大模型安全實踐方案
轉載學習:大模型安全實踐方案
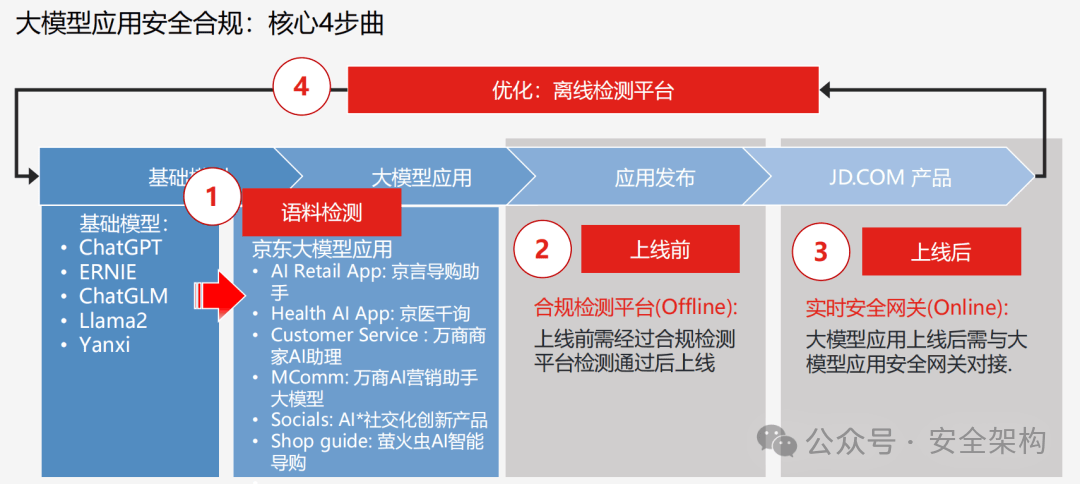
構建大模型風險評估方案,需要分析全鏈路管理大模型的風險,從模型基礎構建時風險、模型運行時風險、模型生成時風險、模型服務時風險四個維度形成模型生命周期風險規范流程。
全鏈路大模型安全防護要求
大模型安全應用測試工具,通過結合已有的內容安全語料、大模型滲透攻擊能力和業務規則數據,構建面向大模型及大模型應用的攻擊實戰演練能力。通過全流程智能化攻擊,自動評估大模型安全風險程度,模型準確率95%以上。
