
淺談HashMap的內部實現
權衡時空
HashMap是以鍵值對的方式存儲數據的。
如果沒有內存限制,那我直接用哈希Map的鍵作為數組的索引,取的時候直接按索引get就行了,可是地價那么貴,哪里有無限制的地盤呢。
如果沒有時間限制的話,我可以把數據放到一個無序數組中,按順序查找,遲早也能找到。可是time is money,光陰那么短暫,誰又等得起呢。
所以,HashMap做了個折中的策略,使用適當的時間和空間做出了權衡,具體可以歸結為“鏈表散列法”,這是一個hash表處理沖突的經典方法。
鏈表散列
那么什么是”鏈表散列法”呢?看下圖:
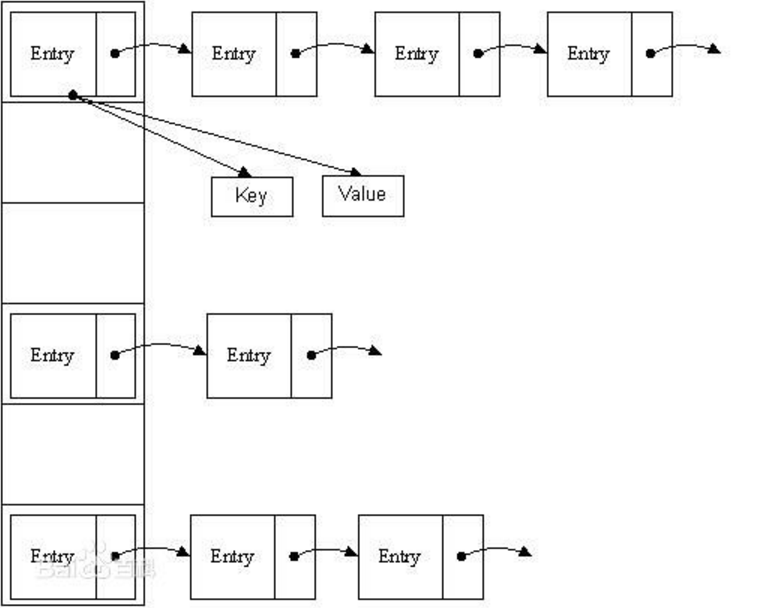
縱向的是一個數組,數組的每一項都是一個鏈表。你可以把這個數組看成是N個桶,每一個桶放著一個鏈子。
數組是干嘛的?數組的每一項負責放鏈表的。
鏈表是干嘛的?負責放Map數據的,比如一個HashMap有兩個鍵,一個是key1,一個是key2。那么該鏈表就會分出兩個節點分別存放這兩個鍵值對(每一個鍵值對是打包放在Entry對象中的)。
鏈表是怎么鏈起來的?Entry包含有key、value、下一個節點next、hash值等,這個next就把各個節點串了起來。
HashMap保存數據的過程為:先計算當前要保存的鍵值對的哈希值(決定著當前鍵值對要放到哪個桶中),根據這個哈希值找到對應的桶。如果桶中沒有數據,那就直接放進去。如果桶中已經放了數據(也即:桶中的鏈條上放著一個或者多個鍵值對),那就順著桶中的這個鏈條一個一個比對,看有沒有key與當前要保存的數據的key相同。如果有相同,直接覆蓋原來key的value。如果沒有相同的,那么將該元素保存在鏈頭(最早保存的元素就會跑到鏈尾)。
裝填因子
桶的數量決定了能放多少個HashMap,而具體用了多少個桶,則直接關系著查找的效率。打個比方,你去隔壁班找小明,班里有10個人,你很快就會找到小明,班里坐著100個人,你可能找半天才能找到。所以你去看HashMap的構造函數是這樣的:
public HashMap(int initialCapacity, float loadFactor) { if (initialCapacity < 0) throw new IllegalArgumentException("Illegal initial capacity: " + initialCapacity); if (initialCapacity > MAXIMUM_CAPACITY) initialCapacity = MAXIMUM_CAPACITY; if (loadFactor <= 0 || Float.isNaN(loadFactor)) throw new IllegalArgumentException("Illegal load factor: " + loadFactor); this.loadFactor = loadFactor; threshold = initialCapacity; init(); } public HashMap(int initialCapacity) { this(initialCapacity, DEFAULT_LOAD_FACTOR); } public HashMap() { this(DEFAULT_INITIAL_CAPACITY, DEFAULT_LOAD_FACTOR); }
三個構造函數都牽動著兩個東西:initialCapacity,loadFactor。前者表示的是桶的初始數量(即數組大小),后者表示“裝填因子”,裝填因子是哈希表在其容量自動增加之前可以達到多滿的一種尺度。比如,數組初始大小為100,如果裝填因子=0.6,表示當數組中存放了60個Map之后,就要把數組擴容后才能繼續存放。這就是為了解決上面講到的效率問題。
