
67
背景介紹
1. 什么是爬蟲
爬蟲,即網絡爬蟲,大家可以理解為在網絡上爬行的一直蜘蛛,互聯網就比作一張大網,而爬蟲便是在這張網上爬來爬去的蜘蛛咯,如果它遇到資源,那么它就會抓取下來。想抓取什么?這個由你來控制它咯。 比如它在抓取一個網頁,在這個網中他發現了一條道路,其實就是指向網頁的超鏈接,那么它就可以爬到另一張網上來獲取數據。這樣,整個連在一起的大網對這之蜘蛛來說觸手可及,分分鐘爬下來不是事兒。
2. 瀏覽網頁的過程
在用戶瀏覽網頁的過程中,我們可能會看到許多好看的圖片,比如 http://image.baidu.com/ ,我們會看到幾張的圖片以及百度搜索框,這個過程其實就是用戶輸入網址之后,經過 DNS 服務器,找到服務器主機,向服務器發出一個請求,服務器經過解析之后,發送給用戶的瀏覽器 HTML、JS、CSS 等文件,瀏覽器解析出來,用戶便可以看到形形色色的圖片了。 因此,用戶看到的網頁實質是由 HTML 代碼構成的,爬蟲爬來的便是這些內容,通過分析和過濾這些 HTML 代碼,實現對圖片、文字等資源的獲取。
3.URL 的含義
URL,即統一資源定位符,也就是我們說的網址,統一資源定位符是對可以從互聯網上得到的資源的位置和訪問方法的一種簡潔的表示,是互聯網上標準資源的地址。互聯網上的每個文件都有一個唯一的 URL,它包含的信息指出文件的位置以及瀏覽器應該怎么處理它。
URL 的格式由三部分組成: ①第一部分是協議 (或稱為服務方式)。 ②第二部分是存有該資源的主機 IP 地址 (有時也包括端口號)。 ③第三部分是主機資源的具體地址,如目錄和文件名等。
爬蟲爬取數據時必須要有一個目標的 URL 才可以獲取數據,因此,它是爬蟲獲取數據的基本依據,準確理解它的含義對爬蟲學習有很大幫助。
