面向智能體與大語(yǔ)言模型的 AI 基礎(chǔ)設(shè)施:選項(xiàng)、工具與優(yōu)化
面向智能體與大語(yǔ)言模型的 AI 基礎(chǔ)設(shè)施:選項(xiàng)、工具與優(yōu)化
本文探討了用于部署和優(yōu)化 AI 智能體(AI Agents)與大型語(yǔ)言模型(LLMs)的各類基礎(chǔ)設(shè)施選項(xiàng)及工具。
無(wú)論采用云、本地還是混合云部署,基礎(chǔ)設(shè)施在 AI 架構(gòu)落地過程中都起著關(guān)鍵作用。本文是 AI 基礎(chǔ)設(shè)施系列文章的一部分,聚焦于部署和優(yōu)化 AI 智能體與大語(yǔ)言模型的多樣化基礎(chǔ)設(shè)施選擇,深入剖析了基礎(chǔ)設(shè)施在 AI 架構(gòu)(尤其是推理環(huán)節(jié))實(shí)現(xiàn)中的核心價(jià)值。我們將詳細(xì)介紹包括開源解決方案在內(nèi)的各類工具,通過圖表展示推理流程,并強(qiáng)調(diào)高效、可擴(kuò)展 AI 部署的關(guān)鍵考量因素。
現(xiàn)代 AI 應(yīng)用對(duì)基礎(chǔ)設(shè)施提出了精密化要求——需承載大語(yǔ)言模型的計(jì)算強(qiáng)度、多智能體系統(tǒng)的復(fù)雜性,以及交互式應(yīng)用的實(shí)時(shí)性需求。核心挑戰(zhàn)不僅在于選擇合適的工具,更在于理解這些工具如何在整個(gè)技術(shù)棧中協(xié)同集成,從而交付可靠、可擴(kuò)展且經(jīng)濟(jì)高效的解決方案。
本指南涵蓋 AI 基礎(chǔ)設(shè)施的全維度內(nèi)容,從硬件加速、模型服務(wù)到監(jiān)控與安全,詳細(xì)解析了經(jīng)過生產(chǎn)環(huán)境驗(yàn)證的開源工具、架構(gòu)模式及實(shí)施策略。
一、AI 基礎(chǔ)設(shè)施在架構(gòu)中的核心作用
AI 架構(gòu)定義了 AI 系統(tǒng)構(gòu)建與部署的藍(lán)圖,而基礎(chǔ)設(shè)施則是支撐該架構(gòu)落地的基石。對(duì)于 AI 智能體與大語(yǔ)言模型而言,基礎(chǔ)設(shè)施直接影響系統(tǒng)性能、可擴(kuò)展性、成本與可靠性。設(shè)計(jì)精良的基礎(chǔ)設(shè)施能夠?qū)崿F(xiàn):
- 更快的推理速度:低延遲對(duì)交互式 AI 智能體和實(shí)時(shí)應(yīng)用至關(guān)重要
- 更強(qiáng)的可擴(kuò)展性:在用戶需求增長(zhǎng)時(shí)保持性能穩(wěn)定
- 更高的成本效益:優(yōu)化資源利用率以降低運(yùn)營(yíng)支出
- 更優(yōu)的可靠性:確保高可用性和容錯(cuò)能力
二、AI 基礎(chǔ)設(shè)施棧:分層架構(gòu)設(shè)計(jì)
現(xiàn)代 AI 基礎(chǔ)設(shè)施棧由七個(gè)相互關(guān)聯(lián)的層級(jí)構(gòu)成,每個(gè)層級(jí)承擔(dān)特定功能,同時(shí)與相鄰層級(jí)實(shí)現(xiàn)無(wú)縫集成。理解這一分層架構(gòu),對(duì)于工具選型、資源分配及運(yùn)維策略制定具有重要指導(dǎo)意義。

