LOCALIZATION, DETECTION AND TRACKING OF MULTIPLE MOVING SOUND SOURCES WITH A CONVOLUTIONAL RECURRENT NEURAL NETWORK
摘要
本文研究了使用卷積遞歸神經網絡對聲音事件進行聯合定位、檢測和跟蹤。我們使用先前提出的用于定位和檢測靜止源的CRNN,并且表明當使用動態場景訓練時,遞歸層能夠實現運動源的空間跟蹤。將該神經網絡的跟蹤性能與結合了多源(波達方向)估計器和粒子濾波器的獨立跟蹤方法進行了比較。它們各自的性能在各種聲學條件下進行評估,如消聲和混響場景、不同角速度下的固定和移動聲源以及不同數量的重疊聲源。結果表明,在各種聲學場景下,CRNN能夠比參數方法更一致地跟蹤多個聲源,但代價是定位誤差更大。
關鍵詞:多目標跟蹤、遞歸神經網絡、聲音事件檢測、聲音定位
1.介紹
聲音事件定位、檢測和跟蹤(SELDT)是識別潛在時間重疊的聲音事件的時間開始和偏移,識別它們的類別,并在它們活動時跟蹤它們各自的空間軌跡的綜合任務。成功地執行SELDT提供了聲學場景的自動描述,機器可以使用該描述來與它們的環境自然地交互。電話會議系統和機器人等應用可以利用這些信息來跟蹤感興趣的聲音事件[1–6]。此外,智能城市和智能家庭可以將其用于音頻監控[7–9]。
利用不同的參數[5,8,10,11]和基于深度神經網絡(DNN)[12]的方法,研究了空間靜止源靜態場景中的定位和檢測。然而,這些方法不使用任何時間建模所需的跟蹤運動源在動態場景。最近,我們提出了一種卷積循環神經網絡(SELDnet),它被證明比目前唯一的基于dnn的方法[12]具有更好的定位和檢測性能。在匹配和不匹配的聲學條件下,SELDnet在全方位和高度定位事件的能力,并且不依賴于依賴于特定麥克風陣列的特征,在[13]中進行了研究和展示。然而,[13]只研究靜態場景。
另一方面,基于空間信息[14-20]、附加光譜信息[21,22]或與視覺信息[23]相結合的靜態和移動源的獨立跟蹤方法已經得到廣泛研究。這些參數的方法通常需要手動調整與場景組成和動態相對應的多個參數,并且必須針對不同的聲音場景手動識別新的參數集。此外,跟蹤通常側重于識別源軌跡,而不考慮源信號內容。在時間重疊軌跡的情況下,軌跡標識被分配給單個軌跡,但這些標識不依賴于源,并且通常被重復用于音頻錄音中來自不同源的軌跡。在大多數情況下,一致關聯和定位之間的平衡決定了跟蹤器的性能。或者,像在提議的seldnet中,先檢測后跟蹤的方法,通過首先檢測活動的聲音事件,然后為每個檢測到的事件分配一個音軌,繞過了關聯問題。只要該系統能夠對時刻變化的條件作出反應,同時具有來自靜止源和運動源的時間和空間重疊的聲音事件,它也能夠檢測和跟蹤感興趣的聲音事件。
