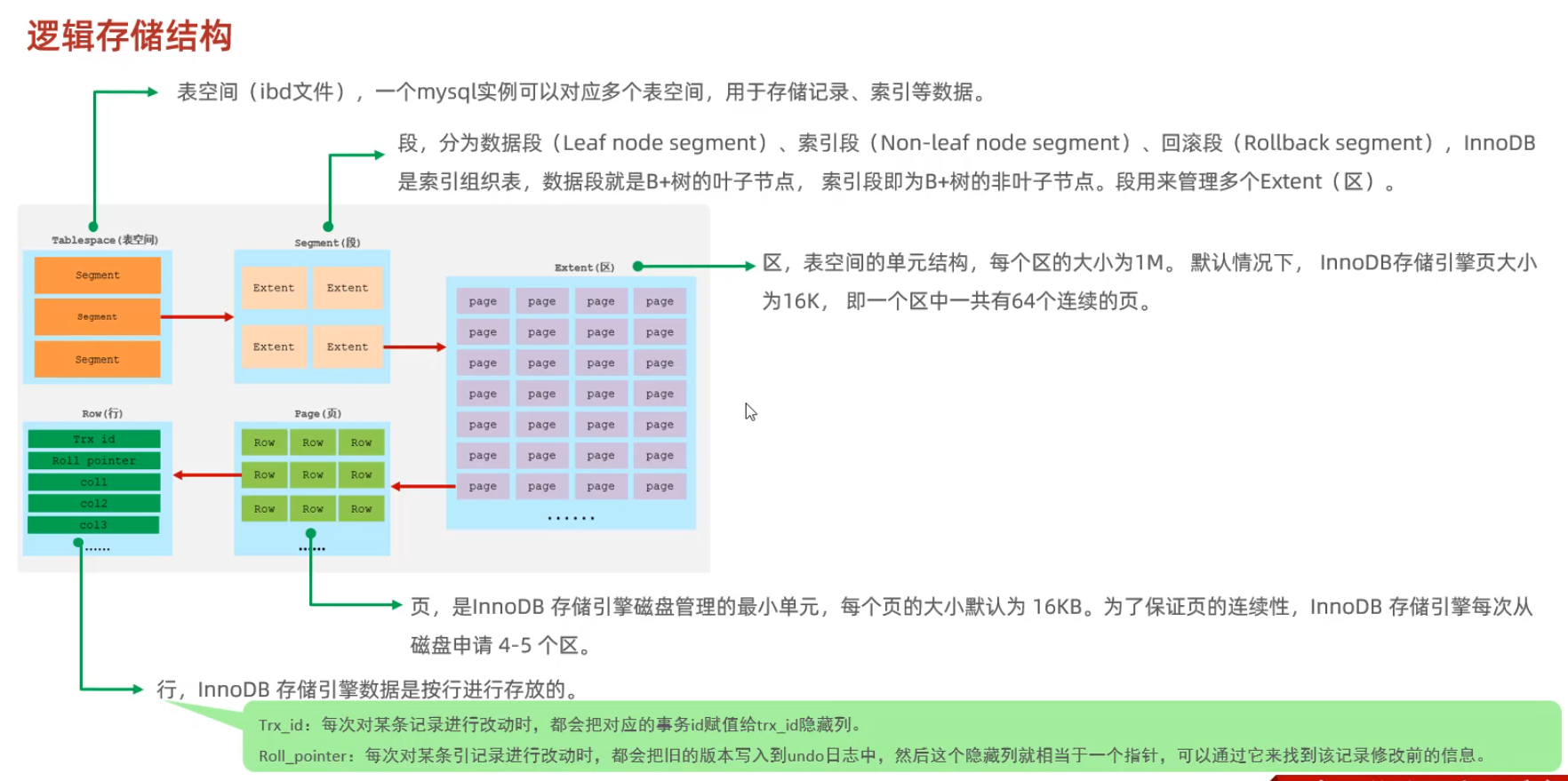
數(shù)據(jù)組織方式:在InnoDB存儲引擎中,表數(shù)據(jù)都是根據(jù)主鍵順序組織存放的,這種存儲方式的表稱為索引組織表(Index organized table, IOT)
頁分裂:頁可以為空,也可以填充一般,也可以填充100%,每個頁包含了2-N行數(shù)據(jù)(如果一行數(shù)據(jù)過大,會行溢出),根據(jù)主鍵排列。
頁合并:當刪除一行記錄時,實際上記錄并沒有被物理刪除,只是記錄被標記(flaged)為刪除并且它的空間變得允許被其他記錄聲明使用。當頁中刪除的記錄到達
MERGE_THRESHOLD(默認為頁的50%),InnoDB會開始尋找最靠近的頁(前后)看看是否可以將這兩個頁合并以優(yōu)化空間使用。
MERGE_THRESHOLD:合并頁的閾值,可以自己設(shè)置,在創(chuàng)建表或創(chuàng)建索引時指定
文字說明不夠清晰明了,具體可以看視頻里的PPT演示過程:https://www.bilibili.com/video/BV1Kr4y1i7ru?p=90
主鍵設(shè)計原則:
- 滿足業(yè)務(wù)需求的情況下,盡量降低主鍵的長度
- 插入數(shù)據(jù)時,盡量選擇順序插入,選擇使用 AUTO_INCREMENT 自增主鍵
- 盡量不要使用 UUID 做主鍵或者是其他的自然主鍵,如身份證號
- 業(yè)務(wù)操作時,避免對主鍵的修改
order by優(yōu)化
- Using filesort:通過表的索引或全表掃描,讀取滿足條件的數(shù)據(jù)行,然后在排序緩沖區(qū) sort buffer 中完成排序操作,所有不是通過索引直接返回排序結(jié)果的排序都叫 FileSort 排序
- Using index:通過有序索引順序掃描直接返回有序數(shù)據(jù),這種情況即為 using index,不需要額外排序,操作效率高
如果order by字段全部使用升序排序或者降序排序,則都會走索引,但是如果一個字段升序排序,另一個字段降序排序,則不會走索引,explain的extra信息顯示的是Using index, Using filesort,如果要優(yōu)化掉Using filesort,則需要另外再創(chuàng)建一個索引,如:create index idx_user_age_phone_ad on tb_user(age asc, phone desc);,此時使用select id, age, phone from tb_user order by age asc, phone desc;會全部走索引
總結(jié):
- 根據(jù)排序字段建立合適的索引,多字段排序時,也遵循最左前綴法則
- 盡量使用覆蓋索引
- 多字段排序,一個升序一個降序,此時需要注意聯(lián)合索引在創(chuàng)建時的規(guī)則(ASC/DESC)
- 如果不可避免出現(xiàn)filesort,大數(shù)據(jù)量排序時,可以適當增大排序緩沖區(qū)大小 sort_buffer_size(默認256k)
group by優(yōu)化
- 在分組操作時,可以通過索引來提高效率
- 分組操作時,索引的使用也是滿足最左前綴法則的
如索引為idx_user_pro_age_stat,則句式可以是select ... where profession order by age,這樣也符合最左前綴法則
limit優(yōu)化
常見的問題如limit 2000000, 10,此時需要 MySQL 排序前2000000條記錄,但僅僅返回2000000 - 2000010的記錄,其他記錄丟棄,查詢排序的代價非常大。
優(yōu)化方案:一般分頁查詢時,通過創(chuàng)建覆蓋索引能夠比較好地提高性能,可以通過覆蓋索引加子查詢形式進行優(yōu)化
例如:
-- 此語句耗時很長
|
count優(yōu)化
MyISAM 引擎把一個表的總行數(shù)存在了磁盤上,因此執(zhí)行 count(*) 的時候會直接返回這個數(shù),效率很高(前提是不適用where);
InnoDB 在執(zhí)行 count(*) 時,需要把數(shù)據(jù)一行一行地從引擎里面讀出來,然后累計計數(shù)。
優(yōu)化方案:自己計數(shù),如創(chuàng)建key-value表存儲在內(nèi)存或硬盤,或者是用redis
count的幾種用法:
- 如果count函數(shù)的參數(shù)(count里面寫的那個字段)不是NULL(字段值不為NULL),累計值就加一,最后返回累計值
- 用法:count(*)、count(主鍵)、count(字段)、count(1)
- count(主鍵)跟count(*)一樣,因為主鍵不能為空;count(字段)只計算字段值不為NULL的行;count(1)引擎會為每行添加一個1,然后就count這個1,返回結(jié)果也跟count(*)一樣;count(null)返回0
各種用法的性能:
- count(主鍵):InnoDB引擎會遍歷整張表,把每行的主鍵id值都取出來,返回給服務(wù)層,服務(wù)層拿到主鍵后,直接按行進行累加(主鍵不可能為空)
- count(字段):沒有not null約束的話,InnoDB引擎會遍歷整張表把每一行的字段值都取出來,返回給服務(wù)層,服務(wù)層判斷是否為null,不為null,計數(shù)累加;有not null約束的話,InnoDB引擎會遍歷整張表把每一行的字段值都取出來,返回給服務(wù)層,直接按行進行累加
- count(1):InnoDB 引擎遍歷整張表,但不取值。服務(wù)層對于返回的每一層,放一個數(shù)字 1 進去,直接按行進行累加
- count(*):InnoDB 引擎并不會把全部字段取出來,而是專門做了優(yōu)化,不取值,服務(wù)層直接按行進行累加
按效率排序:count(字段) < count(主鍵) < count(1) < count(*),所以盡量使用 count(*)
update優(yōu)化(避免行鎖升級為表鎖)
InnoDB 的行鎖是針對索引加的鎖,不是針對記錄加的鎖,并且該索引不能失效,否則會從行鎖升級為表鎖。
如以下兩條語句:update student set no = '123' where id = 1;,這句由于id有主鍵索引,所以只會鎖這一行;update student set no = '123' where name = 'test';,這句由于name沒有索引,所以會把整張表都鎖住進行數(shù)據(jù)更新,解決方法是給name字段添加索引
視圖/存儲過程/觸發(fā)器

視圖
視圖(View)是一種虛擬存在的表。視圖中的數(shù)據(jù)并不在數(shù)據(jù)庫中實際存在,行和列數(shù)據(jù)來自定義視圖的查詢中使用的表,并且是在使用視圖時動態(tài)生成的。
通俗的講,視圖只保存了查詢的SQL邏輯,不保存查詢結(jié)果。所以我們在創(chuàng)建視圖的時候,主要的工作就落在創(chuàng)建這條SQL查詢語句上。
語法
創(chuàng)建視圖:CREATE [OR REPLACE] VIEW 視圖名稱(列名列表)】AS SELECT語句[WITH[CASCADED|LOCAL] CHECK OPTION]
查詢視圖:
查看創(chuàng)建視圖語句:SHOW CRETE VIEW 視圖名稱;
查看視圖數(shù)據(jù):查看視圖數(shù)據(jù):SELECT*FROM 視圖名稱…;
修改視圖:
方式一:CREATE [OR REPLACE]VIEW 視圖名稱(列名列表)AS SELECT語句[WITH[CASCADEDLLOCAL] CHECK OPTION
方式二:ALTER VEW 視圖名稱(列名列表)AS SELECT語句[WITH[CASCADED|LOCAL]CHECK OPTION]
刪除視圖:DROP VIEW [IF EXISTS]視圖名稱[,視圖名稱]
-- 創(chuàng)建視圖
|
檢查選項
視圖的檢查選項:
當使用WITH CHECK OPTION子句創(chuàng)建視圖時,MySOL會通過視圖檢查正在更改的每個行,例如 插入,更新,刪除,以使其符合視圖的定義。MVSOL允許基于另一個視圖創(chuàng)建視圖,它還會檢查依賴視圖中的規(guī)則以保持一致性。
為了確定檢查的范圍,mysql 提供了兩個選項:CASCADED 和 LOCAL,默認值為CASCADED。
cascaded:在對創(chuàng)建時含有該字段的視圖,插入數(shù)據(jù)時,該視圖依賴的視圖都會加上檢查,需要所有條件都滿足才能夠插入成功。
local:在對創(chuàng)建時含有該字段的視圖,插入數(shù)據(jù)時,對于該視圖依賴的視圖中含有檢查語句的條件進行檢查判斷。
更新及作用
視圖的更新:
要使視圖可更新,視圖中的行與基礎(chǔ)表中的行之間必須存在一對一的關(guān)系。
如果視圖包含以下任何一項,則該視圖不可更新:
- 聚合函數(shù)或窗口函數(shù)(SUM()、MIN()、MAX()、COUNT()等
- DISTINCT
- GROUP BY
- HAVINGA
- UNION 或者 UNION ALL
作用:
- 簡單
視圖不僅可以簡化用戶對數(shù)據(jù)的理解,也可以簡化他們的操作。那些被經(jīng)常使用的查詢可以被定義為視圖,從而使得用戶不必為以后的操作每次指定全部的條件。 - 安全
數(shù)據(jù)庫可以授權(quán),但不能授權(quán)到數(shù)據(jù)庫特定行和特定的列上。通過視圖用戶只能查詢和修改他們所能見到的數(shù)據(jù)。 - 數(shù)據(jù)獨立
視圖可幫助用戶屏蔽真實表結(jié)構(gòu)變化帶來的影響。
案例
-- 1.為了保證數(shù)據(jù)庫表的安全性,開發(fā)人員在操作tb_user表時,只能看到的用戶的基本字段,屏蔽手機號和郵箱兩個字段。
|
存儲過程
存儲過程其實就類似 java,c 這種語言,這一部分可以通過文檔快速學(xué)習(xí),不懂的再回過頭看視頻。
存儲過程是事先經(jīng)過編譯并存儲在數(shù)據(jù)庫中的一段 SQL語句的集合,調(diào)用存儲過程可以簡化應(yīng)用開發(fā)人員的很多工作,減少數(shù)據(jù)在數(shù)據(jù)庫和應(yīng)用服務(wù)器之間的傳輸,對于提高數(shù)據(jù)處理的效率是有好處的。
存儲過程思想上很簡單,就是數(shù)據(jù)庫 SOL語言層面的代碼封裝與重用。
特點:
- 封裝,復(fù)用
- 可以接收參數(shù),也可以返回數(shù)據(jù)
- 減少網(wǎng)絡(luò)交互,效率提升
基本語法
查看視圖數(shù)據(jù):SELECT*FROM 視圖名稱…;
查看:
SELECT* FROM INFORMATION SCHEMA.ROUTINES WHERE ROUTINE_SCHEMA='xx';--查詢數(shù)據(jù)庫的存儲過程及狀態(tài)信息SHOW CREATE PROCEDURE 存儲過程名稱;--查詢某個存儲過程的定義
刪除:
DROP PROCEDURE [IF EXISTS]存儲過程名稱;
案例:
-- 存儲過程基本語法
|
變量
系統(tǒng)變量
系統(tǒng)變量 是MySQL服務(wù)器提供,不是用戶定義的,屬于服務(wù)器層面。分為全局變量(GLOBAL)、會話變量(SESSION)。
查看系統(tǒng)變量
SHOW [SESSION |GLOBAL] VARIABLES ; --查看所有系統(tǒng)變量SHOW[SESSION|GLOBAL] VARIABLES LIKE'; --可以通過LKE模糊匹配方式查找變量SELECT @@[SESSION|GLOBAL]系統(tǒng)變量名; -- 查看指定變量的值
-- 變量:系統(tǒng)變量
|
注意:
- 如果沒有指定 session / global,默認 session,會話變量
- myesql 服務(wù)器重啟之后,所設(shè)置的全局參數(shù)會失效,要想不失效,需要更改/etc/my.cnf 中的配置。
用戶定義變量
用戶定義變量 是用戶根據(jù)需要自己定義的變量,用戶變量不用提前聲明,在用的時候直接用“@變量名”使用就可以。其作用域為當前連接。
賦值:
SET @var name = expr [, @var_name = expr]...;SET @var name := expr [, @var_name := expr]...;
SELECT @var name := expr , @var name := expr ...;SELECT 字段名 INTO @var_name FROM 表名;
使用:
SELECT @var_name;
案例:
-- 變量:用戶變量
|
注意:
用戶定義的變量無需對其進行聲明或者初始化,只不過獲取到的值為 NULL。
局部變量
局部變量 是根據(jù)需要定義的在局部生效的變量,訪問之前,需要DECLARE聲明。可用作存儲過程內(nèi)的局部變量和輸入?yún)?shù),局部變量的范圍是在其內(nèi)聲明的BEGIN .. END塊。
聲明:
DECLARE 變量名 變量類型 [DEFAULT..];
變量類型就是數(shù)據(jù)庫字段類型:INT、BIGINT、CHAR、VARCHAR、DATE、TIME等。
賦值:
SET 變量名=值;
SET 變量名:=值;
SELECT 字段名 INTO 變量名 FROM 表名 ...;
案例:
-- 變量:局部變量
|
if 判斷
語法:
IF 條件1 THEN
|
案例:
create procedure p3()
|
參數(shù)(in, out, inout)
| 類型 | 含義 | 備注 |
|---|---|---|
| IN | 該類參數(shù)作為輸入,也就是需要調(diào)用時傳入值 | 默認 |
| OUT | 該類參數(shù)作為輸出,也就是該參數(shù)可以作為返回值 | |
| INOUT | 既可以作為輸入?yún)?shù),也可以作為輸出參數(shù)**** |
用法:
CREATE PROCEDURE 存儲過程名稱([IN/OUT/INOUT 參數(shù)名 參數(shù)類型 ])
|
案例:
-- 根據(jù)傳入(in)參數(shù)score,判定當前分數(shù)對應(yīng)的分數(shù)等級,并返回(out)
|
case
語法一:
CASE case value
|
語法二:
CASE
|
案例:
-- case
|
循環(huán)
while
while 循環(huán)是有條件的循環(huán)控制語句。滿足條件后,再執(zhí)行循環(huán)體中的SQL語句。
語法:
#先判定條件,如果條件為true,則執(zhí)行邏輯,否則,不執(zhí)行邏輯
|
案例:
-- while計算從1累加到 n 的值,n 為傳入的參數(shù)值。
|
repeat
repeat是有條件的循環(huán)控制語句,當滿足條件的時候退出循環(huán)。
與 while 區(qū)別:
- 先進行循環(huán)一次再判斷。相當于 c 語言中的 do while();
- 滿足條件則退出
語法:
#先執(zhí)行一次邏輯,然后判定邏輯是否滿足,如果滿足,則退出。如果不滿足,則繼續(xù)下一次循環(huán)
|
案例:
-- while計算從1累加到 n 的值,n 為傳入的參數(shù)值。
|
loop
LOOP 實現(xiàn)簡單的循環(huán),如果不在SQL邏輯中增加退出循環(huán)的條件,可以用其來實現(xiàn)簡單的死循環(huán)。LOOP可以配合一下兩個語句使用。
- LEAVE:配合循環(huán)使用,退出循環(huán)。
- ITERATE:必須用在循環(huán)中,作用是跳過當前循環(huán)剩下的語句,直接進入下一次循環(huán)。
[begin label:] LOOP
|
案例:
-- loop 計算從1到n之間的偶數(shù)累加的值,n為傳入的參數(shù)值。
|
游標-cursor
游標(CURSOR)是用來存儲查詢結(jié)果集的數(shù)據(jù)類型,在存儲過程和函數(shù)中可以使用游標對結(jié)果集進行循環(huán)的處理。游標的使用包括游標的聲明、OPEN、FETCH和 CLOSE,其語法分別如下。
通俗點講:類似于 c 語言中的結(jié)構(gòu)體,java 中的實體類。
聲明游標
DECLARE 游標名稱 CURSOR FOR 查詢語句;
|
打開游標:
OPEN 游標名稱;
|
獲取游標記錄:
FETCH 游標名稱 INTO 變量[,變量];
|
關(guān)閉游標:
CLOSE 游標名稱;
|
案例:
-- 游標
|
條件處理程序-handler
條件處理程序(Handler)可以用來定義在流程控制結(jié)構(gòu)執(zhí)行過程中遇到問題時相應(yīng)的處理步驟。
語法:
DECLARE handler action HANDLERFOR condition value l, condition value.... statement;
|
案例:
create procedure p11(in uage int)
|
存儲函數(shù):
存儲函數(shù)是有返回值的存儲過程,存儲函數(shù)的參數(shù)只能是IN類型的。
存儲函數(shù)用的較少,能夠使用存儲函數(shù)的地方都可以用存儲過程替換。
語法:
CREATE FUNCTION 存儲函數(shù)名稱([ 參數(shù)列表 ])
|
案例:
create function fun1(n int)
|
觸發(fā)器
觸發(fā)器是與表有關(guān)的數(shù)據(jù)庫對象,指在 insert/update/delete 之前或之后,觸發(fā)并執(zhí)行觸發(fā)器中定義的SQL語句集合。觸發(fā)器的這種特性可以協(xié)助應(yīng)用在數(shù)據(jù)庫端確保數(shù)據(jù)的完整性,日志記錄,數(shù)據(jù)校驗等操作。
使用別名 OLD 和 NEW 來引用觸發(fā)器中發(fā)生變化的記錄內(nèi)容,這與其他的數(shù)據(jù)庫是相似的。現(xiàn)在觸發(fā)器還只支持行級觸發(fā),不支持語句級觸發(fā)。
| 觸發(fā)器類型 | NEW 和 OLD |
|---|---|
| insert 型觸發(fā)器 | NEW 表示將要或者已經(jīng)新增的數(shù)據(jù) |
| update 型觸發(fā)器 | OLD 表示修改之前的數(shù)據(jù),NEW 表示將要或已經(jīng)修改后的數(shù)據(jù) |
| delete 型觸發(fā)器 | OLD 表示將要或者已經(jīng)刪除的數(shù)據(jù) |
語法:
創(chuàng)建:
CREATE TRIGGER trigger name
|
查看:
SHOW TRIGGERS;
|
刪除:
DROP TRIGGER [schema_name.]trigger_name; --如果沒有指定 schema name,默認為當前數(shù)據(jù)庫
|
案例:
-- 插入數(shù)據(jù)觸發(fā)器
|
鎖
介紹:
鎖是計算機協(xié)調(diào)多個進程或線程并發(fā)訪問某一資源的機制。在數(shù)據(jù)庫中,除傳統(tǒng)的計算資源(CPU、RAM、I/0)的爭用以外,數(shù)據(jù)也是一種供許多用戶共享的資源。如何保證數(shù)據(jù)并發(fā)訪問的一致性、有效性是所有數(shù)據(jù)庫必須解決的一個問題,鎖沖突也是影響數(shù)據(jù)庫并發(fā)訪問性能的一個重要因素。從這個角度來說,鎖對數(shù)據(jù)庫而言顯得尤其重要,也更加復(fù)雜。
分類:
MySQL中的鎖,按照鎖的粒度分,分為一下三類:
- 全局鎖:鎖定數(shù)據(jù)庫中的所有表。
- 表級鎖:每次操作鎖住整張表。
- 行級鎖:每次操作鎖住對應(yīng)的行數(shù)據(jù)。
全局鎖
介紹:
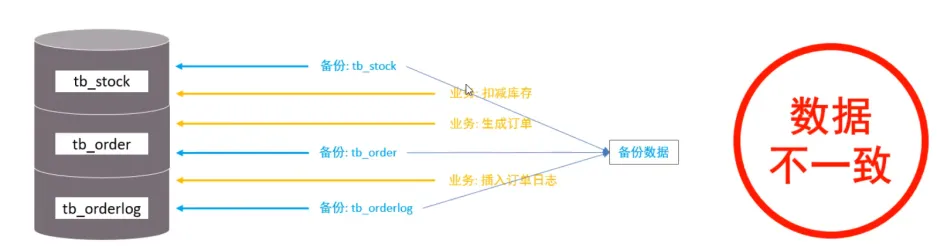
全局鎖就是對整個數(shù)據(jù)庫實例加鎖,加鎖后整個實例就處于只讀狀態(tài),后續(xù)的DML的寫語句,DDL語句,已經(jīng)更新操作的事務(wù)提交語句都將被阻塞。
其典型的使用場景是做全庫的邏輯備份,對所有的表進行鎖定,從而獲取一致性視圖,保證數(shù)據(jù)的完整性。
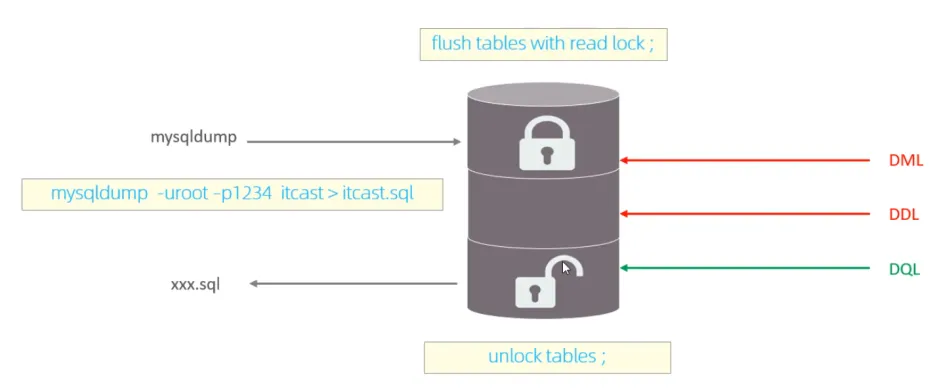
基本操作:
使用全局鎖:flush tables with read lock
釋放全局鎖:unlock tables
演示圖:
特點:
數(shù)據(jù)庫中加全局鎖,是一個比較重的操作,存在以下問題:
- 如果在主庫上備份,那么在備份期間都不能執(zhí)行更新,業(yè)務(wù)基本上就得停擺。
- 如果在從庫上備份,那么在備份期間從庫不能執(zhí)行主庫同步過來的二進制日志(binlog),會導(dǎo)致主從延遲。(該結(jié)構(gòu)會在后續(xù)主從復(fù)制講解)
解決方法:
在InnoDB引擎中,我們可以在備份時加上參數(shù) –single-transaction 參數(shù)來完成不加鎖的一致性數(shù)據(jù)備份。
mysqldump --single-transaction -uroot -p123456 itcast > itcast.sql(只適用于支持「可重復(fù)讀隔離級別的事務(wù)」的存儲引擎)
原理補充:通過加上這個參數(shù),確保了在備份開始時創(chuàng)建一個一致性的快照,通過啟動一個新的事務(wù)來實現(xiàn)這一點。(該事務(wù)的隔離級別是Repeatable Read級別),從而實現(xiàn)在該事務(wù)讀取下一直讀取的是創(chuàng)建時的數(shù)據(jù),而不影響其他事務(wù)的讀寫操作。
表級鎖
每次操作鎖住整張表。鎖定粒度大,發(fā)生鎖的沖突的概率最高,并發(fā)度最低。應(yīng)用在MyISAM、InnoDB、BDB等存儲引擎中。
對于表級鎖,主要分為一下三類:
- 表鎖
- 元數(shù)據(jù)鎖(meta data lock,MDL)
- 意向鎖
表鎖
對于表鎖,分為兩類:
- 表共享讀鎖(read lock)
- 表獨占寫鎖(write lock)
讀鎖不會阻塞其他客戶端的讀,但是會阻塞寫。寫鎖既會阻塞其他客戶端的讀,又會阻塞其他客戶端的寫。
語法:
//表級別的共享鎖,也就是讀鎖;
|
釋放所有鎖:
unlock tables (會話退出,也會釋放所有鎖)
元數(shù)據(jù)鎖
MDL加鎖過程是系統(tǒng)自動控制,無需顯式使用,在訪問一張表的時候會自動加上。MDL鎖主要作用是維護表元數(shù)據(jù)的數(shù)據(jù)一致性,在表
上有活動事務(wù)的時候,不可以對元數(shù)據(jù)進行寫入操作。為了避免DML與DDL沖突,保證讀寫的正確性。
- 對一張表進行 CRUD 操作時,加的是 MDL 讀鎖;
- 對一張表做結(jié)構(gòu)變更操作的時候,加的是 MDL 寫鎖;
| 對應(yīng)SQL | 鎖類型 | 說明 |
|---|---|---|
| lock tables xxx read /write | SHARED_READ_ONLY/SHARED_NO_READ_WRITE | |
| select 、 select … lock in share mode | SHARED_READ | 與SHARED_READ、SHARED_WRITE兼容,與EXCLUSIVE互斥 |
| insert 、update、delete、select …for update | SHARED_WRITE | 與SHARED_READ、SHARED_WRITE兼容,與EXCLUSIVE互斥 |
| alter table … | EXCLYSIVE | 與其他的MDL都互斥 |
查看元數(shù)據(jù)鎖:
select object_type,object_schema,object_name,lock_type,lock_duration from performance_schema.metadata_locks;
意向鎖
為了避免DML在執(zhí)行時,加的行鎖與表鎖的沖突,在InnoDB中引入了意向鎖,使得表鎖不用檢查每行數(shù)據(jù)是否加鎖,使用意向鎖來減
少表鎖的檢查。
意向共享鎖和意向獨占鎖是表級鎖,不會和行級的共享鎖和獨占鎖發(fā)生沖突,而且意向鎖之間也不會發(fā)生沖突,只會和共享表鎖(lock tables … read)和獨占表鎖(lock tables … write)發(fā)生沖突
如果沒有「意向鎖」,那么加「獨占表鎖」時,就需要遍歷表里所有記錄,查看是否有記錄存在獨占鎖,這樣效率會很慢。
那么有了「意向鎖」,由于在對記錄加獨占鎖前,先會加上表級別的意向獨占鎖,那么在加「獨占表鎖」時,直接查該表是否有意向獨占鎖,如果有就意味著表里已經(jīng)有記錄被加了獨占鎖,這樣就不用去遍歷表里的記錄。
意向鎖的目的是為了快速判斷表里是否有記錄被加鎖。
加鎖方式:
意向共享鎖:(先在表上加上意向共享鎖,然后對讀取的記錄加共享鎖)
由 select ... lock in share mode 添加
意向獨占鎖:(先表上加上意向獨占鎖,然后對讀取的記錄加獨占鎖)
由 insert、update、delete、select ... for update 添加
AUTO-INC鎖(補充)


行級鎖
行級鎖,每次操作鎖住對應(yīng)的行數(shù)據(jù)。鎖定粒度最小,發(fā)生鎖沖突的概率最低,并發(fā)度最高。應(yīng)用在InnoDB存儲引擎中。
- 行鎖(Record Lock):鎖定單個行記錄的鎖,防止其他事務(wù)對此行進行update和delete。在RC、RR隔離級別下都支持。
- 間隙鎖(GapLock):鎖定索引記錄間隙(不含該記錄),確保索引記錄間隙不變,防止其他事務(wù)在這個間隙進行insert,產(chǎn)生幻讀。在RR隔離級別下都支持。
- 臨鍵鎖(Next-Key Lock):行鎖和間隙鎖組合,同時鎖住數(shù)據(jù),并鎖住數(shù)據(jù)前面的間隙Gap。在RR隔離級別下支持。
Record Lock(行鎖)
Record Lock 稱為記錄鎖,鎖住的是一條記錄。而且記錄鎖是有 S 鎖和 X 鎖之分。
InnoDB實現(xiàn)了以下兩種類型的行鎖:
- 共享鎖(S):允許一個事務(wù)去讀一行,阻止其他事務(wù)獲得相同數(shù)據(jù)集的排它鎖。
- 排他鎖(X):允許獲取排他鎖的事務(wù)更新數(shù)據(jù),阻止其他事務(wù)獲得相同數(shù)據(jù)集的共享鎖和排他鎖。
| S(共享鎖) | X(排他鎖) | |
|---|---|---|
| S(共享鎖) | 兼容 | 沖突 |
| X(排他鎖) | 沖突 | 沖突 |
行鎖類型:
| SQL | 行鎖類型 | 說明 |
|---|---|---|
| insert,update,delete … | 排他鎖 | 自動加鎖 |
| select | 不加任何鎖 | |
| select … lock in share mode | 共享鎖 | 需要手動select之后加上lock in share mode |
| select … for update | 排他鎖 | 需要手動在select之后for update |
默認情況下,InnoDB在 REPEATABLE READ事務(wù)隔離級別運行,InnoDB使用 next-key鎖進行搜索和索引掃描,以防止幻讀。
- 針對唯一索引進行檢索時,對已存在的記錄進行等值匹配時,將會自動優(yōu)化為行鎖。
- InnoDB的行鎖是針對于索引加的鎖,不通過索引條件檢索數(shù)據(jù),那么!nnoDB將對表中的所有記錄加鎖,此時 就會升級為表鎖。
查看意向鎖及行鎖的加鎖情況:
select object_schema,object_name,index_name,lock_type,lock_mode,lock_data from peformance_schema.data_locks;
Gap Lock(間隙鎖)

