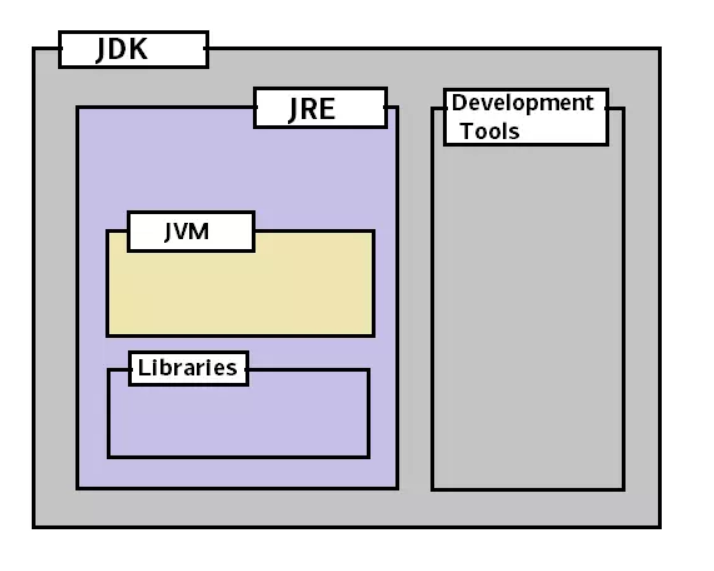
JDK, JRE, JVM的關系
?
解釋器: 逐行轉換字節碼為機器碼
即時編譯器(JIT):將熱點代碼(經常執行的代碼段)編譯成高效的本地機器碼,并緩存起來以供后續直接執行 J ust-I n-T ime Compiler
??
就范圍來說,JDK > JRE > JVM:
JDK = JRE + 開發工具
JRE = JVM + 類庫
jar包 - > java字節碼 - > 機器碼
??
我們利用 JDK (調用 Java API)開發 Java 程序,編譯成字節碼或者打包程序。然后可以用 JRE 則啟動一個 JVM 實例,加載、驗證、執行 Java 字節碼以及依賴庫,運行 Java 程序。而 JVM 將程序和依賴庫的 Java 字節碼解析并變成本地代碼(機器碼 )執行
解釋執行和即使編譯
??
解釋執行 :
在解釋執行階段,Java 虛擬機直接讀取并執行 Java 字節碼(.class 文件中的內容)。每條字節碼指令都被逐條解釋并執行。
解釋執行的優點是啟動速度快,因為不需要等待編譯過程完成。
解釋執行的缺點是執行速度較慢,因為每條指令都需要解釋。
即時編譯(JIT) :
當 Java 虛擬機檢測到某些代碼被頻繁執行(稱為熱點代碼)時,會啟動即時編譯器,將這些熱點代碼編譯成本地機器碼。
編譯后的機器碼可以直接在硬件上運行,執行速度更快。
JIT 編譯的過程是動態的,編譯后的代碼會存儲在內存中,以供后續使用。
字節碼和機器碼的轉換
初始執行 :程序啟動時,Java 虛擬機會先通過解釋執行的方式運行字節碼。熱點檢測 :在執行過程中,Java 虛擬機會監控代碼的執行頻率。JIT 編譯 :當檢測到熱點代碼時,Java 虛擬機會啟動 JIT 編譯器,將這些代碼編譯成機器碼。執行轉換 :一旦代碼被編譯成機器碼,后續的執行會直接使用機器碼,而不是繼續解釋執行字節碼。
性能優化
??
80?20 原則 : 前 20% 的瓶頸 問題, 至少會對性能影響占到 80% 比重
??
三個維度
延遲 95線, 99線 - Latency
吞吐量 TPS, QPS - Throughput
系統容量 -硬件配置 - Capacity
跨平臺
解釋型語言 - 點名 python (但是python很多點都優化了)
運行時要一直依賴解釋器
每次啟動重新解釋
error不運行不報錯
“’. . . ‘”
??