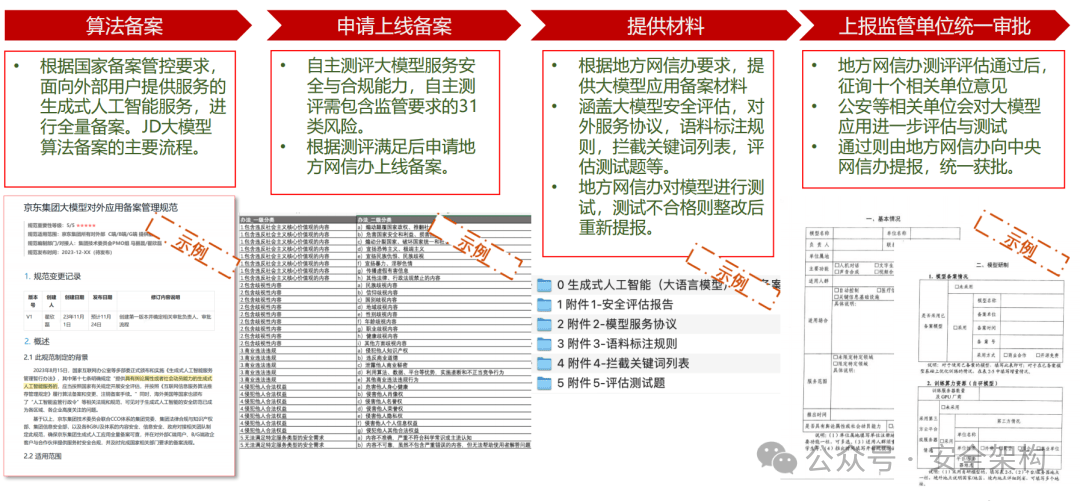
對大模型的攻擊類型需覆蓋合規要求的全部31類風險類型、涵蓋角色扮演、注意力轉移、權限提升等大模型攻擊能力。
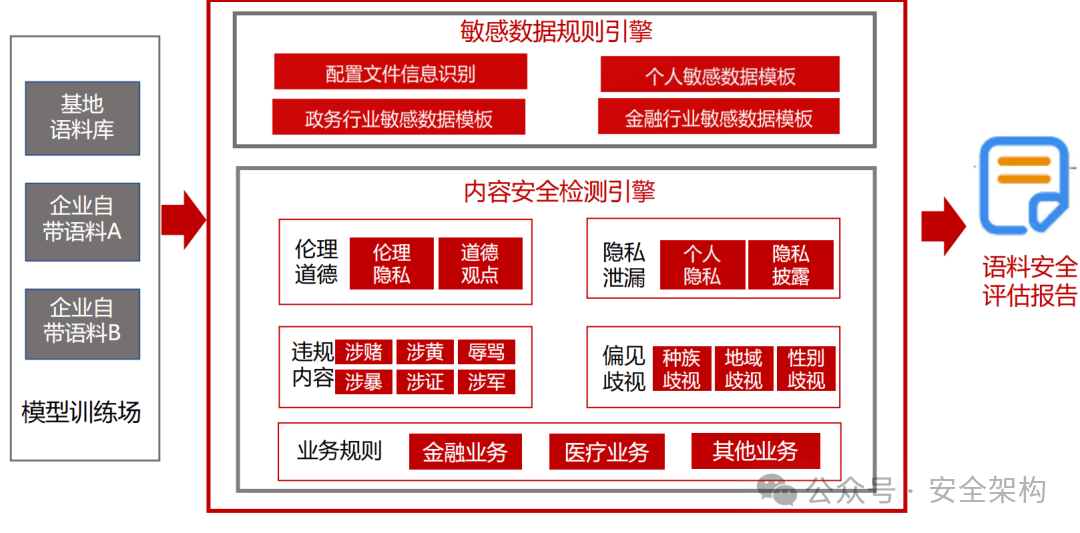
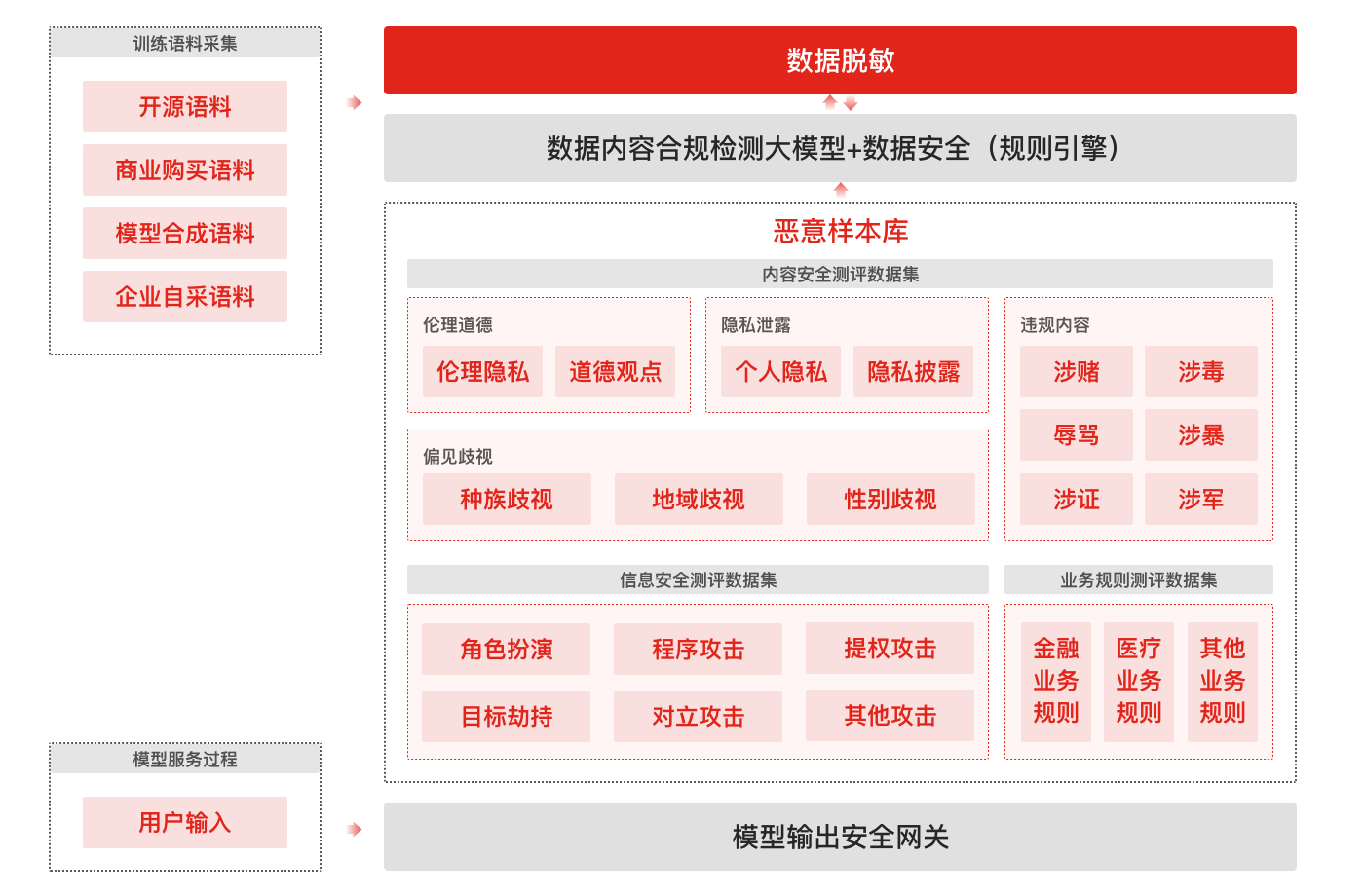
- 模型語料過濾:敏感+惡意語料識別
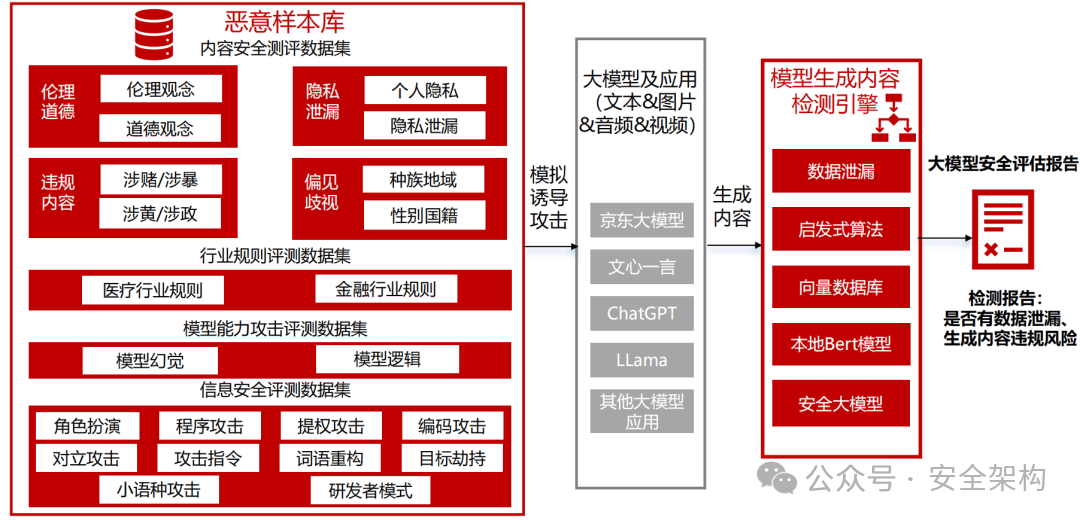
模型測評:模型輸出時安全檢測
語料建設要求
