

3123004548軟件工程個(gè)人項(xiàng)目
| 這個(gè)作業(yè)屬于哪個(gè)課程 | <https://edu.cnblogs.com/campus/gdgy/SoftwareEngineering2024> |
|---|---|
| 這個(gè)作業(yè)要求在哪里 | https://edu.cnblogs.com/campus/gdgy/Class34Grade23ComputerScience/homework/13477 |
| 這個(gè)作業(yè)的目標(biāo) | <設(shè)計(jì)一個(gè)能處理長文本的論文查重算法> |
聲明:本算法實(shí)現(xiàn)的測試環(huán)境為python 3.11
GitHub鏈接:https://github.com/Ascrio/3123004548
PSP表格相關(guān)記錄
| PSP2 1 | Personal Software Process Stages | 預(yù)估耗時(shí)(分鐘) | 實(shí)際耗時(shí)(分鐘) |
|---|---|---|---|
| Planning | 計(jì)劃 | 15 | 10 |
| Estimate | 估計(jì)這個(gè)任務(wù)需要多少時(shí)間 | 330 | 355 |
| Development | 開發(fā) | 15 | 15 |
| Analysis | 需求分析(包括學(xué)習(xí)新技術(shù)) | 30 | 30 |
| Design Spec | 生成設(shè)計(jì)文檔 | 10 | 10 |
| Design Review | 設(shè)計(jì)復(fù)審 | 15 | 15 |
| Coding Standard | 代碼規(guī)范(為目前的開發(fā)制定合適的規(guī)范) | 10 | 20 |
| Design | 具體設(shè)計(jì) | 30 | 50 |
| Coding | 具體編碼 | 120 | 100 |
| Code Review | 代碼復(fù)審 | 5 | 10 |
| Test | 測試(自我測試,修改代碼,提交修改) | 15 | 30 |
| Reporting | 報(bào)告 | 15 | 10 |
| Test Report | 測試報(bào)告 | 15 | 10 |