源碼跨平臺 -cpp
“一次編寫,到處調試”
一份源碼, 不同平臺編譯
產生很多環境方面的配置問題
開發維護成本高
效率高
??
二進制跨平臺 -java字節碼
真正的 “一次編寫,到處(不同平臺)編譯”
編譯生成jar包(通用java字節碼)
部署到不同平臺
JVM通過jar包將字節碼 加載到目標機器
效率比不上本地編譯
Runtime
JVM (Java Virtual Machine) :負責執行字節碼的核心引擎。JRE (Java Runtime Environment) :提供運行時所需的完整環境,包括 JVM 和標準類庫。運行時數據和狀態 :如內存分配、線程狀態、異常處理等,這些是在程序運行時動態管理的。
因此,"runtime" 是一個抽象概念,而 JVM 是實現這個概念的具體技術實體。
編程語言簡評
??
C/C++ 完全相信而且慣著程序員,讓大家自行管理內存,所以可以編寫很自由的代碼,但一個不小心就會造成內存泄漏等問題導致程序崩潰。
Java/Golang 完全不相信程序員,但也慣著程序員。所有的內存生命周期都由 JVM 運行時統一管理。 在絕大部分場景下,你可以非常自由的寫代碼,而且不用關心內存到底是什么情況。 內存使用有問題的時候,我們可以通過 JVM 來信息相關的分析診斷和調整。
Rust 語言選擇既不相信程序員,也不慣著程序員。 讓你在寫代碼的時候,必須清楚明白的用 Rust 的規則管理好你的變量,好讓機器能明白高效地分析和管理內存。 但是這樣會導致代碼不利于人的理解,寫代碼很不自由,學習成本也很高。
Java 基本類型
??
java基本類型不屬于object類, 當int類傳入object類時需要轉換為Integer類的封箱
java內部緩存了int[-128,127]對應的封箱
除 long 和 double 外,其他基本類型與引用類型在解釋執行的方法棧幀中占用的大小是一致的,但它們在堆中占用的大小確不同。在將 Boolean 、byte 、char 以及 short 的值存入字段或者數組單元時,Java 虛擬機會進行掩碼操作。在讀取時,Java 虛擬機則會將其擴展為 int 類型
Java編譯器
自動裝箱與自動拆箱
基本類型 → 對象(int → Integer)
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
可通過調節 java.lang.Integer.IntegerCache.high 調高緩存int的范圍
但是不知道為什么沒有java.___.low
泛型與類型擦除
??
對于泛型方法 傳出參數的類型大概率是(Object.class), 代表著其中的類型擦除
??
并不是每一個泛型參數被擦除類型后都會變成 Object 類。對于限定了繼承類(extend A)的泛型參數,經過類型擦除后,所有的泛型參數都將變成所限定的繼承類(class A)。也就是說,Java 編譯器將選取該泛型所能指代的所有類中層次最高的那個,作為替換泛型的類。
橋接方法
由于泛型擦除 父方法的傳入參數發生改變(Object t) 不符合重寫規則從而引入了橋接方法
class Parent<T> {
public void method(T t) {
System.out.println("Parent");
}
}
class Child extends Parent<String> {
@Override
public void method(String s) {
System.out.println("Child");
}
}
**泛型擦除后的父方法**
public void method(Object t) {
System.out.println("Parent");
}
**java編譯器生成的橋接方法**
public void method(Object t) {
method((String) t);
}
public void method(String s) {
System.out.println("Child");
}
Java對象的內存布局
// Foo foo = new Foo(); 編譯而成的字節碼
0 new Foo
3 dup
4 invokespecial Foo()
7 astore_1
// Foo 類構造器會調用其父類 Object 的構造器
public Foo();
0 aload_0 [this]
1 invokespecial java.lang.Object() [8]
4 return
??
