Spark:單詞計(jì)數(shù)(Word Count)的MapReduce實(shí)現(xiàn)(Java/Python)
 我們?cè)谏弦黄┛椭袑W(xué)習(xí)了如何用Hadoop-MapReduce實(shí)現(xiàn)單詞計(jì)數(shù),現(xiàn)在我們來看如何用Spark來實(shí)現(xiàn)同樣的功能。Spark框架也是MapReduce-like模型,采用“分治-聚合”策略來對(duì)數(shù)據(jù)分布進(jìn)行分布并行處理。不過該框架相比Hadoop-MapReduce,具有以下兩個(gè)特點(diǎn):對(duì)大數(shù)據(jù)處理框架的輸入/輸出,中間數(shù)據(jù)進(jìn)行建模,將這些數(shù)據(jù)抽象為統(tǒng)一的數(shù)據(jù)結(jié)構(gòu)命名為彈性分布式數(shù)據(jù)集。
我們?cè)谏弦黄┛椭袑W(xué)習(xí)了如何用Hadoop-MapReduce實(shí)現(xiàn)單詞計(jì)數(shù),現(xiàn)在我們來看如何用Spark來實(shí)現(xiàn)同樣的功能。Spark框架也是MapReduce-like模型,采用“分治-聚合”策略來對(duì)數(shù)據(jù)分布進(jìn)行分布并行處理。不過該框架相比Hadoop-MapReduce,具有以下兩個(gè)特點(diǎn):對(duì)大數(shù)據(jù)處理框架的輸入/輸出,中間數(shù)據(jù)進(jìn)行建模,將這些數(shù)據(jù)抽象為統(tǒng)一的數(shù)據(jù)結(jié)構(gòu)命名為彈性分布式數(shù)據(jù)集。
1 導(dǎo)引
我們?cè)诓┛?a href="http://www.rzrgm.cn/orion-orion/p/16306899.html" target="_blank">《Hadoop: 單詞計(jì)數(shù)(Word Count)的MapReduce實(shí)現(xiàn) 》中學(xué)習(xí)了如何用Hadoop-MapReduce實(shí)現(xiàn)單詞計(jì)數(shù),現(xiàn)在我們來看如何用Spark來實(shí)現(xiàn)同樣的功能。
2. Spark的MapReudce原理
Spark框架也是MapReduce-like模型,采用“分治-聚合”策略來對(duì)數(shù)據(jù)分布進(jìn)行分布并行處理。不過該框架相比Hadoop-MapReduce,具有以下兩個(gè)特點(diǎn):
-
對(duì)大數(shù)據(jù)處理框架的輸入/輸出,中間數(shù)據(jù)進(jìn)行建模,將這些數(shù)據(jù)抽象為統(tǒng)一的數(shù)據(jù)結(jié)構(gòu)命名為彈性分布式數(shù)據(jù)集(Resilient Distributed Dataset),并在此數(shù)據(jù)結(jié)構(gòu)上構(gòu)建了一系列通用的數(shù)據(jù)操作,使得用戶可以簡單地實(shí)現(xiàn)復(fù)雜的數(shù)據(jù)處理流程。
-
采用了基于內(nèi)存的數(shù)據(jù)聚合、數(shù)據(jù)緩存等機(jī)制來加速應(yīng)用執(zhí)行尤其適用于迭代和交互式應(yīng)用。
Spark社區(qū)推薦用戶使用Dataset、DataFrame等面向結(jié)構(gòu)化數(shù)據(jù)的高層API(Structured API)來替代底層的RDD API,因?yàn)檫@些高層API含有更多的數(shù)據(jù)類型信息(Schema),支持SQL操作,并且可以利用經(jīng)過高度優(yōu)化的Spark SQL引擎來執(zhí)行。不過,由于RDD API更基礎(chǔ),更適合用來展示基本概念和原理,后面我們的代碼都使用RDD API。
Spark的RDD/dataset分為多個(gè)分區(qū)。RDD/Dataset的每一個(gè)分區(qū)都映射一個(gè)或多個(gè)數(shù)據(jù)文件, Spark通過該映射讀取數(shù)據(jù)輸入到RDD/dataset中。