(一)層級(jí)解析與核心工具
- 用戶交互層:用戶請(qǐng)求的入口,客戶端可包括 Web 界面、移動(dòng)應(yīng)用或命令行工具。核心需求是與后端 API 層建立穩(wěn)定、低延遲的連接。
- API 與編排層:負(fù)責(zé)管理用戶請(qǐng)求并編排復(fù)雜工作流
- API 網(wǎng)關(guān)(NGINX、Envoy、Kong):作為統(tǒng)一入口,處理流量接入、身份認(rèn)證、限流及路由
- 智能體框架(LangChain、KAgent、CrewAI、AutoGen):AI 業(yè)務(wù)邏輯核心,其中 KAgent 是專為高效編排設(shè)計(jì)的專用工具,支持 AI 任務(wù)的動(dòng)態(tài)路由與工作流管理
- 數(shù)據(jù)與內(nèi)存層:提供上下文支持和持久化存儲(chǔ),將無(wú)狀態(tài)模型轉(zhuǎn)化為具備知識(shí)儲(chǔ)備的助手
- 向量數(shù)據(jù)庫(kù)(Pinecone、Weaviate、Qdrant、Chroma):用于存儲(chǔ)和查詢高維向量的專用數(shù)據(jù)庫(kù),是檢索增強(qiáng)生成(RAG)的核心組件
- 緩存與內(nèi)存(Redis、SQL 數(shù)據(jù)庫(kù)):Redis 用于低延遲緩存和短期內(nèi)存存儲(chǔ),SQL 數(shù)據(jù)庫(kù)則存儲(chǔ)對(duì)話歷史、用戶偏好等長(zhǎng)期數(shù)據(jù)
- 模型服務(wù)層:推理核心層級(jí),負(fù)責(zé)模型加載與執(zhí)行
- 推理服務(wù)器(vLLM、TGI、TensorRT-LLM、Triton):專為高吞吐量、低延遲推理優(yōu)化的服務(wù)器,支持動(dòng)態(tài)批處理和量化
- 模型注冊(cè)與微調(diào)(Hugging Face、MLflow):集中式倉(cāng)庫(kù),管理從訓(xùn)練到部署的全模型生命周期
- 編排與運(yùn)行時(shí)層:抽象底層硬件的基礎(chǔ)層級(jí)
- 容器編排(Kubernetes):管理容器生命周期,提供可擴(kuò)展性、彈性及高效資源利用率
- 工作流編排(Airflow、Prefect、Dagster):編排復(fù)雜的數(shù)據(jù)和機(jī)器學(xué)習(xí)流水線,支持訓(xùn)練任務(wù)、數(shù)據(jù)攝入等操作
- 硬件層:計(jì)算的物理載體
- 計(jì)算資源(NVIDIA GPU、AWS Inferentia、Google TPU):大語(yǔ)言模型推理必需的專用加速器
- 網(wǎng)絡(luò)設(shè)備(NVLink、InfiniBand):支持多 GPU 和多節(jié)點(diǎn)通信的高速互聯(lián)設(shè)備
(二)層級(jí)依賴與數(shù)據(jù)流
基礎(chǔ)設(shè)施棧的每個(gè)層級(jí)都有明確的職責(zé)范圍,并通過標(biāo)準(zhǔn)化協(xié)議和 API 與其他層級(jí)交互:
- 用戶交互層處理所有外部交互,將用戶請(qǐng)求轉(zhuǎn)換為下游服務(wù)可處理的標(biāo)準(zhǔn)化格式
- API 網(wǎng)關(guān)層提供安全、路由和流量管理核心功能,確保請(qǐng)求經(jīng)過正確認(rèn)證、授權(quán)后分發(fā)至可用資源
- 服務(wù)編排層管理容器化服務(wù)的生命周期,負(fù)責(zé) AI 工作負(fù)載的部署、擴(kuò)縮容和健康監(jiān)控——這一層對(duì) AI 應(yīng)用尤為重要,因其需應(yīng)對(duì)動(dòng)態(tài)資源需求,且需通過精密調(diào)度算法考量 GPU 可用性、模型加載時(shí)間和內(nèi)存約束
- AI 服務(wù)層包含 AI 應(yīng)用的核心業(yè)務(wù)邏輯,涵蓋模型推理引擎、智能體編排系統(tǒng)和工具集成框架,抽象不同 AI 框架的復(fù)雜性并為上游服務(wù)提供統(tǒng)一 API
- 計(jì)算與加速層提供 AI 工作負(fù)載所需的原始計(jì)算能力,通過專用硬件為不同類型操作提供加速支持
- 存儲(chǔ)層管理冷熱數(shù)據(jù),包括模型權(quán)重、向量嵌入和應(yīng)用狀態(tài)
- 監(jiān)控與可觀測(cè)性層提供全層級(jí)的系統(tǒng)性能、用戶行為和運(yùn)維健康狀態(tài)可視化工具有
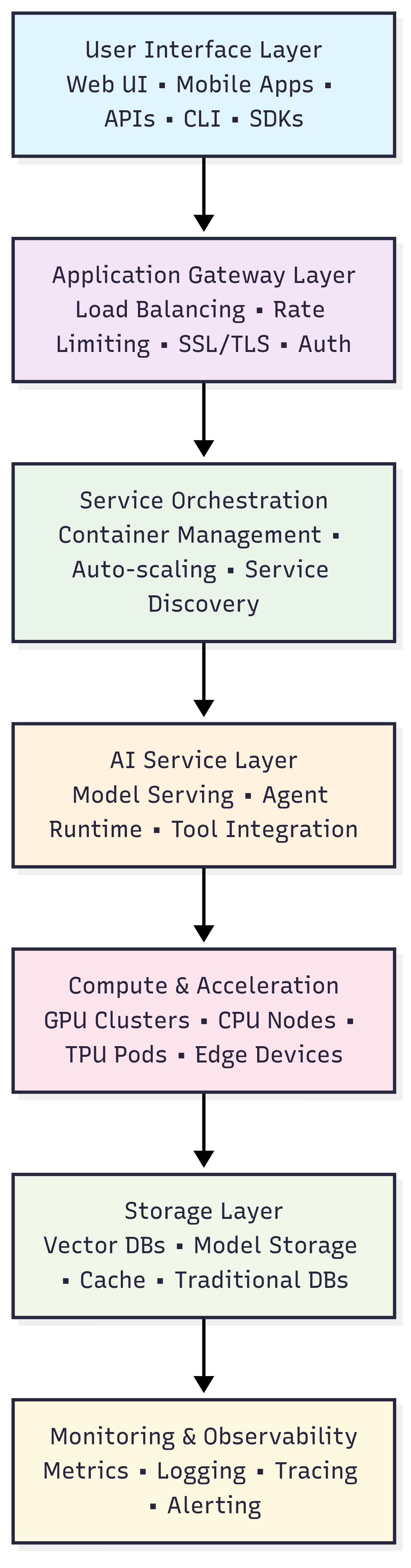
層級(jí)構(gòu)成:用戶交互層 → API 網(wǎng)關(guān)層 → 服務(wù)編排層 → AI 服務(wù)層 → 計(jì)算與加速層 → 存儲(chǔ)層 → 監(jiān)控與可觀測(cè)性層 各層核心功能:
- 用戶交互層:Web UI/移動(dòng)應(yīng)用、API/命令行工具/SDK
- API 網(wǎng)關(guān)層:負(fù)載均衡、限流、SSL/TLS 加密、身份認(rèn)證
- 服務(wù)編排層:容器管理、自動(dòng)擴(kuò)縮容、服務(wù)發(fā)現(xiàn)
- AI 服務(wù)層:模型服務(wù)、智能體運(yùn)行時(shí)、工具集成
- 計(jì)算與加速層:GPU 集群、CPU 節(jié)點(diǎn)、TPU Pod、邊緣設(shè)備
- 存儲(chǔ)層:向量數(shù)據(jù)庫(kù)、模型存儲(chǔ)、緩存、傳統(tǒng)數(shù)據(jù)庫(kù)
- 監(jiān)控與可觀測(cè)性層:指標(biāo)采集、日志記錄、鏈路追蹤、告警通知
三、推理流程:從用戶提示到 AI 響應(yīng)
用戶查詢?cè)?AI 基礎(chǔ)設(shè)施中的流轉(zhuǎn)涉及多個(gè)步驟和工具,以下流程圖展示了完整流程及核心組件的交互關(guān)系。
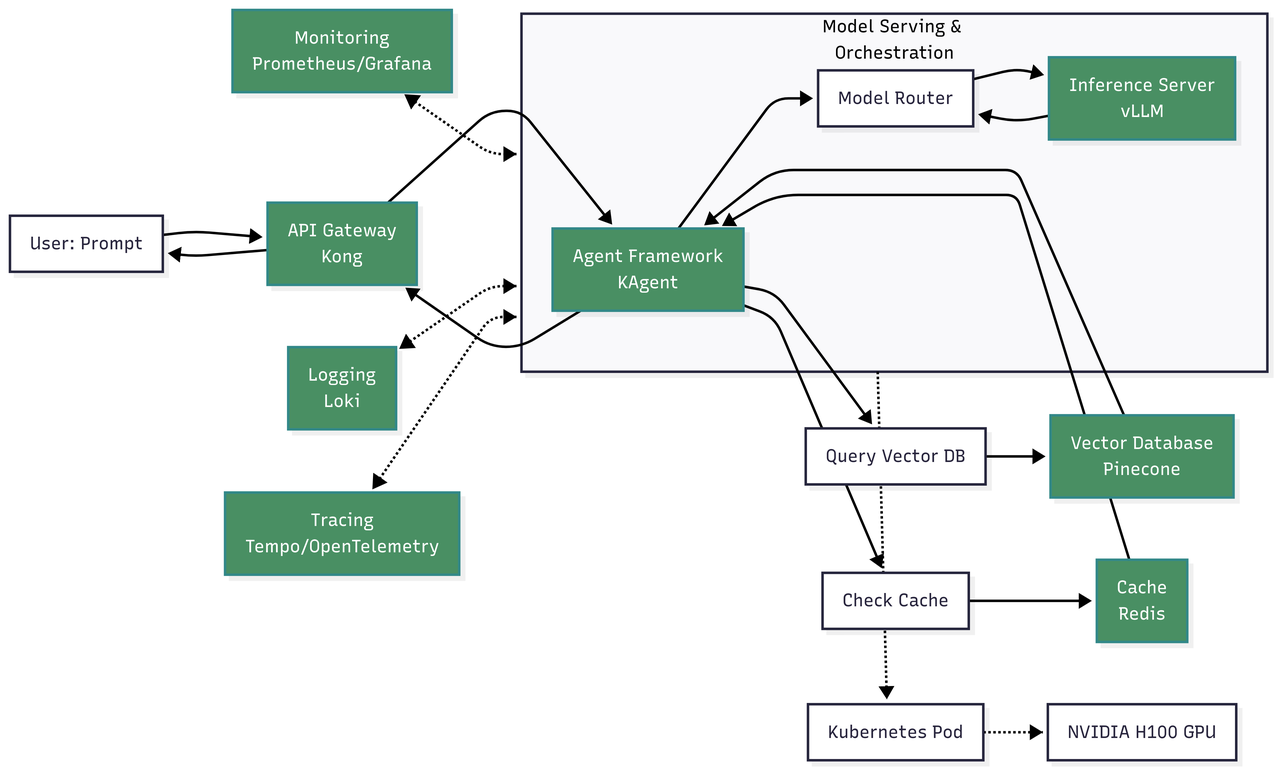
核心組件交互:用戶提示 → API 網(wǎng)關(guān)(Kong)→ 智能體框架(KAgent)→ 模型路由器 → 推理服務(wù)器(vLLM)→ NVIDIA H100 GPU(Kubernetes Pod);配套組件:緩存(Redis)、向量數(shù)據(jù)庫(kù)(Pinecone)、監(jiān)控工具(Prometheus/Grafana)、日志工具(Loki)、鏈路追蹤工具(Tempo/OpenTelemetry)