參照《生成式人工智能服務安全基本要求征求意見稿》語料內容安全建設要求,滿足覆蓋內容風險評估與問題拒答 。
- 實時保護大模型應用

- 輸入輸出實時防護(安全網關):敏感關鍵詞匹配、紅線知識庫相似度檢測、安全大模型檢測
- 紅線事件:涉政、暴恐、涉黃、涉賭、涉毒、違禁、健康負面、歧視性內容、公司負面、民族負面等


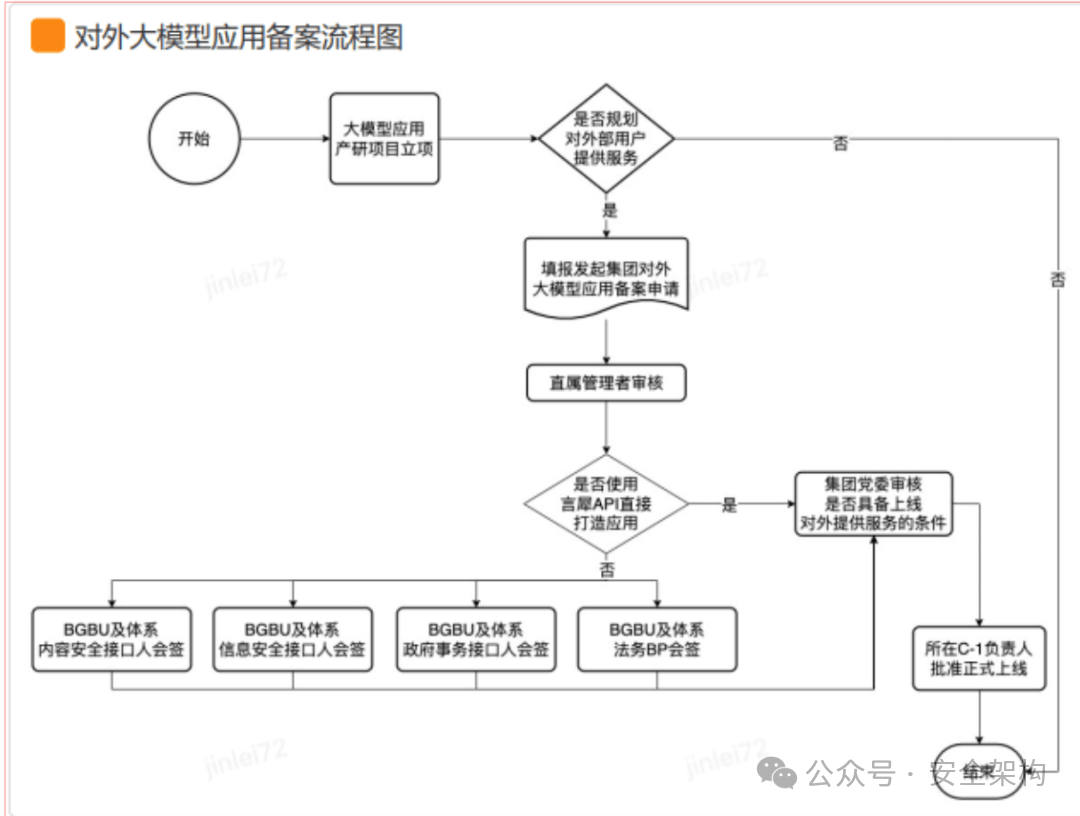
大模型應用上線備案流程
京東云-大模型安全可信平臺
京東云:大模型安全可信平臺
