
Zookeeper入門api與應用
一、 說明
Zookeeper作為一個分布式的服務框架,主要用來解決分布式集群中應用系統的一致性問題,它能提供基于類似于文件系統的目錄節點樹方式的數據存儲,但是 Zookeeper并不是用來專門存儲數據的,它的作用主要是用來維護和監控你存儲的數據的狀態變化。通過監控這些數據狀態的變化,從而可以達到基于數據的集群管理。
二、 常用API
客戶端要連接 Zookeeper 服務器可以通過創建 org.apache.zookeeper. ZooKeeper 的一個實例對象,然后調用這個類提供的接口來和服務器交互。
前面說了 ZooKeeper 主要是用來維護和監控一個目錄節點樹中存儲的數據的狀態,所有我們能夠操作 ZooKeeper 的也和操作目錄節點樹大體一樣,如創建一個目錄節點,給某個目錄節點設置數據,獲取某個目錄節點的所有子目錄節點,給某個目錄節點設置權限和監控這個目錄節點的狀態變化。
這些接口如下表所示:
| String create(String path, byte[] data, List |
創建一個給定的目錄節點 path, 并給它設置數據,CreateMode標識有四種形式的目錄節點,分別是 PERSISTENT:持久化目錄節點,這個目錄節點存儲的數據不會丟失;PERSISTENT_SEQUENTIAL:順序自動編號的目錄節點,這種目錄節點會根據當前已近存在的節點數自動加 1,然后返回給客戶端已經成功創建的目錄節點名;EPHEMERAL:臨時目錄節點,一旦創建這個節點的客戶端與服務器端口也就是 session 超時,這種節點會被自動刪除;EPHEMERAL_SEQUENTIAL:臨時自動編號節點 |
| Stat exists(String path, boolean watch) | 判斷某個 path 是否存在,并設置是否監控這個目錄節點,這里的 watcher 是在創建 ZooKeeper 實例時指定的 watcher,exists方法還有一個重載方法,可以指定特定的watcher |
| Stat exists(String path,Watcher watcher) | 重載方法,這里給某個目錄節點設置特定的 watcher,Watcher 在 ZooKeeper 是一個核心功能,Watcher 可以監控目錄節點的數據變化以及子目錄的變化,一旦這些狀態發生變化,服務器就會通知所有設置在這個目錄節點上的 Watcher,從而每個客戶端都很快知道它所關注的目錄節點的狀態發生變化,而做出相應的反應 |
| void delete(String path, int version) | 刪除 path 對應的目錄節點,version 為 -1 可以匹配任何版本,也就刪除了這個目錄節點所有數據 |
| List |
獲取指定 path 下的所有子目錄節點,同樣 getChildren方法也有一個重載方法可以設置特定的 watcher 監控子節點的狀態 |
| Stat setData(String path, byte[] data, int version) | 給 path 設置數據,可以指定這個數據的版本號,如果 version 為 -1 怎可以匹配任何版本 |
| byte[] getData(String path, boolean watch, Stat stat) | 獲取這個 path 對應的目錄節點存儲的數據,數據的版本等信息可以通過 stat 來指定,同時還可以設置是否監控這個目錄節點數據的狀態 |
| voidaddAuthInfo(String scheme, byte[] auth) | 客戶端將自己的授權信息提交給服務器,服務器將根據這個授權信息驗證客戶端的訪問權限。 |
| Stat setACL(String path,List |
給某個目錄節點重新設置訪問權限,需要注意的是 Zookeeper 中的目錄節點權限不具有傳遞性,父目錄節點的權限不能傳遞給子目錄節點。目錄節點 ACL 由兩部分組成:perms 和 id。 Perms 有 ALL、READ、WRITE、CREATE、DELETE、ADMIN 幾種 而 id 標識了訪問目錄節點的身份列表,默認情況下有以下兩種: ANYONE_ID_UNSAFE = new Id("world", "anyone") 和 AUTH_IDS = new Id("auth", "") 分別表示任何人都可以訪問和創建者擁有訪問權限。 |
