

Gitee鏈接:https://gitee.com/Bluemingiu/project/tree/master/4
作業①:
-
要求:熟練掌握 Selenium 查找HTML元素、爬取Ajax網頁數據、等待HTML元素等內容。使用Selenium框架+ MySQL數據庫存儲技術路線爬取“滬深A股”、“上證A股”、“深證A股”3個板塊的股票數據信息。
-
候選網站:東方財富網:http://quote.eastmoney.com/center/gridlist.html#hs_a_board
-
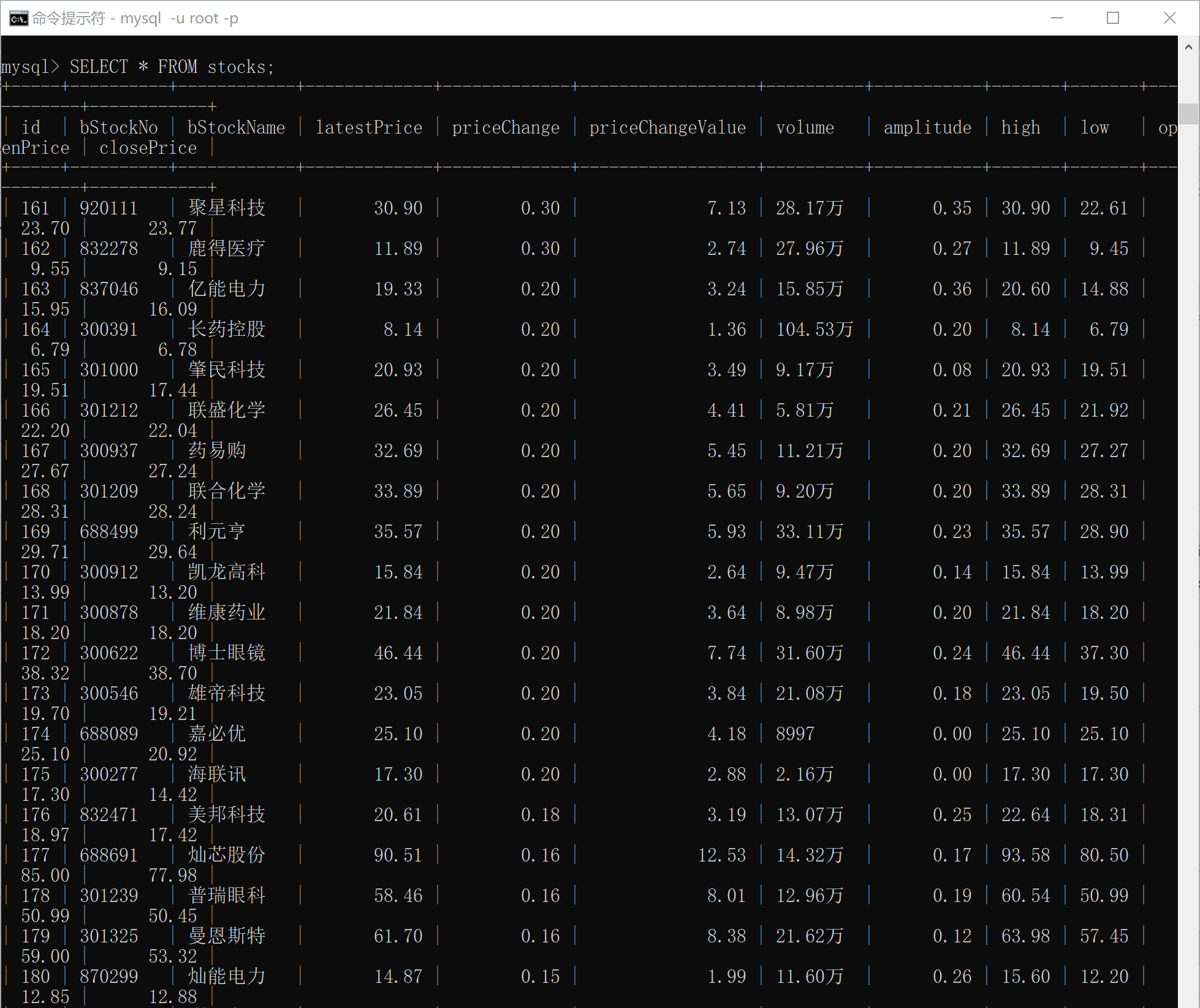
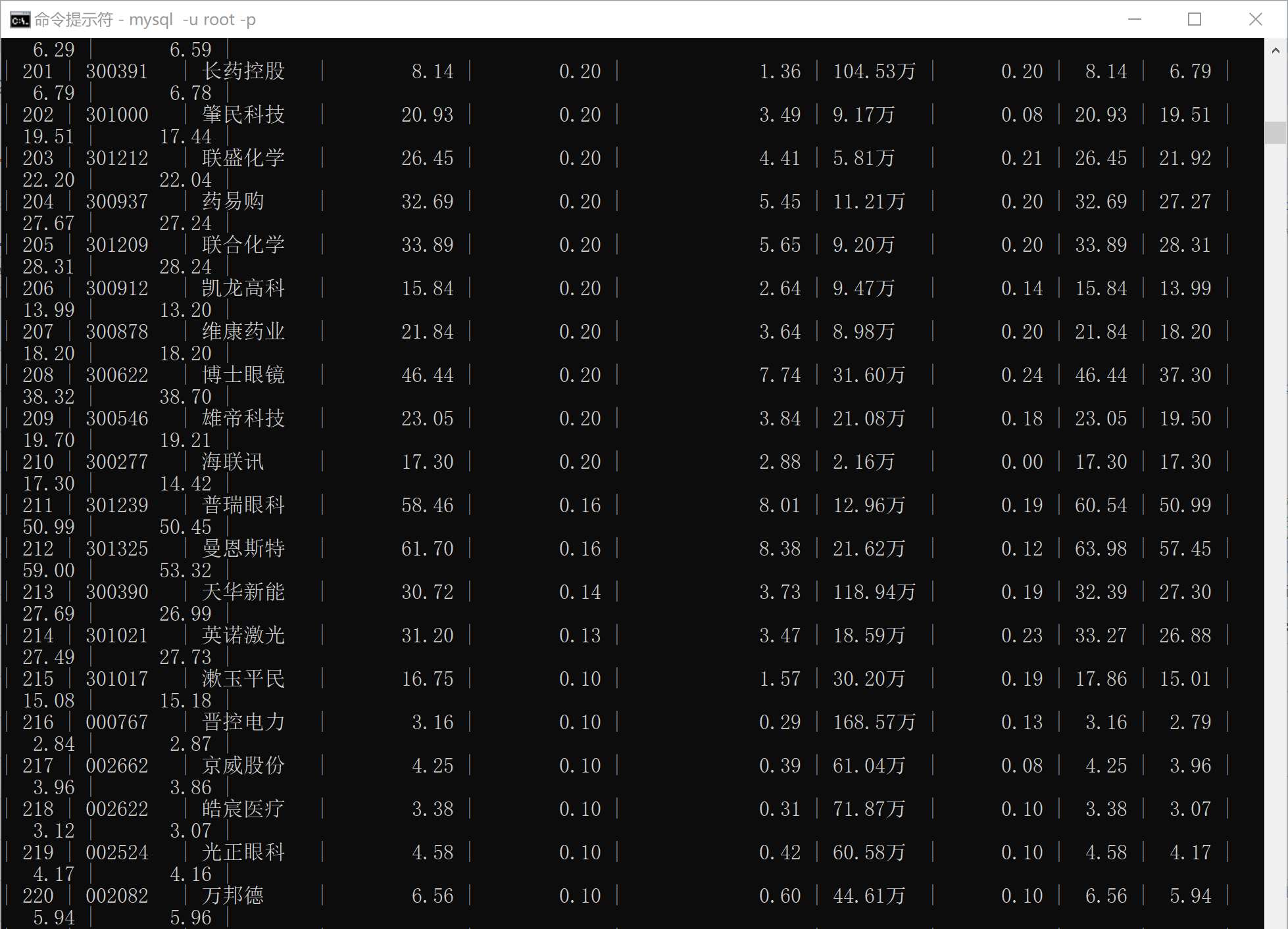
輸出信息:MYSQL數據庫存儲和輸出格式如下,表頭應是英文命名例如:序號id,股票代碼:bStockNo……,由同學們自行定義設計表頭
1. 實驗過程
核心代碼
- 數據爬取
bStockNo = columns[1].text.strip() # 股票代碼
bStockName = columns[2].text.strip() # 股票名稱
latestPrice = columns[4].text.strip() # 最新價
priceChange = columns[5].text.strip() # 漲跌幅
priceChangeValue = columns[6].text.strip() # 漲跌額
volume = columns[7].text.strip() # 成交量
amplitude = columns[9].text.strip() # 振幅
high = columns[10].text.strip() # 最高價
low = columns[11].text.strip() # 最低價
openPrice = columns[12].text.strip() # 今開盤
closePrice = columns[13].text.strip() # 昨收盤
- 頁面點擊與切換
def switch_board_and_scrape(board_xpath):
try:
WebDriverWait(driver, 10).until(
EC.element_to_be_clickable((By.XPATH, board_xpath))
).click()
time.sleep(5) # 等待頁面加載
print(f"已跳轉到 {board_xpath} 板塊")
scrape_page() # 爬取當前板塊第一頁數據
except Exception as e:
print(f"點擊 '{board_xpath}' 失敗:", e)
運行終端截圖