因?yàn)槲覀冞@里采用的本地單機(jī)多線程調(diào)試模式,默認(rèn)分區(qū)數(shù)即為本地機(jī)器使用的線程數(shù),若在代碼中設(shè)置了local[N](使用N個(gè)線程),則默認(rèn)為N個(gè)分區(qū);若設(shè)為local[*](使用本地CPU核數(shù)個(gè)線程),則默認(rèn)分區(qū)數(shù)為本地CPU核數(shù)。大家可以通過調(diào)用RDD對(duì)象的getNumPartitions()查看實(shí)際分區(qū)個(gè)數(shù)。
我們下面的流程描述中,假設(shè)每個(gè)文件對(duì)應(yīng)一個(gè)分區(qū)。
Spark的Map示意圖如下:
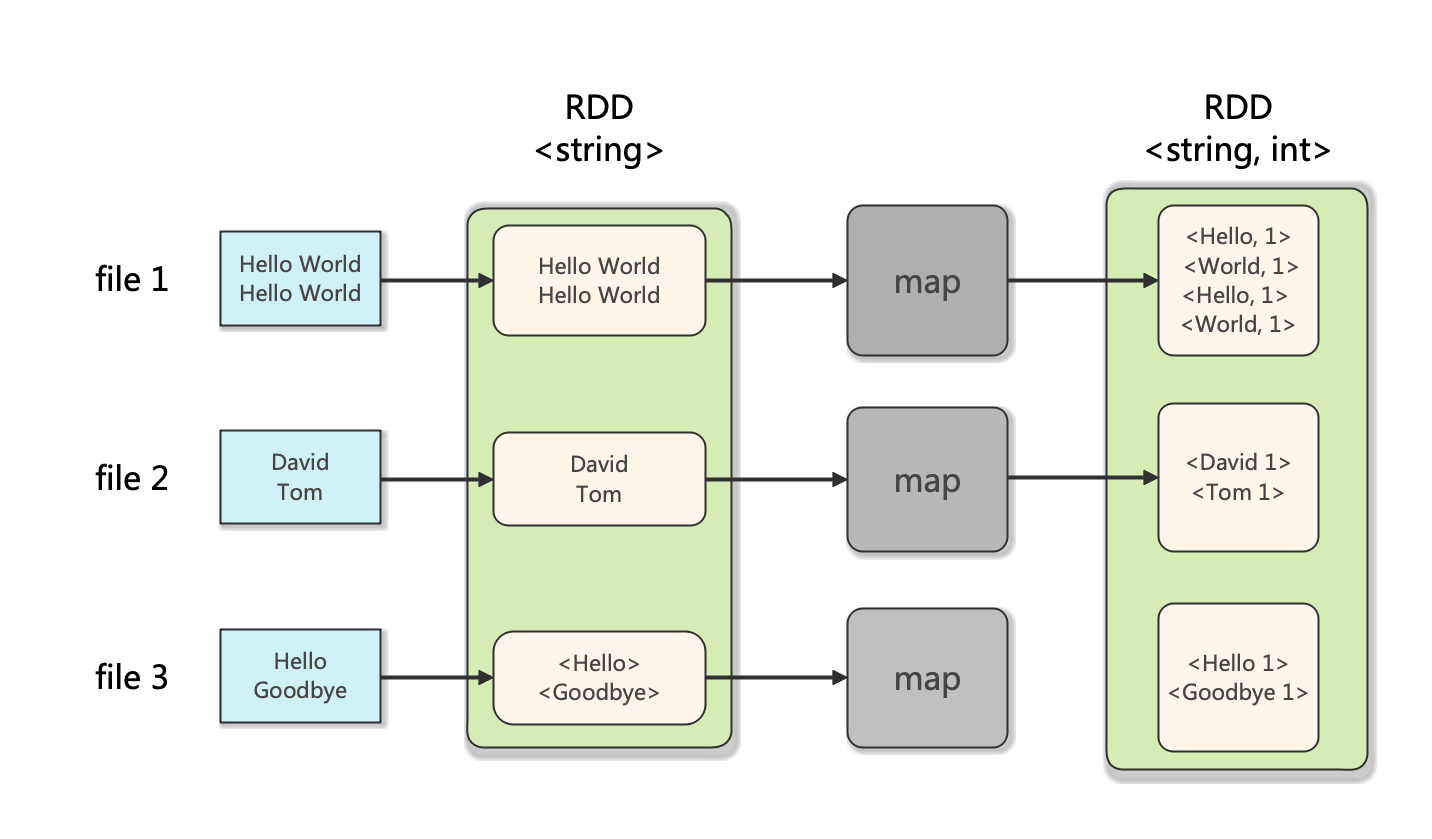
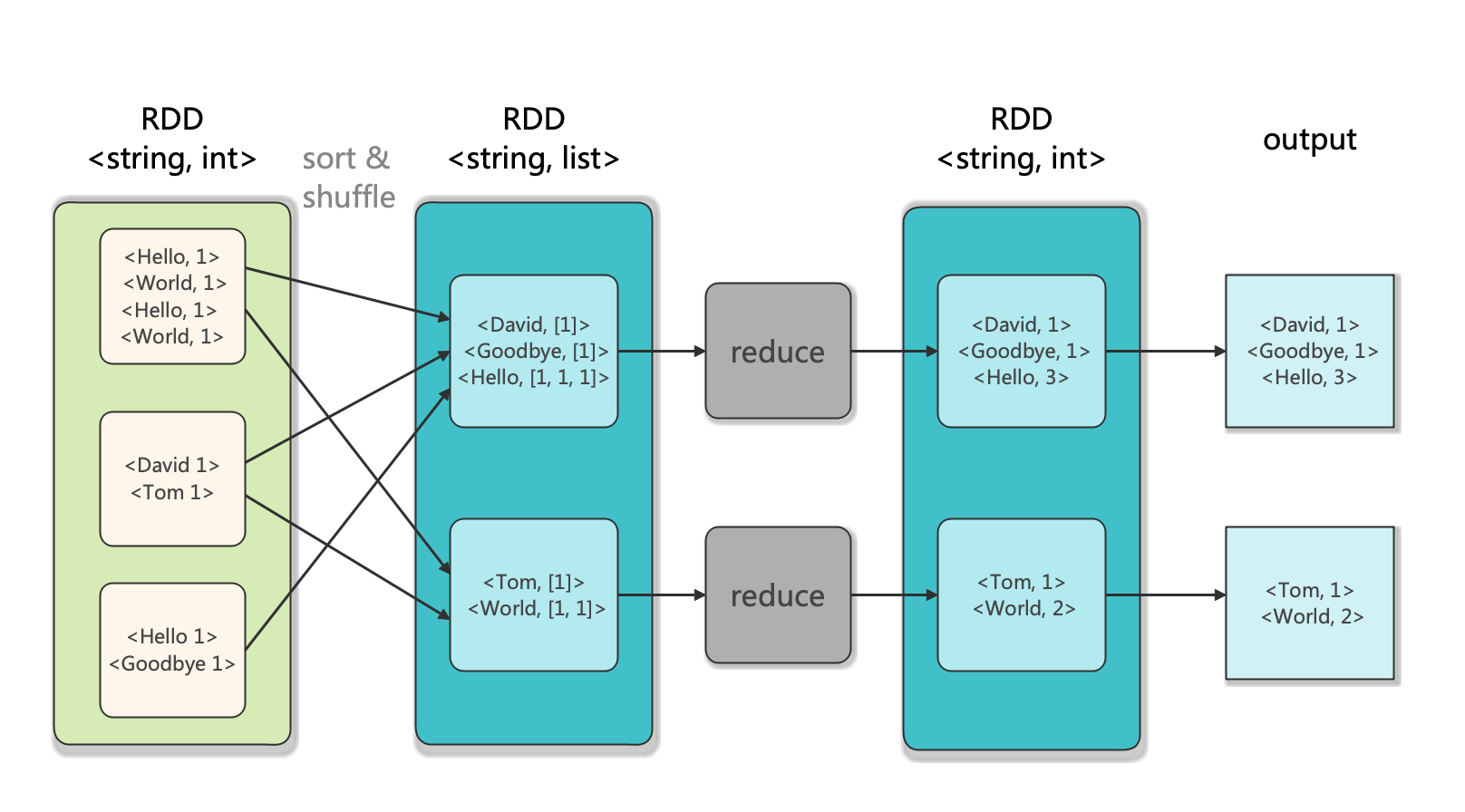
Spark的Reduce示意圖如下:
3. Word Count的Java實(shí)現(xiàn)
項(xiàng)目架構(gòu)如下圖:
Word-Count-Spark
├─ input
│ ├─ file1.txt
│ ├─ file2.txt
│ └─ file3.txt
├─ output
│ └─ result.txt
├─ pom.xml
├─ src
│ ├─ main
│ │ └─ java
│ │ └─ WordCount.java
│ └─ test
└─ target
WordCount.java文件如下:
package com.orion;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
import java.io.*;
import java.nio.file.*;
public class WordCount {
private static Pattern SPACE = Pattern.compile(" ");
public static void main(String[] args) throws Exception {
if (args.length != 3) {
System.err.println("Usage: WordCount <intput directory> <output directory> <number of local threads>");
System.exit(1);
}
String input_path = args[0];
String output_path = args[1];
int n_threads = Integer.parseInt(args[2]);
SparkSession spark = SparkSession.builder()
.appName("WordCount")
.master(String.format("local[%d]", n_threads))
.getOrCreate();
JavaRDD<String> lines = spark.read().textFile(input_path).javaRDD();
JavaRDD<String> words = lines.flatMap(s -> Arrays.asList(SPACE.split(s)).iterator());
JavaPairRDD<String, Integer> ones = words.mapToPair(s -> new Tuple2<>(s, 1));
JavaPairRDD<String, Integer> counts = ones.reduceByKey((i1, i2) -> i1 + i2);
List<Tuple2<String, Integer>> output = counts.collect();
String filePath = Paths.get(output_path, "result.txt").toString();
