

GMP模型里為什么要有P?
關于GMP模型里為什么要有P,進一步推敲問題的背后,其實這個問題本質是想問:”為什么不是 G 和 M 直接綁定就完了,還要搞多一個 P 出來,那么麻煩,為的是什么,是要解決什么問題嗎?
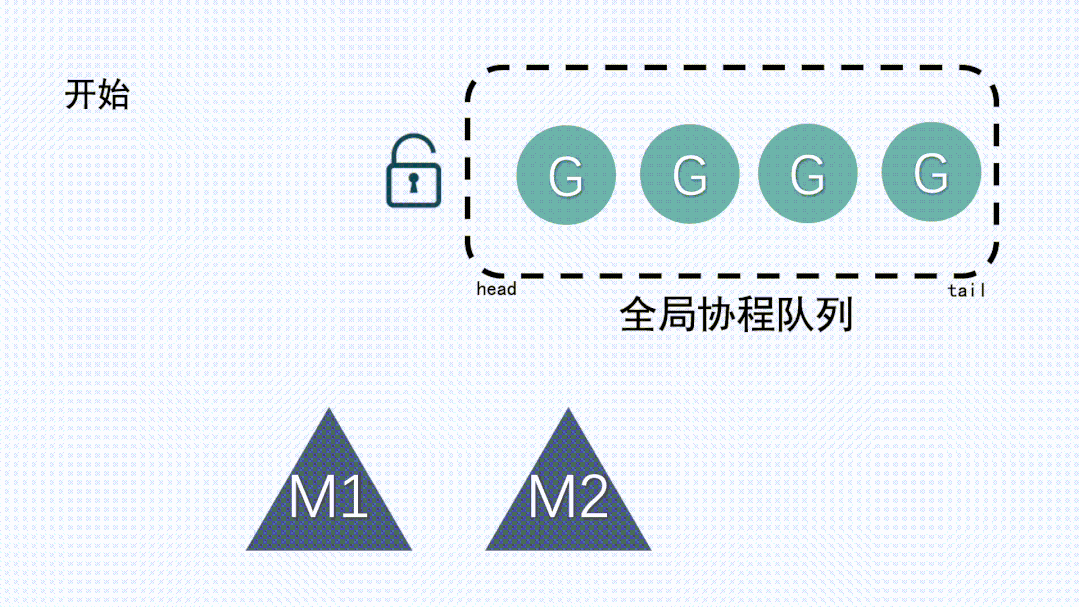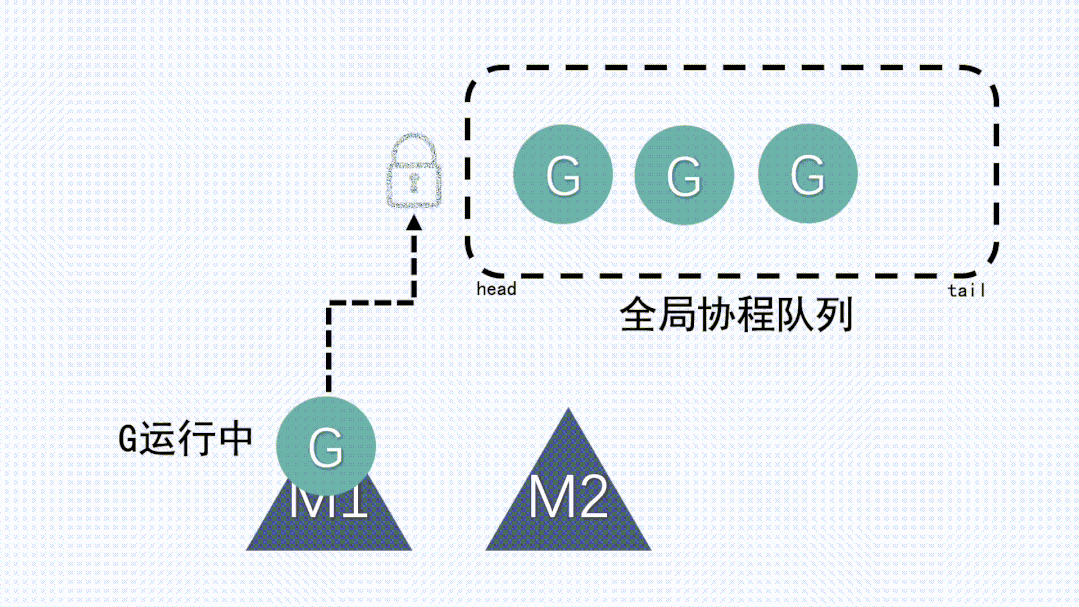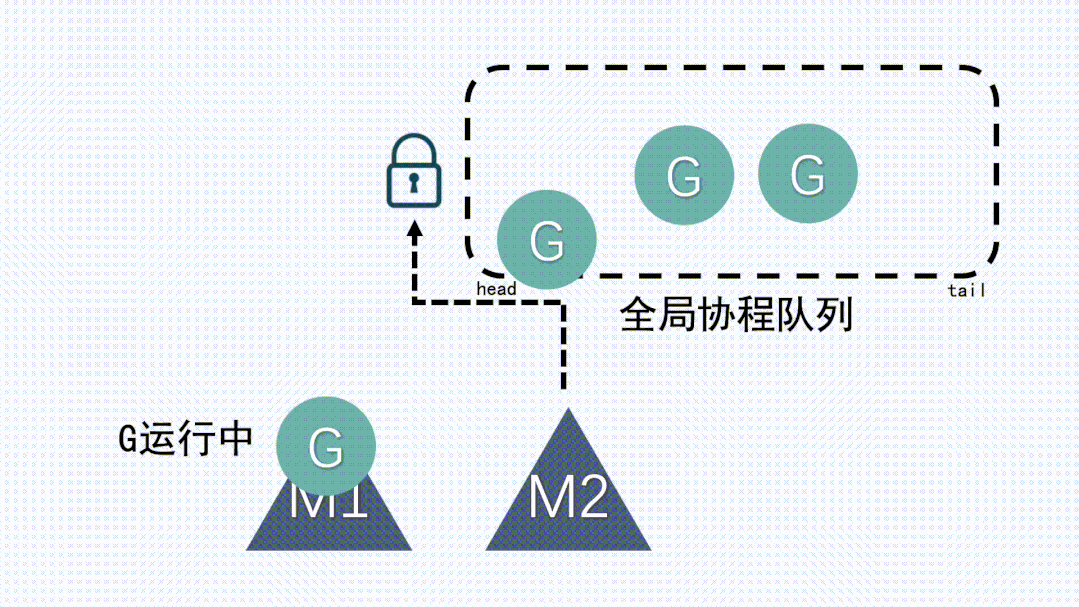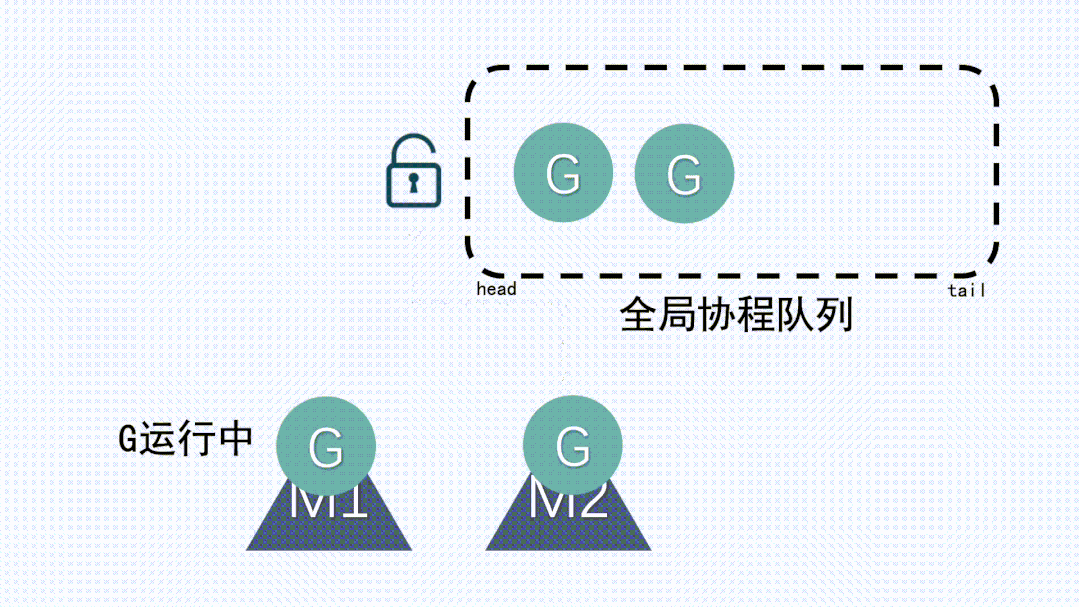
這就要說到go的歷史版本了,在 Go1.1 之前 Go 的調度模型其實就是 GM 模型,也就是沒有 P。 如下圖:
G:gouritine協程。通常在代碼里用 go 關鍵字執行一個方法,那么就等于起了一個G。
M:內核線程,操作系統內核其實看不見G(和P),只知道自己在執行一個線程。G(和P)都是在用戶層上的實現。
-
除了G和M以外,還有一個全局協程隊列,這個全局隊列里放的是多個處于可運行狀態的G。
-
1、M 想要執行、放回 G 都必須訪問全局 G 隊列,并且 M 有多個,即多線程訪問同一資源需要加鎖進行保證互斥 / 同步,所以全局 G 隊列是有互斥鎖進行保護的。
-
