
Hadoop學(xué)習(xí)------Hadoop安裝方式之(二):偽分布部署
要想發(fā)揮Hadoop分布式、并行處理的優(yōu)勢(shì),還須以分布式模式來部署運(yùn)行Hadoop。單機(jī)模式是指Hadoop在單個(gè)節(jié)點(diǎn)上以單個(gè)進(jìn)程的方式運(yùn)行,偽分布模式是指在單個(gè)節(jié)點(diǎn)上運(yùn)行NameNode、DataNode、JobTracker、TaskTracker、SeconderyNameNode5個(gè)進(jìn)程,而分布式模式是指在不同節(jié)點(diǎn)上分別運(yùn)行上述5個(gè)進(jìn)程中的某幾個(gè),比如在某個(gè)節(jié)點(diǎn)上運(yùn)行DataNode和TaskTracker。
前面幾步和單機(jī)部署一樣,可以參照Hadoop學(xué)習(xí)------Hadoop安裝方式之(一):?jiǎn)螜C(jī)部署
這里重點(diǎn)講述幾個(gè)配置文件的修改和部署完成后的測(cè)試。
1、修改core-site.xml 文件
cd /usr/local/hadoop/etc/hadoop/
vi core-site.xml
在其中的<configuration>中添加以下內(nèi)容
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
其中fs.defaultFS:代表配置NN節(jié)點(diǎn)地址和端口號(hào) fs.defaultFS - 這是一個(gè)描述集群中NameNode結(jié)點(diǎn)的URI(包括協(xié)議、主機(jī)名稱、端口號(hào)),集群里面的每一臺(tái)機(jī)器都需要知道NameNode的地址。DataNode結(jié)點(diǎn)會(huì)先在NameNode上注冊(cè),這樣它們的數(shù)據(jù)才可以被使用。獨(dú)立的客戶端程序通過這個(gè)URI跟DataNode交互,以取得文件的塊列表。
hdfs://localhost:9000:其中l(wèi)ocalhost替換為ip或則映射主機(jī)名
hadoop.tmp.dir是hadoop文件系統(tǒng)依賴的基礎(chǔ)配置,很多路徑都依賴它。如果hdfs-site-xml中不配置namenode 和datanode的存放位置,默認(rèn)就放在這個(gè)路徑下
2、修改配置文件 hdfs-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi hdfs-site.xml
其中的<configuration>中添加以下內(nèi)容
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
dfs.replication,它決定著系統(tǒng)里面的文件塊的數(shù)據(jù)備份個(gè)數(shù)。對(duì)于一個(gè)實(shí)際的應(yīng)用,它應(yīng)該被設(shè)為3(這個(gè)數(shù)字并沒有上限,但更多的備份可能并沒有作用,而且會(huì)占用更多的空間)。少于三個(gè)的備份,可能會(huì)影響到數(shù)據(jù)的可靠性(系統(tǒng)故障時(shí),也許會(huì)造成數(shù)據(jù)丟失)
dfs.data.dir這是DataNode結(jié)點(diǎn)被指定存儲(chǔ)數(shù)據(jù)的本地文件系統(tǒng)路徑。DataNode結(jié)點(diǎn)上的這個(gè)路徑?jīng)]必要完全相同。因?yàn)槊颗_(tái)機(jī)器的環(huán)境很可能是不一樣的。但如果每臺(tái)機(jī)器上的這個(gè)路徑都是統(tǒng)一配置的話,工作會(huì)變得簡(jiǎn)單一些。默認(rèn)情況下,它的值是Hadoop.temp.dir,這個(gè)路徑只能用于測(cè)試的目的,因?yàn)椋芸赡軙?huì)丟失掉一些數(shù)據(jù),所以,這個(gè)值最好還是被覆蓋。
dfs.name.dir 這是NameNode結(jié)點(diǎn)存儲(chǔ)Hadoop文件信息的本地系統(tǒng)路徑。這個(gè)值只對(duì)NameNode有效,DataNode并不需要使用它。上面對(duì)于/tmp的警告同樣使用于這里。在實(shí)際應(yīng)用中,它最好被覆蓋掉。
3、配置完成后,執(zhí)行NameNode 的格式化
cd /usr/local/hadoop
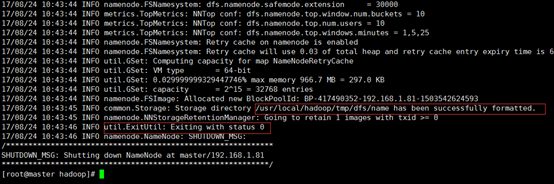
./bin/hdfs namenode –format
成功的話,會(huì)看到 “successfully formatted” 和 “Exitting with status 0” 的提示,若為 “Exitting with status 1” 則是出錯(cuò)
