Dify 工作流實踐--小學生錯題本
大模型火爆以后,催生出一些的基于大模型的新應用,結合大模型的多模態(tài)處理能力,出現了Coze,Dify,DBgpt,FastGpt等企業(yè)級產品。
今天拿Dify做了一個例子,感覺這類產品可以幫助企業(yè)實現不同業(yè)務場景的任務,有一定IT基礎,便可以開發(fā)屬于自己的workflow,chatbot,AI Agent,實現業(yè)務價值。
這里是一個小學生錯題本的案例,可以幫助學習Dify的使用,轉載記錄。
1.前言
錯題本是一種學習工具,用于記錄和總結學生在學習過程中做錯的題目,以便找出學習中的薄弱環(huán)節(jié),提高學習效率和成績。
一下是錯題本定義、作用、建立方法、使用技巧等內容。
- 定義:錯題本是指中小學學生在學習過程中,把自己做過的作業(yè)、習題、試卷中的錯題整理成冊,便于找出自己學習中的薄弱環(huán)節(jié),使得學習重點突出、學習更加有針對性、進而提高學習效率和學習成績的作業(yè)本。錯題本也叫“摘錯本”、“糾錯本”、“改錯本”或“錯題集”。
- 作用:
- 查漏補缺:通過記錄錯題,學生可以發(fā)現自己的知識盲點,及時調整學習策略,有針對性地進行復習和提升。
- 提高學習效率:錯題本幫助學生集中注意力在錯誤上,而不是分散在大量練習中,從而提高復習效率。
- 避免重復錯誤:通過反復回顧和重新解答錯誤的題目,學生可以加深對相關知識點的理解,避免在同樣的問題上犯錯。
- 培養(yǎng)良好的學習習慣:錯題本的使用可以改變學生對錯誤的態(tài)度,使他們對待錯誤更加積極,從而改掉馬馬虎的習慣。
- 建立方法:
- 分類整理:將錯題按錯誤的原因(如概念模糊、思路錯誤、運算錯誤、審題錯誤、粗心大意等)或知識點進行分類整理。
- 記錄方法:在錯題本上記錄原題、正確答案、錯誤原因分析和正確解法。
- 定期回顧:定期回顧錯題本,重新做一遍這些題目,看看自己是否已經掌握之前的知識點,這樣可以有效地鞏固知識,防止再犯同樣的錯誤。
- 使用技巧:

