第 12 章 集合
第 12 章 集合
12.12 Map 接口和常用方法
12.12.1 Map 接口實現類的特點 [很實用]
注意: 這里講的是 JDK8 的 Map 接口特點 Map.java
- Map 與 Collection 并列存在,用于保存具有映射關系的數據(Key-Value)
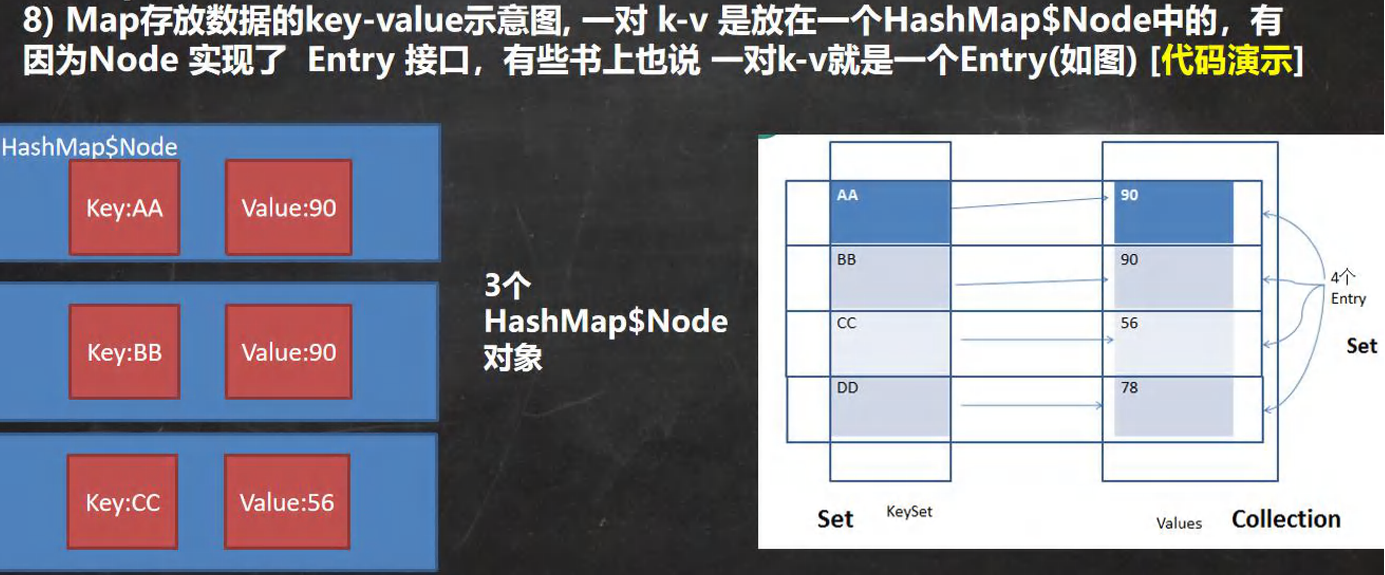
- Map 中的
key和value可以是任何引用類型的數據,會封裝到HashMap$Node對象中 - Map 中的
key不允許重復,原因和HashSet一樣(前面分析過源碼) - Map 中的
value可以重復 - Map 的
key可以為null,value也可以為null;注意key為null時只能有一個,value為null時可以多個 - 常用
String類作為 Map 的key key和value之間存在單向一對一關系,即通過指定的key總能找到對應的value
public class Map_ {
public static void main(String[] args) {
//解讀Map 接口實現類的特點, 使用實現類HashMap
//1. Map與Collection并列存在。用于保存具有映射關系的數據:Key-Value(雙列元素)
//2. Map 中的 key 和 value 可以是任何引用類型的數據,會封裝到HashMap$Node 對象中
//3. Map 中的 key 不允許重復,原因和HashSet 一樣,前面分析過源碼.
//4. Map 中的 value 可以重復
//5. Map 的key 可以為 null, value 也可以為null ,注意 key 為null,
// 只能有一個,value 為null ,可以多個
//6. 常用String類作為Map的 key
//7. key 和 value 之間存在單向一對一關系,即通過指定的 key 總能找到對應的 value
Map map = new HashMap();
map.put("no1", "韓順平");//k-v
map.put("no2", "張無忌");//k-v
map.put("no1", "張三豐");//當有相同的k , 就等價于替換.
