垂直領域大模型的定制化:理論基礎與關鍵技術
學習筆記:垂直領域大模型的定制化:理論基礎與關鍵技術
由于通用大模型不能完全適配特定行業和應用場景,所以需要垂直領域大模型的定制化。
- 對特定行業的知識深度不夠
- 垂直領域大模型:訓練中使用大量特定領域數據
垂直大模型定制的理論基礎
大模型定義
特點:
- 大數據
- 大參數
- 通用性
- 泛化性:在為止數據域中有良好的性能
分類:

構建垂直領域大模型難度:
- 領域數據難以獲取,具有機密性
- 領域數據模態和通用大模型使用的中心模態不同,難于遷移
- 構建難度大,開銷大,技術難
大模型架構
多模態大模型在理論上包含所有單模態大模型的功能和結構。即“單 模 態 大 模 型 就 是 實 現 了 多 模 態 大 模 型 部 分 功 能 的 大 模 型”。
多 模 態 大 模 型 的 結 構 可 以 分 為 以 下 5 個模塊:
- 模態編碼器
- 輸入投影器
- 主干運算器
- 輸出投影器
- 模態解碼器
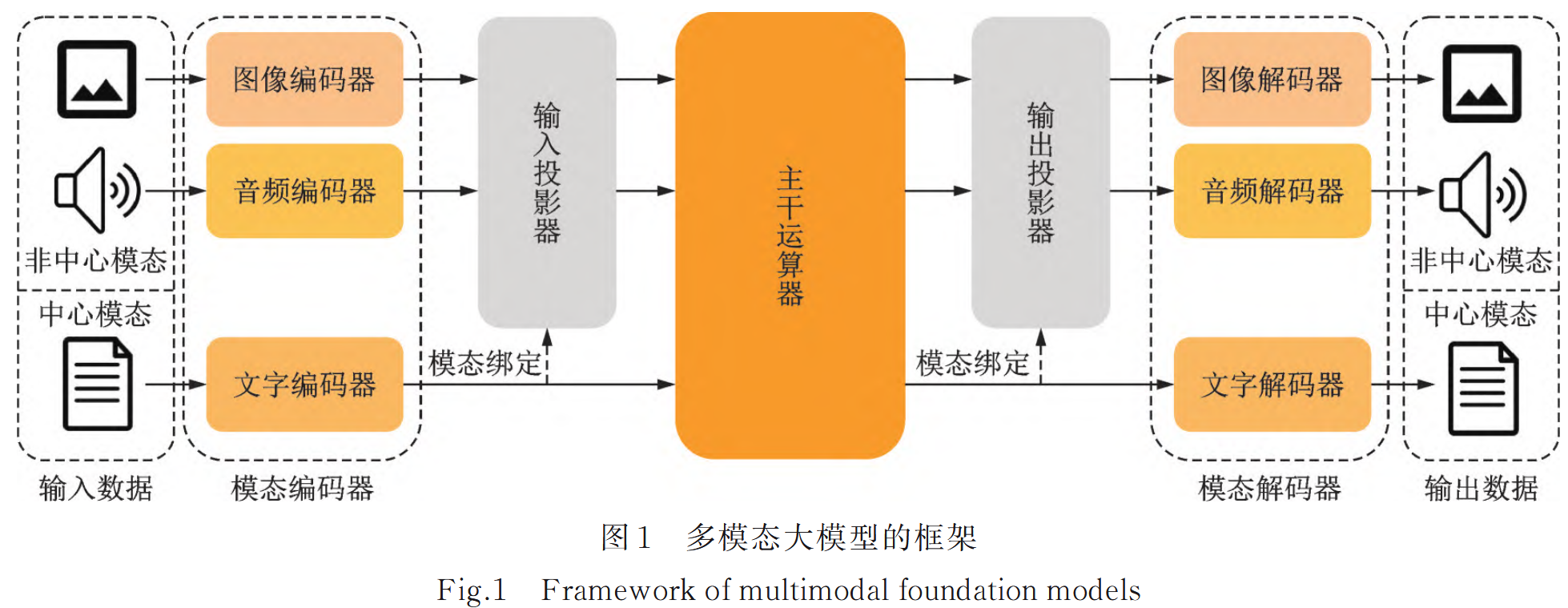
多模態大模型具有一個中心模態,通過模態對齊技術,將其能夠處理的所有模態都投影到該中心模態上。
垂直領域大模型的定制過程:根據業務需求選取所需的模塊組成業務模塊,然后訓練整個模型,其中個別模塊可以通過遷移和微調方式部署實現。
特征提取
由于原始數據中包含大量冗余和噪音信息,通過特征提取能將數據轉換為信息更為密集的特征空間。
深度學習中,可利用神經網絡自動提取特征,即每一層都將上一層的輸入數據進行計算并轉換到一個新的向量空間。
- 自編碼器:通過最小化原向量與重構向量之間的重構誤差,學習數據的有效表示,通過將輸入數據壓縮為低維特征向量,再通過解碼器將低維向量投影回原始數據空間。
