
numastat命令詳解
博客:http://blog.csdn.net/wylfengyujiancheng
一、系統(tǒng)架構(gòu)的演進(jìn)從SMP到NUMA
1、SMP(Symmetric Multi-Processor)

SMP服務(wù)器的主要特征是共享,系統(tǒng)中所有資源(CPU、內(nèi)存、I/O等)都是共享的。也正是由于這種特征,導(dǎo)致了SMP服務(wù)器的主要問題,那就是它的擴(kuò)展能力非常有限。對于SMP服務(wù)器而言,每一個(gè)共享的環(huán)節(jié)都可能造成SMP服務(wù)器擴(kuò)展時(shí)的瓶頸,而最受限制的則是內(nèi)存。由于每個(gè)CPU必須通過相同的內(nèi)存總線訪問相同的內(nèi)存資源,因此隨著CPU數(shù)量的增加,內(nèi)存訪問沖突將迅速增加,最終會(huì)造成CPU資源的浪費(fèi),使 CPU性能的有效性大大降低。
有實(shí)驗(yàn)數(shù)據(jù)表明,SMP型的服務(wù)器CPU最好是2-4顆就OK了,多余的就浪費(fèi)了。
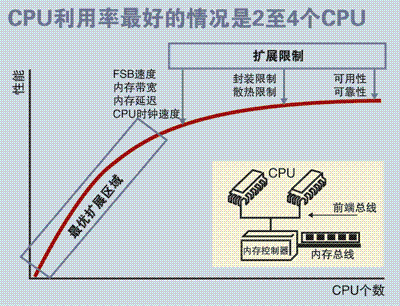
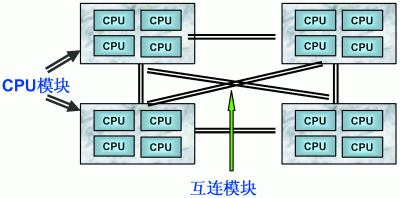
每個(gè)CPU模塊之間都是通過互聯(lián)模塊進(jìn)行連接和信息交互,CPU都是互通互聯(lián)的,同時(shí),每個(gè)CPU模塊平均劃分為若干個(gè)Chip(不多于4個(gè)),每個(gè)Chip都有自己的內(nèi)存控制器及內(nèi)存插槽。
在NUMA中還有三個(gè)節(jié)點(diǎn)的概念:
1)、本地節(jié)點(diǎn):對于某個(gè)節(jié)點(diǎn)中的所有CPU,此節(jié)點(diǎn)稱為本地節(jié)點(diǎn)。
2)、鄰居節(jié)點(diǎn):與本地節(jié)點(diǎn)相鄰的節(jié)點(diǎn)稱為鄰居節(jié)點(diǎn)。
3)、遠(yuǎn)端節(jié)點(diǎn):非本地節(jié)點(diǎn)或鄰居節(jié)點(diǎn)的節(jié)點(diǎn),稱為遠(yuǎn)端節(jié)點(diǎn)。
4)、鄰居節(jié)點(diǎn)和遠(yuǎn)端節(jié)點(diǎn),都稱作非本地節(jié)點(diǎn)(Off Node)。
CPU訪問不同類型節(jié)點(diǎn)內(nèi)存的速度是不相同的,訪問本地節(jié)點(diǎn)的速度最快,訪問遠(yuǎn)端節(jié)點(diǎn)的速度最慢,即訪問速度與節(jié)點(diǎn)的距離有關(guān),距離越遠(yuǎn)訪問速度越慢,此距離稱作Node Distance。應(yīng)用程序要盡量的減少不通CPU模塊之間的交互,如果應(yīng)用程序能有方法固定在一個(gè)CPU模塊里,那么應(yīng)用的性能將會(huì)有很大的提升。
二、NUMA實(shí)踐
1、安裝numactl工具
Linux提供了一個(gè)一個(gè)手工調(diào)優(yōu)的命令numactl(默認(rèn)不安裝)
#yum install numactl -y
1
#numactl --hardware 列舉系統(tǒng)上的NUMA節(jié)點(diǎn)
1
2、查看numa狀態(tài)
# numactl --show
policy: default
preferred node: current
physcpubind: 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31
cpubind: 0 1
nodebind: 0 1
membind: 0 1
1234567
# numastat
node0 node1
numa_hit 1296554257 918018444
numa_miss 8541758 40297198
numa_foreign 40288595 8550361
interleave_hit 45651 45918
local_node 1231897031 835344122
other_node 64657226 82674322
12345678
說明:
numa_hit—命中的,也就是為這個(gè)節(jié)點(diǎn)成功分配本地內(nèi)存訪問的內(nèi)存大小
numa_miss—把內(nèi)存訪問分配到另一個(gè)node節(jié)點(diǎn)的內(nèi)存大小,這個(gè)值和另一個(gè)node的numa_foreign相對應(yīng)。
numa_foreign–另一個(gè)Node訪問我的內(nèi)存大小,與對方node的numa_miss相對應(yīng)
local_node----這個(gè)節(jié)點(diǎn)的進(jìn)程成功在這個(gè)節(jié)點(diǎn)上分配內(nèi)存訪問的大小
other_node----這個(gè)節(jié)點(diǎn)的進(jìn)程 在其它節(jié)點(diǎn)上分配的內(nèi)存訪問大小
很明顯,miss值和foreign值越高,就要考慮綁定的問題。
3、numad服務(wù)
在redhat6中,有一個(gè)numad的服務(wù)(需手工安裝),它可以自動(dòng)的監(jiān)控我們cpu狀況,并自動(dòng)平衡資源,這個(gè)服務(wù)需要在內(nèi)存使用量非常大的時(shí)候才會(huì)有明顯的效果,當(dāng)內(nèi)存空余量較大時(shí),需要關(guān)閉KSM,避免發(fā)生沖突。官方說在某些內(nèi)存使用巨大的環(huán)境中,可能會(huì)提高50%的性能。
# service numad start
1
4、查看cpu和內(nèi)存使用情況
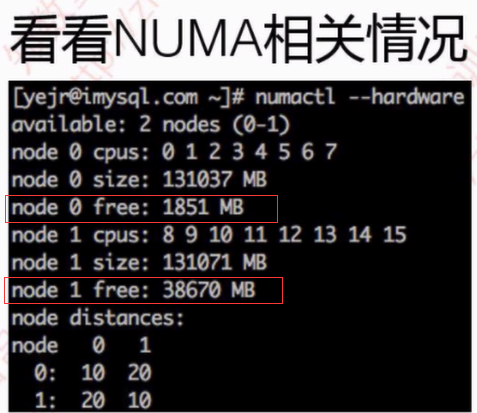
