
C#簡化工作之實現(xiàn)網(wǎng)頁爬蟲獲取數(shù)據(jù)
公眾號「DotNet學(xué)習(xí)交流」,分享學(xué)習(xí)DotNet的點滴。
1、需求
想要獲取網(wǎng)站上所有的氣象信息,網(wǎng)站如下所示:
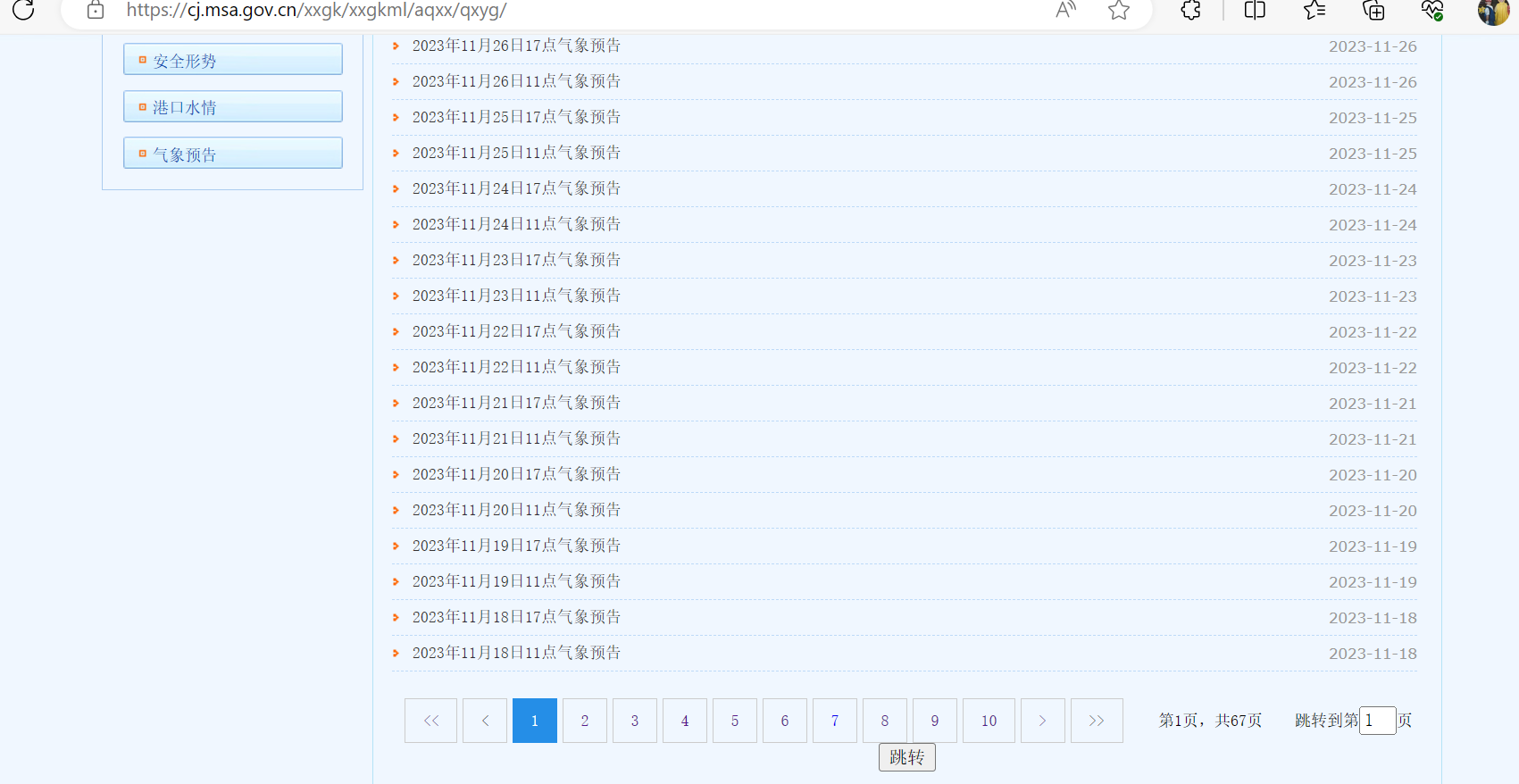
目前總共有67頁,隨便點開一個如下所示:
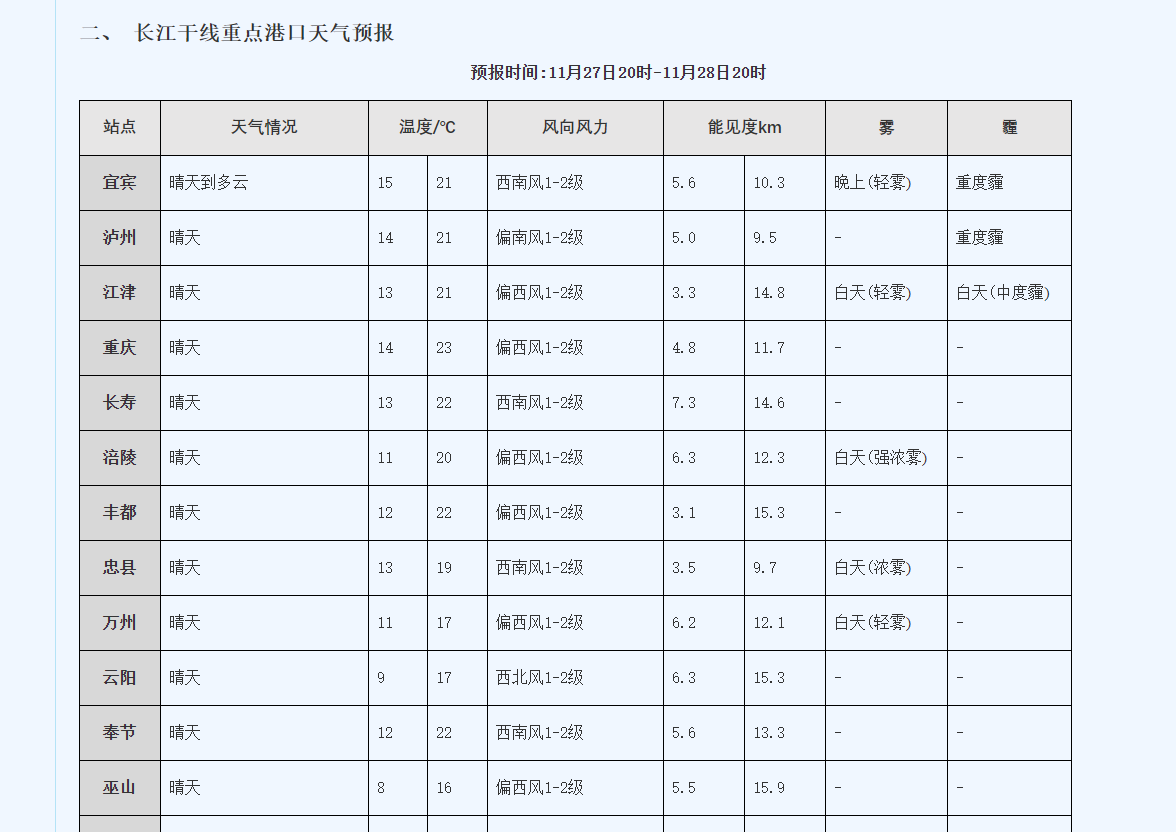
需要獲取所有天氣數(shù)據(jù),如果靠一個個點開再一個個復(fù)制粘貼那么也不知道什么時候才能完成,這個時候就可以使用C#來實現(xiàn)網(wǎng)頁爬蟲獲取這些數(shù)據(jù)。
2、效果
先來看下實現(xiàn)的效果,所有數(shù)據(jù)都已存入數(shù)據(jù)庫中,如下所示:
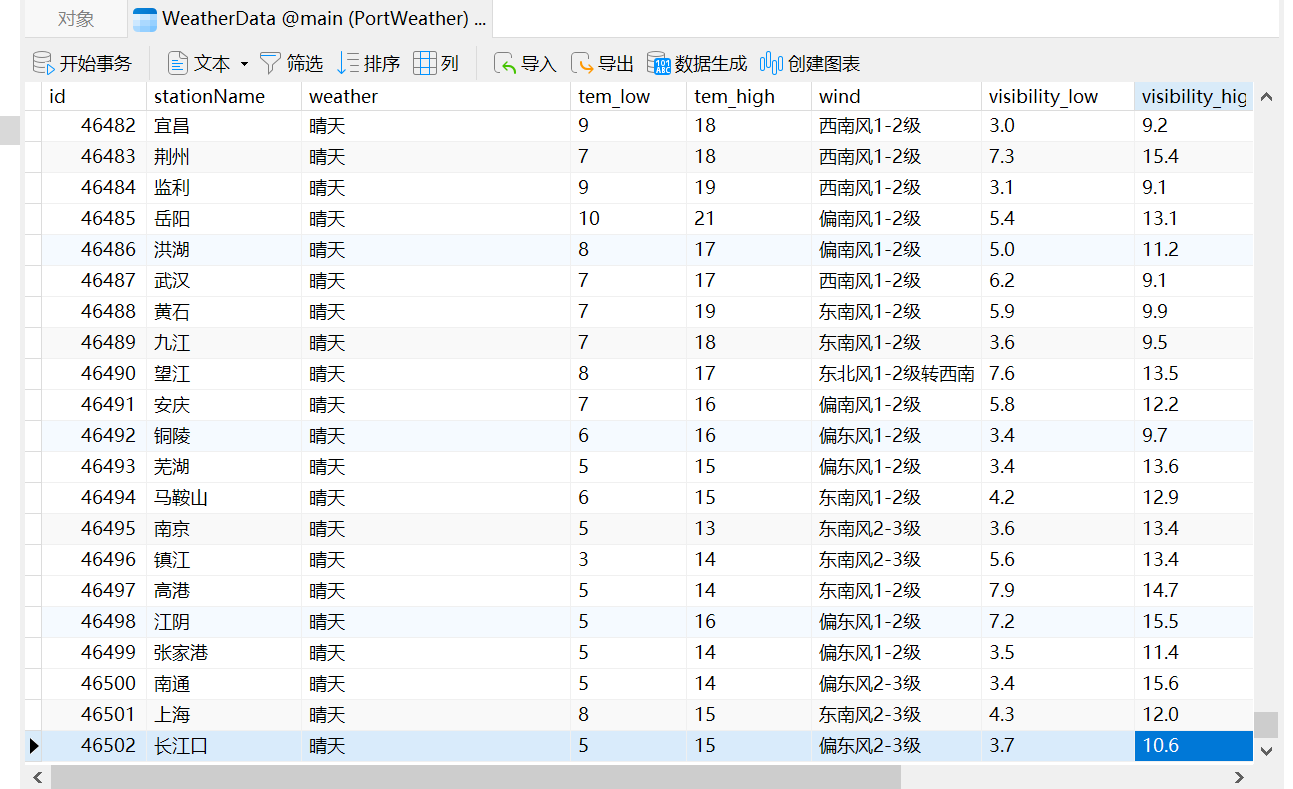
總共有4萬多條數(shù)據(jù)。
3、具體實現(xiàn)
構(gòu)建每一頁的URL
第一頁的網(wǎng)址如下所示:

最后一頁的網(wǎng)址如下所示:
可以發(fā)現(xiàn)是有規(guī)律的,那么就可以先嘗試構(gòu)建出每個頁面的URL
// 發(fā)送 GET 請求
string url = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
HttpResponseMessage response = await httpClient.GetAsync(url);
?
// 處理響應(yīng)
if (response.IsSuccessStatusCode)
{
string responseBody = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody);
//獲取需要的數(shù)據(jù)所在的節(jié)點
var node = doc.DocumentNode.SelectSingleNode("http://div[@class=\"page\"]/script");
string rawText = node.InnerText.Trim();
// 使用正則表達式來匹配頁數(shù)數(shù)據(jù)
Regex regex = new Regex(@"\b(\d+)\b");
Match match = regex.Match(rawText);
if (match.Success)
{
string pageNumber = match.Groups[1].Value;
Urls = GetUrls(Convert.ToInt32(pageNumber));
MessageBox.Show($"獲取每個頁面的URL成功,總頁面數(shù)為:{Urls.Length}");
}
?