在這項工作中,我們研究了基于我們最近提出的SELDnet[13]的檢測和定位系統的多源跟蹤能力。我們表明,使用動態場景數據訓練SELDnet除了可以實現定位和檢測外,還可以實現跟蹤。這種跟蹤能力是由SELDnet的循環層實現的,它可以將空間參數的演化建模為給定序列特征及其空間軌跡信息的序列預測任務。我們證明了循環層對于跟蹤是至關重要的,與獨立的跟蹤器相比,它們額外執行檢測。與前面討論的參數跟蹤方法不同,遞歸層是一種通用的跟蹤方法,它直接從數據中學習,不需要人工跟蹤工程。最后,通過對5個數據集的評估,SELDnet的跟蹤性能與獨立參數跟蹤方法具有可比性,這些數據集分別代表了不同角速度的靜止源和運動源、消聲和混響環境以及不同數量重疊源的場景。該方法和所有研究的數據集都是公開的。
2.方法
一個聲學場景,例如一個公園,其特征在于其中的聲音事件,如狗叫和鳥叫,由它們各自的來源狗和鳥產生。在SELDT任務中,我們旨在聲學上檢測聲音事件的時間活動,并進一步定位空間中產生聲音事件的源并跟蹤它們的運動。當激活時,檢測任務產生每個聲音事件類的開始和偏移時間。類似地,當聲音事件活動時,跟蹤產生聲源運動的空間軌跡。
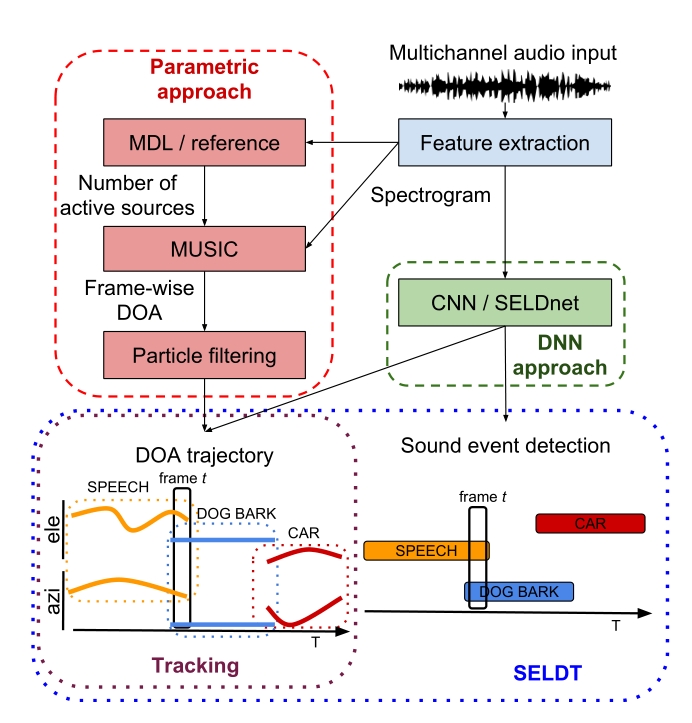
圖1:參數跟蹤和基于DNN的SELDT方法的工作流程。這里顯示跟蹤任務的聲音類著色和命名只是為了更好地可視化概念。在實踐中,跟蹤方法不會產生如圖3所示的聲音類標簽。
SELDnet [13]基于卷積遞歸神經網絡架構,其中當聲音事件被檢測為活動時,以回歸方式估計聲音事件的到達方向(DOA)。如圖1所示,SELDnet的輸入是多聲道音頻記錄,特征提取模塊從中提取頻譜圖的相位和幅度分量。SELDnet將聲譜圖映射到兩個輸出——聲音事件檢測和跟蹤;它們一起產生SELDT輸出。檢測為數據集中存在的聲音類別產生時間活動。當跟蹤處于活動狀態時,它只為每個聲音類別產生一個波達方向軌跡,即,如果同一聲音類別的多個實例在時間上重疊,SELDnet只跟蹤一個或在多個實例之間振蕩。
我們使用在[13]中提出的SELDnet體系結構,三個卷積層各有64個濾波器,然后是兩層128節點門控遞歸單元。循環層的輸出被饋送到密集層的兩個分支,每個分支具有產生檢測和跟蹤估計的128個單元。SELDnet中的卷積層被用作特征提取器,以產生用于檢測和跟蹤的魯棒特征。給定T幀的譜圖輸入,卷積層產生長度為T的幀方向特征。這些特征被映射到兩個長度為T的幀方向輸出,即檢測和跟蹤,使用共享遞歸層。