# numactl --hardware
available: 2 nodes (0-1)
node 0 cpus: 0 2 4 6 8 10 12 14 16 18 20 22 24 26 28 30
node 0 size: 64337 MB
node 0 free: 1263 MB
node 1 cpus: 1 3 5 7 9 11 13 15 17 19 21 23 25 27 29 31
node 1 size: 64509 MB
node 1 free: 30530 MB
node distances:
node 0 1
0: 10 21
1: 21 10
123456789101112
cpu0 可用 內(nèi)存 1263 MB
cpu1 可用內(nèi)存 30530 MB
當(dāng)cpu0上申請內(nèi)存超過1263M時(shí)必定使用swap,這個(gè)是很不合理的。
這里假設(shè)我要執(zhí)行一個(gè)java param命令,此命令需要1G內(nèi)存;一個(gè)python param命令,需要8G內(nèi)存。
最好的優(yōu)化方案時(shí)python在node1中執(zhí)行,而java在node0中執(zhí)行,那命令是:
#numactl --cpubind=0 --membind=0 python param
#numactl --cpubind=1 --membind=1 java param
12
5、NUMA的內(nèi)存分配策略
1.缺省(default):總是在本地節(jié)點(diǎn)分配(分配在當(dāng)前進(jìn)程運(yùn)行的節(jié)點(diǎn)上);
2.綁定(bind):強(qiáng)制分配到指定節(jié)點(diǎn)上;
3.交叉(interleave):在所有節(jié)點(diǎn)或者指定的節(jié)點(diǎn)上交織分配;
4.優(yōu)先(preferred):在指定節(jié)點(diǎn)上分配,失敗則在其他節(jié)點(diǎn)上分配。
因?yàn)镹UMA默認(rèn)的內(nèi)存分配策略是優(yōu)先在進(jìn)程所在CPU的本地內(nèi)存中分配,會(huì)導(dǎo)致CPU節(jié)點(diǎn)之間內(nèi)存分配不均衡,當(dāng)某個(gè)CPU節(jié)點(diǎn)的內(nèi)存不足時(shí),會(huì)導(dǎo)致swap產(chǎn)生,而不是從遠(yuǎn)程節(jié)點(diǎn)分配內(nèi)存。這就是所謂的swap insanity 現(xiàn)象。
舉例:
# numactl --hardware
node 0 cpus: 0 2 4 6
node 0 size: 65490 MB
node 0 free: 24447 MB
node 1 cpus: 1 3 5 7
node 1 size: 65536 MB
node 1 free: 16050 MB
node distances:
node 0 1
0: 10 20
1: 20 10
1234567891011
可以看到numa節(jié)點(diǎn)是2個(gè),cpu物理節(jié)點(diǎn)是8個(gè)
現(xiàn)在我們綁定資源,兩顆cpu,每顆4個(gè)物理節(jié)點(diǎn),那么我們開4個(gè)mysql實(shí)例,每個(gè)實(shí)例綁定2個(gè)cpu物理節(jié)點(diǎn)
numactl --physcpubind=0,3 --localalloc mysqld_multi --defaults-extra-file=/etc/mysqld_multi.cnf start 1
1
–physcpubind 指定綁定的cpu節(jié)點(diǎn),
–localalloc表示使用內(nèi)存方式,不交叉,以免降低性能,
mysqld_multi是mysql實(shí)例啟動(dòng)命令
三、如何關(guān)閉NUMA
方法一:通過bios關(guān)閉
BIOS:interleave = Disable / Enable
方法二:通過OS關(guān)閉
1、編輯 /etc/default/grub 文件,加上:numa=off
GRUB_CMDLINE_LINUX="crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet"
1
2、重新生成 /etc/grub2.cfg 配置文件:
# grub2-mkconfig -o /etc/grub2.cfg
1
3、重啟操作系統(tǒng)
# reboot
1
4、確認(rèn):
# dmesg | grep -i numa
[ 0.000000] Command line: BOOT_IMAGE=/vmlinuz-3.10.0-327.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet[ 0.000000] NUMA turned off[ 0.000000] Kernel command line: BOOT_IMAGE=/vmlinuz-3.10.0-327.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
BOOT_IMAGE=/vmlinuz-3.10.0-327.el7.x86_64 root=/dev/mapper/centos-root ro crashkernel=auto numa=off rd.lvm.lv=centos/root rd.lvm.lv=centos/swap rhgb quiet
---------------------
作者:二進(jìn)制-程序猿
來源:CSDN
原文:https://blog.csdn.net/wylfengyujiancheng/article/details/85417675
版權(quán)聲明:本文為博主原創(chuàng)文章,轉(zhuǎn)載請附上博文鏈接!