總而言之,當我們調用一個構造器時,它將優先調用父類的構造器,直至 Object 類。這些構造器的調用者皆為同一對象,也就是通過 new 指令新建而來的對象。
通過 new 指令新建出來的對象,它的內存其實涵蓋了所有父類中的實例字段。也就是說,雖然子類無法訪問父類的私有實例字段,或者子類的實例字段隱藏了父類的同名實例字段,但是子類的實例還是會為這些父類實例字段分配內存的。
壓縮指針
??
其實很好理解就是相對尋址
只需要存儲偏移量, 存儲壓力變小了
然后偏移量的固定單元大小為8b
long類型就占8b了, 同理double/float,即使int也要4b
即使浪費一點也沒關系用內存換高速緩存不是血賺嗎
?
指針壓縮 :32 位指針本身只能直接尋址 2^32 字節,也就是 4GB 的地址空間。但是,通過在指針和實際內存地址之間引入一個轉換機制,可以擴展尋址范圍。地址轉換 :Java 虛擬機使用一種稱為“地址壓縮和解壓縮”的技術。簡單來說,32 位指針被視為一個偏移量,這個偏移量乘以一個固定值(通常是 8bit)→ 字段重排列,再加上一個基地址,就可以得到實際的 64 位內存地址。尋址范圍 :通過這種方式,32 位指針可以表示的最大偏移量是 2^32?1。當這個偏移量乘以 8 時,最大地址就變成了 2^32×8=235 字節,也就是 32GB。
??
字段重排列,顧名思義,就是 Java 虛擬機重新分配字段的先后順序,以達到內存對齊的目的。Java 虛擬機中有三種排列方法(對應 Java 虛擬機選項 -XX:FieldsAllocationStyle,默認值為 1),但都會遵循如下兩個規則。
其一,如果一個字段占據 C 個字節,那么該字段的偏移量需要對齊至 NC。這里偏移量指的是字段地址與對象的起始地址差值。
以 long 類為例,它僅有一個 long 類型的實例字段。在使用了壓縮指針的 64 位虛擬機中,盡管對象頭的大小為 12 個字節,該 long 類型字段的偏移量也只能是 16,而中間空著的 4 個字節便會被浪費掉。
其二,子類所繼承字段的偏移量,需要與父類對應字段的偏移量保持一致。
在具體實現中,Java 虛擬機還會對齊子類字段的起始位置。對于使用了壓縮指針的 64 位虛擬機,子類第一個字段需要對齊至 4N;而對于關閉了壓縮指針的 64 位虛擬機,子類第一個字段則需要對齊至 8N。
JAVA字節碼
感覺和機器碼類似, 不做過多敘述, 偷懶了哈哈??
??
java字節碼編譯
C1 : 又叫做 Client 編譯器,面向的是對啟動性能有要求的客戶端 GUI 程序,采用的優化手段相對簡單,因此編譯時間較短。
C2 : 又叫做 Server 編譯器,面向的是對峰值性能有要求的服務器端程序,采用的優化手段相對復雜,因此編譯時間較長,但同時生成代碼的執行效率較高。
Graal(java10+) :
從 Java 7 開始,HotSpot 默認采用分層編譯的方式:熱點方法首先會被 C1 編譯
C1內分為三層
no profiling 無數據支持的優化
limit profiling 有一定數據支持的優化
full profiling 全數據支持的優化
而后熱點方法中的熱點會進一步被 C2 編譯。
為了不干擾應用的正常運行,HotSpot 的即時編譯是放在額外的編譯線程中進行的。HotSpot 會根據 CPU 的數量設置編譯線程的數目,并且按 1:2 的比例配置給 C1 及 C2 編譯器。
在計算資源充足的情況下,字節碼的解釋執行和即時編譯可同時進行。編譯完成后的機器碼會在下次調用該方法時啟用,以替換原本的解釋執行。
02正在路上了!!!



 浙公網安備 33010602011771號
浙公網安備 33010602011771號