數據庫查詢內容:
(所有輸出在一張表上,為了方便查看分開截取,由于前期進行嘗試后又刪除表中內容,所以序號從161開始。)
- 滬京深A股:
- 上證A股:

- 深證A股:
2. 心得體會
完成這個股票數據爬取項目后,我深刻體會到網頁結構解析、數據清洗、數據庫操作和瀏覽器自動化的重要性。通過使用 selenium 模擬瀏覽器行為,我能夠應對動態加載的頁面,并提取所需的數據。在數據清洗方面,我處理了不規則的字符和格式(如“萬”和“億”),并確保了數據轉換的準確性。數據庫設計上,我簡化了結構,確保數據正確存儲,并通過事務管理保證了數據的一致性。模擬點擊和頁面切換時,我利用 WebDriverWait 保證頁面完全加載,避免了元素未加載完成的問題。雖然性能方面仍有提升空間(例如引入多線程),但該項目讓我更加熟悉了爬蟲開發的全過程,特別是在異常處理、數據清洗和容錯機制上,進一步提高了程序的穩定性和健壯性。
作業②:
-
要求:熟練掌握 Selenium 查找HTML元素、實現用戶模擬登錄、爬取Ajax網頁數據、等待HTML元素等內容。使用Selenium框架+MySQL爬取中國mooc網課程資源信息(課程號、課程名稱、學校名稱、主講教師、團隊成員、參加人數、課程進度、課程簡介)
-
候選網站:中國mooc網:https://www.icourse163.org,爬取數據庫相關課程
-
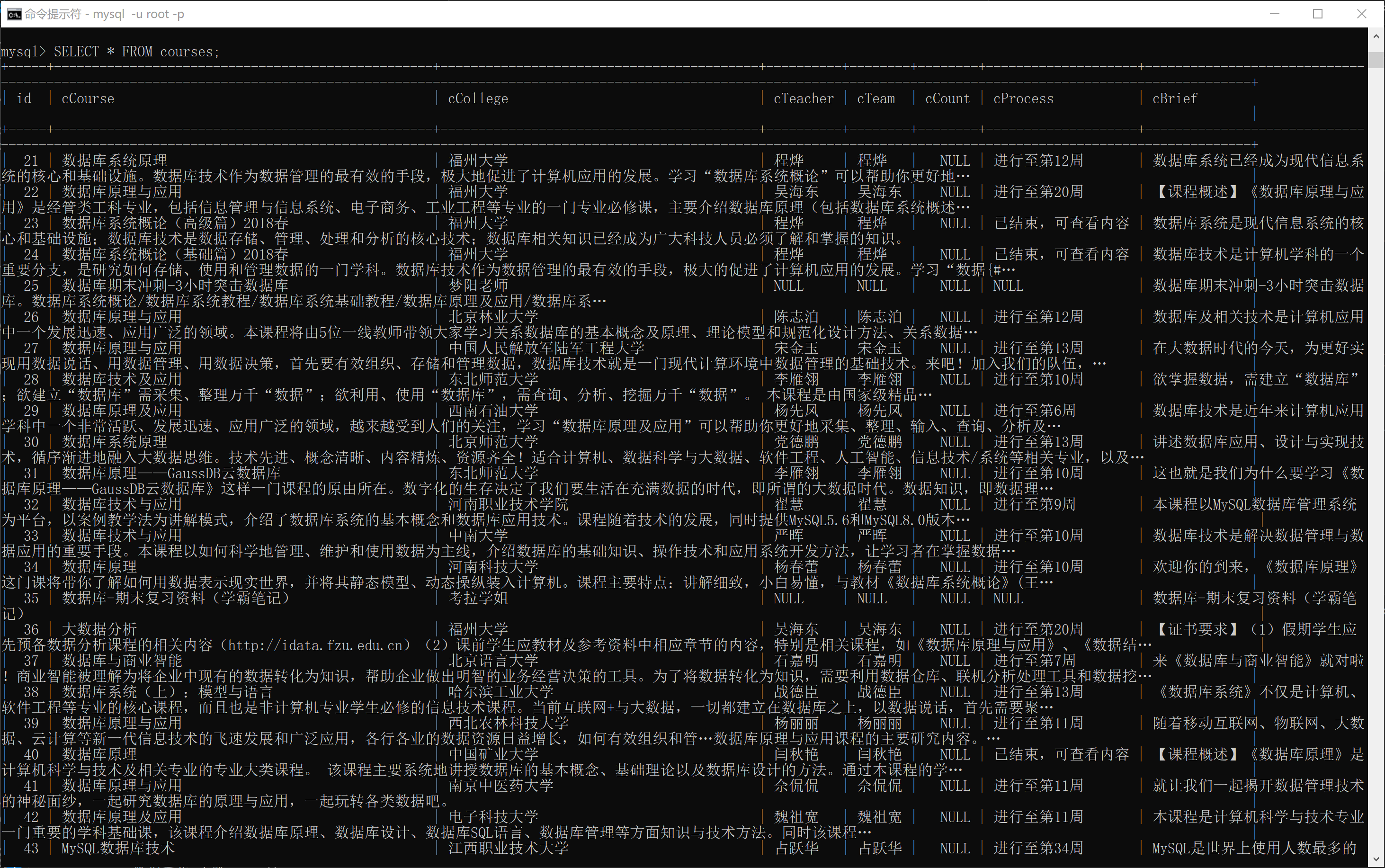
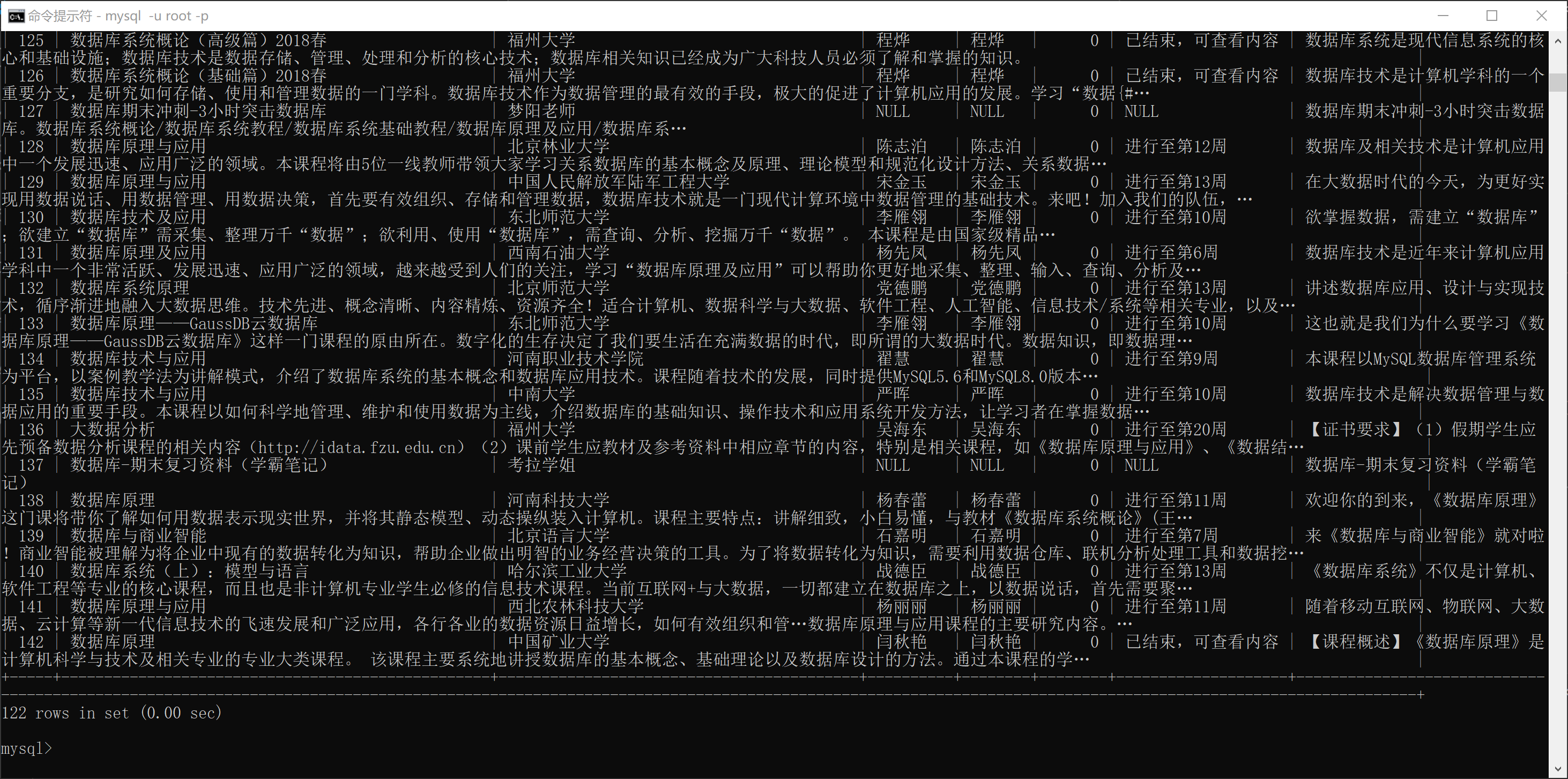
輸出信息:MYSQL數據庫存儲和輸出格式
1. 實驗過程
核心代碼
- 模擬登錄
def login(driver, username, password):
driver.get("https://www.icourse163.org/")
login_button = driver.find_element(By.XPATH, '//*[@id="j-topnav"]/div')
login_button.click()
time.sleep(2)
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.TAG_NAME, "iframe")))
iframe = driver.find_element(By.XPATH,'/html/body/div[13]/div[2]/div/div/div/div/div/div[1]/div/div[1]/div[2]/div[2]/div[1]/div/iframe')
driver.switch_to.frame(iframe)
username_field = driver.find_element(By.XPATH,'//*[@id="phoneipt"]')