循環層利用當前輸入幀以及從先前輸入幀中學習的信息來產生當前幀的輸出。這個過程類似于粒子濾波器,粒子濾波器是一種流行的獨立參數跟蹤器,在本文中也用作基線(參見第3.3節)。當前時間范圍內的粒子濾波預測受到前一個時間范圍內累積的知識和當前時間范圍內的知識的影響。對于本文的跟蹤任務,粒子濾波器需要聲音場景的特定知識,例如聲音事件的空間分布、它們在活動時各自的速度范圍以及它們的出生和死亡概率。
這樣的概念并沒有在SELDnet中使用的遞歸層中顯式建模,而是直接從開發數據集中輸入卷積層特征和相應目標輸出中學習等效信息。事實上,循環層已經被證明可以作為通用跟蹤器[24],它可以從任何連續輸入特征中學習目標源的時間關聯。與僅使用概念表示(如用于跟蹤的逐幀多波達方向)的粒子濾波器不同,循環層與概念表示和潛在表示(如卷積層特征)都無縫工作。
最后,通過使用從檢測和跟蹤計算的損失來訓練SELDnet中的循環層,循環層學習來自對應于相同聲音類別的相鄰幀的波達方向之間的關聯,并因此產生SELDT結果。一般來說,與參數跟蹤器不同,循環層除了檢測它們相應的聲音類別之外,還執行類似的幀方向波達方向跟蹤。此外,循環層不需要參數跟蹤器所需的復雜的特定問題跟蹤器或特征工程。文獻[25]中提出了循環層和粒子濾波之間的理論關系。
3.評估過程
3.1數據集

SELDnet的性能是在表1中總結的五個數據集上評估的。我們繼續使用我們以前工作[13]中的固定源數據集來評估[13]中缺失的參數跟蹤器的跟蹤性能,并與SELDnet進行比較。此外,我們創建了ANSYN和REAL數據集的移動源版本來評估移動源的性能。所研究的數據集是使用合成和真實生活脈沖響應合成的,用于消聲和混響場景。所有數據集的記錄都是30秒長,并以四通道一階環境聲學格式捕獲[26]。每個數據集有三個子集,沒有時間重疊的源O1、最多兩個O2和最多三個時間重疊的源O3。這些子集的每一個都有三個交叉驗證分割,240個記錄用于開發,60個用于評估。所有的合成脈沖響應數據集都有來自11個級別和DOAs的聲音事件,全方位距離和仰角距離∈[- 60,60]。真實的脈沖響應數據集有8個聲音事件類別和全方位范圍和仰角范圍∈[- 40,40]的DOAs。在合成過程中,靜止源數據集中的所有聲音事件都被放置在一個10?方位角和仰角分辨率的空間網格中。有關這些數據集的更多細節,請參閱[13]。