| List |
獲取某個目錄節點的訪問權限列表 |
三、 基本操作
// 創建一個與服務器的連接
ZooKeeper zk = new ZooKeeper("localhost:" + CLIENT_PORT,
ClientBase.CONNECTION_TIMEOUT, new Watcher() {
// 監控所有被觸發的事件
public void process(WatchedEvent event) {
System.out.println("已經觸發了" + event.getType() + "事件!");
}
});
// 創建一個目錄節點
zk.create("/testRootPath", "testRootData".getBytes(), Ids.OPEN_ACL_UNSAFE,
CreateMode.PERSISTENT);
// 創建一個子目錄節點
zk.create("/testRootPath/testChildPathOne", "testChildDataOne".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath",false,null)));
// 取出子目錄節點列表
System.out.println(zk.getChildren("/testRootPath",true));
// 修改子目錄節點數據
zk.setData("/testRootPath/testChildPathOne","modifyChildDataOne".getBytes(),-1);
System.out.println("目錄節點狀態:["+zk.exists("/testRootPath",true)+"]");
// 創建另外一個子目錄節點
zk.create("/testRootPath/testChildPathTwo", "testChildDataTwo".getBytes(),
Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);
System.out.println(new String(zk.getData("/testRootPath/testChildPathTwo",true,null)));
// 刪除子目錄節點
zk.delete("/testRootPath/testChildPathTwo",-1);
zk.delete("/testRootPath/testChildPathOne",-1);
// 刪除父目錄節點
zk.delete("/testRootPath",-1);
// 關閉連接
zk.close();
輸出的結果如下:
已經觸發了 None 事件!
testRootData
[testChildPathOne]
目錄節點狀態:[5,5,1281804532336,1281804532336,0,1,0,0,12,1,6]
已經觸發了 NodeChildrenChanged 事件!
testChildDataTwo
已經觸發了 NodeDeleted 事件!
已經觸發了 NodeDeleted 事件!
當對目錄節點監控狀態打開時,一旦目錄節點的狀態發生變化,Watcher 對象的 process 方法就會被調用。
四、ZooKeeper 典型的應用場景
Zookeeper 從設計模式角度來看,是一個基于觀察者模式設計的分布式服務管理框架,它負責存儲和管理大家都關心的數據,然后接受觀察者的注冊,一旦這些數據的狀態發生變化,Zookeeper 就將負責通知已經在Zookeeper 上注冊的那些觀察者做出相應的反應,從而實現集群中類似 Master/Slave 管理模式,關于Zookeeper 的詳細架構等內部細節可以閱讀 Zookeeper 的源碼。
下面詳細介紹這些典型的應用場景,也就是 Zookeeper 到底能幫我們解決那些問題?下面將給出答案。
4.1 統一命名服務(Name Service)