在os層numa關(guān)閉時(shí),打開bios層的numa會(huì)影響性能,QPS會(huì)下降15-30%;
在bios層面numa關(guān)閉時(shí),無論os層面的numa是否打開,都不會(huì)影響性能。
安裝numactl:
#yum install numactl -y
#numastat 等同于 cat /sys/devices/system/node/node0/numastat ,在/sys/devices/system/node/文件夾中記錄系統(tǒng)中的所有內(nèi)存節(jié)點(diǎn)的相關(guān)詳細(xì)信息。 #numactl --hardware 列舉系統(tǒng)上的NUMA節(jié)點(diǎn)
#numactl --show 查看綁定信息

Redhat或者Centos系統(tǒng)中可以通過命令判斷bios層是否開啟numa
# grep -i numa /var/log/dmesg
如果輸出結(jié)果為: No NUMA configuration found
說明numa為disable,如果不是上面內(nèi)容說明numa為enable,例如顯示:NUMA: Using 30 for the hash shift.
可以通過lscpu命令查看機(jī)器的NUMA拓?fù)浣Y(jié)構(gòu)。
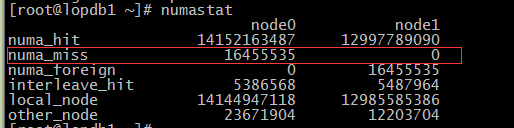
當(dāng)發(fā)現(xiàn)numa_miss數(shù)值比較高時(shí),說明需要對分配策略進(jìn)行調(diào)整。例如將指定進(jìn)程關(guān)聯(lián)綁定到指定的CPU上,從而提高內(nèi)存命中率。
---------------------------------------------
現(xiàn)在的機(jī)器上都是有多個(gè)CPU和多個(gè)內(nèi)存塊的。以前我們都是將內(nèi)存塊看成是一大塊內(nèi)存,所有CPU到這個(gè)共享內(nèi)存的訪問消息是一樣的。這就是之前普遍使用的SMP模型。但是隨著處理器的增加,共享內(nèi)存可能會(huì)導(dǎo)致內(nèi)存訪問沖突越來越厲害,且如果內(nèi)存訪問達(dá)到瓶頸的時(shí)候,性能就不能隨之增加。NUMA(Non-Uniform Memory Access)就是這樣的環(huán)境下引入的一個(gè)模型。比如一臺(tái)機(jī)器是有2個(gè)處理器,有4個(gè)內(nèi)存塊。我們將1個(gè)處理器和兩個(gè)內(nèi)存塊合起來,稱為一個(gè)NUMA node,這樣這個(gè)機(jī)器就會(huì)有兩個(gè)NUMA node。在物理分布上,NUMA node的處理器和內(nèi)存塊的物理距離更小,因此訪問也更快。比如這臺(tái)機(jī)器會(huì)分左右兩個(gè)處理器(cpu1, cpu2),在每個(gè)處理器兩邊放兩個(gè)內(nèi)存塊(memory1.1, memory1.2, memory2.1,memory2.2),這樣NUMA node1的cpu1訪問memory1.1和memory1.2就比訪問memory2.1和memory2.2更快。所以使用NUMA的模式如果能盡量保證本node內(nèi)的CPU只訪問本node內(nèi)的內(nèi)存塊,那這樣的效率就是最高的。
在運(yùn)行程序的時(shí)候使用numactl -m和-physcpubind就能制定將這個(gè)程序運(yùn)行在哪個(gè)cpu和哪個(gè)memory中。玩轉(zhuǎn)cpu-topology 給了一個(gè)表格,當(dāng)程序只使用一個(gè)node資源和使用多個(gè)node資源的比較表(差不多是38s與28s的差距)。所以限定程序在numa node中運(yùn)行是有實(shí)際意義的。
但是呢,話又說回來了,制定numa就一定好嗎?--numa的陷阱。SWAP的罪與罰文章就說到了一個(gè)numa的陷阱的問題。現(xiàn)象是當(dāng)你的服務(wù)器還有內(nèi)存的時(shí)候,發(fā)現(xiàn)它已經(jīng)在開始使用swap了,甚至已經(jīng)導(dǎo)致機(jī)器出現(xiàn)停滯的現(xiàn)象。這個(gè)就有可能是由于numa的限制,如果一個(gè)進(jìn)程限制它只能使用自己的numa節(jié)點(diǎn)的內(nèi)存,那么當(dāng)自身numa node內(nèi)存使用光之后,就不會(huì)去使用其他numa node的內(nèi)存了,會(huì)開始使用swap,甚至更糟的情況,機(jī)器沒有設(shè)置swap的時(shí)候,可能會(huì)直接死機(jī)!所以你可以使用numactl --interleave=all來取消numa node的限制。