Next-Key Lock(臨鍵鎖)

默認情況下,InnODB在 REPEATABLE READ事務(wù)隔離級別運行,InnoDB使用 next-key 鎖進行搜索和索引掃描,以防止幻讀。
- 索引上的等值查詢(唯一索引),給不存在的記錄加鎖時,優(yōu)化為間隙鎖 。
- 索引上的等值查詢(普通索引),向右遍歷時最后一個值不滿足查詢需求時,next-keylock退化為間隙鎖。
- 索引上的范圍查詢(唯一索引)–會訪問到不滿足條件的第一個值為止。
InnoDB引擎
邏輯存儲結(jié)構(gòu)
架構(gòu)
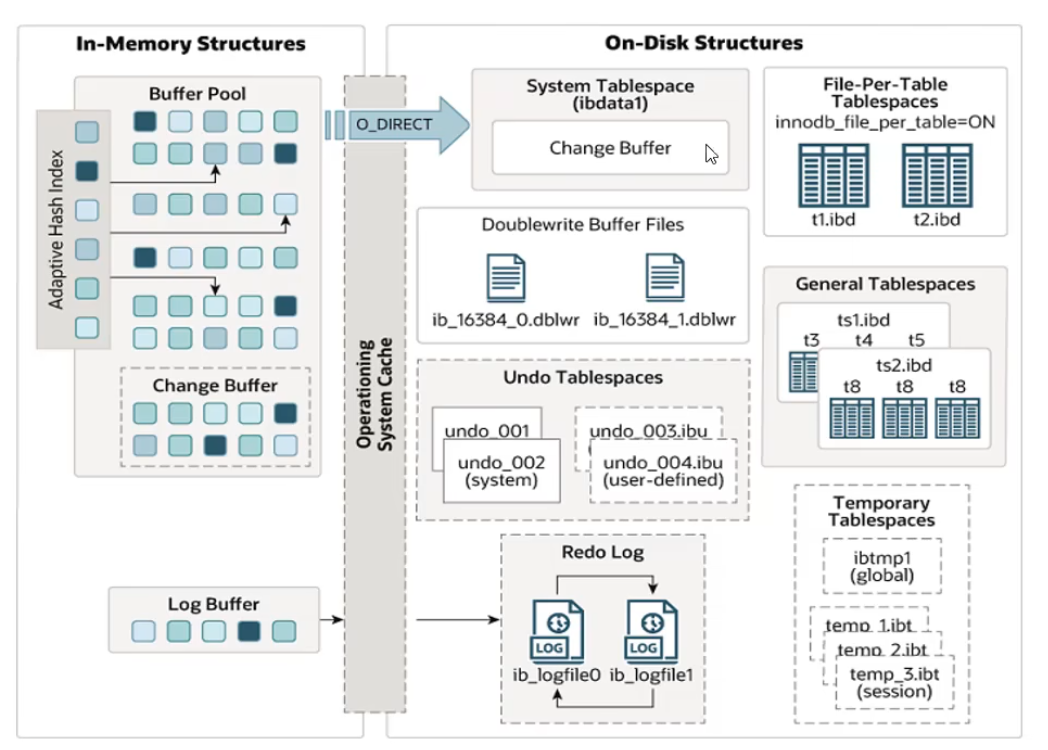
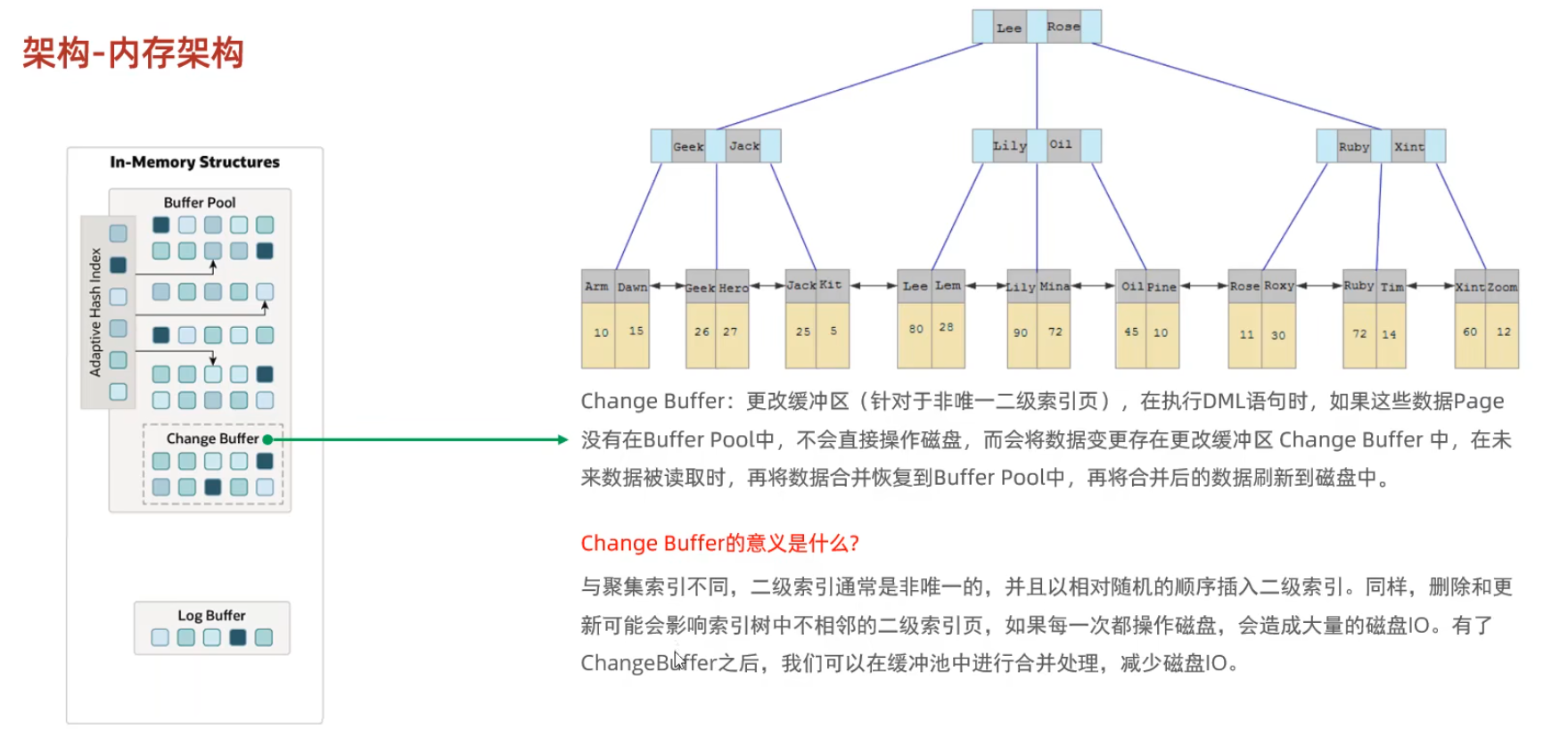
內(nèi)存架構(gòu)



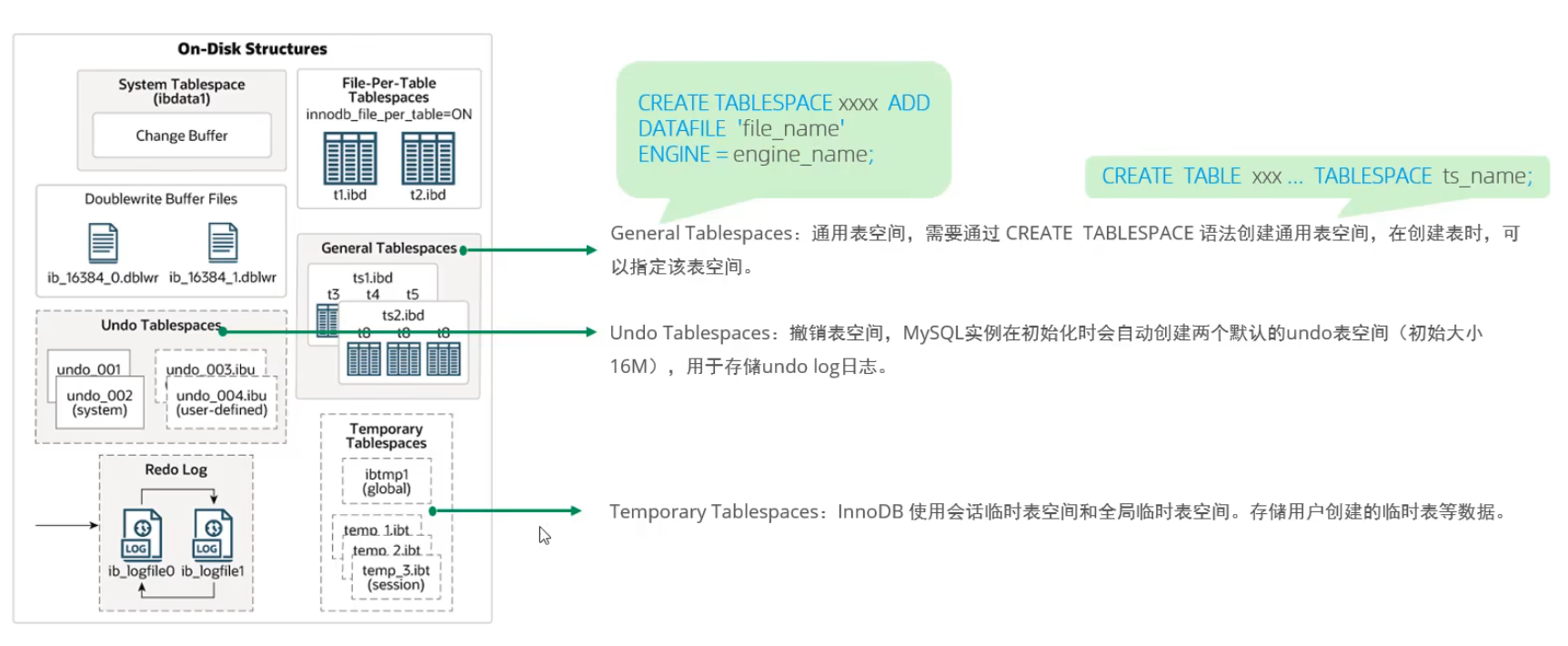
磁盤結(jié)構(gòu)

后臺線程

事務(wù)原理
事務(wù):
事務(wù) 是一組操作的集合,它是一個不可分割的工作單位,事務(wù)會把所有的操作作為一個整體一起向系統(tǒng)提交或撤銷操作請求,即這些操作要么同時成功,要么同時失敗。
特征:
- 原子性(Atomicity):事務(wù)是不可分割的最小操作單元,要么全部成功,要么全部失敗。
- 一致性(Consistency) :事務(wù)完成時,必須使所有的數(shù)據(jù)都保持一致狀態(tài)。
- 隔離性(lsolation):數(shù)據(jù)庫系統(tǒng)提供的隔離機制,保證事務(wù)在不受外部并發(fā)操作影響的獨立環(huán)境下運行。
- 持久性(Durability):事務(wù)一旦提交或回滾,它對數(shù)據(jù)庫中的數(shù)據(jù)的改變就是永久的。
特性原理分類圖:

redo log
重做日志,記錄的是事務(wù)提交時數(shù)據(jù)頁的物理修改,是用來實現(xiàn)事務(wù)的持久性。
該日志文件由兩部分組成:重做日志緩沖(redo log buffer)以及重做日志文件(redo log file),前者是在內(nèi)存中,后者在磁盤中。當事務(wù)提交之后會把所有修改信息都存到該日志文件中,用于在刷新臟頁到磁盤,發(fā)生錯誤時,進行數(shù)據(jù)恢復(fù)使用。
Buffer Pool在產(chǎn)生臟頁數(shù)據(jù)的時候,會先將數(shù)據(jù)存儲到 redo log buffer 再存儲到 redo log 中進行磁盤持久化存儲,在內(nèi)存出現(xiàn)異常(比如突然斷電)時,通過redo log中持久化的數(shù)據(jù)進行回滾。過程如下圖:
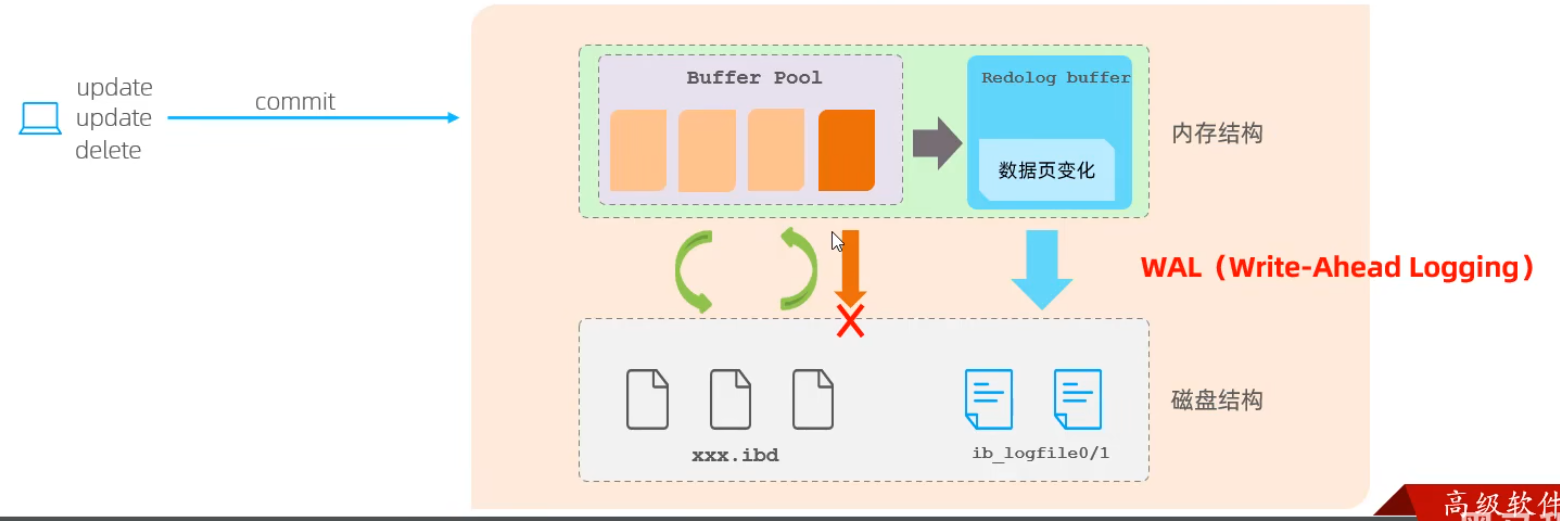
redo log 要寫到磁盤,數(shù)據(jù)也要寫磁盤,為什么要多此一舉?
寫入 redo log 的方式使用了追加操作,所以磁盤操作是順序?qū)?/strong>,而寫入數(shù)據(jù)需要先找到寫入位置,然后才寫到磁盤,所以磁盤操作是隨機寫。
undo log
回滾日志,用于記錄數(shù)據(jù)被修改前的信息,作用包含兩個:提供回滾 和 MVCC(多版本并發(fā)控制)。
undo log 和 redo log 記錄物理日志不一樣,它是邏輯日志。可以認為當 delete 一條記錄時,undo log中會記錄一條對應(yīng)的insert記錄,反之亦然,當 update 一條記錄時,它記錄一條對應(yīng)相反的 update 記錄。當執(zhí)行 rollback 時,就可以從 undo log 中的邏輯記錄讀取到相應(yīng)的內(nèi)容并進行回滾。
Undo log 銷毀:undo log 在事務(wù)執(zhí)行時產(chǎn)生,事務(wù)提交時,并不會立即刪除undol0g,因為這些日志可能還用于 MVCC。
Undo log 存儲:undo log 采用段的方式進行管理和記錄,存放在前面介紹的 rollback segment 回滾段中,內(nèi)部包含1024個 undo log segment.
MVCC
當前讀:
讀取的是記錄的最新版本,讀取時還要保證其他并發(fā)事務(wù)不能修改當前記錄,會對讀取的記錄進行加鎖。對于我們?nèi)粘5牟僮鳎?select…lock in share mode(共享鎖),select… for update、update、insert、delete(排他鎖)都是一種當前讀。
快照讀:
簡單的select(不加鎖)就是快照讀,快照讀,讀取的是記錄數(shù)據(jù)的可見版本,有可能是歷史數(shù)據(jù),不加鎖,是非阻塞讀。
- Read committed:每次select,都生成一個快照讀。
- Repeatable Read:開啟事務(wù)后第一個select語句才是快照讀的地方。
- Serializable:快照讀會退化為當前讀。
MVCC:
全稱 Multi-Version Concurrency Control,多版本并發(fā)控制。指維護一個數(shù)據(jù)的多個版本,使得讀寫操作沒有沖突,快照讀為MVSOL實現(xiàn)MVCC提供了一個非阻塞讀功能。MVCC的具體實現(xiàn),還需要依賴于數(shù)據(jù)庫記錄中的三個隱式字段、undo log日志、read View。
三個隱藏字段

undo log
回滾日志,在insert、update、delete的時候產(chǎn)生的便于數(shù)據(jù)回滾的日志。
當insert的時候,產(chǎn)生的undoloq日志只在回滾時需要,在事務(wù)提交后,可被立即刪除。
而update、delete的時候,產(chǎn)生的undo log日志不僅在回滾時需要,在快照讀時也需要,不會立即被刪除。
那么何時刪除?
- 事務(wù)提交后:
- 對于
INSERT操作,事務(wù)提交后,undo log可以被立即刪除,因為不再需要用于回滾。 - 對于
UPDATE和DELETE操作,undo log不會立即被刪除,因為它們可能在后續(xù)的快照讀取中被使用。
- 對于
- 快照讀取結(jié)束:
- 當所有依賴于該undo log的快照讀取操作結(jié)束后,undo log才會被刪除。這意味著如果有一個事務(wù)正在進行快照讀取,并且依賴于某個undo log,那么這個undo log會一直保留直到該事務(wù)結(jié)束。
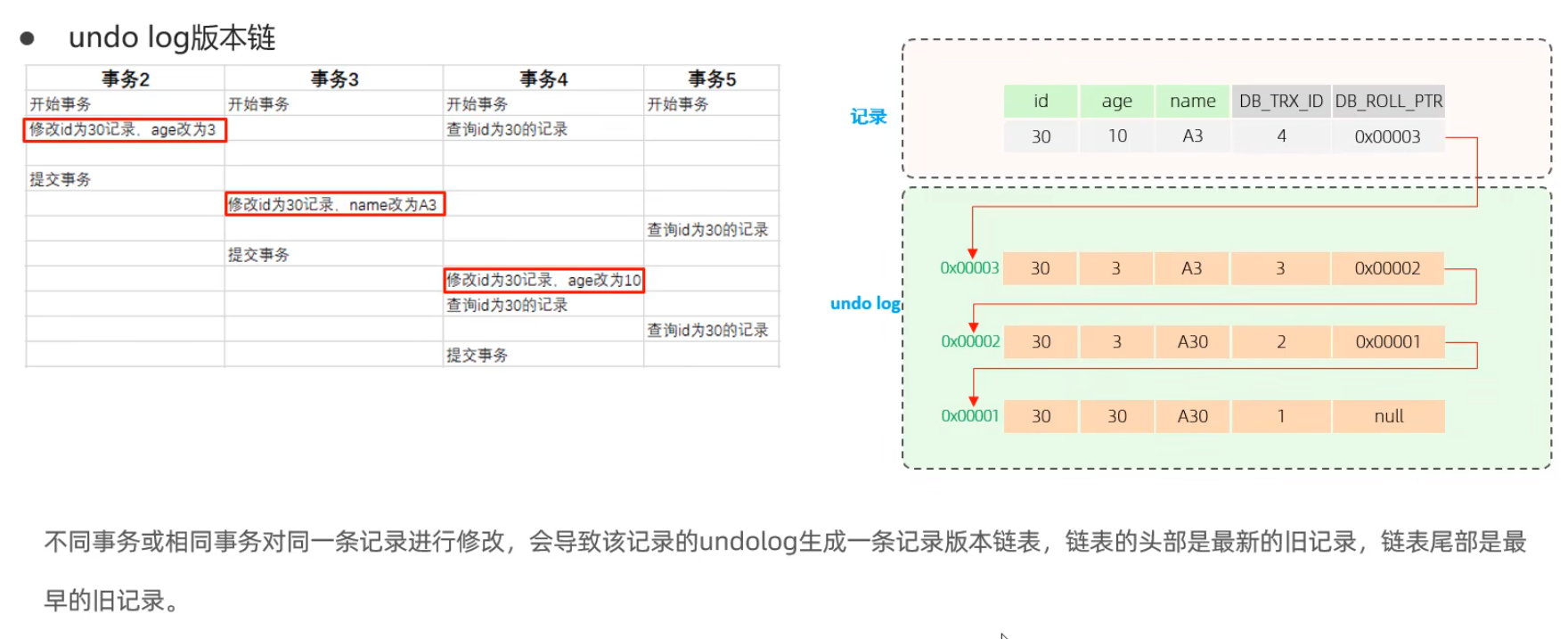
readview
ReadView(讀視圖)是 快照讀 SOL執(zhí)行時MVCC提取數(shù)據(jù)的依據(jù),記錄并維護系統(tǒng)當前活躍的事務(wù)(未提交的)id。
ReadView中包含了四個核心字段:
| 字段 | 含義 |
|---|---|
| m_ids | 當前活躍的事務(wù)ID集合 |
| min_trx_id | 最小活躍事務(wù)ID |
| max_trx_id | 預(yù)分配事務(wù)ID,當前最大事務(wù)ID+1(因為事務(wù)ID是自增的) |
| creator_trx_id | ReadView創(chuàng)建者的事務(wù)ID |

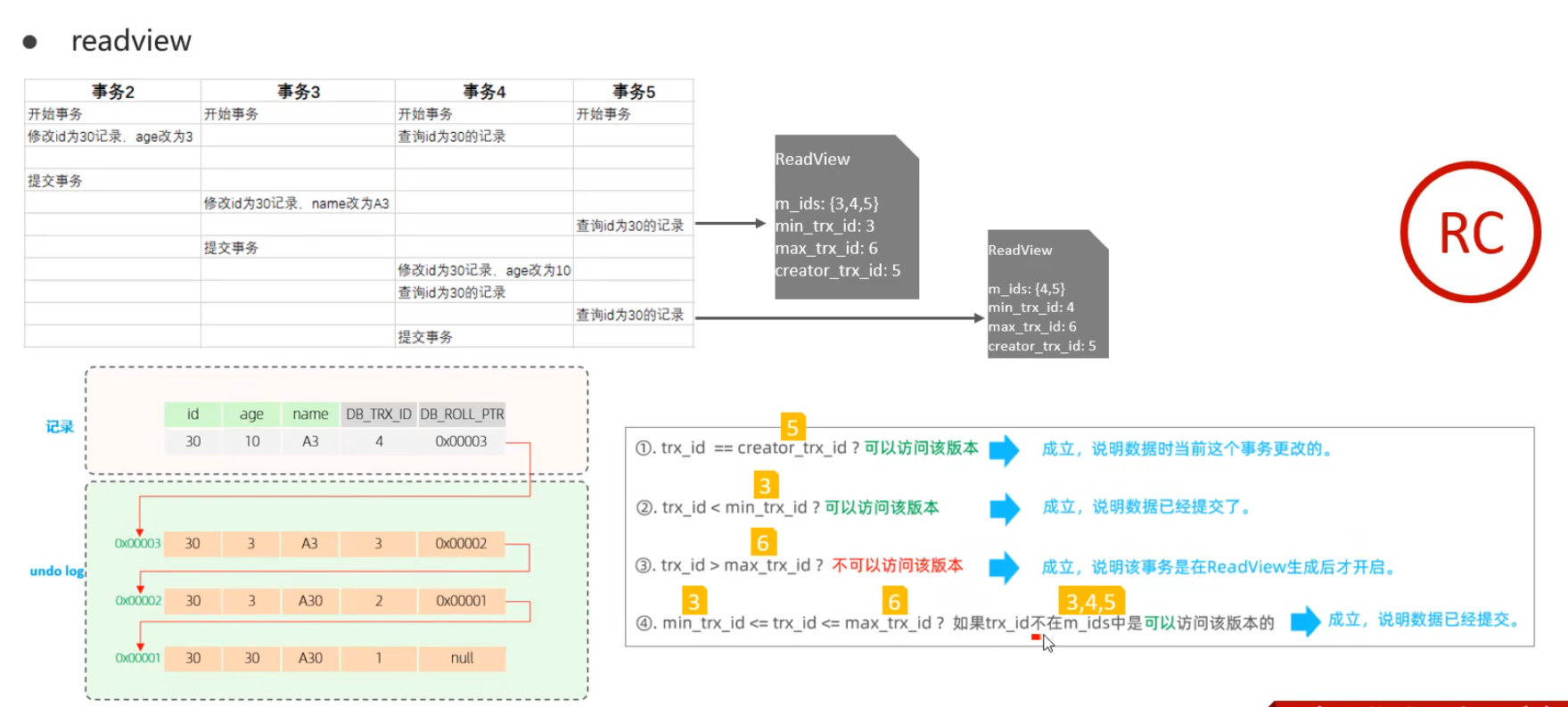
依次比較 undo log 日志中版本數(shù)據(jù)鏈,找到可以進行訪問的版本數(shù)據(jù)。
MySQL管理
系統(tǒng)數(shù)據(jù)庫介紹
Mysql數(shù)據(jù)庫安裝完成后,自帶了一下四個數(shù)據(jù)庫,具體作用如下:
| 數(shù)據(jù)庫 | 含義 |
|---|---|
| mysql | 存儲MVSQL服務(wù)器正常運行所需要的各種信息(時區(qū)、主從、用戶、權(quán)限等) |
| information_schema | 提供了訪問數(shù)據(jù)庫元數(shù)據(jù)的各種表和視圖,包含數(shù)據(jù)庫、表、字段類型及訪問權(quán)限等 |
| performance_schema | 為MySQL服務(wù)器運行時狀態(tài)提供了一個底層監(jiān)控功能,主要用于收集數(shù)據(jù)庫服務(wù)器性能參數(shù) |
| sys | 包含了一系列方便 DBA和開發(fā)人員利用 performance_schema性能數(shù)據(jù)庫進行性能調(diào)優(yōu)和診斷的視圖 |
常用工具
mysql