password_field = driver.find_element(By.XPATH,'//*[@id="login-form"]/div/div[4]/div[2]/input[2]')
username_field.send_keys(username)
password_field.send_keys(password)
time.sleep(1)
button = driver.find_element(By.XPATH, '/html/body/div[2]/div[2]/div[2]/form/div/div[6]/a')
button.click()
WebDriverWait(driver, 60).until(EC.url_changes(driver.current_url))
driver.switch_to.default_content()
time.sleep(2)
- 模擬滾動加載更多課程
def simulate_scroll(driver):
page_height = driver.execute_script("return document.body.scrollHeight")
scroll_step = 3
scroll_delay = 4
current_position = 0
while current_position < page_height:
next_position = current_position + scroll_step
driver.execute_script(f"window.scrollTo(0, {next_position});")
driver.implicitly_wait(scroll_delay)
current_position = next_position
數據庫查詢內容
2. 心得體會
在這個爬蟲項目中,我進行了爬蟲設計的模塊化,通過將代碼拆分為多個獨立的函數,每個函數負責一個具體任務(如數據庫操作、頁面滾動、元素等待等),不僅使代碼更加清晰易懂,也為后期的維護和擴展提供了極大的便利。此外,使用 Selenium 處理動態頁面的能力讓爬取 JavaScript 渲染內容變得更加簡單和高效。尤其是在處理頁面加載和彈窗時,使用顯式等待(WebDriverWait)可以避免元素未加載完全就進行操作的錯誤,提高了爬蟲的穩定性。
作業③:
*要求:掌握大數據相關服務,熟悉Xshell的使用。完成文檔 華為云_大數據實時分析處理實驗手冊-Flume日志采集實驗(部分)v2.docx 中的任務,即為下面5個任務,具體操作見文檔。
1.實驗過程
環境搭建:開通MapReduce服務
1. 開通MRS