綜上所述得出的結(jié)論就是,根據(jù)具體業(yè)務(wù)決定NUMA的使用。
如果你的程序是會(huì)占用大規(guī)模內(nèi)存的,你大多應(yīng)該選擇關(guān)閉numa node的限制(或從硬件關(guān)閉numa)。因?yàn)檫@個(gè)時(shí)候你的程序很有幾率會(huì)碰到numa陷阱。
另外,如果你的程序并不占用大內(nèi)存,而是要求更快的程序運(yùn)行時(shí)間。你大多應(yīng)該選擇限制只訪問本numa node的方法來進(jìn)行處理。
---------------------------------------------------------------------
內(nèi)核參數(shù)overcommit_memory :
它是 內(nèi)存分配策略
可選值:0、1、2。
0:表示內(nèi)核將檢查是否有足夠的可用內(nèi)存供應(yīng)用進(jìn)程使用;如果有足夠的可用內(nèi)存,內(nèi)存申請?jiān)试S;否則,內(nèi)存申請失敗,并把錯(cuò)誤返回給應(yīng)用進(jìn)程。
1:表示內(nèi)核允許分配所有的物理內(nèi)存,而不管當(dāng)前的內(nèi)存狀態(tài)如何。
2:表示內(nèi)核允許分配超過所有物理內(nèi)存和交換空間總和的內(nèi)存
內(nèi)核參數(shù)zone_reclaim_mode:
可選值0、1
a、當(dāng)某個(gè)節(jié)點(diǎn)可用內(nèi)存不足時(shí):
1、如果為0的話,那么系統(tǒng)會(huì)傾向于從其他節(jié)點(diǎn)分配內(nèi)存
2、如果為1的話,那么系統(tǒng)會(huì)傾向于從本地節(jié)點(diǎn)回收Cache內(nèi)存多數(shù)時(shí)候
b、Cache對性能很重要,所以0是一個(gè)更好的選擇
----------------------------------------------------------------------
mongodb的NUMA問題
mongodb日志顯示如下:
WARNING: You are running on a NUMA machine.
We suggest launching mongod like this to avoid performance problems:
numactl –interleave=all mongod [other options]
解決方案,臨時(shí)修改numa內(nèi)存分配策略為 interleave=all (在所有node節(jié)點(diǎn)進(jìn)行交織分配的策略):
1.在原啟動(dòng)命令前面加numactl –interleave=all
如# numactl --interleave=all ${MONGODB_HOME}/bin/mongod --config conf/mongodb.conf
2.修改內(nèi)核參數(shù)
echo 0 > /proc/sys/vm/zone_reclaim_mode ; echo "vm.zone_reclaim_mode = 0" >> /etc/sysctl.conf
----------------------------------------------------------------------
一、NUMA和SMP
NUMA和SMP是兩種CPU相關(guān)的硬件架構(gòu)。在SMP架構(gòu)里面,所有的CPU爭用一個(gè)總線來訪問所有內(nèi)存,優(yōu)點(diǎn)是資源共享,而缺點(diǎn)是總線爭用激烈。隨著PC服務(wù)器上的CPU數(shù)量變多(不僅僅是CPU核數(shù)),總線爭用的弊端慢慢越來越明顯,于是Intel在Nehalem CPU上推出了NUMA架構(gòu),而AMD也推出了基于相同架構(gòu)的Opteron CPU。
NUMA最大的特點(diǎn)是引入了node和distance的概念。對于CPU和內(nèi)存這兩種最寶貴的硬件資源,NUMA用近乎嚴(yán)格的方式劃分了所屬的資源組(node),而每個(gè)資源組內(nèi)的CPU和內(nèi)存是幾乎相等。資源組的數(shù)量取決于物理CPU的個(gè)數(shù)(現(xiàn)有的PC server大多數(shù)有兩個(gè)物理CPU,每個(gè)CPU有4個(gè)核);distance這個(gè)概念是用來定義各個(gè)node之間調(diào)用資源的開銷,為資源調(diào)度優(yōu)化算法提供數(shù)據(jù)支持。
