


一、Hbase 寫入慢時的集群異常指標
關于hbase寫入優化的文章很多,這里主要記錄下,生產hbase集群針對寫入的一次優化過程。
hbase寫入慢時,從hbase集群監控到的一些指標 -hbase 采用HDP 2.6 ,Hbase -1.1.2
- HBase的吞吐量 達到一個峰值之后,瞬間下降,無法穩定 ,對應的Grafana 面板-RPC Received bytes/s
- hbase 每臺服務器的寫入條數不均衡 ,對應監控面板 --Num Write Requests /s
- hbase的member store 一直維持在較小的數據,遠沒有達到機器 設置的 讀寫內容的比例,比如 讀寫內容各站0.4, 對應監控面板-Memstore Size
基于此 任務 目前的寫入慢,并非集群硬件配置造成,而是hbase集群參數設計等設置有問題。
二、重新梳理了hbase了 寫入流程
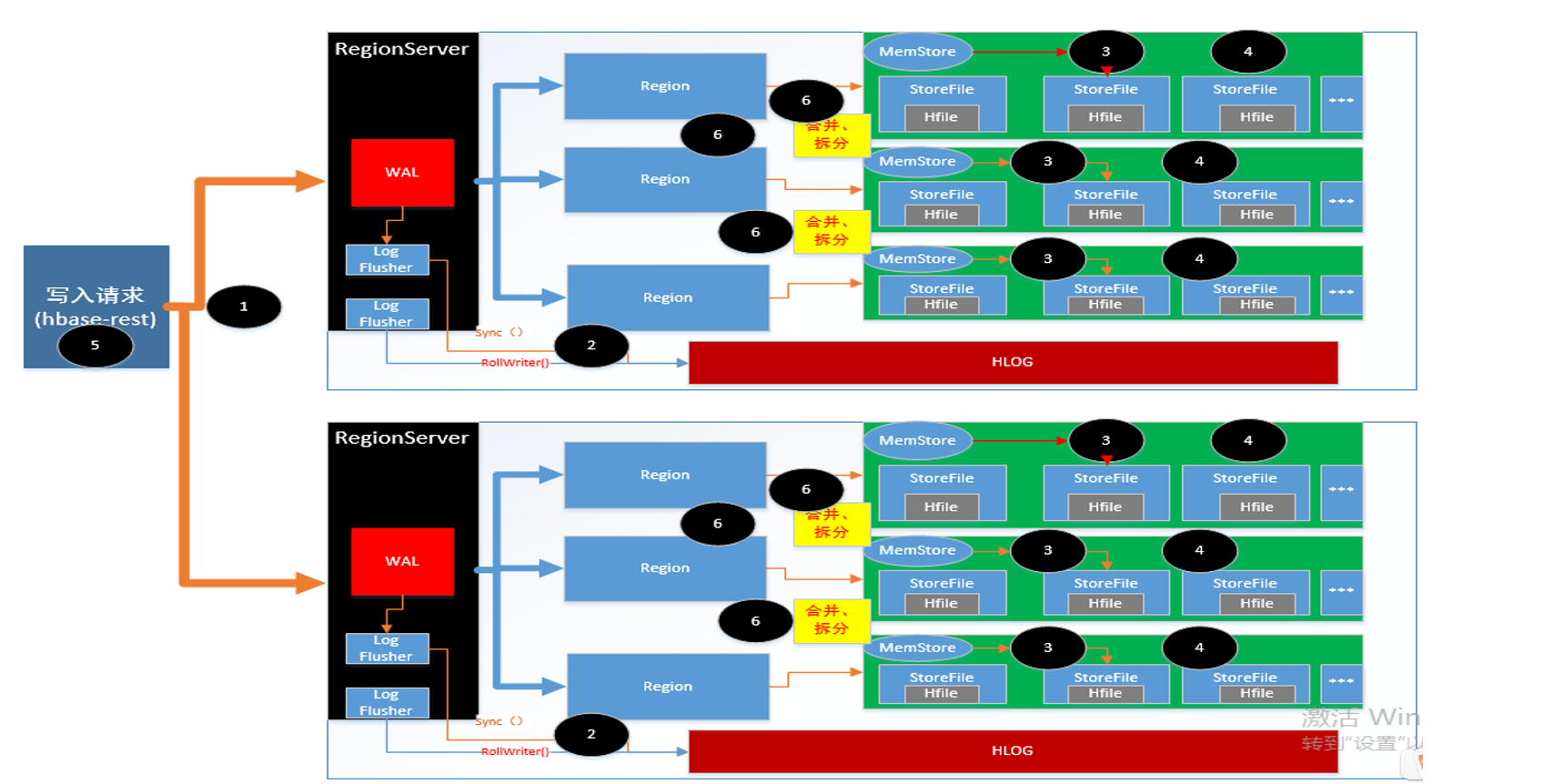
hbase 寫入流程,這里就不在追溯,以上是根據理解,自己畫的寫入流程圖 。可以查詢的資料較多,這里推薦幾個地址
hbase 社區 http://hbase.group/
w3c:https://www.w3cschool.cn/hbase_doc/hbase_doc-vxnl2k1n.html
牛人博客:https://www.iteblog.com/archives/category/hbase/
三、參數優化
基于以上,優化的思路主要分為如下
- 利用分布式集群優勢,確保請求負載均衡
- 集群的RegionServer 在某些情況下會阻止數據的寫入,盡量減少這種情況的發生
- 提高RegionServer 處理外部請求的能力
- 減少客戶端和服務端ipc,請求的次數,可以批量寫入的采用批量寫入
- 增加hbaserest 端并行執行的能力
3.1 利用分布式集群優勢,確保請求負載均衡
- 創建預分區
結合具體數據的RowKey特征創建預分區,注意:如果rowkey 業務數據為GUID,此時要注意guid 的首字母已經做了限制 即0-9 a-f 此時創建再多的分區,起作用的僅是0-9 a-f 開頭的分區
create 'Monitor_RowDataMapping6','d', SPLITS => ['HSF.Response.Receive|', 'HSF.Response.Sent|', 'Teld.SQL|','HSF.Request.Time|', 'HSF.Request.Count|', 'HSF.Request.Receive|','HSF.Request.Sent|','Teld.Boss|','Teld.Core|','Teld.Redis|','Teld.WebApi|','TeldSG.Invoke|']
- rowkey的均衡
- 常用的方法:rowkey的哈希、rowkey的逆轉、 當然 配套的查詢也要做響應的修改
3.2 減少集群阻止寫入的頻率和時間
- 根據數據靈活調整WAL的持久化等級 --當然允許regionserver 重啟之后數據可以丟一部分
WAL默認的等級為同步,會阻塞數據的寫入,一般的持久化等級采用異步即可對于寫入量很大的監控數據不在寫入wal,alter 'Monitor_RowData', METHOD => 'table_att', DURABILITY => 'SKIP_WAL‘

