

utf系列編碼方式(轉(zhuǎn)載)
1、UTF-32
先來(lái)看簡(jiǎn)單的 UTF-32
這個(gè)就是字符所對(duì)應(yīng)編號(hào)的整數(shù)二進(jìn)制形式,四個(gè)字節(jié)。這個(gè)就是直接轉(zhuǎn)換。 比如馬的 Unicode 為:U+9A6C,那么直接轉(zhuǎn)化為二進(jìn)制,它的表示就為:1001 1010 0110 1100。
這里需要說(shuō)明的是,轉(zhuǎn)換成二進(jìn)制后計(jì)算機(jī)存儲(chǔ)的問(wèn)題,我們知道,計(jì)算機(jī)在存儲(chǔ)器中排列字節(jié)有兩種方式:大端法和小端法,大端法就是將高位字節(jié)放到底地址處,比如 0x1234, 計(jì)算機(jī)用兩個(gè)字節(jié)存儲(chǔ),一個(gè)是高位字節(jié) 0x12,一個(gè)是低位字節(jié) 0x34,它的存儲(chǔ)方式為下:
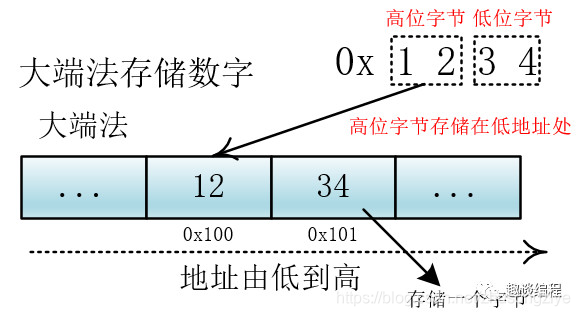
UTF-32 用四個(gè)字節(jié)表示,處理單元為四個(gè)字節(jié)(一次拿到四個(gè)字節(jié)進(jìn)行處理),如果不分大小端的話,那么就會(huì)出現(xiàn)解讀錯(cuò)誤,比如我們一次要處理四個(gè)字節(jié) 12 34 56 78,這四個(gè)字節(jié)是表示 0x12 34 56 78 還是表示 0x78 56 34 12?不同的解釋最終表示的值不一樣。
我們可以根據(jù)他們高低字節(jié)的存儲(chǔ)位置來(lái)判斷他們所代表的含義,所以在編碼方式中有 UTF-32BE 和 UTF-32LE,分別對(duì)應(yīng)大端和小端,來(lái)正確地解釋多個(gè)字節(jié)(這里是四個(gè)字節(jié))的含義。
2、UTF-16
UTF-16 使用變長(zhǎng)字節(jié)表示
① 對(duì)于編號(hào)在 U+0000 到 U+FFFF 的字符(常用字符集),直接用兩個(gè)字節(jié)表示。
② 編號(hào)在 U+10000 到 U+10FFFF 之間的字符,需要用四個(gè)字節(jié)表示。
同樣,UTF-16 也有字節(jié)的順序問(wèn)題(大小端),所以就有 UTF-16BE 表示大端,UTF-16LE 表示小端。
3、UTF-8
UTF-8 就是使用變長(zhǎng)字節(jié)表示,顧名思義,就是使用的字節(jié)數(shù)可變,這個(gè)變化是根據(jù) Unicode 編號(hào)的大小有關(guān),編號(hào)小的使用的字節(jié)就少,編號(hào)大的使用的字節(jié)就多。使用的字節(jié)個(gè)數(shù)從 1 到 4 個(gè)不等。
UTF-8 的編碼規(guī)則是:
① 對(duì)于單字節(jié)的符號(hào),字節(jié)的第一位設(shè)為 0,后面的7位為這個(gè)符號(hào)的 Unicode 碼,因此對(duì)于英文字母,UTF-8 編碼和 ASCII 碼是相同的。
② 對(duì)于n字節(jié)的符號(hào)(n>1),第一個(gè)字節(jié)的前 n 位都設(shè)為 1,第 n+1 位設(shè)為 0,后面字節(jié)的前兩位一律設(shè)為 10,剩下的沒(méi)有提及的二進(jìn)制位,全部為這個(gè)符號(hào)的 Unicode 碼 。
舉個(gè)例子:比如說(shuō)一個(gè)字符的 Unicode 編碼是 130,顯然按照 UTF-8 的規(guī)則一個(gè)字節(jié)是表示不了它(因?yàn)槿绻且粋€(gè)字節(jié)的話前面的一位必須是 0),所以需要兩個(gè)字節(jié)(n = 2)。
根據(jù)規(guī)則,第一個(gè)字節(jié)的前 2 位都設(shè)為 1,第 3(2+1) 位設(shè)為 0,則第一個(gè)字節(jié)為:110X XXXX,后面字節(jié)的前兩位一律設(shè)為 10,后面只剩下一個(gè)字節(jié),所以后面的字節(jié)為:10XX XXXX。
所以它的格式為 110XXXXX 10XXXXXX 。
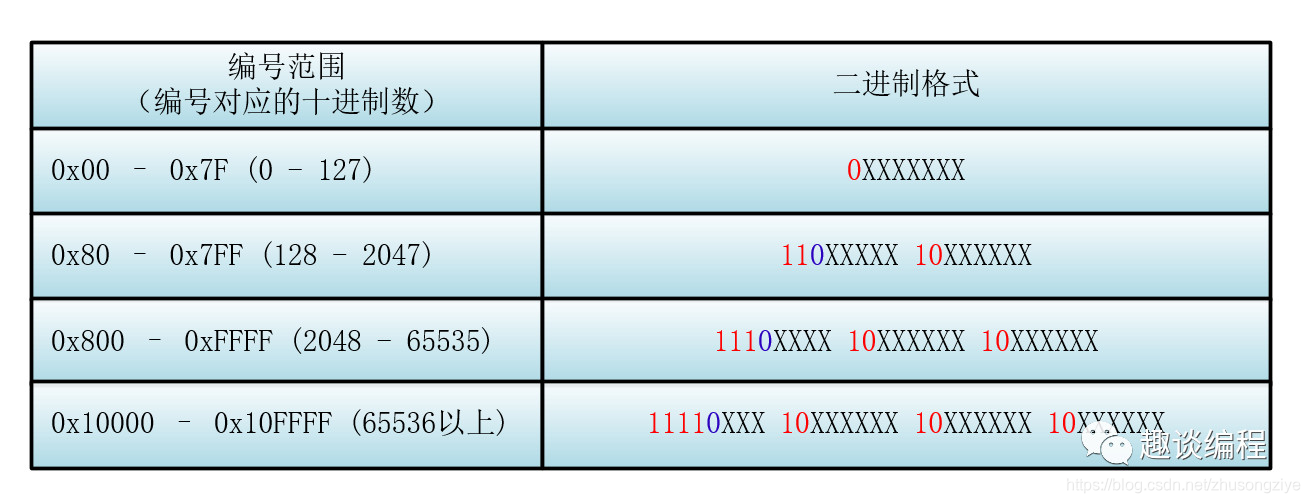
下面我們來(lái)具體看看具體的 Unicode 編號(hào)范圍與對(duì)應(yīng)的 UTF-8 二進(jìn)制格式
那么對(duì)于一個(gè)具體的 Unicode 編號(hào),具體怎么進(jìn)行 UTF-8 的編碼呢?