- 及時整理:錯題本應在做完題后立即整理,這樣可以加強記憶。
- 注重效率:不要過于追求錯題本的美觀,而應該注重效率,用最短的時間做好錯題本。
- 相互交流:通過與同學交流錯題本,可以借鑒彼此的優(yōu)點,共同提高學習效果
![]()
-
我們通過錯題本記錄,分析、復習 差缺補漏 從而幫助學生提高成績。今天就帶大家使用dify工作流來實現一個中小學數學錯題本功能。
因為時間關系這里我們只實現了一個錯題本的收集整理,所以本次分享我們計劃通過2篇文章來實現一個一個中小學數學錯題本功能。
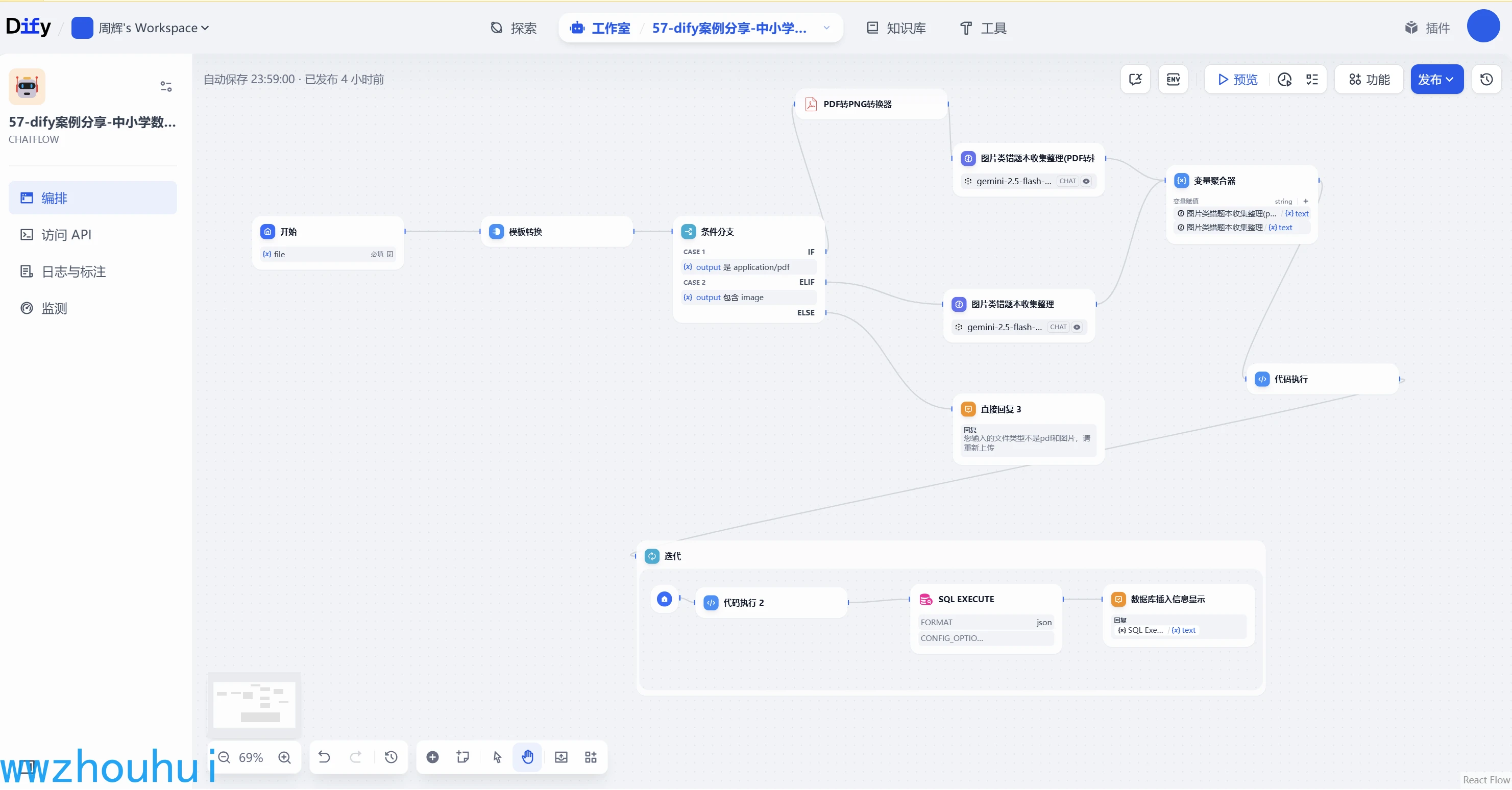
我們先看一下制作好的工作流大概是什么樣子:
![]()
以上錯題本主要的目的是收集學生或者家長上傳的PDF和圖片格式的錯題信息,使用多模態(tài)大模型OCR識別功能把錯題收集整理寫入到數據庫中,相當于錯題本記錄收集功能。后面我們在基于上面的錯題本進行同類型題型出題,實現同類型錯題的強化學習從而幫助中小學生差缺補漏。