(一)步驟拆解
- 初始接入:用戶通過 Web 界面發(fā)送提示詞,請(qǐng)求經(jīng) API 網(wǎng)關(guān)(Kong)路由,網(wǎng)關(guān)完成身份認(rèn)證和限流處理
- 智能體編排:網(wǎng)關(guān)將請(qǐng)求轉(zhuǎn)發(fā)至 KAgent 等智能體框架,框架解析用戶意圖并啟動(dòng)多步驟推理流程
- 上下文檢索(RAG):智能體將提示詞轉(zhuǎn)換為嵌入向量,查詢向量數(shù)據(jù)庫(kù)(Pinecone),獲取內(nèi)部文檔中的相關(guān)上下文
- 內(nèi)存與緩存處理:智能體檢查緩存(Redis)中是否存在相似查詢,并從 SQL 數(shù)據(jù)庫(kù)中檢索長(zhǎng)期上下文
- 模型路由與推理:智能體將增強(qiáng)后的提示詞發(fā)送至模型路由器,路由器調(diào)用推理服務(wù)器(vLLM);服務(wù)器通過動(dòng)態(tài)批處理和 KV 緩存高效生成響應(yīng)
- KV 緩存的作用:在自回歸解碼過程中,KV 緩存存儲(chǔ)之前所有令牌的鍵(Key)和值(Value)向量;生成新令牌時(shí),僅需計(jì)算該令牌的向量,其余向量從緩存中讀取,大幅減少重復(fù)計(jì)算,降低延遲并提升吞吐量
- 響應(yīng)生成與執(zhí)行:生成的響應(yīng)返回至智能體,智能體可對(duì)響應(yīng)進(jìn)行后處理或通過 API 調(diào)用觸發(fā)特定操作;最終響應(yīng)經(jīng) API 網(wǎng)關(guān)返回給用戶
- 可觀測(cè)性監(jiān)控:整個(gè)流程通過 Prometheus 采集指標(biāo)、Loki 記錄日志、OpenTelemetry 實(shí)現(xiàn)鏈路追蹤,確保系統(tǒng)性能全可視
理解端到端推理流程對(duì)于優(yōu)化系統(tǒng)性能和故障排查至關(guān)重要。

簡(jiǎn)化流程:用戶 → 網(wǎng)關(guān) → 路由器 → 驗(yàn)證器 → 模型 → 工具 → 緩存 → 響應(yīng) 核心環(huán)節(jié):請(qǐng)求路由、輸入驗(yàn)證(基于 Pydantic 的 Schema 驗(yàn)證)、推理處理(GPU 加速)、工具執(zhí)行(智能體專用)、響應(yīng)緩存(Redis 提升性能)
四、核心開源工具清單
(一)模型服務(wù)引擎
- vLLM:生產(chǎn)級(jí)推理首選工具,基于分頁(yè)注意力(PagedAttention)算法和連續(xù)批處理技術(shù),吞吐量較傳統(tǒng)框架提升 2-4 倍,支持大型模型的張量并行
- 文本生成推理(TGI):具備企業(yè)級(jí)特性,提供全面監(jiān)控、流式響應(yīng)和兼容 OpenAI 的 API,適合追求運(yùn)維簡(jiǎn)化的生產(chǎn)部署場(chǎng)景
- Ollama:擅長(zhǎng)開發(fā)環(huán)境和邊緣部署,支持自動(dòng)模型管理、量化處理和簡(jiǎn)易配置,是原型開發(fā)和本地部署的理想選擇