二、NUMA相關(guān)的策略
1、每個(gè)進(jìn)程(或線程)都會(huì)從父進(jìn)程繼承NUMA策略,并分配有一個(gè)優(yōu)先node。如果NUMA策略允許的話,進(jìn)程可以調(diào)用其他node上的資源。
2、NUMA的CPU分配策略有cpunodebind、physcpubind。cpunodebind規(guī)定進(jìn)程運(yùn)行在某幾個(gè)node之上,而physcpubind可以更加精細(xì)地規(guī)定運(yùn)行在哪些核上。
3、NUMA的內(nèi)存分配策略有l(wèi)ocalalloc、preferred、membind、interleave。
localalloc規(guī)定進(jìn)程從當(dāng)前node上請求分配內(nèi)存;
而preferred比較寬松地指定了一個(gè)推薦的node來獲取內(nèi)存,如果被推薦的node上沒有足夠內(nèi)存,進(jìn)程可以嘗試別的node。
membind可以指定若干個(gè)node,進(jìn)程只能從這些指定的node上請求分配內(nèi)存。
interleave規(guī)定進(jìn)程從指定的若干個(gè)node上以RR(Round Robin 輪詢調(diào)度)算法交織地請求分配內(nèi)存。
因?yàn)镹UMA默認(rèn)的內(nèi)存分配策略是優(yōu)先在進(jìn)程所在CPU的本地內(nèi)存中分配,會(huì)導(dǎo)致CPU節(jié)點(diǎn)之間內(nèi)存分配不均衡,當(dāng)某個(gè)CPU節(jié)點(diǎn)的內(nèi)存不足時(shí),會(huì)導(dǎo)致swap產(chǎn)生,而不是從遠(yuǎn)程節(jié)點(diǎn)分配內(nèi)存。這就是所謂的swap insanity 現(xiàn)象。
MySQL采用了線程模式,對于NUMA特性的支持并不好,如果單機(jī)只運(yùn)行一個(gè)MySQL實(shí)例,我們可以選擇關(guān)閉NUMA,關(guān)閉的方法有三種:
1.硬件層,在BIOS中設(shè)置關(guān)閉
2.OS內(nèi)核,啟動(dòng)時(shí)設(shè)置numa=off;
3.可以用numactl命令將內(nèi)存分配策略修改為interleave(交叉)。
如果單機(jī)運(yùn)行多個(gè)MySQL實(shí)例,我們可以將MySQL綁定在不同的CPU節(jié)點(diǎn)上,并且采用綁定的內(nèi)存分配策略,強(qiáng)制在本節(jié)點(diǎn)內(nèi)分配內(nèi)存,這樣既可以充分利用硬件的NUMA特性,又避免了單實(shí)例MySQL對多核CPU利用率不高的問題
三、NUMA和swap的關(guān)系
可能大家已經(jīng)發(fā)現(xiàn)了,NUMA的內(nèi)存分配策略對于進(jìn)程(或線程)之間來說,并不是公平的。在現(xiàn)有的Redhat Linux中,localalloc是默認(rèn)的NUMA內(nèi)存分配策略,這個(gè)配置選項(xiàng)導(dǎo)致資源獨(dú)占程序很容易將某個(gè)node的內(nèi)存用盡。而當(dāng)某個(gè)node的內(nèi)存耗盡時(shí),Linux又剛好將這個(gè)node分配給了某個(gè)需要消耗大量內(nèi)存的進(jìn)程(或線程),swap就妥妥地產(chǎn)生了。盡管此時(shí)還有很多page cache可以釋放,甚至還有很多的free內(nèi)存。
四、解決swap問題
雖然NUMA的原理相對復(fù)雜,實(shí)際上解決swap卻很簡單:只要在啟動(dòng)MySQL之前使用numactl –interleave來修改NUMA策略即可。
值得注意的是,numactl這個(gè)命令不僅僅可以調(diào)整NUMA策略,也可以用來查看當(dāng)前各個(gè)node的資源使用情況,是一個(gè)很值得研究的命令。
一、CPU
首先從CPU說起。
你仔細(xì)檢查的話,有些服務(wù)器上會(huì)有的一個(gè)有趣的現(xiàn)象:你cat /proc/cpuinfo時(shí),會(huì)發(fā)現(xiàn)CPU的頻率竟然跟它標(biāo)稱的頻率不一樣:
#cat /proc/cpuinfo
processor : 5
model name : Intel(R) Xeon(R) CPU E5-2620 0 @2.00GHz
cpu MHz : 1200.000
這個(gè)是Intel E5-2620的CPU,他是2.00G * 24的CPU,但是,我們發(fā)現(xiàn)第5顆CPU的頻率為1.2G。
這是什么原因呢?
