

1.用圖與自己的話,簡要描述Hadoop起源與發展階段。
從與谷歌系統的關系,關鍵時間節點,1.x,2.x與3.x的區別,不同公司發行版本等方面來講。
Hadoop起源于Nutch,是Lucene的子項目。以谷歌發表的為解決數十億網頁的存儲和索引問題提供了可行的解決方案的論文為基礎,Nutch的開發人員完成了相應的開源實現谷歌分布式文件系統(GFS)的架構(03年)、MapReduce系統(04年)、HDFS(04年),并從Nutch中剝離成為獨立項目Hadoop。06年Google發表了關于BigTable的論文,促使了后來的Hbase的發展。因此,Hadoop及其生態圈的發展離不開Google的貢獻。
1.不同版本的區別
- 1.x版本系列:hadoop版本當中的第二代開源版本,主要修復0.x版本的一些bug等,該版本已被淘汰
- 2.x版本系列:架構產生重大變化,引入了yarn平臺等許多新特性,是現在使用的主流版本。
- 3.x版本系列:對HDFS、MapReduce、YARN都有較大升級,還新增了Ozone key-value存儲。
2.社區版本
一、免費開源版本Apache:
優點:擁有全世界的開源貢獻者,代碼更新迭代版本比較快,
缺點:版本的升級,版本的維護,版本的兼容性,版本的補丁都可能考慮不太周到
二、免費開源版本HortonWorks:
hortonworks核心產品軟件HDP(ambari),HDF免費開源,提供一整套的web管理界面,供我們可以通過web界面管理我們的集群狀態,2018年,大數據領域的兩大巨頭公司Cloudera和Hortonworks宣布平等合并。
三、軟件收費版本Cloudera:
cloudera主要是美國一家大數據公司在apache開源hadoop的版本上,通過自己公司內部的各種補丁,實現版本之間的穩定運行,大數據生態圈的各個版本的軟件都提供了對應的版本,解決了版本的升級困難,版本兼容性等各種問題。
2.用圖與自己的話,簡要描述名稱節點、數據節點的主要功能及相互關系、名稱節點的工作機制。
①名稱節點的主要功能:負責管理分布式文件系統的命名空間。
②數據節點的主要功能:負責數據的存儲和讀取。