(二)智能體框架
- LangChain:生態(tài)最全面的框架,支持與工具、數(shù)據(jù)源及模型提供商的廣泛集成,模塊化架構(gòu)可靈活構(gòu)建復(fù)雜工作流
- CrewAI:專注于多智能體場(chǎng)景,采用基于角色的設(shè)計(jì),支持智能體協(xié)作和復(fù)雜團(tuán)隊(duì)動(dòng)態(tài)管理
- AutoGen:對(duì)話式 AI 框架,支持多智能體通過協(xié)作推理和協(xié)商解決問題
(三)向量數(shù)據(jù)庫(kù)
- ChromaDB:適合開發(fā)環(huán)境和小規(guī)模部署,Python 集成性優(yōu)異,部署簡(jiǎn)易,采用 SQLite 后端確保可靠性
- Qdrant:生產(chǎn)環(huán)境性能出色,基于 Rust 開發(fā),具備高級(jí)過濾能力和分布式擴(kuò)展特性,支持向量相似度與結(jié)構(gòu)化數(shù)據(jù)結(jié)合的復(fù)雜查詢
- Weaviate:提供企業(yè)級(jí)功能,包括混合搜索、多模態(tài)支持和 GraphQL API,支持靈活的查詢模式
五、AI 智能體架構(gòu)
AI 智能體超越了簡(jiǎn)單模型的范疇,是具備復(fù)雜推理和行動(dòng)能力的系統(tǒng)。
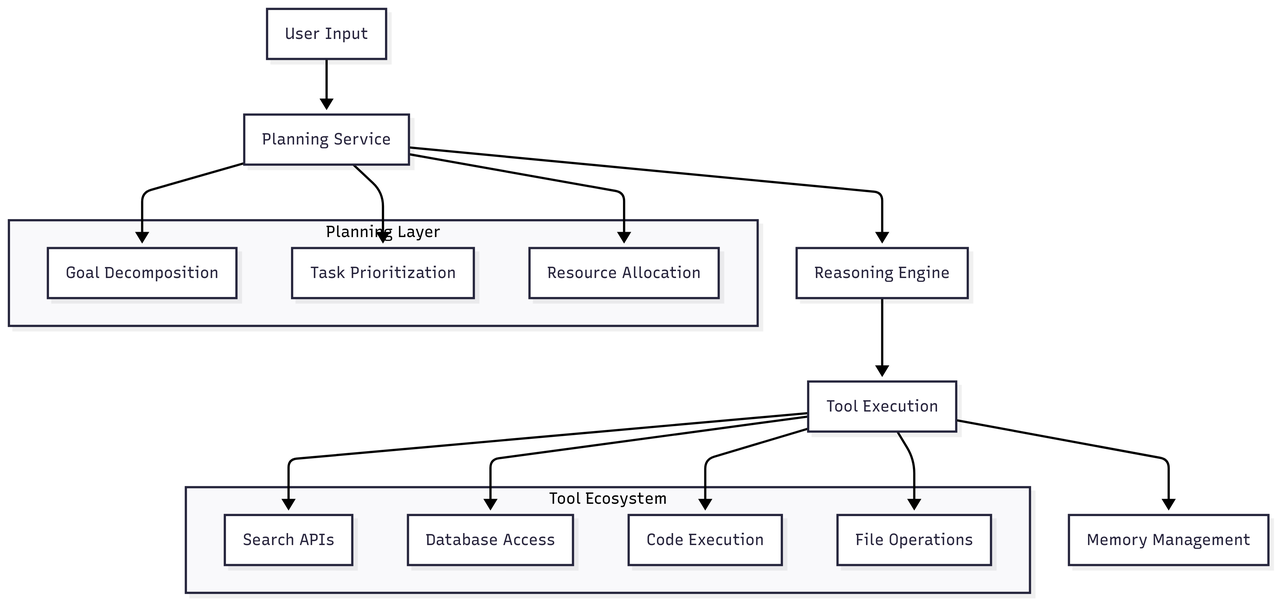
架構(gòu)組成:用戶輸入 → 規(guī)劃服務(wù)(規(guī)劃層:目標(biāo)分解、任務(wù)優(yōu)先級(jí)排序、資源分配、推理引擎)→ 工具執(zhí)行(工具生態(tài):搜索 API、數(shù)據(jù)庫(kù)訪問、代碼執(zhí)行、文件操作)→ 內(nèi)存管理(工作內(nèi)存、情景記憶、語(yǔ)義記憶)
(一)核心組件
- 規(guī)劃服務(wù):將復(fù)雜請(qǐng)求分解為可執(zhí)行的子任務(wù),需考量任務(wù)依賴關(guān)系、資源約束和故障處理機(jī)制
- 工具集成:需實(shí)現(xiàn)動(dòng)態(tài)工具發(fā)現(xiàn)、安全執(zhí)行沙箱隔離和性能監(jiān)控,所有工具需容器化部署,并配置合理的資源限制和網(wǎng)絡(luò)隔離策略
- 內(nèi)存系統(tǒng):管理智能體的各類內(nèi)存——工作內(nèi)存(當(dāng)前上下文)、情景記憶(對(duì)話歷史)和語(yǔ)義記憶(習(xí)得知識(shí))
六、優(yōu)化策略
(一)模型量化
量化技術(shù)可降低內(nèi)存占用并提升推理速度:
- INT8 量化:內(nèi)存占用減少 2 倍,精度損失極小
- INT4 量化:內(nèi)存占用減少 4 倍,精度損失約 2%-5%
(二)模型服務(wù)優(yōu)化
包括 Transformer 模型的 KV 緩存管理、可變請(qǐng)求量的動(dòng)態(tài)批處理,以及多 GPU 部署的張量并行技術(shù)。
1. KV 緩存(鍵值緩存)
KV 緩存是大語(yǔ)言模型高效推理的核心優(yōu)化技術(shù)。若缺少該機(jī)制,每個(gè)令牌生成時(shí)都需重新計(jì)算所有歷史令牌的向量,導(dǎo)致計(jì)算開銷難以承受。