這些其實(shí)都源于CPU最新的技術(shù):節(jié)能模式。操作系統(tǒng)和CPU硬件配合,系統(tǒng)不繁忙的時(shí)候,為了節(jié)約電能和降低溫度,它會(huì)將CPU降頻。這對環(huán)保人士和抵制地球變暖來說是一個(gè)福音,但是對MySQL來說,可能是一個(gè)災(zāi)難。
為了保證MySQL能夠充分利用CPU的資源,建議設(shè)置CPU為最大性能模式。這個(gè)設(shè)置可以在BIOS和操作系統(tǒng)中設(shè)置,當(dāng)然,在BIOS中設(shè)置該選項(xiàng)更好,更徹底。由于各種BIOS類型的區(qū)別,設(shè)置為CPU為最大性能模式千差萬別,我們這里就不具體展示怎么設(shè)置了。
然后我們看看內(nèi)存方面,我們有哪些可以優(yōu)化的。
i) 我們先看看numa
非一致存儲(chǔ)訪問結(jié)構(gòu) (NUMA : Non-Uniform Memory Access) 也是最新的內(nèi)存管理技術(shù)。它和對稱多處理器結(jié)構(gòu) (SMP : Symmetric Multi-Processor) 是對應(yīng)的。簡單的隊(duì)別如下:
如圖所示,詳細(xì)的NUMA信息我們這里不介紹了。但是我們可以直觀的看到:SMP訪問內(nèi)存的都是代價(jià)都是一樣的;但是在NUMA架構(gòu)下,本地內(nèi)存的訪問和非 本地內(nèi)存的訪問代價(jià)是不一樣的。對應(yīng)的根據(jù)這個(gè)特性,操作系統(tǒng)上,我們可以設(shè)置進(jìn)程的內(nèi)存分配方式。目前支持的方式包括:
--interleave=nodes
--membind=nodes
--cpunodebind=nodes
--physcpubind=cpus
--localalloc
--preferred=node
簡而言之,就是說,你可以指定內(nèi)存在本地分配,在某幾個(gè)CPU節(jié)點(diǎn)分配或者輪詢分配。除非 是設(shè)置為--interleave=nodes輪詢分配方式,即內(nèi)存可以在任意NUMA節(jié)點(diǎn)上分配這種方式以外。其他的方式就算其他NUMA節(jié)點(diǎn)上還有內(nèi) 存剩余,Linux也不會(huì)把剩余的內(nèi)存分配給這個(gè)進(jìn)程,而是采用SWAP的方式來獲得內(nèi)存。有經(jīng)驗(yàn)的系統(tǒng)管理員或者DBA都知道SWAP導(dǎo)致的數(shù)據(jù)庫性能 下降有多么坑爹。
所以最簡單的方法,還是關(guān)閉掉這個(gè)特性。
關(guān)閉特性的方法,分別有:可以從BIOS,操作系統(tǒng),啟動(dòng)進(jìn)程時(shí)臨時(shí)關(guān)閉這個(gè)特性。
a) 由于各種BIOS類型的區(qū)別,如何關(guān)閉NUMA千差萬別,我們這里就不具體展示怎么設(shè)置了。
b) 在操作系統(tǒng)中關(guān)閉,可以直接在/etc/grub.conf的kernel行最后添加numa=off,如下所示:
kernel /vmlinuz-2.6.32-220.el6.x86_64 ro root=/dev/mapper/VolGroup-root rd_NO_LUKS LANG=en_US.UTF-8 rd_LVM_LV=VolGroup/root rd_NO_MD quiet SYSFONT=latarcyrheb-sun16 rhgb crashkernel=auto rd_LVM_LV=VolGroup/swap rhgb crashkernel=auto quiet KEYBOARDTYPE=pc KEYTABLE=us rd_NO_DM numa=off
另外可以設(shè)置 vm.zone_reclaim_mode=0盡量回收內(nèi)存。
c) 啟動(dòng)MySQL的時(shí)候,關(guān)閉NUMA特性:
numactl --interleave=all mysqld
當(dāng)然,最好的方式是在BIOS中關(guān)閉。
ii) 我們再看看vm.swappiness。
vm.swappiness是操作系統(tǒng)控制物理內(nèi)存交換出去的策略。它允許的值是一個(gè)百分比的值,最小為0,最大運(yùn)行100,該值默認(rèn)為60。vm.swappiness設(shè)置為0表示盡量少swap,100表示盡量將inactive的內(nèi)存頁交換出去。
具體的說:當(dāng)內(nèi)存基本用滿的時(shí)候,系統(tǒng)會(huì)根據(jù)這個(gè)參數(shù)來判斷是把內(nèi)存中很少用到的inactive 內(nèi)存交換出去,還是釋放數(shù)據(jù)的cache。cache中緩存著從磁盤讀出來的數(shù)據(jù),根據(jù)程序的局部性原理,這些數(shù)據(jù)有可能在接下來又要被讀 取;inactive 內(nèi)存顧名思義,就是那些被應(yīng)用程序映射著,但是 長時(shí)間 不用的內(nèi)存。
我們可以利用vmstat看到inactive的內(nèi)存的數(shù)量:
#vmstat -an 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu-----