什么是結構化和非結構化的數據,處理方式?
非結構化的數據處理
文本、電話號碼、郵箱地址
正則表達式Python正則表達式
HTML文件
正則表達式
XPath
CSS選擇器
結構化的數據處理
JSON文件
JSON Path
轉化為Python類型進行操作(json類)
XML文件
轉化為Python類型(xmltodict)
XPath
CSS選擇器
正則表達式
我們先向對方服務器發送一個請求,對方給我們返回數據,通常獲取到的數據是html數據或者json數據,先來看看非結構化的html處理,也就是我們發起一個請求,對面直接給我們返回的是頁面源碼,這里我們有三種方式可以用來處理數據
- 使用正則表達式處理
- 使用xpath處理
- 使用css選擇器處理
讓我們來試試看
這里我們看一個網站頂點小說(使用這個網站是因為它沒有反爬機制)
這里我們的目標是
首先是正則,基本規則我們之前應該學過,這里提供一個正則測試網站
https://tool.oschina.net/regex/#
可以方便調試
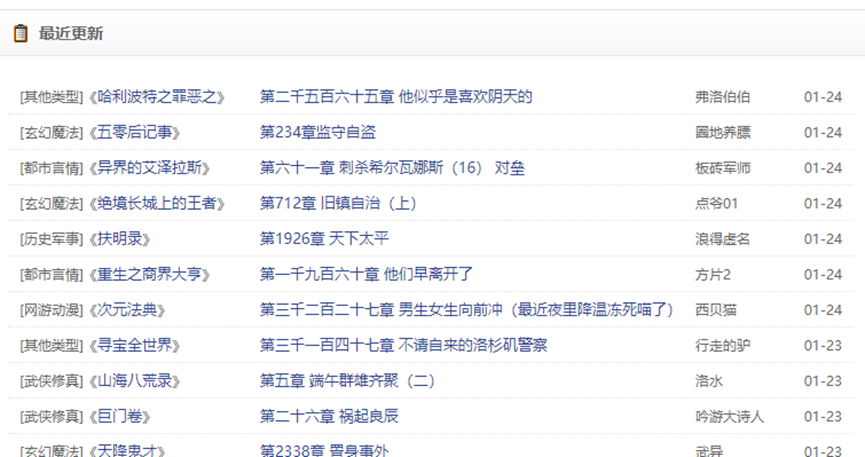
打開F12,選擇要獲取的數據,然后復制html,如圖:
<li><p class="ul1">[其他類型]《<a class="poptext" title="哈利波特之罪惡之書" target="_blank">哈利波特之罪惡之</a>》</p><p class="ul2"><a href="/book/26/26856/17070016.html" target="_blank">第二千五百六十五章 他似乎是喜歡陰天的</a></p><p>弗洛伯伯</p>01-24</li>