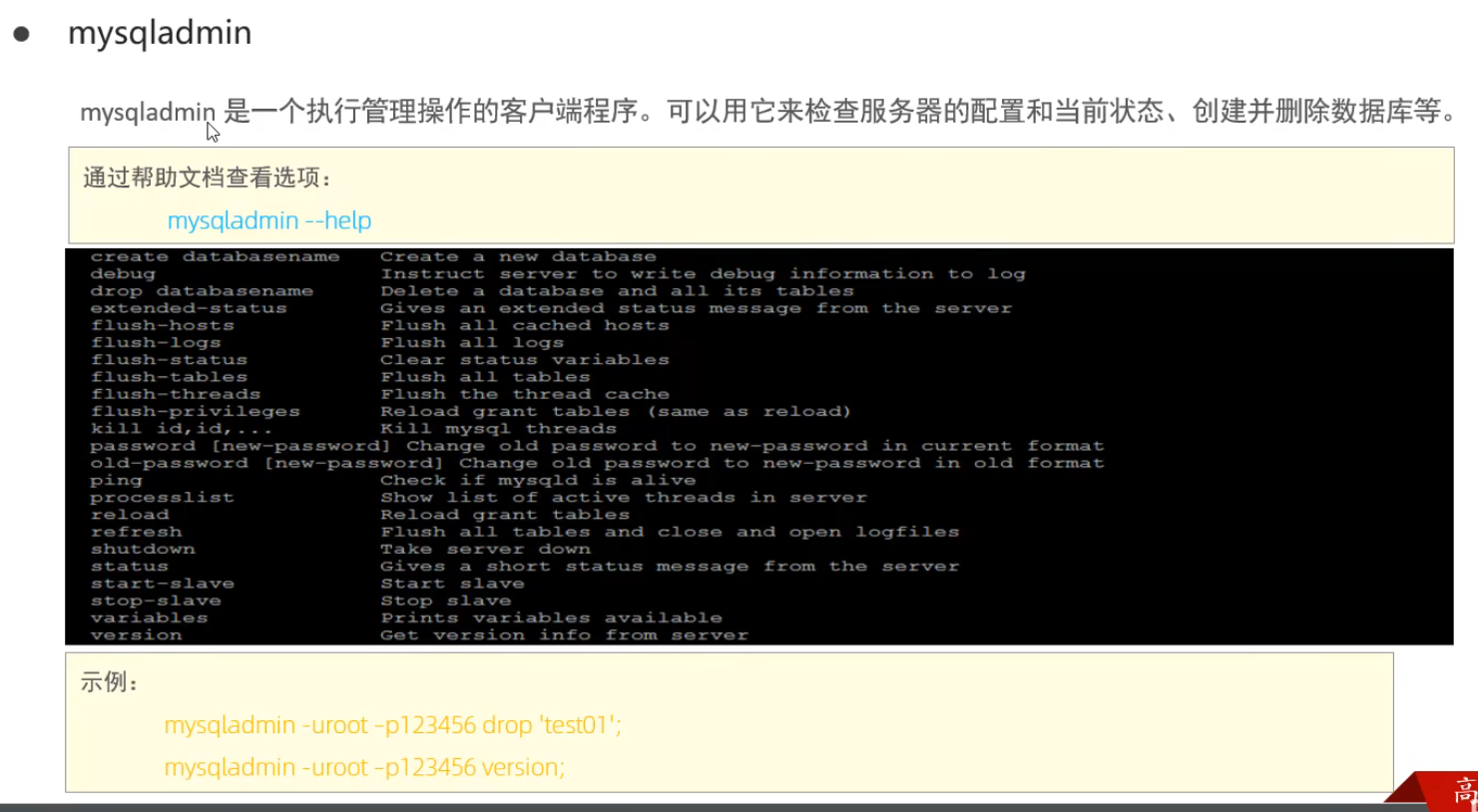
mysqladmin
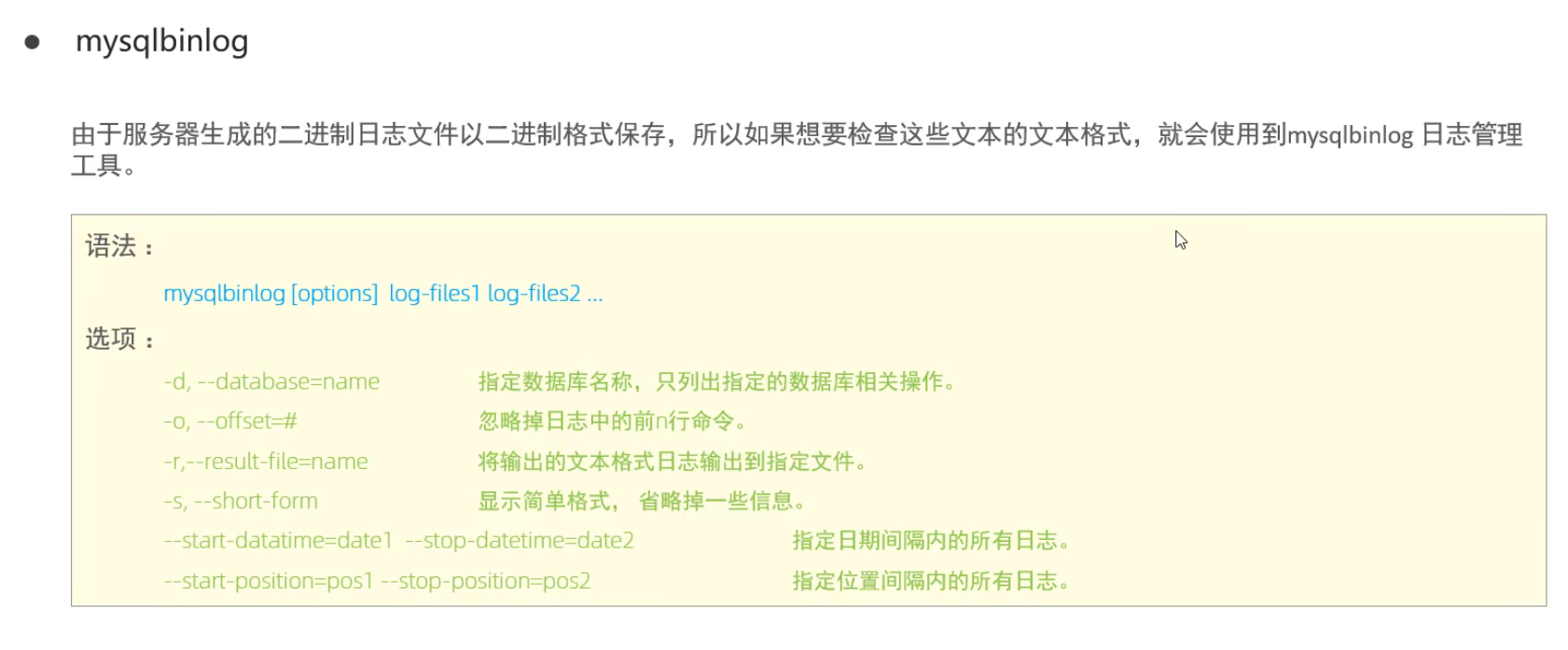
mysqlbinlog
mysqlshow

mysqldump

mysqlimport/source
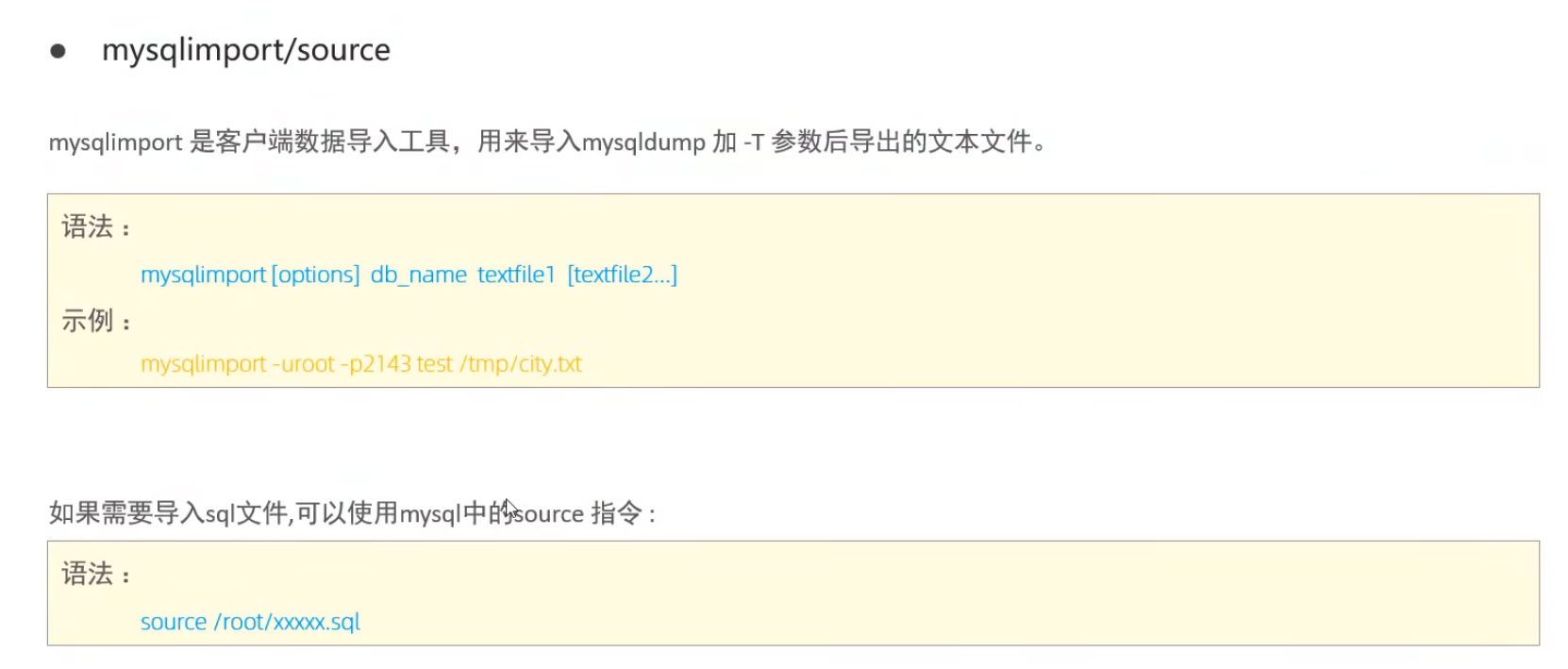
運維篇
日志
錯誤日志
錯誤日志是 MySQL 中最重要的日志之一,它記錄了當 mysqld 啟動和停止時,以及服務(wù)器在運行過程中發(fā)生任何嚴重錯誤時的相關(guān)信息當數(shù)據(jù)庫出現(xiàn)任何故障導(dǎo)致無法正常使用時,建議首先查看此日志。
該日志是默認開啟的,默認存放目錄 /var/log/,默認的日志文件名為 mysqld.log 。查看日志位置:
show variables like '%log_error%'
二進制日志
介紹
二進制日志(BINLOG)記錄了所有的 DDL(數(shù)據(jù)定義語言)語句和 DML(數(shù)據(jù)操縱語言)語句,但不包括數(shù)據(jù)查詢(SELECT、SHOW)語句。
作用:
- 災(zāi)難時的數(shù)據(jù)恢復(fù);
- MySQL的主從復(fù)制。
在MVSOL8版本中,默認二進制日志是開啟著的,涉及到的參數(shù)如下:
show variables like '%log_bin%'
日志格式
MySQL服務(wù)器中提供了多種格式來記錄二進制記錄,具體格式及特點如下:
| 日志格式 | 含義 |
|---|---|
| statement | 基于SQL語句的日志記錄,記錄的是SQL語句,對數(shù)據(jù)進行修改的SQL都會記錄在日志文件中。 |
| row | 基于行的日志記錄,記錄的是每一行的數(shù)據(jù)變更。(默認) |
| mined | 混合了STATEMENT和ROW兩種格式,默認采用STATEMENT,在某些特殊情況下會自動切換為ROW進行記錄。 |
查看參數(shù)方式:show variables like '%binlog_format%';
日志查看
由于日志是以二進制方式存儲的,不能直接讀取,需要通過二進制日志查詢工具 mysqlbinlog 來查看,具體語法:
mysqlbinlog[參數(shù)選項]logfilename
|
日志刪除
對于比較繁忙的業(yè)務(wù)系統(tǒng),每天生成的binlog數(shù)據(jù)巨大,如果長時間不清除,將會占用大量磁盤空間。可以通過以下幾種方式清理日志:
| 指令 | 含義 |
|---|---|
| reset master | 刪除全部 binlog 日志,刪除之后,日志編號,將從 binlog.000001重新開始 |
| purge master logs to ‘binlog.***’ | 刪除 *** 編號之前的所有日志 |
| purge master logs before ‘yyyy-mm-dd hh24:mi:ss’ | 刪除日志為”yyyy-mm-dd hh24:mi:ss”之前產(chǎn)生的所有日志 |
也可以在mysql的配置文件中配置二進制日志的過期時間,設(shè)置了之后,二進制日志過期會自動刪除.
show variables like '%binlog_expire_logs_seconds%'
#該選項用來開啟查詢?nèi)罩荆蛇x值:0或者1;0代表關(guān)閉,1代表開啟
|
慢查詢?nèi)罩?/h3>
慢查詢?nèi)罩居涗浟怂袌?zhí)行時間超過參數(shù) long_query_time 設(shè)置值并且掃描記錄數(shù)不小于 min_examined_row_limit的所有的SQL語句的日志,默認未開啟。long_query_time 默認為 10 秒,最小為0,精度可以到微秒。
#慢查詢?nèi)罩?br>slow_query_log=1
|
默認情況下,不會記錄管理語句,也不會記錄不使用索引進行查找的查詢。可以使用log_slow_admin_statements和更改此行為log_queries_not_using_indexes,如下所述。
#記錄執(zhí)行較慢的管理語句
|
主從復(fù)制


原理
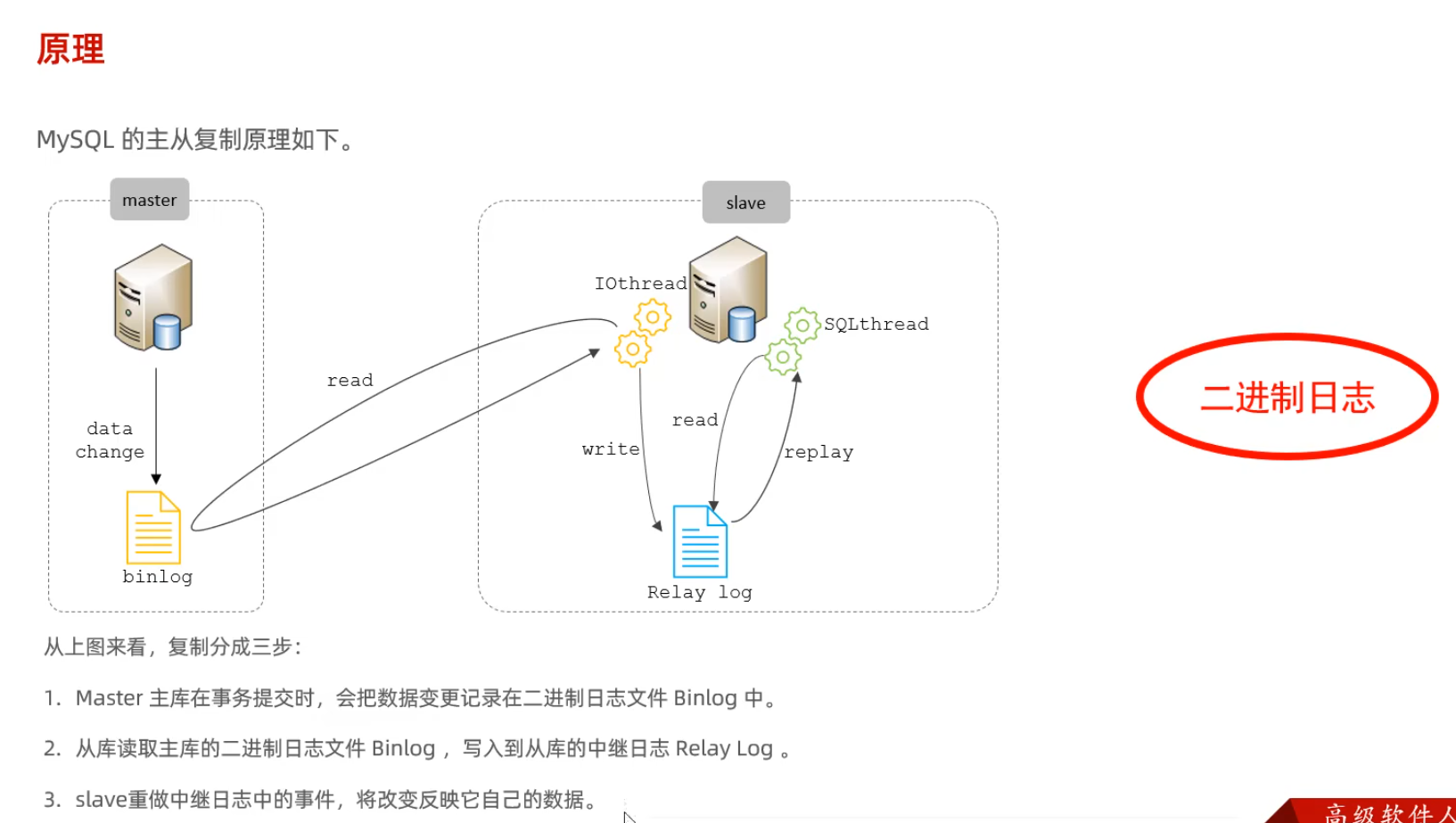
搭建實現(xiàn)
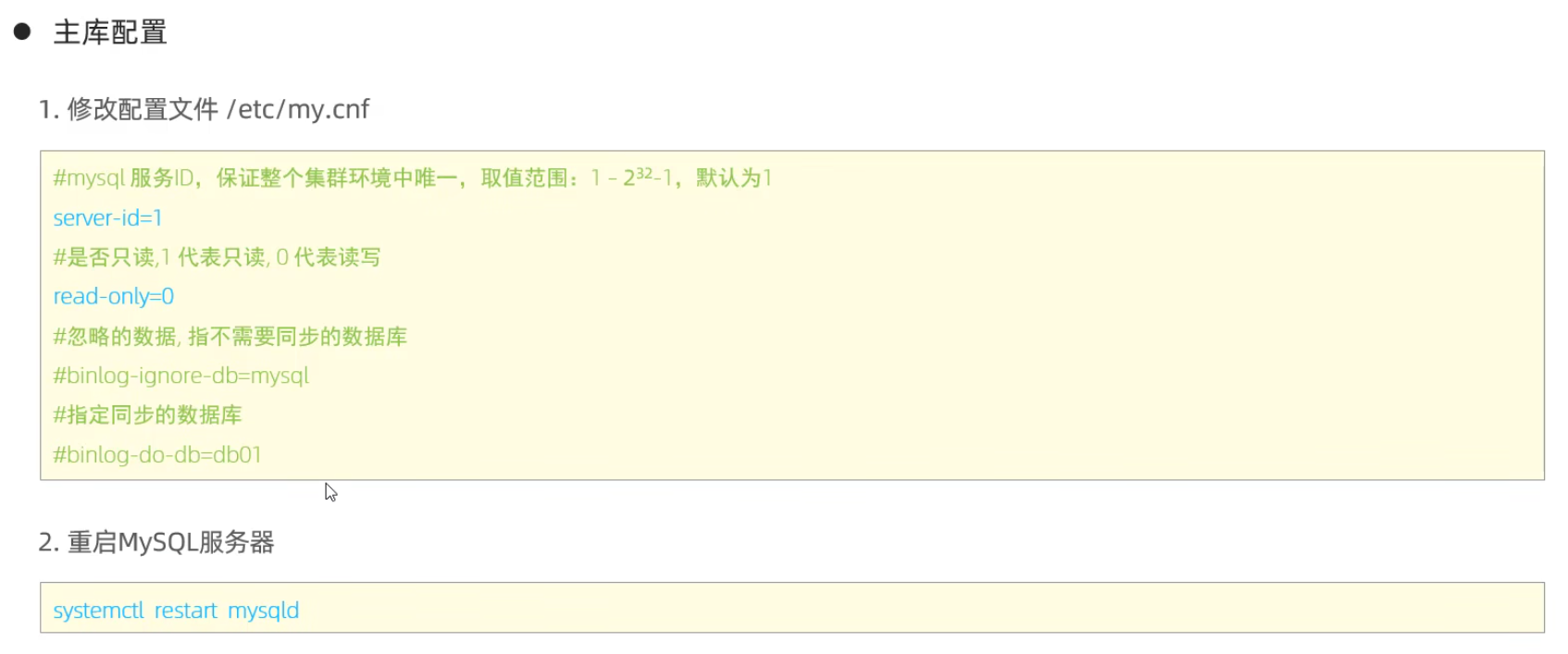
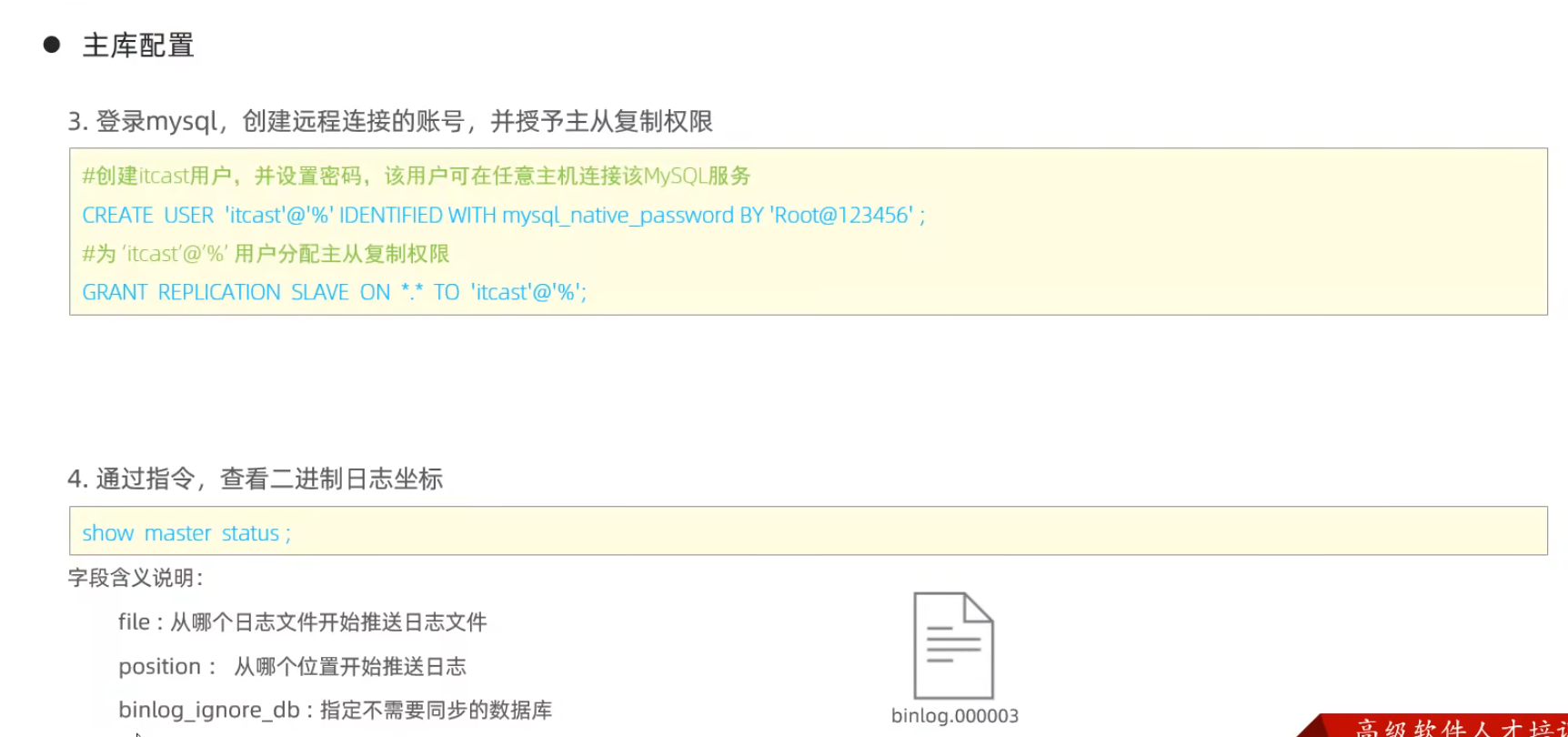
主庫配置