}
?
//構(gòu)造每一頁的URL
public string[] GetUrls(int pageNumber)
{
string[] urls = new string[pageNumber];
for (int i = 0; i < urls.Length; i++)
{
if (i == 0)
{
urls[i] = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index.shtml";
}
else
{
urls[i] = $"https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/index_{i}.shtml";
}
}
return urls;
}
這里使用了HtmlAgilityPack

HtmlAgilityPack(HAP)是一個用于處理HTML文檔的.NET庫。它允許你方便地從HTML文檔中提取信息,修改HTML結(jié)構(gòu),并執(zhí)行其他HTML文檔相關(guān)的操作。HtmlAgilityPack 提供了一種靈活而強大的方式來解析和處理HTML,使得在.NET應(yīng)用程序中進行網(wǎng)頁數(shù)據(jù)提取和處理變得更加容易。
// 使用HtmlAgilityPack解析網(wǎng)頁內(nèi)容
var doc = new HtmlAgilityPack.HtmlDocument();
doc.LoadHtml("需要解析的Html");
//獲取需要的數(shù)據(jù)所在的節(jié)點
var node = doc.DocumentNode.SelectSingleNode("XPath");
那么XPath是什么呢?
XPath(XML Path Language)是一種用于在XML文檔中定位和選擇節(jié)點的語言。它是W3C(World Wide Web Consortium)的標準,通常用于在XML文檔中執(zhí)行查詢操作。XPath提供了一種簡潔而強大的方式來導(dǎo)航和操作XML文檔的內(nèi)容。
構(gòu)建每一天的URL
獲取到了每一頁的URL之后,我們發(fā)現(xiàn)在每一頁的URL都可以獲取關(guān)于每一天的URL信息,如下所示:
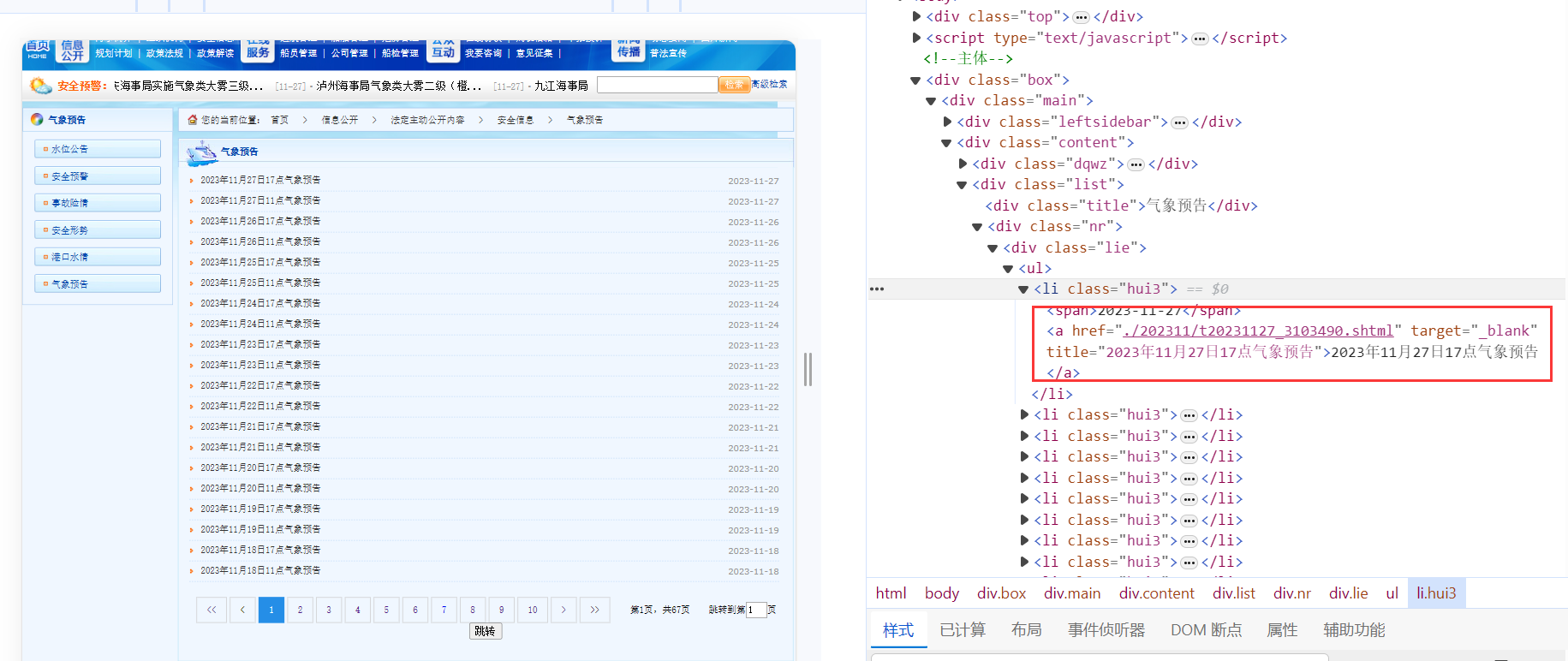
可以進一步構(gòu)建每一天的URL,同時可以根據(jù)a的文本獲取時間,當然也可以通過其他方式獲取時間,但是這種可以獲取到11點或者17點。
代碼如下所示:
for (int i = 0; i < Urls.Length; i++)
{
// 發(fā)送 GET 請求
string url2 = Urls[i];
HttpResponseMessage response2 = await httpClient.GetAsync(url2);
// 處理響應(yīng)
if (response2.IsSuccessStatusCode)
{
string responseBody2 = await response2.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("http://div[@class=\"lie\"]/ul/li");
for (int j = 0; j < nodes.Count; j++)
{
var name = nodes[j].ChildNodes[3].InnerText;
//只有name符合下面的格式才能成功轉(zhuǎn)換為時間,所以這里需要有一個判斷
if (name != "" && name.Contains("氣象預(yù)告"))
{
var dayUrl = new DayUrl();
//string format;
//DateTime date;
// 定義日期時間格式
string format = "yyyy年M月d日H點氣象預(yù)告";
// 解析字符串為DateTime