map.put("no3", "張三豐");//k-v
map.put(null, null); //k-v
map.put(null, "abc"); //等價替換
map.put("no4", null); //k-v
map.put("no5", null); //k-v
map.put(1, "趙敏");//k-v
map.put(new Object(), "金毛獅王");//k-v
// 通過get 方法,傳入 key ,會返回對應的value
System.out.println(map.get("no2"));//張無忌
System.out.println("map=" + map);
}
}
public class MapMethod {
public static void main(String[] args) {
//演示map接口常用方法
Map map = new HashMap();
map.put("鄧超", new Book("", 100));//OK
map.put("鄧超", "孫儷");//替換-> 一會分析源碼
map.put("王寶強", "馬蓉");//OK
map.put("宋喆", "馬蓉");//OK
map.put("劉令博", null);//OK
map.put(null, "劉亦菲");//OK
map.put("鹿晗", "關曉彤");//OK
map.put("hsp", "hsp的老婆");
System.out.println("map=" + map);
// remove:根據鍵刪除映射關系
map.remove(null);
System.out.println("map=" + map);
// get:根據鍵獲取值
Object val = map.get("鹿晗");
System.out.println("val=" + val);
// size:獲取元素個數
System.out.println("k-v=" + map.size());
// isEmpty:判斷個數是否為0
System.out.println(map.isEmpty());//F
// clear:清除k-v
//map.clear();
System.out.println("map=" + map);
// containsKey:查找鍵是否存在
System.out.println("結果=" + map.containsKey("hsp"));//T
}
}
class Book {
private String name;
private int num;
public Book(String name, int num) {
this.name = name;
this.num = num;
}
}
12.12.3 Map 接口遍歷方法
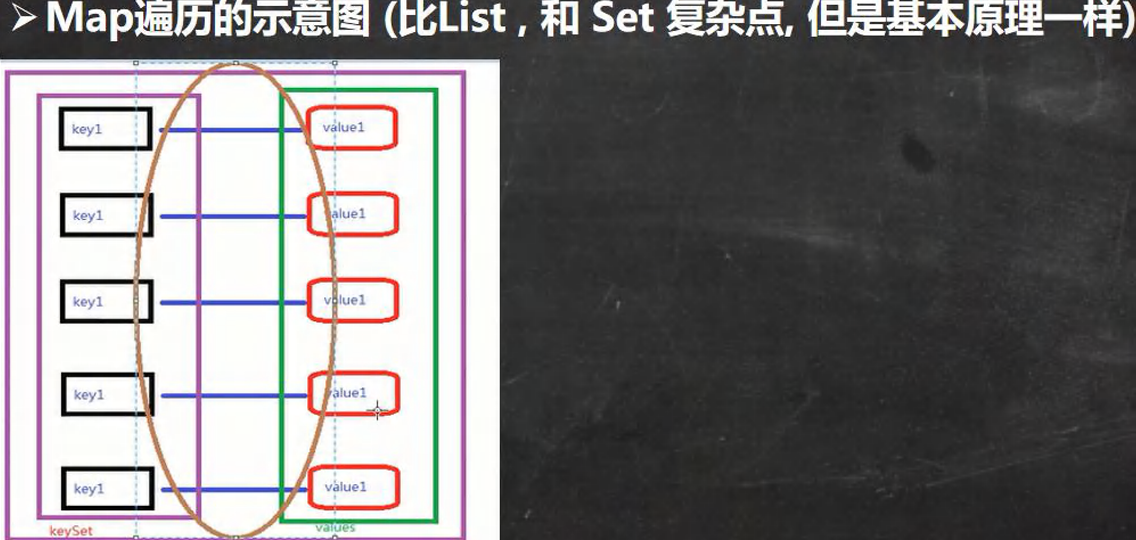
Map遍歷方式案例演示
MapFor.java
containsKey:查找鍵是否存在keySet:獲取所有的鍵entrySet:獲取所有關系 k-vvalues:獲取所有的值
public class MapFor {
public static void main(String[] args) {
Map map = new HashMap();
map.put("鄧超", "孫儷");
map.put("王寶強", "馬蓉");
map.put("宋喆", "馬蓉");
map.put("劉令博", null);
map.put(null, "劉亦菲");
map.put("鹿晗", "關曉彤");
//第一組: 先取出 所有的Key , 通過Key 取出對應的Value
Set keyset = map.keySet();
//(1) 增強for
System.out.println("-----第一種方式-------");
for (Object key : keyset) {
System.out.println(key + "-" + map.get(key));
}
//(2) 迭代器
System.out.println("----第二種方式--------");
Iterator iterator = keyset.iterator();
while (iterator.hasNext()) {
Object key = iterator.next();
System.out.println(key + "-" + map.get(key));
}
//
// //第二組: 把所有的values取出
// Collection values = map.values();
// //這里可以使用所有的Collections使用的遍歷方法
// //(1) 增強for
// System.out.println("---取出所有的value 增強for----");
// for (Object value : values) {
// System.out.println(value);
// }
//
//
// //(2) 迭代器
// System.out.println("---取出所有的value 迭代器----");
// Iterator iterator2 = values.iterator();
// while (iterator2.hasNext()) {
// Object value = iterator2.next();
// System.out.println(value);
//
// }
//
// //第三組: 通過EntrySet 來獲取 k-v
Set entrySet = map.entrySet();// EntrySet<Map.Entry<K,V>>
// //(1) 增強for
System.out.println("----使用EntrySet 的 for增強(第3種)----");
for (Object entry : entrySet) {