| Size Measurement | 計(jì)算工作量 | 20 | 25 |
| Postmortem & Process Improvement Plan | 事后總結(jié),并提出過程改進(jìn)計(jì)劃 | 15 | 20 |
模塊接口的設(shè)計(jì)與實(shí)現(xiàn)過程
設(shè)計(jì)概述
采用基于余弦相似度算法的詞袋模型,設(shè)計(jì)了該論文查重功能,并通過DocumentComparator類來封裝整個(gè)查重算法功能,并采用面向?qū)ο蟮姆绞浇M織代碼,確保模塊化和可維護(hù)性
函數(shù)設(shè)計(jì)以及調(diào)用模塊展示
核心函數(shù)DocumentComparator類包括以下函數(shù)
1._ init _():初始化jieba分詞器
2.fetch_document_data(): 讀取文檔內(nèi)容
3.process_content(): 對內(nèi)容進(jìn)行分詞和預(yù)處理,同時(shí)構(gòu)建詞匯表
4.compute_document_similarity(): 余弦相似度算法計(jì)算兩個(gè)文檔的相似度
5.execute_comparison(): 執(zhí)行完整的比較流程
輔助函數(shù)primary_function()則負(fù)責(zé)處理命令行參數(shù)和程序流程
各函數(shù)之間調(diào)用模塊關(guān)系如下

算法設(shè)計(jì)與流程展示
1.對指定的文本進(jìn)行jieba分詞器處理,將文本處理成詞語序列,同時(shí)過濾處理文本中出現(xiàn)的符號
2.讀取源文檔和目標(biāo)文檔,并對兩個(gè)文檔進(jìn)行分詞和過濾處理
3.使用gensim構(gòu)建詞袋模型(Bag-of-Words Model)
4.計(jì)算文本余弦相似度,并將結(jié)果標(biāo)準(zhǔn)化到[0,1]范圍
5.輸出結(jié)果至文件
核心函數(shù)DocumentComparator 流程圖如下
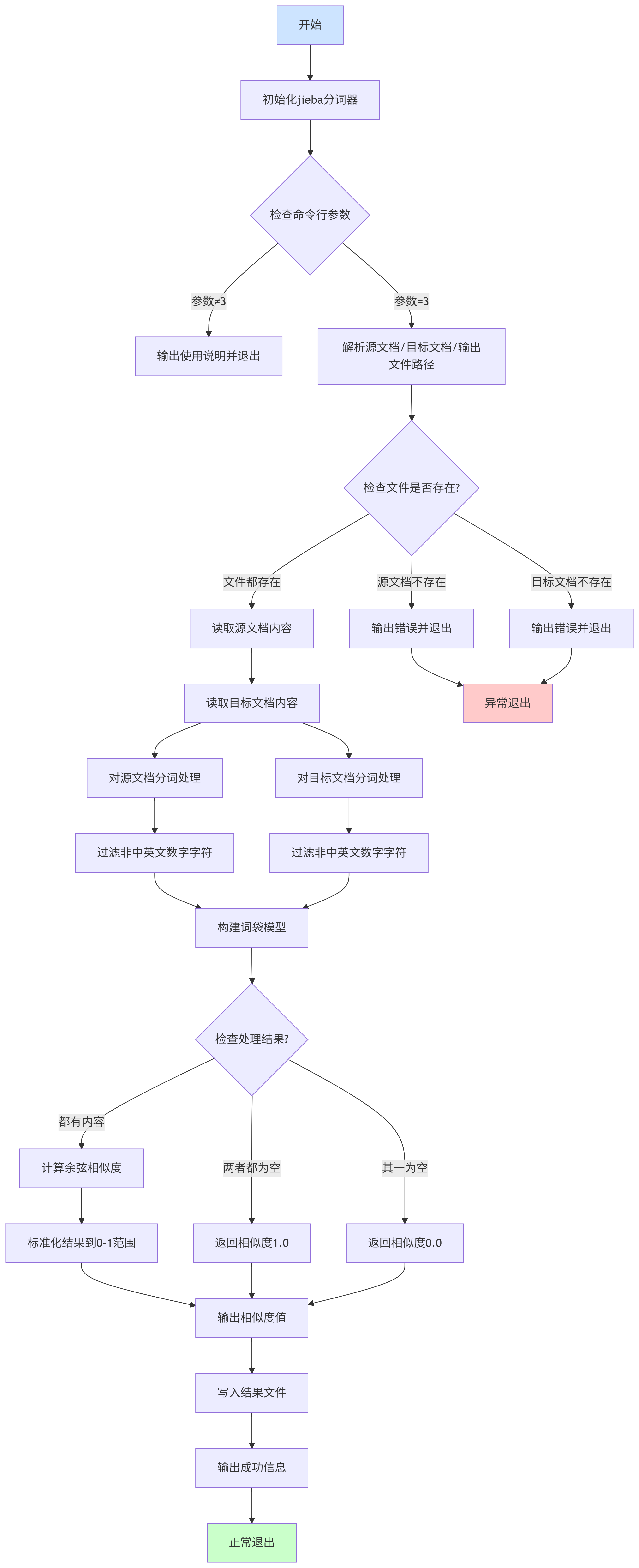
算法的關(guān)鍵點(diǎn)在于文本分詞以及詞袋模型的構(gòu)建,文本分詞為文檔轉(zhuǎn)換成詞頻向量做了鋪墊,而詞袋模型的構(gòu)建是文本查重算法實(shí)現(xiàn)的基礎(chǔ)核心