分布式應用中,通常需要有一套完整的命名規則,既能夠產生唯一的名稱又便于人識別和記住,通常情況下用樹形的名稱結構是一個理想的選擇,樹形的名稱結構是一個有層次的目錄結構,既對人友好又不會重復。說到這里你可能想到了 JNDI,沒錯 Zookeeper 的 Name Service 與 JNDI 能夠完成的功能是差不多的,它們都是將有層次的目錄結構關聯到一定資源上,但是 Zookeeper 的 Name Service 更加是廣泛意義上的關聯,也許你并不需要將名稱關聯到特定資源上,你可能只需要一個不會重復名稱,就像數據庫中產生一個唯一的數字主鍵一樣。
Name Service 已經是 Zookeeper 內置的功能,你只要調用 Zookeeper 的 API 就能實現。如調用 create 接口就可以很容易創建一個目錄節點。
4.2 配置管理(Configuration Management)
配置的管理在分布式應用環境中很常見,例如同一個應用系統需要多臺 PC Server 運行,但是它們運行的應用系統的某些配置項是相同的,如果要修改這些相同的配置項,那么就必須同時修改每臺運行這個應用系統的 PC Server,這樣非常麻煩而且容易出錯。
像這樣的配置信息完全可以交給 Zookeeper 來管理,將配置信息保存在 Zookeeper 的某個目錄節點中,然后將所有需要修改的應用機器監控配置信息的狀態,一旦配置信息發生變化,每臺應用機器就會收到 Zookeeper 的通知,然后從 Zookeeper 獲取新的配置信息應用到系統中。
圖1. 配置管理結構圖:
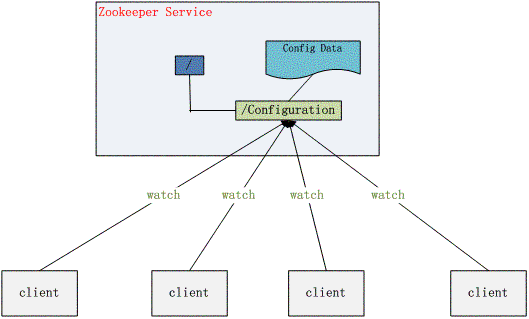
4.3 集群管理(Group Membership)
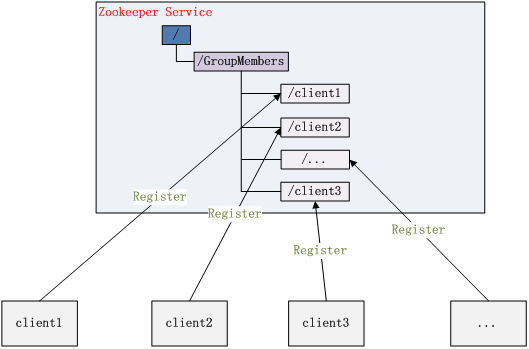
Zookeeper 能夠很容易的實現集群管理的功能,如有多臺 Server 組成一個服務集群,那么必須要一個“總管”知道當前集群中每臺機器的服務狀態,一旦有機器不能提供服務,集群中其它集群必須知道,從而做出調整重新分配服務策略。同樣當增加集群的服務能力時,就會增加一臺或多臺 Server,同樣也必須讓“總管”知道。
Zookeeper 不僅能夠幫你維護當前的集群中機器的服務狀態,而且能夠幫你選出一個“總管”,讓這個總管來管理集群,這就是 Zookeeper 的另一個功能 Leader Election。
它們的實現方式都是在 Zookeeper 上創建一個 EPHEMERAL 類型的目錄節點,然后每個 Server 在它們創建目錄節點的父目錄節點上調用 getChildren(String path, boolean watch) 方法并設置 watch 為 true,由于是 EPHEMERAL 目錄節點,當創建它的 Server 死去,這個目錄節點也隨之被刪除,所以 Children 將會變化,這時 getChildren上的 Watch 將會被調用,所以其它 Server 就知道已經有某臺 Server 死去了。新增 Server 也是同樣的原理。
Zookeeper 如何實現 Leader Election,也就是選出一個 Master Server。和前面的一樣每臺 Server 創建一個 EPHEMERAL 目錄節點,不同的是它還是一個 SEQUENTIAL 目錄節點,所以它是個 EPHEMERAL_SEQUENTIAL 目錄節點。之所以它是 EPHEMERAL_SEQUENTIAL 目錄節點,是因為我們可以給每臺 Server 編號,我們可以選擇當前是最小編號的 Server 為 Master,假如這個最小編號的 Server 死去,由于是 EPHEMERAL 節點,死去的 Server 對應的節點也被刪除,所以當前的節點列表中又出現一個最小編號的節點,我們就選擇這個節點為當前 Master。這樣就實現了動態選擇 Master,避免了傳統意義上單 Master 容易出現單點故障的問題。
圖2. 集群管理結構圖
Leader Election 關鍵代碼
void findLeader() throws InterruptedException {
byte[] leader = null;
try {
leader = zk.getData(root + "/leader", true, null);
} catch (Exception e) {
logger.error(e);
}
if (leader != null) {
following();
} else {
String newLeader = null;
try {
byte[] localhost = InetAddress.getLocalHost().getAddress();