從庫配置
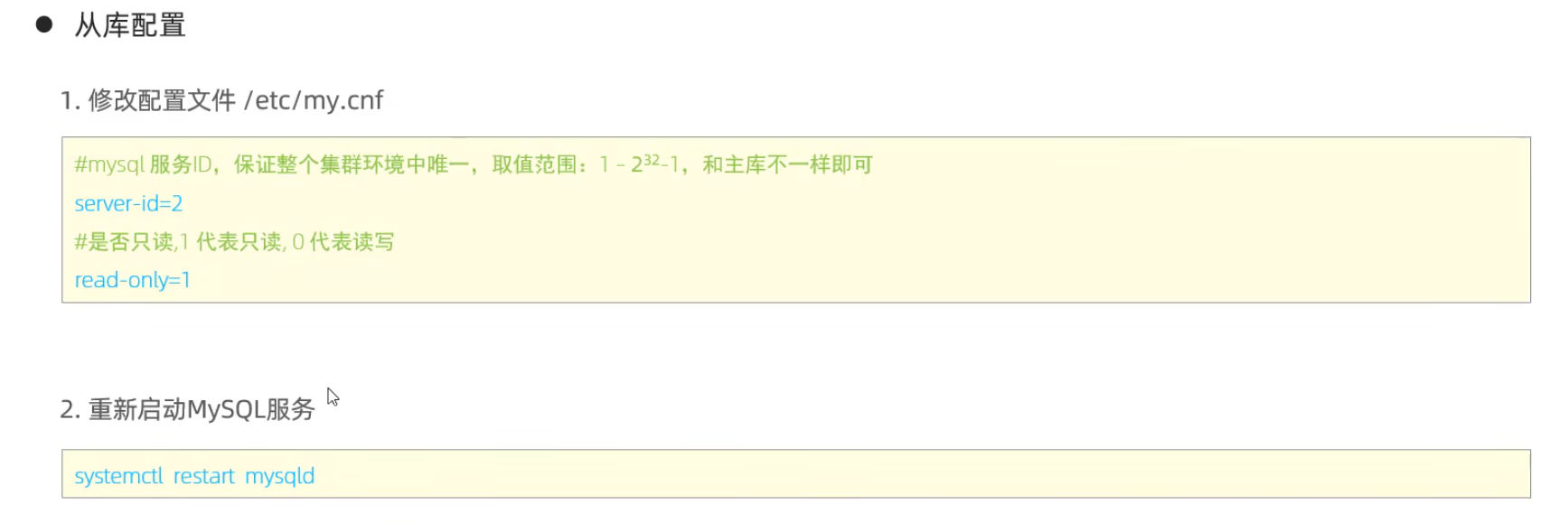
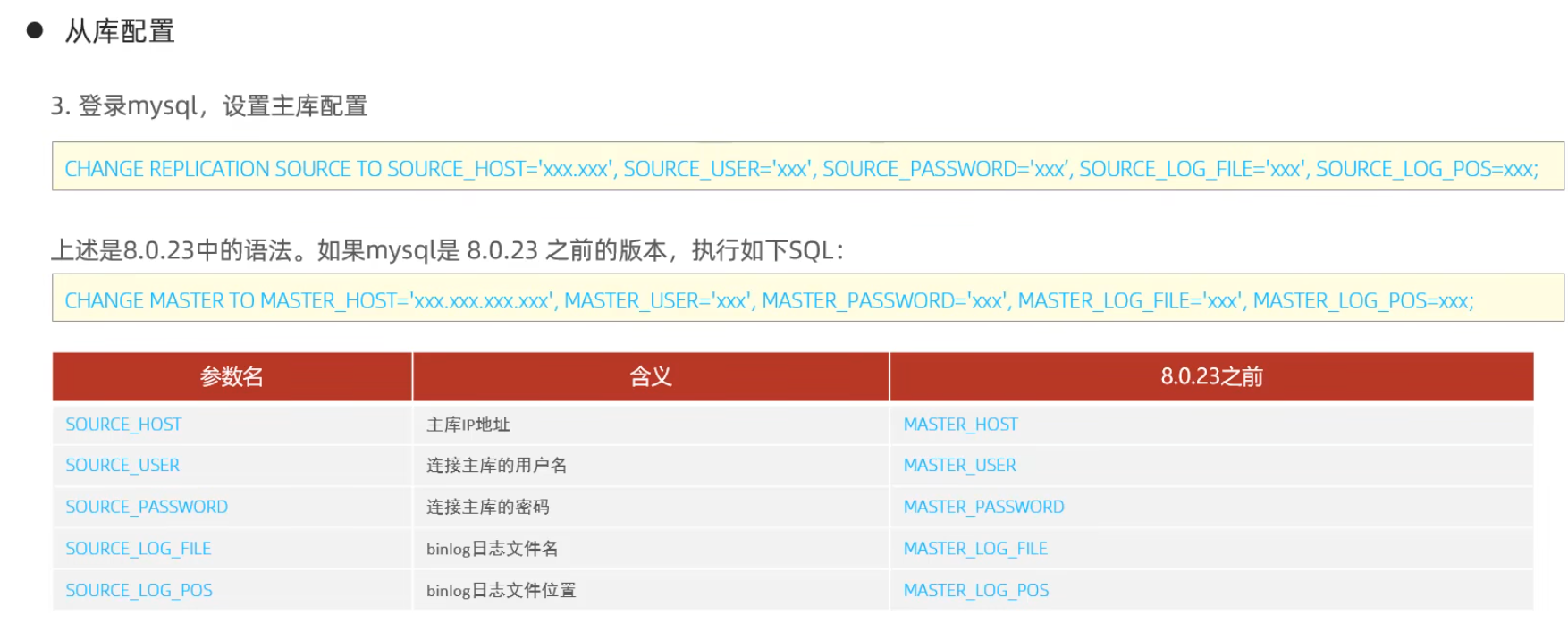
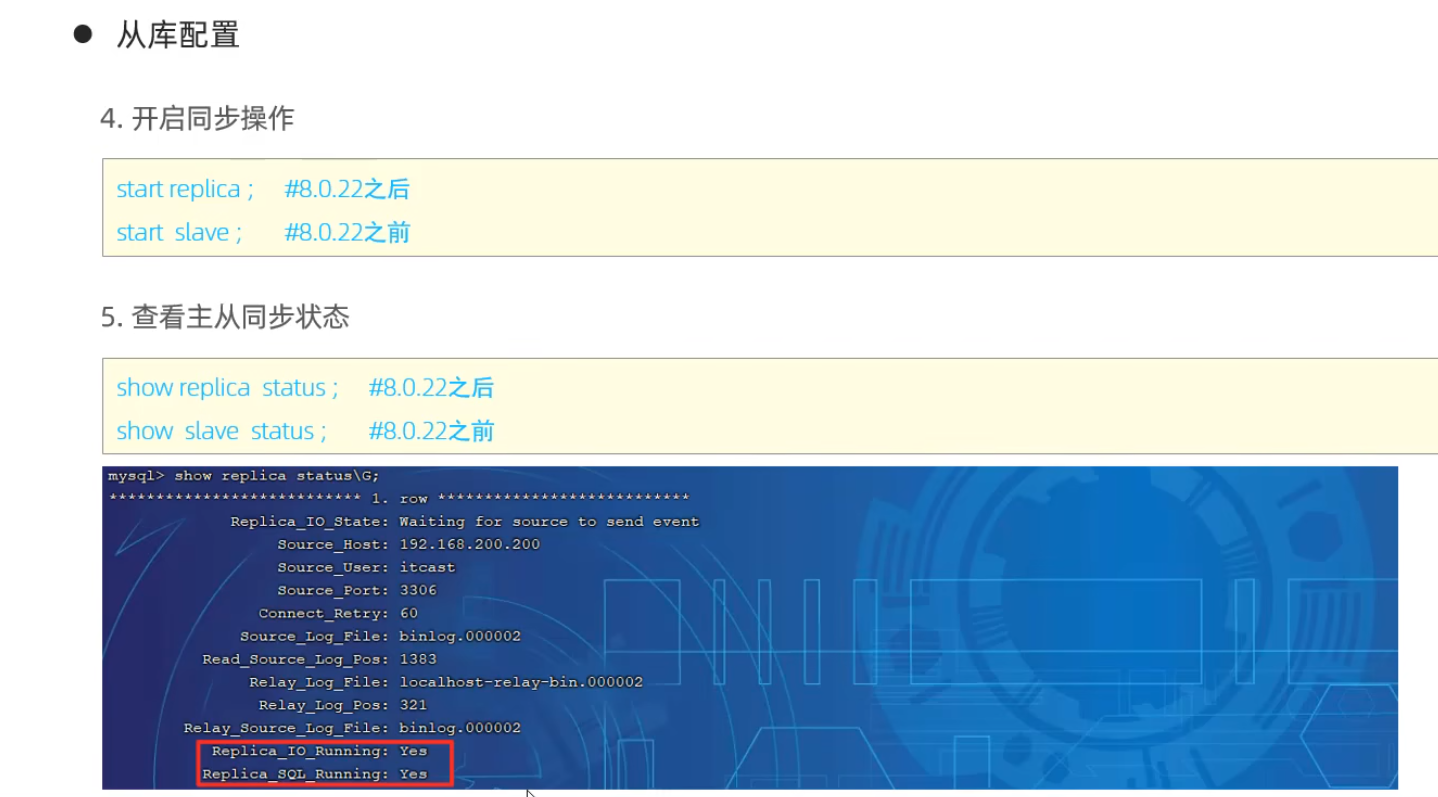
測試
1、在主庫上創(chuàng)建數(shù)據(jù)庫、表,并插入數(shù)據(jù)
create database db01;
|
2、在從庫中查詢數(shù)據(jù),驗證主從是否同步。
分庫分表
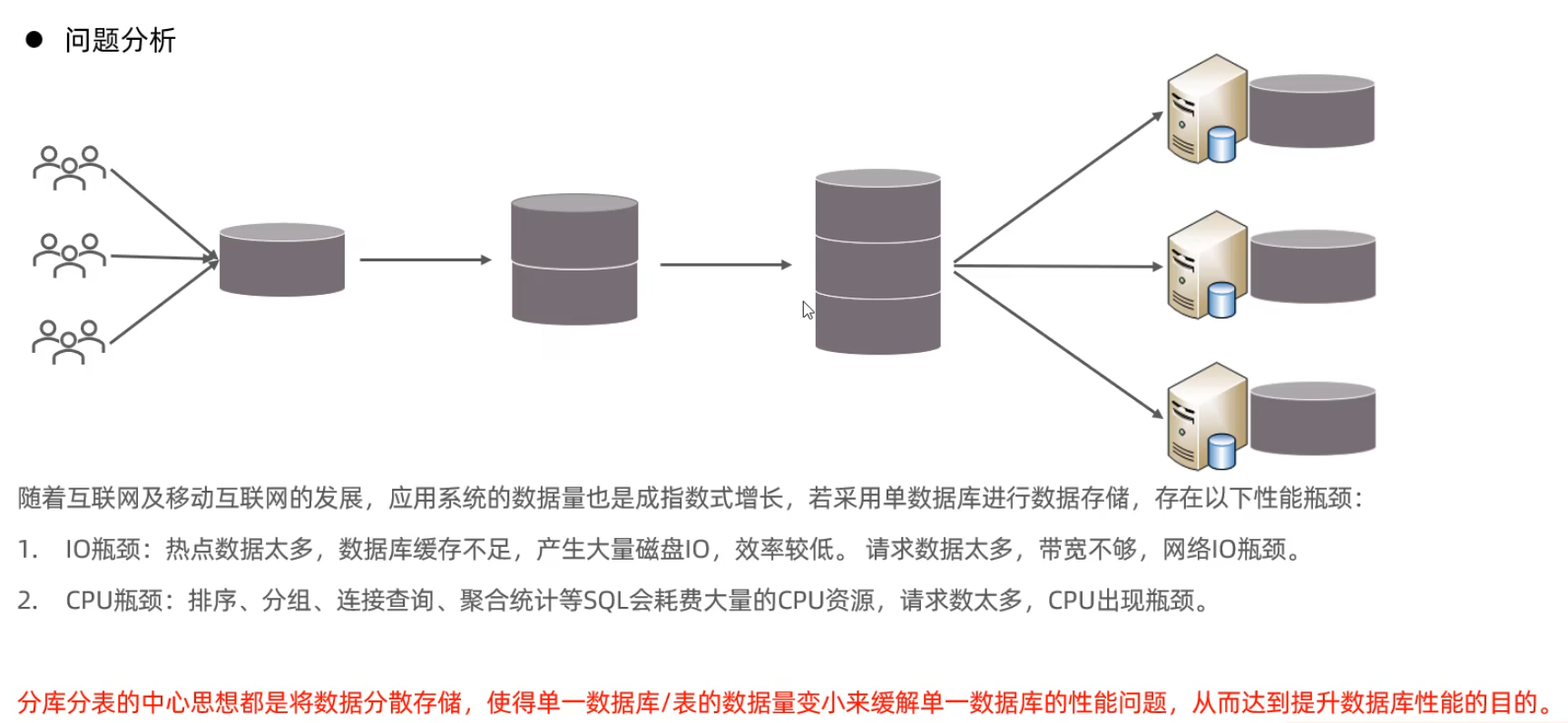
介紹
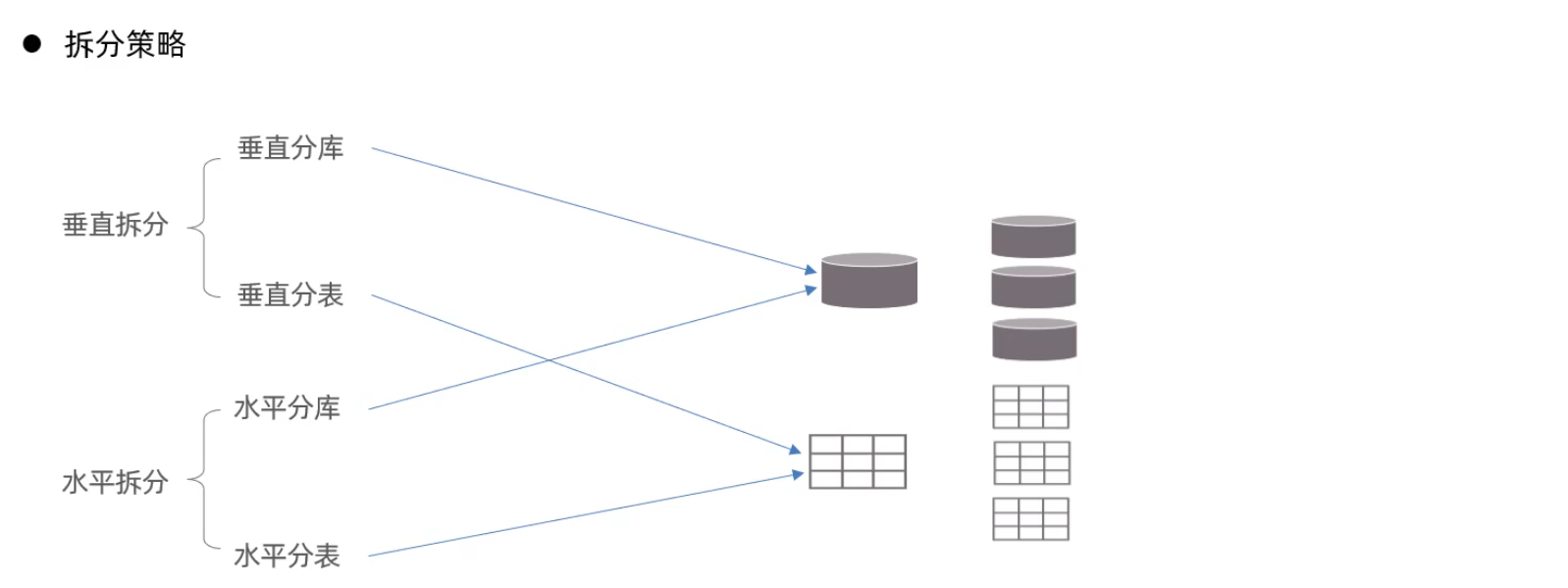
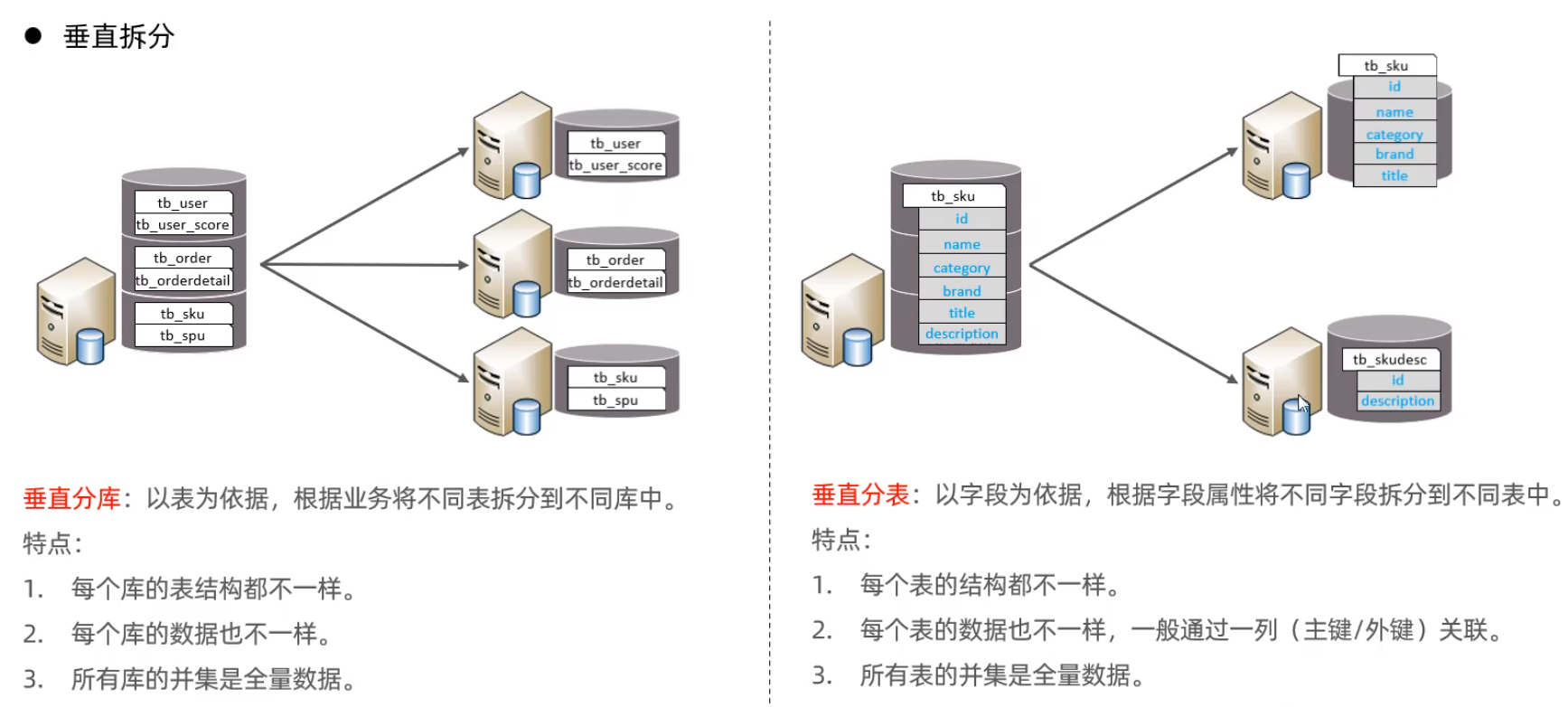
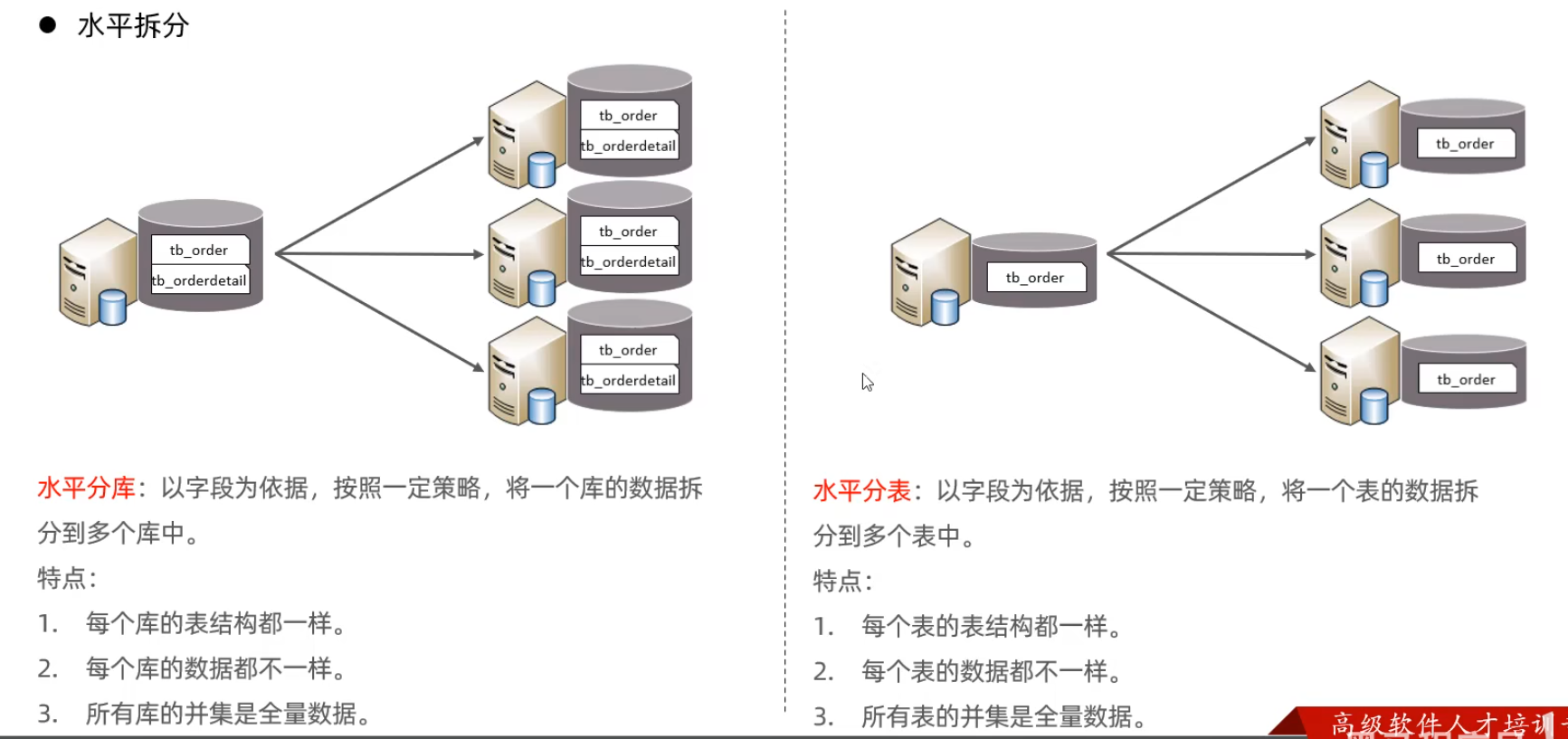
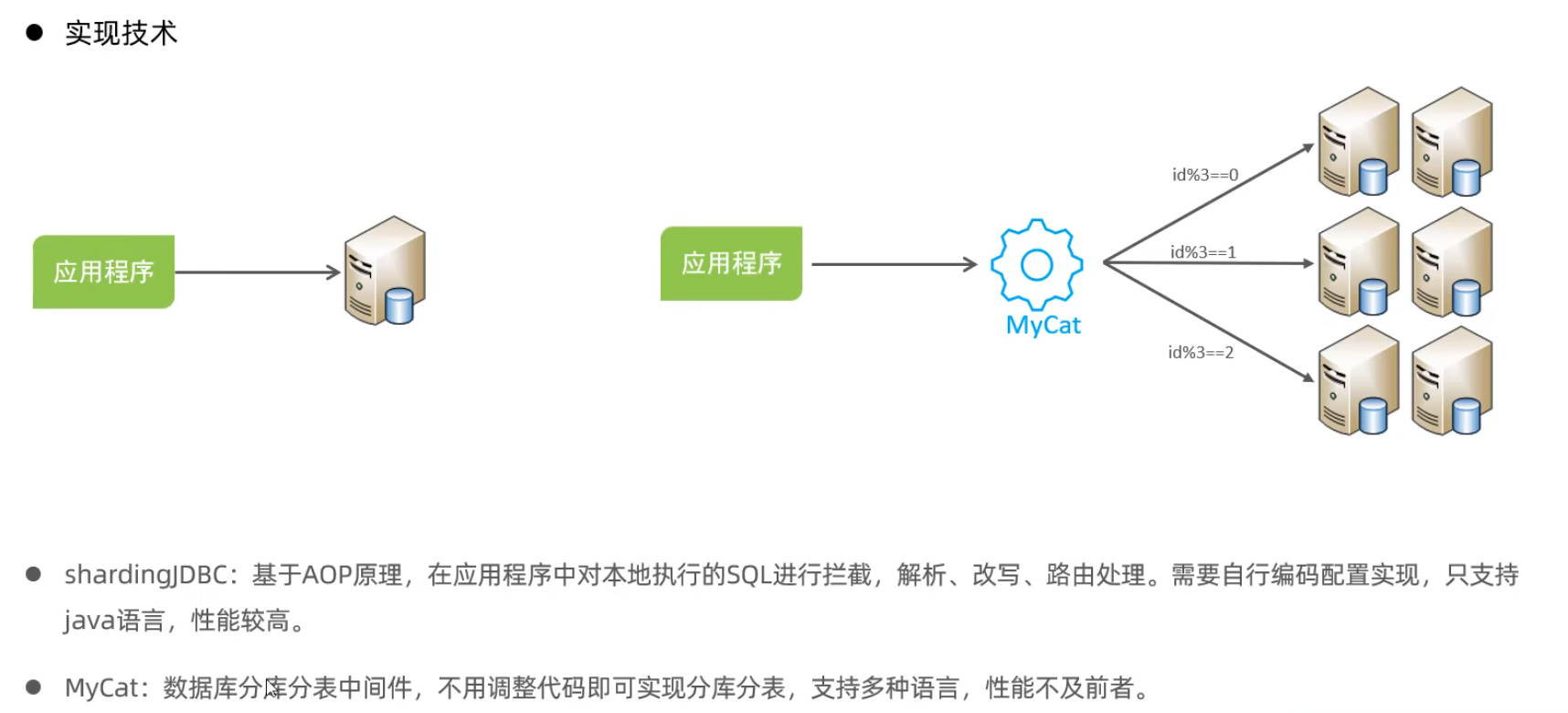
Mycat概述

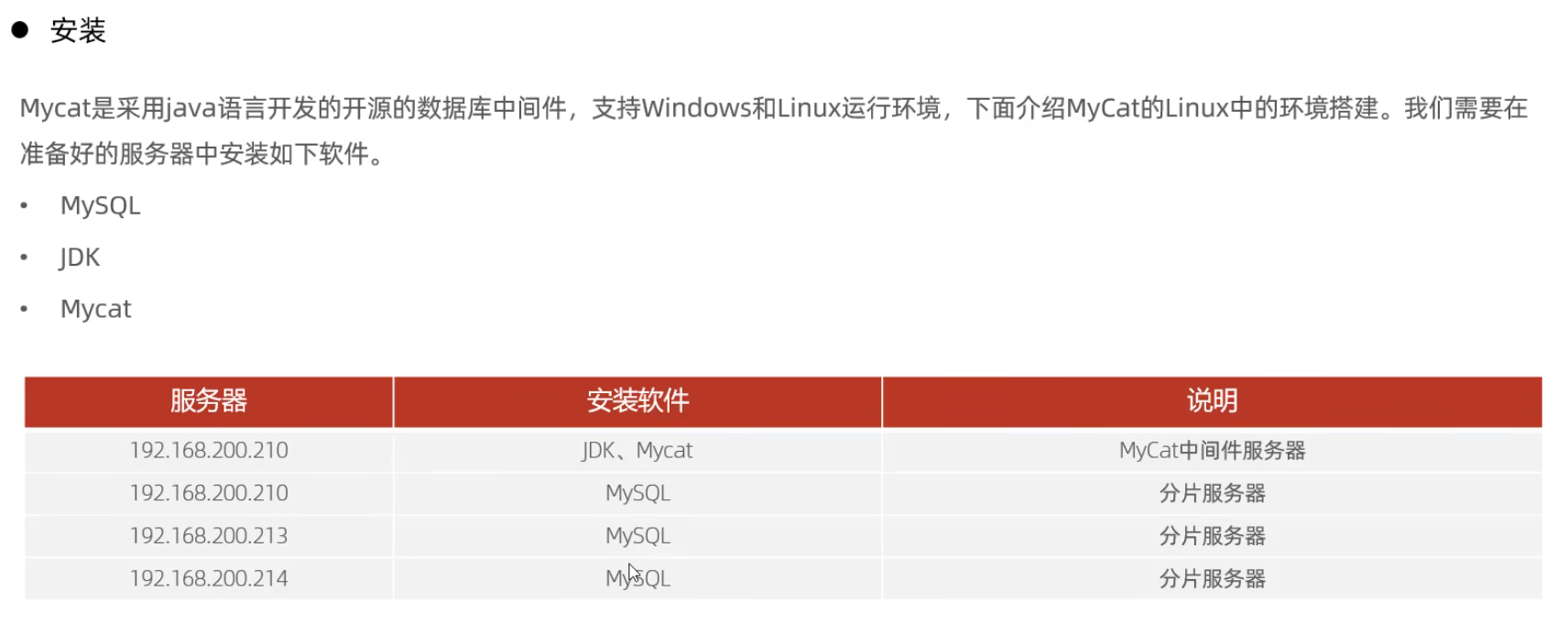
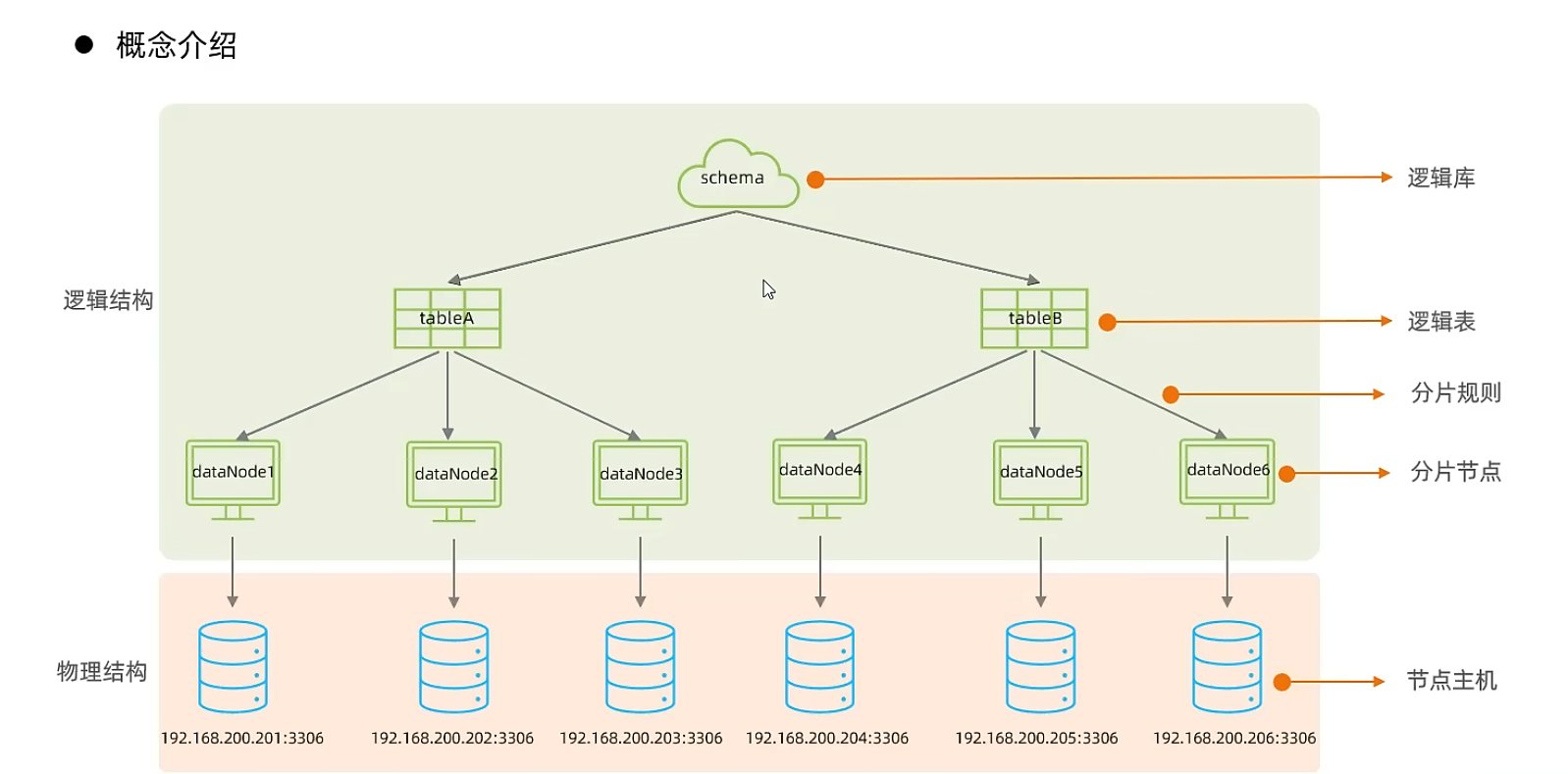
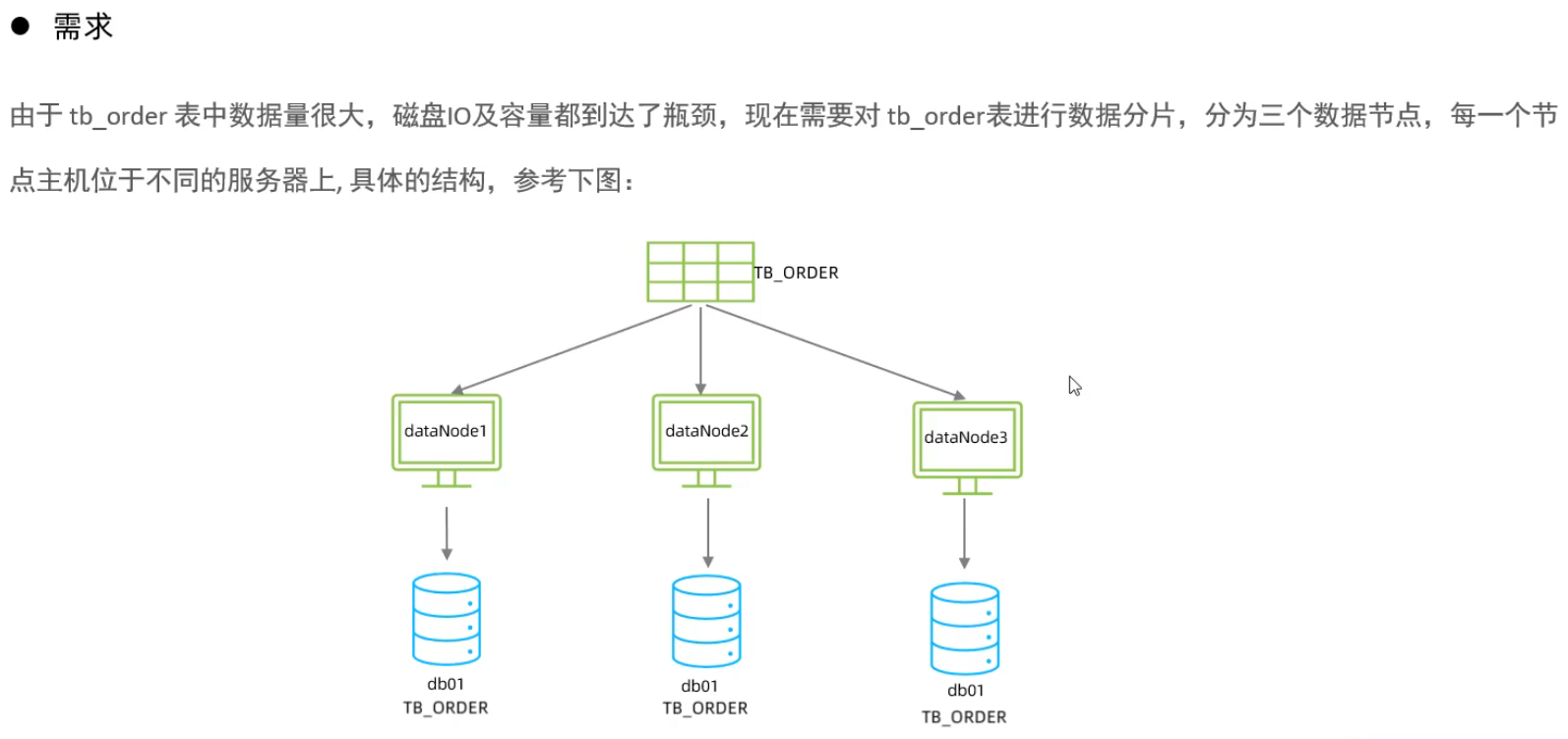
Mycat入門

