

| 項(xiàng)目 | 要求 |
| 課程班級(jí)博客鏈接 | 20級(jí)數(shù)據(jù)班(本) |
| 這個(gè)作業(yè)要求鏈接 | Python數(shù)據(jù)分析五一假期作業(yè) |
| 博客名稱(chēng) | 2003031120—廖威—Python數(shù)據(jù)分析五一假期作業(yè) |
| 要求 | 每道題要有題目,代碼(使用插入代碼,不會(huì)插入代碼的自己查資料解決,不要直接截圖代碼!!),截圖(只截運(yùn)行結(jié)果)。 |
一、分析1996~2015年人口數(shù)據(jù)特征間的關(guān)系(1題50分,共50分)
考查知識(shí)點(diǎn):掌握pyplot常用的繪圖參數(shù)的調(diào)節(jié)方法;掌握子圖的繪制方法;掌握繪制圖形的保存與展示方法;掌握散點(diǎn)圖和折線圖的作用與繪制方法。
需求說(shuō)明:
人口數(shù)據(jù)總共擁有6個(gè)特征,分別為年末總?cè)丝凇⒛行匀丝凇⑴匀丝凇⒊擎?zhèn)人口、鄉(xiāng)村人口和年份。查看各個(gè)特征隨著時(shí)間推移發(fā)生的變化情況可以分析出未來(lái)男女人口比例、城鄉(xiāng)人口變化的方向。
截圖如下:
要求:
(1)使用NumPy庫(kù)讀取人口數(shù)據(jù)。
(2)創(chuàng)建畫(huà)布,并添加子圖。
(3)在兩個(gè)子圖上分別繪制散點(diǎn)圖和折線圖。
(4)保存,顯示圖片。
(5)分析未來(lái)人口變化趨勢(shì)
代碼:
#導(dǎo)入模塊 import numpy as np import matplotlib.pyplot as plt #使?numpy庫(kù)讀取??數(shù)據(jù) data=np.load("D:/Users/ASUS/Desktop/populations.npz",allow_pickle=True)#讀取文件,返回輸入數(shù)組 print(data.files)#查看?件中的數(shù)組 print(data['data']) print(data['feature_names']) plt.rcParams['font.sans-serif'] = 'SimHei' # 設(shè)置中文顯示 plt.rcParams['axes.unicode_minus'] = False# 防止字符無(wú)法顯示 name=data['feature_names']#提取其中的feature_names數(shù)組,視為數(shù)據(jù)的標(biāo)簽 values=data['data']#提取其中的data數(shù)組,視為數(shù)據(jù)的存在位置 #設(shè)置畫(huà)布 p1=plt.figure(figsize=(12,12))#確定畫(huà)布?? pip1=p1.add_subplot(2,1,1)#創(chuàng)建?