
“Alphalens 要求因子數據是雙重索引的 Series,價格數據是日期為索引、資產代碼為列的 DataFrame。通過 Pandas 的 pivot_table 和 set_index,可以輕松完成格式轉換,為因子分析奠定基礎。”
1. 通過rolling方法實現通達信例程
通達信 是一款由中國深圳市財富趨勢科技股份有限公司開發的金融投資軟件,主要用于股票、期貨等金融市場的行情分析、技術研究和交易執行。通達信在國內券商中的覆蓋率超過80%,服務包括招商證券、廣發證券等頭部機構。支持超5000萬投資者,峰值并發用戶達800萬,以界面簡潔、行情更新快著稱。適用于個人投資者、專業交易員及量化分析,尤其適合需要快速響應行情和技術分析的場景。
rolling 是 pandas 庫中用于執行滾動窗口計算的核心方法,適用于時間序列或數據框的滑動統計分析。以下是其核心要點:
- 功能:對數據按固定窗口大小(如時間周期或觀測值數量)滑動,并在每個窗口內執行聚合或自定義計算(如均值、極值等)
- 典型應用:移動平均、波動率計算(標準差)、技術指標(如MACD)等。
核心參數:
| 參數 | 說明 |
|---|---|
| window | 窗口大小(整數或時間偏移,如 '5D') |
| min_periods | 窗口內最少有效數據量,否則結果為 NaN(默認等于 window) |
| center | 窗口對齊方式(False為右對齊,True為居中) |
| win_type | 窗口權重類型(如 'gaussian') |
1.1. HHV(N周期內最高值)
通達信定義:HHV(X, N) 表示在最近 N 個周期內序列 X 的最高值。可以通過 pandas 實現:
def HHV(s: pd.Series, n: int) -> pd.Series:
return s.rolling(n).max()
1.2. LLV(N周期內最低值)
通達信定義:LLV(X, N) 表示在最近 N 個周期內序列 X 的最低值。
def LLV(s: pd.Series, n: int) -> pd.Series:
return s.rolling(n).min()
1.3. HHVBARS(最高值到當前周期的距離)?
通達信定義:HHVBARS(X, N) 表示最近 N 個周期內,最高值所在位置到當前周期的距離(周期數)。
def HHVBARS(s: pd.Series, n: int) -> pd.Series:
def _find_idx(x):
return len(x) - np.argmax(x[::-1]) - 1 if not np.isnan(x).all() else np.nan
return s.rolling(n).apply(_find_idx, raw=True)
1.4. LAST(條件連續滿足的周期數)?
通達信定義:LAST(X, A, B) 表示過去 B 個周期中,有至少 A 個周期滿足條件 X。
def LAST(condition: pd.Series, a: int, b: int) -> pd.Series:
return condition.rolling(b).sum() >= a
1.5. 示例
import pandas as pd
import numpy as np
# 導入數據
start = datetime.date(2023, 1, 1)
end = datetime.date(2023, 12, 31)
df = load_bars(start, end)
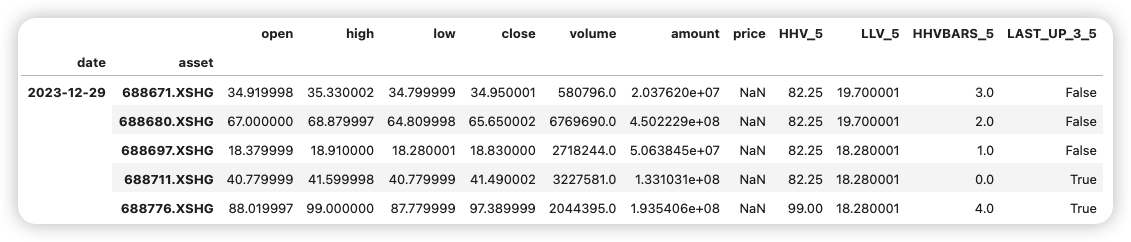
df.tail()
# 應用函數
df['HHV_5'] = HHV(df['high'], 5) # 5日最高價
df['LLV_5'] = LLV(df['low'], 5) # 5日最低價
df['HHVBARS_5'] = HHVBARS(df['high'], 5) # 最高價距離當前的天數
df['LAST_UP_3_5'] = LAST(df['close'] > df['close'].shift(1), 3, 5) # 5日內至少3日上漲
print(df)
2. 補齊分鐘線缺失的復權因子
量化分析中,可能在處理股票分鐘線數據時,復權因子數據存在缺失,需要根據時間進行臨近匹配,確保每個分鐘數據點都有正確的復權因子。復權因子通常是在股票發生拆分或分紅時調整的,這些事件的時間點可能不會正好匹配分鐘線的每個時間戳,例如:
- 復權因子生效時間:2025-03-27 10:30:00(事件觸發時刻)
- 分鐘線時間戳:2025-03-27 10:30:01、10:30:02(交易數據)
!!! Tip
傳統 merge 或 join 方法無法匹配此類時間鄰近但非嚴格相等的數據,需用 ?as-of join 功能解決。使用 merge_asof 可以找到每個分鐘線時間點之前最近的復權因子,確保正確應用調整。
merge_asof 是 Pandas >=0.19.0 引入的時間導向非精確匹配函數,專為此類場景設計。
2.1. 基礎語法和示例
2.1.1. 基礎語法
pd.merge_asof(
left, # 左表(分鐘線數據)
right, # 右表(復權因子數據)
on='time', # 時間列名(必須排序)
direction='backward', # 匹配方向:向前/向后/最近
tolerance=pd.Timedelta('1min'), # 最大時間差
allow_exact_matches=True # 是否允許精確匹配
)
2.1.2. 基礎示例
import pandas as pd
import numpy as np