消聲移動源數據集MANSYN具有與ANSYN相同的聲音事件類別,合成如下。每個事件都被分配一個空間軌跡,該軌跡在一個弧上,與麥克風的距離恒定(在1-10米的范圍內),并且在其持續時間內以恒定的角速度移動。由于選擇了ambisonic雙聲波空間記錄格式,在遠場中平面波源或點源的引導矢量是頻率無關的。因此,當源移動時,不需要時變卷積或脈沖響應插值方案;對單聲道信號的空間編碼采用瞬時ambisonic編碼向量對運動源的各自DOA進行逐次采樣。在MANSYN中合成的軌跡在方位角和仰角都有變化,并且被模擬為具有恒定的角速度,在射程∈[?90?,90?]/s和10步/s。同樣,MREAL數據集合成了真實生活的脈沖響應,從[13]采樣在1?分辨率沿方方位僅。因此,與MANSYN不同的是,MREAL中的聲音事件(與REAL相同)僅沿方位角運動,且角速度恒定,其范圍為∈[?90?,90?]/s和10步/s。
3.2評估
SELDT性能的評估是使用與[13]相同的單獨檢測和跟蹤指標完成的。作為檢測指標,我們使用在沒有重疊的一秒鐘的片段中計算的分數和錯誤率[27]。一種理想的檢測方法的F值為1,錯誤率為零。作為跟蹤度量,我們使用兩個逐幀度量:幀召回率和波達方向誤差。幀召回給出了預測的DOAs數量與引用數量相等的幀的百分比。DOA誤差以預測DOA與參考DOA之間的角度(以度數為單位)計算。為了將多個估計的波達方向與參考相關聯,我們使用匈牙利算法[28]來識別最小的平均角距離,并將其用作波達方向誤差。理想的跟蹤方法是幀召回率為1,DOA錯誤為0(詳見[13])。
3.3基線方法
作為基線方法,我們結合使用MUSIC[29]和RBMCDA粒子濾波器[30]來獲得與[15]相似的跟蹤結果。基線方法的工作流如圖1所示。MUSIC是一種廣泛使用的基于[13,31]子空間的高分辨率波達方向估計方法,可以檢測多個窄帶源。它依賴于從多通道譜圖計算的窄帶空間協方差矩陣的特征分解,并且它還需要源號估計,以便在信號和噪聲子空間之間進行區分。這里,活動源的數量取自數據集的參考。為了獲得寬帶波達方向估計,窄帶協方差矩陣在從50赫茲到8千赫茲的三個連續幀和頻率倉中進行平均。我們在2D角網格上生成的合成MUSIC偽譜上執行2D球形峰值發現,在方位角和仰角上,靜止源的分辨率為10,運動源的分辨率為1。MUSIC MU SGT的最終輸出是一個幀方向的波達方向列表,對應于每個幀中活動源數量的最高峰值。
第二階段產生的參數方法涉及一個粒子濾波跟蹤結果通過處理MUSIC MU SGT的幀方向波達方向信息來產生跟蹤結果。粒子濾波器假設每個時間幀的源數量未知,并使用固定數量的粒子相對于時間來跟蹤它們。在每個時間幀,粒子濾波器接收多個波達方向,并基于從先前時間幀積累的知識,將每個新的波達方向分配給現有軌跡、雜波(噪聲)或新生源之一。此外,它還決定是否有任何現有的軌道已經死亡。粒子濾波器的最終輸出MU SPFGT產生每個活動聲音事件的時間起始偏移和波達方向軌跡。本文中使用的跟蹤器實現已公開發布。有關此方法的詳細信息,請讀者參閱[30]。