(1)工作原理
緩存存儲(chǔ)序列中所有歷史令牌的計(jì)算后鍵(Key)和值(Value)向量;生成新令牌時(shí),模型僅計(jì)算該令牌的 KV 向量,其余向量從緩存中讀取。這一機(jī)制將計(jì)算復(fù)雜度從二次降至線性,顯著提升推理速度。
(2)挑戰(zhàn)與解決方案
- 內(nèi)存占用問題:KV 緩存可能消耗大量 GPU 內(nèi)存,尤其對(duì)于長(zhǎng)序列和大批量請(qǐng)求
- 優(yōu)化技術(shù):通過緩存卸載、量化和淘汰策略等高級(jí)方法,平衡內(nèi)存使用與性能表現(xiàn)
(三)硬件加速優(yōu)化
- GPU 優(yōu)化:聚焦內(nèi)存帶寬利用率提升、計(jì)算密集型與內(nèi)存密集型操作識(shí)別,以及多 GPU 協(xié)同效率優(yōu)化
- CPU 優(yōu)化:充分利用高級(jí)指令集(AVX-512、AVX2)、線程庫(kù)(OpenMP、Intel TBB)和優(yōu)化數(shù)學(xué)庫(kù)(Intel MKL、OpenBLAS)
(四)成本優(yōu)化策略
- 智能緩存:基于語(yǔ)義相似度的 AI 響應(yīng)緩存
- 搶占式實(shí)例:利用閑置資源處理批處理任務(wù)和開發(fā)工作
- 模型共享:?jiǎn)蝹€(gè)模型實(shí)例為多個(gè)應(yīng)用提供服務(wù)
- 動(dòng)態(tài)擴(kuò)縮容:基于隊(duì)列深度和響應(yīng)時(shí)間目標(biāo)進(jìn)行彈性伸縮

優(yōu)化維度:資源合理配置、使用模式優(yōu)化、架構(gòu)優(yōu)化 核心策略:動(dòng)態(tài)擴(kuò)縮容(基于需求自動(dòng)伸縮)、搶占式實(shí)例(降低 50%-90%成本)、緩存策略(響應(yīng)與模型緩存)、批處理(優(yōu)化 GPU 利用率)、模型優(yōu)化(量化與剪枝)、多租戶(共享基礎(chǔ)設(shè)施)
七、綜合工具參考表
以下表格按基礎(chǔ)設(shè)施層級(jí)整理了完整的開源工具清單,為 AI 系統(tǒng)構(gòu)建提供全面參考。
| 層級(jí) | 類別 | 工具 | 核心應(yīng)用場(chǎng)景 |
|---|---|---|---|
| 硬件與云 | GPU 計(jì)算 | ROCm、CUDA Toolkit、OpenCL | 硬件加速、GPU 編程、計(jì)算優(yōu)化 |
| 云管理 | OpenStack、CloudStack、Eucalyptus | 私有云基礎(chǔ)設(shè)施、資源管理 | |
| 容器與編排 | 容器化 | Docker、Podman、containerd、LXC | 應(yīng)用打包、隔離、可移植性 |
| 編排工具 | Kubernetes、Docker Swarm、Nomad | 容器調(diào)度、擴(kuò)縮容、服務(wù)發(fā)現(xiàn) | |
| 分布式計(jì)算 | Ray、Dask、Apache Spark、Horovod | 分布式訓(xùn)練、并行處理、多節(jié)點(diǎn)推理 | |