該算法實(shí)現(xiàn)簡單,無需復(fù)雜的語義分析,適合處理大量文檔,且對詞序不敏感能夠?qū)崿F(xiàn)檢測內(nèi)容重復(fù)而非結(jié)構(gòu)化抄襲,同時(shí)不依賴詞典庫
模塊接口的性能改進(jìn)
最初代碼采用基于給定停用詞列表的simhash算法,經(jīng)運(yùn)行后得出性能分析圖如下
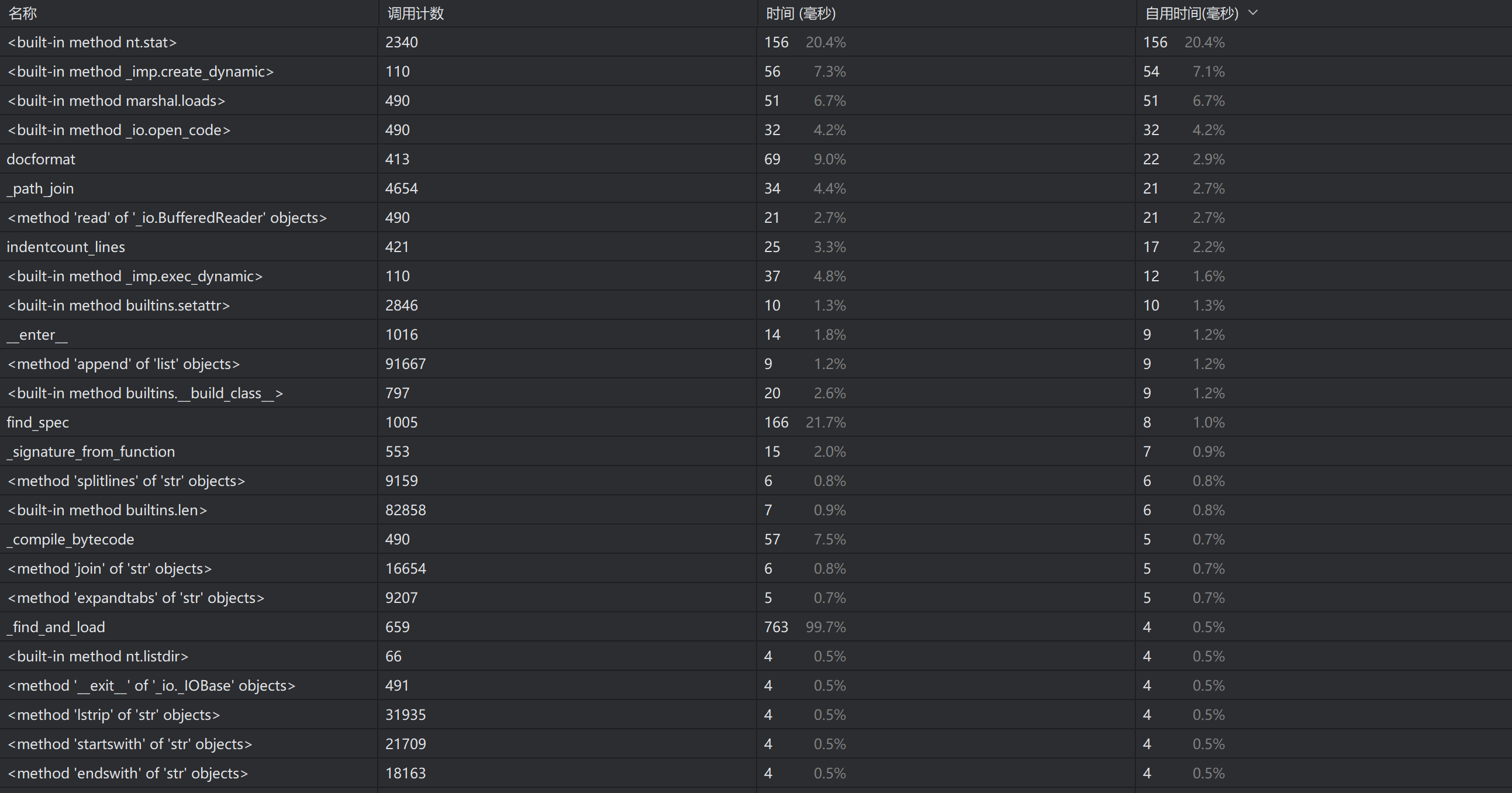
后經(jīng)研究發(fā)現(xiàn),代碼對停用詞列表高度依賴且算法因?yàn)榉磸?fù)查看停用詞導(dǎo)致算法的時(shí)間成本耗費(fèi)很大,同時(shí)存在多處函數(shù)開銷極大的情況(如_find_and_load函數(shù))
同時(shí),該算法存在無法區(qū)分差距較大的文本,導(dǎo)致即使文本完全不同,也有50%以上的相似度,如下圖所示

經(jīng)過代碼改進(jìn),性能圖如下

可見,函數(shù)平均時(shí)間耗費(fèi)有所降低,且函數(shù)利用得到有效提升
同時(shí),對于差異較大的文本,該算法能夠完全區(qū)分并且以此給出較低的相似度
 、
、
在改進(jìn)版的算法中,雖然消耗最大的函數(shù)依舊為_find_and_load函數(shù),但是函數(shù)的平均開銷相比前者有所降低,性能得到一定改進(jìn)
運(yùn)行結(jié)果展示
如下展示兩個(gè)相似文本orig.txt和orig_0.8_add.txt的運(yùn)行結(jié)果
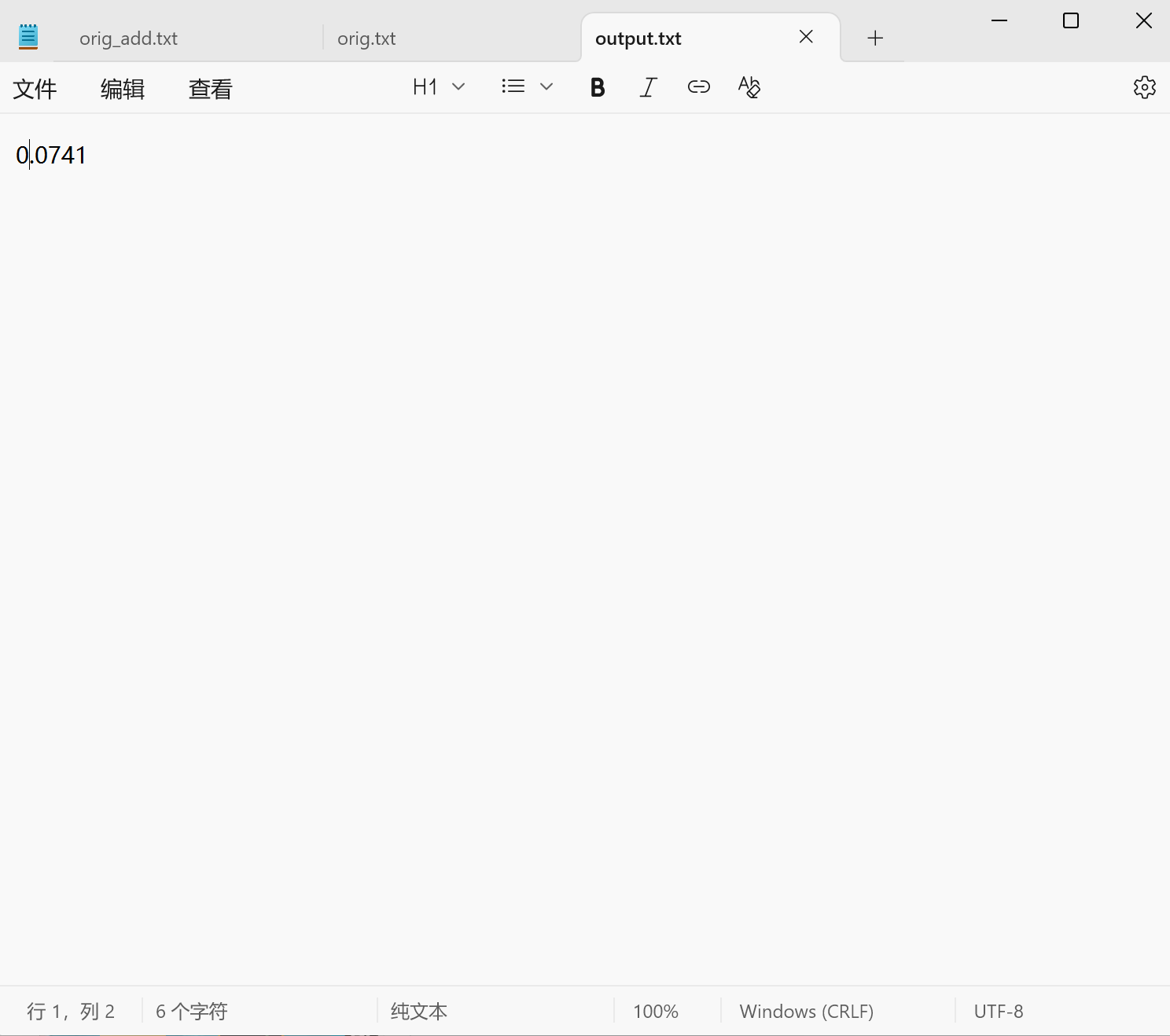
將兩個(gè)文本的路徑代入后,輸入兩個(gè)txt文件的路徑,顯示運(yùn)行結(jié)果圖如下

顯示結(jié)果為99.17%,符合結(jié)果預(yù)期
模塊部分單元測試展示
為了測試代碼穩(wěn)定性,設(shè)計(jì)了18處測試代碼paperchecker.py,經(jīng)測試改進(jìn)代碼已全部通過
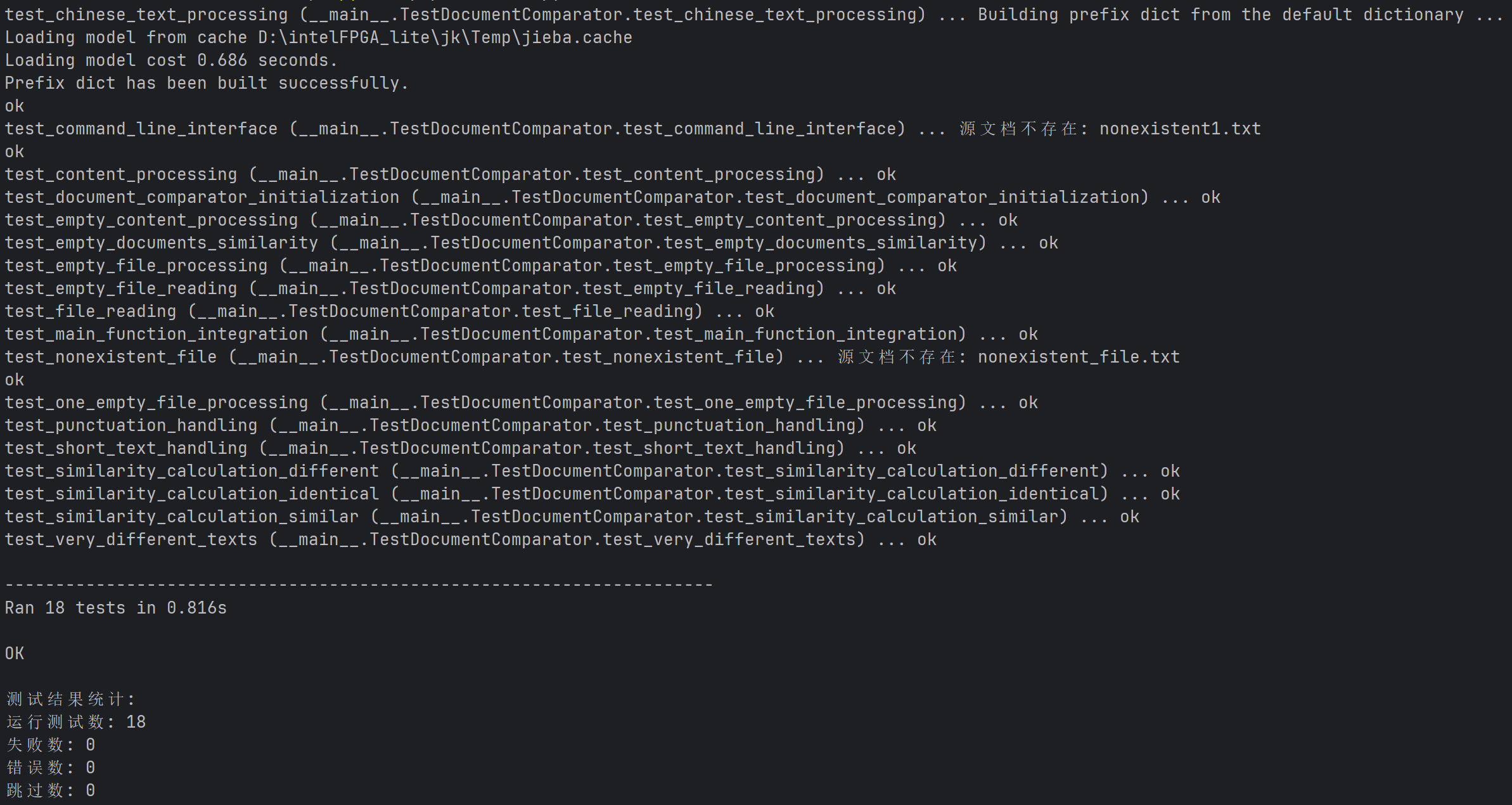
考慮篇幅限制,此處僅展示3處測試代碼
測試一:對于完全相同的文本,相似度應(yīng)為1
def test_similarity_calculation_identical(self):