裝填因子定的小了,查找數據就快些,但是浪費空間。裝填因子大了,空間利用率就高,但是浪費時間。生活就是這樣,顧此失彼在所難免,萬事哪有兩全的呢。系統權衡利弊后,默認給的裝填因子是0.75,這個一般我們是不需要改動的。
除留余數
那么還有個問題。拿到一個Map的哈希值,怎么決定放到哪個桶里呢?如果最后數組中的Map數據都擠到一塊兒那可不行,查詢就會慢。太松了也不行,浪費空間。Java用了一招“除留余數法”,保證數據在數組中分布均勻。
“除留余數法”,就是取模。比如數組的長度是100,Map的哈希值是80,用80%100,余數是80,就放到80那個位置。但是Java可不是那樣干算的呦,且看源碼:
void addEntry(int hash, K key, V value, int bucketIndex) { if ((size >= threshold) && (null != table[bucketIndex])) { resize(2 * table.length); hash = (null != key) ? hash(key) : 0; bucketIndex = indexFor(hash, table.length); } createEntry(hash, key, value, bucketIndex); }
上面代碼就是HashMap中的添加Entry數據的方法。BucketIndex就是當前Map在數組中的索引。第三行擴容且不談,重點在indexFor方法,這個方法就是”取模”。我們點進去看一下:
static int indexFor(int h, int length) { // assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2"; return h & (length-1); }
H是Map的哈希值,length是數組的長度。它直接使用了一個h & (length - 1)。這一句其實就相當于對數組取模,但是直接用二進制的位操作,比數學計算要快的多。這也給了我們程序員一個啟發,能用位運算時盡量用,提高逼格又提高效率。
均勻分布
還有個有趣的地方,上面代碼的注釋部分:length must be a non-zero power of 2,這句是說,數組的長度必須是2的n次方。
為啥是2的n次方呢?
如果不是2的n次方,比如length為15,h分別為2,3,4。那么用h & (length -1)有:
|
h |
Length-1 |
h & (length -1) |
|
0010 |
1110 |
0010,即2 |
|
0011 |
1110 |
0010,即2 |
|
0100 |
1110 |
0100,即4 |
你看,隨便測了三個數字,就發生了碰撞。為什么會這樣呢?
這是因為:如果不是2的n次方,那么2^n – 1的最低位必然為0,而0、1分別和0作“與”運算,結果都為0。也就是說,不論h為多少,h & (length - 1)的結果最低位都是0。那么數組中最低位為1的那些位置就全部空缺著,這就導致數據在數組中分布不均勻了,繼而影響了查詢的效率。
讀取數據的時候就簡單多了,通過key的hash值找到在table數組中的索引處的Entry,然后返回該key對應的value即可。
參考資料:
http://www.rzrgm.cn/chenssy/p/3521565.html
http://blog.csdn.net/zhuanshenweiliu/article/details/39177447
http://blog.csdn.net/tanggao1314/article/details/51457585#t1
http://www.importnew.com/18851.html

 浙公網安備 33010602011771號
浙公網安備 33010602011771號