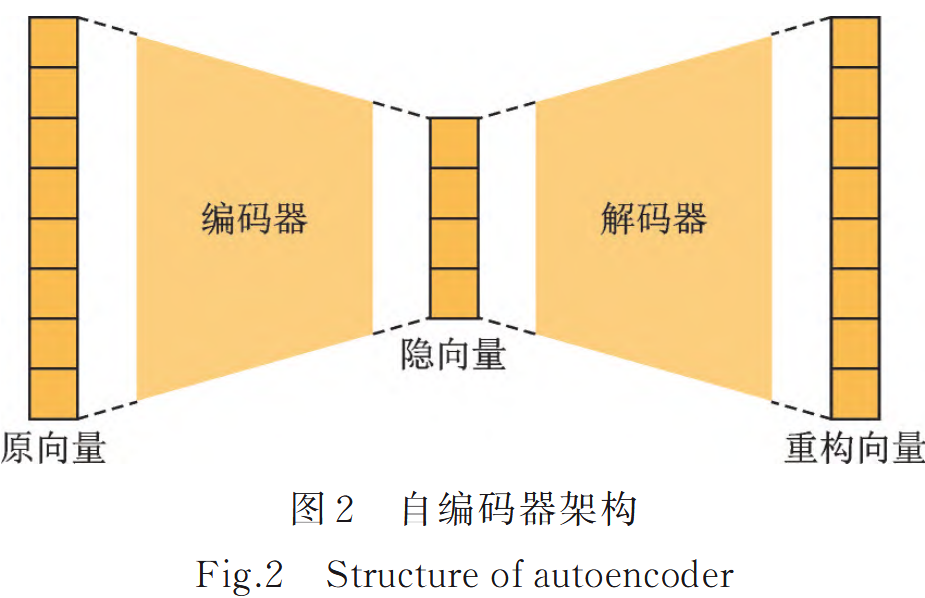
大模型架構中的模態編碼器和模態解碼器就是將兩者對應的自編碼器的編碼和解碼部分,配對成自編碼器來訓練??
- 變分自編碼器:除了最小化重建誤差外,還包括最大化輸入數據的似然概率,從而學習到壓縮向量的分布。
模態對齊
多模態大模型中,需要利用模態對齊,將不同模態的原始數據或特征向量處理成具有相同維度的特征標識,然后通過設計損失函數來表征特征向量間的相關性,進而將各模態的特征向量投影到一個共享的特征空間中。
模態對齊的實現方式:
- 融合編碼器建構
融合編碼器采用Transformer模型的子注意力機制或交叉注意力機制來編碼多模態數據。
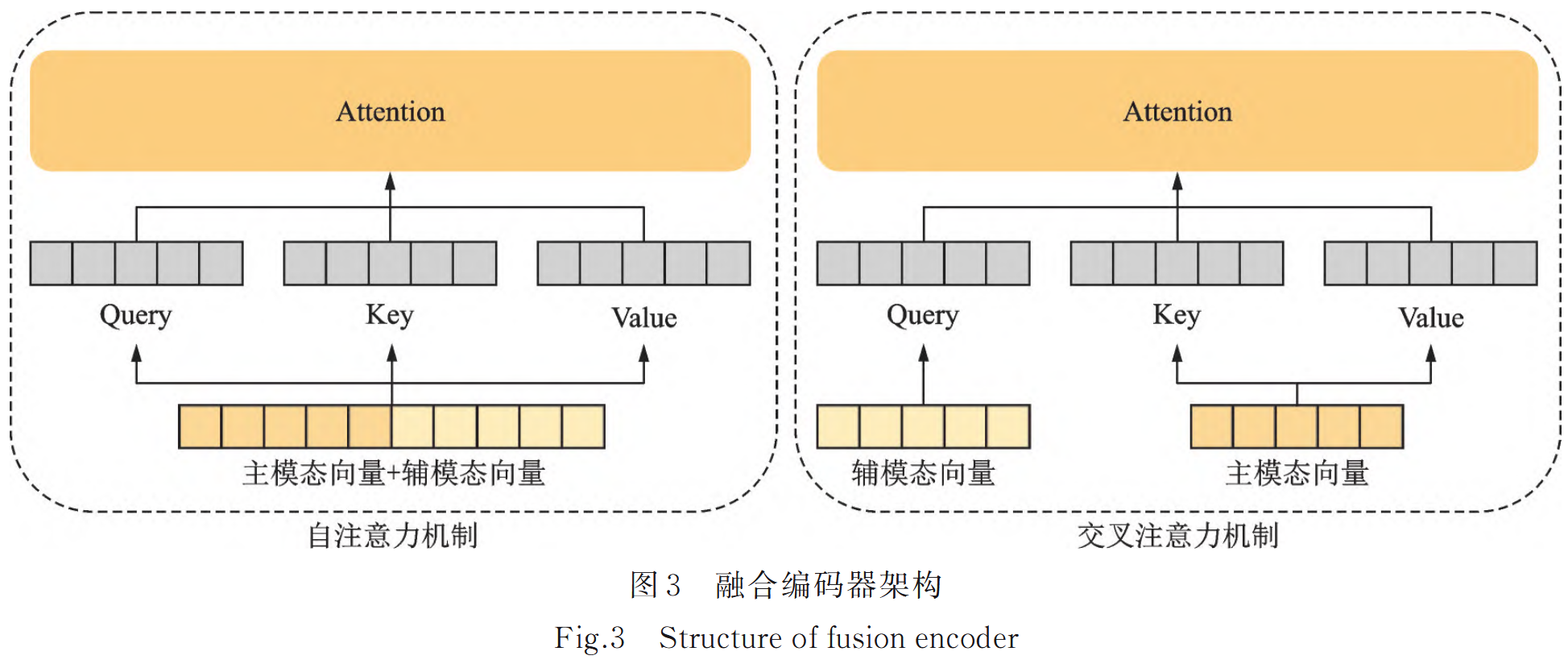
- 基于自注意力機制的方法:拼接主副模態的特征向量輸入Transformer中產生QKV,讓模型自動關注不同模態的特征,并實現跨模態信息融合。
- 基于交叉注意力機制的方法:將模態的特征向量分別計算QKV,進而實現跨模態信息融合。
- 雙編碼器架構
核心原理是為每種模態單獨訓練一個專門的編碼器,利用對比學習的方法,通過語義相似度同步引導兩個編碼器的學習過程,將不同編碼器的輸出特征向量投影到同一個向量空間中。
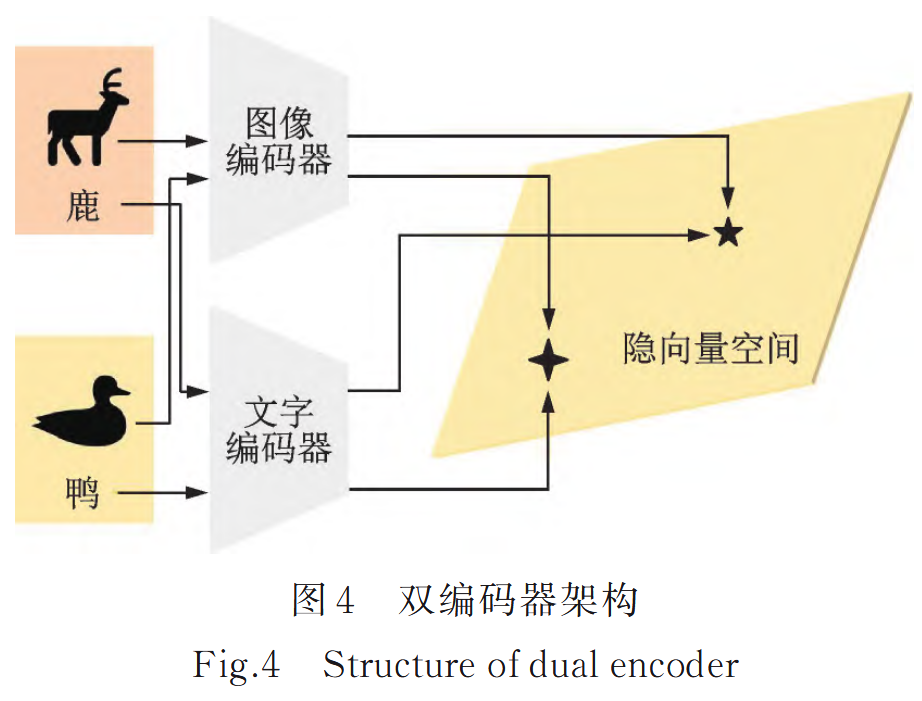
而一一對齊每對模態的成本較高,進而提出橋接對齊的方法:通過將所有其他模態與一個中心模態進行匹配,進而在語義空間中實現所有模態的對齊。
規模冪律
在其他條件給定的情況下,模型的損失函數隨著參數量、計算資源和訓練數據量的增加成指數級下降,這意味著通過增加模型參數量、加大計算資源投入和增加訓練數據量,模型的性能可能有指數級提升。