2. 配置
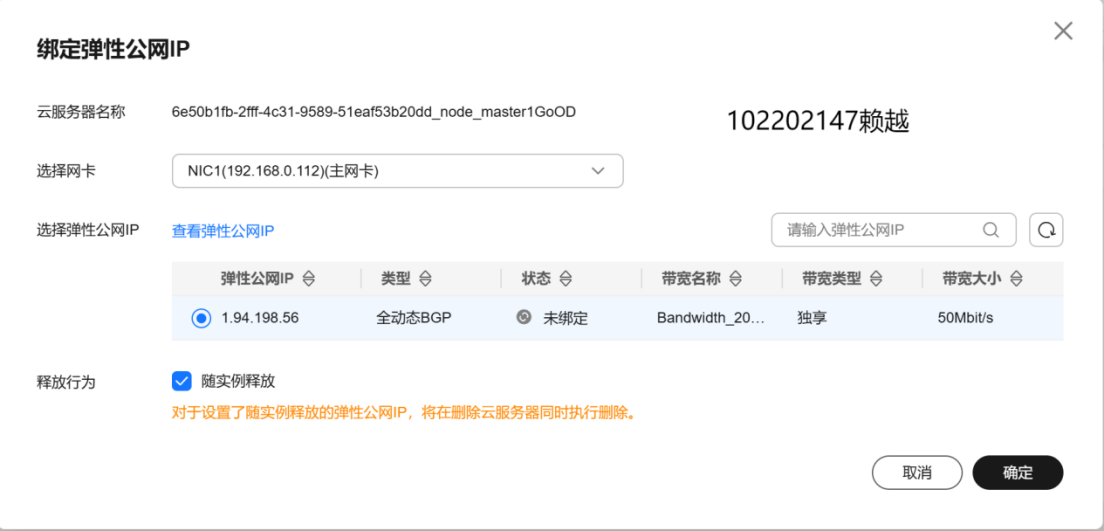

實時分析開發實戰:
1. Python腳本生成測試數據
- 登錄MRS的master節點服務器
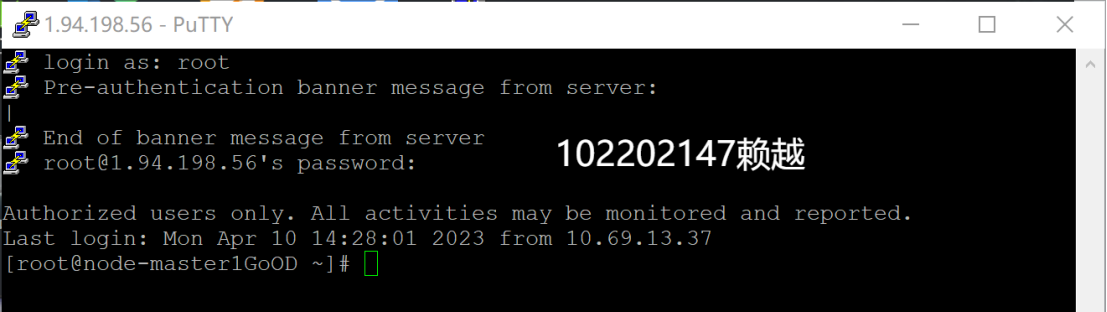
- 編寫Python腳本