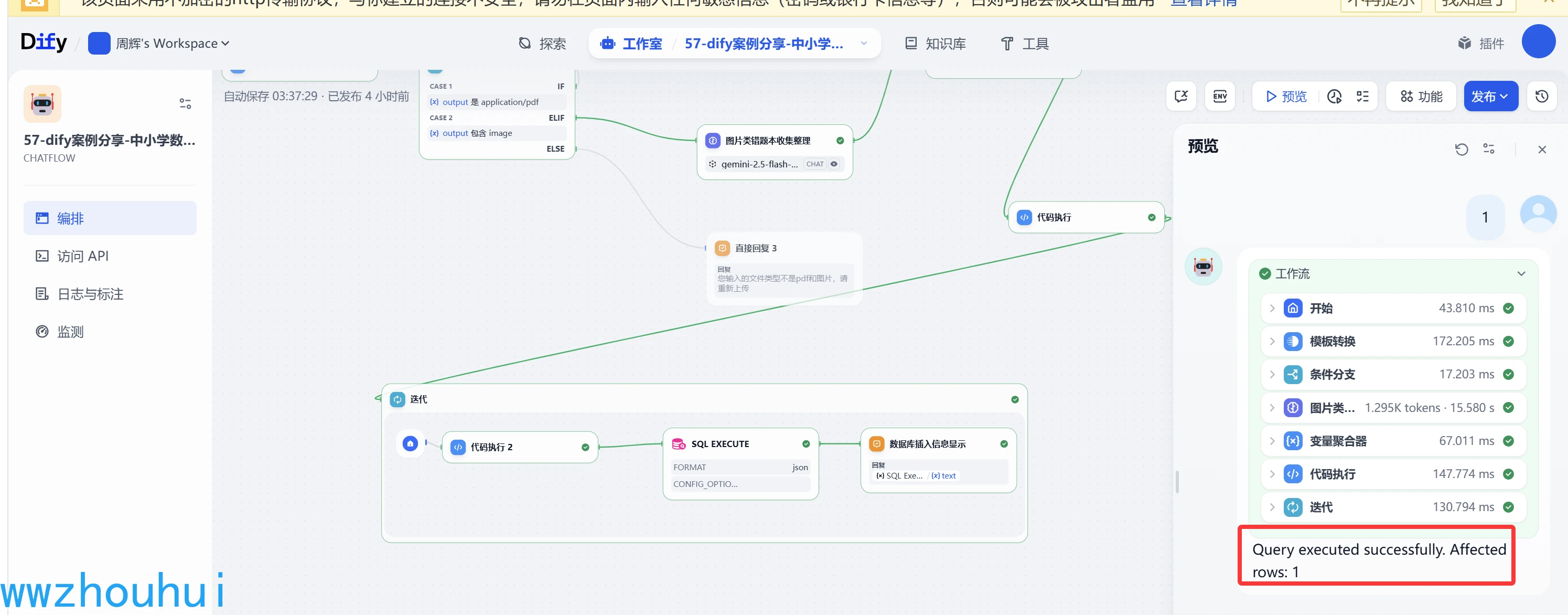
下面看一下實現的效果:
![]()
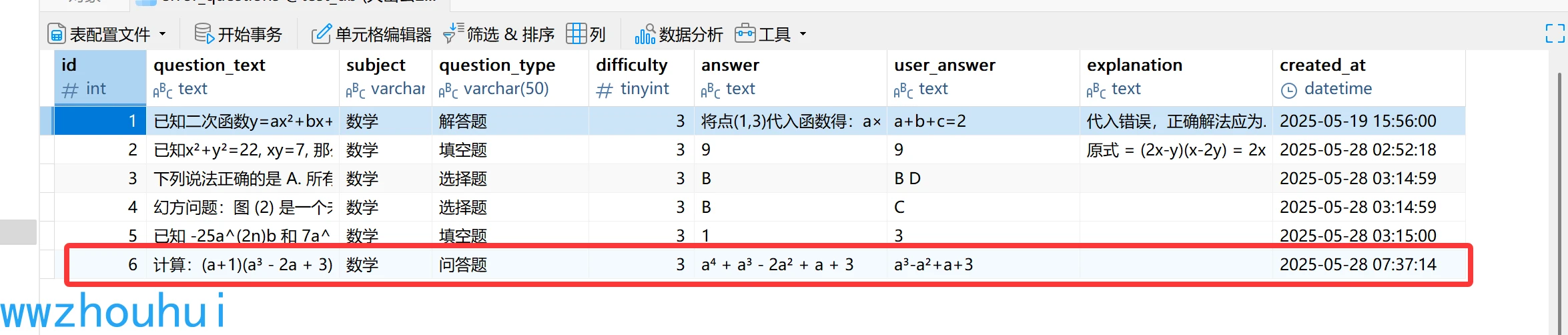
寫入數據庫信息:
![]()
那么這個工作流是如何實現的呢?話不多說下面帶大家手把手搭建這個工作流。
工作流的制作
這個工作流我們首先給大家拆解一下,它用到了開始節(jié)點、模板轉換、條件分支、pdf轉png轉換器(第三方工具)、基于多模態(tài)llm大語言模型、變量聚合器、代碼執(zhí)行、迭代、SQL Execute(第三方工具)等功能,下面我們逐一給大家講解一下。
首先我們用到了2個第三方工具 一個是pdf轉png轉換器,一個是database。
關于database 插件安裝可以看我前期文章《網頁鏈接》
這里我們介紹一下pdf轉png轉換器安裝安裝。
pdf轉png轉換器安裝
我們在插件市場搜索pdf處理
-
找到這個插件安裝。安裝完成后我們在插件列表中查找到,看到下圖信息說明插件安裝完成。
- 同樣的道理我們也能搜索到database這個插件。