text1 = "這是一個(gè)完全相同的測試文本"
text2 = "這是一個(gè)完全相同的測試文本"
processed1 = self.comparator.process_content(text1)
processed2 = self.comparator.process_content(text2)
similarity = self.comparator.compute_document_similarity(processed1, processed2)
self.assertAlmostEqual(similarity, 1.0, delta=0.1)
測試二:對于完全不同的文本,相似度應(yīng)小于0.4
def test_similarity_calculation_different(self):
text1 = "這是第一個(gè)測試文本,關(guān)于人工智能和機(jī)器學(xué)習(xí)"
text2 = "恐懼是生物的本能,勇氣是人類的贊歌"
processed1 = self.comparator.process_content(text1)
processed2 = self.comparator.process_content(text2)
similarity = self.comparator.compute_document_similarity(processed1, processed2)
self.assertLess(similarity, 0.4)
測試三:對于一個(gè)有文本的文件和一個(gè)沒有文本的文件,相似度應(yīng)為0
def test_one_empty_file_processing(self):
content = "這是一個(gè)有內(nèi)容的文件"
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as f:
f.write(content)
temp_file1 = f.name
with tempfile.NamedTemporaryFile(mode='w', delete=False, encoding='utf-8') as f:
temp_file2 = f.name
processed1 = self.comparator.process_content(content)