- 執行腳本測試

2. 配置Kafka
- 下載

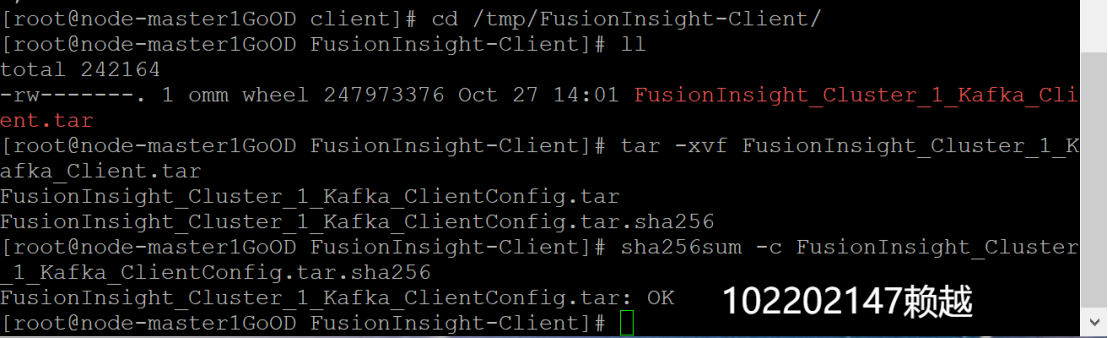
- 校驗下載的客戶端文件包
- 安裝Kafka運行環境

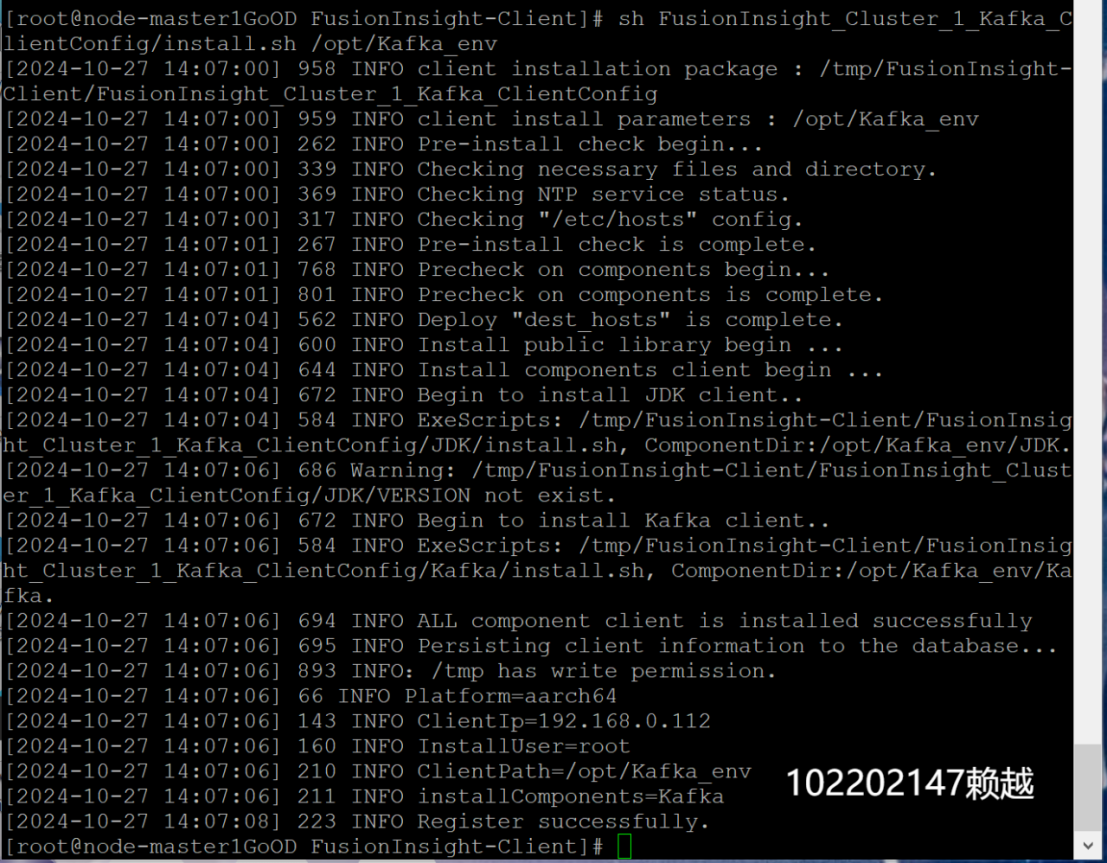
- 安裝Kafka客戶端
- 設置環境變量

- 在kafka中創建topic并查看topic信息

3. 安裝Flume客戶端
- 下載

- 校驗下載的客戶端文件包


- 安裝Flume運行環境
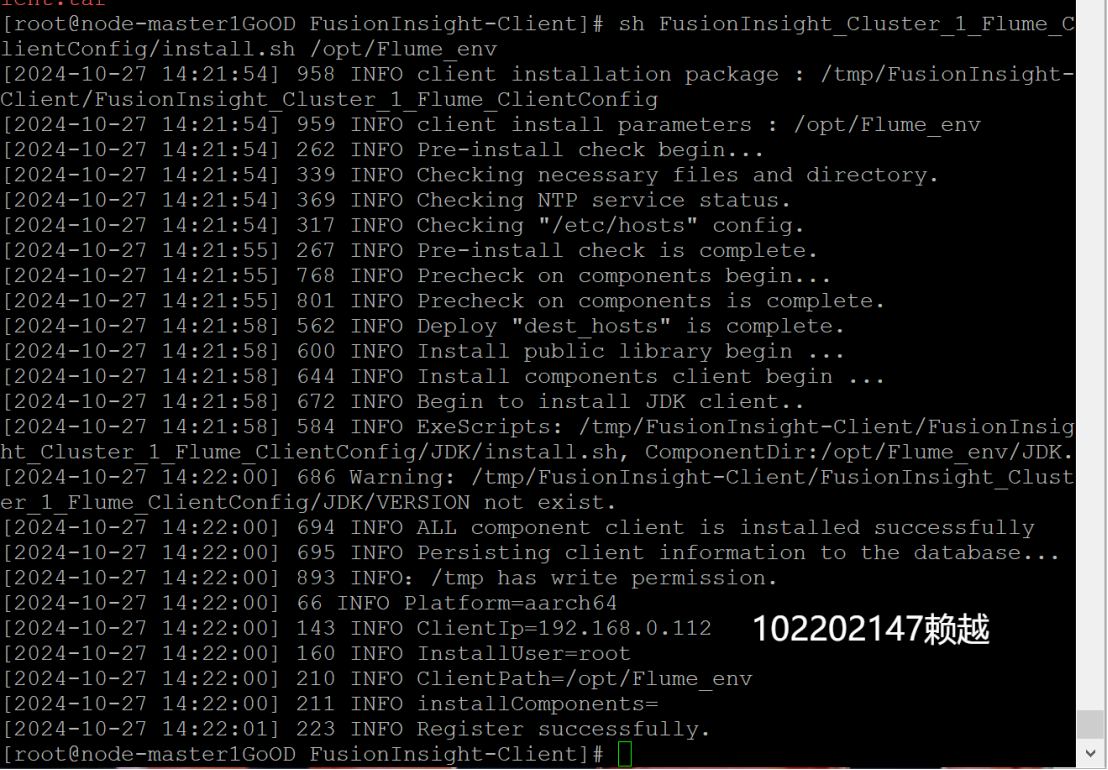