| 工作流管理 | Apache Airflow、Kubeflow、Prefect、Argo Workflows | 機(jī)器學(xué)習(xí)流水線自動(dòng)化、任務(wù)調(diào)度、工作流編排 | |
| 模型運(yùn)行時(shí)與優(yōu)化 | 機(jī)器學(xué)習(xí)框架 | PyTorch、TensorFlow、JAX、Hugging Face Transformers | 模型訓(xùn)練、推理、神經(jīng)網(wǎng)絡(luò)開發(fā) |
| 推理優(yōu)化 | ONNX Runtime、TensorRT、OpenVINO、TVM | 模型優(yōu)化、跨平臺(tái)推理、性能調(diào)優(yōu) | |
| 模型壓縮 | GPTQ、AutoGPTQ、BitsAndBytes、Optimum | 量化、剪枝、模型體積縮減 | |
| 大語(yǔ)言模型服務(wù) | vLLM、Text Generation Inference、Ray Serve、Triton | 高性能大語(yǔ)言模型推理、請(qǐng)求批處理、擴(kuò)縮容 | |
| API 與服務(wù) | 模型部署 | BentoML、MLflow、Seldon Core、KServe | 模型打包、版本管理、部署自動(dòng)化 |
| Web 框架 | FastAPI、Flask、Django、Tornado | REST API 開發(fā)、Web 服務(wù)、微服務(wù) | |
| 負(fù)載均衡 | Nginx、HAProxy、Traefik、Envoy Proxy | 流量分發(fā)、反向代理、服務(wù)網(wǎng)格 | |
| API 網(wǎng)關(guān) | Kong、Zuul、Ambassador、Istio Gateway | API 管理、身份認(rèn)證、限流 | |
| 數(shù)據(jù)與存儲(chǔ) | 向量數(shù)據(jù)庫(kù) | Weaviate、Qdrant、Milvus、Chroma | 嵌入向量存儲(chǔ)、語(yǔ)義搜索、RAG 應(yīng)用 |
| 傳統(tǒng)數(shù)據(jù)庫(kù) | PostgreSQL、MongoDB、Redis、Cassandra | 結(jié)構(gòu)化數(shù)據(jù)存儲(chǔ)、緩存、會(huì)話存儲(chǔ)、元數(shù)據(jù)管理 | |
| 數(shù)據(jù)處理 | Apache Kafka、Apache Beam、Pandas、Polars | 流處理、ETL、數(shù)據(jù)轉(zhuǎn)換 | |
| 特征存儲(chǔ) | Feast、Tecton、Hopsworks、Feathr | 特征工程、特征服務(wù)、版本管理、共享 | |
| 監(jiān)控與可觀測(cè)性 | 基礎(chǔ)設(shè)施監(jiān)控 | Prometheus、Grafana、Jaeger、OpenTelemetry | 指標(biāo)采集、可視化、分布式鏈路追蹤 |
| 機(jī)器學(xué)習(xí)實(shí)驗(yàn)追蹤 | MLflow、Weights & Biases、Neptune.ai、ClearML | 實(shí)驗(yàn)日志、模型版本管理、超參數(shù)追蹤 | |