r b swpd free inact active si so bi bo in cs us sy id wa st
1 0 0 27522384 326928 1704644 0 0 0 153 11 10 0 0 100 0 0
0 0 0 27523300 326936 1704164 0 0 0 74 784 590 0 0 100 0 0
0 0 0 27523656 326936 1704692 0 0 8 8 439 1686 0 0 100 0 0
0 0 0 27524300 326916 1703412 0 0 4 52 198 262 0 0 100 0 0
通過/proc/meminfo 你可以看到更詳細(xì)的信息:
#cat /proc/meminfo | grep -i inact
Inactive: 326972 kB
Inactive(anon): 248 kB
Inactive(file): 326724 kB
這里我們對不活躍inactive內(nèi)存進(jìn)一步深入討論。 Linux中,內(nèi)存可能處于三種狀態(tài):free,active和inactive。眾所周知,Linux Kernel在內(nèi)部維護(hù)了很多LRU列表用來管理內(nèi)存,比如LRU_INACTIVE_ANON, LRU_ACTIVE_ANON, LRU_INACTIVE_FILE , LRU_ACTIVE_FILE, LRU_UNEVICTABLE。其中LRU_INACTIVE_ANON, LRU_ACTIVE_ANON用來管理匿名頁,LRU_INACTIVE_FILE , LRU_ACTIVE_FILE用來管理page caches頁緩存。系統(tǒng)內(nèi)核會(huì)根據(jù)內(nèi)存頁的訪問情況,不定時(shí)的將活躍active內(nèi)存被移到inactive列表中,這些inactive的內(nèi)存可以被 交換到swap中去。
一般來說,MySQL,特別是InnoDB管理內(nèi)存緩存,它占用的內(nèi)存比較多,不經(jīng)常訪問的內(nèi)存也會(huì)不少,這些內(nèi)存如果被Linux錯(cuò)誤的交換出去了,將浪費(fèi)很多CPU和IO資源。 InnoDB自己管理緩存,cache的文件數(shù)據(jù)來說占用了內(nèi)存,對InnoDB幾乎沒有任何好處。
所以,我們在MySQL的服務(wù)器上最好設(shè)置vm.swappiness=1或0
先要說的是,并不是所有的場景都適合綁定的,當(dāng)出現(xiàn)內(nèi)存交叉訪問,或者緩存命中較低時(shí),或者你想把某進(jìn)程運(yùn)行在特定的CPU上時(shí)可以進(jìn)行綁定。那么要先知道怎么查看是否出現(xiàn)了交叉內(nèi)存訪問。
那么除了交叉內(nèi)存訪問,還有什么值得我們?nèi)ソ壎ㄟM(jìn)程呢?
那就了解下內(nèi)存貶值吧:
如果很多進(jìn)程運(yùn)行在CPU的某一個(gè)核心之上,我們都知道,CPU核心都是和L1直接打交道的,而各個(gè)進(jìn)程間呢,還是切換著輪流運(yùn)行的,如果我L1中全部緩存了進(jìn)程A的數(shù)據(jù),那么當(dāng)我進(jìn)程B或進(jìn)程C運(yùn)行時(shí),極有可能會(huì)置換L1中的緩存數(shù)據(jù),如果A進(jìn)程沒有運(yùn)行完,當(dāng)進(jìn)程A再次執(zhí)行時(shí),還需要去置換L1中的緩存數(shù)據(jù),這樣,各個(gè)進(jìn)程運(yùn)行時(shí)可能每次都要置換L1中的數(shù)據(jù),可能大部分時(shí)間都浪費(fèi)在了置換緩存上,所以,我們可以將對性能敏感的進(jìn)程綁定到某一個(gè)或一組核心,將多線程的程序也綁定到某一核心,這樣,將大大提高服務(wù)器性能。
先來說numastat這個(gè)命令:
這個(gè)命令主要是顯示進(jìn)程與每個(gè)numa節(jié)點(diǎn)的內(nèi)存分配的統(tǒng)計(jì)數(shù)據(jù)和分配的成功與失敗情況。先上個(gè)圖:

可以看到我這里只有一個(gè)Node節(jié)點(diǎn),也就是說只有一顆CPU,所以可能看不出效果。
numa_hit---命中的,也就是為這個(gè)節(jié)點(diǎn)成功分配本地內(nèi)存訪問的內(nèi)存大小
numa_miss---把內(nèi)存訪問分配到另一個(gè)node節(jié)點(diǎn)的內(nèi)存大小,這個(gè)值和另一個(gè)node的numa_foreign相對應(yīng)。
numa_foreign--另一個(gè)Node訪問我的內(nèi)存大小,與對方node的numa_miss相對應(yīng)
interleave_hit---這個(gè)參數(shù)暫時(shí)不明確
local_node----這個(gè)節(jié)點(diǎn)的進(jìn)程成功在這個(gè)節(jié)點(diǎn)上分配內(nèi)存訪問的大小
other_node----這個(gè)節(jié)點(diǎn)的進(jìn)程 在其它節(jié)點(diǎn)上分配的內(nèi)存訪問大小
很明顯,miss值和foreign值越高,就要考慮綁定的問題。
numastat的常用參數(shù):