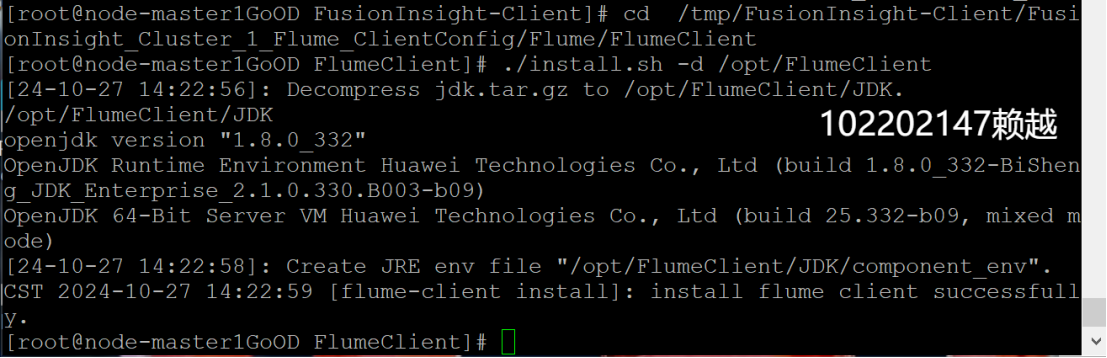
- 安裝Flume客戶端
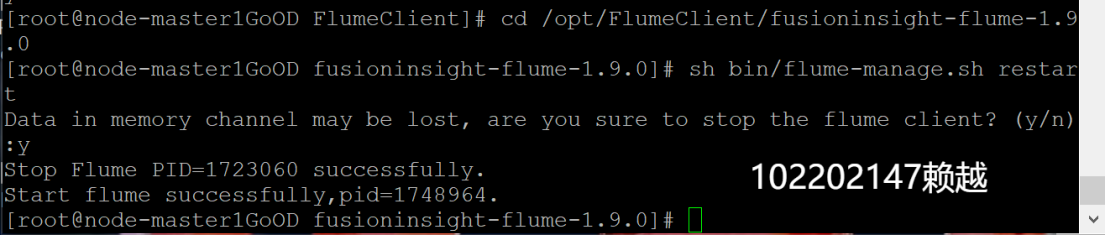
- 重啟Flume服務
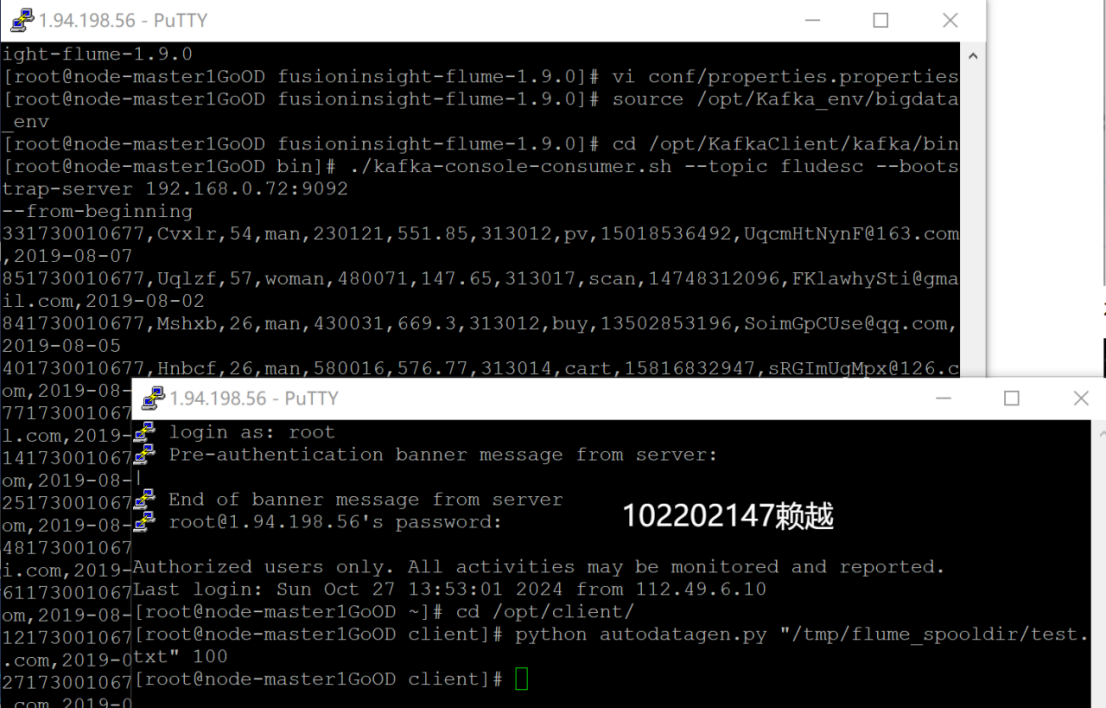
4. 配置Flume采集數據
- 修改配置文件

- 創建消費者消費kafka中的數據
2.心得體會
在完成華為云大數據實時分析處理實驗任務的過程中,我深入理解了大數據處理的幾個關鍵環節,包括數據采集、傳輸和存儲。通過編寫Python腳本生成測試數據,我掌握了如何在大數據平臺上模擬真實數據流。通過進行Kafka的安裝與配置,我理解了消息隊列在實時數據處理中的重要性,并成功創建了Kafka的topic,確保數據能夠可靠地傳輸。Flume的安裝和配置讓我進一步體會到了數據采集的靈活性和高效性,尤其是通過修改配置文件來實現數據流的定制化處理。此外,整個實驗過程中,我通過不斷測試和調試,增強了對大數據處理平臺的理解和操作能力,尤其是在如何協同使用不同的大數據組件(如Kafka和Flume)進行數據的實時采集與分析。這次實驗不僅提升了我對大數據服務的掌握,也讓我更加熟悉了大數據生態中的關鍵技術。

 浙公網安備 33010602011771號
浙公網安備 33010602011771號