- 調整 hbase.hstore.blockingStoreFiles 的大小,默認值為7, 生產環境調整到100000
Memstore 在flush前,會進行storeFile的文件數量校驗,如果大于設定值,則阻止這個Memsore的數據寫入,等待其他線程將storeFile進行合并,為了建設合并的概率,建設寫入的阻塞,提高該參數值 -
由于region split 期間,大量的數據不能讀寫,防止對大的region進行合并造成數據讀寫的時間較長,調整對應的參數,
如果region 大小大于20G,則region 不在進行split
hbase.hstore.compaction.max.size 調整為20G 默認為 Long.MAX_VALUE(9223372036854775807) -
region server在寫入時會檢查每個region對應的memstore的總大小是否超過了memstore默認大小的2倍(hbase.hregion.memstore.block.multiplier決定),
如果超過了則鎖住memstore不讓新寫請求進來并觸發flush,避免產生OOM
hbase.hregion.memstore.block.multiplier 生產為8 默認為2 - 調整 hbase.hstore.blockingStoreFiles 的大小,默認值為7, 生產環境調整到100000
Memstore 在flush前,會進行storeFile的文件數量校驗,如果大于設定值,則阻止這個Memsore的數據寫入,
等待其他線程將storeFile進行合并,為了建設合并的概率,建設寫入的阻塞,提高該參數值 - 增加hlog 同步到磁盤的線程個數
hbase.hlog.asyncer.number 調整大10 默認為5 -
寫入數據量比較大的情況下,避免region中過多的待刷新的memstore,增加memstore的刷新線程個數
hbase.hstore.flusher.count 調整到20 默認為1
3.3 增加RegionServer 服務端的處理能力
- 針對目前每次寫入的數據量變大,調整服務端處理請求的線程數量
hbase.regionserver.handler.count 默認值為10 調整到400
3.4 客戶端請求參數設置
- 增加hbrest 并行處理的線程個數 ---寫入部分是hbrest 服務寫入
hbase.rest.threads.max 調整到400
- 采用hbase的批量寫入
hbase.client.write.buffer 修改為5M

 浙公網安備 33010602011771號
浙公網安備 33010602011771號