3.4實驗
在我們所有的實驗中,SELDnet的基線粒子濾波器參數和輸入譜圖的序列長度都是使用各自子集的開發集進行調整的。在子集的評估集上測試了優化后的方法的性能,并對子集的三種跨驗證劃分進行了詳細的報告。
與基于DNN的方法不同,參數方法需要關于每幀活動源數量的附加信息來估計相應的波達方向。但是,SELDnet從數據本身獲取這些信息。為了有一個公平的比較,我們使用最小描述長度(MDL) [32]原理從輸入譜圖中估計源的數量,并將其與MUSIC一起使用,產生MU SM DL的MUSIC輸出和MU SPF M DL的相應粒子濾波輸出。
最后,我們研究了遞歸層對于SELDT任務的重要性,方法是將它們從SELDnet中移除,并評估只包含卷積層和密集層的模型,以下稱為CNN。跨數據集的最佳CNN架構有五個卷積層,每個層有64個濾波器。
4.結果和討論
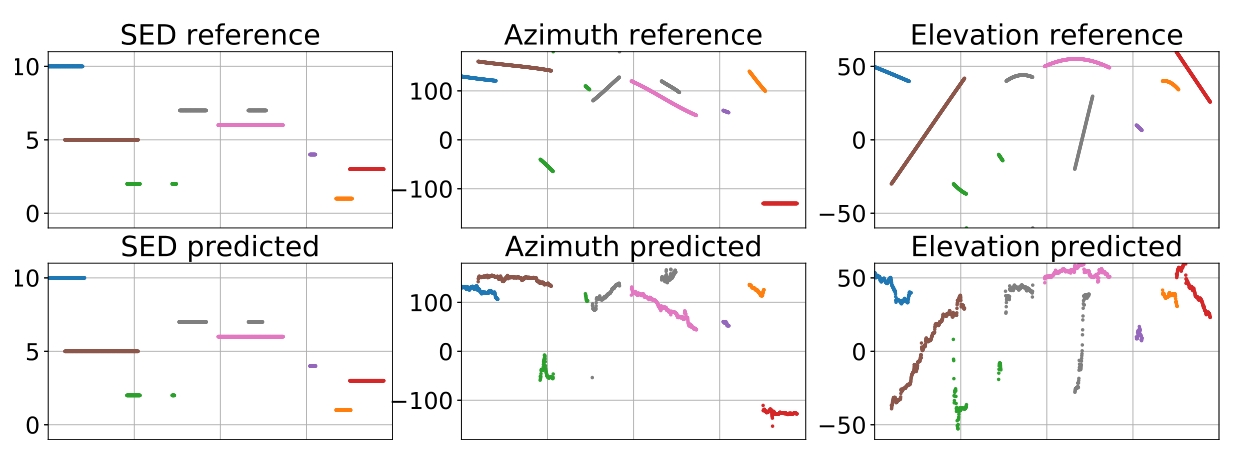
圖2:SELDnet預測及其對MANSYN O2數據集記錄的各自引用的可視化。所有子圖的水平軸表示相同的時間幀。垂直軸代表探測副圖的聲音事件分類指數,其余副圖的DOA方位角和仰角以度數表示。
在調整SELDnet的輸入序列長度時,我們發現256幀的序列在混響數據集中得分最高,而在消聲數據集中得分最高的是512幀。SELDnet的預測和相應的參考在圖2中顯示,分別來自MANSYN O2數據集的1000幀測試序列。每個聲音類在次要情節中都用一種獨特的顏色表示。我們看到,探測到的聲音事件是準確的比較參考。DOA的預測可以看到在參考軌跡周圍有一個小的偏差。這說明SELDnet能夠成功地跟蹤和識別多個重疊的移動源。
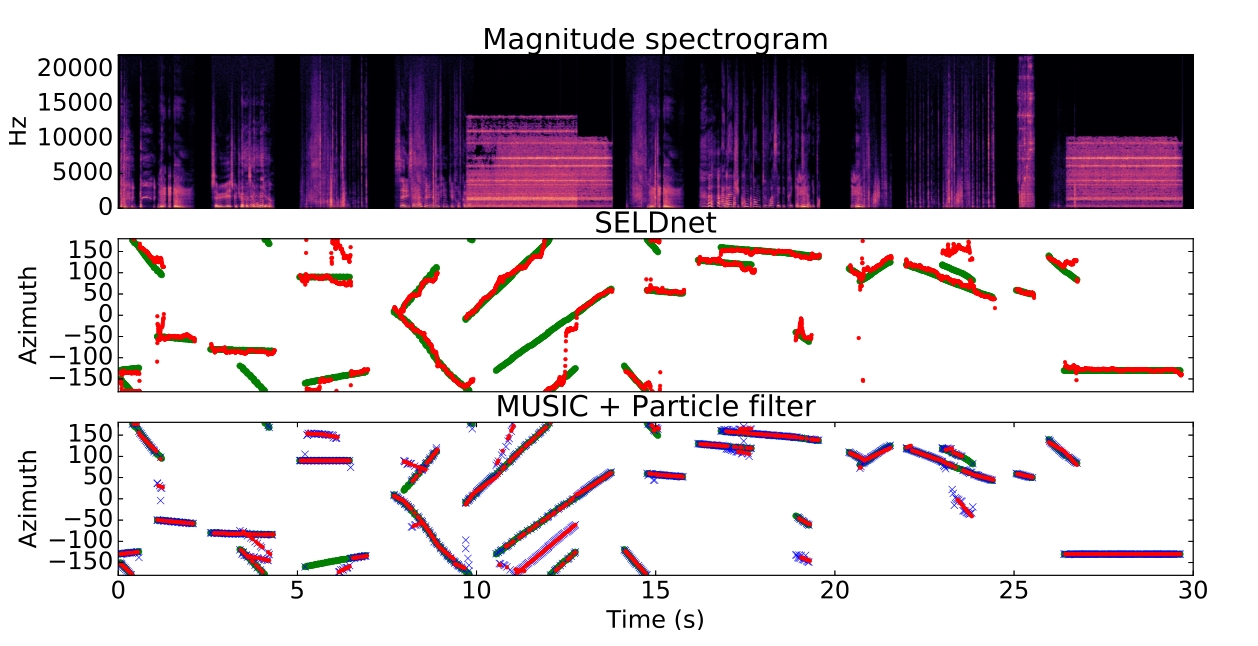
圖3:對于MANSYN O2數據集記錄,這兩種被提議的方法的跟蹤結果是可視化的。上圖為輸入譜圖。中間和底部的圖用紅
色顯示SELDnet和MU SPF GT跟蹤的輸出,分類準確性用綠色顯示。底部圖中的藍色叉表示音樂的幀DOA輸出
圖3可視化展示了SELDnet和基線方法MU SPF GT的跟蹤預測和各自的參考。一般來說,兩種方法的性能在視覺上是可以比較的。這兩種方法在類似的情況下經常被混淆,例如在4-5秒、10-13秒和23-25秒的間隔。
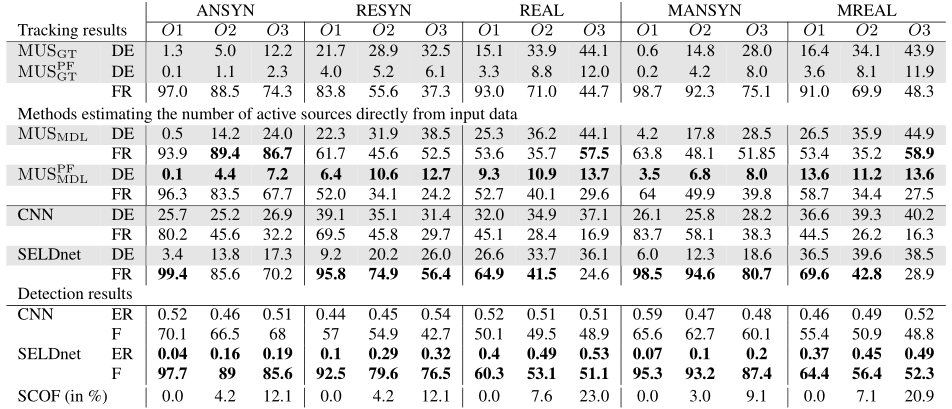
表2:不同數據集的評價結果。DE: DOA錯誤,FR:幀召回,F: F-score, SCOF:同一類重疊幀