//將entry 轉成 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
//(2) 迭代器
System.out.println("----使用EntrySet 的 迭代器(第4種)----");
Iterator iterator3 = entrySet.iterator();
while (iterator3.hasNext()) {
Object entry = iterator3.next();
//System.out.println(next.getClass());//HashMap$Node -實現-> Map.Entry (getKey,getValue)
//向下轉型 Map.Entry
Map.Entry m = (Map.Entry) entry;
System.out.println(m.getKey() + "-" + m.getValue());
}
Map<Integer,Integer> cnt = new HashMap<>();
cnt.put(1,1);
cnt.put(2,2);
for(Map.Entry<Integer,Integer> entry :cnt.entrySet()){
System.out.println(entry.getKey() + "-" + entry.getValue());
}
}
}
12.12.4Map接口課堂練習
public class MapExercise {
public static void main(String[] args) {
//完成代碼
Map hashMap = new HashMap();
//添加對象
hashMap.put(1, new Emp("jack", 300000, 1));
hashMap.put(2, new Emp("tom", 21000, 2));
hashMap.put(3, new Emp("milan", 12000, 3));
//遍歷2種方式
//并遍歷顯示工資>18000的員工(遍歷方式最少兩種)
//1. 使用keySet -> 增強for
Set keySet = hashMap.keySet();
System.out.println("====第一種遍歷方式====");
for (Object key : keySet) {
//先獲取value
Emp emp = (Emp) hashMap.get(key);
if(emp.getSal() >18000) {
System.out.println(emp);
}
}
//2. 使用EntrySet -> 迭代器
// 體現比較難的知識點
// 慢慢品,越品越有味道.
Set entrySet = hashMap.entrySet();
System.out.println("======迭代器======");
Iterator iterator = entrySet.iterator();
while (iterator.hasNext()) {
Map.Entry entry = (Map.Entry)iterator.next();
//通過entry 取得key 和 value
Emp emp = (Emp) entry.getValue();
if(emp.getSal() > 18000) {
System.out.println(emp);
}
}
}
}
/**
* 使用HashMap添加3個員工對象,要求
* 鍵:員工id
* 值:員工對象
*
* 并遍歷顯示工資>18000的員工(遍歷方式最少兩種)
* 員工類:姓名、工資、員工id
*/
class Emp {
private String name;
private double sal;
private int id;
public Emp(String name, double sal, int id) {
this.name = name;
this.sal = sal;
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getSal() {
return sal;
}
public void setSal(double sal) {
this.sal = sal;
}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
@Override
public String toString() {
return "Emp{" +
"name='" + name + '\'' +
", sal=" + sal +
", id=" + id +
'}';
}
}
12.13 Map 接口實現類 - HashMap
12.13.1 HashMap 小結
- Map 接口的常用實現類:HashMap、Hashtable 和 Properties。
- HashMap 是 Map 接口使用頻率最高的實現類。
- HashMap 是以 key-val 對的方式來存儲數據(HashMap$Node 類型)[案例 Entry]
- key 不能重復,但是值可以重復,允許使用 null 鍵和 null 值。
- 如果添加相同的 key,則會覆蓋原來的 key-val,等同于修改。(key 不會替換,val 會替換)
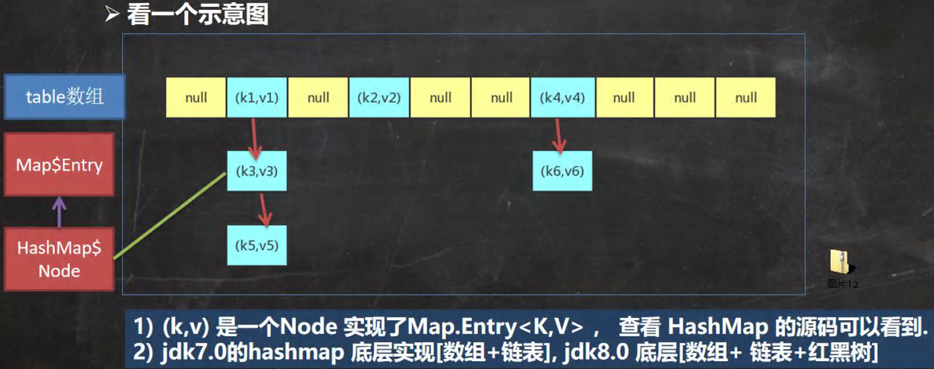
- 與 HashSet 一樣,不保證映射的順序,因為底層是以 hash 表的方式來存儲的。(jdk8 的 hashMap 底層 數組 + 鏈表 + 紅黑樹)
- HashMap 沒有實現同步,因此是線程不安全的,方法沒有做同步互斥的操作,沒有 synchronized
12.13.2 HashMap 底層機制及源碼剖析
12.13.3 HashMap 底層機制及源碼剖析
HashMapSource.java 先說結論-> debug 源碼.
