
mamba-硬件感知算法
掃描操作

提出原因
由于A B C這些矩陣現在是動態的了,因此無法使用卷積表示來計算它們(卷積核是固定的),因此,我們只能使用循環表示,如此也就而失去了卷積提供的并行訓練能力。
-
計算順序性:循環計算不能并行,效率低。每一步 ht 依賴 ht-1,無法像卷積那樣并行
-
內存占用大:中間狀態太多,存儲壓力大.要把所有中間狀態 h_{1…L} 存下來做反向傳播,顯存 O(BLDN)
目標:把 順序性 變成 可并行,把 O(BLDN) 變成 O(BLD) 甚至更低。
同時,我們也需要重新審視SSM的計算問題。我們用三種經典的技術來解決這個問題:核融合、并行掃描和重新計算。
通過這三個技術,讓選擇性狀態空間模型既能動態適應輸入,又能在 GPU 上高效運行,內存使用和 Transformer 差不多,但計算更快
并行掃描

雖然循環計算本質上是順序的,但可以用并行掃描算法(如 Blelloch 算法)來并行化計算,提高效率。
Mamba通過并行掃描(parallel scan)算法使得最終并行化成為可能,其假設我們執行操作的順序與關聯屬性無關。因此,我們可以分段計算序列并迭代地組合它們,即動態矩陣B和C以及并行掃描算法一起創建選擇性掃描算法(selective scan algorithm)
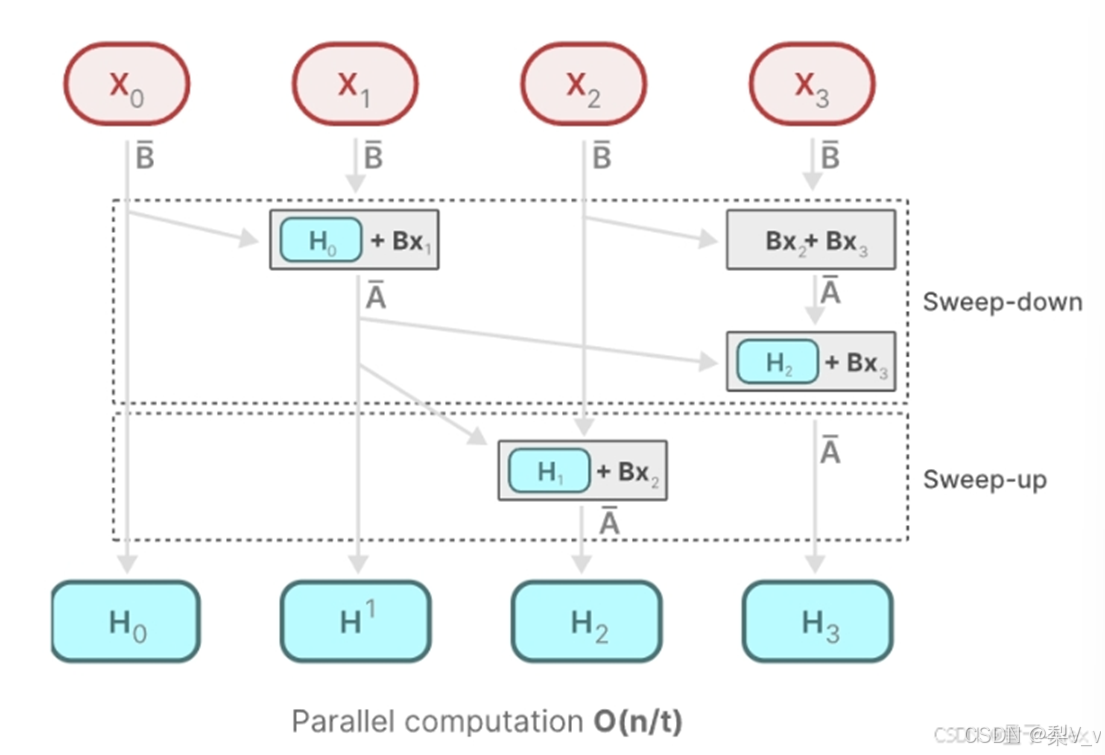
在并行計算中,時間復雜度 O(n/t) 中的 t ,通常代表用于執行任務的處理器或計算單元的數量
核融合
最新 GPU 的一個缺點是其小型但高效的 SRAM 與大型但效率稍低的 DRAM 之間的傳輸 (IO) 速度有限。在 SRAM 和 DRAM 之間頻繁復制信息成為瓶頸。(transformer的方法)


主要思想是利用現代加速器(GPU)的特性,僅在內存層次結構的更高效層級上實現狀態?。具體來說,大多數運算(矩陣乘法除外)都受內存帶寬限制。這包括我們的掃描運算,我們使用核融合來減少內存 IO 數量,與標準實現相比,顯著提高了速度。(把多個計算步驟合并成一個 GPU 核函數,減少內存讀寫。)
具體來說,我們不會在 GPU HBM(高帶寬存儲器)中準備大小為 (B, L, D, N) 的掃描輸入 (??八, ??八),而是將 SSM 參數 (Δ, ??, ??, ??) 直接從慢速 HBM(主存) 加載到快速 SRAM(緩存),在 SRAM 中執行離散化和遞歸,然后將大小為 (B, L, D) 的最終輸出寫回 HBM。
為了避免順序遞歸,我們觀察到,盡管它不是線性的,仍然可以使用高效的并行掃描算法進行并行化。
最后,我們還必須避免保存反向傳播所必需的中間狀態。我們謹慎地運用了經典的重新計算技術來降低內存需求:中間狀態不存儲,而是在輸入從 HBM 加載到 SRAM 時在反向傳播中重新計算。因此,融合的選擇性掃描層與使用 FlashAttention 優化的 Transformer 實現具有相同的內存需求。
重計算
這和 Transformer 中的 FlashAttention 技術類似,能顯著降低內存使用
Flash Attention技術
利用內存的不同層級結構處理SSM的狀態,減少高帶寬但慢速的HBM內存反復讀寫這個瓶頸
具體而言,就是限制需要從 DRAM 到 SRAM 的次數(通過內核融合kernel fusion來實現),避免一有個結果便從SRAM寫入到DRAM,而是待SRAM中有一批結果再集中寫入DRAM中,從而降低來回讀寫的次數

 浙公網安備 33010602011771號
浙公網安備 33010602011771號