4、開啟 NameNode 和 DataNode 守護(hù)進(jìn)程
./sbin/start-dfs.sh
若出現(xiàn)如下SSH提示,輸入yes即可。
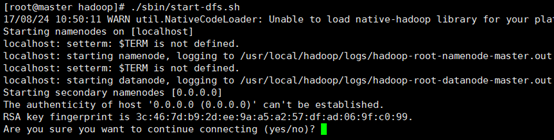
啟動(dòng)時(shí)可能會(huì)出現(xiàn)如下 WARN 提示:WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform… using builtin-java classes where applicable。該 WARN 提示可以忽略,并不會(huì)影響正常使用(該 WARN 可以通過編譯 Hadoop 源碼解決)。

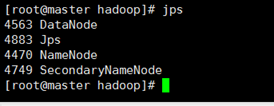
啟動(dòng)完成后,可以通過命令 jps 來判斷是否成功啟動(dòng),若成功啟動(dòng)則會(huì)列出如下進(jìn)程: “NameNode”、”DataNode” 和 “SecondaryNameNode”(如果 SecondaryNameNode 沒有啟動(dòng),請(qǐng)運(yùn)行 sbin/stop-dfs.sh 關(guān)閉進(jìn)程,然后再次嘗試啟動(dòng)嘗試)。如果沒有 NameNode 或 DataNode ,那就是配置不成功,請(qǐng)仔細(xì)檢查之前步驟,或通過查看啟動(dòng)日志排查原因。
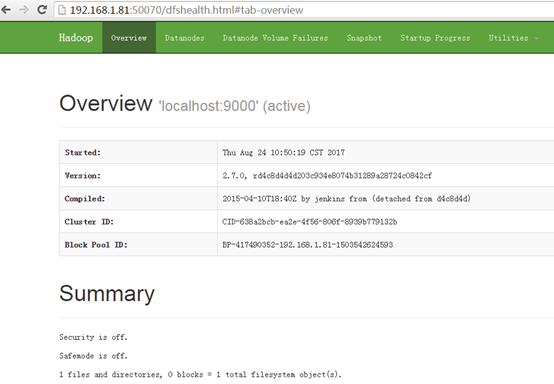
成功啟動(dòng)后,可以訪問 Web 界面 http://localhost:50070 查看 NameNode 和 Datanode 信息,還可以在線查看 HDFS 中的文件。
(Linux系統(tǒng) 無法直接查看,可通過windows系統(tǒng)訪問)
5、運(yùn)行Hadoop偽分布式實(shí)例
偽分布需要我們讀取HDFS上的數(shù)據(jù),要使用HDFS,我們需要在HDFS中創(chuàng)建用戶目錄,并放入幾個(gè)文件。
./bin/hdfs dfs -mkdir -p /user/hadoop
接著將 ./etc/hadoop 中的 xml 文件作為輸入文件復(fù)制到分布式文件系統(tǒng)中,即將 /usr/local/hadoop/etc/hadoop 復(fù)制到分布式文件系統(tǒng)中的 /user/hadoop/input 中。我們使用的是 hadoop 用戶,并且已創(chuàng)建相應(yīng)的用戶目錄 /user/hadoop ,因此在命令中就可以使用相對(duì)路徑如 input,其對(duì)應(yīng)的絕對(duì)路徑就是 /user/hadoop/input:
./bin/hdfs dfs -mkdir input
./bin/hdfs dfs -put ./etc/hadoop/*.xml input
如果報(bào)沒有路徑錯(cuò)誤,說明當(dāng)前登錄的用戶和dfs里建的用戶目錄不對(duì)應(yīng)(比如root),可以切換成hadoop用戶,也可以在把路徑改為全路徑 /user/hadoop/input

復(fù)制完成后,可以通過如下命令查看文件列表
./bin/hdfs dfs -ls input
偽分布式運(yùn)行 MapReduce 作業(yè)的方式跟單機(jī)模式相同,區(qū)別在于偽分布式讀取的是HDFS中的文件(可以將單機(jī)步驟中創(chuàng)建的本地 input 文件夾,輸出結(jié)果 output 文件夾都刪掉來驗(yàn)證這一點(diǎn))。
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output 'dfs[a-z.]+'
查看運(yùn)行結(jié)果
./bin/hdfs dfs -cat output/*
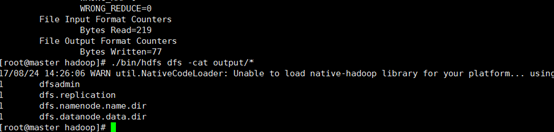
我們也可以將運(yùn)行結(jié)果取回到本地:
rm -r ./output # 先刪除本地的 output 文件夾(如果存在)
./bin/hdfs dfs -get output ./output # 將 HDFS 上的 output 文件夾拷貝到本機(jī)
cat ./output/*
若要關(guān)閉 Hadoop 需要運(yùn)行
./sbin/stop-dfs.sh
注意:下次啟動(dòng) hadoop 時(shí),無需進(jìn)行 NameNode 的初始化,只需要運(yùn)行 ./sbin/start-dfs.sh 就行
6、啟動(dòng)YARN
偽分布式不啟動(dòng) YARN 也可以,一般不會(huì)影響程序執(zhí)行