2、創建、銷毀、調度 G 都需要每個 M 獲取鎖,這就形成了激烈的鎖競爭。
-
3、M 轉移 G 會造成延遲和額外的系統負載,這要求每個M都要能運行新創建的G:比如當 G 中包含創建新協程的時候,M 創建了 G’,為了繼續執行 G,需要把 G’交給 M’執行,也造成了很差的局部性,因為 G’和 G 是相關的,最好放在 M 上執行,而不是其他 M’。
-
4、系統調用 (CPU 在 M 之間的切換) 導致頻繁的線程阻塞和取消阻塞操作增加了系統開銷。
- 而引入P后,P的本地隊列做了一部分這個工作,本的本地隊列對于M來說沒有并發,并且對于全局G隊列的依賴大大降低了。
最終加入了P從GM模型轉變為GMP模型
-
為什么 P 的邏輯不直接加在 M 上
1、G的上下文交由M管理肯定如由P來管理,畢竟M是內核線程,開銷更大
2、M 被系統調用阻塞后,我們是指望把他既有未執行的任務分配給其余繼續運行的M,而不是一阻塞就致使當前M中所有的G都被阻塞。
3、其實引入P后,就有了兩級調度系統,M不再關注于G的上下文,也不用去全局查找G,只需要在當前P的本地G隊列獲取執行G即可,所有與G有關的而可能帶來的問題都交由P完成,而P是用戶層級的,比線程解決這些問題時要方便的多。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號