
個(gè)人項(xiàng)目:論文查重
| 這個(gè)作業(yè)屬于哪個(gè)課程 | <計(jì)科22級(jí)34班> |
|---|---|
| 這個(gè)作業(yè)要求在哪里 | <作業(yè)要求> |
| 這個(gè)作業(yè)的目標(biāo) | <1.在Github倉(cāng)庫(kù)中新建一個(gè)學(xué)號(hào)為名的文件夾。2.用PSP表格記錄下估計(jì)和實(shí)際在程序開發(fā)各個(gè)步驟上耗費(fèi)的時(shí)間。3.使用C++ 、Java語言或者python3實(shí)現(xiàn)論文查重。4.提交的代碼要求經(jīng)過Code Quality Analysis工具的分析并消除所有的警告。5.完成項(xiàng)目的首個(gè)版本之后,請(qǐng)使用性能分析工具Studio Profiling Tools來找出代碼中的性能瓶頸并進(jìn)行改進(jìn)。6.使用Github來管理源代碼和測(cè)試用例,代碼有進(jìn)展即簽入Github。7.使用單元測(cè)試對(duì)項(xiàng)目進(jìn)行測(cè)試,并使用插件查看測(cè)試分支覆蓋率等指標(biāo);寫出至少10個(gè)測(cè)試用例確保程序能夠正確處理各種情況。> |