擴容機制 [和 HashSet 相同]
- HashMap 底層維護了
Node類型的數組table,默認為null - 當創建對象時,將加載因子(
loadfactor)初始化為0.75 - 當添加
key-val時,通過key的哈希值得到在table的索引。然后判斷該索引處是否有元素:- 無元素:直接添加
- 有元素:繼續判斷該元素的
key和準備加入的key是否相等- 相等:直接替換
val - 不相等:判斷是樹結構還是鏈表結構,做出相應處理
- 相等:直接替換
- 容量不夠:擴容
- 第 1 次添加,擴容
table容量為16,臨界值(threshold)為12(16*0.75) - 后續擴容,
table容量變為原來的2倍(如32),臨界值也變為原來的2倍(如24),依次類推 - Java8 中,若一條鏈表元素個數超過
TREEIFY_THRESHOLD(默認8),且table大小>= MIN_TREEIFY_CAPACITY(默認64),會進行樹化(轉紅黑樹 )
public class HashMapSource1 {
public static void main(String[] args) {
HashMap map = new HashMap();
map.put("java", 10);//ok
map.put("php", 10);//ok
map.put("java", 20);//替換value
System.out.println("map=" + map);//
/*解讀HashMap的源碼+圖解
1. 執行構造器 new HashMap()
初始化加載因子 loadfactor = 0.75
HashMap$Node[] table = null
2. 執行put 調用 hash方法,計算 key的 hash值 (h = key.hashCode()) ^ (h >>> 16)
public V put(K key, V value) {//K = "java" value = 10
return putVal(hash(key), key, value, false, true);
}
3. 執行 putVal
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;//輔助變量
//如果底層的table 數組為null, 或者 length =0 , 就擴容到16
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
//取出hash值對應的table的索引位置的Node, 如果為null, 就直接把加入的k-v
//, 創建成一個 Node ,加入該位置即可
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
else {
Node<K,V> e; K k;//輔助變量
// 如果table的索引位置的key的hash相同和新的key的hash值相同,
// 并 滿足(table現有的結點的key和準備添加的key是同一個對象 || equals返回真)
// 就認為不能加入新的k-v
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
else if (p instanceof TreeNode)//如果當前的table的已有的Node 是紅黑樹,就按照紅黑樹的方式處理
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
//如果找到的結點,后面是鏈表,就循環比較
for (int binCount = 0; ; ++binCount) {//死循環
if ((e = p.next) == null) {//如果整個鏈表,沒有和他相同,就加到該鏈表的最后
p.next = newNode(hash, key, value, null);
//加入后,判斷當前鏈表的個數,是否已經到8個,到8個,后
//就調用 treeifyBin 方法進行紅黑樹的轉換
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash && //如果在循環比較過程中,發現有相同,就break,就只是替換value
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value; //替換,key對應value
afterNodeAccess(e);
return oldValue;
}
}
++modCount;//每增加一個Node ,就size++
if (++size > threshold[12-24-48])//如size > 臨界值,就擴容
resize();
afterNodeInsertion(evict);
return null;
}
5. 關于樹化(轉成紅黑樹)
//如果table 為null ,或者大小還沒有到 64,暫時不樹化,而是進行擴容.
//否則才會真正的樹化 -> 剪枝
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
}
*/
}
HashMapSource2.java
模擬 HashMap 觸發擴容、樹化情況,并 Debug 驗證。
public class HashMapSource2 {
public static void main(String[] args) {
HashMap hashMap = new HashMap(64);
for(int i = 1; i <= 12; i++) {
hashMap.put(new A(i), "hello");
// hashMap.put(i, "hello");
}
hashMap.put("aaa", "bbb");
System.out.println("hashMap=" + hashMap);//12個 k-v
//布置一個任務,自己設計代碼去驗證,table 的擴容
//0 -> 16(12) -> 32(24) -> 64(64*0.75=48)-> 128 (96) ->
//自己設計程序,驗證-》 增強自己閱讀源碼能力. 看別人代碼.