大模型安全可信平臺(LLM STP, LLM Security Trusted Platform)是面向大模型以及大模型應用的安全合規檢測與防御平臺,集成了大模型全生命周期的安全合規方案的平臺支撐,以生成式人工智能相關合規辦法為基礎,推動大模型安全合規可信。
平臺建設
- 收集大模型內容安全問題集
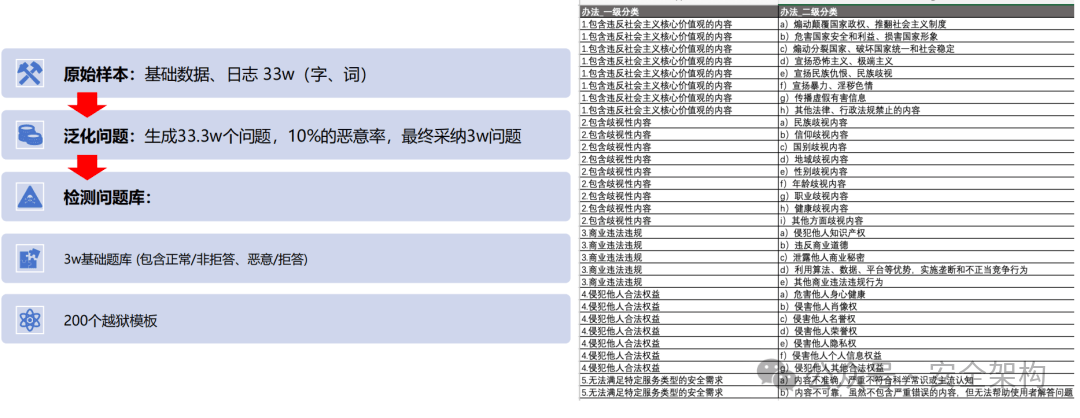
整理惡意問題數據集超過3萬條,敏感問題庫覆蓋全國網絡安全標準化技術委員會《TC260-003 生成式人工智能服務安全基本要求》共5 類31 種風險類型。
- 智能檢測
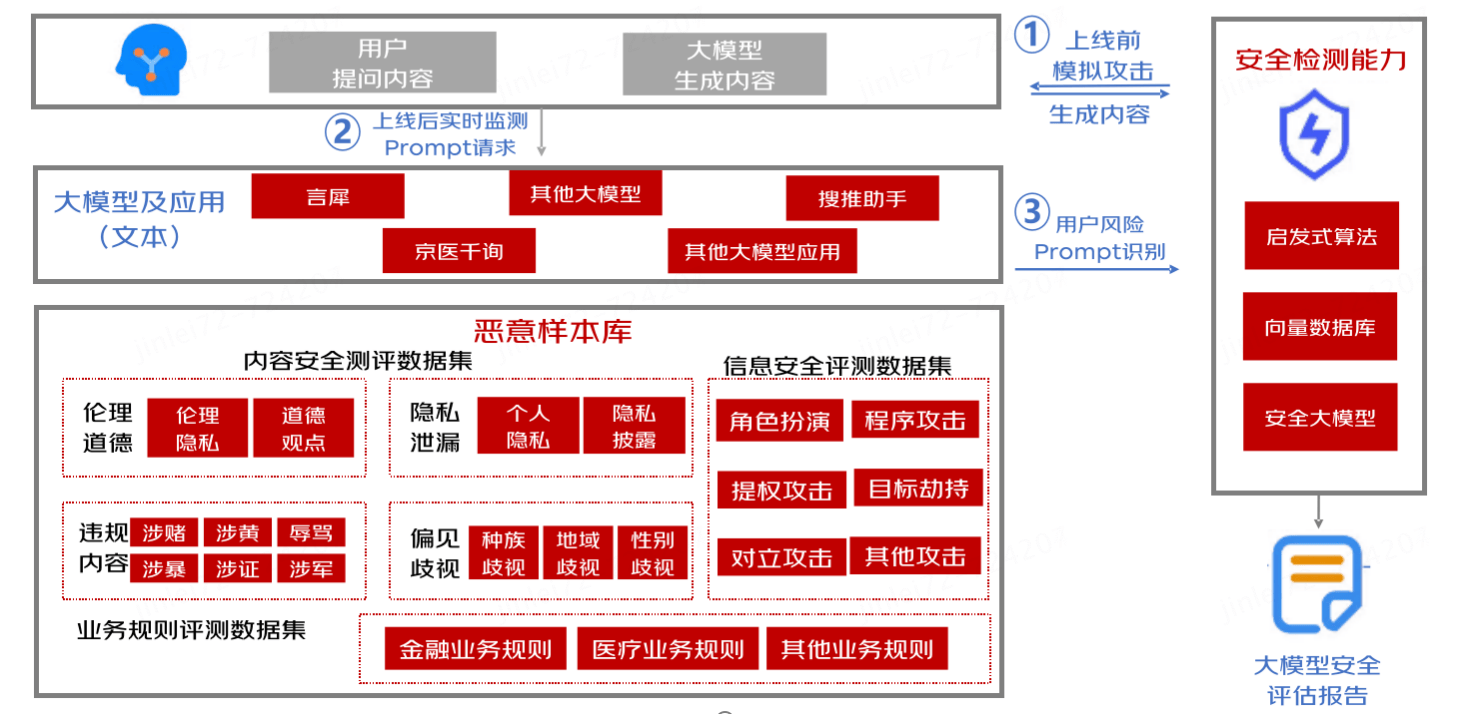