一、Github倉(cāng)庫(kù)
二、PSP表
| PSP2.1 | Personal Software Process Stages | 預(yù)估耗時(shí)(分鐘) | 實(shí)際耗時(shí)(分鐘) |
|---|---|---|---|
| Planning | 計(jì)劃 | 90 | 90 |
| · Estimate | · 估計(jì)這個(gè)任務(wù)需要多少時(shí)間 | 45 | 60 |
| Development | 開發(fā) | 120 | 150 |
| · Analysis | · 需求分析 (包括學(xué)習(xí)新技術(shù)) | 60 | 60 |
| · Design Spec | · 生成設(shè)計(jì)文檔 | 60 | 60 |
| · Design Review | · 設(shè)計(jì)復(fù)審 | 60 | 60 |
| · Coding Standard | · 代碼規(guī)范 (為目前的開發(fā)制定合適的規(guī)范) | 60 | 60 |
| · Design | · 具體設(shè)計(jì) | 60 | 60 |
| · Coding | · 具體編碼 | 30 | 30 |
| · Code Review | · 代碼復(fù)審 | 30 | 30 |
| · Test | · 測(cè)試(自我測(cè)試,修改代碼,提交修改) | 180 | 150 |
| Reporting | 報(bào)告 | 60 | 60 |
| · Test Repor | · 測(cè)試報(bào)告 | 60 | 60 |
| · Size Measurement | · 計(jì)算工作量 | 10 | 10 |
| · Postmorte· 合計(jì)m & Process Improvement Plan | · 事后總結(jié), 并提出過程改進(jìn)計(jì)劃 | 30 | 30 |
| · 合計(jì) | 955 | 970 |
三、需求分析
題目:論文查重
描述如下:
設(shè)計(jì)一個(gè)論文查重算法,給出一個(gè)原文文件和一個(gè)在這份原文上經(jīng)過了增刪改的抄襲版論文的文件,在答案文件中輸出其重復(fù)率。
原文示例:今天是星期天,天氣晴,今天晚上我要去看電影。
抄襲版示例:今天是周天,天氣晴朗,我晚上要去看電影。
要求輸入輸出采用文件輸入輸出,規(guī)范如下:
從命令行參數(shù)給出:論文原文的文件的絕對(duì)路徑。