這里將需要的部分用()包著,每行不一樣的地方都需要修改,你可以用.*?代替它們,不過.*?盡可能少用,因為這會降低正則的匹配效率,這里我們為了方便就先用.*?代替
然后利用正則提取我們想要的部分得到:
import requests from lxml import etree import re from pyquery import PyQuery as pq source = requests.get('https://www.72us.com/').content.decode('gbk') demo = re.compile( '<li><p class="ul1">\[(.*?)\]《<a class="poptext" href="(.*?)" title=".*?" target="_blank">(.*?)</a>》</p><p class="ul2"><a href="(/book/\d+/\d+/\d+\.html)" target="_blank">(.*?)</a></p><p>(.*?)</p>(\d+-\d+)</li>') values = demo.findall(source) print(values)
效果如下

可以看到我們已經成功獲取到了數據,之后根據獲取到的數據項數循環打印即可,但是我們會發現比較難的問題就是整個過程比較麻煩,正則雖然好用,但是如果錯一點點可能提取的結果就天差地別,所以我們這里可以
學習一下xpath
我們這里說的根據xpath獲取數據實際就是根據html的標簽獲取數據
需要先引入包
from lxml import etree
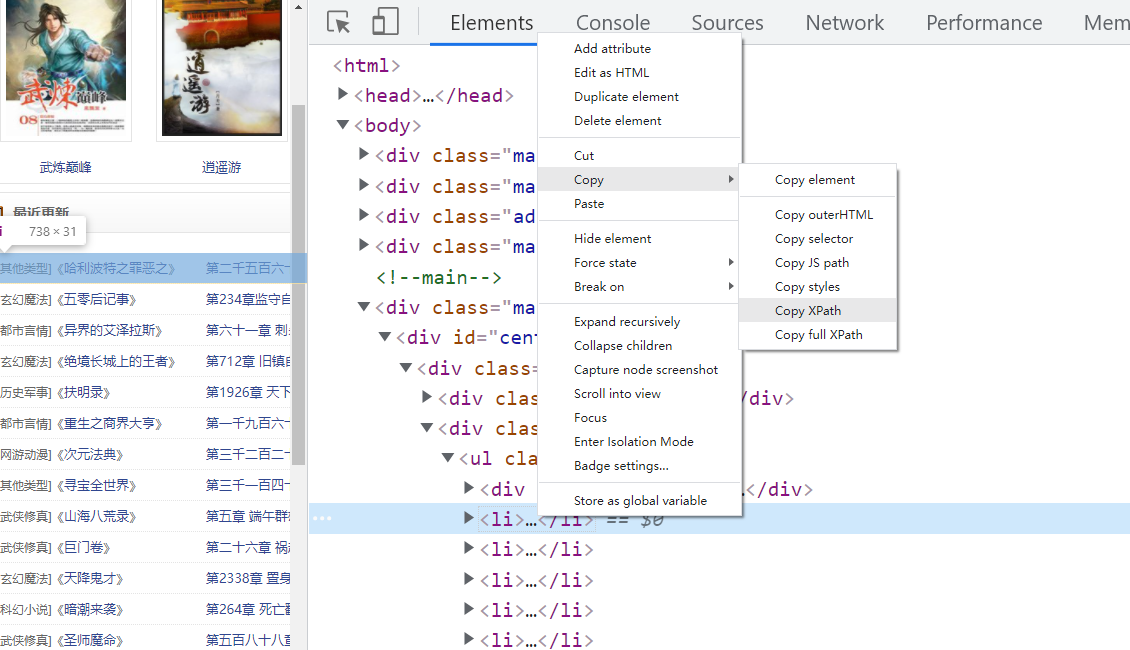
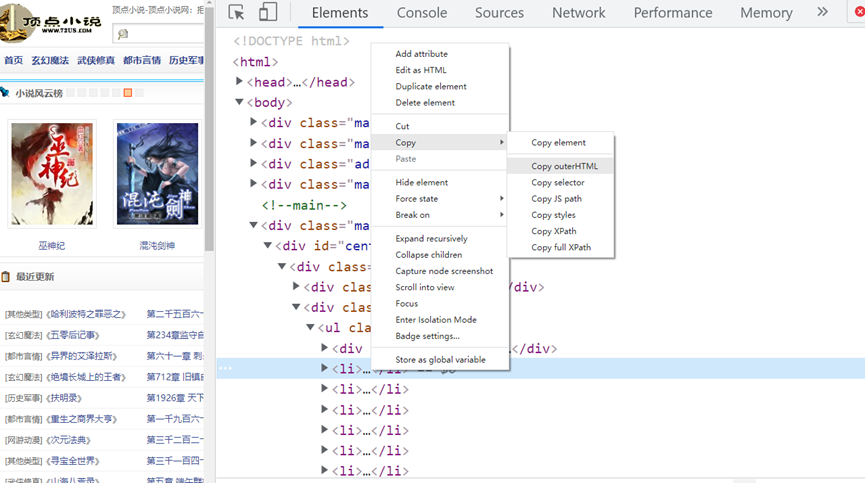
可以這樣復制xpath的路徑,然后得到