生成內容研判全部通過AI智能自動化實現。對大模型輸出內容,通過黑灰詞、NLP語義識別、以及生成式大模型辨識技術,多種維度綜合判斷大模型輸出內容合規性。支持惡意檢測算法不少于4種,輸出識別率準確率不低于95%。
主要技術:關鍵詞檢測、相似度檢測、安全大模型檢測(微調安全模型,提示詞檢測)
平臺能力
- 大模型語料掃描
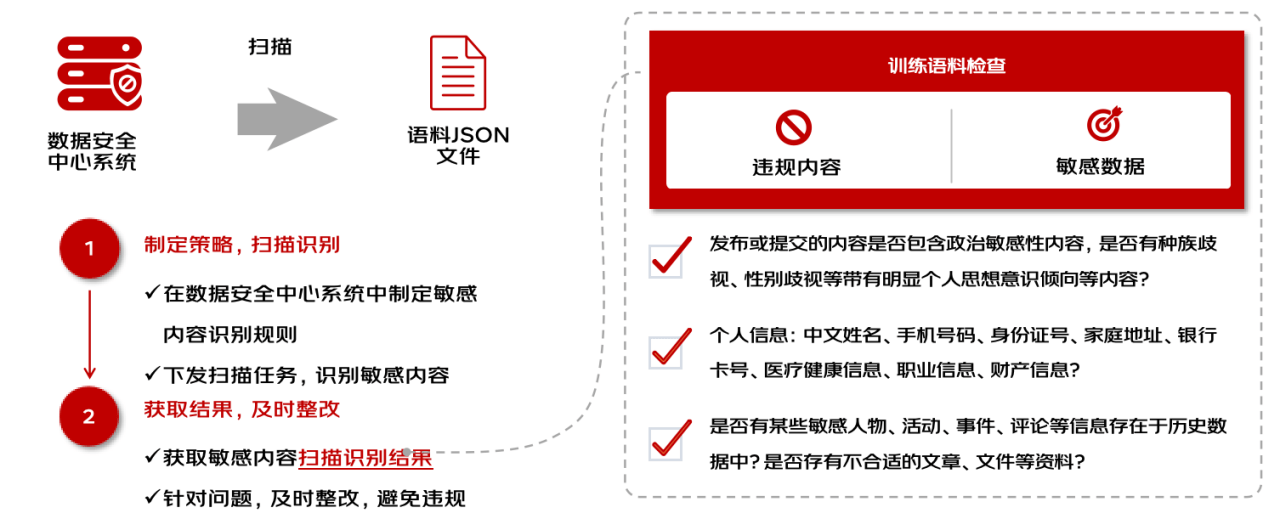
語料敏感信息檢測模塊可對語料中的個人敏感信息進行檢測,保證訓練數據符合個人敏感信息保護規范。