從命令行參數(shù)給出:抄襲版論文的文件的絕對(duì)路徑。
從命令行參數(shù)給出:輸出的答案文件的絕對(duì)路徑。
我們提供一份樣例,課堂上下發(fā),上傳到班級(jí)群,使用方法是:orig.txt是原文,其他orig_add.txt等均為抄襲版論文。
注意:答案文件中輸出的答案為浮點(diǎn)型,精確到小數(shù)點(diǎn)后兩位
四、計(jì)算模塊接口的設(shè)計(jì)與實(shí)現(xiàn)
1.核心算法:
(1)SimHash算法:
- SimHash算法主要有五個(gè)過程:分詞、Hash、加權(quán)、合并、降維。
- 具體可參考SimHash原理與實(shí)現(xiàn)。
(2)計(jì)算海明距離:
- 簡(jiǎn)單的說,海明距離可以理解為,兩個(gè)二進(jìn)制串之間相同位置不同值的個(gè)數(shù)。舉個(gè)例子,[1,1,1,0,0,0]和[1,1,1,1,1,1]的海明距離就是3。
- 在處理大規(guī)模數(shù)據(jù)的時(shí)候,我們一般使用64位的SimHash,正好可以被一個(gè)long型存儲(chǔ)。這種時(shí)候,海明距離在3以內(nèi)就可以認(rèn)為兩個(gè)文本是相似的。
2.實(shí)現(xiàn)思路:
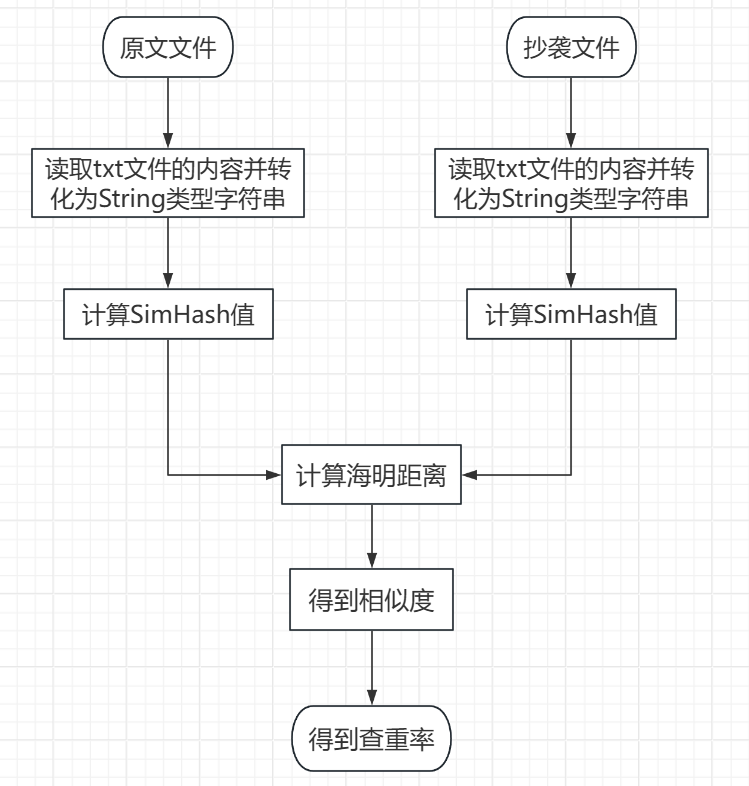
3.接口實(shí)現(xiàn):
(1)讀寫txt文件模塊:
類:TextIO
方法:
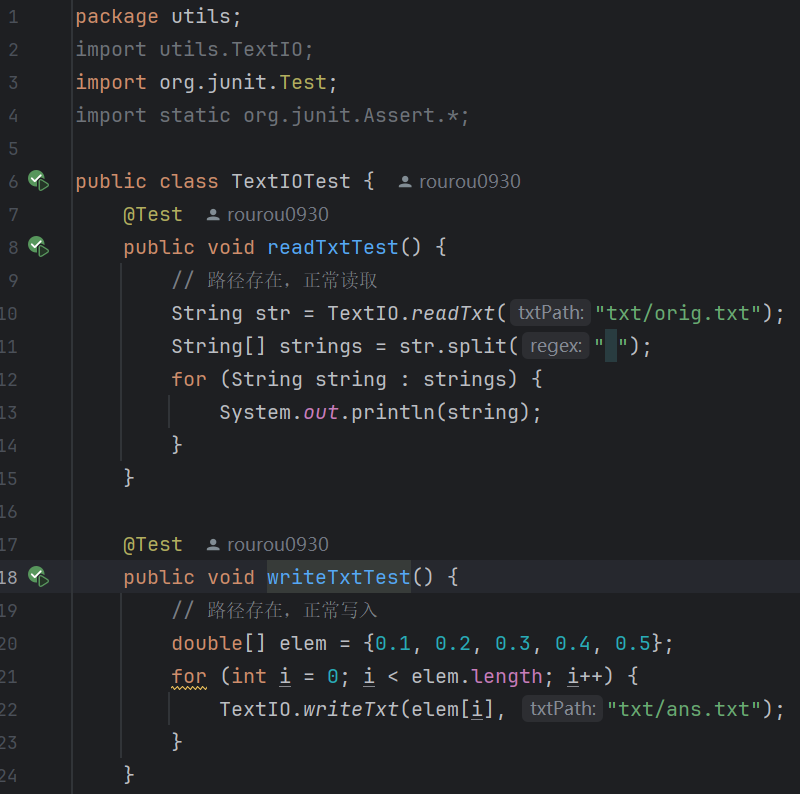
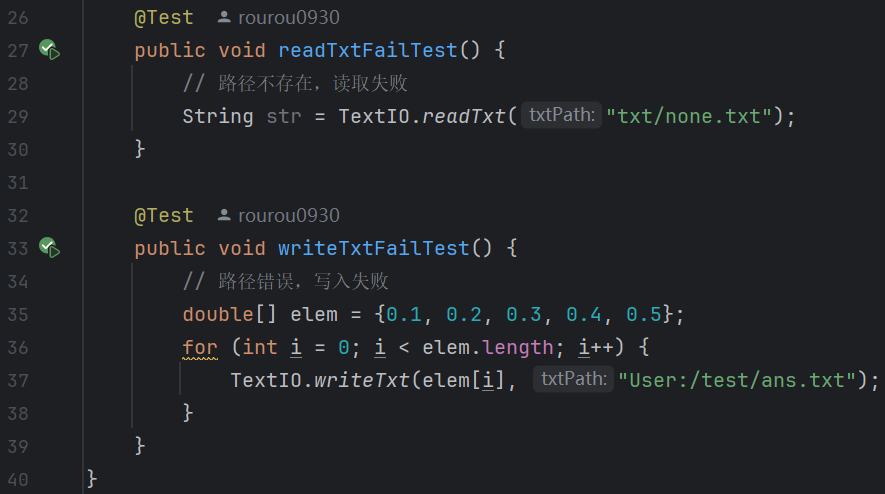
- readTxt:傳入文件絕對(duì)路徑,將文件內(nèi)容轉(zhuǎn)化為 String字符串輸出。
- writeTxt:傳入內(nèi)容、文件全路徑名,將內(nèi)容寫入文件并換行。
(2)計(jì)算SimHash模塊:
類:SimHash
方法:
- getHash:輸入一個(gè)詞,獲取詞的hash值。
- getSimHash:獲取字符串的SimHash值。
主要流程:
-
分詞:使用了外部依賴漢語言處理hankcs包提供的接口,把需要判斷的文本分詞形成這個(gè)文章的特征單詞。
![image]()
-
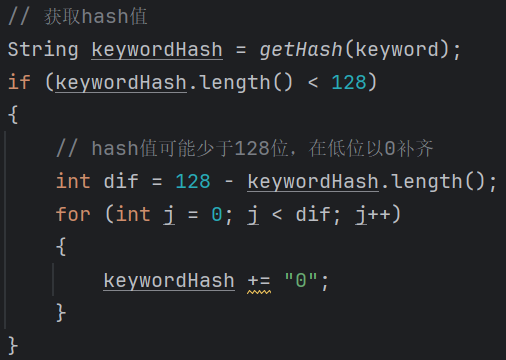
獲取hash值:通過hash算法把每個(gè)詞變成hash值。
![image]()
-
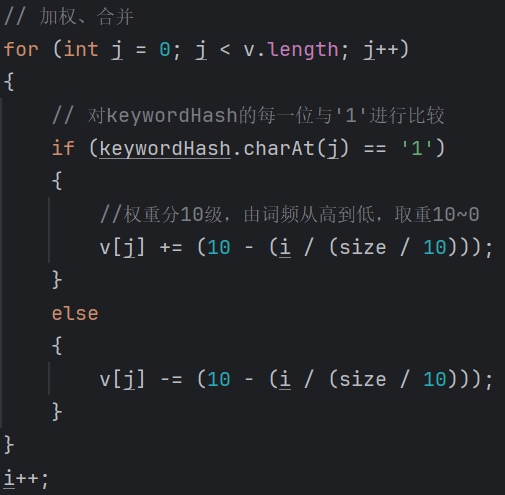