BufferedWriter out = new BufferedWriter(new FileWriter(filePath));
for (Tuple2<?, ?> tuple : output) {
out.write(tuple._1() + ": " + tuple._2() + "\n");
}
out.close();
spark.stop();
}
}
pom.xml文件配置如下:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.WordCount</groupId>
<artifactId>WordCount</artifactId>
<version>1.0-SNAPSHOT</version>
<name>WordCount</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<!-- 集中定義版本號(hào) -->
<properties>
<scala.version>2.12.10</scala.version>
<scala.compat.version>2.12</scala.compat.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<project.timezone>UTC</project.timezone>
<java.version>11</java.version>
<scoverage.plugin.version>1.4.0</scoverage.plugin.version>
<site.plugin.version>3.7.1</site.plugin.version>
<scalatest.version>3.1.2</scalatest.version>
<scalatest-maven-plugin>2.0.0</scalatest-maven-plugin>
<scala.maven.plugin.version>4.4.0</scala.maven.plugin.version>
<maven.compiler.plugin.version>3.8.0</maven.compiler.plugin.version>
<maven.javadoc.plugin.version>3.2.0</maven.javadoc.plugin.version>
<maven.source.plugin.version>3.2.1</maven.source.plugin.version>
<maven.deploy.plugin.version>2.8.2</maven.deploy.plugin.version>
<nexus.staging.maven.plugin.version>1.6.8</nexus.staging.maven.plugin.version>
<maven.help.plugin.version>3.2.0</maven.help.plugin.version>
<maven.gpg.plugin.version>1.6</maven.gpg.plugin.version>
<maven.surefire.plugin.version>2.22.2</maven.surefire.plugin.version>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>11</maven.compiler.source>
<maven.compiler.target>11</maven.compiler.target>
<spark.version>3.2.1</spark.version>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<!--======SCALA======-->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