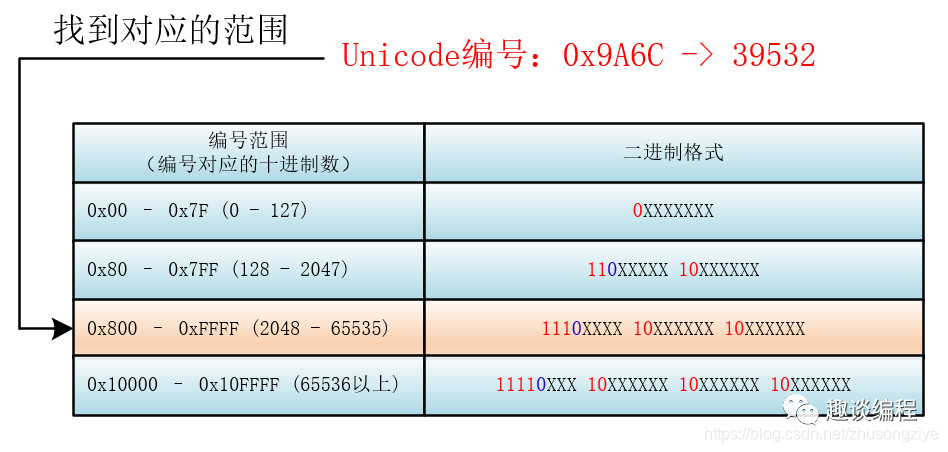
首先找到該 Unicode 編號(hào)所在的編號(hào)范圍,進(jìn)而可以找到與之對(duì)應(yīng)的二進(jìn)制格式,然后將該 Unicode 編號(hào)轉(zhuǎn)化為二進(jìn)制數(shù)(去掉高位的 0),最后將該二進(jìn)制數(shù)從右向左依次填入二進(jìn)制格式的 X 中,如果還有 X 未填,則設(shè)為 0 。
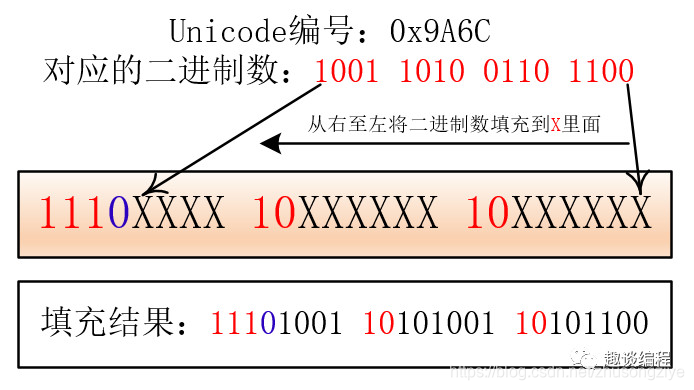
比如:“馬”的 Unicode 編號(hào)是:0x9A6C,整數(shù)編號(hào)是 39532,對(duì)應(yīng)第三個(gè)范圍(2048 - 65535),其格式為:1110XXXX 10XXXXXX 10XXXXXX,39532 對(duì)應(yīng)的二進(jìn)制是 1001 1010 0110 1100,將二進(jìn)制填入進(jìn)入就為:
11101001 10101001 10101100 。
由于 UTF-8 的處理單元為一個(gè)字節(jié)(也就是一次處理一個(gè)字節(jié)),所以處理器在處理的時(shí)候就不需要考慮這一個(gè)字節(jié)的存儲(chǔ)是在高位還是在低位,直接拿到這個(gè)字節(jié)進(jìn)行處理就行了,因?yàn)榇笮《耸轻槍?duì)大于一個(gè)字節(jié)的數(shù)的存儲(chǔ)問(wèn)題而言的。
綜上所述,UTF-8、UTF-16、UTF-32 都是 Unicode 的一種實(shí)現(xiàn)。
原鏈接:https://blog.csdn.net/zhusongziye/article/details/84261211
posted on 2020-04-18 15:25 想變大佬的小孟砸 閱讀(984) 評(píng)論(0) 收藏 舉報(bào)

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)