}
}
class A {
private int num;
public A(int num) {
this.num = num;
}
//所有的A對象的hashCode都是100
@Override
public int hashCode() {
return 100;
}
@Override
public String toString() {
return "\nA{" +
"num=" + num +
'}';
}
}
12.14 Map 接口實現類 - Hashtable
12.14.1 HashTable 的基本介紹
- 存儲結構:存放鍵值對(K-V)
- null 限制:鍵和值都不能為
null,否則拋出NullPointerException - 使用方式:用法與
HashMap基本一致 - 線程安全:
HashTable是線程安全的(方法帶synchronized),HashMap線程不安全 - 底層結構:與
HashMap類似(數組 + 鏈表等,JDK8 后也有樹化邏輯 )
代碼驗證示例(HashTableExercise.java):
Hashtable table = new Hashtable();//ok
table.put("john", 100); //ok
table.put(null, 100); // 異常(鍵為 null 不允許)
table.put("john", null);// 異常(值為 null 不允許)
table.put("lucy", 100); //ok
table.put("lic", 100); //ok
table.put("lic", 88); // 替換值(鍵重復時覆蓋)
System.out.println(table);
12.14.2 Hashtable 和 HashMap 對比
| 特性 | HashMap | Hashtable |
|---|---|---|
| JDK 版本 | 1.2 | 1.0 |
| 線程安全 | 不安全 | 安全(同步) |
| 效率 | 高 | 較低 |
| null 允許 | 鍵/值均可為 null(鍵僅 1 個 null) | 不允許 |
12.15 Map 接口實現類 - Properties
12.15.1 基本介紹
- 繼承關系:繼承
Hashtable并實現Map接口,以鍵值對(K-V)形式存儲數據 - 使用場景:常用于讀取
.properties配置文件(如xxx.properties),加載數據到Properties對象后讀取/修改 - 典型流程:從配置文件加載 → 操作鍵值 → 持久化回文件,常作為系統配置管理方案
12.15.2 基本使用
public class Properties_ {
public static void main(String[] args) {
//解讀
//1. Properties 繼承 Hashtable
//2. 可以通過 k-v 存放數據,當然key 和 value 不能為 null
//增加
Properties properties = new Properties();
//properties.put(null, "abc");//拋出 空指針異常
//properties.put("abc", null); //拋出 空指針異常
properties.put("john", 100);//k-v
properties.put("lucy", 100);
properties.put("lic", 100);
properties.put("lic", 88);//如果有相同的key , value被替換
System.out.println("properties=" + properties);
//通過k 獲取對應值
System.out.println(properties.get("lic"));//88
//刪除
properties.remove("lic");
System.out.println("properties=" + properties);
//修改
properties.put("john", "約翰");
System.out.println("properties=" + properties);
}
}
12.16 TreeSet & TreeMap 核心要點梳理
12.16.1TreeSet 核心邏輯
- 底層依賴與排序機制
TreeSet 底層基于 TreeMap 實現,利用紅黑樹(自平衡二叉搜索樹)維護元素順序,支持兩種排序模式:
- 自然排序:元素實現
Comparable接口,按compareTo規則排序(如String按字典序)。 - 定制排序:通過構造器傳入
Comparator自定義排序規則,優先級高于自然排序。
- 關鍵代碼示例(定制排序)
TreeSet treeSet = new TreeSet(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
// 按字符串長度排序(短 → 長)
return ((String) o1).length() - ((String) o2).length();
}
});
treeSet.add("jack"); // 4
treeSet.add("tom"); // 3
treeSet.add("sp"); // 2
treeSet.add("a"); // 1
treeSet.add("abc"); // 3
// 輸出:[a, sp, tom, abc, jack](按長度排序,長度相同時按自然序)
System.out.println("treeSet=" + treeSet);
- 源碼關鍵流程(結合 TreeMap)
TreeSet 的add操作最終調用 TreeMap 的put方法:
- 排序規則傳遞:構造 TreeSet 時傳入的
Comparator,會賦值給 TreeMap 的comparator屬性。 - 插入邏輯:
- 若
Comparator不為空,遍歷紅黑樹節點,通過comparator.compare(key, t.key)確定插入位置。 - 若比較結果