<scope>provided</scope>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.spark/spark-core -->
<dependency> <!-- Spark dependency -->
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>${spark.version}</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<pluginManagement><!-- lock down plugins versions to avoid using Maven defaults (may be moved to parent pom) -->
<plugins>
<!-- clean lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#clean_Lifecycle -->
<plugin>
<artifactId>maven-clean-plugin</artifactId>
<version>3.1.0</version>
</plugin>
<!-- default lifecycle, jar packaging: see https://maven.apache.org/ref/current/maven-core/default-bindings.html#Plugin_bindings_for_jar_packaging -->
<plugin>
<artifactId>maven-resources-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
</plugin>
<plugin>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.22.1</version>
</plugin>
<plugin>
<artifactId>maven-jar-plugin</artifactId>
<version>3.0.2</version>
</plugin>
<plugin>
<artifactId>maven-install-plugin</artifactId>
<version>2.5.2</version>
</plugin>
<plugin>
<artifactId>maven-deploy-plugin</artifactId>
<version>2.8.2</version>
</plugin>
<!-- site lifecycle, see https://maven.apache.org/ref/current/maven-core/lifecycles.html#site_Lifecycle -->
<plugin>
<artifactId>maven-site-plugin</artifactId>
<version>3.7.1</version>
</plugin>
<plugin>
<artifactId>maven-project-info-reports-plugin</artifactId>
<version>3.0.0</version>
</plugin>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.8.0</version>
<configuration>
<source>11</source>
<target>11</target>
<fork>true</fork>
<executable>/Library/Java/JavaVirtualMachines/jdk-11.0.15.jdk/Contents/Home/bin/javac</executable>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
記得配置輸入?yún)?shù)input、output、3分別代表輸入目錄、輸出目錄和使用本地線程數(shù)(在VSCode中在launch.json文件中配置)。編譯運(yùn)行后可在output目錄下查看result.txt:
Tom: 1
Hello: 3
Goodbye: 1
World: 2
David: 1
可見成功完成了單詞計(jì)數(shù)功能。
4. Word Count的Python實(shí)現(xiàn)
先使用pip按照pyspark==3.8.2:
pip install pyspark==3.8.2
注意PySpark只支持Java 8/11,請(qǐng)勿使用更高級(jí)的版本。這里我使用的是Java 11。運(yùn)行java -version可查看本機(jī)Java版本。
(base) orion-orion@MacBook-Pro ~ % java -version
java version "11.0.15" 2022-04-19 LTS
Java(TM) SE Runtime Environment 18.9 (build 11.0.15+8-LTS-149)
Java HotSpot(TM) 64-Bit Server VM 18.9 (build 11.0.15+8-LTS-149, mixed mode)
項(xiàng)目架構(gòu)如下:
Word-Count-Spark
├─ input
│ ├─ file1.txt
│ ├─ file2.txt
│ └─ file3.txt
├─ output
│ └─ result.txt
├─ src
│ └─ word_count.py
word_count.py編寫如下:
from pyspark.sql import SparkSession
import sys
import os
from operator import add
if len(sys.argv) != 4:
print("Usage: WordCount <intput directory> <output directory> <number of local threads>", file=sys.stderr)
exit(1)
input_path, output_path, n_threads = sys.argv[1], sys.argv[2], int(sys.argv[3])
spark = SparkSession.builder.appName("WordCount").master("local[%d]" % n_threads).getOrCreate()
lines = spark.read.text(input_path).rdd.map(lambda r: r[0])
counts = lines.flatMap(lambda s: s.split(" "))\
.map(lambda word: (word, 1))\
.reduceByKey(add)
output = counts.collect()
with open(os.path.join(output_path, "result.txt"), "wt") as f:
for (word, count) in output:
f.write(str(word) +": " + str(count) + "\n")
spark.stop()
使用python word_count.py input output 3運(yùn)行后,可在output中查看對(duì)應(yīng)的輸出文件result.txt:
Hello: 3
World: 2
Goodbye: 1
David: 1
Tom: 1
可見成功完成了單詞計(jì)數(shù)功能。
參考
- [1] Spark官方文檔: Quick Start
- [2] 許利杰,方亞芬. 大數(shù)據(jù)處理框架Apache Spark設(shè)計(jì)與實(shí)現(xiàn)[M]. 電子工業(yè)出版社, 2021.
- [3] GiHub: Spark官方Java樣例
- [4] similarface: Spark數(shù)據(jù)分區(qū)數(shù)量的原理

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)