
“DataFrame 是 Pandas 的核心數據結構,支持多種數據類型和靈活的操作方式。無論是嵌套字典、NumPy 數組還是 CSV 文件,都可以輕松轉換為 DataFrame,助你快速完成數據分析任務。”
1. 快速探索 DataFrame
1.1. 創建 DataFrame
DataFrame 含有一組有序且有命名的列,每一列可以是不同的數據類型(數值、字符串、布爾值等)。DataFrame 既有行索引也有列索引,可以看作由共用同一個索引的Series組成的字典。雖然DataFrame是二維的,但利用層次化索引,仍然可以用其表示更高維度的表格型數據。如果你使用的是Jupyter notebook,pandas的DataFrame 對象將會展示為對瀏覽器更為友好的HTML表格。
1.1.1. 傳入一個由等長列表或Numpy數組構成的字典
import pandas as pd
data = {"state":["Ohio","Ohio","Ohio","Nevada","Nevada","Nevada"],
"year":[2000,2001,2002,2003,2004,2005],
"pop":[1.5,1.7,3.6,2.4,2.9,3.2]}
frame = pd.DataFrame(data)
frame
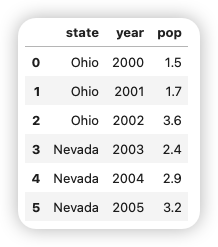
生成的DataFrame會自動加上索引(和Series一樣),且全部列會按照data鍵(鍵的順序取決于在字典中插入的順序)的順序有序排列。
(如果你使用的是Jupyter notebook,pandas的DataFrame對象會展示為對瀏覽器更為友好的HTML表格)
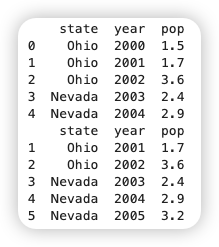
對于特別大的DataFrame,可以使用head方法,只展示前5行。相似地,tail方法會返回最后5行。
print(frame.head())
print(frame.tail())
下面還有幾種創建DataFrame的情況:
# 如果指定了列的順序,則DataFrame的列就會按照指定順序進行排列
frame1 = pd.DataFrame(data=data,columns=["year","state","pop"])
# 如果字典中不包括傳入的列,就會在結果中產生缺失值
frame2 = pd.DataFrame(data=data,columns=["year","state","pop","debt"])
1.1.2. 傳入嵌套字典
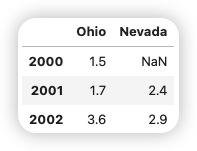
如果將嵌套字典傳給DataFrame,pandas就會將外層字典的鍵解釋為列,將內層字典的鍵解釋為行索引。
populations = {"Ohio":{2000:1.5,2001:1.7,2002:3.6},"Nevada":{2001:2.4,2002:2.9}}
frame3 = pd.DataFrame(populations)
frame3
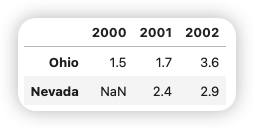
使用類似于Numpy數組的方法,可以對 DataFrame 進行轉置(交換行和列):
frame3.T
內層字典的鍵被合并后形成了結果的索引。如果明確指定了索引,則不會這樣:
pd.DataFrame(populations,index=["2001","2002","2003"])
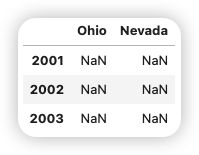
由Series組成的字典差不多也是一樣的用法:
pdata = {"Ohio":frame3["Ohio"][:-1],"Nevada":frame3["Nevada"][:2]}
pd.DataFrame(pdata)
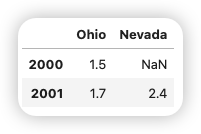
可以向DataFrame構造器輸入的數據:
| 類型 | 說明 |
|---|---|
| ?字典 (Dict) | 鍵為列名,值為列表、NumPy 數組或 Series。每列的長度必須一致。 |
| ?列表 (List) | 列表中的每個元素是一個字典,字典的鍵為列名,值為對應列的數據。 |
| 類型 | 說明 |
|---|---|
| ?NumPy 數組 | 二維數組,每行對應 DataFrame 的一行,每列對應 DataFrame 的一列。 |
| ?Series | 單個 Series 可以構造單列的 DataFrame,多個 Series 可以構造多列。 |
| ?結構化數組 | NumPy 的結構化數組,字段名對應 DataFrame 的列名。 |
| ?其他 DataFrame | 可以通過復制另一個 DataFrame 來創建新的 DataFrame。 |
| ?CSV 文件 | 通過 pd.read_csv() 讀取 CSV 文件并轉換為 DataFrame。 |
| ?Excel 文件 | 通過 pd.read_excel() 讀取 Excel 文件并轉換為 DataFrame。 |
| ?JSON 數據 | 通過 pd.read_json() 讀取 JSON 數據并轉換為 DataFrame。 |