個(gè)兩??列的?圖并開(kāi)始繪制 #在?圖上繪制散點(diǎn)圖 plt.scatter(values[0:20,0],values[0:20,1])#,marker='8',color='red' plt.ylabel('總?cè)丝冢ㄈf(wàn)?)') plt.legend('年末') plt.title('1996~2015年末與各類(lèi)人口散點(diǎn)圖') pip2=p1.add_subplot(2,1,2)#繪制?圖2 plt.scatter(values[0:20,0],values[0:20,2])#,marker='o',color='yellow' plt.scatter(values[0:20,0],values[0:20,3])#,marker='D',color='green' plt.scatter(values[0:20,0],values[0:20,4])#,marker='p',color='blue' plt.scatter(values[0:20,0],values[0:20,5])#,marker='s',color='purple' plt.xlabel('時(shí)間') plt.ylabel('總?cè)丝冢ㄈf(wàn)人)') plt.xticks(values[0:20,0]) plt.legend(['男性','女性','城鎮(zhèn)','鄉(xiāng)村']) #在?圖上繪制折線圖 p2=plt.figure(figsize=(12,12)) p1=p2.add_subplot(2,1,1) plt.plot(values[0:20,0],values[0:20,1])#,linestyle = '-',color='r',marker='8' plt.ylabel('總?cè)丝冢ㄈf(wàn)人)') plt.xticks(range(0,20,1),values[range(0,20,1),0],rotation=45)#rotation設(shè)置傾斜度 plt.legend('年末') plt.title('1996~2015年末總與各類(lèi)人口折線圖') p2=p2.add_subplot(2,1,2) plt.plot(values[0:20,0],values[0:20,2])#,'y-' plt.plot(values[0:20,0],values[0:20,3])#,'g-.' plt.plot(values[0:20,0],values[0:20,4])#,'b-' plt.plot(values[0:20,0],values[0:20,5])#,'p-' plt.xlabel('時(shí)間') plt.ylabel('總?cè)丝冢ㄈf(wàn)人)') plt.xticks(values[0:20,0]) plt.legend(['男性','女性','城鎮(zhèn)','鄉(xiāng)村']) #顯?圖? plt.show()