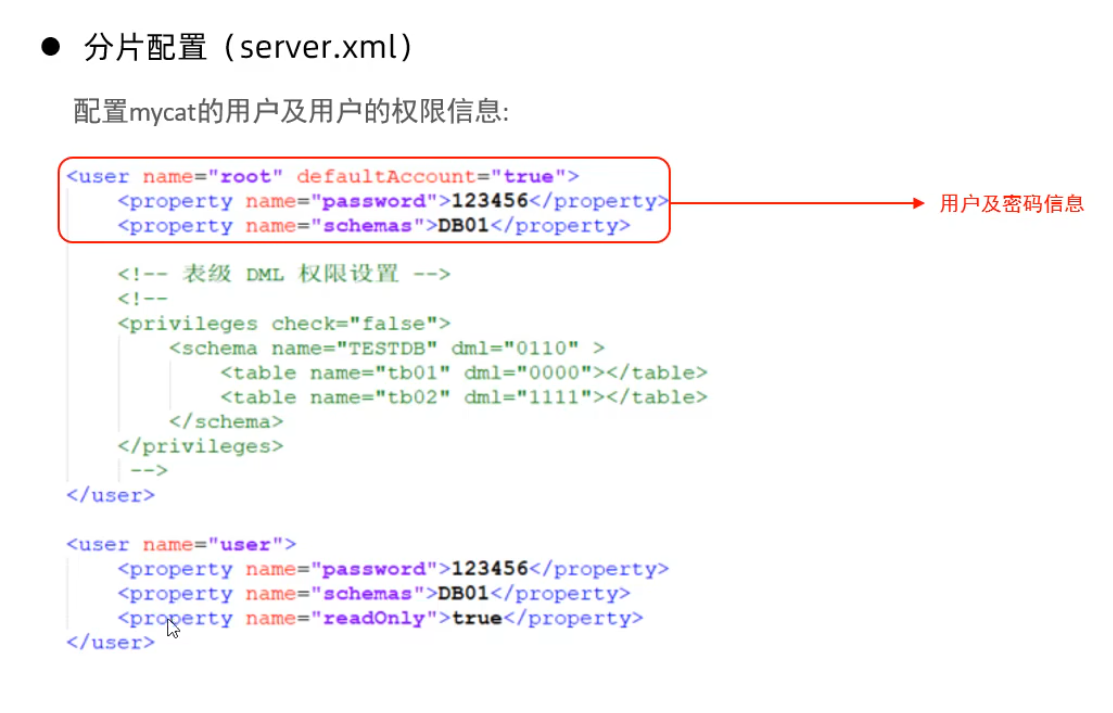
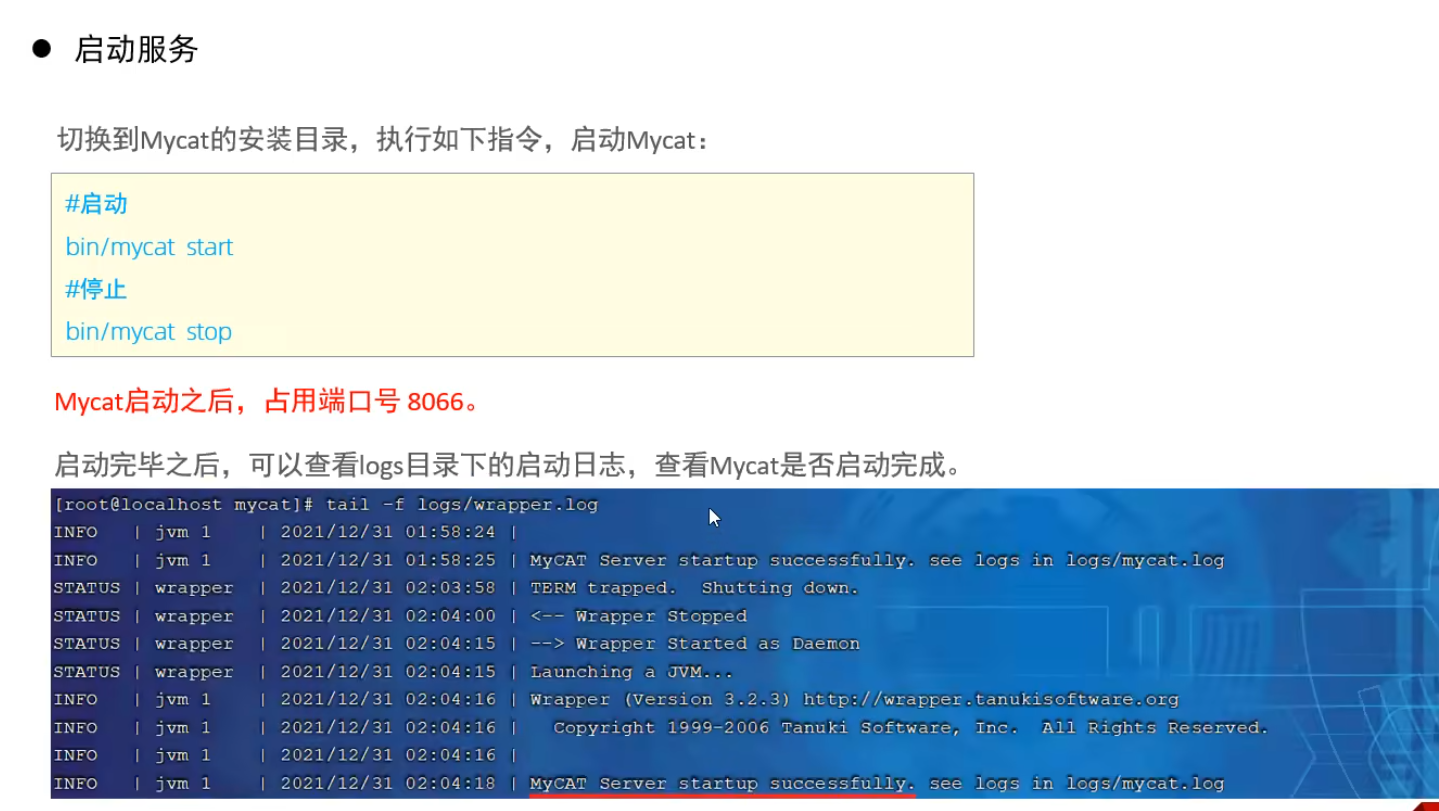
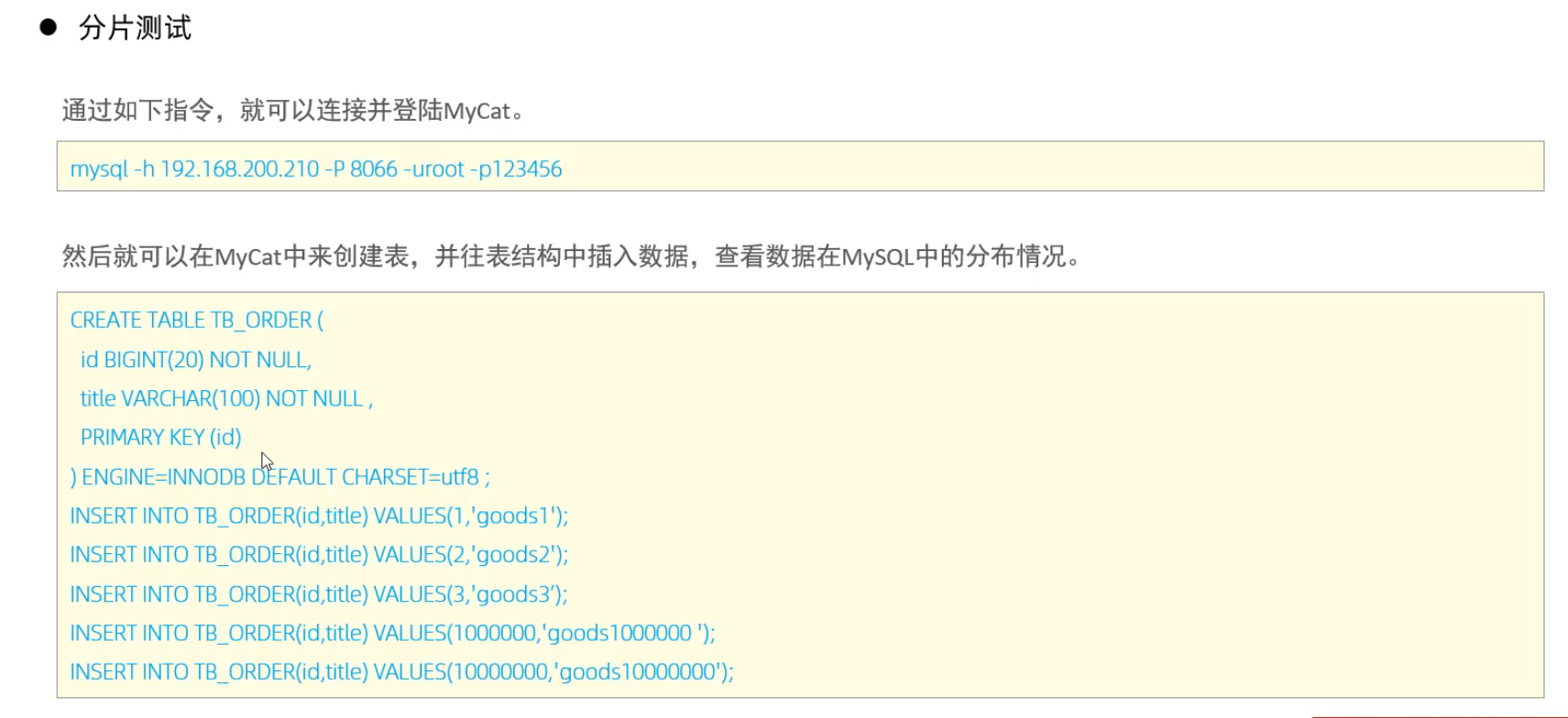
Mycat配置
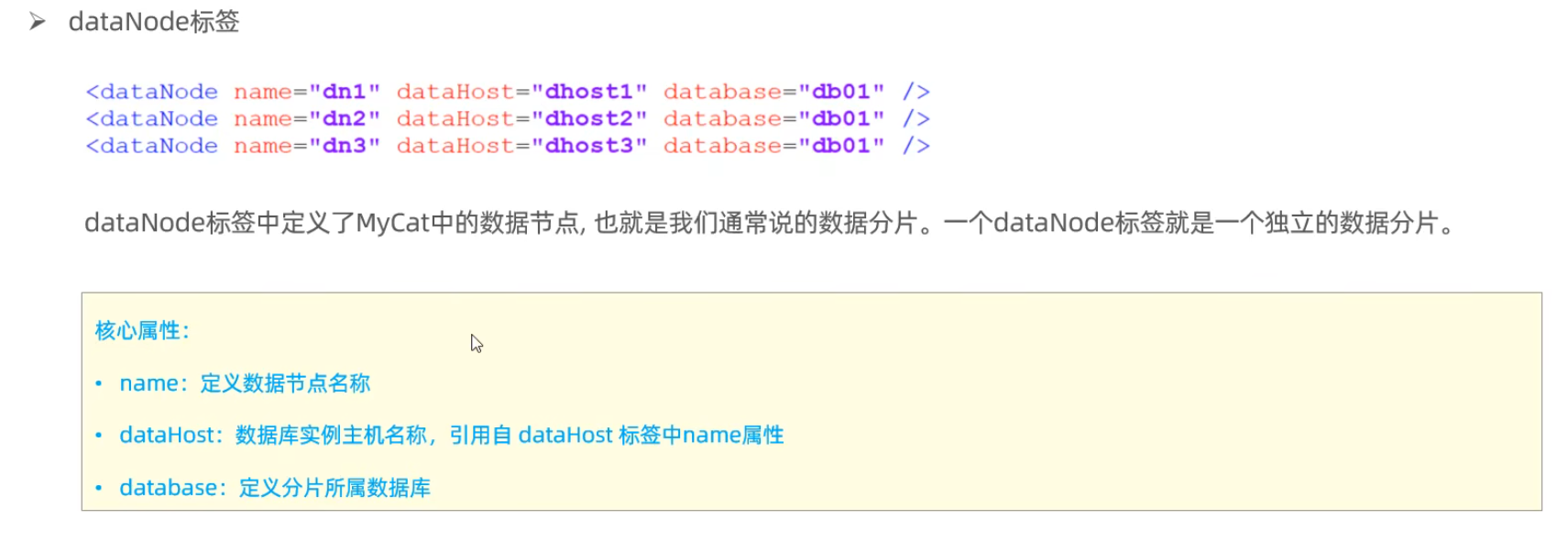
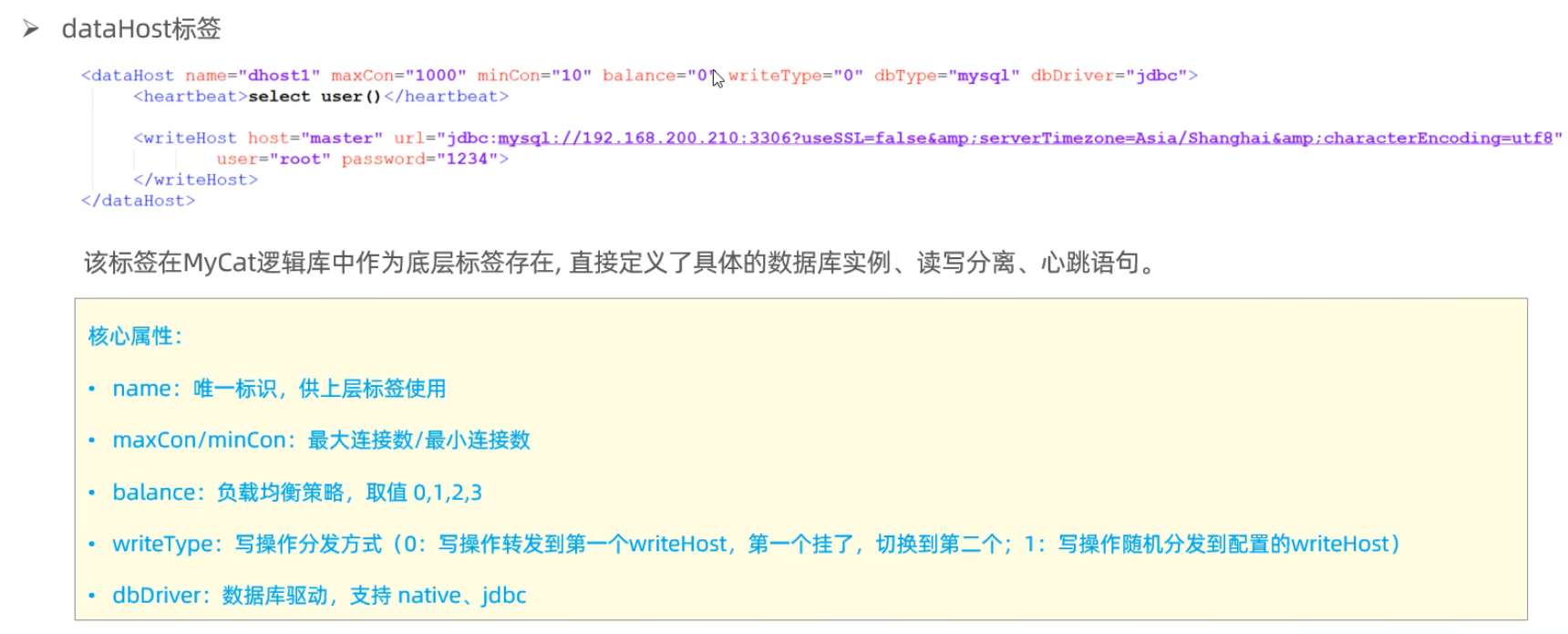
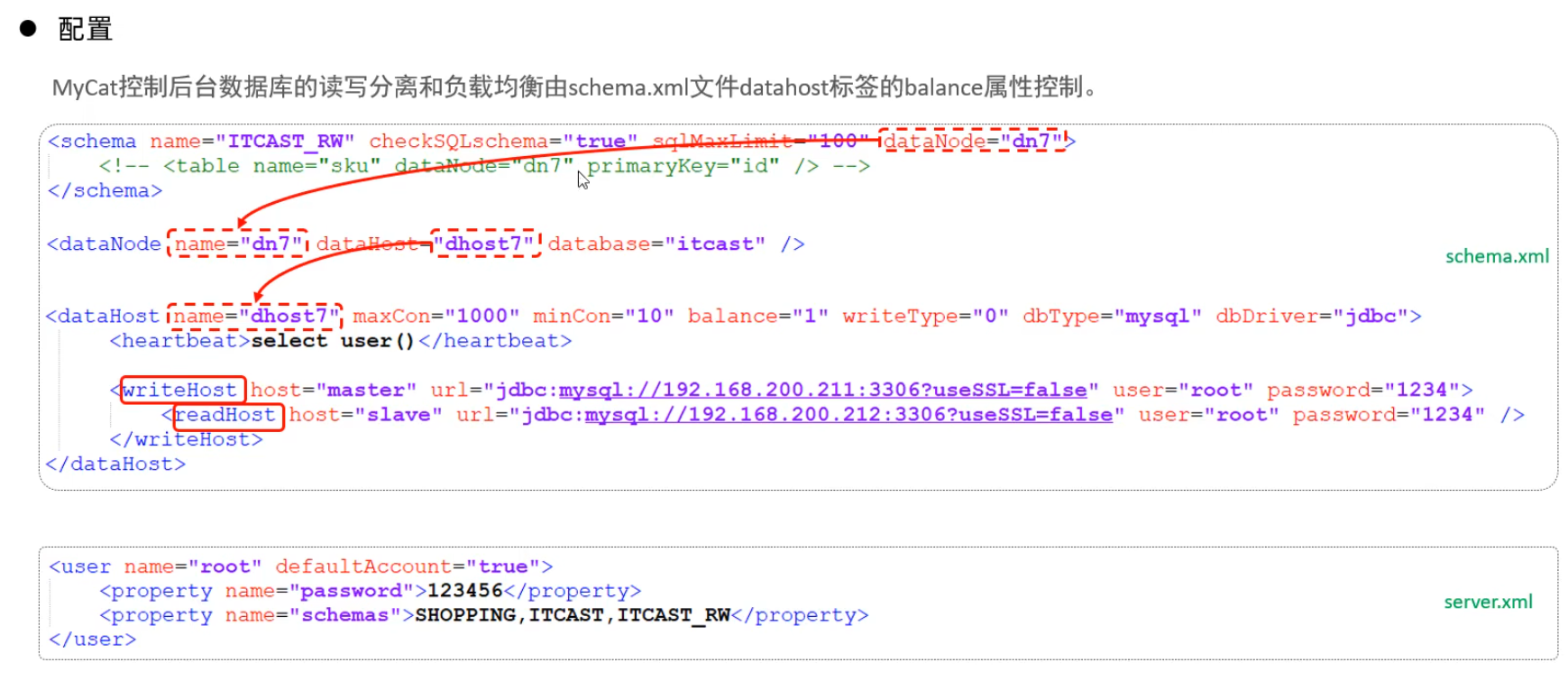
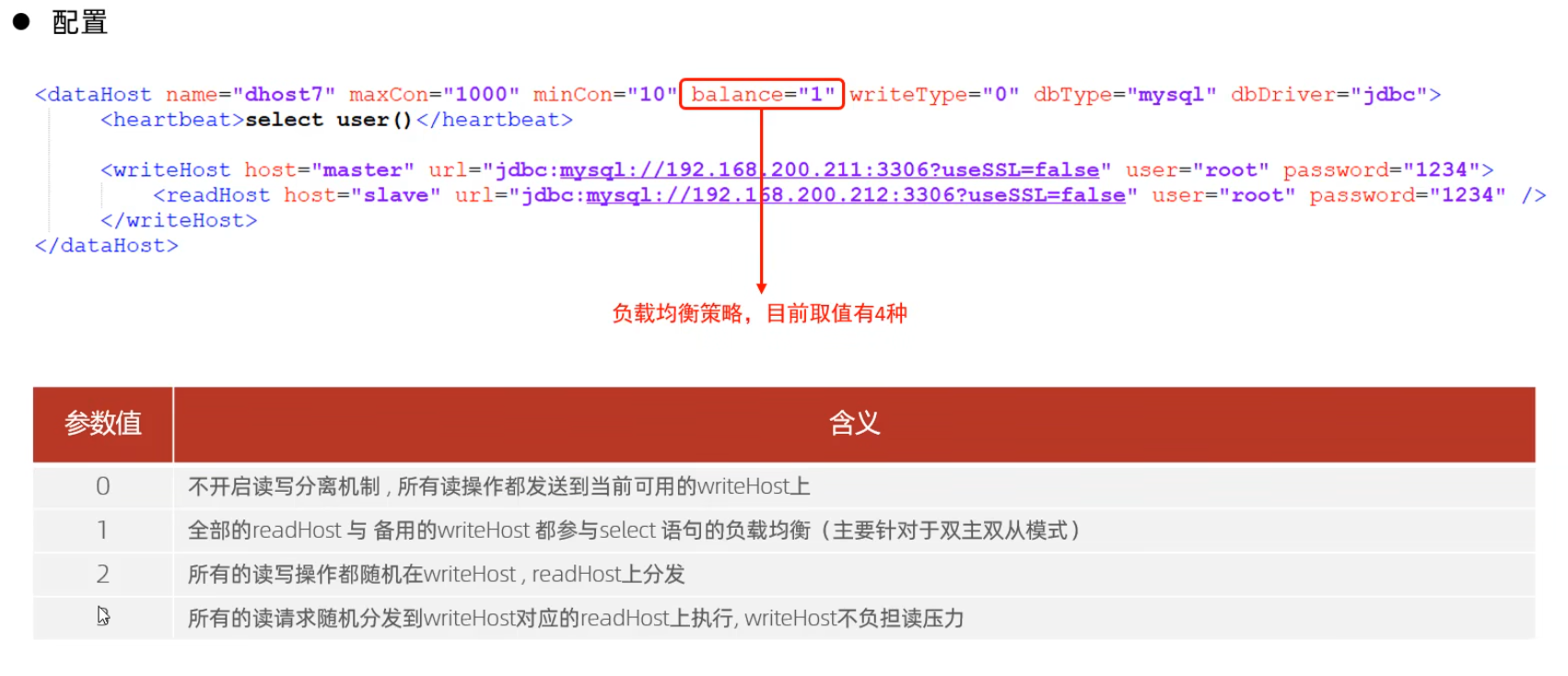
schema.xml
schema.xml作為MyCat中最重要的配置文件之一,涵蓋了MyCat的邏輯庫 、邏輯表 、分片規(guī)則、分片節(jié)點及數(shù)據(jù)源的配置.
主要包含以下三組標簽:
- schema標簽
- datanode標簽
- datahost標簽


rule.xml
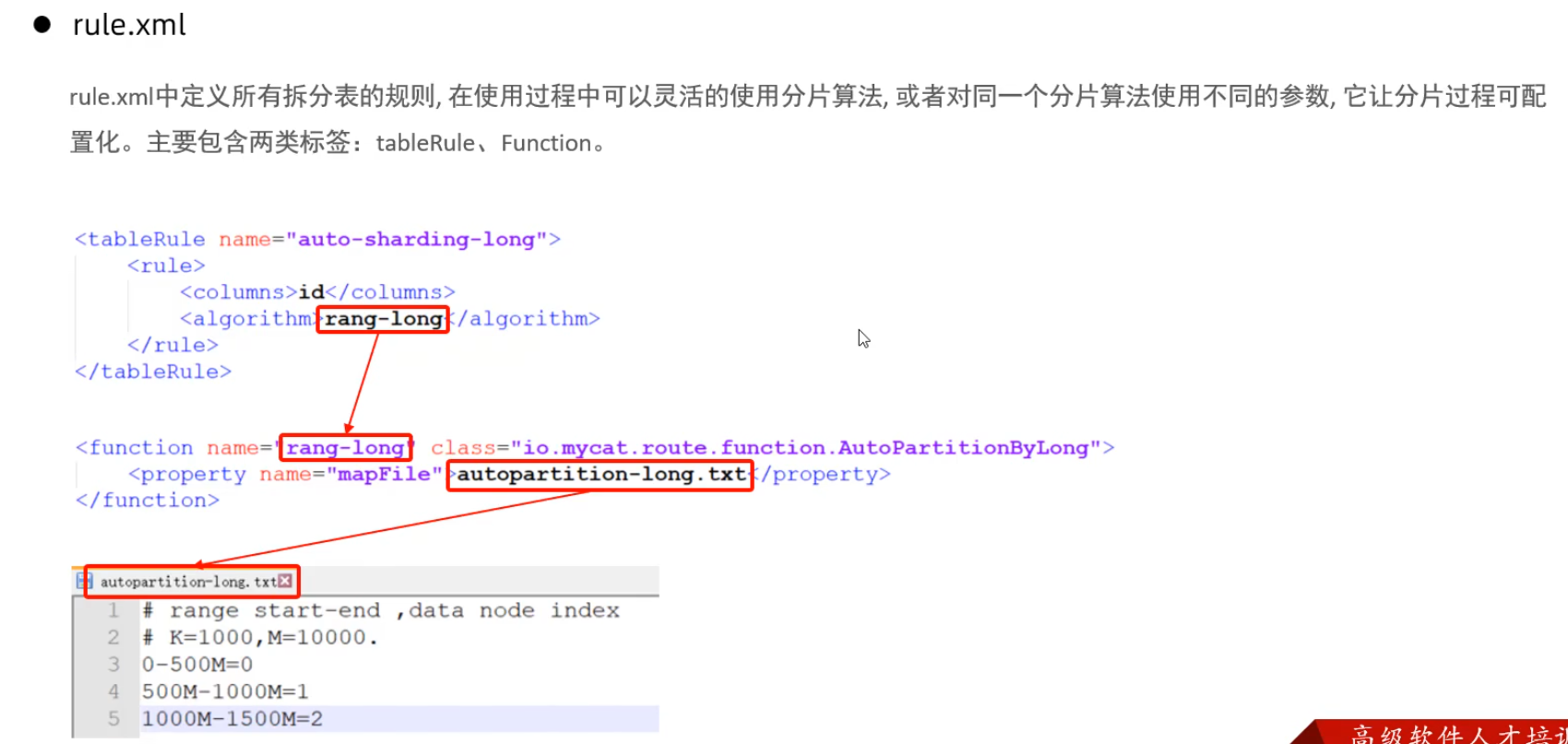


Mycat分片
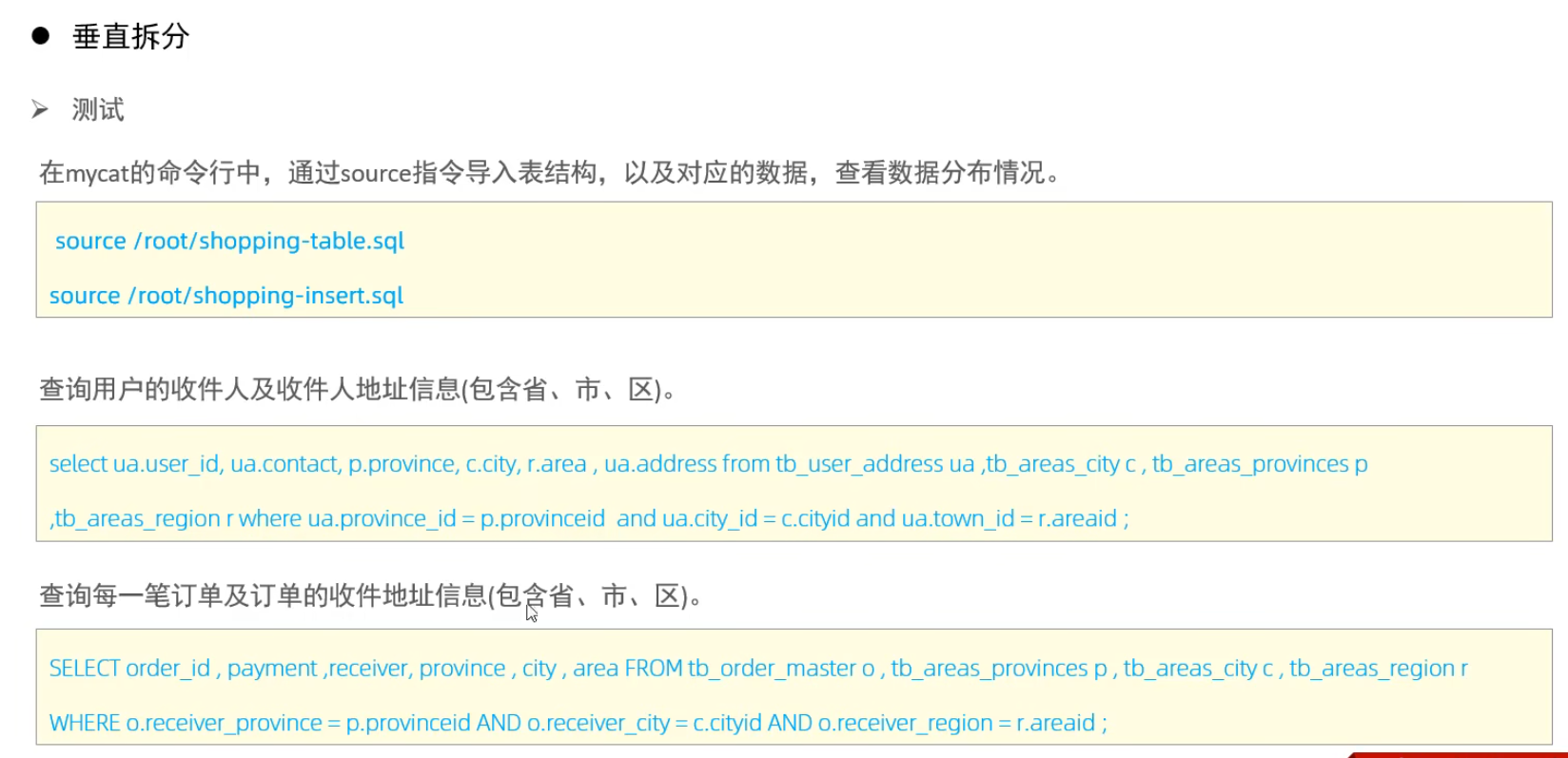
垂直分庫



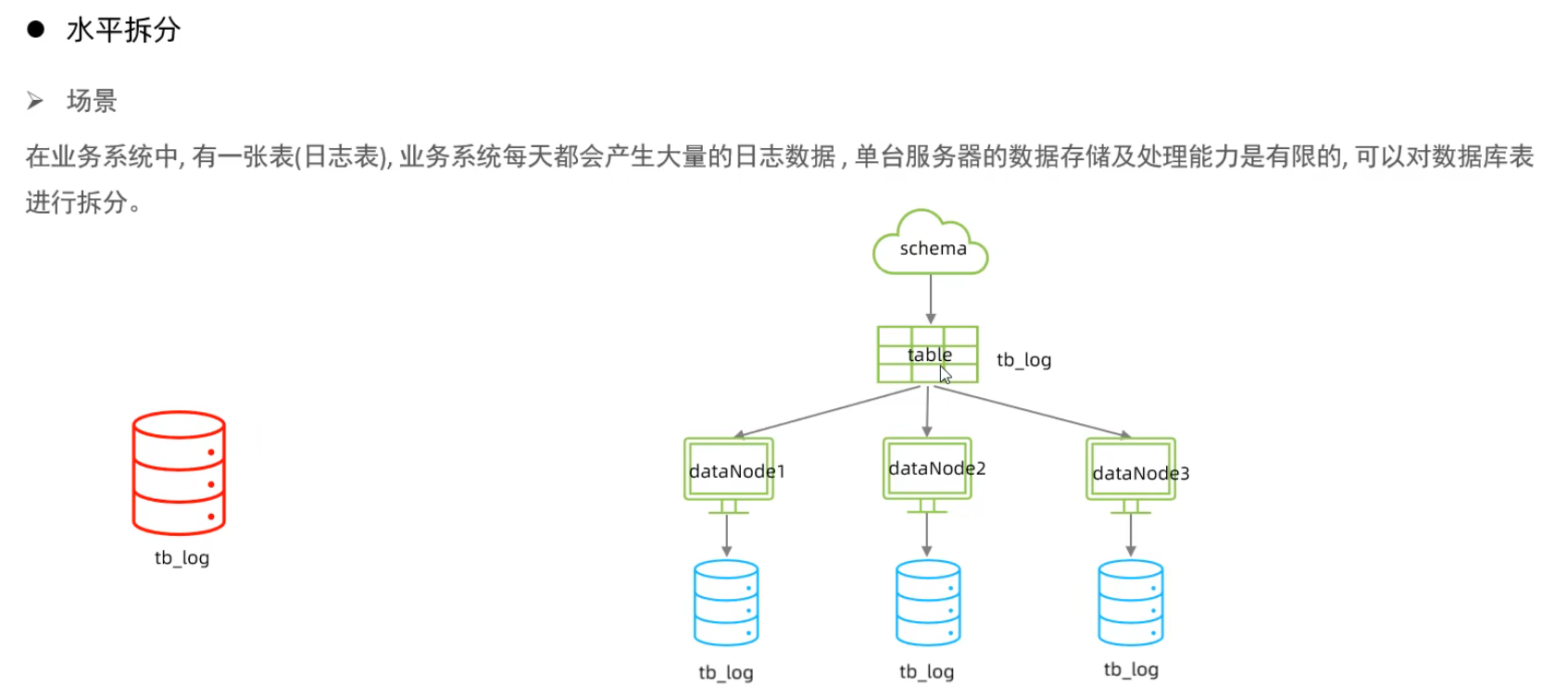
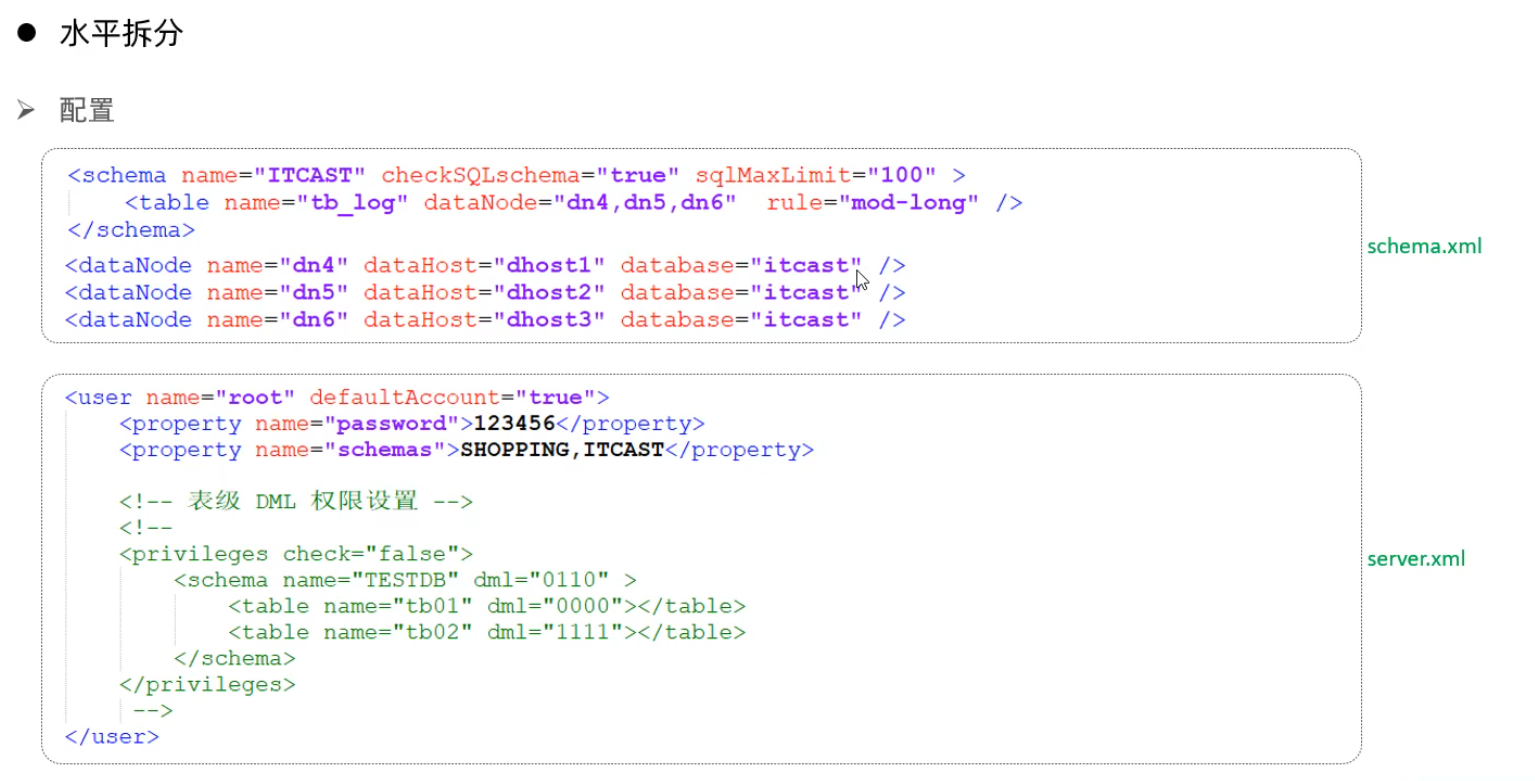
水平分表