//*[@id="centeri"]/div/div[2]/ul/li[1]
這里//代表這是一個相對路徑,前面還有東西,*代表了任意標簽,后面的【】則是對前面*的描述,表示要找到一個上面有id="centeri"屬性的任意標簽,之后是定位到這個標簽的div標簽下的第二個div標簽下的url下的第一個li
我們可以發現我們要的東西都包含在li里,而且是所有li,第一步可以刪除li后面的1,這樣相當于定位到這個位置所有的li而不是只有第一個,之后遍歷,這樣可以用遍歷出來的元素接著獲取需要的元素代碼如下:
import requests from lxml import etree source = requests.get('https://www.72us.com/').content.decode('gbk') values = etree.HTML(source).xpath('//*[@id="centeri"]/div/div[2]/ul/li') for i in values: types = i.xpath('p[1]/text()[1]') book = i.xpath('p[1]/a/text()') print(types,book)
這樣我們獲取書的分類和書名的時候就可以不用再寫前面相同的部分了,而是從不同的部分寫起
獲得
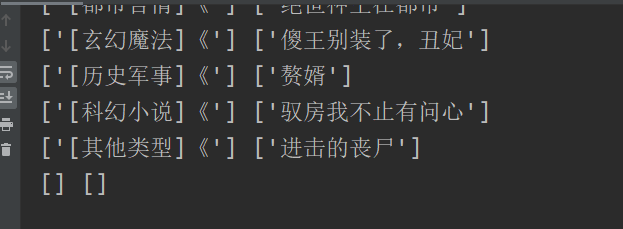
東西是出來了,但是后面有空的,原因就是最后的li是更多,是我們不需要的,直接舍棄就好
另外也需要把分類再處理一下,使用替換和正則都行,代碼如下