結(jié)果:
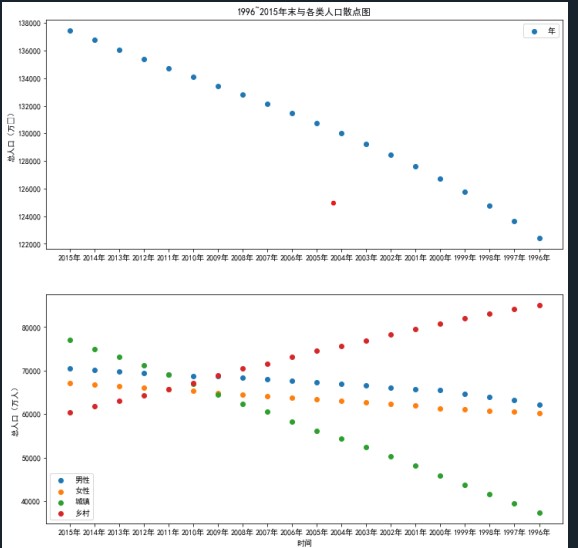
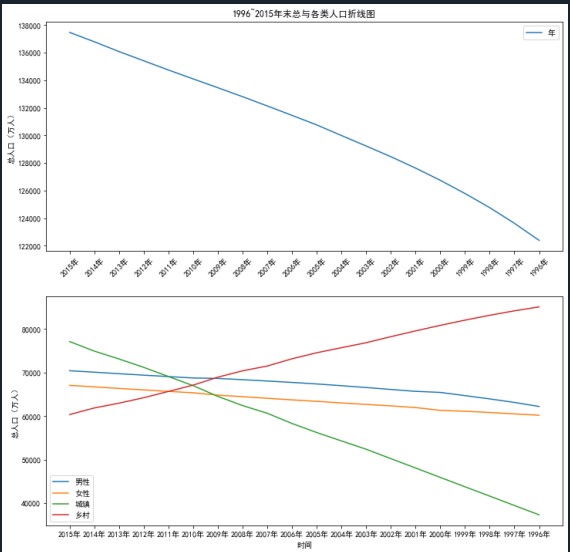
(5)
根據(jù)各個(gè)特征隨著時(shí)間推移發(fā)生的變化情況可以分析出未來(lái)男女人口比例將逐漸趨于平衡狀態(tài),城鄉(xiāng)人口變化方向?qū)⒅饾u城鎮(zhèn)化。
二、讀取并查看P2P網(wǎng)絡(luò)貸款數(shù)據(jù)主表的基本信息(1題10分,共10分)
考查知識(shí)點(diǎn):掌握常見(jiàn)的數(shù)據(jù)讀取方式;掌握DataFrame常用屬性與方法;掌握基礎(chǔ)時(shí)間數(shù)據(jù)處理方法;掌握分組聚合的原理與方法;掌握透視表與交叉表的制作。
需求說(shuō)明:
P2P貸款主表數(shù)據(jù)主要存放了網(wǎng)貸用戶(hù)的基本信息。探索數(shù)據(jù)的基本信息,能夠洞察數(shù)據(jù)的整體分布、數(shù)據(jù)的類(lèi)屬關(guān)系、從而發(fā)現(xiàn)數(shù)據(jù)間的關(guān)聯(lián)。
要求:
(1)使用ndim、shape、memory_usage屬性分別查看維度、大小、占用內(nèi)存信息。
代碼:
#導(dǎo)入模塊 import os import pandas as pd master = pd.read_csv('D:/Users/ASUS/Desktop/Training_Master.csv',encoding='gbk')#讀取csv文件 print('P2P網(wǎng)絡(luò)貸款主表數(shù)據(jù)的維度為:',master.ndim) print('P2P網(wǎng)絡(luò)貸款主表數(shù)據(jù)的形狀大小為:',master.shape) print('P2P網(wǎng)絡(luò)貸款主表數(shù)據(jù)的占用內(nèi)存為:',master.memory_usage) #代碼16-2 print('P2P網(wǎng)絡(luò)貸款主表數(shù)據(jù)的描述性統(tǒng)計(jì)為:\n',master.describe())
結(jié)果:
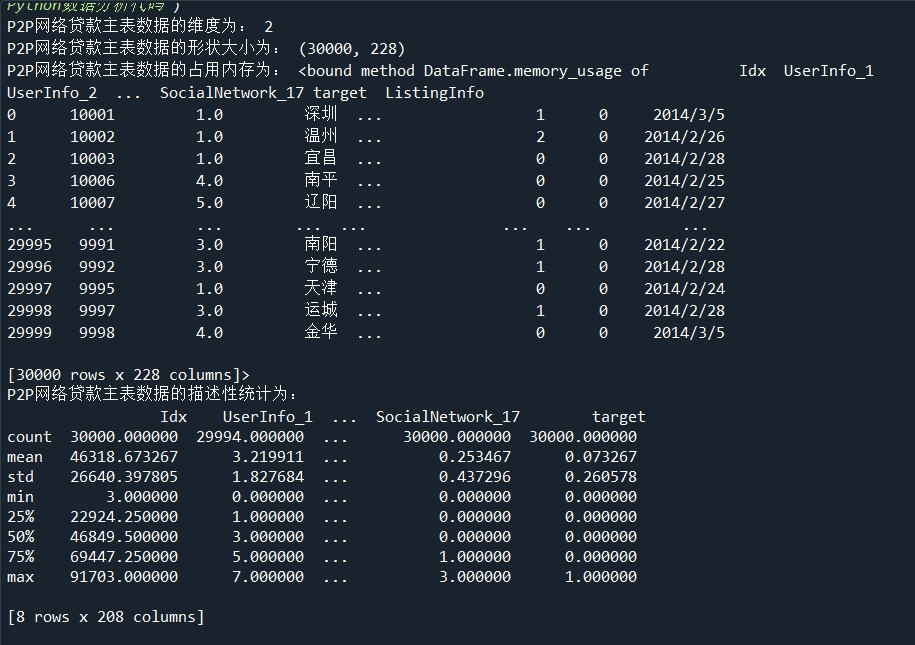
三、提取用戶(hù)信息更新表和登錄信息表的時(shí)間信息(1題10分,共10分)
考查知識(shí)點(diǎn):掌握常見(jiàn)的數(shù)據(jù)讀取方式;掌握DataFrame常用屬性與方法;掌握基礎(chǔ)時(shí)間數(shù)據(jù)處理方法;掌握分組聚合的原理與方法;掌握透視表與交叉表的制作。