分片規(guī)則
范圍分片
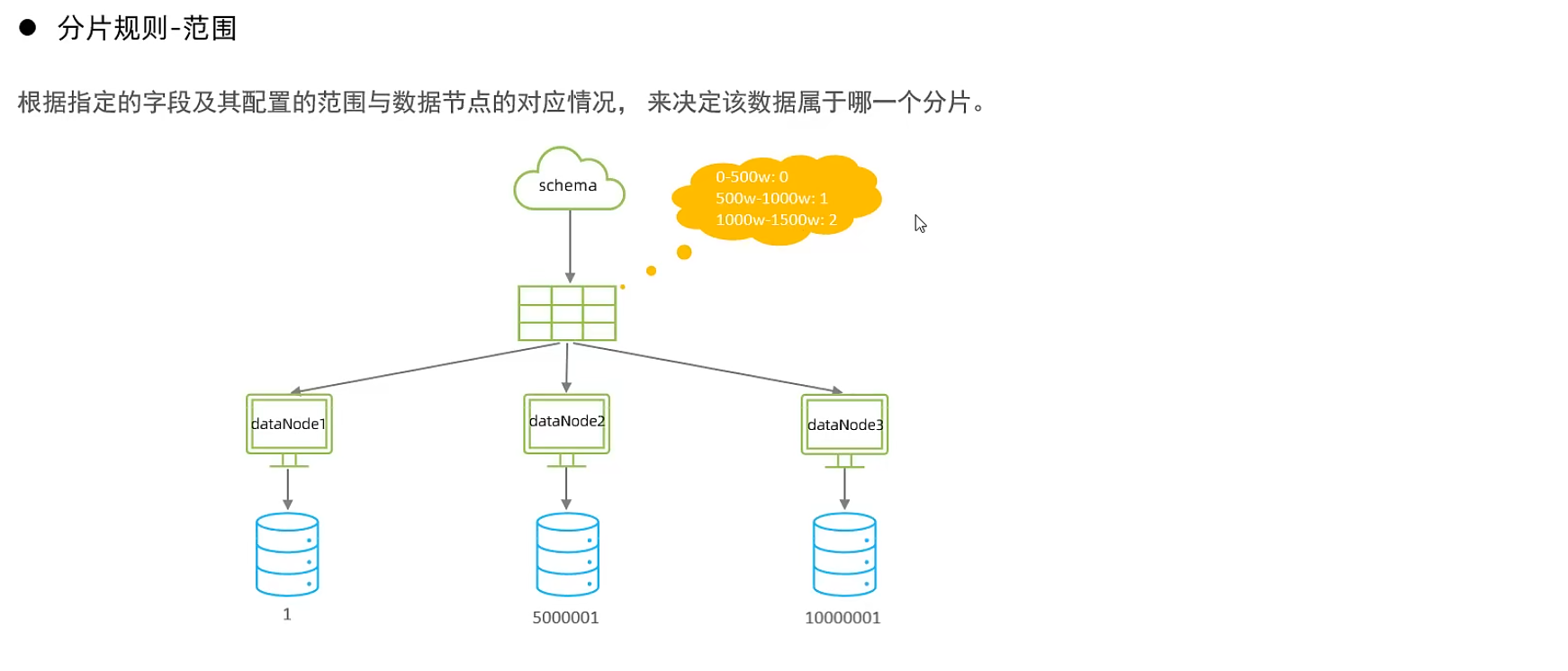
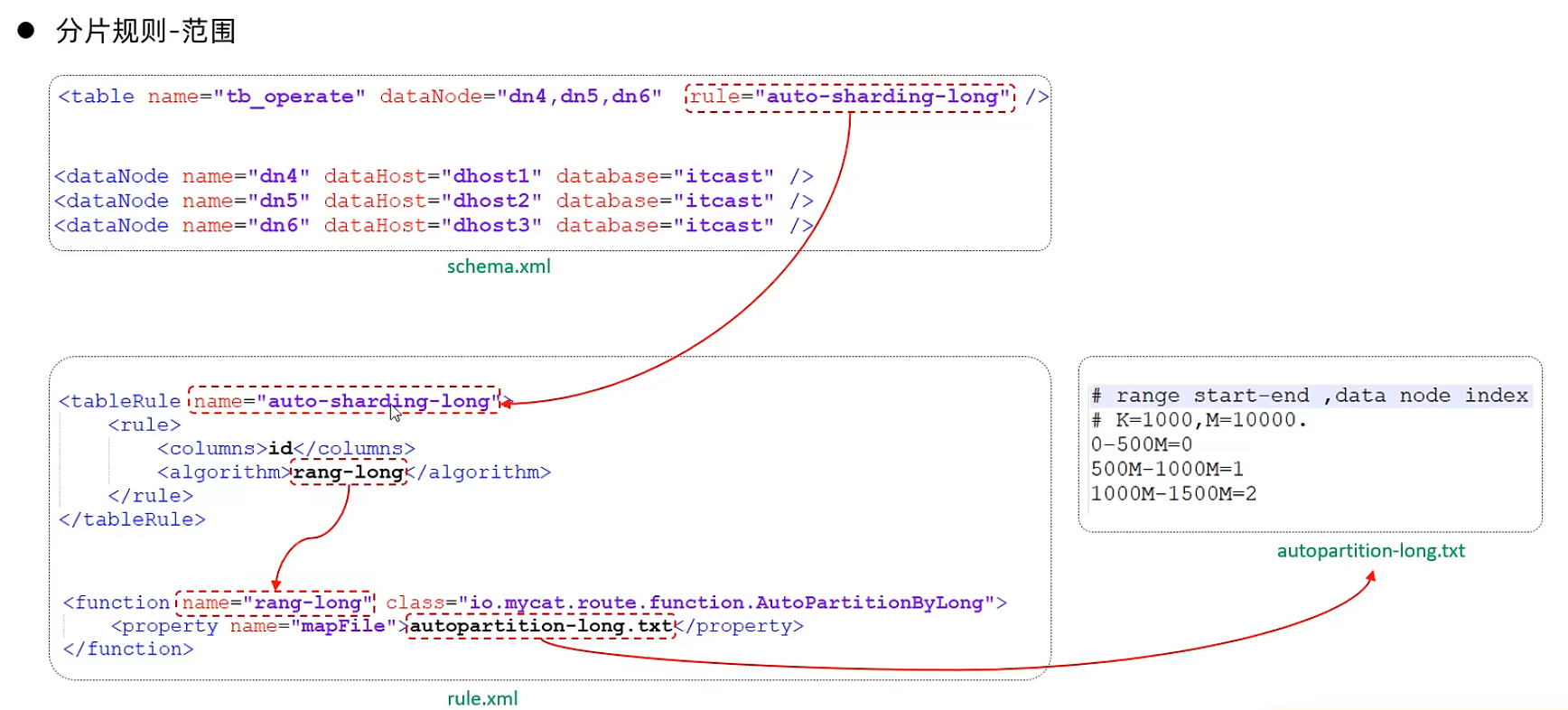
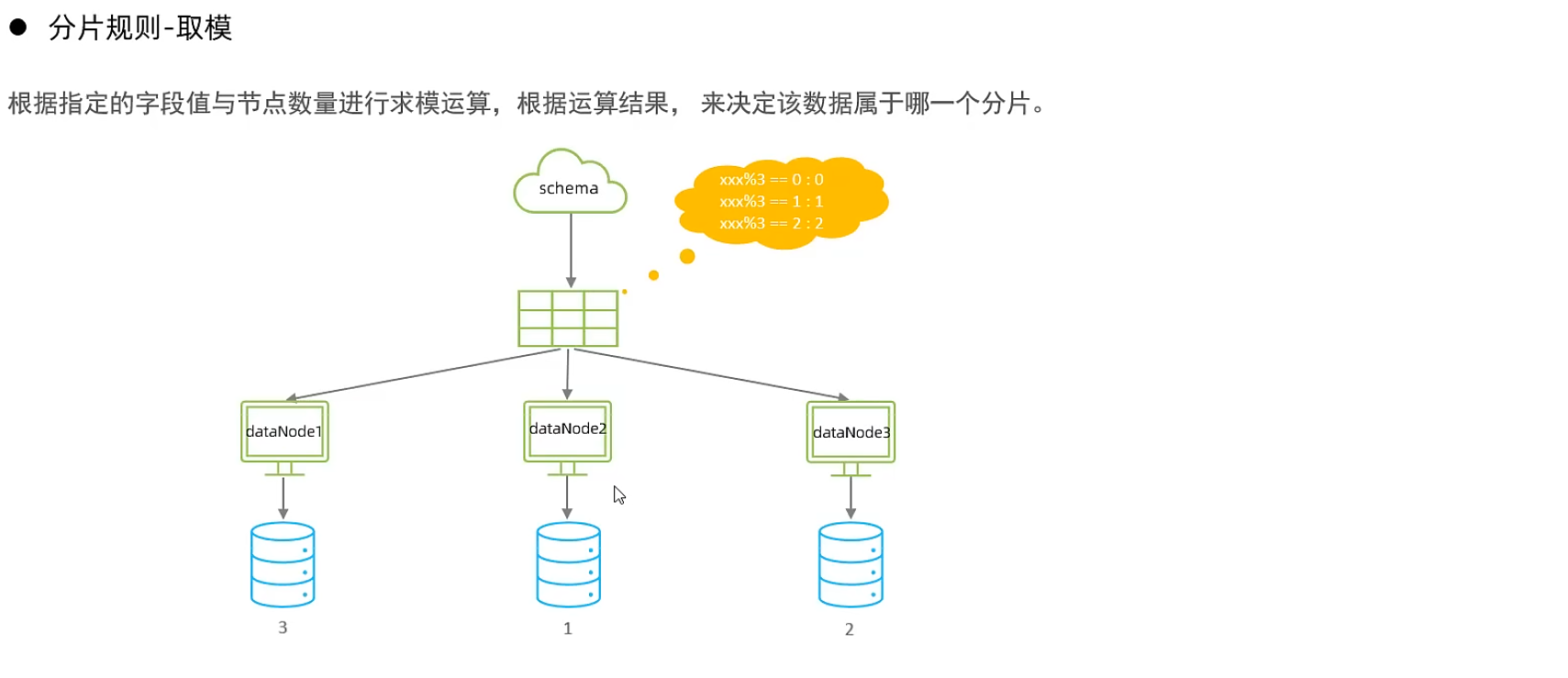
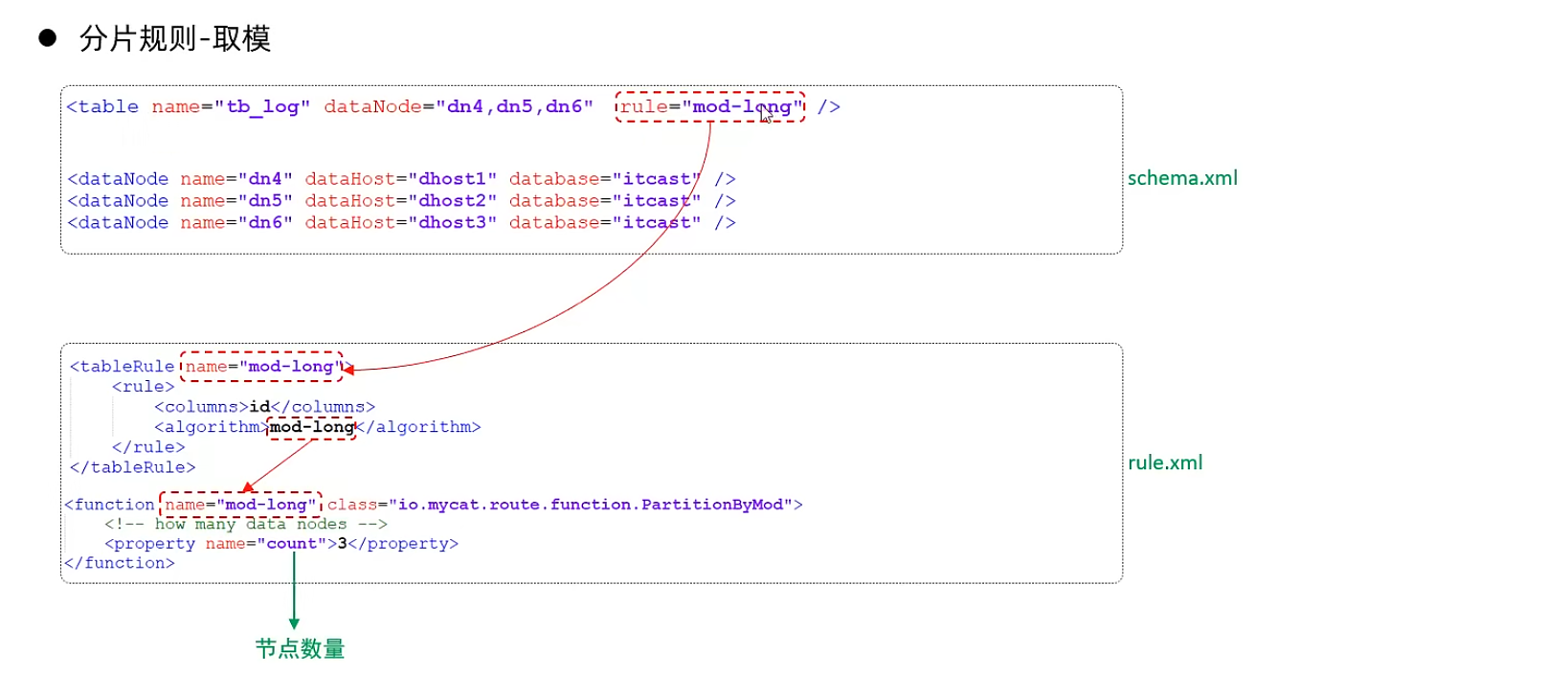
取模分片
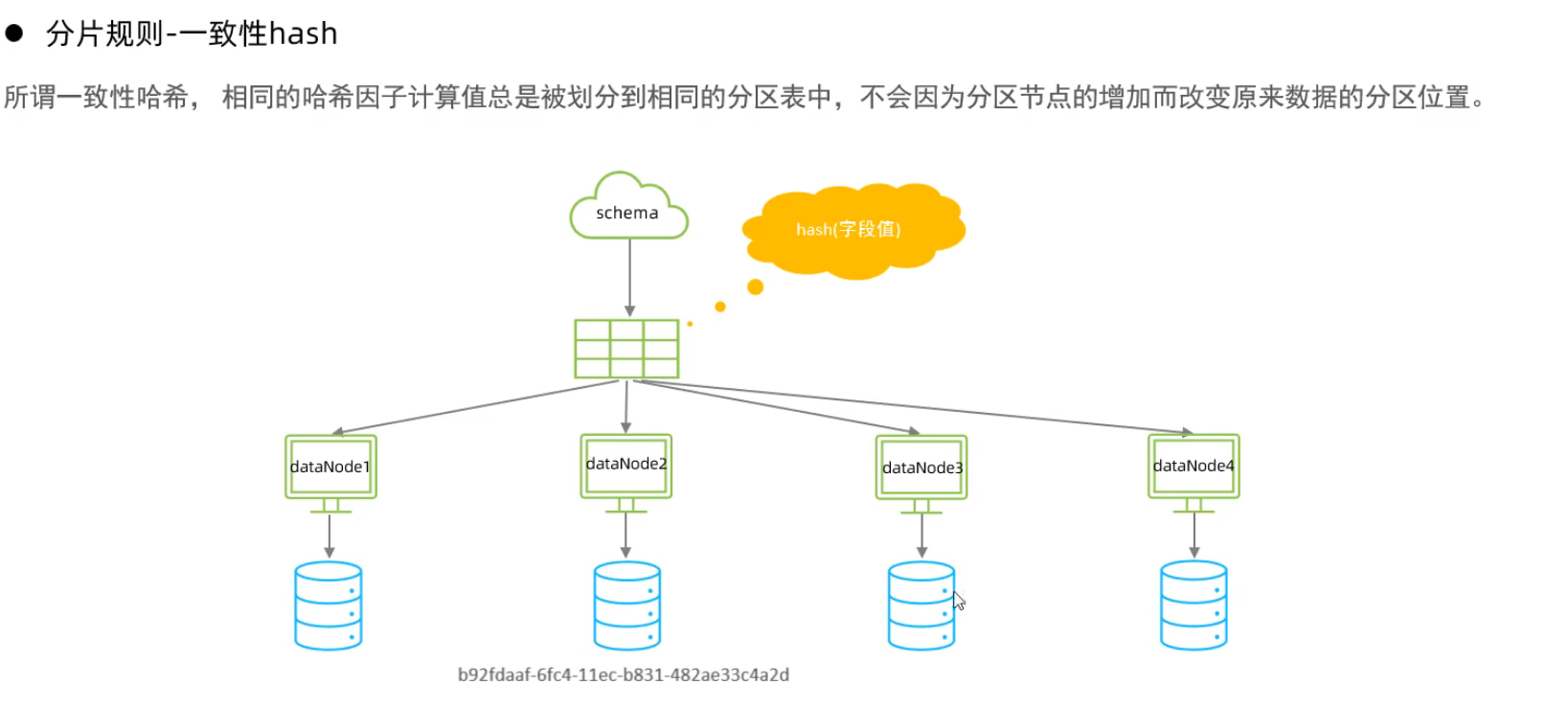
一致性hash算法