import requests from lxml import etree import re source = requests.get('https://www.72us.com/').content.decode('gbk') values = etree.HTML(source).xpath('//*[@id="centeri"]/div/div[2]/ul/li') for i in values[:-1]: types = re.compile('\[(.*?)\]《').findall(i.xpath('p[1]/text()[1]')[0])[0] book = i.xpath('p[1]/a/text()')[0] print(types,book)
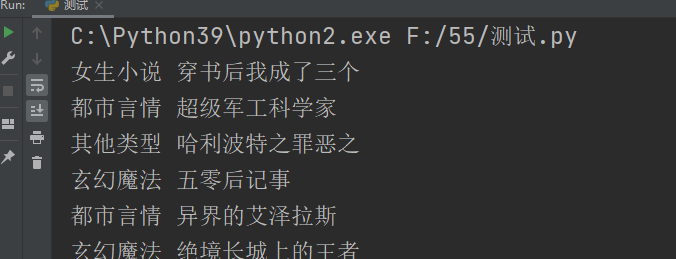
這里我們只獲取了前兩項,其他項請大家自己獲取
好的上面我們簡單使用xpath,接下來我們看下xpath里我們常用的語法
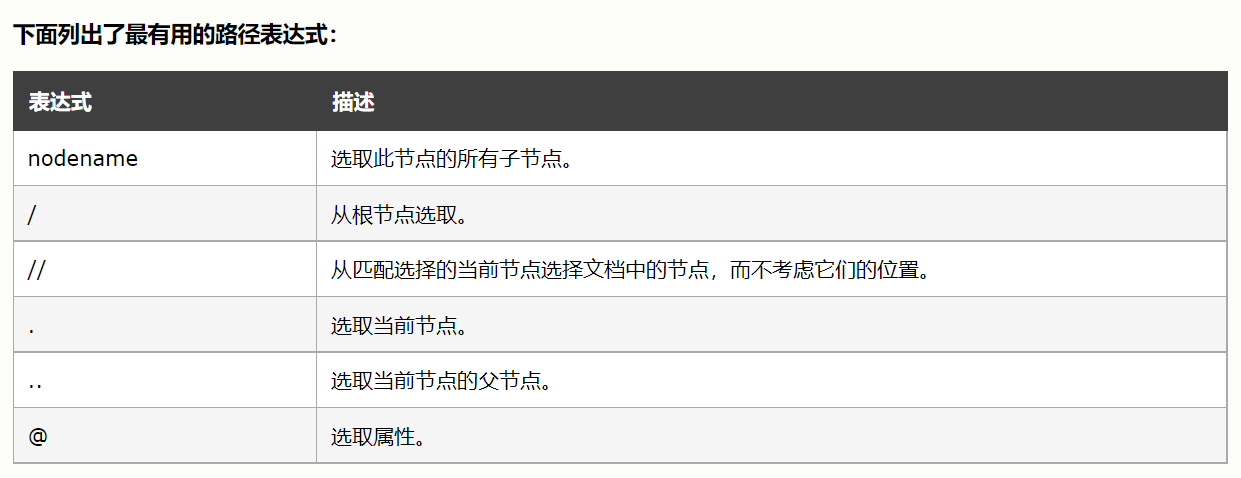

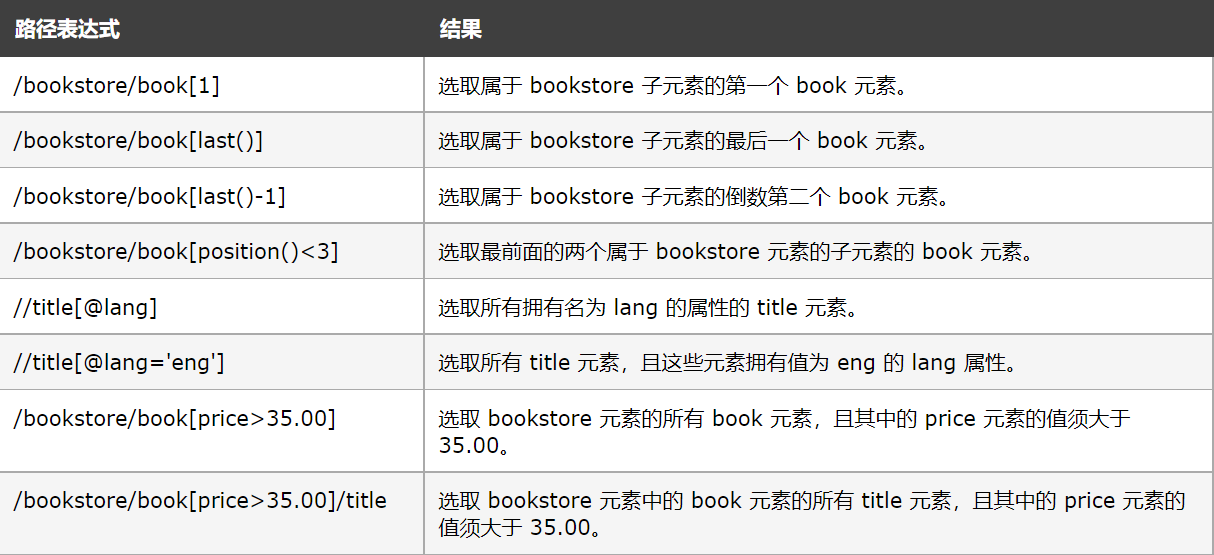

看了上面xpath的介紹,我們應該可以看出xpath的強大了,我們粘貼的xpath實際上是找你當前要定位的元素最近的有id屬性的元素開始,如果沒有就繼續往更外一層找,如果一直沒有,那么就會從根目錄開始了
就不是一個相對路徑了,如果帶有id屬性的元素離你定位的元素比較遠,那么就會導致xpath復制的路徑很長,這樣只要中間稍微變化那原來定位的xpath路徑就會失效,所以我們可以自己來寫,比如我們剛才定位li的那個xpath
'//*[@id="centeri"]/div/div[2]/ul/li'
可以改成
'//ul[@class="update"]/li'