大家可能會(huì)有疑惑,啟動(dòng) Hadoop 后,見不到書上所說的 JobTracker 和 TaskTracker。這是因?yàn)樾掳娴?Hadoop 使用了新的 MapReduce 框架(MapReduce V2,也稱為 YARN,Yet Another Resource Negotiator)
YARN 是從 MapReduce 中分離出來的,負(fù)責(zé)資源管理與任務(wù)調(diào)度。YARN 運(yùn)行于 MapReduce 之上,提供了高可用性、高擴(kuò)展性,上述通過 ./sbin/start-dfs.sh 啟動(dòng) Hadoop,僅僅是啟動(dòng)了 MapReduce 環(huán)境,我們可以啟動(dòng) YARN ,讓 YARN 來負(fù)責(zé)資源管理與任務(wù)調(diào)度。
6.1 修改配置文件 mapred-site.xml
cd /usr/local/hadoop/etc/hadoop/
需要將mapred-site.xml.template 文件改名或者復(fù)制一份
mv mapred-site.xml.template mapred-site.xml
或 cp mapred-site.xml.template mapred-site.xml
然后在進(jìn)行編輯 vi mapred-site.xml
在<configuration> 中添加
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
6.2修改配置文件 yarn-site.xml
cd /usr/local/hadoop/etc/hadoop/
vi yarn-site.xml
在<configuration>中添加
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
6.3 啟動(dòng)YARN 以及檢驗(yàn)
完成前面兩步就可以啟動(dòng) YARN 了(需要先執(zhí)行過 ./sbin/start-dfs.sh)
切換到hadoop主目錄 cd /usr/local/hadoop
./sbin/start-yarn.sh # 啟動(dòng)YARN
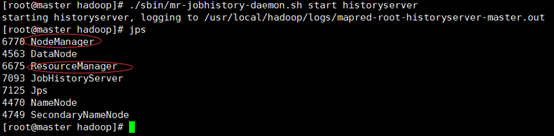
./sbin/mr-jobhistory-daemon.sh start historyserver # 開啟歷史服務(wù)器,才能在Web中查看任務(wù)運(yùn)行情況
開啟后通過 jps 查看,可以看到多了 NodeManager 和 ResourceManager 兩個(gè)后臺(tái)進(jìn)程
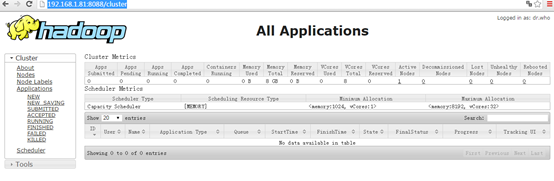
啟動(dòng) YARN 之后,運(yùn)行實(shí)例的方法還是一樣的,僅僅是資源管理方式、任務(wù)調(diào)度不同。觀察日志信息可以發(fā)現(xiàn),不啟用 YARN 時(shí),是 “mapred.LocalJobRunner” 在跑任務(wù),啟用 YARN 之后,是 “mapred.YARNRunner” 在跑任務(wù)。啟動(dòng) YARN 有個(gè)好處是可以通過 Web 界面查看任務(wù)的運(yùn)行情況:http://localhost:8088/cluster
訪問Job History Server的web頁面 http://localhost:19888/

但 YARN 主要是為集群提供更好的資源管理與任務(wù)調(diào)度,然而這在單機(jī)上體現(xiàn)不出價(jià)值,反而會(huì)使程序跑得稍慢些。因此在單機(jī)上是否開啟 YARN 就看實(shí)際情況了。
6.4 關(guān)閉YARN
如果不想啟動(dòng) YARN,務(wù)必把配置文件 mapred-site.xml 重命名,改成 mapred-site.xml.template,需要用時(shí)改回來就行。否則在該配置文件存在,而未開啟 YARN 的情況下,運(yùn)行程序會(huì)提示 “Retrying connect to server: 0.0.0.0/0.0.0.0:8032” 的錯(cuò)誤,這也是為何該配置文件初始文件名為 mapred-site.xml.template。 關(guān)閉命令如下
./sbin/stop-yarn.sh
./sbin/mr-jobhistory-daemon.sh stop historyserver
也可以用下面的啟動(dòng)/停止命令,等同于start/stop-dfs.sh + start/stop-yarn.sh
sbin/start-all.sh
sbin/stop-all.sh
posted on 2017-09-06 16:22 風(fēng)行__雄關(guān)漫道 閱讀(544) 評(píng)論(0) 收藏 舉報(bào)

 浙公網(wǎng)安備 33010602011771號(hào)
浙公網(wǎng)安備 33010602011771號(hào)