DateTime date = DateTime.ParseExact(name, format, null);
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);
dayUrl.Date = date;
dayUrl.Url = realUrl;
dayUrlList.Add(dayUrl);
}
else
{
Debug.WriteLine($"在{name}處,判斷不符合要求");
}
?
}
}
}
// 將數(shù)據(jù)存入SQLite數(shù)據(jù)庫
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"獲取每天的URL成功,共有{dayUrlList.Count}條");
}
在這一步驟需要注意的是XPath的書寫,以及每一天URL的構(gòu)建,以及時間的獲取。
XPath的書寫:
var nodes = doc.DocumentNode.SelectNodes("http://div[@class=\"lie\"]/ul/li");
表示一個類名為"lie"的div下的ul標簽下的所有l(wèi)i標簽,如下所示:
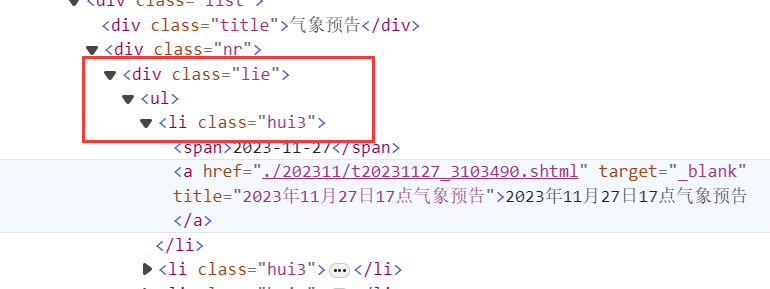
構(gòu)建每一天的URL:
var a = nodes[j].ChildNodes[3];
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = "";
realUrl = newValue + urlText.Substring(1);
這里獲取li標簽下的a標簽,如下所示:
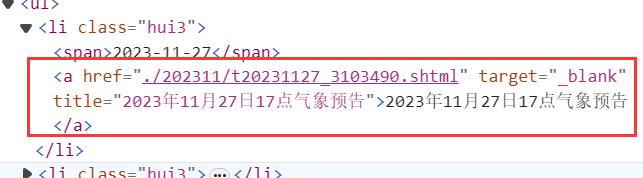
string urlText = a.GetAttributeValue("href", "");
這段代碼獲取a標簽中href屬性的值,這里是./202311/t20231127_3103490.shtml。
string urlText = a.GetAttributeValue("href", "");
string newValue = "https://cj.msa.gov.cn/xxgk/xxgkml/aqxx/qxyg/";
string realUrl = newValue + urlText.Substring(1);
這里是在拼接每一天的URL。
var name = nodes[j].ChildNodes[3].InnerText;
// 定義日期時間格式
string format = "yyyy年M月d日H點氣象預(yù)告";
// 解析字符串為DateTime
DateTime date = DateTime.ParseExact(name, format, null);
這里是從文本中獲取時間,比如文本的值也就是name的值為:“2023年7月15日17點氣象預(yù)告”,name獲得的date就是2023-7-15 17:00。
// 將數(shù)據(jù)存入SQLite數(shù)據(jù)庫
db.Insertable(dayUrlList.OrderBy(x => x.Date).ToList()).ExecuteCommand();
MessageBox.Show($"獲取每天的URL成功,共有{dayUrlList.Count}條");
這里是將數(shù)據(jù)存入數(shù)據(jù)庫中,ORM使用的是SQLSugar,類DayUrl如下:
internal class DayUrl
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public DateTime Date { get; set; }
public string Url { get; set; }
}
最后獲取每一天URL的效果如下所示:

獲取溫度數(shù)據(jù)
需要獲取的內(nèi)容如下:

設(shè)計對應(yīng)的類如下:
internal class WeatherData
{
[SugarColumn(IsPrimaryKey = true, IsIdentity = true)]
public int Id { get; set; }
public string? StationName { get; set; }
public string? Weather { get; set; }
public string? Tem_Low { get; set; }
public string? Tem_High { get; set; }
public string? Wind { get; set; }
public string? Visibility_Low { get; set; }
public string? Visibility_High { get; set; }
public string? Fog { get; set; }
public string? Haze { get; set; }
public DateTime Date { get; set; }
}
增加了一個時間,方便以后根據(jù)時間獲取。
獲取溫度數(shù)據(jù)的代碼如下:
var list = db.Queryable<DayUrl>().ToList();
for (int i = 0; i < list.Count; i++)
{
HttpResponseMessage response = await httpClient.GetAsync(list[i].Url);
// 處理響應(yīng)
if (response.IsSuccessStatusCode)
{
string responseBody2 = await response.Content.ReadAsStringAsync();
doc.LoadHtml(responseBody2);
var nodes = doc.DocumentNode.SelectNodes("http://table");
if (nodes != null)
{
var table = nodes[5];
var trs = table.SelectNodes("tbody/tr");
for (int j = 1; j < trs.Count; j++)
{
var tds = trs[j].SelectNodes("td");
switch (tds.Count)
{
case 8:
var wd8 = new WeatherData();
wd8.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd8.Weather = tds[1].InnerText.Trim().Replace(" ", "");
wd8.Tem_Low = tds[2].InnerText.Trim().Replace(" ", "");
wd8.Tem_High = tds[3].InnerText.Trim().Replace(" ", "");
wd8.Wind = tds[4].InnerText.Trim().Replace(" ", "");
wd8.Visibility_Low = tds[5].InnerText.Trim().Replace(" ", "");
wd8.Visibility_High = tds[6].InnerText.Trim().Replace(" ", "");
wd8.Fog = tds[7].InnerText.Trim().Replace(" ", "");
wd8.Date = list[i].Date;
weatherDataList.Add(wd8);
break;
case 9:
var wd9 = new WeatherData();
wd9.StationName = tds[0].InnerText.Trim().Replace(" ", "");
wd9.Weather = tds[1].InnerText.Trim().Replace(