newLeader = zk.create(root + "/leader", localhost,
ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL);
} catch (Exception e) {
logger.error(e);
}
if (newLeader != null) {
leading();
} else {
mutex.wait();
}
}
}
4.4 共享鎖(Locks)
共享鎖在同一個進程中很容易實現,但是在跨進程或者在不同 Server 之間就不好實現了。Zookeeper 卻很容易實現這個功能,實現方式也是需要獲得鎖的 Server 創建一個 EPHEMERAL_SEQUENTIAL 目錄節點,然后調用 getChildren方法獲取當前的目錄節點列表中最小的目錄節點是不是就是自己創建的目錄節點,如果正是自己創建的,那么它就獲得了這個鎖,如果不是那么它就調用exists(String path, boolean watch) 方法并監控 Zookeeper 上目錄節點列表的變化,一直到自己創建的節點是列表中最小編號的目錄節點,從而獲得鎖,釋放鎖很簡單,只要刪除前面它自己所創建的目錄節點就行了。
圖3. Zookeeper 實現 Locks 的流程圖

同步鎖的關鍵思路
加鎖:
ZooKeeper 將按照如下方式實現加鎖的操作:
1 ) ZooKeeper 調用 create ()方法來創建一個路徑格式為“ _locknode_/lock- ”的節點,此節點類型為sequence (連續)和 ephemeral (臨時)。也就是說,創建的節點為臨時節點,并且所有的節點連續編號,即“ lock-i ”的格式。
2 )在創建的鎖節點上調用 getChildren ()方法,來獲取鎖目錄下的最小編號節點,并且不設置 watch 。
3 )步驟 2 中獲取的節點恰好是步驟 1 中客戶端創建的節點,那么此客戶端獲得此種類型的鎖,然后退出操作。
4 )客戶端在鎖目錄上調用 exists ()方法,并且設置 watch 來監視鎖目錄下比自己小一個的連續臨時節點的狀態。
5 )如果監視節點狀態發生變化,則跳轉到第 2 步,繼續進行后續的操作,直到退出鎖競爭。
解鎖:
ZooKeeper 解鎖操作非常簡單,客戶端只需要將加鎖操作步驟 1 中創建的臨時節點刪除即可。
同步鎖的關鍵代碼
void getLock() throws KeeperException, InterruptedException{
List<String> list = zk.getChildren(root, false);
String[] nodes = list.toArray(new String[list.size()]);
Arrays.sort(nodes);
if(myZnode.equals(root+"/"+nodes[0])){
doAction();
}
else{
waitForLock(nodes[0]);
}
}
void waitForLock(String lower) throws InterruptedException, KeeperException {
Stat stat = zk.exists(root + "/" + lower,true);
if(stat != null){
mutex.wait();
}
else{
getLock();
}
}
總結
Zookeeper 作為 Hadoop 項目中的一個子項目,是 Hadoop 集群管理的一個必不可少的模塊,它主要用來控制集群中的數據,如它管理 Hadoop 集群中的 NameNode,還有 Hbase 中 Master Election、Server 之間狀態同步等。
本文介紹的 Zookeeper 的基本知識,以及介紹了幾個典型的應用場景。這些都是 Zookeeper 的基本功能,最重要的是 Zoopkeeper 提供了一套很好的分布式集群管理的機制,就是它這種基于層次型的目錄樹的數據結構,并對樹中的節點進行有效管理,從而可以設計出多種多樣的分布式的數據管理模型,而不僅僅局限于上面提到的幾個常用應用場景。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號