需求說(shuō)明:
用戶(hù)信息更新表和登錄信息表匯總均存在大量的時(shí)間數(shù)據(jù),提取時(shí)間數(shù)據(jù)內(nèi)存在的信息,一方面可以加深對(duì)數(shù)據(jù)的理解,另一方面能夠探索這部分信息和目標(biāo)的關(guān)聯(lián)程度。同時(shí)用戶(hù)登錄時(shí)間、借款成交時(shí)間、用戶(hù)信息更新時(shí)間這些時(shí)間的時(shí)間差信息冶能反映出P2P網(wǎng)絡(luò)貸款不同用戶(hù)的行為信息。
要求:
(1)使用to_datetime函數(shù)轉(zhuǎn)換用戶(hù)信息更新表和登錄信息表的時(shí)間字符串。
代碼:
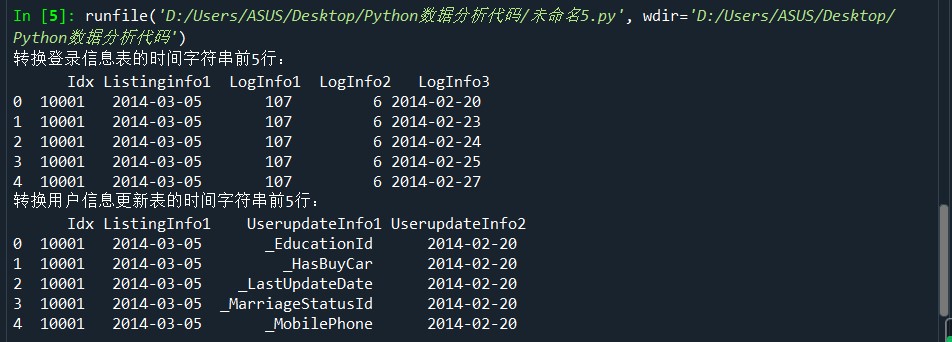
import pandas as pd #讀取文件 LogInfo = pd.read_csv('D:/Users/ASUS/Desktop/Training_LogInfo(1).csv',encoding='gbk') Userupdate = pd.read_csv('D:/Users/ASUS/Desktop/Training_Userupdate.csv',encoding='gbk') # 轉(zhuǎn)換時(shí)間字符串 LogInfo['Listinginfo1']=pd.to_datetime(LogInfo['Listinginfo1']) LogInfo['LogInfo3']=pd.to_datetime(LogInfo['LogInfo3']) print('轉(zhuǎn)換登錄信息表的時(shí)間字符串前5行:\n',LogInfo.head()) Userupdate['ListingInfo1']=pd.to_datetime(Userupdate['ListingInfo1']) Userupdate['UserupdateInfo2']=pd.to_datetime(Userupdate['UserupdateInfo2']) print('轉(zhuǎn)換用戶(hù)信息更新表的時(shí)間字符串前5行:\n',Userupdate.head())
結(jié)果:
四、使用分組聚合方法進(jìn)一步分析用戶(hù)信息更新表和登錄信息表(1題30分,共30分)
考查知識(shí)點(diǎn):掌握常見(jiàn)的數(shù)據(jù)讀取方式;掌握DataFrame常用屬性與方法;掌握基礎(chǔ)時(shí)間數(shù)據(jù)處理方法;掌握分組聚合的原理與方法;掌握透視表與交叉表的制作。
需求說(shuō)明:
分析用戶(hù)信息更新表和登錄信息表時(shí),除了提取時(shí)間本身的信息外,還可以結(jié)合用戶(hù)編號(hào)進(jìn)行分組聚合,然后進(jìn)行組內(nèi)分析。通過(guò)組內(nèi)分析可以得出每組組內(nèi)的最早和最晚信息更新時(shí)間、最早和最晚登錄時(shí)間、信息更新的次數(shù)、登錄的次數(shù)等信息。
要求:
(1)使用groupby方法對(duì)用戶(hù)信息更新表和登錄信息表進(jìn)行分組。
(2)使用agg方法求取分組后的最早和最晚更新及登錄時(shí)間。
(3)使用size方法求取分組后的數(shù)據(jù)的信息更新次數(shù)與登錄次數(shù)。
代碼:
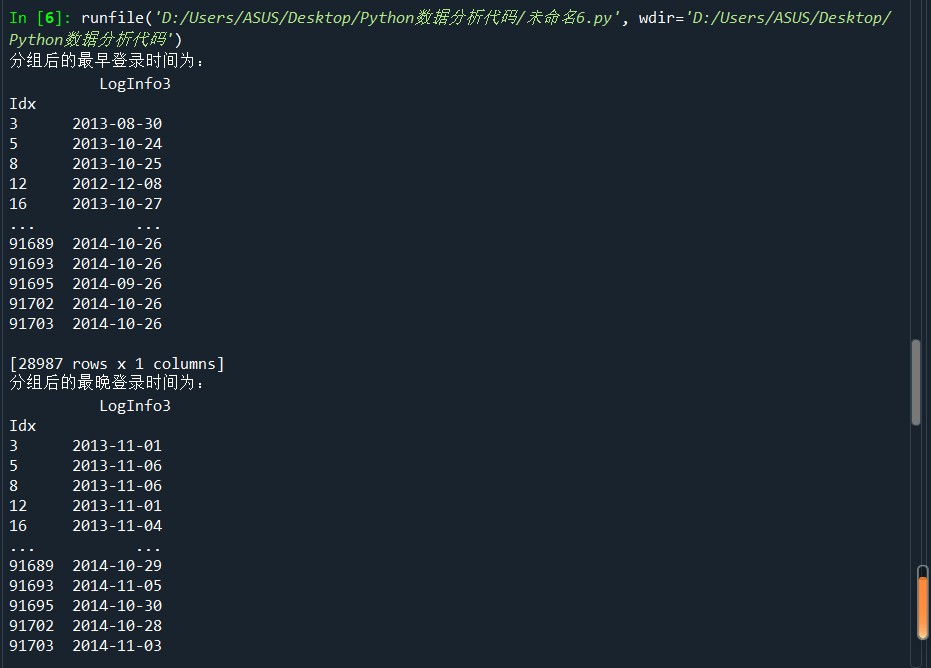
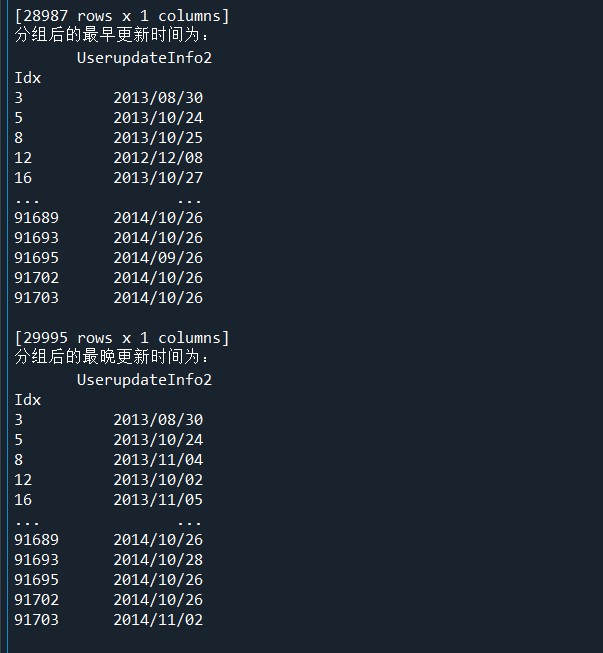
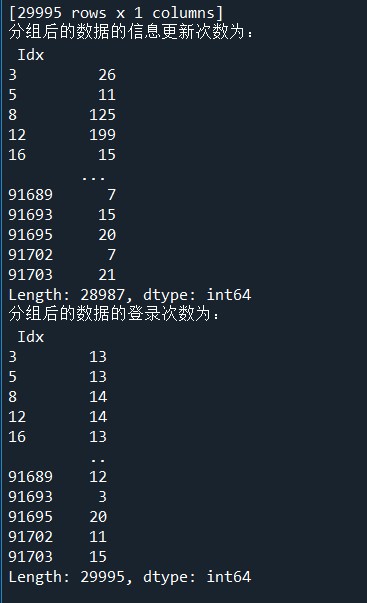
import pandas as pd import numpy as np LogInfo = pd.read_csv('D:/Users/ASUS/Desktop/Training_LogInfo(1).csv',encoding='gbk') Userupdate = pd.read_csv('D:/Users/ASUS/Desktop/Training_Userupdate.csv',encoding='gbk') # 使用groupby方法對(duì)用戶(hù)信息更新表和登錄信息表進(jìn)行分組 LogGroup = LogInfo[['Idx','LogInfo3']].groupby(by = 'Idx') UserGroup = Userupdate[['Idx','UserupdateInfo2']].groupby(by = 'Idx') # 使用agg方法求取分組后的最早,最晚,更新登錄時(shí)間 print('分組后的最早登錄時(shí)間為:\n',LogGroup.agg(np.min)) print('分組后的最晚登錄時(shí)間為:\n',LogGroup.agg(np.max)) print('分組后的最早更新時(shí)間為:\n',UserGroup.agg(np.min)) print('分組后的最晚更新時(shí)間為:\n',UserGroup.agg(np.max)) # 使用size方法求取分組后的數(shù)據(jù)的信息更新次數(shù)與登錄次數(shù) print('分組后的數(shù)據(jù)的信息更新次數(shù)為:\n',LogGroup.size()) print('分組后的數(shù)據(jù)的登錄次數(shù)為:\n',UserGroup.size())
結(jié)果:

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)