加權(quán)、合并:通過 2步驟的hash生成結(jié)果,按照單詞的權(quán)重形成加權(quán)數(shù)字串,把上面各個(gè)單詞算出來的序列值累加,變成一個(gè)序列串。
![image]()
-
降維:把4步算出來的序列串變成 0 1 串,形成最終的SimHash。
![image]()

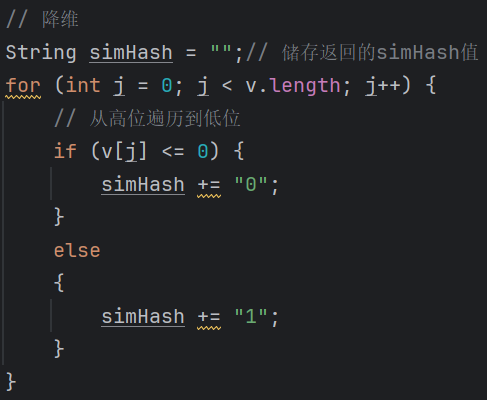
(3)計(jì)算海明距離模塊:
類:Hamming
方法:
-
getHammingDistance:輸入兩個(gè)simHash值,計(jì)算它們的海明距離。
![image]()
-
getSimilarity:輸入兩個(gè)simHash值,輸出它們的相似度。
![image]()
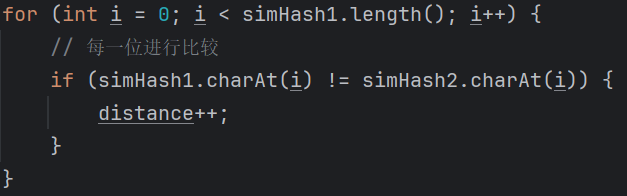
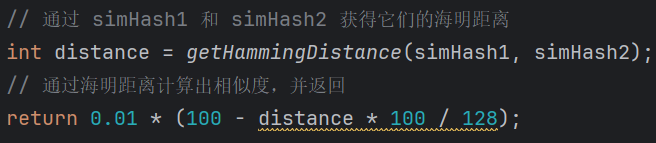
通過比較差異的位數(shù)就可以得到兩串文本的差異,差異的位數(shù),稱之為“海明距離”,通常認(rèn)為海明距離<3的是高度相似的文本。
(4)Main主模塊:
類:Main
主要流程:
- 調(diào)用TextIO,從命令行輸入的絕對(duì)路徑名讀取對(duì)應(yīng)的文件,將文件的內(nèi)容轉(zhuǎn)化為對(duì)應(yīng)的字符串;
- 調(diào)用SimHash,由字符串得出對(duì)應(yīng)的 simHash值;
- 調(diào)用Hamming,由 simHash值求出相似度;
- 調(diào)用TextIO,把相似度寫入最后的結(jié)果文件中。
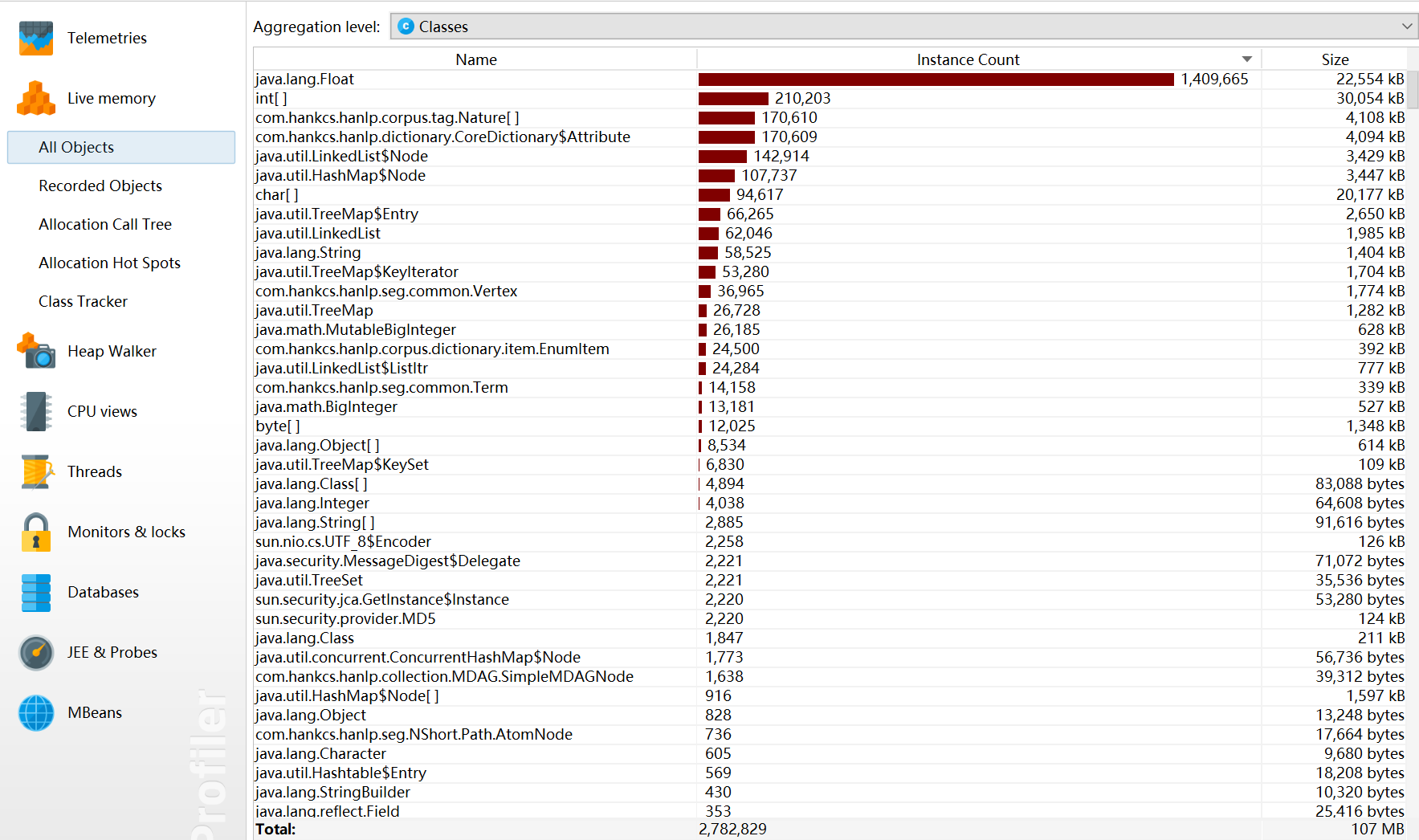
五、性能改進(jìn)
1.overview:
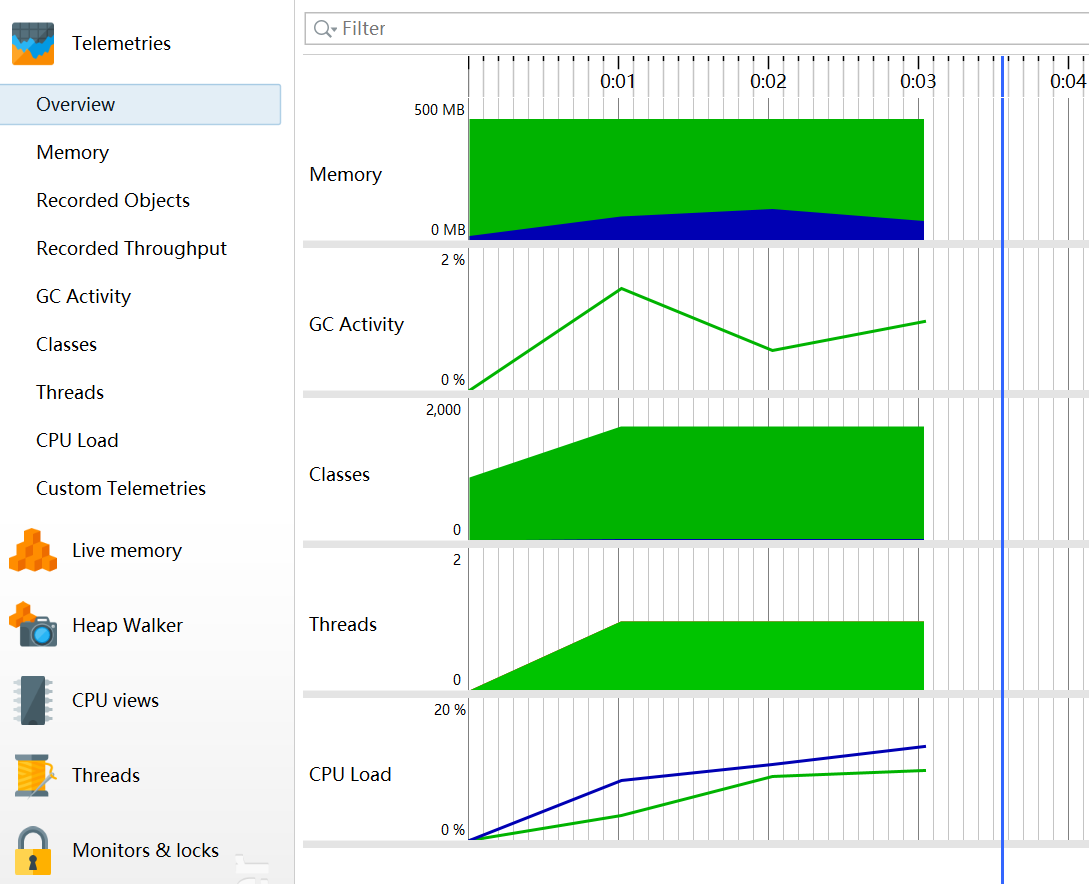
2.方法調(diào)用情況:
六、單元測(cè)試展示
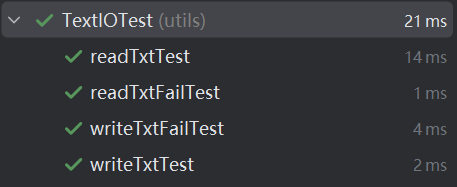
1.TextIOTest:
(1)代碼:
(2)測(cè)試結(jié)果:


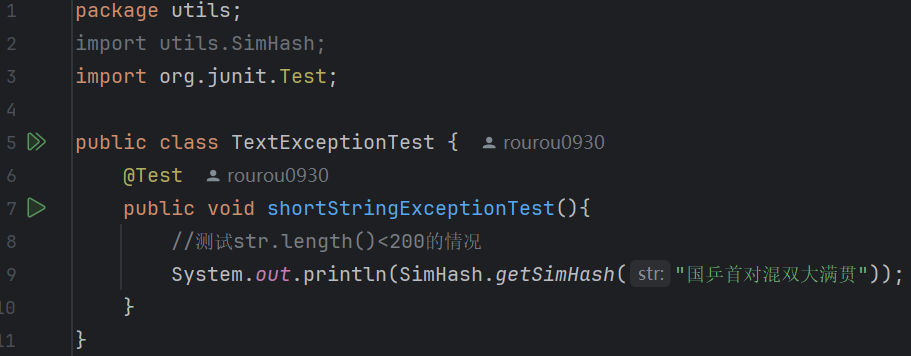
2.TextExceptionTest:
(1)代碼:
(2)測(cè)試結(jié)果:


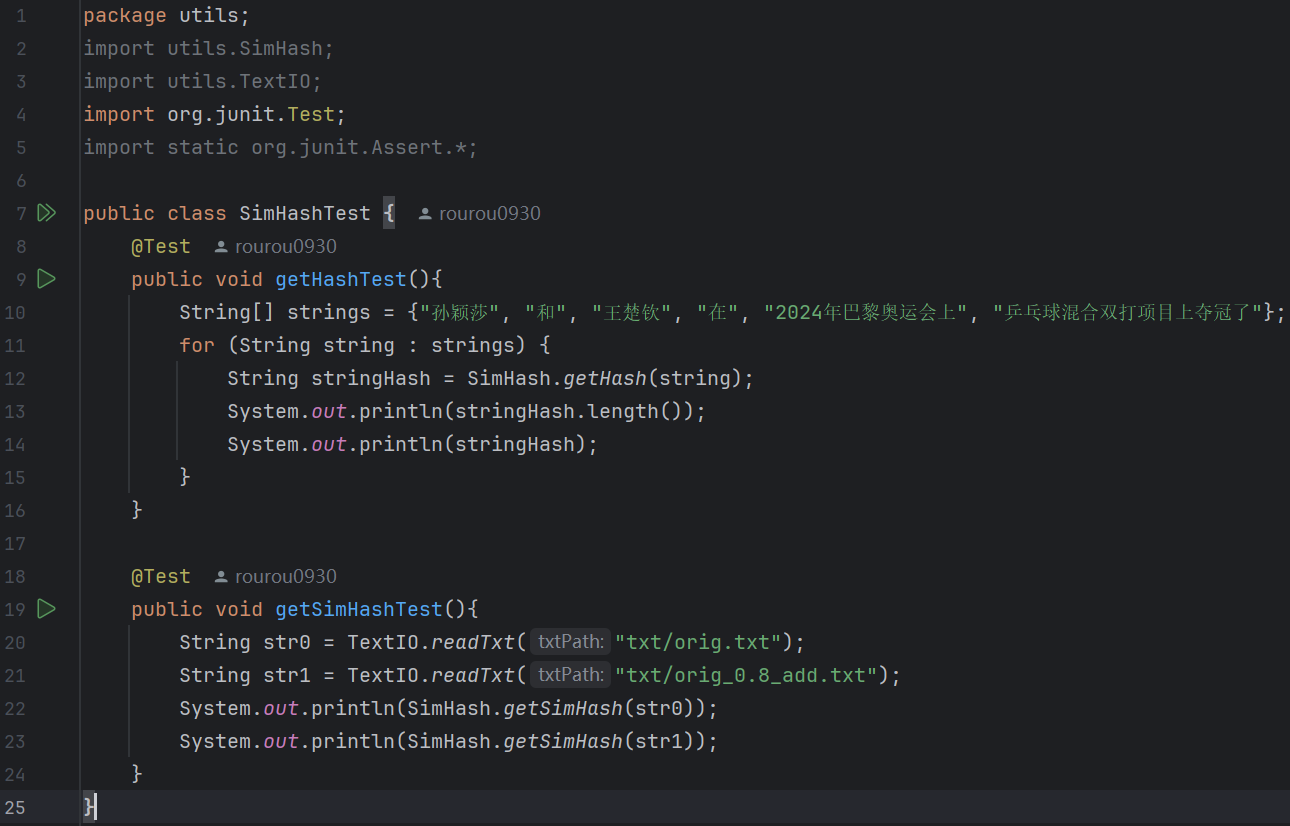
3.SimHashTest:
(1)代碼:
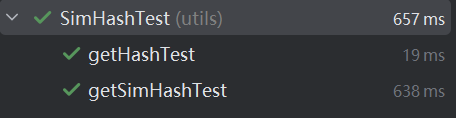