③名稱節點與數據節點的相互關系:名稱節點在系統每次啟動時掃描數據節點重構得到信息,數據節點向名稱節點定期發送自己所存儲的塊的列表。
④名稱節點工作機制:
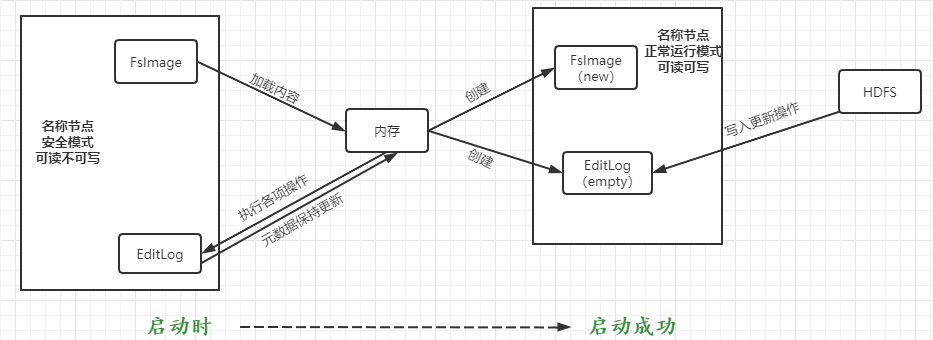
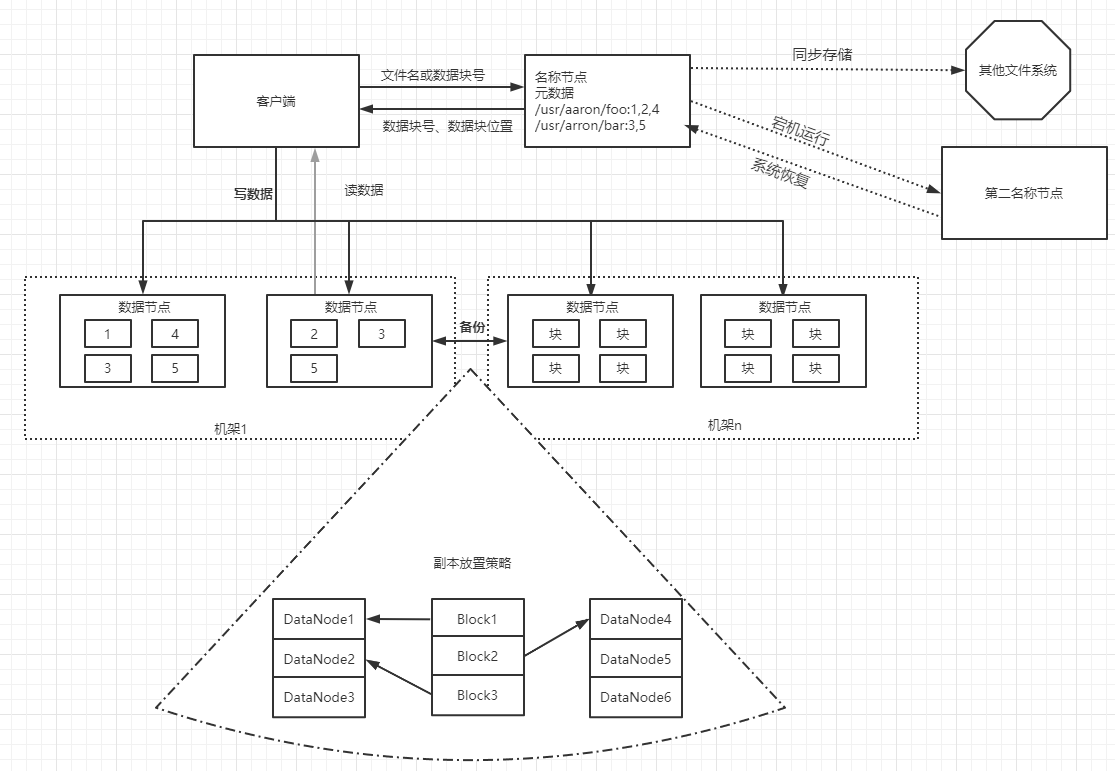
3.分別從以下這些方面,梳理清楚HDFS的 結構與運行流程,以圖的形式描述。
- 客戶端與HDFS
- 客戶端讀
- 客戶端寫
- 數據節點與集群
- 數據節點與名稱節點
- 名稱節點與第二名稱節點
- 數據節點與數據節點
- 數據冗余
- 數據存取策略
- 數據錯誤與恢復
4.簡述HBase與傳統數據庫的主要區別
主要體現在以下幾個方面:
(1)數據類型。傳統數據庫采用關系模型,具有豐富的數據類型和儲存方式,HBase則采用了更加簡單的數據模型。
(2)Hbase無法實現像傳統數據庫中那樣的表與表之間的連接操作。
(3)傳統數據庫是基于行模式存儲的,基于行模式存儲就會浪費許多磁盤空間和內存帶寬。HBase是基于列存儲的,可以獲得較高的數據壓縮比。
(4)傳統數據庫通常可以針對不同列構建復雜的多個索引,以提高數據訪問性能。與關系數據庫不同的是,HBase只有一個索引——行鍵,由于HBase位于Hadoop框架之上,因此可以使用Hadoop MapReduce來快速、高效地生成索引表。
(5)在傳統數據庫中,更新操作會用最新的當前值去替換記錄中原來的舊值,舊值被覆蓋后就不會存在。而在HBase中執行更新操作時,并不會刪除數據舊的版本,而是生成一個新的版本,舊有的版本仍舊保留。
(6)傳統數據庫很難實現橫向擴展,縱向擴展的空間也比較有限。相反,HBase能夠輕易地通過在集群中增加或者減少硬件數量來實現性能的伸縮。
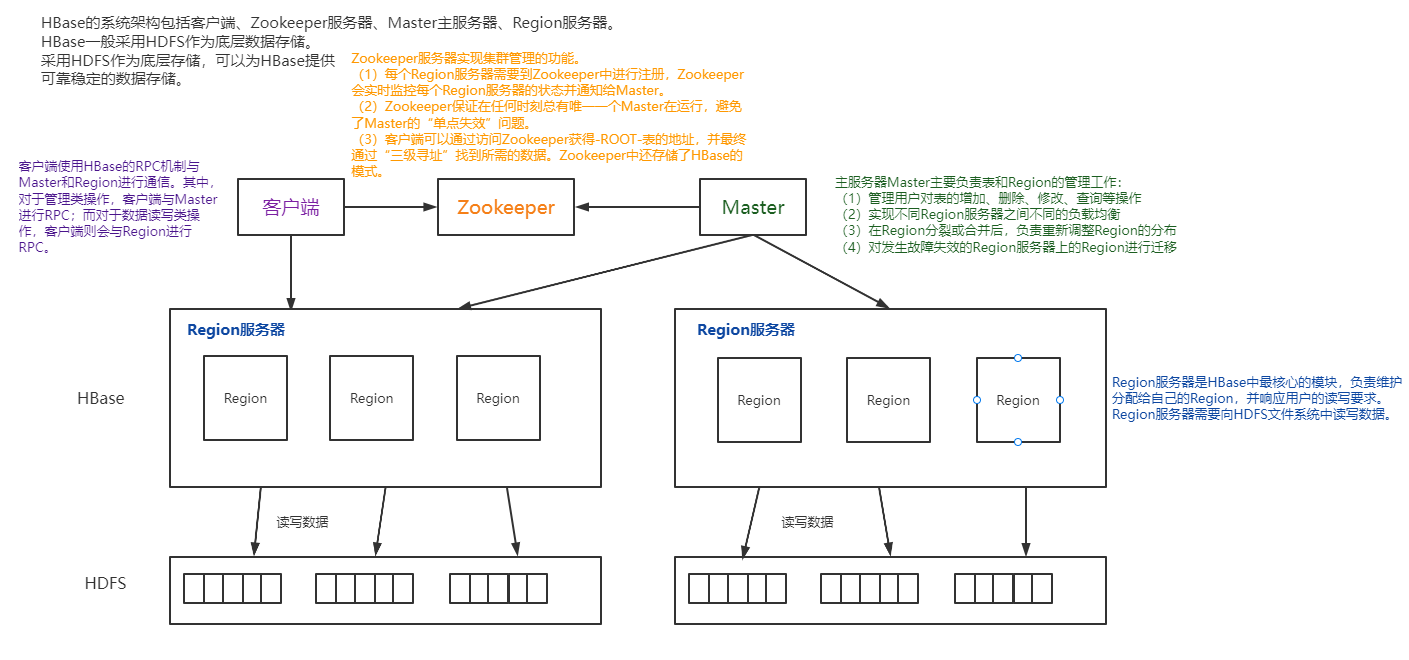
5.梳理HBase的結構與運行流程,以用圖與自己的話進行簡要描述,圖中包括以下內容:
- Master主服務器的功能
- Region服務器的功能
- Zookeeper協同的功能
- Client客戶端的請求流程
- 四者之間的相系關系
- 與HDFS的關聯

 浙公網安備 33010602011771號
浙公網安備 33010602011771號