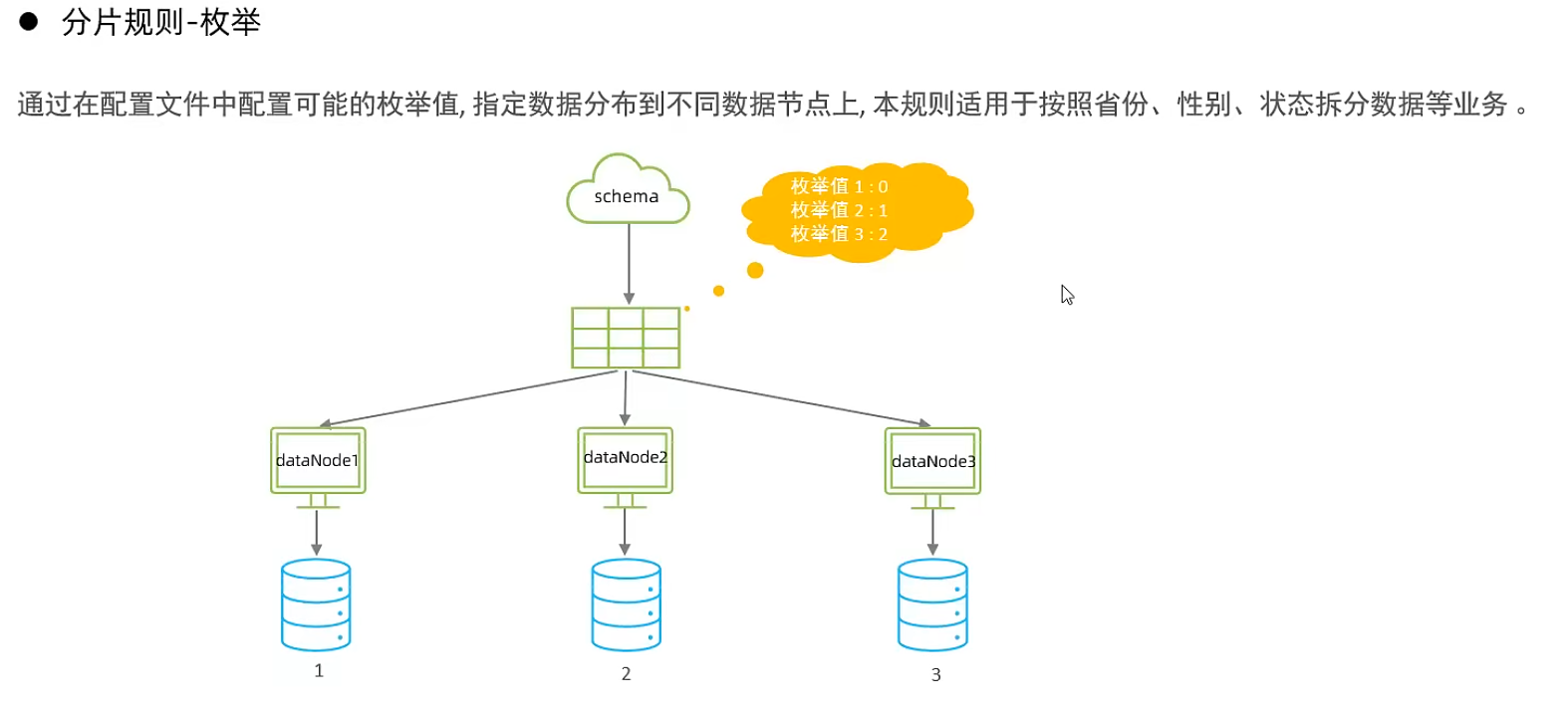
枚舉分片

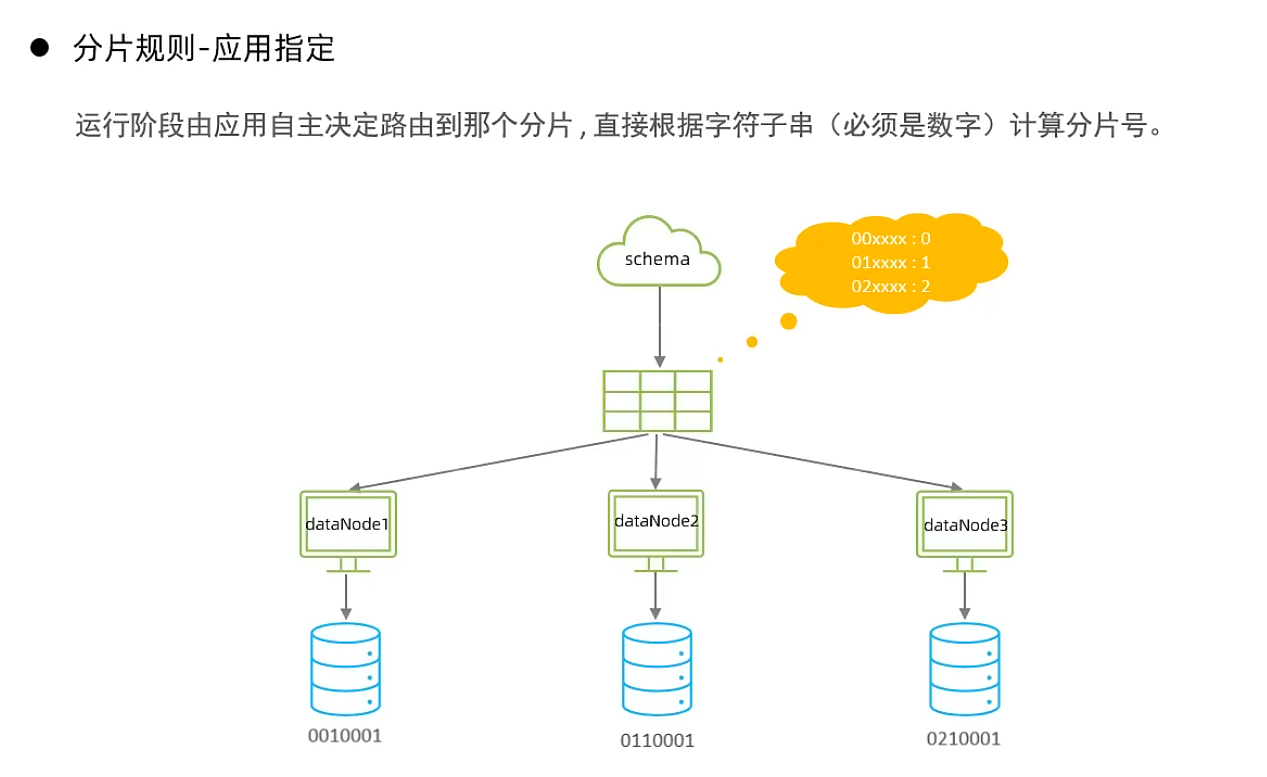
應(yīng)用指定算法
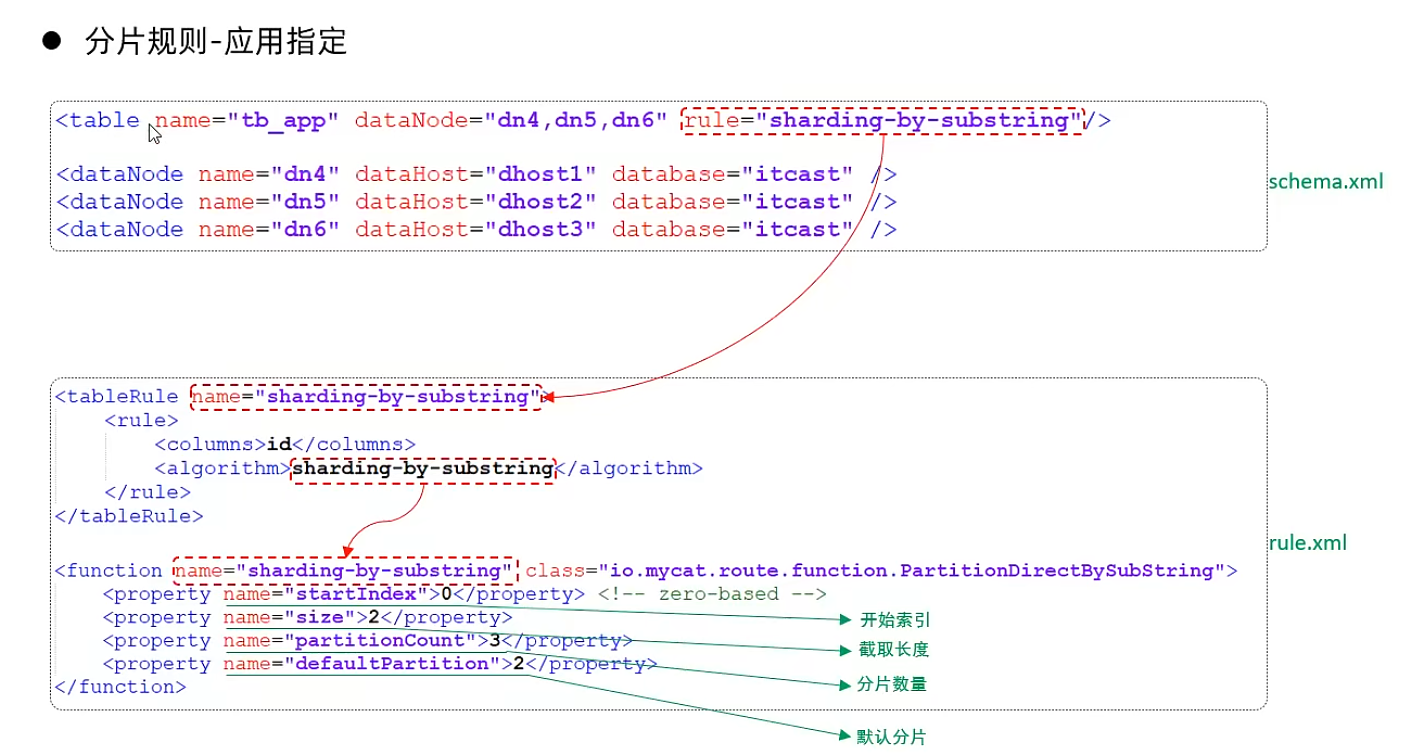
固定hash算法
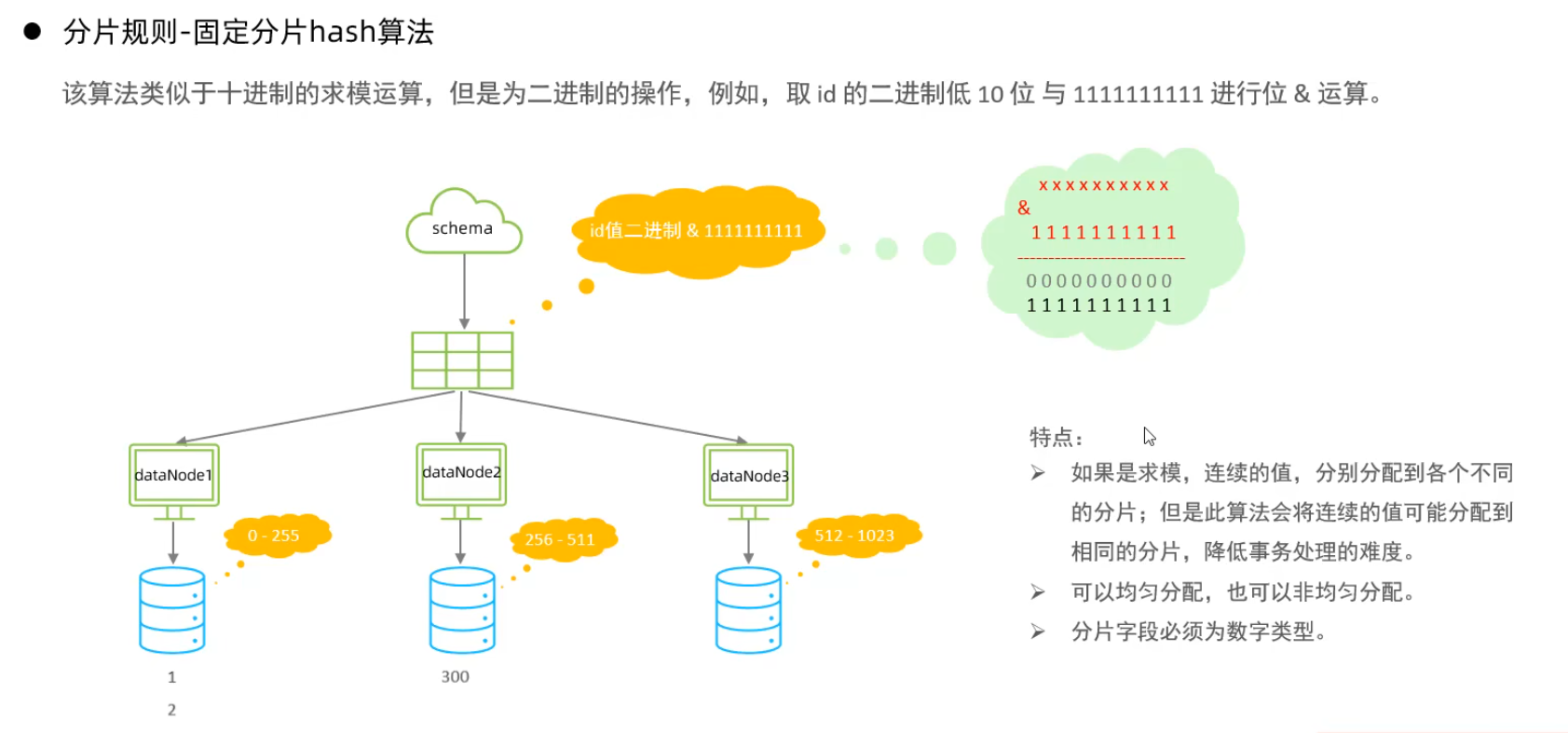
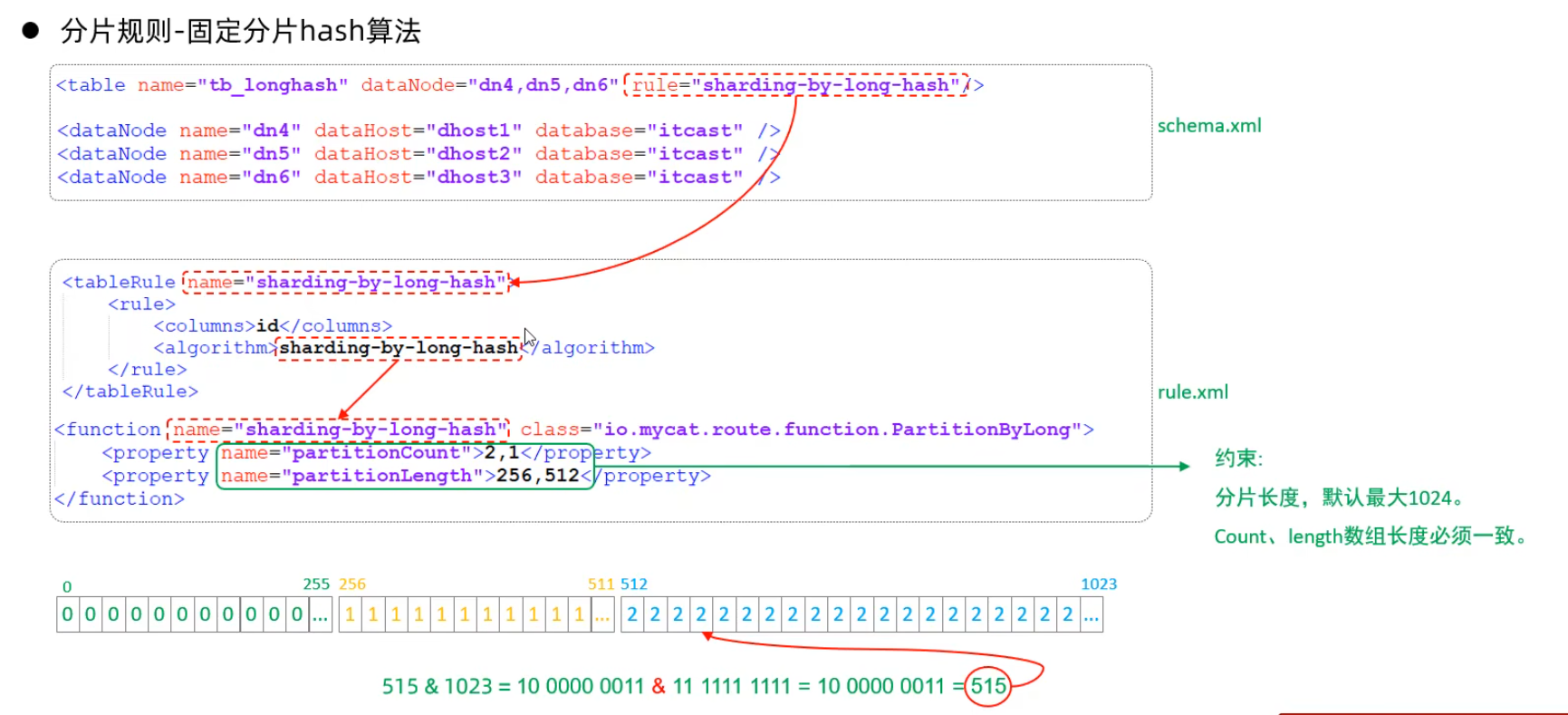
字符串hash解析
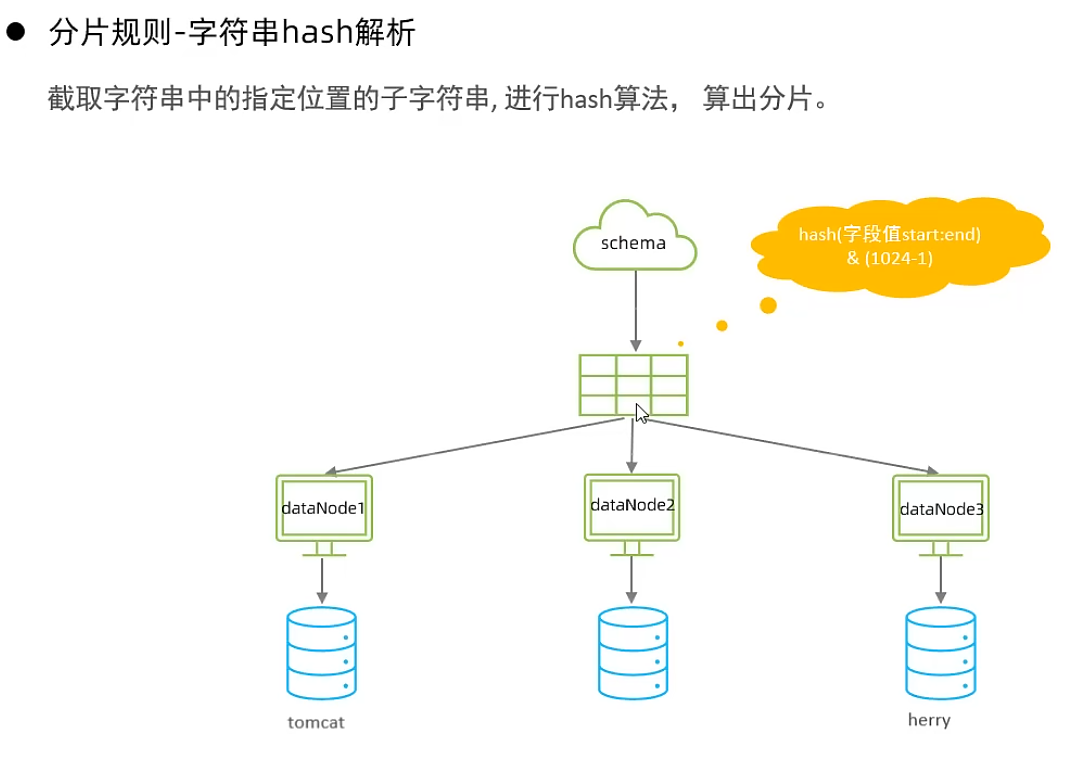
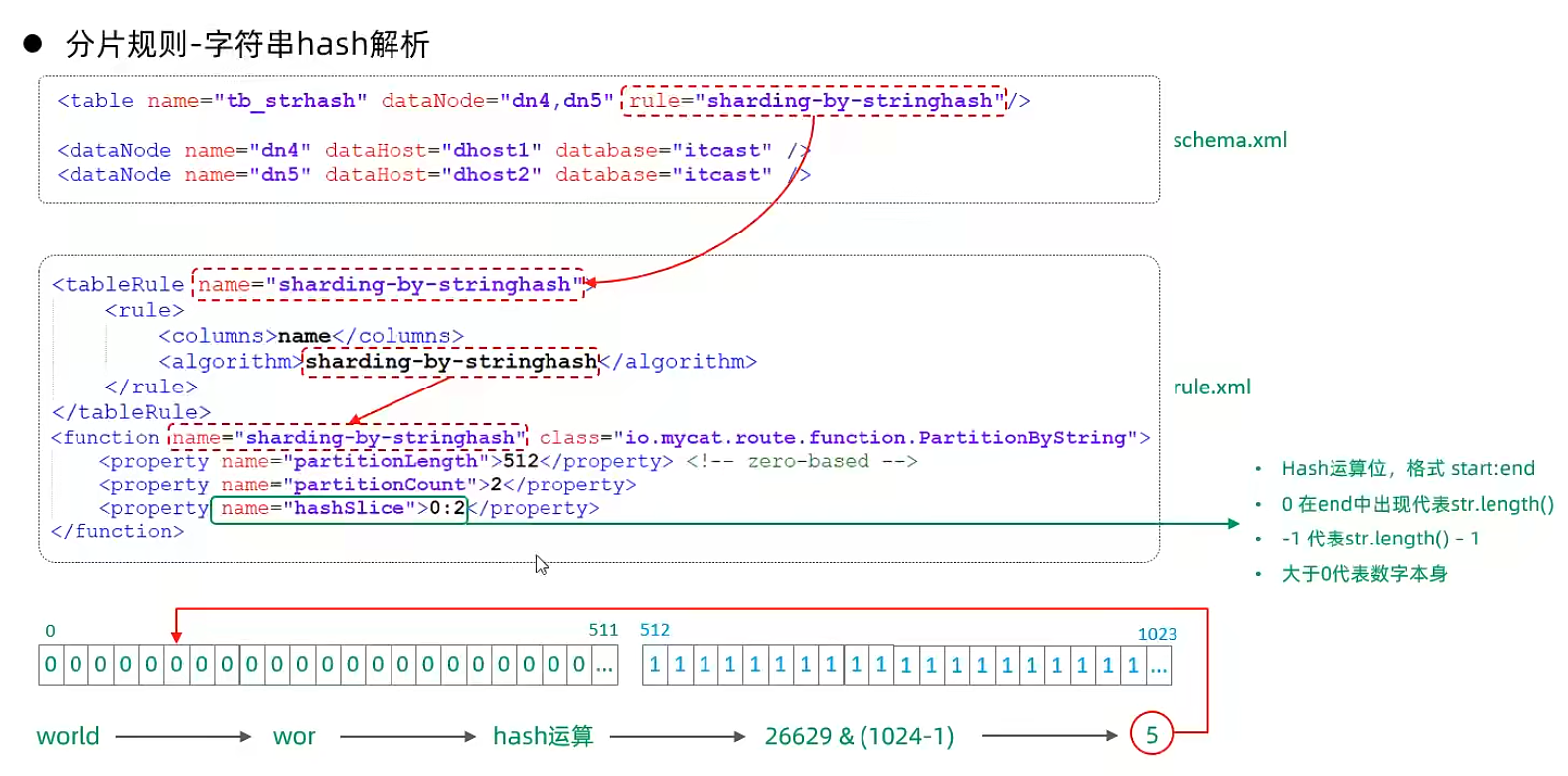
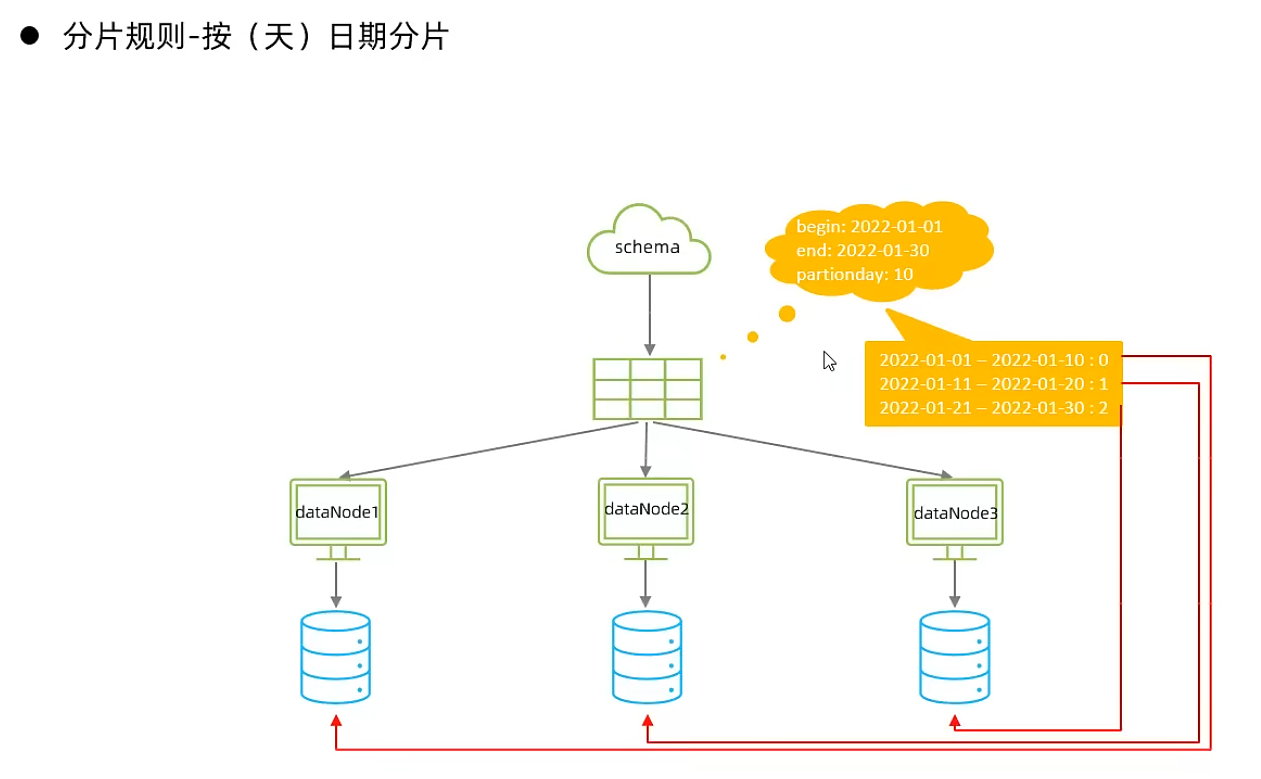
按天分片

