Dify 工作流實踐--PDF工商信息識別
接上篇,這次做一個PDF識別的案例,提取用戶上傳的工商營業執照PDF中的營業范圍信息,并以JSON 格式返回。
做的過程中識別到幾個問題,可能也是大家會遇到的:
1.關于PDF中圖片的處理方法
一般情況下PDF中是文本內容,但是有時候會出現圖片內容,所以針對文本的大模型無法解析,需要想起他辦法
我這里是先將PDF轉為PNG,然后解析文件內容進行處理
2.關于插件PDF process默認錯誤處理方法
在Dify的market中安裝后,使用時會報錯:need http,https file protocal.解決方法:在源文件.env中增加一行:FILES_URL=http://your-ip,重啟即可(這樣上傳的文件將會有一個完整的URL,可以在瀏覽器中預覽)
-----------分割線-------
先看下整體流程結構:

流程描述:
1.上傳文件
2.格式判斷,非PDF直接報錯
3.DOC EXTRCTOR 解析PDF為text
4.判斷如果text非空則表明為純文本PDF,使用qwen-long長文本大模型進行文件讀取分析,按照prompt格式返回結果
5.如果text為空表明為圖片型PDF,先試用PDF PROCESS插件將PDF轉換為PNG,然后使用qwen-vl-72b視覺大模型進行處理,提取文本進行分析,并按照prompt格式返回結果
構建過程就是拖拖拽拽,省略
運行結果:
1.純PDF文件解析
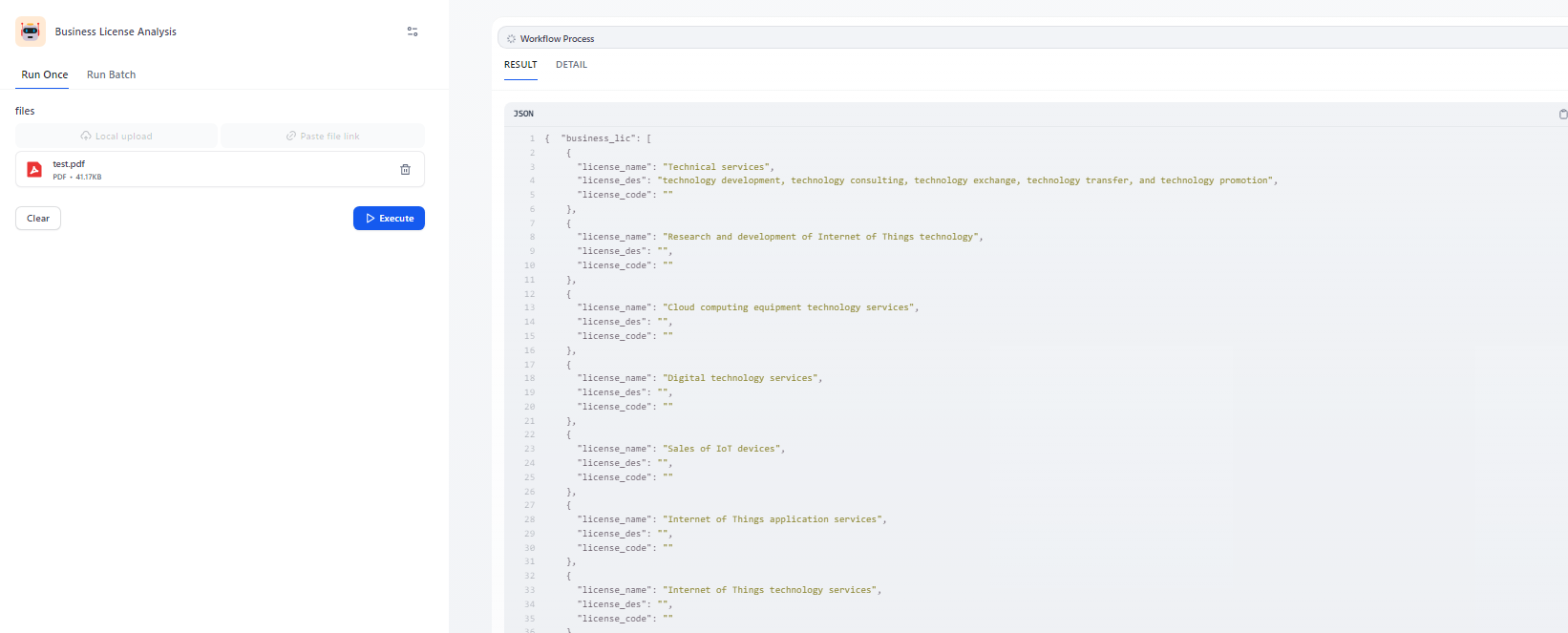
2.圖片型PDF解析

附上dsl文件供參考:DSL

 浙公網安備 33010602011771號
浙公網安備 33010602011771號