涌現現象
模型涌現:隨著模型規模的增加,模型擁有根本更多的參數和更復雜的結構,使得其更好的捕捉數據中的復雜特征和模式,能處理更為復雜的推理任務。
但隨著模型參數量的增加, 對計算資源的需求和過擬合風險也上升,不能無限制增加模型參數量。
垂直領域大模型的定制方法
垂直領域大模型的定制化方法分為:

基于全架構通用大模型的垂直領域增強
若通用大模型能夠完全處理所需的模態數據,就無需修改模型架構,只需對其進行垂直領域增強。根據是否改變大模型參數,又分為:
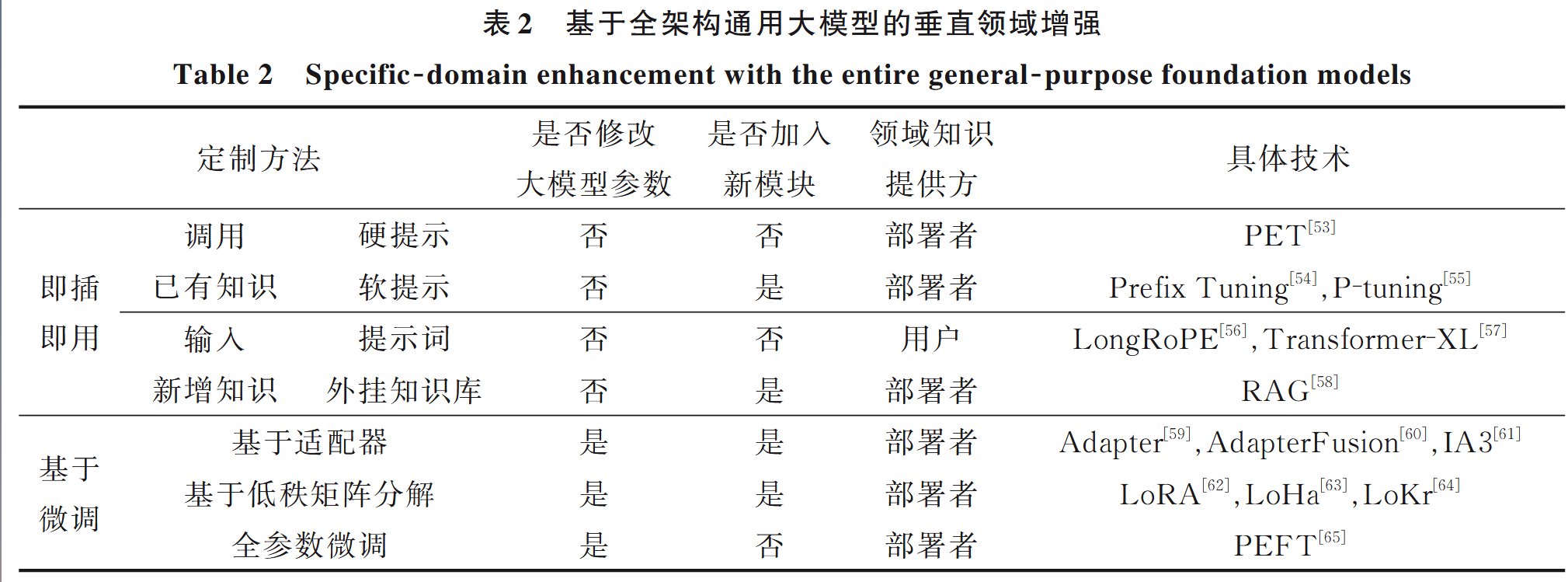
即插即用
分為兩種方式:
- 調用已有知識
盡可能調用通用大模型中已經存儲的垂直領域知識,通過對提示詞進行”微調“,即優化提示詞,將一段精心優化后的提示詞插入到輸入數據前面作為模型上下文來影響生成結果。又分為:
- 硬提示
訓練一個提示詞優化模型?通過在少量監督數據上進行訓練模型,并對無監督數據進行集成預測,從而實現對模型的指導。
- 軟提示
前綴提示詞微調:添加可學習的前綴向量到輸入序列的開始部分來適應特定下游任務,只更新前綴向量,而不是模型參數。
P-tuning微調:核心是將提示詞也視為模型可以學習的一部分,讓模型不僅學習如何相應給定的任務,還學習如何生成最佳的提示詞,和deepseek的”think“類似?
- 輸入新增知識
通過輸入領域知識的方式賦予大模型對垂直領域任務的處理能力,又分為:
- 通過提示詞輸入知識
是few shot?將領域知識放到提示詞中,這樣受限于最大提示詞長度,限制模型長文本輸入能力的三個核心問題:位置編碼的局限性、注意力機制的資源消耗、長距離依賴問題。
針對上述問題,提出無損長文本技術,通過外推和內插兩個方法實現:
a. 外推:擴展模型的上下文窗口,涉及改進位置編碼機制。如Longformer、LongRoPE、BigBird等。
b.內插:在模型現有序列長度能力范圍內,通過調整和優化注意力機制來提升對長文本處理能力。如BERT、XL-Net、Transformer-XL等。
- 通過外掛知識庫輸入知識
知識庫+RAG實現
基于微調
在盡可能保留通用大模型預訓練知識的同時,對其進行針對性垂直領域知識增強改造,微調方法分為:

- 基于適配器的微調
適配器微調是一種在預訓練模型中插入小型可訓練適配器模塊的方法,微調過程中,只有適配器模塊的參數會被更新,預訓練模型原有的參數保持不變。如AdapterFusion、IA3。
- 基于低秩矩陣分解的微調
通過將預訓練模型中的權重矩陣分解為低秩矩陣的乘積來減少需要更新的參數量,微調時保持原有預訓練參數不變,只更新低秩分解矩陣。
a. 低秩適配(LoRA):通過奇異值分解將模型參數分解為低秩矩陣的乘積

b. 自適應低秩適配(AdaLoRA)是LoRA的改進,可以自適應決定哪些層的參數需要更新,通過自適應學習率和任務特定的參數調整策略,是模型能夠根據任務的特定需求自動調整微調的強度和范圍。
c. 低秩Hadamard積微調
d. 低秩Kronecker積微調
- 全參數微調
全參數微調,所需大量的計算資源和較長的訓練時間。
基于預訓練模塊的垂直領域大模型的改造
主要技術是遷移學習,在大模型架構中,模態編碼器、主干運算器和模態解碼器3個模塊承載了大量知識,所以主要對這三個模塊機型改造。
- 基于預訓練的模態編碼器的遷移學習
將預訓練模型的前置特征提取模塊作為預訓練數據的模態編碼器,再在該模塊后對接下游任務模塊即可實現任務需求。有2種實現方式:
- 同一模態遷移不同數據域
需要對源域和目標域數據的特征分布進行對齊,通過對源域的預訓練模態編碼器在目標域上進行微調,使其能適應新數據的特征。
- 遷移到不同模態
采用跨模態遷移,借用其他模態的編碼器來處理新的數據類型。
- 基于預訓練的主干運算器的遷移學習
需要構建相應的前置模塊來將數據編碼為主干運算器能夠處理的特征向量。有兩種方式:
- 遷移單一的預訓練主干運算器
遷移預訓練的模型的主干運算器到垂直領域應用時,需要在有限的領域數據集上進行微調,以適應特定領域的數據特征和任務需求。
- 模塊化組合多個預訓練主干運算器
允許根據任務需求,將多個專門化的預訓練模型整合到一個統一的框架中,即混合專家模型(MOE),使用門控機制和混合策略動態選擇和組合專家模型的輸出。
門控機制根據輸入數據的特征來為每個專家生成一個權重或分數,標識每個專家對當前輸入的重要性。
混合策略是將多個專家的輸出按照一定的策略結合起來,生成最終的輸出,策略比如為平均、加權平均等。
- 基于預訓練的模態解碼器的遷移學習
- 微調預訓練的模態解碼器
通過在特定任務的數據集上進行微調來適應新的任務需求,即對解碼器的最后幾層進行調整,或增加新的層、
- 遷移跨模態生成式的模態解碼器
通過條件編碼器將條件信息編碼為特征向量,然后再與原始數據的特征向量結合,實現條件生成。
無預訓練模塊的垂直領域大模型全架構構建
單模態大模型由模態編碼器、主干運算器和模態解碼器組成。以llama2為例,采用字節對編碼(BPE)算法實現編解碼功能,主干運算器是一個自回歸Transformer模型。實現了”輸入原始文本-輸入文本特征向量-輸出文本特征向量-輸出原始文本“的完整流程。
