AWS redshift+glue+s3 數據ETL總結
近期接觸一個從Azure 上遷移數倉到AWS的案例。一直想總結一下,在這個case中接觸到的工具以及方法。
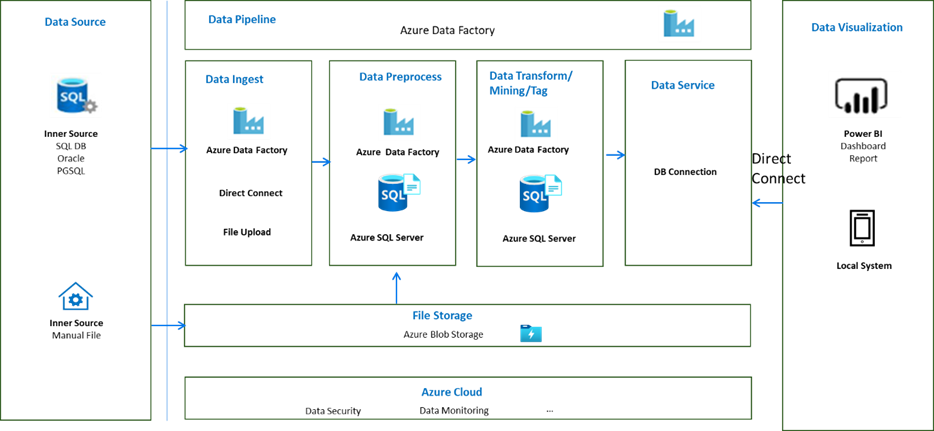
原來的架構
目標架構:

在AWS上形成了基于 s3+aws glue+redshift構建的數據體系,其中S3可用作數據湖存儲,Glue用作ETL/ELT工具,redshift是基于postgresql的列式存儲,作為數倉
在這個技術棧上構建了一個demo,實現下面場景:
從天氣API上獲取指定地區天氣信息,經過簡單數據處理(ETL),存儲到redshift上指定表中。
步驟:
1.準備資源并賦予相應IAM權限
資源:S3,glue ,redshift,創建S3目錄:pocs3inputdev/weather_info/,
創建redshift表:


CREATE TABLE weatherdata ( city VARCHAR(256) ENCODE ZSTD, province VARCHAR(256) ENCODE ZSTD, adcode VARCHAR(64) ENCODE ZSTD, timestamp TIMESTAMP ENCODE DELTA32K, weather VARCHAR(256) ENCODE ZSTD, temperature VARCHAR(64) ENCODE ZSTD, winddirection VARCHAR(128) ENCODE ZSTD, windpower VARCHAR(64) ENCODE ZSTD, humidity VARCHAR(64) ENCODE ZSTD, reporttime VARCHAR(256) ENCODE ZSTD ) DISTKEY(adcode) SORTKEY(timestamp);
ps:注意redshift的DDL格式,主要關注DISTKEY,SORTKEY,以及字段的加密算法ENCODE
權限:glue中訪問S3 PUT /DELETE權限,glue中對S3的fullaccess權限,glue中對redshift的fullaccess權限。
2.所有ETL的表都在glue的Meta catelog中管理,所以需要先在glue中建表
創建數據庫dw-pbi-poc-glue-db
通過“Add table”創建表s3_weather_info,手動設置字段,指定S3目錄:s3://pocs3inputdev/weather_info/
(也可以通過“Add tables using crawler”,指定S3目錄,可以自動識別csv的head,并自動創建表)
3.在glue中創建job, 組裝workflow 形成pipeline
我們設計兩個job,job1使用python shell模式實現讀取API,獲取數據存儲到S3上(CSV)
job2實現讀取S3上數據,經過ETL(簡單字段映射等),存儲到redshift指定表
job1:
glue-->ETL jobs-->script editor-->python
import requests import pandas as pd import boto3 from datetime import datetime import json def get_weather_data_and_save_to_s3(): # API endpoint and parameters url = "https://restapi.amap.com/v3/weather/weatherInfo" params = { 'key': 'd84fdf9cc1f19710bb7ff6c3cd924726', 'city': '110102', 'extensions': 'base', 'output': 'JSON' } # Make HTTP GET request response = requests.get(url, params=params) if response.status_code == 200: data = response.json() # Process the weather data if data.get('status') == '1' and 'lives' in data: weather_info = data['lives'][0] # Get the first (and likely only) record # Create a DataFrame with the weather data df = pd.DataFrame([{ 'timestamp': datetime.now().isoformat(), 'province': weather_info.get('province', ''), 'city': weather_info.get('city', ''), 'adcode': weather_info.get('adcode', ''), 'weather': weather_info.get('weather', ''), 'temperature': weather_info.get('temperature', ''), 'winddirection': weather_info.get('winddirection', ''), 'windpower': weather_info.get('windpower', ''), 'humidity': weather_info.get('humidity', ''), 'reporttime': weather_info.get('reporttime', '') }]) # Save CSV to local C drive with UTF-8 BOM encoding for proper Chinese display # local_file_path = f"C:/Users/a765902/Desktop/KGS 材料/spike poc/weather_data.csv" # # Use pandas to_csv with proper encoding # df.to_csv(local_file_path, index=False, encoding='utf-8-sig') # print(f"Successfully saved CSV to local drive: {local_file_path}") csv_buffer=df.to_csv(index=False) try: # 你的 boto3 調用 # Upload to S3 s3_client = boto3.client('s3') bucket_name = 'pocs3inputdev' # Replace with your bucket name #file_name = f"weather_data_{datetime.now().strftime('%Y%m%d')}.csv" file_name = f"weather_info/weather_data.csv" # Upload the CSV data to S3 s3_client.put_object( Bucket=bucket_name, Key=file_name, Body=csv_buffer, ContentType='text/csv' ) print(f"Successfully saved weather data to s3://{bucket_name}/weather_info/{file_name}") return f"s3://{bucket_name}/weather_info/{file_name}" except Exception as e: print(f"Error: {e}") raise else: print("Error: Invalid response data from weather API") return None else: print(f"Error: HTTP {response.status_code} - {response.text}") return None # Execute the function if __name__ == "__main__": get_weather_data_and_save_to_s3()
job2:
glue-->ETL jobs-->Visual ETL
拖拉拽相應控件,最終腳本:
import sys from awsglue.transforms import * from awsglue.utils import getResolvedOptions from pyspark.context import SparkContext from awsglue.context import GlueContext from awsglue.job import Job from awsglue import DynamicFrame args = getResolvedOptions(sys.argv, ['JOB_NAME']) sc = SparkContext() glueContext = GlueContext(sc) spark = glueContext.spark_session job = Job(glueContext) job.init(args['JOB_NAME'], args) # Script generated for node Amazon S3 AmazonS3_node1754055290874 = glueContext.create_dynamic_frame.from_options(format_options={"quoteChar": "\"", "withHeader": True, "separator": ",", "optimizePerformance": False}, connection_type="s3", format="csv", connection_options={"paths": ["s3://pocs3inputdev/weather_data.csv"], "recurse": True}, transformation_ctx="AmazonS3_node1754055290874") # Script generated for node Rename Field RenameField_node1754055306801 = RenameField.apply(frame=AmazonS3_node1754055290874, old_name="winddirection", new_name="direction", transformation_ctx="RenameField_node1754055306801") # Script generated for node Amazon Redshift AmazonRedshift_node1754055312487 = glueContext.write_dynamic_frame.from_options(frame=RenameField_node1754055306801, connection_type="redshift", connection_options={"redshiftTmpDir": "s3://aws-glue-assets-455512573562-cn-northwest-1/temporary/", "useConnectionProperties": "true", "dbtable": "public.weatherdata", "connectionName": "Redshift connection", "preactions": "CREATE TABLE IF NOT EXISTS public.weatherdata (timestamp VARCHAR, province VARCHAR, city VARCHAR, adcode VARCHAR, weather VARCHAR, temperature VARCHAR, direction VARCHAR, windpower VARCHAR, humidity VARCHAR, reporttime VARCHAR);"}, transformation_ctx="AmazonRedshift_node1754055312487") job.commit()
創建workflow,通過trigger串聯job1,job2

trigger方式可以設置為按天,按周,按需,自定義等

 浙公網安備 33010602011771號
浙公網安備 33010602011771號