processed2 = self.comparator.process_content("")
similarity = self.comparator.compute_document_similarity(processed1, processed2)
self.assertEqual(similarity, 0.0)
os.unlink(temp_file1)
os.unlink(temp_file2)
測試結(jié)束后,以覆蓋率(pycharm自帶功能)運(yùn)行代碼,結(jié)果如下圖所示

模塊部分異常處理說明
異常一:文檔讀取階段異常
目標(biāo):當(dāng)用戶傳入的文檔路徑無效(如文件不存在、無權(quán)限、編碼錯(cuò)誤等),避免程序因 FileNotFoundError、UnicodeDecodeError等異常而中斷
處理方式:使用 try-except捕獲所有可能的讀取異常,打印具體錯(cuò)誤信息,并返回空字符串 ""作為兜底內(nèi)容
def fetch_document_data(self, document_location):
try:
with open(document_location, 'r', encoding='UTF-8') as file_obj:
return file_obj.read()
except Exception as error:
print(f"文檔讀取異常 {document_location}: {error}")
return ""
對應(yīng)代碼測試片段如下
class TestDocumentFetcher(unittest.TestCase):
def test_fetch_nonexistent_file(self):
comparator = DocumentComparator()
result = comparator.fetch_document_data("dummy_nonexistent_file_12345.txt")
self.assertEqual(result, "") # 應(yīng)返回空字符串
異常二:內(nèi)容處理階段異常
目標(biāo):對讀取到的原始內(nèi)容進(jìn)行分詞和過濾,但如果傳入的內(nèi)容為空(比如上個(gè)階段讀取失敗返回了 ""),則直接返回空列表,避免后續(xù)處理出錯(cuò)。