根據設計,SELDnet被限制為只能識別給定聲音類的一個DOA。但在現實生活中,同一類聲音可能同時出現多個實例。這在研究的數據集中也可以看到,表2中的最后一行(SCOF)顯示了同一類與自身重疊的幀的百分比。相比之下,參數化方法在設計上沒有這樣的限制,并且在這些幀中可能比SELDnet表現得更好(盡管來自不同DOAs的高度相關的聲音事件很容易降低參數化方法(如MUSIC)的性能)。在圖3的10-13 s區間內可以觀察到這兩種方法在這種場景中的性能。SELDnet只跟蹤兩個源中的一個,而參數化方法跟蹤兩個重疊的源,并在兩個軌跡之間引入額外的假軌跡。
表2給出了研究方法的定量結果。總趨勢如下。重疊源個數越多,SELDnet和參數法的跟蹤性能越差。在數據集中,使用時間粒子濾波跟蹤器可以顯著提高DOA誤差,但代價是較低的幀回憶率。
使用參數化方法的總體性能降低(MU SPF GT> MU SPF MDL)。這種減少在幀回憶度量中尤其明顯,對于混響源和移動源場景數據集顯著下降,這表明需要更健壯的源檢測和計數方案。
SELDnet的幀回憶率始終優于MU SPF MDL,但對數據集的DOA估計較差。之間的相似關系觀察SELDnet 和MU SPF GT采用模擬脈沖響應生成的數據集,而對于現實中的脈沖響應數據幀召回SELDnet比MU SPF GT差。這可能表明需要更廣泛的學習對于實際的脈沖響應數據集而言,更大的數據庫和更強的模型。
使用循環層肯定有助于SELDT任務。從可視化中可以看出,CNN的跟蹤性能很差,DOA軌跡失真且方差大,導致數據集間DOA誤差很差,如表2所示。這表明遞歸層對于SELDT任務是至關重要的,它可以執行類似于RBMCDA粒子過濾器的任務,即識別相關的幀間DOAs,并將這些DOAs在不同的時間幀中對應于相同的聲音類。
5. 結論
在本文中,我們提出了第一種基于深度神經網絡的方法SELDnet,用于檢測動態聲學場景中每個聲音事件的時間開始和偏移時間,在空間中定位它們并在活動時跟蹤它們的位置,以及最終識別聲音事件類別的組合任務。SELDnet的性能是在五個不同的數據集上進行評估的,這些數據集包含固定和移動源、消聲和混響場景以及不同數量的重疊源。結果表明,SELDnet采用的遞歸層對跟蹤性能至關重要。此外,將SELDnet的跟蹤性能與基于多信號分類和粒子濾波的獨立參數方法進行了比較。總的來說,SELDnet跟蹤性能與參數方法相當,并實現了更高的跟蹤幀召回率,但角度誤差更大。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號