我們創(chuàng)建工作流,使用chatflow
開始
這個開始節(jié)點參數就是文件,這個文件支持圖片和PDF兩種格式的文件。


模板轉換
這里我們考慮到用戶輸入的有可能是PDF、也有可能是圖片,我們需要通過模板轉換獲取filetype 這個文件的類型。
輸入變量這里我們設定一個參數:filetype 對應的值 從file 文件中獲取mime-type

模板轉換 代碼部分內容如下:
{{ filetype }}
條件分支
這個地方主要的是目的是通過前面模板轉換獲取的filetype 判斷文件屬性是PDF 還是image

2個添加分之分別對應 PDF處理和圖片處理,當然后面如果用戶輸入的不是這個兩個文件格式類型,系統為了保證系統可用不是這2個文件類型直接返回一個錯題信息提醒,我們這里直接使用回復提醒用戶:
PDF轉PNG轉換器
上面IF條件分支如果用戶上傳的PDF文件,我們需要借助PDF轉換工具實現PDF轉圖片功能。
llm大語言模型
接下來我們使用多模態(tài)大語言模型實現用戶上傳的圖片或者PDF轉PNG轉換后的圖片進行OCR識別。
這里我們使用的了google gemini2.5-flash-preview-05-20模型,當然如果你需要效果好可以使用付費版本的gemini-2.5-pro-preview-05-20。這個模型是需要google 付費會員的,如果大家沒有也可以推薦大家使用302.AI網站上提供的gemini-2.5-pro-preview-05-06版本的模型。
網站地址https://share.302.ai/TjtOq6
在api超市里面可以選擇 gemini模型
系統提示詞


# 角色定義 你是一位中小學錯題收集與整理專家,擅長從學生的考試題目中提取錯誤題目,并按照題型(選擇題、填空題、判斷題、問答題)進行分類歸納。你會為每道錯題提供正確答案,并生成一份結構化的錯題本,以JSON格式呈現 ,便于學生復習和存入數據庫。 # 任務目標 根據用戶提供的考試題目和錯誤信息,完成以下任務: 1. **提取錯誤題目**:識別并提取所有答錯的題目。 2. **分類整理**:將錯誤題目按照以下四類進行分類: - **選擇題** - **填空題** - **判斷題** - **問答題** 3. **JSON格式輸出**: - 生成一個包含所有題目的JSON對象。 - 即使某類題型沒有錯題,也保留該類型的空數組。 4. **符合數據庫結構**:確保輸出的JSON格式符合給定的數據庫表結構。 # 輸入格式 請?zhí)峁┮韵滦畔ⅲ?- 考試題目列表(包括題干、選項(如有)、學生答案和正確答案)。 - 學生的錯誤標記(哪些題目是錯誤的)。 - 學科信息。 - 難度等級(1-5)。 # 輸出格式 生成一份JSON格式的錯題本,結構如下: ```json { "error_questions": [ { "question_text": "題目內容", "subject": "學科名稱", "question_type": "題目類型", "difficulty": "難度等級", "answer": "正確答案", "user_answer": "用戶答案", "explanation": "解析(如有)" }, // ... 更多題目 ] }
視覺模型我們需要開啟,另外我們需要選擇轉換后的圖片

這里我們強調一下,我們使用提示詞讓多模態(tài)大模型把錯題識別解析出來并生成固定格式的數據,方便我們后面把信息寫入到數據庫中。
變量聚合器
2個多模態(tài)模型輸出的內容是一樣的,所以我們把2個流程合并,使用一個叫做變量聚合器的工具把輸出結果統一。
變量賦值的部分是2個多模態(tài)模型的輸出
代碼執(zhí)行
這個代碼執(zhí)行目的是把變量聚合器輸出的信息轉換成字典信息,方便后面處理。
輸入的參數arg1 輸入的內容是上個流程節(jié)點的輸出(變量聚合器輸出)
變量聚合器輸出內容大概是下面數據格式
{ "error_questions": [ { "question_text": "若 x+y=1, xy=-2,則 (2-x)(2-y) 的值為", "subject": "數學", "question_type": "選擇題", "difficulty": 3, "answer": "0", "user_answer": "B", "explanation": "" }, { "question_text": "已知 x2+y2=22, xy=7,那么 (2x-y)(x-2y) 的值為", "subject": "數學", "question_type": "填空題", "difficulty": 3, "answer": "9", "user_answer": "-139", "explanation": "" }, { "question_text": "計算: (a+1)(a2-2a+3)", "subject": "數學", "question_type": "問答題", "difficulty": 2, "answer": "a3 - a2 + a + 3", "user_answer": "a3 - a2 + a + 3", "explanation": "" } ] }