cmp = 0,視為重復元素,不插入;否則根據cmp大小插入左子樹(cmp < 0)或右子樹(cmp > 0)。
- 若
12.16.2TreeMap 核心邏輯
- 底層結構與排序機制
TreeMap 底層基于 紅黑樹 實現,鍵(Key)需支持排序:
- 自然排序:Key 實現
Comparable接口,按compareTo排序。 - 定制排序:構造器傳入
Comparator,自定義排序規則,直接決定 Key 的存儲順序。
- 關鍵代碼示例(定制排序)
TreeMap treeMap = new TreeMap(new Comparator() {
@Override
public int compare(Object o1, Object o2) {
// 按字符串長度倒序排序(長 → 短)
return ((String) o2).length() - ((String) o1).length();
}
});
treeMap.put("jack", "杰克"); // 4
treeMap.put("tom", "湯姆"); // 3
treeMap.put("kristina", "克瑞斯提諾"); // 8
treeMap.put("smith", "斯密斯"); // 5
treeMap.put("hsp", "韓順平"); // 3(因長度與 "tom" 相同,且比較規則下視為重復,無法插入)
// 輸出:{kristina=克瑞斯提諾, smith=斯密斯, jack=杰克, tom=湯姆}(按長度倒序)
System.out.println("treemap=" + treeMap);
- 源碼關鍵流程
TreeMap 的put方法核心邏輯:
- 初始化紅黑樹:首次
put時,直接創建根節點Entry。 - 遍歷紅黑樹:若傳入
Comparator(cpr != null),循環比較新 Key 與當前節點 Key:cmp < 0:向左子樹遍歷;cmp > 0:向右子樹遍歷;cmp = 0:替換當前節點值(視為 Key 重復,不新增節點)。
- 維護紅黑樹平衡:插入新節點后,通過旋轉、變色操作恢復紅黑樹性質(保證 O(log n) 復雜度)。
12.16.3TreeSet vs TreeMap 核心差異
| 對比項 | TreeSet | TreeMap |
|---|---|---|
| 存儲形式 | 僅存元素(Key),基于 TreeMap 封裝 | 存儲鍵值對(Key-Value) |
| 排序對象 | 元素本身(Key) | 顯式定義的 Key |
| 典型場景 | 需有序去重的集合(如詞匯表排序) | 需有序關聯映射的場景(如配置表) |
| 底層依賴 | 完全依賴 TreeMap(Key 存儲,Value 占位) | 直接基于紅黑樹實現 |
12.16.4核心設計思想總結
- 紅黑樹的價值:通過自平衡機制,保證插入、查詢、刪除的時間復雜度穩定在 O(log n),避免普通二叉搜索樹退化(如鏈表化導致 O(n) 復雜度)。
- 排序的靈活性:支持
Comparable(自然排序)和Comparator(定制排序),覆蓋“類默認排序”與“場景化排序”需求。 - TreeSet 的本質:TreeMap 的“Key 集合視圖”,利用 TreeMap 的排序能力實現元素有序存儲,簡化有序集合的使用成本。
通過理解紅黑樹的底層支撐與排序規則的傳遞邏輯,可清晰掌握 TreeSet/TreeMap 的有序性實現,靈活應對“需按自定義規則排序”的業務場景(如按字符串長度、對象屬性等排序)。
12.17 總結-開發中如何選擇集合實現類(記住)
在開發中,選擇集合實現類主要看業務操作特點,結合集合特性選,分析流程:
- 判斷存儲類型:是存一組對象(單列)還是一組鍵值對(雙列)
- 一組對象(單列)→ Collection 接口
- 允許重復 → List
- 增刪多:選
LinkedList(底層雙向鏈表) - 改查多:選
ArrayList(底層可變對象數組)
- 增刪多:選
- 不允許重復 → Set
- 無序:選
HashSet(底層基于HashMap,哈希表結構:數組+鏈表+紅黑樹 ) - 排序:選
TreeSet(需實現排序規則,如Comparable/Comparator) - 插入&取出順序一致:選
LinkedHashSet(維護數組+雙向鏈表,保證順序 )
- 無序:選
- 允許重復 → List
- 一組鍵值對(雙列)→ Map
- 鍵無序:選
HashMap(底層哈希表,JDK7 數組+鏈表;JDK8 數組+鏈表+紅黑樹 ) - 鍵排序:選
TreeMap(按鍵排序,需實現排序規則 ) - 鍵插入&取出順序一致:選
LinkedHashMap(維護鏈表記錄順序 ) - 讀取配置文件:選
Properties(繼承Hashtable,專用于.properties文件讀寫 )
- 鍵無序:選
按業務需求(增刪/改查頻率、是否需順序/排序、是否鍵值對等),匹配對應集合即可。
12.18 Collections 工具類
12.18.1 Collections 工具類介紹
- Collections 是操作 Set、List、Map 等集合的工具類
- 提供一系列靜態方法,用于集合元素的排序、查詢、修改等操作
12.18.2 排序操作(均為 static 方法)
-
reverse(List):反轉 List 中元素順序 -
shuffle(List):隨機打亂 List 元素順序 -
sort(List):按元素自然順序對 List 升序排序(需元素實現Comparable) -
sort(List, Comparator):按指定Comparator規則對 List 排序 -
swap(List, int, int):交換 List 中指定索引i和j處的元素 -
應用案例演示:
Collections.java
public class Collections_ {
public static void main(String[] args) {
//創建ArrayList 集合,用于測試.