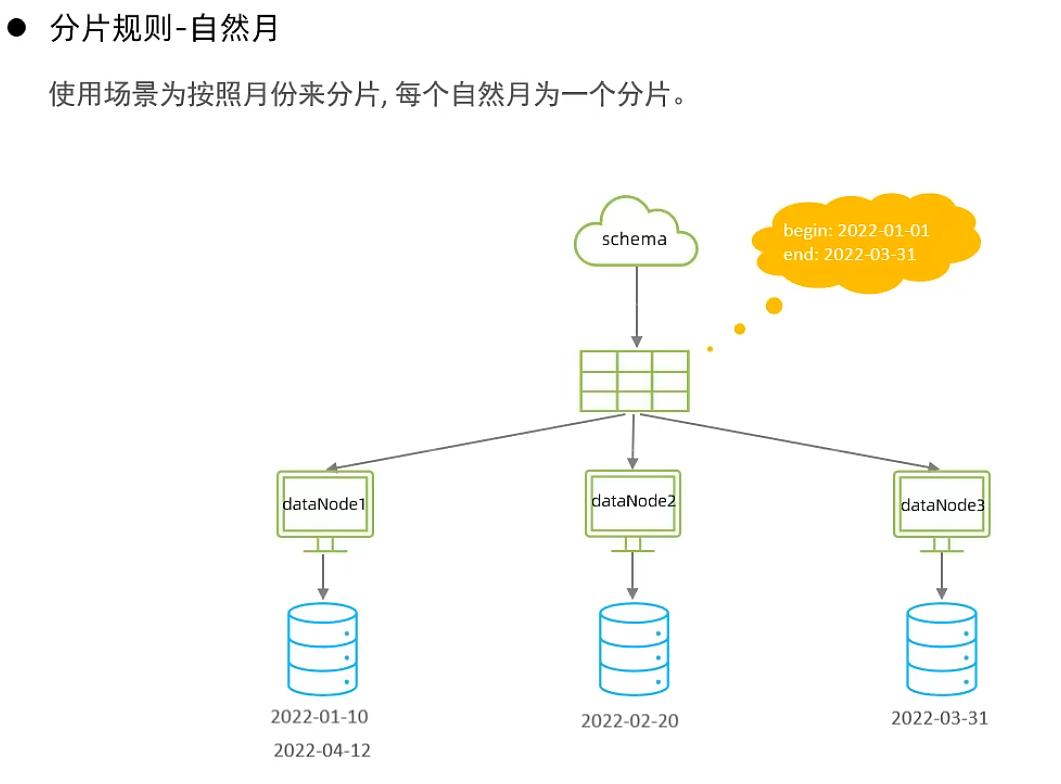
按自然月分片

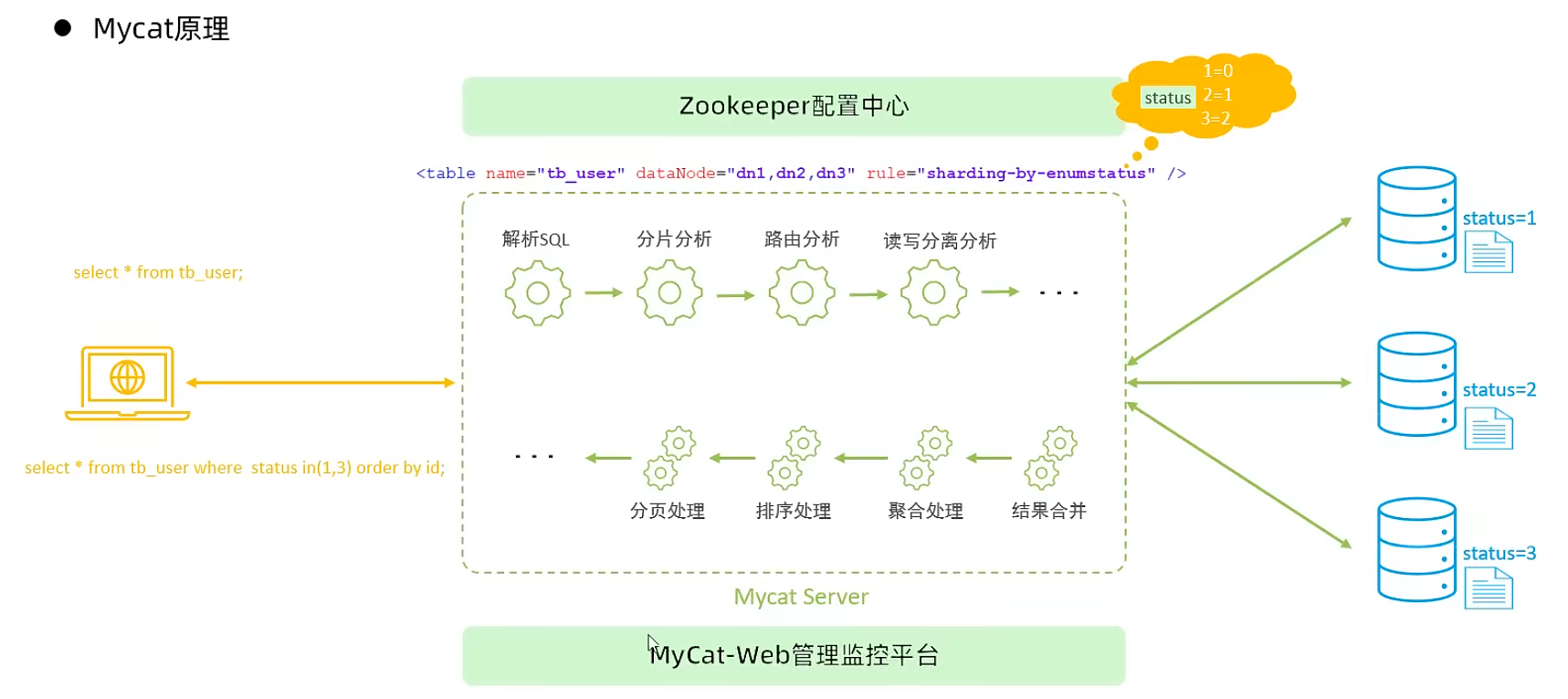
Mycat管理及監(jiān)控

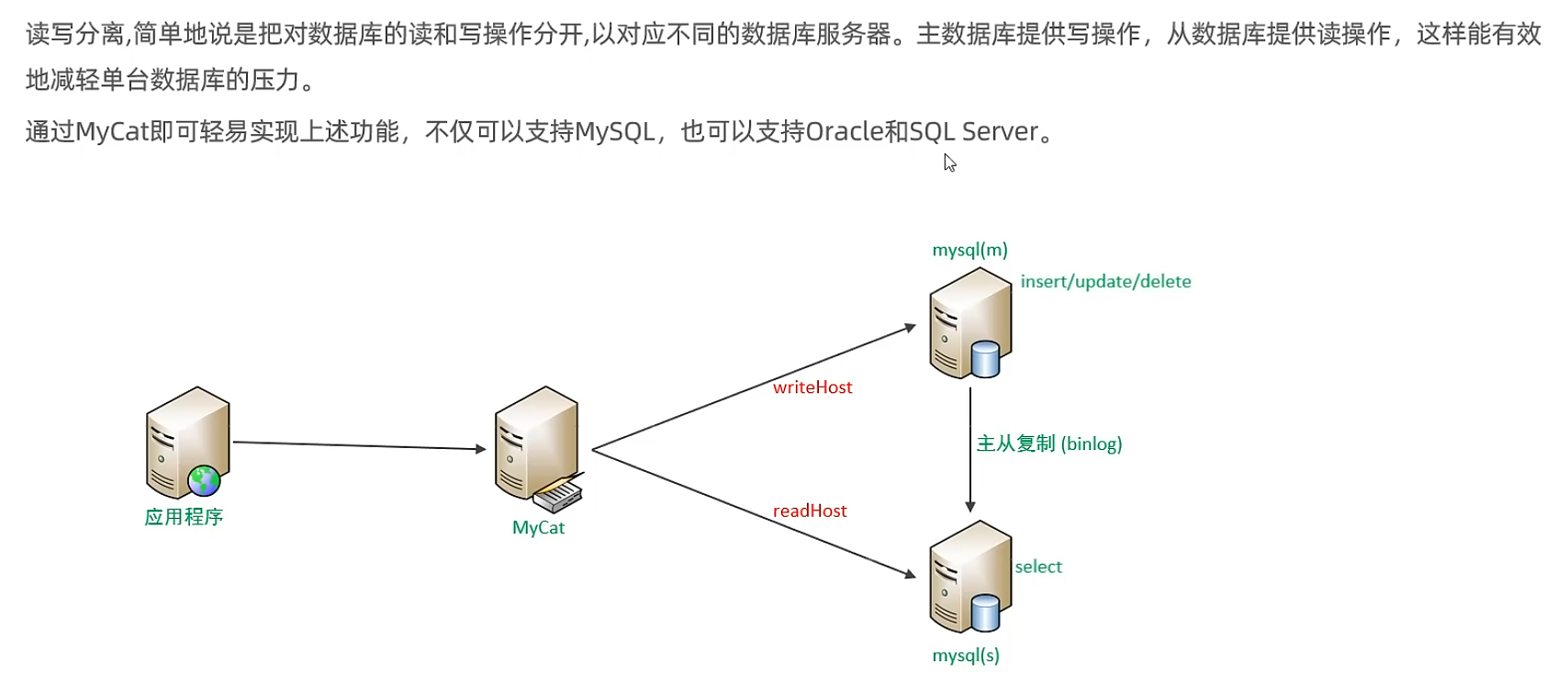
讀寫分離

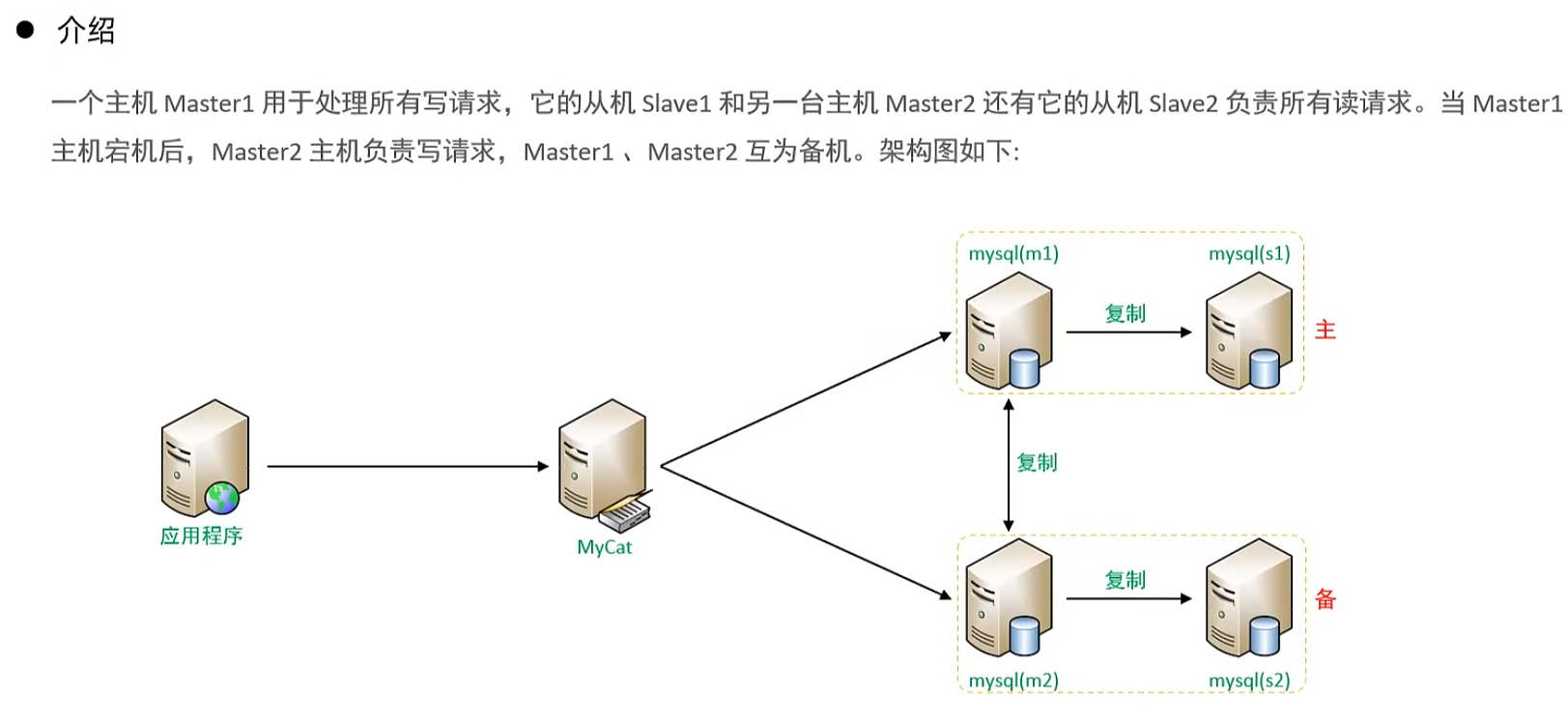
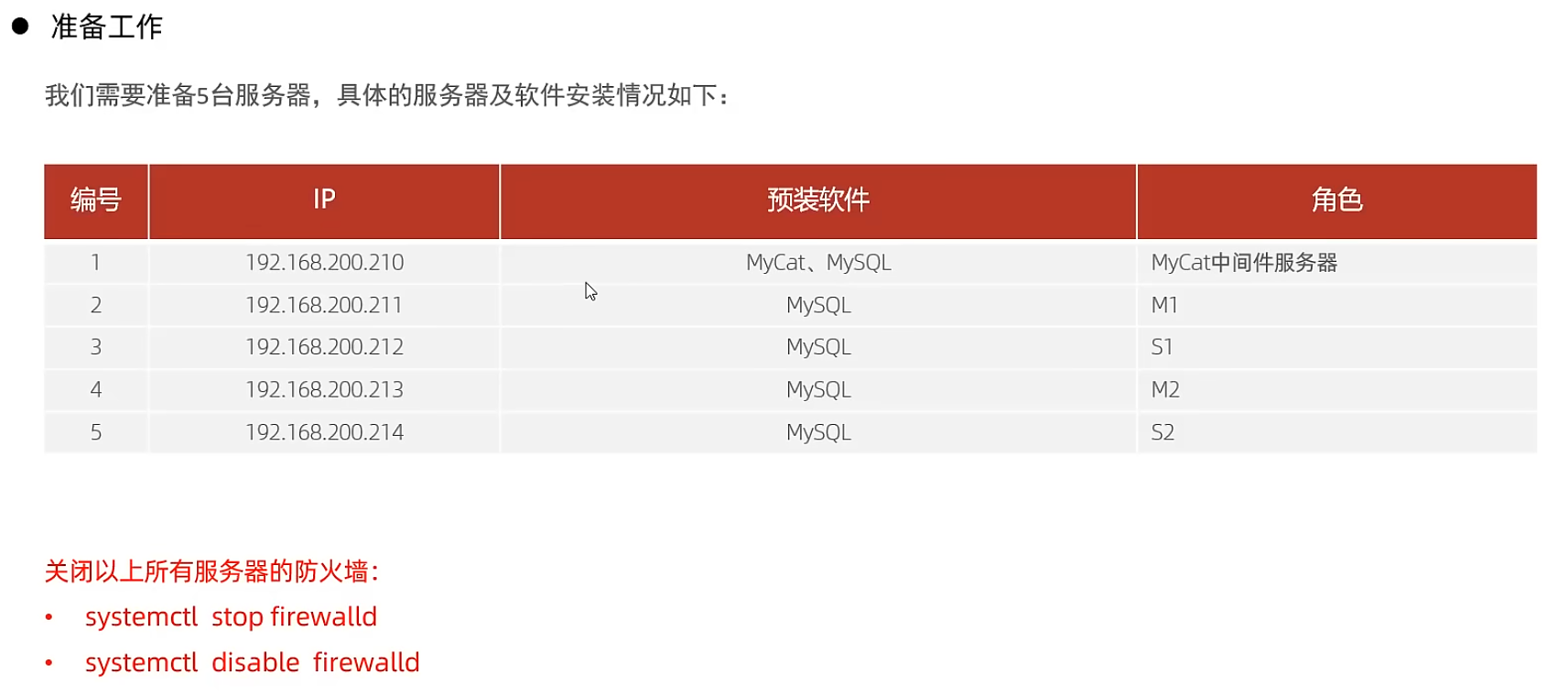
介紹
一主一從讀寫分離
雙主雙從
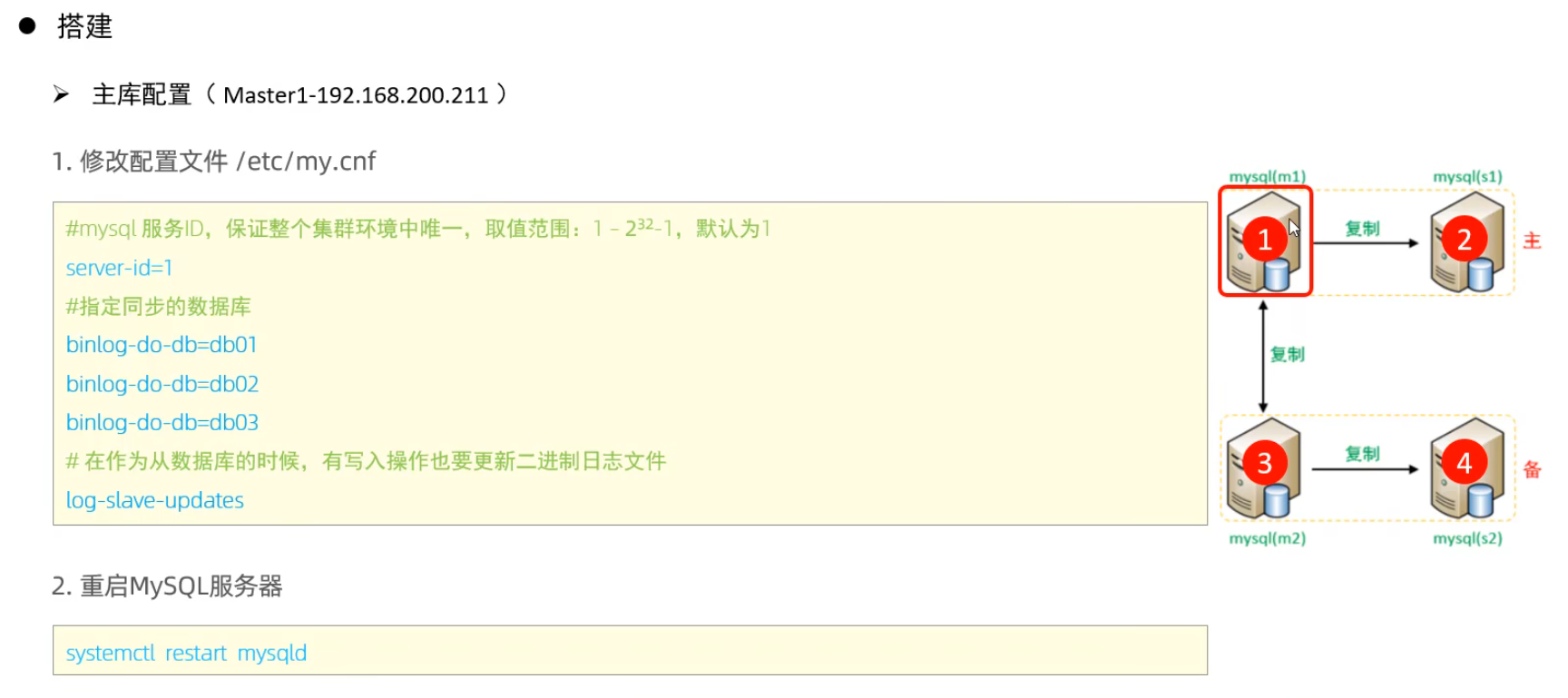
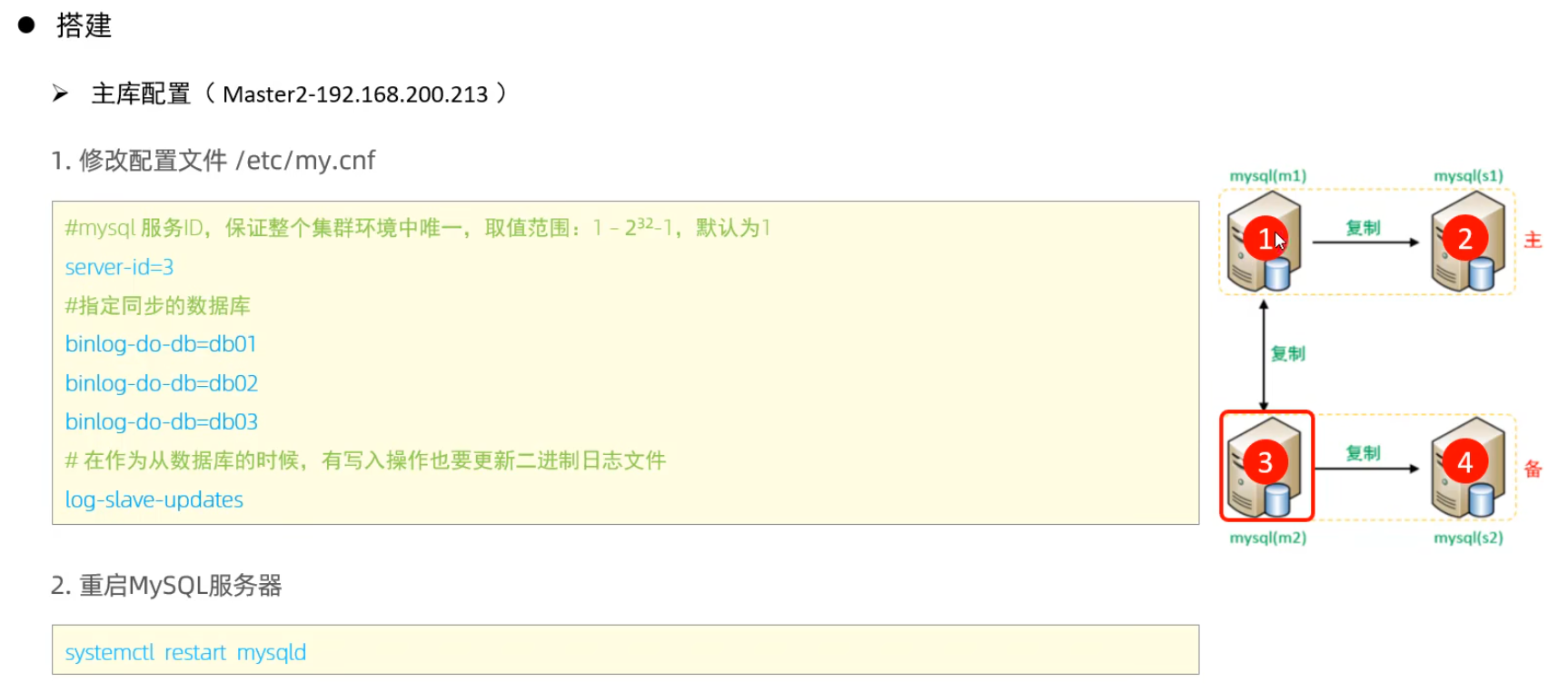
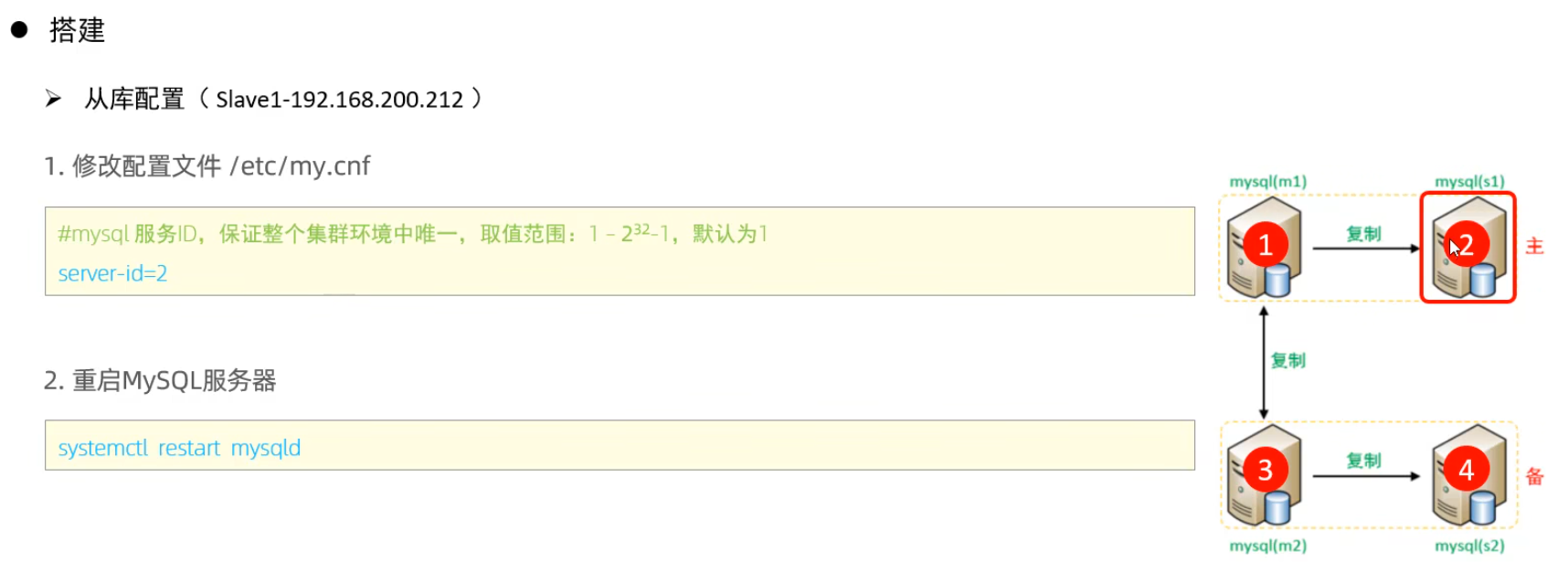
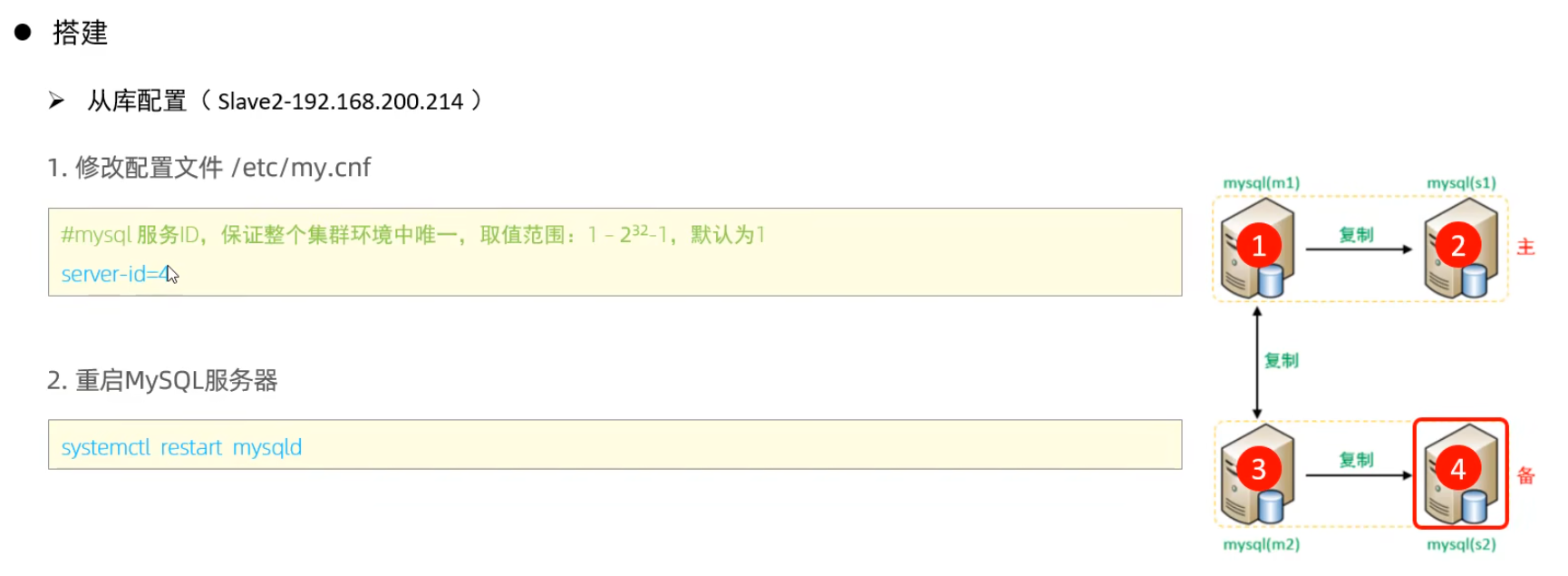
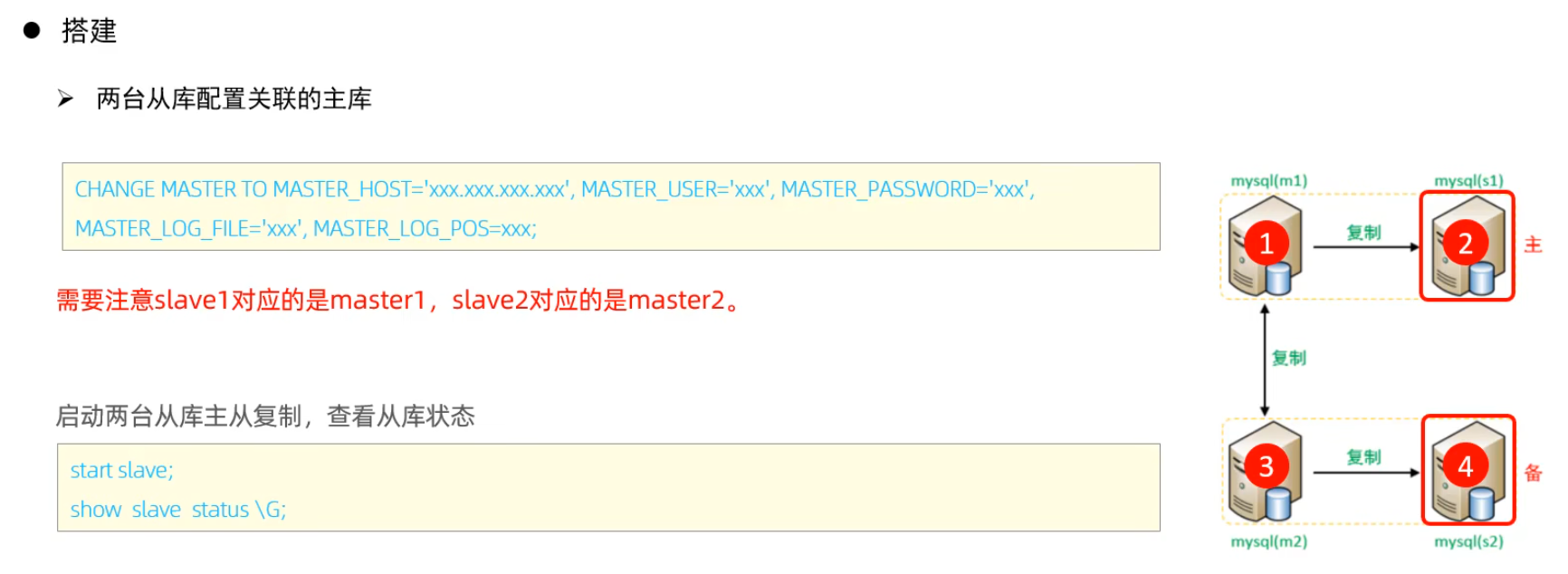
測試:
分別在兩臺主庫Master1、Master2上執(zhí)行DDL、DML語句,查看涉及到的數(shù)據(jù)庫服務(wù)器的數(shù)據(jù)同步情況。
create database db01;
|
雙主雙從讀寫分離
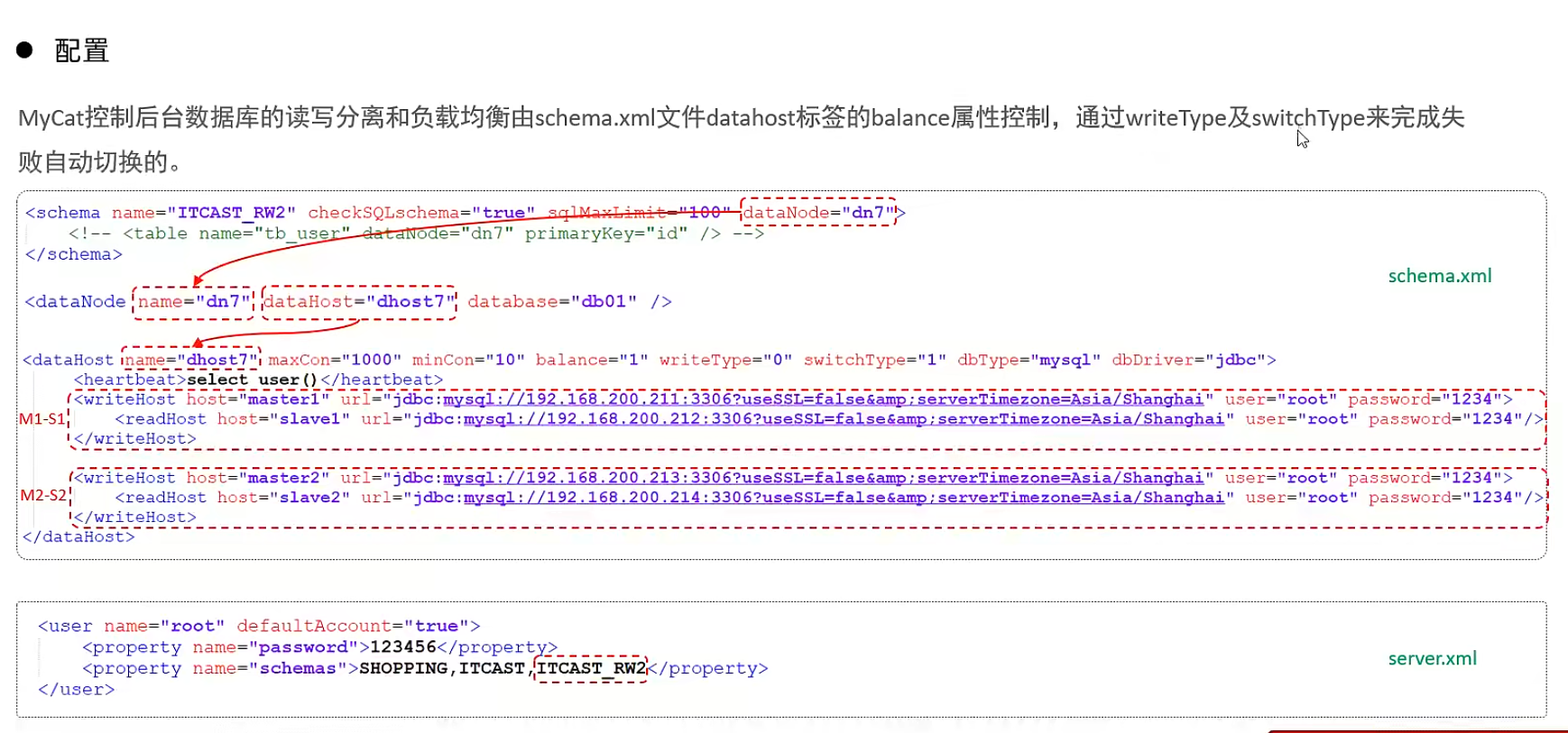
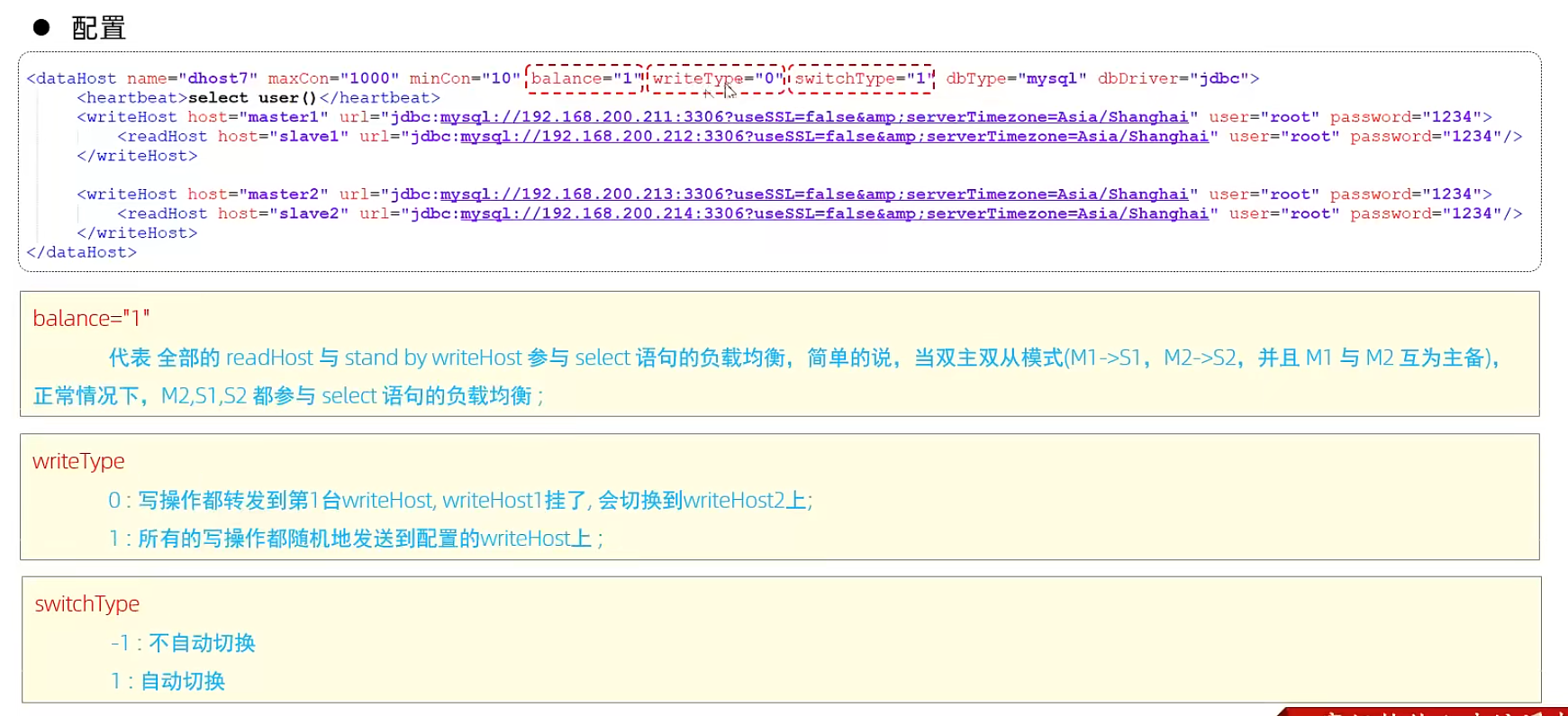
測試:
登錄MyCat,測試查詢及更新操作,判定是否能夠進行讀寫分離,以及讀寫分離的策略是否正確。
當主庫掛掉一個之后,是否能夠自動切換。
數(shù)據(jù)類型
整型
| 類型名稱 | 取值范圍 | 大小 |
|---|---|---|
| TINYINT | -128?127 | 1個字節(jié) |
| SMALLINT | -32768?32767 | 2個宇節(jié) |
| MEDIUMINT | -8388608?8388607 | 3個字節(jié) |
| INT (INTEGHR) | -2147483648?2147483647 | 4個字節(jié) |
| BIGINT | -9223372036854775808?9223372036854775807 | 8個字節(jié) |
無符號在數(shù)據(jù)類型后加 unsigned 關(guān)鍵字。
浮點型
| 類型名稱 | 說明 | 存儲需求 |
|---|---|---|
| FLOAT | 單精度浮點數(shù) | 4 個字節(jié) |
| DOUBLE | 雙精度浮點數(shù) | 8 個字節(jié) |
| DECIMAL (M, D),DEC | 壓縮的“嚴格”定點數(shù) | M+2 個字節(jié) |
日期和時間
| 類型名稱 | 日期格式 | 日期范圍 | 存儲需求 |
|---|---|---|---|
| YEAR | YYYY | 1901 ~ 2155 | 1 個字節(jié) |
| TIME | HH:MM:SS | -838:59:59 ~ 838:59:59 | 3 個字節(jié) |
| DATE | YYYY-MM-DD | 1000-01-01 ~ 9999-12-3 | 3 個字節(jié) |
| DATETIME | YYYY-MM-DD HH:MM:SS | 1000-01-01 00:00:00 ~ 9999-12-31 23:59:59 | 8 個字節(jié) |
| TIMESTAMP | YYYY-MM-DD HH:MM:SS | 1980-01-01 00:00:01 UTC ~ 2040-01-19 03:14:07 UTC | 4 個字節(jié) |
字符串
| 類型名稱 | 說明 | 存儲需求 |
|---|---|---|
| CHAR(M) | 固定長度非二進制字符串 | M 字節(jié),1<=M<=255 |
| VARCHAR(M) | 變長非二進制字符串 | L+1字節(jié),在此,L< = M和 1<=M<=255 |
| TINYTEXT | 非常小的非二進制字符串 | L+1字節(jié),在此,L<2^8 |
| TEXT | 小的非二進制字符串 | L+2字節(jié),在此,L<2^16 |
| MEDIUMTEXT | 中等大小的非二進制字符串 | L+3字節(jié),在此,L<2^24 |
| LONGTEXT | 大的非二進制字符串 | L+4字節(jié),在此,L<2^32 |
| ENUM | 枚舉類型,只能有一個枚舉字符串值 | 1或2個字節(jié),取決于枚舉值的數(shù)目 (最大值為65535) |
| SET | 一個設(shè)置,字符串對象可以有零個或 多個SET成員 | 1、2、3、4或8個字節(jié),取決于集合 成員的數(shù)量(最多64個成員) |
二進制類型
| 類型名稱 | 說明 | 存儲需求 |
|---|---|---|
| BIT(M) | 位字段類型 | 大約 (M+7)/8 字節(jié) |
| BINARY(M) | 固定長度二進制字符串 | M 字節(jié) |
| VARBINARY (M) | 可變長度二進制字符串 | M+1 字節(jié) |
| TINYBLOB (M) | 非常小的BLOB | L+1 字節(jié),在此,L<2^8 |
| BLOB (M) | 小 BLOB | L+2 字節(jié),在此,L<2^16 |
| MEDIUMBLOB (M) | 中等大小的BLOB | L+3 字節(jié),在此,L<2^24 |
| LONGBLOB (M) | 非常大的BLOB | L+4 字節(jié),在此,L<2^32 |
權(quán)限一覽表
具體權(quán)限的作用詳見官方文檔
GRANT 和 REVOKE 允許的靜態(tài)權(quán)限
| Privilege | Grant Table Column | Context |
|---|---|---|
ALL [PRIVILEGES] |
Synonym for “all privileges” | Server administration |
ALTER |
Alter_priv |
Tables |
ALTER ROUTINE |
Alter_routine_priv |
Stored routines |
CREATE |
Create_priv |
Databases, tables, or indexes |
CREATE ROLE |
Create_role_priv |
Server administration |
CREATE ROUTINE |
Create_routine_priv |
Stored routines |
CREATE TABLESPACE |
Create_tablespace_priv |
Server administration |
CREATE TEMPORARY TABLES |
Create_tmp_table_priv |
Tables |
CREATE USER |
Create_user_priv |
Server administration |
CREATE VIEW |
Create_view_priv |
Views |
DELETE |
Delete_priv |
Tables |
DROP |
Drop_priv |
Databases, tables, or views |
DROP ROLE |
Drop_role_priv |
Server administration |
EVENT |
Event_priv |
Databases |
EXECUTE |
Execute_priv |
Stored routines |
FILE |
File_priv |
File access on server host |
GRANT OPTION |
Grant_priv |
Databases, tables, or stored routines |
INDEX |
Index_priv |
Tables |
INSERT |
Insert_priv |
Tables or columns |
LOCK TABLES |
Lock_tables_priv |
Databases |
PROCESS |
Process_priv |
Server administration |
PROXY |
See proxies_priv table |
Server administration |
REFERENCES |
References_priv |
Databases or tables |
RELOAD |
Reload_priv |
Server administration |
REPLICATION CLIENT |
Repl_client_priv |
Server administration |
REPLICATION SLAVE |
Repl_slave_priv |
Server administration |
SELECT |
Select_priv |
Tables or columns |
SHOW DATABASES |
Show_db_priv |
Server administration |
SHOW VIEW |
Show_view_priv |
Views |
SHUTDOWN |
Shutdown_priv |
Server administration |
SUPER |
Super_priv |
Server administration |
TRIGGER |
Trigger_priv |
Tables |
UPDATE |
Update_priv |
Tables or columns |
USAGE |
Synonym for “no privileges” | Server administration |
GRANT 和 REVOKE 允許的動態(tài)權(quán)限
| Privilege | Context |
|---|---|
APPLICATION_PASSWORD_ADMIN |
Dual password administration |
AUDIT_ABORT_EXEMPT |
Allow queries blocked by audit log filter |
AUDIT_ADMIN |
Audit log administration |
AUTHENTICATION_POLICY_ADMIN |
Authentication administration |
BACKUP_ADMIN |
Backup administration |
BINLOG_ADMIN |
Backup and Replication administration |
BINLOG_ENCRYPTION_ADMIN |
Backup and Replication administration |
CLONE_ADMIN |
Clone administration |
CONNECTION_ADMIN |
Server administration |
ENCRYPTION_KEY_ADMIN |
Server administration |
FIREWALL_ADMIN |
Firewall administration |
FIREWALL_EXEMPT |
Firewall administration |
FIREWALL_USER |
Firewall administration |
FLUSH_OPTIMIZER_COSTS |
Server administration |
FLUSH_STATUS |
Server administration |
FLUSH_TABLES |
Server administration |
FLUSH_USER_RESOURCES |
Server administration |
GROUP_REPLICATION_ADMIN |
Replication administration |
GROUP_REPLICATION_STREAM |
Replication administration |
INNODB_REDO_LOG_ARCHIVE |
Redo log archiving administration |
NDB_STORED_USER |
NDB Cluster |
PASSWORDLESS_USER_ADMIN |
Authentication administration |
PERSIST_RO_VARIABLES_ADMIN |
Server administration |
REPLICATION_APPLIER |
PRIVILEGE_CHECKS_USER for a replication channel |
REPLICATION_SLAVE_ADMIN |
Replication administration |
RESOURCE_GROUP_ADMIN |
Resource group administration |
RESOURCE_GROUP_USER |
Resource group administration |
ROLE_ADMIN |
Server administration |
SESSION_VARIABLES_ADMIN |
Server administration |
SET_USER_ID |
Server administration |
SHOW_ROUTINE |
Server administration |
SYSTEM_USER |
Server administration |
SYSTEM_VARIABLES_ADMIN |
Server administration |
TABLE_ENCRYPTION_ADMIN |
Server administration |
VERSION_TOKEN_ADMIN |
Server administration |
XA_RECOVER_ADMIN |
Server administration |
圖形化界面工具
- Workbench(免費): http://dev.mysql.com/downloads/workbench/
- navicat(收費,試用版30天): https://www.navicat.com/en/download/navicat-for-mysql
- Sequel Pro(開源免費,僅支持Mac OS): http://www.sequelpro.com/
- HeidiSQL(免費): http://www.heidisql.com/
- phpMyAdmin(免費): https://www.phpmyadmin.net/
- SQLyog: https://sqlyog.en.softonic.com/
安裝
小技巧
- 在SQL語句之后加上
\G會將結(jié)果的表格形式轉(zhuǎn)換成行文本形式 - 查看Mysql數(shù)據(jù)庫占用空間:
SELECT table_schema "Database Name"
|
- 本文作者: DHC
- 本文鏈接: https://jimhackking.github.io/運維/MySQL學(xué)習(xí)筆記/
- 版權(quán)聲明: 本博客所有文章除特別聲明外,均采用 BY-NC-SA 許可協(xié)議。轉(zhuǎn)載請注明出處!

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號