處理的代碼如下:
import json def main(arg1: str) -> dict: try: # 移除可能存在的Markdown代碼塊標記 cleaned_json = arg1.strip() if cleaned_json.startswith('```json'): cleaned_json = cleaned_json[7:] if cleaned_json.endswith('```'): cleaned_json = cleaned_json[:-3] # 處理轉義字符,并確保正確的編碼處理 # cleaned_json = cleaned_json.encode('utf-8').decode('unicode_escape').encode('latin1').decode('utf-8') # **替換轉義符**:將 \\n 轉為 \n(適用于 JSON 中用雙反斜杠表示換行的場景) cleaned_json = cleaned_json.replace('\\\\n', '\\n') # 將四個反斜杠轉為兩個(JSON 標準轉義) # 將 JSON 字符串解析為 Python 字典 result_dict = json.loads(cleaned_json) return {"error_questions": result_dict["error_questions"]} # 返回解析結果 except json.JSONDecodeError as e: return {"error": f"JSON 解析失敗: {e}"} except Exception as e: return {"error": f"發(fā)生未知錯誤: {e}"}
輸出變量是error_questions 是一個數組對象。(因為一張圖片 可能會出現多個錯題,所以我們用數組對象輸出)
迭代
這里我們用到了dify工作流的迭代。
輸入參數:error_questions 數據對象
輸出參數:sql Execute
在迭代里面我們大概有3個子組件實現迭代出來
代碼執(zhí)行
這個代碼執(zhí)行可以理解就是我們通過循環(huán)數組把數組里面的字典數據取出
輸入變量 arg1 輸入參數 迭代/item object

代碼:
def main(arg1: dict) -> dict: # 提取輸入字典的字段 question_text = arg1.get("question_text", "") subject = arg1.get("subject", "") question_type = arg1.get("question_type", "") # 確保 difficulty 是字符串類型 difficulty = arg1.get("difficulty", "") if not isinstance(difficulty, str): difficulty = str(difficulty) answer = arg1.get("answer", "") user_answer = arg1.get("user_answer", "") explanation = arg1.get("explanation", "") # 返回包含所有字段的字典 return { "question_text": question_text, "subject": subject, "question_type": question_type, "difficulty": difficulty, # 確保此處為字符串 "answer": answer, "user_answer": user_answer, "explanation": explanation }
返回,這個返回字段內容比較多,對應上面的return返回
SQL Execute
這里我們需要用的database 第三方組件。
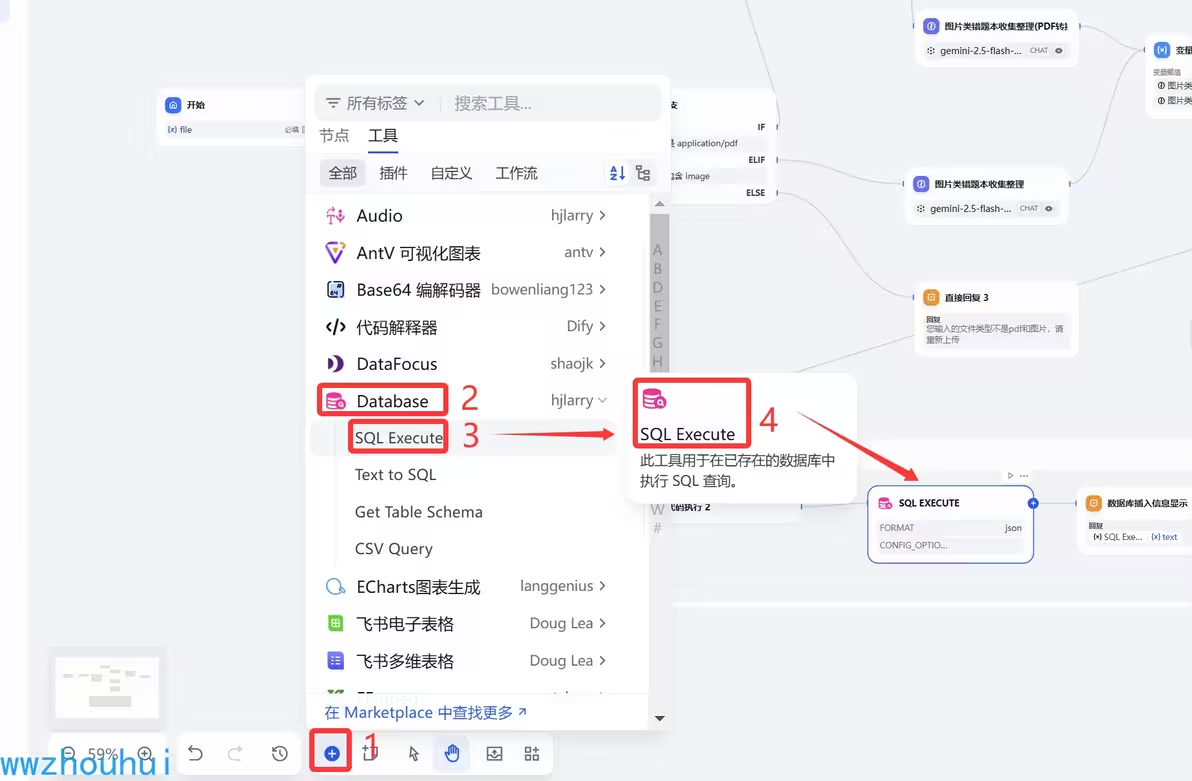
輸入變量這里我們填寫下面的SQL:
INSERT INTO error_questions (question_text, subject, question_type, difficulty, answer, user_answer, explanation) VALUES ('{{#1747669724911.question_text#}}','{{#1747669724911.subject#}}','{{#1747669724911.question_type#}}','{{#1747669724911.difficulty#}}','{{#1747669724911.answer#}}','{{#1747669724911.user_answer#}}','{{#1747669724911.explanation#}}');