List list = new ArrayList();
list.add("tom");
list.add("smith");
list.add("king");
list.add("milan");
list.add("tom");
// reverse(List):反轉 List 中元素的順序
Collections.reverse(list);
System.out.println("list=" + list);
// shuffle(List):對 List 集合元素進行隨機排序
// for (int i = 0; i < 5; i++) {
// Collections.shuffle(list);
// System.out.println("list=" + list);
// }
// sort(List):根據元素的自然順序對指定 List 集合元素按升序排序
Collections.sort(list);
System.out.println("自然排序后");
System.out.println("list=" + list);
// sort(List,Comparator):根據指定的 Comparator 產生的順序對 List 集合元素進行排序
//我們希望按照 字符串的長度大小排序
Collections.sort(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
//可以加入校驗代碼.
return ((String) o2).length() - ((String) o1).length();
}
});
System.out.println("字符串長度大小排序=" + list);
// swap(List,int, int):將指定 list 集合中的 i 處元素和 j 處元素進行交換
//比如
Collections.swap(list, 0, 1);
System.out.println("交換后的情況");
System.out.println("list=" + list);
//Object max(Collection):根據元素的自然順序,返回給定集合中的最大元素
System.out.println("自然順序最大元素=" + Collections.max(list));
//Object max(Collection,Comparator):根據 Comparator 指定的順序,返回給定集合中的最大元素
//比如,我們要返回長度最大的元素
Object maxObject = Collections.max(list, new Comparator() {
@Override
public int compare(Object o1, Object o2) {
return ((String)o1).length() - ((String)o2).length();
}
});
System.out.println("長度最大的元素=" + maxObject);
//Object min(Collection)
//Object min(Collection,Comparator)
//上面的兩個方法,參考max即可
//int frequency(Collection,Object):返回指定集合中指定元素的出現次數
System.out.println("tom出現的次數=" + Collections.frequency(list, "tom"));
//void copy(List dest,List src):將src中的內容復制到dest中
ArrayList dest = new ArrayList();
//為了完成一個完整拷貝,我們需要先給dest 賦值,大小和list.size()一樣
for(int i = 0; i < list.size(); i++) {
dest.add("");
}
//拷貝
Collections.copy(dest, list);
System.out.println("dest=" + dest);
//boolean replaceAll(List list,Object oldVal,Object newVal):使用新值替換 List 對象的所有舊值
//如果list中,有tom 就替換成 湯姆
Collections.replaceAll(list, "tom", "湯姆");
System.out.println("list替換后=" + list);
}
}
12.18.3 排序操作
(均為 static 方法)
應用案例演示
12.18.4 查找、替換
Object max(Collection):按元素自然順序,返回集合最大元素Object max(Collection, Comparator):按Comparator規則,返回集合最大元素Object min(Collection):返回集合最小元素(自然順序)Object min(Collection, Comparator):按Comparator規則,返回集合最小元素int frequency(Collection, Object):返回集合中指定元素的出現次數void copy(List dest, List src):把src內容復制到dest(需dest容量 ≥src)boolean replaceAll(List list, Object oldVal, Object newVal):用newVal替換list里所有oldVal
12.19 Java 集合去重與代碼分析題目整理
12.19.1簡答題:HashSet 和 TreeSet 如何實現去重
題目內容
試分析 HashSet 和 TreeSet 分別如何實現去重
答案與解釋
1. HashSet 去重機制
HashSet 基于 HashMap 實現(底層用 HashMap 存儲元素,Value 固定為一個占位對象),去重依賴 hashCode() + equals():
- 存儲元素時,先調用對象的
hashCode()計算哈希值,根據哈希值找到HashMap中對應的桶(數組索引)。 - 若桶為空,直接存入元素。
- 若桶不為空,遍歷桶中已存在的元素,依次調用
equals()比較:- 若
equals()返回true,視為重復元素,不存入; - 若
equals()返回false,視為不同元素,存入桶中(鏈表或紅黑樹,根據情況轉換 )。
- 若
2. TreeSet 去重機制
TreeSet 基于 TreeMap 實現(底層用 TreeMap 存儲元素,Value 固定為一個占位對象),去重依賴 排序規則(Comparator 或 Comparable):
- 若創建 TreeSet 時傳入
Comparator(定制排序),則通過Comparator.compare(Object o1, Object o2)比較元素:- 若返回
0,視為重復元素,不存入; - 若返回非
0,視為不同元素,按排序規則插入紅黑樹。
- 若返回
- 若未傳入
Comparator,則要求元素實現Comparable接口,通過Comparable.compareTo(Object o)比較:- 若返回
0,視為重復元素,不存入; - 若返回非
0,視為不同元素,按自然排序插入紅黑樹。
- 若返回
12.19.2 代碼分析題 1:TreeSet 添加自定義對象是否拋異常
題目內容
下面代碼運行會不會拋出異常,并從源碼層面說明原因(考察讀源碼 + 接口編程 + 動態綁定):
TreeSet treeSet = new TreeSet();
treeSet.add(new Person());
答案與解釋
會拋出 ClassCastException 異常,原因如下:
TreeSet 底層依賴 TreeMap,而 TreeMap 要求 Key 必須支持排序(要么實現 Comparable 接口,要么創建時傳入 Comparator)。
-
源碼關鍵邏輯:
TreeMap 的put方法中,若未傳入Comparator,會嘗試將 Key 強轉為Comparable類型,并調用compareTo方法:if (cpr == null) { if (key == null) throw new NullPointerException(); @SuppressWarnings("unchecked") Comparable<? super K> k = (Comparable<? super K>) key; do { // ... 遍歷紅黑樹,調用 k.compareTo(...) } while (t != null); } -
異常觸發條件:
若Person類未實現Comparable接口,強轉Comparable會失敗,拋出ClassCastException(運行時異常)。
12.19.3 代碼分析題 2:HashSet 元素操作后的輸出結果
題目內容
已知:Person 類按照 id 和 name 重寫了 hashCode 和 equals 方法,問下面代碼輸出什么?