# 生成示例數據(假設復權因子在非整分鐘時間點更新)
minute_data = {
'time': [
'2025-03-27 10:29:58', # 完整日期+時間
'2025-03-27 10:30:01',
'2025-03-27 10:30:03',
'2025-03-27 10:30:05',
'2025-03-27 10:30:08' # 確保所有時間包含日期
],
'price': [100.2, 101.5, 102.0, 101.8, 103.2]
}
df_trade = pd.DataFrame(minute_data).sort_values('time')
adjust_data = {
'time': [
'2025-03-27 10:29:55',
'2025-03-27 10:30:00',
'2025-03-27 10:30:06'
],
'adjust_factor': [1.0, 0.95, 1.02]
}
df_adjust = pd.DataFrame(adjust_data).sort_values('time')
# 強制轉換為 datetime 類型(處理混合格式)
df_trade['time'] = pd.to_datetime(
df_trade['time'],
format='%Y-%m-%d %H:%M:%S',
errors='coerce'
)
df_adjust['time'] = pd.to_datetime(
df_adjust['time'],
format='%Y-%m-%d %H:%M:%S',
errors='coerce'
)
assert df_trade['time'].dtype == 'datetime64[ns]', "交易數據時間列轉換失敗"
assert df_adjust['time'].dtype == 'datetime64[ns]', "復權因子時間列轉換失敗"
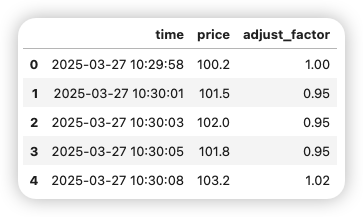
# 關鍵步驟:按時間向前匹配最近的復權因子
merged = pd.merge_asof(
df_trade,
df_adjust,
on='time',
direction='backward', # 取<=當前時間的最近值
tolerance=pd.Timedelta(minutes=1) # 最多允許1分鐘間隔
)
merged
2.2. 進階技巧
2.2.1. 多標的匹配(股票代碼分組)
# 假設數據包含多只股票
merged = pd.merge_asof(
df_trade.sort_values('time'),
df_adjust.sort_values('time'),
on='time',
by='symbol', # 按股票代碼分組匹配
direction='backward'
)
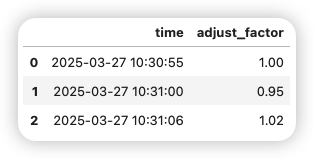
2.2.2. 動態調整因子生效時間
若復權因子生效時間需要提前或延后,可預處理右表時間:
df_adjust['time'] = df_adjust['time'] + pd.Timedelta(seconds=30) # 延后30秒生效
df_adjust
2.2.3. 處理缺失值
merged['adjust_factor'] = merged['adjust_factor'].ffill() # 前向填充缺失值
2.3. 與其他方法對比
| 方法 | 適用場景 | 優點 | 缺點 |
|---|---|---|---|
| merge_asof | 時間鄰近匹配 | 處理非對齊時間戳效率高 | 需預先排序數據 |
| merge | 精確時間匹配 | 結果精確 | 無法處理時間偏差 |
| concat | 簡單堆疊 | 快速合并 | 不處理時間關聯 |
3. 為Alphalens準備數據
在使用Alphalens進行因子分析時,我們往往需要將因子數據和價格數據整理成特定的格式。Alphalens要求因子數據是一個具有雙重索引(日期和資產)的Series,而價格數據是DataFrame,行是日期,列是資產,值是價格。這一點非常重要,如果格式不對,Alphalens會報錯。
因此,我們需要知道如何從原始數據轉換到這種格式。這里我們考慮使用pivot_table來轉換價格數據,以及使用set_index來創建因子數據的雙重索引。
3.1. 數據格式規范(Alphalens 強制要求)
3.1.1. 因子數據格式
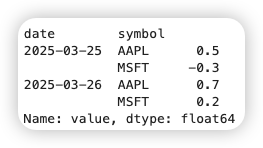
需構建雙重索引的 Series,索引順序為:日期 -> 資產代碼,值為因子數值:
# 原始數據示例(含日期、股票代碼、因子值)
raw_factor = pd.DataFrame({
'date': ['2025-03-25', '2025-03-25', '2025-03-26', '2025-03-26'],
'symbol': ['AAPL', 'MSFT', 'AAPL', 'MSFT'],
'value': [0.5, -0.3, 0.7, 0.2]
})
# 轉換為Alphalens格式
factor = raw_factor.set_index(['date', 'symbol'])['value']
factor.index = pd.MultiIndex.from_arrays(
# 確保日期為datetime類型
[pd.to_datetime(factor.index.get_level_values('date')),
factor.index.get_level_values('symbol')]
)
factor
3.1.2. ?價格數據格式