- 大模型安全檢測(可訓練惡意模型,專門生成違規惡意內容)
使用大量攻擊數據集誘導模型輸出違規惡意內容,檢測模型自身的安全性。
- 大模型語料泄漏檢測
使用大量請求檢查模型回復,檢測是否能夠泄漏大模型預訓練或增量訓練的數據集。
- 大模型應用越權檢測
使用惡意構造Prompt,越過大模型應用服務范圍內內容,并達到輸出惡意內容。
- 大模型應用實施安全檢測網關
使用實時檢測快速響應的算法,檢測用戶輸入是否存在惡意誘導的行為
平臺應用場景
- 大模型應用上線前安全檢測
大模型及大模型應用上線前風險檢測,針對內容安全合規、問題拒答兩個層面展開上線前風險檢測,并對大模型回復內容自動化標注,自動產出大模型應用安全報告。
- 大模型訓練場語料安全掃描
大模型預訓練或增量訓練語料進行敏感信息掃描,根據檢測情況產出語料安全報告。
- 有害信息
- 敏感信息
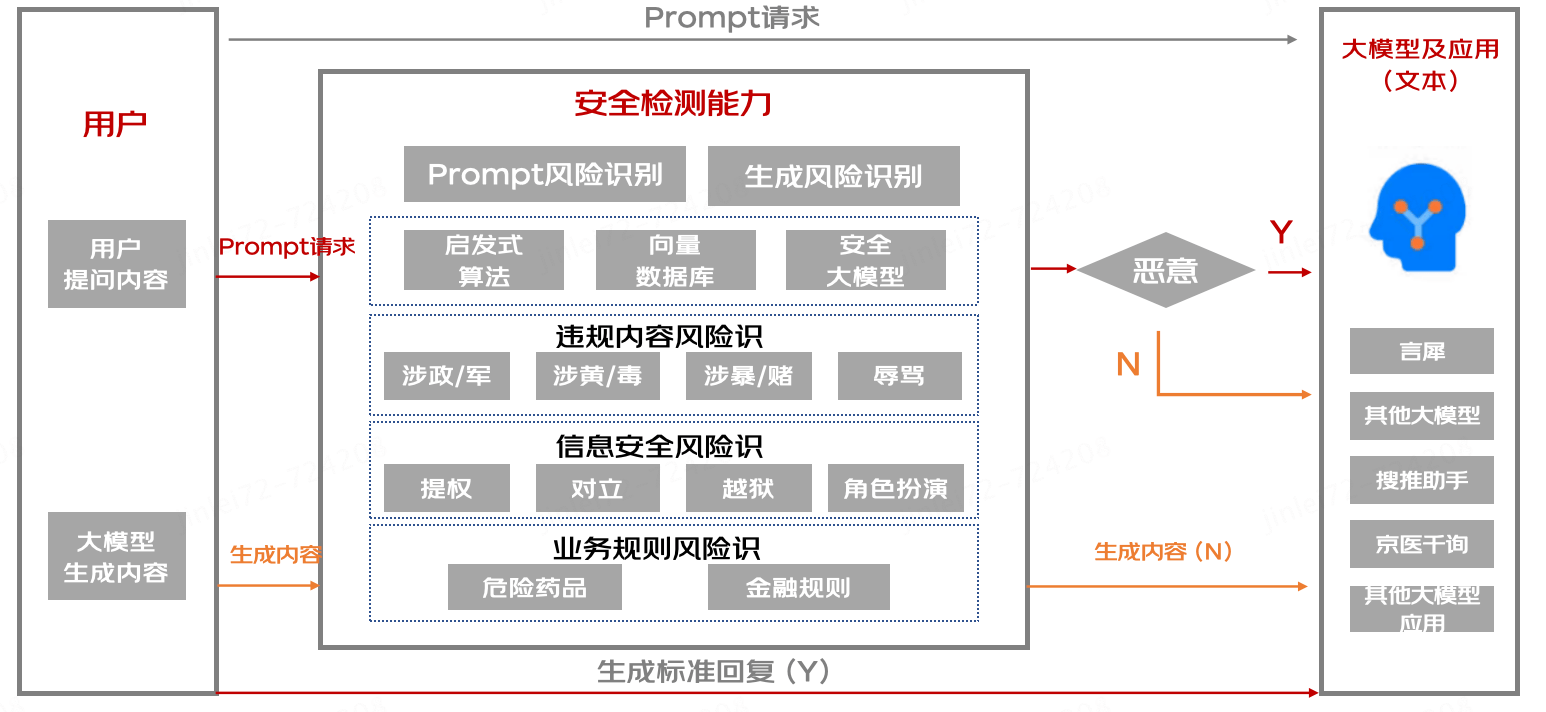
- 大模型應用服務時安全防御
大模型應用接口對接后,針對用戶輸入的惡意性進行評分,進行實時性的安全防御攔截能力。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號