HashSet set = new HashSet();
Person p1 = new Person(1001, "AA");
Person p2 = new Person(1002, "BB");
set.add(p1);
set.add(p2);
p1.name = "CC";
set.remove(p1);
System.out.println(set); // 輸出 1
set.add(new Person(1001, "CC"));
System.out.println(set); // 輸出 2
set.add(new Person(1001, "AA"));
System.out.println(set); // 輸出 3
答案與解釋
需結合 HashSet 去重邏輯 和 對象屬性修改的影響 分析:
-
初始狀態(添加
p1、p2)
set.add(p1)和set.add(p2)后,set中有兩個元素:Person(1001, "AA")、Person(1002, "BB")。 -
修改
p1.name并調用set.remove(p1)
p1的name被修改為"CC",但HashSet底層HashMap的哈希桶是根據插入時的hashCode確定的。- 調用
set.remove(p1)時,先計算p1當前的hashCode(基于id=1001、name="CC"),找到對應的哈希桶。 - 遍歷桶中元素,調用
equals比較:- 原
p1(id=1001、name="AA")已被修改為name="CC",但HashSet中存儲的元素是修改前的p1嗎?不,p1是同一個對象,修改其屬性后,hashCode和equals結果會變化。 - 實際邏輯:
remove(p1)會根據當前p1的hashCode和equals找元素。由于p1的name已改為"CC",與HashSet中存儲的原p1(name="AA"時的狀態)的equals比較會返回false(因為name不同),因此 無法刪除原p1。
- 原
此時 set 仍包含:Person(1001, "CC")(原 p1,但屬性已改)、Person(1002, "BB")?
不,實際 HashSet 中存儲的是對象引用,p1 被修改后,HashSet 中對應的元素屬性也會變。但 remove 邏輯因 equals 比較失敗,無法刪除,所以 set 此時仍有 2 個元素:p1(name="CC")、p2。
但嚴格來說,HashSet 的 remove 是根據對象當前狀態的 hashCode 和 equals 判斷的。由于 p1 修改后 hashCode 變化(假設 hashCode 依賴 name),原哈希桶位置可能改變,導致 remove 無法找到正確的元素,最終 set 仍保留 p1(修改后)和 p2,System.out.println(set) 輸出 [Person(1001, CC), Person(1002, BB)](假設 Person 的 toString 輸出屬性 )。
- 添加
new Person(1001, "CC")
新對象Person(1001, "CC")的hashCode和equals(與p1比較):
hashCode相同(id=1001、name="CC")。equals返回true(屬性相同)。
但 HashSet 中已有 p1(name="CC"),因此 新對象無法插入,set 仍為 2 個元素。
- 添加
new Person(1001, "AA")
新對象Person(1001, "AA")的hashCode和equals(與p1比較):
hashCode不同(name不同)。equals返回false(name不同)。
因此 新對象會被插入,set 變為 3 個元素:p1(name="CC")、p2、Person(1001, "AA")。
最終輸出總結(假設 Person 重寫 toString 輸出 id 和 name)
System.out.println(set);→[Person(1001, CC), Person(1002, BB)]System.out.println(set);→[Person(1001, CC), Person(1002, BB)](添加new Person(1001, "CC")失敗 )System.out.println(set);→[Person(1001, CC), Person(1002, BB), Person(1001, AA)]
關鍵坑點
修改 HashSet 中已存對象的屬性(影響 hashCode 或 equals),會導致后續 remove、contains 等操作異常,因為哈希桶位置和比較邏輯已被破壞。避免在存入集合后修改對象的關鍵屬性(或確保修改后重新插入、刪除舊對象 )。
以上題目覆蓋了 HashSet、TreeSet 的核心去重邏輯,以及集合操作中對象屬性修改的影響,需結合源碼和接口實現深入理解。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號