需構建 ?日期為索引、資產代碼為列名 的 DataFrame:
# 原始數據示例(含日期、股票代碼、收盤價)
raw_price = pd.DataFrame({
'date': ['2025-03-25', '2025-03-25', '2025-03-26', '2025-03-26'],
'symbol': ['AAPL', 'MSFT', 'AAPL', 'MSFT'],
'close': [150, 280, 152, 285]
})
# 轉換為Alphalens格式
prices = raw_price.pivot(index='date', columns='symbol', values='close')
prices.index = pd.to_datetime(prices.index) # 日期轉換為datetime類型
3.2. 關鍵預處理操作
3.2.1. 時間索引對齊
# 檢查時間范圍是否重疊
print("因子時間范圍:", factor.index.get_level_values('date').min(), "~",
factor.index.get_level_values('date').max())
print("價格時間范圍:", prices.index.min(), "~", prices.index.max())
# 若存在時間缺口,用前向填充(避免未來數據)
prices = prices.ffill()
3.2.2. 異常值處理
# Winsorize去極值(保留98%數據)
factor_clipped = factor.clip(
lower=factor.quantile(0.01),
upper=factor.quantile(0.99)
)
# 標準化處理(Z-score)
factor_normalized = (factor - factor.mean()) / factor.std()
3.2.3. 缺失值處理
# 刪除缺失值超過50%的資產
valid_symbols = factor.unstack().isnull().mean() < 0.5
factor = factor.loc[:, valid_symbols[valid_symbols].index.tolist()]
# 前向填充剩余缺失值
factor = factor.groupby(level='symbol').ffill()
3.3. 高級操作技巧
3.3.1. 多因子
# 假設存在動量因子和市值因子
factor_mom = ... # 動量因子數據
factor_size = ... # 市值因子數據
# 橫向拼接為MultiIndex列
combined = pd.concat(
[factor_mom.rename('momentum'), factor_size.rename('size')],
axis=1
)
# 轉換為雙層索引
combined = combined.stack().swaplevel(0, 1).sort_index()
3.3.2. ?行業中性化處理
# 假設有行業分類數據
industries = pd.Series({
'AAPL': 'Technology',
'MSFT': 'Technology',
'XOM': 'Energy'
}, name='industry')
# 按行業分組標準化
factor_neutral = factor.groupby(
industries, group_keys=False
).apply(lambda x: (x - x.mean()) / x.std())
3.4. 數據驗證與接口對接
3.4.1. 格式驗證
# 檢查因子索引層級
assert factor.index.names == ['date', 'symbol'], "因子索引命名錯誤"
# 檢查價格數據類型
assert prices.columns.dtype == 'object', "價格數據列名應為資產代碼"
3.4.2. Alphalens 接口調用
from alphalens.utils import get_clean_factor_and_forward_returns
# 生成分析數據集
factor_data = get_clean_factor_and_forward_returns(
factor=factor,
prices=prices,
periods=(1, 5, 10), # 1/5/10日收益率
quantiles=5, # 分為5組
filter_zscore=3 # 剔除3倍標準差外的異常值
)
# 生成完整分析報告
import alphalens
alphalens.tears.create_full_tear_sheet(factor_data)
3.5. 常見問題解決方案
| 問題現象 | 解決方法 |
|---|---|
| ValueError: 價格數據包含未來信息 | 檢查價格數據時間戳是否晚于因子時間戳,用prices = prices.shift(1) 滯后一期 |
| KeyError: 資產代碼不匹配 | 使用prices.columns.intersection(factor.index.get_level_values('symbol')) 取交集 |
| 圖表顯示空白 | 在Jupyter Notebook中運行,并添加%matplotlib inline 魔術命令 |
通過上述操作,可高效完成從原始數據到Alphalens兼容格式的轉換,確保因子分析的準確性。實際應用中建議先在小樣本數據上測試,再擴展至全量數據。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號