而多模態大模型還包括輸入投影器和輸出投影器來實現模態對齊。以llama2為例,采用自回歸Transformer作為主干運算器,然后將主干運算器處理后的圖像和音頻特征經過MLP轉換回圖像域,作為控制向量輸入到基于DF架構的生成模型中,得到最終的圖像和文本結果。
所以,大致流程為:
- 構建大模型時首先確定數據模態
- 接著構建相應模塊實現模態編碼器和輸入投影器,將不同模態的原始數據轉換為主干運算器能夠處理的中心模態特征向量
- 隨后涉及輸出投影器和模態解碼器,將主干于是暖其處理后的特征向量轉為各模態的原始數據形式
- 完成模型結構設計后,可開始訓練
構建模態編碼器
編碼器即從數據中提取特征向量的神經網絡,有以下步驟:
- 預處理為合適的數據結構:選擇合適的數據結構,如音頻處理時將時域信號轉為頻譜圖,推薦系統時用圖譜。還需要考慮多種任務輸入之間的適配性。
- 設計網路架構:根據數據結構設計相應的網絡結構,如文本數據用Transformer架構來捕捉長距離依賴關系,圖像數據用CNN架構來提取特征。
- 訓練模態編碼器:使用樣本數量和種類充足的數據集進行預訓練,預訓練方式有:
- 將模態編碼器和模態解碼器組合成自編碼器,以最小化重構誤差為目標進行無監督訓練
- 針對特定任務設計模型,使用該任務的損失函數進行有監督訓練,訓練完成后將模型的上游部分遷移作為模態編碼器
構建輸入投影器
作用是將來自不同模態的數據投影到一個共同的特征空間中,通過”模態對齊“實現,即通過融合編碼器或雙編碼器架構實現,也即采用橋接器策略來整合不同模態的輸入向量,還是通過微調方法使不同模態的投影器互相靠近。
構建主干運算器
作用是對中心模態的特征向量進行理解和生成,構建主干運算器首先選定數據模態,當前主流的Transformer架構,是由解碼器和編碼器構成,【編碼器負責分析輸入數據,提取緊湊的特征標識,解碼器利用特征標識來生成數據,所以編碼器理解能力更強,解碼器生成能力更強】,具體架構分為:
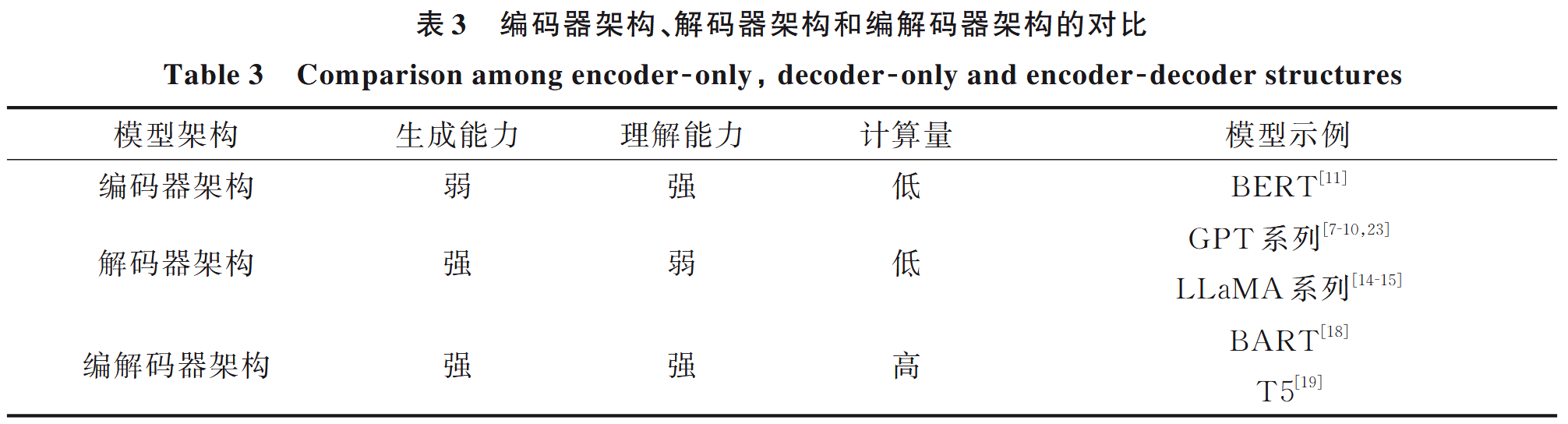
- 基于編碼器架構的主干運算器
通常用于需要理解輸入文本,如文本分析、情感分析等,只能生成固定長度的輸出,生成能力較弱,面對生成任務,主干運算器僅能處理缺失序列補全這種廣義生成任務,如BERT。
- 基于解碼器結構的主干運算器
減少參數量和計算開銷,限制模型長度列處理能力,在生成輸出序列時不需要顯示的上下文表示,而是通過自注意力機制在序列內部自動捕獲信息,該架構通常通過自回歸生成方式,即根據先前的生成內容逐個生成詞或字符,來完成文本生成,如GPT系列和llama等。
- 基于編解碼器架構的主干運算器
導致模型參數量和計算成本較高,如BART、T5等。
構建輸出投影器及模態解碼器
分為生成式和判決式,生成式解碼器在滿足條件信息的前提下,生成高質量的數據樣本,判決式模態解碼器有更精確的恢復能力,側重于根據輸入向量準確重建數據樣本。
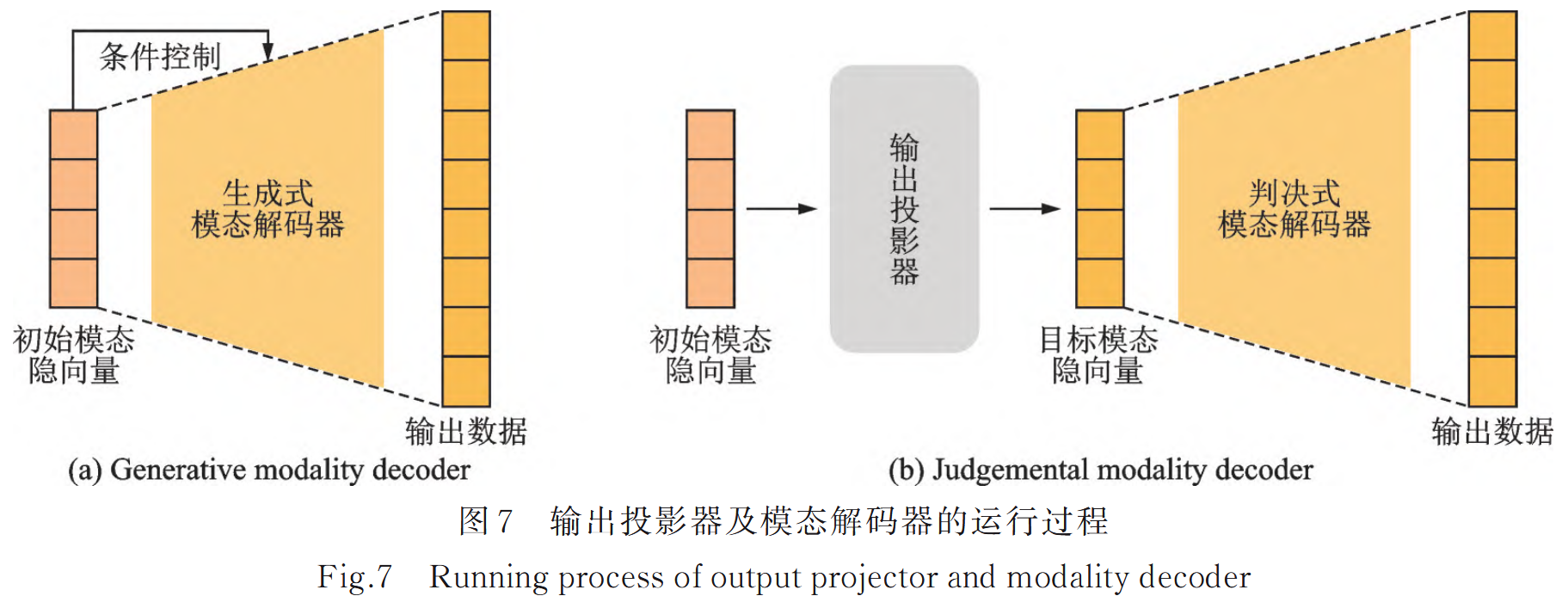
- 生成式模態解碼器
當其他模態的特征向量作為條件信息,將生成的數據作為解碼器輸出時,這類解碼器為生成式模態解碼器。不強制要求構建顯示的輸出投影器,如DiT模型能夠根據前一步的結果和條件向量逐步生成圖像,交叉注意力機制實現了輸出投影器。
生成式模態解碼器通常使用端到端的訓練策略,訓練目標是最小化生成數據與真實數據之間的差異,并確保生成數據滿足給定的條件,以及還可以使用對抗性訓練以提升生成質量。
- 判決式模態解碼器