| 大語(yǔ)言模型可觀測(cè)性 | LangKit、Arize Phoenix、LangSmith、Helicone | 大語(yǔ)言模型性能監(jiān)控、提示詞評(píng)估、使用分析 | |
| 日志與分析 | ELK Stack、Fluentd、Loki、Vector | 日志聚合、搜索、分析、告警 | |
| 應(yīng)用與智能體 | 智能體框架 | LangChain、AutoGen、CrewAI、LlamaIndex | 智能體開發(fā)、多智能體系統(tǒng)、工具集成 |
| 工作流自動(dòng)化 | n8n、Apache Airflow、Temporal、Zapier Alternative | 業(yè)務(wù)流程自動(dòng)化、工作流編排 | |
| 安全與訪問控制 | Keycloak、HashiCorp Vault、Open Policy Agent | 身份認(rèn)證、密鑰管理、策略執(zhí)行 | |
| 測(cè)試與質(zhì)量保障 | DeepEval、Evidently、Great Expectations、Pytest | 模型測(cè)試、數(shù)據(jù)驗(yàn)證、質(zhì)量保障 |
八、結(jié)語(yǔ):基礎(chǔ)設(shè)施作為戰(zhàn)略優(yōu)勢(shì)
構(gòu)建成功的 AI 基礎(chǔ)設(shè)施需要在即時(shí)需求與長(zhǎng)期可擴(kuò)展性之間取得平衡——應(yīng)從成熟、簡(jiǎn)潔的解決方案起步,逐步增加系統(tǒng)復(fù)雜度。
AI 基礎(chǔ)設(shè)施架構(gòu)設(shè)計(jì)是一項(xiàng)核心工程任務(wù),直接影響 AI 產(chǎn)品的性能、成本和可靠性。基于分層架構(gòu)構(gòu)建的精良系統(tǒng),結(jié)合 Kubernetes、vLLM、KAgent 和 Pinecone 等工具,能夠支撐大規(guī)模部署并提供流暢的用戶體驗(yàn)。
AI 基礎(chǔ)設(shè)施領(lǐng)域發(fā)展迅速,但聚焦于開源工具構(gòu)建堅(jiān)實(shí)基礎(chǔ)、實(shí)現(xiàn)全面可觀測(cè)性并追求運(yùn)維卓越,將幫助企業(yè)在把握 AI 技術(shù)進(jìn)步的同時(shí),保持系統(tǒng)的可靠性和可擴(kuò)展性。盡管不同企業(yè)的實(shí)施路徑因需求差異而有所不同,但本指南提供的框架將為構(gòu)建具備實(shí)際業(yè)務(wù)價(jià)值的 AI 基礎(chǔ)設(shè)施提供清晰 roadmap。
理解并實(shí)施 KV 緩存等高級(jí)優(yōu)化技術(shù),是 AI 系統(tǒng)從原型階段邁向生產(chǎn)級(jí)部署的關(guān)鍵。隨著 AI 技術(shù)的不斷演進(jìn),高效的基礎(chǔ)設(shè)施將持續(xù)成為核心差異化優(yōu)勢(shì),助力企業(yè)部署功能強(qiáng)大、可擴(kuò)展且成本效益優(yōu)異的 AI 應(yīng)用。

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)