values = etree.HTML(source).xpath('//ul[@class="update"]/li')
效果和剛才沒有任何變化
關于xpath 還有一些實用的東西
starts-with 顧名思義,匹配一個屬性開始位置的關鍵字
contains 匹配一個屬性值中包含的字符串
text() 匹配的是顯示文本信息,此處也可以用來做定位用
例如
//input[starts-with(@name,'name1')] 查找name屬性中開始位置包含'name1'關鍵字的頁面元素
//input[contains(@name,'na')] 查找name屬性中包含na關鍵字的頁面元素
<a >百度搜索</a>
xpath寫法為 //a[text()='百度搜索']
或者 //a[contains(text(),"百度搜索")]
這么多用法不可能一天用熟,多練習才是關鍵
那么如何使用css的格式提取數據呢?其實xpath和css差不多,都是通過標簽獲取數據,兩個精通一個就行了,那么我們看看css形式的
1.安裝方法
pip install pyquery
2.引用方法
from pyquery import PyQuery as pq
3.簡介
pyquery 是類型jquery 的一個專供python使用的html解析的庫,使用方法類似bs4。
如果修改一下,代碼應該是這樣的
import requests from lxml import etree import re from pyquery import PyQuery as pq source = requests.get('https://www.72us.com/').content.decode('gbk') doc = pq(source) li = doc('.update li').items() for i in list(li)[:-1]: demo = re.compile('\[(.