
處理xml(html)中的空格
xml文檔(包括html)是從一個獨立的根結(jié)點開始,它包含指向子節(jié)點的指針。每一個子節(jié)點都包含指針指向它的父節(jié)點、相鄰節(jié)點和子節(jié)點。標準dom中,dom指針不僅可以指向元素,也可以指向文本節(jié)點。 請看以下html代碼:
 <body> <h1>DOM簡介</h1> <p id="test">DOM是一個表達XML文檔的標準</p> <p>你隨處可見dom的身影
<body> <h1>DOM簡介</h1> <p id="test">DOM是一個表達XML文檔的標準</p> <p>你隨處可見dom的身影 </p></body>
</p></body>我想獲得id為test的p元素的下一個p元素,可能理所當然的認為用document.getElementById('test').nextSibling就能獲得。其實不然。在ie中確實能夠獲得你想要的,而在firefox、Opera9和Safari中你只能獲得一個空格。《精通javascript》上提供了一個函數(shù),用于處理xm中的這些空格,其作用原理就是找出文本節(jié)點,并刪除這些節(jié)點,以達到刪除這些空格的目的。
 function cleanWhitespace(element){
function cleanWhitespace(element){
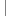 //如果不提供參數(shù),則處理整個HTML文檔 element = element || document; //使用第一個子節(jié)點作為開始指針 var cur = element.firstChild; //一直到?jīng)]有子節(jié)點為止
//如果不提供參數(shù),則處理整個HTML文檔 element = element || document; //使用第一個子節(jié)點作為開始指針 var cur = element.firstChild; //一直到?jīng)]有子節(jié)點為止 while (cur != null){
while (cur != null){ //如果節(jié)點為文本節(jié)點,應(yīng)且包含空格 if ( cur.nodeType == && ! /\S/.test(cur.nodeValue)){ //刪除這個文本節(jié)點 element.removeChild( cur ); //否則,它就是一個元素 } else if (cur.nodeType == 1){ //遞歸整個文檔 cleanWhitespace( cur );
//如果節(jié)點為文本節(jié)點,應(yīng)且包含空格 if ( cur.nodeType == && ! /\S/.test(cur.nodeValue)){ //刪除這個文本節(jié)點 element.removeChild( cur ); //否則,它就是一個元素 } else if (cur.nodeType == 1){ //遞歸整個文檔 cleanWhitespace( cur );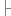 } cur = cur.nextSibling;//遍歷子節(jié)點 }
} cur = cur.nextSibling;//遍歷子節(jié)點 }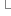 }
} 正如書中作者所提到的,該函數(shù)的缺點是必須遍歷每個DOM元素和文本節(jié)點,會嚴重降低網(wǎng)站的加載速度。每一次為文檔注入新的html,都需要重新掃描dom中的新內(nèi)容,確保沒有增加新的有空格填充的文本節(jié)點。
在這里,不妨做一個簡單的判斷,如果id為test的p元素的下一個節(jié)點是文本節(jié)點(即nodeType為3)的話,就繼續(xù)往下遍歷。如果是元素節(jié)點的話,則不需要往下遍歷。代碼如下:
var testP = document.getElementById('test'); var reason = testP.nextSibling; if(reason.nodeType == 1){ alert(reason.innerHTML); } else if(reason.nodeType == 3){ alert(reason.nextSibling.innerHTML); } } 對非IE瀏覽器,可以用常量來表明不同的DOM節(jié)點類型。document.ELEMENT_NODE、document.TEXT_NODE、document.DOCUMENT_NODE代表元素節(jié)點、文本節(jié)點、文檔節(jié)點。
最后,利用數(shù)組寫了一個函數(shù),能夠有效的處理dom中的空格,其原理就是將一個元素的的父元素找出來,然后通過它父元素的childNodes屬性找出該元素的所有兄弟元素。遍歷該元素和它的兄弟元素,將所有元素節(jié)點放在一個數(shù)組里。這樣調(diào)用這個數(shù)組,就只有元素節(jié)點而沒有文本節(jié)點,也就沒有了討厭的空格。
該函數(shù)如下:
function cleanWhitespaces(elem){ var elem = elem || document; var parentElem = elem.parentNode; var childElem = parentElem.childNodes; var childElemArray = new Array; for (var i=0; i<childElem.length; i++){ if (childElem[i].nodeType==1){ childElemArray.push(childElem[i]); } } return childElemArray;}最后完整的一個示例如下:
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd"><html xmlns="http://www.w3.org/1999/xhtml"><head><meta http-equiv="Content-Type" content="text/html; charset=utf-8" /><title>DOMWhitespace</title><script type="text/javascript">window.onload = function(){ var testP = document.getElementById('test'); cleanWhitespaces(testP); alert(testP.innerHTML);}function cleanWhitespaces(elem){ var elem = elem || document; var parentElem = elem.parentNode; var childElem = parentElem.childNodes; var childElemArray = new Array; for (var i=0; i<childElem.length; i++){ if (childElem[i].nodeType==1){ childElemArray.push(childElem[i]); } } return childElemArray;} </script></head><body> <h1>DOM簡介</h1> <p id="test">dom的廣泛使用是有道理的,以下是一些原因:</p> <p>你隨處可見dom的身影</p> <ul> <li><a href="" title="">link1</a></li> <li><a href="" title="">link2</a></li> </ul></body></html>
function removeWhitespace(xml){ var loopIndex; for (loopIndex = 0; loopIndex < xml.childNodes.length; loopIndex++){ var currentNode = xml.childNodes[loopIndex]; if (currentNode.nodeType == 1){ removeWhitespace(currentNode); } if (((/^\s+$/.test(currentNode.nodeValue))) &&(currentNode.nodeType == 3)){ xml.removeChild(xml.childNodes[loopIndex--]); } }}
原理是對元素的所有的子節(jié)點做一個遍歷。然后做一個判斷,如果是子元素節(jié)點(nodeType = 1),則遍歷該子元素的所有的子節(jié)點,用遞歸檢查是否包含空白節(jié)點;如果處理的子節(jié)點是文本節(jié)點(nodeType = 3),則檢查是否是純粹的空白節(jié)點,如果是,就將它從xml對象中刪除。
這個函數(shù),應(yīng)該和上面我自己寫的函數(shù)作用和使用方法基本一樣。非常不錯的函數(shù)。
本博文發(fā)布3天后,我在《ajax寶典》上又看到了一個用于處理xml中空格的好函數(shù)。原理還是一樣的,代碼如下:

 浙公網(wǎng)安備 33010602011771號
浙公網(wǎng)安備 33010602011771號