這里我們用到了數據庫相關知識,我們需要提前在數據庫創(chuàng)建一個叫做error_questions 表。
表結構內容如下:
CREATE TABLE error_questions ( id INT PRIMARY KEY AUTO_INCREMENT, question_text TEXT NOT NULL COMMENT '題目內容', subject VARCHAR(50) NOT NULL COMMENT '學科', question_type VARCHAR(50) NOT NULL COMMENT '題目類型', difficulty TINYINT NOT NULL COMMENT '難度等級(1-5)', answer TEXT COMMENT '答案', user_answer TEXT COMMENT '用戶答案', explanation TEXT COMMENT '解析', created_at DATETIME DEFAULT CURRENT_TIMESTAMP COMMENT '創(chuàng)建時間' );
直接回復
這里我們?yōu)榱朔奖阏{試,在循環(huán)迭代里面使用直接回復。里面有2個值1個是變量聚合器輸出,1個是SQL 執(zhí)行輸出

以上我們就完成了錯題本的收集整理工作流了。
目前這個工作流只完成了第一階段問題收集整合工作,后面我們需要基于這個錯題本生成同類型錯題并生成錯題和打印功能。感興趣的小伙伴可以持續(xù)關注。
3.驗證及測試
我們制作好的工作流可以在工作流平臺上驗證測試一下,點擊左上角“預覽”按鈕,
測試數據連接地址:
圖片版 https://halo-1258720957.cos.ap-shanghai.myqcloud.com/2025test/%E5%8E%9F%E5%A7%8B%E8%AF%95%E5%8D%B71.png
PDF版 https://halo-1258720957.cos.ap-shanghai.myqcloud.com/2025test/2025-02-11%2021.56_11.pdf


這樣我們就完成了中小學錯題本收集整理的工作流-第一階段制作和測試。
本案例借助 Dify 豐富的插件和靈活的工作流設計能力,我們通過新建工作流,依次添加開始、模板轉換、條件分支、pdf 轉 png 轉換器、基于多模態(tài) llm 大語言模型、變量聚合器、代碼執(zhí)行、迭代、SQL Execute 等節(jié)點,成功搭建了一個可以收集學生或家長上傳的 PDF 和圖片格式錯題信息,并使用多模態(tài)大模型 OCR 識別功能將錯題收集整理寫入數據庫的工作流。
這個工作流能夠大大提高錯題收集整理的效率,幫助學生及時發(fā)現自己的知識盲點,有針對性地進行復習和提升,避免在同樣的問題上犯錯。無論是學生自主學習還是家長輔助輔導,都能快速準確地將錯題進行分類整理,形成有效的錯題本。
轉載自:https://www.bilibili.com/opus/1072188772435623941

 浙公網安備 33010602011771號
浙公網安備 33010602011771號