只負責直接將特征向量恢復成原始數據的形式,需要配合顯式的輸出投影器將其他模態域上的特征向量轉換為目標模態來使用。顯式輸出投影器采用監督學習的訓練方式,即模型接收來自其他模態的特征向量作為輸入,并學習將這些特征投影為目標模態的特征向量,通過最小化兩個向量間的誤差來提升投影準確度。
垂直領域大模型的應用實例
- 通信領域
處理網絡日志數據,優化信號傳輸和調度策略,實現通信網絡內生智能,構建通信大模型。
- 自動駕駛領域
大模型對車輛的感知、決策和規劃。
- 數學推理領域
利用預訓練模型理解和解釋數學工時,利用微調技術對特定數學推理問題進行求解。
- 醫療領域
模擬醫生的診療過程,為患者提供初步醫療咨詢和建議。
- 法律領域
對法律文書進行分析,識別文本中關鍵信息和法律概念,提供精確的案件分析和法律咨詢。
用于案件預測,通過分析歷史案例和相關法律條文,預測案件結果(已有案件,為什么還需預測),為律師制定辯護策略提供數據支撐。
- 藝術領域
輔助、設計或生成藝術作品等。
- 金融領域
構建信用評分系統,預測股市等。
垂直領域大模型定制化發展方向
- 數據方面挑戰
- 特定領域數據獲取昂貴又耗時
- 數據收集的隱私保護
- 多模態理解能力有待提升
- 處理新數據模態
- 構建處理多種模態數據的統一模型
- 模型架構方面挑戰
- 垂直領域大模型構架需要高度模塊化和可定制性
- 模型可解釋性,設計可視化工具展示模型內部工作機制
- 算力方面挑戰
- 輕量化部署
- 分布式訓練和推理
- 安全方面挑戰
- 增強魯棒性
- 開發和部署高效的惡意輸入檢測機制
- 隱私保護即使減少模型對敏感數據的依賴,確保用戶數據安全和隱私
- 工作流程和政策加強
- 安全的模型推理環境:TEE

 浙公網安備 33010602011771號
浙公網安備 33010602011771號