(2)測(cè)試結(jié)果:

4.HammingTest:
(1)代碼:
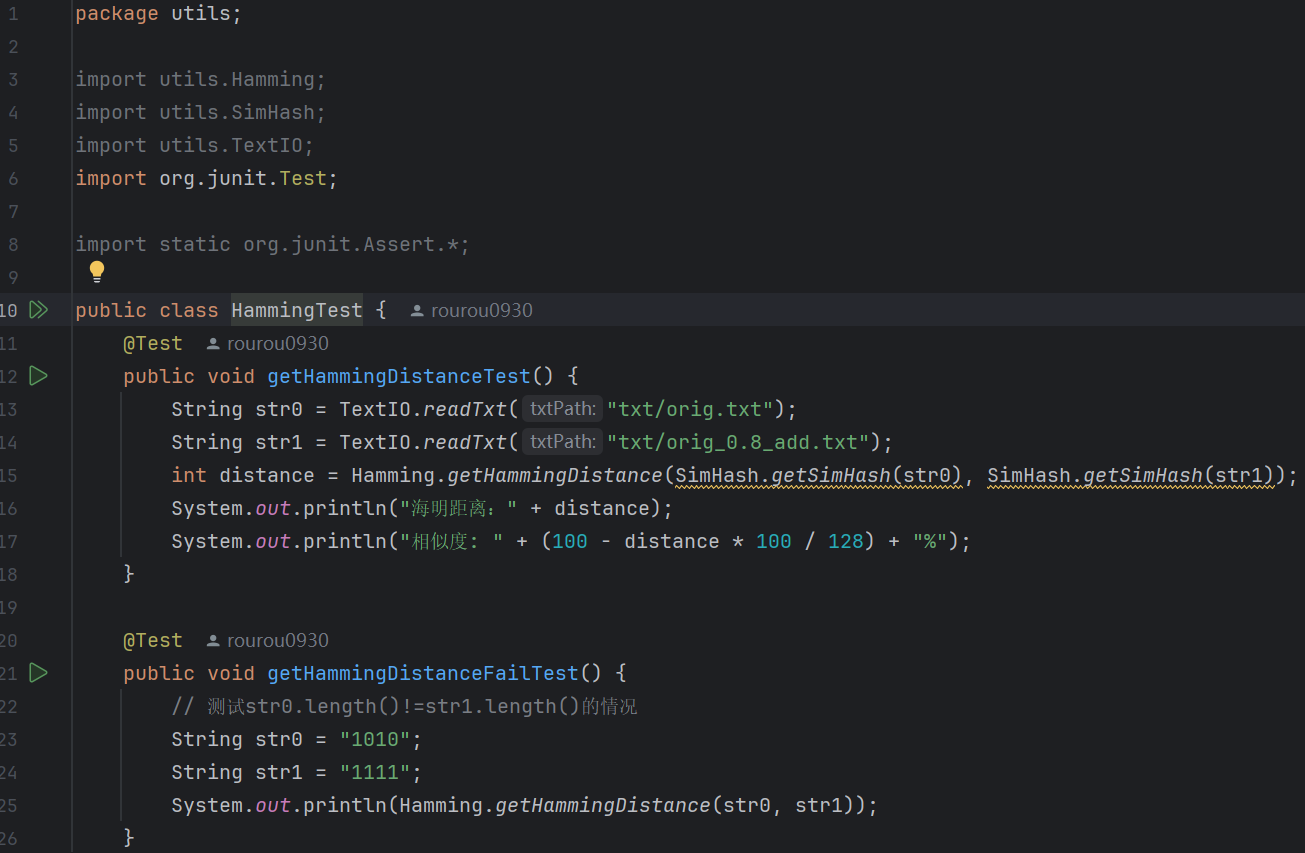

(2)測(cè)試結(jié)果:
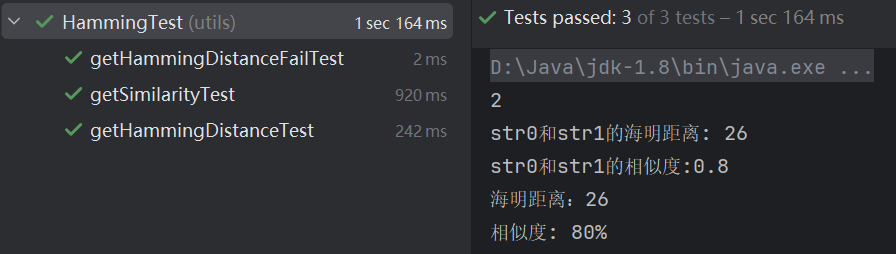
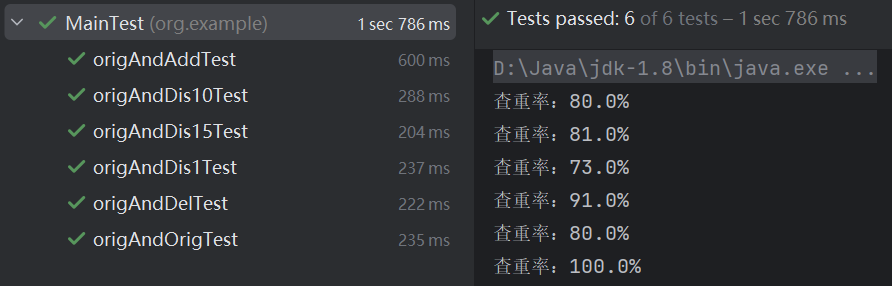
5.MainTest:
(1)代碼:
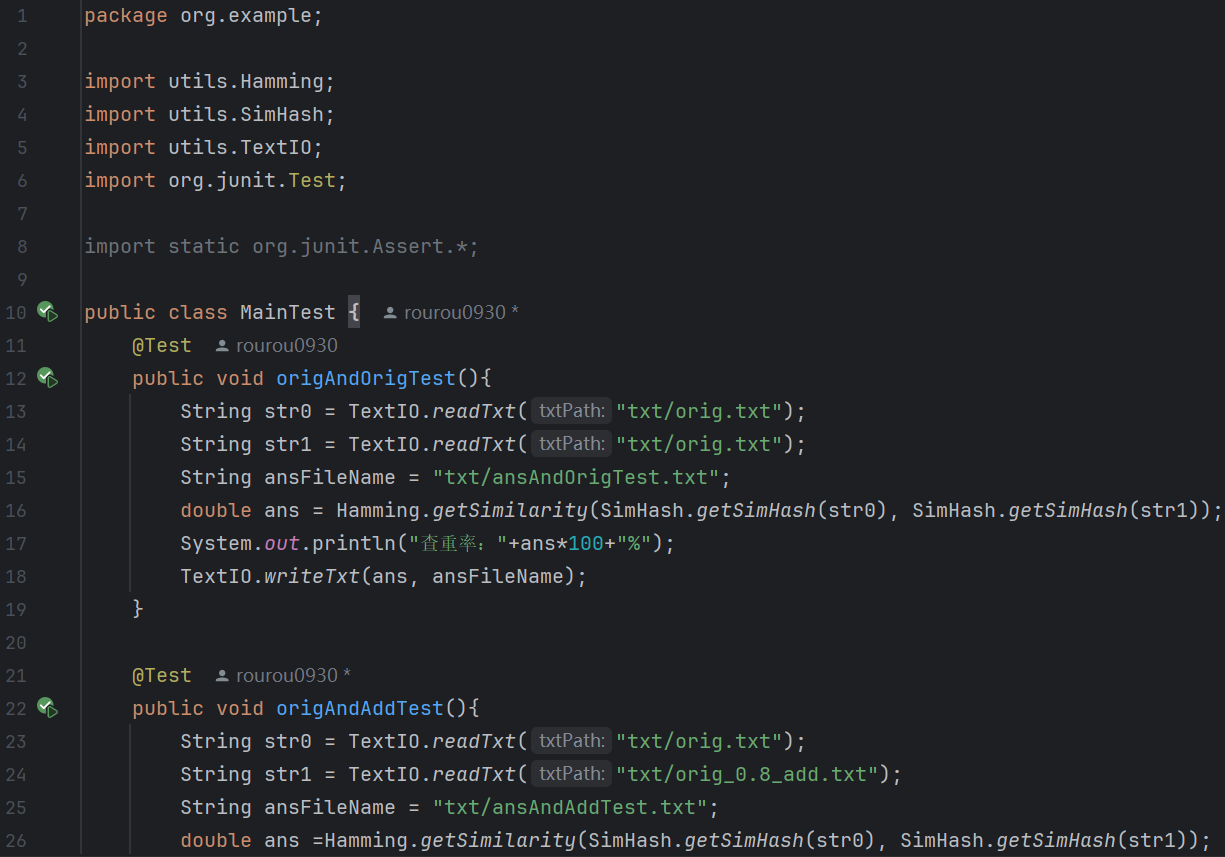
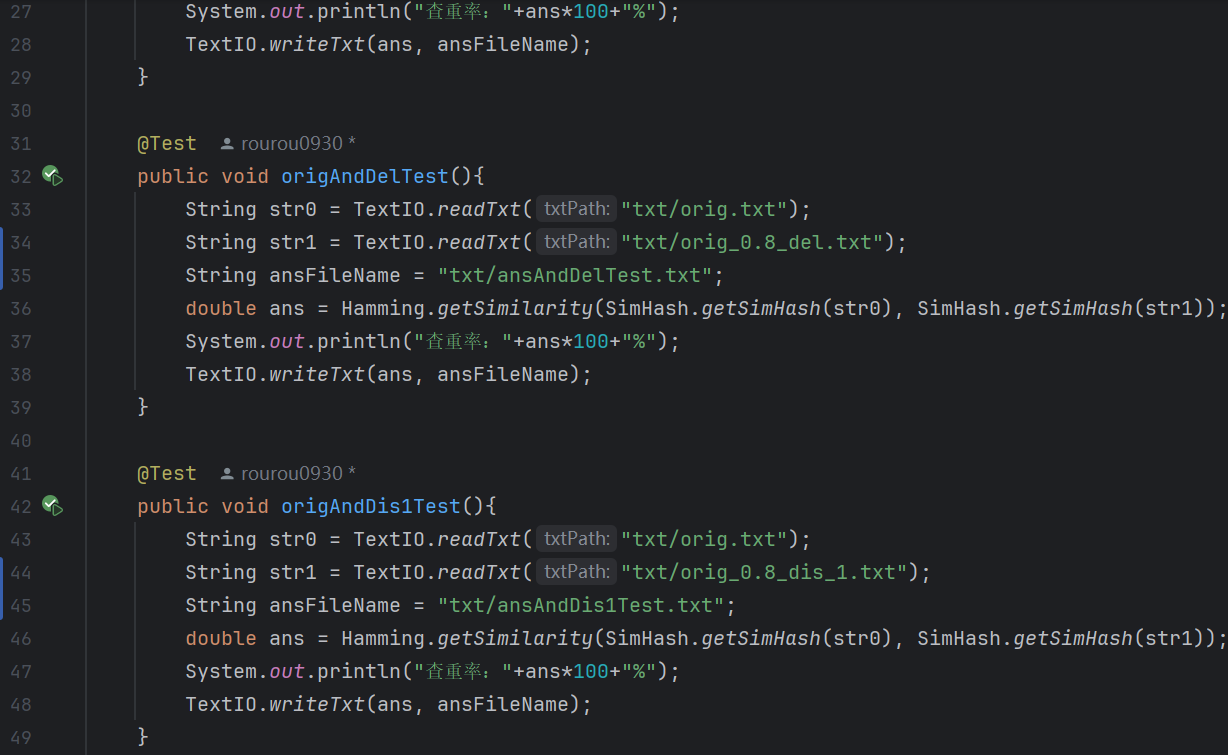
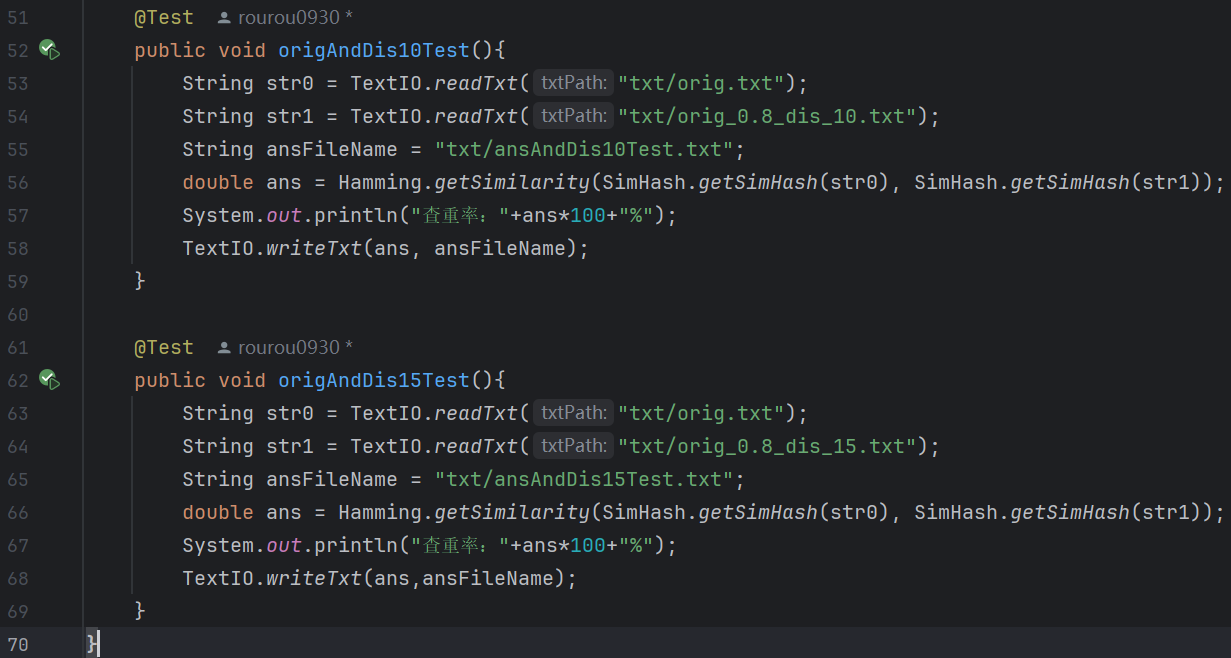
(2)測(cè)試結(jié)果:
七、異常處理說明:
當(dāng)文本長(zhǎng)度太短時(shí),HanLp無法取得關(guān)鍵字,需要拋出異常。
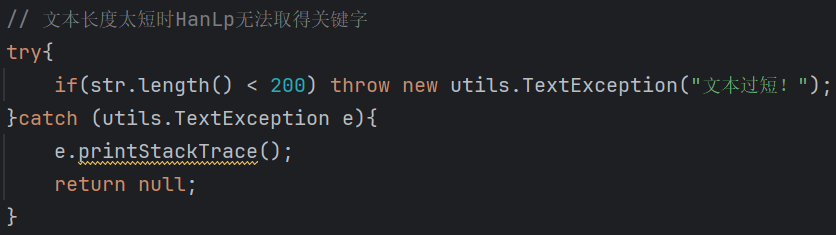
實(shí)現(xiàn)了一個(gè)處理這個(gè)異常的類:ShortStringException

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)