*?)\]《(.*?)》').findall(i.find('.ul1').text())[0] types = demo[0] book = demo[1] print(types,book)
這里我們只是簡單使用一下,如果想了解更多關于css選擇器的用法可以百度
接下來就是全站抓取的思路了
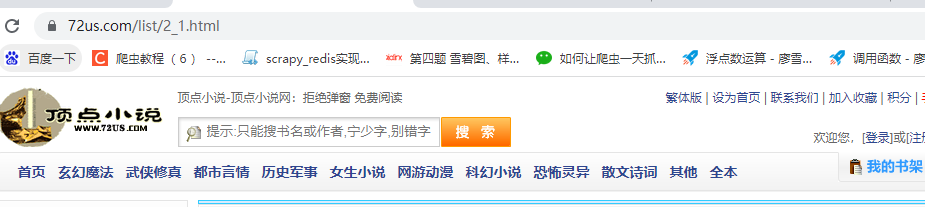
根據導航條知道,不同的分類所對應的url前面的數不同
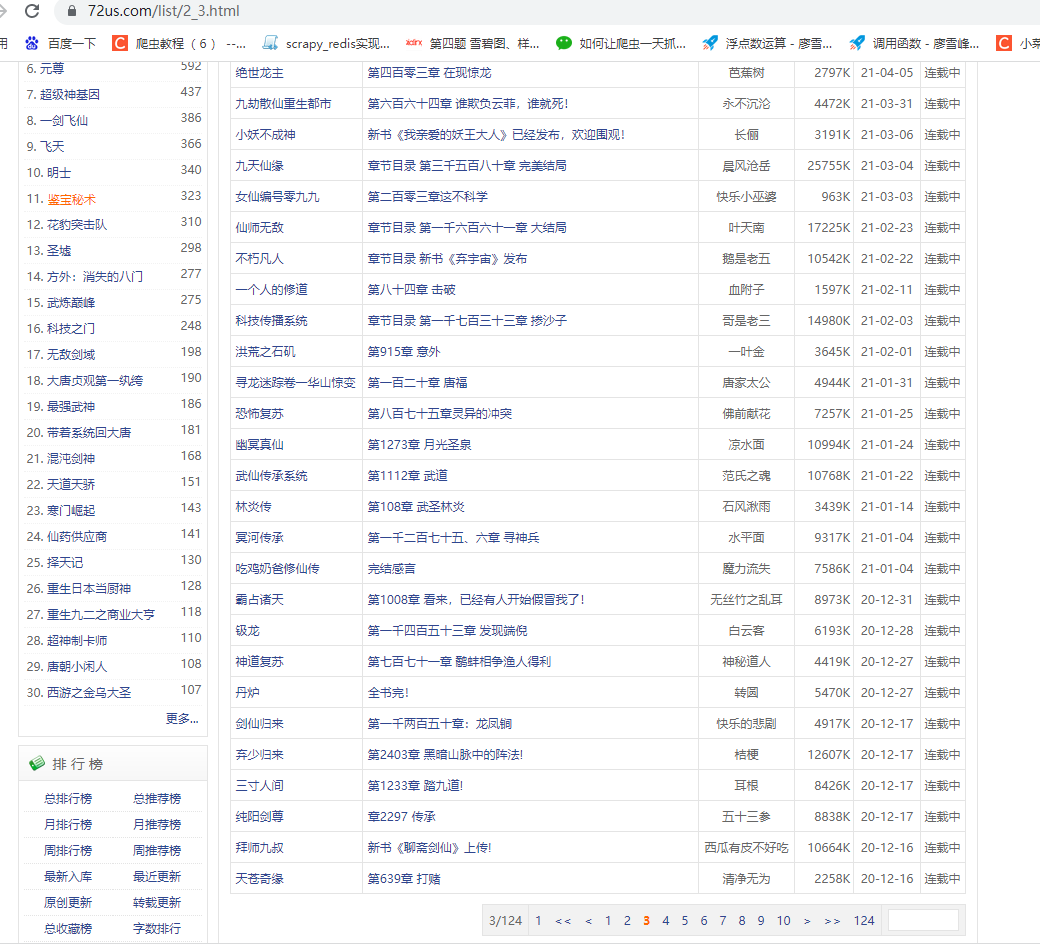
再翻頁,發現后面的數對應的是頁數,這里頁數是3,分類是武俠修真,對應的是前面的數字2
如果能夠獲取每個分類下的最大頁數,那么就可以通過兩層循環,遍歷出每個分類下的所有頁所對應的url
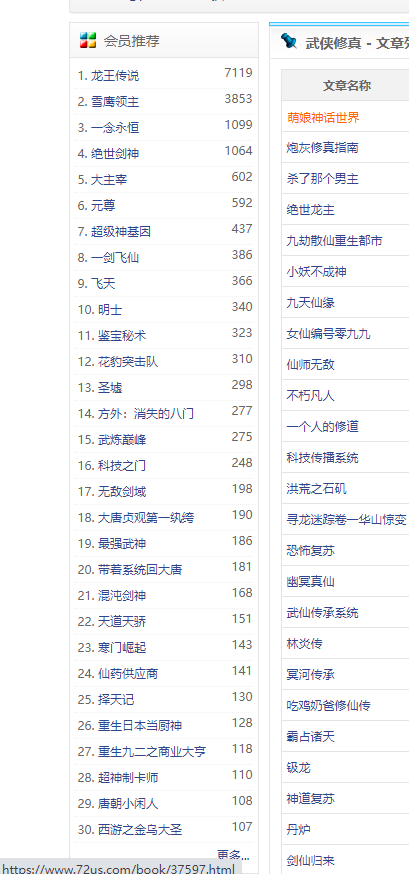
鼠標移動到超鏈接上,左下角可以看到超鏈接里有書的ID,這里是37597,如果能獲取到書的ID,那么我們就可以進到列表頁面,我們查看下章節列表頁面:
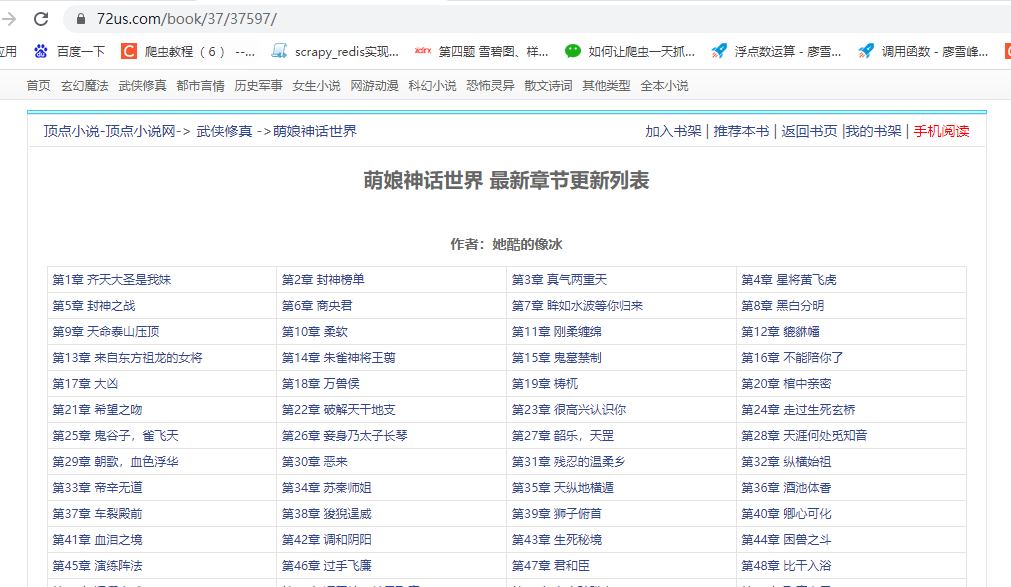
可以看到,章節列表頁的鏈接就是書的id的前2位,加上書的ID,我們只要得到了書的ID就可以拼出章節列表頁的鏈接,然后請求獲取到這本書所對應的章節列表頁的源碼
之后再獲取每個章節的鏈接,那么就可以獲取這本書每個章節的名字和內容了,之后入庫,這里我們如果要存mysql數據庫,那么使用pymysql 批量插入即可

 浙公網安備 33010602011771號
浙公網安備 33010602011771號