-c:緊湊的顯示信息,并將內(nèi)存四舍五入到MB單位,如果節(jié)點(diǎn)較多,可以使用這個(gè)參數(shù),看圖,來看下效果:

單位都變成了MB了
-m:顯示每個(gè)節(jié)點(diǎn)中,系統(tǒng)范圍內(nèi)使用內(nèi)存的情況,可以與其它參數(shù)組合使用:

-n:以原格式顯示,但單位為MB
-p:可以指定pid或指定某Node

-s:進(jìn)行排序,查看的更直觀:

-z:忽略所有為0的行和列
下面再來說一下一個(gè)綁定的命令,numactl,這個(gè)命令可以將某個(gè)進(jìn)程綁定到某個(gè)node或某個(gè)node上的某個(gè)或某組核心上。
--show:可以查看當(dāng)前的numa策略,
-H:可以顯示各Node中內(nèi)存使用情況
--membind:只從某節(jié)點(diǎn)分配內(nèi)存,當(dāng)某節(jié)點(diǎn)內(nèi)存不足,則會(huì)分配失敗,格式:
numactl --membind=nodes program(nodes寫你要分配的節(jié)點(diǎn)0或1或者其它節(jié)點(diǎn)數(shù),后面是程序,可以寫絕對路徑,也可寫服務(wù)啟動(dòng)腳本)
--numactl:把進(jìn)程綁定到某節(jié)點(diǎn)上,用法如下:
numactl --cpunodebind=nodes program(nodes為Cpu節(jié)點(diǎn),后面跟程序,)
--physcpubind:把進(jìn)程綁定到某核心上,如果程序運(yùn)行,用法如下(參數(shù)太長就簡寫了,其它簡寫參數(shù)自己Man):
numactl -C 1,3 httpd
--localalloc:指令永遠(yuǎn)在當(dāng)前節(jié)點(diǎn)分配內(nèi)存,用法:
numactl -l httpd
--preferred:如果指定的內(nèi)存無法分配足夠的空間,可以指定去某一個(gè)節(jié)點(diǎn)的內(nèi)存分配,格式如下:
numactl --preferred=0 httpd
上面的大部分參數(shù)需要停止服務(wù)后執(zhí)行。機(jī)器重啟配置失效。
在redhat6中,有一個(gè)numad的服務(wù)(需手工安裝),它可以自動(dòng)的監(jiān)控我們cpu狀況,并自動(dòng)平衡資源,這個(gè)服務(wù)需要在內(nèi)存使用量非常大的時(shí)候才會(huì)有明顯的效果,當(dāng)內(nèi)存空余量較大時(shí),需要關(guān)閉KSM,避免發(fā)生沖突。官方說在某些內(nèi)存使用巨大的環(huán)境中,可能會(huì)提高50%的性能。
兩種使用方法:
1.service numad start
2.numad -S 0 -p pid 使用numad -i 0 停止
numad暫時(shí)沒有使用過,了解的不多。。
原文鏈接:http://blog.51cto.com/hl914/1557615
yum install numactl
numastat
numactl --hardware
cat /sys/class/net/enp129s0f0/device/numa_node
mpstat
-P ALL
lscpu
1、centos 安裝支持numa命令
yum install numactl
2、驗(yàn)證系統(tǒng)是否支持numa
如果輸出結(jié)果為:
No NUMA configuration found
說明numa為disable,如果不是上面的內(nèi)容說明numa為enable
numastat
numactl --hardware
5、查看網(wǎng)卡對應(yīng)的numa node
enp129s0f0是網(wǎng)卡的名字
cat /sys/class/net/enp129s0f0/device/numa_node
mpstat -P ALL(需要安裝sysstat)
7、 測試(訪問不同節(jié)點(diǎn)的內(nèi)存的IO)(參考http://blog.csdn.net/wu7244582/article/details/52807117)
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.823497 s, 1.3 GB/s
1024+0 records in
1024+0 records out
1073741824 bytes (1.1 GB) copied, 0.936182 s, 1.1 GB/s
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.09543 s, 980 MB/s
1048576+0 records in
1048576+0 records out
1073741824 bytes (1.1 GB) copied, 1.11862 s, 960 MB/s
---------------------
作者:懶少
來源:CSDN
原文:https://blog.csdn.net/shaoyunzhe/article/details/53606584
版權(quán)聲明:本文為博主原創(chuàng)文章,轉(zhuǎn)載請附上博文鏈接!

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)