| ?SQL 查詢結果 | 通過 pd.read_sql() 讀取 SQL 查詢結果并轉換為 DataFrame。 |
| ?HTML 表格 | 通過 pd.read_html() 從 HTML 頁面中提取表格并轉換為 DataFrame。 |
| ?剪貼板數據 | 通過 pd.read_clipboard() 從剪貼板中讀取數據并轉換為 DataFrame。 |
如果設置了DataFrame的index和columns的name屬性,則這些信息也會顯示出來:
frame3.index.name = "year"
frame3.columns.name = "state"
frame3
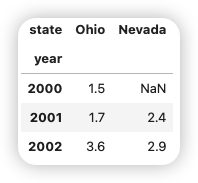
# 二維的ndarray的DataFrame形式返回
frame3.to_numpy()
# 如果DataFrame各列的數據類型不同,則返回數組會選用能兼容所有列的數據類型:
frame2.to_numpy()

1.2. DataFrame 的合并和連接
在 Pandas 中,concat、join 和 merge 是用于合并和連接 DataFrame 的三種主要方法。它們各有不同的用途和適用場景,以下是詳細說明。
1.2.1. ?concat:基于軸的數據拼接
concat 主要用于沿指定軸(行或列)將多個 DataFrame 或 Series 拼接在一起。
參數說明:
- ?objs:需要拼接的 DataFrame 或 Series 列表。
- ?axis:拼接方向,0 表示按行拼接(默認),1 表示按列拼接。
- join:拼接方式,'outer'(默認,保留所有索引)或 'inner'(僅保留共同索引)。
- ignore_index:是否忽略原索引并生成新索引,默認為 False。
- keys:為拼接后的數據添加層次化索引。
示例:
import pandas as pd
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]})
df2 = pd.DataFrame({'A': [5, 6], 'B': [7, 8]})
# 按行拼接
result = pd.concat([df1, df2], axis=0)
print(result)
# 按列拼接
result = pd.concat([df1, df2], axis=1)
print(result)
適用場景:
- 將多個結構相似的數據集簡單堆疊在一起。
- 不需要基于鍵值匹配,只需按行或列拼接。
1.2.2. merge:基于鍵值的合并
merge 用于根據一個或多個鍵將兩個 DataFrame 合并在一起,類似于 SQL 中的 JOIN 操作。
參數說明:
- ?left:左側的 DataFrame。
- right:右側的 DataFrame。
- ?how:合并方式,可選 'inner'(默認,內連接)、'left'(左連接)、'right'(右連接)、'outer'(外連接)。
- ?on:用于合并的列名(鍵),必須在兩個 DataFrame 中都存在。
- left_on/right_on:當兩個 DataFrame 的鍵列名不同時,分別指定左側和右側的鍵列。
- suffixes:當兩個 DataFrame 中存在重復列名時,用于區分的后綴。
示例:
df1 = pd.DataFrame({'key': ['A', 'B', 'C'], 'value1': [1, 2, 3]})
df2 = pd.DataFrame({'key': ['B', 'C', 'D'], 'value2': [4, 5, 6]})
# 內連接
result = pd.merge(df1, df2, on='key', how='inner')
print(result)
# 外連接
result = pd.merge(df1, df2, on='key', how='outer')
print(result)
適用場景:
- 需要根據某些列(鍵)將兩個表關聯。
- 類似于 SQL 中的 JOIN,適合處理結構化數據。
1.2.3. join:基于索引的合并
join 是基于索引將兩個 DataFrame 合并在一起,是 merge 的簡化版。
參數說明:
- other:要連接的另一個 DataFrame。
- ?on:用于連接的列名或索引。
- ?how:連接方式,可選 'left'(默認,左連接)、'right'(右連接)、'outer'(外連接)、'inner'(內連接)。
- ?lsuffix/rsuffix:當兩個 DataFrame 中存在重復列名時,分別指定左側和右側的后綴。
示例:
df1 = pd.DataFrame({'A': [1, 2], 'B': [3, 4]}, index=['x', 'y'])
df2 = pd.DataFrame({'C': [5, 6], 'D': [7, 8]}, index=['x', 'y'])
# 基于索引的左連接
result = df1.join(df2, how='left')
print(result)
適用場景:
- 基于索引進行簡單的數據合并。
- 適合處理索引對齊的數據。
| 方法 | 主要用途 | 適用場景 | 靈活性 | 性能 |
|---|---|---|---|---|
| concat | 基于軸的數據拼接 | 簡單堆疊數據,結構相似的數據集 | 按行或列拼接 | 適合大規模數據 |
| merge | 基于鍵值的合并,類似于 SQL 的 JOIN | 結構化數據,需要關聯表 | 支持多種連接方式 | 適合小規模數據 |
| join | 基于索引的合并 | 索引對齊的數據 | 簡化版 merge |
適合簡單操作 |
1.3. 刪除行和列
關鍵字del可以像在字典中那樣刪除列。
frame2["eastern"] = frame2["state"] = "ohio"
print(frame2)
del frame2["eastern"]
print(frame2.columns)
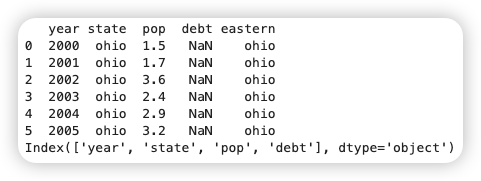
1.1.4. 定位、讀取和修改
1.1.4.1. 獲取列
通過類似于字典標記或點屬性的方式,可以將DataFrame的列獲取為一個Series。
print(frame2["state"])
print(frame2.year)
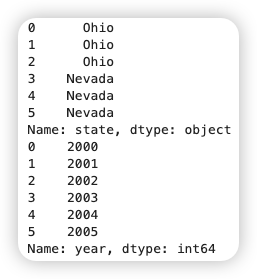
如果列名包含空格或下劃線以外的符號,是不能用點屬性的方式訪問的。
1.1.4.2. 修改列
import numpy as np
# 通過賦值的方法修改列
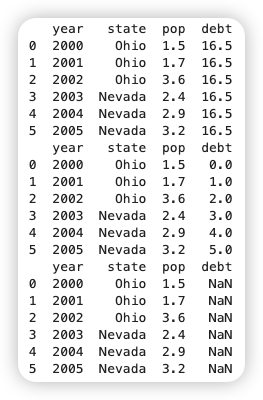
frame2["debt"] = 16.5
print(frame2)
frame2["debt"] = np.arange(6.)
print(frame2)
# 將列表和數組賦值給某個列
val = pd.Series([1.2,-1.5,-1.7],index=["two","four","five"]) # 長度必須與DataFrame保持一致
frame2["debt"] = val
print(frame2)
1.1.4.2. 獲取行(iloc和loc)
通過iloc和loc屬性,也可以通過位置或名稱的方式進行獲取行。
print(frame2.loc[1])
print(frame2.iloc[2])

1.1.5. 轉置
轉置操作是將 DataFrame 的行和列進行互換,即將行變為列,列變為行。Pandas 提供了兩種方法來實現轉置:
- T 屬性:直接調用 DataFrame.T 進行轉置。
- ?transpose() 方法:通過 DataFrame.transpose() 實現轉置。
import pandas as pd
# 創建一個示例 DataFrame
data = {'Name': ['Tom', 'Jack', 'Steve'], 'Age': [28, 34, 29],
'City': ['London', 'New York', 'Sydney']}
df = pd.DataFrame(data)
# 使用 T 屬性轉置
transposed_df = df.T
print(transposed_df)
# 使用 transpose() 方法轉置
transposed_df = df.transpose()
print(transposed_df)
注意事項:
- 轉置操作會改變 DataFrame 的結構,但不會修改原始數據。
- 如果 DataFrame 包含混合數據類型,轉置后可能需要重新調整數據類型。
1.1.6. 重采樣(resample)
重采樣是將時間序列數據從一個頻率轉換為另一個頻率的過程。Pandas 提供了 resample() 方法來實現重采樣,支持以下兩種類型:
- ?上采樣(Upsampling)?:將低頻數據轉換為高頻數據(如將日數據轉換為小時數據)。
- ?下采樣(Downsampling)?:將高頻數據轉換為低頻數據(如將分鐘數據轉換為小時數據)。
import pandas as pd
# 創建一個示例時間序列 DataFrame
data = {'date': pd.date_range(start='1/1/2020', periods=100, freq='D'),
'price': range(100)}
df = pd.DataFrame(data)
df.set_index('date', inplace=True)
# 下采樣:將日數據轉換為月數據,并計算每月的平均價格
monthly_avg_price = df['price'].resample('M').mean()
print(monthly_avg_price)
# 上采樣:將日數據轉換為小時數據,并使用前向填充
hourly_price = df['price'].resample('H').ffill()
print(hourly_price)
注意事項:
- 重采樣需要 DataFrame 的索引為時間類型。
- 可以使用
fillna()或interpolate()方法處理缺失值。
---13

 浙公網安備 33010602011771號
浙公網安備 33010602011771號