處理方式??:首先判斷 content_data是否為空,如果是,則返回空列表 [],而不是繼續(xù)分詞。
def process_content(self, content_data):
if not content_data: # 處理空字符串(包括空文件)
return []
segmented_data = jieba.lcut(content_data)
filtered_result = []
for segment in segmented_data:
if re.match(r"[a-zA-Z0-9\u4e00-\u9fa5]", segment): # 保留中/英文字符和數(shù)字
filtered_result.append(segment)
return filtered_result
對應(yīng)代碼測試片段如下
def test_process_empty_content(self):
comparator = DocumentComparator()
result = comparator.process_content("")
self.assertEqual(result, []) # 空內(nèi)容應(yīng)返回空列表
模型改進(jìn)建議及使用說明
模型改進(jìn)建議
該模型存在以下局限性
1.對于短文本且近義詞占比較多的相似文本,算法難以區(qū)分其相似度并會給出低于期望的相似度
2.難以區(qū)分極少數(shù)可能存在前后文關(guān)系的亦或是語序關(guān)系的文本
基于該局限性,給出如下可能改進(jìn)方向
1.引入新模型,考慮詞匯序列等信息
2.結(jié)合語義向量,使用深度學(xué)習(xí)模型
使用說明
main.py
運(yùn)行時(shí),用戶需往命令行里輸入對應(yīng)格式
python main.py [原文文件路徑] [抄襲版論文的文件路徑] [答案文件路徑]

輸入后,函數(shù)將輸出結(jié)果至答案txt文件中
paperchecker.py
運(yùn)行時(shí),需確保main.py文件存在且包含DocumentComparator類,往命令行輸入python paperchecker.py即可運(yùn)行18種單元測試,并給出對應(yīng)結(jié)果


 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號